i
UNTUK PEMANTAUAN DISTRIBUSI SEPEDA MOTOR
DI PD.WIJAYA ABADI BANDUNG
Oleh
JAKA ADI SWARA
10106048
PD. Wijaya Abadi Bandung adalah perusahaan yang bergerak di bidang jual beli dan juga mendistribusikan sepeda motor bermerek Honda terhadap konsumen perorangan maupun perusahaan. Seiring terus berlalunya proses transaksi distribusi, datapun akan terus terbentuk hingga bertumpuk-tumpuk sehingga perusahaan kesulitan untuk menganalisa data guna meningkatkan strategi pendistribusian sepeda motor. Dari data tersebut perusahaan ingin adanya pengolahan data lebih lanjut untuk menemukan informasi/pengetahuan baru yang berguna. Informasi yang diinginkan pihak perusahaan adalah bersifat pengklasifikasian keterkaitan suatu perusahaan target pendistribusiannya dengan atribut tipe motor dan kode warna yang ada pada data distribusi penjualan sepeda motor.
Untuk mendapatkan informasi tersebut secara lebih cepat dan efisien perlu kiranya suatu bantuan teknologi informasi, dalam hal ini yaitu data mining. Data mining merupakan metode pencarian informasi (pengetahuan) baru yang terkandung dalam data yang sangat besar. Deicision Tree merupakan salah satu metode klasifikasi dan prediksi yang sangat kuat dan terkenal dalam penerapan data mining. Pemilihan metode ini didasarkan pada informasi yang ingin diperoleh yaitu informasi yang bersifat klasifikasi. Keuntungan dalam metode ini adalah efektif dalam menganalisis sejumlah besar atribut dari data yang ada dan mudah dipahami oleh pengguna akhir.
Hasil keluaran dari aplikasi ini adalah informasi yang bersifat klasifikasi dalam bentuk Decision Tree. Aplikasi ini dapat menguji nilai dari atribut untuk mengetahui pola aturan dari pendistribusian yang ada sehingga perusahaan mempunyai bekal pengetahuan dalam mendistribusikan sepeda motor ke perusahaan target pendistribusiannya.
iii Assalamu’alaikum Wr. Wb.,
Alhamdulillahi rabbil’alamin. Segala puji dan syukur penyusun panjatkan kepada Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penyusun dapat menyelesaikan Tugas Akhir yang berjudul “Aplikasi Data
Mining Menggunakan Metode Decision Tree Untuk Pemantauan Distribusi
Penjualan Sepeda Motor Di PD. Wijaya Abadi Bandung”.
Tak lupa shalawat serta salam tetap tercurah kepada jungjunan kita Nabi Besar Muhammad SAW. Atas petunjuknya kepada umat muslim di dunia dari jalan yang gelap menuju yang terang benderang yaitu Addinul Islam.
Tugas Akhir ini disusun untuk memenuhi salah satu syarat untuk melengkapi program perkuliahan Strata 1 pada jurusan Teknik Informatika Universitas Komputer Indonesia. Tugas Akhir ini disusun berdasarkan kegiatan penelitian yang telah dilaksanakan di PD. Wijaya Abadi Bandung.
Hal ini tentu saja tidak terlepas dari dukungan dan sumbang asih semua pihak yang telah membantu dalam menyelesaikan Tugas Akhir ini. Oleh karena itu pada kesempatan ini penyusun ingin sekali mengucapkan rasa terima kasih pada semua pihak yang telah membantu penyusun dalam mewujudkan ini semua. Dalam hal ini, penyusun mengucapkan terima kasih kepada:
1. Kedua orang tua (Bapa dan Mamah), serta seluruh keluarga atas segala do’a, kasih sayang, semangat dan dorongan moril maupun materil.
iv
membantu dalam kelancaran dari berbagai permasalahan mengenai perkuliahan.
4. Bapak Edi Mulyana, M.T., selaku dosen pembimbing yang telah meluangkan waktunya untuk membimbing, memberi masukan dan berbagi pengetahuan dalam penyusunan tugas akhir ini.
5. Ibu Tati Harihayati M., S.T.,M.T., selaku dosen penguji I yang telah memberikan saran serta kritiknya dalam penyempurnaan skripsi ini.
6. Andi Susanto selaku Manajer PD. Wijaya Abadi yang telah memberikan ijin tempat penelitian dan masukan pada tugas akhir ini.
7. Teman-teman yang telah ikut mendukung dan membantu terutama Angga Nurmaulana, Erika Susilo, dan Chandra Normansyah serta selalu mendoakan, memberi semangat, motivasi, dan berbagi pengetahuan kepada penyusun. 8. Kepada seluruh sahabat saya khususnya kelas IF-2 angkatan 2006, atas do’a
dan dukungannya.
9. Kepada semua pihak yang tidak sempat disebutkan satu persatu, semua memiliki andil yang sangat besar atas perjuangan saya. Semoga semua amal dan kebaikannya diberikalan balasan setimpal oleh Allah SWT.
Penyusun menyadari bahwa Tugas Akhir ini masih kurang sempurna, oleh karena itu penyusun berharap saran dan kritik yang membangun demi kesempurnaan laporan Tugas Akhir ini. Semoga laporan ini bisa bermanfaat bagi siapapun dan dapat digunakan sebagaimana mestinya. Amin.
v LEMBAR JUDUL
LEMBAR PENGESAHAN
ABSTRAK ……… i
ABSTRACT ………... ii
KATA PENGANTAR ……….. iii
DAFTAR ISI ……….. v
DAFTAR TABEL ……….. x
DAFTAR GAMBAR ……… xi
DAFTAR SIMBOL ……… xiii
DAFTAR LAMPIRAN ………... xiv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 3
1.2 Perumusan Masalah ... 3
1.3 Maksud dan Tujuan ... 3
1.3.1 Maksud ... 3
1.3.2 Tujuan ... 3
1.4 Batasan Masalah ... 4
1.5 Metodologi Penelitian ... 5
a. Pengumpulan Data ... 5
vi
2.1 Profil Perusahaan ... 10
2.1.1 Sejarah Perusahaan ... 10
2.1.2 Visi dan Misi Perusahaan ... 11
2.1.3 Struktur Organisasi dan Job Description ... 11
2.2 Landasan Teori ... 15
2.2.1 Data ... 15
2.2.2 Informasi ... 16
2.2.3 Pengetahuan ... 18
2.2.4 Basis Data ... 19
2.2.4.1 Penerapan Basis Data ... 21
2.2.4.2 Kegunaan Basis Data ... 21
2.2.4.3 Abstraksi Basis Data ... 22
2.2.4.4 Bahasa Basis Data ... 23
2.2.4.5 Struktur Sistem Secara Keseluruhan ... 23
2.2.5 Data Mining ... 24
2.2.5.1 Model dalam Data Mining ... 25
2.2.5.2 Pengelompokan Data Mining ... 28
vii
BAB III ANALISIS DAN PERANCANGAN ... 33
3.1 Analisis Sistem ... 33
3.1.1 Analisis Masalah ... 33
3.1.2 Analisis Data ... 34
3.1.3 Analisis Metode Decision Tree ... 39
3.1.4 Analisis Kebutuhan Non Fungsional ... 46
3.1.4.1 Analisis Kebutuhan Pengguna (User) ... 47
3.1.4.2 Analisis Kebutuhan Perangkat Keras (Hardware) ... 48
3.1.4.3 Analisis Kebutuhan Perangkat Lunak (Software) ... 49
3.1.5 Analisis Kebutuhan Fungsional... 50
3.1.5.1 Diagram Konteks ... 50
3.1.5.2 Diagram Alir Data Level 1 ... 51
3.1.5.3 Diagram Alir Data Level 2 Proses 1 Proses Data Mining ... 52
3.1.5.4 Diagram Alir Data Level 2 Proses 2 Proses Testing ... 53
3.1.5.5 Spesifikasi Proses ... 53
3.1.5.6 Kamus Data ... 58
3.2 Perancangan Sistem ... 60
viii
3.2.3 Perancangan Antarmuka ... 64
3.2.3.1 Perancangan Form ... 64
3.2.3.1.1 Perancangan Form Menu Utama ... 64
3.2.3.1.2 Perancangan Form Konfigurasi Atribut ... 65
3.2.3.1.3 Perancangan Form Data Kasus ... 65
3.2.3.1.4 Perancangan Form Decision Tree ... 66
3.2.3.1.5 Perancangan Form Uji Data... 66
3.2.3.1.6 Perancangan Form Pola Aturan ... 67
3.2.3.1.7 Peracangan Form About ... 68
3.2.3.1.8 Perancangan Pesan ... 68
3.2.4 Perancangan Prosedural ... 68
3.2.4.1 Prosedural Konfigurasi Atribut ... 69
3.2.4.2 Prosedural Decision Tree ... 70
BAB IV IMPLEMENTASI DAN PENGUJIAN ... 71
4.1 Implementasi ... 71
4.1.1 Implementasi Perangkat Keras ... 71
4.1.2 Implementasi Perangkat Lunak ... 71
ix
4.2.1 Rencana Pengujian ... 78
4.2.2 Kasus dan Hasil Pengujian Alpha ... 79
4.2.2.1 Konfigurasi Atribut... 79
4.2.2.2 Decision Tree ... 80
4.2.2.3 Uji Data ... 80
4.2.2.4 Pola Aturan ... 80
4.2.3 Kesimpulan Pengujian Alpha ... 81
4.2.4 Pengujian Beta (Hasil Kuisioner Pengguna) ... 81
4.2.4.1 Hasil Kuisioner ... 82
4.2.5 Kesimpulan Hasil Pengujian Beta ... 85
BAB V KESIMPULAN DAN SARAN ... 86
5.1 Kesimpulan ... 86
5.2 Saran ... 86
87
[1] Feri Sulianta, Dominikus Juju, (2010), Data Mining Meramalkan Bisnis
Perusahaan, Jakarta : Elex Media Komputindo.
