METODE KLASIFIKASI
BACKPROPAGATION
ADITYA RIANSYAH LESMANA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
METODE KLASIFIKASI
BACKPROPAGATION
ADITYA RIANSYAH LESMANA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
ADITYA RIANSYAH LESMANA. License plate identification using zone based feature
extraction and artificial neural network backpropagation as the classifier method supervised by
MUSHTHOFA Skom Msc.
Automatic license plate identification is one of the important features required for vehicle data recording system to be use in applications such as parking system, automatic highway gate system, etc. Several research has been conducted to devise a reliable method to identify vehicle license plate. In this research, we aim to implement an automatic license plate identification system using the zone based feature extraction method and artificial neural network for classification. The data is obtained from 100 units of vehicle using a 5 MP mobile phone camera. The preprocessing step consists of converting the images to grayscale, followed by noise reduction using median filter, edge detection using Canny with a threshold of 0,2 and 0,5. Afterwards, we perform segmentation using 8-connected labelling component to obtain the characters. The zone based feature extraction
used is image centroid and zone using the most efficient zone. The fastest and the highest accuracy
will be choosen as the most efficient zone. In this research 14 zone extraction have an efficient
result. We used the backpropagation neural network with 25 input neurons, 30 hidden neurons,
and 36 output neurons representing each characthers (alphabet and numerals). The best result for
indvidual character recognation is 85,32% while the best recognition rate for the whole plate is 40,61%.
Keywords: Optical character recognition, license plate recognition, segmentation, image centroid
Judul Skripsi : Identifikasi Plat Nomor Kendaraan Dengan Zone Based Feature Extraction
Menggunakan Metode Klasifikasi Bacpropagation
Nama : Aditya Riansyah Lesmana
NRP : G64096002
Disetujui
Pembimbing
Mushthofa SKom MSc NIP 19820325 200912 1 003
Diketahui
Ketua Departemen Ilmu Komputer
Dr Ir Agus Buono MSi MKom NIP 19660702 199302 1 001
PRAKATA
Bismillahirrahmaanirrahiim.
Puji dan syukur penulis panjatkan ke hadirat Allah Subhanahu Wa Ta’ala atas segala limpahan
rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang Identifikasi Plat
Nomor Kendaraan Dengan Zone Based Feature Extraction Menggunakan Metode Klasifikasi
Bacpropagation.
Penulis sadar bahwa tugas akhir ini tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Pada kesempatan ini, penulis ingin mengucapkan terima kasih kepada:
1 Orang tua tercinta Bapak Heriansyah dan Ibu Anita Sari Lesmana atas segala do’a, dukungan,
dan kasih sayang yang tiada henti. Juga kepada Natasya Baharta, adik penulis yang selalu mendukung dan memotivasi penulis.
2 Bapak Mushthofa SKom MSc selaku dosen pembimbing tugas akhir. Terima kasih atas
kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3 Ibu Yeni Herdiyeni Ssi Mkom Ibu dan Bapak Dr Eng Wisnu Ananta Kusuma ST MT selaku
dosen penguji, serta seluruh dosen dan staf Departemen Ilmu Komputer FMIPA IPB.
4 Rekan-rekan satu bimbingan, Anis, Mono, dan Nina yang banyak bertukar pikiran dan ide
dalam pengerjaan tugas akhir ini.
5 Rekan-rekan penghuni WH Arief, Desta, Pauji, dan lain-lain yang banyak menyumbangkan
ilmu dan ide dalam pengerjaan tugas akhir ini.
6 Sahabat-sahabatku Abe, Novi, Alka, Lutfi, Andy, dan seluruh teman-teman Alih Jenis Ilmu
Komputer Angkatan 4. Terima kasih atas semangat dan kebersamaan selama penyelesaian tugas akhir ini.
7 Pramesti Anggi Anjelia atas semua semangat yang telah diberikan hingga penulis dapat
menyelesaikan tugas akhir ini dengan baik.
8 Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam
pelaksanaan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran dan kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, September 2012
RIWAYAT HIDUP
Penulis bernama lengkap Aditya Riansyah Lesmana, lahir di Bogor, Jawa Barat pada tanggal 14 Oktober 1988. Penulis merupakan sulung dari dua bersaudara dari pasangan Bapak Heriansyah dan Ibu Anita Sari Lesmana.
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat ... 1
TINJAUAN PUSTAKA ... 2
Edge Detection ... 2
Canny’s Edge Detection ... 2
Image Segmentation ... 2
Zone Based Feature Extraction ... 2
K-Fold Cross Validation ... 2
Jaringan Saraf Tiruan ... 2
Backpropagation ... Error! Bookmark not defined. METODE PENELITIAN ... 4
Pengumpulan Data ... 4
Restorasi dan Perbaikan Citra ... 4
Deteksi Tepi ... 4
Ekstraksi Ciri ... 5
Image Centroid and Zone (ICZ) ... 5
K-Fold Cross Validation ... 5
Klasifikasi Citra ... 5
Evaluasi dan Analisis Hasil ... 6
Lingkungan Pengembangan Sistem ... 6
HASIL DAN PEMBAHASAN ... 6
Pengumpulan Data ... 6
Pra-proses Citra ... 6
Deteksi Tepi ... 7
Segmentasi Citra ... 7
Normalisasi Citra ... 7
Ekstraksi Ciri ... 8
Klasifikasi Citra ... 9
Pengujian Karakter ... 10
Pengujian Plat ... 13
KESIMPULAN DAN SARAN ... 13
Kesimpulan ... 13
Saran ... 14
DAFTAR PUSTAKA ... 14
DAFTAR TABEL
Halaman
1 Pembagian subset ... 5
2 Waktu pemrosesan ekstraksi fitur menggunakan ICZ. ... 9
3 Waktu pemrosesan ICZ menggunakan 4 - 14 zona. ... 9
4 Waktu pemrosesan ICZ menggunakan 16 - 25 zona. ... 9
5 Hasil pengujian karakter. ... 10
6 Hasil deteksi karakter dengan akurasi rendah. ... 11
7 Hasil ICZ untuk karakter R dan A ... 11
8 Hasil ICZ untuk karakter S dan X. ... 12
9 Hasil ICZ untuk karakter U dan 5. ... 12
10 Hasil pengujian 65 plat. ... 13
11 Hasil pengujian plat dengan toleransi kesalahan. ... 13
DAFTAR GAMBAR
Halaman 1 Arsitektur backpropagation ... 32 Skema metode penelitian ... 4
3 Contoh hasil deteksi tepi Canny. ... 4
4 Contoh hasil Segmentasi ... 5
5 Data sampel. ... 6
6 Hasil deteksi tepi Canny ... 7
7 Labeling pada angka nol ... 7
8 Proses segmentasi ... 7
9 Normalisasi karakter. ... 8
10 Titik beban pada huruf F. ... 8
11 Pembagian zona ekstraksi fitur. ... 8
12 Pola angka 0 (nol) dengan 4 zona (atas), 14 zona (tengan) dan 25 zona (bawah). ... 8
13 Hasil praproses yang baik... 9
14 Hasil praproses yang kurang baik. ... 9
15 Pembagian 14 zona pada huruf D. ... 10
16 Pembagian 4 zona pada huruf D. ... 10
17 Pembagian 25 zona pada huruf D. ... 11
18 Pola hasil ekstraksi karakter D (kiri atas), K(kanan atas), L (kiri bawah), dan M (kanan bawah). 11 19 Pola karakter R dan A. ... 11
20 Pola karakter S dan X. ... 12
21 Pola karakter U dan 5. ... 12
22 Pola ekstraksi 50 karakter R (atas) dan P (bawah). ... 12
DAFTAR LAMPIRAN
Halaman 1 Pola ekstraksi fitur semua karakter. ... 152 Hasil pelatihan backpropagation . ... 17
3 Hasil deteksi karakter menggunakan 4 zona. ... 18
4 Hasil deteksi karakter menggunakan 6 zona. ... 19
5 Hasil deteksi karakter menggunakan 8 zona. ... 20
6 Hasil deteksi karakter menggunakan 10 zona. ... 21
7 Hasil deteksi karakter menggunakan 12 zona. ... 22
9 Hasil deteksi karakter menggunakan 16 zona. ... 24
10 Hasil deteksi karakter menggunakan 18 zona. ... 25
11 Hasil deteksi karakter menggunakan 20 zona. ... 26
12 Hasil deteksi karakter menggunakan 22 zona. ... 27
13 Hasil deteksi karakter menggunakan 25 zona. ... 28
14 Hasil deteksi plat menggunakan 4 zona. ... 29
15 Hasil deteksi plat menggunakan 6 zona. ... 30
16 Hasil deteksi plat menggunakan 8 zona. ... 31
17 Hasil deteksi plat menggunakan 10 zona. ... 32
18 Hasil deteksi plat menggunakan 12 zona. ... 33
19 Hasil deteksi plat menggunakan 14 zona. ... 34
20 Hasil deteksi plat menggunakan 16 zona. ... 35
21 Hasil deteksi plat menggunakan 18 zona. ... 36
22 Hasil deteksi plat menggunakan 20 zona. ... 37
23 Hasil deteksi plat menggunakan 22 zona. ... 38
PENDAHULUAN
Latar Belakang
Nomor polisi merupakan identitas unik yang tertera pada plat kendaraan bermotor. Nomor tersebut direpresentasikan dengan kumpulan huruf dan angka yang mewakili data kendaraan itu sendiri dan juga pemiliknya. Plat tersebut dapat digunakan untuk berbagai kebutuhan pencatatan data kendaraan, misalnya dalam suatu sistem parkir gedung. Proses pencatatan dari sistem tersebut masih banyak yang dilakukan secara manual oleh manusia. Hal tersebut
memungkinkan terjadinya human error dan
permasalahan waktu pencatatan yang terbatas. Di samping itu, perkembangan produksi kendaraan saat ini semakin cepat, khususnya di Indonesia yang menjadi salah satu target distribusi terbesar dari berbagai produsen kendaraan bermotor. Seiring dengan perkembangan tersebut diperlukan suatu mekanisme yang dapat melakukan pencatatan data dan pengenalan plat kendaraan dengan lebih cepat dan tepat, salah satunya adalah
sistem Optical Character Recognition (OCR)
yang dalam implementasinya akan melakukan identifkasi karakter dari suatu
input data berupa citra. Input tersebut akan diproses lebih jauh secara digital sehingga dapat dilakukan tahap pengenalan menggunakan beberapa metode yang ada. Citra dari sebuah plat diambil menggunakan perlatan optikal (kamera, CCTV). Kemudian akan dilakukan identifikasi pada setiap karakter yang ada.
