1
PENDAHULUAN
1.1Latar Belakang Masalah
PT. Trimitra Tunas Sakti adalah sebuah perusahaan yang sudah berdiri sejak tahun 2006 merupakan perusahaan yang bergerak dalam bidang penjualan produk – produk yang berasal dari Indosat, produk yang dijual seperti kartu perdana atau starter pack (SP), pulsa isi ulang elektronik dan voucher fisik. Untuk memasarkan produknya PT. Trimitra Tunas Sakti memiliki agent retail outlet, yaitu bagian dari pemasaran yang melayani end user secara langsung, sehingga keberadaan dari agent retail outlet ini sangat penting untuk menentukan bagaimana strategi bisnis perusahaan untuk meningkatkan keuntungan perusahaan, dan memperluas segmentasi pasar. Agent retail outlet yang terdapat di wilayah Jawa Timur ini sebanyak 9407.
sehingga penjualan produk menurun, dan penurunan pelayanan terhadap agent retail outlet.
Metode yang dapat digunakan dalam menganalisis data yang sangat banyak adalah metode data mining, yaitu suatu metode yang digunakan untuk melihat pola atau set data yang berukuran besar [1]. Dalam data mining terdapat beberapa metode yang dapat digunakan tergantung tujuan yang akan dicapai. Salah satu metode yang dapat digunakan adalah metode clustering, yaitu suatu metode yang memisahkan data / vector kedalam sejumlah kelompok (cluster) menurut karakteristiknya masing – masing.
Maka dari itu PT. Trimitra Tunas Sakti wilayah Jawa Timur memerlukan metode clustering untuk dapat memanfaatkan data penjualan yang sanagat banyak tersebut, untuk mendapatkan suatu pengetahuan yang digunakan sebagai acuan dalam menentukan strategi bisnis, dengan melihat penjualan dari setiap agent retail outlet.
Dari pertimbangan atas penjelasan yang telah dipaparkan di atas, maka dibutuhkan suatu aplikasi “Penerapan Data Mining Pada Penjualan Produk Di PT. Trimitra Tunas Sakti Kantor Wilayah Jawa Timur Menggunakan Metode Clustering”.
1.2Rumusan Masalah
Berdasarkan latar belakang yang disebutkan di atas, maka permasalahan yang dibahas dan diteliti adalah :
Bagaimana cara menerapkan data mining pada penjualan produk di PT. Trimitra Tunas Sakti wilayah Jawa Timur menggunakan metode clustering. 1.3Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan tugas akhir ini adalah untuk membangun sebuah aplikasi Data Mining pada data penjualan produk PT. Trimitra Tunas Sakti Kantor Wialyah Jawa Timur dengan metode Clustering.
1. Untuk membantu pihak marketing dalam melakukan analisis data penjualan produk.
2. Untuk memperbaiki analisis pengelompokan agent retail outlet yang sedang berjalan.
3. Untuk membantu pihak marketing menyebarkan informasi secara cepat kepada agent retail outlet mengenai kebijakan perusahaan yang akan diterapkan dari hasil menganalisis data penjualan
1.4Batasan Masalah
Untuk menghindari pembahasan yang meluas, maka penulis hanya membatasi permasalahan sebagai berikut :
a. Data yang akan dianalisis merupakan data penjualan produk yang dilakukan oleh agent retail outlet dalam kurun waktu 1 minggu pada bulan Februari 2015 dari tanggal 1 – 7 Februari.
b. Data yang digunakan untuk proses data mining adalah, data agen retail outlet, dan data penjualan produk.
c. Analisis data penjualan produk dilakukan dalam kurun waktu satu minggu sekali.
d. Metode yang digunakan untuk melakukan peng- cluster- an adalah metode hierarki dengan algoritma yang digunakan adalah Agglomerative Hierarchical Clustering (AHC).
e. Sistem yang akan dibangun merupakan apikasi yang berbasis web. f. Bahasa pemrograman yang akan digunakan adalah PHP dan MySQL
sebagai pengolahan database.
g. Analisis dan pemodelan yang digunakan dalam membangun sistem ini adalah pemodelan terstruktur.
1.5Metodelogi Penelitian
Metode penelitian deskriptif adalah suatu metode untuk meneliti status sekelompok manusia, suatu objek, suatu set kondisi suatu sistem pemikiran ataupun suatu kelas peristiwa pada masa sekarang. Tujuan dari penelitian dskriptif ini adalah untuk membuat deskripsi, gambaran atau lukisan secara sistematis, faktual, dan akurat mengenai fakta-fakta, sifat-sifat serta hubungan antar fenomena yang diselidiki.
1.5.1 Metode Pengumpulan Data
Metode penugmpulan data yang digunakan adalah sebagai berikut : 1. Studi Lapangan
Studi lapangan merupakan teknik pengumpulan data yang dilakukan dengan cara melakukan penelitian ke instansi yang terkait. Studi lapangan ini dilakukan dengan menggunakan 2 cara, yaitu :
a. Observasi
Observasi merupakan kegiatan pengamatan langsung ditempat penelitian untuk mengumpulkan data yang dibutuhkan.
b. Wawancara
Wawancara merupakan teknik pengumpulan data dengan mengadakan Tanya jawab secara langsung yang berkaitan dengan topic yang diambil.
2. Studi Literatur
Studi literatur merupakan teknik pengumpulan literatur, jurnal, paper, buku – buku, dan bacaan – bacaan yang ada kaitannya dengan penelitian.
1.5.2 Metode Data Mining
1. Fase pemahaman bisnis
Tahap awal ini berfokus pada pemahaman tujuan dan kebutuhan proyek dari perspektif bisnis, kemudian mengubah pengetahuan tersebut menjadi sebuah masalah data mining dan rencana awal yang dirancang untuk mencapai tujuan.
2. Fase pemahaman data
Tahap pemahaman data dimulai dengan mengumpulkan data, mengidentifikasi masalah kualitas data, menemukan pengetahuan terhadap data, dan membentuk hipotesis mengenai informasi yang tersembunyi.
3. Fase persiapan data
Tahap persiapan data mencakup semua kegiatan yang diperlukan untuk membangun dataset akhir (data yang akan dimasukan kedalam modeling tools) dari data mentah awal. Tugas dalam tahapan persiapan data ini memungkinkan akan dilakukan beberapa kali dan tidak dalm urutan yang ditentukan.
4. Fase pemodelan
Pada tahapan ini, memilih dan mengaplikasikan teknik pemodelan yang sesuai, kemudian melakukan kalibrasi untuk mengoptimalkan hasil. Biasanya, terdapat beberapa teknik data mining yang sama untuk permasalahan yang sama. Beberapa teknik memiliki spesifikasi persyaratan pada bentuk data, oleh karean itu, akan kembali ke tahap persiapan data sering diperlukan.
5. Fase evaluasi
yang belum dipertimbangkan. Di akhir dari tahap ini harus ditentukan penggunaan hasil proses data mining.
6. Deployment
Tahap pembangunan ini merupakan tahapan implementasi untuk pembangunan aplikasi berupa representasi pengetahuan yang telah diperoleh sihingga dapat digunakan oleh pengguna.
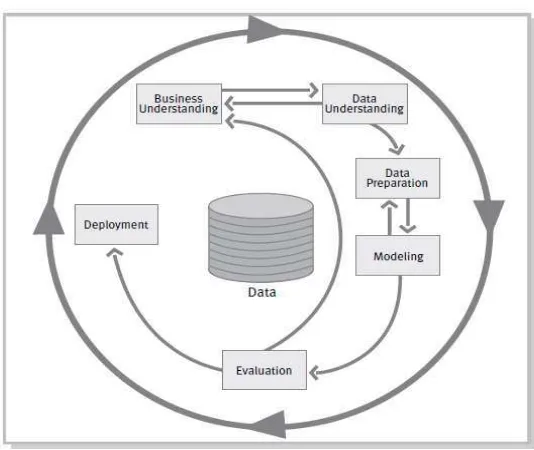
Gambar 1.1 Phase of the CRISP-DM References Model
1.6 Sistematika Penulisan
Sistematika penulisan disusun untuk memberikan gambaran secara umum mengenai permasalahan dan pemecahannya. Sisteamtika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULIAN
BAB 2 TINJAUAN PUSTAKA
Pada bab ini akan menjelaskan mengenai objek dari penelitain, dan teori – teori pendukung yang berhubungan dengan pembangunan sistem.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini menganalisis masalah dari data hasil penelitian, kemudian dilakukan proses perancagnan sistem yang akan dibangun sesuai dengan analisis yang telah dilakukan.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi mengenai implementasi dan analisis dari perancangan sistem yang dilakukan, serta melakukan ujicoba terhadap sistem yang telah dibangun, dan hasil dari uji coba terhadap sistem tersbut.
BAB 5 KESIMPULAN DAN SARAN
9
TINJAUAN PUSTAKA
2.1Tinjauan Tempat Penelitian 2.1.1 Sejarah Perusahaan
PT. Trimitra Tunas Sakti adalah sebuah perusahaan yang sudah berdiri sejak tahun 2006 merupakan perusahaan yang bergerak dalam bidang penjualan produk – produk yang berasal dari Indosat, produk yang dijual seperti kartu perdana atau stater pack (SP), pulsa isi ulang elektronik dan voucher fisik . PT. Trimitra Tunas Sakti ini memiliki dua wilayah yaitu di Karawang dan Jawa Timur.
Pada saat ini kantor cabang yang dimiliki oleh PT. Trimitra Tunas Sakti adalah yang terdapat di wilayah Karawang dan wilayah Jawa Timur diantaranya adalah :
1. Renggas Dengklok (Karawang). 2. Jombang (Jawa Timur).
3. Lamongan (Jawa Timur). 4. Madiun (Jawa Timur). 5. Magetan (Jawa Timur).
6. Ponorogo / Pacitan (Jawa Timur). 7. Nganjuk (Jawa Timur).
Produk – produk Indosat yang didistribusikan oleh PT. Trimitra Tunas Sakti ini adalah :
1. Kartu perdana isi ulang Indosat (Mentari dan IM3). 2. Kartu Internet isi ulang Indosat.
2.1.2 Logo Perusahaan
Logo yang dimiliki oleh PT. Trimitra Tunas Sakti terdiri dari beberapa segitiga yang membentuk seperti layang – layang dan terdiri dari nama perusahaanya, seperti terlihat pada gambari berikut ini :
Gambar 2. 1 Logo Perusahaan 2.1.3 Visi dan Misi
Adapun visi dan misi dari PT. Trimitra Tunas Sakti adalah : 1. Visi
Menjadi perusahaan yang handal dan terpercaya di industri telekomunikasi.
2. Misi
- Memberikan pelayanan terbaik kepada pelanggan - Menghasilkan laba yang maksimal untuk perusahaan 2.1.4 Struktur Organisasi Perusahaan
Berikut ini merupakan struktur organisasi yang terdapat di PT. Trimitra Tunas Sakti :
Direktur
GM Sales & Marketing
Branch Manager
IT Manager HRD & GA
Dan berikut ini merupakan tugas dan wewenang dari masing – masing bagian pada struktur organisasi perusahaan diatas :
a. Direktur
Tugas dan wewenang yang dimiliki oleh direktur diantaranya adalah : 1. Menentukan kebijakan tertinggi perusahaan.
2. Bertanggung jawab terhadap keuntungan dan kerugian perusahaan. 3. Mengangkat dan memberhentikan karyawan persusahaan.
4. Memelihara dan mengawasi kekayaan perseroan terbatas.
5. Bertanggung jawab dalam memimpin dan membina efektif dan efisien.
6. Mewakili perusahaan, mengadakan perjanjian – perjanjian, merencanakan dan mengawasi pelaksanaan tugas personalia yang bekerja pada perusahaan.
7. Menyusun dan melaksanakan kebijakan umum pabrik sesuai dengan kebijakan RUPS (Rapat Umum Pemegang Saham).
8. Menetapkan besarnya deviden perusahaan. b. General Manager dan Marketing
Manager umum adalah manager yang memiliki tanggung jawab seluruh bagian atau fungsional pada suatu perusahaan atau organisasi. Manager umum memimpin beberapa unit bidang fungsi pekerjaan yang mengepalai beberapa atau seluruh manager fungsional. Pada perusahaan yang berskala kecil mungkin cukup diperlukan satu orang manager umum, sedangkan pada perusahaan atau organisasi yang berkaliber besar biasanya memiliki beberapa orang manager umum yang bertanggung-jawab pada area tugas yang berbeda-beda.
Tugas dan tanggung jawab dari seorang Manager Penjualan atau Marketing Manager adalah:
1. Bertanggung jawab terhadap Manager Umum
3. Membuat analisa terhadap pangsa pasar dan menentukan strategi penjualan terhadap konsumen atau pelanggan.
4. Menganalisis laporan yang dibuat oleh bawahannya.
5. Mengoptimalkan kerja staf dan administrasi dibawah wewenangnya untuk mencapai tujuan perusahaan.
6. Memberikan pelayanan yang prima kepada setiap konsumen atau pelanggan.
7. Manajer pemasaran bertanggung-jawab terhadap perolehan hasil penjualan dan penggunaan dana promosi.
8. Manajer pemasaran membina bagian pemasaran dan membimbing seluruh karyawan dibagian pemasaran
c. Brach Manager
Tugas dan wewenang yang dimiliki oleh branch manager adalah sebagai berikut :
1. Merencanakan langkah strategis cabang, mengatur penjadwalan kunjungan dan target sales untuk pencapaian target penjualan secara maksimal
2. Memonitor dan mengevaluasi pencapaian target penjualan secara berkelanjutan
3. Memantau tugas penagihan kolektor dan tempo pembayaran customer
4. Mereview dan memastikan kesiapan sales order untuk proses pengiriman barang
5. Berkoordinasi dengan pusat dan cabang lain untuk penentuan wilayah penjualan dan koordinasi target penjualan
6. Memonitor dan mengevaluasi pasar dan kompetitor untuk melihat kedudukan cabang dengan pasar sejenis di area yang sama, menganalisa kebutuhan pasar untuk menyusun dan mengusulkan strategi penjualan
d. Finance controller
Tugas dan wewenang yang dimiliki oleh finance controller adalah sebagai berikut :
1. Mengarahkan, mengkoordinasikan dan mengukur kinerja keuangan perusahaan atas operasi harian seluruh bagian divisi dan departemen dalam perusahaan untuk tujuan perencanaan keuangan dan manajemen anggaran.
2. Memantau dan menganalisis transaksi keuangan harian, bulanan dan tahunan dan dibandingkan dengan anggaran.
3. Mengarahkan dan mengkoordinasikan pembiayaan utang dan pembayaran utang dengan lembaga eksternal.
4. Melakukan koordinasi dengan seluruh bagian dalam perusahaan untuk penyusunan laporan keuangan bulanan dan tahunan, perencanaan dan proyeksi keuangan sesuai rencana bisnis perusahaan.
5. Melakukan analisa keuangan untuk membuat usulan pertimbangan bagi atasan untuk proses negosiasi kontrak dan pengambilan keputusan atas produk investasi, rencana jangka pendek dan jangka panjang perusahaan, anggaran dan target keuangan setiap bagian dan perusahaan secara keseluruhan, pembuatan kebijakan dan perbaikan prosedur.
6. Menyajikan data keuangan yang diperlukan untuk komite perencanaan dan pembuatan kebijakan keuangan.
7. Melakukan proses audit keuangan langsung dan memberikan rekomendasi untuk perbaikan prosedural.
8. Memastikan dokumen yang berhubungan dengan kegiatan akuntansi tercatat dalam pembukuan yang akurat dan benar.
9. Memastikan dan menghitung kewajiban perpajakan yang timbul dari transaksi yang ada.
11. Memastikan bahwa setiap pencatatan dalam pembukuan yang material dapat diungkapkan.
12. Memastikan seluruh pencatatan akurat dan konsisten terhadap standar akuntansi keuangan yang berlaku.
2.2Landasan Teori
Landasan teori ini akan menjelaskan teori – teori yang digunakan dalam pembangunan sistem ini.
2.2.1 Konsep Data dan Informasi 2.2.1.1Pegertian Data
Secara konspetual, data adalah deskripsi mengenai benda, kejadian, aktivitas dan transaksi, yang tidak memiliki makna atau tidak berpengaruh secara langsung kepada pengguna [7].
2.2.1.2Pengertain Informasi
Informasi sebagai data yang telah di proses sedemikian rupa sehingga meningkatkan pengetahuan seseorang yang menggunakan data tersebut [7].
Data Proses Informasi
Gambar 2. 3 Transformasi data menjadi informasi
Gambar 2.4 memperlihatkan bagaimana siklus informasi yang menggambarkan pengolahan data menjadi informasi dan pemakaian informasi untuk mengambil keputusan, hingga akhirnaya dari tindakan hasil pengambilan keputusan tersebut dihasilkan data kembali [7].
Masukan
2.2.2 Basis Data (Database)
Basis data (Database) adalah sekumpulan informasi bermanfaat yang diorganisasikan ke dalam tata cara yang khusus [8].
Database adalah kumpulan data, umumnya mendeskripsikan aktivitas suatu organisasi yang berhubungan atau. Misalnya, database suatu minimarket atau toko mungkin berisi informasi mengenai hal breikut :
- Entitas produk, entitas transaksi, entitas detail transaksi, entitas karyawan, entitas pemasok barang.
- Hubungan antar entitas, seperti produk yang dijual akan dicatat di detail transaksi, detail transaksi akan di catat di trasansaksi, setiap transaski akan disahkan oleh karyawan, dan pemasok akan memasukan produk – produk ke toko.
2.2.3 Database Management System (DBMS)
Management sistem basisi data adalah perangkat lunak yang di rancang untuk membantu dalam hal pemeliharaan dan utilitas kumpulan data dalam jumlah besar [8].
