IDENTIFIKASI PLAT NOMOR MENGGUNAKAN FITUR
ZONING
DENGAN KLASIFIKASI
SUPPORT VECTOR MACHINE
INTAN AYU OCTAVIA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Identifikasi Plat Nomor Menggunakan Fitur Zoning dengan Klasifikasi Support Vector Machine adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
INTAN AYU OCTAVIA. Identifikasi Plat Nomor Menggunakan Fitur Zoning dengan Klasifikasi Support Vector Machine. Dibimbing oleh MUSHTHOFA.
Pendeteksian identifikasi kendaraan merupakan salah satu permasalahan yang cukup penting dengan semakin bertambahnya jumlah kendaraan. Oleh karena itu, diperlukan sebuah metode berbasis teknologi komputer yang mampu mengidentifikasi kendaraan berdasarkan nomor platnya secara cepat dan akurat. Beberapa penelitian sebelumnya telah menerapkan metode ekstraksi fitur image centroid and zone (ICZ) dan beberapa jenis model klasifikasi untuk mengenali plat nomor kendaraan. Pada penelitian ini, metode ekstraksi fitur ICZ dan metode klasifikasi dengan support vector machine (SVM) akan digunakan untuk pengenalan plat nomor. Jenis SVM yang digunakan adalah multi class SVM one against all menggunakan kernel linear, polynomial, dan RBF. Pengujian dilakukan dua kali, yaitu: pada masing-masing karakter serta pada keseluruhan plat (dengan atau tanpa toleransi kesalahan). Dari ketiga kernel tersebut kernel yang menghasilkan akurasi terbaik adalah kernel polynomial dengan nilai C sama dengan 0.125 dan d sama dengan 2 adalah 95.44% sedangkan akurasi yang dihasilkan pada pengujian plat tanpa toleransi kesalahan adalah 81.54% dan pengujian plat dengan toleransi kesalahan sama dengan 1 adalah 90.77%.
Kata kunci: identifikasi plat nomor, image centroid and zone (ICZ), kernel, multi class SVM one against all
ABSTRACT
INTAN AYU OCTAVIA. License Plate Identification Using Zoning Feature with Support Vector Machine Classification. Supervised by MUSHTHOFA.
Vehicle identification detection is one of the significant problems with the increasing number of vehicles. Therefore, a computer-based method is needed that can identify the vehicle based on license plate numbers quickly and accurately. Previous research have applied the image centroid and zone (ICZ) feature extraction method to identify vehicle license plates. In this research, ICZ and support vector machine (SVM) will be used for license plate identification. SVM which is used is the multi class SVM one against all using linear kernel, the polynomial, and RBF. The testing is performanced twice, on each character and on the overall plate (with or without fault tolerance). From the three kernels, the kernel which produces the best accuracy is the polynomial kernel with a value of C equals to 0.125 and d equals to 2 with on accuracy of 95.44%, while the accuracy produced at plate testing without fault tolerance is 81.54% and testing with fault tolerance equal to 1 is 90.77%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
INTAN AYU OCTAVIA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
IDENTIFIKASI PLAT NOMOR MENGGUNAKAN FITUR
ZONING
Penguji:
Judul Skripsi: Identifikasi Plat Nomor Menggunakan Fitur Zoning dengan Klasifikasi Support Vector Machine
Nama : Intan Ayu Octavia NIM : G64104059
Disetujui oleh
Mushthofa, SKom MSc Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala curahan rahmat, taufik, hidayah, dan karunia-Nya, sehingga penulis dapat menyelesaikan karya ilmiah dengan judul Identifikasi Plat Nomor Menggunakan Fitur Zoning dengan Klasifikasi Support Vector Machine.
Penulis menyadari dalam penyusunan karya ilmiah telah banyak mendapatkan bantuan, dukungan, serta saran dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada pihak yang telah membantu, yaitu:
1 Orang tua tercinta Bapak H Anwar Firmansyah dan Ibu Hj Erna Nelly, kakak
penulis Johs Verlian Guntur Firmansyah atas segala do’a, cinta, restu, kasih
sayang, dukungan, nasehat, serta perhatian yang telah diberikan kepada penulis.
2 Bapak Mushthofa, SKom MSc selaku dosen pembimbing tugas akhir yang telah memberikan ilmu, kesabaran, dan dukungan dalam penyelesaian tugas akhir.
3 Bapak Dr Ir Agus Buono, MSi MKom dan Bapak Muhammad Asyhar Agmalaro, SSi MKom selaku dosen penguji yang telah memberikan saran dan seluruh dosen dan staf Departemen Ilmu Komputer FMIPA IPB.
4 Aditya Riansyah Lesmana, SKom yang telah memberikan data dan informasi yang dibutuhkan penulis dalam penyusunan karya ilmiah.
5 Angga Nugraha, Lina Herlina, Diah Daru Asih, Septy Kurniawati, Simi Haslinda, Asterika Prawesthi, dan Rahmi Juwita Sukma yang selalu memberikan dukungan dan semangat kepada penulis.
6 Rekan-rekan satu bimbingan, Rizkina, Putri, dan Hafhara atas bantuan dan kerjasamanya selama bimbingan.
7 Teman-teman Ilkomerz Angkatan 5 atas kebersamaannya.
8 Seluruh pihak baik yang turut membantu secara langsung maupun tidak langsung dalam penyusunan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Oleh karena itu, penulis mengharapkan adanya masukan berupa saran dan kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini.
Akhir kata penulis ucapkan terima kasih atas semua bantuan dan kerjasamanya. Semoga karya ilmiah ini dapat bermanfaat bagi pembaca.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup 2
TINJAUAN PUSTAKA 3
Edge Detection 3
Canny’s Edge Detection 3
Image Segmentation 4
Zone Based Feature Extraction 4
K-Fold Cross Validation 4
Support Vector Machine 4
Soft Margin 6
Multi Class SVM 8
METODE 8
Pengumpulan Data 9
Praproses citra 9
Restorasi dan Perbaikan Citra 9
Deteksi Tepi 10
Segmentasi Citra 10
Ekstrasi Ciri 10
Image Centroid and Zone 10
Data Latih dan Data Uji 12
Pelatihan pada SVM 13
Pengujian pada SVM 13
Klasifikasi Citra 16
Lingkungan Pengembangan Sistem 16
HASIL DAN PEMBAHASAN 17
Pengumpulan Data 17
Praproses Citra 17
Deteksi Tepi 18
Segmentasi Citra 19
Normalisasi Citra 19
Ekstraksi Ciri 20
Klasifikasi Citra 22
Pengujian Per Karakter 22
Kernel Linear 23
Kernel Polynomial 24
Kernel RBF 25
Pengujian Pada Plat 27
SIMPULAN DAN SARAN 29
Simpulan 29
Saran 30
DAFTAR PUSTAKA 30
LAMPIRAN 32
RIWAYAT HIDUP 40
DAFTAR TABEL
1 Pembagian subset 13
2 Nilai kepercayaan data pada SVM 15
3 Nilai pengujian per karakter 23
4 Akurasi pada kernel linear 24
5 Akurasi terbaik kernel polynomial pada setiap nilai d 25
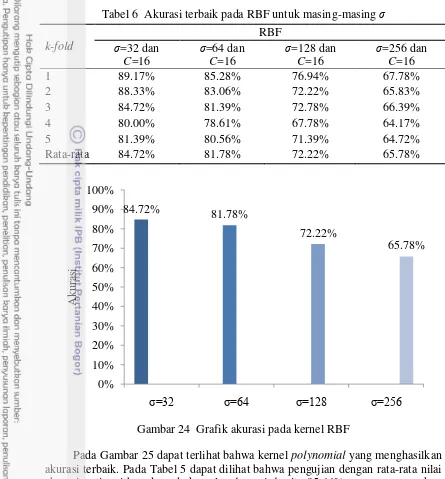
6 Akurasi terbaik pada RBF untuk masing-masing σ 26
7 Persentase akurasi pengujian karakter dengan kernel 27
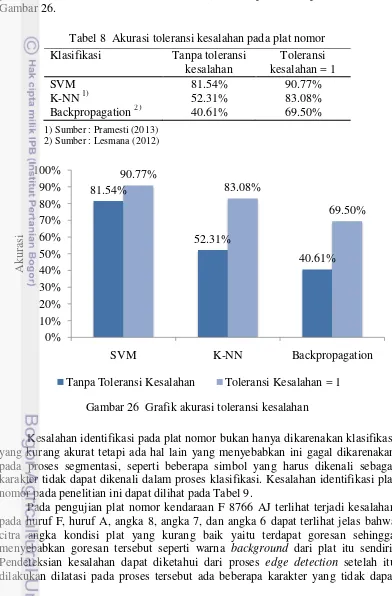
8 Akurasi toleransi kesalahan pada plat nomor 28
9 Contoh kesalahan pada plat nomor 28
DAFTAR GAMBAR
6 Contoh citra dalam perhitungan ekstraksi ciri ICZ 11
7 Contoh citra dengan pembagian zona 12
14 Gambar hasil praproses citra 18
15 Hasil deteksi tepi dengan metode deteksi tepi Canny 18 16 Labelling pada angka nol 19
17 Proses segmentasi pada plat 19
18 Normalisasi pada karakter 20
19 Ilustrasi pembagian zona pada ekstraksi fitur 20
20 Pola ekstraksi fitur pada huruf P 21
21 Pola ekstraksi fitur pada huruf I 21
22 Hasil dari citra dengan praproses yang baik (kanan) dan praproses
yang kurang baik (kiri) 21
23 Grafik akurasi kernel polynomial 25
24 Grafik akurasi pada kernel RBF 26
25 Akurasi rata-rata pda setiap kernel 27
26 Grafik akurasi toleransi kesalahan 28
DAFTAR LAMPIRAN
1 Pengujian karakter pada SVM 32
2 Akurasi SVM pada kernel polynomial 34
3 Akurasi SVM pada kernel RBF 35
4 Hasil deteksi karakter pada 25 zona menggunakan kernel polynomial 37
1
PENDAHULUAN
Latar Belakang
Seiring dengan perkembangan produksi kendaraan yang semakin cepat. Indonesia merupakan target distribusi terbesar bagi kendaraan bermotor. Pada kendaraan tersebut terdapat nomor polisi yang tertera pada plat yang merupakan identitas unik yang terdiri dari huruf dan angka. Plat tersebut merepresentasikan data kendaraan dan pemiliknya yang saat ini masih dilakukan secara manual.
