ABSTRAK
IIN LESMANAWATI. Pengklasifikasian Nilai Mutu Ujian Komprehensif Mahasiswa Departemen Statistika IPB Menggunakan Semi Naive Bayesian Classifier. Di bawah bimbingan BAGUS SARTONO dan FARIT MOCHAMAD AFENDI.
Proses klasifikasi nilai mutu Ujian Komprehensif merupakan salah satu upaya untuk mengetahui potensi kelulusan mahasiswa dalam ujian komprehensif. Informasi mengenai potensi kelulusan mahasiswa dalam Ujian Komprehensif diharapkan dapat digunakan untuk meminimalisasi kegagalan mahasiswa dalam Ujian Komprehensif. Pengklasifikasian nilai mutu Ujian Komprehensif dapat dilakukan dengan menggunakan Semi Naive Bayesian Classifier. Metode semi naive Bayesian classifier yang digunakan adalah deleting attributes: Backwards Sequential Elimination (BSE) dan Forwards Sequential Selection (FSS); joining attributes: Backwards Sequential Elimination and Joining (BSEJ); danTree Augmented Naive Bayes(TAN). Hasil klasifikasi menggunakan semi naive Bayesian classifier ini dibandingkan dengan hasil klasifikasi menggunakan Simple Naive Bayesian classifier(SNB).
PENGKLASIFIKASIAN NILAI MUTU UJIAN KOMPREHENSIF
MAHASISWA DEPARTEMEN STATISTIKA IPB MENGGUNAKAN
SEMI NAIVE BAYESIAN CLASSIFIER
IIN LESMANAWATI
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
IIN LESMANAWATI. Pengklasifikasian Nilai Mutu Ujian Komprehensif Mahasiswa Departemen Statistika IPB Menggunakan Semi Naive Bayesian Classifier. Di bawah bimbingan BAGUS SARTONO dan FARIT MOCHAMAD AFENDI.
Proses klasifikasi nilai mutu Ujian Komprehensif merupakan salah satu upaya untuk mengetahui potensi kelulusan mahasiswa dalam ujian komprehensif. Informasi mengenai potensi kelulusan mahasiswa dalam Ujian Komprehensif diharapkan dapat digunakan untuk meminimalisasi kegagalan mahasiswa dalam Ujian Komprehensif. Pengklasifikasian nilai mutu Ujian Komprehensif dapat dilakukan dengan menggunakan Semi Naive Bayesian Classifier. Metode semi naive Bayesian classifier yang digunakan adalah deleting attributes: Backwards Sequential Elimination (BSE) dan Forwards Sequential Selection (FSS); joining attributes: Backwards Sequential Elimination and Joining (BSEJ); danTree Augmented Naive Bayes(TAN). Hasil klasifikasi menggunakan semi naive Bayesian classifier ini dibandingkan dengan hasil klasifikasi menggunakan Simple Naive Bayesian classifier(SNB).
PENGKLASIFIKASIAN NILAI MUTU UJIAN KOMPREHENSIF
MAHASISWA DEPARTEMEN STATISTIKA IPB MENGGUNAKAN
SEMI NAIVE BAYESIAN CLASSIFIER
IIN LESMANAWATI
Skripsi
sebagai salah satu syarat memperoleh gelar Sarjana Sains
pada Departemen Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Pengklasifikasian Nilai Mutu Ujian Komprehensif Mahasiswa
Departemen Statistika IPB menggunakan
Semi Naive Bayesian
Classifier
Nama
: Iin Lesmanawati
NIM
: G14104058
Menyetujui :
Pembimbing I,
Bagus Sartono, M.Si
NIP. 132311923
Pembimbing II,
Farit Mochamad Afendi, M.Si
NIP. 132314007
Mengetahui :
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Drh. Hasim, DEA
NIP. 131578806
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 4 Maret 1986 sebagai anak kedua dari lima bersaudara, anak dari pasangan Encep Rachmat dan Yayah Sadiah.
Penulis menyelesaikan pendidikan dasar di SD Negeri Sukamaju 1 pada tahun 1998 dan menyelesaikan pendidikan menengah lanjutan pertama di SLTP Negeri 3 Depok pada tahun 2001. Pada tahun 2004 penulis menyelesaikan pendidikan menengah lanjutan atas di SMU Negeri 1 Depok dan pada tahun yang sama pula diterima di Departemen Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor melalui Seleksi Penerimaan Mahasiswa Baru (SPMB).
KATA PENGANTAR
Alhamdulillahirabbil’alamin, segala puji dan syukur dipanjatkan kehadirat Allah SWT atas segala hidayah, nikmat, dan karunia-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini yang berjudul “Pengklasifikasian Nilai Mutu Ujian Komprehensif Mahasiswa Departemen Statistika IPB Menggunakan Semi Naive Bayesian Classifier”. Shalawat serta salam semoga selalu tercurahkan kepada Rasulullah SAW, keluarga, para sahabat, dan umatnya hingga akhir zaman.
Selesainya karya ilmiah ini tidak lepas dari bantuan dan doa dari orang-orang yang dengan tidak bosan-bosannya memberikan dukungan kepada penulis. Oleh karena itu, pada kesempatan ini penulis ingin menyampaikan terima kasih yang sebesar-besarnya kepada :
1. Bapak Bagus Sartono dan Bapak Farit Mochamad Afendi yang telah banyak memberikan bimbingan, saran, serta kritik sehingga karya ilmiah ini dapat diselesaikan.
2. Orang tua, kakak serta adik-adikku yang tersayang yang selalu setia mendoakan dan memberikan semangat.
3. Segenap staf pengajar di Departemen Statistika FMIPA IPB yang telah memberikan pengajaran terbaik sehingga penulis dapat menyelesaikan studi dan karya ilmiah ini. 4. Seluruh staf pegawai Departemen Statistika FMIPA IPB : Bu Markonah, Bu Sulis, Bu
Dedeh, Bang Sudin, Pak Ian, Bu Aat, Mang Dur, dan Mang Herman yang telah banyak membantu penulis selama menjalankan studi dan menyelesaikan karya ilmiah ini.
5. Teman-teman seperjuangan Statistika 41, atas segala kerjasama dan kebersamaan yang telah diberikan selama empat tahun ini. Terutama untuk Vinny, Leisha, dan Renita yang tidak bosan-bosan memberikan tumpangan kost-nya selama ini.
6. Bi Teti yang telah memberi motivasi bagi penulis agar terus menjadi lebih baik. Ate, Thanks for being my second Mom!
7. Semua pihak yang telah memberikan dukungan kepada penulis yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa masih banyak kekurangan dalam karya ilmiah ini. Namun, penulis berharap semoga karya ilmiah ini dapat bermanfaat.
Depok, Agustus 2008
DAFTAR ISI
Halaman
DAFTAR TABEL... vii
DAFTAR GAMBAR ... vii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN... 1
Latar Belakang ... 1
Tujuan ... 1
TINJAUAN PUSTAKA... 1
Ujian Komprehensif... 1
Simple Naive Bayesian... 1
Kaidah peluang Bayes ... 1
Asumsi naive... 2
Laplace adjustment... 2
Semi Naive Bayesian ... 2
Deleting attributes ... 2
Backward Sequential Elimination and Joining (BSEJ) ... 3
Tree Augmented Naive Bayesian (TAN) ... 4
BAHAN DAN METODE ... 4
Bahan ... 4
Metode ... 5
HASIL DAN PEMBAHASAN ... 5
Deskripsi Data Nilai Mahasiswa ... 5
Klasifikasi MenggunakanSimple Naive Bayesian... 6
Klasifikasi Menggunakan Metode Semi Naive Bayesian... 7
Backwards Sequential Elimination (BSE)... 7
Forward Sequential Selection (FSS) ... 7
Backward Sequential Elimination and Joining (BSEJ) ... 8
Tree Augmented Naive Bayesian (TAN) ... 8
Perbandingan Metode SNB, BSE, FSS, BSEJ, dan TAN ... 9
Penerapan Metode Semi Naive Bayesian Menggunakan Indeks Asosiasi... 9
Tingkat Kesalahan Klasifikasi dengan Mempertimbangkan Jenis Kesalahan yang Dihasilkan ... 11
KESIMPULAN DAN SARAN ... 13
Kesimpulan ... 13
Saran ... 13
DAFTAR PUSTAKA ... 13
DAFTAR TABEL
Halaman
1. Daftar Kategori dari Peubah Penjelas... 6
2. Peluang Prior Ujian Komprehensif ... 6
3. Ketepatan Klasifikasi Data In-Sample SNB... 7
4. Ketepatan Klasifikasi Data Out-Sample SNB ... 7
5. Ketepatan Klasifikasi Data In-Sample BSE ... 7
6. Ketepatan Klasifikasi Data Out-Sample BSE... 7
7. Ketepatan Klasifikasi Data In-Sample FSS ... 8
8. Ketepatan Klasifikasi Data Out-Sample FSS ... 8
9. Ketepatan Klasifikasi Data In-Sample BSEJ... 8
10. Ketepatan Klasifikasi Data Out-Sample BSEJ... 8
11. Ketepatan Klasifikasi Data In-Sample TAN ... 9
12. Ketepatan Klasifikasi Data Out-Sample TAN... 9
13. Perbandingan Tingkat Kesalahan Klasifikasi SNB dan Semi Naive Bayesian... 9
14. Tingkat Kesalahan Klasifikasi Semi Naive Bayesian dengan Indeks Asosiasi... 10
15. Ketepatan Klasifikasi Data In-Sample Deleting attributes... 10
16. Ketepatan Klasifikasi Data Out-Sample Deleting attributes... 10
17. Ketepatan Klasifikasi Data In-Sample Joining attributes... 11
18. Ketepatan Klasifikasi Data Out-Sample Joining attributes... 11
19. Perbandingan Tingkat Kesalahan Klasifikasi SNB dan Semi Naive Bayesian dengan Bobot Pengali... 12
20. Tingkat Kesalahan KlasifikasiSemi Naive Bayesian menggunakan Indeks Asosiasi dengan Bobot Pengali ... 12
21. Koefisien Korelasi antara Prediksi dan Aktual dari SNB dan Semi Naive Bayesian... 12
22. Koefisien Korelasi antara Prediksi dan Aktual dari Semi Naive Bayesian Menggunakan Indeks Asosiasi... 12
DAFTAR GAMBAR
Halaman 1. Struktur Simple Naive Bayesian... 4
2. Struktur Augmented Naive Bayes... 4
DAFTAR LAMPIRAN
Halaman
1. Koefisien Korelasi antar Peubah Penjelas ... 14
2. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Metode Statistika I... 15
3. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Metode Statistika II ... 15
4. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Teori Statistika I ... 15
5. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Teori Statistika II ... 15
6. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Metode Penarikan Contoh ... 16
7. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Perancangan Percobaan ... 16
PENDAHULUAN
Latar Belakang
Ujian Komprehensif merupakan salah satu mata kuliah wajib bagi mahasiswa tingkat akhir Departemen Statistika Institut Pertanian Bogor. Kegagalan mahasiswa dalam menghadapi Ujian Komprehensif dapat menghambat proses kelulusan mahasiswa, sehingga mahasiswa yang bersangkutan akan membutuhkan waktu yang lebih lama untuk menyelesaikan studinya di Departemen Statistika. Oleh karena itu, Departemen Statistika IPB perlu mengetahui potensi kelulusan mahasiswa agar dapat melakukan tindakan-tindakan yang dapat meminimalisasi kegagalan mahasiswa dalam Ujian Komprehensif.
