APLIKASI BERBASIS WEB UNTUK DETEKSI PENCILAN TITIK
PANAS MENGGUNAKAN ALGORITME
CLUSTERING
K-MEANS DAN
FRAMEWORK
SHINY
AGISHA MUTIARA YOGA ASMARANI SUCI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Aplikasi Berbasis Web untuk Deteksi Pencilan Titik Panas Menggunakan Algoritme Clustering K-Means dan Framework Shiny adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
AGISHA MUTIARA YOGA ASMARANI SUCI. Aplikasi Berbasis Web untuk Deteksi Pencilan Titik Panas Menggunakan Algoritme Clustering K-Means dan Framework Shiny. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Analisis pencilan data titik panas Provinsi Riau tahun 2011 hingga 2012 sebagai indikator terjadinya kebakaran telah dilakukan, tetapi hal tersebut dirasa kurang membantu dalam upaya pencegahan kebakaran. Hal tersebut dikarenakan hasil dari analisis pencilan hanya dapat digunakan oleh orang tertentu dan tidak dapat dengan mudah dan cepat untuk diakses oleh pengguna. Tujuan penelitian ini adalah membuat aplikasi berbasis web untuk mendeteksi pencilan dan memvisualisaikan pencilan berdasarkan waktu dan lokasi. Deteksi pencilan telah dilakukan pada penelitian sebelumnya dengan menggunakan metode clustering k-means dengan pendekatan pencilan global dan pencilan kolektif pada data titik panas Provinsi Riau tahun 2001 sampai 2012. Pada penelitian ini dibuat aplikasi berbasis web menggunakan framework Shiny dengan bahasa pemrograman R. Aplikasi ini menyediakan beberapa fungsi, yaitu ringkasan dan visualisasi dari data yang dipilih, clustering data titik panas dengan algoritme k-means, visualisasi hasil clustering dan sum square error (SSE), serta menampilkan pencilan global maupun kolektif dan melihat penyebarannya dengan visualisasi pencilan pada peta Provinsi Riau.
Kata kunci: clustering, k-means, pencilan, Shiny, titik panas
ABSTRACT
AGISHA MUTIARA YOGA ASMARANI SUCI. A Web Based Application for Outliers Detection on Hotspot Data using the K-Means Clustering Algorithm and the Shiny Framework. Supervised by IMAS SUKAESIH SITANGGANG.
Outliers analysis on hotspot data as an indicator of fire occurences in Riau Province between 2001 and 2012 have been done, but it was less helpful in fire prevention efforts. This is because the results can only be used by certain people and can not be easily and quickly accessed by users. The purpose of this research is to create a web-based application to detect outliers on Hotspot data and to visualize the outliers based on the time and location. Outliers detection was done in the previous research using the k-means clustering method with global and collective outlier approach in Riau Province Hotspot data between 2001 and 2012. This work aims to develop a web-based application using the framework Shiny with the R programming language. This application provides several functions including summary and visualization of the selected data, clustering hotspot data using k-means algorithm, visualization of the clustering results and sum square error (SSE), and displaying global and collective outliers and visualization of outlier spread on Riau Province Map.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
APLIKASI BERBASIS WEB UNTUK DETEKSI PENCILAN TITIK
PANAS MENGGUNAKAN ALGORITME
CLUSTERING
K-MEANS DAN
FRAMEWORK
SHINY
AGISHA MUTIARA YOGA ASMARANI SUCI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Aplikasi Berbasis Web untuk Deteksi Pencilan Titik Panas Menggunakan Algoritme Clustering K-Means dan Framework Shiny
Nama : Agisha Mutiara Yoga Asmarani Suci
NIM : G64110020
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2015 ini ialah pencilan, dengan judul Aplikasi Berbasis Web untuk Deteksi Pencilan Titik Panas Menggunakan Algoritme Clustering K-Means dan Framework Shiny.
Penulis menyadari bahwa dalam proses penulisan skripsi ini banyak mengalami kendala, namun berkat bantuan, bimbingan, kerjasama dari berbagai pihak dan berkah dari Allah subhanahu wa ta'ala sehingga kendala-kendala yang dihadapi tersebut dapat diatasi. Untuk itu penulis menyampaikan ungkapan terima kasih juga disampaikan kepada Agus Irianto selaku ayah, Sri Wahyuni selaku ibu serta seluruh keluarga atas segala doa dan kasih sayangnya. Serta ucapan terima kasih dan penghargaan kepada Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku pembimbing yang telah dengan sabar, tekun, tulus dan ikhlas meluangkan waktu, tenaga, dan pikiran memberikan bimbingan, motivasi, arahan, dan saran-saran yang sangat berharga kepada penulis selama menyusun skripsi. Terima kasih tak lupa saya sampaikan juga kepada sahabat-sahabat seperjuangan saya, yaitu Pristi Sukmasetya, Rachma Hermawati, Lusi Maulina Erman, Yenni Puspitasari, Nadia Rahmah, Nida Zakiya Nurul Haq, Gita Puspita Siknun, Nalar Istiqomah, dan Pha Hy Thah yang selalu mendukung saya. Terima kasih juga saya ucapkan kepada seluruh teman-teman Ilmu Komputer IPB angkatan 48 dan Muhammad Al Mabruri. Ucapan Terima kasih juga saya saya tujukan kepada Bapak Aziz Kustiyo, SSi MKom dan Ibu Rina Trisminingsih, SKomp MT selaku penguji atas segala masukan dan saran yang telah diberikan. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 3
TINJAUAN PUSTAKA 3
Titik Panas (Hotspot) 3
Pencilan 3
Deteksi Pencilan Berbasis Clustering 3
Algoritme K-means 4
Framework Shiny 5
METODE PENELITIAN 5
Data Penelitian 5
Tahapan Penelitian 5
Lingkungan Pengembangan 7
HASIL DAN PEMBAHASAN 8
Clustering Menggunakan Algoritme K-means 8
