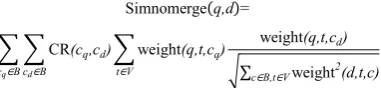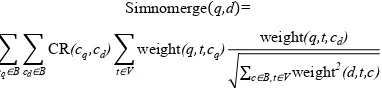XML RETRIEVAL DOKUMEN BAHASA INDONESIA
MENGGUNAKAN ALGORITME SIMNOMERGE
ANELA FEBRID YUNITA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
XML RETRIEVAL DOKUMEN BAHASA INDONESIA
MENGGUNAKAN ALGORITME SIMNOMERGE
ANELA FEBRID YUNITA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
ANELA FEBRID YUNITA. XML Retrieval for Bahasa Indonesia Document using Simnomerge Algorithm. Supervised by JULIO ADISANTOSO.
XML Retrieval is one of the information retrieval system which use structured elements in documents as a unit that can be retrieved. Queries used in XML Retrieval are tagged pieces of the document collection.
This research is comparing the retrieval of relevant documents to irrelevant documents by using 130 documents of medicinal plants and 20 queries. Simnomerge algorithm is used in this research because different XML contexts are kept separate for the weighting. Each query is divided into 5 queries for unstructured retrieval system, 8 queries for XML retrieval with XML context depth 1, and 7 queries for XML retrieval with XML context depth 2. The result of this research shows that the XML retrieval can improve performance of the retrieval system by getting more relevant documents. At the relevant documents, average precision of XML retrievals query for an XML context depth 1 is 0.911, or a 15.5% increase from the unstructured retrieval system. Average precision of XML retrievals query for XML context depth 2 is 0.981, or a 22.5% increase from the unstructured retrieval system. Meanwhile, for the irrelevant document the average precision of XML retrieval for XML context depth 1 is 0.246 or a 36.5% decrease from the unstructured retrieval system. The average precision of XML retrieval for XML context depth 2 is 0.329 or a 28.8% decrease from the unstructured retrieval system.
Judul Skripsi : XML Retrieval Dokumen Bahasa Indonesia Menggunakan Algoritme Simnomerge Nama : Anela Febrid Yunita
NIM : G64096009
Disetujui Pembimbing
Ir Julio Adisantoso MKom NIP 19620714 198601 1 002
Diketahui
Ketua Departemen Ilmu Komputer
Dr Ir Agus Buono MSi MKom NIP 19660702 199302 1 001
RIWAYAT HIDUP
PRAKATA
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan ke hadirat Allah Subhanahuwa
ta’ala atas segala karunia-Nya sehingga tugas akhir ini berhasil diselesaikan. Topik tugas akhir yang dipilih dalam penelitian adalah XML Retrieval Dokumen Bahasa Indonesia Menggunakan Algoritme Simnomerge.
Penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
Orang tua tercinta Bapak Setyo Trie Warsono dan Ibu Sis Wahyuni, Kakak Elena Astrid Yunita, Adik Rizky Rio Pamungkas, serta seluruh keluarga besar atas segala doa dan dukungan yang selalu diberikan.
Bapak Ir Julio Adisantoso MKom selaku dosen pembimbing tugas akhir. Terima kasih atas bantuan, pengarahan dan kesabarannya selama penyelesaian tugas akhir ini.
Bapak Ahmad Ridha Skom MS dan Bapak Sony Hartono Wijaya SKom MKom selaku penguji. Terima kasih atas segala saran dan kritik membangun yang diberikan.
Rekan-rekan satu bimbingan Rina Kurniawati dan Dewi Susanti. Terima kasih atas kebersamaan dan semangat selama penyelesaian penelitian ini.
Yunie Purnamasari, Syahrul Fathi, Adi Darliansyah, Aokirinduan Hayyi A.Q. dan teman-teman Ilkom X4 lainnya. Terima kasih atas semangat dan kebersamaannya selama penyelesaian tugas akhir ini.
Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam pelaksanaan tugas akhir.
Semoga Allah subhanahu wata’ala membalas amal baik dan jasa seluruh pihak yang turut membantu dalam pelaksanaan tugas akhir.
Bogor, Juni 2012
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA Sistem Temu Kembali Informasi ... 1
XML Retrieval ... 1
Pembobotan BM25 ... 2
Simnomerge Similarity ... 2
Recall dan Precision ... 2
METODE PENELITIAN Koleksi Dokumen Pengujian ... 2
Praproses Dokumen ... 3
Context Resemblance (CR) ... 3
Algoritme Simnomerge ... 3
Pengujian Sistem Temu Kembali ... 3
Asumsi ... 3
Lingkungan Pengembangan ... 3
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian ... 3
Praproses Dokumen ... 4
Pemrosesan Query ... 4
Hasil Temu Kembali ... 4
Pengujian Sistem Temu Kembali ... 4
Pengujian pada Dokumen Relevan ... 4
Pengujian pada Dokumen Tidak Relevan ... 6
Analisis Perbandingan Sistem ... 7
Analisis Perbandingan Sistem Temu Kembali Informasi Berbasis Teks ... 7
Analisis Perbandingan Sistem XML Retrieval ... 7
KESIMPULAN DAN SARAN Kesimpulan ... 8
Saran ... 8
DAFTAR PUSTAKA ... 8
DAFTAR TABEL
Halaman
1 Deskripsi koleksi dokumen ... 3
2 Hasil perhitungan AVP pada dokumen relevan ... 5
3 Hasil perhitungan AVP pada dokumen tidak relevan ... 6
4 Perbandingan AVP sistem temu kembali berbasis teks ... 7
5 Perbandingan AVP XML retrieval ... 7
DAFTAR GAMBAR
Halaman 1 Gambaran umum XML retrieval. ... 32 Kurva recall dan precision tanpa tagging. ... 5
3 Kurva recall dan precision dengan konteks XML 1. ... 5
4 Kurva recall dan precision dengan konteks XML 2. ... 5
5 Kurva recall dan precision dokumen relevan. ... 5
6 Kurva recall dan precision tanpa tagging. ... 6
7 Kurva recall dan precision dengan konteks XML 1. ... 6
8 Kurva recall dan precision dengan konteks XML 2. ... 6
9 Kurva recall dan precision dokumen tidak relevan. ... 6
10 Perbandingan AVP sistem temu kembali informasi berbasis teks. ... 7
11 Perbandingan AVP XML retrieval. ... 8
DAFTAR LAMPIRAN
Halaman 1 Contoh dokumen pengindeksan pada Sphinx Search ... 102 Contoh dokumen pengujian ... 11
3 Deskripsi query ... 12
4 Daftar query dan dokumen relevan ... 14
5 Daftar query dan dokumen yang tidak relevan ... 15
6 Hasil kinerja sistem dalam temu kembali dokumen relevan ... 16
7 Hasil kinerja sistem dalam temu kembali dokumen yang tidak relevan ... 17
PENDAHULUAN
Latar Belakang
Sistem temu kembali informasi merupakan sarana bagi seseorang untuk mendapatkan berbagai informasi yang diinginkan dengan mudah. Informasi yang ingin didapat direpresentasikan dalam bentuk query. Query tersebut nantinya akan mengalami proses temu kembali sehingga menghasilkan informasi atau dokumen yang relevan.
Pada dasarnya, pengolahan data pada sistem temu kembali informasi dapat dilakukan secara tidak terstruktur dan terstruktur. Sistem temu kembali informasi tidak terstruktur mem-bandingkan kemiripan (similarity) query dengan semua kumpulan term pada dokumen. Kumpulan term pada dokumen dapat berupa kata-kata, gambar, dan lain-lain. Dengan kata lain, sistem temu kembali informasi tidak pernah memperhatikan struktur dokumen. Selain itu, unit yang akan ditemukembalikan berupa dokumen secara lengkap, sedangkan pada sistem temu kembali informasi terstruktur setiap elemen terstruktur yang terdapat pada dokumen dapat menjadi unit yang akan ditemukembalikan. Metode pada sistem temu kembali informasi terstruktur dikenal dengan sebutan XML retrieval. Pada XML retrieval, format dokumen yang digunakan adalah dokumen dengan struktur XML. XML retrieval menggunakan query dengan struktur tagging dari koleksi dokumen XML dan akan dibandingkan kemiripannya dengan setiap elemen XML pada koleksi dokumen tersebut sehingga lebih fleksibel.
Permasalahan dalam XML retrieval adalah pengguna hanya ingin mengembalikan bagian dari dokumen, bukan keseluruhan dokumen seperti sistem temu kembali informasi yang tidak terstruktur. Oleh karena itu di dalam XML retrieval unit-unit yang akan diindeks harus bisa mempresentasikan keseluruhan elemen yang ada di dalam dokumen. Permasalahan lainnya, ialah cara membedakan konteks yang berbeda dari setiap term ketika menghitung peringkat.
Terdapat beberapa penelitian terkait mengenai XML retrieval. Carmel et al. (2002) membangun sistem XML retrieval dengan menambahkan vector space model untuk menemukembalikan dokumen. Lalmas (2009) melakukan pendekatan terhadap query pada tagging XML yang tidak lengkap dan mempresentasikan hasil peringkat dokumen XML terurut secara relevan. Gusdiana (2011) mengimplementasikan algoritme Simnomerge untuk membangun sistem temu kembali dengan
koleksi dokumen XML dan membandingkan kinerja pembobotan tf, idf, dan tf-idf.