Salah satu cara yang dapat ditempuh untuk mengetahui potensi kelulusan mahasiswa adalah dengan melakukan proses klasifikasi nilai mutu Ujian Komprehensif mahasiswa. Melalui pengklasifikasian ini, nilai mutu Ujian Komprehensif yang akan diperoleh mahasiswa menjadi dapat diprediksi. Simple naive Bayesian merupakan salah satu algoritma pengklasifikasian objek yang berdasarkan pada penerapan Teorema Bayes dengan menggunakan asumsi bahwa peubah-peubah penjelas yang digunakan sebagai dasar pengklasifikasian bersifat saling bebas.
Pada penerapannya, asumsi kebebasan antar-peubah penjelas ini sering tidak terpenuhi, sehingga berkembanglah suatu metode pengklasifikasian semi naive Bayesian yang dibangun untuk mengurangi pengaruh ketakbebasan antar peubah penjelas, yang diharapkan dapat meningkatkan akurasi dugaan (ketepatan klasifikasi) dari simple naive Bayesian classifier.
Tujuan
Tujuan yang ingin dicapai dalam penelitian ini antara lain :
1. Memperkenalkan metode Semi Naive Bayesian sebagai salah satu metode pengklasifikasian objek.
2. Membandingkan metode Simple Naive Bayesian dan Semi Naive Bayesian (deleting attributes, joining attributes, dan tree augmented naive Bayesian) dalam kemampuan mengklasifikasikan nilai mutu Ujian Komprehensif mahasiswa Departemen Statistika IPB.
TINJAUAN PUSTAKA
Ujian Komprehensif
Ujian Komprehensif merupakan ujian yang diadakan secara tertulis untuk mengukur pemahaman mahasiswa mengenai keterkaitan antar berbagai mata kuliah pokok bidang statistika yang mencakup Metode Statistika I dan II, Teori Statistika I dan II, Perancangan Percobaan, serta Metode Penarikan Contoh (Dit. AJMP-IPB, 2004).
Simple Naive Bayesian (SNB)
Simple naive Bayesian classifier merupakan salah satu metode pengklasifikasi berpeluang sederhana yang berdasarkan pada penerapan Teorema Bayes dengan asumsi antar peubah penjelas saling bebas (Wikipedia, 2008).
Kaidah Peluang Bayes
Teorema Bayes yang dibangun oleh Thomas Bayes, seorang matematikawan dan teologiawan Inggris abad 18, dipublikasikan untuk pertama kalinya pada tahun 1763.
Dalil Bayes menyatakan bahwa jika U suatu ruang contoh dan {A1, ..., An} merupakan sekatan U dengan P(Ai)≠ 0, i = 1,..., n; Ai∩Aj = Ø untuk i≠j, danB suatu kejadian pada U dengan P(B) ≠ 0, maka secara matematis, kaidah peluang Bayes dapat dituliskan sebagai berikut: n
i i i
i i i i A B P A P A P A B P B P B A P B A P 1 ) | ( ) ( ) ( ) | ( ) ( ) ( ) | (
(Nasoetion & Rambe, 1984).
Pada penelitian ini, kejadian Ai merupakan kejadian seorang mahasiswa Statistika IPB masuk dalam kelas ke-i (kejadian mahasiswa Statistika IPB mendapatkan nilai mutu Ujian Komprehensif A, B, C, atau D), sedangkan B adalah karakteristik mahasiswa tersebut, yang dalam penelitian ini merupakan karakteristik multi-variables. Misalnya, kejadian B adalah kejadian seorang mahasiswa Statistika IPB mendapatkan nilai mutu Metode Statistika I = A, nilai mutu Metode Statistika II = A, nilai mutu Teori Statistika I = A, dan seterusnya.
Jika nilai P(Ai | B) dapat diperoleh untuk semua i = 1, 2, …, n, maka mahasiswa tersebut akan dikategorikan masuk kelas ke-k (1 ≤ k ≤ n) jika peluang masuk kelas ke-k adalah yang paling besar, atau
Hal tersebut dapat terjadi karena memaksimumkan P(Ai|B) sama dengan memaksimumkan P(B|Ai) P(Ai).
Nilai P(Ai) dapat diduga menggunakan peluang priornya, yaitu frekuensi relatifnya. Dalam penelitian ini, P(Ai) adalah proporsi mahasiswa Departemen Statistika IPB pada setiap kategori nilai mutu Ujian Komprehensif. Sedangkan P(B|Ai) dapat diketahui dengan mencari frekuensi relatif kejadian B dengan syarat Ai (Sartono, 2007).
Asumsi naive
Telah disebutkan bahwa B adalah kejadian multi peubah. Kalau diandaikan B terdiri atas p buah peubah yaitu B1, B2, …, Bp maka
P(B | Ai) = P(B1, B2, …, Bp | Ai). Pada tahap inilah asumsi yang naif digunakan, yaitu antar kejadian atau peubah Bi memiliki sifat saling bebas. Asumsi ini berimplikasi pada hasil bahwa
P(B | Ai) = P(B1, B2, …, Bp | Ai)
= P(B1 | Ai) P(B2 | Ai) … P(Bp | Ai) (Sartono, 2007).
Pada kasus seluruh Bi diskret dan memiliki mi buah macam nilai, mendapatkan P(B1 | Ai) dapat dilakukan dengan cara mengisolasi data yang memiliki kelas Ai. Kemudian
) ( ) ( ) | ( i i i i i i A n A b n A b B
P
P(Bi=bi | Ai = ai) dapat bernilai 0, sehingga peluang objek yang memliki peubah Bi=bi masuk ke kelas ai akan selalu bernilai 0. Hal ini akan berakibat kurang baik pada hasil klasifikasi. Akan lebih baik jika P(Bi=bi | Ai = ai) ini diberi nilai yang sangat kecil.
Laplace adjusment: Teknik untuk menghindari nilai peluang sebesar 0 atau 1, sering disarankan menggunakan nilai termuluskan i i i i i i i m A n A b n A b B P ) ( 1 ) ( ) | (
Semi Naive Bayesian
Metode Semi Naive Bayesian secara garis besar dapat dibagi dalam dua kelompok. Kelompok pertama membangun simple naive Bayesian dengan menggunakan sekumpulan peubah penjelas baru yang dapat dihasilkan dari proses deleting attributes dan joining attributes. Kelompok kedua membangun simple naive Bayesian dengan membuat struktur garis penghubung secara jelas di antara peubah-peubah penjelas yang menunjukkan hubungan ketidakbebasan
(saling mempengaruhi) antar peubah penjelas (Zheng & Webb, 2005).
Pada penelitian ini, metode semi naive Bayesian yang digunakan adalah deleting attributes, joining attributes, dan tree augmented naive Bayesian.
Deleting Attributes
Zheng & Webb (2005) menjelaskan bahwa ada dua pendekatan yang dapat digunakan dalam deleting attributes, yaitu Backwards Sequential Elimination (BSE) dan Forward Sequential Selection (FSS).
Baik BSE maupun FSS memiliki tujuan yang sama, yaitu memilih/menentukan himpunan bagian dari peubah penjelas yang dapat menyebabkan terjadinya peningkatan akurasi terbesar dari simple naive Bayesian.
BSE diawali dengan menggunakan keseluruhan set peubah penjelas, kemudian dilakukan proses eliminasi peubah, yang proses pengeliminasian peubah tersebut dapat menyebabkan terjadinya peningkatan akurasi terbesar. Sedangkan FSS menggunakan cara yang berlawanan dengan BSE, yaitu diawali dengan set peubah penjelas yang kosong, kemudian dilakukan proses penambahan peubah yang dapat menyebabkan terjadinya peningkatan akurasi paling besar. Baik proses eliminasi maupun penambahan peubah terus dilakukan hingga tidak ada lagi peningkatan akurasi yang dapat terjadi.
Himpunan bagian dari peubah-peubah yang terpilih diasumsikan saling bebas dan dinotasikan sebagai Atts = {Bg1, ..., Bgh}. Kaidah klasifikasi pada BSE dan FSS dilakukan dengan memilih
h g gj j i
i i a a b P a P 1 ) | ( ) ( max arg
Algoritma BSE adalah sebagai berikut:
1. Diawali dengan proses klasifikasi simple naive Bayesian dengan menggunakan seluruh peubah penjelas.
( P0 = p adalah banyaknya peubah penjelas mula-mula ; P = P0 ; n = p-1; i = 1).
2. Hitung akurasi dugaan klasifikasi yang dihasilkan, notasikan sebagai C0.
3. Tentukan kombinasi n peubah penjelas yang mungkin terbentuk dari p peubah penjelas yang tersedia dengan cara mengeliminasi sebuah peubah penjelas. 4. Lakukan proses klasifikasi simple naive
ketiga serta hitung akurasi dugaan klasifikasinya.