Deteksi Pencilan Kolektif pada Data Titik Panas Harian 9 Deteksi Pencilan Global pada Data Titik Panas Harian 10
Pembuatan Aplikasi dengan Framework Shiny 11
SIMPULAN DAN SARAN 19
Simpulan 19
Saran 20
DAFTAR PUSTAKA 20
DAFTAR TABEL
1 Hasil clustering k-means dengan nilai k sebesar 10 8 2 Nilai SSE untuk hasil clustering k-means dengan nilai k sebesar 10 9
3 Hasil deteksi pencilan kolektif 9
4 Hasil deteksi pencilan global 10
5 Library yang digunakan dalam pembuatan aplikasi 12
6 Evaluasi pengujian 19
DAFTAR GAMBAR
1 Tahapan penelitian 6
2 Menu-menu yang tersedia pada aplikasi yang dibangun 13
3 Tampilan sub-menu data summary 13
4 Tampilan sub-menu data plot 14
5 Tampilan sub-menu clustering summary 14
6 Tampilan menu SSE 15
7 Tampilan sub-menu k-means plot 15
8 Tampilan sub-menu collective outlier summary 16
9 Tampilan sub-menu collective outlier plot 16
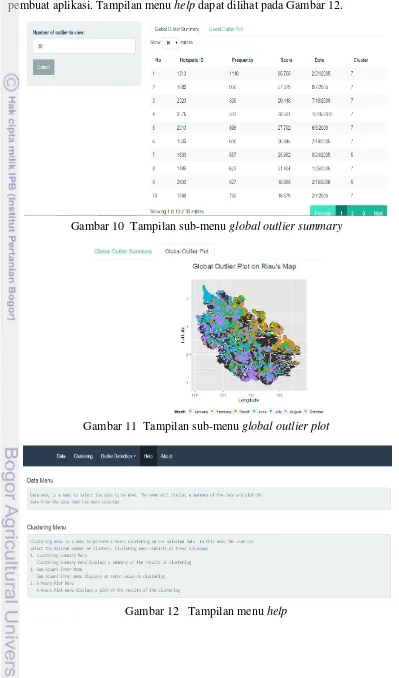
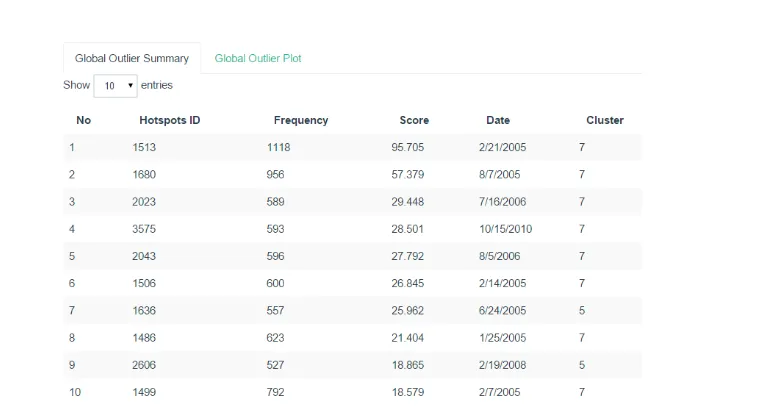
10 Tampilan sub-menu global outlier summary 17
11 Tampilan sub-menu global outlier plot 17
12 Tampilan menu help 17
13 Hasil clustering dengan aplikasi yang dibangun 18 14 Hasil deteksi pencilan kolektif dengan aplikasi yang dibangun 18 15 Hasil deteksi pencilan global dengan aplikasi yang dibangun 19
DAFTAR LAMPIRAN
1 Data titik panas harian Provinsi Riau 22
2 Perintah dalam R untuk visualisasi clustering 23 3 Hasil pengujian aplikasi berbasis web untuk deteksi pencilan titik panas
PENDAHULUAN
Latar Belakang
Hutan tropis Indonesia dalam hal luasannya menempati urutan ketiga setelah Brasil dan Republik Demokrasi Kongo, selain itu Indonesia juga memiliki hutan mangrove yang terluas di dunia (FWI 2001). Menurut BB SDLP (2008), Indonesia memiliki lahan gambut terluas di antara negara tropis, yaitu sekitar 21 juta ha, yang tersebar terutama di Sumatera, Kalimantan, dan Papua.
Saat ini hutan di Indonesia menghadapi ancaman kerusakan hutan yang salah satunya, yaitu kebakaran hutan. Kebakaran hutan semakin menarik perhatian internasional sebagai isu lingkungan dan ekonomi setelah bencana El Nino yang terjadi pada tahun 1997-1998. Secara total untuk tahun 1997-1998, bencana tersebut menghanguskan 22 juta hektar lahan yang 14 juta hektarnya adalah hutan (Rowell dan Moore 2010). Menurut Wanggai (2009) umumnya penyebab kebakaran hutan adalah manusia dan pada dasarnya manusia kurang hati-hati dalam mengelola hutan sehingga terjadi kebakaran hutan.
Pada awal Maret 2014, kebakaran hutan dan lahan gambut di provinsi Riau melonjak hingga melampaui saat terjadinya krisis kabut asap Asia Tenggara pada Juni 2013. Sejak 20 Februari hingga 11 Maret 2014, Global Forest Watch mendeteksi 3101 peringatan titik api dengan tingkat keyakinan tinggi di Pulau Sumatera dengan menggunakan data titik panas aktif NASA (Sizer et al. 2014). Angka tersebut melebihi 2643 total jumlah peringatan titik panas yang terdeteksi pada puncak krisis kebakaran dan kabut asap pada 13-30 Juni 2013 (Sizer et al. 2014). Data titik panas aktif NASA diperoleh dari pengamatan satelit yang menggunakan sensor bernama moderate resolution imaging spectroradiometer (MODIS).
Strategi yang dapat dilakukan sebagai upaya untuk pencegahan terjadinya kebakaran diantaranya adalah pendekatan sistem informasi kebakaran dengan sistem pemantauan titik panas (Adinugroho et al. 2005). Menurut Adinugroho et al. (2005), data titik panas dapat dijadikan sebagai salah satu indikator tentang kemungkinan terjadinya kebakaran hutan dan lahan, sehingga diperlukan analisis. Analisis yang dapat dilakukan untuk kejadian titik panas, yaitu analisis pencilan dengan menggunakan algoritme clustering.
2
yaitu wilayah yang memiliki cluster hotspot terluas adalah provinsi Kalimantan Barat yang memiliki 3528 hotspot.
Saat ini perkembangan tekonologi di Indonesia sangat pesat. Hampir semua masyarakat Indonesia membutuhkan internet. Dengan menggunakan internet memungkinkan untuk melakukan komunikasi jarak jauh secara cepat dan murah. Hasil deteksi pencilan data titik panas perlu didistribusikan secara cepat agar para pemangku kepentingan dapat mengambil keputusan sedini mungkin sebagai upaya antisipasi menghadapi kebakaran maupun pemadaman kebakaran. Oleh karena hal tersebut, menyebabkan perlu dibuatnya sebuah aplikasi berbasis web sehingga pada penelitian ini akan dibangun aplikasi berbasis web untuk mendeteksi pencilan global dan kolektif titik panas harian menggunakan algoritme clustering K-Means. Aplikasi berbasis web tersebut menggunakan Shiny, yaitu web application framework untuk R.
Perumusan Masalah
Pada penelitian Baehaki (2014) telah dilakukan deteksi pencilan data titik panas harian dengan menggunakan algoritme k-means, akan tetapi penelitian tersebut hanya memakai fungsi-fungsi yang terdapat pada R dan belum diimplementasikan ke dalam sebuah aplikasi berbasis web agar pengguna lebih mudah dalam mendeteksi pencilan.
Berdasarkan latar belakang di atas, perumusan masalah dalam penelitian ini adala :
1 Bagaimana penerapan algoritme clustering k-means untuk mendeteksi pencilan data titik panas?
2 Bagaimana menerapkan Shiny sebagai web application framework dalam pembuatan aplikasi berbasis web untuk mendeteksi pencilan data titik panas ? 3 Bagaimana memvisualisasikan dan menampilkan pencilan titik panas yang
dihasilkan dari clustering?
Tujuan Penelitian
Tujuan penelitian ini adalah membangun aplikasi berbasis web untuk mendeteksi pencilan data titik panas harian dengan menggunakan metode clustering k-means dan framework Shiny dengan bahasa pemrograman R.