Selama beberapa tahun terakhir telah dilakukan banyak penelitian mengenai hal ini dan masih terus dikembangkan untuk mencari metode terbaik dalam memecahkan permasalahan ini. Setiawan (2008) melakukan penelitian dalam pendeteksian plat nomor
menggunakan metode feature reduction
Principle Component Analysis (PCA) dan
Euclidean distance. Dari penelitian tersebut didapat rata-rata akurasi sebesar 84.3%. Lim et al (2009) juga menggunakan PCA sebagai metode ekstraksi fiturnya, namun pada tahap
klasifikasinya menggunakan metode
K-Nearest Neighbor. Penelitian tersebut mencapai tingkat keberhasilan sebesar 82%. Selain itu, Wahyono (2009) mencoba
menggunakan jaringan saraf tiruan Learning
Vector Quantization sebagai metode klasifikasi, sedangkan metode ekstraksi fitur berdasarkan blok. Walaupun pada penelitian tersebut masih banyak kesalahan pada metode
ekstraksi fitur, namun tingkat keberhasilan yang didapat masih cukup besar, yaitu 78%.
Sehubungan dengan itu penelitian ini dilakukan dengan menggunakan jaringan saraf
tiruan backpropagation sebagai metode
klasifikasi, sedangkan image centroid and
zone (ICZ)dipilih sebagai metode ektrasi ciri. Seperti mengacu pada penelitian yang telah dilakukan oleh Rajashekararadhya (2008).
Pada penelitian tersebut digunakan zone based
feature extraction untuk mengenali tulisan tangan pada karakter India.
Pada penelitian ini dilakukan percobaan dengan menggabungkan metode ekstraksi ciri
ICZ dan jaringan saraf tiruan backpropagation
serta melihat tingkat keberhasilan dari kedua metode tersebut. Selain itu juga dapat dikembangkan menjadi metode yang tepat, cepat dan efisien sebagai solusi permasalahan di atas.
Tujuan
Tujuan dilakukannya penelitian ini adalah untuk:
1 Menerapkan metode Image Centroid and
Zone (ICZ)untuk melakukan ekstraksi ciri pada citra plat nomor kendaraan, dan
jaringan saraf tiruan backpropagation .
2 Mencari pembagian zona yang efisien dan
tepat untuk mendeteksi plat nomor.
3 Menguji tingkat akurasi dari metode yang
digunakan.
Ruang Lingkup
Ruang lingkup dari penelitian ini terbatas pada:
1 Plat nomor yang dikenali hanya plat
nomor mobil selain kendaraan dinas pemerintah dan militer.
2 Data yang diolah berasal dari citra dengan
format JPEG.
3 Plat nomor yang digunakan dalam
penelitian adalah plat dengan warna dasar hitam dan warna karakter putih
4 Karakter yang dikenali adalah huruf
alphabet kapital (A sampai Z) dan angka (0 sampai 9).
5 Pemotretan plat dilakukan dari depan atau
belakang kendaraan secara berhadapan lurus.
6 Hanya bagian plat nomor yang akan
digunakan sebagai data yang diteliti.
Manfaat
sistem pengenalan plat kendaraan secara otomatis. Dengan itu pada akhirnya penelitian ini dapat menjadi solusi permasalahan pencatatan data kendaraan, khususnya di Indonesia.
TINJAUAN PUSTAKA
Edge Detection
Edge detection adalah teknik yang digunakan untuk mendeteksi tepi dari objek yang ada dalam sebuah citra. Proses ini dilakukan dengan cara menelusuri citra secara vertikal dan horizontal untuk menemukan perbedaan nilai keabuan yang signifikan
antara suatu pixel dengan tetangganya
(Acharya & Ray 2005).
Canny’s Edge Detection
Algoritme deteksi tepi Canny kuat
terhadap noise dan pada saat yang sama dapat
mendeteksi tepi dengan error yang kecil. Menurut (Acharya & Ray 2005) ada beberapa proses penting yang dilakukan dalam deteksi tepi Canny, yaitu:
1 Non-Maxima Suppresion, yaitu,
penghilangan nilai-nilai yang tidak
maksimum.
2 Double Thresholding, ini merupakan salah satu kelebihan dari algoritme Canny. Dua
buah threshold dipilih untuk menentukan
jalur tepi.
Image Segmentation
Menurut Gonzalez et al (2003), segmentasi citra merupakan proses pembagian sebuah citra dalam sejumlah bagian atau objek tertentu. Tingkat pembagian wilayah bergantung kepada masalah yang akan diselesaikan.
Zone Based Feature Extraction
Pendekatan yang dilakukan untuk melakukan ekstraksi fitur berbasis zona, yaitu
Image Centroid and Zone (ICZ). Berikut ini tahap-tahap yang harus dilakukan untuk masing-masing pendekatan tersebut (Rajashekararadhya 2008) :
1 Hitung centroid dari citra.
2 Bagi menjadi n buah zona yang sama
besar proporsinya.
3 Hitung jarak antara titik centroid dengan
koordinat pixel yang memiliki nilai.
4 Ulangi langkah 3 untuk pixel yang ada di
semua zona.
5 Hitung rata-rata jarak yang telah didapat
pada langkah 3
6 Ulangi langkah 5 hingga didapat
masing-masing rata-rata jarak dari setiap zona.
7 Akhirnya n buah fitur akan didapat untuk
melakukan klasifikasi dan pengenalan.
K-Fold Cross Validation
Cross validation kadang-kadang disebut
sebagai rotation estimation. Dataset v dibagi
menjadi k subset (fold) yang saling bebas
secara acak, yaitu D1, D2,..., Dk dengan ukuran yang sama. Pelatihan dan pengujian
dilakukan sebanyak k kali, setiap kali iterasi
ke-t (t = 1, 2, ..., k) dilatih pada D/Dt dan diuji
pada Dt. Perkiraan akurasi pada cross
validation dengan membagi jumlah keseluruhan klasifikasi yang benar dengan
seluruh instances pada dataset (Kohavi 1995).
Jaringan Saraf Tiruan
Menurut Fausett (1994) jaringan saraf
tiruan (artificial neural network) atau
disingkat JST adalah sistem komputasi yang arsitektur dan operasinya diilhami dari pengetahuan tentang sel saraf biologi di dalam otak. JST dapat digambarkan sebagai model matematis dan komputasi untuk fungsi aproksimasi nonlinear, klasifikasi data,
cluster, dan regresi non-parametric atau sebagai sebuah simulasi dari koleksi model saraf biologi, dengan asumsi bahwa:
1 Pengolahan informasi terjadi pada banyak
elemen sederhana yang disebut neuron.
2 Sinyal dikirimkan melalui suatu
penghubung antar neuron.
3 Setiap penghubung antar neuron memiliki
bobot yang secara khusus akan melipatgandakan sinyal yang dikirimkan.
4 Setiap neuron menerapkan fungsi aktivasi
terhadap input untuk menentukan sinyal
output.
Berdasarkan cara memodifikasi bobotnya, ada 2 macam pelatihan, yaitu:
1 Pelatihan dengan supervisi. Pada pelatihan
ini terdapat sejumlah pasangan data (input
-output) yang dipakai untuk melatih jaringan hingga diperoleh bobot yang diinginkan. Pasangan data tersebut berfungsi untuk melatih jaringan hingga diperoleh bentuk yang terbaik. Metode yang termasuk ke dalam jenis ini adalah Single Perseptron, Multi Perseptron, dan
Backpropagation .
2 Pelatihan tanpa supervisi. Pada pelatihan
jaringan dimodifikasi berdasarkan parameter tersebut. Metode JST yang termasuk ke dalam kategori ini adalah
Self-Organizing Map (SOM) dan Learning Vector Quantization (LVQ).
Backpropagation
Backpropagation merupakan algoritme pembelajaran yang terawasi dan biasanya digunakan oleh perceptron dengan banyak lapisan untuk mengubah bobot-bobot yang terhubung dengan neuron-neuron yang ada pada lapisan tersembunyinya (Fausset 1994). Fungsi aktivasi yang digunakan pada metode ini adalah fungsi sigmoid biner yang memiliki rentang dari 0 – 1.
f(x) =
1
1 +e-1 f(x) =f(x)(1 –f(x))
Fungsi lain yang sering digunakan adalah fungsi sigmoid bipolar.
f(x) = 2
Pelatihan sebuah jaringan yang
menggunakan backpropagation terdiri atas 3
langkah, yaitu: pelatihan pola input secara
feedforward, perhitungan dan
backpropagation dari kumpulan kesalahan dan penyesuaian bobot. Sesudah pelatihan, aplikasi dari jaringan hanya terdiri atas fase
feedforward. Bahkan, jika pelatihan menjadi lambat, sebuah jaringan yang dilatih dapat
menghasilkan output-nya sendiri secara cepat.
Bentuk arsitektur backpropagation dapat
dilihat pada Gambar 1
Gambar 1 Arsitektur backpropagation
Berikut ini adalah langkah-langkah proses
pelatihan pada JST backpropagation dengan
satu layer tersembunyi dan fungsi aktivasi
sigmoid biner:
1 Inisialisasi semua bobot dengan bilangan
acak kecil.
2 Jika kondisi penghentian belum terpenuhi,
lakukan langkah 3-10.
3 Untuk setiap pasang data pelatihan,
lakukan langkah 4-9.
Fase I: Propagasi Maju
4 Tiap unit masukan (Xi, i = 1,...,n)
menerima sinyal dan meneruskannya ke unit tersembunyi di atasnya.
5 Masing-masing unit di lapisan
tersembunyi dikalikan dengan faktor penimbang dan dijumlahkan serta ditambah dengan biasnya.
