SRI NEVI GANTINI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa tesis Analsis Faktor-Faktor Keberhasilan Mahasiswa Menggunakan Regresi Logistik dan Metode CHAID (Studi Kasus: Mahasiswa Farmasi UHAMKA) adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka dibagian akhir tesis ini.
Bogor, Januari 2011
Sri Nevi Gantini
SRI NEVI GANTINI. Analisis Faktor-Faktor Keberhasilan Mahasiswa Menggunakan Regresi Logistik dan Metode CHAID (Studi Kasus: Mahasiswa Farmasi UHAMKA). Dibimbing oleh BUNAWAN SUNARLIM dan UTAMI DYAH SYAFITRI.
Data kemampuan akademik mahasiswa berupa transkrip nilai dapat dijadikan sebagai salah satu alat untuk mengukur prestasi mahasiswa. Kemampuan akademik ini dapat dilihat dari nilai indeks prestasi kumulatif (IPK). Banyak faktor yang mempengaruhi tingkat keberhasilan akademik mahasiswa, antara lain faktor yang berasal dari dalam dan luar diri mahasiswa. Faktor yang berasal dari dalam diri mahasiswa yaitu: minat, kesiapan, motivasi, usaha, semangat dan persepsi. Sedangkan faktor yang berasal dari luar diri mahasiswa antara lain: lingkungan sosial, lingkungan keluarga dan lingkungan kampus. Lingkungan kampus memiliki peranan yang sangat penting dalam meningkatkan keberhasilan mahasiswa bila dibanding dengan lingkungan lainnya.
Sebagai upaya meningkatkan kualitas lulusan, Universitas Muhammadiyah Prof. DR. HAMKA (UHAMKA) menggunakan beberapa strategi, salah satunya adalah strategi pembelajaran. Strategi pembelajaran dipandang sebagai salah satu strategi pokok untuk meningkatkan mutu lulusan UHAMKA. Dalam menentukan kebijakan terutama strategi pembelajaran UHAMKA menerapkan kebijakan bahwa penerimaan mahasiswa baru perlu didukung dengan data yang memadai dan dapat menjadi suatu acuan, sehingga kebijakan yang dijalankan dapat optimal. Data tentang mahasiswa baru perlu dianalisa agar data tersebut dapat dijadikan sebagai bahan informasi yang akurat.
Analisis terhadap kemampuan dasar mahasiswa baru dilakukan untuk membantu pimpinan UHAMKA dalam menentukan kebijakan, terutama dalam hal penerimaan mahasiswa baru. Analisis ini merupakan hal yang sangat penting agar UHAMKA mendapatkan mahasiswa-mahasiswa yang berkualitas.
Salah satu badan yang dijadikan acuan standar mutu Pendidikan Tinggi di Indonesia adalah Badan Akreditasi Nasional Perguruan Tinggi. Salah satu standar lulusan adalah IPK. Pada penelitian disamping menyelesaikan permasalahan yang ada ingin dikaji pula pendekatan dari sisi pemodelan statistika yang berkaitan dengan ukuran sampel yang besar.
metode CHAID faktor yang mempunyai asosiasi paling kuat dengan keberhasilan mahasiswa yaitu kategori rataan nilai STTB. Hasil segmentasi CHAID menunjukkan bahwa mahasiswa yang berhasil yaitu perempuan yang memiliki rataan nilai STTB 7.00-7.99 dan mahasiswa yang memiliki rataan nilai STTB ≥ 8.00.
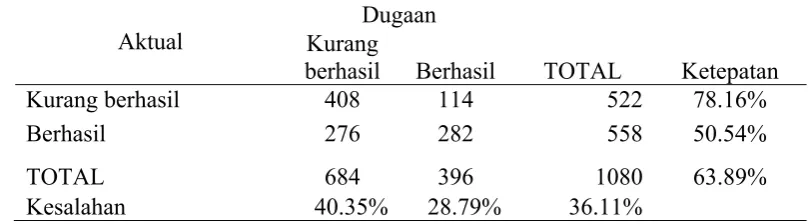
Proses analisis pada regresi logistik dengan cut off 0.5 dan analisis menggunakan metode CHAID diperoleh nilai sensitivity 50.54%, nilai specificity
78.16%, nilai total ketepatan klasifikasi 63.89% dan nilai total kesalahan klasifikasi 36.11%.
© Hak Cipta milik IPB, tahun 2011
Hak Cipta dilindungi Undang-undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB
SRI NEVI GANTINI
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
rahmat dan karunia-Nya sehingga penulis bisa menyelesaikan karya ilmiah ini. Judul karya ilmiah ini adalah “Analisis Faktor-Faktor Keberhasilan Mahasiswa Menggunakan Regresi Logistik dan Metode CHAID (Studi kasus: Mahasiswa Farmasi UHAMKA)”. Karya ini merupakan salah satu syarat kelulusan yang harus dipenuhi untuk mendapatkan gelar Magister Sains pada Program Studi Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Dalam penulisan karya ilmiah ini penulis mendapatkan banyak ilmu, inspirasi, dan pelajaran yang begitu berharga, sehingga penulis ingin mengucapkan banyak terima kasih, diantaranya kepada Bapak Ir. Bunawan Sunarlim, MS dan Ibu Utami Dyah Syafitri, M.Si selaku pembimbing I dan pembimbing II atas bimbingannya dan telah memberikan waktu, saran dan masukkannya kepada penulis. Disamping itu, terima kasih penulis ucapkan kepada seluruh dosen Departemen Statistika IPB terutama kepada Ibu Dr. Ir. Erfiani M.Si selaku Ketua Program Studi Statistika yang selalu memberi motivasi, arahan dan perhatiannya, kepada Bapak Dr. Ir. Hari Wijayanto, M.Si selaku penguji tesis, atas nasehat dan ilmu yang bermanfaat dan seluruh staf Program Studi Statistika.
Ucapan terimakasih juga penulis sampaikan kepada Departemen Pendidikan Tinggi atas beasiswa yang diberikan kepada penulis, serta semua teman-teman Program Studi Statistika IPB atas dukungannya selama pembuatan karya ilmiah ini.
Semoga karya ilmiah ini dapat bermanfaat.
Bogor, Januari 2011
Penulis dilahirkan di Bandung pada tanggal 6 November 1964, menyelesaikan pendidikan di SMA Perguruan Rakyat I Jakarta pada tahun 1984 dan menyelesaikan perkuliahan di Universitas Padjadjaran Bandung Fakutas MIPA jurusan Matematika pada tahun 1988. Pada tahun 2007 diterima di Program Studi Statistika Pascasarjana IPB, dengan beasiswa dari Direktorat Jenderal Perguruan tinggi.
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 4
TINJAUAN PUSTAKA Tingkat Keberhasilan Mahasiswa ... 5
Regresi Logistik ... 5
Pendugaan Parameter ... 6
Pengujian Parameter... 7
Pereduksian Peubah ... 8
Tabel Kasifikasi ... 8
Interpretasi Koefisien ... 9
Metode CHAID ... 10
Ketepatan dan Kesalahan Klasifikasi ... 12
METODOLOGI Metodologi Pengumpulan Data ... 14
Metode Analisis ... 16
HASIL DAN PEMBAHASAN Deskripsi Karakteristik Responden Berdasarkan Peubah Penjelas ... 19
Deskripsi Karakteristik Responden Berdasarkan Tingkat Keberhasilan 21 Model Regresi Logistik ... 23
Interpretasi Koefisien ... 25
Keakuratan Model ... 25
Metode CHAID ... 27
Perbandingan Hasil Klasifikasi Regresi Logistik dan Metode CHAID .. 29
SIMPULAN DAN SARAN ... 30
DAFTAR PUSTAKA ... 31
DAFTAR TABEL
1 Model Regresi Logistik dengan Satu Peubah Penjelas Dikotom ... 10
2 Klasifikasi Respon ... 13
3 Peubah-peubah Penjelas yang digunakan dalam analisis dan peubah bonekanya ... 16
4 Hasil Analisis Regresi Logistik Model Penuh ... 23
5 Analisis Regresi Logistik Hasil Uji Backward Elimination ... 24
6 Nilai Dugaan Peluang untuk Setiap Kombinasi Peubah Penjelas ... 24
7 Rasio Odds dari Peubah Penjelas yang Nyata ... 25
8 Klasifikasi Metode Regresi Logistik dengan Cut Off 0.3 sampai dengan 0.4 ... 26
9 Klasifikasi Metode Regresi Logistik dengan Cut Off 0.5 ... 26
10 Klasifikasi Metode Regresi Logistik dengan Cut Off 0.6 sampai dengan 0.8 ... 26
11 Segmentasi CHAID ... 28
12 Klasifikasi Metode CHAID... 29
DAFTAR GAMBAR
1 Diagram Alur Analisis Data ... 18
2 Persentase Responden Berdasarkan Peubah-Peubah Penjelas ... 20
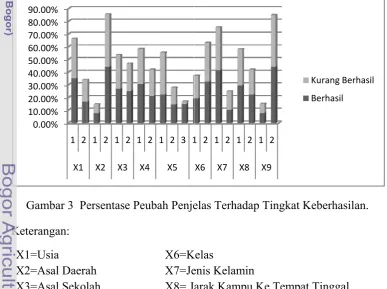
3 Persentase Peubah Penjelas Terhadap Tingkat Keberhasilan ... 22
4 Dendogram CHAID Status Keberhasilan Mahasiswa ... 28
DAFTAR LAMPIRAN
Tabulasi Silang Peubah Penjelas dan Peubah Respon ... 33
Nilai Log Likelihood ... 37
PENDAHULUAN
Latar Belakang
Universitas Muhammadiyah Prof. DR. HAMKA (selanjutnya disebut
UHAMKA) merupakan salah satu perguruan tinggi swasta milik Persyarikatan
Muhammadiyah yang berkedudukan di Jakarta. Sebagai salah satu amal usaha
Muhammadiyah, UHAMKA adalah perguruan tinggi berbasis Islam yang
bersumber pada Al-Qur’an dan As-Sunah serta berasaskan Pancasila dan UUD
1945. Dalam melaksanakan tugas caturdharma Perguruan Tinggi Muhammadiyah,
kampus menyelenggarakan pembinaan ketakwaan dan keimanan kepada Allah
SWT, pendidikan dan pengajaran, penelitian, dan pengabdian pada masyarakat
menurut tuntutan Islam. UHAMKA membina 7 Fakultas dan 1 Program
Pascasarjana. Salah satu program studi yang dibina UHAMKA adalah Prodi
Farmasi yang berada di Fakultas Matematika dan Ilmu Pengetahuan Alam.