Manfaat Penelitian
3 Ruang Lingkup Penelitian
Ruang lingkup penelitian ini, ialah:
1 Penelitian menggunakan data titik panas harian Provinsi Riau tahun 2001-2012 yang diambil oleh sensor MODIS dan telah dilakukan praproses oleh Baehaki (2014), dan
2 Pembuatan aplikasi ini menggunakan framework Shiny dan bahasa pemrograman R.
TINJAUAN PUSTAKA
Titik Panas (Hotspot)
Menurut Suwarsono et al. (2013), titik panas merupakan suatu daerah di permukaan bumi yang memiliki suhu relatif lebih tinggi dibandingkan daerah di sekitarnya berdasarkan ambang batas suhu tertentu. Menurut Guswanto dan Heriyanto (2009), ambang batas yang digunakan oleh Kementrian Kehutanan dan Japan International Cooperation Agency untuk data titik panas satelit NOAA adalah 315 K atau 42o C.
Pemantauan titik panas merupakan suatu upaya untuk mengendalikan terjadinya kebakaran hutan atau lahan secara dini. Pemantauan titik panas dilakukan dengan remote sensing atau yang biasa disebut sebagai penginderaan jarak jauh dengan menggunakan satelit. Satelit Terra (EOS AM) dan satelit Aqua (EOS PM) adalah dua satelit yang meggunakan sensor MODIS untuk memantau titik panas. Titik panas merupakan suatu indikasi potensi akan terjadinya kebakaran hutan atau lahan. Pada semua titik panas belum tentu akan terjadi kebakaran, sehingga analisis lebih lanjut perlu dilakukan.
Pencilan
Pencilan adalah objek data yang secara signifikan menyimpang dari kumpulan objek-objek yang dihasilkan dengan mekanisme berbeda. Pencilan terdiri atas beberapa tipe (Han et al. 2012), yaitu :
1 Pencilan global
Pencilan global adalah objek data yang secara signifikan menyimpang dari kumpulan data atau tidak sesuai dengan pola pada umumnya. Pencilan global juga disebut point anomaly dan merupakan tipe pencilan yang paling sederhana. 2 Pencilan kolektif
Pencilan kolektif adalah bagian dari objek-objek data yang seluruhnya menyimpang secara signifikan dari keseluruhan kumpulan data.
Deteksi Pencilan Berbasis Clustering
4
memiliki kemiripan yang tinggi, tetapi sangat berbeda dengan kelompok yang lain (Han et al. 2012). Sebuah cluster adalah kumpulan catatan yang mirip satu sama lain dan berbeda dengan catatan dalam kelompok yang lainnya (Larose 2005).
Metode berbasis clustering berasumsi bawa objek-objek data normal milik kelompok yang besar dan padat. Menurut metode berbasis clustering, suatu data dikatakan pencilan apabila data tersebut milik kelompok kecil atau jarang, atau tidak tergabung dalam kelompok (Han et al. 2012).
Metode deteksi pencilan berbasis clustering salah satunya, yaitu deteksi pencilan menggunakan clustering k-means. Dalam metode tersebut, sebuah pencilan dikatakan pencilan global apabila jarak antara objek dengan pusat cluster atau centroid jauh atau besar. Pendekatan pencilan global dapat diukur dengan nilai outlier score. Semakin besar nilai outlier score, semakin besar kemungkinan objek tersebut merupakan pencilan global. Rasio untuk mengukur jarak sebuah objek yang didefinisikan sebagai berikut (Han et al. 2012):
outlier score = dist o, cl o dari objek data, dan
��� : rata-rata dist �, �� .
Teknik dari skala nilai pencilan menetapkan outlier score untuk setiap pengukuran data yang tergantung pada derajat pengukuran yang dianggap sebagai pencilan dan memberikan daftar peringkat pencilan. Seorang analis dapat memilih untuk menganalisis n pencilan teratas yang memiliki nilai pencilan terbesar atau menggunakan ambang batas cut-off untuk memilih pencilan. Ambang batas tersebut sering kali sulit untuk dipilih dan biasanya ditentukan dan ditetapkan oleh pengguna (Zhang et al. 2010).
Selain itu, pendekatan pencilan kolektif dalam metode clustering, yaitu apabila objek adalah bagian dari anggota cluster yang kecil atau cluster minoritas, seluruh objek dalam cluster tersebut merupakan pencilan (Han et al. 2012).
Algoritme K-means
Algoritme k-means adalah sebuah teknik yang berbasis centroid dan merupakan salah satu metode partitioning. Perbedaan antara sebuah objek pCi
dan ci, representasi dari cluster diukur dengan dist(p,ci). Ci adalah cluster ke-i,
sedangkan ci dalah centroid cluster ke-i. Dist(x,y) adalah jarak Euclid antara dua
objek atau titik x dan y. Kualitas sebuah cluster Ci dapat diukur dengan sum
square error (SSE). SSE didefinisikan sebagai berikut (Han et al. 2012) SSE = ∑ ∑ki=1 p∈Cidist(p,ci)2
dengan SSE adalah total dari squared error untuk semua objek-objek pada kumpulan data, p adalah titik yang merepresentasikan objek, k sebagai jumlah dari cluster-cluster, dan ciadalah titik pusat cluster Ci (Han et al. 2012).
5 Keluaran dari algoritme k-means, yaitu kumpulan dari k cluster. Langkah-langkah untuk melakukan clustering dengan menggunakan algoritme k-means (Han et al. 2012), yaitu:
1 Pilih k objek sebagai centroid atau titik pusat awal dari cluster,
2 Masukkan objek-objek ke dalam cluster yang objeknya adalah yang paling mirip berdasarkan nilai rata-rata dari objek-objek yang berada di dalam sebuah cluster,
3 Memperbaharui titik pusat cluster, yaitu menghitung nilai rata-rata dari objek-objek untuk setiap cluster,
4 Ulangi langkah ke-dua dan ke-tiga sampai objek-objek yang berada pada cluster tidak ada yang berbeda.
Framework Shiny
Shiny adalah sebuah package dari bahasa pemrograman R yang memudahkan pengguna dalam membangun aplikasi berbasis web. Shiny memberikan queries dan ringkasan data kepada pengguna melalui web browser yang modern dengan mudah. Selain itu, Shiny juga dilengkapi dengan berbagai widget untuk membangun antarmuka pengguna yang interaktif dan dapat dengan mudah diintegrasikan dengan HTML maupun CSS, bahkan JavaScript dan JQuery dapat digunakan untuk memperluas cakupan aplikasi Shiny (Beely 2013).
Shiny membuat sangat mudah untuk membangun aplikasi web interaktif dengan R. Fungsi reaktif yang otomatis mengikat antara input dan output dan bermacam-macam widget pada Shiny memungkinkan untuk membangun aplikasi yang user friendly, responsif, dan baik dengan mudah (RStudio 2014).
METODE PENELITIAN
Data Penelitian
Data yang digunakan pada penelitian ini adalah data titik panas harian di Provinsi Riau pada tahun 2001-2012. Data titik panas harian ini merupakan data dari penelitian yang telah dilakukan praproses data oleh Baehaki (2014). Dataset berisi nomor indeks titik panas, tahun dan indeks titik panas, tanggal terjadinya titik panas, dan frekuensi titik panas. Data fisik untuk longitude dan latitude titik panas serta tanggal titik panas diperoleh dari unduh data satelit MODIS milik National Aeronautics and Space Administration (NASA) yang dapat diunduh pada halaman web1.