Zinj=V0j+
i= 1n
XiVij
Kemudian hitung nilai masing-masing unit tersembunyi sesuai dengan fungsi aktivasi yang digunakan :
Zj=f(Zinj)
6 Masing-masing unit keluaran (Yk, k =
1,...,m) dikalikan dengan faktor
penimbangnya dan dijumlahkan:
Yink=W0k+
i= 1
p
ZjWjk
Kemudian hitung nilai unit keluaran sesuai dengan fungsi aktivasi yang digunakan :
Yk=f(Yink)
Fase II: Propagasi mundur
7 Masing-masing unit keluaran (Yk, k =
1,...,m) meneriman pola target sesuai
dengan pola masukan saat pelatihan dan dihitung galatnya:
k= (tk–Yk)f(Yink)
Menghitung perbaikan faktor penimbang
(kemudian untuk memperbaiki Wjk).
Wjk=.k.Zj
Menghitung perbaikan koreksi:
W0k=.k
8 Masing-masing penimbang yang
menghubungkan unit-unit lapisan keluaran dengan unit-unit pada lapisan tersembunyi dikalikan delta dan dijumlahkan sebagai masukan ke unit-unit lapisan berikutnya:
inj=
k= 1
m
kWjk
Selanjutnya dikalikan dengan turunan dari fungsi aktivasinya.
j=injf(Yinj)
9 Masing-masing keluaran unit (Yk,
k=1,…,m) diperbaiki bias dan
penimbangnya (j=0,...,p):
Wjk(baru) =Wjk(lama) +Wjk
Masing-masing keluaran unit (Zj,
j=1,…,p) diperbaiki bias dan
Vjk(baru) =Vjk(lama) +Vjk
10 Uji kondisi pemberhentian (akhir iterasi).
METODE PENELITIAN
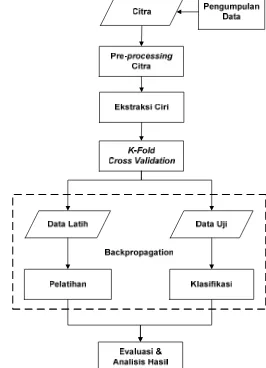
Untuk dapat melakukan penelitian yang baik, maka diperlukan sebuah metode penelitian yang baik dan terencana pula. Pada penelitian ini akan dilakukan identifikasi karakter pada plat nomor kendaraan bermotor. Skema metode penelitian ini dapat dilihat pada Gambar 2.
Gambar 2 Skema metode penelitian
Pengumpulan Data
Data yang digunakan pada penelitian ini berupa citra yang diambil menggunakan
kamera handphone dengan resolusi sebesar 5
MP. Citra yang dikumpulkan harus memperhatikan jumlah kemunculan masing-masing karakter, dengan sebaran frekuensi yang merata untuk setiap karakter. Hal tersebut dilakukan agar data latih yang dimiliki dapat lebih akurat untuk setiap karakter yang ada.
Selain itu perlu diperhatikan juga bahwa semua citra yang dikumpulkan harus memiliki resolusi yang sama. Karena kamera yang digunakan memiliki resolusi 5 MP dan akan menghasilkan citra dengan resolusi yang cukup besar, citra perlu diubah terlebih dahulu ke resolusi yang lebih kecil dengan tetap memperhatikan kualitas citra. Dengan demikian, pemrosesan citra yang akan dilakukan dapat lebih cepat.
Pra-proses citra
Agar citra dapat diekstraksi dan dilakukan pengenalan pola, perlu melalui tahap
pra-proses terlebih dahulu. Data yang didapat dari proses pengumpulan sebelumnya merupakan citra dengan format warna RGB. Proses identifikasi karakter pada plat nomor tidak perlu memperhatikan perbedaan warna RGB, oleh karena itu akan lebih efisien jika diubah
ke dalam format grayscale. Proses konversi
dalam format grayscale dapat menggunakan
rumus:
0.2989 * R + 0.5870 * G + 0.1140 * B
R, G, dan B merupakan intensitas dari masing-masing warna merah, hijau, dan biru pada citra. Dengan mengonversi format warna ke grayscale tentu saja dapat mempercepat komputasi pada tahap berikutnya.
Restorasi dan Perbaikan Citra
Pada dasarnya, citra yang diambil menggunakan sebuah kamera terkadang
memiliki noise yang dapat mengurangi
kualitas citra dan menghilangkan informasi yang diperlukan dalam proses pengenalan karakter. Oleh karena itu perlu dilakukan restorasi menggunakan filter yang ada, salah
satunya adalah filter median yang cukup
efisien dalam merestorasi citra dengan noise
bertipe salt & pepper. Untuk lebih
meningkatkan kualitas citra juga dapat
dilakukan proses sharpening atau smoothing
sesuai dengan kebutuhannya.
Deteksi Tepi
Jika citra sudah bersih dari noise,
selanjutnya dilakukan proses pendeteksian tepi. Setiap objek yang ada pada citra akan
dideteksi menggunakan algoritme Canny.
Algoritme ini dipilih karena cukup baik dalam mendeteksi tepi. Selain memiliki kemampuan untuk meletakkan dan menandai semua tepi yang ada sesuai dengan pemilihan parameter-parameter konvolusi yang dilakukan,
algortima Canny juga memberikan
fleksibilitas yang sangat tinggi dalam hal menentukan tingkat deteksi ketebalan tepi sesuai dengan yang kita inginkan. Contoh hasil deteksi tepi Canny dapat dilihat pada Gambar 3.
Gambar 3 Contoh hasil deteksi tepi Canny.
Segmentasi Citra
dan memilih mana objek yang merupakan karakter dan mana yang bukan. Hal tersebut dilakukan dengan mensegmentasi citra berdasarkan area. Objek yang memiliki piksel-piksel yang terhubung akan dianggap menjadi satu area. Masing-masing area tersebut akan diberi label untuk kemudian dihitung luas areanya satu per satu. Untuk
mendeteksi apakah suatu pixel terhubung
dengan pixel tetangganya digunakan metode
8-connected.
{(x-1, y-1), (x-1,y), (x-1,y-1), (x,y-1), (x,y+1), (x+1,y-1), (x+1,y), (x+1,y+1)}
Selanjutnya akan ditentukan suatu batas yang menjadi acuan untuk menduga apakah objek tersebut merupakan karakter atau bukan berdasarkan luas areanya. Contoh hasil segmentasi dapat dilihat pada Gambar 4.
Gambar 4 Contoh hasil segmentasi
Ekstraksi Ciri
Tahapan ini dilakukan untuk mendapatkan fitur yang menjadi ciri dari setiap karakter pada plat nomor. Fitur tersebut nantinya akan menjadi acuan dalam proses klasifikasi dan pengenalan pola.
Dalam penelitian ini pendekatan yang digunakan adalah ekstraksi fitur berbasis area,
yaitu Image Centroid and Zone
Image Centroid and Zone (ICZ)
Pendekatan menggunakan Image
Centroid and Zone (ICZ) ini merupakan metode yang cukup sederhana dalam implementasinya. Sebelum dilakukan tahapan pada metode ini perlu dipastikan bahwa setiap karakter yang ada memiliki dimensi yang
sama besar. Kemudian dihitung nilai centroid
dengan rumus sebagai berikut:
Xc=x 1.p 1 +x 2.p 2 + ... +xn.pn
Setelah didapat centroid dari citra, bagi
citra input menjadi empat area yang sama
besar. Selanjutnya dicari jarak antara centroid
dengan koordinat pixel yang memiliki nilai 1
(warna putih). Jarak akan dihitung menggunakan metode Euclidean dua dimensi. Berikut ini rumus jarak menggunakan
Euclidean dengan P = (Xp, Yp) dan Q = (Xq,
Proses tersebut akan dilakukan hingga
semua pixel yang ada pada semua area
dihitung. Tahap terhakhir yang dilakukan adalah menghitung rata-rata jarak pada setiap area. Rata-rata tersebutlah yang akan dijadikan sebagai data klasifikasi.
Untuk mencari jumlah zona yang efisien untuk pendeteksian plat nomor kendaraan ini perlu dilakukan beberapa pembagian zona. Setiap pembagian zona ini akan memiliki performa yang berbeda. Pembagian zona terus dilakukan selama performa masih meningkat. Apabila terjadi penurunan performa, akan diambil zona yang terkecil dengan performa yang paling besar.
K-Fold Cross Validation
Seluruh data citra yang ada akan dibagi
menjadi lima subset, yaitu fold1, fold2, fold3,
fold4 dan fold5. Hal tersebut dilakukan untuk
mencari akurasi menggunakan 5-cross-fold
validation. Pembagian subset dapat dilihat pada Tabel 1.
Tabel 1 Pembagian subset
Subset Data Latih Data Uji
Klasifikasi Citra
Untuk dapat mengklasifikasikan karakter pada plat nomor diperlukan suatu struktur
neural network dengan output sebanyak 36 (
26 huruf dan 10 angka ). Input yang
Dalam melakukan pelatihan dan pengujian data, karakter akan diambil satu per satu dari kumpulan citra plat yang ada. Setiap karakter yang akan dilatih harus dipastikan memiliki luas area (dimensi) yang sama satu sama lain.
Jaringan saraf tiruan dengan metode
backpropagation cocok diterapkan dalam penelitian ini. Walaupun dalam komputasi metode ini terbilang cukup berat karena terus menerus menghitung nilai eror yang terjadi, namun justru metode tersebut yang diperlukan untuk menutupi apabila terjadi kekurangan pada proses ekstraksi ciri.
Evaluasi dan Analisis Hasil
Tahap ini merupakan tahap terakhir untuk mengevaluasi kekurangan dan kelebihan dari metode yang digunakan. Hal tersebut dilihat dari perbandingan hasil klasifikasi citra dengan nomor polisi aslinya. Hasil yang tidak sesuai maupun sesuai dicatat untuk menentukan seberapa besar akurasi dari metode ini. Untuk menghitung akurasi berikut digunakan:
akurasi=nbenar
n 100%
nbenar : Jumlah citra yang dideteksi benar.
n : Jumlah data yang ada.
