DETEKSI PENCILAN PADA DATA TITIK PANAS
MENGGUNAKAN CLUSTERING
BERBASIS MEDOIDS
MOHAMAD BENTAR CAHYADAHRENA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Deteksi Pencilan pada Data Titik Panas Menggunakan Clustering Berbasis Medoids adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2015
ii
ABSTRAK
MOHAMAD BENTAR. Deteksi Pencilan pada Data Titik Panas Berdasarkan Clustering berbasis K-Medoids. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Kebakaran hutan adalah salah satu bencana yang dampaknya sangat merugikan. Kebakaran hutan dan lahan di Indonesia disebabkan oleh beberapa faktor diantaranya, musim kemarau yang panjang, kelalaian manusia dan pihak yang tidak bertanggung jawab yang sengaja membakar demi mencapai tujuan tertentu. Titik panas (hotspot) merupakan indikator terjadinya kebakaran hutan. Tujuan dari penelitian ini adalah mendeteksi pencilan hotspot pada tahun 2001 hingga 2012 yang diperoleh dari FIRM NASA. Deteksi pencilan ini menggunakan metode clustering berbasis medoids yaitu PAM dan CLARA. Hasil algoritme PAM pencilan titik panas terjadi pada nilai k=17 dengan cluster ke 13,14,15,16 dan 17. Algoritme CLARA pencilan titik panas terjadi pada nilai k=19 dengan cluster ke 14,15,17 dan 19. Algoritme PAM dan CLARA terjadi pada bulan Februari, Maret, Juni, Juli dan Agustus. Hasil analisis pencilan dapat diharapkan membantu pihak berwenang dalam menentukan daerah yang berpotensi prioritas pencegahan terjadinya kebakaran hutan.
Kata kunci: clustering, deteksi pencilan, kebakaran hutan,k-medoids, titik panas ABSTRACT
MOHAMAD BENTAR CAHYADAHRENA. Outlier Detection in Data Clustering based Hotspots Based K-Medoids. Supervised by IMAS SUKAESIH SITANGGANG.
Forest fire is one of disasters which has a very adverse impact. Land and forest fires in Indonesia are caused by several factors, such as prolonged drought, human negligence and irresponsible parties who deliberately set fire to achieve certain goals. Hotspot is an indicator of forest fires. The purpose of this study is to detect outliers in hotspots in 2001 until 2012. Hotspot data were obtained from the NASA FIRM. The outlier detection was performed using medoid based clustering methods, namely PAM and CLARA. The result of PAM algorithm show that outliers occur in cluster k=17 with medoid 13,14,15,16 and 17. The result of CLARA algorithm show that outliers occur in cluster k = 19 with medoid 14,15,17 and 19. PAM and CLARA algorithm detect outliers in February, March, June, July and August. Clustering results are expected to assist the authorities in determining potential areas for forest fires prevention.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DETEKSI PENCILAN PADA DATA TITIK PANAS
MENGGUNAKAN CLUSTERING
BERBASIS MEDOIDS
MOHAMAD BENTAR CAHYADAHRENA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
iv
Penguji 1: Hari Agung Adrianto, SKom MSi
Judul Skripsi : Deteksi Pencilan pada Data Titik Panas Menggunakan Clustering Berbasis Medoids
Nama : Mohamad Bentar Cahyadahrena
NIM : G64124070
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
vi
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juli 2014 adalah Deteksi Pencilan pada Data Titik Panas Menggunakan Clustering Berbasis Medoids.
Terima kasih penulis ucapkan kepada ayah tercinta M. Dahlan, ibu tercinta Susrina dan seluruh keluarga. Ungkapan terima kasih juga disampaikan kepada Ibu Dr Imas Sukaesih Sitanggang, SSi, Mkom selaku pembimbing, teman – teman Vilbar dan Riverside Gunung Gede, Shofyan, Salman, Dyha Beahaki, Nuke Arincy serta seluruh teman-teman Alih Jenis Ilmu Komputer IPB angkatan 7, atas segala doa dan kasih sayangnya.