Tahapan Penelitian
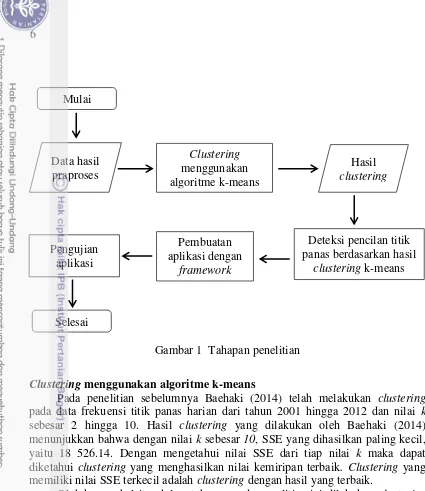
Tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 1.
1
6
Gambar 1 Tahapan penelitian Clustering menggunakan algoritme k-means
Pada penelitian sebelumnya Baehaki (2014) telah melakukan clustering pada data frekuensi titik panas harian dari tahun 2001 hingga 2012 dan nilai k sebesar 2 hingga 10. Hasil clustering yang dilakukan oleh Baehaki (2014) menunjukkan bahwa dengan nilai k sebesar 10, SSE yang dihasilkan paling kecil, yaitu 18 526.14. Dengan mengetahui nilai SSE dari tiap nilai k maka dapat diketahui clustering yang menghasilkan nilai kemiripan terbaik. Clustering yang memiliki nilai SSE terkecil adalah clustering dengan hasil yang terbaik.
Oleh karena hal itu, dalam tahapan pada penelitian ini dilakukan clustering dengan algoritme k-means pada perangkat lunak R. Algoritme k-means tersebut diberikan masukkan berupa data frekuensi titik api harian dari tahun 2001 hingga 2012 juga nilai k sebesar10. Selain melakukan clustering, pada tahapan ini juga dilakukan penghitungan nilai SSE dari nilai k sebesar 10 dengan perangkat lunak R. Penghitungan nilai SSE dilakukan untuk mengetahui clustering dengan nilai kemiripan terbaik.
Deteksi pencilan titik panas berdasarkan hasil clustering K-Means
Setelah dilakukan clustering k-means pada data frekuensi titik panas harian Provinsi Riau tahun 2001 hingga 2012 dengan nilai k sebesar 10 kemudian dilakukan deteksi pencilan data titik panas. Deteksi pencilan global menggunakan clustering k-means dilakukan dengan menghitung nilai outlier score masing-masing data titik panas harian. Pada tahapan ini, pencilan global yang dideteksi sebanyak 30 pencilan, dan 30 pencilan global merupakan pencilan yang memiliki nilai outlier score terbesar.
Mulai
Data hasil praproses
Deteksi pencilan titik panas berdasarkan hasil
clustering k-means Hasil clustering
Pembuatan aplikasi dengan
framework Shiny
Selesai
Clustering menggunakan algoritme k-means
7 Deteksi pencilan kolektif menggunakan clustering k-means dilakukan dengan menentukan persentase minimum jumlah anggota setiap cluster. Pada tahapan ini, persentase minimum jumlah anggota yang digunakan, yaitu 1% sehingga pencilan kolektif merupakan cluster-cluster yang memiliki jumlah anggota kurang dari sama dengan 1%.
Pembuatan aplikasi dengan framework Shiny
Pada tahapan ini, setelah didapatkan hasil deteksi pencilan global dan pencilan kolektif dengan clustering menggunakan algoritme k-means, lalu dibuat aplikasi untuk mendeteksi pencilan data titik panas Provinsi Riau. Aplikasi dibuat di perangkat lunak R dengan menggunakan framework Shiny. Aplikasi yang dibangun dengan menggunakan framework Shiny terdiri atas dua komponen fail, yaitu fail server.r serta fail ui.r.
Fail server.r merupakan kumpulan baris program yang berisi fungsi-fungsi yang digunakan pada apalikasi yang dibangun. Fungsi-fungsi yang terdapat pada fail server.r, antara lain fungsi clustering dengan algoritme k-means, fungsi menghitung nilai SSE, fungsi deteksi pencilan global dan kolektif, fungsi visualiasasi pencilan global dan kolektif pada peta Provinsi Riau dan lain sebagainya. Fail ui.r merupakan kumpulan baris program yang merepresentasikan atribut-atribut pada antar muka yang ditampilkan pada halaman web browser. Atribu-atribut tersebut, yaitu headerPanel, sidebarPanel, mainPanel, navigationPanel, dan sebagainya.
Pengujian Aplikasi
Pada tahapan ini dilakukan pengujian pada aplikasi yang dibangun dengan Shiny. Pengujian dilakukan untuk kelima fungsi utama dalam aplikasi yang dibangun dibandingkan dengan keluaran yang diperoleh dari perangkat lunak R secara manual.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
Perangkat lunak: 1 Sistem operasi Windows 8
2 Bahasa pemrograman R versi 3.1.1 3 RStudio versi 0.98.1062
4 Package Shiny, FPC, Datasets, Rgdal, Ggplot2, dan Maptools 5 Web browser
Perangkat keras:
1 Processor Intel Core i7-3632QM 2.20 GHz 2 RAM 4 GB
8
#membaca data frekuensi titik panas harian data <- read.csv("data/data.kmeansall.csv") set.seed(1000)
#fungsi algoritme K-Means k <- 10
result <- kmeans(data$frek, k) class <- c(1 : k)
size <- result$size
center <- (result$centers[result$cluster]) total_size <- sum(result$size)
persentase <- round (100*(size/total_size), digits = 3) center <- round (result$centers, digits = 3)
hasil <- data.frame(class, size, center, persentase) names(hasil) <- c("Cluster", "Jumlah Anggota", "Center",
"Persentase") #fungsi SSE
distance <- sqrt((data$frek - center)^2) sum_distance <- sum (distance)
percent <- 100*(result$betweenss/result$totss)
sse_result <- data.frame(k, sum_distance, result$tot.withinss, percent)
names(sse_result) <- c("Class", "SSE", "Total Within", "Percent")
HASIL DAN PEMBAHASAN
Clustering Menggunakan Algoritme K-means
Data titik panas Provinsi Riau tahun 2001 hingga 2012 dilakukan clustering menggunakan algoritme k-means dengan nilai k sebesar 10. Hasil clustering pada Tabel 1 dengan nilai k sebesar 10, yaitu bahwa cluster yang memiliki jumlah anggota terbesar adalah cluster 9 dengan jumlah anggota sebanyak 3250 dan center sebesar 1.825 serta cluster yang memiliki anggota terkecil adalah cluster 7 dengan jumlah anggota sebanyak 17 dengan center 713.471. Kode algoritme k-means pada data frekuensi titik panas harian Provinsi Riau tahun 2001 hingga 2012 dengan nilai k sebesar 10 dapat sebagai berikut ini:
Tabel 1 Hasil clustering k-means dengan nilai k sebesar 10 Cluster Jumlah anggota Center Persentase
1 248 47.605 5.658 %
9
#fungsi deteksi pencilan kolektif dengan persentase jumlah anggota cluster kurang dari 1 persen
threshold <- 1
persen_outlier <- persen[x[persen < threshold]] kelas_outlier <- hasil$kelas[x[persen < threshold]]
outlier_kolektif <- data.frame(kelas_outlier, persen_outlier) names(outlier_kolektif) <- c("Kelas", "Persen")
Tabel 2. Diketahui bahwa dengan nilai k sebesar 10, SSE yang dihasilkan, yaitu 498 898.5.
