BAB IV
METODOLOGI PENELITIAN
4.1. Jenis Penelitian
Penelitian ini menggunakan metode penelitian kuantitatif yaitu metode penelitian yang digunakan untuk meneliti pada populasi atau sampel tertentu. Pengumpulan data menggunakan instrument penelitian, analisis data bersifat kuantitatif/statistikal dengan tujuan untuk menguji hipotesis yang sudah ditetapkan. Penelitian kuantitatif bersifat konfirmasi karena metode penelitian kuantitatif bersifat menguji hipotesis dari suatu teori yang telah ada sebelumnya.
4.2 Definisi dan Operasional Variabel
1. Return on assets (ROA). Rasio profitabilitas dangan proksi return on aset
(ROA) untuk mengukur kemampuan perusahaan dalam menghasilkan keuntungan atas sejumlah aset yang miliki oleh Perusahaan tersebut.
2. Current ratio (CR) Rasio likuiditas dengan proksi current assets (CR) untuk
mengukur kemampuan perusahaan dalam membayar kewajiban jangka pendeknya pada saat jatuh tempo.
3. Growth of assets. variabel growth menggunakan proksi pertumbuhan asset
(growth of assets) perusahaan yaitu merupakan perubahan (peningkatan atau
4. Dividend payout ratio (DPR) merupakan rasio atau persentase dari laba bersih
yang akan dibayarkan sebagai deviden tunai kepada para pemegang saham. 5. Tingkat Inflasi. Merupakan tingkat inflasi secara tahunan yang dikeluarkan
oleh Pemerintah Indonesia. Data diperoleh dari website Bank Indonesia. 6. Nilai tukar USD. Merupakan nilai tukar mata uang suatu negara terhadap
mata uang negara lain dalam ini nilai tukar mata uang Rupiah terhadap USD. Dalam penelitian ini menggunakan nilai tukar berdasarkan data kurs tengah Bank Indonesia.
7. Tingkat suku bunga. Merupakan tingkat suku bunga yang dikeluarkan oleh Pemetintah Indonesia melalui Bank Indonesia.
4.3. Pengukuran Variabel
Variabel yang diteliti dalam penelitian ini terdiri dari variabel dependen dan independen. Variabel dependen merupakan variabel yang sifatnya dipengaruhi oleh variabel lain sedangkan variabel independen adalah variabel yang sifatnya memperngaruhi variabel lain. Variabel independen dalam penelitian ini adalah return on assets, current ratio, growth of assets, dividend payout ratio, tingkat Inflasi, nilai
tukar USD, tingkat suku bunga. Sedangkan yang menjadi variabel dependen adalah struktur modal perusahaan dengan proksi short term debt to assets ratio, long term debt to assets ratio dan total debt to assets ratio. Dibawah ini informasi indikatorr
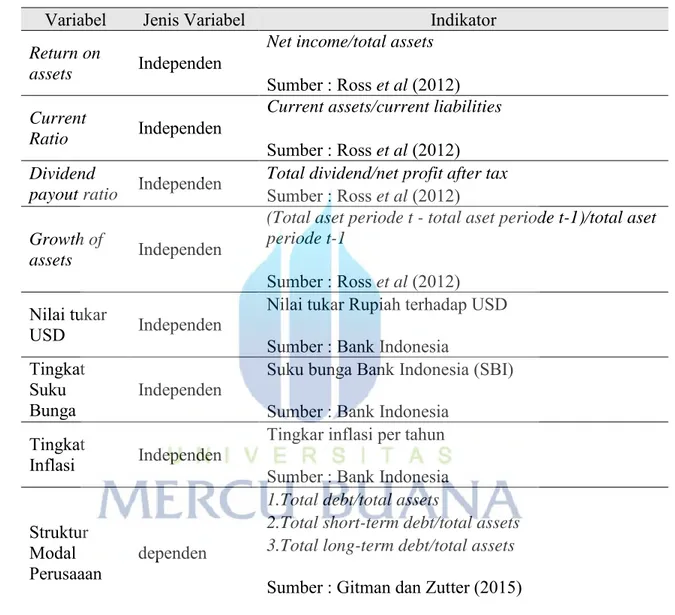
Tabel 4.1. Variabel dan Pengukuran
Variabel Jenis Variabel Indikator
Return on
assets Independen
Net income/total assets
Sumber : Ross et al (2012) Current
Ratio Independen
Current assets/current liabilities
Sumber : Ross et al (2012) Dividend
payout ratio Independen
Total dividend/net profit after tax
Sumber : Ross et al (2012) Growth of
assets Independen
(Total aset periode t - total aset periode t-1)/total aset periode t-1
Sumber : Ross et al (2012)
Nilai tukar
USD Independen
Nilai tukar Rupiah terhadap USD Sumber : Bank Indonesia
Tingkat Suku
Bunga Independen
Suku bunga Bank Indonesia (SBI) Sumber : Bank Indonesia
Tingkat
Inflasi Independen
Tingkar inflasi per tahun Sumber : Bank Indonesia Struktur
Modal
Perusaaan dependen
1.Total debt/total assets
2.Total short-term debt/total assets 3.Total long-term debt/total assets
Sumber : Gitman dan Zutter (2015)
4.4. Populasi dan Sampel Penelitian
Populasi dalam penelitian ini adalah Perusahaan sektor telekomunikasi yang terdaftar di Bursa Efek Indonesia per tahun 2015.
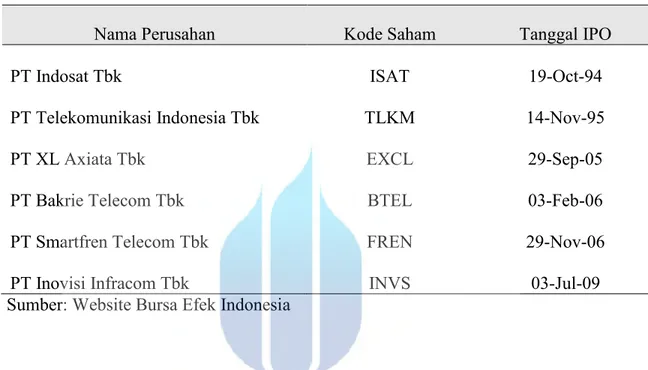
Tabel 4.2. Daftar Perusahaan Sektor Telekomunikasi per Tahun 2015
Nama Perusahan Kode Saham Tanggal IPO
PT Indosat Tbk ISAT 19-Oct-94
PT Telekomunikasi Indonesia Tbk TLKM 14-Nov-95
PT XL Axiata Tbk EXCL 29-Sep-05
PT Bakrie Telecom Tbk BTEL 03-Feb-06
PT Smartfren Telecom Tbk FREN 29-Nov-06
PT Inovisi Infracom Tbk INVS 03-Jul-09
Sumber: Website Bursa Efek Indonesia
Pemilihan sampel dalam penelitian ini dilakukan dengan tehnik purposive sampling yaitu teknik pengambilan sampel dimana setiap elemen populasi tidak
memiliki kesempatan yang sama untuk dipilih menjadi sampel, dan kriteria pemilihan sampel disesuaikan dengan tujuan penelitian. Perusahaan yang menjadi sampel dalam penelitian ini adalah perusahaan sektor telekomunikasi yang sudah terdaftar di Bursa Efek Indonesia periode 2006 sampai dengan 2014. Kriteria pemilihan sampel antara lain sebagai berikut:
1. Perusahaan sektor telekomunikasi yang tercatat di Bursa Efek Indonesia pada tahun 2006 sampai dengan 2014 secara berturut-turut.
2. Perusahaan telah melaporkan laporan keuangannya kepada pihak otoritas terkait dalam hal ini Bursa Efek Indonesia mulai dari tahun 2006 sampai dengan 2014 secara rutin.
4.5. Teknik Pengumpulan Data
Data yang digunakan dalam penelitian ini adalah data sekunder. Data sekunder dalam penelitian ini merupakan data berupa laporan keuangan perusahaan sektor telekomunikasi yang terdaftar di BEI periode 2006-2014. Data tersebut diperoleh dalam bentuk yang sudah tertera dan dikumpulkan serta diolah pihak lain dan sudah dalam bentuk publikasi. Data yang dikumpulkan merupakan data laporan keuangan yaitu neraca dan laporan laba rugi.
4.6. Metode Analisis
Data-data yang diperoleh dari hasil penelitian selanjutnya dianalisis dengan model analisis regresi data panel dengan menggunakan bantuan program software Eviews versi 8.1 yang bertujuan untuk mengetahui seberapa besar pengaruh return on assets, current ratio, growth of assets, dividend payout ratio, tingkat inflasi, nilai
tukar USD dan tingkat suku bunga terhadap struktur modal Perusahaan sektor telekomunikasi.
Model persamaan data panel yang merupakan gabungan dari data cross section dan data time series adalah sebagai berikut:
dimana:
Yit = variabel terikat (dependen) Xit = variabel bebas (independen) i = entitas ke-i
t = periode ke-t
Persamaan di atas merupakan model regresi linier berganda dari beberapa variabel independen dan satu variabel dependen. Estimasi model regresi linier berganda bertujuan untuk memprediksi parameter model regresi yaitu nilai konstanta (α) dan koefisien regresi (βi). Konstanta biasa disebut dengan intersep dan koefisien regresi biasa disebut dengan slope. Regresi data panel memiliki tujuan yang sama dengan regresi linier berganda, yaitu memprediksi nilai intersep dan slope. Penggunaan data panel dalam regresi akan menghasilkan intersep dan slope yang berbeda pada setiap entitas / perusahaan dan setiap periode waktu. Model regresi data panel yang akan diestimasi membutuhkan asumsi terhadap intersep, slope dan variabel gangguannya.
Ada beberapa kemungkinan yang akan muncul atas adanya asumsi terhadap intersep, slope dan variabel gangguannya:
1) Diasumsikan intersep dan slope adalah tetap sepanjang periode waktu dan seluruh entitas/perusahaan. Perbedaan intersep dan slope dijelaskan oleh variabel gangguan (residual).
2) Diasumsikan slope adalah tetap tetapi intersep berbeda antar entitas/perusahaan.
3) Diasumsikan slope tetap tetapi intersep berbeda baik antar waktu maupun antar individu.
4) Diasumsikan intersep dan slope berbeda antar individu.
5) Diasumsikan intersep dan slope berbeda antar waktu dan antar individu.
4.6.1. Model Regresi Data Panel
Data panel adalah gabungan antara data runtut waktu (time series) dan data
silang (cross section). Data runtut waktu biasanya meliputi satu objek/individu
(misalnya harga saham, kurs mata uang, SBI, atau tingkat inflasi), tetapi meliputi beberapa periode (bisa harian, bulanan, kuartalan, atau tahunan). Data silang terdiri dari atas beberapa atau banyak objek, sering disebut responden (misalnya perusahaan) dengan beberapa jenis data (misalnya; laba, biaya iklan, laba ditahan, dan tingkat investasi) dalam suatu periode waktu tertentu.
Regresi dengan menggunakan data panel disebut model regresi data panel. Ada beberapa keuntungan yang diperoleh dengan menggunakan data panel. Pertama, data panel merupakan gabungan data data time series dan cross section mampu
menyediakan data yang lebih banyak sehingga akan menghasilkan degree of freedom
yang lebih besar.
Kedua, menggabungkan informasi dari data time series dan cross section
(ommited-variable). Untuk mengestimasi parameter model dengan data panel,
terdapat beberapa teknik yang ditawarkan, yaitu:
4.6.1.1. Common effect Model
Common effect model merupakan pendekatan model data panel yang paling
sederhana karena hanya mengkombinasikan data time series dan cross section. Pada
model ini tidak diperhatikan dimensi waktu maupun individu, sehingga diasumsikan bahwa perilaku data perusahaan sama dalam berbagai kurun waktu. Metode ini bisa menggunakan pendekatan ordinary least square (OLS) atau teknik kuadrat terkecil
untuk mengestimasi model data panel.
4.6.1.2. Fixed effect model
Fixed effect model mengasumsikan bahwa perbedaan antar individu dapat
diakomodasi dari perbedaan intersepnya. Untuk mengestimasi data panel model fixed effects menggunakan teknik variable dummy untuk menangkap perbedaan intersep
antar perusahaan, perbedaan intersep bisa terjadi karena perbedaan budaya kerja, manajerial, dan insentif. Namun demikian slopnya sama antar perusahaan. Model estimasi ini sering juga disebut dengan teknik least squares dummy variable (LSDV)
4.6.1.3. Random effect model
Random effect model akan mengestimasi data panel dimana variabel
random effect perbedaan intersep diakomodasi oleh error terms masing-masing
perusahaan. Keuntungan menggunkan model random effect yakni menghilangkan
heteroskedastisitas. Model ini juga disebut dengan error component model (ECM)
atau teknik generalized least square (GLS).
4.6.2.Uji Pemilihan Model
Pada dasarnya ketiga teknik atau model estimasi data panel dapat dipilih sesuai dengan keadaan penelitian, dilihat dari jumlah individu dan variabel penelitiannya. Namun demikian, ada beberapa cara yang dapat digunakan untuk menentukan teknik mana yang paling tepat dalam mengestimasi parameter data panel. Menurut Widarjono (2007: 258), ada tiga uji untuk memilih teknik estimasi data panel yaitu:
1. Uji Chow digunakan untuk memilih antara metode commom effect atau
metode fixed effect.
2. Uji Hausman yang digunakan untuk memilih antara metode fixed effect atau metode random effect.
3. Uji lagrange multiplier (LM) digunakan untuk memilih antara
metode commom effect atau metode random effect.
Menurut, Nachrowi (2006, 318), pemilihan metode fixed effect atau
metode random effect dapat dilakukan dengan pertimbangan tujuan analisis, atau ada
diolah oleh salah satu metode saja akibat berbagai persoalan teknis matematis yang melandasi perhitungan.
4.6.2.1. Uji Chow
Untuk mengetahui model mana yang lebih baik dalam pengujian data panel, bisa dilakukan dengan penambahan variabel dummy sehingga dapat diketahui bahwa intersepnya berbeda dapat diuji dengan uji Statistik F. Uji ini digunakan untuk mengetahui apakah teknik regresi data panel dengan metode fixed effect lebih baik
dari regresi model data panel tanpa variabel dummy atau metode common effect.
Hipotesis nul pada uji ini adalah bahwa intersep sama, atau dengan kata lain model yang tepat untuk regresi data panel adalah common effect, dan hipotesis
alternatifnya adalah intersep tidak sama atau model yang tepat untuk regresi data panel adalah fixed effect.
Nilai Statistik F hitung akan mengikuti distribusi statistik F dengan derajat kebebasan (degree of freedom) sebanyak m untuk numerator dan sebanyak n –
k untuk denumerator. m merupakan merupakan jumlah restriksi atau pembatasan di dalam model tanpa variabel dummy. Jumlah restriksi adalah jumlah individu dikurang satu. merupakan jumlah observasi dan k merupakan jumlah parameter dalam model fixed effect. Jumlah observasi (n) adalah jumlah individu dikali dengan
jumlah periode, sedangkan jumlah parameter dalam model fixed effect (k) adalah jumlah variabel ditambah jumlah individu. Apabila nilai F hitung lebih besar dari F kritis maka hipotesis nul ditolak yang artinya model yang tepat untuk regresi data
panel adalah model fixed effect. Dan sebaliknya, apabila nilai F hitung lebih kecil dari
F kritis maka hipotesis nul diterima yang artinya model yang tepat untuk regresi data panel adalah model common effect.
4.6.2.2. Uji Lagrange Multiplier (LM)
Menurut Widarjono (2007: 260), untuk mengetahui apakah model random effect lebih baik dari model common effect digunakan lagrange multiplier (LM). Uji
signifikansi random effect ini dikembangkan oleh Breusch-Pagan. Pengujian
didasarkan pada nilai residual dari metode common effect.
Uji LM ini didasarkan pada distribusi Chi-Squares dengan derajat kebebasan (df) sebesar jumlah variabel independen. Hipotesis nulnya adalah bahwa model yang tepat untuk regresi data panel adalah common effect, dan hipotesis alternatifnya
adalah model yang tepat untuk regresi data panel adalah random effect. Apabila nilai
LM hitung lebih besar dari nilai kritis Chi-Squares maka hipotesis nul ditolak yang artinya model yang tepat untuk regresi data panel adalah model random effect. Dan
sebaliknya, apabila nilai LM hitung lebih kecil dari nilai kritis Chi-Squares maka hipotesis nul diterima yang artinya model yang tepat untuk regresi data panel adalah model common effect.
4.6.2.3. Uji Hausman
Hausman telah mengembangkan suatu uji untuk memilih apakah metode fixed effect dan metode random effect lebih baik dari metode common effect. Uji hausman
ini didasarkan pada ide bahwa least squares dummy variables (LSDV) dalam metode
metode fixed effect dan generalized least squares (GLS) dalam metode random Effect
adalah efisien sedangkan ordinary least squares (OLS) dalam metode common effect
tidak efisien. Dilain pihak, alternatifnya adalah metode OLS efisien dan GLS tidak efisien. Karena itu, uji hipotesis nulnya adalah hasil estimasi keduanya tidak berbeda sehingga uji hausman bisa dilakukan berdasarkan perbedaan estimasi tersebut.
Statistik uji Hausman mengikuti distribusi statistik Chi-Squares dengan derajat kebebasan (df) sebesar jumlah variabel bebas. hipotesis nulnya adalah bahwa model yang tepat untuk regresi data panel adalah model random effect dan hipotesis
alternatifnya adalah model yang tepat untuk regresi data panel adalah model fixed effect. Apabila nilai statistik Hausman lebih besar dari nilai kritis Chi-Squares maka
hipotesis nul ditolak yang artinya model yang tepat untuk regresi data panel adalah model fixed effect. Dan sebaliknya, apabila nilai statistik Hausman lebih kecil dari
nilai kritis Chi-Squares maka hipotesis nul diterima yang artinya model yang tepat untuk regresi data panel adalah model random effect.
4.6.3. Uji Hipotesis
Menurut Nachrowi (2006), uji hipotesis berguna untuk menguji signifikansi koefisien regresi yang didapat. Artinya, koefisien regresi yang didapat secara statistik tidak sama dengan nol, karena jika sama dengan nol maka dapat dikatakan bahwa tidak cukup bukti untuk menyatakan variabel bebas mempunyai pengaruh terhadap variabel terikatnya. Untuk kepentingan tersebut, maka semua koefisien regresi harus
diuji. Ada dua jenis uji hipotesis terhadap koefisien regresi yang dapat dilakukan, yaitu:
4.5.3.1. Uji Signifikansi Bersama-sama ( Uji Statistik F)
Uji-F diperuntukkan guna melakukan uji hipotesis koefisien (slope) regresi
secara bersamaan, dengan kata lain digunakan untuk memastikan bahwa model yang dipilih layak atau tidak untuk mengintepretasikan pengaruh variabel bebas terhadap variabel terikat. Menurut Ghozali (2013:98) Uji statistik F pada dasarnya menunjukkan apakah semua variabel independen atau variabel bebas yang dimasukkan dalam model mempunyai pengaruh secara bersama-sama terhadap variabel dependen atau variabel terikat. Hipotesis nol (Ho) yang hendak diuji adalah apakah semua parameter dalam model sama dengan nol, atau:
Ho: b1 = …= bk = 0
Artinya, apakah semua variabel independen bukan merupakan penjelas yang signifikan terhadap variabel dependen. Hipotesis alternatifnya (HA) tidak semua parameter secara Bersama-sama sama dengan no, atau:
HA: b1 ≠ b2……≠ b k ≠ 0
Artinya, Semua variabel independen secara Bersama-sama merupakan penjelas yang signifikan terhadap variabel dependen.
Jika Uji-F dipergunakan untuk menguji koefisien regresi secara bersamaaan, maka Uji-t digunakan untuk menguji koefisien regresi secara individu. Pengujian dilakukan terhadap koefisien regresi populasi, apakah sama dengan nol, yang berarti variabel bebas tidak mempunyai pengaruh signifikan terhadap variabel terikat, atau tidak sama dengan nol, yang berarti variabel bebas mempunyai pengaruh signifikan terhadap variabel terikat. Menurut Ghozali (2013:98) Uji statistic t pada dasarkan menunjukkan seberapa jauh pengaruh saru variabel penjelas / independen secara individual dalam menerangkan variasi variabel dependen. Hipotesis nol (Ho) yang hendak diuji adalah apakah suatu parameter (bi) sama dengan nol, atau :
H0: bi = 0
Artinya, Apakah suatu variabel independen bukan merupakan penjelas yang signifikan terhadap variabel dependen. Hipotesis alternatifnya (HA) parameter suatu variabel tidak sama dengan nol, atau :
HA: bi ≠ 0
Artinya, Variabel tersebut merupakan penjelas yang signifikan terhadap variabel dependen.
4.5.4. Koefisien Determinasi
Koefisien determinasi (goodness of fit) dinotasikan dengan R-squares yang
merupakan suatu ukuran yang penting dalam regresi, karena dapat menginformasikan baik atau tidaknya model regresi yang terestimasi. Nilai Koefisien Determinasi mencerminkan seberapa besar variasi dari variabel terikat dapat diterangkan oleh
variabel bebasnya. Bila nilai koefisien determinasi sama dengan 0, artinya variasi dari variabel terikat tidak dapat diterangkan oleh variabel-variabel bebasnya sama sekali. Sementara bila nilai koefisien determinasi sama dengan 1, artinya variasi variabel terikat secara keseluruhan dapat diterangkan oleh variabel-variabel bebasnya. Dengan demikian baik atau buruknya suatu persamaan regresi ditentukan oleh R-squares-nya