SKRIPSI
RINI JANNATI 101402072
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PREDIKSI PRODUKSI PANEN KELAPA SAWIT MENGGUNAKAN
JARINGAN SARAF RADIAL BASIS FUNCTION (RBF)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana
Teknologi Informasi
RINI JANNATI
101402072
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
Judul : PREDIKSI PRODUKSI PANEN KELAPA SAWIT
MENGGUNAKAN JARINGAN SARAF RADIAL
BASIS FUNCTION (RBF)
Kategori : SKRIPSI
Nama : RINI JANNATI
Nomor Induk Mahasiswa : 101402072
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dani Gunawan, S.T., M.T. Dr. Erna Budhiarti Nababan, M.IT
NIP. 19820915201212 1 002 NIP. –
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi
Ketua,
Muhammad Anggia Muchtar, S.T., MM.IT
iii
PERNYATAAN
PREDIKSI PRODUKSI PANEN KELAPA SAWIT MENGGUNAKAN JARINGAN
SARAF RADIAL BASIS FUNCTION (RBF)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 10 September 2015
Rini Jannati
UCAPAN TERIMA KASIH
Puji dan syukur penulis ucapkan kepada Allah SWT atas segala rahmat dan
karuniaNya yang telah memberikan kesempatan kepada penulis untuk dapat
menyelesaikan skripsi ini. Skripsi ini merupakan persyaratan untuk mendapatkan gelar
Sarjana Teknologi Informasi, Program Studi (S1) Teknologi Informasi, Fakultas Ilmu
Komputer dan Teknologi Informasi, Universitas Sumatera Utara.
Skripsi ini penulis persembahkan kepada orangtua penulis, Bapak Ir. H. Eka
Asmarahadi Putra dan Ibu Ir. Hj. Herlina yang selalu memberi doa, cinta, kasih
sayang, semangat, perhatian, dan pengorbanan. Semoga Allah SWT selalu
memberikan kebahagiaan kepada keduanya baik di dunia maupun di akhirat kelak.
Terima kasih penulis ucapkan kepada kakak penulis, Erlyani Fachrosi, S.Psi yang
selalu mendukung, menyemangati dan membantu penulis dalam pengerjaan skripsi
ini.
Penulis menyadari bahwa penelitian ini tidak akan terwujud tanpa bantuan dari
banyak pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada
1. Ibu Dr. Erna Budhiarti Nababan, M.IT sebagai dosen pembimbing I dan Bapak
Dani Gunawan, S.T., M.T. sebagai dosen pembimbing II yang selalu memberikan
arahan dalam proses pengerjaan skripsi ini.
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc sebagai dosen penguji I dan Ibu
Sarah Purnamawati, S.T., M.Sc. sebagai dosen penguji II yang telah memberikan
kritik dan saran yang membangun dalam penyempurnaan skripsi ini.
3. Bapak Muhammad Anggia Muchtar, S.T., MM.IT selaku Ketua Program Studi S1
Teknologi Informasi.
4. Bapak Mohammad Fadly Syahputra, B.Sc., M.Sc.IT selaku Sekretaris Program
Studi S1 Teknologi Informasi.
5. Bapak Dedy Arisandi, S.T., M.Kom selaku dosen pembimbing akademik yang
v
6. Teman-teman penulis, Dian Puspitasari Sebayang, Sharfina Faza, Nurul Putri
Ibrahim, Maslimona Harimita Ritonga, Tri Annisa, Amelia Febriani, Nadya, Ovy
Rizki dan Wanda yang telah bersedia menjadi teman diskusi penulis dan
memberikan semangat dalam menyelesaikan skripsi ini.
7. Teman-teman angkatan 2010 Teknologi Informasi dan UKM Fotografi USU
khususnya angkatan V, semoga kita meraih kesuksesan.
8. Seluruh staf pengajar dan staf administrasi Program Studi S1 Teknologi Informasi
dan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera
Utara.
Penulis menyadari bahwa skripsi ini masih terdapat kekurangan. Oleh
karena itu, penulis mengharapkan kritik dan saran yang bersifat membangun
ABSTRAK
Kelapa sawit merupakan komoditas utama dan unggulan di Indonesia. Pada industri
kelapa sawit, hasil produksi kelapa sawit merupakan hal yang terpenting. Hasil
produksi kelapa sawit dalam waktu dan jumlah yang tepat merupakan sesuatu yang
diinginkan oleh perusahaan perkebunan. Oleh karena itu, dibutuhkan prediksi
produksi untuk dijadikan acuan target produksi kelapa sawit. Penentuan target
produksi dibutuhkan suatu metode yang mampu memprediksi hasil produksi kelapa
sawit. Pada penelitian ini dipakai metode jaringan saraf Radial Basis Function. Radial
Basis Function (RBF) merupakan sebuah kernel atau arsitektur jaringan saraf tiruan
yang terdiri dari tiga layer yaitu input, hidden, dan output layer. Pada proses input
layer ke hidden layer digunakan algoritma K-Means dan hiddenlayer ke outputlayer
digunakan algoritma Least Means Square. Hasil prediksi dengan metode RBF
memiliki MAPE sebesar 11.75% dengan kombinasi parameter inputnode = 5, hidden
node = 3, learning rate = 0.75.
vii
THE PREDICTION PRODUCTION PALM OIL USING RADIAL BASIS
FUNCTION NEURAL NETWORK
ABSTRACT
Palm oil is a mayor and superior commodity in Indonesia. In the palm oil industry, the
outcome of palm oil production is the most important. The outcome of palm oil
production in the right time and the right amount is something that is desired by the
industry. According to this, industry needs to be target forecast production palm oil.
Determining target production is required a method to predict the outcome of palm oil
prediction. In this study used the method of Radial Basis Function Neural Network
(RBFNN). RBFNN is a kernel or neural network architecture which consists of three
layer, input, hidden, and output layer. On the input layer to hidden layer used
K-Means Algorithm and hidden layer to output layer is used Least K-Means Square
Algorithm. Prediction result using RBFNN method has MAPE of 11.75% with a
combination of parameters input nodes is 5, hidden nodes is 3, learning rate is 0.75.
DAFTAR ISI
Hal
PERSETUJUAN ii
PERNYATAAN iii
UCAPAN TERIMA KASIH iv
ABSTRAK vi
ABSTRACT vii
DAFTAR ISI viii
DAFTAR TABEL xi
DAFTAR GAMBAR xiii
BAB 1 PENDAHULUAN 1
1.1Latar Belakang 1
1.2Rumusan Masalah 3
1.3Tujuan Penelitian 3
1.4Batasan atau Ruang Lingkup Penelitian 4
1.5Manfaat Penelitian 4
1.6Metodologi Penelitian 4
1.7Sistematika Penulisan 5
BAB 2 LANDASAN TEORI 7
2.1 Produksi Kelapa Sawit 7
ix
2.2.1 Data Cleaning 9
2.2.2 Data Selecting 10
2.2.3 Transformasi Data 10
2.2.4 Peramalan 11
2.3 Jaringan Saraf Tiruan 15
2.3.1 Radial Basis Function 18
2.3.1.1 Tahap Data Pre-processing 20
2.3.1.2 Tahap I: InputLayer ke HiddenLayer 22
2.3.1.3 Tahap II: HiddenLayer ke OutputLayer 24
2.3.2 Menghitung Nilai Error 25
2.4 Penelitian Terdahulu 25
2.4.1 Penelitian Kasus Prediksi Produksi Kelapa Sawit 25
2.4.2 Penelitian Kasus Prediksi dengan Menggunakan RBF 27
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 29
3.1 Metode Penelitian 29
3.2 Dataset yang Digunakan 30
3.3 Cleaning Data 31
3.4 Transformasi Data 32
3.5 Pembagian Data 34
3.6 Prediksi Data 34
3.6.1 Data Pre-processing 35
3.7 Perancangan Antarmuka 44
3.7.1 Rancangan Tampilan Awal 44
3.7.2 Rancangan Tampilan Halaman Transformasi 45
3.7.3 Rancangan Tampilan Halaman Training 46
3.7.4 Rancangan Tampilan Halaman Testing 47
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM 49
4.1 Implementasi Sistem 49
4.1.1 Spesifikasi Hardware dan Software yang Digunakan 49
4.1.2 Implementasi Data 50
4.2 Pengujian Sistem 50
BAB 5 KESIMPULAN DAN SARAN 58
5.1 Kesimpulan 58
5.2 Saran 59
xi
DAFTAR TABEL
Hal
TABEL 2.1. Variabel Data yang digunakan 21
TABEL 2.2. Penelitian Terdahulu 27
TABEL 3.1. Sampel Data Produksi Kelapa Sawit 30
TABEL 3.2. Sampel Data Bernilai 0 pada Data Produksi 31
TABEL 3.3. Sampel Data yang Telah Dibersihkan 32
TABEL 3.4. Sampel Data yang Telah ditransformasi 33
