PENERAPAN METODE RULE-BASED DENGAN
UNSUPERVISED
LEARNING
UNTUK PELABELAN DOKUMEN BERBAHASA
INDONESIA
Oleh:
M Karibun H S
G64101053
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
M KARIBUN H S. Penerapan Metode Rule-based dengan Unsupervised Learning untuk Pelabelan Dokumen Berbahasa Indonesia . Dibimbing oleh YENI HERDIYENI dan PANJI WASMANA.
Penelitian ini menerapkan metode Rule-based dengan Unsupervised Learning untuk pelabelan dokumen teks berbahasa Indonesia. Metode Rule-based menggunakan pola kata untuk menentukan label dari kata yang tidak diketahui. Pola diperoleh melalui proses pembelajaran otomatis dan diurutkan berdasarkan frekuensi kemunculan. Pelabelan kata yang ambigu atau tidak diketahui labelnya dilakukan dengan cara melihat pola kata sekitar dan mengambil pola kata dengan frekuensi kemunculan terbesar. Penambahan metode pengujian jenis imbuhan pada sistem diharapkan dapat meningkatkan pengenalan label pada dokumen.
Penelitian menggunakan 102 dokumen teks yang terdiri dari 305.989 token untuk proses pelatihan dan menghasilkan 7.706 rule. Basis data rule yang diperoleh dari proses pembelajaran dan basis data perubahan jenis kata berdasarkan imbuhan digunakan untuk proses pengujian sistem. Pengujian menggunakan 52 dokumen teks yang terdiri dari 131.719 token. Pengujian menghasilkan 97,82 % token
yang berhasil dikenali . Pengujian manual terhadap 3 dokumen yang terdiri dari 431 token menghasilkan tingkat kebenaran 85,85%.
Kata Kunci: Part of Speech Tagging, Natural Language, Information Retrieval, Algoritma Eric Brill, dan
PENERAPAN METODE UNSUPERVISED LEARNING RULE-BASED
PART OF SPEECH TAGGING
UNTUK PELABELAN PADA
DOKUMEN BERBAHASA INDONESIA
M Karibun H S
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOG OR
Judul : Penerapan Metode Rule-based dengan Unsupervised Learning untuk Pelabelan Dokumen Berbahasa Indonesia.
Nama : M Karibun H S NRP : G64101053
Menyetujui,
Pembimbing I Pembimbing II
Yeni Herdiyeni, S.Si., M.Kom Panji Wasmana, S.Kom., M.Si
NIP. 132 282 665 NIP. 132 311 917
Mengetahui,
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Dr. Ir. Yonny Koesmaryono, M.Si NIP. 131 473 999
RIWAYAT HIDUP
Penulis dilahirkan di RSCM, Jakarta pada tanggal 17 November 1981 sebagai anak pertama dari dua bersaudara, anak dari pasangan Bapak Hamdan Eddy Yassin dan Ibu Pipiet Senja. Penulis menikah pada tanggal 15 Februari 2000 dengan Seli Siti Sholihat.
Penulis menyelesaikan sekolah menengah umum di SMUN 3 Depok, lulus pada tahun 1999. Setelah lulus melanjutkan pendidikannya di Jurusan Biologi Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Indonesia selama dua tahun (1999-2001). Pada tahun 2001, penulis mengikuti Seleksi Penerimaan Mahasiswa Baru (SPMB) ke Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Penulis sempat aktif di Badan Kerohanian Islam Mahasiswa (BKIM) pada tahun 2001-2002 dan menjadi ketua angkatan 38 BKIM Baranangsiang. Selama kuliah, penulis pernah menjadi staf pengajar di Pengabdian Pada Masyarakat (P2M) Fakultas Teknik Universitas Indonesia Salemba pada tahun 2001-2004. Penulis juga pernah menjadi Asisten Dosen Praktikum Departemen Ilmu Komputer pada tahun 2002-2004. Penulis pernah menjadi ketua Bareng Karib Silaturahmi Mahasiswa Ilkom (Bakar Singkong) pada tahun 2002. Penulis juga menjadi anggota Divisi Riset dan Development di Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) pada tahun 2003-2004. Pada tahun 2004 penulis menjadi pengajar pada pelatihan Microsoft Visual C++ 6.0 di P2M FTUI. Pada tahun 2005 penulis melakukan Praktik Kerja Lapang (PKL) di Divisi Hukum Bank Indonesia Thamrin Jakarta.
Bidang yang diminati penulis berkaitan dengan kecerdasan buatan, yaitu Computational Linguistic,
PRAKATA
Alhamdulillahirobbil’alamin penulis ucapkan atas segala limpahan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan karya il miah ini.
Melalui lembar ini, penulis ingin menyampaikan penghargaan dan terima kasih kepada semua fihak atas bantuan, dorongan, saran, kritik, serta koreksi yang ditujukan selama penulisan karya ilmiah ini. Ucapan terima kasih penulis ucapkan kepada:
1. Istri tercinta, Seli Siti Sholihat, atas semua kasih sayang, cinta, bimbingan, dan segala hal yang tak mungkin tersebut satu persatu disini. Semoga cinta kita tetap abadi dan semoga keluarga kita termasuk keluarga yang dirahmati Allah, keluarga sakinah.
2. Mama tercinta dan tersayang, Pipiet Senja, atas semua doa dan kesempatan mengenal kasih sayang ibu di dunia ini. Serta papa, Hamdan Eddy Yassin, atas semua bantuan finansialnya.
3. Adik, Adzimattinur Siregar, yang telah mensuplai komik penghilang stress selama penulisan karya ilmiah ini.
4. Mertua, Sri Mulyati dan khususnya Engkos Kosasih atas semua nasihat, bimbingan, dan kesempatan untuk mengenal semua warna kehidupan.
5. Ibu Yeni Herdiyeni, S.Si, M.Kom. dan bapak Panji Wasmana, S.Kom, M.Si. sebagai pembimbing skripsi I dan II atas segala bimbingan, saran, kritik, dan kesabarannya atas penelitian ini.
6. Seluruh staf pengajar Departemen Ilmu Komputer atas semua ilmu dan contoh kepribadiannya selama penulis kuliah di Departemen Ilmu Komputer.
7. Usep Aris Sutandi, S.Kom. atas segala bentuk persahabatan, saran, kritik, dan contekan format penulisan karya ilmiahnya.
8. Semua penghuni DC-7 pada tahun 2002-2004 atas semua bentuk persahabatan, kesenangan, dan pendidikan kepribadiannya.
9. Ibu Yayuk dan seluruh staf administrasi Departemen Ilmu Komputer atas segala pengabdian dan kesabarannya.
Akhir kata, semoga karya ilmiah ini dapat dipergunakan untuk kemashlahatan kita bersama.