Oleh karena itu, diperlukan suatu mekanisme untuk melakukan pengenalan plat kendaraan secara cepat dan tepat. Salah satunya optical character recognition (OCR) yang mengidentifikasi karakter dari input berupa citra. Input tersebut akan diproses secara digital sehingga dapat dilakukan tahap pengenalan menggunakan beberapa metode yang ada. Terkait dengan metode ini, pengambilan citra dari sebuah plat dapat dilakukan dengan menggunakan peralatan optikal (kamera, CCTV). Selanjutnya dilakukan identifikasi dari setiap karakter yang ada. Dalam mengimplementasikan mekanisme tersebut perlu dilakukan beberapa tahap pemrosesan digital.
Selama beberapa tahun terakhir telah dilakukan banyak penelitian mengenai hal ini dan masih terus dikembangkan untuk mencari metode terbaik dalam memecahkan permasalahan tersebut. Setiawan (2008) melakukan penelitian untuk pendeteksian plat nomor menggunakan metode feature reduction principle component analysis (PCA) dan Euclidean distance. Dari penelitian tersebut didapatkan rata-rata akurasi sebesar 84.30%. Lim et al. (2009) juga menggunakan PCA untuk feature reduction namun pada tahap klasifikasinya menggunakan metode k-nearest neighbor (K-NN). Pada penelitian tersebut mencapai tingkat keberhasilan sebesar 82%. Selain itu, Wahyono (2009) mencoba menggunakan jaringan syaraf tiruan learning vector quantization sebagai metode klasifikasi dan ekstrasi fitur berdasarkan blok. Walaupun pada penelitian tersebut masih banyak kesalahan pada metode ekstrasi fitur, namun tingkat keberhasilan yang didapat masih cukup besar yaitu 78%. Pada tahun 2012 penelitian yang dilakukan Lesmana mengenai identifikasi karakter pada plat nomor kendaraan menggunakan image centroid and zone (ICZ) sebagai ekstraksi ciri dan metode klasifikasi backpropagation menghasilkan akurasi 69.50%, ekstraksi ciri yang digunakan mengacu pada penelitian yang telah dilakukan oleh Rajashekararadhya (2008). Pada tahun 2013 Pramesti melanjutkan penelitian yang dilakukan oleh Lesmana (2012) mengenai identifikasi plat nomor kendaraan menggunakan ekstraksi fitur ICZ dan ZCZ menggunakan metode klasifikasi K-NN dan menghasilkan akurasi 83.08%. Penelitian dengan menggunakan metode backpropagation menghasilkan akurasi yang kecil. Anisah (2012) telah melakukan penelitian mengenai pengenalan iris mata dengan support vector machine (SVM) menggunakan ekstraksi ciri log-gabor filter dan menghasilkan akurasi 95.55% untuk data set mata kiri dan 93.33% untuk data set mata kanan. Sebagai salah satu solusi untuk masalah tersebut, akan dicoba dengan metode klasifikasi SVM.
2
pengklasifikasi yang sangat baik dalam menangani data set berdimensi tinggi. SVM sudah diterapkan pada berbagai bidang. Byun dan Lee (2003) telah melakukan survei yang menyatakan bahwa SVM menunjukkan kinerja yang baik pada banyak kehidupan nyata, namun baiknya kinerja SVM dari segi eksekusi tidak dicantumkan.
Oleh karena itu, berdasarkan hal tersebut klasifikasi menggunakan SVM lebih baik daripada klasifikasi jaringan syaraf tiruan backpropagation. Hal tersebut dapat terlihat karena akurasi yang dihasilkan dengan klasifikasi SVM lebih tinggi daripada akurasi dengan metode klasifikasi backpropagation. Sehingga diharapkan penelitian dengan SVM akan menghasilkan akurasi yang lebih baik.
Tujuan Penelitian Tujuan dilakukannya penelitian ini adalah:
1 Menerapkan metode ICZuntuk melakukan ekstraksi ciri pada citra plat nomor kendaraan dengan metode klasifikasi SVM.
2 Menguji tingkat akurasi dari metode yang digunakan dan membandingkan akurasi pada klasifikasi K-NN dan backpropagation yang menggunakan ekstraksi ciri ICZ.
Manfaat Penelitian
Manfaat dari dilakukannya penelitian ini diharapkan dapat menjadi sebuah konsep dasar dalam mengembangkan sistem pengenalan plat kendaraan secara otomatis. Dengan itu pada akhirnya dapat menjadi solusi permasalahan pencatatan data kendaraan, khusunya di Indonesia.
Ruang Lingkup
Ruang lingkup dari penelitian ini terbatas pada beberapa hal, yaitu:
1 Plat nomor yang dikenali hanya plat nomor dengan format standar (bukan format TNI/POLRI).
2 Data yang diolah berasal dari citra dengan format JPEG.
3 Karakter yang dikenali adalah huruf alphabet kapital (A sampai Z) dan angka (0 sampai 9).
4 Pemotretan plat dilakukan dari depan atau belakang kendaraan secara berhadapan lurus.
3
TINJAUAN PUSTAKA
Edge Detection
Deteksi tepi menurut Acharya dan Ray (2005) pada dasarnya adalah mendeteksi perubahan lokal yang signifikan berdasarkan tingkat intensitas pada gambar. Perubahan tingkat intensitas diukur dengan gradien gambar. Bahwa f (x,y) adalah fungsi dua dimensi, gradiennya adalah sebuah vektor.
�
� =
Besarnya gradien dapat dihitung dalam beberapa cara:
� , = �2+ �2 memastikan ketebalan noise yang baik dan pada saat yang sama mendeteksi titik tepi yang benar dengan kesalahan minimal. Deteksi tepi Canny telah mengoptimalkan proses deteksi tepi dengan memaksimalkan rasio signal-to-noise dari gradien. Sebuah faktor lokalisasi tepi, yang menjamin bahwa tepi yang terdeteksi dilokalisir seakurat mungkin. Ada beberapa proses penting yang dilakukan dalam deteksi tepi Canny, yaitu:
1 Non-maxima suppression, detektor tepi Canny menghasilkan tepi tebal yang lebih lebar dari pixel. Pengoperasian non-maxima suppression menipiskan luas daerah gradiennya. Dalam salah satu tekniknya, besarnya tepi dari dua pixel tepi tetangga, tegak lurus terhadap arah tepi yang diperhitungkan dan besarnya tepi yang lebih rendah dibuang.
2 Double thresholding, gambar/citra gradien diperoleh setelah non-maxima suppression yang mungkin masih mengandung titik-titik tepi yang salah. Untuk menghilangkan titik tepi yang salah, sebuah ambang batas yang sesuai dipilih sedemikian rupa sehingga semua titik tepi yang besarnya lebih besar dari ambang batas dapat dipertahankan sebagai titik tepi yang benar, sementara yang lainnya akan dihapus sebagai titik tepi yang salah.
4
pemilihan ambang batas menjadi masalah pada optimasi rasio kemungkinan maksimum berdasarkan teori keputusan Bayes.
Image Segmentation
Segmentasi citra adalah proses untuk meminimalkan kesalahan klasifikasi dan mengurangi ketidakpastian statistik. Hal ini telah mengakibatkan pengembangan beberapa algoritma berdasarkan sifat lokal dan global pixel dalam gambar. Teknik thresholding adalah teknik yang sederhana menurut Gonzalez et al.(2003).
Zone Based Feature Extraction
Metode ekstraksi fitur berbasis zona memberikan hasil yang baik bahkan ketika langkah sebelum proses tertentu dimulai seperti filtering, smoothing, dan menghapus zona yang tidak dianggap. Pada bagian ini, akan dijelaskan konsep metode ekstraksi, ciri yang digunakan untuk mengekstraksi fitur untuk klasifikasi yang efisien dan pengenalan. Tahapan yang harus dilakukan untuk ekstraksi fitur ini (Rajashekararadhya 2008), yaitu:
1 Hitung centroid dari citra.
2 Bagi ke dalam n buah zona yang sama besar proporsinya.
3 Hitung jarak antara titik centroid dengan koordinat pixel yang memiliki nilai. 4 Ulangi langkah 3 untuk pixel yang ada di semua zona.
5 Hitung rata-rata dari jarak yang telah didapat pada langkah 3.
6 Ulangi langkah 5 hingga didapat masing-masing rata-rata jarak dari setiap zona.
7 Akhirnya n buah fitur akan didapat untuk melakukan klasifikasi dan pengenalan.
K-Fold Cross Validation
Cross validation kadang-kadang disebut sebagai rotation estimation. Dataset V dibagi menjadi ksubset (fold) yang saling bebas secara acak, yaitu: D1, D2,..., Dk dengan ukuran yang sama. Pelatihan dan pengujian dilakukan sebanyak k kali, setiap kali iterasi ke-t (t = 1, 2, ..., k) dilatih pada D/Dt dan diuji pada Dt. Perkiraan akurasi pada cross validation dengan membagi jumlah keseluruhan klasifikasi yang benar dengan seluruh instances pada dataset (Kohavi 1995).