TABEL 3.5. Model Data yang Digunakan jumlah Variabel = 1 36
TABEL 3.6. Nilai-Nilai Parameter 36
TABEL 3.7. Nilai Input untuk n = 1 37
TABEL 3.8. Nilai Awal Center 37
TABEL 3.9. Hasil Jarak Data pada Masing-Masing HiddenNode 39
TABEL 3.10. Nilai Center Setelah Di-update 39
TABEL 3.11. Nilai Fungsi Gaussian pada n = 1 40
TABEL 3.12. Inisialisasi Nilai Awal Weigths 41
TABEL 3.13. Nilai Weight yang Telah Di-update Pada n = 1 42
TABEL 3.14. Nilai Center Akhir 43
TABEL 3.15. Nilai Weight Akhir 43
TABEL 4.2. Hasil Pengujian 55
xiii
DAFTAR GAMBAR
Hal
GAMBAR 2.1. Pola Data Horizontal 14
GAMBAR 2.2. Pola Data Musiman 14
GAMBAR 2.3. Pola Data Siklis 15
GAMBAR 2.4. Pola Data Trend 15
GAMBAR 2.5. Arsitektur Umum Jaringan Saraf Tiruan Multilayer 16
GAMBAR 2.6. Arsitektur Jaringan Saraf Radial Basis Function 19
GAMBAR 2.7. Data Time Series Prediksi Harga Emas Pada Tahap Pelatihan untuk
Mempresentasikan Form Baris Waktu (Timeline) 20
GAMBAR 2.8. Langkah-langkah Proses Pelatihan untuk Input dan Target Vektor
Matriks 21
GAMBAR 2.9. Flowchart Algoritma K-MeansClustering 22
GAMBAR 3.1. Arsitektur Umum dari Proses Penelitian 29
GAMBAR 3.2. Tahap Pelatihan 34
GAMBAR 3.3. Data Time Series untuk Pre-processing Pelatihan 35
GAMBAR 3.4. Langkah 1 untuk n = 1 36
GAMBAR 3.5. Proses Pengujian 43
GAMBAR 3.6. Rancangan Tampilan Awal program 44
GAMBAR 3.8. Rancangan Tampilan Halaman Training 46
GAMBAR 3.9. Rancangan Tampilan Halaman Testing 48
GAMBAR 4.1. Memilih Training File dengan Menggunakan Tombol Browse 51
GAMBAR 4.2. Proses Pengisian Nilai Parameter yang digunakan 52
GAMBAR 4.3. Hasil Pengujian Kinerja Sistem Pada Menu Training 53
GAMBAR 4.4. Memilih Testing File dengan Menggunakan Tombol Browse 55
GAMBAR 4.5. Hasil Pengujian Kinerja Sistem Pada Menu Testing 55
vi
ABSTRAK
Kelapa sawit merupakan komoditas utama dan unggulan di Indonesia. Pada industri
kelapa sawit, hasil produksi kelapa sawit merupakan hal yang terpenting. Hasil
produksi kelapa sawit dalam waktu dan jumlah yang tepat merupakan sesuatu yang
diinginkan oleh perusahaan perkebunan. Oleh karena itu, dibutuhkan prediksi
produksi untuk dijadikan acuan target produksi kelapa sawit. Penentuan target
produksi dibutuhkan suatu metode yang mampu memprediksi hasil produksi kelapa
sawit. Pada penelitian ini dipakai metode jaringan saraf Radial Basis Function. Radial
Basis Function (RBF) merupakan sebuah kernel atau arsitektur jaringan saraf tiruan
yang terdiri dari tiga layer yaitu input, hidden, dan output layer. Pada proses input
layer ke hidden layer digunakan algoritma K-Means dan hiddenlayer ke outputlayer
digunakan algoritma Least Means Square. Hasil prediksi dengan metode RBF
memiliki MAPE sebesar 11.75% dengan kombinasi parameter inputnode = 5, hidden
node = 3, learning rate = 0.75.
THE PREDICTION PRODUCTION PALM OIL USING RADIAL BASIS
FUNCTION NEURAL NETWORK
ABSTRACT
Palm oil is a mayor and superior commodity in Indonesia. In the palm oil industry, the
outcome of palm oil production is the most important. The outcome of palm oil
production in the right time and the right amount is something that is desired by the
industry. According to this, industry needs to be target forecast production palm oil.
Determining target production is required a method to predict the outcome of palm oil
prediction. In this study used the method of Radial Basis Function Neural Network
(RBFNN). RBFNN is a kernel or neural network architecture which consists of three
layer, input, hidden, and output layer. On the input layer to hidden layer used
K-Means Algorithm and hidden layer to output layer is used Least K-Means Square
Algorithm. Prediction result using RBFNN method has MAPE of 11.75% with a
combination of parameters input nodes is 5, hidden nodes is 3, learning rate is 0.75.
BAB 1
PENDAHULUAN
Bab ini akan membahas mengenai latar belakang penelitian, rumusan masalah, tujuan
penelitian, batasan masalah, manfaat penelitian dan sistematika penulisan.
1.1. Latar Belakang
Kelapa sawit merupakan komoditas pertanian utama dan unggulan di Indonesia.
Produksi kelapa sawit cenderung meningkat dari tahun ke tahun sehingga industri
kelapa sawit akan memiliki prospek yang cukup cerah dan menjanjikan. Hasil dari
produksi kelapa sawit selain berupa bahan baku minyak goreng juga berupa bahan
baku oleochemical (Kacaribu, 2013). Industri kelapa sawit harus mempersiapkan
bahan baku tersebut sesuai dengan permintaan pasar untuk memenuhi kebutuhan
tersebut.
Hasil produksi kelapa sawit merupakan hal yang terpenting dalam industri
kelapa sawit. Hasil produksi kelapa sawit dalam waktu dan jumlah yang tepat
merupakan sesuatu yang diinginkan oleh perusahaan perkebunan. Oleh karena itu,
perusahaan perkebunan negara atau swasta membutuhkan prediksi produksi untuk
melakukan perancangan biaya dan juga memenuhi permintaan pasar. Hasil prediksi
produksi tersebut dijadikan acuan target produksi kelapa sawit. Pada perusahaan
kelapa sawit terutama pada perusahaan perseorangan, prediksi produksi kelapa sawit
biasanya mengalami kendala berupa hasil produksi yang tidak mencapai target terlalu
besar. Sehingga diperlukan metode yang tepat untuk menghasilkan prediksi produksi
yang tepat. yang tidak mencapai target terlalu besar, sehingga diperlukan prediksi
Prediksi merupakan suatu usaha untuk meramalkan keadaan di masa
mendatang melalui pengujian keadaan di masa lalu (Rambe, 2002). Upaya untuk
melakukan prediksi produksi kelapa sawit dapat dilakukan dengan bantuan teknologi
informasi. Teknologi basis data dalam perusahaan merupakan kebutuhan pokok. Data
tersebut dapat diolah dengan menggunakan konsep data mining. Data mining
merupakan proses kegiatan yang meliputi pengumpulan, pemakaian data historis
untuk menemukan keteraturan pola atau hubungan dalam set data berukuran besar
(Santosa, 2007). Data mining memiliki sifat prediksi (prediction driven) untuk
menjawab pertanyaan apa dan sesuatu yang bersifat tidak pasti yang digunakan untuk
validasi hipotesis, querying dan pelaporan, analisis multidimensi (dimensional
summary) serta analisis statistik (Hermawati, 2013).
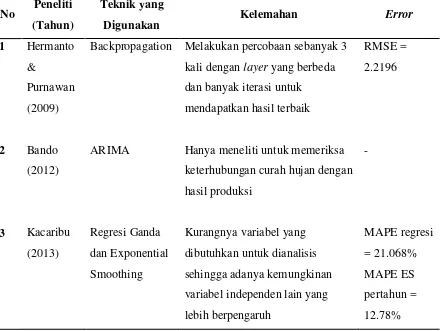
Penelitian Bando (2012) melakukan penelitian mengenai prediksi produksi
kelapa sawit dengan menggunakan metode ARIMA (Autoregressive Integrated
Moving Average) untuk memprediksi curah hujan dan produksi kelapa sawit dalam
jangka waktu yang pendek yang menghasilkan data mengenai hasil peramalan
produksi dalam bentuk grafik dengan indikator curah hujan. Penelitian lain oleh
Hermantoro dan Purnawan (2009) menggunakan metode Artificial Neural Network
(ANN) berdasarkan tujuh data parameter dengan menggunakan kualitas lahan yaitu
curah hujan, ketinggian dari permukaan laut, kelerengan, umur tanaman, batuan,
solium, dan keasaman tanah. Hasil dari penelitian tersebut saat pengujian mendapat
nilai R2=0.8901 dan nilai RMSE = 2.2196 dengan model 7-3-1. Kacaribu (2013) menggunakan metode regresi ganda dan Exponential Smoothing dengan variabel
bebas berupa umur tanaman, jumlah pohon, curah hujan dan dosis pupuk. Penelitian
menghasilkan perbandingan data hasil produksi dengan kedua metode dengan nilai
MAPE regresi ganda = 22% dan keterhubungan variabel dengan hasil produksi.