Lingkungan Pengembangan Sistem
Proses pengerjaan penelitian ini menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut :
Perangkat keras berupa notebook:
Processor Intel Pentium Dual-Core @1.73GHz,
RAM kapasitas 1 GB,
Harddisk kapasitas 150GB,
Monitor dengan resolusi 1280x800 piksel. Perangkat lunak berupa:
Sistem operasi Microsoft Windows Vista.
Aplikasi pemrograman Matlab R2008b.
HASIL DAN PEMBAHASAN
Pengumpulan Data
Dalam penelitian ini tentunya data yang diperlukan adalah data berupa citra. Data tersebut didapat dengan melakukan pemotretan mobil sebanyak 100 unit dan secara otomatis akan didapatkan pula 100 buah citra plat nomor yang unik. Pemotretan dilakukan di halaman parkir kampus IPB Baranangsiang Bogor.
Dari 100 buah citra yang ada kemudian diambil potongan karakter yang mewakili angka dan huruf pada plat nomor. Untuk masing-masing karakter diambil secara unik dan acak sebanyak 50 buah. Seperti kita ketahui jumlah angka (0-9) dan huruf (A-Z) yang ada adalah 36 karakter, berarti akan didapat 1800 karakter yang nantinya akan dijadikan sebagai data latih dan data uji. Selain itu citra plat nomor yang ada juga akan dijadikan sebagai data uji. Contoh data sampel dapat dilihat pada Gambar 5.
Gambar 5 Data sampel.
Pra-proses Citra
Foto yang didapat dari proses pengumpulan data tidak semuanya memiliki kualitas yang baik. Sangat memungkinkan
ditemukan noise yang dapat mengurangi
akurasi dalam pendeteksian karakter. Selain itu masih banyak informasi pada citra yang tidak dibutuhkan dan dapat memperlambat proses pendeteksian. Untuk itu perlu dilakukan optimalisasi sehingga pada akhirnya data yang ada sudah siap untuk diproses.
Pada awalnya didapat foto dengan model warna RGB. Model warna tersebut terlalu
kompleks karena menggunakan tiga layer
warna, yaitu Red, Green, dan Blue. Untuk itu
dilakukan konversi dari warna RGB menjadi
grayscale. Proses konversi tersebut dilakukan
dengan menghilangkan informasi hue dan
saturation, sedangkan informasi luminance
pada citra dipertahankan.
Langkah berikutnya adalah membersihkan
noise menggunakan median filter. Metode ini
sangat cocok untuk menghilangkan noise
berupa salt & pepper. Jika kita melihat
dengan kasat mata, salt & pepper akan terlihat
seperti bintik warna hitam atau putih. Kali ini digunakan median filter dua dimensi dengan
batas matriks 3x3. Nilai pixel akan diubah
dengan membandingkan pixel tujuan dengan
pixel tetangga, kemudian dicari nilai tengah
dari pixel tersebut. Banyaknya pixel yang
Deteksi Tepi
Proses deteksi dilakukan menggunakan
metode canny’s edge detection dengan
threshold 0.2 dan 0.5. Nilai threshold ini mempengaruhi seberapa detail proses deteksi tepi yang akan dilakukan. Hal ini merupakan salah satu kelebihan dari metode Canny.
Tahapan ini akan menghasilkan citra biner yang merepresentasikan garis tepi dari setiap objek pada citra. Garis tepi inilah yang nantiya akan digunakan untuk memisahkan karakter yang diperlukan dengan objek lainnya. Didapatnya garis tepi disetiap objek, akan mempercepat pemrosesan citra dan lebih efisien. Hasil deteksi tepi menggunakan metode Canny pada salah satu plat nomor dapat dilihat pada Gambar 6.
Gambar 6 Hasil deteksi tepi Canny.
Segmentasi Citra
Segmentasi citra dilakukan untuk memisahkan informasi yang akan diproses lebih lanjut. Pada penelitian ini, informasi
yang akan diproses adalah pixel-pixel yang
mewakili angka dan huruf. Perlu dicari mana
pixel yang mewakili huruf atau angka dan mana yang bukan keduanya.
Tahap pertama yang dilakukan adalah
dengan melakukan labeling, yaitu
pengelompokan pixel yang terhubung dengan
memperhatikan 8 pixel tetangganya. Setiap
pixel yang terhubung akan dikelompokan dan diberi label. Berikutnya dapat kita ketahui panjang dan lebar area untuk masing-masing label. Kedua variabel ini yang akan dijadikan sebagai parameter untuk memprediksi mana
pixel yang mewakili huruf dan angka. Setiap label akan diukur panjang dan lebar areanya dengan kondisi sebagai berikut:
If 105 pixel < P < 140 pixel
And 20 pixel < L < 100 pixel Then label = karakter
Else
label ≠ karakter
Semua label yang memenuhi syarat berarti dianggap sebagai karakter. Permasalahan berikutnya yang muncul adalah adanya label yang seharusnya merupakan satu karakter utuh, namun komputer tidak langsung mengenali label tersebut sebagai satu karakter yang utuh. Sebagai contoh pada angka 0 (nol), angka tersebut secara visual diwakili oleh dua
buah elips. Karena algoritme labeling yang
dilakukan adalah memeriksa pixel yang
terhubung, sedangkan pada angka 0 (nol) terlihat jelas bahwa dua buah elips terpisah jauh, sehingga secara otomatis elips tersebut dianggap sebagai label yang berbeda. Ilustrasi permasalahan tersebut dapat dilihat pada Gambar 7.
Gambar 7 labeling pada angka nol
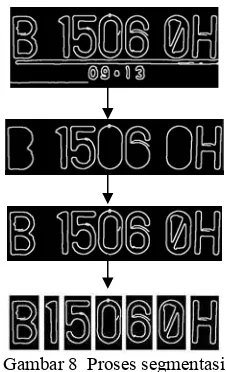
Hal tersebut berlaku bagi setiap karakter yang memiliki kondisi seperti angka 0 (nol). Untuk menangani permasalahan tersebut solusinya adalah dengan memeriksa posisi masing-masing label. Jika salah satu label berada di dalam area label lainnya, label-label tersebut akan dijadikan satu. Hingga tahap ini telah dihasilkan kumpulan label berupa matriks yang mewakili setiap karakter pada plat. Ilustrasi proses segmentasi dapat dilihat pada Gambar 8.
Gambar 8 Proses segmentasi
Normalisasi Citra
ukuran ini dilakukan secara konsisten pada semua karakter tidak akan mempengaruhi informasi yang diperlukan pada tahapan ekstraksi ciri. Gambar 9 menunjukkan perubahan beberapa karakter.
Gambar 9 Normalisasi karakter.
Ekstraksi Ciri
Sesuai dengan metode penelitian ekstraksi
ciri yang digunakan adalah pendekatan image
centroid and zone (ICZ). Tahap pertama yang
dilakukan ialah mencari centroid atau titik
beban dari setiap karakter. Titik beban yang didapat dari setiap karakter tidak selalu sama.
Hal tersebut bergantung pada sebaran pixel
setiap karakter. Gambar 10 menunjukkan
centroid untuk huruf “F”.
Gambar 10 Titik beban pada huruf F.
Berikutnya, karakter akan dibagi menjadi beberapa zona yang sama besar. Pada penelitian ini dicari zona yang efisien untuk melakukan pendeteksian plat nomor. Oleh karena itu, perlu dilakukan beberapa percobaan pembagian zona, yaitu 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, dan 25. Banyaknya jumlah pembagian zona ini akan mempengaruhi ciri dari masing-masing karakter. Pada setiap pembagian zona tersebut, jumlah baris selalu lebih banyak daripada jumlah kolom atau keduanya sama banyak. Gambar 11 mengilustrasikan pembagian untuk masing-masing zona.
Gambar 11 Pembagian zona ekstraksi fitur.
Untuk setiap zona dihitung masing-masing
jarak antara centroid dan pixel yang memiliki
nilai 1 (warna putih). Proses perhitungan jarak ini akan dilakukan terus menerus hingga
didapat jarak dari semua pixel . Pada akhirnya
akan dihitung rata-rata jarak yang ada di setiap zona. Nilai rata-rata tersebut merupakan ciri yang merepresentasikan bentuk dari setiap karakter. Setelah dikumpulkan ternyata nilai rata-rata tersebut membentuk suatu pola yang berbeda bagi setiap karakter. Pola ini dapat dijadikan pertimbangan untuk membedakan karakter pada proses klasifikasi. Masing-masing pola mewakili hasil ekstraksi setiap karakter.
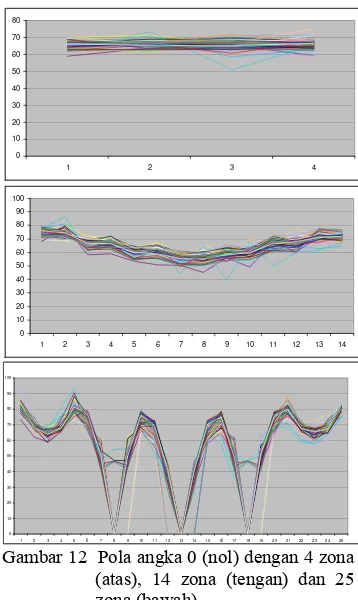
Gambar 12 menunjukkan pola angka 0 (nol) yang dibentuk dari hasil ekstraksi fitur sebanyak 50 karakter dengan pembagian 4, 14 dan 25 zona.
0 10 20 30 40 50 60 70 80
1 2 3 4
0 10 20 30 40 50 60 70 80 90 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14
0 10 20 30 40 50 60 70 80 90 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Gambar 12 Pola angka 0 (nol) dengan 4 zona (atas), 14 zona (tengan) dan 25 zona (bawah).
Gambar 13 menunjukkan hasil praproses angka 0 (nol) yang baik.
Gambar 13 Hasil praproses yang baik.
Namun ada beberapa hasil praproses yang kurang baik sehingga mempengaruhi hasil ekstraksi dan tentu saja pola yang didapat pun tidak akan mirip. Hal ini terlihat pada Gambar 14.
Gambar 14 Hasil praproses yang kurang baik.