Support Vector Machine
5 margin yang maksimal antara ruang input non-linear dengan ruang ciri menggunakan kaidah kernel (Cortes dan Vapnik 1995). Prinsip kerja SVM ialah linear classifier, tetapi dapat bekerja juga pada problem non-linear dengan memasukkan konsep kernel trick pada ruang kerja berdimensi tinggi.
Misalkan data dinotasikan sebagai xi ∊ ℜn, untuk label kelas dari data xi dinotasikan y ∊ {+1,-1} dengan i = 1,2,…,l dengan l adalah banyak data. Pemisahan data secara linear pada metode SVM dapat dilihat pada Gambar 1.
Gambar 1 Ilustrasi linearly separable data (Wang et al. 2009)
Margin adalah jarak antara hyperplane dan pattern terdekat dari masing-masing kelas. Pattern yang paling dekat disebut support vector. Nilai margin antara dua kelas adalah = 1
| |. Dengan w adalah vector bobot yang tegak lurus terhadap hyperplane (bidang normal). Hal tersebut dapat dirumuskan sebagai Quadratic Margin yaitu mencari titik minimal dapat dilihat pada Persamaan 1, dengan memperhatikan Persamaan 2.
min� = 1
2
2 (1)
. + −1≥ 0,∀ (2)
Problem ini dapat diselesaikan dengan menggunakan fungsi Lagrange Multiplier berikut:
, , = 1
2| |
2− ( ( . + −1))
=1
( = 1,2, . . , ) (3)
6
=1
− 1
2
, =1
(4)
Perhitungan diatas menghasilkan yang kebanyakan bernilai positif. Data yang berkorelasi dengan yang positif disebut sebagai support vector.
Soft Margin
Berdasarkan fungsi-fungsi diatas dapat memisahkan kelas secara sempurna dengan menggunakan hyperplane. Terkadang dua buah kelas tidak dapat terpisah secara sempurna. Sehinggan Persamaan 2 tidak dapat terpenuhi dan optimasi tidak dapat dilakukan. Dalam penyelesaian masalah ini SVM menyediakan teknik softmargin yang akan memodifikasi Persamaan 2 dengan memasukan slack variable (�>0) sehingga persamaan nya adalah
. + ≥1− �,� > 0 (5)
Dan Persamaan 1 diubah menjadi Persamaan 6 dan ilusrasi terdapat pada Gambar 2:
min� ,� = 1
2
2+ � �
=1
(6)
Gambar 2 Soft margin hyperplane (Wang et al. 2009)
Parameter C digunakan untuk mengontrol trade off antara margin dan error klasifikasi � dan rentang nilai yang digunakan adalah 2-4, 2-3, 2-2, 2-1, 20, 21, 22, 23, dan 24. Nilai C yang besar berarti akan memberikan penalti yang lebih besar terhadap error klasifikasi. Setelah nilai ai ditemukan, kelas dari data pengujian x dapat ditentukan berdasarka nilai fungsi keputusan:
= +
7 dengan,
= support vector
ns = jumlah support vector
= data yang akan diklasifikasikan.
Pencarian bidang pemisah terbaik dengan penambahan variable � disebut soft margin hyperplane. Dengan demikian dual problem yang dihasilkan pada non-linear problem sama dengan dual problem yang dihasilkan dengan linear problem. Hanya saja rentang ai antara 0 ≥ ai ≥C.
Cara lain pada data yang tidak dapat dipisahkan secara linear ialah memodifikasi SVM dengan memasukan fungsi �(x). Pencarian ini hanya bergantung pada dot product dari data yang sudah dipetakan pada ruang baru yang berdimensi lebih tinggi yaitu �( ) �( ). Ilustrasi terdapat pada Gambar 3.
Gambar 3 Fungsi � memetakan data ke ruang vektor yang berdimensi lebih tinggi (Gisler 2008)
8
Multi Class SVM
Pada SVM, terdapat metode untuk mengklasifikasikan data yang memiliki lebih dari dua kelas, yaitu: metode one against one dan one against all. Pada metode one against all, dibangun k buah model SVM (k adalah jumlah kelas). Setiap model klasifikasi ke-i dilatih dengan menggunakan keseluruhan data. Untuk mencari solusi permasalahan, Persamaan 7 digunakan (Hsu dan Lin 2002).
�
1
2( ) + �
s.t Φ + ≥ 1− � → = ,
Φ + ≥ −1 +� → ≠ ,� ≥ 0 (7)
METODE
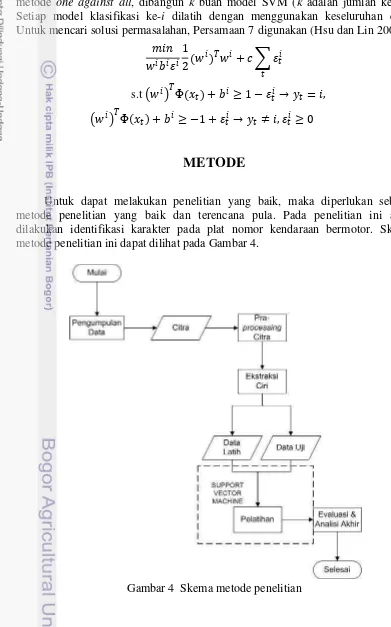
Untuk dapat melakukan penelitian yang baik, maka diperlukan sebuah metode penelitian yang baik dan terencana pula. Pada penelitian ini akan dilakukan identifikasi karakter pada plat nomor kendaraan bermotor. Skema metode penelitian ini dapat dilihat pada Gambar 4.
9 Pengumpulan Data
Data yang digunakan pada penelitian ini berupa data yang telah digunakan pada penelitian Lesmana (2012). Citra yang diambil pada penelitian tersebut menggunakan kamera handphone dengan resolusi sebesar 5 MP. Citra yang dikumpulkan harus memperhatikan jumlah kemunculan masing-masing karakter, dimana sebaran frekuensinya merata untuk setiap kaarkter. Hal tersebut dilakukan agar data latih yang dimiliki dapat lebih akurat untuk setiap karakter yang ada.
Selain itu perlu diperhatikan juga bahwa semua citra yang dikumpulkan harus memiliki resolusi yang sama. Kamera yang digunakan memiliki resolusi 5 MP dan akan menghasilkan citra dengan resolusi yang cukup besar, maka perlu diubah terlebih dahulu ke resolusi yang lebih kecil yang dilakukan secara manual dengan tetap memperhatikan kualitas citra. Dengan demikian pemrosesan citra yang akan dilakukan dapat lebih cepat. Berikut contoh citra yang digunakan dapat dilihat pada Gambar 5.
Gambar 5 Plat nomor kendaraan
Praproses citra
Para proses citra dilakukan untuk meningkatkan kualitas pola pada citra. Data yang didapat dari proses pengumpulan data merupakan citra dengan format warna RGB. Dalam proses identifikasi karakter pada plat nomor tidak perlu memperhatikan perbedaan warna RGB. Oleh karena itu, akan lebih efisien jika diubah ke dalam format grayscale. Proses konversi dalam format grayscale dapat menggunakan rumus:
Pixel = (0.2989 × R) + (0.5870 × G) + (0.1140 × B)
Dengan R, G, dan B merupakan intensitas dari masing-masing warna merah, hijau, dan biru pada citra. Dengan mengkonversi format warna ke grayscale tentu saja dapat mempercepat komputasi pada tahap berikutnya.
Restorasi dan Perbaikan Citra
10
Deteksi Tepi
Citra yang ada akan dikurangi noise-nya yang terdeteksi oleh filter yang digunakan. Setiap objek yang ada pada citra akan dideteksi menggunakan algoritma Canny. Algoritma ini dipilih karena cukup baik dalam mendeteksi tepi. Selain memiliki kemampuan untuk meletakkan dan menandai semua tepi yang ada sesuai dengan pemilihan parameter-parameter konvolusi yang dilakukan, algortima Canny juga memberikan fleksibilitas yang sangat tinggi dalam hal menentukan tingkat deteksi ketebalan tepi sesuai dengan yang diinginkan.
Segmentasi Citra
Dalam identifikasi karakter pada plat nomor perlu dilakukan segmentasi citra untuk mengeliminasi objek yang tidak diperlukan dan memilih mana objek yang merupakan karakter dan mana yang bukan. Hal tersebut dilakukan dengan segmentasi citra berdasarkan area. Objek yang memiliki pixel-pixel yang terhubung akan dianggap menjadi satu area. Masing-masing area tersebut akan diberi label untuk kemudian dihitung luas areanya satu per satu. Untuk mendeteksi apakah suatu pixel terhubung dengan pixel tetangganya menggunakan metode 8connected. Selanjutnya akan ditentukan suatu batas yang menjadi acuan untuk menduga apakah objek tersebut merupakan karakter atau bukan berdasarkan luas areanya.
Ekstrasi Ciri
Tahapan ini dilakukan untuk mendapatkan fitur yang menjadi ciri dari setiap karakter pada plat nomor. Fitur tersebut nantinya akan menjadi acuan dalam proses klasifikasi dan pengenalan pola. Dalam penelitian ini pendekatan yang digunakan adalah ekstrasi fitur berbasis area yaitu ICZ.