Depok, Oktober 2005
DAFTAR ISI
Halaman
DAFTAR TABEL……….………....……vii
DAFTAR LAMPIRAN……….………...vii
PENDAHULUAN Latar Belakang………. .……….……...1
Tujuan………...………. ……...2
Ruang Lingkup Penelitian……… ….……2
TINJAUAN PUSTAKA Pembagian Jenis Kata……….. ……….2
Grammar……….. ……… ….……3
Token……… ……….4
Part of Speech……….. ……… ……….4
Stemming……….. ……….4
Nth Order Tagging……… ……….4
Polisemi……… ……….4
Kinerja sistem………...……….5
METODOLOGI Transformation Based Learning………...……….………5
Proses Pelabelan Kata………...……….5
Pemberian Label berdasarkan Imbuhan……… ……….6
HASIL DAN PEMBAHASAN Implementasi sistem………...8
Basis data sistem………...……….………9
Proses pembelajaran………. ……… ………..9
Ukuran pengujian ………..……….9
Hasil pengujian………..………9
Persentase pengujian tagset dan imbuhan……….………...10
Persentase token yang ambigu………..………… …………...10
Persentase pengujian pola………..………..10
Persentase token yang berhasil dikenali………... ……… ………10
Persentase token yang tidak berhasil diidentifikasi………..……… ……...10
Persentase token yang berhasil diidentifikasi secara benar……… …….11
KESIMPULAN DAN SARAN Kesimpulan………... ………. …….11
Saran………. ………. …….11
DAFTAR PUSTAKA……… ………11
LAMPIRAN………... ………13
DAFTAR TABEL Halaman 1. Spesifikasi implementasi sistem………..………9
2. Data hasil pembelajaran……… ………..9
3. Data hasil pengujian sistem………... ……….9
DAFTAR GAMBAR Halaman 1. Proses tokenizing teks……… ……….5
2. Proses pelabelan kata.………...……… ………..6
DAFTAR LAMPIRAN
1
PENDAHULUAN
Latar Belakang
Part-of-Speech Tagging adalah proses pemberian label klasifikasi pada setiap bagian dari dokumen teks berbasis bahasa natural.
Part-of-Speech Tagging yang akurat merupakan langkah awal yang kritis bagi pemrosesan bahasa natural (Vasilakopoulos, 2003). Part-o f-Speech Tagging juga merupakan suatu tahapan penting dalam Question Answering System (QAS). Posisi Part-of-Speech Tagging dalam QAS dapat dilihat pada Lampiran 1. Pada lampiran terlihat bahwa keluaran dari proses Part-of-Speech Tagging
merupakan dasar dari pengubahan suatu dokumen teks menjadi bentuk logik. QAS menggunakan keluaran dari Part-of-Speech Tagging untuk mencari jawaban terhadap pertanyaan yang diajukan pada sistem mengenai suatu dokumen teks.
Beberapa penelitian mengenai Part-of-Speech Tagging yang telah dilakukan sebelumnya, dapat dikelompokkan seperti pada Lampiran 2 (James, 1995).
Pengelompokan pertama adalah sistem
supervised dan unsupervised. Pada sistem
supervised, dokumen yang sudah dilabeli secara manual dimasukkan ke dalam sistem untuk dipelajari. Selanjutnya sistem akan membentuk basis data pola berdasarkan dokumen yang dimasukkan. Sementara pada sistem unsupervised, tidak dilakukan pelabelan secara manual pada dokumen yang dimasukkan untuk dipelajari oleh sistem. Sehingga sistem diharuskan untuk melabeli setiap kata dan mempelajari sendiri pola-pola yang ada.
Masing-masing pendekatan memiliki kelebihan dan kekurangan. Pendekatan
supervised memudahkan sistem untuk mengenali kata atau pola yang baru. Kekurangan dari pendekatan ini adalah lamanya waktu pembelajaran yang dibutuhkan dan besarnya kemungkinan keputusan yang ambigu. Sementara pada sistem unsupervised, dapat diharapkan terbentuknya sebuah sistem yang mengerti semua bahasa yang ada. Kekurangan dari sistem ini adalah lamanya atau sulitnya proses pelabelan ketika sistem diperkenalkan pada sesuatu yang baru dan belum memiliki referensi sebelumnya.
Pembagian selanjutnya adalah Part-of-Speech Tagging berbasis rule, stochastic dan
neural network. Pada Part-of-Speech Tagging
berbasis rule, sistem mengandalkan ketersediaan basis data pola yang akan digunakan untuk memutuskan klasifikasi sebuah kata. Sementara pada stochastic, sistem akan menggunakan prinsip-prinsip statistik dalam pengklasifikasian kata. Dan pada pendekatan dengan teknik neural network, sistem akan menggunakan teknik jaringan saraf tiruan untuk menggolongkan kata-kata yang dimasukkan ke dalam sistem (James, 1995).
Beberapa penelitian yang telah dilakukan di antaranya:
- Penelitian Part-of-Speech Tagging dengan menggunakan algoritma Baum-Welch menghasilkan tingkat akurasi 86,6% (Cutting et al, 1992). Penelitian menggunakan Penn Treebank Corpus yang terdiri dari 120.000 kata.
- Penelitian Eric Brill (1995), Unsupervised Learning Rule-based Part-of-Speech Tagging dapat mengidentifikasi secara benar lebih dari 90% token ambigu. Penelitian menggunakan data pelatihan 120.000 kata dan data tes 200.000 kata. - Penelitian Rabiner (1989), Hidden Markov
Models Part-of-Speech Tagging memiliki tingkat akurasi 96,5%. Penelitian ini juga menggunakan Penn Treebank yang terdiri dari 120.000 kata. Penelitian ini juga menggunakan Brown Corpus sebagai perbandingan yang tersusun dari 350.000 kata.
- Penelitian Weischedel (1993), Maximum Entropy Model Part -of-Speech Tagging, memiliki tingkat akurasi 85%. Penelitian ini menggunakan Penn Treebank yang terdiri dari 120.000 kata dan Wall Street Journal Corpus sebagai perbandingan yang tersusun dari 133.805 kata.
2
Tujuan
Penelitian ini bertujuan untuk mengimplementasikan metode Rule-based
dengan Unsupervised Learning untuk pelabelan kata dalam bahasa Indonesia.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi: 1. Pembelajaran dan pembentukan basis data
pola kata dalam kalimat
2. Pembentukan basis data referensi kata 3. Pembuatan metode penentuan label kata
berdasarka n imbuhan
4. Perhitungan dan pengukuran kinerja sistem
TINJAUAN PUSTAKA
Pembagian Jenis Kata
Secara sederhana, terdapat 10 jenis kata dalam bahasa Indonesia (Keraf, 1980):
1. Kata benda atau Nomina (N)
Kata benda adalah nama dari semua benda dan segala yang dibendakan. Selanjutnya kata-kata benda, menurut wujudnya, dibagi atas:
a.Kata benda konkrit b.Kata benda abstrak 2. Kata kerja atau Verba (Vb)
Semua kata yang menyatakan perbuatan atau laku digolongkan ke dalam kata kerja. Bila suatu kata kerja menghendaki adanya suatu pelengkap maka disebut kata kerja transitif, misalnya: memukul, menangkap, melihat, mendapat, dan sebagainya. Sebaliknya bila kata kerja tersebut tidak membutuhkan suatu pelengkap maka disebut kata kerja intransitif, misalnya:
menangis, meninggal, berjalan, berdiri,
dan sebagainya.
3. Kata sifat atau Adjektif (Adj)
Kata yang menyatakan sifat atau hal keadaan dari suatu benda: tinggi, rendah, lama, baru, dan sebagainya digolongkan sebagai kata sifat.
4. Kata ganti atau Pronomina (Pro)
Yang termasuk dalam jenis kata ini adalah segala kata yang dipakai untuk menggantikan kata benda atau yang dibendakan. Pembagian tradisional menggolongkan kata-kata ini ke dalam suatu jenis kata yang tersendiri.
Kata ganti menurut sifat dan fungsinya dapat dibedakan atas:
a.Kata ganti orang atau Pronomina Personalia
b.Kata ganti kepemilikan atau Pronomina Possessiva
c.Kata ganti petunjuk atau Pronomina Demonstrative
d.Kata ganti penghubung atau Pronomina Relativa
e.Kata ganti penanya atau Pronomina Interrogativa
f.Kata ganti tak tentu atau Pronomina Indeterminativa
5. Kata bilangan atau Numeralia (Num) Kata bilangan adalah kata yang menyatakan jumlah benda atau jumlah kumpulan atau urutan tempat dari nama-nama benda. Menurut sifatnya, kata bilangan dapat dibagi atas:
- Kata bilangan utama (Nume ralia Cardinalia): satu, dua, tiga, seratus, dan sebagainya.