Database management sistem atau DBMS, adalah perangkat lunak yang didesain untuk membantu memelihara dan memanfaatkan kumpulan data yang besar. Kebutuhan terhadap sistem tersebut, termasuk juga penggunaanya, berkembang secara cepat. Alternatif penggunaan DBMS adalah untuk menyimpan data dalam file dan menulis kode aplikasi tertentu untuk penggunanya. Penggunaan DBMS memiliki beberapa manfaat penting diantaranya adalah [8]:
a. Kemandirian data
Program aplikasi idealnya tidak diekspose pada detail representasi dan penyimpanan data. DBMS menyediakan suatu pandangan abstrak tentang data yang menyembunyikan detail tersebut.
b. Akses data efisien
terutama penting jika data disimpan pada alat penyimpanan eksternal.
c. Integritas dan keamanan data
Jika data selalu diakses melalui DBMS, maka DBMS dapat memanfaatkan batasan integritas. Misalnya, sebelum menyimpan informasi gaji untuk suatu karyawan, DBMS dapat memeriksa bahwa besarnya tidak melebihi anggaran departemen. DBMS juga dapat memanfaatkan kontrol akses yang menentukan data apa yang boleh dilihat oleh kelas pengguna yang berbeda.
d. Administrasi data
Ketika beberapa pengguna berbagi data, pemutusan administrasi data dapat memberikan perbaikan yang signifikan. Para profesional berpengalaman yang memahami sifat data yang akan diolah, dan memahami bagaimana kelompok pengguna yang berbeda menggunakan data tersebut, dapat menjadi tanggung jawab untuk mengatur representasi data untuk meminimalkan redudansi dan untuk memfinetune penympanan data guna melakukan pengambilan data yang efisien.
e. Akses konkuren dan crash recovery
DBMS menjadwalkan akses konkuren pada data dalam cara tertentu pada data alam cara tertentu sehingga pengguna data memandang data sebagi data yang sedang diakses oleh hanya satu pengguna pada satu waktu. Lebih lanjut, DBMS memproteksi pengguna dari efek kegagalan sistem.
f. Waktu pengembangan aplikasi terkurangi
aplikasi yang berdiri sendiri karena banyak tugas penting ditangani oleh DBMS.
Manipulasi basis data meliputi pembuatan pernyataan (query) untuk mendapatkan informasi tertentu, melakukan pembaharuan atau penggantian (update) data, serta pembuatan report dari data. Tujuan utama DBMS adaah untuk menyediakan tinjauan abstrak dari data bagi pengguna. Jadi sistem menyembunyikan informasi mengenai bagaimana data disimpan dan dirawat, tetapi data tetap dapat diambil.
2.2.4 Pengertian Data Mining
Data mining atau sering disebut juga dengan knowledge discovery in database (KDD), adalah kegiatan yang meliputi penugmpulan, pemakaian data historis untuk menemukan keterurutan, pola atau hubungan dalam set data berukuran besar, keluaran dari data mining ini dapat dipakai untuk memperbaiki pengambilan keputusan dimasa depan [1].
Data mining didefinisikan sebagai suatu set teknik yang digunakan secara otomatis untuk mengeksplorasi secara menyeluruh dan membawa ke permukaan raslasi – relasi yang kompleks pada set data yang sangat bersar [3].
Data mining adalah proses yang menggunakan teknik statistik, perhitungan, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan terkait dari berbagai basis data besar [4].
Dari pengertian mengenai data mining di atas maka dapat disimpulkan bahwa data mining adalah suatu disiplin ilmu yang digunakan untuk mencari suatu pengetahuan dari tumupkan data tersebut dengan menggunakan sebuah metode data mining. Data mining membantu pengguna dengan menemukan hubungan dan menyajikan dengan cara yang dapat dipahami sehingga hubungan tersebut dapat menjadi dasar pengambilan keputusan.
matematika pengolahan citra, dan sebagainya, sehingga penerapan data mining menjadi kasus semakin luas.
statistik
Munculnya data minng didasarkan pada jumlah data yang tersimpan dalam basis data semakin besar. Misalnya dalam sebuah toko, ada beberapa transaksi pelanggan yang terjadi dalam sehari dan beberapa juta data yang sudah tersimpan dalam sebulan. Dalam perusahaan dapat menghasilkan beberapa juta data produksi barang, ataupun apabila mendapatkan sebuah rekomendasi untuk membeli barang dari sebuah sistem belanja ketika membeli suatu produk.
2.2.5 Arsitektur Dara Mining
Pada umumnya sistem data mining terdiri dari komponen – komponen berikut [5]:
a. Database, data warehouse
Media dalam ha ini bisa jadi berupa database, data warehouse, spreadsheet, atau jenis – jenis penampungan informasi lainnya. Data cleaning dan data integration dapat dilakukan pada data tersebut. b. Database, atau data warehouse server
c. Basis pengalaman (knowladge base)
Merupakan basis pengetahuan yang digunakan sebagai panduan dalam pencarian pola.
d. Data mining engine
Bagian dari software yang menjalankan program berdasarkan algoritma yang ada.
e. Pattern evaluation module
Bagian dari software yang berfungsi untuk menemukan paterrn atau pola –pola yang yang terdapat di dalam database yang diolah sehingga nantinya proses data mining dapat menentukan konwladge yang sesuai. f. Graphical user interface
Bagian ini merupakan sarana antara user dan sistem data mining untuk berkomunikasi, dimana user dapat berinteraksi dengan sistem melalui data mining query, untuk menyediakan informasi yang dapat membantu user untuk melakukan browsing pada databse dan data warehouse, mengevaluasi pattern yang telah dihasilkan, dan menampilkan pattern tersebut dengan tampilan yang berbeda – beda.
Gambar 2. 6 Arsitektur data mining
2.2.6 Himpunan Data Dalam Data Mining
1. Tipe data numerik adalah suatu tipe data yang dapat dikalkulasi (dapat dilakukan penjumlahan, pengurangan, perkalian, pembagian).
2. Tipe data nominal adalah suatu tipe data yang tidak dapat dikalkulasi, contoh datanya adalah data jenis kelamin yang isinya adalah laki – laki, atau perempuan.
Gambar 2. 7 Himpunan Data
2.2.7 Metode Data Mining
Pekerjaan yang berkaitan dengan data mining dapat dibagi menjadi empat kelompok [6] :
a. Model prediksi (Prediction modelling)
Pekerjaan ini berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat.
Model prediksi ini digunakan ketika tipe data yang dimiliki oleh himpunan data merupakan tipe data numerik, dan ciri khas dari model prediksi ini merupakan dataset dalam bentuk time series. Contoh algoritma yang dapat digunakan dalam model prediksi ini adalah algoritma neural network (ANN).
Gambar 2. 8 Contoh data saham
Dari data saham tersebut dilakukan pembelajaran misalnya dengan neural network sehingga didapakan sebuah pengetahuan, pengetahuan yang didapatkan berupa pengahuan berapa harga sahama kedepan. b. Analisis Cluster
Analisis cluster / kelompok melakukan pengelompokan ke dalam sejumlah kelompok berdasarkan kesamaan karakteristik masing – masing data pada kelompok – kelompok yang ada. Data – data yang masuk ke dalam batas kesamaan dengan kelompoknya akan bergabung ke dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan kelompok tersebut.
Metode clustering digunakan apabila dataset yang dimiliki tidak memiliki label, metode clustering ini tidak memerlukan guru dalam melakukan pembelajaranya atau biasa disebut dengan unsupervised learning, hal ini yang membedakan model clustering dengan model
yang lainya.
c. Analisis Asosiasi
Analsisi asosiasi digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Pola yang ditemukan biasanya merepresentasikan bentuk aturan implikasi atau subset fitur. Tujuanya adalah untuk menemukan pola yang menarik dengan cara yang efisien.
Penerapan yang paling dekat dengan kehidupan sehari – hari adalah analisis data keranjang belanja. Jika Ibu rumah tangga akan membeli kebutuhan rumah tangga (misalnya beras) di sebuah super market, maka sangat besar kemungkinan ibu rumah tangga tersebut juga akan membeli kebutuhan rumah tangga yang lain, misalnya minyak atau telur, dan tidak munggkin (atau jarang) membeli barang lain seperti topi atau buku. Dengan mengetahui hubungan yang lebih kuat antara beras dengan telur daripada beras dengan topi, maka retailer dapat menentukan barang – barang yang sebaiknya disediakan dalam jumlah yang cukup banyak.
d. Deteksi Anomali
Gambar 2. 9 Pekerjaan utama data mining
2.2.8 Pengelompokan (Clustering)
Clustering merupakan pekerjaan yang memisahkan data / vector ke dalam sejumlah kelompok (cluster) menurut karakteristiknya masing – masing. Data – data yang memiliki kemiripan karakteristik yang berkumpul dalam cluster yang sama, dan data – data dengan karakteristik berbeda akan terpisah dalam cluster yang berbeda. Tidak diperlukan label baru bisa diberikan ketika cluster sudah terbentuk. Karena tidak adanya target label kelas untuk setiap data maka clustering sering disebut juga pembelajaran tidak terbimbing (unsupervised learning) [6].
Teknik clustering banyak diterapkan dalam berbagai bidang, seperti kedoktrean, teknik clustering dapat digunakan untuk mengelompokan jenis
– jenis penyakit berbahaya berdasarkan karakteristik atau sifat – sifat penyakit pasien. Dalam bidang keshatan dapat digunakan untuk mengelompokan jenis makanan berdasarkan kandungan kalori, vitamin, protein. Dalam bidang klimatologi dapat digunakan untuk mengetahui pola angin dan kondisi cuaca di udara sehingga bias diketahui wilayah – wilayah yang retang terhadap cuaca buruk, dan sebagainya.
data. Biasanya proses clustering dalam tujuan ini hanya sebagai proses awal untuk kemudian dilanjutkan dengan pekerjaan inti seperti summarization (rata – rata, standar deviasi), pelebelan kelas pada setiap kelompok untuk kemudian digunakan sebagai data latih klasifikasi, dan sebaginya. Sementara jika tujuanya untuk penggunaan, biasanya tujuan utama untuk mencari prototype cluster yang paling representative terhadap data dan memberikan abstraksi dari setiap objek data dalam cluster di mana sebuah data terletak di dalamnya.
Berdasrkan strukturnya, clustering terbagi menjadi dua, yaitu hirarki dan partisi. Dalam pengelompokan berbasis hirarki (hierarchical clustering), satu data tunggal bisa dianggap sebuah cluster, dua atau lebih cluster kecil dapat bergabung menjadi sebuah cluster bersar. Begitu seterusnya hingga semua data dapat bergabung menjadi sebuah cluster. Pengelompokan berbasis partisi membagi set data ke dalam sejumlah cluster yang tidak bertumpang – tindih antara satu cluster dengan cluster yang lain, artinya setiap data hanya menjadi anggota satu cluster saja.
Teknik clustering berdasarkan keanggotaanya dibedakan menjadi dua bagian, yaitu eklusif dan tumpang-tindih. Dalam kategori eklusif, sebuah data bias dipastikan hanya menjadi satu cluster dan tidak menjadi anggota di cluster yang lain. Metode clustering yang termasuk kategori ini adalah K – Means, DBSCAN, dan SOM. Sementara yang termasuk kategori tumpang-tindih adalah metode clustering yang membolehkan sebuah data menjadi anggota di lebih dari satu cluster, misalnya Fuzy C-Means.
Menghitung jarak dengan menggunakan Euclidean :
� = √∑�
�= � − � …………..………..(2.1)
Dimana :
d = Jarak
r = jumlah fitur dalam vektor Xi = nilai fitur X ke i
Yi = nilai fitur Y ke i
2.2.8.1Teknik Clustering
Tujuan utama dari metode cluster adalah pengelompokan sejumlah data atau obyek ke dalam cluster (grup) sehingga dalam setiap cluster akan berisi data yang semirip mungkin. Dalam clustering akan berusaha untuk menenpatkan obyek yang mirip (jaraknya dekat) dalam satu cluster sangat mirip satu sama lain dan berbeda dengan obyek dalam klaster – klaster yang lain.
Ada dua pendekatan dalam teknik clustering, yaitu partisi dan hirarki. Dalam teknik partisi akan mengelompokan obyek X1, X2, X3,…., Xn ke dalam
k cluster. Ini bias dilakukan dengan menentukan pusat cluster awal, lalu dilakukan relokasi obyek berdasarkan kriteria tertentu samapi dicapai pengelompokan yang optimum. Dalam cluster hirarki dimulai dengan membuat m cluster dimana setiap cluster beranggotakan satu obyek dan berakhir dengan satu cluster diaman anggotanya adalah m obyek. Pada setiap tahap dalam prosedurnya, satu cluster digabung satu cluster yang lain. Penghentian atau cut-off bias dilakukan ketika jumlah cluster yang diinginkan sudah tercapai [6].
2.2.8.2Analisis Cluster Berbasis Hirarki
Dalam statistik, pengelompokan berbasis hirarki adalah metode analisis cluster yang berusaha untuk membangun sebuah hirarki cluster. Strategi untuk mengelompokan berbasis hirarki pada umumnya terdapat dua jenis, yaitu agglomerative dan divisive.
rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai cluster yang lebih besar. Proses terbut diulang terus sehingga tampak bergerak ke atas membentuk hirarki.
Divisive merupakan metode pengelompokan data berbasis hirarki dengan pendekatan top down, yaitu proses pengelompokan dimulai dari satu cluster yang berisi semua data, kemudian secara rekursif memecah cluster menjadi dua cluster sampai cluster hanya berisi data tunggal (data itu sendiri). Untuk cara ini, dibutuhkan adalah keputusan cluster yang manakah yang akan dipecah pada setiap langkah dan bagaimana cara memechakanya. 2.2.8.3Agglomerative Hierarchical Clustering (AHC)
Agglomerative hierarchical clustering merupakan algoritma yang digunakan untuk mengukur kedekatan diantara dua cluster. Terdapat tiga cara yang digunakan AHC, diantaranya adalah, metode single linkage, complete linkage, average linkage.
Single linkage memberikan hasil apabila cluster – cluster digabugkan menurut jarak yang paling dekat diantara dua cluster. Complete linkage terjadi apabila kelompok – kelompok digabung menurut jarak antara yang paling jauh diantara dua cluster. Average linkage digabungkan menurut jarak rata – rata antara pasangan – pasangan anggota masing – masing himpunan diantara dua cluster.
Berikut ini merupakan tahapan dari algoritma Agglomerative : 1. Tentukan jumlah cluster yang akan dibentuk.
2. Hitung matriks kedekatan berdasarkan jarak yang digunakan (misalkan dengan menggunakan matriks euclidean ditance yang terdapat dalam persamaan 2.1).
3. Ulangi langkah empat dan lima, hingga , menghasilkan jumlah cluster.
4. Gabung dua cluster terdekat berdasarkan parameter kedekatan yang ditemntukan (misalkan dengan metode single linkage pada persamaan 2.2).
Pada metode single linkage (Min), kedekatan diantara dua cluster ditentukan dari jarak terdekat (terkecil) diantara pasangan diantara dua dari cluster berbeda (satu dari cluster pertama satu dari cluster lainnya) atau disebut juga dengan kemiripan yang paling maksimal. Dengan cara seperti ini maka akan dimulai dari masing – masing data sebagai cluster, kemudain mencari tetangga terdekat dan menggunakan single linkage untuk menggabungkan dua cluster berikutnya hingga semuanya bergabung menjadi satu cluster.
Berikut ini merupakan persamaan single linkage :
� , = min{� , }; � , ∈ �……….(2.2)
D = Matriks kedekatan jarak antar cluster.
2.2.8.4Contoh Penerapan Clustering Menggunakan Algortima AHC
Contoh diberikan 5 data dan pengukuran jarak menggunakan jarak Euclidean, dengan menggunakan metode single linkage.
Tabel 2. 1Set data untuk dihitung Data ke –i Fitur x Fitur y
1 1 1
2 4 1
3 6 1
4 1 2
5 2 3
Yang pertama dilakukan adalah menghitung jarak dengan menggunakan euclidean pada semua pasangan dua data. Hasil dari perhitungan dengan menggunakan euclidean adalah sebagai berikut :
� = � , =
[ ]
K = jumlah data n, tahapan selanjutnya adalah memilih jarak dua cluster
yang paling kecil.
min{� , } = � =
Dari proses perhitungan dengan menggunakan metode single linkage maka didapatkan bawha jarak yang paling minimum adalah cluster 1 dan cluster 3, maka kedua cluster ini akan digabung. Untuk melanjutkan tingkat pengelompokan berikutnya maka jarak – jarak antara cluster (13) dengan cluster yang tersisia 2,4, dan 5 dihitung kembali dengan menggunakan metode single linkage. Jarak – jarak yang didapatkan adalah:
d(13)2 = min {d12 ,d(32)} = min {3,4} = 3
d(13)4 = min {d14 ,d(34)} = min {5,4} = 4
d(13)5 = min {d15 ,d(35)} = min {7,6} = 6
Dengan menghapus baris – baris dan kolom – kolom matriks D yang bersesuain dengan cluster 1 dan 3 dan menambahkan baris dan kolom untuk cluster 1 dan 3, dan menambahkan baris dan kolom untuk cluster (13), maka didapatkan matriks yang baru :
� = � , = [ ]
Tahapan selanjutnya adalah memilih kembali jarak dua cluster yang paling kecil.
min{� , } = � =
Maka cluster yang terpilih adalah cluster 4 dan 5, maka cluster 4 dan cluster 5 digabung. Kemudian untuk menghitung jarak – jarak antara cluster (45) dengan cluster lain yang tersisa yaitu (13) dan 2 dihitung kembali dengan menggunakan metode single linkage. Jarak – jarak yang didapatkan adalah :
d(45)(13) = min {d41 ,d43, d51, d53 )} = min {5,4,7,6} = 4
dengan menhapus baris – baris dan kolom – kolom matriks D yang bersesuaian dengan cluster 4 dan cluster 5 dan menambahkan baris dan kolom untuk cluster (45), maka didapatkan matriks jarak yang baru :
� = � , = [ ]
Selanjutnya dipilih kembali jarak dua cluster yang paling kecil.
min{� , } = � =
Terpilih cluster (13) dan 2, maka cluster (13) dan 2 digabung. Untuk melanjutkan tingkat clustering berikutnya, maka jarak – jarak antara cluster (13) dan 2 dengan cluster yang lain yang tersisisa yaitu (45) dihitung kembali dengan menggunakan metode single linkage. Jarak – jarak yang didapatkan adalah :
d(123)(45) = min {d14 ,d43, d24, d25, d34, d35)} = min {5,7,4,4,4,6} = 4
Dengan menghapus baris – baris dan kolom – kolom matriks D yang bersesuaian dengan cluster (13) dan 2, dan menambahkan baris dan kolom untuk cluster (123), maka matriks yang baru yang didapatkanya adalah :
� = � , = [ ]
Jadi cluster (123) dan (45) digabung membentuk cluster tunggal dari semua 5 data, (12345), ketika jarak terdekat mencapai 4.
1 3 2 4 5
Gambar 2. 10Dendrogram hasil clustering berbasis hirarki 2.2.9 Tahapan Data Mining
Dalam menyelesaikan penelitian data mining terdapat sebuah standar yang dapat digunakan untuk menyelesaikan penelitian data mining, standar tersebut dinamakan dengan Cross – Industry Standard for Data Mining (CRISP-DM). CRISP-DM merupakan suatu standar yang telah dikembangkan pada tahun 1996 yang ditunjukan untuk melakukan proses analisis dari satu industri sebagai strategi pemecahan masalah dari bisnis atau unit penelitian [2].
Berikut ini merupakan tahapan – tahapan dalam CISP-DM [2] : 1. Pemahaman bisnis
Tahapan pemahaman bisnis ini merupakan tahapan awal pada pemahaman tujuan dan kebutuhan proyek dari perspektif bisnis, kemudian mengubah pengetahuan tersebut menjadi sebuah masalah data mining dan rencana awal untuk mencapai tujuan. Dalam tahapan pemahaman bisnis ini dibagi menjadi beberapa bagian :
a. Identifikasi tujuan bisnis
Dalam tahapan ini bertujuan untuk memahami proses bisnis yang ingin dicapai.
b. Pemahaman situasi
c. Penentuan sasaran data mining
Dalam proses penentuan sasaran data mining ini adalah untuk menentukan kriteria sukses dari data mining.
2. Pemahaman Data
Tahap pemahaman data ini merupakan tahapan untuk memahami data yang berkaitan dengan penelitian yang akan dilakukan, dalam tahapan pemahaman data ini terdapat beberapa tahapan diantaranya adalah : a. Pengumpulan data awal
Dalam pengumpulan data awal ini digunakan untuk mengumpulkan data yang akan digunakan.
b. Penjelasan data.
Data yang telah diperoleh dari tahapan pengumpulan data kemudian dijelaskan dalam tahapan penjelasan data ini.
c. Eksplorasi data
Tahapan eksplorasi data ini betujuan untuk mejelaskan data melalui statistika, ataupun dengan menggunakan visualisasi data. 1. Analisis statistik deskriptif
Dengan menggunakan analisis statistik deskriptif ini adalah untuk membantu terciptanya tujan dari data mining .Analisis statistik deskriptif digunakan adalah dengan mencari nilai – nilai dibawah ini :
a. Nilai minimal b. Nilai maksimal
c. Nilai rata – rata dengan menggunakan rumus [12] :
………..(2.3)
d. Nilai standar deviasi dengan menggunakan rumus [12] :
� =∑ ��−��− 2………...(2.4)
2. Visualisasi data
1. Mising value. 2. Outlier
Outlier adalah data yang secara nyata berbeda dengan data yang lain [13]. Metode yang dapat digunakan untuk mendeteksi outllier berdasarkan teknis statistik. Metode ini menggunakan threshold untuk dinyatakan sebagai outlier. Perhitungan thershold menggunakan persamaan (2.5) Batas atas = mean + 2 * standar deviasi………….(2.5) Batas bawah = mean –2 * standar deviasi……….(2.5) d. Evaluasi data
Dalam tahapan evaluasi ini bertujuan untuk mengevaluasi data yang telah dilakukan dalam tahapan eksplorasi data.
3. Persiapan Data
Tahapan persiapan data ini merupakan tahapan yang mencakup semua kegiatan yang diperlukan untuk membangun dataset akhir (data yang akan digunakan dalam modeling tools) dari data mentah awal, dalam tahapan persiapan data ini terdapat beberapa tahapan diantaranya adalah :
a. Pemilihan data
Tahapan pemilihan data ini merupakan tahapan yang digunakan untuk memilih data yang akan digunakan, pemilihan tersebut meliputi pemilihan atribut ataupun pemilihan baris.
b. Pembersihan data
Tahapan pembersihan data merupakan tahapan untuk menghilangakan atau membersihkan data yang dihasilkan dalam tahapan evaluasi data.
c. Penyiapan data awal
4. Pemodelan
Tahapan pemodelan merupakan tahapan pemilihan model dan mengaplikasikan model yang sesuai. Dalam tahapan pemodelan ini terdapat beberapa tahapan diantaranya adalah :
a. Memilih teknik pemodelan
Dalam tahapan ini digunakan untuk memilih teknik pemodelan yang sesuai dengan permasalahan dan tujuan yang ingin dicapai. b. Pembuatan model
Dalam tahapan ini dijelasakan mengenai teknik pemodelan yang telah dipilih
c. Analisis pengujian model
Dalam tahapan ini model yang telah dipilih dijalankan dengan menggunakan kasus uji.
5. Evaluasi
Dalam tahapan ini akan dilakukan evaluasi terhadap model yang telah digunakan apakah model yang telah digunakan tersebut dapat mencapai tujuan yang ditetapkan pada fase pemahaman bisnis. Dalam tahapan evaluasi ini terdapat beberapa tahapan yang digunakan daintaranya adalah :
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan.
b. Menetapkan apakah model yang digunakan sudah sesuai dengan tujuan pada fase awal.
c. Menentukan apakah terdapat permasalahan dari tahapan pemahaman bisnis yang tidak tertangani.
d. Mengambil keputusan yang berkaitan dengan penggunaan hasil dari data mining.
6. Deployment
yang telah diperoleh sihingga dapat digunakan oleh pengguna
Gambar 2. 11Phase of the CRISP-DM References Model
2.2.10 Validitas Cluster
Validitas cluster ini digunakan untuk mengetahui berapa jumlah cluster yang tepat, salah satu matriks yang dapat digunakan untuk memvaliditas cluster adalah matriks Silhouette Index (SI), yaitu suatu matriks yang digunakan untuk mengevaluasi cluster dengan cara mengukur seberapa tepat sebuah data dalam suatu cluster. Untuk menghitung nilai Si dari sebuah data ke-I, terdapat dua kompnen aitu ai dan bi, ai adalah rata – rata
jarak ke-i terhadap semua data lainya dalam suatu cluster, sedangkan bi
didapatkan dengan menghitung rata – rata jarak data ke-i, kemudian diambil nilai terkecil [6].
Persamaan yang digunakan untuk mencari nilai aij
aij=
− ∑�= �(xi
j, x
rj)………..(2.6)
Persamaan yang digunakan untuk mencari nilai bij
………..(2.7)
………..………(2.8)
Nilai ai untuk mengukur seberapa mirip sebuah data dengan cluster
yang diikutinya, nilai yang semakin kecil menandakan semakin tepatna data tersebut dalam cluster tersebut. Nilai bi yang besar menandakan
seberapa jeleknya data terhadap cluster yang lain. Nilai SI yang terdapat dalam rentang [-1..+1]. Nilai SI yang mendekati 1 menandakan bahwa data tersebut semakin tepat dalam cluster tersebut. Nilai SI negatif menandakan bahwa data tersebut tidak tepat berada dalam cluster tersebut. SI bernilai 0 berarti data tersebut posisinya berada di perbatasan antar cluster [6].
Untuk nilai SI dari sebuah cluster didapatkan dengan menggunakan rata – rata nilai SI semua data bergabung dalam cluster teresebut, seperti pada persamaan berikut :
SIj = ∑�= SIij………..(2.9)
Dan untuk nilai SI global didapatkan dengan menggunakan persamaan sebagai berikut :
SIj = ∑ = SIj………..(2.10)
2.2.11 Alat – alat Pemodelan Sistem
Pemodelan sistem merupakan hal yang penting bagi kelangsungan sistem itu sendiri. Pemodelan sistem adalah suatu upaya untuk menjaga efektivitas sistem dalam memenuhi kebutuhan pengguna sistem. Pemodelan sistem dapat bererti menyusun sistem yang baru untuk menggantikan sistem yang lama secara keseluruhan atau memperbaiki sistem yang sudah ada [9]. 2.2.11.1 Entity Relationship Diagram (ERD)
Entity relationship diagram ini memiliki beberapa elemen sebagai berikut [8]:
1. Entity
Pada ERD, entitas digambarkan dengan menggunakan sebuah bentuk persegi panjang. Entitas adalah objek nyata yang dapat dibedakan dengan objek lain, misalnya mahasiswa, buku, karyawan dan lain – lain. Entitas diberi nama dengan kata benda. Entitas ini memiliki atribut, contohnya entitas karyawan memiliki atribut : NIK, Nama, Jabatan.
2. Relasi
Dalam ERD, relasi dapat digambarkan dalam sebuah bentuk belah ketupat. Relasi yang digunakan untuk menyatakan hubungan antara satu entitas dengan entitas yang lainya. Untuk penamaan relasi biasanya menggunakan kata kerja dasar. Misalnya entitas mahasiswa berleasi dengan entitas buku makapenamaan dari relasinya adalah meminjam, jadi ketika diagram tersebut dibaca dapat lebih mudah.
3. Atribut
Atribut adalah sesuatu yang menjelaskan mengenai maksud entitas maupun relasi, sehingga dikatakan atribut adalah elemen dari setiap entitas dan relasi.
4. Kardinalitas
Kardinalitas relasi digunakan untuk menunjukan maksimum tupel yang dapat berelasi dengan entitas pada entitas yang lain. Terdapat tiga macam kardinalitas relasi, yaitu :
a. one to one
b. One to Many atau Many to One
Tingkat hubungan satu ke banyak adalah hubungan yang menyatakan dari satu entitas tersebut memiliki banyak kejadian dengan entitas yang berelasi, dan sebaliknya. c. Many to many
Tingkat hubungan banyak ke banyak terjadi apabila kejadian pada sebuah entitas akan mempunyai banyak hubungan dengan kejadian entitas lainya, baik dilihat dari sisi entitas yang pertama maupaun dilihat dari sisi yang kedua. Ketika terdapat dua entitas yang memiliki kardinalitas many to many maka akan menghasilkan sebuah enititas yang baru.
2.2.11.2 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) menggambarkan aliran data atau informasi di mana di dalamnya terlihat keterkaitan di antara data yang ada. Terdapat banyak simbol – simbol yang digunakan dalam pembuatan DFD. DFD merupakan salah satu alat analisis dan teknik pemodelan terbaik untuk menggambarkan proses dan kebutuhan fungsional dari suatu sistem [10].
DFD merupakan serangkain diagram yang menggambarkan kegiatan – kegiatan yang ada dalam satu sistem. Teknik pembuatan DFD dimulai dengan menggambarkan sistem secara global dan dilanjutkan dengan analisis masing – masing bagian.
2.2.11.3 Kamus Data
Kamus data adalah suaut daftar data elemen yang terorganisir dengan definisi yang tetap dan sesuai dengan sistem, sehingga user dan analis sistem mempunyai pengertian yang samam mengenai input, output dan komponen data store.
2.2.12 PHP
PHP (Hypertext Preprocessor), bahasa pemrograman PHP merupakan bahasa berbentuk skrip yang ditempatkan dalam server dan diproses didalam server, hasilnya dikirim ke client tempat user menggunakan browser [11].
Secara khusus, PHP dirancang untuk membentuk aplikasi web dinamis (membentuk suatu tampilan berdasarkan permintaan terkini). Pada prinsipnya PHP mempunyai fungsi yang sama dengan skrip – skrip seperti ASP (Active Server Page), Could Fusion, ataupun Perl. PHP adalah sebuah bahasa pemrograman yang dapat digunakan secara command line, atau dapat dikatakan bahwa skrip PHP dapat dijalankan dengan melibatkan web browser maupun browser.
Pada saat ini PHP cukup popular sebagai piranti pemrograman web, tertama dilingkungan Linux. Walaupun demikian PHP sebenarnya juga dapat digunakan pada server – server yang berbasis UNIX, Windowa, Macintosh.
2.2.13 MySQL
MySQL adalah suatu perangkat lunak database relasi (Relational Database Management Sistem RDBMS), seperti halnya ORACLE, Postgresql,MSSQL dan sebagainya. MySQL dengan SQL merupakan dua hal yang berbeda, SQL (Structured Query Language) adalah sintak perintah
39 3.1 Analisis Sistem
Analisis sistem dapat diartikan sebagai penguraian dari suatu sistem yang utuh ke dalam bagian – bagian komponennya dengan tujuan untuk melakukan identifikasi dan mengevaluasi permasalahan, kesempatan, hambatan yang terjadi dan kebutuhan yang diharapkan sehingga dapat diusulkan perbaikannya.
3.1.1 Analisis Masalah
Berdasarkan hasil wawancara yang telah dilakukan dengan pihak marketing maka didapatkan hasil sebagai berikut :
1. Dalam menentukan strategi bisnis perusahaan, pihak marketing menganalisis data penjualan produk dengan cara mengelompokan setiap agent retail outlet berdasarkan nominalnya (pendapatan uangnya) yang dilakukan oleh agent retail outlet dalam kurun waktu seminggu sekali. 2. Pengelompokan yang dilakukan berdasarkan nominalnya tidak cukup
membantu untuk dijadikan acuan dalam menentukan strategi bisnis perusahaan dikarenakan tidak menggambarkan bagaimana penjualan masing – masing agent retail outlet terhadap produk.
3. Analisis yang dilakukan dengan menganlisis data yang terdapat dalam format *.xls atau *.xlsx secara manual.
4. Analisis data yang dihasilkan berupa kesimpulan dari penjualan yang telah dilakukan oleh agent retail outlet, kesimpulan dari analisis ini akan dijadikan acuan untuk menentukan strategi bisnis perusahaan.
6. Perusahaan memerlukan waktu yang lama untu memberitahukan kebijakan perusahaan yang diambil dari strategi bisnis perusahaan kepada agent retail outlet.
3.1.2 Analisis Pengelompokan yang Sedang Berjalan
Berdasarkan hasil wawancara yang telah dilakukan dengan pihak marketing PT. Trimitra Tunas Sakti, dalam melakukan pengelompokan agent retail outlet dilakukan berdasarkan nominalnya (uang pendapatannya), pengelompokan yang dilakukan bergantung kebutuhan dari strategi bisnis yang akan dihasilkan, akan tetapi biasanya pihak marketing melakukan pengelompokan agent retail outlet dengan jumlah 3 kelompok.
3.1.3 Analisis Data Mining
Berdasarkan tahapan – tahapan yang terdapat dalam CRISP-DM, maka dalam penelitian data mining di PT. Trimitra Tunas Sakti ini terdapat beberapa tahapan sebagai berikut :
3.1.3.1 Pemahaman Bisnis
Tahap pemahaman bisnis ini merupakan tahapan awal, dalam tahapan ini fokus untuk memahami tujuan dan kebutuhan dari sudut pandang bisnis PT. Trimitra Tunas Sakti. Dalam tahapan bisnis ini terdapat beberapa tahapan diantaranya adalah :
a. Identifikasi Tujuan Bisnis
Dalam proses bisnisnya yang paling utama di PT. Trimitra Tunas Sakti adalah menjual produk ke end user, untuk melakukan hal tersebut maka PT.Trimitra Tunas Sakti menggunakan agent retail outlet untuk menjual produknya ke end user. Maka dari itu banyak strategi bisnis yang ditentukan dari penjualan produk yang dilakukan oleh agent retail outlet. Untuk mendapatkan strategi bisnis tersebut pihak marketing melakukan analisis data penjualan produk yang dilakukan oleh agent retail outlet dengan cara mengelompokan agent retail outlet dalam kurun waktu 1
b. Penentuan Sasaran Data Mining 1. Tujuan data mining
Tujuan dari penerapan data mining pada penjualan produk dalam penelitian ini adalah untuk membentuk pengelompokan data agent retail outlet berdasarkan penjualan produk yang telah dilakukan oleh agent retail outlet. Dengan penerapan data mining ini diharapkan dapat membantu pihak marketing dalam menentukan strategi bisnis perusahaan.
2. Kriteria sukses data mining
Kriteria sukses terhadap penelitian ini adalah apabila dapat mengelompokan agent retail outlet yang sama berdasarkan kemampuanya dalam menjual setiap produk.
3.1.3.2 Pemahaman Data
Tahapan pemahaman data merupakan tahapan kedua yang dilakukan setelah tahapan pemahaman bisnis. Dalam tahapan pemahaman data ini terdapat beberapa langkah diantaranya adalah :
a. Pengumpulan data awal
Data yang digunakan dalam penelitian ini adalah data penjualan produk yang dilakukan oleh agent retail outlet dalam kurun waktu 1 minggu pada bulan Februari 2015 yaitu dari tanggal 1 Februari – 7 Februari. Data yang terlibat dalam data penjualan produk ini adalah, data agent retail outlet, data yang digunakan untuk proses analisis berupa file Excel dengan format *.xls atau *.xlxs.
Data yang digunakan untuk proses perhitungan secara manual dengan mengambil sebanyak 100 data agent retail outlet untuk dilakukan pegelompokan.
b. Penjelasan data
tabel D.2, dan penjelasan dari masing – masing tabel yang digunakan dapat dilihat pada tabel – tabel dibawah ini.
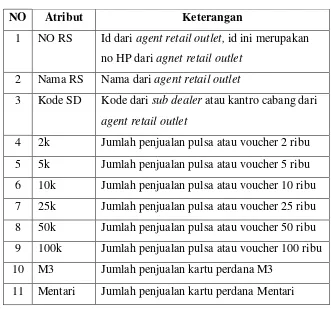
Berikut ini merupakan penjelasan dari masing – masing atribut pada tabel penjualan produk, dan tabel agent retail outlet yang terdapat pada lampiran D Tabel D.1 dan Tabel D.2:
Tabel 3.1 Penjelasan atribut data tabel penjualan produk
NO Atribut Keterangan
1 NO RS Id dari agent retail outlet, id ini merupakan no HP dari agnet retail outlet
2 Nama RS Nama dari agent retail outlet
3 Kode SD Kode dari sub dealer atau kantro cabang dari agent retail outlet
4 2k Jumlah penjualan pulsa atau voucher 2 ribu 5 5k Jumlah penjualan pulsa atau voucher 5 ribu 6 10k Jumlah penjualan pulsa atau voucher 10 ribu 7 25k Jumlah penjualan pulsa atau voucher 25 ribu 8 50k Jumlah penjualan pulsa atau voucher 50 ribu 9 100k Jumlah penjualan pulsa atau voucher 100 ribu 10 M3 Jumlah penjualan kartu perdana M3
11 Mentari Jumlah penjualan kartu perdana Mentari
Tabel 3.2 Penjelasan atribut tabel agent retail outlet
NO Atribut Keterangan
1 NO RS Id dari agent retail outlet, id ini merupakan no HP dari agnet retail outlet
c. Ekspolarsi Data
Tahapan eksplorasi data ini dapat membantu terciptanya tujuan dari data mining, dalam penelitian tugas akhir ini meliputi analisis statistik deskriptif dan visualisasi data, data yang akan digunakan untuk tahapan eksplorasi data ini adalah data sampel yang terdapat pada lampiran D Tabel D.1
1. Analisis statistik deskriptif
Analisis deskriptif ini dilakukan pada atribut (field) 2k, 5k, 10k, 12k, 25k, 50k, dan 100k, m3, dan mentari. Analisis dilakukan terhadap atribut tersebut dikarenakan atribut pengelompokan yang akan dilakukan berdasarkan penjualan produk.
Analisis pada setiap atribut produk dilakukan untuk melihat kualitas dari data. Dalam tahapan analisis data ini akan diambil satu produk yaitu produk 5k untuk dilakukan tahapan analisis data, dengan cara yang sama anlisis data tersebut dapat dilakukan pada setiap produk. Berikut ini analisis yang akan dilakukan diantaranya adalah :
a. Nilai minimal
Nilai minimal ini digunakan untuk mengetahui berapa jumlah penjualan produk yang paling sedikit dalam produk tersebut. Dengan mengetahui nilai minimal akan memberikan gambaran berapa nilai terkecil dari data penjualan produk sebelum dilakukan proses data mining. Untuk menentukan nilai minimal dicari dengan membandingkan setiap nilai sehingga mendapatkan nilai terkecil. Berikut ini adalah nilai minimal dari produk 5k seperti yang terlihat pada Lampiran D Tabel D.1 :
Min 5k = 0 b. Nilai maksimal
sebelum dilakukan proses data mining. Nilai maksimal ini didapatkan dengan membanding kan setiap data sehingga mendpatkan nilai yang paling besar.
Dan berikut ini merupakan nilai maksimal dari produk 5k seperti yang terlihat pada Lampiran D Tabel D.1 :
Max 5k = 2200 c. Nilai rata – rata
Nilai rata – rata ini untuk mengetahui berapa jumlah rata – rata penjualan produk yang telah dilakukan oleh agent retail outlet pada setiap produk. Dengan nilai rata – rata ini akan memberikan gambaran menganai berapa jumlah rata – rata dari penjualan produk tersebut sebelum masuk kedalam tahapan data minig. Cara untuk mendapatkan nilai rata – rata dapat menggunakan persamaan (2.3). Dalam data produk 5k total produk yang terjual seperti yang terlihat pada Lampiran D Tabel D.1 adalah sebanyak : 12880 Dengan jumlah data yang ada adalah 100 data.
Maka dengan menggunakan persamaan (2.3) didapatkan hasil sebagai berikut :
X
=
88=
128.8d. Standar deviasi
Standar deviasi ini digunakan untuk menggambarkan bagaimana penyebaran data dari nilai rata – rata atau simpangan dari nilai rata - rata. Dengan mengethui nilai standar deviasi ini maka akan memberikan bagaimana simpangan rata – rata dari data yang akan diteliti sebelum kedalam proses data mining dan dengan standard deviasi ini juga dapat digunakan untuk melihat outlier dalam data, untuk menghitung standar deviasi tersebut dapat menggunakan persamaan (2.4) :
Dalam produk 5k rata – rata jumlah penjualan produk adalah: Rata – Rata X = 128.8
∑� (xix) = �=
S2 =
−
=
102548.26S = √ . = .
Dari proses diatas maka didapatkan hasil sebagai berikut : Tabel 3.3 Hasil analisis statistik deskriptif No Nama
2. Visualisasi
Visualisasi data dilakukan terhadap atribut produk 2k, 5k, 10k, 12k, 25k, 50k, 100k, m3, dan mentari, berikut ini merupakan hasil visualisasi dari atribut tersebut :
a. Dari setiap atribut tersebut produk pada lampiran D tabel D.1 nilai missing value 0% (tidak ada data yang hilang).
b. Dari data penjualan tersebut akan dilihat apakah terdapat outlier atau tidak, dan berikut ini merupakan cara yang dapat dilakukan untuk melihat data outlier dengan menggunakan persamaan (2.5):
Dengan menggunakan persamaan (2.5) tersebut maka pada produk 5k adalah sebagai berikut:
Batas atas outlier 5k = 128.8+ 2 x 320.232 = 128.8+ 640.464 = 769.264
Batas bawah outlier 5k = 128.8- 2 x 320.232 = 128.8- 640.464 = -511.664
Dengan menggunakan persamaan (2.5) maka didapatkan batas atas dan batas bawah untuk masing – masing produk sebagai berikut :
Tabel 3.4 Batas atas dan batas bawah outlier
No Produk Batas atas Batas bawah
1 2k 0 0
2 5k 769.264 -511.664
3 10k 380.808 -226.988
4 12k 0 0
5 25k 59.092 -42.6726
6 50k 18.934 -13.7172
7 100k 1.157 -0.97723
8 M3 164.207 13.05294
9 Mentari 129.441 18.53923
Dari penentuan batas atas dan batas bawah maka apabila jumlah penjualan yang terdapat dalam produk 5k melebihi batas atas outlier 5k atau kurang dari batas bawah outlier 5k, maka data tersebut dinyatakan outlier. Maka data yang termasuk outlier dalam produk 5k adalah sebagai berikut : 20,52,82,93,95. Dengan menggunakan cara yang sama yaitu dengan menggunakan persamaan (2.4) diatas maka diperoleh hasil outlier sebagai berikut :
2. Dalam produk 10k terdapat beberapa nilai yang outlier diantaranya adalah : 20, 21, 27, 52,95, 96.
3. Dalam produk 12k tidak terdapat outlier.
4. Dalam produk 25k terdapat beberapa outlier diantanya adalah : 11, 20, 32, 44,96.
5. Dalam produk 50k terdapat beberapa nilai outlier diantanya adalah : 11,20,32, 56.
6. Dalam produk 100k terdapat nilai outlier yang terdapat pada data : 11.
7. Dari produk M3 terdapat data outlier yaitu pada data : 13, 9, 30, 41, 42.
8. Dari produk mentari terdapat data outlier yaitu pada data : 24, 25,31, 36, 37, 45,93.
Untuk hasil yang lengkapnya dari proses pengecekan outlier ini dapat dilihat pada lampiran D pada Tabel D.3.
c. Mengevaluasi kualitas data
Pada tahapan ini dilakukan pemeriksaan terhadap data yang akan digunakan, dari tahapan pemeriksaan data ini diperoleh bebrapa hasil diantaranya adalah :
a. Dari 100 data penjualan dari seluruh produk tersebut memiliki 20 data outlier yaitu pada data ke 9,11, 12,13, 20, 21, 27, 30, 32, 36, 37, 41, 42, 44, 45, 52, 56, 82, 93, 95, dan data ke-96 atau dapat dilihat pada lampiran D pada tabel D.3. b. Data pejualan produk tersebut tidak memiliki missing value. 3.1.3.3 Persiapan Data
a. Pemilihan data
Pemilihan data memiliki tugas meliputi pemilihan atribut dan baris, atribut yang akan digunakan dalam penelitian ini merupakan atribut hasil dari penggabungan antara tabel penjualan produk, dan tabel agent retial outlet. Field yang dipilih untuk dilakukan proses pengelompokan (clustering) adalah atribut no rs, 2k, 5k, 10k, 25k, 50k, 100k, m3, mentari.
b. Pembersihan data
Pada proses pembersihan data adalah proses untuk membersihkan data yang dihasilkan pada tahapan mengvaluasi data. Pada tahap pembersihan data ini melakukan pembersihan data sebagai berikut :
1. Nilai yang bersifat outlier akan tetap diproses, untuk melakukan pengelompokan agent retail outlet ini digunakan algoritma yang tahan terhadap adanya outlier.
2. Dari data penjualan produk tidak terdapat missing value, untuk mencegah terjadinya missing value maka setiap nilai yang kosong akan diganti dengan nilai 0.
c. Penyiapan Data Awal
Pada proses penyiapan data ini akan disiapkan data yang akan digunakan dalam tahapan pemodelan. Data yang akan digunakan dalam tahapan pemodelan seperti terlihat dalam lampiran D pada Tabel D.4:
3.1.3.4 Pemodelan
Tahapan selanjutnya dari kerangka kerja CRISP-DM adalah tahapan pemodelan, pada tahapan ini memilih dan mempersiapkan pemodelan yang sesuai.
a. Teknik pemodelan
b. Analisis pengujian model
Kasus yang akan diuji dengan menggunakan algoritma AHC ini adalah sebagai berikut :
1. Data yang digunakan
Data yang akan digunakan untuk melakukan pengelompokan ini adalah data penjualan produk yang dilakukan selama satu minggu, jumlah data yang digunakan adalah sebanyak 100 record data, seperti terlihat dalam lampiran D Tabel D.4:
2. Menentukan jumlah cluster
Jumlah kelompok yang akan dibentuk adalah sebanyak tiga kelompok berdasarkan jumlah kelompok yang biasa dibentuk oleh pihak marketing. 3. Menghitung jarak antar data
Inisialisasi cluster awal adalah sebanyak 100 cluster karena data(n) = cluster(c), kemudian dihitung jarak antara data dengan cluster yang ada dengan menggunakan Euclidean (persamaan 2.1).
Berikut ini meruapakan proses perhitungan jarak antar data dengan menggunakan matriks Euclidean.
� , = √ − + −− +− −+ +− −+ −+ +− = .
Dengan cara yang sama yaitu dengan menggunakan matriks Euclidean dilakukan perhitungan terhadap seluruh data, maka dihasilkan matriks jarak seperti terlihat dalam lampiran D pada Tabel D.5.
4. Menghitung kedekatan antara dua cluster.
Dalam tahapan ini akan dihitung jarak antara dua cluster dengan menggunakan metode single linkage (persamaan 2.2), dengan metode ini akan mencari jarak yang paling kecil dari dua cluster.
Iterasi 1 :
D(1,2) = min {D1,D2} = 22.5832
pembentukan cluster tersebut menggunakan metode single linkage yang terdapat dalam persamaan 2.2. Dengan menggunakan metode single linkage akan mencari jarak yang paling dekat. Dari setiap iterasi yang dilakukan akan menggabungkan dua cluster, sehingga Jumlah iterasi yang akan dihasilkan dari jumlah 100 data dengan cluster yang akan dibentuk sebanyak 3 cluster maka akan menghasilkan sebanyak 97 iterasi. Dari iterasi yang pertama jarak yang paling dekat adalah cluster 14 dengan 22, maka kedua cluster tersebut digabungkan menjadi satu cluster dan cluster yang terbentuk pada iterasi ke 1 ini menghasilkan sebanyak 99 cluster (proses iterasi ini dapat dilihat dalam lampiran D pada Tabel D.6).
Proses ini terus dilakukan hingga mendapatkan hasil akhir dengan jumlah cluster sebanyak tiga cluster. Hasil akhir dari pengelompokan ini terbentuk sebanyak tiga kelompok dengan masing – masing kelompok ditunjukan pada lampiran D pada tabel D.7,D.8, dan D.9. Dan untuk hasil dalam bentuk dendrogram dapat dilihat dalam lampiran D Gambar D.1. Dari hasil pengelompokan tersebut maka diperoleh rata – rata penjualan produk dari masing – masing kelompok sebagai berikut:
Tabel 3.5 Rata – rata penjualan produk dari masing – masing cluster
Cluster 2k 5k 10k 12k 25k 50k 100k M3 mentari
Cluster1 0 96.7041 78.4286 0 8.37776 2.6633 0.0918 88.3980 73.3673
Cluster2 0 2200 3 0 0 0 0 128 72
Gambar 3.1.Cluster 1
Gambar 3.3. Cluster 3
Dari proses pengelompokan dengan menggunakan algoritma AHC didapatkan hasil sebagai berikut :
a. Dengan menggunakan jumlah cluster sebanyak tiga cluster dari jumlah data yang digunakan sebanyak 100 data, 98 data terdapat pada cluster 1, 1 data pada cluster 2, dan 1 data dalam cluster 3.
b. Dengan menggunakan algortima AHC ini pengelompokan akan cenderung berkumpul dalam satu cluster, hal ini dikarenakan setiap iterasi yang dilakukan akan mencari nilai terkecil dari setiap cluster, dan nilai terkecil tersebut yang akan digunakan untuk dibandingkan dengan cluster lain.
c. Rata – rata jumlah penjualan dalam cluster 1 cenderung merata dari setiap produknya.
d. Rata – rata jumlah penjualan produk dalam cluster 2 merupakan jumlah penjualan produk yang tertinggi dari produk 5k dan produk m3, dalam cluster ini tidak semua produk dapat di jual, sehingga tidak terlalu merata.
3.1.4 Spesifikasi Kebutuhan Perangkat Lunak
Analisis spesifikasi kebutuhan perangkat lunak bertujuan untuk menjelaskan kebutuhan – kebutuhan dari perangkat lunak yang akan dibangun. Analisis kebutuhan perngkat lunak ini meliputi analisis kebutuhan fungsional dan non fungsional.
3.1.4.1Spesifikasi Kebutuhan Fungsional
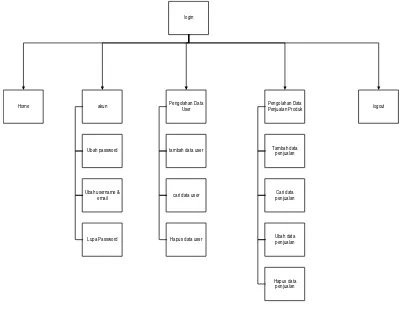
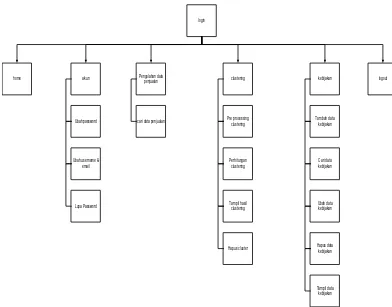
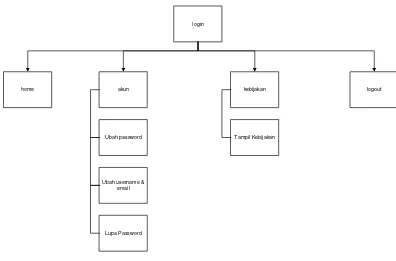
Spesifikasi kebutuhan fungsional memiliki tugas untuk menjelaskan penyediaan layanan pada sistem terhadap masukan tertentu, menjelaskan fungsionalitas dari sistem, serta menjelaskan secara detail layanan yang terdapat dalam sistem. Beikut ini merupakan spesifikasi kebutuhan fungsionalitas yang akan dibangun.
Tabel 3.6 Spesifikasi kebutuhan perangkat lunak
Nomor Spesifikasi Kebutuhan Fungsional
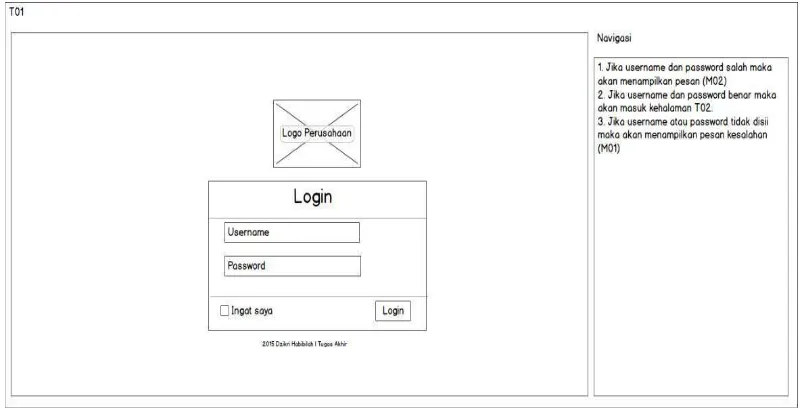
SKPL-F-1 User dapat melakukan login
SKPL-F-2 Sistem memiliki menu yang dapat dipilih oleh user
SKPL-F-3 Sistem dapat mengeksport hasil pengelompokan
SKPL-F-4 Sistem dapat mengelompokan agent retail outlet berdasarkan penjualan produknya.
SKPL-F-5 Sistem dapat menyimpan hasil dari pengelompokan data agent retail outlet SKPL-F-6 Sistem dapat menyajikan hasil dari
pengelompokan
3.1.4.2Spesifikasi Kebutuhan Non Fungsional
Tabel 3.7 Spesifikasi kebutuhan non fungsional
Nomor Spesifikasi Kebutuhan Non Fungsional
SKPL-NF-1 User dibedakan kedalam tiga kategori, yaitu, bagian marketing, bagian admin / IT, dan agent retail outlet.
SKPL-NF-2 Login menggunakan username dan password SKPL-NF-3 Sistem menampilkan menu seuasi dengan
hak akses dari user.
SKPL-NF-4 User dapat memilih menu sesuai dengan hak akses yang diberikan
SKPL-NF-5 Sistem dapat mengeksport data penjualan dengan format *.xls atau *.xlsx
SKPL-NF-6 Sistem dapat menyimpan hasil clustering / pengelompokan kedalam database
SKPL-NF-7 Sistem dapat menampilkan hasil pengelompokan dalam bentuk tabel
SKPL-NF-8 Sistem dapat menampilkan hasil pengelompokan dalam bentuk grafik
SKPL-NF-9 Sistem yang akan dibangun berbasis web
3.1.5 Analisis Spesifikasi Kebutuhan Non Fungsional
3.1.5.1Analisis Kebutuhan Perangkat Keras
Berdasarkan pengamatan yang dilakukan di PT. Trimitra Tunas Sakti wilayah Jawa Timur, spesifikasi perangkat keras yang digunakan oleh PT. Trimitra Tunas Sakti wilayah Jawa timur secara umum adalah:
Tabel 3.8 Spesifikasi Perangkat Keras yang sedang digunakan
No Perangkat Keras Spesifikasi
1 Prosesor Intel Core i3 1.80 GHz
2 VGA 226 MB
3 Memory RAM 2GB DDR3
4 Harddisk 250 GB
5 Monitor LCD 16 inchi
6 Keyboard Standard Port USB / PS2 7 Mouse Standard Port USB / PS2
8 Printer Standard
Dan adapun spesifikasi pernagkat keras yang dibutuhkan untuk mengimplementasikan sistem yang akan dibangun adalah sebagai beikut :
Tabel 3.9 Spesifikasi perngakat keras yang dibutuhkan
No Perangkat Keras Spesifikasi
1 Prosesor Intel Core i3 1.80 GHz
2 VGA 226 MB
3 Memory RAM 2GB DDR3
4 Harddisk 160 GB
5 Monitor LCD 16 inchi
6 Keyboard Standard Port USB