5. Tentukan kombinasi peubah penjelas yang menghasilkan tingkat akurasi dugaan terbesar. Notasikan tingkat akurasi dugaan klasifikasi terbesar tersebut sebagai Ci. 6. Bandingkan Cidengan C0:
Jika Ci ≤ C0, proses eliminasi peubah berhenti/selesai.
Jika Ci> C0, kembali ke langkah tiga untuk melanjutkan proses eliminasi peubah dari n peubah penjelas yang diperoleh pada langkah lima dengan menetapkan C0 = Ci ; n = n-1; P = P-1; i = i +1.
7. Proses eliminasi peubah penjelas berhenti jika semua peubah penjelas sudah keluar/ sudah dieliminasi.
Algoritma FSS adalah sebagai berikut:
1. Diawali dengan set peubah penjelas kosong.
(P0 = 0 adalah banyaknya peubah penjelas mula-mula; n = P0+2; i = 1 ).
2. Tambahkan satu peubah penjelas dan lakukan proses klasifikasi simple naive Bayesian dengan menggunakan satu peubah penjelas untuk setiap peubah penjelas yang tersedia.
3. Tentukan peubah penjelas yang menghasilkan tingkat akurasi dugaan terbesar. Notasikan tingkat akurasi dugaan terbesar tersebut sebagai C0.
4. Tambahkan kembali satu peubah penjelas sebagai dasar klasifikasi, lalu tentukan kombinasi n peubah penjelas yang mungkin terbentuk dari p peubah penjelas yang tersedia. Kombinasi harus mengandung peubah penjelas yang diperoleh pada langkah tiga.
5. Lakukan kembali proses klasifikasi simple naive Bayesian untuk setiap kombinasi peubah penjelas yang telah terbentuk pada langkah empat serta hitung akurasi dugaan klasifikasinya.
6. Tentukan kombinasi peubah penjelas pada langkah empat yang menghasilkan tingkat akurasi dugaan terbesar. Notasikan tingkat akurasi dugaan terbesar tersebut sebagai Ci. 7. Bandingkan Cidengan C0 :
Jika Ci ≤ C0, proses penambahan peubah berhenti/selesai.
Jika Ci > C0, kembali ke langkah empat untuk melanjutkan proses penambahan peubah dari n peubah penjelas yang diperoleh pada langkah enam dengan menetapkan C0 = Ci ; n = n+1; i = i+1.
8. Proses penambahan peubah penjelas berhenti jika semua peubah penjelas yang tersedia sudah masuk/sudah ditambahkan.
Backward Sequential Elimination and Joining (BSEJ)
Menciptakan susunan peubah penjelas baru dengan cara menggabungkan beberapa peubah penjelas yang tidak saling bebas merupakan pendekatan lain untuk memenuhi asumsi kebebasan antar peubah penjelas.
Pada dasarnya, BSEJ memiliki tahapan yang mirip dengan BSE, yaitu mengeliminasi peubah penjelas secara bertahap, dimana proses pengeliminasian peubah penjelas tersebut dapat menyebabkan terjadinya peningkatan akurasi prediksi klasifikasi paling besar. Adapun yang membedakannya dengan BSE adalah pada proses eliminasi peubah penjelas. Pada BSEJ, eliminasi peubah tidak hanya dilakukan dengan menghilangkan peubah penjelas, melainkan juga dengan menggabungkan beberapa peubah penjelas menjadi satu peubah penjelas yang baru. Proses penggabungan/penghapusan peubah ini berhenti jika sudah tidak terjadi lagi peningkatan akurasi.
Hasil dari penggabungan peubah yang baru dinotasikan sebagai JoinAtts = {Joing1, ..., Joingh}. Sedangkan peubah awal yang belum digabung atau dieliminasi dinotasikan sebagai {Bl1, . . . ., Blq}. Klasifikasi pada BSEJ dilakukan dengan memilih q l l
r r i
h g
g
j j i
i i a a b P a join P a P 1 1 ) | ( ) | ( ) ( max arg
(Zheng & Webb, 2005).
Algoritma BSEJ adalah sebagai berikut: 1. Diawali dengan proses klasifikasi simple
naive Bayesian dengan menggunakan seluruh peubah penjelas.
( P0 = p adalah banyaknya peubah penjelas mula-mula ; P = P0 ; n = p-1; i = 1).
2. Hitung akurasi dugaan klasifikasi yang dihasilkan, notasikan sebagai C0.
3. Tentukan susunan/kombinasi n peubah penjelas dari p peubah penjelas yang tersedia dengan cara mengeliminasi sebuah peubah penjelas atau menggabungkan dua/ lebih peubah penjelas menjadi sebuah peubah penjelas baru.
5. Tentukan kombinasi peubah penjelas yang menghasilkan tingkat akurasi dugaan terbesar. Notasikan tingkat akurasi dugaan klasifikasi terbesar tersebut sebagai Ci. 6. Bandingkan Cidengan C0 :
Jika Ci ≤ C0, proses eliminasi maupun penggabungan peubah berhenti/selesai. Jika Ci > C0, kembali ke langkah tiga untuk melanjutkan proses eliminasi maupun penggabungan peubah dari n peubah penjelas yang diperoleh pada langkah lima dengan menetapkan C0 = Ci ;n = n-1 ; P = P-1 ; i = i +1.
7. Proses eliminasi atau penggabungan peubah penjelas berhenti jika semua peubah penjelas sudah keluar/sudah dieliminasi.
Tree Augmented Naive Bayesian (TAN)
Berbeda dengan BSE, FSS, dan BSEJ, yang membangun simple naive Bayesian dengan menggunakan kumpulan peubah baru hasil dari proses deleting atau joining, TAN merupakan suatu teknik pendekatan untuk mengatasi keterbatasan simple naive Bayesian dengan cara mengubah struktur simple naive Bayesian untuk menggambarkan secara jelas dari adanya ketidakbebasan (saling mempengaruhi) antar peubah penjelas (Zheng & Webb, 2005).
Model TAN merupakan bagian dari keluarga Bayesian networks yang memiliki syarat bahwa peubah kelas tidak memiliki parents dan setiap peubah penjelas memiliki parents yang terdiri dari peubah kelas dan paling banyak satu peubah penjelas lainnya (Cerquides & Mantaras, 2003).
Simple naive Bayesian merupakan bentuk yang paling sederhana dari Bayesian network.
Gambar 1: Struktur simple naive Bayesian
Gambar 2 : Struktur augmented naive Bayes
Gambar 1 merupakan struktur Bayesian Networks dari simple naive Bayesian. Dari Gambar 1 terlihat bahwa antar peubah penjelas tidak terdapat hubungan saling mempengaruhi.
Sedangkan dari Gambar 2 dapat dilihat bahwa setiap peubah penjelas dipengaruhi oleh paling banyak satu selain dari peubah kelas. Parents dari setiap peubah penjelas Bi dinotasikan sebagai π(Bi). Klasifikasi pada TAN dilakukan dengan memilih
( | , ( ))
) ( max arg
1
p
j j i j
i i
a
b a b P a
P
Algoritma TAN adalah sebagai berikut: 1. Diawali dengan proses klasifikasi simple
naive Bayesian dengan menggunakan seluruh peubah penjelas.
( P0= p adalah banyaknya peubah penjelas mula-mula dan P1 = 0 adalah banyaknya peubah penjelas yang memiliki parents selain peubah kelas ; i = 1).
2. Hitung akurasi dugaan klasifikasi yang dihasilkan, notasikan sebagai C0.
3. Tentukan semua struktur TAN (terdiri dari p peubah penjelas) yang mungkin terbentuk jika banyaknya peubah penjelas yang memiliki parents selain peubah kelas adalah P1+1.
4. Lakukan proses klasifikasi simple naive Bayesian untuk setiap struktur TAN yang telah terbentuk pada langkah ketiga serta hitung akurasi dugaan klasifikasinya. 5. Tentukan struktur TAN yang menghasilkan
tingkat akurasi dugaan terbesar. Notasikan tingkat akurasi dugaan klasifikasi terbesar tersebut sebagai Ci.
6. Bandingkan Cidengan C0 :
Jika Ci ≤ C0, proses penentuan struktur TAN berhenti/selesai.
Jika Ci> C0, kembali ke langkah tiga untuk melakukan proses penentuan struktur TAN baru (melanjutkan dari struktur TAN yang diperoleh pada langkah lima) dengan menetapkan C0 = Ci ; P1 = P1+1 ; i = i +1. 7. Proses penentuan struktur TAN berhenti
jika banyaknya peubah penjelas maksimum yang bisa memiliki parents sudah terpenuhi.
BAHAN DAN METODE
Bahan
Bahan penelitian yang digunakan adalah data nilai 353 mahasiswa Departemen Statistika IPB angkatan 1998-2004, yang meliputi nilai mutu Ujian Komprehensif dan
Bp
A
B2
B1
Bp
B1 B2
nilai mutu beberapa mata kuliah pokok bidang Statistika, yaitu Metode Statistika I, Metode Statistika II, Teori Statistika I, Teori Statistika II, Perancangan Percobaan, dan Metode Penarikan Contoh.
Metode
Dalam penelitian ini, selain menggunakan simple naive Bayesian, juga akan dicobakan metode semi naive Bayesian menggunakan algoritma (BSE, FSS, BSEJ, dan TAN) dan indeks asosiasi. Langkah-langkah metode penelitian adalah sebagai berikut :
1. Melakukan proses cleaning data untuk menyamakan kode-kode mata kuliah yang digunakan.
2. Membagi data ke dalam dua bagian. Dari total data nilai 353 mahasiswa, sebanyak 282 data (80%) dijadikan data in-sample untuk membangun model dan sisanya sebanyak 71 data (20%) dijadikan data out-sample untuk validasi.
3. Membuat model klasifikasi Simple Naive Bayesian dan menghitung akurasi dugaan klasifikasi in-sample dan out-sample. 4. Membuat model klasifikasi Semi Naive
Bayesian dengan menggunakan algoritma BSE, FSS, BSEJ, dan TAN.