Jaringan saraf tiruan adalah salah satu cabang ilmu dari bidang ilmu
kecerdasan buatan dan merupakan alat untuk memecahkan masalah terutama
dibidang-bidang yang melibatkan pengelompokan dan pengenalan pola (pattern
recognition) (Puspitaningrum, 2006). Jaringan saraf tiruan cocok digunakan untuk
masalah prediksi. Salah satu jaringan saraf tiruan yang akan diterapkan pada
penelitian ini adalah Radial Basis Function (RBF). RBF berbeda dari pendekatan
3
menggunakan kalkulasi yang lebih mudah sehingga metode ini dapat belajar lebih
cepat dan memiliki error yang lebih kecil dibandingkan MLP (Jayawardena et al,
1997). Jaringan RBF memiliki algoritma pelatihan dengan pembelajaran supervised
(terawasi) dan unsupervised (tidak terawasi) yang dipakai secara bersamaan. Pada
umumnya untuk pembelajaran tidak terawasi menggunakan algoritma K-means,
sedangkan untuk pembelajaran terawasi dapat menggunakan algoritma Least Means
Square (LMS). Algoritma K-means digunakan karena perhitungannya yang sederhana
dan mampu mencari sendiri nilai center yang terbaik bagi data, sedangkan LMS
digunakan untuk mencari nilai weight yang akan digunakan untuk proses pengujian.
Penggunaan metode RBF ini sudah pernah diterapkan dalam beberapa kasus seperti
prediksi harga saham (Tan et al, 2012), prediksi harga emas (Hussein et al, 2011),
pengenalan pola tanda tangan (Jariah et al, 2011), dan klasifikasi genre musik
(Gardhianta, 2013).
Pada penelitian ini, penulis akan memprediksikan produksi panen kelapa
sawit dengan menggunakan jaringan saraf RBF. Pemilihan input dilakukan
berdasarkan atribut yang ada. Output yang akan dihasilkan merupakan prediksi hasil
produksi panen yang dapat digunakan untuk target produksi panen. Dengan pemilihan
algoritma, input dan output yang akan digunakan, diharapkan RBF akan memberikan
hasil prediksi yang dibutuhkan oleh perusahaan.
1.2. Rumusan Masalah
Penentuan target produksi diperlukan untuk memenuhi rencana kerja dan penentuan
biaya produksi pada suatu perusahaan perkebunan. Perusahaan memerlukan prediksi
hasil produksi panen yang tepat untuk dijadikan acuan target produksi panen. Oleh
karena itu, dibutuhkan sebuah aplikasi untuk memprediksi hasil produksi panen
kelapa sawit agar perusahaan lebih mudah menentukan target produksi.
1.3. Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah memprediksi produksi kelapa sawit dengan
1.4. Batasan atau Ruang Lingkup Penelitian
Batasan masalah dibuat untuk mencegah meluasnya pembahasan dan agar lebih
terarah. Batasan-batasan tersebut adalah sebagai berikut.
1. Data yang dianalisis adalah data-data hasil produksi harian kelapa sawit pada
perusahaan perkebunan negara daerah Sumatera Utara pada periode 2010
-2013.
2. Hasil prediksi tidak mempertimbangkan pengaruh-pengaruh lain seperti
faktor alam selain dari atribut input yang digunakan.
3. Hasil prediksi tidak mempertimbangkan kejadian pencurian dan pertimbangan
yang menyebabkan kehilangan produksi secara disengaja ataupun tidak.
4. Hanya melakukan perbandingan hasil prediksi dan menguji performa metode
yang dipakai.
1.5. Manfaat Penelitian
Manfaat penelitian ini adalah sebagai berikut.
1. Mengidentifikasi dan mengimplementasika data dengan jaringan saraf RBF.
2. Mengetahui kemampuan jaringan saraf RBF dalam memprediksi produksi
panen kelapa sawit.
3. Menghasilkan prediksi hasil produksi panen kelapa sawit.
4. Penelitian dapat dijadikan sebagai bahan rujukan untuk penelitian lain.
1.6. Metodologi Penelitian
Tahapan-tahapan yang akan dilakukan pada pelaksanaan penelitian ini adalah sebagai
berikut.
1. Studi literatur
Studi literatur yang dilakukan dalam penelitian ini adalah mengumpulkan bahan
bahan referensi tentang prediksi produksi kelapa sawit, faktor yang mempengaruhi
dan jaringan saraf tiruan serta bahan pembelajaran pendukung dari banyak sumber
5
2. Analisis permasalahan
Pada tahap ini dilakukan analisis dari bahan referensi yang telah dikumpulkan,
untuk memahami teknik prediksi data mining, faktor-faktor produksi dan jaringan
saraf tiruan dalam penelitian ini.
3. Pengumpulan data
Pada tahap ini dilakukan pengumpulan serta pembagian data yang telah didapat.
Pembagian data dikelompokkan menjadi data latih dan data uji.
4. Pembangunan program
Pada tahap ini dibangun program dengan mengimplementasikan jaringan saraf
RBF untuk memprediksi hasil produksi panen kelapa sawit dari data yang telah
dikumpulkan.
5. Analisis dan evaluasi hasil
Pada tahap ini dilakukan analisis dan evaluasi terhadap hasil yang didapat melalui
implementasi jaringan saraf Radial Basis Function dengan menghitung hasil error
antara nilai aktual dan nilai hasil prediksi.
6. Dokumentasi dan pelaporan
Pada tahap ini dilakukan dokumentasi dan penyusunan laporan hasil evaluasi dan
analisis serta implementasi jaringan saraf Radial Basis Function pada aplikasi
prediksi produksi kelapa sawit.
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri atas lima bagian utama sebagai berikut:
Bab I : Pendahuluan
Bab ini berisi latar belakang dari penelitian, rumusan masalah, tujuan penelitian,
batasan masalah, manfaat penelitian, metodologi penelitian serta sistematika
penulisan.
Bab II : Landasan Teori
Bab ini berisi teori yang diperlukan untuk memahami permasalahan yang dibahas
prediksi, jaringan saraf tiruan dan materi pendukung yang lainnya akan dibahas dalam
bab ini.
Bab III : Analisis dan Perancangan
Bab ini membahas analisis dan penerapan metode jaringan saraf Radial Basis
Function untuk memprediksi produksi kelapa sawit. Pada bab ini juga akan dijabarkan
arsitektur umum, proses yang akan dilakukan termasuk perancangan aplikasi prediksi.
Bab IV : Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari analisis dan perancangan yang
disusun pada Bab III. Selain itu akan dijabarkan hasil implementasi yang didapatkan.
Bab V : Kesimpulan dan Saran
Bab ini berisi kesimpulan dari rancangan yang telah dibahas pada bab-bab
sebelumnya terutama pada bab III dan bab IV. Bagian akhir dari bab ini akan berisi
BAB 2
LANDASAN TEORI
Bab ini akan membahas tentang teori-teori pendukung dan penelitian sebelumnya
yang berhubungan dengan prediksi produksi kelapa sawit dan penerapan jaringan
saraf Radial Basis Function (RBF).
2.1. Produksi Kelapa Sawit
Kelapa sawit terdiri daripada dua spesies Arecaceae atau famili palma yang digunakan
untuk pertanian komersil dalam pengeluaran minyak kelapa sawit. Pohon Kelapa
Sawit Afrika, Elaeis guineensis, berasal dari Afrika barat di antara Angola dan
Gambia, manakala pohon kelapa sawit Amerika, Elaeis oleifera, berasal dari Amerika
Tengah dan Amerika Selatan.
Bagian yang paling utama pada industry kelapa sawit adalah buah dari kelapa
sawit. Bagian daging buah menghasilkan minyak kelapa sawit mentah yang diolah
menjadi bahan baku minyak goreng. Untuk memenuhi permintaan minyak kelapa
sawit diperlukan produksi kelapa sawit pada industri kelapa sawit.
Produksi minyak kelapa sawit merupakan hasil panen buah kelapa sawit dari
suatu area perkebunan kelapa sawit. Produksi kelapa sawit merupakan sumber
penghasilan utama dalam perusahaan. Perlu adanya penyusunan biaya produksi untuk
mendapatkan produksi kelapa sawit yang tinggi. Hal ini dikarenakan jika produksi
kelapa sawit tinggi maka keuntungan perusahaan dari penjualan hasil produksi akan
meningkat. Penyusunan biaya produksi perusahaan memerlukan peramalan produksi
kelapa sawit sebagai target produksi agar anggaran yang dikeluarkan oleh perusahaan
menjadi optimal karena pengeluaran perusahaan disesuaikan berdasarkan
Beberapa faktor yang mempengaruhi produksi kelapa sawit menurut Septianita
(2009) yaitu luas produksi, tenaga kerja, bibit, pupuk urea dan herbisida. Dari
penelitian tersebut diketahui bahwa luas produksi berpengaruh secara signifikan
terhadap produksi terlihat bahwa tingkat penggunaan lahan pada usaha tani kelapa
sawit menunjukkan adanya penambahan faktor tersebut terhadap peningkatan faktor
produksi. Faktor lain seperti tenaga kerja juga berpengaruh terhadap produksi namun
tidak signifikan karena faktor produksi sudah maksimal jika ditambah satu persen
maka hanya akan menurunkan tingkat produksi.