Bahi (2011) membangun sistem XML retrieval menggunakan koleksi dokumen dalam bahasa Indonesia. Namun, koleksi dokumen yang digunakan memiliki struktur XML yang belum lengkap dan spesifik untuk setiap dokumennya. Oleh karena itu pada penelitian ini, akan diterapkan metode XML retrieval menggunakan koleksi dokumen dengan struktur yang lengkap sehingga diharapkan hasil pengembalian informasi lebih baik dan spesifik. Tujuan
Tujuan penelitian ini ialah:
Mengimplementasikan XML retrieval
menggunakan algoritme Simnomerge untuk dokumen berbahasa Indonesia.
Membandingkan kinerja sistem temu kembali informasi menggunakan metode XML retrieval dengan sistem temu kembali informasi tidak terstruktur (berbasis teks).
Ruang Lingkup
Ruang lingkup penelitian ini ialah:
Pengguna mengetahui struktur XML pada dokumen.
Struktur tagging pada dokumen XML yang digunakan dalam pengindeksan memiliki kedalaman konteks 1.
TINJAUAN PUSTAKA
Sistem Temu Kembali Informasi
Temu kembali informasi berkaitan dengan cara merepresentasikan, menyimpan, meng-organisasikan dan mengakses informasi. Mengorganisasikan dan merepresentasikan informasi harus memudahkan pengguna dalam mengakses informasi yang dibutuhkan. Namun, mengetahui karakterisasi informasi yang dibutuhkan pengguna bukanlah hal yang sederhana. Pengguna harus menerjemahkan terlebih dahulu informasi yang dibutuhkan menjadi query yang akan diproses oleh sistem temu kembali informasi. Tujuan utama sistem temu kembali informasi adalah mengembalikan informasi yang mungkin berguna atau relevan (Baeza-Yates & Ribeiro-Neto 1999).
XML Retrieval
XML retrieval merupakan metode sistem temu kembali terstuktur menggunakan dokumen XML. Tujuan XML retrieval adalah mengembalikan bagian dokumen yaitu pada elemen XML yang merupakan hasil temu kembali dari sebuah query (Manning et al. 2008).
Pembobotan BM25
Pembobotan BM25 telah dikembangkan sejak awal tahun 1980, tetapi sampai saat ini masih digunakan secara luas. Ide utama BM25 adalah memberi pembobotan pada dokumen yang memiliki query yang langka dan sering muncul pada dokumen tersebut (Aksyonoff 2011). Pseudocode untuk memperoleh BM25 yang digunakan pada Sphinx Search ialah:
1 BM25=0
2 foreach(inmatching_keywords) { 3 n=total_matching_docs(keyword) 4 N=total_documents_collection 5 k1=1.2
6 TF=occurrence_count(keyword) 9 IDF=log((N-n+1)/n)/log(1+N) 10 BM25= BM25 + TF*IDF/(TF+k1) 11 }
12 Normalization: 13 BM25=0.5+BM25
/(2*num_keywords(query))
dengan:
N : Total dokumen dalam korpus, n : Total dokumen yang mengandung
query,
TF : Frekuensi term t pada dokumen, IDF : Inverted indeks dokumen, dan k1 : Positif parameter (1.2). Simnomerge Similarity
Fungsi ukuran kesamaan pada XML retrieval disebut Simnomerge karena setiap konteks XML yang berbeda disimpan terpisah untuk tujuan pembobotan. Dalam Simnomerge similarity, terdapat nilai Context Resemblance (CR) yang merupakan ukuran kemiripan konteks query dan konteks dokumen (Manning et al. 2008), yang dirumuskan sebagai berikut:
(c,cd) {
c
cd c cd
c cd
dengan |c |adalah banyaknya node pada query dan cd adalah banyaknya node pada dokumen.
Oleh karena itu, Simnomerge similarity dapat dirumuskan sebagai berikut (Manning et al. 2008):
,d
∑ ∑ c,cd ∑ ,t,c ,t,cd
√∑c ,t d,t,c
t cd
c
dengan adalah himpunan kata unik, adalah kumpulan semua konteks XML, c adalah panjangnya node pada query, cd adalah panjangnya node pada dokumen, ,t,c adalah bobot term pada konteks query, ,t,cd adalah bobot term t pada konteks dokumen dan √∑c ,t d,t,c adalah fungsi normalizer untuk menormalisasi panjang dokumen.
Recall dan Precision
Recall adalah perbandingan antara dokumen relevan yang ditemukembalikan a dan dokumen relevan yang terdapat pada korpus
ecall a
Precision adalah perbandingan antara dokumen relevan yang ditemukembalikan
a dan dokumen yang ditemukembalikan
A (Baeza-Yates & Ribeiro-Neto 1999).
recision a A
Average precision (AVP) berfungsi untuk mengevaluasi secara kuantitatif kinerja temu kembali yang diperoleh dengan menggunakan eleven standard recall yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1 (Baeza-Yates & Ribeiro-Neto 1999).
METODE PENELITIAN
Penelitian ini dilakukan dalam empat tahap, antara lain, praproses, penghitungan nilai CR untuk menentukan tingkat kemiripan antara query dengan konteks XML yang ada pada indeks, pemeringkatan dokumen menggunakan algoritme Simnomerge, dan evaluasi. Gambaran umum proses XML retrieval menggunakan algoritme Simnomerge dapat dilihat pada Gambar 1.
Koleksi Dokumen Pengujian
Praproses Dokumen
Pada praproses, setiap dokumen dari koleksi dokumen akan diberi tag. Pada tahap selanjutnya dilakukan proses penghilangan kata-kata umum yang tidak memiliki makna atau disebut dengan stopwords. Dokumen hasil praproses akan diboboti dan diindeks sehingga inverted index diperoleh dan pencarian dokumen berdasarkan query yang diberikan dapat dilakukan. Pembobotan yang digunakan pada penelitian ini adalah pembobotan BM25.
Context Resemblance (CR)
Query yang dimasukkan setelah mengalami praproses akan dihitung nilai CRnya. Nilai CR diperoleh ketika XML path pada query terdapat pada XML path koleksi dokumen. Diperoleh konteks XML yang memiliki kemiripan antara konteks XML yang dibentuk dari query dengan konteks XML yang berada pada koleksi dokumen. Query dengan nilai CR lebih besar dari nol memenuhi syarat untuk memasuki tahap selanjutnya.
Algoritme Simnomerge
Kumpulan konteks XML yang telah diperoleh selanjutnya diboboti dan diurutkan. Kemudian, hasil pencarian ditampilkan. Pengujian Sistem Temu Kembali
Pengujian dilakukan dengan mengukur akurasi kinerja sistem. Parameter yang digunakan untuk mengukur akurasi tersebut adalah nilai recall dan precision yang dihasilkan. Semakin baik nilai recall dan precision, maka akan semakin baik kemampuan suatu sistem temu kembali informasi. Perhitungan recall dan precision dilakukan pada potongan tagging yang berbeda untuk setiap query, sesuai dengan kedalaman masing-masing tagging. Hasil perhitungan recall dan precision akan dibandingkan dalam bentuk kurva. Selain itu, akan dihitung pula nilai average precision. Asumsi
Asumsi-asumsi yang digunakan pada penelitian ini ialah:
Tidak ada kesalahan dalam pengetikan
query.
Query berkaitan dengan koleksi dokumen.
Lingkungan Pengembangan
Perangkat lunak yang digunakan pada penelitian ini ialah:
Sistem Operasi Windows 7.
Sphinx Search.
Apache Xampp.
Notepad++, sebagai program editor.
Perangkat keras yang digunakan pada penelitian ini adalah:
Prosesor Intel Core i5 2.40 GHz.
RAM 4 GB.
Harddisk 500 GB.
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
Penelitian ini menggunakan 130 dokumen mengenai tanaman obat di Indonesia. Dokumen diperoleh dari website Sentra Informasi IPTEK. Deskripsi dari dokumen dapat dilihat pada Tabel 1.
Dokumen pada penelitian ini memiliki struktur tagging bersarang, tetapi pada saat pengindeksan menggunakan Sphinx Search, struktur tagging yang digunakan tidak bersarang (Lampiran 1 - 2).
Dokumen tanaman obat dikelompokkan ke dalam tag-tag berikut:
<doc></doc>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<docno></docno>, tag ini menunjukkan ID dari dokumen.
<nama></nama>, tag ini menunjukkan nama dari suatu jenis tanaman obat dan melingkupi tag <nama-latin> </nama-latin> dan tag <nama-lokal></nama-lokal>.
<nama-latin></nama-latin>, tag ini menunjukkan nama latin tanaman obat
<nama-lokal></nama-lokal>, tag ini menunjukkan nama daerah tanaman obat.
<sinonim></sinonim>, tag ini menunjukkan nama sinonim dari tanaman obat.
<familia></familia>, tag ini menunjukkan nama famili dari tanaman obat.
<deskripsi></deskripsi>, tag ini menunjukkan deskripsi dari tanaman obat.