[2] Hakim, Lukmanul, (2008), Membongkar Trik Rahasia Para Master PHP,
Yogyakarta : Lokomedia.
[3] Hakim, Lukmanul, (2009), Trik Rahasia Master PHP Terbongkar Lagi,
Yogyakarta : Lokomedia.
[4] Kadir, Abdul, (2005), Pemrograman Database Dengan Delphi 7, Yogyakarta :
ANDI.
[5] Kadir, Abdul, (2003), Pengenalan Sistem Informasi, Yogyakarta : ANDI.
[6] Kusrini, Emha Taufiq Luthfi, (2009), Algoritma Data Mining,
Yogyakarta : ANDI.
[7] Pressman, Roger, (2001), Software Engineering : A Practitioner’s Approach,
1
1.1 Latar Belakang
PD. Wijaya Abadi Bandung adalah perusahaan yang bergerak di bidang jual
beli sepeda motor bermerek Honda. Dalam kegiatan operaisonalnya, PD. Wijaya
Abadi juga mendistribusikan sepeda motor terhadap konsumen perorangan
maupun perusahaan. Setiap mendistribusikan sepeda motor, perusahaan biasanya
mencatat data transaksi distribusi sepeda motor ke dalam database.
Pada proses pendistribusian sepeda motor, PD. Wijaya Abadi biasa
mendistribusikan sepeda motor ke salah satu perusahaan target pendistibusiannya
dalam satu hari. Dari data distribusi sepeda motor yang diperoleh, bahwa dalam
satu hari PD. Wijaya Abadi bisa mendistribusikan sebayak 30 unit motor. Seiring
terus berlalunya proses, datapun akan terus terbentuk hingga bertumpuk-tumpuk.
Dengan demikian, perusahaan kesulitan untuk menganalisa data guna
meningkatkan strategi pendistribusian sepeda motor.
Dari hasil wawancara dengan kepala perusahaan PD. Wijaya Abadi
Bandung bahwa dari data tersebut perusahaan ingin adanya pengolahan data lebih
lanjut untuk menemukan informasi/pengetahuan baru yang berguna sebagai bahan
evaluasi dan pemantauan distribusi penjualan sepeda motor sehingga di kemudian
waktu perusahaan memiliki bekal pengetahuan dan aturan dalam pendistribusian
motor tersebut. Informasi yang diinginkan pihak perusahaan adalah bersifat
atribut tipe motor dan kode warna yang ada pada data distribusi penjualan sepeda
motor. Karena, perusahaan biasanya menganalisa data transaksi penjualan sepeda
motor berdasarkan atribut tipe motor dan kode warna apa saja yang biasa
didistribusikan.
Hasil pengamatan data yang ada sebelumnya hingga sekarang, ternyata tiap
data memiliki format atau pola data yang sama dan mengalami peningkatan
jumlah distribusi penjualan dari tahun ke tahun. Untuk mendapatkan informasi
tersebut secara lebih cepat dan efisien perlu kiranya suatu bantuan teknologi
informasi, dalam hal ini yaitu data mining. Target data yang akan di-mining
adalah data distribusi penjualan sepeda motor di PD. Wijaya Abadi.
Data mining merupakan metode pencarian informasi (pengetahuan) baru
yang terkandung dalam data yang sangat besar. Dalam data mining terdapat
beberapa metode yaitu prediksi, klasifikasi, pengklusteran, dan asosiasi. Salah
satu metode yang akan digunakan dalam membangun aplikasi ini adalah metode
klasifikasi dengan decision tree. Deicision Tree merupakan salah satu metode
klasifikasi dan prediksi yang sangat kuat dan terkenal dalam penerapan data
mining. Pada dasarnya Decision Tree mengubah data menjadi pohon keputusan
(decision tree) dan aturan-aturan keputusan (rule). Pemilihan metode ini
didasarkan pada informasi yang ingin diperoleh yaitu informasi yang bersifat
klasifikasi. Keuntungan dalam metode ini adalah efektif dalam menganalisis
sejumlah besar atribut dari data yang ada dan mudah dipahami oleh pengguna
Berdasarkan permasalahan yang dihadapi perusahaan, maka perlu dibuat
sebuah aplikasi dengan judul Aplikasi DataMining dengan Metode DecisionTree
untuk Pemantauan Distribusi Penjualan Sepeda Motor di PD. Wijaya Abadi
Bandung.
1.2 Perumusan Masalah
Dari latar belakang ditemukan beberapa masalah yang dirumuskan dalam
suatu rumusan masalah yaitu bagaimana membangun Aplikasi Data Mining
dengan Metode Decision Tree untuk Pemantauan Distribusi Penjualan Sepeda
Motor Di PD. Wijaya Abadi Bandung.
1.3 Maksud dan Tujuan
Dari permasalahan yang ada, maksud dan tujuan dibangunnya aplikasi ini
adalah:
1.3.1 Maksud
Pembuatan laporan ini dimaksudkan untuk membangun aplikasi Data
Mining untuk pemantauan distribusi penjualan sepeda motor di PD. Wijaya Abadi
Bandung.
1.3.2 Tujuan
Tujuan yang akan dicapai dari dibangunnya aplikasi ini adalah:
1. Mampu memberi informasi pengklasifikasian pada distribusi penjualan
sepeda motor menggunakan data mining dalam bentuk pohon keputusan
2. Memberikan bekal pengetahuan dan aturan dalam mengambil keputusan
mendistribusikan sepeda motor di PD.Wijaya Abadi ke
perusahaan-perusahaan target pendistribusiannya.
3. Mampu menghasilkan pola berupa keterkaitan antara atribut tipe_motor,
kode_warna terhadap nama_perusahaan yang dijadikan aturan dalam
pendistribusian sepeda motor.
1.4 Batasan Masalah
Dalam penyelesaian tugas akhir ini diberikan batasan masalah agar tujuan
dan sasaran yang diinginkan dapat tercapai. Adapun batasan masalah sebagai
berikut :
a. Proses yang dilibatkan dalam aplikasi yang dibangun adalah berupa proses
data mining.
b. Database yang digunakan adalah database yang menggunakan Interbase
sebagai Database Management System (DBMS) dan telah melalui proses data
preprocessing yang hannya menyertakan informasi-informasi yang dibutuhkan
saja dengan membuang informasi yang tidak dibutuhkan (efisiensi).
c. Keluaran yang dihasilkan aplikasi ini berupa informasi berupa
pengklasifikasian keterkaitan sebuah perusahaan dengan atribut-atribut dalam
data distribusi penjualan sepeda motor berupa pohon keputusan atau decision
tree.
d. Analisis pemodelan yang digunakan adalah berdasarkan aliran data terstruktur.
informasi yaitu menggunakan Diagram Konteks dan Data Flow Diagram
(DFD).
e. Teknik yang digunakan dalam proses data mining adalah classification
menggunakan metode decision tree dan tidak melibatkan atau menyertakan
teknik yang lain.
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan untuk membangun aplikasi data
mining ini menggunakan metode analisis deskriptif yaitu suatu metode yang
bertujuan untuk mendapatkan gambaran yang jelas tentang hal-hal yang
diperlukan, melalui tahap pengumpulan data dan tahap pembangunan perangkat
lunak.
a. Pengumpulan Data
Tahap pengumpulan data adalah tahap awal dalam melakukan suatu
penelitian. Metodologi yang digunakan dalam mengunpulkan data yang berkaitan
dengan penyusunan laporan dan pembuatan aplikasi ini adalah sebagai berikut:
1) Studi Literatur
Studi literatur adalah tahap pengumpulan data yang diperoleh dengan cara
mempelajari Teori Data Mining termasuk metode Decision Tree dan
2) Studi Lapangan
Studi lapangan adalah tahap pengumpulan data dengan mengadakan
penelitian dan peninjauan langsung terhadap permasalah yang ada di PD.
Wijaya Abadi Bandung.
3) Wawancara
Wawancara adalah tahap pengumpulan data dengan cara tanya jawab
langsung dengan pihak PD. Wijaya Abadi Bandung dan staf terkait
terhadap permasalahan yang diambil.
b. Pembangunan Perangkat Lunak
Teknik analisis data dalam pembangunan perangkat lunak menggunakan
paradigma perangkat lunak secara waterfall. Waterfall adalah sebuah
pengembangan model perangkat lunak yang dilakukan secara berurutan atau
sekuensial, sebagaimana diperlihatkan pada Gambar 1.1.
Rekayasa Sistem : tahap ini merupakan kegiatan pengumpulan data sebagai
pendukung pembangunan sistem serta menentukan ke
arah mana aplikasi ini akan dibangun.