Pada fungsi algoritme k-means di perangkat lunak R, fungsi untuk menghitung nilai SSE sudah tersedia, yaitu dengan memanggil komponen keluaran fungsi k-means tot.withinss yang ditampilkan hasilnya pada Tabel 2 dengan nama total within. Tot.withinss pada fungsi k-means di perangkat lunak R dihitung dengan menggunakan z-score. Kualitas hasil clustering pada Tabel 2 merupakan salah satu keluaran fungsi algoritme k-means pada R. Perhitungan kualitas hasil clustering pada R didapatkan dari membagi betwenss dengan totss. Betweenss dan totss merupakan komponen yang tersedia pada keluaran fungsi k-means pada R.
Tabel 2 Nilai SSE untuk hasil clustering k-means dengan nilai k sebesar 10 Jumlah cluster SSE Total within Kualitas hasil clustering
10 498868.5 498868.5 97.555 %
Deteksi Pencilan Kolektif pada Data Titik Panas Harian
Jumlah anggota setiap cluster merupakan dasar penentuan untuk deteksi pencilan kolektif. Cluster yang memiliki jumlah anggota paling kecil disebut sebagai pencilan kolektif. Kode program bahasa R untuk mendeteksi pencilan kolektif dapat dilihat sebagai berikut:
Setelah kode program tersebut dijalankan didapatkan hasil bahwa cluster yang memiliki jumlah anggota dibawah 1% adalah cluster 7 dengan 17 anggota (0.390%), cluster 5 dengan 19 anggota (0.430%), cluster 10 dengan 23 anggota (0.520%), cluster 8 dengan 38 anggota (0.870%), dan cluster 4 dengan 40 anggota (0.910%), hal tersebut dapat dilihat pada Tabel 4 . Maka berdasarkan pendekatan pencilan kolektif ditetapkan bahwa cluster 7, 5, 10, 8, dan 4 merupakan pencilan kolektif.
Tabel 3 Hasil deteksi pencilan kolektif Cluster Jumlah anggota Persen
4 40 0.910 %
5 19 0.430 %
7 17 0.390 %
8 38 0.870 %
10
Deteksi Pencilan Global pada Data Titik Panas Harian
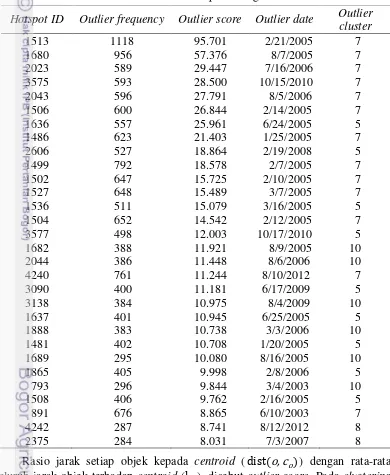
Penentuan pencilan global dilakukan dengan mengambil 30 objek yang memiliki outlier score terbesar. Sebuah objek yang masuk kedalam tiga puluh data yang memiliki outlier score terbesar dikatakan memiliki nilai kesamaan atau kemiripan yang rendah dalam cluster, sehingga objek tersebut dikatakan sebagai pencilan global. 30 objek yang termasuk ke dalam pencilan global dapat dilihat pada Tabel 4.
Tabel 4 Hasil deteksi pencilan global
11
Perintah center <- (result$centers[result$cluster]) berfungsi untuk mencari center atau centroid dari masing-masing cluster. Penghitungan jarak menggunakan fungsi jarak Euclid dengan perintah distance <-
sqrt((data$frek - center)^2), lalu dicari rata-rata dari jarak dengan perintah
mean_distance<-round(mean(distance^2),digits=3). Penghitungan outlier
score dengan perintah outlier_score <- round(distance/mean_distance,
digits = 3).
Pembuatan Aplikasi dengan Framework Shiny
Pada tahap ini dilakukan pembuatan aplikasi berbasis web dengan framework Shiny dan bahasa R untuk mendeteksi pencilan titik panas harian Provinsi Riau tahun 2001 hingga 2012 dengan menggunakan algoritme clustering k-means. Aplikasi Shiny terdiri atas bagian server dan antarmuka yang terdapat dalam satu folder. Bagian server disimpan dalam fail server.r yang berisi instruksi-instruksi yang digunakan pada aplikasi. Potongan program fail server.r dapat dilihat sebagai berikut:
# memilih input data
selectedData <- reactive({switch(input$year,
"2001-2012" = myobj <- read.csv("data.kmeansall.csv",
header=TRUE, sep =",")),
"2001" = myobj <- (read.csv("data.kmeans2001.csv",
header=TRUE, sep =",")),
"2002" = myobj <- (read.csv("data.kmeans2002.csv",
header=TRUE, sep =",")),
"2003" = myobj <- (read.csv("data.kmeans2003.csv",
header=TRUE, sep =",")),
"2004" = myobj <- (read.csv("data.kmeans2004.csv",
header=TRUE, sep =",")),
"2005" = myobj <- (read.csv("data.kmeans2005.csv",
header=TRUE, sep =",")),
"2004" = myobj <- (read.csv("data.kmeans2004.csv",
header=TRUE, sep =",")),
"2005" = myobj <- (read.csv("data.kmeans2005.csv",
header=TRUE, sep =",")),
"2006" = myobj <- (read.csv("data.kmeans2006.csv",
header=TRUE, sep =",")),
"2007" = myobj <- (read.csv("data.kmeans2007.csv",
header=TRUE, sep =",")), #fungsi outlier score
jumlah <- result$size
center <- (result$centers[result$cluster]) distance <- sqrt((data$frek - center)^2)
mean_distance <- round(mean(distance), digits = 3)
outlier_score <- round(distance/mean_distance, digits = 3) (data$no[order(outlier_score, decreasing =T)[1:30]])
outlier_frek <- (data$frek[outlier_index])
(outlier_score[order(outlier_score, decreasing=T)[1:30]]) (result$cluster[order(outlier_score, decreasing = T)[1:30]]) (data$tgl[order(outlier_score, decreasing = T)[1:30]])
data.frame(outlier_index, outlier_frek, outlier_os, outlier_date, outlier_kelas)
12
#menu navigasi bar
navbarPage("",tabPanel("Data",
sidebarLayout(sidebarPanel(width="4",
selectInput("year", "Year of Riau's Hotspot Data :", choices = c("2001-2012","2001","2002",
"2003","2004","2005","2006","2007","2008","2009","2010 ","2011","2012")),
actionButton("submit", "Submit")),
mainPanel(tags$h4(textOutput("text_summary"), align = "center"),dataTableOutput("summary_of_data",
br(),br(),tags$h4(textOutput("text_data_plot"), align = "center"),
plotOutput('data_plot')))))), tabPanel("Clustering",
sidebarPanel(width = "3", selectInput("clusters", "Number
of Cluster:", choices = c(2 : 10), selected = "10"),
actionButton("clustering", "Clustering"),
tags$h5(textOutput("warning_text"), align = "justify", style = "color : red")),
mainPanel(width = "7",
tabsetPanel( …
"2008" = myobj <- (read.csv("data.kmeans2008.csv", header=TRUE, sep =",")),
"2009" = myobj <- (read.csv("data.kmeans2009.csv",
header=TRUE, sep =",")),
"2010" = myobj <- (read.csv("data.kmeans2010.csv",
header=TRUE, sep =",")),
"2011" = myobj <- (read.csv("data.kmeans2011.csv",
header=TRUE, sep =",")),
"2012" = myobj <- (read.csv("data.kmeans2012.csv",
header=TRUE, sep =",")))}) #memilih jumlah cluster
clust <- reactive({
switch(input$clusters,"2" = capt <- 2,"3" = capt <- 3,"4" = capt
<- 4,"5" = capt <- 5,"6" = capt …
Bagian antarmuka disimpan dalam fail ui.r yang berisi instruksi-instruksi untuk menampilkan atribut-atribut antarmuka aplikasi pada halaman web browser. Potongan fail ui.r sebagai berikut:
Pada aplikasi ini, digunakan beberapa library yang dapat dilihat pada Tabel 5. Input dataset pada aplikasi ini adalah fail .csv yang berisi index, tahun dan hari, tanggal, serta frekuensi dari titik panas. Dataset ini dijadikan sebuah objek sebagai global environment dan akan digunakan sebagai input fungsi K-Means.
Tabel 5 Library yang digunakan dalam pembuatan aplikasi Library Fungsi
Fpc Mengimplementasikan algoritme clustering K-Means pada bahasa R Shiny Membuat aplikasi dengan framework Shiny
Datasets Mengimpelentasikan datasets Rgdal Memvisualisasikan hasil clustering Ggplot2 Memvisualisasikan hasil clustering Maptools Memvisualisasikan hasil clustering
13 menggunakan NavbarPage, yaitu merupakan menu-menu yang tersedia dalam aplikasi berupa menu navigasi. Tampilan 5 menu pada aplikasi dapat dilihat pada Gambar 2.
Pengguna dapat memilih dataset mana yang akan digunakan untuk proses clustering pada menu data dengan dropdown button. Dataset tersebut terdiri atas dataset frekuensi titik panas harian Provinsi Riau tahun 2001 hingga 2012. Objek dataset ini dibuat reaktif untuk menanggapi setiap perubahan data permintaan pengguna. Menu data terdiri atas 2 sub-menu, yaitu sub-menu data summary dan sub-menu data plot.
Pada sub-menu data summary, data yang sudah dipilih akan ditampilkan ringkasannya berupa nilai minimum, kuartil pertama, median atau nilai tengah, nilai rata-rata, kuartil ketiga, dan nilai maksimum dari frekuensi. Tampilan sub-menu data summary dapat dilihat pada Gambar 3.
Sedangkan pada sub-menu data plot akan ditampilkan grafik berupa grafik garis yang menunjukkan trend atau penyebaran frekuensi titik panas terhadap indeks hari. Grafik pada sub-menu data plot dibuat reaktif. Reaktif berarti tanggap terhadap perubahan masukan, sehingga plot akan berubah-ubah sesuai masukan data yang dipilih oleh pengguna. Tampilan sub-menu data plot dapat dilihat pada Gambar 4.
Jika pengguna ingin melakukan clustering, maka pengguna harus memilih menu clustering. Fungsi k-means pada aplikasi ini bersifat reaktif, sehingga setiap perubahan nilai input akan menyebabkan pemanggilan ulang fungsi k-means dan menghasilkan cluster baru tanpa perlu memuat ulang halaman browser. Menu clustering terdiri atas 3 sub-menu, yaitu sub-menu clustering summary, sub-menu sum square error, dan sub-menu K-Means plot.
Gambar 2 Menu-menu yang tersedia pada aplikasi yang dibangun
14
Objek cluster, size of cluster, center of cluster dan percent yang merupakan hasil clustering digabungkan untuk membentuk data frame baru yang akan ditampilkan pada sub-menu clustering summary. Instruksi untuk menampilkan data frame baru tersebut adalah fungsi renderDataTable pada fail server.r dan fungsi dataTableOutput pada fail ui.r. Tampilan sub-menu clustering summary dapat dilihat pada Gambar 5.
Objek number of cluster, SSE, Total Withins dan percent yang merupakan hasil clustering digabungkan untuk membentuk data frame baru yang akan ditampilkan pada sub-menu sum square error. Tampilan sub-menu sum square error dapat dilihat pada Gambar 6.
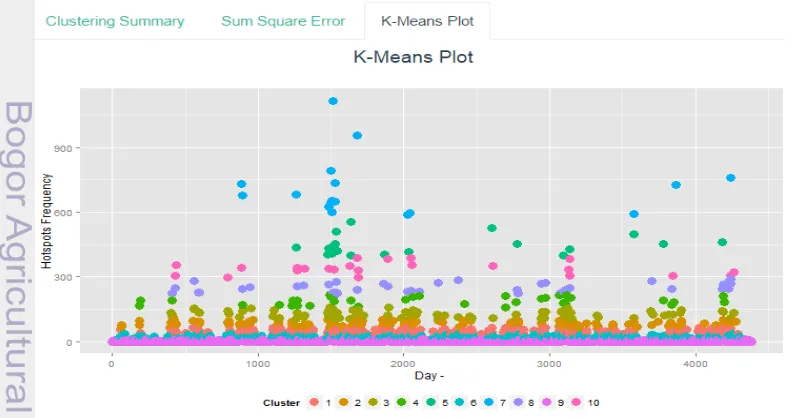
Pada sub-menu K-Means plot akan ditampilkan visualisasi hasil clustering. Untuk memvisualisasikan hasil clustering digunakan library ggplot2. Intruksi yang digunakan untuk menampilkan visualisasi tersebut adalah renderPlot pada fail server.r dan plotOutput pada fail ui.r. Tampilan sub-menu K-Means plot dapat
Gambar 4 Tampilan sub-menu data plot
15
dilihat pada Gambar 7.
Menu outlier detection adalah menu yang berfungsi untuk mendeteksi pencilan. Menu tersebut terdiri atas dua menu, yaitu menu global outlier dan menu collective outlier. Jika pengguna ingin mendeteksi pencilan kolektif, maka pengguna harus memilih menu collective outlier, sedangkan jika ingin mendeteksi pencilan global maka memilih menu global outlier.
Pada menu collective outlier pengguna dapat memilih persentase jumlah anggota minimal pada suatu cluster dengan memasukkan nilai persentasenya pada kolom yang sudah disediakan. Menu collective outlier terdiri atas dua sub-menu, yaitu sub-menu collective outlier summary dan sub-menu collective outlier plot.
Sub-menu collective outlier summary menampilkan hasil deteksi pencilan kolektif secara umum. Hasil deteksi berupa tabel yang terdiri atas objek cluster dan percent. Jika pengguna ingin melihat lebih jelas objek-objek mana saja yang termasuk pencilan kolektif, maka pengguna dapat memilih atau menekan tombol detil information yang tersedia pada mainPanel sub-menu collective outlier summary. Tampilan sub-menu collective outlier summary dapat dilihat pada Gambar 8.