Image Centroid and Zone
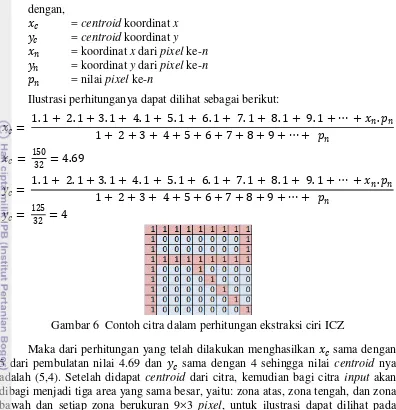
Pendekatan menggunakan ICZ ini merupakan metode yang cukup sederhana dalam implementasinya. Sebelum dilakukan tahapan pada metode ini perlu dipastikan bahwa setiap karakter yang ada memiliki dimensi yang sama besar. Contoh ilustrasi gambar dengan ukuran 9×9 pixel terdapat pada Gambar 6. Langkah pertama yang dilakukan adalah menghitung nilai centroid dengan rumus sebagai berikut:
= 1.�1 + 2.�2 +⋯ + .�
�1+ �2+⋯+ �
= 1.�1 + 2.�2 +⋯ + .�
11 dengan,
= centroid koordinat x = centroid koordinat y
= koordinat x dari pixel ke-n = koordinat y dari pixel ke-n
� = nilai pixel ke-n
Ilustrasi perhitunganya dapat dilihat sebagai berikut:
= 1. 1 + 2. 1 + 3. 1 + 4. 1 + 5. 1 + 6. 1 + 7. 1 + 8. 1 + 9. 1 +⋯ + .� 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +⋯+ �
= 150
32 = 4.69
= 1. 1 + 2. 1 + 3. 1 + 4. 1 + 5. 1 + 6. 1 + 7. 1 + 8. 1 + 9. 1 +⋯ + .� 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +⋯+ �
= 125 32 = 4
Gambar 6 Contoh citra dalam perhitungan ekstraksi ciri ICZ
Maka dari perhitungan yang telah dilakukan menghasilkan sama dengan 5 dari pembulatan nilai 4.69 dan sama dengan 4 sehingga nilai centroid nya adalah (5,4). Setelah didapat centroid dari citra, kemudian bagi citra input akan dibagi menjadi tiga area yang sama besar, yaitu: zona atas, zona tengah, dan zona bawah dan setiap zona berukuran 9×3 pixel, untuk ilustrasi dapat dilihat pada Gambar 7. Selanjutnya dicari jarak antara centroid dengan koordinat pixel yang memiliki nilai 1 (warna putih). Jarak akan dihitung menggunakan metode Euclidean dua dimensi. Berikut ini rumus jarak menggunakan Euclidean dengan P = ( �, �)dan C = ( , ).
d �,� ( � − )2+ (
� − )2
d = jarak antara dua titik P = koordinat titik berat C = koordinat pixel
� = koordinat x titik berat � = koordinat y titik berat
12
Gambar 7 Contoh citra dengan pembagian zona
Perhitungan zona atas dapat dilihat pada ilustrasi Gambar 7 sehingga perhitungannya sebagai berikut:
(1,1) → jarak = 1− 5 2+ 1− 4 2 = 5
(2,1) → jarak = 2− 5 2+ 1− 4 2 = 4.24
(3,1) → jarak = 3− 5 2+ 1− 4 2 = 3.61
(4,1) → jarak = 4− 5 2+ 1− 4 2 = 3.16
(5,1) → jarak = 5− 5 2+ 1− 4 2 = 3.00
(6,1) → jarak = 6− 5 2+ 1− 4 2 = 3.16
(7,1) → jarak = 7− 5 2+ 1− 4 2 = 3.61
(8,1) → jarak = 8− 5 2+ 1− 4 2 = 4.24
(9,1) → jarak = 9− 5 2+ 1− 4 2 = 5.00
(1,2) → jarak = 1− 5 2+ 2− 4 2 = 4.47
(9,2) → jarak = 9− 5 2+ 2− 4 2 = 4.47
(1,3) → jarak = 1− 5 2+ 3− 4 2 = 4.12
(9,3) → jarak = 9− 5 2+ 3− 4 2 = 4.12
Setelah semua jarak setiap pixel ke centroid pada zona atas didapat maka dilakukan perhitungan rata-rata jarak sebagai berikut:
Rataan jarak1 = 1
13( 1,1 + 2,1 + 3,1 + …+ 9,3 )
Maka hasil perhitungan rata-rata jarak pada zona atas adalah 4.02. Proses tersebut akan dilakukan pada zona tengah dan zona bawah dan rata-rata jarak pada zona tengah dan bawah adalah 2.45 dan 5.34. Rata-rata tersebutlah yang akan dijadikan sebagai data klasifikasi. Sehingga ekstraksi ciri yang didapat adalah [4.02 2.45 5.34].
Data Latih dan Data Uji
13 dilakukan sebanyak lima kali, sampai semua fold pernah berperan sebagai data latih dan data uji. Dalam setiap pengulangan nilai akurasi akan dihitung sehingga akurasi terakhir adalah rata-rata nilai akurasi 5 kali pengulangan yang dilakukan. Pembagian subset dapat dilihat pada Tabel 1.
Tabel 1 Pembagian subset
Subset Data latih (indeks) Data uji (indeks) Fold 1 11 – 50 1 – 10 Fold 2 1 – 10, 21 – 50 11 – 20 Fold 3 1 – 20, 31 – 50 21 – 30 Fold 4 1 – 30, 41 – 50 31 – 40 Fold 5 1 – 40 41 – 50
Pelatihan pada SVM
Pelatihan data dilakukan dengan menggunakan 3 kemungkinan kernel, yaitu:
1 Kernel linear.
2 Kernel polynomial, membutuhkan parameter d. 3 Kernel RBF, membutuhkan parameter σ.
Masing-masing kernel dicoba dengan nilai parameter fungsi kernel, hal ini dilakukan pada fungsi kernel polynomial dan kernel RBf terkecuali kernel linear. Sehingga didapat beberapa model SVM yang masing-masing akan diuji dan akan dihasilkan nilai output dari masing-masing model klasifikasi yang dapat menentukan kelas untuk data uji tersebut.
Pengujian pada SVM
Pengujian akan dilakukan pada semua model yang telah ditentukan pada proses pelatihan. Setelah itu dibandingkan kinerja dari masing-masing model tersebut. Kemudian dicari nilai kepercayaannya. Nilai kepercayaan ini akan digunakan pada penentuan kelas dengan metode oneagainstall.
Pada metode SVM, dilakukan proses mencari jarak antara data dengan hyperplane. Jarak yang dimaksud dilambangkan oleh x dan y ilustrasi dapat dilihat pada Gambar 8. Variabel x adalah jarak antara data pada kelas B dan hyperplane, sedangkan y adalah jarak antara data pada kelas A dan hyperplane. Nilai jarak tersebut disesuaikan dengan tanda dari masing-masing kelas.
14
Pada SVM klasifikasi dua buah kelas memperhatikan tanda positif atau negatif pada masing-masing kelas tanpa memperhatikan jarak antara data dengan hyperplane. Pada metode one against all melakukan perhitungan jarak antara data dengan hyperplane.
Gambar 9 Ilustrasi SVM 1
Sebagai ilustrasi kasus one against all dapat dilihat pada Gambar 9, Gambar 10, Gambar 11, dan Gambar 12. Pada SVM ini akan dilakukan pengujian terhadap empat buah data, yaitu: A, B, C, dan D. Data tersebut diklasifikasikan menjadi empat kelas (kelas 1, kelas 2, kelas 3, dan kelas 4). Pada metode one against all jika data akan diklasifikasikan menjadi empat kelas, maka jumlah SVM pun menjadi empat. SVM yang terbentuk akan sebanyak kelas yang ada. Gambar 9 merupakan ilustrasi SVM 1 yang membagi kelas menjadi kelas 1 dan kelas bukan 1. Gambar 10 adalah ilustrasi SVM 2 yang membagi kelas menjadi kelas 2 dan kelas bukan 2. Gambar 11 merupakan ilustrasi SVM 3 yang membagi kelas menjadi kelas 3 dan kelas bukan 3. Gambar 12 merupakan ilustrasi SVM 4 yang membagi kelas menjadi kelas 4 dan kelas bukan 4.
Gambar 10 Ilustrasi SVM 2
15
Gambar 12 Ilustrasi SVM 4
Tabel 2 Nilai kepercayaan data pada SVM
SVM A B C D
Hasil dari klasifikasi data A, B, C, dan D dapat dilihat pada Tabel 2. Hasil tersebut diperoleh dari kondisi berikut:
Jika semua kelas pada masing-masing SVM menerima data (tanda yang dimiliki data sesuai dengan tanda yang dimiliki kelas) maka absolutkan nilai dari data lalu pilih nilai kepercayaan yang terbesar.
Jika hanya satu kelas yang menerima data (hanya ada satu data yang tandanya sesuai dengan tanda yang dimiliki kelas) kemudian akan diklasifikasikan ke kelas yang menerima data tersebut.
Jika data tidak diterima dikelas manapun (tanda yang dimilik data tidak ada yang sesuai dengan tanda yang dimiliki kelas) kemudian absolutkan nilai dari data dan cari nilai kepercayaan yang terkecil karena nilai yang didapat adalah nilai penolakan yang terkecil.