Analisis Sistem : mengumpulkan kebutuhan secara lengkap kemudian
dianalisis dan didefinisikan kebutuhan yang harus
dipenuhi oleh aplikasi yang akan dibangun. Tahap ini
harus dikerjakan secara lengkap untuk bisa menghasilkan
desain yang lengkap.
Perancangan Sistem : perancangan antarmuka dari hasil analisis kebutuhan
yang telah selesai dikumpulkan secara lengkap.
Pengkodean Sistem : hasil perancangan sistem diterjemahkan ke dalam
kode-kode dengan menggunakan bahasa pemrograman yang
sudah ditentukan. Aplikasi yang dibangun langsung diuji
baik secara unit.
Pengujian Sistem : penyatuan unit-unit program kemudian diuji secara
keseluruhan.
Pemeliharaan Sistem : mengoperasikan aplikasi dilingkungannya dan
melakukan
pemeliharaan, seperti penyesuaian atau perubahan karena
adaptasi dengan situasi yang sebenarnya.
Umpan Balik : merupakan respon dari pengguna sistem yang bisa
digunakan untuk mengetahui sejauh mana aplikasi yang
1.6 Sistematika Penulisan
Sistematika penulisan laporan ini disusun untuk memberikan gambaran
umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini
adalah sebagai berikut:
BAB I PENDAHULUAN
Menguraikan tentang latar belakang permasalahan, mencoba merumuskan
inti permalsahan yang dihadapi, menentukan tujuan dan kegunaan penelititan
yang kemudian diikuti dengan pembatasan masalah, asumsi, serta sistematika
penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini terbagi menjadi dua bagian, yaitu: tinjauan umum perusahaan dan
landasan teori. Tinjauan umum perusahaan berisi tentang sejarah singkat
perusahaan, visi, misi, dan struktur organisasi sedangkan landasan teori berisi
teori-teori pendukung dalam membangun aplikasi data mining untuk pemantauan
distribusi penjualan sepeda motor di PD. Wijaya Abadi Bandung berbasis web.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisis kebutuhan dalam membangun aplikasi ini dan
menganilisis masalah dari model penelitian untuk memperlihatkan keterkaitan
antar variabel yang diteliti dalam membangun aplikasi. Selain itu terdapat juga
perancangan antarmuka untuk aplikasi yang akan dibangun sesuai dengan hasil
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi hasil implementasi dari hasil analisis dan perancangan yang
telah dibuat disertai juga dengan hasil pengujian dari aplikasi ini yang dilakukan
di PD. Wijaya Abadi Bandung sehingga diketahui apakah sistem yang dibangun
sudah memenuhi syarat sebagai aplikasi yang user-friendly.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan tentang keseluruhan dari pembangunan aplikasi
10 2.1 Profil Perusahaan
2.1.1 Sejarah Perusahaan
PD. Wijaya Abadi adalah dealer resmi sepeda motor Honda, yang
mendapat distribusi dari PT. Daya Adira Mustika, sebagai main dealer regional
Jawa Barat. PD Wijaya Abadi didirikan pada tanggal 30 Juni 1996 dan beralamat
di Jl. Kopo Sayati Km.7 No.84.
PD. Wijaya Abadi bergerak dalam penjualan sepeda motor merk Honda.
Dalam melayani pembelian para konsumennya, PD. Wijaya Abadi memberikan
layanan penjualan secara tunai maupun kredit, sehingga memudahkan konsumen
dalam melakukan transaksi pembelian sepeda motor. Untuk penjualan secara
kredit, pihak perusahaan melakukan kerja sama dengan beberapa leasing
company. Di antaranya : PT. Adira Finance, PT. Federal International Finance,
PT. Summit Oto Finance, dan PT. WOM Finance.
Seiring dengan semakin berkembangnya dunia bisnis di Jawa Barat, maka
PD. Wijaya Abadi berusaha menjadi dealer resmi sepeda motor Honda yang dapat
bersaing secara kompeten dengan pesaingnya. Hal ini ditunjukan dengan beberapa
prestasi yang telah kami capai selama perusahaan didirikan. Prestasi yang terakhir
kami capai adalah ranking 3 “The Best Growth” se-Jawa Barat tahun 2006, yang
dinilai berdasarkan besarnya peningkatan jumlah penjualan dari tahun ke tahun
Sesuai dengan visi perusahaan kami, maka PD. Wijaya Abadi berusaha
menjadi mitra bisnis terpercaya bagi para pebisnis di Jawa Barat, dengan
memberikan pelayanan terbaik kami, sehingga konsumen merasa puas. Karena
kepuasan konsumen adalah harapan dan tujuan kami.
2.1.2 Visi dan Misi Perusahaan
Visi
Menjadi dealer terbaik.
Misi
1. Membangun system perusahaan yang baik 2. Membangun sales team yang kuat
3. Membangun relasi dengan konsumen yang baik 4. Mencapai hasil penjualan yang baik
2.1.3 Struktur Organisasi dan Job Description
a. Struktur Organisasi PD. Wijaya Abadi Bandung
Struktur organisasi yang ada di PD. Wijaya Abadi Bandung dapat dilihat
pada Gambar 2.1.
b. Job Description
b.1Kepala Perusahaan
Tugas, wewenang, dan tanggung jawab kepala cabang perusahaan :
1) Memberikan laporan kemajuan cabang kepada Direksi Pusat termasuk
keuangannya.
2) Mengambil semua tindakan yang diperlukan agar cabang berjalan
lancar.
3) Menjalankan Program Perusahaan untuk cabang itu/mengejar target.
4) Berhak atas promosi dan bonus jika cabang maju melebihi target
Perusahaan.
b.2Sales & Marketing
Tugas dan tanggung jawab Sales & Marketing :
1) Menentukan harga jual, produk yang akan dilaunching, jadwal
kunjungan serta sistem promosi untuk memastikan tercapainya target
penjualan.
2) Menganalisa dan mengembangkan strategi marketing untuk
meningkatkan jumlah pelanggan dan layanan sesuai dengan target
yang ditentukan.
3) Melakukan evaluasi kepuasan pelanggan dari hasil survey seluruh
sales team untuk memastikan tercapainya target kepuasan pelanggan
4) Menerapkan budaya, sistem, dan peraturan intern perusahaan serta
menerapkan manajemen biaya, untuk memastikan budaya perusahaan
dan sistem serta peraturan dijalankan dengan optimal.
b.3Personalia & Umum
Personalia mempunyai tugas sebagai berikut:
1) Mengendalikan dan menyelenggarakan kegiatan dibidang administrasi
kepegawaian.
2) Melaksnakan Proses kegiatan Penggajian, kenaikan pangkat, kenaikan
berkala, mutasi, kesejahteraan pegawai dan pembinaan pegawai.
3) Mengurus Proses Askes, Astek, Taspen dan proses pegawai yang telah
mencapai usia pensiun dan penghargaan.
4) Memberikan saran-saran dan pertimbangan kepada Direksi tentang
langkah-langkah atau tindakan yang perlu tentang kepegawaian.
5) Membuat laporan kegiatan Bagian Kepegawaian dan melaksanakan
Tugas lain yang berhubungan dengan Tugasnya yang diberikan oleh
atasan.
b.4Keuangan & Administrasi
Tugas staff administrasi adalah membuat layanan administrasi
dibawah pengawasan pimpinan/line managernya. Tugasnya (biasanya)
meliputi admin, logistic, dan lainnya yang mendukung pelaksanaan
administasi berjalan lancar. Tugas detailnyanya misalnya:
1) Menjaga dan meng-update informasi administasi mulai dari office
2) mempersiapkan arrangement meeting detail, absensi staff, serta
3) melakukan hal hal seperti surat menyurat dengan staff lainya,
Bagian Keuangan mempunyai tugas melaksanakan urusan
keuangan di lingkungan Badan Perusahaan.
Bagian Keuangan menyelenggarakan fungsi:
1) penyusunan dokumen pelaksanaan anggaran Badan,
2) pelaksanaan urusan perbendaharaan Badan,
3) akuntansi pelaksanaan anggaran dan penyusunan laporan keuangan
Badan.
b.5Supervisor
Tugas utama supervisor adalah melakukan supervisi terhadap para
staf pelaksanan rutinitas aktivitas bisnis perusahaan sehari-hari. Supervisor
adalah level kepemimpinan yang tidak boleh membuat kebijakan yang
bersifat strategis, tapi hanya menerjemahkan dan meneruskan kebijakan
strategis atasannya kepada para bawahan untuk dikerjakan secara efektif
dan produktif. Peran penting seorang supervisor adalah sebagai
koordinator unit kerja.
b.6Kepala Bengkel
Bertanggung jawab atas kelancaran operasional mekanis dan mesin-mesin
b.7Kepala Mekanik
Bertanggung jawab atas perencanaan, pengkoordinasian, pengarahan, dan
pengawasan atas pelaksanaan kegiatan maintenance dan repair mesin dan
peralatan mekanik produksi.