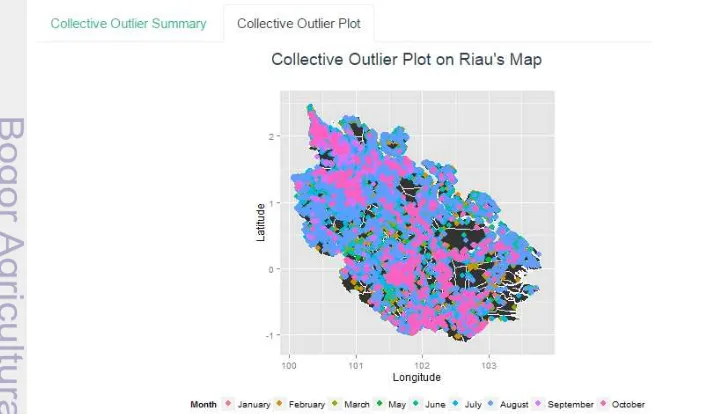
Sub-menu collective outlier plot menampilkan visualisasi hasil deteksi pencilan kolektif. Koordinat lintang dan bujur titik panas yang dideteksi sebagai pencilan kolektif divisualisasikan kedalam peta Provinsi Riau. Pencilan kolektif divisualisasikan berdasarkan bulan adanya titik panas yang dibedakan dengan warna. Tampilan sub-menu collective outlier plot dapat dilihat pada Gambar 9.
Gambar 6 Tampilan menu SSE
16
Pada menu global outlier pengguna dapat memilih jumlah outlier yang diinginkan berdasarkan nilai outlier score terbesar pada kolom yang sudah disediakan. Menu global outlier terdiri atas dua sub-menu, yaitu sub-menu global outlier summary dan sub-menu global outlier plot. Sub-menu global outlier summary menampilkan hasil deteksi pencilan. Hasil deteksi berupa tabel yang terdiri atas objek no, index, frequency, score, date, dan cluster. Tampilan sub-menu global outlier summary dapat dilihat pada Gambar 10.
Sub-menu global outlier plot menampilkan visualisasi hasil deteksi pencilan global. Koordinat lintang dan bujur titik panas yang dideteksi sebagai pencilan global divisualisasikan kedalam peta Provinsi Riau. Koordinat lintang dan bujur disimpan dalam fail dengan format .csv dan peta Provinsi Riau disimpan dalam failnya dengan format shp. Pencilan global divisualisasikan berdasarkan bulan adanya titik panas yang dibedakan dengan warna. Tampilan sub-menu global outlier plot dapat dilihat pada Gambar 11.
Gambar 8 Tampilan sub-menu collective outlier summary
17 Menu help adalah menu yang berisi penjelasan mengenai fungsi-fungsi setiap menu yang terdapat pada aplikasi, sedangkan menu about adalah menu yang berisi penjelasan mengenai aplikasi, tujuan pembuatan aplikasi, serta pembuat aplikasi. Tampilan menu help dapat dilihat pada Gambar 12.
Gambar 10 Tampilan sub-menu global outlier summary
Gambar 11 Tampilan sub-menu global outlier plot
18
Pengujian Aplikasi
Hasil clustering yang dilakukan secara manual dengan perangkat lunak R dan hasil clustering yang dilakukan oleh aplikasi berbasis web menghasilkan hasil yang sama untuk jumlah cluster (k) adalah 10. Contoh untuk perbandingan hasil clustering dengan menggunakan perangkat lunak R dan aplikasi yang dibangun, yaitu pada perangkat lunak R dan aplikasi yang dibangun, cluster 1 memiliki jumlah anggota 248, center 47.605, dan persentase 5.658%. Hasil clustering dengan aplikasi yang dibangun dapat dilihat pada Gambar 13.
Deteksi pencilan kolektif dengan jumlah anggota kurang dari 1% yang dilakukan secara manual dengan perangkat lunak R sesuai dengan deteksi pencilan kolektif oleh aplikasi berbasis web yang dibangun. Cluster yang dideteksi sebagai pencilan adalah cluster 4, 5, 7, 8, dan 10. Hasil deteksi pencilan kolektif pada aplikasi yang dibangun dapat dilihat pada Gambar 14.
Selain itu 30 pencilan global yang dideteksi secara manual dengan R pada juga berhasil dideteksi dengan benar pada aplikasi berbasis web yang dibangun. Pencilan yang dideteksi sebagai pencilan global pada perangkat lunak R dan aplikasi yang dibangun sama-sama dideteksi berdasarkan nilai outlier score terbesar. Hasil deteksi pencilan global dengan aplikasi yang dibangun dapat dilihat pada Gambar 15.
Pengujian fungsi-fungsi utama yang tersedia pada aplikasi, dilakukan dengan menggunakan ujicoba blackbox. Fungsi-fungsi yang akan diujicoba, yaitu clustering dengan algoritme k-means, deteksi pencilan global dan kolektif,
Gambar 13 Hasil clustering dengan aplikasi yang dibangun
19
visualisasi hasil deteksi pencilan, visualisasi hasil clustering, SSE, serta menampilkan menu help dan about. Setelah dilakukan ujicoba blackbox, fungsi-fungsi utama yang tersedia pada aplikasi berjalan sesuai fungsi-fungsinya. Hasil evaluasi pengujian dengan blackbox dapat dilihat pada Tabel 6.
Tabel 6 Evaluasi pengujian
SIMPULAN DAN SARAN
Simpulan
Kesimpulan dari hasil penelitian ini, yaitu objek yang menjadi pencilan adalah objek dengan frekuensi titik panas tertinggi, yaitu berada pada cluster 4, 5, 7, dan 10 berdasarkan pendekatan kolektif sebanyak 59 titik panas serta 30 objek berdasarkan pendekatan global. Aplikasi berbasis web untuk deteksi pencilan titik panas menggunakan algoritme clustering k-means dan framework Shiny menyediakan beberapa fungsi utama, yaitu ringkasan dan plot dari data yang dipilih, clustering data titik panas dengan algoritme k-means, memvisualisasikan hasil clustering dalam bentuk scatter plot dan SSE, serta deteksi pencilan global maupun kolektif dan melihat penyebarannya dengan visualisasi pencilan pada peta Provinsi Riau.
No. Nama fungsi Hasil
1 Data summary Ok
2 Data plot Ok
3 Clustering summary Ok
4 SSE Ok
5 K-means plot Ok
6 Collective outlier summary Ok 7 Collective outlier plot Ok 8 Global outlier summary Ok 9 Global outlier plot Ok
10 Help Ok
11 About Ok
20
Saran
Saran yang dapat dilakukan untuk penelitian selanjutnya agar aplikasi lebih baik, yaitu:
1 Memperbaiki antarmuka aplikasi agar lebih user friendly
2 Data yang digunakan diintegrasikan dengan database server sehingga kapasitas penyimpanan data lebih besar
3 Memperbaiki masukan data agar pengguna dapat memilih data berdasarkan rentang tahunnya.
4 Melakukan kajian tentang antarmuka pengguna untuk aplikasi yang telah dibangun
DAFTAR PUSTAKA
Adinugroho WC, Suryadiputra INN, Saharjo BH, Siboro L. 2005. Panduan Pengendalian Kebakaran Hutan dan Lahan Gambut. Bogor (ID): Wetlands International-Indonesia Programme and Wildlife Habibat Canada.
Baehaki DAM. 2014. Deteksi pencilan data titik api di Provinsi Riau menggunakan algoritme clustering k-means [skripsi]. Bogor (ID): Institut Pertanian Bogor.