2.2. Data Mining
Data mining merupakan proses kegiatan yang meliputi pengumpulan, pemakaian data
historis untuk menemukan keteraturan pola atau hubungan dalam set data berukuran
besar. Pengenalan pola merupakan bagian dari data mining. Pengenalan pola
melakukan pengelompokkan objek ke berbagai kelas dan dari data tersebut dapat
diketahui kecendrungan pola. Pengenalan pola mengacu kepada kasus klasifikasi dan
regresi (Santosa, 2007).
Tugas utama dari data mining dibagi menjadi dua yaitu descriptive dan
predictive. Descriptive merupakan kemampuan untuk mengidentifikasi keunikan data,
pola, trend, hubungan dan anomaly pada data. Descriptive dibagi menjadi asosiasi,
segmentasi dan clustering. Predictive merupakan pengembangan model dari beberapa
fenomena yang memungkinkan dilakukan estimasi nilai dan prediksi untuk masa
depan. Predictive dibagi menjadi klasifikasi dan regresi. Regresi termasuk kepada
estimasi dan peramalan atau prediksi (Myatt & Johnson, 2009).
Atribut dibutuhkan untuk proses data mining. Atribut disebut sebagai variabel
dan ada juga yang menyebutnya dengan fitur. Variabel-variabel yang akan digunakan,
akan dikelompokkan menjadi input dan output. Format data akan dinyatakan dalam
bentuk matrik dimana baris menyatakan objek atau observasi dan kolom dinyatakan
variabel (Santosa, 2007).
Metode dalam data mining untuk memproses data-data yang ada dibagi
menjadi dua pendekatan yaitu supervised dan unsupervised. Supervised learning
9
dan pengujian. Unsupervised learning merupakan pembelajaran yang tidak terawasi
sehingga metode yang diterapkan tanpa ada proses pelatihan.
2.2.1 Data Cleaning
Menurut Myatt dan Johnson (2009) sebelum memproses data diperlukan cleaning
data pada data tabel untuk mengidentifikasi data. Tujuannya adalah untuk
menghindari data error, tidak ada entri data dan data yang hilang. Nilai pada data
sering hilang pada tabel data, tetapi pendekatan data mining tidak dapat diproses
sampai kasus ini diselesaikan. Ada lima pilihan untuk melakukan cleaning data yaitu
menghapus data yang memiliki nilai kosong pada tabel data, menghapus variabel yang
memiliki data kosong pada tabel data, mengganti nilai data dengan nilai komputasi,
mengganti nilai data dengan nilai secara prediksi pada model yang umum
menggunakan field yang lain pada data tabel.
Situasi yang sama jika terjadi hilang data ketika variabel yang dimaksudkan
diperlakukan sebagai variabel angka berisi nilai teks, atau angka spesifik yang
memiliki arti khusus. Teks atau angka spesifik kemungkinan akan dijadikan nilai
angka untuk menggantikan teks dan angka spesifik. Masalah lain muncul ketika nilai
dengan data tabel salah. Nilai mungkin menjadi salah sebagai hasil dari data entri
yang error. Keluaran pada data mungkin error dan dapat ditemukan menggunakan
metode yang berbeda berdasarkan variabel, sebagai contohnya menghitung nilai score
a-z untuk nilai masing-masing yang merepresentasikan nilai standar deviasi dari nilai
mean.
Ploting data menggunakan box plot atau frekuensi histogram dapat
mengidentifikasi nilai data yang signifikan dari nilai mean. Variabel noise yang berisi
sudut error digantikan variabel dengan versi biner yang lebih merepresentasikan
secara akurat variasi data yang mungkin dibutuhkan, proses ini disebut data
smoothing. Metode yang lainnya, seperti visualisasi data, clustering, dan model
regresi dapat juga digunakan untuk mengidentifikasi anomali data yang terlihat tidak
sama dengan data lainnya atau yang tidak cocok dengan data trend untuk data
2.2.2 Data Selecting
Data selecting dilakukan untuk memilih variabel data yang akan digunakan dan
membagi data menjadi data latih dan data uji. Menurut Kaastra dan Boyd (1996) ada
dua tipe pemilihan variabel yaitu teknikal input dan fundamental input. Teknikal input
adalah penetapan nilai variabel yang berpengaruh atau indikator perhitungan dari nilai
yang lalu, sedangkan fundamental input adalah penetapan variabel ekonomis yang
dipercaya mempengaruhi variabel output dan mungkin membantu peningkatan
prediksi.
Pembagian data dalam data mining menurut Kaastra dan Boyd (1996) dibagi
menjadi tiga yaitu
a. Training data (data latih)
Data latih terdiri dari data set yang banyak. Biasanya digunakan oleh jaringan
saraf untuk melakukan pengenalan pola.
b. Testing data (data uji)
Data uji berjumlah 10-30% data dari training set. Data Uji digunakan untuk
mengevaluasi kemampuan jaringan saraf setelah dilatih.
c. Validation data (data validasi)
Data validasi digunakan untuk pengecekan akhir kemampuan jaringan saraf
yang telah dilatih.
2.2.3 Tranformasi Data
Transformasi data dibutuhkan untuk membuat variabel baru dari kolom data yang
sudah ada untuk merefleksikan lebih dekat tujuan dari projek atau pendekatan kualitas
prediksi. Sebuah data ditransformasi agar dapat digunakan untuk beberapa analisis
teknik terutama pada bidang analisis data. Transformasi data digunakan untuk
mengatur nilai yang diukur pada suatu skala menjadi nilai yang lebih kecil sehingga
seluruh atribut data memiliki jangkauan yang lebih kecil dalam jangkauan nilai 0
sampai 1 (Siang, 2012).
Ada beberapa rumusan transformasi data yang dapat digunakan menurut Siang
11
1. Transformasi polinomial
′ = ln (2.1)
Dengan,
′ = nilai data setelah transformasi polynomial
= nilai data pada data aktual
2. Transformasi normal
′= 0−
��− (2.2)
Dengan,
′ = nilai data setelah transformasi normal
= nilai data pada data aktual
= nilai minimum pada data aktual
= nilai maksimum pada data aktual
3. Transformasi linear
Transformasi nilai data pada interval [0.1,0.9]
′ = . −
− + . (2.3)
Dengan,
′ = nilai data setelah transformasi linear
= nilai data pada data aktual
= nilai minimum data aktual
= nilai maksimum data aktual
2.2.4 Peramalan
Peramalan adalah suatu kegiatan bisnis yang memperkirakan penjualan, penggunaan
suatu produk sehingga produk tersebut dapat dibuat dalam kuantitas yang tepat
(Gaspersz, 2010). Dugaan terhadap permintaan yang akan datang berdasarkan pada
Menurut Gaspersz (2010), langkah-langkah yang harus dilakukan dalam
menjamin efisiensi untuk melakukan peramalan. Langkah-langkah tersebut adalah
sebagai berikut.
1. Menentukan tujuan peramalan
2. Memilih item yang akan diramalkan
3. Menentukan rentang waktu peramalan
4. Memilih model peramalan
5. Mengumpulkan dan menganalisis data
6. Validasi model peramalan
7. Membuat peramalan
8. Implementasi hasil peramalan
9. Memantau keandalan hasil peramalan
Peramalan dilakukan berdasarkan jangka waktu yang diperlukan. Peramalan
ini dilakukan untuk mengambil keputusan sehingga peramalan ini menghasilkan suatu
kemungkinan keadaan yang akan terjadi. Berdasarkan horison waktu, peramalan
dapat dikelompokkan dalam tiga bagian (Herjanto, 2006), yaitu:
1. Peramalan jangka pendek, jangka waktu kurang dari tiga bulan.
Misalnya, peramalan yang berhubungan dengan perencanaan pembelian
material, penjadwalan kerja dan penugasan karyawan.
2. Peramalan jangka menengah, mencakup waktu antara 3 bulan sampai 18
bulan. Misalnya, peramalan perencanaan penjualan, perencanaan produksi
dan perencanaan tenaga kerja tidak tetap.
3. Peramalan jangka panjang, mencakup waktu yang lebih besar dari 18
bulan. Misalnya peramalan yang diperlukan dalam kaitannya dengan
penanaman modal, perencanaan fasilitas dan perencanaan kegiatan litbang.