2.2 Landasan Teori
2.2.1 Data
Menurut Abdul Kadir (2003: 29), data adalah deskripsi tentang benda,
kejadian, aktivitas, dan transaksi, yang tidak mempunyai makna atau tidak
berpengaruh secara langsung kepada pemakai. Data merupakan bentuk jamak dari
datum, berasal dari bahasa Latin yang berbarti “sesuatau yang diberikan”. Dalam
penggunaan sehari-hari, data berarti suatu pernyataan yang diterima secara apa
adanya. Pernyataan ini adalah suatu variabel yang bentuknya dapat berupa angka,
kata-kata, atau citra.
Dalam keilmuan (ilmiah), fakta dikumpulkan untuk menjadi data. Data
kemudian diolah sehingga dapat diutarakan secara jelas dan tepat sehingga dapat
dimengerti oleh orang lain yang tak langsung mengalaminya sendiri, hal ini
dinamakan deskripsi. Pemilahan banyak data sesuai dengan persamaan atau
perbedaan yang dikandungnya dinamakan klasifikasi.
Secara konseptual, data adalah deskripsi tentang benda, kejadian, aktivitas,
dan transaksi, yang tidak mempunyai makna atau tidak berpengaruh secara
langsung kepada pemakai. Data dapat berupa nilai yang terformat, teks, citra,
Data yang terformat adalah data dengan suatu format tertentu. Misalnya, data
yang menyatakan tanggal atau jam, atau menyatakan nilai mata uang.
Teks adalah sederetan huruf, angka, dan simbol-simbol khusus (misalnya + dan $)
yang kombinasinya tidak tergantung pada masing-masing item secara individual.
Contoh teks adalah artikel majalah.
Citra (image) adalah data dalam bentuk gambar. Citra dapat berupa grafik, foto,
hasil rontgen, dan tanda tangan, ataupun gambar yang lain.
Audio adalah data dalam bentuk suara. Instrumen music, suara orag atau suara
binatang, gemericik air, detak jantung merupakan beberapa contoh data audio.
Video menyatakan data dalam bentuk sejumlah gambar yang bergerak dan bias
saja dilengkapi dengan suara. Video dapat digunakan untuk mengabadikan suatau
kejadian atau aktivitas.
2.2.2 Informasi
Informasi adalah data yang sudah diolah, dibentuk, atau dimanipulasi
sesuai dengan keperluan tertentu atau hasil dari pengolahan data yang secara
prinsip memiliki nilai atau value yang lebih dibandingkan data mentah. Informasi
dapat juga dianggap seuatu data untuk diolah kembali dan menjadikan informasi
Gambar 2. 2 Siklus Informasi
Menurut Burch dan Grudnitski (1989) Gambar 2.2 memperlihatkan siklus
informasi, yaitu menggambarkan pengolahan data menjadi informasi dan
pemakaian informasi untuk mengambil keputusan, hingga akhirnya dari tindakan
hasil pengambilan keputusan tersebut dihasilkan data kembali.
Jadi, hal yang terpenting untuk membedakan informasi dengan data,
informasi itu mempunyai kandungan “makna”, sedangkan data tidak. Pengertian
data di sini merupakan hal yang sangat penting, karena berdasarkan maknalah si
penerima dapat memahami infomasi tersebut dan secara lebih jauh dapat
menggunakannya untuk menarik suatu kesimpulan atrau bahkan mengambil
keputusan.
Informasi mempunyai tingkat kualitas yang ditentukan beberapa hal, antara lain:
1. Akurat, informasi harus bebas dari kesalahan-kesalahan dan harus jelas
2. Tepat pada waktunya, informasi yang dating tidak boleh terlambat pada
penerima.
3. Relevan, informasi harus mempunyai manfaat bagi pemakainya.
4. Lengkap, informasi berisi informasi yang dibutuhkan.
5. Jelas, isi informasi sesuai dengan keperluan pemakai.
2.2.3 Pengetahuan
Menurut Alter (1992), pengetahuan (knowledge) adalah kombinasi dari
naluri, gagasan aturan, dan prosedur yang mengarahkan tindakan atau keputusan.
Sebagai gambaran, informasi yang dipadukan dengan pengalaman masa lalu dan
keahlian akan memberikan suatu pengetahuan yang tentu saja memiliki nilai yang
tinggi. Sebuah gambaran tentang hubungan antara data, informasi, dan
pengetahuan ditunjukkan pada gambar berikut.
Gambar 2. 3 Hubungan data, informasi, dan pengetahuan
Gambar 2.3 memperlihatkan bahwa data diformat, dipilih, dan diringkas
pengetahuan tentang cara melakukannya. Selanjutnya, informasi yang dihasilkan
dimasukkan ke tahap berikutnya dan diproses menjadi suatu hasil. Hasil ini
diakumulasikan sebagai pengetahuan yang kemudian digunakan untuk melakukan
pemrosesan data atau pemrosesan informasi.
Bersama-sama dengan data dan informasi, pengetahuan sering
digambarkan dalam bentuk piramida, sperti gambar di bawah ini.
Gambar 2. 4 Gambaran data, informasi, dan pengetahuan menurut abstraksi
Gambar 2.4 menunjukkan bahwa dilihat dari derajat abstraksi,
pengetahuanlah yang memiliki kuantitas paling abstrak, sedangkan jika dilihat
dari kuantitas, pengetahuanlah yang memiliki kuantitas paling kecil.
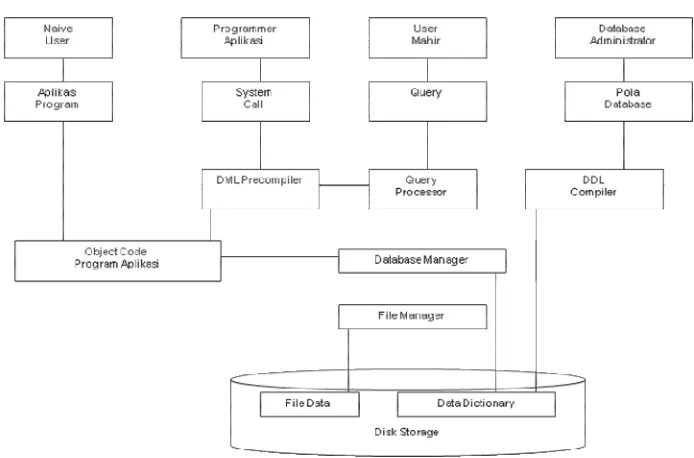
2.2.4 Basis Data
Basis Data adalah kumpulan data yang terintegrasi atau saling
berhubungan satu sama lain yang disimpan sedemikian rupa agar dapat
Sistem basis data adalah sistem yang terdiri atas kumpulan file (tabel)
yang saling berhubungan (dalam sebuah basis data disebuah sistem komputer) dan
sekumpulan program (DBMS) yang memungkinkan beberapa pemakai dan/atau
program lain untuk mengakses dan memanipulasi file-file (tabel-tabel) tersebut.
Dalam sebuah Basis Data, secara lengkap akan terdapat komponen-komponen
utama yaitu:
1) Perangkat keras (hardware)
2) Sistem operasi (operating system),
3) Basis Data (database),
4) Sistem (aplikasi /perangkat lunak) pengelola basis data (DBMS),
5) Pemakai (user).
Ada beberapa jenis/tipe pemakai terhadap suatu sistem basis data yang dibedakan
berdasarkan cara mereka berinteraksi terhadap sistem.
1) Pengguna Awam (Naive User) yaitu pemakai yang tidak berpengalaman,
berinteraksi dengan sistem tanpa menulis program, tinggal menjalankan
satu menu dan memilih proses yang telah ada atau telah dibuat sebelumnya
oleh programmer.
2) User Mahir yaitu pemakai yang berinteraksi dengan sistem tanpa menulis
modul program. Mereka menyatakan query (untuk akses data) dengan
bahasa query yang telah disediakan oleh DBMS.
3) Programmer Aplikasi yaitu pemakai yang berinteraksi dengan basis data
melalui Data Manipulation Language (DML), yang dibuat dengan bahasa
4) User khusus yaitu pemakai yang menulis aplikasi basis data non
konvensional, tetapi untuk keperluan-keperluan khusus, seperti untuk
aplikasi AI, sistem pakar, pengolahan citra dan lain-lain.
2.2.4.1Penerapan Basis Data
Bidang-bidang fungsional yang telah umum memanfaatkan basis data
demi efisiensi, akurasi dan kecepatan operasi antara lain: bidang perbankan yang
melakukan pengelolaan data nasabah/data tabungan/data pinjaman, pembuatan
laporan-laporan akuntansi, pelayanan informasi pada nasabah/calon nasabah dan
lain-lain. Kemudian bidang asuransi, bidang pendidikan/sekolah, telekomunikasi,
rumah sakit dan lain-lain.
2.2.4.2Kegunaan Basis Data
Penyusunan suatu basis data digunakan untuk mengatasi masalah masalah
pada penyusunan data yaitu:
1) Redundansi dan Inkonsistensi data
2) Kesulitan dalam pengaksesan data
3) Isolasi data untuk standardisasi
4) Multiple User (banyak pemakai)
5) Masalah keamanan (security)
6) Masalah integritas (kesatuan)
2.2.4.3Abstraksi Basis Data
Abstraksi data merupakan tingkatan/level dalam bagaimana pemakai
melihat data dalam sebuah sistem basis data. Abstraksi data dalam sistem basis
data dibagi menjadi tiga level yaitu:
1) Level Fisik (Physical Level), merupakan level terendah dalam abstraksi
data, yang menunjukkan bagaimana (how) sesungguhnya suatu data
disimpan.