Semakin mirip pola yang didapat dari hasil ekstraksi 50 karakter yang sama, akan semakin memperkuat ciri dari karakter tersebut dan juga mudah dikenali pada proses pendeteksian nanti. Pola dari semua karakter dengan pembagian zona sebanyak 14 zona dapat dilihat pada Lampiran 1.
Untuk permasalahan waktu pemrosesan, setiap proses ICZ yang dilakukan tentunya memiliki waktu pemrosesan yang berbeda-beda bagi setiap zona. Waktu pemrosesan ini bergantung pada spesifikasi perangkat keras yang digunakan dan juga algoritme pemrograman yang diimplementasikan. Waktu pemrosesan untuk 1800 karakter pada penelitian ini dapat dilihat pada Tabel 2.
Tabel 2 Waktu pemrosesan ekstraksi fitur menggunakan ICZ.
Zona Waktu Pemrosesan
4 118.19
Pada Tabel 2 terlihat bahwa perbedaan waktu proses ekstraksi fitur tidak terartur berdasarkan jumlah zona. Akan tetapi, untuk jumlah zona yang sangat banyak cenderung memerlukan waktu yang lebih lama. Untuk menganalisis mengenai waktu proses ekstraksi
fitur ini dapat dilihat pada Tabel 3 dan Tabel 4 yang menampilkan waktu proses terhadap 10 plat nomor.
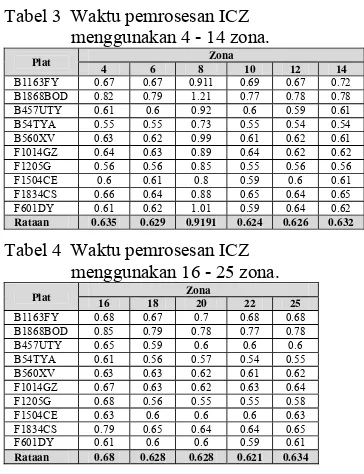
Tabel 3 Waktu pemrosesan ICZ menggunakan 4 - 14 zona.
Plat Zona
4 6 8 10 12 14
B1163FY 0.67 0.67 0.911 0.69 0.67 0.72 B1868BOD 0.82 0.79 1.21 0.77 0.78 0.78 B457UTY 0.61 0.6 0.92 0.6 0.59 0.61 B54TYA 0.55 0.55 0.73 0.55 0.54 0.54 B560XV 0.63 0.62 0.99 0.61 0.62 0.61 F1014GZ 0.64 0.63 0.89 0.64 0.62 0.62 F1205G 0.56 0.56 0.85 0.55 0.56 0.56 F1504CE 0.6 0.61 0.8 0.59 0.6 0.61 F1834CS 0.66 0.64 0.88 0.65 0.64 0.65 F601DY 0.61 0.62 1.01 0.59 0.64 0.62 Rataan 0.635 0.629 0.9191 0.624 0.626 0.632
Tabel 4 Waktu pemrosesan ICZ menggunakan 16 - 25 zona.
Plat Zona
16 18 20 22 25
B1163FY 0.68 0.67 0.7 0.68 0.68 B1868BOD 0.85 0.79 0.78 0.77 0.78 B457UTY 0.65 0.59 0.6 0.6 0.6 B54TYA 0.61 0.56 0.57 0.54 0.55 B560XV 0.63 0.63 0.62 0.61 0.62 F1014GZ 0.67 0.63 0.62 0.63 0.64 F1205G 0.68 0.56 0.55 0.55 0.58 F1504CE 0.63 0.6 0.6 0.6 0.63 F1834CS 0.79 0.65 0.64 0.64 0.65 F601DY 0.61 0.6 0.6 0.59 0.61 Rataan 0.68 0.628 0.628 0.621 0.634
Dari Tabel 3 dan 4, hampir semua zona memiliki rata-rata waktu pemrosesan terhadap 10 plat nomor yang tidak berbeda jauh, yaitu berkisar di 0.6 sampai 0.63 detik. Terlihat bahwa banyaknya zona tidak mempengaruhi waktu pemrosesan plat karena proses pembagian zona ini hanya membatasi
banyaknya pixel yang dihitung untuk
masing-masing zona. Semakin sedikit pembagian
zona, jumlah pixel pada setiap zona akan
semakin banyak. Hal tersebut menyebabkan perbandingan antara jumlah zona dan
banyaknya pixel akan berbanding terbalik.
Oleh karena itu perbedaan waktu pemrosesan tidak akan terpaut jauh.
Klasifikasi Citra
Pada tahap ini dilakukan pelatihan data dan pengujian data. Untuk tahap pelatihan dilakukan terhadap hasil ektraksi 1440 citra yang terdiri atas 36 karakter dan untuk setiap karakter memiliki 40 sampel, sehingga tersisa masing-masing 10 sampel yang akan menjadi data uji.
Penentuan data uji dan data latih ini
menggunakan metode k-fold cross validation,
dengan nilai k adalah 5. Dihasilkan 5 subset atau variasi data uji dan data latih. Pemilihan banyaknya subset ini berdasarkan dengan rasio yang diinginkan, yaitu 80% untuk data latih dan 20% untuk data uji.
Setiap subset data latih akan dibentuk
1440, Angka n mewakili jumlah zona pada proses ekstraksi ciri dan 1440 adalah banyaknya sampel karakter. Matriks data latih ini akan dipasangkan dengan matriks target dengan ukuran 36 x 1440. 36 merupakan jumlah kelas yang mewakili angka dan huruf. Semua data latih akan diklasifikasikan menggunakan jaringan saraf tiruan
backpropation dengan struktur sebagai berikut :
Input layer : 25
Hidden Layer : 30
Output Layer : 36
Training Function : TRAINLM
Transfer Function
Layer 1 : LOGSIG
Layer 2 : TANSIG
Learn Function : LEARNGDM
Maximum Epoch : 1000 Epoch
Minimum Gradient : 1e-010
Maximum Fail : 6
Setelah semua data latih telah diklasifikasikan, didapat jaringan saraf tiruan yang digunakan untuk melakukan proses pengujian data. Pengujian dilakukan terhadap masing-masing karakter dan juga pada plat nomor secara utuh. Hasil pelatihan dari setiap JST dapat dilihat pada Lampiran 2.
Pengujian Karakter
Hasil akurasi dari pengujian ini tentunya akan berbeda-beda bergantung terhadap performa setiap proses pelatihan. Dalam mendeteksi karakter, masing-masing JST memiliki akurasi yang baik hanya untuk beberapa karakter tertentu.
Setiap karakter diuji sebanyak 50 kali sesuai dengan subset yang sudah disiapkan
pada proses k-fold cross validation. Matriks
confusion dari hasil pengujian karakter tersebut dapat dilihat pada Lampiran 3 hingga 13 dan hasil pengujian karakter menggunakan beberapa zona dan struktur JST yang telah ditentukan sebelumnya tertera pada Tabel 5.
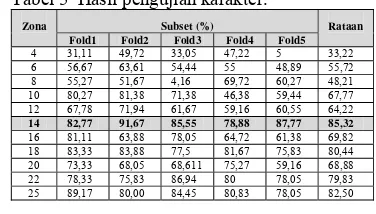
Tabel 5 Hasil pengujian karakter.
Zona Subset (%) Rataan
Fold1 Fold2 Fold3 Fold4 Fold5
4 31,11 49,72 33,05 47,22 5 33,22 6 56,67 63,61 54,44 55 48,89 55,72 8 55,27 51,67 4,16 69,72 60,27 48,21 10 80,27 81,38 71,38 46,38 59,44 67,77 12 67,78 71,94 61,67 59,16 60,55 64,22 14 82,77 91,67 85,55 78,88 87,77 85,32 16 81,11 63,88 78,05 64,72 61,38 69,82 18 83,33 83,88 77,5 81,67 75,83 80,44 20 73,33 68,05 68,611 75,27 59,16 68,88 22 78,33 75,83 86,94 80 78,05 79,83 25 89,17 80,00 84,45 80,83 78,05 82,50
Pada Tabel 5 terlihat perubahan tingkat akurasi yang fluktuaktif, namun jika merata-ratakan hasil akurasi tersebut secara garis
besar terjadi peningkatan hingga zona ke-14 dan berangsur turun untuk zona berikutnya. Pembagian 14 zona memiliki rata-rata tingkat akurasi terbesar, yaitu 85.32%. Oleh karena itu, zona ke-14 merupakan zona yang tepat dan efisien untuk memproses ciri dari setiap karakter pada plat nomor. Walapun pada Tabel 5 terlihat bahwa ketika menggunakan 25 zona juga menghasilkan tingkat akurasi yang cukup tinggi dan tidak berbeda jauh dari 14 zona, yaitu sebesar 82.50%. Tetapi, ada pertimbangan berikutnya untuk memilih zona yang efisien, yaitu waktu saat pemrosesan untuk 14 dan 25 zona terdapat perbedaan yang cukup berpengaruh, yaitu 126.77 detik untuk 14 zona dan 162.37 detik untuk 25 zona. Jumlah zona yang tidak terlalu banyak waktu pemrosesan menjadi lebih cepat dan tetap dapat menghasilkan tingkat akurasi yang tinggi. Dengan demikian, 14 zona tetap lebih efisien dalam menentukan ciri karakter pada penelitian ini. Gambar 15 menunjukkan huruf D yang dibagi menjadi 14 zona.
Gambar 15 Pembagian 14 zona pada huruf D.
Pembagian zona yang terlalu sedikit akan menyebabkan karakter sulit dikenali karena hanya memiliki sedikit ciri yang unik pada masing-masing zona sehingga ciri yang didapat untuk masing-masing karakter tidak akurat. Terlihat pada karakter yang dibagi dalam 4 zona. Ukuran setiap zona terlalu besar memungkinkan banyaknya kemiripan yang terjadi pada karakter. Sebagai contoh, Gambar 16 menunjukkan huruf D yang dibagi menjadi 4 zona.
Gambar 16 Pembagian 4 zona pada huruf D.
Sebaliknya, pembagian zona yang terlalu banyak pun kurang baik digunakan karena ukuran zona yang terlampau kecil juga berpotensi menimbulkan kemiripan ciri antara karakter. Dengan ukuran zona yang kecil akan
banyak ditemukan zona yang bernilai null,
karena pada bagian tersebut tidak ada pixel
yang menjadi pertimbangan untuk menentukan ciri setiap karakter. Selain itu, waktu komputasi yang diperlukan akan semakin lama karena banyaknya zona yang
Sebagai contoh, Gambar 17 menunjukkan huruf D yang dibagi menjadi 25 zona.