Pengumpulan data yang relevan berupa informasi yang dapat menghasilkan
peramalan yang akurat. Pemilihan teknik peramalan yang tepat akan memanfaatkan
informasi data yang diperoleh secara maksimal. Menurut Jumingan (2009) teknik
13
1. Teknik peramalan kualitatif
Teknik kualitatif merupakan teknik peramalan yang bersifat subjektif
berdasarkan pendapat dari suatu pihak atau berdasarkan hasil penelitian
questioner yang telah dilakukan. Data pada teknik ini tidak dapat
direpresentasikan secara tegas ke dalam suatu angka atau nilai.
2. Teknik peramalan kuantitatif
Teknik kuantitatif merupakan teknik peramalan berdasarkan data masa lalu
atau data historis dan dapat dibuat dalam bentuk angka.
Dalam peramalan dikenal istilah prediksi. Prediksi merupakan suatu usaha
untuk meramalkan keadaan di masa mendatang melalui pengujian keadaan di masa
lalu (Rambe, 2002). Data historis diolah secara sistematik dan digabungkan dengan
suatu metode tertentu akan memperoleh prediksi keadaan pada masa datang. Prediksi
ini menggunakan data kuantitatif sebagai pelengkap informasi melakukan peramalan
(Herjanto, 2006). Peramalan menurut Heizer (2005) dapat dikelompokkan
berdasarkan sumber peramalannya sebagai berikut.
1. Model data time series atau runtun waktu
Model data time series merupakan suatu jenis peramalan secara
kuantitatif. Model ini sering disebut model kuantitatif intrinsik.
Tujuannya adalah menemukan pola dalam deret data historis dan
mengekstrapolasikan pola dalam deret data tersebut ke pola data masa
depan.
2. Model data causal
Model data causal merupakan suatu jenis peralaman yang
menggunakan hubungan sebab-akibat sebagai asumsi dari apa yang
terjadi di masa lalu akan terulang kembali. Model ini disebut dengan
peramalan kuantitatif ekstrasik, sesuai digunakan untuk pengambilan
keputusan dan kebijakan.
3. Model data judgemental
Model data judgemental merupakan suatu jenis peramalan yang
mencakup untuk memasukkan faktor-faktor kualitatif atau subjektif ke
Model data time series dan causal digunakan sebagai metode peramalan
kuantitatif. Pada umumnya metode peramalan causal meliputi faktor-faktor yang
berhubungan dengan variabel yang diprediksi seperti analisi regresi sedangkan metode
peramalan time series menggunakan data masa lalu yang telah dikumpulkan untuk
dianalisis secara teratur dengan menggunakan teknik yang tepat (Sani, 2013).
Hasilnya dapat dijadikan acuan untuk peramalan nilai di masa yang akan datang.
Peramalan harus mendasarkan analisisnya pada pola data yang ada. Empat pola data
yang lazim ditemui dalam peramalannya adalah sebagai berikut (Aryanto, 2012).
1. Pola data horizontal
Pola ini terjadi bila data berfluktuasi di sekitar rata-ratanya. Produk yang
penjualannya tidak meningkat atau menurun selama waktu tertentu
termasuk jenis ini. Struktur datanya dapat digambarkan sebagai berikut ini.
Gambar 2.1 Pola Data Horizontal
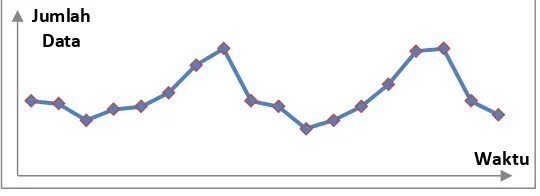
2. Pola data musiman
Pola musiman terjadi bila nilai data dipengaruhi oleh faktor musiman
(misalnya kuartal tahun tertentu, bulanan atau hari-hari pada minggu
tertentu). Struktur datanya dapat digambarkan sebagai berikut ini.
Gambar 2.2 Pola Data Musiman Jumlah
Data
Waktu
Jumlah Data
15
3. Pola data siklis
Pola ini terjadi bila data dipengaruhi oleh fluktuasi ekonomi jangka
panjang seperti yang berhubungan dengan siklus bisnis. Struktur datanya
dapat digambarkan sebagai berikut.
Gambar 2.3 Pola Data Siklis
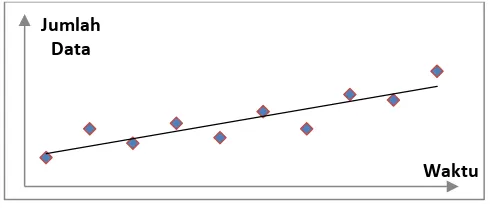
4. Pola data trend
Pola trend terjadi bila ada kenaikan atau penurunan sekuler jangka panjang
dalam data. Struktur datanya dapat digambarkan sebagai berikut.
Gambar 2.4 Pola Data Trend
2.3. Jaringan Saraf Tiruan
Jaringan saraf tiruan (Artificial Neural Network) adalah pemrosesan suatu informasi
yang terinspirasi oleh sistem jaringan saraf biologis (Smith, 2003). Jaringan saraf
tiruan juga merupakan cabang ilmu kecerdasan buatan dan alat untuk memecahkan
masalah terutama di bidang-bidang yang melibatkan pengelompokan data yang
memiliki kecendrungan untuk menyimpan pengetahuan yang bersifat pengalaman dan
membuatnya untuk siap digunakan (Sutojo et al, 2011).
Jumlah Data
Waktu
Jumlah Data
Jaringan saraf tiruan disusun dengan asumsi yang sama dengan jaringan saraf
biologis karena pengolahan informasi terjadi pada elemen-elemen pemrosesan
(neuron-neuron), sinyal antara dua buah neuron diteruskan melalui link koneksi,
setiap link koneksi memiliki weight yang terasosiasi, dan setiap neuron menerapkan
sebuah fungsi aktifasi terhadap input jaringan dengan tujuan agar dapat menentukan
sinyal output (Puspitaningrum, 2006).
Input Layer Middle Layer Output Layer
Input
Gambar 2.5 Arsitektur Umum Jaringan Saraf Tiruan Multilayer
Cara belajar jaringan saraf tiruan dilakukan seperti berikut ini.
1. Pada jaringan saraf tiruan, node atau unit-unit input di-input kan informasi
yang sebelumnya telah diketahui hasil keluarannya.
2. Weights antar koneksi dalam suatu arsitektur diberi nilai awal dan kemudian
jaringan tersebut dijalankan. Weights ini digunakan untuk belajar dan
mengingat suatu informasi.
3. Pengaturan weights dilakukan secara terus-menerus dan menggunakan kriteria
tertentu sampai diperoleh keluaran yang diharapkan.
Tujuan jaringan saraf tiruan dilatih adalah untuk mencapai keseimbangan
antara memorisasi dan generalisasi. Kemampuan memorisasi dilakukan untuk
memanggil kembali secara sempurna pola yang telah dipelajari. Kemampuan
generalisasi dilakukan untuk menghasilkan respons yang bisa diterima terhadap
pola-pola input yang serupa dengan pola-pola sebelumnya yang telah dipelajari. Sehingga,
jaringan saraf tiruan akan tetap memberikan tanggapan yaing baik berupa keluaran
17
Pada pembelajaran jaringan saraf tiruan, terdapat dua kelompok pembelajaran
yaitu sebagai berikut.
1. Jaringan saraf tiruan umpan maju (feed-forward networks), merupakan graf
yang tidak mempunyai loop dan bergerak maju. Contoh jaringan umpan
maju adalah single-layer perceptron, multilayer perceptron dan radial
basis fuction.
2. Jaringan saraf tiruan umpan balik (recurrent-feedback networks),
merupakan graf yang memiliki loop koneksi balik. Contoh jaringan ini
adalah competitive networks, kohonen’s SOM, hopfield network, dan ART
model.
Pada feed-forward networks, diterapkan fungsi aktivasi kedalam weight dan
input dilakukan perhitungan yang hasilnya dianggap sebagai sinyal berbobot yang
diteruskan kelapisan di atasnya. Sinyal yang berbobot tersebut menjadi input bagi
lapisan selanjutnya. Fungsi aktivasi diterapkan pada lapisan tersebut untuk
menghitung output jaringan. Proses ini dilakukan terus menerus sampai kondisi
berhenti terpenuhi.
Kelebihan-kelebihan yang diberikan oleh jaringan saraf tiruan adalah sebagai
berikut (Sutojo et al, 2011).
1. Belajar Adaptive yang merupakan kemampuan untuk mempelajari
bagaimana melakukan pekerjaan berdasarkan data yang diberikan untuk
pelatihan dan pengalaman awal.
2. Self-Organisation yang merupakan sebuah jaringan saraf tiruan dapat
membuat representasi sendiri dari informasi yang diterimanya selama
proses pembelajaran.
3. Real Time Operation yang merupakan perhitungan jaringan saraf tiruan
dapat dilakukan secara parallel sehingga perangkat keras yang dirancang
dan diproduksi secara khusus agar dapat mengambil keuntungan dan
kemampuan ini.