<habitat></habitat>, tag ini menunjukkan habitat dari tanaman obat.
<bagian></bagian>, tag ini menunjukkan bagian tanaman obat yang digunakan.
<manfaat></manfaat>, tag ini menunjukkan manfaat dan penyakit yang dapat disembuhkan dari jenis tanaman obat.
<sifat></sifat>, tag ini menunjukkan sifat kimiawi dan efek farmakologis dari tanaman obat.
<komposisi></komposisi>, tag ini menunjukkan kandungan kimia dari tanaman obat.
<penyakit></penyakit>, tag ini menunjukkan penyakit yang dapat disembuhkan dari jenis tanaman obat.
Praproses Dokumen
Praproses dokumen dilakukan dengan menggunakan fungsi indexing Sphinx Search. Sphinx Search tidak dapat melakukan peng-indeksan dokumen dengan struktur tagging bersarang, sehingga digunakan struktur tagging tidak bersarang. Praproses dokumen melibatkan proses pembuangan stopwords.
Pemrosesan Query
Jumlah query yang digunakan pada penelitian ini ialah 20 query (Lampiran 3 - 5). Query pada sistem ini menggunakan query XML. Setiap query dipasangkan dengan
tagging XML pada dokumen. Struktur XML yang digunakan pada dokumen ialah struktur tagging bersarang sehingga menghasilkan kedalaman konteks XML yang berbeda-beda.
Query tanpa menggunakan potongan tagging, antara lain:
sakit kuning
masuk angin
asam urat
kulit
kencing manis
Query yang menggunakan tagging dengan kedalaman konteks XML 1, antara lain:
/manfaat#tekanan darah tinggi
/manfaat#muntah darah
/manfaat#radang paru
/manfaat#infeksi ginjal
/penyakit#saluran kemih
/sifat#anti radang
/manfaat#kanker darah
/manfaat#radang saluran napas
Query yang menggunakan tagging dengan kedalaman konteks XML 2, antara lain:
/nama/nama-lokal#asam jawa
/nama/nama-lokal#bayam
/nama/nama-lokal#belimbing asam
/nama/nama-lokal#daun jintan
/nama/nama-lokal#sirih
/nama/nama-lokal#buah makasar
/nama/nama-lokal#ekor kucing
Hasil Temu Kembali
Pada penelitian ini, pembobotan yang digunakan yaitu fungsi pembobotan BM25 yang telah disediakan oleh Sphinx Search. Jumlah dokumen teratas yang diambil adalah 30 dokumen.
Pengujian Sistem Temu Kembali
Proses pengujian dilakukan untuk mem-bandingkan kinerja sistem pada dokumen relevan dan dokumen yang tidak relevan atau yang tidak seharusnya muncul pada hasil temu kembali.
Pengujian pada Dokumen Relevan
Pengujian dilakukan pada 20 query uji. Proses temu kembali informasi dengan query uji dilakukan untuk mendapatkan nilai recall dan
precision untuk 30 dokumen teratas. Setelah itu, dilakukan perhitungan interpolasi maksimum untuk mendapatkan nilai AVP (Lampiran 6).
Pengujian terhadap query uji terbagi men-jadi tiga jenis query, yaitu:
Pengujian query tanpa memperhatikan struktur XML dokumen ini bertujuan membandingkan kinerja sistem temu kembali tidak berstruktur dengan XML retrieval.
Gambar 2 mengilustrasikan kinerja sistem temu kembali tidak terstruktur. Nilai AVP dari proses temu kembali sebesar 0.756.
2 Query XML dengan kedalaman konteks XML sebesar 1
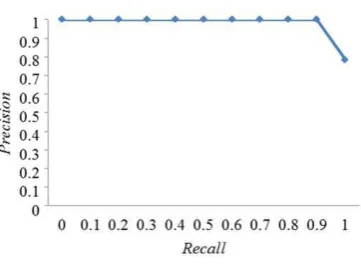
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 1 sebesar 0.911 atau meningkat 15.5% dari query tanpa memperhatikan struktur tagging. Gambar 3 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 1.
3 Query XML dengan kedalaman konteks XML sebesar 2
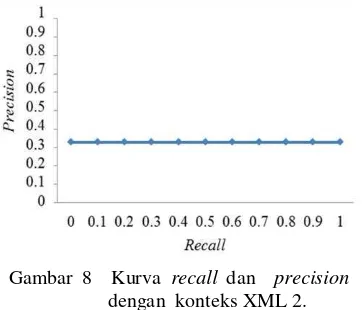
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 2 sebesar 0,981 atau meningkat 22.5% dari query tanpa memperhatikan struktur tagging. Gambar 4 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 2.
Tabel 2 menunjukkan bahwa kinerja XML retrieval meningkat 15.5% dan 22.5% dibandingkan dengan kinerja sistem temu kembali tidak terstruktur. Hasil pengujian ini menunjukkan pembobotan BM25 dan Simnomerge similarity menghasilkan temu kembali yang lebih baik. Hal ini dikarenakan XML retrieval menggunakan query dengan potongan tagging dari koleksi dokumen XML dalam proses perhitungan, sehingga temu kembali informasi menghasilkan jawaban yang lebih spesifik dan relevan sesuai dengan kebutuhan pengguna.
Tabel 2 Hasil perhitungan AVP pada dokumen relevan
Jenis Query AVP
Tanpa tagging 0.756
Kedalaman konteks sebesar 1 0.911 Kedalaman konteks sebesar 2 0.981
Gambar 5 menunjukkan bahwa XML retrieval peningkatan kinerja yang lebih baik dibandingkan sistem temu kembali tidak terstruktur. Kedalaman konteks juga mempengaruhi kinerja sistem temu kembali informasi. Penambahan tag bersarang pada dokumen dapat meningkatkan kinerja sebesar 98.1%.
Gambar 2 Kurva recall dan precision tanpa tagging.
Gambar 3 Kurva recall dan precision dengan konteks XML 1.
Gambar 4 Kurva recall dan precision dengan konteks XML 2.
Pengujian pada Dokumen Tidak Relevan
Pengujian dilakukan pada 20 query uji sama seperti pengujian pada dokumen relevan. Proses temu kembali informasi dengan query uji dilakukan untuk mendapatkan nilai recall dan precision untuk 30 dokumen teratas. Selain itu, dilakukan perhitungan interpolasi maksimum untuk mendapatkan nilai AVP (Lampiran 7).
Pengujian terhadap query uji terbagi men-jadi 3 jenis query yaitu:
1 Query tanpa memerhatikan struktur XML dokumen
Gambar 6 mengilustrasikan kinerja sistem temu kembali tidak terstruktur. Nilai AVP dari proses temu kembali sebesar 0.611.
2 Query XML dengan kedalaman konteks XML sebesar 1
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 1 sebesar 0.246 atau menurun 36.5% dari query tanpa memerhatikan struktur tagging. Gambar 7 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 1.
3 Query XML dengan kedalaman konteks XML sebesar 2
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 2 sebesar 0.329 atau menurun 28.2% dari query tanpa
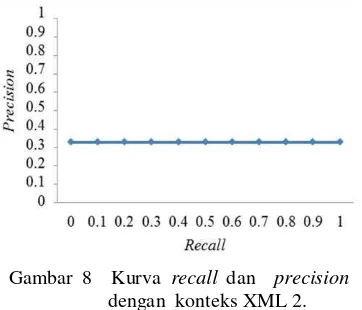
memerhatikan struktur tagging. Gambar 8 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 2.
Nilai AVP pada pengujian sistem temu kembali dengan dokumen yang tidak relevan mengalami penurunan dibandingkan dengan pengujian sistem temu kembali dengan dokumen relevan. Penurunan pada pengujian query tanpa memperhatikan struktur tagging tidak telalu signifikan dibandingkan dengan pengujian menggunakan query XML. XML retrieval dapat mengurangi kinerja sistem temu kembali dalam menemukembalikan dokumen yang tidak relevan.
Gambar 9 menunjukkan bahwa kinerja XML retrieval menurun masing-masing sebesar 36.5% dan 28.2% dibandingkan dengan kinerja sistem temu kembali tidak terstruktur. Nilai AVP masing-masing query dapat dilihat pada Tabel 3.
Tabel 3 Hasil perhitungan AVP pada dokumen tidak relevan
Jenis Query AVP
Tanpa tagging 0.611
Kedalaman konteks sebesar 1 0.246 Kedalaman konteks sebesar 2 0.329 Gambar 6 Kurva recall dan precision
tanpa tagging.
Gambar 7 Kurva recall dan precision dengan konteks XML 1.
Gambar 8 Kurva recall dan precision dengan konteks XML 2.