Gambar 17 Pembagian 25 zona pada huruf D.
Sebagai fokus pembahasan dilakukan analisis terhadap hasil pengujian dengan pembagian zona yang paling efisien, yaitu 14 zona. Pada pengujian tersebut ada beberapa karakter yang berhasil dideteksi 100%, yaitu D, K, L, M, dan P. Hal ini terjadi karena pada proses ekstraksi fitur karakter-karakter tersebut memiliki pola hasil ekstraksi yang seragam, sehingga memiliki ciri yang unik dan mudah untuk dikenali di antara karakter-karakter lainnya. Gambar 18 menunjukkan pola hasil ekstraksi dari 50 karakter D, K, L, M, dan P.
Pola huruf D
0
Pola huruf K
0
Pola huruf L
0
Pola huruf M
0
Gambar 18 Pola hasil ekstraksi karakter D, K, L, dan M.
Selain karakter-karakter yang berhasil dideteksi secara sempurna, ternyata ada
beberapa karakter yang tingkat akurasinya masih tergolong rendah, yaitu masih di bawah 70%. Tabel 6 menunjukkan hasil deteksi pada karakter yang memiliki tingkat akurasi rendah.
Tabel 6 Hasil deteksi karakter dengan akurasi rendah.
Karakter Hasil Deteksi (n)
R A(5), S(4), 2(3), P(2), Z(2), 3(1), G(1), N(1), Q(1)
S X(6), C(4), 9(3), G(3), 1(2), 3(2), 5(1), B(4), J(1), O(1), V(1), Y(1)
U 5(9), 6(3), D(3), N(2), W(2), O(1)
Pada Tabel 6, n merupakan banyaknya
karakter yang terdeteksi. Untuk karakter R kesalahan deteksi paling banyak dianggap sebagai karakter A, karakter S sebagai karakter X, dan karakter U sebagai karakter 5. Dari bentuk masing-masing karakter tersebut memang terlihat bahwa kesalahan deteksi yang terjadi meleset cukup jauh. Namun pada dasarnya dalam melakukan pendeteksian karakter, hasil klasifikasi didapat berdasarkan
rata-rata jarak setiap zona terhadap centroid
yang menjadi ciri dari masing-masing karakter. Jika kita membandingkan rata-rata setiap zona dari masing-masing karakter tersebut, akan terlihat kemiripan pada beberapa zona yang ditunjukan dengan perbedaan nilai rata-rata zona yang tidak terlalu jauh. Zona akan dianggap mirip apabila memiliki perbedaan rata-rata jarak antara 0
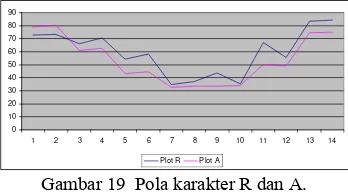
sampai 3 pixel. Gambar 19 menunjukkan
perbandingan pola karakter R dan A.
0
Karakter R dan A memiliki kemiripan pola pada zona 7 dan zona 10. Kemiripan dari karakter R dan A berdasarkan hasil ICZ dapat dilihat pada Tabel 7.
Z1 78,99129 80,47618 Z2
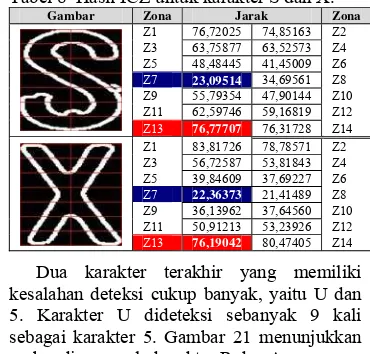
Berikutnya karakter S dideteksi sebagai X sebanyak 6 kali. Hal ini terjadi juga karena adanya kemiripan pada beberapa zona dari kedua karakter tersebut. Gambar 20 menunjukkan perbandingan pola karakter S dan X.
Karakter S dan X memiliki 2 zona yang mirip, yaitu zona 7 dan zona 13. Kemiripan dari karakter S dan X berdasarkan hasil ICZ dapat dilihat pada Tabel 8.
Tabel 8 Hasil ICZ untuk karakter S dan X.
Dua karakter terakhir yang memiliki kesalahan deteksi cukup banyak, yaitu U dan 5. Karakter U dideteksi sebanyak 9 kali sebagai karakter 5. Gambar 21 menunjukkan perbandingan pola karakter R dan A.
0
Kedua karakter ini memiliki banyak zona yang mirip, yaitu zona 1, 2, 9, 11, 13, dan 14. Oleh karena itu ketika dideteksi kedua karakter ini memiliki kesalahan terbanyak.
Kemiripan dari karakter U dan 5 berdasarkan hasil ICZ dapat dilihat pada Tabel 9.
Tabel 9 Hasil ICZ untuk karakter U dan 5.
Selain kesalahan deteksi di atas masih ada beberapa kesalahan deteksi yang terlihat cukup jauh perbedaannya jika dilihat berdasarkan bentuknya. Hal ini terjadi karena ada beberapa karakter dengan pola ekstraksi fitur pada proses pelatihan yang tidak seragam. Selain itu, ciri dari setiap karakter hanya dilihat berdasarkan rata-rata jarak setiap
pixel dan centroid, yang memungkinkan beberapa karakter memiliki jumlah pixel yang sama pada beberapa zona tertentu. Sebagai contoh pada Tabel 6, karakter R sempat dideteksi sebagai karakter P sebanyak dua kali. Untuk dapat menjelaskan permasalahan ini dapat dilihat dari hasil ekstraksi fitur 50 karakter R dan P pada Gambar 22.
Gambar 22 Pola ekstraksi 50 karakter R (atas) dan P (bawah).
Pengujian Plat
Pengujian berikutnya yang harus dilakukan adalah pengujian terhadap plat secara utuh. Pada dasarnya hasil akurasi dari pengujian plat ini bergantung pada hasil akurasi pada setiap karakter. Akurasi pengujian plat juga akan lebih kecil bila dibandingkan dengan akurasi pengujian setiap karakter. Karena pada kehidupan nyata jika terjadi kesalahan deteksi pada salah satu karakter yang ada pada plat, pendeteksian itu dianggap salah. Namun, agar proses pendeteksian plat nomor ini menjadi lebih fleksibel, ditampilkan juga hasil pengujian plat gabungan antara pengujian plat tanpa toleransi kesalahan dan dengan toleransi kesalahan deteksi karakter pada plat sebanyak satu kali untuk masing-masing plat. Hasil pendeteksian plat dapat dilihat pada Lampiran 14 hingga 24.
Pengujian dilakukan terhadap 65 plat nomor kendaraan menggunakan JST dengan semua zona ekstraksi fitur, hasilnya tertera pada Tabel 10.
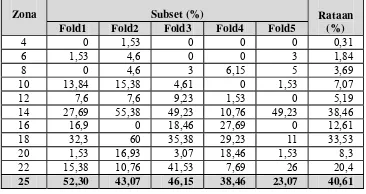
Tabel 10 Hasil pengujian 65 plat.
Zona Subset (%) Rataan
(%)
Berdasarkan hasil pengujian plat pada Tabel 10 terlihat bahwa tingkat akurasi tertinggi terjadi pada JST yang menggunakan 25 zona, yaitu sebesar 40.61%. Akurasi tertinggi ini berbeda ketika melakukan pengujian karakter. Akurasi tertinggi terjadi dengan menggunakan 14 zona. Seharusnya akurasi tertinggi pada pengujian plat ini juga terjadi pada 14 zona. Namun pengujian plat yang menggunakan 14 zona menghasilkan rata-rata akurasi sebesar 38.46%. Walaupun demikian, perbedaan akurasi ini tetap mengikuti akurasi pengujian per karakter. Jika akurasi per karakter besar, akurasi pada pengujian plat ini juga akan besar.
Berikutnya akurasi pengujian plat dengan toleransi kesalahan sebanyak satu kali. Sebanyak 65 plat yang ada akan dikelompokan berdasarkan jumlah karakter yang terdiri di dalamnya. Hasil akurasi dilihat berdasarkan persentase kesalahan dari masing-masing plat tersebut. Plat yang masih dianggap benar diberikan toleransi kesalahan
sebesar 25%. Hasilnya dapat dilihat pada Tabel 11.
Tabel 11 Hasil pengujian plat dengan toleransi kesalahan.
Zona Subset (%) Rataan
(%) 20 13,84 53,84 12,30 53,84 20,00 30,76 22 60,00 38,46 80,00 47,69 55,00 56,31 25 81,5 69,20 75,30 72,30 49,20 69,50
Pada Tabel 11 terlihat bahwa akurasi tertinggi juga terjadi pada 25 zona, yaitu sebesar 69.50% sesuai dengan akurasi plat tanpa toleransi pada Tabel 8. Dengan adanya toleransi kesalahan ini, proses pendeteksian plat nomor menjadi lebih fleksibel untuk dikembangkan menjadi suatu sistem deteksi plat nomor kendaraan.
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian yang telah dilakukan untuk mendetksi karakter pada plat nomor
menggunakan zone based feature extraction
dengan metode klasifikasi JST
backpropagtion dapat disimpulkan sebagai berikut:
1 Pada penelitian pendeteksian plat nomor
ini telah berhasil menggunakan
pendekatan Image Centroid and Zone
sebagai metode ekstraksi fitur dan jaringan
saraf tiruan backpropagation sebagai
metode klasifikasi. .
2 Pembagian zone menggunakan metode
Image Centroid and Zone yang paling efisien terhadap pendeteksian plat nomor ini adalah sebanyak 14 zona karena memiliki waktu pemrosesan yang lebih cepat, yaitu 126.77 detik untuk 1800 karakter.
3 Waktu pemrosesan dan jumlah pembagian
zona berbanding lurus. Semakin banyak zona yang digunakan, waktu pemrosesan yang dibutuhkan akan lebih banyak.
4 Pembagian zona untuk melakukan
5 Tingkat akurasi tertinggi untuk pendeteksian karakter mencapai 85.32 %. Nilai tersebut merupakan rata-rata tertinggi pada JST yang menggunakan 14
zona ekstraksi fitur. Banyaknya karakter
yang diuji adalah 1800 karakter berdasarkan penentuan subset pada tahap k-fold cross validation.
6 Tingkat akurasi tertinggi untuk
pendeteksian terhadap 65 buah plat nomor adalah 40.61%. Nilai tersebut merupakan rata-rata tertinggi pada JST yang
menggunakan 25 zona ekstraksi fitur.
7 Tingkat akurasi tertinggi untuk
pendeteksian terhadap 65 buah plat nomor dengan toleransi kesalahan sebanyak satu kali adalah 69.50%. Nilai tersebut merupakan rata-rata tertinggi pada JST
yang menggunakan 25 zona ekstraksi fitur.
Saran
Untuk terus mengembangkan penelitian ini perlu dilakukan saran sebagai berikut:
1 Dapat dilakukan pendeteksian plat
menggunakan metode ekstraksi fitur dan metode klasifikasi lainnya.
2 Dalam melakukan proses ekstraksi fitur
dapat menggunakan metode yang lebih
kompleks dari image centroid and zone
dan metode klasifikasi yang lebih sederhana dari jaringan saraf tiruan
backpropagation .
3 Menambahkan foto-foto plat nomor
kendaraan bermotor yang nantinya akan dijadikan sebagai data latih dan data uji.
4 Dapat dikembangkan untuk membangun
suatu sistem pencatatan plat nomor dengan berbagai kebutuhan yang terintegrasi oleh metode pendeteksian karakter pada plat nomor.
DAFTAR PUSTAKA
Acharya T, Ray A K.. 2005. Image
Processing Principles and Applications.
Canada: Willey Interscene.
Fausett L. 1994. Fundamental of Neural Network Architectures, Algorithms and Aplication. New Jersey: Prentice Hall.
Gonzales RC, Woods RE, Eddins SL. 2003.
Digital Image Processing Second Edition.
Prentice Hall : Upper Saddle River, NJ.
Kohavi R. 1995. A study of cross-validation
and bootstrap for accuracy estimation
and model selection. Proceedings of the 14th International Joint Conference on Artificial Intelligence; Quebec, 20-25 Agu 1995, hlm 1137-1143.
Lim R, et al. Sistem Pengenalan Plat Nomor
Mobil Dengan Metode Principal
Component Analysis [Skripsi]. Teknik Elektro Fakultas Teknologi Industri, Universitas Kristen Petra.
Rajashekararadhya S V. 2008. Efficient Zone
Based Feature Extraction Algorithm For Handwritten Numeral Recognition of Four Popular South Indian Scripts
[Journal]. Chennai: Department of Electrical and Electronics Engineering, CEG, Anna University.
Setiawan A. 2008. Sistem Pengenalan Plat Nomor Mobil Untuk Aplikasi Informasi
Karcis Parkir[Skripsi]. Surabaya : Teknik
Komputer, Institut Teknologi Sepuluh Nopember.
Siang J J. 2005. Jaringan Saraf Tiruan & Pemrogramannya Menggunakan Matlab. Yogyakarta : ANDI.
Wahyono E S. 2009. Identifikasi Nomor Polisi Mobil Menggunakan Metode
Jaringan Saraf Buatan Learning Vector
LAM
P
IR
AN
Lampiran 1Pola ekstraksi fitur semua karakter.
Lampiran 2 Hasil pelatihan backpropagation .
Zona Performance Epoch Time Gradient MU
4
0,913 34 06.36 0,0106 0,01
0,0592 24 04.54 0,00456 0,01
0,0707 47 09.17 0,00199 0,01
0,0542 26 05.14 0,000574 0,01
0,0844 56 11.01 0,00224 0,01
6
0,0425 63 12.25 6.17e-05 0,01
0.0276 48 09.29 0.000225 0.10
0.0557 30 06.09 0.00822 0.10
0.0421 30 06.13 0.00459 0.001
0.0548 33 06.43 0.000993 0.10
8
0.0475 30 06.26 0.00411 0.1
0.605 48 09.50 0.00719 1
0.113 35 07.54 4.2e-11 1.00e-12
0.0210 58 13.25 3.81e-11 1.00e-09
0.0394 60 11.38 7.71e-07 0.0001
10
0.0180 31 07.07 5.90e-08 1.00e-7
0.0161 28 06.33 4.96e-07 1.00e-06
0.0256 24 05.38 0.000149 0.0001
0.0671 90 20.24 0.000157 0.01
0.0451 45 10.19 0.000386 0.001
12
0.0304 46 10.54 3.32e-06 1.00e-07
0.0230 22 05.18 0.000119 1
0.0377 41 09.48 0.000114 0.01
0.0404 39 09.37 0.000762 0.01
0.0434 26 06.24 0.00102 0.01
14
0.0153 42 09.06 3.29e-07 1.00e-05
0.00103 28 06.04 4.26e-11 1.00e-11
0.00810 51 10.56 7.75e-11 1.00e-08
0.0154 25 05.30 4.42e-06 1.00e-05
0.00617 34 07.21 0.00483 0.1
16
0.0171 81 18.18 2.65e-10 1.00e-09
0.0335 57 14.04 1.63e-05 0.1
0.00971 50 12.30 4.81e-05 0.01
0.0239 25 06.22 6.52e-05 0.01
0.0309 46 11.32 0.000583 0.001
18
0.0126 35 09.31 3.54e-05 0.1
0.007 27 07.22 0.000309 0.01
0.0115 51 12.32 6.23e-05 1.00e-05
0.0150 36 09.43 9.90e-06 0.001
0.0176 40 10.45 7.83e-05 0.001
20
0.250 44 12.31 0.00925 1
0.0343 69 19.26 9.53e-08 0.0001
0.0330 53 14.56 0.000182 0.1
0.0233 60 16.45 0.000206 0.1
0.0409 42 11.56 0.000268 0.01
22
0.0196 32 09.08 1.67e-06 1.00e-07
0.0213 33 09.09 2.91e-11 1.00e-11
0.00682 57 15.33 3.55e-06 0.01
0.0122 35 09.42 0.0120 0.01
Lampiran 3 Hasil deteksi karakter menggunakan 4 zona.
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
0 8 1 1 0 0 0 0 0 0 0 0 2 0 8 0 0 1 5 0 0 0 0 0 2 0 0 8 1 0 0 12 0 1 0 0 0
1 0 27 6 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 2 1 0 0 10 0 0 0 0 0
2 0 3 27 0 0 0 0 0 1 0 0 3 0 0 0 0 0 0 0 0 0 0 5 2 0 0 0 0 1 0 6 0 0 2 0 0
3 0 0 0 39 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 0 0 0 0 0
4 0 0 9 0 17 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 4 0 0 10 1 0 0 2 0
5 0 0 0 1 0 21 2 0 0 0 0 1 0 0 1 0 0 3 1 0 2 0 1 1 0 0 2 2 0 0 10 0 1 0 0 1
6 0 0 0 0 0 9 11 0 3 3 0 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 1 5 1 10 0 3 0 0 1
7 0 0 0 3 0 0 0 30 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 6 0 0 0 0 10 0 0 0 0 0
8 0 1 0 1 0 1 11 0 7 2 0 2 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 2 7 0 10 0 0 1 0 0
9 0 0 0 0 0 0 0 0 3 23 0 4 0 0 0 0 0 0 1 0 0 0 5 0 2 0 0 1 1 0 10 0 0 0 0 0
A 0 0 0 0 0 0 0 0 0 0 29 0 0 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 10 7 0 0 1 0
B 1 0 0 0 0 3 0 0 3 1 0 15 0 0 0 0 0 2 0 0 0 0 6 2 0 0 5 0 1 0 11 0 0 0 0 0
C 1 0 0 0 0 0 1 0 0 0 1 0 24 0 6 0 0 0 0 0 2 0 0 2 0 0 1 0 0 0 12 0 0 0 0 0
D 5 0 1 0 0 0 0 0 0 0 0 3 0 11 0 0 0 4 0 0 1 0 1 0 0 0 5 2 0 0 17 0 0 0 0 0
E 0 0 0 0 0 0 0 0 0 0 0 0 19 0 10 1 0 0 0 0 4 0 0 1 0 0 5 0 0 0 10 0 0 0 0 0
F 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 23 1 0 0 0 6 0 0 0 0 3 0 8 0 1 6 1 0 0 0 0
G 0 2 0 8 0 1 0 0 3 0 0 6 0 0 0 0 9 0 0 0 0 0 8 2 0 0 0 0 0 0 11 0 0 0 0 0
H 2 0 0 0 0 6 0 0 3 0 0 2 1 2 0 0 0 8 1 0 1 0 1 0 0 0 9 1 0 0 13 0 0 0 0 0
I 0 1 0 1 0 0 0 0 1 3 1 3 0 0 0 0 0 0 15 0 0 0 4 4 0 0 0 1 3 1 10 0 1 0 1 0
J 9 0 0 1 0 0 0 0 0 0 0 0 0 0 10 8 0 0 0 10 0 0 0 1 0 3 0 0 0 6 2 0 0 0 0 0
K 0 1 0 0 0 8 0 0 0 0 0 0 0 0 7 0 0 1 2 0 1 0 9 1 0 0 1 8 0 0 11 0 0 0 0 0
L 0 0 0 0 0 0 0 0 0 0 0 0 0 10 10 0 0 0 0 0 0 20 0 0 0 0 0 0 0 0 10 0 0 0 0 0
M 0 0 0 0 0 0 0 0 1 5 0 1 0 0 0 0 1 0 0 0 0 0 23 1 0 0 2 0 0 0 16 0 0 0 0 0
N 0 0 1 0 0 3 1 0 0 1 0 4 0 0 0 2 0 1 4 0 0 0 2 9 1 2 5 1 2 0 10 0 0 1 0 0
O 0 4 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 13 0 2 0 0 1 8 0 0 4 0 0 10 0 1 0 0 5
P 0 0 1 0 0 0 0 2 0 0 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 29 0 0 0 0 10 0 0 0 1 0
Q 4 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 1 4 0 0 24 0 0 0 12 0 0 0 0 0
R 1 0 0 0 0 2 1 0 0 3 0 3 0 0 0 0 1 3 7 0 6 0 2 0 4 0 2 3 0 0 11 1 0 0 0 0
S 0 0 0 0 0 1 0 0 1 4 0 0 0 0 0 0 0 0 3 0 0 0 2 1 1 0 0 0 21 0 10 0 0 6 0 0
T 0 0 0 0 2 0 0 0 2 0 2 1 0 0 0 0 0 0 1 0 0 0 0 0 0 3 0 0 0 7 10 1 6 10 5 0
U 2 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 4 0 0 0 1 0 2 0 0 0 6 0 0 0 33 0 0 0 0 0
V 0 0 4 0 0 0 0 0 0 0 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 10 15 0 0 1 0
W 0 0 0 0 0 11 0 0 0 0 0 0 0 0 4 0 0 0 4 0 0 0 1 0 0 0 0 0 2 1 10 0 16 1 0 0
X 0 0 4 0 5 1 1 1 3 1 5 0 0 0 0 0 0 0 1 0 0 0 0 0 5 0 0 0 3 5 10 1 1 2 1 0
Y 0 0 1 0 6 0 0 0 0 0 6 0 0 0 0 0 0 0 1 0 0 0 0 0 0 3 0 0 0 3 10 0 0 0 20 0
Lampiran 4 Hasil deteksi karakter menggunakan 6 zona.