Program Studi Farmasi berlokasi di Kampus Jalan Limau II Kebayoran
Baru, Jakarta Selatan dan Kampus Jalan Delima II/IV Klender, Jakarta Timur.
Kampus ini berdiri sejak tanggal 30 Mei 1997 melalui surat keputusan Dirjen
Dikti Depdikbud Republik Indonesia Nomor: 1138/DIKTI/Kep/1997 tentang
penetapan perubahan IKIP Muhammadiyah Jakarta menjadi Universitas
Muhammadiyah Prof. DR. HAMKA. (UHAMKA 2009). Sampai saat ini
UHAMKA telah meluluskan kurang lebih 700 Sarjana Farmasi (S.Si) (sumber:
Data lulusan Farmasi UHAMKA TA 2009/2010).
Program studi Farmasi bertujuan menghasilkan Sarjana Sains (S.Si) dalam
bidang Farmasi yang bersifat profesional di bidang Farmasi, tanggap terhadap
perkembangan serta kemajuan teknologi dalam bidang Farmasi, mampu
mengatasi masalah yang dihadapi masyarakat serta mampu bersaing antara para
pencari kerja dalam proses mencari pekerjaan yang sesuai. Untuk memenangkan
persaingan itu mahasiswa dituntut untuk dapat mengembangkan potensi diri
secara holistik yang mencakup unsur fisik, mental, dan kepribadian sebagai
sumber daya manusia yang bermutu di masa depan. Mahasiswa adalah pemangku
kepentingan utama internal dan sekaligus sebagai pelaku proses nilai tambah
pendidikan, penelitian, dan layanan/pengabdian kepada masyarakat. Untuk itu,
mahasiswa perlu memiliki nilai-nilai profesionalisme, kemampuan adaptif, kreatif
dan inovatif dalam mempersiapkan diri memasuki dunia profesi atau dunia kerja,
dengan demikian akan diperoleh lulusan yang memenuhi standar kompetensi yang
diinginkan.
Lulusan adalah status yang dicapai mahasiswa setelah menyelesaikan proses
pendidikan sesuai dengan persyaratan kelulusan yang ditetapkan oleh program
studi sarjana. Sebagai salah satu keluaran langsung dari proses pendidikan yang
dilakukan oleh program studi sarjana adalah lulusan yang bermutu yang memiliki
ciri penguasaan kompetensi akademik termasuk hard skills dan soft skills
sebagaimana dinyatakan dalam sasaran mutu serta dibuktikan dengan kinerja
lulusan di masyarakat sesuai dengan profesi dan bidang ilmu.
Untuk mencapai lulusan yang demikian, program studi harus menempatkan
mahasiswa sebagai pemangku kepentingan utama sekaligus sebagai pelaku proses
seperti yang dijelaskan di atas sehingga visi dan misi dapat terwujud dan
terlaksana. Pada akhirnya akan tercapai lulusan yang mampu bersaing dan
bermutu tinggi, serta memiliki kompetensi yang sesuai dengan kebutuhan dan
tuntutan pemangku kepentingan.
Sebagai acuan atas keunggulan mutu mahasiswa dan lulusan yang terkait
erat dengan mutu, maka Badan Akreditasi Nasional Perguruan Tinggi (BAN PT)
telah mengeluarkan standar mutu mahasiswa dan lulusan sehingga dapat
dipertanggungjawabkan kepada seluruh pemangku kepentingan (stakeholders) dan sebagai gambaran terhadap kompetensi mahasiswa itu sendiri. Setiap standar
dan elemen dalam instrumen akreditasi dinilai secara kualitatif maupun kuantitatif
dengan menggunakan quality grade descriptor sebagai berikut: Sangat Baik, Baik dan Cukup.
Data kemampuan akademik mahasiswa berupa transkrip nilai dapat
dijadikan sebagai salah satu alat untuk mengukur prestasi mahasiswa.
Kemampuan akademik ini dapat dilihat dari nilai indeks prestasi kumulatif (IPK).
Banyak faktor yang mempengaruhi tingkat keberhasilan akademik mahasiswa,
antara lain faktor yang berasal dari dalam dan luar diri mahasiswa. Faktor yang
semangat dan persepsi. Sedangkan faktor yang berasal dari luar diri mahasiswa
antara lain: lingkungan sosial, lingkungan keluarga dan lingkungan kampus.
Lingkungan kampus memiliki peranan yang sangat penting dalam meningkatkan
keberhasilan mahasiswa bila dibanding dengan lingkungan lainnya.
Sebagai upaya meningkatkan kualitas lulusan, UHAMKA menggunakan
beberapa strategi, salah satunya adalah strategi pembelajaran. Strategi
pembelajaran dipandang sebagai salah satu strategi pokok untuk meningkatkan
mutu lulusan UHAMKA. Kebijakan kampus yang digunakan dalam penerapan
strategi pembelajaran ini adalah meningkatkan pembelajaran, pembaharuan
kebijakan dalam proses pembelajaran yaitu pembaharuan dalam menggunakan
metodologi pembelajaran, dan analisis prestasi belajar.
Dalam menentukan kebijakan terutama strategi pembelajaran UHAMKA
menerapkan kebijakan bahwa penerimaan mahasiswa baru perlu didukung dengan
data yang memadai dan dapat menjadi suatu acuan, sehingga kebijakan yang
dijalankan dapat optimal. Data tentang mahasiswa baru perlu dianalisa agar data
tersebut dapat dijadikan sebagai bahan informasi yang akurat.
Analisis terhadap kemampuan dasar mahasiswa baru dilakukan untuk
membantu pimpinan UHAMKA dalam menentukan kebijakan, terutama dalam
hal penerimaan mahasiswa baru. Analisis ini merupakan hal yang sangat penting
agar UHAMKA mendapatkan mahasiswa-mahasiswa yang berkualitas.
Beberapa peneliti telah mengembangkan metode regresi logistik dan metode
CHAID untuk kasus yang berbeda. (Ture et al 2006) melakukan penelitian
menggunakan 873 responden pada kasus “prestasi akademik” yang
menyimpulkan bahwa metode CHAID mempunyai kesalahan klasifikasi yang
lebih kecil yaitu 32.3% dibandingkan dengan regresi logistik sebanyak 35.71%.
Penelitian lain yang dilakukan (Atti 2008) menggunakan 827 responden untuk
kasus “penyakit jantung koroner” menyimpulkan bahwa metode CHAID
mempunyai kesalahan klasifikasi yang lebih kecil yaitu 30.7% dibandingkan
dengan regresi logistik yang nilainya 32.8%.
Sehubungan dengan penerimaan mahasiswa baru yang berkualitas dan
dalam rangka penyelesaian studi, penulis melakukan penelitian tentang
hubungan antara peubah respon dengan peubah penjelas berskala kategori,
menggunakan metode regresi logistik dan metode CHAID untuk kasus mahasiswa
Farmasi UHAMKA dengan jumlah responden 1080.
Tujuan
1. Menentukan model berdasarkan faktor-faktor yang nyata mempengaruhi
tingkat keberhasilan mahasiswa Farmasi UHAMKA dalam mencapai IPK
lebih dari 2.75 pada semester 6 dengan menggunakan regresi logistik dan
metode CHAID.
2. Membandingkan dugaan keberhasilan dengan keadaan sebenarnya dari hasil
klasifikasi menggunakan metode regresi logistik dan metode CHAID.
Hasil penelitian ini diharapkan dapat memberikan informasi yang
dibutuhkan dan menjadi bahan masukkan bagi program Farmasi UHAMKA
TINJAUAN PUSTAKA
Tingkat Keberhasilan Mahasiswa
Secara garis besar, faktor-faktor yang mempengaruhi keberhasilan mahasiswa
dalam pendidikan (Munthe 1983, diacu dalam Halim 2009) adalah:
1. Faktor intelektual seperti masalah belajar, bakat, dan kecerdasan.
2. Faktor nonintelektual seperti sosial, emosional, jenis kelamin, kesehatan,
keuangan, pengembangan pribadi, keluarga, pemanfaatan waktu luang,
agama, dan akhlak.
Menurut (Munandar 1987, diacu dalam Sampoerno 2002), kualitas
mahasiswa banyak dipengaruhi oleh berbagai faktor, antara lain:
1. Latar belakang keluarga; dukungan orang tua, taraf sosial ekonomi orang
tua.
2. Lingkungan belajar di rumah; sarana dan prasarana yang tersedia.
3. Lingkungan kampus dan dosennya; mampu bersosialisasi.
4. Motivasi; minat untuk berprestasi, keuletan.
Motivasi merupakan keseluruhan daya penggerak psikis didalam diri
mahasiswa yang menimbulkan kegiatan belajar dan memberikan arahan pada
kegiatan belajar demi mencapai tujuan. Motivasi dapat menentukan baik tidaknya
pencapai tujuan sehingga semakin besar motivasi akan semakin besar peluang
mahasiswa untuk memperoleh keberhasilan.
Regresi Logistik
Regresi logistik adalah suatu analisis statistika yang mendeskripsikan
hubungan antara peubah respon yang memiliki dua kategori atau lebih dengan satu
atau lebih peubah penjelas berskala kategori atau interval (Hosmer & Lemeshow
2000). Pendekatan model persamaan regresi logistik digunakan karena dapat
Jika data hasil pengamatan memiliki p peubah bebas yaitu x1,x2,...,xpdengan
peubah respon Y, dengan Y mempunyai dua kemungkinan nilai 0 dan 1, Y = 1 menyatakan bahwa respon memiliki kriteria yang ditentukan dan sebaliknya Y = 0 tidak memiliki kriteria, maka peubah respon Y mengikuti sebaran Bernoulli dengan
parameter
π
( )
x
i sehingga fungsi sebaran peluang:( )
[
( )
]
i[
( )
]
yii y
i
i x x
y
f = π 1−π 1− ,
y
i=
0
,
1
(1)Model umum regresi logistik dengan p peubah penjelas yaitu:
π
( )
x(
(
( )
( )
)
)
x x g g exp 1 exp += (2)
dimana π(x) = E(Y|x) adalah kondisi rataan bersyarat dari Y jika x diketahui apabila regresi logistik digunakan, dengan melakukan transformasi logit diperoleh
( )
( )
( )
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = x x x π π 1 lng (3)
dengan g
( )
x =β
0 +β
1x1+...+β
pxp , g(x) merupakan penduga logit yangberperan sebagai fungsi linear dari peubah penjelas, karena fungsi penghubung
yang digunakan adalah fungsi penghubung logit maka sebaran peluang yang
digunakan disebut sebaran logistik (McCullagh & Nelder 1989).