Analisis Perbandingan Sistem
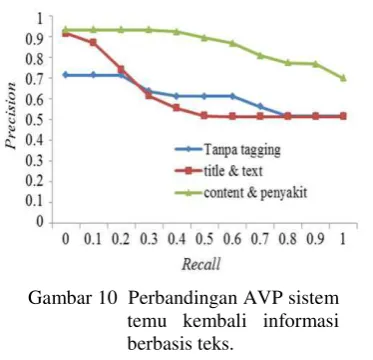
Analisis perbandingan sistem bertujuan membandingkan hasil temu kembali sistem yang digunakan oleh Bahi (2011) dengan sistem yang digunakan pada penelitian ini. Sistem yang digunakan oleh Bahi (2011) menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat. Sistem yang menggunakan 1000 dokumen pertanian menggunakan 30 query uji dan hanya menemukembalikan tag title dan tag text. Sistem yang menggunakan 93 dokumen tanaman obat menggunakan 13 query uji dan hanya melakukan temu kembali pada tag content dan tag penyakit. Terdapat dua kondisi analisis perbandingan dalam penelitian ini, yaitu perbandingan sistem informasi berbasis teks analisis perbandingan XML retrieval.
Analisis Perbandingan Sistem Temu Kembali Informasi Berbasis Teks
Analisis perbandingan sistem temu kembali informasi berbasis teks bertujuan mem-bandingkan kinerja kedua sistem sebelum menerapkan XML retrieval. Analisis per-bandingan dilakukan dengan membandingkan nilai AVP dari query uji yang dihasilkan oleh masing-masing sistem. Pada penelitian ini, sistem tidak memperhatikan struktur tagging, sedangkan pada sistem yang digunakan Bahi (2011), untuk 1000 dokumen pertanian, sistem melakukan temu kembali pada tag title dan tag text saja. Untuk 93 dokumen tanaman obat, sistem melakukan temu kembali pada tag content dan penyakit saja.
Tabel 4 menunjukkan perbandingan nilai AVP yang dihasilkan kedua sistem informasi berbasis teks.
Tabel 4 Perbandingan AVP sistem temu kembali berbasis teks
Jenis Tagging Jumlah Query
AVP Tanpa tagging 20 query 0.7560 title & text 30 query 0.6153 content & penyakit 13 query 0.8589
Dari Tabel 4 diketahui bahwa sistem yang digunakan oleh Bahi (2011) mampu memperoleh nilai AVP yang lebih baik ketika sistem tersebut menggunakan 93 dokumen tanaman obat, dengan perbedaan nilai AVP sebesar 0.1029. Namun, sistem pada penelitian ini mampu memperoleh nilai AVP yang lebih baik dibanding sistem yang digunakan oleh Bahi (2011) ketika menggunakan 1000 dokumen pertanian, dengan perbedaan nilai AVP sebesar 0.1407.
Gambar 10 menunjukkan perbandingan kinerja sistem temu kembali informasi berbasis teks.
Analisis Perbandingan Sistem XML Retrieval
Analisis perbandingan sistem XML retrieval bertujuan membandingkan kinerja kedua sistem saat menerapkan XML retrieval. Analisis perbandingan dilakukan dengan mem-bandingkan nilai AVP dari query uji yang dihasilkan oleh masing-masing sistem dengan kedalaman konteks XML 1 dan kedalaman konteks XML 2. Tabel 5 menunjukkan perbandingan nilai AVP yang dihasilkan kedua sistem XML retrieval.
Tabel 5 Perbandingan AVP XML retrieval Jenis Tagging Jumlah
Query Uji
AVP Kedalaman konteks 2 20 query 0.9810 Kedalaman konteks 1 20 query 0.9110 Tagging title 30 query 0.5005 Tagging text 30 query 0.6156 Tagging content 13 query 0.5968 Tagging penyakit 13 query 0.6273 Dari Tabel 5, diketahui bahwa XML retrieval yang digunakan pada penelitian ini mampu memperoleh nilai AVP yang lebih baik dibandingkan sistem yang digunakan oleh Bahi (2011). Dokumen XML yang digunakan pada sistem ini memiliki struktur dengan kedalaman konteks XML hingga 2 (tag bersarang), mampu meningkatkan kinerja sistem. Faktor utama yang menyebabkan terjadinya perbedaan tersebut adalah perbedaan proses penamaan struktur tagging XML. Struktur XML yang digunakan pada sistem ini lebih lengkap dan detail sehingga hasil temu kembali informasi lebih spesifik.
Gambar 11 menunjukkan perbandingan kinerja XML retrieval dengan kedalaman konteks XML 1 dan 2. Pada gambar tersebut diketahui bahwa, struktur XML dokumen dengan kedalaman konteks 2 dapat meningkatkan kinerja sistem temu kembali.
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian yang telah dilakukan, dapat disimpulkan bahwa:
XML retrieval dapat menghasilkan lebih banyak dokumen yang relevan.
Kedalaman konteks XML dapat me-ningkatan kinerja sistem sehingga dihasilkan jawaban yang lebih spesifik.
Struktur XML yang lebih lengkap pada dokumen dapat meningkatkan kinerja XML
retrieval.
Saran
Penelitian selanjutnya yang terkait dengan XML retrieval disarankan untuk melakukan penelitian dengan:
Menggunakan jumlah koleksi dokumen yang lebih banyak.
Menggunakan dokumen XML dengan struktur yang lebih bervariasi.
DAFTAR PUSTAKA
Aksyonoff A. 2011. Introduction to Search with Sphinx b s p l: O’ lly
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. Harlow: Addison Wesley.
Bahi MN. 2011. XML retrieval untuk dokumen bahasa Indonesia [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam,. Institut Pertanian Bogor.
Carmel D, Efraty N, Landau GM, Maarek YS, Mass Y. 2002. An extension of the vector space model for querying XML documents via XML fragments. Di dalam: Proceedings of the SIGIR 2002 Workshop on XML and Information Retrieval; Tempere, 11-15 Agu 2002. Tempere: SIGIR. hlm 14-25.
Gusdiana B. 2010 Implementasi algoritme simnomerge untuk information retrieval dengan koleksi dokumen terstruktur XML [skripsi]. Bandung: Fakultas Teknik Informatika, Institut Teknologi Telkom. Lalmas M. 2009. XML retrieval. Synthesis
Lectures on Information Concepts, Retrieval and Services 1:1-111.
Manning CD, Rhagavan P, Schütze H. 2008. Introduction to Information Retrieval. Cambridge: Cambridge University Press. Gambar 11 Perbandingan AVP XML
Lampiran 1 Contoh dokumen pengindeksan pada Sphinx Search <sphinx:document id="34">
<docno>034</docno> <nama>Blustru</nama>
<nama-latin>Luffa cylindrica [L.] Roem.</nama-latin>
<nama-lokal>NAMA DAERAH: Sumatera: blustru (Melayu),- hurung jawa, ketola, timput (Palembang). Jawa: lopang, oyong (Sunda), bestru, blestru, blustru (Jawa). Maluku: dodahala (Halmahera), petola panjang, p. cina. NAMA ASING: Si gua luo (C), patola, taboboc (Tag.), sponskomkommer, zeefkomkommer (B), sponge gourd, gourd towel, loofah (I). Nama simplisia Retinervus Luffae Fructus (sabut buah blustru), Luffae Folium, (daun blustru).</nama-lokal>
<sinonim>L.aegyptica Mill., L. pentandra Roxb., L. cattupincinna Ser., L. faetida Sieb. et Zucc., L. petola Ser., Momordica cylirzdrica L.</sinonim>
<familia>cucurbitaceae.</familia>
<deskripsi>Terna semusim, panjang batangnya dapat mencapai 2-10 m, memanjat dengan sulur-sulur (alat pembelit) yang keluar dari ketiak daun. Daun tunggal, panjang tangkai daun 4-9 cm, letak berseling. Helaian daun bulat telur melebar, berlekuk menjari 5-7 buah, pangkal daun berbentuk jantung, tulang daun menonjol di bawah, warna permukaan atas daun hijau tua, warna permukaan bawah daun hijau muda, panjang 6-25 cm, lebar 7,5-27 cm. Bunga berkelamin tunggal, terdapat dalam satu pohon. Kata kunci : Blustru, nyeri sendi</deskripsi>
<habitat>Blustru ditanam di ladang, dirambatkan pada pagar halaman sebagai tanaman sayur, atau tumbuh liar di semak, tepi sungai, dan pantai;</habitat>
<bagian>Bagian tumbuhan yang digunakan sebagai obat adalah seluruh bagian tumbuhan, seperti buah, kulit buah, tangkai buah, biji, sabut, daun, bunga, batang, dan akar.</bagian>