2) Level Lojik/Konseptual (Conceptual Level),merupakan level lebih tinggi
berikutnya dalam abstraksi data yang menggambarkan data apa (what)
yang sebenarnya disimpan dalam basis data dan hubungan relasi yang
terjadi antara data.
3) Level Pandangan Pemakai (View Level), merupakan level tertinggi dari
abstraksi data yang hanya menunjukkan satu bagian dari keseluruhan basis
data.
Hubungan antar level tersebut dapat digambarkan (Kristanto:1996) pada
Gambar 2.5.
2.2.4.4Bahasa Basis Data
Sebuah bahasa basis data biasanya dapat dibagi ke dalam 2 bentuk yaitu:
1) Data Definition Language (DDL)
Yaitu struktur/skema basis data yang menggambarkan/mewakili desain
basis data secara keseluruhan dispesifikasikan dengan bahasa khusus.
2) Data Manipulation Language (DML)
Yaitu perintah-perintah yang digunakan untuk mengubah, memanipulasi,
dan mengambil data pada basis data.
3) DCL (Data Control Language) yang berkaitan dengan pengaturan
sekuritas terhadap basis data.
2.2.4.5Struktur Sistem Secara Keseluruhan
Pada Gambar 2.6 memperlihatkan struktur sistem basis data secara
keseluruhan.
2.2.5 Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan
penemuan pengetahuan di dalam database. Menurut Turban (2005), data mining
adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan,
dan machine lerarning untuk mengekstraksi dan mengidentifikasi informasi yang
bermanfaat dan pengetahuan yang terkait dari berbagai database besar.
Perkembangan data mining yang pesat tidak dapat lepas dari
perkembangan teknologi informasi yang memungkinkan data dalam jumlah besar
terakumulasi. Sebagai contoh, toko swalayan merekam setiap penjualan barang
dengan memakai alat POS (point of sales). Database data penjualan tersebut bisa
mencapai beberapa GB (Giga byte) setiap harinya untuk sebuah jaringan toko
swalayan berskala nasional. Perkembangan internet juga punya andil cukup besar
dalam akumulasi data. Tetapi pertumbuhan yang pesat dari akumulasi data itu
telah menciptakan kondisi yang sering disebut sebagai rich of data but poor of
information karena data yang terkumpul itu tidak dapat digunakan untuk aplikasi
yang berguna. Tidak jarang kumpulan data itu dibiarkan begitu saja seakan-akan
kuburan data (data tombs). Investasi yang besar di bidang IT untuk
mengumpulkan data berskala besar ini perlu dijustifikasi dengan didapatnya nilai
tambah dari kumpulan data ini.
Kebutuhan dari dunia bisnis yang ingin memperoleh nilai tambah dari
data yang telah mereka kumpulkan telah mendorong penerapan teknik-teknik
analisa data dari berbagai bidang seperti statistik, kecerdasan buatan dan
besar memberikan tantangan-tantangan baru yang akhirnya memunculkan
metodologi baru yang disebut data mining ini. Bermula dari penerapan di dunia
bisnis, sekarang ini data mining juga diterapkan pada bidang-bidang lain yang
memerlukan analisa data berskala besar seperti bioinformasi dan pertahanan
negara.
Beberapa faktor yang mendukung perlunya dilakukan data mining adalah:
1. Data telah mencapai jumlah dan ukuran yang sangat besar
2. Telah dilakukan proses data warehousing
3. Kemampuan Komputasi yang semakin terjangkau
4. Persaingan bisnis yang semakin ketat
2.2.5.1Model dalam Data Mining
Terdapat dua tipe atau mode operasi yang bias digunakan untuk mencari
informasi yang dibutuhkan user lewat proses data mining, yaitu model verifikasi
dan knowledge discovery.
Model verifikasi menggunakan pendekatan top down dengan mengambil
hipotesa dari user dan memeriksa validitasnya dengan data sehingga bias
dibuktikan kebenaran hipotesa.
Model Knowledge Discovery menggunakan pendekatan bottom up untuk
mendapatkan informasi yang sebelumnya tidak diketahui. Model ini terbagi
menjadi dua, yaitu directed knowledge discovery dan undirected knowledge
discovery. Pada directed knowledge discovery, data mining akan mencoba
dan lain-lain) terhadap field-field yang lain. Sedangkan pada undirected
knowledge discovery tidak ada field karena komputer akan mencari pola yang ada
pada data. Jadi, undirected knowledge discovery digunakan untuk mengenali
hubungan / relasi yang ada pada data sedangkan directed knowledge discovery
akan menjelaskan hubungan relasi tersebut.
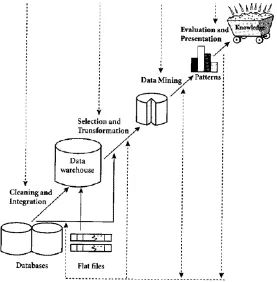
Gambar 2. 7 Tahap-tahap Data Mining
Gambar 2.7 merupakan tahapan proses dalam data mining dan dapat dijelaskan
sebagai berikut:
1. Data Selection
Pemilihan (seleksi) data baru sekumpulan data operasional perlu dilakukan
Database) dimulai. Data hasil seleksi yang akan digunakan untuk proses data
mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Preprocessing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
cleaning pada data yang menjadi fokus KDD.
Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa
data yang inkonsisten, dan memperbaiki kesalahan pada data, sperti kesalahan
cetak (tipografi).
3. Transformasi
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data
tersebut sesuai untuk proses data mining. Proses coding dalam KDD
merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi
yang akan cari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data
terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode,
atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau
algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara
keseluruhan.
5. Interpretasi / Evaluasi
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan
dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap
Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan
bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
2.2.5.2Pengelompokan Data Mining
Menurut Larose (2005), data mining dibagi menjadi beberapa kelompok
berdasarkan tugas yang dapat dilakukan,yaitu:
1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari
cata untuk menggambarkan pola dan kecenderungan yang terdapat
dalam data.
2. Estimasi
Estimasi hamper sama dengan klasifikasi, kecuali variabel target
estimasi lebih kea rah numeric daripada ke arah kategori.
3. Prediksi
Prediksi hamper sama dengan klasifikasi dan estimasi, kecuali bahwa
dalam prediksi nilai dari hasil aka nada di masa mendatang. Beberapa
metode dan teknik yang digunakan dalam klasifikasi dan estimasi
dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki
kemiripan. Kluster adlah kumpulan record yang memiliki kemiripan
satu dengan yang lainnya dan memiliki ketidakmiripan dengan
record-record dalam kluster lain.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang
muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut
anlisis keranjang belanja.
2.2.5.3Decision Tree (Pohon Keputusan)
Pohon keputusan merupakan salah satu metode klasifikasi dan prediksi
yang sangat kuat dan terkenal dalam penerapan data mining. Pada dasarnya
Decision Tree mengubah data menjadi pohon keputusan (decision tree) dan
aturan-aturan keputusan (rule).
Gambar 2. 8 Konsep Decision Tree
Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan
hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah
Menurut Berry & Linoff (2004), sebuah pohon keputusan adalah sebuah
struktur yang dapat digunakan untuk membagi kumpulan data yang besar menjadi
himpunan-himpunan record yang kebih kecil dengan menerapkan serangkaian
aturan-aturan keputusan. Dengan masing-masing rangkaian pembagian, anggota
himpunan hasil menjadi mirip satu dengan yang lain.
Sebuah pohon keputusan mungkin dibangun dengan saksama secara
manual atau dapat tumbuh secara otomatis dengan menerapkan salah satu atau
beberapa algoritma pohon keputusan untuk memodelkan himpunan data yang
belum terklasifikasi. Banyak algoritma yang dapat dipakai dalam pembentukan
pohon keputusan, antara lain ID3, CART, dan C4.5 (Larose, 2005).
Variabel tujuan biasanya dikelompokkan denga pasti dan model pohon
keputusan lebih mengarah pada perhitungan probabilitas dari tiap-tiap record
-terhadap kategori-kategori tersebut atau untuk mengklasifikasi record dengan
mengelompokkannya dalam satu kelas.
Menurut Basuki & Syarif (2003), proses pada pohon keputusan adalah
mengubah bentuk data (tabel) menjadi model pohon, mengubah model pohon
menjadi rule, dan menyederhanakan rule.
2.2.5.3.1 Konsep Data Dalam Decision Tree
Data dalam pohon keputusan biasanya dinyatakan dalam bentuk tabel
dengan atribut dan record. Atribut menyatakan suatu parameter yang dibuat
sebagai criteria dalam pembentukan tree. Misalkan unutuk menentukan main
tenis, kriteria yang diperhatikan adalah cuaca, angin, dan temperature. Salah satu
dengan target atribut. Atribut memiliki nilai-nilai yang dinamakan dengan
instance. Misalkan atribut cuaca mempunyai instance berupa cerah, berawan, dan
hujan seperti tampak pada Gambar 2.9.
Gambar 2. 9 Konsep Data dalam Decision Tree
Untuk mengubah bentuk data (tabel) menjadi model tree, dalam kasus ini
menggunakan algoritma ID3, setelah diperoleh model berupa tree, maka tree ini
bisa dikonversikan ke dalam rule seperti tampak pada Gambar 2.10.