5. Membuat model klasifikasi Semi Naive Bayesian dengan menggunakan indeks asosiasi.
6. Menghitung tingkat kesalahan klasifikasi dengan mempertimbangkan jenis kesalahan yang terjadi. Jenis kesalahan prediksi yang jauh dari aktual diberi bobot/koefisien pengali yang lebih besar. Selain itu, dihitung juga korelasi antara prediksi dengan aktual untuk setiap metode klasifikasi semi naive Bayesian dan SNB. 7. Membandingkan akurasi dugaan klasifikasi
Semi Naive Bayesian, baik yang menggunakan algoritma maupun indeks asosiasi, terhadap akurasi dugaan klasifikasi simple naive Bayesian.
Perangkat lunak yang digunakan dalam penelitian ini adalah Microsoft Excel, SPSS 13.0 for Windows, dan MINITAB 14.
HASIL DAN PEMBAHASAN
Deskripsi Data Nilai Mahasiswa
Pengklasifikasian nilai mutu Ujian Komprehensif mahasiswa Departemen Statistika IPB dilakukan dengan menggunakan data nilai dari 353 mahasiswa Departemen Statistika IPB angkatan 1998-2004. Data nilai
yang digunakan meliputi nilai mutu dari tujuh mata kuliah, yaitu Ujian Komprehensif, Metode Statistika I Metode Statistika II, Teori Statistika I, Teori Statistika II, Perancangan Percobaan, serta Metode Penarikan Contoh. Nilai mutu Ujian Komprehensif merupakan peubah respon, sedangkan nilai mutu dari keenam mata kuliah lainnya merupakan peubah penjelas. Peubah respon dan peubah penjelas yang digunakan dalam penelitian ini masing-masing bersifat kategorik.
Daftar peubah penjelas dan kategori dari masing-masing peubah penjelas disajikan pada Tabel 1. Penentuan kategori dari setiap peubah penjelas mengikuti kaidah bahwa kategori dari setiap peubah penjelas yang banyak individunya tidak mencapai 5% dari total seluruh individu, akan digabung dengan kategori terdekat dari peubah penjelas yang sama.
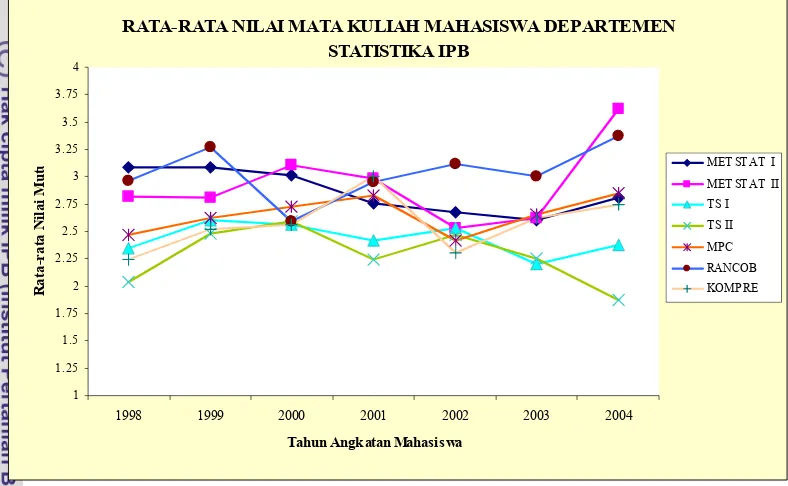
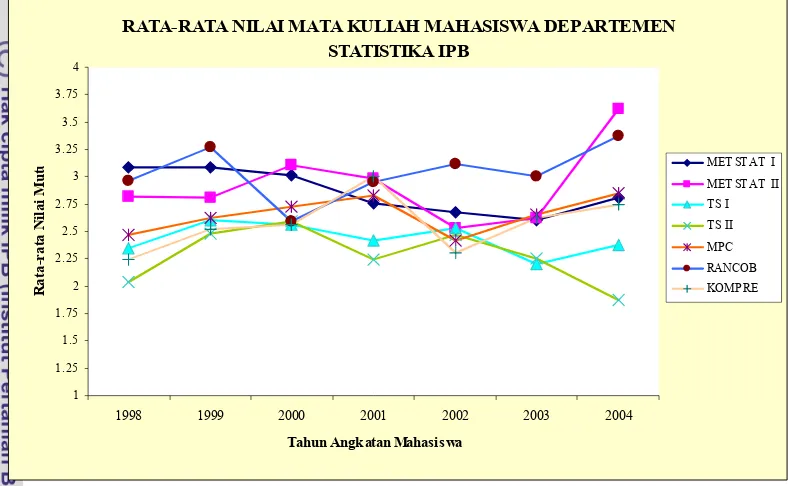
Sedangkan Gambar 3 menunjukkan pola pergerakan rata-rata nilai mata kuliah Ujian Komprehensif, Metode Statistika I, Metode Statistika II, Teori Statistika I, Teori Statistika II, Perancangan Percobaan, serta Metode Penarikan Contoh dari mahasiswa Departemen Statistika IPB angkatan 1998-2004. Terlihat bahwa Teori Statistika I dan Teori Statistika II memiliki profil yang sangat mirip. Selama kurun waktu tersebut dapat dilihat bahwa mata kuliah Teori Statistika I dan Teori Statistika II memiliki rata-rata nilai yang cenderung berada di bawah rata-rata nilai mata kuliah lainnya. Mata kuliah lain yang memiliki kemiripan profil adalah Metode Statistika II, Metode Penarikan Contoh, dan Ujian Komprehensif. Ketiga mata kuliah tersebut memiliki rata-rata nilai yang cenderung meningkat pada tahun angkatan 1998-2001, kemudian menurun pada tahun angkatan 2001-2002, dan sejak tahun angkatan 2002-2004 kembali mengalami peningkatan. Sedangkan mata kuliah Metode Statistika I dan Perancangan Percobaan memiliki profil yang berbeda dengan mata kuliah lainnya. Perancangan Percobaan terlihat cenderung memiliki rata-rata nilai yang lebih tinggi dibandingkan seluruh mata kuliah lainnya. Namun, sama seperti Metode Statistika II, Perancangan Percobaan juga cenderung mengalami perubahan rata-rata nilai yang cukup besar pada setiap pergantian tahun angkatan mahasiswa.
mahasiswa yang memiliki nilai mutu yang baik pada satu jenis mata kuliah akan cenderung memiliki nilai mutu yang baik pula pada mata kuliah yang lainnya.
Selain itu, tabel koefisien korelasi pada Lampiran 1 juga menunjukkan bahwa setiap peubah penjelas memiliki asosiasi yang cukup
kuat terhadap peubah respon. Indeks asosiasi terbesar antar peubah penjelas terjadi di antara Metode Statistika II dan Metode Penarikan Contoh. Sedangkan peubah penjelas yang memiliki asosiasi terkuat dengan peubah respon adalah Metode Penarikan Contoh.
RATA-RATA NILAI MATA KULIAH MAHASISWA DEPARTEMEN STATISTIKA IPB
1 1.25 1.5 1.75 2 2.25 2.5 2.75 3 3.25 3.5 3.75 4
1998 1999 2000 2001 2002 2003 2004
Tahun Angkatan Mahasiswa
R
a
ta
-r
a
ta
N
il
a
i
M
u
tu MET ST AT I
MET ST AT II T S I T S II MPC RANCOB KOMP RE
Gambar 3. Grafik Nilai Rata-Rata Mata Kuliah Ujian Komprehensif dan Mata Kuliah Pokok Mahasiswa Departemen Statistika IPB
Tabel 1. Daftar Kategori dari Peubah Penjelas Peubah Penjelas Kategori
A B Nilai mutu Metode Statistika I
(mst1)
CD A B Nilai mutu Metode Statistika II
(mst2)
CD A B C Nilai mutu Teori Statistika I
(ts1)
D A B C Nilai mutu Teori Statistika II
(ts2)
DE A B Nilai mutu Metode Penarikan
Contoh (mpc)
CD A B Nilai mutu Perancangan
Percobaan (rcb)
CD
Klasifikasi Menggunakan Simple Naive Bayesian
Tahapan dalam penentuan klasifikasi nilai mutu Ujian Komprehensif dengan metode simple naive Bayesian :
1. Menentukan peluang prior dari masing-masing kategori nilai mutu Ujian Komprehensif.
Tabel 2. Peluang Prior Ujian Komprehensif Nilai mutu Ujian
Komprehensif N
Peluang Prior
A 33 0.117
B 98 0.348
C 137 0.486
D 14 0.05
Total 282 1
2. Menentukan peluang bersyarat dari setiap kategori peubah penjelas. Lampiran 2-7 menyajikan nilai peluang bersyarat dari enam peubah penjelas.
pada tahap 1 dan peluang bersyarat pada tahap 2.
4. Menentukan kaidah klasifikasi berdasarkan nilai peluang bersama yang terbesar.
Dengan menerapkan tahapan di atas, akan diperoleh prediksi klasifikasi nilai mutu Ujian Komprehensif dari masing-masing mahasiswa Departemen Statistika IPB. Tabel klasifikasi nilai mutu Ujian Komprehensif yang dihasilkan adalah sebagai berikut:
Tingkat ketepatan klasifikasi (Correct Classification Rate) yang dihasilkan oleh metode SNB untuk data in-sample sebesar 59.93%, sedangkan tingkat ketepatan klasifikasi untuk data out-sample sebesar 47.89%.
Klasifikasi Menggunakan Metode Semi Naive Bayesian
Backwards Sequential Elimination (BSE)
Penerapan algoritma BSE menghasilkan susunan peubah penjelas baru yang merupakan himpunan bagian dari enam peubah penjelas pada simple naive Bayesian yang dapat menyebabkan terjadinya peningkatan akurasi dari metode simple naive Bayesian. Susunan peubah penjelas baru tersebut terdiri dari tiga peubah penjelas, yaitu nilai mutu Metode Statistika II, nilai mutu Metode Penarikan
Contoh, dan nilai mutu Perancangan Percobaan.