Dari ketiga kondisi tersebut, dapat diketahui bahwa:
A diklasifikasi ke dalam kelas 1. Semua SVM (keempat SVM) menerima nilai yang ada, yaitu: pada SVM 1 adalah +7 (nilai dari kelas 1 adalah positif), pada SVM 2 adalah -2 (nilai dari kelas 2 adalah negatif), SVM 3 adalah +6 (nilai dari kelas 3 adalah positif), dan SVM 4 adalah -2 (nilai dari kelas 4 adalah negatif). Absolutkan semua nilai kemudian cari nilai kepercayaan yang terbesar. Hasil yang didapat adalah nilai 7. Nilai tersebut merupakan milik SVM 1 yang menyatakan bahwa nilai tersebut diklasifikasikan ke dalam kelas 1.
16
C diklasifikasikan ke dalam kelas 2 karena hanya satu SVM yang menerima nilai tersebut yaitu SVM 2. Nilai kepercayaan SVM 2 adalah -4 (nilai dari kelas 2 adalah negatif) sedangkan pada SVM 1 nilai kepercayaan yang didapat adalah -2 (nilai dari kelas 1 adalah positif), SVM 3 nilai kepercayaan yang didapat adalah -7 (nilai dari kelas 3 adalah positif), dan pada SVM 4 nilai kepercayaan yang didapat adalah +3 (nilai dari kelas 4 adalah negatif). Oleh karena itu, nilai kepercayaan tersebut masuk ke dalam kelas 2.
D diklasifikasikan ke dalam kelas 3 karena tidak ada SVM yang menerima nilai tersebut. SVM 1 memperoleh nilai kepercayaan -5 (nilai dari kelas 1 adalah positif), SVM 2 nilai kepercayaan yang diperoleh adalah +5 (nilai dari kelas 2 adalah negatif), nilai kepercayaan SVM 3 adalah -4 (nilai dari kelas 3 adalah positif), dan SVM 4 nilai kepercayaan yang diperoleh adalah +6 (nilai dari kelas 4 adalah negatif). Sehingga dari keempat nilai yang ada dicari nilai kepercayaan yang terkecil karena nilai tersebut merupakan nilai penolakan yang terkecil.
Klasifikasi Citra
Pada klasifikasi karakter dalam plat nomor diperlukan suatu struktur SVM dengan output sebanyak 36 (26 huruf dan 10 angka). Input yang diperlukan akan bergantung pada banyaknya elemen vektor yang dihasilkan pada tahap ekstrasi ciri di atas. Dalam melakukan pelatihan dan pengujian data, karakter akan diambil satu per satu dari kumpulan citra plat yang ada. Setiap karakter yang akan dilatih harus dipastikan memiliki luas area (dimensi) yang sama satu sama lain.
Evaluasi dan Analisis Hasil
Tahap ini merupakan tahap terakhir untuk mengevaluasi kekurangan dan kelebihan dari metode yang digunakan. Hal tersebut dilihat dari perbandingan hasil klasifikasi citra dengan nomor polisi aslinya. Hasil yang tidak sesuai maupun sesuai dicatat untuk menentukan seberapa besar akurasi dari metode ini. Untuk menghitung akurasi dapat menggunakan rumus sebagai berikut:
=�
� × 100%
� : jumlah citra yang berhasil terdekteksi N : jumlah data yang ada.
Lingkungan Pengembangan Sistem
Proses pengerjaan penelitian ini menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
Perangkat keras berupa notebook:
17 RAM kapasitas 2 GB.
Harddisk kapasitas 250 GB.
Monitor dengan resolusi 1 280×800 pixel. Perangkat lunak berupa:
Sistem operasi Microsoft Windows 7. Aplikasi pemrograman Matlab R2008b.
HASIL DAN PEMBAHASAN
Pengumpulan Data
Penelitian ini menggunakan data berupa citra. Citra diambil dari pemotretan 100 unit, sehingga dihasilkan 100 buah citra plat yang unik. Pemotretan dilakukan di halaman parkir kampus IPB Baranang Siang Bogor. Dari 100 buah citra kemudian diambil potongan karakter. Setiap karakter diambil secara unik dan acak sebanyak 50 buah. Karakter sendiri dapat berupa angka (0–9) dan huruf (A– Z) jika dijumlahkan menjadi 36 karakter sehingga karakter yang digunakan dalam penelitian ini adalah 1 800 karakter yang nantinya akan digunakan sebagai data latih dan data uji. Selain itu citra plat nomor yang ada dapat digunakan sebagai data uji plat. Contoh data karakter yang telah dipotong dapat dilihat pada Gambar 13.
Gambar 13 Contoh data karakter
Praproses Citra
Citra yang telah didapatkan dari hasil pemotretan tidak selalu memiliki kualitas baik terkadang mengandung noise, hal ini dapat menyulitkan dalam proses deteksi citra sehingga dapat berpegaruh pada akurasi. Selain itu terdapat informasi yang tidak dibutuhkan dari citra yang dapat memperlambat proses pendeteksian. Oleh karena itu, perlu adanya proses yang harus dilakukan sehingga citra yang didapatkan memiliki kualitas yang baik untuk diproses lebih lanjut.
18
model warna grayscale. Konversi model dilakukan dengan cara menghilangkan informasi hue dan saturation dan mempertahankan informasi luminance.
Tahapan selanjutnya adalah menghilangkan noise pada citra dengan menggunakan metode median filter. Metode ini sering digunakan untuk menghilang noise berupa salt & pepper. Salt & pepper dapat dilihat seperti bintik putih atau hitam yang terdapat pada pixel gambar. Median filter yang digunakan adalah dua dimensi dengan batas matriks 3×3. Cara kerja median filter adalah membaca nilai pixel yang akan diproses beserta pixel-pixel tetangganya, urutkan nilai-nilai pixel dari yang paling kecil hingga yang paling besar, dan pilih nilai pada bagian tengah untuk nilai yang baru bagi pixel (x,y). Banyaknya pixel yang dibandingkan tergantung dari batas matriks yang ditentukan. Ilustrasi praproses citra dapat dilihat pada Gambar 14.
Gambar 14 Gambar hasil praproses citra
Deteksi Tepi
Proses deteksi tepi yang dilakukan menggunakan metode deteksi tepiCanny dengan threshold 0.5. Nilai ini digunakan karena mendeteksi tepi secara benar sehingga menghasilkan deteksi tepi pada plat dengan hasil yang baik. Nilai threshold mempengaruhi seberapa dalam deteksi tepi yang akan dilakukan. Hal ini merupakan salah satu kelebihan metode ini. Pada proses ini dapat menghasilkan citra biner yang merepresentasikan garis tepi dari setiap objek pada citra. Garis tepi ini yang digunakan untuk memisahkan karakter yang diperlukan dengan objek lainnya. Hal ini dapat mempercepat pengolahan citra agar lebih efisien. Citra hasil deteksi tepi menggunakan metode deteksi tepi Canny pada plat dapat dilihat pada Gambar 15.
Gambar 15 Hasil deteksi tepi dengan metode deteksi tepi Canny
19 Segmentasi Citra
Pada proses ini dilakukan segmentasi citra untuk memisahkan informasi yang akan diproses pada tahap selanjutnya. Informasi yang dimaksud adalah pixel-pixel pada karakter angka dan huruf. Informasi yang didapat akan dipisahkan antara pixel yang mewakili huruf, karakter atau bukan keduanya.
Tahapan yang harus dilakukan adalah melakukan labelling dengan cara mengelompokan pixel yang terhubung langsung dan memperhatikan 8 pixel tetangganya. Setiap pixel yang terhubung akan dikelompokan dan diberi label. Sehingga dapat diketahui panjang dan lebar area untuk setiap label. Variabel tersebut akan dijadikan parameter untuk menentukan pixel yang mewakili huruf dan angka. Panjang dan lebar area label dapat diukur sebagai berikut: jika 105 pixel < P < 140 pixel dan 20 pixel < L < 100 pixel maka label merupakan karakter selainnya bukan karakter.
Label yang memenuhi syarat akan dianggap huruf atau angka. Pada beberapa kasus label yang harusnya menjadi satu karakter tetapi komputer tidak membaca label tersebut sebagai karakter yang utuh, misalnya angka 0 (nol) yang diwakili oleh dua buah elips yang berukuran besar dan didalamnya elips yang berukuran lebih kecil. Karena algoritma labelling mengecek pixel yang saling berhubungan. Sedangkan angka 0 terdiri dari dua buah elips yang terpisah dan memiliki jarak sehingga menjadi dua buah label yang berbeda. Untuk lebih jelasnya dapat dilihat pada Gambar 16.
Gambar 16 Labelling pada angka nol
Kondisi ini berlaku untuk setiap angka ataupun huruf yang memiliki kondisi seperti angka 0. Untuk mengatasi kondisi seperti ini, maka akan dilakukan pengecekan pada setiap label. Jika salah satu label berada pada area label lainya, maka label tersebut dianggap satu. Pada tahap ini sudah terkumpul label-label yang mewakili karakter pada suatu plat dapat dilihat pada Gambar 17.
Gambar 17 Proses segmentasi pada plat
Normalisasi Citra
Pada hasil segmentasi sebelumnya telah didapatkan karakter-karakter yang telah terpotong dari suatu plat, didapatkan ukuran area yang berbeda pada setiap karakter. Hal ini dapat mempersulit dalam proses ekstraksi ciri. Oleh karena itu, ukuran area setiap karakter akan dilakukan normalisasi menjadi 150×150 pixel. Setiap karakter akan dirubah menjadi ukuran tersebut walaupun hal ini
20
menyebabkan bentuk karakter akan menjadi tidak proporsional. Normalisasi sendiri dilakukan untuk semua karakter yang ada dan tidak akan mempengaruhi informasi yang diperlukan pada proses ekstraksi ciri. Untuk lebih jelasnya bentuk normalisasi dapat dilihat pada Gambar 18.
Gambar 18 Normalisasi pada karakter
Ekstraksi Ciri
Dalam penelitian ini ekstraksi ciri yan digunakan adalah image centroid and zone (ICZ). Tahapan pertama dalam ekstraksi ciri yang harus dilakukan adalah mencari nilai centroid dari setiap karakter yang telah melewati proses segmentasi. Centroid pada setiap karakter tidak selalu sama, hal ini dikarenakan jumlah pixel yang berbeda pada setiap karakter. Selanjutnya karakter akan dibagi menjadi n zona bagian yang sama. Nilai n pada penelitian ini 25 karena pada zona ini menghasilkan akurasi terbaik dari beberapa zona, yaitu: 5, 10, 14, 15, 20, dan 25. Pembagian zona dengan kelipatan 5 untuk mempermudah dalam melakukan pengujian. Pada setiap pembagian zona, jumlah baris selalu lebih banyak daripada jumlah kolom atau jumlah baris sama dengan jumlah kolom. Setiap citra akan dibagi kedalam jumlah zona yang sama. Ilustrasi dari jumlah zona untuk n yang digunakan dapat dilihat pada Gambar 19.
5 Zona 10 Zona 14 Zona
15 Zona 20 Zona 25 Zona
Gambar 19 Ilustrasi pembagian zona pada ekstraksi fitur
21 Gambar 20 merupakan pola ekstraksi fitur 25 zona pada huruf P dengan menggunakan 50 citra. Pada Gambar 20 dapat dilihat bahwa tidak semua karakter P memiliki pola yang sama, tetapi pola yang terbentuk memiliki kemiripan pada karakter yang sama. Hal ini terjadi akibat metode ICZ menghitung nilai rata-rata jarak pada setiap zona berdasarkan hasil praproses yang dilakukan pada citra. Hasil praproses pada citra tidak selalu merepresentasikan bentuk aslinya dengan baik sehingga berpengaruh pada proses ekstraksi fitur dan akibat ini pola yag terbentuk tidak semua sama untuk suatu karakter. Pada Gambar 20 pola untuk ekstraksi fitur pada huruf P dan Gambar 21 pola untuk ekstraksi fitur pada huruf I. Pada Gambar 20 terlihat pola yang dihasilkan lebih baik dan hampir semua huruf P memiliki pola yang sama sedangkan pada Gambar 21 dapat dilihat pola yang dihasilkan oleh huruf I kurang baik sehingga pola yang dihasilkan untuk huruf I memiliki bentuk yang beragam. Hal ini pun berpengaruh pada akurasi yang dihasilkan oleh masing karakter dengan pengujian 50 citra untuk masing-masing karakter. Pada karakter P menghasilkan akurasi 100 % sedangkan pada huruf I menghasilkan akurasi 86 %.
Gambar 22 (kanan) adalah hasil dari praproses citra yang kurang baik dan Gambar 22 (kiri) merupakan hasil dari praproses citra yang baik.
Gambar 20 Pola ekstraksi fitur pada huruf P
Gambar 21 Pola ekstraksi fitur pada huruf I
Gambar 22 Hasil dari citra dengan praproses yang tidak baik (kanan) dan praproses yang baik (kiri)
22
Klasifikasi Citra
Pada tahap ini dilakukan proses pembagian data latih dan data uji pada semua citra karakter karena akan dilakukan proses pelatihan dan pengujian. Jumlah karakter yang digunakan adalah 36 karakter yang terdiri dari angka dan huruf dan masing-masing karakter terdiri dari 50 citra sehingga jumlah seluruh citra adalah 1800 citra. Pembagian jumlah data latih adalah 40 citra dan data uji adalah 10 citra untuk masing-masing karakter.
Metode yang digunakan dalam menentukan data uji dan data latih menggunakan k-fold cross validation dengn k yang bernilai 5. Sehingga didapat 5 subset atau variasi pada data latih dan data uji. Pemilihan subset ini berdasarkan persentase data yang diinginkan, yaitu: 80% untuk data latih dan 20% untuk data uji. Matriks yang terbentuk untuk data latih adalah n×1 440 dan data uji n×360. Huruf n mewakili jumlah zona yang telah ditentukan pada tahap ekstraksi ciri, 1 440 adalah banyaknya sampel karakter data latih, dan 360 banyaknya sampel karakter data uji. Jumlah kelas dari penelitian ini adalah 36 kelas sesuai dengan jumlah karakter yang digunakan.
Klasifikasi yang digunakan adalah suport vector machine (SVM) dengan 3 kernel, yaitu:
1 Kernel linear
2 Kernel polynomial dengan d ( 2 dan 3 )
3 Kernel radian basis function (RBF) dengan σ( 25, 26 , 27 dan 28 )
Pengujian Per Karakter
Setelah proses ekstraksi fitur, dilakukan pengujian dan pelatihan dengan menggunakan klasifikasi SVM. SVM hanya dapat melakukan klasifikasi dua kelas. Oleh karena itu, kita harus memodifikasi fungsi SVM agar dapat melakukan klasifikasi untuk banyak kelas, fungsi yang digunakan adalah multi class SVM dengan metode one against all. Pada teknik ini dapat dibuat SVM sebanyak kelas yang ada yaitu 36 buah. Setiap SVM mewakili setiap kelas, contoh SVM 1
mewakili kelas “nol” sehingga SVM ini hanya dapat mengenali citra karakter “nol” dan “bukan nol”.
Pemodelan SVM dibangun dengan 3 fungsi kernel, yaitu: kernel linear (polynomial berderajat 1), kernel polynomial berderajat 2 dan 3, kernel RBF. Pengujian yang dilakukan menghasilkan nilai akurasi yang berbeda-beda. Nilai dari pengujian dapat dilihat pada Tabel 3.
23 Pengujian dilakukan pada karakter untuk mengetahui sama atau tidaknya tanda antara nilai pada SVM pada proses pelatihan dengan nilai output. Nilai output merupakan hasil dari pengujian pada SVM. Pada proses pengujian adanya kesamaan tanda antara nilai pada SVM 1 dengan nilai output. SVM 1 merupakan SVM yang mewakili kelas 1. Oleh karena itu, nilai yang dihasilkan pada pengujian karakter adalah kelas 1 karena hanya ada satu SVM yang memiliki kesamaan tanda antara nilai SVM dengan nilai output, yaitu pada SVM 1 dengan nilai kepercayaan -2.0875 (nilai dari kelas 1 adalah negatif) sedangkan pada SVM 2 sampai SVM 36 (nilai dari kelas 2 sampai dengan kelas 36 adalah positif). Proses pengujian ini dilakukan pada semua data uji. Contoh beberapa data pada pengujian karakter dapat dilihat pada Lampiran 1.
Tabel 3 Nilai pengujian per karakter
24
Tabel 4 Akurasi pada kernel linear
k-fold Linear dihasilkan dengan menggunakan σ sama dengan 2 sedangkan jika d sama dengan 3 akurasi yang dihasilkan akan menurun walaupun penurunan akurasinya tidak terlalu signifikan. Sedangkan jika d sama dengan 4 akan membutuhkan waku yang lama dan akan mengalami penurunan akurasi karena dimensi yang diolah akan semain banyak. Dimensi data yang dihasilkan akan semakin banyak jika nilai d yang digunakan akan semakin tinggi dapat dilihat pada rumus dibawah ini:
� + , = + + −1 …( + 1)
!
C adalah kombinasi dari n dan d, n adalah dimensi awal dan d merupakan nilai orde dari kernel polynomial menurut Chang et al. pada tahun 2010. Sebagai contoh diketahui nilai d sama dengan 2 dan banyaknya fitur (n) adalah 1800.
� 1800 + 2,2 = 1800 + 2 !
Nilai tersebut merupakan nilai dimensi fitur yang baru yang akan digunakan untuk proses pengolahan klasifikasi dengan meggunakan metode kernel polynomial. Nilai fitur yang baru sangat besar, hal ini dapat akan membantu dalam proses pengujian dan memudahkan tahapan klasifikasi sehingga menghasilkan akurasi yang tinggi. Akurasi kernel polynomial untuk semua fold dapat dilihat pada Lampiran 2.
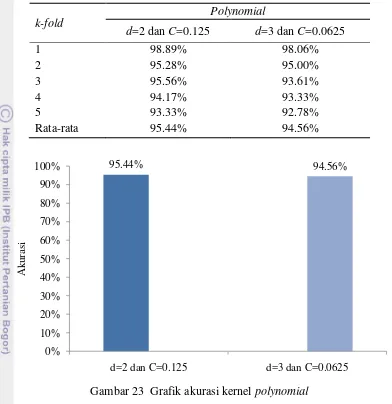
25 Tabel 5 Akurasi terbaik kernel polynomial pada setiap nilai d
k-fold
Gambar 23 Grafik akurasi kernel polynomial
Kernel RBF
Hasil pengujian karakter dengan menggunakan kernel RBF akan menghasilkan akurasi tertinggi pada RBF dengan nilai σ sama dengan 32 dan C sama dengan 16 adalah 84.72%. Pada Tabel 6 dapat dilihat kecenderungan nilai σ, jika semakin tinggi nilai σ maka akurasi yang dihasilkan akan semakin menurun. Akurasi terendah dihasilkan pada σ sama dengan 256. Akurasi terbaik pada setiap
σ pada kernel RBF terdapat dilihat pada Tabel 6 dan grafiknya ditampilkan pada Gambar 24. Akurasi pada setiap fold untuk masing-masing σ terdapat pada Lampiran 3.
26
Tabel 6 Akurasi terbaik pada RBF untuk masing-masing σ k-fold
Gambar 24 Grafik akurasi pada kernel RBF
Pada Gambar 25 dapat terlihat bahwa kernel polynomial yang menghasilkan akurasi terbaik. Pada Tabel 5 dapat dilihat bahwa pengujian dengan rata-rata nilai akurasi tertinggi berada pada kernel polynomial yaitu 95.44% yang menggunakan 25 zona. Matriks konvolusi pengujian karakter terdapat pada Lampiran 4.
27 Tabel 7 Persentase akurasi pengujian karakter dengan kernel
k-fold
Gambar 25 Akurasi rata-rata pda setiap kernel
Pengujian Pada Plat
Proses ini dilakukan pada plat secara utuh. Pengujian yang dilakukan pada setiap karakter yang menggunakan k-fold sedangkan pada pengujian plat menggunakan keseluruhan hasil dari ekstraksi fitur dengan jumlah 25 zona. Plat yang digunakan pada proses klasifikasi adalah 65 citra plat kendaraan. Pada dasarnya pengujian plat ini tergantung pada pengujian karakter. Akurasi yang dihasilkan dari pengujian plat akan lebih kecil daripada akurasi pengujian karakter. Hal ini disebabkan dalam kehidupan nyata, jika terdapat 1 kesalahan dalam pembacaan plat nomor maka deteksi plat tersebut dinyatakan salah tetapi untuk beberapa kasus kesalahan pada salah satu karakter dapat ditoleransi, seperti halnya untuk kepentingan kepolisian. Oleh karena itu, pengujian plat ini dinyatakan lebih efisien akan diberikan toleransi kesalahan dalam pembacaan maksimal 1 huruf karena terkadang hal ini bermanfaat untuk kepentingan dalam
28
pencarian plat. Dari pengujian yang dilakukan akurasi yang dihasilkan adalah 89.23% tanpa toleransi kesalahan dan 98.46% untuk toleransi kesalahan sama dengan 1. Akurasi tertinggi dihasilkan pada toleransi sama dengan 1. Hasil pendeteksian pada semua plat dapat dilihat pada Lampiran 5. Perbandingan akurasi plat tanpa toleransi kesalahan dan toleransi kesalahan sama dengan 1 pada penelitian Pramesthi (2013) dan Lesmana (2012) dapat dilihat pada Tabel 8 dan Gambar 26.
Tabel 8 Akurasi toleransi kesalahan pada plat nomor Klasifikasi Tanpa toleransi
Gambar 26 Grafik akurasi toleransi kesalahan
Kesalahan identifikasi pada plat nomor bukan hanya dikarenakan klasifikasi yang kurang akurat tetapi ada hal lain yang menyebabkan ini gagal dikarenakan pada proses segmentasi, seperti beberapa simbol yang harus dikenali sebagai karakter tidak dapat dikenali dalam proses klasifikasi. Kesalahan identifikasi plat nomor pada penelitian ini dapat dilihat pada Tabel 9.
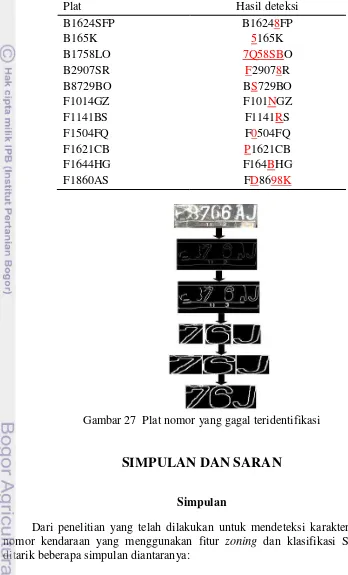
Pada pengujian plat nomor kendaraan F 8766 AJ terlihat terjadi kesalahan pada huruf F, huruf A, angka 8, angka 7, dan angka 6 dapat terlihat jelas bahwa citra angka kondisi plat yang kurang baik yaitu terdapat goresan sehingga menyebabkan goresan tersebut seperti warna background dari plat itu sendiri. Pendeteksian kesalahan dapat diketahui dari proses edge detection setelah itu dilakukan dilatasi pada proses tersebut ada beberapa karakter yang tidak dapat
29 dibaca, yaitu: huruf F, huruf A, angka 8, angka 7, dan angka 6, maka proses segmentasi akan dilakukan dari hasil proses edge detection dan dilatasi. Untuk lebih jelasnya dapat dilihat pada Gambar 27.
Tabel 9 Contoh kesalahan pada plat nomor
Plat Hasil deteksi
B1624SFP B16248FP
B165K 5165K
B1758LO 7Q58SBO
B2907SR F29078R
B8729BO BS729BO
F1014GZ F101NGZ
F1141BS F1141RS
F1504FQ F0504FQ
F1621CB P1621CB
F1644HG F164BHG
F1860AS FD8698K
Gambar 27 Plat nomor yang gagal teridentifikasi
SIMPULAN DAN SARAN
Simpulan
30
1 Pada penelitian pendeteksian plat nomor telah berhasil menggunakan pendekatan image centroid and zone sebagai metode ekstraksi fitur dan metode klasifikasi support vector machine.
2 Rataan akurasi kernel polynomial dengan parameter nilai C sama dengan 0.25 dan nilai d sama dengan 2 yaitu 95.44% menghasilkan akurasi lebih tinggi daripada kernel linear dengan parameter nilai C sama dengan 2 yaitu 88.89% dan kernel RBF dengan parameter nilai C yaitu 0.0625 dan nilai σ sama dengan 256 yang digunakan dalam penelitian yaitu 60.39%.
3 Rataan akurasi pada deteksi karakter pada plat sebanyak 65 buah plat nomor kendaraan menggunakan ekstraksi fitur ICZ dan klasifikasi SVM adalah 81.54%.
4 Rataan akurasi pada deteksi karakter pada plat sebanyak 65 buah plat nomor kendaraan menggunakan ekstraksi fitur ICZ dan klasifikasi SVM dengan toleransi kesalahan sebanyak 1 adalah 90.77%.
5 Metode akurasi pada karakter yang dihasilkan pada penelitian ini lebih tinggi daripada penelitian yang menggunakan klasifikasi backpropagation (Lesmana 2012) yaitu 85.32% dan menghasilkan akurasi yang lebih rendah dibandingkan klasifikasi yang menggunakan K-NN yaitu 97%.
Saran
Agar penelitian ini terus berkembang perlu dilakukan beberapa saran antara lain:
1 Dapat dilakukan pendeteksian plat menggunakan metode ekstraksi fitur dan klasifikasi lainya untuk meningkatkan akurasi.
2 Menambahkan foto-foto plat nomor kendaraan lain yang diambil dari variasi posisi pengambilan citra untuk proses pengujian dan dalam format plat nomor kendaraan yang berbeda-beda.
3 Dapat dikembangkan untuk membangun suatu sistem pencatatan plat nomor dengan berbagai kebutuhan yang terintegrasi oleh metode pendeteksian karakter pada plat nomor.
DAFTAR PUSTAKA
Acharya T, Ray AK. 2005. Image Processing Principles and Applications. Hoboken (US): J Wiley.
Anisah SZ. 2012. Pengenalan iris mata dengan support vector machine menggunakan ekstraksi ciri log-gabor filter [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Byun H, Lee S. 2003. A survey on pattern applications of support vector machines. International Journal of Pattern Recognition and Artificial Intelligence. 17(3):459-486.
31 Cortes C, Vapnik V. 1995. Support-vector networks. Machine Learning 20:
273-297.
Gisler H. 2008. An interactive painting based on image selection and voice input [tesis]. Fribourg (CH): University of Fribourg.
Gonzales RC, Woods RE, Eddins SL. 2003. Digital Image Processing 2nd ed. Upper Saddle River (US): Prentice Hall.
Hsu C, Lin C. 2002. A comparison of methods for multi-class support vector machines. IEEE Transactions on Neural Networks. 13(2): 415-425.
Kohavi R. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. Di dalam: Proceedings of the 14th International Joint Conference on Artificial Intelligence; 1995 Agu 20-25; Quebec, Kanada. hlm 1137-1143.
Lesmana AR. 2012. Identifikasi karakter pada plat nomor kendaraan menggunakan zone based feature extraction dengan metode klasifikasi backpropagation [skripsi]. Bogor (ID): Institut Peranian Bogor.
Lim R, Gunadi K, Vendy LW. Sistem pengenalan plat nomor mobil dengan metode principal component analysis [skripsi]. Surabaya (ID): Universitas Kristen Petra.
Pramesti RP. 2012. Identifikasi karakter pada plat nomor kendaraan menggunakan ekstraksi fitur ICZ dan ZCZdengan metode klasifikasi K-NN [skripsi]. Bogor (ID): Institut Peranian Bogor.
Rajashekararadhya SV, Ranjan PV. 2008. Efficient zone based feature extration algorithm for handwritten numeral recognition of four popular South Indian scripts. Journal of Theoretical and Applied Information Technology. 4(12): 1171-1181.
Setiawan A. 2008. Sistem pengenalan plat nomor mobil untuk aplikasi informasi karcis parkir[skripsi]. Surabaya (ID): Institut Teknologi Sepuluh Nopember. Wahyono ES. 2009. Identifikasi nomor polisi mobil menggunakan metode
jaringan syaraf buatan learning vector quantization [skripsi]. Depok (ID): Universitas Gunadarma.
32
Lampiran 1 Pengujian karakter pada SVM SVM
Pengujian karakter
Nilai Nilai output Nilai Nilai output Nilai Nilai output Nilai Nilai output Nilai Nilai output
SVM 1 0 3.504 1 -2.0875 1 -0.7066 1 -1.0211 0 1.2155
SVM 2 0 1.2054 0 1.1624 0 1.5279 0 1.3436 0 1.3901
SVM 3 0 1.7196 0 1.6299 0 1.6632 0 2.0846 0 1.242
SVM 4 0 1.4711 0 2.6652 0 1.4414 0 1.7243 0 2.8586
SVM 5 0 0.9862 0 1.5579 0 1.6771 0 1.6578 0 1.446
SVM 6 0 1.9493 0 2.9345 0 2.66 0 2.7785 6 0.8169
SVM 7 1 -1.6766 0 1.843 0 0.3742 0 1.2507 0 1.7167
SVM 8 0 2.0138 0 2.378 0 1.666 0 1.5541 0 1.4576
SVM 9 0 1.885 0 4.3098 0 0.2002 0 8.8486 0 1.9608
SVM 10 0 2.33 0 3.3222 0 3.2553 0 2.135 0 2.6713
SVM 11 0 1.5814 0 1.5081 0 1.2721 0 1.2205 0 1.2203
SVM 12 0 -1.57 0 4.5627 0 1.0976 0 2.0242 0 5.0856
SVM 13 0 0.4577 0 1.4542 0 0.9099 0 1.3451 0 1.2693
SVM 14 0 0.6853 0 1.3526 0 2.1776 0 1.1793 0 1.6993
SVM 15 0 1.186 0 1.1944 0 1.2072 0 1.1214 0 1.1614
SVM 16 0 1.2082 0 1.2595 0 1.2625 0 1.218 0 1.2484
SVM 17 0 11.2981 0 1.221 0 11.5122 0 6.1161 0 4.3678
SVM 18 0 1.65 0 1.7155 0 1.5392 0 1.8025 0 1.4368
SVM 19 0 1.4607 0 1.5505 0 1.8631 0 1.9431 0 1.1749
SVM 20 0 1.2201 0 1.1781 0 1.1884 0 1.141 0 1.1656
SVM 21 0 2.1433 0 1.7909 0 2.0817 0 1.6558 0 1.2796
33 Lampiran 1 Lanjutan
SVM
Pengujian karakter
34
Lampiran 2 Akurasi SVM pada kernel polynomial
k-fold Polynomiald=2
C=0.0625 C=0.125 C=0.25 C=0.5 C=1 C=2 C=4 C=8 C=16 1 98.89% 98.89% 98.61% 98.06% 98.06% 98.06% 98.06% 98.06% 98.06% 2 95.56% 95.28% 94.72% 95.56% 95.56% 95.56% 95.56% 95.56% 95.56% 3 94.72% 95.56% 95.56% 95.28% 95.56% 95.56% 95.56% 95.56% 95.56% 4 93.33% 94.17% 94.72% 94.44% 94.44% 94.17% 94.17% 94.17% 94.17% 5 93.61% 93.33% 92.78% 92.22% 91.94% 92.50% 92.50% 92.50% 92.50% Rata-rata 95.22% 95.44% 95.28% 95.11% 95.11% 95.17% 95.17% 95.17% 95.17%
k-fold Polynomiald= 3
35 Lampiran 3 Akurasi SVM pada kernel RBF
k-fold RBF σ=32
C=0.0625 C=0.125 C=0.25 C=0.5 C=1 C=2 C=4 C=8 C=16 1 68.33% 67.22% 68.06% 72.78% 77.22% 82.50% 85.28% 87.50% 89.17% 2 63.33% 64.17% 66.11% 71.67% 72.50% 80.83% 83.33% 85.28% 88.33% 3 57.78% 60.83% 66.94% 67.22% 72.50% 77.50% 81.67% 83.33% 84.72% 4 57.78% 58.33% 64.72% 64.72% 67.78% 74.44% 79.17% 78.33% 80.00% 5 58.06% 57.50% 65.00% 69.44% 71.67% 77.78% 80.56% 81.67% 81.39% Rata-rata 61.06% 61.61% 66.17% 69.17% 72.33% 78.61% 82.00% 83.22% 84.72%
k-fold RBF σ=64
36
Lampiran 3 Lanjutan
k-fold RBF σ=128
C=0.0625 C=0.125 C=0.25 C=0.5 C=1 C=2 C=4 C=8 C=16 1 67.22% 68.06% 67.22% 67.50% 67.22% 66.11% 67.78% 72.78% 76.94% 2 62.50% 62.22% 62.50% 62.50% 63.06% 63.06% 65.83% 70.83% 72.22% 3 58.06% 58.06% 58.06% 58.06% 57.50% 62.50% 66.39% 67.22% 72.78% 4 57.50% 58.06% 57.50% 57.50% 55.28% 55.56% 64.44% 64.72% 67.78% 5 57.22% 55.83% 57.22% 57.22% 56.67% 57.50% 64.72% 69.44% 71.39% Rata-rata 60.50% 60.44% 60.50% 60.56% 59.94% 60.94% 65.83% 69.00% 72.22%
k-fold
RBF σ=256
37 Lampiran 4 Hasil deteksi karakter pada 25 zona menggunakan kernel polynomial
38
Lampiran 5 Akurasi pada plat nomor kendaraan
No Plat Hasil deteksi 25 zona
Tanpa kesalahan Kesalahan = 1
1 B1093NFC B1093NFC B1093NFC B1093NFC
2 B1163FY B1163FY B1163FY B1163FY
3 B1202TJC B1202TJC B1202TJC B1202TJC
4 B1272KKC B1272KKC B1272KKC B1272KKC
5 B1329ZUE B1329ZUE B1329ZUE B1329ZUE
6 B1459MH B1459MH B1459MH B1459MH
7 B1506OH B1506OH B1506OH B1506OH
8 B1623UKV B1623UKV B1623UKV B1623UKV
9 B1624SFP B16248FP B16248FP
10 B1633ZFB B1633ZFB B1633ZFB B1633ZFB
11 B165K 5165K 5165K
12 B1731SFR B1731SFR B1731SFR B1731SFR
13 B1758LO 7Q58SBO
14 B1760RFQ B1760RFQ B1760RFQ B1760RFQ
15 B1822UKB B1822UKB B1822UKB B1822UKB
16 B1827SKJ B1827SKJ B1827SKJ B1827SKJ
17 B1868BOD B1868BOD B1868BOD B1868BOD
18 B2039BS B2039BS B2039BS B2039BS
19 B2228LL B2228LL B2228LL B2228LL
20 B2809GB B2809GB B2809GB B2809GB
21 B2825YT G2SR5YT
No Plat Hasil deteksi 25 zona
Tanpa kesalahan Kesalahan = 1
22 B2833XY B2833XY B1760RFQ B1760RFQ
23 B2907SR F29078R B1822UKB B1822UKB
24 B2999WO B2999WO B1827SKJ B1827SKJ
25 B457UTY B457UTY B1868BOD B1868BOD
26 B54TYA B54TYA B2039BS B2039BS
27 B560XV B560XV B2228LL B2228LL
28 B7044UR B7044UR B2809GB B2809GB
29 B8161GN B8161GN B1760RFQ B1760RFQ
30 B8554PD B8554PD B1822UKB B1822UKB
31 B8729BO BS729BO BS729BO
32 B8966VD B8966VD B8966VD B8966VD
33 BM1013TM BM1013TM BM1013TM BM1013TM
34 F1014GZ F101NGZ F101NGZ
35 F1034HB F1034HB F1034HB F1034HB
36 F1114GN F1114GN F1114GN F1114GN
37 F1139HI F1139HI F1139HI F1139HI
38 F1141BS F1141RS F1141RS
39 F1197HK F1197HK F1197HK F1197HK
40 F1205G F1205G F1205G F1205G
41 F1206CS F1206CS F1206CS F1206CS
39
47 F1512BI F1512BI F1512BI F1512BI
48 F1549BM F1549BM F1549BM F1549BM
49 F1575CJ F1575CJ F1575CJ F1575CJ
50 F1580CV F1580CV F1580CV F1580CV
51 F1600D F1600D F1600D F1600D
52 F1621CB P1621CB P1621CB
53 F1622NL F1622NL F1622NL F1622NL
54 F1644HG F164BHG F164BHG
No Plat Hasil deteksi 25 zona
Tanpa kesalahan Kesalahan = 1
55 F1697AU F1697AU F1697AU F1697AU
56 F1720HB F1720HB F1720HB F1720HB
57 F1745GP F1745GP F1745GP F1745GP
58 F1761CT F1761CT F1761CT F1761CT
59 F1794H F1794H F1794H F1794H
60 F1804CN F1804CN F1804CN F1804CN
61 F1834CS F1834CS F1834CS F1834CS
62 F1860AS FD8698K
63 F1877CU F1877CU F1877CU F1877CU
64 F212AX F212AX F212AX F212AX
65 F601DY F60RDY F60RDY F60RDY
40
RIWAYAT HIDUP
Penulis bernama lengkap Intan Ayu Octavia, lahir di Bogor, Jawa Barat pada tanggal 20 Oktober 1988. Penulis merupakan anak terakhir dari pasangan Bapak H Anwar Firmansyah dam Ibu Hj Erna Nelly.