<manfaat>1. Buah digunakan untuk mengatasi: demam, rasa haus, batuk sesak, keputihan,h aid tidak teratur, air susu ibu (ASI) tidak lancar, sukar buang air besar, pendarahan, seperti air seni berdarah, mimisan, dan bisul; 2. Biji digunakan untuk mengatasi : muka,tangan, dan kaki bengkak (edema), batu saluran kencing, cacingan, sakit pinggang, dan wasir; 3. Daun digunakan untuk mengatasi: sesak napas, tidak datang haid (amenore), orkitis, luka bakar, bisul, kurap, dan digigit ular; 4. Kulit buah digunakan untuk mengatasi: bisul, abses daerah rektum (ujung usus besar), dan luka; 5. Bunga digunakan untuk mengatasi: batuk disertai sesak, sakit tenggorokan, sinusitis, wasir, dan bisul; 6. Sabut digunakan untuk mengatasi: sakit dada, sakit perut, sakit pinggang, rematik sendi, pegal linu, batuk berdahak, tidak datang haid, payudara bengkak, air susu ibu (ASI) sedikit, wasir, orkitis, dan bisul; 7. Arang dari sabut digunakan untuk : menghentikan pendarahan, seperti pendarahan diluar haid, air seni berdarah, dan berak darah; 8. Akar digunakan untuk mengatasi: migrain,sakit pinggang, sakit tenggorokan, bisul yang tidak mau pecah, dan payudara bengkak (mastitis); 9. Batang digunakan untuk mengatasi: rasa baal, haid tidak teratur, hidung berlendir, dan bengkak (edema); 10. Tangkai buah digunakan untuk pengobatan: cacar air pada anak-anak. Kata kunci : Blustru, nyeri sendi</manfaat>
<sifat>Blustru berkhasiat sebagai peluruh dahak, penghenti pendarahan (hemostatis), pencahar ringan (laksatif), serta membersihkan panas;</sifat>
<komposisi>Buah Blustru mengandung saponin triterpen, luffein (zat pahit), citrulline, dan cucurbitacin. Getah mengandung saponin, lendir, lemak, protein, xylan, dan vitamin (B dan C). Biji mengandung minyak lemak, squalene, a-spinasterol, cucurbitacin B, dan protein. Bunga mengandung glutamin, asam aspartat, arginin, lisin, dan alanin. Sabut mengandung xylan, xylose, mannosan, galactan, saponin, selulosa, galaktosa, manitosa, dan vitamin (A, B, dan C). Daun dan batang mengandung saponin dan tanin.</komposisi>
Lampiran 2 Contoh dokumen pengujian <?xml version="1.0" encoding="utf-8"?> <doc>
<docno>034</docno> <nama>Blustru
<nama-latin>Luffa cylindrica [L.] Roem.</nama-latin>
<nama-lokal>NAMA DAERAH: Sumatera: blustru (Melayu),- hurung jawa, ketola, timput (Palembang). Jawa: lopang, oyong (Sunda), bestru, blestru, blustru (Jawa). Maluku: dodahala (Halmahera), petola panjang, p. cina. NAMA ASING: Si gua luo (C), patola, taboboc (Tag.), sponskomkommer, zeefkomkommer (B), sponge gourd, gourd towel, loofah (I). Nama simplisia Retinervus Luffae Fructus (sabut buah blustru), Luffae Folium, (daun blustru).</nama-lokal>
</nama>
<sinonim>L.aegyptica Mill., L. pentandra Roxb., L. cattupincinna Ser., L. faetida Sieb. et Zucc., L. petola Ser., Momordica cylirzdrica L.</sinonim>
<familia>cucurbitaceae.</familia>
<deskripsi>Terna semusim, panjang batangnya dapat mencapai 2-10 m, memanjat dengan sulur-sulur (alat pembelit) yang keluar dari ketiak daun. Daun tunggal, panjang tangkai daun 4-9 cm, letak berseling. Helaian daun bulat telur melebar, berlekuk menjari 5-7 buah, pangkal daun berbentuk jantung, tulang daun menonjol di bawah, warna permukaan atas daun hijau tua, warna permukaan bawah daun hijau muda, panjang 6-25 cm, lebar 7,5-27 cm. Bunga berkelamin tunggal, terdapat dalam satu pohon. Kata kunci : Blustru, nyeri sendi</deskripsi>
<habitat>Blustru ditanam di ladang, dirambatkan pada pagar halaman sebagai tanaman sayur, atau tumbuh liar di semak, tepi sungai, dan pantai;</habitat>
<bagian>Bagian tumbuhan yang digunakan sebagai obat adalah seluruh bagian tumbuhan, seperti buah, kulit buah, tangkai buah, biji, sabut, daun, bunga, batang, dan akar.</bagian>
<manfaat>1. Buah digunakan untuk mengatasi: demam, rasa haus, batuk sesak, keputihan,h aid tidak teratur, air susu ibu (ASI) tidak lancar, sukar buang air besar, pendarahan, seperti air seni berdarah, mimisan, dan bisul; 2. Biji digunakan untuk mengatasi : muka,tangan, dan kaki bengkak (edema), batu saluran kencing, cacingan, sakit pinggang, dan wasir; 3. Daun digunakan untuk mengatasi: sesak napas, tidak datang haid (amenore), orkitis, luka bakar, bisul, kurap, dan digigit ular; 4. Kulit buah digunakan untuk mengatasi: bisul, abses daerah rektum (ujung usus besar), dan luka; 5. Bunga digunakan untuk mengatasi: batuk disertai sesak, sakit tenggorokan, sinusitis, wasir, dan bisul; 6. Sabut digunakan untuk mengatasi: sakit dada, sakit perut, sakit pinggang, rematik sendi, pegal linu, batuk berdahak, tidak datang haid, payudara bengkak, air susu ibu (ASI) sedikit, wasir, orkitis, dan bisul; 7. Arang dari sabut digunakan untuk : menghentikan pendarahan, seperti pendarahan diluar haid, air seni berdarah, dan berak darah; 8. Akar digunakan untuk mengatasi: migrain,sakit pinggang, sakit tenggorokan, bisul yang tidak mau pecah, dan payudara bengkak (mastitis); 9. Batang digunakan untuk mengatasi: rasa baal, haid tidak teratur, hidung berlendir, dan bengkak (edema); 10. Tangkai buah digunakan untuk pengobatan: cacar air pada anak-anak. Kata kunci : Blustru, nyeri sendi</manfaat>
<sifat>Blustru berkhasiat sebagai peluruh dahak, penghenti pendarahan (hemostatis), pencahar ringan (laksatif), serta membersihkan panas;</sifat>
<komposisi>Buah Blustru mengandung saponin triterpen, luffein (zat pahit), citrulline, dan cucurbitacin. Getah mengandung saponin, lendir, lemak, protein, xylan, dan vitamin (B dan C). Biji mengandung minyak lemak, squalene, a-spinasterol, cucurbitacin B, dan protein. Bunga mengandung glutamin, asam aspartat, arginin, lisin, dan alanin. Sabut mengandung xylan, xylose, mannosan, galactan, saponin, selulosa, galaktosa, manitosa, dan vitamin (A, B, dan C). Daun dan batang mengandung saponin dan tanin.</komposisi>
Lampiran 3 Deskripsi query
Query Deskripsi
sakit kuning Query untuk mencari dokumen mengenai tanaman obat yang dapat mengobati sakit kuning. Pencarian dilakukan tanpa memperhatikan tag
masuk angin Query untuk mencari dokumen mengenai tanaman obat yang dapat mengobati masuk angin. Pencarian dilakukan tanpa
memperhatikan tag
asam urat Query untuk mencari dokumen mengenai tanaman obat yang dapat mengobati asam urat. Pencarian dilakukan tanpa memperhatikan tag
kulit Query untuk mencari dokumen mengenai tanaman obat yang dapat mengobati penyakit pada kulit atau luka. Pencarian dilakukan tanpa memperhatikan tag
kencing manis Query untuk mencari dokumen mengenai tanaman obat yang dapat mengobati kencing manis. Pencarian dilakukan tanpa
memperhatikan tag /manfaat#tekanan darah
tinggi
Query untuk mencari dokumen mengenai tanaman obat yang memiliki manfaat dapat mengobati tekanan darah tinggi. Pencarian dilakukan berdasarkan tag <manfaat></manfaat>
/manfaat#muntah darah Query untuk mencari dokumen mengenai tanaman obat yang memiliki manfaat dapat mengobati muntah darah. Pencarian dilakukan berdasarkan tag <manfaat></manfaat>
/manfaat#radang paru Query untuk mencari dokumen mengenai tanaman obat yang memiliki manfaat dapat mengobati radang paru. Pencarian dilakukan berdasarkan tag <manfaat></manfaat>
/manfaat#infeksi ginjal Query untuk mencari dokumen mengenai tanaman obat yang memiliki manfaat dapat mengobati infeksi ginjal. Pencarian dilakukan berdasarkan tag <manfaat></manfaat>
/penyakit#saluran kemih
Query untuk mencari dokumen mengenai tanaman obat yang dapat mengobati penyakit pada saluran kemih. Pencarian dilakukan berdasarkan tag <penyakit></penyakit>
/sifat#anti radang Query untuk mencari dokumen mengenai tanaman obat yang memiliki sifat sebagai anti radang. Pencarian dilakukan berdasarkan tag <sifat></sifat >
/manfaat#kanker darah Query untuk mencari dokumen mengenai tanaman obat yang memiliki manfaat dapat mengobati tekanan darah tinggi. Pencarian dilakukan berdasarkan tag <manfaat></manfaat>
/manfaat#radang saluran napas
Query untuk mencari dokumen mengenai tanaman obat yang memiliki manfaat dapat mengobati radang saluran napas. Pencarian dilakukan berdasarkan tag <manfaat></manfaat>
/nama/nama-lokal#asam jawa
Query untuk mencari dokumen mengenai nama lokal tanaman obat asam jawa. Pencarian dilakukan berdasarkan tag <nama><nama-lokal></nama-lokal></nama>
/nama/nama-lokal#bayam
Lajutan Lampiran 3
Query Deskripsi
/nama/nama-lokal#belimbing asam
Query untuk mencari dokumen mengenai nama lokal tanaman obat belimbing asam. Pencarian dilakukan berdasarkan tag
<nama><nama-lokal></nama-lokal></nama> /nama/nama-lokal#daun
jintan
Query untuk mencari dokumen mengenai tanaman obat daun jintan. Pencarian dilakukan berdasarkan tag <nama><nama-lokal></nama-lokal></nama>
/nama/nama-lokal#sirih Query untuk mencari dokumen mengenai nama lokal tanaman obat sirih. Pencarian dilakukan berdasarkan tag
<nama><nama-lokal></nama-lokal></nama> /nama/nama-lokal#buah
makasar
Query untuk mencari dokumen mengenai nama lokal tanaman obat buah makasar. Pencarian dilakukan berdasarkan tag
<nama><nama-lokal></nama-lokal></nama> /nama/nama-lokal#ekor
kucing
Lampiran 4 Daftar query dan dokumen relevan
Query Dokumen Relevan
sakit kuning 011, 017, 020, 038, 046, 049, 069, 072, 074, 087, 114
masuk angin 017, 020, 094
asam urat 114
kulit 002, 006, 007, 009, 011, 013, 014, 015, 016, 020, 022, 024, 025, 027, 028, 030, 032, 033, 034, 038, 046, 049, 051, 054, 055, 060, 061, 064, 067, 068, 072, 076, 078, 080, 081, 082, 083, 087, 089, 090, 092, 094, 097, 099, 102, 103, 106, 107, 108, 110, 111, 114, 116, 118, 121, 122, 123, 127, 129
kencing manis 002, 007, 009, 012, 019, 023, 024, 029, 031, 033, 038, 041, 048, 063, 066, 074, 080, 089, 091, 093, 094, 095, 104, 108, 114 /manfaat#tekanan darah
tinggi
006, 007, 020, 023, 024, 025, 035, 043, 046, 048, 050, 055, 062, 074, 077, 085, 091, 096, 114, 12
/manfaat#muntah darah 001, 006, 010, 018, 029, 031, 035, 049, 068, 077, 078, 100, 108, 125
/manfaat#radang paru 016, 031, 033, 054, 090, 100
/manfaat#infeksi ginjal 006, 011, 069, 085, 091, 100, 102, 126
/penyakit#saluran kemih 001, 006, 009, 022, 033, 038, 041, 043, 047, 048, 050, 057, 058, 066, 083, 085, 091, 094, 100, 102, 105, 114, 116, 126, 127, 128 /sifat#anti radang 001, 002, 003, 004, 007, 010, 024, 025, 030, 031, 040, 043, 044,
047, 049, 055, 065, 067, 069, 072, 080, 084, 086, 097, 100, 103, 106, 108, 114, 118, 120, 125, 126, 127, 130
/manfaat#kanker darah 029, 070 /manfaat#radang saluran
napas
004, 022, 028, 042, 043, 047, 054, 058, 071, 072, 074, 077, 084, 096, 101, 110, 127
/nama/nama-lokal#asam jawa
014
/nama/nama-lokal#bayam 001, 021, 022, 035
/nama/nama-lokal#belimbing asam
023, 025 /nama/nama-lokal#daun
jintan
071 /nama/nama-lokal#sirih 015, 110 /nama/nama-lokal#buah
makasar
039 /nama/nama-lokal#ekor
kucing
Lampiran 5 Daftar query dan dokumen yang tidak relevan
Query Dokumen Tidak Relevan
sakit kuning 007, 014, 024, 025, 031, 039, 043, 061, 062, 063, 107, 108, 112, 118, 122, 127, 128
masuk angin 074, 086, 102
asam urat 006, 074, 075
kulit 018, 031, 047, 048, 050, 057, 059, 062, 063, 065, 077, 084, 093, 095, 101, 109, 113, 117
kencing manis 025, 118, 126, 127 /manfaat#tekanan darah
tinggi
021, 053
/manfaat#muntah darah 053
/manfaat#radang paru 084, 102, 114, 127 /manfaat#infeksi ginjal 074
/penyakit#saluran kemih /sifat#anti radang
/manfaat#kanker darah 031, 043, 114, 123 /manfaat#radang saluran
napas
/nama/nama-lokal#asam jawa
023, 025, 055, 109
/nama/nama-lokal#bayam
/nama/nama-lokal#belimbing asam /nama/nama-lokal#daun jintan
103
/nama/nama-lokal#sirih /nama/nama-lokal#buah makasar
051
/nama/nama-lokal#ekor kucing
Lampiran 6 Hasil kinerja sistem dalam temu kembali dokumen relevan
Recall Precision
Tanpa Tagging Kedalaman Konteks 1 Kedalaman Konteks 2
0 0.827 0.958 1.000
0.1 0.807 0.958 1.000
0.2 0.765 0.958 1.000
0.3 0.773 0.952 1.000
0.4 0.773 0.952 1.000
0.5 0.765 0.952 1.000
0.6 0.765 0.863 1.000
0.7 0.765 0.863 1.000
0.8 0.718 0.855 1.000
0.9 0.717 0.855 1.000
1 0.637 0.855 0.786
Lampiran 7 Hasil kinerja sistem dalam temu kembali dokumen yang tidak relevan
Recall Precision
Tanpa Tagging Kedalaman Konteks 1 Kedalaman Konteks 2
0 0.713 0.280 0.329
0.1 0.713 0.280 0.329
0.2 0.713 0.280 0.329
0.3 0.636 0.249 0.329
0.4 0.611 0.249 0.329
0.5 0.611 0.249 0.329
0.6 0.611 0.235 0.329
0.7 0.561 0.235 0.329
0.8 0.516 0.235 0.329
0.9 0.516 0.235 0.329
1 0.516 0.181 0.329
ABSTRACT
ANELA FEBRID YUNITA. XML Retrieval for Bahasa Indonesia Document using Simnomerge Algorithm. Supervised by JULIO ADISANTOSO.
XML Retrieval is one of the information retrieval system which use structured elements in documents as a unit that can be retrieved. Queries used in XML Retrieval are tagged pieces of the document collection.
This research is comparing the retrieval of relevant documents to irrelevant documents by using 130 documents of medicinal plants and 20 queries. Simnomerge algorithm is used in this research because different XML contexts are kept separate for the weighting. Each query is divided into 5 queries for unstructured retrieval system, 8 queries for XML retrieval with XML context depth 1, and 7 queries for XML retrieval with XML context depth 2. The result of this research shows that the XML retrieval can improve performance of the retrieval system by getting more relevant documents. At the relevant documents, average precision of XML retrievals query for an XML context depth 1 is 0.911, or a 15.5% increase from the unstructured retrieval system. Average precision of XML retrievals query for XML context depth 2 is 0.981, or a 22.5% increase from the unstructured retrieval system. Meanwhile, for the irrelevant document the average precision of XML retrieval for XML context depth 1 is 0.246 or a 36.5% decrease from the unstructured retrieval system. The average precision of XML retrieval for XML context depth 2 is 0.329 or a 28.8% decrease from the unstructured retrieval system.
PENDAHULUAN
Latar Belakang
Sistem temu kembali informasi merupakan sarana bagi seseorang untuk mendapatkan berbagai informasi yang diinginkan dengan mudah. Informasi yang ingin didapat direpresentasikan dalam bentuk query. Query tersebut nantinya akan mengalami proses temu kembali sehingga menghasilkan informasi atau dokumen yang relevan.
Pada dasarnya, pengolahan data pada sistem temu kembali informasi dapat dilakukan secara tidak terstruktur dan terstruktur. Sistem temu kembali informasi tidak terstruktur mem-bandingkan kemiripan (similarity) query dengan semua kumpulan term pada dokumen. Kumpulan term pada dokumen dapat berupa kata-kata, gambar, dan lain-lain. Dengan kata lain, sistem temu kembali informasi tidak pernah memperhatikan struktur dokumen. Selain itu, unit yang akan ditemukembalikan berupa dokumen secara lengkap, sedangkan pada sistem temu kembali informasi terstruktur setiap elemen terstruktur yang terdapat pada dokumen dapat menjadi unit yang akan ditemukembalikan. Metode pada sistem temu kembali informasi terstruktur dikenal dengan sebutan XML retrieval. Pada XML retrieval, format dokumen yang digunakan adalah dokumen dengan struktur XML. XML retrieval menggunakan query dengan struktur tagging dari koleksi dokumen XML dan akan dibandingkan kemiripannya dengan setiap elemen XML pada koleksi dokumen tersebut sehingga lebih fleksibel.
Permasalahan dalam XML retrieval adalah pengguna hanya ingin mengembalikan bagian dari dokumen, bukan keseluruhan dokumen seperti sistem temu kembali informasi yang tidak terstruktur. Oleh karena itu di dalam XML retrieval unit-unit yang akan diindeks harus bisa mempresentasikan keseluruhan elemen yang ada di dalam dokumen. Permasalahan lainnya, ialah cara membedakan konteks yang berbeda dari setiap term ketika menghitung peringkat.