Penulis menyadari bahwa karya tulis ini masih jauh dari sempurna karena keterbatasan pengalaman dan pengetahuan yang dimiliki penulis. Oleh karena itu, penulis mengharapkan saran dan kritik yang dapat digunakan untuk perbaikan di masa-masa yang akan datang.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
Clustering Data Titik Panas Menggunakan Algoritme PAM dan CLARA 3
Deteksi Pencilan Titik Panas Berdasarkan Hasil Clustering Terbaik 4
Analisis Pencilan 4
Presentasi Pencilan 4
HASIL DAN PEMBAHASAN 5
Pengumpulan Data Titik Panas 5
viii
DAFTAR TABEL
1 Hasil clustering menggunakan algoritme PAM pada clusterk=17 6 2 Hasil clustering menggunakan algoritme CLARA pada clusterk=19 8 3 Persentase anggota cluster hasil algoritme PAM dengan nilai k=17 9 4 Presentase anggota cluster hasil algoritme CLARA dengan nilai k=19 10
DAFTAR GAMBAR
1 Tahapan penelitian 2
2 Dekomposisi frekuensi titik panas 6
3 Scatterplot hasil clustering algoritme PAM untuk k=17 7 4 Scatterplot hasil clustering algoritme CLARA untuk k=19 9 5 Plot data titik panas tahun 2001 sampai dengan tahun 2012 12 6 Plot data titik panas tahun 2001 sampai dengan tahun 2012 12 7 Jumlah pencilan algoritme PAM pada setiap bulan pada tahun 2001 -
2012 13
8 Jumlah pencilan algoritme CLARA pada setiap bulan pada tahun 2001
- 2012 13
9 Jumlah objek deteksi pencilan per tahun algoritme PAM 14 10 Jumlah objek deteksi pencilan per tahun algoritme CLARA 14 11 Visualisasi objek deteksi pencilan algoritme PAM 15 12 Visualisasi objek deteksi pencilan algoritme CLARA 15
DAFTAR LAMPIRAN
1 Hasil clustering menggunakanalgoritme PAM 17 2 Hasil clustering menggunakan algoritme CLARA 20 3 Visualiasi peta anggota cluster algoritme PAM 23 4 Visualisasi peta anggota cluster algoritme CLARA 25
PENDAHULUAN
Latar Belakang
Kebakaran hutan menjadi perhatian internasional sebagai isu lingkungan dan ekonomi, khususnya pada tahun 1997/1998 yang menghanguskan lahan hutan seluas 25 juta hektar di seluruh dunia. Menurut (BAPPENAS-ADB 1999) total luas hutan di Indonesia yang terbakar sekitar 9,75 juta ha. Kebakaran dianggap sebagai ancaman potensial bagi pembangunan berkelanjutan karena efeknya secara langsung terhadap ekosistem, peningkatan emisi karbon dan dampaknya bagi keanekaragaman hayati. Kebakaran hutan mengakibatkan masalah yang berulang bahkan selama bertahun-tahun. Indonesia mengalami kebakaran hutan yang paling hebat pada tahun 1997. Lembaga Sosial Masyarakat (LSM) nasional dan internasional memberikan bantuan biaya kebakaran hutan pada tahun 1997/1998 untuk menekan meluasnya masalah kebakaran hutan. Kebijakan dalam mengendalikan kebakaran hutan sangat bervariasi pada sektor kehutanan dan pertanian, perkebunan kelapa sawit dan perkebunan rakyat. Kebijakan tersebut meliputi pelarangan atau pembekuan izin pembukaan lahan, pencegahan kegiatan pembalakan liar dan pemberian hukum bagi pihak yang sengaja membuka lahan dengan cara membakar hutan (Tacconi 2003).
Berbagai studi mengenai kebakaran hutan sudah banyak dilakukan, namun belum banyak mengatasi kebakaran hutan di Indonesia. Pencegahan kebakaran hutan dapat dilakukan salah satunya dengan mengetahui sebaran titik panas. Salah satu penelitian sebelumnya telah dilakukan terkait sebaran titik panas adalah deteksi pencilan titik panas yang dilakukan oleh Baehaki (2014). Deteksi pencilan ini, dilakukan untuk mendapatkan frekuensi kemunculan titik panas yang melampaui batas normal. Informasi mengenai wilayah terjadinya kebakaran hutan dapat digunakan oleh pihak terkait sebagai upaya pencegahan dan kebijakan. Penentuan kebijakan dalam tata guna lahan yang memilki kontribusi dalam terjadinya kebakaran hutan.
Penelitian ini menggunakan metode clustering pada data titik panas tahun 2001 hingga 2012. Teknik datamining yang diterapkan adalah metode clustering dengan pengelompokkan titik panas. Metode clustering yang digunakan adalah metode k-medoids Partitioning Around Medoids (PAM) dan Clustering Large Application (CLARA). Hasil clustering tersebut selanjutnya dilakukan deteksi pencilan kolektif. Hasil penelitian ini menyajikan tanggal terjadinya kebakaran hutan dan ditampilkan secara visualiasasi Provinsi Riau dalam bentuk peta.
Perumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana pencilan diidentifikasi dari data titik panas menggunakan metode clustering berbasis k-medoids dan informasi tentang karakteristik pencilan titik panas.