Pendugaan Parameter
Pendugaan parameter βi pada model logit dilakukan dengan metode penduga
kemungkinan maksimum, karena asumsi kehomogenan ragam galat tidak dipenuhi.
Jika antara amatan yang satu dengan amatan yang lain diasumsikan bebas, maka
fungsi kemungkinan maksimumnya adalah:
( )
∏
(
)
= = n i i i y f l 1 πβ (4)
parameter βi diduga dengan memaksimumkan persamaan diatas. Untuk
memudahkan perhitungan dilakukan pendekatan logaritma, sehingga fungsi
log-kemungkinan sebagai berikut, menurut (McCullagh & Nelder 1989):
( )
[
l β]
ln
∑
[
(
) (
)
]
∑
(
)
= = ⎥⎦ ⎤ ⎢ ⎣ ⎡ − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = − − + = n i i i i i n i i i i
i y y
y 1 1 1 ln 1 ln 1 ln 1 ln π π π π
Substitusi ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − i i π π 1
ln dengan
β
0 +β
1xi1+...+β
pxip danπ
i dengan(
)
(
i p ip)
ip p i x x x x β β β β β β + + + + + + + ... exp 1 ... exp 1 1 0 1 1 0
sehingga fungsi log kemungkinan menjadi
( )
[ ]
∑
(
)
(
(
)
)
= ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ + + + + + + + − + + + + = ni i p ip
ip p i ip p i i x x x x x x y l
1 0 1 1
1 1 0 1 1 0 ... exp 1 ... exp 1 ln ... ln β β β β β β β β β
β (6)
Nilai dugaan βi dapat diperoleh dengan memaksimumkan ln
[ ]
l( )
β yaitu denganmembuat turunan pertama ln
[
l( )
β]
terhadap βi dengan i = 0, 1, 2, …, p. Secaraanalitik penurunan ini sangatlah tidak mudah, oleh karena itu secara teknis
pendugaan βi diperoleh dari proses iterasi yaitu dengan menggunakan algoritma
Iteratively Reweighted Least Square (IRLS) (McCullagh & Nelder 1989).
Pengujian Parameter
Pengujian terhadap parameter model dilakukan untuk mengetahui pengaruh
peubah penjelas dalam model. Uji parameter yang digunakan adalah statistik:
1. Uji G
2. Uji Wald (W)
βi diduga dengan metode kemungkinan maksimum maka untuk menguji
peranan peubah penjelas di dalam model secara bersama-sama digunakan uji rasio
kemungkinan yaitu Uji G (Hosmer & Lemeshow 2000). Adapun rumus untuk uji G
berdasarkan hipotesis H0:
β
1 =β
2 =...=β
p =0 lawan H1: paling sedikit ada satu βi≠ 0 (i = 1, 2, …, p) adalah:
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = 1 0 ln 2 L L
G (7)
dimana
L
0 likelihood tanpa peubah penjelas dan L1 likelihood dengan peubahpenjelas.
Statistik G akan mengikuti sebaran
χ
2dengan derajat bebas p. Kriteriakeputusan yang diambil yaitu menolak H0 jika Ghitung > χ2p(α) (Hosmer &
Statistik Uji Wald digunakan untuk menguji parameter βi (Hosmer &
Lemeshow 2000). Rumus untuk Uji Wald berdasarkan hipotesis
H0: βi= 0 lawan H1: βi ≠ 0 (i = 0,1, 2, …, p) adalah:
( )
i i iE S W
β β
ˆ ˆ
ˆ
= (8)
dengan βˆ merupakan penduga i βi dan SˆE
( )
β
ˆ merupakan penduga galat baku darii
βˆ . Statistik W mengikuti sebaran normal baku. Kriteria keputusan adalah H0
ditolak jika
2
α
Z
Whitung > .
Pereduksian Peubah
Salah satu metode pereduksian peubah penjelas yaitu backward elimination. Analisis dimulai dengan model penuh yaitu memasukkan seluruh peubah penjelas
ke dalam model kemudian peubah diuji satu persatu mulai dari peubah yang
memiliki nilai-p yang paling besar, metode ini menggunakan uji Khi-kuadrat jika ada peubah yang tidak nyata pada nilai yang ditentukan peubah tersebut
dikeluarkan dari model. Setiap proses eliminasi selesai maka akan dilakukan uji
kebaikan model untuk menguji bahwa model dapat menggambarkan data dengan
baik. Analisis akan selesai jika tidak ada lagi peubah yang dapat dieliminasi dari
model (Garson 2010).
Tabel Klasifikasi
Untuk melihat ketepatan dugaan yang digambarkan pada model regresi
logistik digunakan tabel klasifikasi yang merupakan tabel 2x2 untuk peubah respon
yang biner, beberapa hal yang terkait dengan tabel klasifikasi antara lain:
1. Tingkat ketepatan, yakni jumlah dugaan yang tepat berdasarkan jumlah
contohnya.
2. Sencitivity, adalah persentase dugaan yang tepat pada kategori tandingan dari peubah respon (misal peubah yang berkategori 1 pada regresi logistik
3. Specitivity, adalah persentase dugaan yang tepat dari kategori pembanding dari peubah respon (misal peubah yang berkategori 0 pada regresi logistik
biner).
4. Tingkat kesalahan positif adalah persentase banyaknya kesalahan pada
peubah respon yang didugaan bernilai 1 tetapi yang terjadi bernilai 0,
kemudian dibandingkan dengan total kejadian yang didugaan bernilai 1.
5. Tingkat kesalahan negatif adalah persentase banyaknya kesalahan pada
peubah respon yang didugaan bernilai 0 tetapi yang terjadi bernilai 1,
kemudian dibandingkan dengan total kejadian yang didugaan bernilai 0
(Garson 2010).
Interpretasi Koefisien
Pada regresi linier, koefisien β1 merupakan beda antara nilai Y pada X=x+1
dengan nilai Y pada X=x.
( )
x
Y
x
=
β
0+
β
1(9)
(
x 1) ( )
Y xY + −
= 1
β (10)
Sedangkan pada regresi logistik β1= g
(
x+1) ( )
−g x menunjukkan peubahnilai logit untuk setiap satu unit peubah pada peubah bebas X. Untuk model regresi logistik dengan satu peubah penjelas dikotom dapat dilihat pada Tabel 1.
Nilai odds (rasio antara Y=1 dengan Y=0 untuk X=1) adalah ⎥
⎦ ⎤ ⎢
⎣ ⎡
− (1) 1 ) 1 ( π π
sedangkan untuk X=0 adalah ⎥
⎦ ⎤ ⎢
⎣ ⎡
− (0) 1 ) 0 ( π π
. Log dari kedua odds tersebut
didefinisikan sebagai g(1) dan g(0) . Rasio odds (ψ ) didefinisikan sebagai rasio dari odds untuk X =1 dengan X =0 sehingga:
) exp( )] 0 ( 1 /( ) 0 ( [ )] 1 ( 1 /( ) 1 ( [ 1 β π π π π ψ = − −
= (11) ) 0 ( ) 1 ( ))] 0 ( 1 /( ) 0 ( [ ))] 1 ( 1 /( ) 1 ( [ ln
ln =g −g
− − = π π π π
Tabel 1 Model Regesi Logistik dengan Satu Peubah Penjelas Dikotom
Peubah Respon Peubah Penjelas
x=1 x=0
y=1 ) exp( 1 ) exp( ) 1 ( 1 0 1 0 β β β β π + + + = ) exp( 1 ) exp( ) 0 ( 0 0 β β π + = y=0 ) exp( 1 1 ) 1 ( 1 1 0 β β π + + = − ) exp( 1 1 ) 0 ( 1 0 β π + = −
Jumlah 1 1
Dengan demikian, pada model logistik dengan satu peubah penjelas dikotom,
koefisien β1 adalah model beda logit, sedangkan exp(β1) nilai rasio odds.
Interpretasi koefisien untuk model regresi logistik dapat dilakukan dengan
melihat rasio oddsnya. Jika suatu peubah penjelas mempunyai tanda koefisien positif, maka nilai rasio oddsnya akan lebih besar dari satu, sebaliknya jika tanda koefisiennya negatif maka nilai rasio oddsnya akan lebih kecil dari satu. Rasio odds
memiliki selang kepercayaan (1-
α
)100% sebagai berikut: )] ˆ ( ˆ ˆ exp[ 2 1 ii Z SE β
β α
−
± (13)
Metode CHAID
Chi-square Automatic Interaction Detecion (CHAID) pertama kali diperkenalkan dalam sebuah artikel berjudul “ An Exploratory Tecnique for Investigating Large Quantities of Categorical Data” oleh Dr. G.V. Kass pada tahun 1980. CHAID merupakan salah satu tipe dari metode AID (Automatic Interaction Detecion). Metode AID adalah suatu teknik untuk menganalisis kelompok data berukuran besar dengan membaginya menjadi sub-sub kelompok
yang tidak saling tumpang tindih (Kass 1980). Tehnik pemecahan (splitting)
kelompok menjadi beberapa sub kelompok sehingga diperoleh sub-sub kelompok
yang secara maksimal saling berbeda.
Metode ini terutama dikembangkan untuk menelusuri keterkaitan struktural
dalam data survey (Fielding 1977). Peubah-peubah tersebut dapat berupa satu
peubah respon dengan beberapa peubah penjelas atau beberapa peubah respon
dengan beberapa peubah penjelas. Metode CHAID merupakan teknik eksplorasi
cukup efisien untuk menduga peubah-peubah penjelas yang paling nyata terhadap
peubah respon.
Pada prisipnya cara kerja metode CHAID memisahkan data kedalam
beberapa kelompok secara bertahap. Tahap pertama diawali dengan membagi data
menjadi beberapa kelompok berdasarkan satu peubah penjelas yang pengaruhnya
paling nyata terhadap peubah respon. Masing-masing kelompok yang diperoleh
diperiksa secara terpisah untuk membaginya menjadi beberapa kelompok
berdasarkan peubah penjelas dan seterusnya hingga pada akhirnya diperoleh
kelompok-kelompok pengamatan yang memiliki respon dan peubah penjelas
tertentu yang berkaitan, hasil analisis metode CHAID adalah suatu dendogram
pemisahan.
Metode CHAID digunakan bila peubah responnya berskala nominal atau
ordinal dengan kriteria statistik uji khi-kuadrat pada setiap pemisahannya. Proses pemisahan dilakukan secara iteratif dimulai dari peubah bebas yang mempunyai
asosiasi paling kuat dengan peubah tak bebas yang digambarkan oleh besarnya
nilai-p (p-value) berdasarkan uji khi-kuadrat ((Magidson & Vermunt 2006). Dalam proses ini juga akan dilakukan penggabungan kategori-kategori dalam satu peubah
bebas yang tidak memiliki asosiasi yang nyata dengan peubah tak bebas. Secara
singkat algoritma CHAID adalah sebagai berikut, menurut (Kass 1980):
1. Membuat tabulasi silang antara kategori-kategori peubah penjelas dengan
kategori-kategori peubah respon.
2. Membuat subtabel berukuran 2xd yang mungkin, d adalah banyaknya kategori peubah respon. Kemudian cari nilai semua subtabel tersebut. Dari
seluruh yang diperoleh, cari yang terkecil katakan . Jika
ditetapkan, db 1 , maka kedua kategori peubah
penjelas yang memiliki digabung menjadi satu kategori. Untuk
peubah ordinal penggabungan hanya dapat dilakukan terhadap kategori yang
berurutan.
3. Jika terdapat kategori gabungan yang terdiri dari tiga atau lebih kategori asal,
maka harus dilakukan pembagian biner terhadap kategori gabungan tersebut,
dari pembagian ini dicari terbesar. Jika terbesar > , maka
4. Setelah diperoleh penggabungan optimal untuk setiap peubah penjelas hitung
nilai-p masing-masing tabel yang dibentuk (tabel yang mengalami pengurangan kategori, nilai-p nya dikalikan dengan pengganda Bonferoni
sesuai dengan tipe peubahnya). Cari nilai-p yang terkecil. Jika nilai-p terkecil < yang telah ditetapkan, maka X pada nilai-p tersebut adalah peubah penjelas yang pengaruhnya paling nyata bagi peubah respon.
5. Jika pada tahap 4 diperoleh peubah yang pengaruhnya paling nyata, kembali ke
tahap 1 untuk setiap bagian data hasil pemisahan.
Statistik uji yang digunakan adalah dengan rumus:
keterangan:
r = total baris
c = total kolom
i = indeks baris
j = indeks kolom
= nilai sel baris ke-i kolom ke-j
= nilai harapan sel baris ke-i kolom ke-j
Pengganda Bonferoni untuk tabel yang mengalami pengurangan kategori sesuai dengan tipe peubahnya:
1. Peubah monotonik yaitu bila kategori berskala ordinal
1 1
2. Peubah bebas yaitu bila kategori berskala nominal
∑ 1 ! !
Ketepatan dan Kesalahan Klasifikasi
Salah satu ukuran kebaikan model dalam regresi logistik yaitu model yang
mempunyai peluang salah klasifikasi minimal (Hosmer & Lemeshow 2000).
Ketepatan dan kesalahan klasifikasi dari model dapat dilihat dalam tabel klasifikasi.
Tabel klasifikasi untuk peubah respon dikotom terdiri atas dua kolom nilai dugaan
classification) terhadap amatan harus menentukan nilai cutpoint (c) dan dibandingkan dengan peluang dugaan . Jika lebih besar atau sama
dengan c maka nilai dugaan termasuk pada respon y=1 dan selain itu y=0. Tabel 2 memperlihatkan tabel klasifikasi secara umum.
Tabel 2 Klasifikasi Respon
Amatan
Dugaan
Total Ketepatan 1 0
1 a b (a + b) = n1. a/n1.
0 c d (c + d) = n0. d/n0.
Total (a + c) = n.1 (b +d) = n.0 (a + b + c + d) = n (a + d)/n
Kesalahan c/n.1 b/n.0 (b + c)/n
Ketepatan klasifikasi (correct classification) terdiri atas specificity dan
sentisivity. Specificity atau ketepatan klasifikasi dalam menduga kejadian bahwa respon tidak memiliki kriteria yang diharapkan yaitu pada y=0 sebesar d/n0.100%,
untuk mengevaluasi ketepatan klasifikasi dalam menduga kejadian bahwa respon
memiliki kriteria yang diharapkan yaitu y=1 atau disebut juga sensitivity yang nilainya sebesar a/n1.100%, sedangkan ketepatan klasifikasi yaitu ketepatan
klasifikasi dalam menduga kejadian secara tepat dapat diduga oleh model yang
nilainya (a+d)/n100%.
Selain ketepatan klasifikasi dapat pula diketahui besarnya kesalahan
klasifikasi (misclassification rate). Kesalahan klasifikasi dalam menduga kejadian respon terdiri atas kesalahan positf atau negatif. Kesalahan positif nilainya sebesar
c/n.1100% dinyatakan sebagai persentase besarnya kesalahan ketika respon diduga
memiliki kriteria yang ditentukan yaitu y=1 tapi amatan sebenarnya bernilai y=0 dan sebaliknya kesalahan negatif yang nilainya sebesar b/n.0100% dinyatakan
sebagai persentase besarnya kesalahan ketika respon diduga tidak memiliki kriteria
yang diharapkan y=0 namun amatan sebenarnya bernilai y=1. Kesalahan klasifikasi diartikan sebagai besarnya kesalahan klasifikasi terhadap kesalahan keseluruhan
kejadian yang dapat diperoleh dengan cara merasiokan total klasifikasi yang tidak
METODOLOGI
Metodologi Pengumpulan Data
Data yang digunakan dalam penelitian ini adalah data sekunder yaitu data mahasiswa S1 Program Studi Farmasi UHAMKA angkatan 1998 sampai dengan 2006 yang diperoleh dari Biro Administrasi Akademik dan Kemahasiswaan (BAAK) UHAMKA. Data tersebut belum dilakukan elektonik file, sehingga data yang ada diambil dari arsip pendaftaran mahasiswa baru kemudian dimasukkan soft copy. Proses mengambilan data dilakukan selama 6 bulan, karena dibutuhkan koordinasi dengan kepala tata usaha, bagian akademik dan ketua program studi, dari data yang ada sulit mendapatkan peubah yang sesuai dengan teori untuk dianalisa maka perlu dipilih peubah-peubah yang akan digunakan. Peubah-peubah yang dipilih diduga dapat mempengaruhi keberhasilan mahasiswa kemudian dari peubah-peubah tersebut dikategorikan. Selanjutnya dicari nilai IPK pada semester enam dari masing-masing data yang dapat diperoleh dari BAAK.
Badan Akreditasi Nasional Perguruan Tinggi (BAN PT 2008) sebagai lembaga resmi negara yang memberikan penilaian terhadap program studi menetapkan nilai Indek Prestasi Kumulatif sebagai berikut :
1. Sangat baik : Jika IPK ≥ 3.5
2. Baik : Jika 2.75 < IPK < 3.5 3. Cukup : Jika 2 ≤ IPK ≤ 2.75
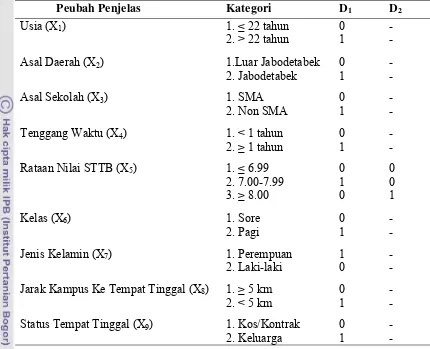
Pada penelitian ini nilai IPK mahasiswa dikelompokan menjadi dua bagian yaitu mahasiswa yang berhasil dengan kriteria IPK lebih dari 2.75 (y=1) dan yang kurang berhasil dengan kriteria IPK maksimal 2.75 (y=0). Sedangkan untuk peubah penjelas terdapat pada Tabel 3. Pemilihan Kategori terhadap peubah penjelas didasarkan pada eksplorasi awal. Apabila n pada suatu kategori relatif kecil maka kategori akan digabungkan terhadap kategori lain. Adapun alasan/keterangan pemilihan peubah penjelas sebagai berikut:
2. Asal daerah dikelompokkan berdasarkan tempat kelahiran responden, yaitu diluar ataupun dalam area Jabodetabek, karena sebagian besar responden berasal dari Jabodetabek.
3. Asal sekolah dibagi menjadi kategori Sekolah Menengah Atas ataupun diluar dari Sekolah Menengah Atas, seperti Sekolah Menengah Farmasi, Sekolah Analisis Kimia dan Sekolah Perawat Kesehatan.
4. Peubah penjelas tenggang waktu merujuk pada masa alih atau masa tunggu responden dari sejak lulus Sekolah Lanjutan Tingkat Atas sampai masuk perguruan tinggi. Adapun waktu tenggang yang dimaksud adalah < 1 tahun artinya langsung kuliah atau ≥ 1 tahun artinya menganggur terlebih dahulu. 5. Rataan nilai STTB yaitu rataan nilai yang tercantum pada Surat Tanda Tamat
Belajar di Sekolah Lanjutan Tingkat Atas responden. Peubah penjelas ini dibagi tiga kategori yaitu: rataan nilai STTB ≤ 6.99, rataan nilai STTB 7.00-7.99, rataan nilai STTB ≥ 8.00, berdasarkan eksplorasi.
6. Di UHAMKA, responden menjalankan perkuliahan dalam kelas pagi atau kelas sore. Oleh karena itu peubah penjelas kelas dibagi menjadi kelas sore dan kelas pagi.
7. Jenis kelamin dikategorikan menjadi perempuan dan laki-laki.
8. Jarak kampus ke tempat tinggal diasumsikan sebagai jarak tempat responden menetap selama kuliah terhadap kampus yaitu ≥ 5 km atau < 5 km.
9. Peubah penjelas status tempat tinggal digolongkan responden tinggal mandiri yaitu kos/kontrak atau dengan keluarga.
Tabel 3 Peubah-peubah penjelas yang digunakan dalam analisis dan peubah bonekanya
Peubah Penjelas Kategori D1 D2
Usia (X1) 1. ≤ 22 tahun 0 -
2. > 22 tahun 1 -
Asal Daerah (X2) 1.Luar Jabodetabek 0 -
2. Jabodetabek 1 -
Asal Sekolah (X3) 1. SMA 0 -
2. Non SMA 1 -
Tenggang Waktu (X4) 1. < 1 tahun 0 -
2. ≥ 1 tahun 1 -
Rataan Nilai STTB (X5) 1. ≤ 6.99 0 0
2. 7.00-7.99 1 0
3. ≥ 8.00 0 1
Kelas (X6) 1. Sore 0 -
2. Pagi 1 -
Jenis Kelamin (X7) 1. Perempuan 1 -
2. Laki-laki 0 -
Jarak Kampus Ke Tempat Tinggal (X8) 1. ≥ 5 km 0 -
2. < 5 km 1 -
Status Tempat Tinggal (X9) 1. Kos/Kontrak 0 -
2. Keluarga 1 -
Metode Analisis
1. Eksplorasi data terhadap data awal, jika dari data yang diperoleh ada yang tidak lengkap maka observasi tersebut dikeluarkan dari populasi amatan.
2. Data yang diperoleh diringkas dengan cara menyajikan persentase untuk setiap peubah-peubah penjelas yang diamati dan membuat tabulasi silang dari peubah respon dan peubah penjelas.
3. Melakukan pendugaan parameter yaitu dengan membuat model persamaan regresi logistik.
4. Melakukan pengujian parameter, ada dua tahap dalam melakukan pengujian ini, yaitu:
a. Dengan statistik uji-G. Statistik uji-G dilakukan untuk menguji parameter secara bersama-sama.
5. Mengeluarkan beberapa peubah penjelas yang tidak ada pengaruhnya terhadap peubah respon berdasarkan hasil statistik uji-G dan uji-Wald dengan prosedur
backward elimination.
6. Melakukan interpretasi koefisien. Langkah ini dilakukan setelah tidak ada lagi peubah penjelas yang tidak nyata.
7. Memprediksi peluang keberhasilan dari peubah-peubah yang nyata.
8. Melakukan analisis klasifikasi dengan menggunakan persamaan regresi logistik yang diperoleh berdasarkan nilai dugaan peluangnya.
9. Melakukan analisis klasifikasi dengan menggunakan hasil percabangan akhir dari metode CHAID.
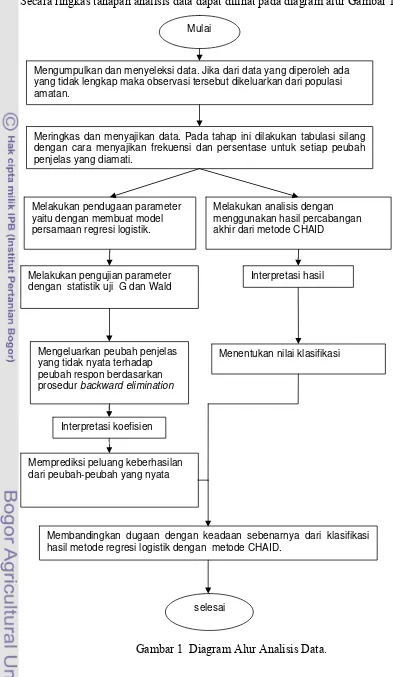
Secara ringkas tahapan analisis data dapat dilihat pada diagram alur Gambar 1.
[image:31.595.72.465.91.768.2]
Gambar 1 Diagram Alur Analisis Data.
Mulai
Mengumpulkan dan menyeleksi data. Jika dari data yang diperoleh ada yang tidak lengkap maka observasi tersebut dikeluarkan dari populasi amatan.
Meringkas dan menyajikan data. Pada tahap ini dilakukan tabulasi silang dengan cara menyajikan frekuensi dan persentase untuk setiap peubah penjelas yang diamati.
Melakukan analisis dengan menggunakan hasil percabangan akhir dari metode CHAID
Melakukan pendugaan parameter yaitu dengan membuat model persamaan regresi logistik.
Melakukan pengujian parameter dengan statistik uji G dan Wald
Interpretasi hasil
Mengeluarkan peubah penjelas yang tidak nyata terhadap peubah respon berdasarkan prosedur backward elimination
Menentukan nilai klasifikasi
Membandingkan dugaan dengan keadaan sebenarnya dari klasifikasi hasil metode regresi logistik dengan metode CHAID.
Interpretasi koefisien
Memprediksi peluang keberhasilan dari peubah-peubah yang nyata
HASIL DAN PEMBAHASAN
Deskripsi Karakteristik Responden Berdasarkan Peubah Penjelas
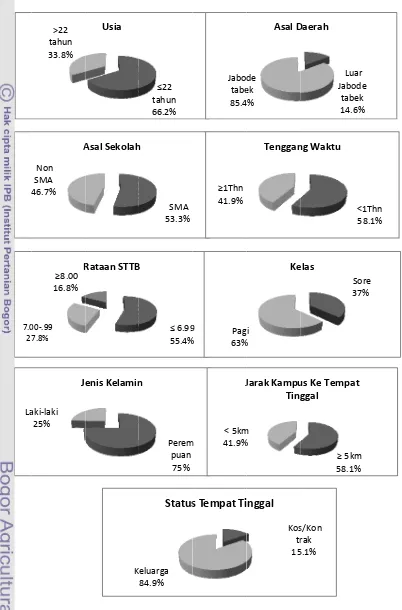
Hasil analisis mengenai persentase responden berdasarkan peubah-peubah penjelas ditunjukkan pada Gambar 2. Usia responden ≤ 22 tahun sebanyak 66.2% lebih banyak dibandingkan yang usia > 22 tahun yaitu 33.8% artinya mahasiswa yang masuk pada prodi Farmasi sebagian besar berusia sesuai dengan perkiraan usia responden pada semester enam.
Persentase responden berdasarkan asal daerah, yang berasal dari luar Jabodetabek sebanyak 14.6% lebih sedikit dibandingkan dari Jabodetabek yaitu 85.4% ini disebabkan kurangnya promosi dari prodi Farmasi di luar Jabodetabek. Berdasarkan asal sekolah yang berasal dari SMA sebanyak 53.3% sedangkan yang berasal dari Non SMA sebanyak 46.7% artinya prodi Farmasi lebih diminati oleh siswa SMA dibandingkan siswa Non SMA.
Berdasarkan tenggang waktu, yang memiliki masa tenggang waktu < 1 tahun sebanyak 58.1% lebih besar dibandingkan ≥ 1 tahun yaitu 41.9% artinya yang diterima pada prodi Farmasi sebagian besar mereka yang baru lulus sekolah atau tidak menganggur dulu. Berdasarkan rataan nilai STTB sebagian besar responden memiliki rataan nilai ≤ 6.99 sebanyak 55.4% sedangkan yang rataan nilai 7.00-7.99 sebanyak 27.8% dan yang rataan nilai STTB ≥ 8.00 sebanyak 16.8% artinya siswa yang diterima sebagian besar yang memiliki prestasi cukup.
Persentase responden berdasarkan kelas, yang kelas sore 37% lebih sedikit dibandingkan kelas pagi yaitu 63% hal ini disebabkan belajar di pagi hari akan lebih nyaman dibanding sore hari sehingga kelas pagi lebih banyak diminati mahasiswa. Berdasarkan jenis kelamin, perempuan sebanyak 75.2% jauh lebih banyak dibandingkan laki-laki yaitu 24.8% artinya prodi Farmasi lebih diminati perempuan dibanding laki-laki.
84.9% kamp 4 7.0 27 La
[image:33.595.76.478.120.730.2]% ini diseb pus sehingg Gambar 2 >22 tahun 33.8% Non SMA 46.7% A
00‐.99 7.8%
8.00 16.8%
R
aki‐laki 25%
Je
babkan tem ga tidak perl
Persentase Usia
Asal Sekolah
Rataan STTB
enis Kelamin
K mpat tingga lu kos. e Responden 22 tahun 66.2% SMA 53.3% h 6.99 55.4% B Perem puan 75% n eluarga 84.9% Status al keluarga n Berdasark 1Thn 41.9% 9 % Pag 63% m
< 5km 41.9%
J
s Tempat Ti
Jabo tabe 85.4 mereka tid kan Peubah-Tenggan i % Ke m %
Jarak Kampu Tin Kos tr 15 inggal de ek 4%
Asal D
dak terlalu
-Peubah Pen ng Waktu
S 3
elas
5k 58.1
us Ke Tempa ggal s/Kon rak 5.1% Lu Jabo tab 14.6 Daerah
u jauh dari
njelas.
Deskripsi Karakteristik Responden Berdasarkan Tingkat keberhasilan
Karakteristik responden berdasarkan peubah penjelas pada Tabel 3 dan tabulasi silang pada Lampiran 1, dapat diamati pada Gambar 3. Pada gambar 3 ditunjukkan bahwa responden yang memiliki usia ≤ 22 tahun tingkat keberhasilannya 35.0%, lebih tinggi dibandingkan responden yang memiliki usia > 22 tahun yaitu 16.7%, hal ini disebabkan jika pada semester enam mahasiswa berusia > 22 tahun artinya mahasiswa tersebut pada saat sekolah dasar atau sekolah lanjutan mengalami suatu masalah mungkin terlambat mendaftar sekolah atau pernah tidak naik kelas, hal ini dapat mempengaruhi tingkat keberhasilan.
Responden yang berasal dari Jabodetabek tingkat keberhasilannya 44.1% jauh lebih besar dibandingkan dengan responden yang berasal dari luar Jabodetabek yaitu 7.6% artinya mahasiswa yang berasal dari Jabodetabek memiliki daya saing lebih tinggi dibandingkan mahasiswa yang dari luar Jabodetabek. Responden yang berasal dari SMA tingkat keberhasilannya 26.7% hampir sama dengan tingkat keberhasilan responden yang berasal dari Non SMA yaitu 25%.
Responden yang memiliki tenggang waktu < 1 tahun artinya tidak sempat menganggur memiliki tingkat keberhasilan 30.6% sedangkan responden yang memiliki tenggang waktu ≥ 1 tahun tingkat keberhasilannya 21.1% artinya responden yang baru lulus akan lebih berhasil dibandingkan yang sempat menganggur.
Responden yang memiliki rataan nilai STTB ≤ 6.99 tingkat keberhasilannya 22.3%, yang rataan nilai STTB 7.00-7.99 tingkat keberhasilannya 14.5% dan yang rataan nilai STTB ≥ 8.00 tingkat keberhasilannya 14.8%, ini menunjukkan tingkat keberhasilan paling tinggi diperoleh pada kategori rataan nilai STTB ≤ 6.99.
laki-l laki-l tingk mem kelua kos/k mem sehin maha menu masi kelam G Kete X1= X2= X3= X4= X5= 0 10 20 30 40 50 60 70 80 90 Responden laki yaitu laki. Responden kat keberhas miliki tingka arga tingk kontrak yai mikirkan bia ngga diduga asiswa yang Kesembi unjukkan ba ng-masing min.
Gambar 3 Pe rangan: =Usia =Asal Daera =Asal Sekol =Tenggang =Rataan Nil 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 1 2 X1 n perempua 10.2% hal
n yang jar silan 29.5% at keberhasi kat keberha
itu 7.7% i aya tempat a untuk mem g harus mem
ilan peuba ahwa antara kategori jau ersentase Pe ah lah Waktu lai STTB
1 2 1 2 1 X2 X3 X
an tingkat k ini disebab
rak kampus % dan respon
ilan 22.1%. asilannya ini disebab tinggal, ha mperoleh ke mikirkan bia ah penjelas a tingkat ke uh berbeda eubah Penje X6=K X7=Je X8= J X9=St
1 2 1 2 3 1 X4 X5
keberhasilan bkan perem
s ke tempa nden jarak k
Responden 44.0% leb bkan tingga al ini mengu eberhasilan aya tempat t s yang di eberhasilan a yaitu kateg
elas Terhad
Kelas enis Kelami
arak Kampu tatus Tempa
1 2 1 2 1 2 X6 X7 X8
nnya 41.5% mpuan lebih
at tinggalny kampus ke t n yang bert bih tinggi
al dirumah urangi beba n akan lebih
tinggal. iamati ada dan tingka gori rataan dap Tingkat in
u Ke Tempa at Tinggal
2 1 2 8 X9
lebih tingg h tekun dib
ya ≥ 5 km tempat tingg tempat tingg dibanding h sendiri ti an pikiran m h mudah dib
a dua peu at kurang be nilai STTB
Keberhasila
at Tinggal
Kurang Ber Berhasil
gi dari pada bandingkan
m memiliki gal < 5 km gal dengan gkan yang idak perlu mahasiswa bandingkan ubah yang erhasil dari B dan jenis
an.
Model Regresi Logistik
Analisis regresi logistik dengan menggunakan 9 peubah penjelas dapat dilihat pada Tabel 4 yang menghasilkan nilai statistik uji-G sebesar 157.156 dengan derajat bebasnya 10 dan log likelihood sebesar -669.421 dengan
nilai-p=0.000, sehingga dapat ditarik kesimpulan bahwa paling sedikit ada satu tidak sama dengan nol diantara peubah penjelas tersebut pada taraf nyata 5%. Uji Wald pada model regresi logistik menunjukkan hanya ada dua peubah penjelas yaitu X5 dan X7 yang nyata pada taraf 5%, jadi rataan nilai STTB (X5)
dan jenis kelamin (X7) berpengaruh terhadap keberhasilan untuk mendapatkan
IPK lebih dari 2.75.
Tabel 4 Hasil Analisis Regresi Logistik Model Penuh Peubah
Penjelas SE Wald Nilai-p
Rasio Odds
X1(1) -0.069 0.185 0.138 0.710 0.933
X2(1) -0.122 0.205 0.354 0.552 0.885
X3(1) 0.052 0.146 0.125 0.724 1.053
X4(1) -0.060 0.178 0.114 0.735 0.942
X5(1) 0.521 0.145 12.848 0.000 1.684
X5(2) 2.385 0.245 95.071 0.000 10.858
X6(1) -0.053 0.141 0.140 0.708 0.949
X7(1) 0.592 0.155 14.671 0.000 1.807
X8(1) 0.045 0.139 0.103 0.748 1.046
X9(1) 0.084 0.210 0.161 0.689 1.088
Konstant -0.778 0.277 7.866 0.005 0.459
dengan nilai nilai-p sebesar 0.000. Pada Tabel 5 dapat dilihat peubah yang masuk dalam model dan nilai nilai-p dari hasil uji Wald sebagai berikut:
Tabel 5 Analisis Regresi Logistik Hasil Uji Backward Elimination
Peubah SE Wald Nilai-p Rasio Odds
X5(1) 0.522 0.144 13.105 0.000 1.685
X5(2) 2.389 0.244 96.256 0.000 10.907
X7(1) 0.601 0.153 15.414 0.000 1.825
Constant -0.857 0.147 34.021 0.000 0.424
Berdasarkan peubah penjelas yang nyata pada Tabel 5 diperoleh model logit sebagai berikut:
-0.857 + 0.522X5(1) + 2.389X5(2) + 0.601X7(1)
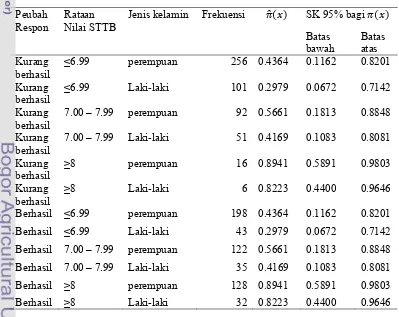
Berdasarkan kedua peubah penjelas dan peubah boneka yang terpilih maka didapat nilai dugaan peluang keberhasilan untuk setiap kombinasi peubah penjelas, nilai tersebut ditunjukkan pada Tabel 6.
Tabel 6 Nilai Dugaan Peluang untuk Setiap Kombinasi Peubah Penjelas
Peubah Respon
Rataan Nilai STTB
Jenis kelamin Frekuensi SK 95% bagi
Batas bawah
Batas atas Kurang
berhasil
≤6.99 perempuan 256 0.4364 0.1162 0.8201
Kurang berhasil
≤6.99 Laki-laki 101 0.2979 0.0672 0.7142
Kurang berhasil
7.00 – 7.99 perempuan 92 0.5661 0.1813 0.8848
Kurang berhasil
7.00 – 7.99 Laki-laki 51 0.4169 0.1083 0.8081
Kurang berhasil
≥8 perempuan 16 0.8941 0.5891 0.9803
Kurang berhasil
≥8 Laki-laki 6 0.8223 0.4400 0.9646
Berhasil ≤6.99 perempuan 198 0.4364 0.1162 0.8201
Berhasil ≤6.99 Laki-laki 43 0.2979 0.0672 0.7142
Berhasil 7.00 – 7.99 perempuan 122 0.5661 0.1813 0.8848
Berhasil 7.00 – 7.99 Laki-laki 35 0.4169 0.1083 0.8081
Berhasil ≥8 perempuan 128 0.8941 0.5891 0.9803
[image:37.595.75.474.439.756.2]Interpretasi Koefisien
Interpretasi koefisien pada regresi logistik dapat dilakukan dengan menggunakan rasio odds. Jika suatu peubah memiliki nilai koefisien yang bertanda positif maka nilai rasio odds di atas satu, sedangkan nilai koefisien yang bertanda negatif maka nilai rasio odds di bawah satu. Nilai dugaan rasio odds
beserta selang kepercayaan 95% untuk masing-masing peubah penjelas dapat dilihat pada Tabel 7.
Tabel 7 Rasio Odds dari Peubah Penjelas yang Nyata
Dugaan Rasio Odds
SK 95% Bagi Rasio Odds Peubah Penjelas
Batas Bawah
Batas Atas Rataan_nilai_STTB(1) 1.685 1.270 2.236 Rataan_nilai_STTB(2) 10.907 6.767 17.580
Jenis_kelamin(1) 1.825 1.351 2.463
Peubah penjelas yang berpengaruh nyata terhadap tingkat keberhasilan mahasiswa Farmasi UHAMKA adalah rataan nilai STTB dan jenis kelamin. Rataan nilai STTB 7.00 – 7.99 memiliki nilai rasio odds 1.685, artinya dugaan peluang mahasiswa berhasil yang memiliki rataan nilai STTB 7.00 – 7.99 adalah 1.685 kali dibanding mahasiswa yang memiliki rataan nilai STTB ≤ 6.99. Rataan nilai STTB ≥ 8 memiliki nilai rasio odds 10.907, artinya dugaan peluang mahasiswa berhasil yang memiliki rataan nilai STTB ≥ 8 adalah 10.907 kali dibanding mahasiswa yang memiliki rataan nilai STTB ≤ 6.99. Untuk jenis kelamin perempuan memiliki nilai rasio odds 1.825, artinya dugaan peluang berhasil perempuan adalah 1.825 kali dibanding laki-laki, artinya dugaan peluang berhasil perempuan lebih besar dari peluang berhasil laki-laki.
Keakuratan Model
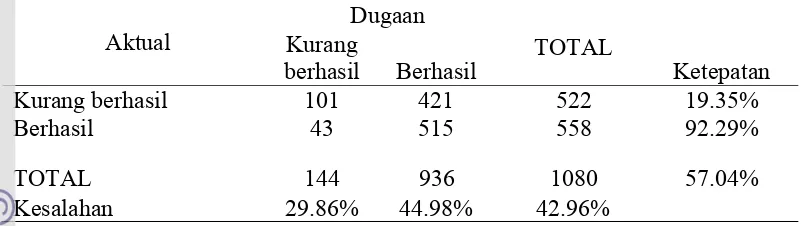
Tabel 8 Klasifikasi Metode Regresi Logistik dengan Cut Off 0.3 sampai dengan 0.4
Aktual
Dugaan
TOTAL
Ketepatan Kurang
berhasil Berhasil Kurang berhasil
Berhasil
101 43
421 515
522 558
19.35% 92.29%
TOTAL 144 936 1080 57.04%
Kesalahan 29.86% 44.98% 42.96%
Tabel 8 menunjukkan berdasarkan regresi logistik dengan nilai cut off
sebesar 0.3 sampai dengan 0.4 maka diperoleh nilai sensitivity 92.29% dan nilai
specificity 19.35% dengan nilai kesalahan positif 44,98%, nilai kesalahan negatif 29.86% dan nilai total ketepatan klasifikasi 57.04% serta nilai total kesalahan klasifikasi42.96%.
Tabel 9 Klasifikasi Metode Regresi Logistik dengan Cut Off 0.5
Aktual
Dugaan
TOTAL
Ketepatan Kurang
berhasil Berhasil Kurang berhasil
Berhasil
408 276
114 282
522 558
78.16% 50.54%
TOTAL 684 396 1080 63.89%
Kesalahan 40.35% 28.79% 36.11%
Tabel 9 menunjukkan berdasarkan regresi logistik dengan nilai cut off
sebesar 0.5 maka diperoleh nilai sensitivity 50.54% dan nilai specificity 78.16% dengan nilai kesalahan positif 28.79%, nilai kesalahan negatif 40.35% dan nilai total ketepatan klasifikasi 63.89 % serta nilai total kesalahan klasifikasi 36.11%.
Tabel 10 Klasifikasi Metode Regresi Logistik dengan Cut Off 0.6 sampai dengan 0.8
Aktual
Dugaan
TOTAL
Ketepatan Kurang
berhasil Berhasil
Kurang berhasil 500 22 522 95.79%
Berhasil 398 160 558 28.68%
TOTAL 898 182 1080 61.11%
Kesalahan 44.32% 12.09% 38.89%
Tabel 10 menunjukkan berdasarkan regresi logistik dengan nilai cut off
specificity 95.79% dengan nilai kesalahan positif 12.09%, nilai kesalahan negatif 44.32% dan nilai total ketepatan klasifikasi 61.11% serta nilai total kesalahan klasifikasi 38.89%.
Cut off yang digunakan yaitu 0.5 karena dari semua nilai yang dicobakan (0.3 sampai dengan 0.4, 0.5, 0.6 sampai dengan 0.8), nilai 0.5 merupakan cut off yang paling optimum dalam ketepatan keseluruhan model, ketepatan dugaan mahasiswa yang kurang berhasil sebesar 78.16% dari 522 mahasiswa yang kurang berhasil sebanyak 408 mahasiswa diklasifikasikan dengan benar. Sedangkan dari 558 mahasiswa yang berhasil sebanyak 282 atau 50.54% diklasifikasikan dengan benar. Ketepatan untuk keseluruhan model sebesar 63.89%.
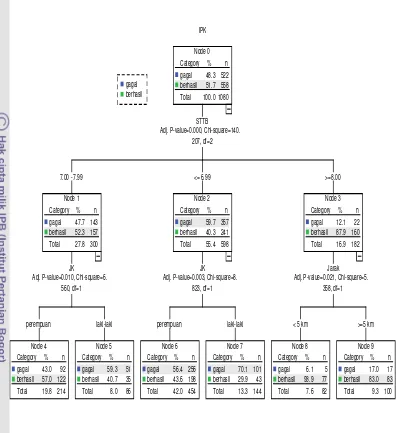
Metode CHAID
Dendogram hasil pemisahan analisis CHAID pada Gambar 4 dengan α=0.05 menunjukkan bahwa peubah yang memiliki asosiasi paling kuat dengan tingkat keberhasilan yaitu kategori rataan nilai STTB, dari 1080 responden 27.8% merupakan responden dengan nilai STTB antara 7.00-7.99 dan 52.3% diantaranya yang berhasil, responden dengan rataan nilai STTB ≤ 6.99 yang berhasil hanya 40.3%, sedangkan pada responden dengan rataan nilai STTB ≥ 8.00 yang berhasil sangat besar yaitu 87.9%.
Gambar 4 Dendogram CHAID Status Keberhasilan Mahasiswa.
Tabel 11 menunjukkan bahwa mahasiswa yang berhasil yaitu yang memiliki rataan nilai STTB 7.00-7.99 berjenis kelamin perempuan dan mahasiswa dengan rataan nilai STTB ≥ 8, sedangkan yang kurang berhasil yaitu mahasiswa memiliki rataan nilai STTB 7.00-7.99 berjenis kelamin laki-laki dan mahasiswa memiliki rataan nilai STTB ≤ 6.99.
Tabel 11 Segmentasi CHAID
Berhasil Kurang berhasil
• Rataan nilai STTB 7.00-7.99. perempuan
• Rataan nilai STTB 7.00-7.99. laki-laki
• Rataan nilai STTB ≥ 8 • Rataan nilai STTB ≤ 6.99
Node 0 Category % n
48.3 522 gagal
51.7 558 berhasil Total 100.0 1080
STTB Adj. P-value=0.000, Chi-square=140.
207, df=2 IPK
Node 1 Category % n
47.7 143 gagal
52.3 157 berhasil Total 27.8 300
JK Adj. P-value=0.010, Chi-square=6.
560, df=1 7.00 - 7.99
Node 2 Category % n
59.7 357 gagal
40.3 241 berhasil Total 55.4 598
JK Adj. P-value=0.003, Chi-square=8.
823, df=1 <= 6.99
Node 3 Category % n
12.1 22 gagal
87.9 160 berhasil Total 16.9 182
Jarak Adj. P-value=0.021, Chi-square=5.
358, df=1 >=8.00
Node 4 Category % n
43.0 92 gagal
57.0 122 berhasil Total 19.8 214
perempuan
Node 5 Category % n
59.3 51 gagal
40.7 35 berhasil Total 8.0 86
laki-laki
Node 6 Category % n
56.4 256 gagal
43.6 198 berhasil Total 42.0 454
perempuan
Node 7 Category % n
70.1 101 gagal
29.9 43 berhasil Total 13.3 144
laki-laki
Node 8 Category % n
6.1 5 gagal
93.9 77 berhasil Total 7.6 82
< 5 km
Node 9 Category % n
17.0 17 gagal
83.0 83 berhasil Total 9.3 100
>=5 km gagal
Perbandingan Hasil Klasifikasi Regresi Logistik dan Metode CHAID
Tabel 9 menunjukkan berdasarkan regresi logistik dengan nilai cut off
[image:42.595.105.510.325.437.2]sebesar 0.5 maka diperoleh nilai sensitivity 50.54% dan nilai specificity 78.16% dengan nilai kesalahan positif 28.79%, nilai kesalahan negatif 40.35% dan nilai total ketepatan klasifikasi 63.89% serta nilai total kesalahan klasifikasi 36.11%.
Tabel 12 menunjukkan berdasarkan metode CHAID diperoleh nilai
sensitivity 50.54% dan nilai specificity 78.16% dengan nilai kesalahan positif 28.79%, nilai kesalahan negatif 40.35% dan nilai total ketepatan klasifikasi 63.89% serta nilai total kesalahan klasifikasi 36.11%.
Tabel 12 Klasifikasi Metode CHAID
Aktual
Dugaan
Ketepatan Kurang
berhasil Berhasil TOTAL
Kurang berhasil 408 114 522 78.16%
Berhasil 276 282 558 50.54%
TOTAL 684 396 1080 63.89%
SIMPULAN DAN SARAN
Simpulan
Faktor-faktor yang mempengaruhi tingkat keberhasilan mahasiswa Farmasi Universitas Muhammadiyah Prof. DR. HAMKA yaitu rataan nilai STTB dan jenis kelamin. Berdasarkan nilai rasio oddsnya mahasiswa yang memperoleh rataan nilai STTB ≥ 8 diduga berpeluang lebih berhasil dibandingkan dengan mahasiswa yang memperoleh rataan nilai STTB 7.00-7.99 dan mahasiswa yang memperoleh rataan nilai STTB 7.00-7.99 diduga berpeluang lebih berhasil dibandingkan dengan mahasiswa yang memperoleh rataan nilai STTB ≤ 6.99, mahasiswa perempuan diduga berpeluang lebih berhasil dibandingkan laki-laki.
Dendogram CHAID menunjukkan bahwa peubah yang mempunyai asosiasi paling kuat dengan tingkat keberhasilan yaitu kategori rataan nilai STTB. Berdasarkan hasil segmentasi CHAID, mahasiswa yang berhasil yaitu mahasiswa dengan rataan nilai STTB 7.00-7.99 berjenis kelamin perempuan dan mahasiswa yang memiliki rataan nilai STTB ≥ 8.
Proses analisis pada regresi logistik dengan cut off 0.5 diperoleh nilai
sensitivity 50.54%, nilai specificity 78.16% dan nilai ketepatan klasifikasi63.89% serta nilai kesalahan klasifikasi 36.11%. Hasil klasifikasi menggunakan CHAID diperoleh nilai yang sama seperti pada klasifikasi hasil regresi logistik dengan cut off 0.5.
Saran
Agresti A. 2007. An Introduction toCategorical Data Analysis. New York. John Wiley and Sons.
Atti A. 2008. Analisis Faktor Risiko Penyakit Jantung Koroner dengan Menggunakan Metode Regresi logistik dan CHAID: Kasus di RSUP Dr. Wahidin Sudirohusodo Makasar [Tesis]. Bogor: Program Pasca Sarjana. IPB.
BAN-PT. 2008. Pedoman Evaluasi-diri Program Studi. Jakarta.
Fielding A. 1977. Binary Segmentation: The Automatic Interaction Detector and Related Tecnique for Exploring Data Stucture. London, New York, Sidney, Toronto: John Wiley & Sons.
Halim M. 2009. Identifikasi Faktor-Faktor yang Berperan Terhadap Pencapaian Indeks Prestasi Kumulatif Mahasiswa Departemen Statistika IPB [Skripsi] Bogor: Jurusan Statistika FMIPA IPB.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. New York. John Wiley and Sons.
Garson 2010. Logistic Regression: Statnotes. North Carolina State University.
Kass GV. 1980. An Explorasi Technique for Investigating large Quantities of Categorical Data. App. Statist 29(2):119-127.
Magidson J, Vermunt JK 2006. An Extention of CHAID Tree-based Segmentation Algoritm to Multiple Dependent. Departement of methodology and Statistic, Tilburg University, Netherland.
McCullagh P. Nelder. J. A. 1989. Generalized Linear Models 2nd
Sampoerno PD. 2002. Analisis kualitas Mahasiswa dalam Pencapaian Pendidikannya dengan Menggunakan Metode Partial Least Squares. Studi kasus: Mahasiswa jurusan Matematika FMIPA Universitas Jakarta [Tesis]. Bogor: Program Pasca Sarjana. IPB.
Edition. London. Chapman & Hall.
Ture M. Akturk. Kurt I. Dagdeviren N. 2006. The effect of Health Status. Nutrition and Some Other Factors on low School Performance Using Induction Tecnique. Trakya Universitesi Tip Fakultesi Dergisi.
Lampiran 1 Tabulasi Silang Peubah Penjelas dan Peubah Respon
Tabulasi Silang Usia dan IPK
IPK
Kurang Berhasil Berhasil Total
Usia 22 tahun Count 337 378 715
% of Total 31.20% 35.00% 66.20%
> 22 tahun Count 185 180 365
% of Total 17.10% 16.70% 33.80%
Total Count 522 558 1080
% of Total 48.30% 51.70% 100%
Tabulasi Silang Asal Daerah dan IPK
IPK
Total Kurang
berhasil Berhasil Asal
Daerah
Luar
Jabodetabek
Count 76 82 158
% of
Total 7.00% 7.60% 14.60%
Jabodetabek Count 446 476 922
% of
Total 41.30% 44.10% 85.40%
Total Count 522 558 1080
% of
Total 48.30% 51.70% 100.00%
Tabulasi Silang Asal Sekolah dan IPK
IPK
Total
Kurang
berhasil Berhasil Asal
sekolah
SMA Count 288 288 576
% of
Total 26.70% 26.70% 53.30%
Non SMA
Count 234 270 504
% of
Total 21.70% 25.00% 46.70%
Total Count 522 558 1080
% of
Lampiran 1 (lanjutan)
Tabulasi Silang Tenggang Waktu dan IPK
IPK
Total
Kurang
berhasil Berhasil Tenggang
waktu
< 1 tahun
Count 297 330 627
% of
Total 27.50% 30.60% 58.10%
1 tahun
Count 225 228 453
% of
Total 20.80% 21.10% 41.90%
Total Count 522 558 1080
% of
Total 48.30% 51.70% 100.00%
Tabulasi Silang STTB dan IPK
IPK
Total
Kurang
berhasil Berhasil
STTB 6.99 Count 357 241 598
% of
Total 33.10% 22.30% 55.40%
7.00 - 7.99 Count 143 157 300
% of
Total 13.20% 14.50% 27.80%
8.00 Count 22 160 182
% of
Total 2.00% 14.80% 16.90%
Total Count 522 558 1080
% of
Total 48.30% 51.70% 100.00%
Lampiran 1 (lanjutan)
Tabulasi Silang Kelas dan IPK
IPK
Total
Kurang
berhasil Berhasil
Kelas Sore Count 192 208 400
% of
Total 17.80% 19.30% 37.00%
Pagi Count 330 350 680
% of
Total 30.60% 32.40% 63.00%
Total Count 522 558 1080
% of
Total 48.30% 51.70% 100.00%
Tabulasi Silang Jenis Kelamin dan IPK
IPK
Total
Kurang
berhasil Berhasil
JK Perempuan Count 364 448 812
% of
Total 33.70% 41.50% 75.20%
laki-laki Count 158 110 268
% of
Total 14.60% 10.20% 24.80%
Total Count 522 558 1080
% of
Total 48.30% 51.70% 100.00%
Tabulasi Silang Jarak Kampus Ke tempat Tinggal dan IPK
IPK
Total
Kurang
berhasil Berhasil
Jarak 5 km Count 308 319 627
% of
Total 28.50% 29.50% 58.10%
< 5 km Count 214 239 453
% of
Total 19.80% 22.10% 41.90%
Total Count 522 558 1080
% of
Lampiran 1 (lanjutan)
Tabulasi Silang Status Tempat Tinggal dan IPK
IPK
Total
Kurang
berhasil Berhasil Tempat
tinggal
kost/kontrak Count 80 83 163
% of
Total 7.40% 7.70% 15.10%
keluarga Count 442 475 917
% of
Total 40.90% 44.00% 84.90%
Total Count 522 558 1080
% of
Log Likehood tanpa Peubah Penjelas
Iteration -2 Log likelihood
Coefficients Constant
Step 1 1495.998 0.067
2 1495.998 0.067
Log Likehood dengan Peubah Penjelas
Iteration
-2 Log likelihood
Coefficients
Constant Usia(1)
Asal _Daerah(1)
Asal_ sekolah(1)
Tenggang _Waktu(1)
Rataan_nilai _STTB(1)
Rataan _nilai_ STTB
(2) Kelas(1)
Jenis_ kelamin(1)
Jarak_ke _Kampus
(1)
status_ tmpt_ tinggal
(1)
Step 1 1 1344.25 -0.714 -0.063 -0.105 0.045 -0.053 0.504 1.882 -0.047 0.518 0.036 0.071
2 1338.946 -0.774 -0.069 -0.121 0.051 -0.06 0.521 2.312 -0.052 0.587 0.044 0.083
3 1338.842 -0.778 -0.069 -0.122 0.052 -0.06 0.521 2.383 -0.053 0.592 0.045 0.084
4 1338.842 -0.778 -0.069 -0.122 0.052 -0.06 0.521 2.385 -0.053 0.592 0.045 0.084
5 1338.842 -0.778 -0.069 -0.122 0.052 -0.06 0.521 2.385 -0.053 0.592 0.045 0.084
Log Likehood Tereduksi
Step -2 Log likelihood
Cox & Snell R
Square Nagelkerke R Square
SRI NEVI GANTINI. Analisis Faktor-Faktor Keberhasilan Mahasiswa Menggunakan Regresi Logistik dan Metode CHAID (Studi Kasus: Mahasiswa Farmasi UHAMKA). Dibimbing oleh BUNAWAN SUNARLIM dan UTAMI DYAH SYAFITRI.
Data kemampuan akademik mahasiswa berupa transkrip nilai dapat dijadikan sebagai salah satu alat untuk mengukur prestasi mahasiswa. Kemampuan akademik ini dapat dilihat dari nilai indeks prestasi kumulatif (IPK). Banyak faktor yang mempengaruhi tingkat keberhasilan akademik mahasiswa, antara lain faktor yang berasal dari dalam dan luar diri mahasiswa. Faktor yang berasal dari dalam diri mahasiswa yaitu: minat, kesiapan, motivasi, usaha, semangat dan persepsi. Sedangkan faktor yang berasal dari luar diri mahasiswa antara lain: lingkungan sosial, lingkungan keluarga dan lingkungan kampus. Lingkungan kampus memiliki peranan yang sangat penting dalam meningkatkan keberhasilan mahasiswa bila dibanding dengan lingkungan lainnya.
Sebagai upaya meningkatkan kualitas lulusan, Universitas Muhammadiyah Prof. DR. HAMKA (UHAMKA) menggunakan beberapa strategi, salah satunya adalah strategi pembelajaran. Strategi pembelajaran dipandang sebagai salah satu strategi pokok untuk meningkatkan mutu lulusan UHAMKA. Dalam menentukan kebijakan terutama strategi pembelajaran UHAMKA menerapkan kebijakan bahwa penerimaan mahasiswa baru perlu didukung dengan data yang memadai dan dapat menjadi suatu acuan, sehingga kebijakan yang dijalankan dapat optimal. Data tentang mahasiswa baru perlu dianalisa agar data tersebut dapat dijadikan sebagai bahan informasi yang akurat.
Analisis terhadap kemampuan dasar mahasiswa baru dilakukan untuk membantu pimpinan UHAMKA dalam menentukan kebijakan, terutama dalam hal penerimaan mahasiswa baru. Analisis ini merupakan hal yang sangat penting agar UHAMKA mendapatkan mahasiswa-mahasiswa yang berkualitas.
Salah satu badan yang dijadikan acuan standar mutu Pendidikan Tinggi di Indonesia adalah Badan Akreditasi Nasional Perguruan Tinggi. Salah satu standar lulusan adalah IPK. Pada penelitian disamping menyelesaikan permasalahan yang ada ingin dikaji pula pendekatan dari sisi pemodelan statistika yang berkaitan dengan ukuran sampel yang besar.
metode CHAID faktor yang mempunyai asosiasi paling kuat dengan keberhasilan mahasiswa yaitu kategori rataan nilai STTB. Hasil segmentasi CHAID menunjukkan bahwa mahasiswa yang berhasil yaitu perempuan yang memiliki rataan nilai STTB 7.00-7.99 dan mahasiswa yang memiliki rataan nilai STTB ≥ 8.00.
Proses analisis pada regresi logistik dengan cut off 0.5 dan analisis menggunakan metode CHAID diperoleh nilai sensitivity 50.54%, nilai specificity
78.16%, nilai total ketepatan klasifikasi 63.89% dan nilai total kesalahan klasifikasi 36.11%.
Gambar
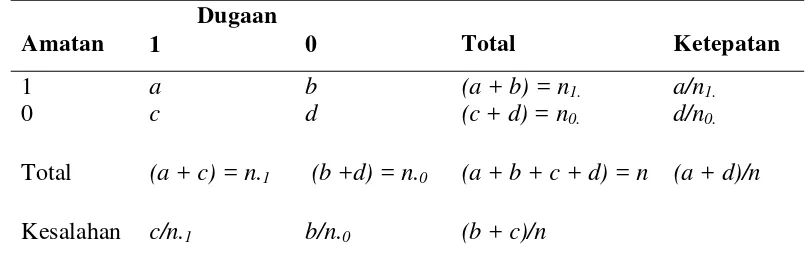
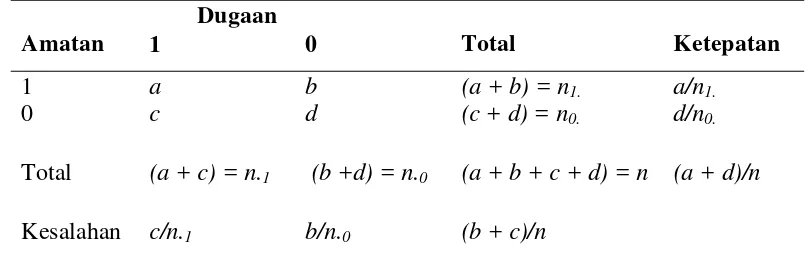
Dokumen terkait
Tujuan umum dari penelitian ini adalah mengetahui perbedaan pengetahuan dan sikap tentang prakonsepsi sebelum dan sesudah dilakukan preconception counseling pada
Pemindahtanganan barang milik daerah berupa tanah dan/atau bangunan sebagaimana dimaksud dalam Pasal 61 ayat (2), ditetapkan dengan Keputusan Walikota..
Beberapa butir saran yang penting untuk diperhatikan dan dipertimbangkan ialah (i) mempertahankan dan mengembangkan aspek pengetahuan dan keterampilan secara
Background merupakan lokasi atau setting dimana animasi itu berada. Background dapat dibuat secara sederhana atau kompleks sesuai keinginan. Atau sesuai dengan tema cerita
Berdasarkan hasil pengujian statistik deskriptif di atas, komponen VAIC TM dan kinerja keuangan (ROA, ROE, ROI) pada perusahaan perbankan yang tercatat di BEI periode 2012
[r]
Tujuan dari penelitian ini adalah untuk meninjau bukti dari 5 tahun terakhir (2006-2011) mengenai hubungan antara durasi tidur dan obesitas pada anak – anak dan untuk