Terdapat beberapa penelitian terkait mengenai XML retrieval. Carmel et al. (2002) membangun sistem XML retrieval dengan menambahkan vector space model untuk menemukembalikan dokumen. Lalmas (2009) melakukan pendekatan terhadap query pada tagging XML yang tidak lengkap dan mempresentasikan hasil peringkat dokumen XML terurut secara relevan. Gusdiana (2011) mengimplementasikan algoritme Simnomerge untuk membangun sistem temu kembali dengan
koleksi dokumen XML dan membandingkan kinerja pembobotan tf, idf, dan tf-idf.
Bahi (2011) membangun sistem XML retrieval menggunakan koleksi dokumen dalam bahasa Indonesia. Namun, koleksi dokumen yang digunakan memiliki struktur XML yang belum lengkap dan spesifik untuk setiap dokumennya. Oleh karena itu pada penelitian ini, akan diterapkan metode XML retrieval menggunakan koleksi dokumen dengan struktur yang lengkap sehingga diharapkan hasil pengembalian informasi lebih baik dan spesifik. Tujuan
Tujuan penelitian ini ialah:
Mengimplementasikan XML retrieval
menggunakan algoritme Simnomerge untuk dokumen berbahasa Indonesia.
Membandingkan kinerja sistem temu kembali informasi menggunakan metode XML retrieval dengan sistem temu kembali informasi tidak terstruktur (berbasis teks).
Ruang Lingkup
Ruang lingkup penelitian ini ialah:
Pengguna mengetahui struktur XML pada dokumen.
Struktur tagging pada dokumen XML yang digunakan dalam pengindeksan memiliki kedalaman konteks 1.
TINJAUAN PUSTAKA
Sistem Temu Kembali Informasi
Temu kembali informasi berkaitan dengan cara merepresentasikan, menyimpan, meng-organisasikan dan mengakses informasi. Mengorganisasikan dan merepresentasikan informasi harus memudahkan pengguna dalam mengakses informasi yang dibutuhkan. Namun, mengetahui karakterisasi informasi yang dibutuhkan pengguna bukanlah hal yang sederhana. Pengguna harus menerjemahkan terlebih dahulu informasi yang dibutuhkan menjadi query yang akan diproses oleh sistem temu kembali informasi. Tujuan utama sistem temu kembali informasi adalah mengembalikan informasi yang mungkin berguna atau relevan (Baeza-Yates & Ribeiro-Neto 1999).
XML Retrieval
XML retrieval merupakan metode sistem temu kembali terstuktur menggunakan dokumen XML. Tujuan XML retrieval adalah mengembalikan bagian dokumen yaitu pada elemen XML yang merupakan hasil temu kembali dari sebuah query (Manning et al. 2008).
Pembobotan BM25
Pembobotan BM25 telah dikembangkan sejak awal tahun 1980, tetapi sampai saat ini masih digunakan secara luas. Ide utama BM25 adalah memberi pembobotan pada dokumen yang memiliki query yang langka dan sering muncul pada dokumen tersebut (Aksyonoff 2011). Pseudocode untuk memperoleh BM25 yang digunakan pada Sphinx Search ialah:
1 BM25=0
2 foreach(inmatching_keywords) { 3 n=total_matching_docs(keyword) 4 N=total_documents_collection 5 k1=1.2
6 TF=occurrence_count(keyword) 9 IDF=log((N-n+1)/n)/log(1+N) 10 BM25= BM25 + TF*IDF/(TF+k1) 11 }
12 Normalization: 13 BM25=0.5+BM25
/(2*num_keywords(query))
dengan:
N : Total dokumen dalam korpus, n : Total dokumen yang mengandung
query,
TF : Frekuensi term t pada dokumen, IDF : Inverted indeks dokumen, dan k1 : Positif parameter (1.2). Simnomerge Similarity
Fungsi ukuran kesamaan pada XML retrieval disebut Simnomerge karena setiap konteks XML yang berbeda disimpan terpisah untuk tujuan pembobotan. Dalam Simnomerge similarity, terdapat nilai Context Resemblance (CR) yang merupakan ukuran kemiripan konteks query dan konteks dokumen (Manning et al. 2008), yang dirumuskan sebagai berikut:
(c,cd) {
c
cd c cd
c cd
dengan |c |adalah banyaknya node pada query dan cd adalah banyaknya node pada dokumen.
Oleh karena itu, Simnomerge similarity dapat dirumuskan sebagai berikut (Manning et al. 2008):
,d
∑ ∑ c,cd ∑ ,t,c ,t,cd
√∑c ,t d,t,c
t cd
c
dengan adalah himpunan kata unik, adalah kumpulan semua konteks XML, c adalah panjangnya node pada query, cd adalah panjangnya node pada dokumen, ,t,c adalah bobot term pada konteks query, ,t,cd adalah bobot term t pada konteks dokumen dan √∑c ,t d,t,c adalah fungsi normalizer untuk menormalisasi panjang dokumen.
Recall dan Precision
Recall adalah perbandingan antara dokumen relevan yang ditemukembalikan a dan dokumen relevan yang terdapat pada korpus
ecall a
Precision adalah perbandingan antara dokumen relevan yang ditemukembalikan
a dan dokumen yang ditemukembalikan
A (Baeza-Yates & Ribeiro-Neto 1999).
recision a A
Average precision (AVP) berfungsi untuk mengevaluasi secara kuantitatif kinerja temu kembali yang diperoleh dengan menggunakan eleven standard recall yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1 (Baeza-Yates & Ribeiro-Neto 1999).
METODE PENELITIAN
Penelitian ini dilakukan dalam empat tahap, antara lain, praproses, penghitungan nilai CR untuk menentukan tingkat kemiripan antara query dengan konteks XML yang ada pada indeks, pemeringkatan dokumen menggunakan algoritme Simnomerge, dan evaluasi. Gambaran umum proses XML retrieval menggunakan algoritme Simnomerge dapat dilihat pada Gambar 1.
Koleksi Dokumen Pengujian
Praproses Dokumen
Pada praproses, setiap dokumen dari koleksi dokumen akan diberi tag. Pada tahap selanjutnya dilakukan proses penghilangan kata-kata umum yang tidak memiliki makna atau disebut dengan stopwords. Dokumen hasil praproses akan diboboti dan diindeks sehingga inverted index diperoleh dan pencarian dokumen berdasarkan query yang diberikan dapat dilakukan. Pembobotan yang digunakan pada penelitian ini adalah pembobotan BM25.
Context Resemblance (CR)
Query yang dimasukkan setelah mengalami praproses akan dihitung nilai CRnya. Nilai CR diperoleh ketika XML path pada query terdapat pada XML path koleksi dokumen. Diperoleh konteks XML yang memiliki kemiripan antara konteks XML yang dibentuk dari query dengan konteks XML yang berada pada koleksi dokumen. Query dengan nilai CR lebih besar dari nol memenuhi syarat untuk memasuki tahap selanjutnya.
Algoritme Simnomerge
Kumpulan konteks XML yang telah diperoleh selanjutnya diboboti dan diurutkan. Kemudian, hasil pencarian ditampilkan. Pengujian Sistem Temu Kembali
Pengujian dilakukan dengan mengukur akurasi kinerja sistem. Parameter yang digunakan untuk mengukur akurasi tersebut adalah nilai recall dan precision yang dihasilkan. Semakin baik nilai recall dan precision, maka akan semakin baik kemampuan suatu sistem temu kembali informasi. Perhitungan recall dan precision dilakukan pada potongan tagging yang berbeda untuk setiap query, sesuai dengan kedalaman masing-masing tagging. Hasil perhitungan recall dan precision akan dibandingkan dalam bentuk kurva. Selain itu, akan dihitung pula nilai average precision. Asumsi
Asumsi-asumsi yang digunakan pada penelitian ini ialah:
Tidak ada kesalahan dalam pengetikan
query.
Query berkaitan dengan koleksi dokumen.
Lingkungan Pengembangan
Perangkat lunak yang digunakan pada penelitian ini ialah:
Sistem Operasi Windows 7.
Sphinx Search.
Apache Xampp.
Notepad++, sebagai program editor.
Perangkat keras yang digunakan pada penelitian ini adalah:
Prosesor Intel Core i5 2.40 GHz.
RAM 4 GB.
Harddisk 500 GB.
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
[image:30.595.105.287.78.448.2]Penelitian ini menggunakan 130 dokumen mengenai tanaman obat di Indonesia. Dokumen diperoleh dari website Sentra Informasi IPTEK. Deskripsi dari dokumen dapat dilihat pada Tabel 1.
[image:30.595.314.497.677.739.2]Dokumen pada penelitian ini memiliki struktur tagging bersarang, tetapi pada saat pengindeksan menggunakan Sphinx Search, struktur tagging yang digunakan tidak bersarang (Lampiran 1 - 2).
Dokumen tanaman obat dikelompokkan ke dalam tag-tag berikut:
<doc></doc>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<docno></docno>, tag ini menunjukkan ID dari dokumen.
<nama></nama>, tag ini menunjukkan nama dari suatu jenis tanaman obat dan melingkupi tag <nama-latin> </nama-latin> dan tag <nama-lokal></nama-lokal>.
<nama-latin></nama-latin>, tag ini menunjukkan nama latin tanaman obat
<nama-lokal></nama-lokal>, tag ini menunjukkan nama daerah tanaman obat.