Tujuan Penelitian
2
1 Melakukan clustering titik panas menggunakan algoritme berbasis medoids yaitu algoritme PAM dan CLARA.
2 Mendeteksi pencilan titik panas berdasarkan hasil clustering terbaik. 3 Analisis pencilan titik panas yang dihasilkan.
Manfaat Penelitian
Hasil penelitian ini yaitu karakteristik pencilan titik panas yang diharapkan dapat mempermudah pihak terkait dalam pengambilan keputusan dan upaya pencegahan titik panas kebakaran hutan.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini meliputi:
1 Data titik panas yang digunakan data tahun 2001 sampai dengan 2012 dari FIRM NASA dan diperoleh dari penelitian sebelumnya (Baehaki 2014). 2 Pencilan yang dideteksi adalah pencilan kolektif.
METODE
Tahapan Penelitian
Pengumpulan Data Titik Panas dengan tanggal 31 Desember 2012 dengan ID tanggal = 4383.
Data titik panas tersebut terdiri dari atribut latitude, longitude, brightness, acq_date, acq_time, bright_t31 dan frp. Atribut latitude dan longitude menggambarkan letak geografis titik panas, brightness, bright_t31 dan frp merupakan tingkat visualisasi kecerahan pada titik panas, acq_date dan acq_time merupakan keterangan tanggal titik panas yang muncul.
Clustering Data Titik Panas Menggunakan Algoritme PAM dan CLARA
Terdapat beberapa algoritme clustering berbasis medoid, diantaranya PAM dan CLARA. Algoritme PAM k-medoid menggunakan data yang mewakili ditengah cluster sebagai centroid. Algoritme PAM bekerja secara efisien pada dataset yang kecil untuk merepresentasikan dataset yang asli, sedangkan algoritme CLARA menggunakan sebuah sample acak dari dataset yang besar untuk clustering dari multiple sample acak dan mengembalikan hasil clustering menjadi sebuah output (Han et al. 2012).
Pada algoritme k-medoid PAM dan CLARA terdapat nilai k merupakan jumlah cluster dan nilai n adalah jumlah banyaknya objek. Objek dipartisi ke dalam beberapa kelompok yang diwakili satu nilai centroid . Centroid adalah nilai tengah dari objek yang dikelompokan. Algoritme PAM adalah sebagai berikut (Han et al. 2012):
1 Memilih nilai kcluster dari sebuah dataset D sebagai objek perwakilan; 2 Ulangi:
2.1 Tetapkan setiap objek k cluster dengan objek representatif terdekat;
yang barudari k objek representatif;
Algoritme CLARA mengangani objek yang berbentuk point dan mengambil sample besar dari dataset dan menerapkan untuk menghasilkan nilai medoid optimal untuk sample. Kualitas yang dihasilkan nilai medoid diukur dengan perbedaan rata-rata antara setiap objek dalam seluruh dataset D dan medoid clusternya. Algoritme CLARA adalah sebagai berikut (Wei et al. 2000).
1 Tentukan minimum cost dari sebuah dataset D sebagai objek 2 Ulangi:
2.1 Tentukan S dengan s objek secara acak dari D 2.2 Tentukan medoid M dari S
4
Maka,
Minimum cost = Cost (M,D); Set terbaik = C;
Ulangi hingga selesai C tidak berubah. dengan:
Deteksi Pencilan Titik Panas Berdasarkan Hasil Clustering Terbaik
Setelah diketahui nilai k terbaik kemudian dilakukan pendeteksian pencilan pada hasil clustering berbasis medoid. Pencilan digunakan untuk melihat anomali kemunculan titik panas. Deteksi pencilan berbasis clustering ini terdapat tiga pendekatan. Pendekatan pertama adalah bila objek tidak temasuk ke dalam kelas manapun, maka objek tersebut diidentifikasi sebagai pencilan. Pendekatan kedua adalah apabila terdapat jarak yang besar antara objek dan kelas terdekat, maka objek tersebut merupakan pencilan. Pendekatan ketiga yaitu bila objek adalah bagian dari anggota kelas yang kecil, maka seluruh objek dalam kelas tersebut merupakan pencilan (Han et al. 2012).
Deteksi pencilan dapat dilihat dengan mengevaluasi jarak nilai antara setiap data yang multi dimensional. Deteksi pencilan dalam penelitian ini adalah pencilan kolektif. Pencilan kolektif merupakan pendekatan menggunakan nilai yang dilihat dari titik pusat setiap cluster (Han et al. 2012).
Analisis Pencilan
Pada tahap ini diperlihatkan objek pencilan dari hasil clustering. Data hasil deteksi pencilan dianalisis untuk mengetahui informasi yang terdapat pada data titik panas seperti ukuran pemusatan dan tanggal yang terdeteksi pencilan kolektif.
Presentasi Pencilan
Pada tahap ini pencilan kolektif titik panas dipresentasikan dalam bentuk peta. Hasil pencilan kolektif tersebut adalah output dari algoritme PAM dan CLARA dengan cluster nilai k terbaik.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut: Processor Intel Core i5
RAM 4 GB
Monitor LCD 14.0” HD
2 Perangkat lunak:
Sistem Operasi Windows 7 Ultimate
Microsoft Excel 2010 untuk pengolahan angka
Rstudio untuk komputasi statistik, clustering dan grafis
HASIL DAN PEMBAHASAN
Pengumpulan Data Titik Panas
Pengumpulan data titik panas telah dilakukan oleh penelitian sebelumnya oleh Baehaki (2014). Data penelitian ini titik panas dari bulan Januari 2001 hingga Desember 2012 awalnya sebanyak 156703 record data. Kemudian data tersebut dilakukan tahap pembersihan dengan memisahkan batas area titik panas berdasarkan kepulauan Riau, sehingga data berkurang menjadi sebanyak 111091 record data. Praproses data menggunakan perangkat lunak basis data spatial DBMS PostgreSQL dan Quantum GIS untuk menampilkan layer berdasarkan titik panas kepulauan Riau.
Hasil pengolahan data titik panas oleh Baehaki (2014) dilakukan agregasi data. Kejadian titik panas dalam satu hari dijadikan sebagai frekuensi titik panas. Data tersebut menghasilkan sebanyak 4383 record data titik panas harian dan frekuensi data panas bulanan sebanyak 144 data.
Setelah frekuensi data titik panas harian didapatkan, dilakukan dekomposisi dengan menjalankan kode R berikut:
>data.stl0103 <- read.csv('data/dataperharian.csv')
temp.hotspot0103<->ts(data.stl0103$frek,frequency=365,start=c(2001)) >dectimes <- decompose(temp.hotspot0103)
>plot(dectimes)
>stl.hotspot0103<-stl(temp.hotspot0103, "periodic", robust=TRUE)
>stl.outlier <- which(stl.hotspot0103$weights < 1e-1)
6
Gambar 2 Dekomposisi frekuensi titik panas
Pada Gambar 2 menunjukkan hasil dekomposisi harian data titik panas dengan asumsi jumlah hari pada satu tahun sebanyak 365 hari. Label time merupakan tanggal kejadian titik panas dari tahun 2001 hingga 2012. Label trend menunjukkan kenaikkan frekuensi titik panas tahun 2005 yang kemudian mengalami penurunan tahun 2007 hingga 2009 dan mengalami kenaikan tahun 2010. Label seasonal ditunjukkan frekuensi titik panas mengalami kenaikkan pada awal dan pertengahan tahun sepanjang tahun 2001 hingga 2012.
Clustering Data Titik Panas Menggunakan Algoritme Berbasis Medoid PAM dan CLARA
Algoritme PAM
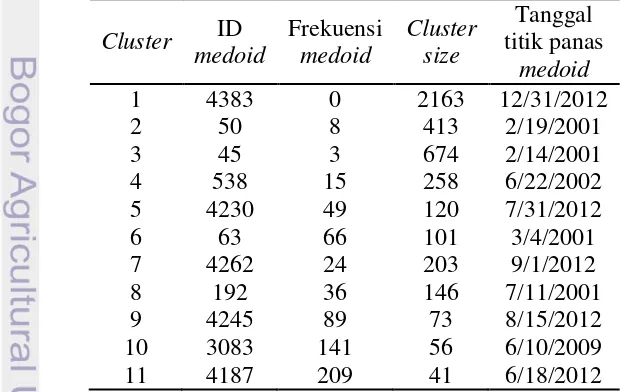
Hasil clustering dengan menggunakan metode PAM pada titik panas kepulauan Riau menghasilkan pencilan dengan cluster k=17. Pencarian nilai k terbaik menggunakan algoritme PAM adalah nilai k=2 hingga nilai k=20. Cluster k=17 yang merupakan hasil cluster yang paling baik dan terdapat nilai frekuensi yang sangat besar dari frekuensi cluster lainnya yaitu 956. Hasil pencarian nilai k tersebut dapat dilihat pada Tabel 1.
Tabel 1 Hasil clustering menggunakan algoritme PAM pada clusterk=17
Cluster ID mewakili tanggal medoid dan tanggal 2/21/2005. Kedua tanggal tersebut merupakan nilai pencilan. Kode R untuk menghasilkan cluster tersebut dijalankan sebagai berikut:
> library("cluster")
Mengaktifkan library cluster
> datap <-read.csv("D:/data.csv")
Memasukan data.csv kedalam variable datap > datap
> resultp<-pam(datap$frek,17, FALSE, "euclidean") Cluster pam dengan variable result dengan parameter kolom frekuensi, nilai k=17, matiksnya “eiclidean” > summary(resultp)
Melihat hasil clustering
Berdasarkan kode program di atas algoritme PAM dapat dipanggil dengan mengaktifkan library cluster setelah data.csv dimasukan ke dalam variabel
datap. Data tersebut dikelompokan menggunakan fungsi PAM dan fungsi
summary digunakan untuk melihat hasil clustering pada data.csv. Visualisasi
hasil cluster ke-17 dapat dilihat pada scatter plot Gambar 3.
8
Berdasarkan Gambar 3, titik pada scatterplot yangberbentuk belah ketupat merupakan kejadian titik panas. Garis x merupakan ID medoid dan garis y merupakan frekuensi titik panas. Pada cluster ke-17 dengan ID medoid 1680 memiliki nilai frekuensi yang paling besar yaitu 956 yang diindikasikan sebagai pencilan. Scatter plot menunjukan adanya nilai frekuensi di bawah 200 yang sering muncul. Sehingga dikategorikan sebagai nilai yang paling berdekatan atau dominan terjadinya titik panas.
Algoritme CLARA
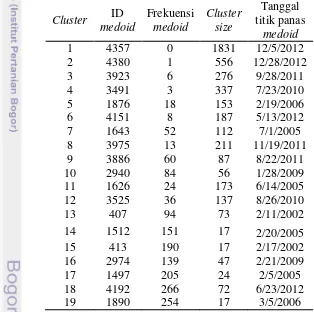
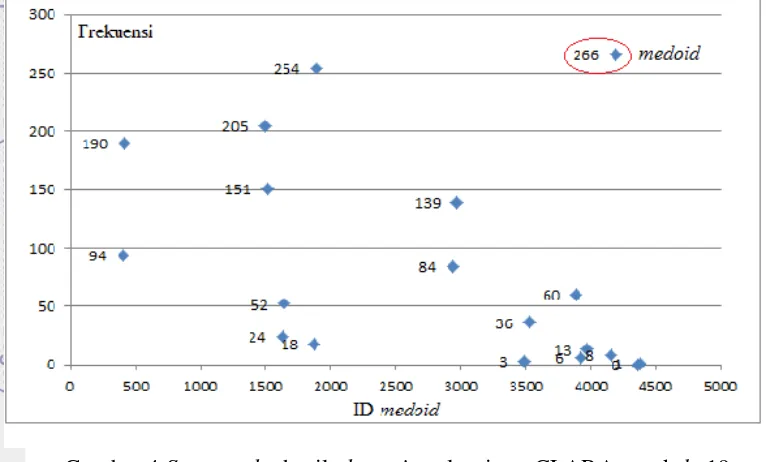
Hasil clustering dengan menggunakan metode CLARA pada titik panas kepulauan Riau menghasilkan pencilan dengan cluster k=19. Pencarian nilai k terbaik menggunakan algoritme CLARA adalah nilai k=2 hingga nilai k=20. Cluster k=19 yang merupakan hasil cluster yang paling baik dan terdapat nilai frekuensi yang sangat besar dari frekuensi cluster lainnya yaitu 266. Hasil pencarian nilai k tersebut dapat dilihat pada Tabel 2.
Tabel 2 Hasil clustering menggunakan algoritme CLARA pada clusterk=19
Cluster ID yang mewakili tanggal medoid. 72 anggota tanggal tersebut merupakan nilai pencilan. Kode R untuk menghasilkan cluster tersebut dijalankan sebagai berikut:
> library("cluster")
> datac<-read.csv("D:/data.csv")
Membaca data.csv, memasukan kedalam variable datac > resultc<-clara(datac$frek,19)
Cluster metode clara dengan variable result, untuk kolom frekuensi dan nilai k=19
> summary(resultc) Melihat hasil cluster
Berdasarkan kode program di atas algoritme CLARA dapat dipanggil dengan mengaktifkan library cluster setelah data.csv dimasukan ke dalam variabel datac. Data tersebut dikelompokan menggunakan fungsi CLARA dan fungsi summary untuk melihat hasil clustering pada data.csv. Visualisasi hasil cluster ke-18 dapat dilihat pada scatter plot Gambar 4.
Gambar 4 Scatterplot hasil clustering algoritme CLARA untuk k=19 Berdasarkan Gambar 4 titik pada scatterplot berbentuk belah ketupat yang merupakan simbol kejadian titik panas. Garis x merupakan IDmedoid dan garis y merupakan frekuensi hotspot. Pada cluster ke-18 dengan ID medoid 4192 memiliki nilai frekuensi yang paling besar yaitu 266 yang diindikasikan sebagai pencilan. Scatterplot menunjukan adanya nilai frekuensi dibawah 100 nilai yang sering muncul. Sehingga dikategorikan sebagai nilai yang paling berdekatan atau dominan terjadinya titik panas.
Deteksi Pencilan Titik Panas Berdasarkan Hasil Clustering Terbaik
Algoritme PAM
Hasil clustering terbaik pada algoritme PAM dengan nilai k=17 terdapat anggota medoid dengan persentase di bawah 1%. Presentase ini berdasarkan pendekatan clustering yaitu bila objek adalah bagian dari anggota yang kecil, maka seluruh objek dalam kelas merupakan pencilan (Han et al. 2012). Anggota setiap cluster 13, 14, 15, 16 dan 17 dapat dilihat pada Lampiran 1. Persentase anggota cluster terdapat pada Tabel 3.
10
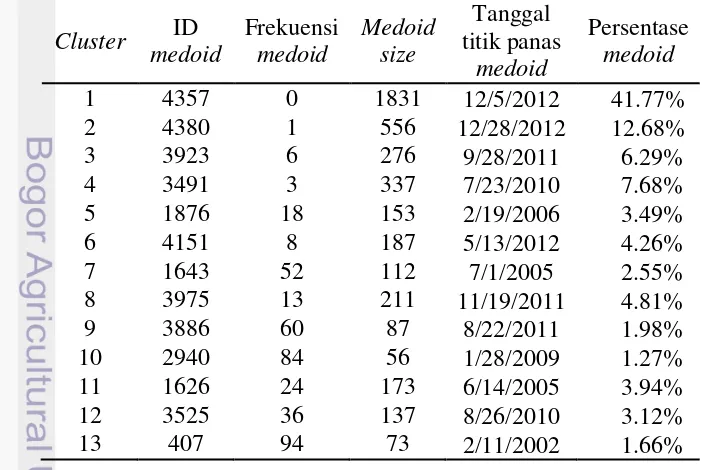
Hasil clustering terbaik pada algoritme CLARA dengan nilai k=19 terdapat anggota medoid dengan persentase dibawah 1%. Presentase ini berdasarkan pendekatan clustering yaitu bila objek adalah bagian dari anggota yang kecil, maka seluruh objek dalam kelas merupakan pencilan (Han et al. 2012). Anggota setiap cluster 14, 15, 17 dan 19 dapat dilihat pada Lampiran 2. Hasil persentase cluster terlihat pada Tabel 4.
Tabel 4 Presentase anggota cluster hasil algoritme CLARA dengan nilai k=19
Cluster ID
Pencilan kolektif berdasarkan banyaknya jumlah anggota setiap cluster. Cluster yang memiliki sedikit anggota merupakan pencilan. Algoritme PAM pada Tabel 3 yang memiliki anggota terkecil terletak pada cluster 11 dengan 41 anggota, cluster 14 dengan 28 anggota, cluster 13 dengan 17 anggota, cluster 14 dengan 28 anggota, cluster 15 dengan 16 anggota, cluster 16 dengan 22 anggota dan cluster 17 dengan 2 anggota. Algoritme CLARApada Tabel 4 yang memiliki anggota terkecil terletak pada cluster 14 dengan 17 anggota, cluster 15 dengan 17 anggota, cluster 17 dengan 24 anggota dan cluster 19 dengan 17 anggota. Semua anggota algoritme PAM dan CLARA tersebut persentase anggotanya di bawah 1% yang disebut sebagai pencilan kolektif.
Lampiran 1 merupakan jumlah anggota setiap cluster algoritme PAM. Lampiran 1 menunjukan jumlah anggota cluster ke-13 banyak terjadi titik panas pada bulan Agustus 2004, 2005, 2006 dan 2009. Anggota cluster ke-14 banyak terjadi titik panas pada bulan Juli 2002, 2003, 2007, 2009 dan 2011. Anggota cluster ke-15 banyak terjadi titik panas pada bulan Juni 2003, 2004, 2005 dan Februari 2005. Anggota cluster ke-16 banyak terjadi titik panas pada bulan Maret 2005, 2011, Juni 2004, 2005, 2009, 2012 dan Agustus 2005, 2006, 2008, 2009. Anggota cluster ke-17 banyak terjadi titik panas pada bulan Januari 2005 dan Agustus 2005. Berdasarkan hasil algoritme PAM ini dapat disimpulkan pencilan terjadi pada bulan Februari, Maret, Juni, Juli dan Agustus dari Januari 2001 hingga Desember 2012 dan hasil visualisasi peta setiap anggota cluster dapat dilihat pada Lampiran 3.
Lampiran 2 merupakan jumlah anggota setiap cluster algoritme CLARA. Lampiran 2 jumlah anggota cluster ke-14 banyak terjadi titik panas pada bulan Juli 2001, 2002, 2005 dan 2009. Anggota cluster ke-15 banyak terjadi titik panas pada bulan Juni 2003, 2004, 2005, 2009 dan 2012 serta terjadi pada bulan Juli 2001, 2006, 2009 dan 2011. Anggota cluster ke-17 banyak terjadi titik panas pada bulan Februari 2002, 2005 dan 2009. Anggota cluster ke-19 banyak terjadi titik panas pada bulan Juli 2003, 2006, 2009, 2011 dan 2012. Berdasarkan hasil algoritme CLARA ini dapat disimpulkan pencilan terjadi pada bulan Februari, Maret, Juni , Juli dan Agustus dari Januari 2001 hingga Desember 2012 dan hasil visualisasi peta setiap anggota cluster dapat dilihat pada Lampiran 4.
12
Gambar 5 Plot data titik panas tahun 2001 sampai dengan tahun 2012 Berdasarkan Gambar 5 titik pada scatter plot berbentuk simbol segitiga berwarna hitam merupakan pencilan titik panas. Sumbu garis x merupakan ID medoid dan garis y merupakan frekuensi hotspot. Hasil visualisasi pada Gambar 4 terlihat bahwa frekuensi yang sering muncul adalah frekuensi di bawah nilai 200 dengan berbagai macam warna dan bentuk. Nilai frekuensi diatas 800 merupakan pencilan dengan rentang nilai diantara hari ke-1000 sampai ke-2000. Pencilan tersebut titik panas terjadi sekitar tahun 2005.
Presentasi Pencilan
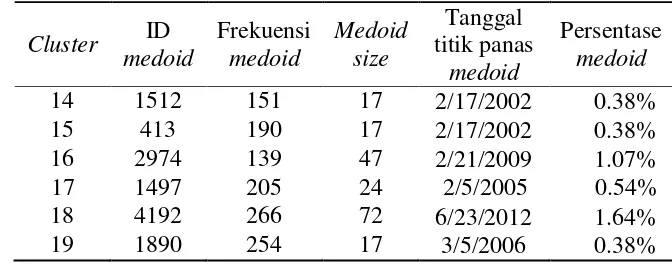
Hasil algoritme PAM dan CLARA dapat disimpulkan pencilan titik panas terjadi bulan Februari, Maret, Juni, Juli dan Agustus. Pencilan secara keseluruhan bulan Januari 2001 hingga Desember 2012. Hasil visualiasi pencilan titik panas berdasarkan bulan pada Gambar 7 dan Gambar 8.
Gambar 7 Jumlah pencilan algoritme PAM pada setiap bulan pada tahun 2001 - 2012
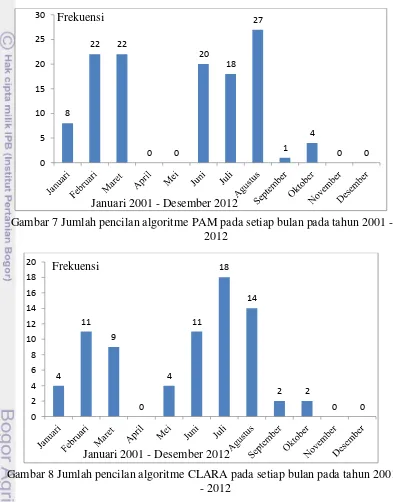
Gambar 8 Jumlah pencilan algoritme CLARA pada setiap bulan pada tahun 2001 - 2012
Gambar 7 dan Gambar 8 menunjukan algoritme PAM pencilan banyak terjadi pada bulan Februari sebanyak 22 objek, bulan Maret sebanyak 22 objek, bulan Juni sebanyak 20 objek, bulan Juli 18 objek dan bulan Agustus sebanyak 27 objek. Algoritme CLARA pencilan banyak terjadi pada bulan Februari sebanyak
8
Januari 2001 - Desember 2012
4
14
11 objek, bulan Maret sebanyak 9 objek, bulan Juni sebanyak 11 objek, bulan Juli 18 objek dan bulan Agustus sebanyak 14 objek.
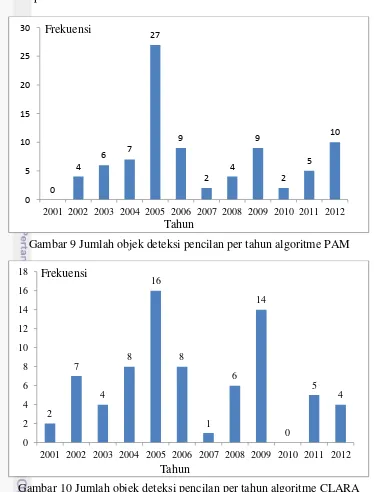
Visualisasi jumlah pencilan per tahun algoritme sebagai hasil PAM dan CLARA pada Gambar 9 dan Gambar 10.
Gambar 9 Jumlah objek deteksi pencilan per tahun algoritme PAM
Gambar 10 Jumlah objek deteksi pencilan per tahun algoritme CLARA Berdasarkan hasil algoritme PAM, pencilan banyak terjadi pada tahun 2005 sebanyak 27 objek dan algoritme CLARA, pencilan banyak terjadi pada tahun 2005 sebanyak 16 objek dan tahun 2009 sebanyak 14 objek. Hasil pencilan algoritme PAM dan CLARA divisualisakan dalam bentuk kalender bulan dan tahun dapat dilihat pada Lampiran 5.
Visualisasi jumlah pencilan dalam bentuk peta sebagai hasil algoritme PAM dan CLARA pada Gambar 11 dan Gambar 12.
0
2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012
Frekuensi
2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012
Frekuensi
Gambar 11 Visualisasi objek deteksi pencilan algoritme PAM
Gambar 11 dapat dilihat bahwa objek yang terdeteksi sebagai pencilan algoritme PAM menyebar di seluruh Provinsi Riau. Pada bulan Februari banyak pencilan terdeteksi di Kota Pekan Baru dan Kab. Indragiri Hilir serta menyebar di Kota Dumai. Pada bulan Maret pencilan mayoritas muncul di Kota Dumai serta menyebar di seluruh Provinsi Riau. Pada bulan Juni, Juli dan Agustus pencilan muncul secara merata di seluruh Provinsi Riau.
Gambar 12 Visualisasi objek deteksi pencilan algoritme CLARA
16
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menunjukan deteksi pencilan dari 4383 objek titik panas. Hasil algoritme PAM pencilan titik panas terjadi pada k=17 dengan cluster ke-11,13,14,15,16 dan 17 serta terjadinya pada bulan Februari, Maret, Juni, Juli dan Agustus. Hasil algoritme CLARA menunjukan pencilan titik panas pada k=19 dengan cluster ke 14,15,17 dan 19 serta terjadi pada bulan Februari, Maret, Juni, Juli dan Agustus. Frekuensi tertinggi menunjukan pencilan secara keseluruhan bulan Januari 2001 sampai dengan Desember 2012 adalah dengan frekuensi 1118. Kejadian tersebut terjadi pada tanggal 2/21/2005. Hasil algoritme PAM, bulan Februari banyak pencilan terdeteksi di Kota Pekan Baru dan Kab. Indragiri Hilir serta menyebar di Kota Dumai, bulan Maret pencilan mayoritas muncul di Kota Dumai serta menyebar di seluruh Provinsi Riau dan bulan Juni, Juli dan Agustus pencilan muncul secara merata di seluruh Provinsi Riau. Hasil algoritme CLARA, bulan Februari pencilan terdeksi berkumpul di Kota Dumai, bagian utara Kab. Indragiri dan bagian tenggara Kota Pekan Baru dan bulan Maret, Juni, Juli, Agustus pencilan tersebar hampir di seluruh Provinsi Riau.
Saran
Penelitian ini memiliki kekurangan dalam menentukan nilai k. Dalam penelitian ini menggunakan nilai k=2 sampai k=20 dengan asumsi hasil yang didapatkan dengan nilai k terbaik. Penelitian selanjutnya diharapkan menggunakan metode yang lain dengan penentuan nilai k yang lebih optimal.
DAFTAR PUSTAKA
Baehaki D. 2014. Deteksi pencilan data titik panas di provinsi Riau menggunakan algoritme clustering K-Means [skripsi]. Bogor(ID): Insitut Pertanian Bogor. BAPPENAS-ADB. 1999. Causes, Extent, Impact and Costs of 1997/1998 Fires
and Drought. National Development Planning Agency (BAPPENAS) and Asia Development Bank, Jakarta.
Han J, Kamber M, Pei J. 2012. Data Mining Concepts and Techniques Third Edition. San Massachusetts (US): Morgan Kaufmann Publisher.
Liao TW. 2005. Clustering of time series data—a survey. Pattern Recognition [Internet]. [diunduh 2014 Mei 30]. 38(1). 1857-1874. Tersedia pada: http://arxiv.org/ftp/arxiv/papers/1005/1005.4270.pdf
Tacconi L. 2003. Kebakaran Hutan di Indonesia: Penyebab, Biaya dan Implikasi Kebijakan[paper]. Bogor(ID): Center For International Forestry Research Wei C, Lee Y, Hsu C. 2000. Empirical Comparison of Fast Clustering Algorithms
20 Lampiran 2 Hasil clustering menggunakan algoritme CLARA
Lampiran 3 Visualiasi peta anggota cluster algoritme PAM a Cluster 13 dengan ID medoid 1524
b Cluster 14 dengan ID medoid 1484
24
d Cluster 16 dengan ID medoid 3136
e Cluster 17 dengan ID medoid 1680
Lampiran 4 Visualisasi peta anggota cluster algoritme CLARA a. Cluster 14 dengan ID medoid 1512
b. Cluster 15 dengan ID medoid 413
26
28
Tahun Jan Feb Mar Apr Mei Jun Jul Agus Sept Okt Nov Des
2009 20(199),18(202)c 20(230)d
3(174)b, 13(214),17(205)c,
4(241),31(247)d
7(202)c
2010 5(242)d
2011 8(185)b 2(171),21(183)b
2012 18(209)c,
30
2008 21(350)b,9(527)e 18(210)a 1(182),3(