Kelemahan-kelemahan jaringan saraf tiruan adalah sebagai berikut (Kasabov,
1) Kesulitan memilih arsitektur dari system karena jaringan saraf tiruan
memiliki arsitektur yang tetap dengan jumlah neuron serta koneksi yang
tetap sehingga akan sulit untuk beradaptasi dengan informasi yang baru.
2) Dalam mempelajari data baru, jaringan akan cenderung melupakan
pengetahuan yang lama.
3) Pelatihan pada jaringan akan memerlukan banyak iterasi serta propagasi
data melalui struktur jaringan sehingga perlu waktu yang lama.
4) Kurangnya fasilitas representasi pengetahuan pada jaringan.
2.3.1Radial Basis Function
Radial basis function (RBF) merupakan sebuah fungsi yang dinyatakan dengan nilai
yang bergantung pada jarak antar argumen atau jarak antara nilai center (Lukaszyk,
2004). Sama seperti multilayer perceptron (MLP) yang memiliki lapisan hidden
dengan fungsi sigmoid yang dapat belajar dengan fungsi perkiraan, jaringan RBF
menggunakan pendekatan yang sedikit berbeda. Menurut Bullinaria (2004) fitur utama
RBF adalah sebagai berikut.
1. Terdapat dua layer yang bersifat feed-forward
2. Hidden node mengimplementasikan bagian RBF berupa fungsi Gaussian
3. Output node mengimplementasikan fungsi linear yang sama seperti MLP
4. Jaringan untuk pengujian dibagi menjadi dua bagian, yang pertama weight dari
input ke hidden dan kemudian weight dari hidden ke output
5. Pengujian atau pembelajaran sangat cepat.
6. Interpolasi jaringan sangat baik
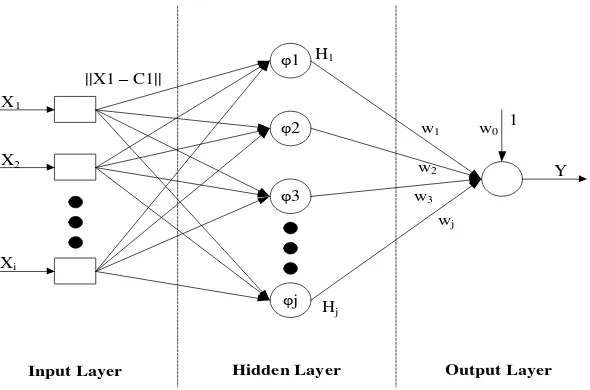
Struktur jaringan RBF terdiri dari tiga layer yaitu input layer, hidden layer, dan
output layer. Pada input layer terdiri dari source node (unit sensor) yang
menghubungkan jaringan dengan lingkungannya. Pada layer kedua yang biasa disebut
dengan hidden layer mengaplikasikan sebuah transformasi nonlinear dari input ke
hidden, sehingga dibutuhkan sebuah metode unsupervised learning untuk
mengaplikasikannya. Pada output layer berupa linear sehingga pada layer ini
dibutuhkan metode supervised learning untuk prosesnya. Struktur jaringan RBF dapat
19
φ1
φ2
φ3
φj
Input Layer Hidden Layer Output Layer X1
Gambar 2.6 Arsitektur Jaringan Radial Basis Function (Haykin, 2009)
Pada jaringan RBF, hidden layer menggunakan biasanya fungsi Gaussian
sebagai radial basis function. Fungsi Gaussian dinyatakan dengan,
� = exp {−||� −� ||�2 2} (2.4)
dimana φj adalah fungsi Gaussiandan σ adalah standar deviasi dari fungsi Gaussian
ke j dengan nilai center (Cj). Fungsi σ dinyatakan dengan (Zhang & Li, 2012),
σ = ��
√ (2.5)
dimana dmax merupakan nilai jarak atau distance terbesar pada hidden j dan Cj merupaka nilai center pada hidden j.
Metode unsupervised learning yang digunakan untuk jaringan RBF biasanya
adalah pendekatan K-Means. Pembelajaran dengan metode tersebut dilakukan untuk
menentukan nilai center dan standar deviasi dari variabel input pada setiap node di
hidden layer. Setelah mendapatkan nilai pada hidden node tahap selanjutnya hidden
layer ke output layer yang menggunakan metode supervised learning dengan
pembelajaran yang sama dengan MLP. Pada training set, elemen-elemennya terdiri
dari unsur nilai variabel independen (input) dan variabel dependen (output). Sebagai
contoh, hubungan variabel independen dengan fungsi aktivasi adalah sebagai berikut.
dengan nilai x merupakan nilai vektor dan nilai y merupakan nilai skalar, dan nilai y
bergantung kepada fungsi f dengan komposisi nilai x adalah sebagai berikut(Orr,
1996).
=
[ . . .
]
(2.7)
2.3.1.1Tahap Data Pre-processing
Menurut Kaastra dan Boyd (1996) data pre-processing merupakan proses
menganalisis dan mentransformasikan variabel input dan output untuk membantu
jaringan mempelajari pola data. Data pre-processing dilakukan untuk:
a. Meminimalisasikan data noise
b. Menyoroti hubungan yang penting
c. Mendeteksi tren
d. Meratakan distribusi variabel
Pada tahap pelatihan, data dikumpulkan untuk melakukan proses pelatihan.
Data-data tersebut dirakit sebagai pra-proses time series data. Pada penelitian Hussein
et al (2011), data tersebut direpresentasikan seperti Gambar 2.7.
Gambar 2.7 Data Time Series Prediksi Harga Emas Pada Tahap Pelatihanuntuk Merepresentasikan Form Baris Waktu (Timeline)
Hussein et al (2011) melakukan prediksi harga emas hari esok dengan
menggunakan harga emas hari kemarin dan hari ini. Sehingga harga emas hari esok
adalah output dan harga emas hari kemarin dan hari ini merupakan input. Misalkan
input yang digunakan adalah 2 node dan menghasilkan 1 output. Penjelasan
21
Tabel 2.1 Variabel Data yang digunakan
Harga Penjelasan Variabel
Harga kemarin Harga (n) dengan n = 1,2,3….
Harga hari ini Harga (n+1) dengan n = 1,2,3….
Harga esok hari Harga (n+2) dengan n = 1,2,3….
Dan tahapan prediksi harga emas dapat dilihat pada Gambar 2.8
Pada gambar 2.11, vector matriks input terdiri dari baris dan kolom. Pada baris
input, data yang ditunjukkan merupakan data yang digunakan untuk mencari nilai
prediksi sedangkan untuk kolom (sama seperti pada vector matriksoutput) merupakan
data yang akan digunakan untuk proses jaringan selanjutnya.
2.3.1.2Tahap I: Input Layer ke Hidden Layer
Dalam mendesain jaringan RBF, dibutuhkan suatu metode untuk menghitung nilai
parameter dari unit Gaussian yang diperlukan di hidden layer dengan data yang tidak
berlabel. Oleh karena itu diperlukan sebuah metode unsupervised learning yang
berupa metode K-Means. Metode K-Means merupakan salah satu bentuk metode
pemetaan pada dirinya sendiri (Self Organizing Map) yang juga dikembangkan dalam
permodelan NN.
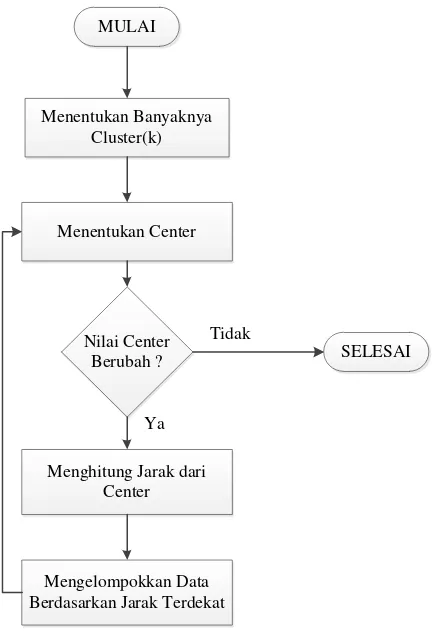
Tahapan algoritma K-means clustering dapat dilakukan seperti yang di
Gambar 2.9.
MULAI
Menentukan Banyaknya Cluster(k)
Menentukan Center
Nilai Center Berubah ?
Menghitung Jarak dari Center
Mengelompokkan Data Berdasarkan Jarak Terdekat
SELESAI
Ya
Tidak
23
Pertama kali yang dilakukan dalam algoritma K-means clustering adalah
menentukan kelompok atau cluster dengan syarat jumlah kelompok yang akan dibuat
harus lebih kecil dengan jumlah data yang digunakan, kelompok pada jaringan radial
basis function yang dimaksud adalah jumlah hidden yang akan digunakan.
Kedua, menentukan nilai center secara acak.