- Kata bilangan tingkat (Numeralia Ordinalia): pertama, kedua, ketiga, kelima, kesepuluh, dan sebagainya. - Kata bilangan tak tentu: beberapa,
segala, semua, tiap-tiap, dan sebagainya. - Kata bilangan kumpulan: berdua,
bertiga, bertujuh, dan sebagainya. 6. Kata keterangan atau Adverbia (Adv)
Kata-kata keterangan atau adverbia adalah kata-kata yang memberi keterangan tentang:
PENERAPAN METODE RULE-BASED DENGAN
UNSUPERVISED
LEARNING
UNTUK PELABELAN DOKUMEN BERBAHASA
INDONESIA
Oleh:
M Karibun H S
G64101053
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
M KARIBUN H S. Penerapan Metode Rule-based dengan Unsupervised Learning untuk Pelabelan Dokumen Berbahasa Indonesia . Dibimbing oleh YENI HERDIYENI dan PANJI WASMANA.
Penelitian ini menerapkan metode Rule-based dengan Unsupervised Learning untuk pelabelan dokumen teks berbahasa Indonesia. Metode Rule-based menggunakan pola kata untuk menentukan label dari kata yang tidak diketahui. Pola diperoleh melalui proses pembelajaran otomatis dan diurutkan berdasarkan frekuensi kemunculan. Pelabelan kata yang ambigu atau tidak diketahui labelnya dilakukan dengan cara melihat pola kata sekitar dan mengambil pola kata dengan frekuensi kemunculan terbesar. Penambahan metode pengujian jenis imbuhan pada sistem diharapkan dapat meningkatkan pengenalan label pada dokumen.
Penelitian menggunakan 102 dokumen teks yang terdiri dari 305.989 token untuk proses pelatihan dan menghasilkan 7.706 rule. Basis data rule yang diperoleh dari proses pembelajaran dan basis data perubahan jenis kata berdasarkan imbuhan digunakan untuk proses pengujian sistem. Pengujian menggunakan 52 dokumen teks yang terdiri dari 131.719 token. Pengujian menghasilkan 97,82 % token
yang berhasil dikenali . Pengujian manual terhadap 3 dokumen yang terdiri dari 431 token menghasilkan tingkat kebenaran 85,85%.
Kata Kunci: Part of Speech Tagging, Natural Language, Information Retrieval, Algoritma Eric Brill, dan
PENERAPAN METODE UNSUPERVISED LEARNING RULE-BASED
PART OF SPEECH TAGGING
UNTUK PELABELAN PADA
DOKUMEN BERBAHASA INDONESIA
M Karibun H S
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOG OR
Judul : Penerapan Metode Rule-based dengan Unsupervised Learning untuk Pelabelan Dokumen Berbahasa Indonesia.
Nama : M Karibun H S NRP : G64101053
Menyetujui,
Pembimbing I Pembimbing II
Yeni Herdiyeni, S.Si., M.Kom Panji Wasmana, S.Kom., M.Si
NIP. 132 282 665 NIP. 132 311 917
Mengetahui,
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Dr. Ir. Yonny Koesmaryono, M.Si NIP. 131 473 999
RIWAYAT HIDUP
Penulis dilahirkan di RSCM, Jakarta pada tanggal 17 November 1981 sebagai anak pertama dari dua bersaudara, anak dari pasangan Bapak Hamdan Eddy Yassin dan Ibu Pipiet Senja. Penulis menikah pada tanggal 15 Februari 2000 dengan Seli Siti Sholihat.
Penulis menyelesaikan sekolah menengah umum di SMUN 3 Depok, lulus pada tahun 1999. Setelah lulus melanjutkan pendidikannya di Jurusan Biologi Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Indonesia selama dua tahun (1999-2001). Pada tahun 2001, penulis mengikuti Seleksi Penerimaan Mahasiswa Baru (SPMB) ke Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Penulis sempat aktif di Badan Kerohanian Islam Mahasiswa (BKIM) pada tahun 2001-2002 dan menjadi ketua angkatan 38 BKIM Baranangsiang. Selama kuliah, penulis pernah menjadi staf pengajar di Pengabdian Pada Masyarakat (P2M) Fakultas Teknik Universitas Indonesia Salemba pada tahun 2001-2004. Penulis juga pernah menjadi Asisten Dosen Praktikum Departemen Ilmu Komputer pada tahun 2002-2004. Penulis pernah menjadi ketua Bareng Karib Silaturahmi Mahasiswa Ilkom (Bakar Singkong) pada tahun 2002. Penulis juga menjadi anggota Divisi Riset dan Development di Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) pada tahun 2003-2004. Pada tahun 2004 penulis menjadi pengajar pada pelatihan Microsoft Visual C++ 6.0 di P2M FTUI. Pada tahun 2005 penulis melakukan Praktik Kerja Lapang (PKL) di Divisi Hukum Bank Indonesia Thamrin Jakarta.
Bidang yang diminati penulis berkaitan dengan kecerdasan buatan, yaitu Computational Linguistic,
PRAKATA
Alhamdulillahirobbil’alamin penulis ucapkan atas segala limpahan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan karya il miah ini.
Melalui lembar ini, penulis ingin menyampaikan penghargaan dan terima kasih kepada semua fihak atas bantuan, dorongan, saran, kritik, serta koreksi yang ditujukan selama penulisan karya ilmiah ini. Ucapan terima kasih penulis ucapkan kepada:
1. Istri tercinta, Seli Siti Sholihat, atas semua kasih sayang, cinta, bimbingan, dan segala hal yang tak mungkin tersebut satu persatu disini. Semoga cinta kita tetap abadi dan semoga keluarga kita termasuk keluarga yang dirahmati Allah, keluarga sakinah.
2. Mama tercinta dan tersayang, Pipiet Senja, atas semua doa dan kesempatan mengenal kasih sayang ibu di dunia ini. Serta papa, Hamdan Eddy Yassin, atas semua bantuan finansialnya.
3. Adik, Adzimattinur Siregar, yang telah mensuplai komik penghilang stress selama penulisan karya ilmiah ini.
4. Mertua, Sri Mulyati dan khususnya Engkos Kosasih atas semua nasihat, bimbingan, dan kesempatan untuk mengenal semua warna kehidupan.
5. Ibu Yeni Herdiyeni, S.Si, M.Kom. dan bapak Panji Wasmana, S.Kom, M.Si. sebagai pembimbing skripsi I dan II atas segala bimbingan, saran, kritik, dan kesabarannya atas penelitian ini.
6. Seluruh staf pengajar Departemen Ilmu Komputer atas semua ilmu dan contoh kepribadiannya selama penulis kuliah di Departemen Ilmu Komputer.
7. Usep Aris Sutandi, S.Kom. atas segala bentuk persahabatan, saran, kritik, dan contekan format penulisan karya ilmiahnya.
8. Semua penghuni DC-7 pada tahun 2002-2004 atas semua bentuk persahabatan, kesenangan, dan pendidikan kepribadiannya.
9. Ibu Yayuk dan seluruh staf administrasi Departemen Ilmu Komputer atas segala pengabdian dan kesabarannya.
Akhir kata, semoga karya ilmiah ini dapat dipergunakan untuk kemashlahatan kita bersama.
Depok, Oktober 2005
DAFTAR ISI
Halaman
DAFTAR TABEL……….………....……vii
DAFTAR LAMPIRAN……….………...vii
PENDAHULUAN Latar Belakang………. .……….……...1
Tujuan………...………. ……...2
Ruang Lingkup Penelitian……… ….……2
TINJAUAN PUSTAKA Pembagian Jenis Kata……….. ……….2
Grammar……….. ……… ….……3
Token……… ……….4
Part of Speech……….. ……… ……….4
Stemming……….. ……….4
Nth Order Tagging……… ……….4
Polisemi……… ……….4
Kinerja sistem………...……….5
METODOLOGI Transformation Based Learning………...……….………5
Proses Pelabelan Kata………...……….5
Pemberian Label berdasarkan Imbuhan……… ……….6
HASIL DAN PEMBAHASAN Implementasi sistem………...8
Basis data sistem………...……….………9
Proses pembelajaran………. ……… ………..9
Ukuran pengujian ………..……….9
Hasil pengujian………..………9
Persentase pengujian tagset dan imbuhan……….………...10
Persentase token yang ambigu………..………… …………...10
Persentase pengujian pola………..………..10
Persentase token yang berhasil dikenali………... ……… ………10
Persentase token yang tidak berhasil diidentifikasi………..……… ……...10
Persentase token yang berhasil diidentifikasi secara benar……… …….11
KESIMPULAN DAN SARAN Kesimpulan………... ………. …….11
Saran………. ………. …….11
DAFTAR PUSTAKA……… ………11
LAMPIRAN………... ………13
DAFTAR TABEL Halaman 1. Spesifikasi implementasi sistem………..………9
2. Data hasil pembelajaran……… ………..9
3. Data hasil pengujian sistem………... ……….9
DAFTAR GAMBAR Halaman 1. Proses tokenizing teks……… ……….5
2. Proses pelabelan kata.………...……… ………..6
DAFTAR LAMPIRAN
1
PENDAHULUAN
Latar Belakang
Part-of-Speech Tagging adalah proses pemberian label klasifikasi pada setiap bagian dari dokumen teks berbasis bahasa natural.
Part-of-Speech Tagging yang akurat merupakan langkah awal yang kritis bagi pemrosesan bahasa natural (Vasilakopoulos, 2003). Part-o f-Speech Tagging juga merupakan suatu tahapan penting dalam Question Answering System (QAS). Posisi Part-of-Speech Tagging dalam QAS dapat dilihat pada Lampiran 1. Pada lampiran terlihat bahwa keluaran dari proses Part-of-Speech Tagging
merupakan dasar dari pengubahan suatu dokumen teks menjadi bentuk logik. QAS menggunakan keluaran dari Part-of-Speech Tagging untuk mencari jawaban terhadap pertanyaan yang diajukan pada sistem mengenai suatu dokumen teks.
Beberapa penelitian mengenai Part-of-Speech Tagging yang telah dilakukan sebelumnya, dapat dikelompokkan seperti pada Lampiran 2 (James, 1995).
Pengelompokan pertama adalah sistem
supervised dan unsupervised. Pada sistem
supervised, dokumen yang sudah dilabeli secara manual dimasukkan ke dalam sistem untuk dipelajari. Selanjutnya sistem akan membentuk basis data pola berdasarkan dokumen yang dimasukkan. Sementara pada sistem unsupervised, tidak dilakukan pelabelan secara manual pada dokumen yang dimasukkan untuk dipelajari oleh sistem. Sehingga sistem diharuskan untuk melabeli setiap kata dan mempelajari sendiri pola-pola yang ada.
Masing-masing pendekatan memiliki kelebihan dan kekurangan. Pendekatan
supervised memudahkan sistem untuk mengenali kata atau pola yang baru. Kekurangan dari pendekatan ini adalah lamanya waktu pembelajaran yang dibutuhkan dan besarnya kemungkinan keputusan yang ambigu. Sementara pada sistem unsupervised, dapat diharapkan terbentuknya sebuah sistem yang mengerti semua bahasa yang ada. Kekurangan dari sistem ini adalah lamanya atau sulitnya proses pelabelan ketika sistem diperkenalkan pada sesuatu yang baru dan belum memiliki referensi sebelumnya.
Pembagian selanjutnya adalah Part-of-Speech Tagging berbasis rule, stochastic dan
neural network. Pada Part-of-Speech Tagging
berbasis rule, sistem mengandalkan ketersediaan basis data pola yang akan digunakan untuk memutuskan klasifikasi sebuah kata. Sementara pada stochastic, sistem akan menggunakan prinsip-prinsip statistik dalam pengklasifikasian kata. Dan pada pendekatan dengan teknik neural network, sistem akan menggunakan teknik jaringan saraf tiruan untuk menggolongkan kata-kata yang dimasukkan ke dalam sistem (James, 1995).
Beberapa penelitian yang telah dilakukan di antaranya:
- Penelitian Part-of-Speech Tagging dengan menggunakan algoritma Baum-Welch menghasilkan tingkat akurasi 86,6% (Cutting et al, 1992). Penelitian menggunakan Penn Treebank Corpus yang terdiri dari 120.000 kata.
- Penelitian Eric Brill (1995), Unsupervised Learning Rule-based Part-of-Speech Tagging dapat mengidentifikasi secara benar lebih dari 90% token ambigu. Penelitian menggunakan data pelatihan 120.000 kata dan data tes 200.000 kata. - Penelitian Rabiner (1989), Hidden Markov
Models Part-of-Speech Tagging memiliki tingkat akurasi 96,5%. Penelitian ini juga menggunakan Penn Treebank yang terdiri dari 120.000 kata. Penelitian ini juga menggunakan Brown Corpus sebagai perbandingan yang tersusun dari 350.000 kata.
- Penelitian Weischedel (1993), Maximum Entropy Model Part -of-Speech Tagging, memiliki tingkat akurasi 85%. Penelitian ini menggunakan Penn Treebank yang terdiri dari 120.000 kata dan Wall Street Journal Corpus sebagai perbandingan yang tersusun dari 133.805 kata.
2
Tujuan
Penelitian ini bertujuan untuk mengimplementasikan metode Rule-based
dengan Unsupervised Learning untuk pelabelan kata dalam bahasa Indonesia.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi: 1. Pembelajaran dan pembentukan basis data
pola kata dalam kalimat
2. Pembentukan basis data referensi kata 3. Pembuatan metode penentuan label kata
berdasarka n imbuhan
4. Perhitungan dan pengukuran kinerja sistem
TINJAUAN PUSTAKA
Pembagian Jenis Kata
Secara sederhana, terdapat 10 jenis kata dalam bahasa Indonesia (Keraf, 1980):
1. Kata benda atau Nomina (N)
Kata benda adalah nama dari semua benda dan segala yang dibendakan. Selanjutnya kata-kata benda, menurut wujudnya, dibagi atas:
a.Kata benda konkrit b.Kata benda abstrak 2. Kata kerja atau Verba (Vb)
Semua kata yang menyatakan perbuatan atau laku digolongkan ke dalam kata kerja. Bila suatu kata kerja menghendaki adanya suatu pelengkap maka disebut kata kerja transitif, misalnya: memukul, menangkap, melihat, mendapat, dan sebagainya. Sebaliknya bila kata kerja tersebut tidak membutuhkan suatu pelengkap maka disebut kata kerja intransitif, misalnya:
menangis, meninggal, berjalan, berdiri,
dan sebagainya.
3. Kata sifat atau Adjektif (Adj)
Kata yang menyatakan sifat atau hal keadaan dari suatu benda: tinggi, rendah, lama, baru, dan sebagainya digolongkan sebagai kata sifat.
4. Kata ganti atau Pronomina (Pro)
Yang termasuk dalam jenis kata ini adalah segala kata yang dipakai untuk menggantikan kata benda atau yang dibendakan. Pembagian tradisional menggolongkan kata-kata ini ke dalam suatu jenis kata yang tersendiri.
Kata ganti menurut sifat dan fungsinya dapat dibedakan atas:
a.Kata ganti orang atau Pronomina Personalia
b.Kata ganti kepemilikan atau Pronomina Possessiva
c.Kata ganti petunjuk atau Pronomina Demonstrative
d.Kata ganti penghubung atau Pronomina Relativa
e.Kata ganti penanya atau Pronomina Interrogativa
f.Kata ganti tak tentu atau Pronomina Indeterminativa
5. Kata bilangan atau Numeralia (Num) Kata bilangan adalah kata yang menyatakan jumlah benda atau jumlah kumpulan atau urutan tempat dari nama-nama benda. Menurut sifatnya, kata bilangan dapat dibagi atas:
- Kata bilangan utama (Nume ralia Cardinalia): satu, dua, tiga, seratus, dan sebagainya.
- Kata bilangan tingkat (Numeralia Ordinalia): pertama, kedua, ketiga, kelima, kesepuluh, dan sebagainya. - Kata bilangan tak tentu: beberapa,
segala, semua, tiap-tiap, dan sebagainya. - Kata bilangan kumpulan: berdua,
bertiga, bertujuh, dan sebagainya. 6. Kata keterangan atau Adverbia (Adv)
Kata-kata keterangan atau adverbia adalah kata-kata yang memberi keterangan tentang:
3
e.Seluruh kalimat
Kata keterangan sendiri dibagi lagi menjadi beberapa macam:
- Kata keterangan kualitatif (Adverbium kualitatif). Adalah kata keterangan yang menerangkan atau menjelaskan suasana atau situasi dari suatu perbuatan. Contohnya: ia berjalan perlahan-lahan. Biasanya kata keterangan ini dinyatakan dengan mempergunakan kata depan
dengan + kata sifat.
- Kata keterangan waktu (Adverbium temporal). Adalah keterangan yang menunjukkan atau menjelaskan berlangsungnya suatu peristiwa dalam suatu bidang waktu: sekarang, nanti, kemarin, kemudian, sesudah itu, lusa, sebelum, minggu depan, bulan depan,
dan lain-lain.
- Kata keterangan tempat (Adverbium lokatif). Adalah kata yang memberi penjelasan atas berlangsungnya suatu peristiwa atau perbuatan dalam suatu ruang. Contohnya: di sini, di situ, di sana, dan sebagainya.
- Kata keterangan kecaraan (Adverbium modalitas). Adalah kata-kata yang menjelaskan suatu peristiwa karena tanggapan si pembicara atas berlangsungnya peristiwa tersebut. Dalam hal ini subjektivitas lebih ditonjolkan. Contohnya: memang, niscaya, pasti, sungguh, tentu, tidak, bukannya, bukan, dan sebagainya. - Kata keterangan aspek. Menjelaskan
berlangsungnya suatu peristiwa secara objektif, bahwa suatu peristiwa terjadi dengan sendirinya tanpa suatu pengaruh atau pandangan dari pembicara. Contoh:
pun, lah, sedang, sementara, dan sebagainya.
- Dan masih banyak lagi pembedaan kata keterangan.
7. Kata sambung atau Conjunctiva (Conj) Kata sambung adalah kata yang menghubungkan kata-kata, bagian-bagian kalimat, atau menghubungkan kalimat-kalimat. Contoh: apabila, ketika, bia, jika, atau, dan sebagainya.
8. Kata depan atau Prepositio (Prep)
Kata depan adalah kata yang merangkaikan kata-kata atau bagian-bagian kalimat. Contoh: di, ke, dari, dan sebagainya. 9. Kata sandang atau Articula (A rt)
kata sandang tidak mengandung suatu arti, tetapi memiliki fungsi. Contoh: yang, itu, nya, si, sang, hang, dang.
10. Kata seru atau Interjectio (Int)
Kata seru adalah kata yang paling tua dalam bahasa. Kata ini merupakan ungkapan perasaan seseorang. Contoh:
wah, yah, ah, dan sebagainya.
Grammar
Grammar dari suatu bahasa adalah skema untuk menspesifikasikan kalimat dalam bahasa tersebut. Grammar mengindikasikan hubungan sintaksis untuk mengkombinasikan kata ke dalam bentuk frase dan klausa.
Grammar G didefinisikan sebagai sebuah bentuk yang terdiri dari 4 elemen yang terbatas (Krulee, 1991).
Sebuah grammar G = (N, Σ, P, So) dimana
1. N adalah sebuah set dari non terminal.
2. Σ adalah sebuah set dari simbol terminal yang digunakan untuk mendefinisikan ka ta aktual.
3. P adalah sebuah set dari aturan grammar. 4. So adalah sebuah non terminal yang
berfungsi sebagai simbol inisiasi untuk setiap deretan penurunan.
Sebuah grammar dikatakan linier ke kanan jika dan hanya jika setiap produksi pada
grammar tersebut memiliki bentuk: X àαY atau X àα
Dimana X dan Y adalah non terminal yang terdapat dalam N dan α adalah sebuah simbol terminal yang terdapat dalam Σ.
Untuk lebih umumnya, sebuah grammar
dikatakan bersifat context-sensitive jika setiap produksi pada gramar G = (N, Σ, P, So)
memiliki bentuk γ1χγ2 = γ1αγ2 dimana χ berada
4
Token
Token adalah sederetan karakter yang membentuk satu kesatuan informasi dalam sebuah dokumen teks.
Proses pemisahan token pada dokumen disebut sebagai tokenize. Sementara program yang melakukan proses tersebut disebut sebagai
tokenizer (Jones, 1994).
Part of Speech
Part of Speech adalah pengklasifikasian kata secara grammar. Klasifikasi kata dapat terdiri dari kata benda, kata kerja, kata penghubung, dan sebagainya.
Ada 3 pendekatan pengklasifikasian kata yang dapat digunakan. Pendekatan pertama adalah pendekatan formal. Pada pendekatan ini, anatomi dari kata digunakan sebagai penentu klasifikasi dari kata. Sebagai contoh, kata yang berawalan me- dapat digolongkan langsung sebagai kata kerja.
Pendekatan kedua adalah pendekatan sintaktik. Pendekatan ini menggunakan klasifikasi dari kata lain di dekat kata yang tidak teridentifikasi. Sebagai contoh, kata Adj dalam bahasa Indonesia biasanya muncul tepat setelah kata benda: Jendela kotor, Meja baru,
dan sebagainya.
Pendekatan terakhir adalah pendekatan
notional atau konteks . Pada pendekatan ini, sebuah klasifikasi dipahami maknanya dan digunakan sebagai penentu penggolongan kata. Sebagai contoh, kata benda adalah kata yang merepresentasikan suatu objek. Pendekatan ini sangat sulit diformulasikan. Dan karenanya kurang begitu dipakai dalam pengklasifikasian kata (Jones , 1994).
Stemming
Stemming adalah proses pemotongan imbuhan pada kata untuk mendapatkan kata dasarnya (Porter, 1980). Dengan proses stemming, kata mencadangkan akan dipisahkan menjadi bentuk me-cadang-kan. Dengan kata dasar cadang yang berhasil diekstraksi.
Nth Order Tagging
Menurut Brill (1992 ), dalam menentukan label dari sebuah token, pertimbangan konteks dapat menggunakan label dari token lain di sekitar token yang bermasalah.
Kemungkinan dari jumlah token yang dipertimbangkan antara lain:
- 0th order. Disebut juga sebagai unigram tagger. Pada metode ini, penentuan label dari token yang tidak diketahui dilakukan berdasarkan frekuensi label yang paling tinggi tanpa mempertimbangkan label dari token sekitarnya.
- 1st order. Disebut juga sebagai bigram tagger. Pada metode ini, penentuan label dari token yang tidak diketahui dilakukan berdasarkan frekuensi label yang paling tinggi dengan mempertimbangkan label dari token lain yang terletak di n-1 dan n+1
di sekitar token yang tidak diketahui. Contoh:
N – X – V à X/? Dari data pelatihan: N – N – V = A frekuensi N – V – V = B frekuensi Jika A>B, maka X à N
- 2nd order. Disebut juga sebagai trigram tagger. Pada metode ini, penentuan label dari token yang tidak diketahui dilakukan berdasarkan frekuensi label yang paling tinggi dengan mempertimbangkan label dari token lain yang terletak di n -2, n-1, n+1, dan n+2 di sekitar token yang tidak diketahui.
Contoh:
N – N – X – V – Prep à X/? Dari data pelatihan
N – N – N – V – Prep = A frekuensi N – N – Prep – V – Prep = B frekuensi Jika A>B, maka X à Prep
Polisemi
Khasanah bahas a Indonesia mengenal beberapa kata yang memiliki lebih dari satu jenis kata yang dikenal dengan istilah polisemi
5
Kinerja sistem
Pengukuran kinerja sistem menggunakan rumus: P=
tkn
id
Σ
Σ
x100% dimanaP=Persentase token yang berhasil diidentifikasi.
Σid=Jumlah token yang berhasil diidentifikasi.
Σtkn=Jumlah token yang dicek.
METODOLOGI
Penetapan label jenis untuk setiap kata dilakukan dengan mempertimbangkan 4 hal: kamus, ciri kata, jenis imbuhan yang menyertai kata, dan pola kata pada kalimat.
Transformation Based Learning
Salah satu metode yang banyak digunakan dalam proses tagging adalah
Transformation Based Learning (TBL), sebuah metode machine learning yang diperkenalkan oleh Eric Brill (1995).
Ide utama dari metode TBL adalah pengekstraksian rule secara otomatis selama proses pelatihan dan pengurutan rule yang diperoleh berdasarkan frekuensi kemunculannya. Rule digunakan untuk memperbaiki pelabelan awal dan disebut sebagai transformation rule. Sehingga dibutuhkan sebuah proses pembelajaran dengan cara memasukkan rule-rule yang biasa terdapat dalam sebuah kalimat serta membangun sema cam kamus yang menyediakan data awal klasifikasi dari setiap kata.
Sistem terlebih dahulu akan mencari label dari setiap kata pada kamus yang disediakan. Seandainya kata tersebut terdapat dalam kamus, maka tugas sistem selesai. Sementara seandainya sis tem tidak menemukan kata yang dicari pada kamus, atau menemukan kata yang ambigu, maka sistem akan mengandalkan dan melihat pola pada kalimat yang paling sesuai sehingga kata yang dicari dapat ditentukan klasifikasinya.
Secara garis besar, sistem yang dibangun akan berjalan seperti pada Lampiran 3.
Proses Pelabelan Kata
Penjelasan mengenai proses pelabelan untuk setiap kata dapat dirinci sebagai berikut: - Langkah pertama adalah pemisahan setiap
token dalam dokumen dengan cara pengecekan setiap karakter dalam dokumen. Proses detailnya bisa dilihat pada gambar 1.
Gambar 1 Proses tokenizing teks.
Setiap karakter dicek oleh sistem. Selama karakter tersebut berupa karakter A-Z , a-z, atau 0-9 (fungsi isAlpha), maka karakter tersebut dimasukkan ke dalam token aktif. Ketika sistem menemukan karakter khusus (fungsi isSpesialChar), maka sistem akan mulai mencari token selanjutnya. Proses terus berulang selama belum ditemukan karakter penanda akhir dokumen (fungsi
notEOF). Ketika karakter akhir dokumen
ditemukan (fungsi isEOF), maka proses pemisahan selesai dengan hasil rangkaian token yang telah berhasil diidentifikasi. Token khusus seperti alamat email, angka, dan tanggal langsung diidentifikasi dan diberi label pada proses ini (fungsi isSpecialToken).
- Kemudian, setelah setiap kata dapat diidentifikasi, satu persatu kata tersebut dicek keberadaannya dalam tagset yang sudah ada pada database. Proses dapat dilihat pada gambar 2.
Gambar 2 Proses pelabelan kata.
6
- Kata yang masih belum teridentifikasi akan dicek bentuk imbuhannya. Proses dapat dilihat pada gambar 3.
Gambar 3 Proses pengecekan imbuhan
Pengecekan imbuhan dilakukan dengan cara mencari bentuk perubahan imbuhan yang sesuai dengan kata tersebut untuk mendapatkan kata dasar dari kata. Kemudian diadakan pengecekan untuk kata dasar yang didapatkan pada tagset. Bila ada, sistem akan mencari bentuk perubahan label dari kata dasar dengan mempertimbangkan jenis imbuhan yang didapatkan.
- Bila label yang didapatkan dari rumus frase belum fix atau merujuk pada satu label, atau bahkan belum ditemukan label yang sesuai untuk kata yang ditanyakan, langkah terakhir adalah melakukan pengecekan pada pola bigram dan trigram yang didapatkan pada pembelajaran (Gambar 2).
Langkah-langkah yang dilakukan pada proses pembelajaran pola kalimat adalah:
- Pengidentifikasian setiap ka limat pada dokumen berdasarkan karakter pemisah kalimat.
- Pemotongan setiap kata berdasarkan karakter pemisah kata.
- Pelabelan setiap kata.
Kombinasi kata yang labelnya diketahui akan dicek keberadaannya pada database pola kata. Bila tidak ada, pola baru akan ditambahkan pada database pola, sementara bila sudah ada, frekuensi pola akan ditambah.
Pemberian Label berdasarkan Imbuhan
Bahasa Indonesia mengenal penggabungan berbagai jenis imbuhan untuk membentuk satu kata.
Untuk mengekstrak kata dasar dari kata yang berimbuhan seperti ini, diperlukan sebuah proses tersendiri. Dimulai dengan pemeriksaan akhiran terlebih dahulu, karena sifat akhiran pada bahasa Indonesia yang tidak bertumpuk,
kemudian dilanjutkan dengan pemeriksaan awalan secara berulang sampai ditemukan kata dasar yang valid pada tagset.
Rincian proses pengecekan imbuhan dapat dilihat pada Gambar 3 dengan penjelasan sebagai berikut:
Kata yang dicek: abCd
Di mana a dan b adalah awalan, C adalah kata dasar yang ingin diekstrak, dan d adalah akhiran. Proses yang terjadi:
abCd à abC-d, yang berarti akhiran d sudah dapat diidentifikasi.
abC à a-bC, pada proses ini, awalan a telah berhasil diidentifikasi.
bC à b-C, pada akhirnya, awalan b berhasil diidentifikasi dan kata dasar C berhasil diekstrak.
Proses di atas menghasilkan:
Imbuhan: a-b dan d
Kata dasar: C
Kemudian dilakukan pengecekan jenis kata pada tagset:
C à L
dimana L adalah jenis kata. Jenis kata yang dicek akan ditentukan dengan proses:
Kata dasar: C à L
Proses pengecekan jenis kata berdasarkan imbuhan berjalan sebagai berikut:
L-d à M , dimana M adalah jenis kata yang terbentuk jika jenis kata L diberi akhiran d.
b-M à N, N adalah jenis kata yang terbentuk bila jenis kata M diberi awalan b.
a-N à O, O adalah jenis kata yang terbentuk bila jenis kata N diberi awalan a.
Sehingga diperoleh jenis kata yang dicek:
abCd à O
Contoh pemrosesan kata berimbuhan memperbarui akan berjalan sebagai berikut:
Pada database rule akhiran diperoleh rule:
7
Sehingga kata dasar yang diperoleh:
Memperbaru
Karena pada pengecekan tagset tidak ditemukan kata tersebut, dilakukan pengecekan awalan.
Pada database rule awalan, diperoleh rule:
Memp* à p*
Sehingga kata dasar yang diperoleh:
Perbaru
Pengecekan pada tagset masih tidak akan menemukan kata di atas. Sehingga diadakan pengecekan awalan sekali lagi dengan hasil rule:
Perb* à b*
Yang akan menghasilkan kata dasar:
Baru à Adj/Adv
Yang berarti bahwa kata baru memiliki dua kemungkinan label, Adj atau Adv.
Dari proses di atas, ditemukan bahwa kata
memperbarui adalah kata berimbuhan dengan morfologi:
Me-per-baru-i
Karena sistem bertujuan untuk menentukan label dari kata memperbarui, maka sistem akan mengubah susunan di atas menjadi:
Me-per-Adj/Adv-i
Dari susunan tersebut, sistem mengetahui bahwa ada dua kemungkinan label kata dasar. Sistem kemudian akan melakukan pengecekan untuk setiap kemungkinan label tersebut dalam penentuan label kata keseluruhan.
Proses untuk baru à Adj:
Me-per-Adj-i
Dari database pembentukan label berdasarkan imbuhan, diperoleh rule :
Per-Adj à V
Sehingga susunan morfologi kata akan diubah menjadi:
Me-V-i
Selanjutnya, berdasarkan database pembentukan label juga, diperoleh rule:
Me-V à V
Yang akan mengubah susunan morfologi kata menjadi:
V-i
Terakhir, dari database diperoleh rule:
V-i à V
Sehingga pada akhirnya, sistem akan menyimpulkan bahwa:
Me-per-Adj –I à V
Proses di atas akan berulang pada pengecekan untuk baru à Adv yang akan menghasilkan:
Me-per-Adv-I à V
Karena kedua kemungkinan label tersebut menghasilkan label yang sama, V, maka sistem akan memberikan label pada kata memperbarui
à V.
Pada kasus jenis kata polisemi seperti pada kata beruang, setiap kata akan mengalami proses pengecekan pada tagset dan pengecekan imbuhan. Contoh:
Beruang itu mandi di sungai.
Orang yang beruang banyak itu seorang laki-laki.
Melalui pengecekan pada tagset, diperoleh:
Beruang/N itu/Pron mandi/V di/Prep sungai/N. Orang/N yang/P beruang/N banyak/Adv itu/Pron seorang/Num laki-laki/N.
Pengecekan berlanjut ke pengecekan imbuhan yang menghasilkan:
Beruang/N,V itu/Pron mandi/V di/Prep sungai/N.
Orang/N yang/P beruang /N,V banyak/Adv itu/Pron seorang/Num laki-laki/N.
Yang menunjukkan bahwa kata beruang dapat memiliki label N dan V. Label V pada kata
beruang diperoleh dari:
ber-uang à V ber-ruang à V
8
Untuk menghilangkan ambiguitas label pada kata beruang tersebut, dilakukan pengecekan pola yang menghasilkan:
N – Pron – V – Prep – N = A frekuensi
V – Pron – V – Prep – N = B frekuens i Jika A>B maka kata beruang pada kalimat
Beruang itu mandi di sungai.
Akan diberi label N yang menghasilkan pelabelan:
Beruang/N itu/Pron mandi/V di/Prep sungai/N.
Sementara pada pengecekan pola kalimat:
N – P – N – Adv – Pron = A frekuensi
N – P – V – Adv – Pron = B frekuensi Jika A<B, maka kata beruang pada kalimat
Orang yang beruang banyak itu seorang laki-laki.
Akan diberi label V yang menghasilkan pelabelan:
Orang/N yang/P beruang/V banyak/Adv itu/Pron seorang/Num laki-laki/N.
Sistem merepresentasikan aturan-aturan penambahan imbuhan dalam dua tabel basis data. Tabel pertama berisi aturan perubahan kata dasar oleh imbuhan dan tabel kedua berisi aturan perubahan kata dasar oleh akhiran.
Pembentukan tabel sebagai representasi aturan dimaksudkan untuk memberikan sifat fleksibilitas pada sistem. Sehingga diharapkan perubahan kata dasar dalam bahasa apapun akan dapat diakomodasi sistem dengan menggunakan fungsi yang sama. Perubahan bahasa hanya memerlukan perubahan pada basis data awalan dan akhiran tanpa perlu mengubah pemrosesan kata pada sistem.
Pengumpulan data perubahan bentuk kata dasar oleh imbuhan, pembentukan jenis kata berimbuhan, dan ciri kata dalam bahasa Indonesia dilakukan secara manual dengan mengacu pada buku acuan bahasa Indonesia.
HASIL DAN PEMBAHASAN
Implementasi Sistem
Sistem dibangun dan dijalankan pada PC dengan klasifikasi:
Tabel 3 PC Specification implementasi sistem Operating System Windows XP tanpa
Service Pack
RAM 512 MB
Prosesor Athlon XP 2400+ 1.8 GHz Hard Disk Seagate 120 GB 7200
RPM Graphic Card NVIDIA GeForce 4
440 MMX Bahasa
Pemrograman
Microsoft Visual Basic 6.0 Sistem Database Microsoft Access
2000
Basis data sistem
Basis data yang digunakan oleh sistem dalam proses pembelajaran dan pengecekan adalah:
- Data tagset yang terdiri dari 29.339 kata dan 9 jenis kata. Jenis kata seru (interjectio) tidak terdapat pada tagset. - Data perubahan jenis kata berdasarkan
jenis imbuhan yang terdiri dari 411 rule. - Data aturan perubahan kata berdasarkan
imbuhan yang terdiri dari 295 rule. Proses pe mbelajaran
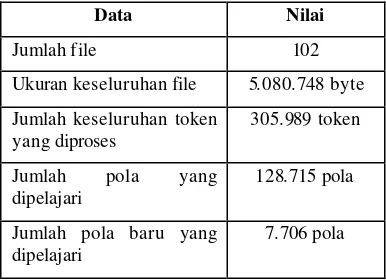
Proses pembelajaran yang dilakukan oleh sistem menghasilkan data yang dapat dilihat pada tabel 1.
Tabel 1 Data hasil pembelajaran Data Nilai
Jumlah file 102
Ukuran keseluruhan file 5.080.748 byte Jumlah keseluruhan token
yang diproses
305.989 token
Jumlah pola yang dipelajari
128.715 pola
Jumlah pola baru yang dipelajari
9
Rata-rata pola baru yang dipelajari per file
107,03 pola
Waktu pembelajaran keseluruhan
3:18:07
Rata-rata waktu pembelajaran per file
0:02:45
Jumlah pola yang terdiri dari 5 komponen
5.747 pola
Pembelajaran dilakukan dengan menggunakan file berformat RTF (Rich Text File). File merupakan gabungan dari hasil konversi file PDF (Portable Document File) yang berasal dari CD Tutorial IlmuKomputer.com edisi 1/2004, berita kompas tahun 2003, cerpen, dan novel.
Ukuran pengecekan
Proses pengecekan sistem dilakukan pada 52 file teks dengan format Rich Text File
(.RTF) yang terdiri dari cerpen, novel, dan berita dari surat kabar Kompas tahun 2003.
Ukuran file pengecekan keseluruhan adalah 1.999.544 byte dengan jumlah token keseluruhan 129.320 token.
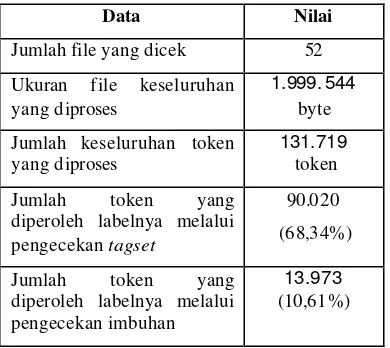
Hasil pengecekan
Pengecekan yang dilakukan terhadap sistem menghasilkan data sebagai berikut:
Tabel 2 Data hasil pengecekan sistem Data Nilai Jumlah file yang dicek 52 Ukuran file keseluruhan
yang diproses
1.999. 544
byte Jumlah keseluruhan token
yang diproses
131.719
token Jumlah token yang
diperoleh labelnya melalui pengecekan tagset
90.020 (68,34%)
Jumlah token yang diperoleh labelnya melalui pengecekan imbuhan
13.973
(10,61%)
Jumlah token yang ambigu 26.872
(20, 40%) Jumlah token yang
diperoleh labelnya melalui pengecekan pola
46.368
(35,2%)
Jumlah token yang berhasil diidentifikasi
128.851 (97,82%)
Jumlah token yang tidak berhasil diidentifikasi 2.868 (2,18%) Waktu pemrosesan keseluruhan 2:25:39
Rata-rata waktu pemrosesan per file
0:06:56
Rata-rata waktu pemrosesan per token
0:0:0.07 detik
PEMBAHASAN
Persentase pengecekan tagset dan imbuhan Jumlah token yang dikenali melalui pengecekan tagset hanya 68,34%. Hal ini dikarenakan tagset tidak mengandung data kata berulang, nama, singkatan, istilah, dan kata seru.
Persentase token yang ambigu
Token dianggap ambigu apabila memiliki lebih dari satu label. Token yang ambigu terdiri dari:
- Token yang memperoleh lebih dari satu label pada pengecekan tagset. Contoh:
yang à P/Prep
- Token yang memperoleh label yang berbeda antara hasil pengecekan tagset
dengan hasil pengecekan imbuhan. Contoh: beruang à N (dari tagset)/V (dari imbuhan)
Semua kemungkinan di atas menyebabkan persentase token ambigu yang dihasilkan cukup besar, 20,40%.
Persentase pengecekan pola
10
- Pola sudah pernah dipelajari pada waktu proses pembelajaran
- Minimal ada satu token lain di sekitar token yang bermasalah yang sudah memiliki label yang fix.
Dengan persyaratan di atas, token yang berhas il dikenali melalui pengecekan pola adalah 35,2 %.
Persentase token yang berhasil dikenali Persentase token yang berhasil dikenali dari keseluruhan proses pengecekan adalah 97,82%.
Sebanyak 68,34% dari keseluruhan token diperoleh labelnya melalui pengecekan pada tagset.
Sebanyak 10,61% dari keseluruhan token diperoleh labelnya melalui metode pengenalan imbuhan.
Perhitungan persentase token yang berhasil dikenali diperoleh dari jumlah token yang sudah tidak ambigu dibagi jumlah token keseluruhan yang dicek.
Persentase token yang tidak berhasil diidentifikasi
Persentase token yang tidak dikenali adalah 2,18%. Persentase ini disebabkan hal-hal berikut:
- Ukuran tagset yang kecil. Dibandingkan dengan Kamus Besar Bahasa Indonesia yang terdiri dari 62.100 kata dasar, tagset yang digunakan sistem yang terdiri dari 29.357 kata termasuk kata berimbuhan tentu saja sangat kecil. Hal ini menyebabkan banyaknya kata yang tidak terdaftar pada tagset.
- Dokumen pelatihan dan pengecekan melibatkan dokumen cerpen, tutorial, dan novel. Beberapa dokumen mengandung istilah-istilah komputer yang berasal dari bahasa inggris dan juga bahasa percakapan yang tidak baku. Hal ini tentu saja sangat mempengaruhi tingkat pengenalan label token.
- Pada sistem Unsupervised Learning Part-of-Speech Tagging Eric Brill (1995), semua kata terlebih dahulu diberikan label berdasarkan label yang terbanyak. Pada
sistem ini, untuk menghindari kesalahan pada waktu pengecekan pola, semua kata dianggap tidak diketahui labelnya terlebih dahulu.
Persentase token yang berhasil diidentifikasi secara benar
Pengecekan secara manual dilakukan terhadap dokumen yang diuji untuk menghitung persentase token yang berhasil diidentifikasi secara benar. Hasil pengecekan menunjukkan bahwa dari 431 token, 11 token tidak berhasil diidentifikasi. Sementara jumlah token yang berhasil diidentifikasi secara benar sebanyak 359 token atau 85,85%. Pengecekan dilakukan dengan membandingkan label hasil proses sistem dengan Kamus Besar Bahasa Indonesia.
Dari hasil pengecekan secara manual, dapat dihitung bahwa sebanyak 11,6% token dilabeli secara salah oleh sistem. Angka ini berasal dari beberapa kemungkinan:
- Data tagset yang kurang akurat. Sehingga pelabelan berdasarkan pencarian pada tagset akan menghasilkan label yang salah.
- Beberapa pola kata yang jarang digunakan akan memiliki frekuensi kemunculan yang kecil. Sehingga sistem akan lebih memilih pola kata lain yang memiliki frekuensi kemunculan lebih besar walaupun pola kata tersebut salah .
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini mengimplementasikan metode Unsupervised Learning Rule-based Part-of-Speech Tagging untuk pelabelan kata dalam bahasa Indonesia.
Penelitian ini menambahkan metode pengecekan jenis imbuhan pada metode
Unsupervised Learning Rule-based Part-of-Speech Tagging sehingga berhasil mengenali 97,85% token. Persentase token yang berhasil dikenali secara benar adalah 85,85%.
11
Saran
Tagset yang digunakan pada penelitian hanya memuat sebagian kecil dari khazanah kata dalam bahasa Indonesia. Sistem akan berjalan lebih baik bila menggunakan tagset yang lebih besar.
Algoritma yang lebih baik dalam proses pencarian data maupun pemrosesan teks dapat mempercepat waktu eksekusi sistem.
Tingkat keberhasilan pengenalan label kata dapat ditingkatkan dengan menggunakan pengenalan frase berdasarkan aturan yang berlaku pada bahasa Indonesia.
DAFTAR PUSTAKA
Brill E. 1992. A simple rule -based part of speech tagger. In Proceedings of the Third Annual Conference on Applied Natural Language Processing. Itali: Trento.
Brill E. 1995. Transformation-based error-driven learning and natural language processing: A case study in Part-of-Speech Tagging. Computational Linguistic (no. 21) 4:543-566.
Cutting D, Kupiec J, Pedersen J, dan Sibun P. 1992. A Practical Part -of-Speech Tagger. In Proceedings of the Third Annual Conference on Applied Natural Language Processing. Itali: Trento. [Depdiknas] Departemen Pendidikan Nasional.
2003. Kamus Besar Bahasa Indonesia.
Ed ke-3. Jakarta: Balai Pustaka.
Jones KS. 1994. Natural Language Processing: she need something old and something new (maybe something borrowed and something blue, too). In Proceeding of Association for Computational Linguistic. England: Cambridge. James A. 1995. Natural Language
Understanding. CA: Benjamin Cummings.
Keraf G. 1980. Tatabahasa Indonesia. Flores: Nusa Indah.
Krulee G. 1991. Computer Processing of Natural Language. USA: Prentice-Hall.
Porter MF. 1980. An Algorithm for Suffix Stripping. Program 14 (no. 3) 7:130-137
.
Rabiner LR. 1989. A Tutorial on hidden Markov Models and Selected Application in Speech Recognition. In
Proceeding of the IEEE.
Vasilakopoulos A. 2003. Improved unknown word guessing by decision tree induction for POS Tagging with TBL. In
Proceeding of CLUK 2003. Edinburg. Weischedel R, Meteer M, Schwartz R,
Ramshaw L, dan Palmucci J. 1993. Coping with Ambiguity and Unknown Words through Probabilistic Models.
Lampiran 3 Proses rule-based tagging
Pengubahan dokumen menjadi
Plain Teks