2.2.5.3.2 Atribut Selection Measure
Pengukuran informasi yang didapatkan (information gain) bertujuan untuk
memilih suat atribut yang diuji (test atribut) di setiap node dalam struktur pohon.
Atribut dengan nilai informasi tertinggi (greatest entropy) dipilih sebagai suatu
atribut dalam suatu node yang sedang diproses.
Jika S merupakan suatu kumpulan dari s data sampel, atribut label kelas memiliki
isi (value) m yang berbeda, Ci (for i=1..m). Jika si merupakan jumlah sampel S
dalam kelas Ci dimana pi merupakan probabilitas dari label sampel data dari Ci,
maka:
(3.1)
Jika atribut A memiliki v isi yang berbeda {a1,a2,…,av}, atribut A dapat
digunakan untuk membagi S ke dalam subset v, {S1, S2,…, Sv}, dimana Sj terdiri
dari sampel dalam S yang memiliki isi ajdari A. Jika A terpilih sebagai atribut
yang diuji (atribut terbaik untuk dibagi atau dipartisi), kemudian subset ini alam
berhubungan dengan cabang dari node yang berisi kumpulan S. Jika Sij
merupakan jumlah sampel dari kelas Ci di dalam suatu subset Sj, maka Entropy:
(3.2)
Dari persamaan (3.1) dan (3.2), maka :
33 3.1 Analisis Sistem
Analisis sistem dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk mengidentifikasikan dan mengevaluasi permasalahan-permasalahan, kesempatan-kesempatan, hambatan-hambatan yang terjadi dan kebutuhan-kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan-perbaikannya.
3.1.1 Analisis Masalah
PD. Wijaya Abadi Bandung adalah perusahaan yang bergerak di bidang jual beli sepeda motor bermerek Honda. Dalam kegiatan operaisonalnya, PD. Wijaya Abadi juga mendistribusikan sepeda motor terhadap konsumen perorangan maupun perusahaan.
dan kode warna pada data distribusi penjualan sepeda motor yang tersimpan dalam suatu database Wijaya Abadi, sehingga perusahaan memiliki bekal pengetahuan dan aturan dalam pendistribusiannya.
3.1.2 Analisis Data
Database PD.Wijaya Abadi terbagi ke dalam beberapa tabel, secara garis besar tabel-tabel tersebut adalah tabel Warna, tabel TipeMotor, tabel Perusahaan dan sebagai target data dalam penerapan teknik data mining adalah perusahaan target pendistribusian yang tersimpan dalam tabel DistribusiMotor. Setiap variabel/atribut pengambilan keputusan mewakili satu dimensi tertentu, dalam hal ini dimensi yang dilibatkan adalah DsitribusiMotor. Struktur tabel Distribusi Motor dapat ditunjukan pada Tabel 3.1.
Tabel 3. 1 Struktur Tabel DistribusiMotor
Tabel DistribusiMotor TIPE_MOTOR KODE_WARNA TGL_DISTRIBUSI
NO_DISTRIBUSI TGL_PENJUALAN NAMA_PERUSAHAAN
Data preprocessing merupakan hal yang penting dalam proses data mining, hal-hal yang termasuk di dalamnya adalah:
a. DataSelection
Sebelum masuk ke proses Data Preprocessing, yang harus dilakukan lebih awal adalah pemilihan data (data selection). Pada database PD.Wijaya Abadi, data yang akan diproses untuk di-mining yaitu data DistribusiMotor. Data DistribusiMotor ini nantinya akan menjadi Data Kasus dalam proses operasional data mining. Dari data yang ada, kolom yang diambil sebagai atribut/variabel keputusan adalah kolom nama_perusahaan, sedangkan kolom yang diambil sebagai variabel penentu dalam pembentukan pohon keputusan adalah kolom:
1. tipe_motor 2. kode_warna
Pemilihan variabel-variabel tersebut dengan pertimbangan bahwa jumlah nilai variabelnya tidak banyak dan tidak unik sehingga diharapkan suatu motor masuk dalam satu klasifikasi nilai variabel tersebut cukup banyak.
b. Data Preprocessing / Data Cleaning
1. Mengabaikan tupel, dilakukan jika value dari suatu tupel hilang atau tidak ada. Metode ini sangatlah tidak efektif apabila terdapat banyak atribut dengan tupel-tupel kosong.
2. Menambahkan isi terhadap atribut yang kosong tersebut secara manual, namun pendekatan ini sangatlah memakan waktu dan tidak efektif bila diterapkan pada data yang sangat besar.
c. Data Transformation
Dalam proses ini, data ditransformasikan ke dalam bentuk yang sesuai untuk proses data mining.
d. DataReduction
Reduksi data dilakukan dengan menghilangkan atribut-atribut yang tidak diperlukan sehingga ukuran dari database menjadi kecil dan hanya menyertakan atribut-atribut yang diperlukan dalam proses data mining. Hal ini dikarenakan proses data mining akan lebih efisien terhadap data yang lebih kecil. Dari proses data reduction tersebut maka dibuat tabel dengan atribut-atribut yang siap untuk proses klasifikasi, dalam hal ini tabel KASUS seperti pada Tabel 3.2.
Tabel 3. 2 Struktur Tabel KASUS
Tabel KASUS TIPE_MOTOR KODE_WARNA NAMA_PERUSAHAAN
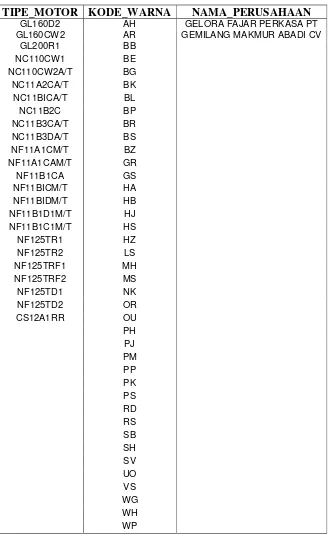
Tabel 3. 3 Hasil Proses Data Preprocessing
TIPE_MOTOR KODE_WARNA NAMA_PERUSAHAAN
GL160D2 AH GELORA FAJAR PERKASA PT
GL160CW2 AR GEMILANG MAKMUR ABADI CV
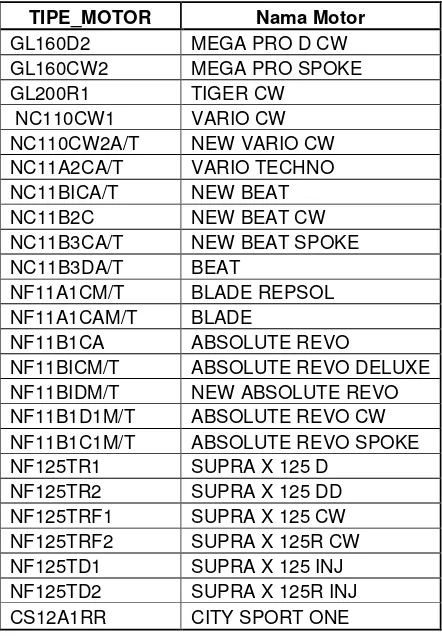
Atribut tipe_motor biasanya berisi nilai berupa jenis-jenis motor Honda. Nilai dari atribut tipe_motor di atas dapat dijelaskan pada Tabel 3.4.
Tabel 3. 4 Keterangan Atribut Tipe Motor
TIPE_MOTOR Nama Motor
GL160D2 MEGA PRO D CW
GL160CW2 MEGA PRO SPOKE
GL200R1 TIGER CW NF11B1C1M/T ABSOLUTE REVO SPOKE NF125TR1 SUPRA X 125 D
CS12A1RR CITY SPORT ONE
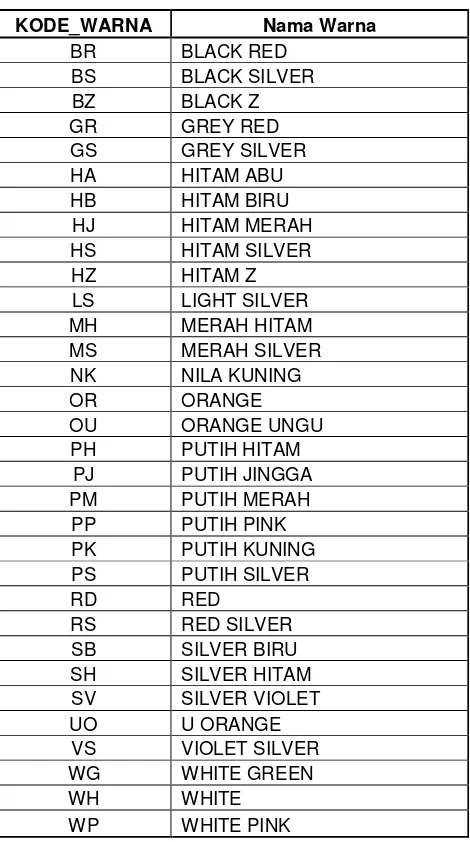
Sedangkan untuk atribut kode_warna ini berisi kombinasi dua warna. Nilai dari atribut kode_warna pada Tabel 3.3 dapat dijelaskan pada Tabel 3.5.
Tabel 3. 5 Keterangan Atribut Kode Warna
KODE_WARNA Nama Warna
KODE_WARNA Nama Warna
3.1.3 Analisis Metode Decision Tree
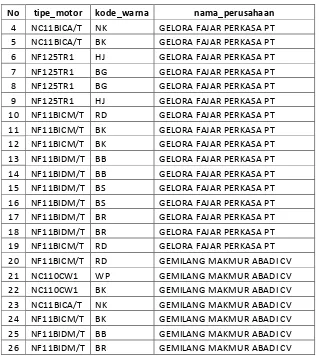
Dari proses Data Preprocessing yang telah dilakukan maka dihasilkan tabel yang siap untuk proses klasifikasi, seperti pada Tabel 3.6.
Tabel 3. 6 Tabel KASUS
No tipe_motor kode_warna nama_perusahaan
No tipe_motor kode_warna nama_perusahaan 10 NF11BICM/T RD GELORA FAJAR PERKASA PT 11 NF11BICM/T BK GELORA FAJAR PERKASA PT 12 NF11BICM/T BK GELORA FAJAR PERKASA PT 13 NF11BIDM/T BB GELORA FAJAR PERKASA PT 14 NF11BIDM/T BB GELORA FAJAR PERKASA PT 15 NF11BIDM/T BS GELORA FAJAR PERKASA PT 16 NF11BIDM/T BS GELORA FAJAR PERKASA PT 17 NF11BIDM/T BR GELORA FAJAR PERKASA PT 18 NF11BIDM/T BR GELORA FAJAR PERKASA PT 19 NF11BICM/T RD GELORA FAJAR PERKASA PT 20 NF11BICM/T RD GEMILANG MAKMUR ABADI CV 21 NC110CW1 WP GEMILANG MAKMUR ABADI CV 22 NC110CW1 BK GEMILANG MAKMUR ABADI CV 23 NC11BICA/T NK GEMILANG MAKMUR ABADI CV 24 NF11BICM/T BK GEMILANG MAKMUR ABADI CV 25 NF11BIDM/T BB GEMILANG MAKMUR ABADI CV 26 NF11BIDM/T BR GEMILANG MAKMUR ABADI CV
Proses klasifikasi dimulai dengan mengecek isi dari atribut kelas data (nama_perusahaan) karena isi atribut tersebut berbeda maka digunakan fungsi entropy untuk mendapatkan informasi tertinggi (highest information gain) dengan perhitungan sebagai berikut:
I(s1,s2) =
1. Atribut tipe_motor a. GL200R1
I(s11,s12) =
b. NC110CW1 I(s21,s22) =
c. NC11BICA/T I(s31,s32) =
d. NF125TR1 I(s41,s42) =
e. NF11BICM/T I(s51,s52) =
f. NF11BIDM/T I(s61,s62) =
=
= 0.691
Gain(tipe_motor) = I(s1,s2) - E(tipe_motor) = 0.84 – 0.691 = 0.15
Nilai entropy untuk atribut tipe_motor yang dihasilkan adalah 0.691, yang berarti bahwa tingkat keberagaman untuk nilai dari atirbut tipe_motor adalah 0.691. Sedangkan untuk nilai gain atau nilai yang efektif untuk mengklasifikasikan atribut tipe_motor sebesar 0.15.
2. Atribut kode_warna a. BE
I(s11,s12) = I(1,0) = 0 b. WG
I(s21,s22) = I(1,0) = 0 c. NK
I(s31,s32) = I(2,1) =
d. BK
I(s41,s42) = I(3,2) = e. BS
I(s51,s52) = I(2,0) = 0 f. BR
g. HJ
I(s71,s72) = I(2,0) = 0 h. BG
I(s81,s82) = I(2,0) = 0 i. RD
I(s91,s92) = I(2,1) =
j. BB
I(s101,s102) = I(2,1) = k. WP
I(s111,s112) = I(0,1) = 0 E(kode_warna)
=
= 0.61
G(kode_warna) = (s1,s2) - E(kode_warna) = 0.84 – 0.61 = 0.23
Nilai entropy untuk atribut tipe_motor yang dihasilkan adalah 0.61, yang berarti bahwa tingkat keberagaman untuk nilai dari atirbut tipe_motor adalah 0.691. Sedangkan untuk nilai gain atau nilai yang efektif untuk mengklasifikasikan atribut tipe_motor sebesar 0.23.
akan diuji. Dimana sebuah node dibuat dengan label kode_warna dan cabang dari node tersebut tumbuh berdasarkan isi atribut kode_warna dan data dipartisi berdasarkan isi atribut tersebut. Pohon keputusan yang terbentuk dapat ditunjukan pada Gambar 3.1.
Untuk isi atribut kode_warna BE, WG, HJ, BG, BS, dan WP memiliki sampel kelas data yang sama, maka sudah dapat diambil sebagai keputusan seperti digambarkan pada Gambar 3.2.
NC11BICA/T NC11BICA/T
NC11BICA/T !
" NC11BICA/T ## NF11BICM/T # NF11BICM/T
NC110CW1 !
NF11BICM/T !
#$ NF11BICM/T #% NF11BICM/T
$ NF11BICM/T !
# NF11BIDM/T # NF11BIDM/T
" NF11BIDM/T !
#& NF11BIDM/T #' NF11BIDM/T
( NF11BIDM/T !
)
*
) !
Dari proses klasifikasi di atas dapat diperoleh informasi bahwa isi atribut kode_warna BE, WG, HJ, BG, dan BS ini biasa didistribusikan ke perusahaan
GELORA FAJAR PERKASA PT dan kode_warna WP ini biasa didstribusikan ke GEMILANG MAKMUR ABADI CV.
Oleh karena atribut penentu yang digunakan hanya dua atribut, yaitu kode_warna dan tipe_motor maka proses klasifikasi berhenti pada tahap-2, karena sudah tidak atribut lain yang akan diklasifikasikan. Sehingga untuk kode_warna NK, BK, RD, BB, and BR tidak terklasifikasi.
3.1.4 Analisis Kebutuhan Non Fungsional
Analisis non fungsional adalah sebuah langkah dimana seorang pembangun perangkat lunak menganalisis sumber daya yang akan menggunakan perangkat lunak yang dibangun.
Analisis non fungsional tidak hanya menganalisis siapa saja yang akan menggunakan aplikasi tetapi juga menganalisis perangkat keras dan perangkat lunak yang dimiliki oleh pemesan, sehingga dapat ditentukan kompabilitas aplikasi yang dibangun terhadap sumber daya yang ada. Setelah melakukan analisis non fungsional, maka dilanjutkan ke langkah berikutnya yaitu menentukan kebutuhan non fungsional sistem yang akan dibangun untuk disesuaikan dengan fakta yang ada.
dipenuhi maka sistem yang dibangun tidak akan berjalan baik sesuai yang diharapkan.
Analisis non fungsional dan kebutuhan non fungsional yang dilakukan dibagi dalam tiga tahap, yaitu:
1. Kebutuhan pengguna (user).
2. Kebutuhan perangkat keras (hardware). 3. Kebutuhan perangkat lunak (software).
3.1.4.1Analisis Kebutuhan Pengguna (User)
Manajer PD. Wijaya Abadi adalah orang biasa menganalisis data-data transaksi, salah satunya transaksi distribusi penjualan sepeda motor yang tersimpan pada database perusahaan. Hal tersebut berhubungan dengan aplikasi yang akan dibangun, bahwa pengguna (user) aplikasi data mining ini adalah Manajer PD. Wijaya Abadi Bandung, dimana keterlibatannya dalam menggunakan aplikasi ini harus mengacu pada spesifikasi pengguna sebagai berikut:
1. Terbiasa menggunakan aplikasi yang ada di system operasi Windows 2. Memiliki pengetahuan mengenai database
3. Mengetahui atribut yang dianggap kuat untuk dilibatkan dalam proses data mining
Tabel 3. 7 Spesifikasi Pengguna (User)
Pengguna Hak Akses Pendidikan Tingkat
Keterampilan Pengalaman kualifikasi kebutuhan pengguna aplikasi data mining ini.
3.1.4.2Analisis Kebutuhan Perangkat Keras (Hardware)
Dari hasil pengamatan di perusahaan, penggunaan komputer oleh manajer PD. Wijaya Abadi berjumlah satu unit komputer. Berdasarkan analisis yang telah dilakukan, dapat diketahui spesifikasi perangkat keras yang digunakan di PD. Wijaya Abadi saat ini adalah sebagai berikut:
a.Processor 2 GHz b.Harddisk 80 GB c.RAM 1 GB
d.Monitor 17 inch dengan resolusi minimal 1024 X 768 pixels
Kebutuhan hardware yang disarankan untuk menjalankan aplikasi ini adalah sebagai berikut :
d.Monitor yang mendukung kualitas warna 16 bit dengan resolusi 800 X 600 pixels
Berdasakan spesifikasi yang telah ada, secara keseluruhan kebutuhan perangkat keras untuk aplikasi ini telah terpenuhi.
3.1.4.3Analisis Kebutuhan Perangkat Lunak (Software)
Perangkat lunak merupakan sarana pendukung lainnya bagi pembangunan aplikasi data mining ini. Adapun perangkat lunak yang terpasang di komputer manajer PD. Wijaya Abadi saat ini secara umum adalah sebagai berikut:
a. Sistem Operasi Windows XP b. Microsoft Office
Sedangkan perangkat lunak yang disarankan untuk menjalankan aplikasi ini adalah sebagai berikut:
a. Sistem Operasi
Untuk sistem operasi windows disarankan, karena sistem operasi ini banyak dikenal oleh user awam dan lebih mudah untuk dipelajari.
b. Microsoft Office
c. Database Management System
Database Management System (DBMS) adalah sistem untuk mengelola basisdata yang digunakan. Untuk aplikasi data mining ini digunakan Borland Interbase sebagai DBMS.
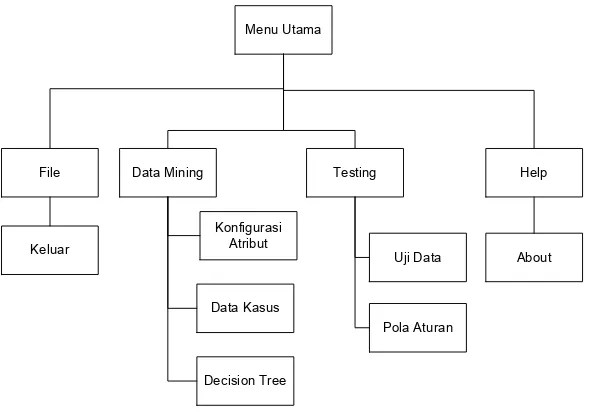
3.1.5 Analisis Kebutuhan Fungsional
Setelah melakukan analisis kebutuhan non fungsional maka dilanjutkan ke langkah berikutnya yaitu analisis kebutuhan fungsional. Dalam langkah ini dilakukan penentuan entitas-entitas baik entitas internal maupun entitas eksternal, data yang mengalir, serta prosedur-prosedur yang bisa dilakukan oleh masing-masing entitas.
3.1.5.1Diagram Konteks
Diagram konteks merupakan salah satu alat bantu dalam melakukan analisis terstruktur. Diagram konteks ini menggambarkan suatu sistem secara garis besarnya atau keseluruhannya saja. Dalam Diagram konteks juga digambarkan entitas eksternal yang merupakan brainware yang menghasilkan data yang akan diolah oleh sistem maupun tujuan dari informasi yang dihasilkan oleh sistem. Dikarenakan tidak cukupnya penggambaran dalam satu halaman maka diagram konteks dibagi menjadi dua bagian (dalam kenyataannya tetap dilihat sebagai satu diagram konteks). Adapun diagram konteks yang diusulkan ditunjukan oleh Gambar 3.3.
Nilai Atribut Atribut
Info Uji Data Info Data Kasus
Info Pola Aturan Info Klasifikasi
Atribut
0
Aplikasi Data Mining Menggunakan Metode
Decision Tree
+
User DistribusiMotor
3.1.5.2Diagram Alir Data Level 1
Diagram alir data merupakan sebuah representasi dari suatu sistem yang menggambarkan bagian-bagian dari sistem tersebut beserta keterkaitan antara bagian-bagian yang ada. Dari diagram alir data ini seseorang bisa mengetahui sumber dari informasi di dalam sistem maupun tujuan dari masukan yang berasal dari entitas eksternal. Adapun diagram alir data level 1 dari aplikasi Data Mining ditunjukan oleh Gambar 3.4.
Atribut
3.1.5.3Diagram Alir Data Level 2 Proses 2 Proses Data Mining
Gambar 3.5 menunjukan diagram alir data pada proses Data Mining.
Atribut
Atribut
[Data Tree]
[Info Data Kasus]
Data Kerja Data Sub_kerja
Data Kasus
Data Atribut
Data Atribut
[Atribut]
[Data Kasus] [Info Klasifikasi]
[Atribut]
User KASUS
2.1
Pengkonfigurasian Atribut
2.2
Penampilan Data Kasus
2.3
Pembentukan Decision Tree
D_ATRIBUT SUB_KERJA[N]
KERJA[N]
TREE
3.1.5.4Diagram Alir Data Level 2 Proses 3 Proses Testing
Gambar 3.6 menunjukan diagram alir data pada proses Testing.
[Info Uji Data]
Gambar 3. 6 DFD Level 2 Proses Testing
3.1.5.5Spesifikasi Proses
Proses-proses yang terdapat pada Diagram Alir Data akan dijelaskan lebih terperinci pada spesifikasi proses, sebagaimana diperlihatkan pada Tabel 3.8.
Tabel 3. 8 Spesifikasi Proses
No. Proses Keterangan
1
No. Proses 1
Nama Proses Proses Preprocessing
Sumber DistribusiMotor
Input Atribut, Nilai Atribut
Output Atribut, Nilai Atribut
Deskripsi Melakukan proses cleaning terhadap atribut yang akan digunakan untuk proses data mining
Logika Proses
Dalam proses Preprocessing meliputi proses: 1. Data Selection
2. Data Cleaning 3. Data Transformation 4. Data Reduction
2 No. Proses 2
Sumber User, Tabel KASUS
Input Aksi, Atribut, Data Kasus
Output Decision Tree
Deskripsi Melakukan penggalian data (data mining) dengan melakukan proses klasifikasi
Logika Proses 1. User memilih menu Data Mining 2. User memilih submenu
3
No. Proses 3
Nama Proses Proses Testing
Sumber User, Tabel TREE
Input Data Testing, Data Tree
Output Pola Aturan
Deskripsi Melakukan proses pengujian terhadap data terhadap pola aturan yang sudah terbentuk
Logika Proses 1. User memilih menu Testing 2. User memilih submenu
4
No. Proses 2.1
Nama Proses Pengkonfigurasian Atribut
Sumber User, Tabel KASUS
Input Aksi, Atribut
Output Data Atribut
Deskripsi Melakukan pengaturan terhadap atribut yang akan digunakan sebagai atribut penentu dan atribut tujuan
Logika Proses
MessageDlg('Pilih nama atributnya!', mtInformation, [mbOK],0); ParamByName('namalama').AsString := LVAtribut.Selected.Caption;
if CbAktif.Checked = true then ParamByName('is_aktif').AsString := 'Y'
except
Nama Proses Penampilan Data Kasus
Sumber Tabel KASUS
Input Data Kasus
Output Data Kasus
Deskripsi Menampilkan item data dari data kasus yang akan diproses
data mining sesuai atribut yang telah dikonfigurasi
Logika Proses
procedure TFrmKasus.FormShow(Sender: TObject); var i : integer;
begin
DBGKasus.Columns.Clear;
DM.IBTable1.TableName := 'Kasus'; DM.IBTable1.Active := false; DM.IBTable1.Active := true; DM.DS.DataSet := DM.IBTable1; DBGKasus.DataSource := DM.DS; //ambil jumlah atribut aktif with DM.Q1 do
begin Close;
SQL.Text := 'SELECT NAMA_ATRIBUT FROM D_ATRIBUT WHERE IS_AKTIF = ''Y''';
Open;
Nama Proses Pembentukan Decision Tree
Sumber Tabel KASUS, Tabel D_ATRIBUT
Input Data Kasus, Data Atribut
Output Decision Tree
Deskripsi Melakukan penggalian data (data mining) dengan melakukan proses klasifikasi berupa pohon keputusan (decision tree)
Logika Proses Algorithm: Generate_decision_tree.
Input: The training samples, samples, represented by discrete-valued attribute; the
set of candidate attributes, attribute-list.
Output: A decision tree.
Method:
1. create a node N;
2. if samples are all of the same class, C then
3. return N as a leaf node labeled with the class C;
4. if attribute-list is empty then
5. return N as a leaf node labeled with the most common class in samples;//majority voting
6. select test-attribute, the attribute among attribute-list
with the highest information gain; 7. label node N with test-attribute;
8. for each known value ai of test-attribute; 9. grow a branch from node N for the condition
test-attribute = ai;
10. let si be the set of samples in samples for which test-attribute = ai; // a partition
11. if si is empty then
12. attach a leaf labeled with the most common class in
samples;
13. else attach the node returned by Generate_decision_tree (si, attribute-listtest-attribute);
7
No. Proses 3.1
Nama Proses Proses Uji Data
Sumber User, Tabel TREE
Input Data Testing, Data Tree
Output Info Testing
Deskripsi Melakukan pengujian data terhadap pola aturan yang sudah terbentuk
Logika Proses begin
if BtnNext.Caption = '&Mulai' then begin
LVAtribut.Items.Clear; with DM.Q1 do
begin
//cari induk Close;
SQL.Text := 'select id_node, node from tree where induk is null';
ParamByName('induk').AsInteger := id_node; ParamByName('nilai').AsString :=
Nama Proses Pembentukan Pola Aturan
Sumber Tabel TREE
Input Data Tree
Output Pola Aturan
Deskripsi Menampilkan pola aturan yang sudah terklasifikasi Logika Proses var noaturan, level : integer;
daftar : TListItem; QTemp : TIBQuery;
procedure Tampil (id_node : integer; nilai : string);
begin
inc (level); try
with TIBQuery.Create(self) do begin
QTemp := FindComponent('TIQ'+ IntToStr(Level)) as TIBQuery;