<sinonim></sinonim>, tag ini menunjukkan nama sinonim dari tanaman obat.
<familia></familia>, tag ini menunjukkan nama famili dari tanaman obat.
<deskripsi></deskripsi>, tag ini menunjukkan deskripsi dari tanaman obat.
<habitat></habitat>, tag ini menunjukkan habitat dari tanaman obat.
<bagian></bagian>, tag ini menunjukkan bagian tanaman obat yang digunakan.
<manfaat></manfaat>, tag ini menunjukkan manfaat dan penyakit yang dapat disembuhkan dari jenis tanaman obat.
<sifat></sifat>, tag ini menunjukkan sifat kimiawi dan efek farmakologis dari tanaman obat.
<komposisi></komposisi>, tag ini menunjukkan kandungan kimia dari tanaman obat.
<penyakit></penyakit>, tag ini menunjukkan penyakit yang dapat disembuhkan dari jenis tanaman obat.
Praproses Dokumen
Praproses dokumen dilakukan dengan menggunakan fungsi indexing Sphinx Search. Sphinx Search tidak dapat melakukan peng-indeksan dokumen dengan struktur tagging bersarang, sehingga digunakan struktur tagging tidak bersarang. Praproses dokumen melibatkan proses pembuangan stopwords.
Pemrosesan Query
Jumlah query yang digunakan pada penelitian ini ialah 20 query (Lampiran 3 - 5). Query pada sistem ini menggunakan query XML. Setiap query dipasangkan dengan
tagging XML pada dokumen. Struktur XML yang digunakan pada dokumen ialah struktur tagging bersarang sehingga menghasilkan kedalaman konteks XML yang berbeda-beda.
Query tanpa menggunakan potongan tagging, antara lain:
sakit kuning
masuk angin
asam urat
kulit
kencing manis
Query yang menggunakan tagging dengan kedalaman konteks XML 1, antara lain:
/manfaat#tekanan darah tinggi
/manfaat#muntah darah
/manfaat#radang paru
/manfaat#infeksi ginjal
/penyakit#saluran kemih
/sifat#anti radang
/manfaat#kanker darah
/manfaat#radang saluran napas
Query yang menggunakan tagging dengan kedalaman konteks XML 2, antara lain:
/nama/nama-lokal#asam jawa
/nama/nama-lokal#bayam
/nama/nama-lokal#belimbing asam
/nama/nama-lokal#daun jintan
/nama/nama-lokal#sirih
/nama/nama-lokal#buah makasar
/nama/nama-lokal#ekor kucing
Hasil Temu Kembali
Pada penelitian ini, pembobotan yang digunakan yaitu fungsi pembobotan BM25 yang telah disediakan oleh Sphinx Search. Jumlah dokumen teratas yang diambil adalah 30 dokumen.
Pengujian Sistem Temu Kembali
Proses pengujian dilakukan untuk mem-bandingkan kinerja sistem pada dokumen relevan dan dokumen yang tidak relevan atau yang tidak seharusnya muncul pada hasil temu kembali.
Pengujian pada Dokumen Relevan
Pengujian dilakukan pada 20 query uji. Proses temu kembali informasi dengan query uji dilakukan untuk mendapatkan nilai recall dan
precision untuk 30 dokumen teratas. Setelah itu, dilakukan perhitungan interpolasi maksimum untuk mendapatkan nilai AVP (Lampiran 6).
Pengujian terhadap query uji terbagi men-jadi tiga jenis query, yaitu:
Pengujian query tanpa memperhatikan struktur XML dokumen ini bertujuan membandingkan kinerja sistem temu kembali tidak berstruktur dengan XML retrieval.
Gambar 2 mengilustrasikan kinerja sistem temu kembali tidak terstruktur. Nilai AVP dari proses temu kembali sebesar 0.756.
2 Query XML dengan kedalaman konteks XML sebesar 1
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 1 sebesar 0.911 atau meningkat 15.5% dari query tanpa memperhatikan struktur tagging. Gambar 3 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 1.
3 Query XML dengan kedalaman konteks XML sebesar 2
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 2 sebesar 0,981 atau meningkat 22.5% dari query tanpa memperhatikan struktur tagging. Gambar 4 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 2.
[image:32.595.320.501.81.215.2]Tabel 2 menunjukkan bahwa kinerja XML retrieval meningkat 15.5% dan 22.5% dibandingkan dengan kinerja sistem temu kembali tidak terstruktur. Hasil pengujian ini menunjukkan pembobotan BM25 dan Simnomerge similarity menghasilkan temu kembali yang lebih baik. Hal ini dikarenakan XML retrieval menggunakan query dengan potongan tagging dari koleksi dokumen XML dalam proses perhitungan, sehingga temu kembali informasi menghasilkan jawaban yang lebih spesifik dan relevan sesuai dengan kebutuhan pengguna.
Tabel 2 Hasil perhitungan AVP pada dokumen relevan
Jenis Query AVP
Tanpa tagging 0.756
Kedalaman konteks sebesar 1 0.911 Kedalaman konteks sebesar 2 0.981
[image:32.595.97.290.168.683.2]Gambar 5 menunjukkan bahwa XML retrieval peningkatan kinerja yang lebih baik dibandingkan sistem temu kembali tidak terstruktur. Kedalaman konteks juga mempengaruhi kinerja sistem temu kembali informasi. Penambahan tag bersarang pada dokumen dapat meningkatkan kinerja sebesar 98.1%.
Gambar 2 Kurva recall dan precision tanpa tagging.
Gambar 3 Kurva recall dan precision dengan konteks XML 1.
[image:32.595.316.503.433.484.2]Gambar 4 Kurva recall dan precision dengan konteks XML 2.
[image:32.595.318.493.586.740.2] Pengujian pada Dokumen Tidak Relevan
Pengujian dilakukan pada 20 query uji sama seperti pengujian pada dokumen relevan. Proses temu kembali informasi dengan query uji dilakukan untuk mendapatkan nilai recall dan precision untuk 30 dokumen teratas. Selain itu, dilakukan perhitungan interpolasi maksimum untuk mendapatkan nilai AVP (Lampiran 7).
Pengujian terhadap query uji terbagi men-jadi 3 jenis query yaitu:
1 Query tanpa memerhatikan struktur XML dokumen
Gambar 6 mengilustrasikan kinerja sistem temu kembali tidak terstruktur. Nilai AVP dari proses temu kembali sebesar 0.611.
2 Query XML dengan kedalaman konteks XML sebesar 1
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 1 sebesar 0.246 atau menurun 36.5% dari query tanpa memerhatikan struktur tagging. Gambar 7 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 1.
3 Query XML dengan kedalaman konteks XML sebesar 2
Nilai AVP dari pencarian query XML dengan kedalaman konteks XML 2 sebesar 0.329 atau menurun 28.2% dari query tanpa
memerhatikan struktur tagging. Gambar 8 mengilustrasikan hasil kinerja sistem pada query XML dengan kedalaman konteks 2.
Nilai AVP pada pengujian sistem temu kembali dengan dokumen yang tidak relevan mengalami penurunan dibandingkan dengan pengujian sistem temu kembali dengan dokumen relevan. Penurunan pada pengujian query tanpa memperhatikan struktur tagging tidak telalu signifikan dibandingkan dengan pengujian menggunakan query XML. XML retrieval dapat mengurangi kinerja sistem temu kembali dalam menemukembalikan dokumen yang tidak relevan.
[image:33.595.319.500.125.280.2] [image:33.595.315.502.522.718.2]Gambar 9 menunjukkan bahwa kinerja XML retrieval menurun masing-masing sebesar 36.5% dan 28.2% dibandingkan dengan kinerja sistem temu kembali tidak terstruktur. Nilai AVP masing-masing query dapat dilihat pada Tabel 3.
Tabel 3 Hasil perhitungan AVP pada dokumen tidak relevan
Jenis Query AVP
Tanpa tagging 0.611
Kedalaman konteks sebesar 1 0.246 Kedalaman konteks sebesar 2 0.329 Gambar 6 Kurva recall dan precision
tanpa tagging.
Gambar 7 Kurva recall dan precision dengan konteks XML 1.
Gambar 8 Kurva recall dan precision dengan konteks XML 2.
Analisis Perbandingan Sistem
Analisis perbandingan sistem bertujuan membandingkan hasil temu kembali sistem yang digunakan oleh Bahi (2011) dengan sistem yang digunakan pada penelitian ini. Sistem yang digunakan oleh Bahi (2011) menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat. Sistem yang menggunakan 1000 dokumen pertanian menggunakan 30 query uji dan hanya menemukembalikan tag title dan tag text. Sistem yang menggunakan 93 dokumen tanaman obat menggunakan 13 query uji dan hanya melakukan temu kembali pada tag content dan tag penyakit. Terdapat dua kondisi analisis perbandingan dalam penelitian ini, yaitu perbandingan sistem informasi berbasis teks analisis perbandingan XML retrieval.
Analisis Perbandingan Sistem Temu Kembali Informasi Berbasis Teks
Analisis perbandingan sistem temu kembali informasi berbasis teks bertujuan mem-bandingkan kinerja kedua sistem