[BB SDLP] Balai Besar Penelitian dan Pengembangan Sumberdaya Lahan Pertanian. 2008. Laporan Tahunan 2008, Konsorsium Penelitian dan Pengembangan Perubahan Iklim pada Sektor Pertanian. Bogor (ID): BB SDLP.
Beeley C. 2013. Web Application Development with R Using Shiny. Birmingham (UK): Packt.
[FWI] Forest Watch Indonesia. 2001. Keadaan Hutan Indonesia. Bogor (ID): FWI.
Guswanto, Heriyanto E. 2009. Operational weather system for national fire danger rating. Jurnal Meteorologi dan Geofisika. 10(2): 77-87.
Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques. Ed ke-3. Massachusetts (US): Morgan Kaufmann.
Larose DT. 2005. Discovering Knowledge in Data: An Introduction to Data Mining. New Jersey (US): J Wiley.
Mardhiyyah R. 2014. Clustering dataset titik panas dengan algoritme DBSCAN menggunakan web framework Shiny pada bahasa pemrograman R [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Rowell A, Moore PF. 2010. Global Review of Forest Fires. Gland (CH): IUCN. RStudio. 2014. Package ‘shiny’ [internet]. [diunduh 2014 Des 23]. Tersedia pada:
http://cran.r-project.org/web/packages/shiny/shiny.pdf.
Sizer N, Anderson J, Stolle F, Minnemeyer S, Higgins M, Leach A, Alisjahbana A, Utami A. 2014. Kebakaran hutan di Indonesia mencapai tingkat tertinggi sejak kondisi darurat kabut asap Juni 2013 [internet]. [diunduh 2014 Okt 8]. Tersedia pada: http://www.wri.org/blog/2014/03/kebakaran-hutan-di-indonesia-mencapai-tingkat-tertinggi-sejak-kondisi-darurat-kabut.
21 MODIS di Kalimantan [Model development of burned area identification using MODIS imagery in Kalimantan]. Jurnal Penginderaan Jauh. 10(2): 93-112.
Wanggai F. 2009. Manajemen Hutan. Manokwari (ID): Grasindo.
22
Lampiran 1 Data titik panas harian Provinsi Riau
gid latitude Longitude acq_date
1 2.010000000000000 100.456000000000000 2001-01-07
2 0.155000000000000 101.302000000000000 2001-01-12
3 2.161000000000000 100.809000000000000 2001-01-14
4 1.607000000000000 101.562000000000000 2001-01-14
5 1.606000000000000 101.572000000000000 2001-01-14
6 1.145000000000000 100.580000000000000 2001-01-14
7 0.793000000000000 102.011000000000000 2001-01-14
8 0.060000000000000 101.750000000000000 2001-01-14
9 0.057000000000000 101.723000000000000 2001-01-14
10 -0.206000000000000 101.550000000000000 2001-01-21
11 -0.210000000000000 101.544000000000000 2001-01-21
12 0.799000000000000 102.004000000000000 2001-01-27
13 0.361000000000000 103.263000000000000 2001-02-12
14 0.370000000000000 103.261000000000000 2001-02-12
15 0.369000000000000 103.252000000000000 2001-02-12
16 0.377000000000000 103.239999999999000 2001-02-12
17 0.386000000000000 103.239000000000000 2001-02-12
18 0.402000000000000 103.241000000000000 2001-02-12
19 0.400000000000000 103.230999999999000 2001-02-12
20 -0.827000000000000 101.842000000000000 2001-02-14
21 -0.817000000000000 101.840000000000000 2001-02-14
22 0.556000000000000 101.013000000000000 2001-02-14
23 1.601000000000000 101.565000000000000 2001-02-15
24 0.931000000000000 103.114999999999000 2001-02-15
25 1.577000000000000 101.601000000000000 2001-02-16
26 2.018000000000000 100.453000000000000 2001-02-17
27 1.606000000000000 101.563000000000000 2001-02-17
28 1.605000000000000 101.572000000000000 2001-02-17
29 1.597000000000000 101.565000000000000 2001-02-17
30 1.575000000000000 101.590000000000000 2001-02-17
31 1.573000000000000 101.599000000000000 2001-02-17
32 1.572000000000000 101.608000000000000 2001-02-17
33 1.470000000000000 102.236000000000000 2001-02-17
34 0.794000000000000 102.009000000000000 2001-02-17
35 0.797000000000000 101.927000000000000 2001-02-17
23 Lampiran 2 Perintah dalam R untuk visualisasi clustering
opar <- par(bg = "white")
w <- c(4,5,7,1,1,6,1,1,3,1) #pilihan warna untuk setiap
cluster
warna <- w[hasil$cluster]
p <- c(1,1,1,6,3,1,4,0,1,2) #jenis karakter setiap cluster
point <- p[hasil$cluster]
plot(x=data$frek, pch=hasil$cluster, col=1, cex=0.8, ylab="frekuensi hotspot", xlab="hari ke-")
#plot(x=data$frek, pch=1, col=hasil$cluster+1, cex=0.8, ylab="frekuensi hotspot", xlab="hari ke-")
# plot cluster centers i<-1
for(i in 1:10){
lines(x=c(0,4383), y=c(hasil$centers[i], hasil$centers[i])) }
kelas <- c('1','2','3','4','5','6','7','8','9','10') #text (x=rep(-100,10), y=hasil$centers, labels=kelas) text (x=-100, y=hasil$centers[c(9,1,3)]+5,
lines(x=c(i*365+j,i*365+j), y=c(1000,1118)) }
else{
24 Lampiran 3 Hasil pengujian aplikasi berbasis web untuk deteksi pencilan titik panas menggunakan algoritme clustering K-Means dan
framework Shiny
Deskripsi Prosedur Pengujian Penguji Masukan Hasil yang diharapkan
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih sub-menu data
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih sub-menu data plot
Agisha
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering
5 Memilih sub-menu clustering summary
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering 5 Memilih sub-menu K-Means
25 Lampiran 3 Lanjutan
Deskripsi Prosedur Pengujian Penguji Masukan Hasil yang diharapkan
Hasil
Pengujian Kesimpulan Pengujian
menampilkan SSE
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering
5 Memilih sub-menu Sum square error
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering
5 Memilih jumlah pencilan 6 Menekan tombol detect
7 Memilih menu global outlier summary
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering
5 Memilih jumlah pencilan 6 Menekan tombol detect
26 Lampiran 3 Lanjutan
Deskripsi Prosedur Pengujian Penguji Masukan Hasil yang diharapkan
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering
5 Memasuk-kan nilai minimum anggota
6 Menekan tombol detect
7 Memilih menu collective outlier summary
1 Memilih data yang digunakan 2 Menekan tombol submit
3 Memilih jumlah cluster
4 Menekan tombol clustering
5 Memasuk-kan nilai minimum anggota
6 Menekan tombol detect
7 Memilih menu collective outlier plot
1 Memilih menu help Agisha Mutiara
27
RIWAYAT HIDUP
Penulis dilahirkan di Wonogiri kelurahan Baturetno kecamatan Baturetno Provinsi Jawa Tengah pada tanggal 24 April 1993. Penulis adalah anak pertama dari dua bersaudara, anak dari pasangan Agus Irianto dan Sri Wahyuni.