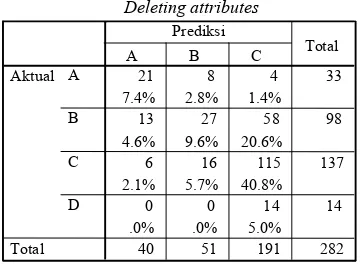
Tabel klasifikasi nilai mutu Ujian Komprehensif yang dihasilkan dari penerapan algoritma BSE adalah sebagai berikut:
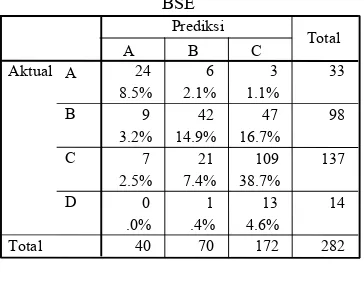
Tingkat ketepatan klasifikasi yang dihasilkan oleh metode BSE untuk data in-sample sebesar 62.06%, sedangkan tingkat ketepatan klasifikasi untuk data out-sample sebesar 53.52%.
Forward Sequential Selection (FSS)
Sama halnya dengan algoritma BSE, penerapan algoritma FSS juga menghasilkan susunan peubah penjelas baru yang merupakan himpunan bagian dari enam peubah penjelas yang digunakan pada simple naive Bayesian. Susunan peubah penjelas yang baru tersebut dipilih karena dapat meningkatkan akurasi dari metode simple naive Bayesian.
Susunan peubah penjelas baru yang terbentuk dari penerapan algoritma FSS tersebut terdiri dari lima peubah penjelas, yaitu nilai mutu Metode Statistika I, nilai mutu Metode Statistika II, nilai mutu Teori Statistika II, nilai mutu Metode Penarikan Contoh, dan nilai mutu Perancangan Percobaan. Sedangkan Tabel klasifikasi nilai mutu Ujian Komprehensif yang dihasilkan adalah sebagai berikut:
Tabel 3. Ketepatan Klasifikasi Data In-sample
SNB
23 8 2 0 33
8.2% 2.8% .7% .0% 14 39 45 0 98 5.0% 14% 16% .0%
5 25 103 4 137 1.8% 8.9% 37% 1.4%
0 0 10 4 14
.0% .0% 3.5% 1.4% 42 72 160 8 282 A B C D Aktual Total
A B C D
Prediksi
Total
BSE
24 6 3 33
8.5% 2.1% 1.1%
9 42 47 98
3.2% 14.9% 16.7% 7 21 109 137 2.5% 7.4% 38.7%
0 1 13 14
.0% .4% 4.6% 40 70 172 282 A B C D Aktual Total
A B C
Prediksi
Total
Tabel 5. Ketepatan Klasifikasi Data In-Sample
Tabel 4. Ketepatan Klasifikasi Data Out-Sample
SNB
2 2 1 0 5
2.8% 2.8% 1.4% .0%
1 11 18 0 30
1.4% 15% 25% .0%
1 10 21 3 35
1.4% 14% 30% 4.2%
0 0 1 0 1
.0% .0% 1.4% .0%
4 23 41 3 71
A B C D Aktual Total
A B C D
Prediksi
Total
Tabel 6. Ketepatan Klasifikasi Data Out-Sample
BSE
2 0 3 5
2.8% .0% 4.2%
4 8 18 30
5.6% 11.3% 25.4%
3 4 28 35
4.2% 5.6% 39.4%
0 0 1 1
.0% .0% 1.4%
9 12 50 71
A B C D Aktual Total
A B C
Prediksi
Tingkat ketepatan klasifikasi yang dihasilkan oleh metode FSS untuk data in-sample sebesar 61.35%, sedangkan tingkat ketepatan klasifikasi untuk data out-sample sebesar 56.34%.
Backward Sequential Elimination and Joining (BSEJ)
Penerapan algoritma BSEJ menciptakan susunan peubah penjelas baru yang terdiri dari hanya satu peubah penjelas baru hasil penggabungan keenam peubah penjelas pada simple naive Bayesian. Jika peubah penjelas baru yang dihasilkan dari algoritma BSEJ adalah join, maka join ini merupakan penggabungan dari keenam peubah penjelas pada simple naive Bayesian. Jika seorang mahasiswa memiliki nilai mutu Metode Statistika I = A, nilai mutu Metode Statistika II = A, nilai mutu Teori Statistika I = A, nilai mutu Teori Statistika II = A, nilai mutu Metode Penarikan Contoh = A, dan nilai mutu Perancangan Percobaan = A, mahasiswa tersebut akan memiliki peubah penjelas join = AAAAAA.
Tabel klasifikasi nilai mutu Ujian Komprehensif yang dihasilkan berdasarkan algoritma BSEJ adalah sebagai berikut:
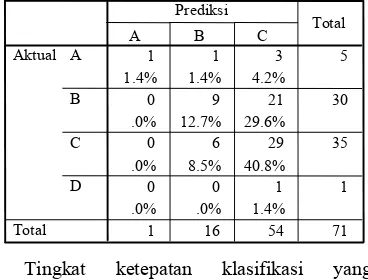
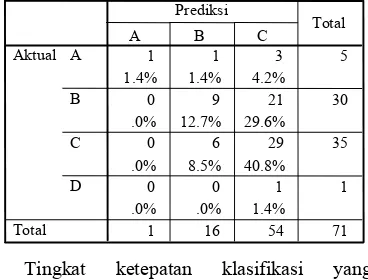
Tingkat ketepatan klasifikasi yang dihasilkan oleh metode BSEJ untuk data in-sample sebesar 75.18%, sedangkan tingkat ketepatan klasifikasi untuk data out-sample sebesar 54.93%.
Tree Augmented Naive Bayesian (TAN)
Penerapan algoritma TAN menghasilkan perubahan struktur simple naive Bayesian yang menggambarkan adanya ketidakbebasan (saling mempengaruhi) antar peubah penjelas. Peubah penjelas yang terbentuk masih terdiri dari enam peubah penjelas, yaitu nilai mutu Metode Statistika I, nilai mutu Metode Statistika II, nilai mutu Teori Statistika I, nilai mutu Teori Statistika II, nilai mutu Metode Penarikan Contoh, dan nilai mutu Perancangan Percobaan. Perbedaannya adalah dalam penentuan peluang bersyarat setiap kategori dari peubah penjelas nilai mutu Teori Statistika I, nilai mutu Teori Statistika II, dan nilai mutu Perancangan Percobaan, yang selain dipengaruhi oleh peubah kelas juga dipengaruhi oleh salah satu peubah penjelas lain. Nilai mutu Teori Statistika I dan nilai mutu Teori Statistika II sama-sama dipengaruhi oleh nilai mutu Metode Statistika I, sedangkan nilai mutu Perancangan Percobaan dipengaruhi oleh nilai mutu Teori Statistika I. Struktur tree augmented naive
FSS
23 6 4 33
8.2% 2.1% 1.4%
14 40 44 98
5.0% 14.2% 15.6% 5 22 110 137 1.8% 7.8% 39.0%
0 0 14 14
.0% .0% 5.0% 42 68 172 282 A B C D Aktual Total
A B C
Prediksi
Total
BSEJ
8 6 19 33
2.8% 2.1% 6.7%
0 71 27 98
.0% 25.2% 9.6%
0 4 133 137
.0% 1.4% 47.2%
0 1 13 14
.0% .4% 4.6% 8 82 192 282 A B C D Aktual Total
A B C
Prediksi
Total
Tabel 9. Ketepatan Klasifikasi Data In-Sample
Tabel 8. Ketepatan Klasifikasi Data Out-Sample
FSS
2 1 2 5
2.8% 1.4% 2.8%
1 11 18 30
1.4% 15.5% 25.4%
1 7 27 35
1.4% 9.9% 38.0%
0 0 1 1
.0% .0% 1.4%
4 19 48 71
A B C D Aktual Total
A B C
Prediksi
Total
Tabel 10. Ketepatan Klasifikasi Data Out-Sample
BSEJ
1 1 3 5
1.4% 1.4% 4.2%
0 9 21 30
.0% 12.7% 29.6%
0 6 29 35
.0% 8.5% 40.8%
0 0 1 1
.0% .0% 1.4%
1 16 54 71
A B C D Aktual Total
A B C
Prediksi
Total
Bayesian yang dihasilkan dapat dilihat pada Lampiran 8.
Tabel klasifikasi nilai mutu Ujian Komprehensif yang dihasilkan berdasarkan algoritma TAN adalah sebagai berikut:
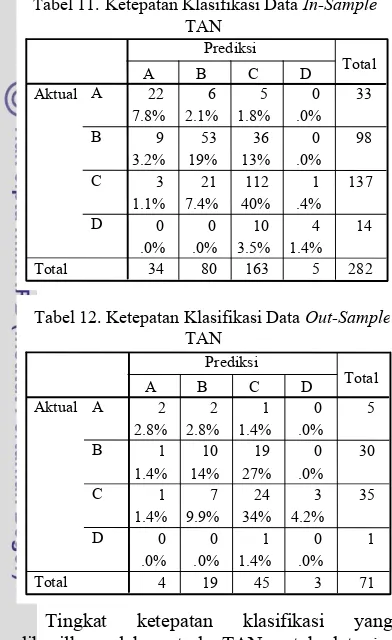
Tingkat ketepatan klasifikasi yang dihasilkan oleh metode TAN untuk data in-sample sebesar 67.73%, sedangkan tingkat ketepatan klasifikasi untuk data out-sample sebesar 50.70%.
Perbandingan Metode SNB, BSE, FSS, BSEJ dan TAN
Metode klasifikasi dinyatakan memiliki akurasi yang baik jika memiliki tingkat kesalahan klasifikasi yang minimum. Tingkat kesalahan klasifikasi yang dihasilkan oleh metode klasifikasi SNB dan semi naive Bayesian disajikan pada Tabel 13.
Dari Tabel 13 terlihat bahwa metode semi naive Bayesian efektif digunakan untuk meningkatkan akurasi dari metode simple naïve Bayesian. Namun, peningkatan akurasi yang dihasilkan belum tentu merupakan peningkatan akurasi yang terbesar (maksimal). Hal ini ditunjukkan dengan adanya perbedaan tingkat kesalahan klasifikasi yang dihasilkan oleh BSE dan FSS.
Tabel 13. Perbandingan Tingkat Kesalahan Klasifikasi SNB dan Semi Naive Bayesian
Metode Misclassification Klasifikasi in-sample out-sample
SNB 40.07% 52.11%
BSE 37.94% 46.48%
FSS 38.65% 43.66%
BSEJ 24.82% 45.07%
TAN 32.27% 49.30%
Secara keseluruhan dapat dilihat bahwa keempat metode semi naive Bayesian memiliki tingkat kesalahan klasifikasi yang lebih kecil dibandingkan dengan metode simple naive Bayesian, baik untuk data in-sample maupun out-sample.
Adanya perbedaan tingkat kesalahan klasifikasi yang cukup jauh antara data in-sample dan out-sample disebabkan oleh ukuran data yang digunakan tidak cukup besar, sehingga berakibat pada nilai peluang dari setiap kategori peubah penjelas maupun peubah respon yang belum stabil.
Kesalahan prediksi klasifikasi yang dihasilkan untuk data in-sample, baik dalam simple naive Bayesian maupun dalam semi naive Bayesian, didominasi oleh jenis kesalahan prediksi yang tidak jauh dari nilai data aktual, misalnya saja kebanyakan mahasiswa yang memiliki nilai mutu Ujian Komprehensif A diprediksi akan mendapat nilai mutu Ujian Komprehensif antara A-B. Begitu pula dengan mahasiswa yang memiliki nilai mutu Ujian Komprehensif aktual B, sebagian besar akan diprediksi mendapat nilai mutu Ujian Komprehensif B-C. Mahasiswa yang memiliki nilai mutu Ujian Komprehensif aktual C juga sebagian besar akan diprediksi mendapat nilai mutu Ujian Komprehensif B-C. Sedangkan mahasiswa yang memiliki nilai mutu Ujian Komprehensif aktual D sebagian besar akan diprediksi mendapat nilai mutu Ujian Komprehensif C.
Penerapan Metode Semi Naive Bayesian Menggunakan Indeks Asosiasi
Selain menggunakan algoritma BSE, FSS, dan BSEJ, metode semi naive Bayesian (deleting attributes dan joining attributes) dapat diterapkan dengan menggunakan indeks asosiasi (korelasi). Tahapan metode semi naive Bayesian dalam mengklasifikasikan nilai mutu Ujian Komprehensif menggunakan indeks asosiasi (korelasi) adalah sebagai berikut : 1. Menggerombolkan keenam mata kuliah
yang menjadi peubah penjelas. Indeks
Tabel 11. Ketepatan Klasifikasi Data In-Sample
TAN
22 6 5 0 33
7.8% 2.1% 1.8% .0%
9 53 36 0 98
3.2% 19% 13% .0% 3 21 112 1 137 1.1% 7.4% 40% .4%
0 0 10 4 14
.0% .0% 3.5% 1.4% 34 80 163 5 282 A
B
C
D Aktual
Total
A B C D
Prediksi
Total
Tabel 12. Ketepatan Klasifikasi Data Out-Sample
TAN
2 2 1 0 5
2.8% 2.8% 1.4% .0%
1 10 19 0 30
1.4% 14% 27% .0%
1 7 24 3 35
1.4% 9.9% 34% 4.2%
0 0 1 0 1
.0% .0% 1.4% .0%
4 19 45 3 71
A
B
C
D Aktual
Total
A B C D
Prediksi
asosiasi digunakan sebagai ukuran kemiripan antar dua mata kuliah (peubah penjelas). Banyaknya gerombol yang terbentuk menunjukkan banyaknya peubah penjelas yang akan digunakan.
2. Deleting attributes: Ambil satu mata kuliah sebagai peubah penjelas dari seiap gerombol yang terbentuk. Kemudian lakukan proses klasifikasi SNB. Ulangi langkah 2 ini untuk semua susunan kombinasi peubah penjelas yang mungkin. Kombinasi peubah penjelas yang dipilih adalah kombinasi peubah penjelas yang menghasilkan tingkat ketepatan klasifikasi terbesar.
Joining attributes: Gabungkan setiap peubah penjelas (mata kuliah) yang berada dalam satu gerombol, sehingga seolah-olah membentuk peubah penjelas baru yang banyaknya sesuai dengan banyaknya gerombol yang terbentuk pada langkah 1. Kemudian lakukan proses klasifikasi SNB.
Setelah melakukan eksplorasi terhadap beberapa metode perbaikan jarak (pautan), digunakan metode pautan Complete Linkage untuk menggerombolkan peubah penjelas dengan ukuran kedekatan adalah korelasi antar peubah penjelas. Metode pautan Complete Linkage tersebut menghasilkan tiga gerombol. Gerombol pertama terdiri dari Metode Statistika I, Teori Statistika I, dan Teori Statistika II. Gerombol kedua terdiri dari Metode Statistika II dan Metode Penarikan Contoh. Sedangkan gerombol ketiga hanya terdiri dari Perancangan Percobaan.
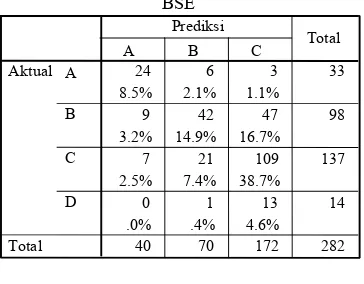
Metode Statistika II, Teori Statistika II, dan Perancangan Percobaan merupakan susunan peubah penjelas yang menghasilkan tingkat ketepatan klasifikasi terbaik pada deleting attributes.
Besarnya tingkat kesalahan klasifikasi yang dihasilkan disajikan pada Tabel 14.
Tabel 14. Tingkat Kesalahan Klasifikasi Semi Naive Bayesian dengan Indeks Asosiasi
Misclassification Rate Metode semi
naive Bayesian in-sample out-sample deleting
attributes 42.20% 53.52%
joining
attributes 34.04% 45.07%
Tabel 14 menunjukkan bahwa penggunaan indeks asosiasi dalam membangun model klasifikasi semi naive Bayesian tidak memberikan hasil sebaik penggunaan
algoritma BSE, FSS, BSEJ, dan TAN. Penggunaan indeks asosiasi pada deleting attributes menghasilkan tingkat kesalahan klasifikasi yang lebih besar dibandingkan dengan SNB, baik untuk data in-sample maupun out-sample. Sedangkan penggunaan indeks asosiasi pada joining attributes masih cukup efektif dalam meningkatkan akurasi prediksi klasifikasi dari metode SNB, karena menghasilkan tingkat kesalahan klasifikasi yang lebih kecil dibandingkan SNB, baik untuk data in-sample maupun out-sample. Namun, tingkat kesalahan ini masih lebih besar jika dibandingkan dengan tingkat kesalahan klasifikasi BSEJ.
Tabel 15 dan Tabel 16 menunjukkan bahwa metode deleting attributes memiliki peluang salah mengklasifikasikan nilai mutu Ujian Komprehensif yang cukup besar. Terutama dalam mengklasifikasikan mahasiswa yang sebenarnya mendapat nilai mutu Ujian Komprehensif B. Mahasiswa yang secara aktual mendapat nilai mutu Ujian Komprehensif B memiliki peluang yang lebih besar untuk diklasifikasikan mendapat nilai mutu Ujian Komprehensif C. Selain itu, jenis kesalahan yang dihasilkan oleh deleting attributes memiliki resiko kesalahan yang cukup besar. Hal ini dapat dilihat dari adanya salah klasifikasi nilai mutu Ujian Komprehensif yang seharusnya A diprediksi
Tabel 15. Ketepatan Klasifikasi Data In-Sample
Deleting attributes
21 8 4 33
7.4% 2.8% 1.4%
13 27 58 98
4.6% 9.6% 20.6% 6 16 115 137 2.1% 5.7% 40.8%
0 0 14 14
.0% .0% 5.0% 40 51 191 282 A
B
C
D Aktual
Total
A B C
Prediksi
Total
Tabel 16. Ketepatan Klasifikasi Data Out-sample
Deleting attributes
3 0 2 5
4.2% .0% 2.8%
3 4 23 30
4.2% 5.6% 32.4%
3 6 26 35
4.2% 8.5% 36.6%
0 0 1 1
.0% .0% 1.4%
9 10 52 71
A
B
C
D Aktual
Total
A B C
Prediksi
menjadi C, B diprediksi menjadi D, atau sebaliknya. Peluang terjadinya jenis kesalahan ini pada deleting attributes cukup besar dibandingkan metode semi naive Bayesian lainnya.
Tabel 17 dan Tabel 18 menunjukkan bahwa metode joining attributes memiliki peluang kesalahan klasifikasi yang lebih kecil dibandingkan deleting attributes. Dapat dilihat bahwa mahasiswa yang mendapat nilai mutu Ujian Komprehensif B memiliki peluang terbesar untuk diprediksi mendapat nilai mutu Ujian Komprehensif B. Peluang terjadinya jenis kesalahan dengan resiko kesalahan yang cukup tinggi pada joining attributes tidak sebesar pada deleting attributes.
Tingkat Kesalahan Klasifikasi dengan Mempertimbangkan Jenis Kesalahan yang
Dihasilkan
Penghitungan tingkat kesalahan klasifikasi (misclassification rate) hingga sejauh ini dilakukan dengan tidak mempertimbangkan jenis kesalahan yang dihasilkan. Mahasiswa yang sebenarnya mendapat nilai mutu Ujian Komprehensif A, namun diprediksi mendapat nilai mutu Ujian Komprehensif C, dibandingkan dengan mahasiswa yang sebenarnya mendapat nilai mutu Ujian Komprehensif A, namun diprediksi mendapat
nilai mutu Ujian Komprehensif B, dianggap memiliki resiko kesalahan yang sama.
Penghitungan tingkat kesalahan klasifikasi dengan mempertimbangkan jenis kesalahan perlu dilakukan pada penelitian ini. Hal ini dimungkinkan karena data nilai mutu Ujian Komprehensif yang akan diprediksi merupakan data kategorik ordinal. Dengan mempertimbangkan jenis kesalahan yang dilakukan, maka mahasiswa yang sebenarnya mendapat nilai mutu Ujian Komprehensif A, namun diprediksi mendapat nilai mutu Ujian Komprehensif C akan memiliki resiko kesalahan yang lebih tinggi dibandingkan dengan mahasiswa yang sebenarnya mendapat nilai mutu Ujian Komprehensif A, namun diprediksi mendapat nilai mutu Ujian Komprehensif B. Sedangkan penghitungan tingkat ketepatan klasifikasi (correct classification rate) masih tetap sama, yaitu 1 dikurangi misclassification rate.
Pada penghitungan tingkat kesalahan klasifikasi dengan mempertimbangkan jenis kesalahan, jenis kesalahan yang memiliki resiko kesalahan lebih tinggi akan diberi bobot pengali yang lebih besar. Prosedur penghitungan tingkat kesalahan klasifikasi adalah sebagai berikut:
1. Menentukan besarnya bobot/koefisien pengali untuk setiap jenis kesalahan yang terjadi.
- hasil prediksi yang sama dengan nilai aktual diberi bobot 0
- kesalahan prediksi yang menyimpang satu tingkat dari nilai aktual diberi bobot 1 - kesalahan prediksi yang menyimpang dua
tingkat dari nilai aktual diberi bobot 2 - kesalahan prediksi yang menyimpang tiga
tingkat dari nilai aktual diberi bobot 3 2. Mengalikan setiap unsur pada Tabel
Ketepatan Klasifikasi yang dihasilkan dari metode SNB dan semi naive Bayesian dengan bobot pengali yang telah ditentukan pada tahap 1.
3. Menjumlahkan setiap unsur pada Tabel Ketepatan Klasifikasi yang telah dikalikan dengan bobot pengalinya.
4. Tingkat kesalahan klasifikasi diperoleh dengan membagi hasil yang diperoleh pada tahap 3 dengan tiga kali total amatan/objek pada Tabel Ketepatan Klasifikasi yang bersesuaian.
Setelah melakukan tahapan di atas diperoleh tingkat kesalahan klasifikasi yang baru untuk setiap metode klasifikasi yang digunakan (SNB dan semi naive Bayesian). Tingkat kesalahan klasifikasi yang baru ini dapat dilihat pada Tabel 19-20.
Tabel 17. Ketepatan Klasifikasi Data In-sample
Joining attributes
22 7 4 33
7.8% 2.5% 1.4%
7 51 40 98
2.5% 18.1% 14.2% 3 21 113 137 1.1% 7.4% 40.1%
0 0 14 14
.0% .0% 5.0% 32 79 171 282 A
B
C
D Aktual
Total
A B C
Prediksi
Total
Tabel 18. Ketepatan Klasifikasi Data Out-sample
Joining attributes
2 1 2 5
2.8% 1.4% 2.8%
1 11 18 30
1.4% 15.5% 25.4%
2 7 26 35
2.8% 9.9% 36.6%
0 0 1 1
.0% .0% 1.4%
5 19 47 71
A
B
C
D Aktual
Total
A B C
Prediksi
Tabel 19. Perbandingan Tingkat Kesalahan Klasifikasi SNB dan Semi Naive Bayesian
dengan Bobot Pengali
Misclassification Rate Metode
Klasifikasi in-sample out-sample
SNB 14.18% 18.31%
BSE 13.95% 18.31%
FSS 13.95% 15.96%
BSEJ 10.64% 16.43%
TAN 11.70% 17.37%
Tabel 20. Tingkat Kesalahan Klasifikasi Semi Naive Bayesian menggunakan Indeks
Asosiasi dengan Bobot Pengali Misclassification Rate Metode semi
naive Bayesian in-sample out-sample deleting
attributes 15.25% 20.19%
joining
attributes 12.17% 16.90%
Tabel 19 menunjukkan bahwa dengan mempertimbangkan jenis kesalahan yang dihasilkan, tingkat kesalahan klasifikasi dari metode SNB dan semi naive Bayesian menjadi lebih kecil dibandingkan dengan tingkat kesalahan klasifikasi yang tidak mempertimbangkan jenis kesalahan (Tabel 13). Namun informasi yang diperoleh masih sama, yaitu metode semi naive Bayesian efektif digunakan untuk meningkatkan akurasi dari metode simple naive Bayesian. Informasi tambahan yang bisa diperoleh adalah penghitungan tingkat kesalahan dengan mempertimbangkan jenis kesalahan mampu menunjukkan bahwa FSS lebih baik dari BSE dalam mengklasifikasikan nilai mutu Ujian Komprehensif. Selain itu juga terlihat bahwa tingkat kesalahan klasifikasi yang dihasilkan oleh BSEJ dan TAN tidak jauh berbeda.
Tabel 20 juga menunjukkan bahwa dengan mempertimbangkan jenis kesalahan yang dihasilkan, tingkat kesalahan klasifikasi dari metode semi naive Bayesian menggunakan indeks asosiasi menjadi lebih kecil dibandingkan dengan tingkat kesalahan klasifikasi yang tidak mempertimbangkan jenis kesalahan (Tabel 14). Perubahan tingkat kesalahan klasifikasi ini tidak mengubah hasil yang diperoleh, yaitu penggunaan indeks asosiasi dalam membangun model klasifikasi semi naive Bayesian tidak memberikan hasil sebaik penggunaan algoritma BSE, FSS, BSEJ, dan TAN. Terlihat bahwa deleting attributes tetap memiliki tingkat kesalahan klasifikasi yang lebih besar dari SNB.
Selain menghitung tingkat kesalahan klasifikasi dengan mempertimbangkan jenis kesalahan, dihitung juga nilai korelasi antara prediksi nilai mutu Ujian Komprehensif dengan nilai mutu Ujian Komprehensif aktual yang dihasilkan oleh SNB dan semi naive Bayesian. Koefisien korelasi yang dihasilkan dapat dilihat pada Tabel 21-22.
Tabel 21. Koefisien Korelasi antara Prediksi dan Aktual dari SNB dan Semi Naive Bayesian
Koefisien korelasi Spearman’s rho Metode
Klasifikasi
in-sample out-sample
SNB 0.565 0.263
BSE 0.519 0.230
FSS 0.545 0.262
BSEJ 0.580 0.197
TAN 0.609 0.320
Tabel 22. Koefisien Korelasi antara Prediksi dan Aktual dari Semi Naive Bayesian
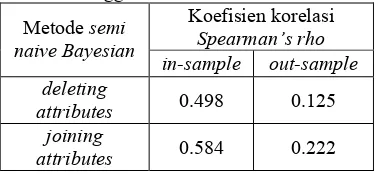
Menggunakan Indeks Asosiasi Koefisien korelasi
Spearman’s rho Metode semi
naive Bayesian
in-sample out-sample deleting
attributes 0.498 0.125
joining
attributes 0.584 0.222
Tabel 22 menunjukkan bahwa metode deleting attributes menghsilkan korelasi paling rendah antara prediksi dengan aktual, baik untuk data in-sample maupun out-sample. Bahkan, koefisien korelasi ini tetap yang paling rendah jika dibandingkan dengan koefisien korelasi yang dihasilkan oleh BSE, FSS, BSEJ, dan TAN. Metode deleting attributes juga cenderung memiliki peluang salah mengklasifikasikan yang cukup besar, serta menghasilkan jenis kesalahan dengan resiko kesalahan yang cukup besar juga dibandingkan dengan metode semi naive Bayesian lainnya (Tabel 15).
KESIMPULAN DAN SARAN
Kesimpulan
Metode semi naive Bayesian memiliki kemampuan yang lebih baik dalam mengklasifikasikan nilai mutu Ujian Komprehensif mahasiswa Departemen Statistika IPB dibandingkan dengan metode SNB. Hal ini ditunjukkan dengan tingkat kesalahan klasifikasi yang dihasilkan oleh keempat metode semi naive Bayesian lebih kecil dibandingkan dengan SNB.
Meskipun efektif dalam meningkatkan ketepatan klasifikasi dari metode SNB, peningkatan akurasi yang dihasilkan belum tentu merupakan peningkatan akurasi yang paling maksimum.
Penggunaan indeks asosiasi pada metode semi naive Bayesian memiliki komputasi yang lebih sederhana dan lebih cepat dibandingkan penggunaan algoritma, namun tidak memberikan hasil sebaik algoritma BSE, FSS, BSEJ, dan TAN dalam meningkatkan ketepatan prediksi klasifikasi dari SNB.
Metode semi naive Bayesian yang menghasilkan korelasi tinggi antara prediksi nilai mutu Ujian Komprehensif dengan nilai mutu Ujian Komprehensif aktual akan cenderung memiliki tingkat kesalahan klasifikasi yang kecil dengan jenis kesalahan yang dihasilkan memiliki resiko kesalahan yang kecil juga.
Saran
Perlu adanya ukuran data yang cukup besar dan pemenuhan asumsi kebebasan agar tingkat kesalahan klasifikasi dapat diperkecil. Ukuran data yang digunakan sebaiknya lebih besar dari total kemungkinan kombinasi kategori seluruh peubah penjelas.
Sebaiknya dilakukan pengembangan terhadap algoritma BSE, FSS, BSEJ, dan TAN agar penggunaan metode semi naive Bayesian dapat meningkatkan akurasi dugaan klasifikasi SNB secara maksimum.
DAFTAR PUSTAKA
Cerquides J., R. L. de Mantaras. 2003. Tractable Bayesian Learning of Tree Augmented Naive Bayes Classifiers.
Technical Report TR-2003-04.
(http://www.iiia.csic.es/~mantaras/Report IIIA-TR-2003-04-pdf)
[22 Mei 2008]
Dit. AJMP-IPB. 2004. Panduan Program Sarjana. Edisi 2004. IPB Press, Bogor.
Nasoetion A. H., A. Rambe. 1984. Teori Statistika Untuk Ilmu-Ilmu Kuantitatif. Edisi kedua. Bhratara Karya Aksara, Jakarta.
Sartono B. 2007. Pengklasifikasian Kolektibilitas Nasabah Kredit Menggunakan Metode Simple Naïve Bayesian Classifier. Institut Pertanian Bogor, Bogor.
Wikipedia. 2008. Naive Bayes Classifier. (http://en.wikipedia.org/wiki/Naive_bayes _classifier)
[14 Januari 2008]
Lampiran 1. Koefisien Korelasi antar Peubah Penjelas
Correlations
1.000 .370** .333** .322** .244** .263** .270** . .000 .000 .000 .000 .000 .000 282 282 282 282 282 282 282 .370** 1.000 .314** .248** .451** .251** .378** .000 . .000 .000 .000 .000 .000
282 282 282 282 282 282 282 .333** .314** 1.000 .324** .178** .226** .294** .000 .000 . .000 .003 .000 .000
282 282 282 282 282 282 282 .322** .248** .324** 1.000 .285** .254** .321** .000 .000 .000 . .000 .000 .000
282 282 282 282 282 282 282 .244** .451** .178** .285** 1.000 .287** .420** .000 .000 .003 .000 . .000 .000
282 282 282 282 282 282 282 .263** .251** .226** .254** .287** 1.000 .384** .000 .000 .000 .000 .000 . .000
282 282 282 282 282 282 282 .270** .378** .294** .321** .420** .384** 1.000 .000 .000 .000 .000 .000 .000 . 282 282 282 282 282 282 282 Correlation Coefficient
Sig. (2-tailed) N
Correlation Coefficient Sig. (2-tailed)
N
Correlation Coefficient Sig. (2-tailed)
N
Correlation Coefficient Sig. (2-tailed)
N
Correlation Coefficient Sig. (2-tailed)
N
Correlation Coefficient Sig. (2-tailed)
N
Correlation Coefficient Sig. (2-tailed)
N METSTAT1
METSTAT2
TS1
TS2
MPC
RANCOB
KOMPRE Spearman's rho
METSTAT1 METSTAT2 TS1 TS2 MPC RANCOB KOMPRE
15
Lampiran 2. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Metode Statistika I
mst1 P(mst1 | kompre = A) P(mst1 | kompre = B) P(mst1 | kompre = C) P(mst1 | kompre = D)
A 0.636 0.316 0.182 0.143
B 0.242 0.306 0.409 0.143
CD 0.121 0.378 0.409 0.714
Lampiran 3. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Metode Statistika II
mst2 P(mst2 | kompre = A) P(mst2 | kompre = B) P(mst2 | kompre = C) P(mst2 | kompre = D)
A 0.806 0.317 0.179 0.118
B 0.167 0.337 0.436 0.235
CD 0.028 0.337 0.386 0.647
Lampiran 4. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Teori Statistika I
ts1 P(ts1 | kompre = A) P(ts1 | kompre = B) P(ts1 | kompre = C) P(ts1 | kompre = D)
A 0.27 0.049 0.021 0.056
B 0.459 0.441 0.361 0.222
C 0.243 0.471 0.56 0.444
D 0.027 0.039 0.057 0.278
Lampiran 5. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Teori Statistika II
ts2 P(ts2 | kompre = A) P(ts2 | kompre = B) P(ts2 | kompre = C) P(ts2 | kompre = D)
A 0.216 0.078 0.028 0.056
B 0.432 0.324 0.177 0.111
C 0.324 0.471 0.674 0.667
Lampiran 6. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Metode Penarikan Contoh
mpc P(mpc | kompre = A) P(mpc | kompre = B) P(mpc | kompre = C) P(mpc | kompre = D)
A 0.389 0.158 0.05 0.059
B 0.5 0.495 0.379 0.176
CD 0.111 0.347 0.571 0.765
Lampiran 7. Peluang Bersyarat dari Peubah Penjelas Nilai Mutu Perancangan Percobaan
rcb P(rcb | kompre = A) P(rcb | kompre = B) P(rcb | kompre = C) P(rcb | kompre = D)
A 0.694 0.386 0.214 0.059
B 0.194 0.406 0.443 0.353
CD 0.083 0.208 0.343 0.588
Lampiran 8. Struktur Tree Augmented Naive Bayesyang diperoleh pada Klasifikasi Nilai Mutu Ujian Komprehensif
mpc rcb
mst2 mst1
kompre
PENGKLASIFIKASIAN NILAI MUTU UJIAN KOMPREHENSIF
MAHASISWA DEPARTEMEN STATISTIKA IPB MENGGUNAKAN
SEMI NAIVE BAYESIAN CLASSIFIER
IIN LESMANAWATI
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENDAHULUAN
Latar Belakang
Ujian Komprehensif merupakan salah satu mata kuliah wajib bagi mahasiswa tingkat akhir Departemen Statistika Institut Pertanian Bogor. Kegagalan mahasiswa dalam menghadapi Ujian Komprehensif dapat menghambat proses kelulusan mahasiswa, sehingga mahasiswa yang bersangkutan akan membutuhkan waktu yang lebih lama untuk menyelesaikan studinya di Departemen Statistika. Oleh karena itu, Departemen Statistika IPB perlu mengetahui potensi kelulusan mahasiswa agar dapat melakukan tindakan-tindakan yang dapat meminimalisasi kegagalan mahasiswa dalam Ujian Komprehensif.
Salah satu cara yang dapat ditempuh untuk mengetahui potensi kelulusan mahasiswa adalah dengan melakukan proses klasifikasi nilai mutu Ujian Komprehensif mahasiswa. Melalui pengklasifikasian ini, nilai mutu Ujian Komprehensif yang akan diperoleh mahasiswa menjadi dapat diprediksi. Simple naive Bayesian merupakan salah satu algoritma pengklasifikasian objek yang berdasarkan pada penerapan Teorema Bayes dengan menggunakan asumsi bahwa peubah-peubah penjelas yang digunakan sebagai dasar pengklasifikasian bersifat saling bebas.
Pada penerapannya, asumsi kebebasan antar-peubah penjelas ini sering tidak terpenuhi, sehingga berkembanglah suatu metode pengklasifikasian semi naive Bayesian yang dibangun untuk mengurangi pengaruh ketakbebasan antar peubah penjelas, yang diharapkan dapat meningkatkan akurasi dugaan (ketepatan klasifikasi) dari simple naive Bayesian classifier.
Tujuan
Tujuan yang ingin dicapai dalam penelitian ini antara lain :
1. Memperkenalkan metode Semi Naive Bayesian sebagai salah satu metode pengklasifikasian objek.
2. Membandingkan metode Simple Naive Bayesian dan Semi Naive Bayesian (deleting attributes, joining attributes, dan tree augmented naive Bayesian) dalam kemampuan mengklasifikasikan nilai mutu Ujian Komprehensif mahasiswa Departemen Statistika IPB.
TINJAUAN PUSTAKA
Ujian Komprehensif
Ujian Komprehensif merupakan ujian yang diadakan secara tertulis untuk mengukur pemahaman mahasiswa mengenai keterkaitan antar berbagai mata kuliah pokok bidang statistika yang mencakup Metode Statistika I dan II, Teori Statistika I dan II, Perancangan Percobaan, serta Metode Penarikan Contoh (Dit. AJMP-IPB, 2004).
Simple Naive Bayesian (SNB)
Simple naive Bayesian classifier merupakan salah satu metode pengklasifikasi berpeluang sederhana yang berdasarkan pada penerapan Teorema Bayes dengan asumsi antar peubah penjelas saling bebas (Wikipedia, 2008).
Kaidah Peluang Bayes
Teorema Bayes yang dibangun oleh Thomas Bayes, seorang matematikawan dan teologiawan Inggris abad 18, dipublikasikan untuk pertama kalinya pada tahun 1763.
Dalil Bayes menyatakan bahwa jika U suatu ruang contoh dan {A1, ..., An} merupakan sekatan U dengan P(Ai)≠ 0, i = 1,..., n; Ai∩Aj = Ø untuk i≠j, danB suatu kejadian pada U dengan P(B) ≠ 0, maka secara matematis, kaidah peluang Bayes dapat dituliskan sebagai berikut: n
i i i
i i i i A B P A P A P A B P B P B A P B A P 1 ) | ( ) ( ) ( ) | ( ) ( ) ( ) | (
(Nasoetion & Rambe, 1984).
Pada penelitian ini, kejadian Ai merupakan kejadian seorang mahasiswa Statistika IPB masuk dalam kelas ke-i (kejadian mahasiswa Statistika IPB mendapatkan nilai mutu Ujian Komprehensif A, B, C, atau D), sedangkan B adalah karakteristik mahasiswa tersebut, yang dalam penelitian ini merupakan karakteristik multi-variables. Misalnya, kejadian B adalah kejadian seorang mahasiswa Statistika IPB mendapatkan nilai mutu Metode Statistika I = A, nilai mutu Metode Statistika II = A, nilai mutu Teori Statistika I = A, dan seterusnya.
Jika nilai P(Ai | B) dapat diperoleh untuk semua i = 1, 2, …, n, maka mahasiswa tersebut akan dikategorikan masuk kelas ke-k (1 ≤ k ≤ n) jika peluang masuk kelas ke-k adalah yang paling besar, atau
PENDAHULUAN
Latar Belakang
Ujian Komprehensif merupakan salah satu mata kuliah wajib bagi mahasiswa tingkat akhir Departemen Statistika Institut Pertanian Bogor. Kegagalan mahasiswa dalam menghadapi Ujian Komprehensif dapat menghambat proses kelulusan mahasiswa, sehingga mahasiswa yang bersangkutan akan membutuhkan waktu yang lebih lama untuk menyelesaikan studinya di Departemen Statistika. Oleh karena itu, Departemen Statistika IPB perlu mengetahui potensi kelulusan mahasiswa agar dapat melakukan tindakan-tindakan yang dapat meminimalisasi kegagalan mahasiswa dalam Ujian Komprehensif.
Salah satu cara yang dapat ditempuh untuk mengetahui potensi kelulusan mahasiswa adalah dengan melakukan proses klasifikasi nilai mutu Ujian Komprehensif mahasiswa. Melalui pengklasifikasian ini, nilai mutu Ujian Komprehensif yang akan diperoleh mahasiswa menjadi dapat diprediksi. Simple naive Bayesian merupakan salah satu algoritma pengklasifikasian objek yang berdasarkan pada penerapan Teorema Bayes dengan menggunakan asumsi bahwa peubah-peubah penjelas yang digunakan sebagai dasar pengklasifikasian bersifat saling bebas.
Pada penerapannya, asumsi kebebasan antar-peubah penjelas ini sering tidak terpenuhi, sehingga berkembanglah suatu metode pengklasifikasian sem