Ketiga, menghitung jarak data ke center digunakan Euclidean norm. Nilai
Euclidean norm dapat dinyatakan dengan (Haykin,2009),
d(Xi, Cj) = ||Xi– Cj||2 (2.8)
dengan nilai Xi adalah nilai vector input dari data ke i dan nilai Cj adalah nilai vector
dari centerhidden ke j.
Keempat, kelompokkan data sesuai dengan kelompoknya, yaitu data yang
memiliki jarak terpendek pada masing-masing hidden (jumlah kelompok = jumlah
hidden). Misalkan jumlah hidden adalah dua sehingga jumlah kelompok dua, ketika
d(x1,c1) < d(x1,c2) maka nilai x1 masuk ke kelompok 1 dan lakukan hal yang sama dengan data selanjutnya
Kelima, memperbaharui nilai center dengan cara merata-ratakan nilai anggota
kelompok yang dapat dinyatakan sebagai berikut.
= × ∑= (2.9)
dengan ni merupakan jumlah anggota kelompok.
Lakukan langkah pertama sampai kelima hingga nilai center tidak berubah lagi.
Metode K-Means memiliki beberapa keuntungan penggunaan pada jaringan
RBF ini, yaitu
1. Algoritma K-Means merupakan algoritma dengan komputasi yang efisien
karena seluruh yang kompleks dijadikan linear pada angka cluster
2. Ketika cluster dengan lengkap didistribusikan datanya, maka akan dengan
2.3.1.2Tahap II: Hidden Layer ke Output Layer
Setelah K-Means digunakan pada input layer ke hidden layer maka proses selanjutnya
hidden layer ke output layer yang merupakan pembelajaran terawasi yang sama
seperti penggunaan pada MLP, output layer dilatih dengan menggunakan Least Means
Square.
Inisialisasi weight pada hidden layer sampai output layer dilakukan inisialisasi weight
secara acak. Lalu dilakukan penghitungan seluruh output (Yk) pada jaringan yang dinyatakan dengan (Haykin,2009) ,
� = ∑�= � (2.10)
dimana,
Yk = nilai node pada output k dari nodehidden ke j L = nomor dari data pelatihan
φj = fungsi Gaussian pada node j
wkj = nilai weightoutput dari node ke j pada hidden layer ke output k
Setelah itu dilakukan langkah selanjutnya untuk menghitung error atau selisih
hasil pada output Yk yang dinyatakan dengan,
� = − � (2.11)
dimana,
δk = unit kesalahan yang akan dipakai dalam perubahan weight layar tk = hasil normalisasi data dari data input.
Yk = output pada node k
Setelah tingkat kesalahan didapat tidak sesuai dengan yang diinginkan maka
dihitung suku perubahan weight wkj (yang akan dipakai nanti pada saat merubah weight wkj) dengan laju percepatan α yang dinyatakan dengan,
∆ = �� � (2.12)
Pada fase ini tidak dilakukan perhitungan kesalahan pada hidden layer. Hal ini
25
objektif dari algoritma K-means sehingga nilai yang didapat sudah sesuai. Lalu tahap
selanjutnya adalah tahap perubahan weight dengan menghitung semua perubahan
weight wkj yang dinyatakan dengan,
= + ∆ (2.13)
Proses tersebut terus dilakukan sampai weight(wkj) tidak berubah lagi.
2.3.2. Menghitung Nilai Error
Menghitung nilai error sangat penting untuk melihat hasil pelatihan pada jaringan
sarat tiruan. Hal ini dikarenakan pada tahap pelatihan nilai error yang diharapkan
adalah nilai yang paling kecil. Outputerror adalah perhitungan error yang merupakan
hasil dari perbedaan nilai target dan nilai output yang didapat. Nilai ini akan
digunakan untuk menghitung nilai error. The Means Absolute Percentage Error
(MAPE) merupakan metode perhitungan error untuk mengevaluasi metode
peramalan. Pendekatan ini menghitung kesalahan peramalan yang besar karena nilai
output error yang didapat dari perbedaan antara target dan output dibagi nilai target.
Perhitungan nilai MAPE dapat dinyatakan sebagai berikut.
�� � = ∑ �− ̂�
� × %
= (2.14)
2.4. Penelitian Terdahulu
Berikut ini adalah penjelasan mengenai penelitian terdahulu dari kasus penelitian
kelapa sawit dan jaringan saraf radial basis function.
2.4.1 Penelitian kasus prediksi produksi kelapa sawit
Penelitian mengenai prediksi produksi kelapa sawit sudah pernah dilakukan. Metode
prediksi yang dilakukan pada penelitian-penelitian tersebut menggunakan metode
time-series dan juga menggunakan metode statistik.
Hermanto dan Purnawan (2009) mengenai prediksi produksi menggunakan
jaringan saraf tiruan dengan algoritma backpropagation. Penelitian tersebut
hujan, ketinggian dari permukaan laut, kelerengan, umur tanaman, batuan, solium, dan
keasaman tanah. Percobaan dengan beberapa layer untuk mendapatkan hasil terbaik
yaitu 3 layer, 4 layer dan 5 layer. Hasil terbaik didapat pada percobaan 3 layer pada
iterasi ke 30000, dengan laju pembelajaran sebesar 0.9, dan momentum sebesar 0.9.
Hasil pelatihan yang didapat dengan R2=0.9998 dan RMSE = 0.0709 dan hasil pengujian dengan R2 = 0.8901 dan RMSE = 2.2196.
Penelitian lain dilakukan Bando (2012) menggunakan metode ARIMA untuk
memprediksi curah hujan dengan produksi kelapa sawit. Tahapan yang dilakukannya
sebagai berikut.
1. Tahap identifikasi
Pada tahap identifikasi dilakukan perumusan kelompok model-model yang
umum. Kemudian melakukan penetapan model untuk sementara.
2. Penaksiran parameter dan pengujian
Tahap ini dilakukan penaksiran parameter sementara. Kemudian diperiksa
apakah model tersebut memadai. Jika ya, maka tahap lanjut ke penerapan.
Namun, jika tidak maka tahapan mengulang ke penaksiran parameter.
3. Penerapan
Pada tahap ini dilakukan model untuk peramalan. Data yang digunakan ada
dua yaitu data curah hujan dan data produksi. Lalu data-data tersebut
digunakan dengan metode ARIMA untuk mendapatkan hasil peramalan
selanjutnya.
Kacaribu (2013) menggunakan dua metode untuk membandingkan prediksi
produksi kelapa sawit yaitu menggunakan metode causal berupa regresi ganda dan
metode time-series berupa exponential smoothing. Adapun tahapan-tahapan yang
dilakukannya sebagai berikut.
1. Identifikasi masalah
2. Mengumpulkan dan mempersiapkan data untuk dianalisis
3. Mengolah data (dengan menggunakan regresi ganda dan exponential
smoothing)
4. Melakukan pengujian untuk metode regresi ganda
27
6. Menentukan metode yang cocok untuk peramalan
7. Membuat program aplikasi
Backpropagation Melakukan percobaan sebanyak 3
kali dengan layer yang berbeda
dan banyak iterasi untuk
ARIMA Hanya meneliti untuk memeriksa
keterhubungan curah hujan dengan
2.4.2 Penelitian kasus prediksi dengan menggunakan Radial Basis Function
Prediksi menggunakan jaringan RBF ini telah digunakan di beberapa peramalan
seperti peramalan saham, banjir, finansial, dan lainnya. Pada peramalan saham, Tan et
al (2012) melakukan peramalan dengan model jaringan RBF dan mendapatkan hasil
yang baik yang dapat dilihat dari hasil error nilai prediksinya. Model jaringan RBF ini
malalui dua tahap yaitu klustering dan penentuan weight. Pada pelatihan, klustering
akan berhenti jika nilai error yang dihasilkan program lebih kecil dari nilai toleransi
Pada penelitian Jayawerdana et al (1997), RBF digunakan untuk memprediksi
level air saat terjadi musim hujan. Hasil prediksi dinyatakan jaringan RBF yang
menggunakan metode K-Means lebih baik daripada MLP dengan algoritma
backpropagation. Jaringan RBF berbasis linear dalam parameter dan menjamin
nilai-nilai optimal. Pengembangan model jaringan RBF memerlukan sedikit trial and error
sehingga peramalan yang dilakukan hanya memerlukan sedikit waktu dan usaha dari
pada penggunaan jaringan MLP dengan pendekatan bacpropagation.
Pada penelitian Husein et al (2011), peneliti menampilkan pemakaian data
untuk jaringan saraf RBF dan juga membandingkan nilai yang didapat dengan
menggunakan tiga metode yaitu Single Radial Basis Function Network, Multiple
Radial Basis Function Network dan Auto Regressive Model. Dari ketiga metode
tersebut performa terbaik dihasilkan pada metode Auto Regressive Model lalu Multiple
Radial Basis Function Network.