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
0 27 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 0 11 0 0 0 7 0 0 0 0 0
1 2 17 7 4 0 1 0 4 1 1 0 1 0 1 0 0 0 0 0 0 0 5 0 0 0 0 0 0 3 0 0 2 0 0 0 1
2 0 1 31 1 0 0 0 0 0 0 2 4 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 2 0 1 0 1 0 1 0 5
3 0 1 0 36 0 0 0 2 0 0 1 7 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1
4 0 0 0 1 30 0 0 0 0 0 14 1 0 0 0 0 0 0 0 0 3 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
5 0 0 2 0 0 22 4 0 3 0 4 3 1 1 0 0 0 2 0 0 0 0 0 2 0 0 2 2 0 0 0 0 2 0 0 0
6 0 0 0 0 0 5 32 0 6 0 0 0 1 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0
7 0 0 0 0 0 0 0 48 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1
8 0 1 0 0 0 3 6 0 18 4 0 1 1 0 0 0 0 1 0 0 0 0 3 0 4 0 1 2 2 0 0 2 1 0 0 0
9 0 0 0 0 0 1 2 0 4 20 1 7 0 0 0 0 0 0 0 0 0 0 2 0 3 0 0 3 6 0 1 0 0 0 0 0
A 0 1 4 0 2 0 0 0 0 0 23 0 0 0 0 0 0 0 2 0 1 2 1 0 1 0 0 0 2 1 0 10 0 0 0 0
B 0 0 1 0 0 0 0 0 3 3 0 21 0 1 0 0 0 3 0 0 0 0 8 4 0 0 3 3 0 0 0 0 0 0 0 0
C 1 0 0 0 0 1 0 0 0 0 0 0 35 0 0 2 0 0 0 0 5 0 0 0 0 0 3 0 0 0 0 0 1 1 1 0
D 6 0 0 1 0 0 0 0 0 0 0 0 0 38 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0
E 0 0 7 0 0 0 0 0 0 0 0 0 0 0 30 0 0 3 0 0 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
F 0 0 0 10 0 0 0 0 0 1 0 0 0 0 0 26 0 0 0 9 3 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
G 0 5 0 1 0 4 4 1 0 0 0 0 0 0 0 0 25 0 0 0 0 0 3 0 1 0 0 0 0 0 6 0 0 0 0 0
H 0 0 0 0 0 0 0 0 0 0 0 6 0 0 1 0 0 36 0 0 0 3 0 0 0 0 0 2 0 0 0 0 2 0 0 0
I 0 0 3 0 1 1 0 1 1 3 9 0 0 0 0 0 0 0 11 1 0 0 0 1 0 0 0 5 3 1 0 4 0 5 0 0
J 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 32 6 0 0 1 0 0 0 0 0 0 0 0 0 0 0 9
K 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 41 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1
L 10 2 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 37 0 0 0 0 0 0 0 0 0 0 0 0 0 0
M 0 0 1 0 0 0 5 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 38 0 0 0 0 0 0 0 4 0 0 0 0 0
N 0 0 0 0 0 4 0 0 0 0 0 2 0 0 0 0 0 6 1 1 0 0 0 23 0 0 0 8 0 0 0 0 3 0 0 2
O 0 0 0 0 0 0 3 0 9 0 0 0 3 0 0 0 6 0 0 0 0 0 7 0 19 0 0 0 1 0 0 0 2 0 0 0
P 0 1 0 2 0 0 0 2 0 0 0 4 0 0 0 12 0 0 8 8 0 0 0 0 0 12 0 0 0 0 1 0 0 0 0 0
Q 9 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 1 0 0 0 0 0
R 0 1 0 0 0 0 0 0 0 2 5 0 0 0 0 0 0 2 0 0 1 0 3 16 0 0 0 16 2 0 1 1 0 0 0 0
S 0 0 4 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 1 25 0 0 8 2 0 0 1
T 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 33 0 0 0 8 5 0
U 0 0 0 0 0 1 0 0 0 3 0 0 1 5 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 37 0 0 0 0 0
V 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 1 0 37 1 0 1 0
W 2 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 2 4 0 0 0 3 0 0 0 0 35 0 1 0
X 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 2 0 0 1 0 5 0 0 0 0 0 0 0 3 12 0 0 0 20 0 6
Y 0 0 0 0 0 0 0 4 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 22 1 1 5 1 10 0
Lampiran 5 Hasil deteksi karakter menggunakan 8 zona.
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
0 24 0 0 0 0 0 2 1 0 0 0 0 5 1 0 1 0 0 0 1 0 0 0 0 0 0 12 0 0 0 2 0 1 0 0 0
1 10 16 2 1 0 0 0 1 0 0 5 0 0 0 0 0 0 0 2 0 0 0 1 0 0 0 0 1 0 1 0 8 2 0 0 0
2 11 0 35 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0
3 10 0 0 16 0 0 1 2 0 0 1 1 0 0 0 0 0 0 1 0 0 0 3 2 4 0 0 0 2 0 0 2 5 0 0 0
4 10 0 0 0 18 0 0 0 0 0 4 0 1 0 0 0 0 0 0 3 4 0 0 1 0 0 0 0 3 1 0 0 5 0 0 0
5 10 0 0 0 0 37 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
6 10 0 0 0 0 2 21 0 6 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 7 0 0 0
7 7 1 0 3 0 3 0 18 0 0 2 0 0 0 2 0 0 0 2 2 0 0 0 0 0 1 0 0 0 1 1 6 0 0 0 1
8 10 0 0 0 0 0 1 0 25 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 4 0 1 0 2 0 0 0 4 0 0 1
9 14 0 4 1 0 0 2 0 6 0 1 2 2 0 0 2 1 0 0 0 0 0 0 1 6 2 0 1 3 0 0 1 1 0 0 0
A 10 1 0 0 0 0 0 1 0 0 18 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 11 0 3 2 0
B 10 1 0 1 0 0 0 0 6 0 1 16 0 9 0 0 1 1 0 0 0 0 0 0 0 0 0 2 0 0 0 0 2 0 0 0
C 11 0 1 0 0 0 5 0 0 0 0 0 28 2 0 0 2 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
D 10 0 0 0 0 0 0 0 0 0 0 0 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
E 10 0 0 0 0 0 0 0 0 0 0 0 0 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
F 9 0 0 0 0 0 0 0 0 0 1 0 0 0 1 37 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
G 10 2 3 1 0 0 3 0 3 0 0 0 0 4 0 0 15 0 0 0 0 0 0 0 1 0 8 0 0 0 0 0 0 0 0 0
H 10 0 0 0 0 0 0 0 1 0 0 0 0 7 1 0 0 20 0 0 0 0 5 6 0 0 0 0 0 0 0 0 0 0 0 0
I 10 0 0 1 0 0 0 0 0 0 2 2 0 0 0 0 0 0 11 0 2 0 0 2 0 0 0 0 0 0 0 4 3 13 0 0
J 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 37 0 0 0 0 0 0 0 0 5 0 0 0 1 0 0 1
K 10 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 34 0 1 1 0 0 0 0 0 0 0 0 0 3 0 0
L 10 0 8 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 18 0 2 0 10 0 0 0 0 0 0 0 0 0 0
M 10 0 0 0 0 2 1 0 1 0 0 3 0 0 0 0 0 3 0 0 0 0 30 0 0 0 0 0 0 0 0 0 0 0 0 0
N 10 0 0 0 0 0 3 0 0 0 0 0 1 0 3 0 0 2 0 0 1 0 0 25 0 0 0 4 0 0 0 0 0 0 0 1
O 10 0 0 0 0 0 11 0 7 0 1 0 3 0 2 0 0 0 0 0 0 0 0 0 10 0 0 0 2 0 0 0 4 0 0 0
P 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 0 0 0 0 0 0 0 0 0 0
Q 19 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 0 24 0 0 0 1 0 0 0 0 0
R 10 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 35 0 0 1 0 0 0 0 0
S 10 0 6 0 0 0 0 0 0 0 5 0 1 0 0 0 0 0 0 0 0 0 0 1 2 1 0 0 15 0 0 0 8 1 0 0
T 10 0 0 0 0 2 0 0 0 0 3 0 0 0 0 0 0 0 0 0 4 1 0 0 0 0 0 0 0 21 0 4 0 5 0 0
U 10 0 0 0 0 2 0 0 3 0 0 1 0 5 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 28 0 0 0 0 0
V 10 2 0 0 1 0 0 0 0 0 3 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 26 0 4 0 0
W 10 0 0 0 0 4 3 0 0 3 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 1 26 0 0 0
X 10 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 32 0 4
Y 10 0 0 0 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 1 0 3 0 6 3 8 9 4