Berdasarkan ketiga penelitian tersebut dapat dijadikan acuan penggunaan
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini akan membahas mengenai analisis jaringan saraf Radial Basis Function (RBF)
untuk memprediksi produksi kelapa sawit dan tahap-tahap yang dilakukan dalam
perancangan sistem yang akan dibangun.
3.1.Metode Penelitian
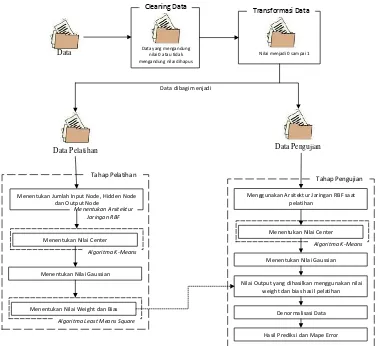
Arsitektur umum dari penelitian dapat dilihat pada Gambar 3.1.
Data Nilai menjadi 0 sampai 1
Transformasi Data Menentukan Jumlah Input Node , Hidden Node
dan Output Node
Nilai Output yang dihasilkan menggunakan nilai weight dan bias hasil pelatihan Menggunakan Arsitektur Jaringan RBF saat
pelatihan
Denormalisasi Data
Hasil Prediksi dan Mape Error Data dibagi menjadi
Metode yang diajukan untuk penelitian ini adalah penggunaan jaringan saraf
RBF. Langkah-langkah yang dilakukan adalah mengumpulkan data produksi harian
panen kelapa sawit yang akan digunakan sebagai data pelatihan dan data pengujian.
Dataset tersebut dikumpulkan dari 01 Januari 2010 – 31 Desember 2013. Setelah data
tersebut didapatkan, dilakukan cleaning data dan setelah itu data ditransformasikan
agar data-data tersebut dapat diproses dengan baik. Lalu data tersebut dibagi menjadi
data uji dan data latih.
Untuk tahap pelatihan ditentukan jaringan RBF yang akan digunakan pada
tahap pengujian yaitu: jumlah hidden node, nilai learning rate, jumlah maksimum
iterasi, dan nilai weight dan bias. Setelah nilai parameter tersebut didapat, lalu
dilakukan pengujian nilai-nilai tersebut pada tahap pengujian.
3.2.Dataset yang Digunakan
Dataset yang digunakan pada penelitian ini merupakan dokumen produksi kelapa
sawit yang telah dikumpulkan dari tahun 2010-2013. Data-data tersebut disimpan
dalam bentuk excel lalu tabel-tabel yang ada dilakukan normalisasi data hingga data
tersebut dapat dijadikan database atau data dalam bentuk excel berekstensi *.csv.
Keseluruhan data berjumlah 1461 dengan pembagian data untuk pelatihan berasal dari
tahun 2010-2012 dan data untuk pengujian berasal dari tahun 2013.
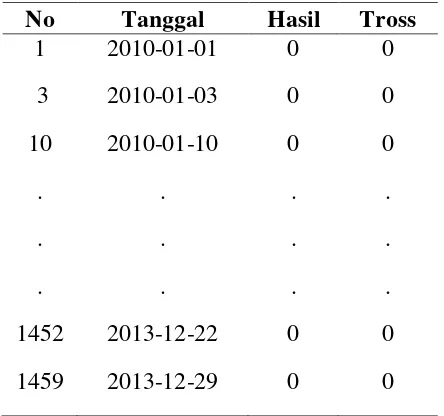
Data terdiri dari hasil panen yang tersimpan dan tross berdasarkan tahun tanam
atau yang telah ditotalkan keseluruhan. Bentuk data produksi yang akan digunakan
dapat dilihat pada Tabel 3.1.
Tabel 3.1 Sampel Data Produksi Kelapa Sawit
No Tanggal Hasil Tross
1 2010-01-01 0 0
2 2010-01-02 26070 1931
31
Tabel 3.1 Sampel Data Produksi Kelapa Sawit (Lanjutan)
No Tanggal Hasil Tross
merupakan data-data yang tidak bernilai atau bernilai 0. Data yang bernilai 0 berasal
dari data pada hari tidak dilakukan panen. Oleh karena itu data-data tersebut dibuang
agar dapat dilakukan prediksi berdasarkan hari kerja. Contoh data yang bernilai 0
dapat dilihat pada Tabel 3.2.
Tabel 3.2 Sampel Data Bernilai 0 pada Data Produksi
Terdapat 252 data yang dibersihkan karena bernilai 0 pada data panen tahun
2000. Data yang tersisa setelah dibersihkan yang siap diproses ada 1195 data. Data
setelah dibersihkan dapat dilihat pada Tabel 3.3.
Tabel 3.3 Sampel Data yang Telah Dibersihkan
No Tanggal Hasil Tross
Setelah data dibersihkan tahap selanjutnya adalah transformasi data. Data-data itu
dinormalisasikan agar nilai data dapat diproses dengan mudah. Data-data tersebut
diubah menjadi nilai dalam rentang 0.1 sampai dengan 0.9 dengan menggunakan
persamaan 2.3
Data yang tersimpan dengan ekstensi *.csv diproses pada program untuk
ditransformasikan. Contoh hitungan nilai data untuk proses normalisasi data dapat
dilihat seperti berikut ini.
a. Pada kolom hasil (tabel tahun 2000):
33
Nilai data(d) = 26070.
Maka Nilai normalisasi(1) = −
− = 0.338812.
b. Pada kolom tross (tabel tahun 2000):
Nilai minimum data (dmin) = 514. Nilai maksimum data (dmax) = 3466. Nilai data(d) = 1931
Maka Nilai normalisasi(1) = −
− = 0.480014.
Hasil keseluruhan normalisasi data dapat dilihat pada Tabel 3.6.
Tabel 3.4 Sampel Data yang Telah Ditransformasi
No Tanggal Hasil Tross
1189 12/27/2013 0.25488 0.28625
1190 12/28/2013 0.20967 0.24594
3.5. Pembagian Data
Setelah data ditransformasikan dan dibagi menjadi data latih dan data uji, selanjutnya
dilakukan prediksi dengan menggunakan jaringan saraf RBF. Data yang berjumlah
1191 data dibagi menjadi 75% data latih dan 25% data uji.
3.6. Proses Pelatihan
Proses prediksi dilakukan adalah dengan membandingkan data aktual dengan data
output dari data uji hasil prediksi dengan jaringan RBF. Pada proses prediksi
dilakukan pelatihan data untuk mendapatkan weight dan parameter lain agar dapat
melakukan pengujian sistem. Langkah yang dilakukan pada proses pelatihan dapat
35
3.6.1 Data Pre-processing
Data proses yang akan digunakan pada jaringan saraf tiruan merupakan data yang
berbentuk vektor. Data-data yang digunakan untuk proses merupakan data kemarin,
data hari ini dan data hasilnya adalah data untuk hari selanjutnya.
Data(1) Data(2) Data(3) Data(4) Data(5) Data(6) Data(895) Data(896)
Skala data
Hari
1 2 3 4 5 6 895 896
Gambar 3.3 Data Time Series untuk Pre-processing Pelatihan
Penetapan pemilihan jumlah variabel dilakukan berdasarkan kemungkinan
pengaruh variabel tersebut dengan nilai yang akan dihasilkan. Variabel yang akan
digunakan ada dua yaitu sebagai berikut.
a. Hasil produksi
Hasil produksi merupakan berat keseluruhan jumlah produksi kelapa sawit.
b. Jumlah tross
Tross merupakan jumlah buah seluruh tandan kelapa sawit. Hampir sama
dengan berat tandan, hubungan jumlah tross dengan hasil produksi berpengaruh
pada berat keseluruhan hasil produksi.
Tahapan praproses pelatihan yang akan dilakukan pada proses prediksi ini
adalah
1. Langkah penggunaan data misalkan menggunakan 5 input data untuk
mendapatkan hasil prediksi hari selanjutnya dapat dilihat pada Tabel 3.5.
Tabel 3.5 Model Data yang Digunakan Jumlah Variabel = 1
Data Hari Ke Variabel yang digunakan
Penentuan jumlah input node yang ditentukan berdasarkan seberapa banyak
data masa lalu yang akan dipakai untuk memprediksi jumlah hasil produksi di hari
selanjutnya. Misalkan data yang digunakan sebanyak lima data, maka akan ada 5 input
dengan jumlah variabel yang dipakai sebanyak 1 variabel dalam satu jaringan.
Variabel n merupakan alur data yang akan digunakan untuk selanjutnya dan
menghasilkan output n selanjutnya. Sehingga arsitektur jaringan RBF yang digunakan
dapat dilihat pada Gambar 3.4.
Gambar 3.4 Arsitektur Jaringan RBF yang Digunakan (Haykin, 2009)
Input data yang digunakan adalah 5 dengan 1 variabel dan menghasilkan 1
output. Aturan penggunaan data tersebut seperti pada tabel digambarkan pada Gambar
3.5.
yang dibutuhkan. Sebagai pelatihan awal, nilai parameter dapat ditentukan
seperti yang tertulis pada Tabel 3.6. �
