(Studi Kasus : PT. Tridaya Artaguna Santara)
Skripsi
Oleh
Rizky Evita Putri 11160910000022
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2021 M / 1442 H
(Studi Kasus : PT. Tridaya Artaguna Santara)
Skripsi
Diajukan Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer (S.Kom)
Oleh
Rizky Evita Putri 11160910000022
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2021 M / 1442 H
LEMBAR PERSETUJUAN
IMPLEMENTASI DATA MINING UNTUK PREDIKSI EFEKTIVITAS PADA MESIN INJECTION MENGGUNAKAN ALGORITMA C4.5
(Studi Kasus : PT. Tridaya Artaguna Santara) Skripsi
Oleh :
Rizky Evita Putri 11160910000022
LEMBAR PENGESAHAN
PERNYATAAN ORISINALITAS
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI
Nama : Rizky Evita Putri Program Studi : Teknik Informatika
Judul :
ABSTRAK
Mesin injection merupakan mesin yang memproduksi dalam industri pembuatan berbagai macam produk berbahan dasar plastik. Berdasarkan wawancara dengan pihak dari PT. Tridaya Artaguna Santara mesin injection ini bekerja secara masspro atau terus menerus dan kapasitas produksi yang tinggi, namun memiliki kekurangan saat mesin bekerja secara terus menerus selama hampir 21 jam perhari akan menurunkan efektivitas pada mesin. Jika ada kerusakan pada mesin injcetion biaya investasi dan perawatannya tinggi. Data pada mesin injection dapat digunakan untuk mengoptimalkan atau membuat pengerjaan suatu produk dengan mesin tersebut menjadi efektif dengan pengimplementasian data mining.
Data mining mempunyai teknik klasifikasi dan prediksi, hasilnya berupa sebuah informasi yang dapat digunakan pada masa mendatang. Penelitian ini mengimplementasikan teknik data mining untuk prediksi efektivitas pada mesin injection menggunakan algoritma C4.5 dan tool rapidminer. Menggunakan tahapan Knowledge Discovery in Database dimana sebelum masuk ke tahapan data mining digunakan metode OEE (Overall Equipment Effectiveness) yaitu untuk mengetahui tingkat efektivitas pada setiap data. Pada penelitian ini menghasilkan sebuah model decision tree dari algoritma C4.5 dengan 19 rule yang dapat digunakan untuk prediksi perkiraan dimasa mendatang. Pengujian digunakan confusion matrix dengan nilai accuracy 88.30%, recall 84.91% dan precision 93.75% dan menghasilkan performance keakurasian dengan nilai AUC sebesar 0.873 dan dapat dikategorikan sebagai klasifikasi baik.
Kata Kunci : Mesin injection, Prediksi, Data Mining, Algoritma C4.5 Jumlah Pustaka : 13 e-book, 42 jurnal, 2 skripsi/tesis, 2 website
Jumlah Halaman : VI BAB + xv Halaman + 162 Halaman
Implementasi Data Mining untuk Prediksi Efektivitas pada Mesin Injection menggunakan Algoritma C4.5 (Studi Kasus : PT. Tridaya Artaguna Santara)
KATA PENGANTAR
Alhamdulillah, segala puji dan syukur penulis panjatkan kepada Allah Subhanahu wa Ta’ala yang telah memberikan rahmat, hidayah, serta nikmat -Nya sehingga penulis dapat menyelesaikan penulisan, pelaksanaan dan penyusunan skripsi ini. Sholawat serta salam semoga senantiasa tercurahkan kepada Nabi Muhammad Shalallahu Alaihi Wassalam beserta keluarganya, para sahabatnya serta umatnya hingga akhir zaman. Penulisan skripsi ini mengambil judul :
IMPLEMENTASI DATA MINING UNTUK PREDIKSI EFEKTIVITAS PADA MESIN INJECTION MENGGUNAKAN ALGORITMA C4.5
(Studi Kasus : PT. Tridaya Artaguna Santara)
Penulisan skripsi ini disusun sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri (UIN) Syarif Hidayatullah Jakarta . Penulis sangat menyadari bahwa skripsi ini tidak akan bisa terselesaikan tanpa bantuan, saran, kritik, dan dukungan dari berbagai pihak. Oleh karena itu dalam kesempatan kali ini penulis ingin mengucapkan terima kasih kepada :
1. Nashrul Hakiem, S.Si., M.T., Ph.D selaku Dekan Fakultas Sains dan Teknologi.
2. Dr. Imam Marzuki Shofi, M.T selaku Ketua Program Studi Teknik Informatika Fakultas Sains dan Teknologi.
3. Siti Ummi Masruroh, M.Sc dan Hendra Bayu Suseno, M.T selaku Dosen Pembimbing I dan II yang senantiasa membimbing, mengarahkan, dan memotivasi penulis selama penyusunan skripsi.
4. Seluruh Dosen dan Staf Karyawan Fakultas Sains dan Teknologi, khususnya Program Studi Teknik Informatika yang telah memberikan ilmu, dukungan dan bantuan selama masa perkuliahan.
5. Kedua orang tua dan adik penulis yang selalu memberikan dukungan, selalu mendoakan, selalu memberi kasih sayang bagaimanapun kondisi penulis.
6. Sugeng, S.T dan Budi Ardyanto selaku manajer mold maker dan operator staff mesin injection PT. Tridaya Artaguna Santara yang telah bersedia meluangkan waktunya untuk di wawancara dan memberikan banyak informasi yang sangat membantu dalam skripsi ini.
7. Ghifary Roosfadhila teman dekat penulis yang selalu meluangkan waktunya untuk berdiskusi bersama, selalu menjadi pendengar yang baik disaat penulis berkeluh kesah dan juga tak henti memberikan dukungan untuk penulis.
8. Teman-teman penulis sekaligus teman seperjuangan, Nur Febriana Widiyanti, Ibnah Tul, Etna Syirfa yang selalu menemani penulis dari awal perkuliahan hingga saat ini, dan juga terimakasih kepada Velia Handayani yang selalu mau di repotkan.
9. Sahabat penulis Anggi Lestari yang selalu memberikan dukungan dan waktunya untuk menghibur penulis.
10. Teman -teman seangkatan 2016 prodi Teknik Informatika kelas A, B, C dan D terima kasih karena telah berjuang bersama dan saling support.
11. Keluarga besar Himpunan Mahasiswa Teknik Informatika (HIMTI) UIN Jakarta Khususnya kepengurusan tahun 2018-2020 yang telah memberikan kesempatan untuk berorganisasi dan berproses bersama.
12. Seluruh pihak dan teman-teman yang tidak bisa disebutkan satu persatu yang telah membantu penulis hingga saat ini.
Penulisan skripsi ini masih jauh dari kata sempurna. Untuk itu, sangat diperlukan kritik dan saran yang membangun bagi penulis, dan dapat disampaikan melalui email [email protected]. Penulis memohon maaf atas segala kekurangan ataupun kesalahan baik dari segi keilmuan atau penulisan. Akhir kata, semoga skripsi ini dapat bermanfaat bagi penulis dan orang lain.
Tangerang, Agustus 2021
Rizky Evita Putri
DAFTAR ISI
LEMBAR PERSETUJUAN ... iii
ABSTRAK ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR GAMBAR ... xiii
DAFTAR TABEL ... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 5
1.3 Tujuan Penelitian ... 5
1.4 Manfaat Penelitian ... 5
1.4.1. Manfaat Bagi Penulis ... 5
1.4.2. Manfaat Bagi Universitas ... 5
1.4.3. Manfaat Bagi Perusahaan... 6
1.5 Batasan Masalah ... 6
1.5.1. Metode ... 6
1.5.2. Tools ... 6
1.5.3. Proses ... 6
1.6 Metodologi Penelitian ... 8
1.6.1. Metode Pengumpulan Data ... 8
1.6.2. Metode Knowledge Discovery in Database ... 8
1.7 Sistematika Penulisan ... 9
BAB II LANDASAN TEORI ... 11
2.1 Implementasi ... 11
2.2 Data Mining ... 11
2.2.1. Operasi Data Mining ... 12
2.2.2. Pengelompokan Data Mining ... 13
2.2.3. Alat Bantu Data Mining ... 14
2.3 Knowledge Discovery in Database (KDD) ... 15
2.3.1. Tahap-tahap Knowledge Discovery in Database (KDD) ... 15
2.4 Decision Tree ... 16
2.4.1. Algoritma C4.5 ... 17
2.5 Klasifikasi ... 18
2.6 Prediksi ... 20
2.6.1. Teknik Prediksi ... 20
2.7 Rapidminer ... 20
2.7.1. Operators dan Repositories View ... 21
2.7.2. Confusion Matrix ... 22
2.8 Kurva ROC dan AUC ... 24
2.9 Mesin Injection ... 24
2.9.1. Bagian-bagian Mesin Injection ... 26
2.9.2. Rear Under Guard ... 27
2.10 Overall Equipment Effectiveness (OEE) ... 28
2.10.1. Availability ... 28
2.10.2. Performance ... 29
2.10.3. Quality ... 29
2.11 Microsoft Excel ... 29
2.12 Metode Pengumpulan Data... 29
2.12.1. Wawancara ... 30
2.12.2. Observasi ... 31
2.13 Studi Literatur Sejenis ... 32
BAB III METODOLOGI PENELITIAN ... 40
3.1 Metode Pengumpulan Data ... 40
3.1.1. Studi Pustaka ... 40
3.1.2. Wawancara ... 40
3.1.3. Observasi ... 41
3.2 Metode Knowledge Discovery in Database (KDD) ... 41
3.2.1. Selection ... 41
3.2.2. Preprocessing ... 42
3.2.3. Transformation ... 42
3.2.4. Data Mining ... 42
3.2.5. Interpretation/Evaluation ... 43
3.3 Alur Penelitian ... 44
BAB IV ANALISIS DAN IMPLEMENTASI ... 45
4.1 Knowledge Discovery in Database ... 45
4.1.1. Selection ... 45
4.1.2. Preprocessing ... 49
4.1.3. Transformation ... 50
4.1.4. Data Mining ... 50
4.1.5. Interpretation/Evaluation ... 55
BAB V HASIL DAN PEMBAHASAN ... 56
5.1 Hasil ... 56
5.2 Pengujian ... 83
BAB VI PENUTUP ... 89
6.1 Kesimpulan ... 89
6.2 Saran ... 89
DAFTAR PUSTAKA ... 91
LAMPIRAN ... 97
Lampiran 1. Surat Dosen Pembimbing Skripsi ... 97
Lampiran 2. Surat Permohonan Penelitian Skripsi ... 98
Lampiran 3. Hasil Wawancara dengan Manajer Mold Maker ... 99
Lampiran 4. Hasil Wawancara dengan Staff Operator Mesin Injection ... 101
Lampiran 5. Data perhitungan Overall Equipment Effectiveness (OEE)... 104
Lampiran 6. Data Hasil Seleksi... 108
Lampiran 7. Data Preprocessing ... 121
Lampiran 8. Data Transformation ... 134
Lampiran 9. Data Training ... 147
Lampiran 10. Data Testing ... 159
DAFTAR GAMBAR
Gambar 2. 1 Knowledge Discovery in Database (KDD) Process ... 15
Gambar 2. 2 Operators and Repositories View ... 21
Gambar 2. 3 Confusion Matrix ... 22
Gambar 2. 4 Mesin Injection ... 25
Gambar 2. 5 Mesin Injection ... 25
Gambar 2. 6 Gambar Bagian-bagian Mesin Injection ... 26
Gambar 2. 7 Standar Benchmark OEE ... 28
Gambar 3. 1 Alur Penelitian ... 44
Gambar 4. 1 Dataset Produksi Rear Under Mesin Injection ... 46
Gambar 4. 2 Standar Benchmark OEE ... 48
Gambar 4. 3 Data Selection ... 49
Gambar 4. 4 Data Prerprocessing ... 49
Gambar 4. 5 Data Transformation ... 50
Gambar 4. 6 Node Akar ... 55
Gambar 5. 1 Tampilan Awal Aplikasi Rapiminer ... 56
Gambar 5. 2 Tampilan Untuk Mengimport Data ... 57
Gambar 5. 3 Tampilan Pemilihan Import Data ... 58
Gambar 5. 4 Tampilan Setelah Mengimport Data ... 59
Gambar 5. 5 Tampilan Process Pada Rapidminer Studio 9.8.001 ... 59
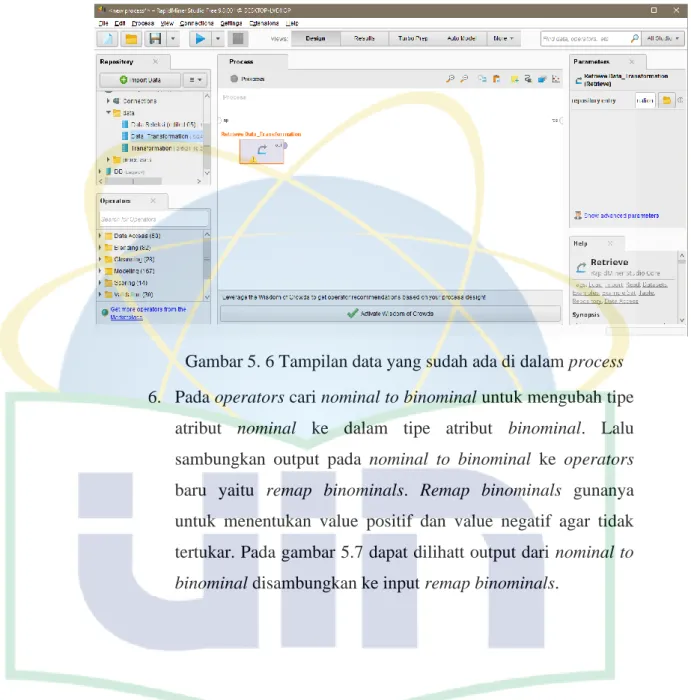
Gambar 5. 6 Tampilan Data yang Sudah ada di dalam Process ... 60
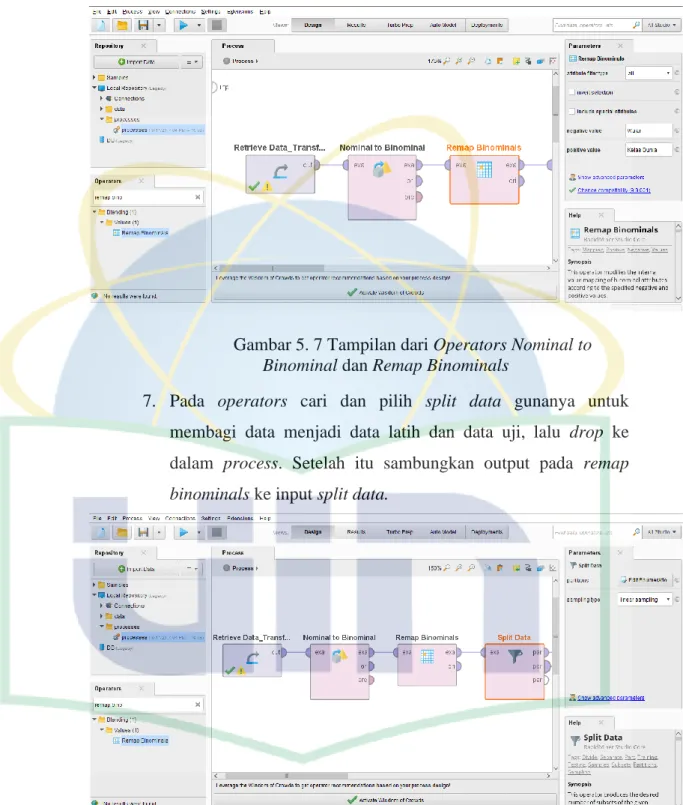
Gambar 5. 7 Tampilan dari Operators ... 61
Gambar 5. 8 Split Data dari Operators ... 61
Gambar 5. 9 Tampilan Parameter List : Partitions... 62
Gambar 5. 10 Tampilan Operators Set Role pada Process ... 63
Gambar 5. 11 Tampilan Operators Apply Model pada Process ... 63
Gambar 5. 12 Tampilan untuk mengganti Sampling Type ... 64
Gambar 5. 13 Tampilan Operators W-J48 pada Process ... 64
Gambar 5. 14 Tampilan menyambungkan W-J48 ke Multiply ... 65
Gambar 5. 15 Tampilan output Multiply disambungkan ke Apply Model ke-2 .. 65
Gambar 5. 17 Tampilan Operators pada Process ... 67
Gambar 5. 18 Hasil ExampleSet Data Testing ... 67
Gambar 5. 19 Hasil ExampleSet Data Training ... 68
Gambar 5. 20 Hasil Pohon Keputusan ekstensi WEKA J-48 ... 68
Gambar 5. 21 Hasil Akurasi Data Testing dari Confusion Matrix ... 69
Gambar 5. 22 Hasil Model Pohon Keputusan dan Rule dari Algoritma C4.5 ... 81
Gambar 5. 23 Accuracy pada Data Testing ... 84
Gambar 5. 24 Accuracy pada Data Training... 85
Gambar 5. 25 Recall Data Testing ... 86
Gambar 5. 26 Recall Data Training ... 86
Gambar 5. 27 Precision Data Testing ... 87
Gambar 5. 28 Precision Data Training... 87
Gambar 5. 29 Kurva ROC/AUC data testing ... 88
Gambar 5. 30 Kurva ROC/AUC data training ... 88
DAFTAR TABEL
Tabel 2. 1 Penelitian Sejenis ... 32
Tabel 4. 1 Tabel Data Training ... 52
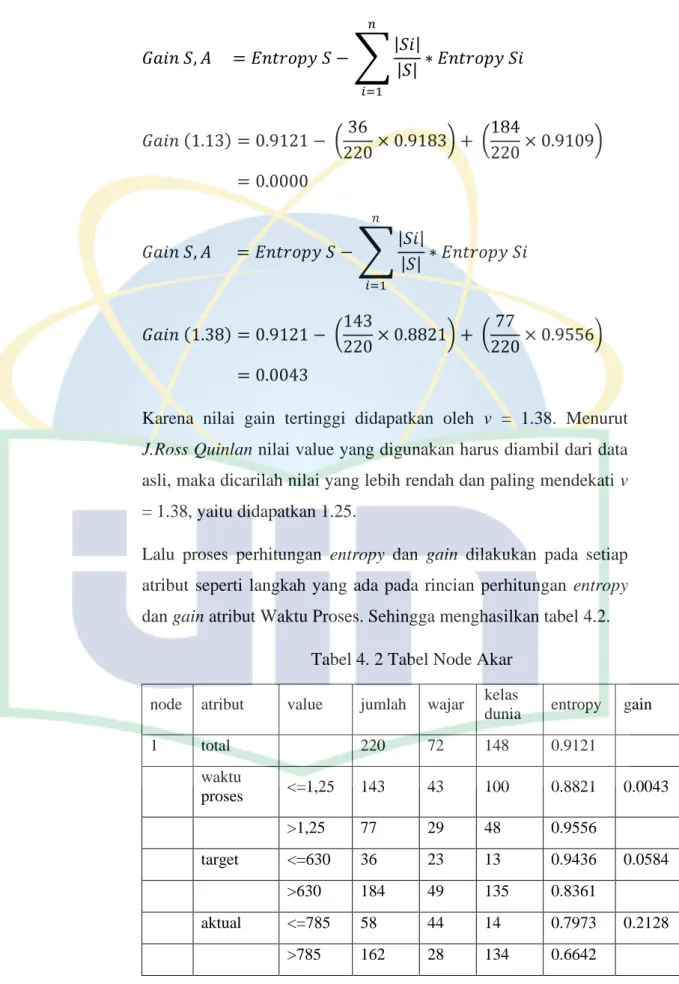
Tabel 4. 2 Tabel Node Akar ... 54
Tabel 5. 1 Node 1 atau Node Akar... 69
Tabel 5. 2 Node 2 Waktu Terbuang ... 70
Tabel 5. 3 Node 2.1 Produk Bagus ... 70
Tabel 5. 4 Node 2.1.1 Produk Bagus ... 71
Tabel 5. 5 Node 2.1.2 Waktu Proses ... 71
Tabel 5. 6 Node 2.1.2.1 Produk Bagus ... 72
Tabel 5. 7 Node 2.1.2.1.1 Produk Bagus ... 72
Tabel 5. 8 Node 2.1.2.1.2 Waktu Proses ... 72
Tabel 5. 9 Node 2.2 Waktu Terbuang ... 73
Tabel 5. 10 Node 3 Waktu Terbuang ... 73
Tabel 5. 11 Node 3.1 Waktu Proses ... 74
Tabel 5. 12 Node 3.1.1 Aktual ... 74
Tabel 5. 13 Node 3.1.1.1 Waktu Berjalan ... 75
Tabel 5. 14 Node 3.1.1.2 Waktu Proses ... 75
Tabel 5. 15 Node 3.1.1.2.1 Aktual ... 76
Tabel 5. 16 Node 3.1.1.2.2 Waktu Proses ... 76
Tabel 5. 17 Node 3.1.2 Waktu Proses ... 76
Tabel 5. 18 Node 3.2 Waktu Berjalan ... 77
Tabel 5. 19 Node 3.2.1 Produk Bagus ... 77
Tabel 5. 20 Node 3.2.2 Produk Bagus ... 78
Tabel 5. 21 Node 3.2.2.1 Waktu Proses ... 78
Tabel 5. 22 Node 3.2.2.2 Waktu Proses ... 79
Tabel 5. 23 Node 3.2.2.2.1 Waktu Berjalan ... 79
dalam bidang jasa manufacturing untuk melakukan bisnis dalam pembuatan rubber dan plastic-injection. Saat ini PT. Tridaya Artaguna Santara menyediakan beragam solusi teknik untuk produksi Die Casting.
Perusahaan ini mempunyai banyak fasilitas dan produk yang pengerjaannya berdasarkan Purchase Order (PO) dari customer. Suatu kegiatan produksi merupakan proses dari terbuatnya suatu barang atau jasa yang memerlukan faktor-faktor produksi seperti bahan baku, tenaga kerja, alat, modal, dan sistem kerja. Dalam perusahaaan ini dibutuhkan banyak mesin untuk membuat macam-macam produk yang dikerjakan berdasarkan PO. Untuk proses machining molding dan die casting digunakan mesin CNC sedangkan untuk trial dan produksi plastik komponen otomotif digunakan mesin injection. Salah satu contoh barang yang diproduksi dengan mesin injection adalah body yang ada pada motor.
PT. Tridaya Artaguna Santara memiliki fasilitas dan produk yang beragam. Berdasarkan wawancara dan observasi yang telah dilakukan dengan Bapak Sugeng selaku manajer bagian mold maker pada 10 Desember 2020 mengatakan kendala yang sering terjadi ada pada mesin itu sendiri, semakin lama usia mesin, semakin menurun pula efektivitas sebuah mesin dan juga ada kendala pada perawatan atau maintenace pada mesin. Jika pada mesin terjadi kerusakan maka memerlukan biaya dan waktu tambahan untuk memperbaiki mesin.
Terkadang perusahaan ingin produksi mencapai target lebih cepat atau produksi melebihi target, yang mengharusnya mesin bekerja lebih cepat dari biasanya. Bapak Budi Ardyanto selaku staff operator mesin injection juga mengatakan pada wawancara 10 Desember 2020 bahwa terkadang produksi tidak mencapai target. Berdasarkan wawancara pula
dikatakan mesin injection sifatnya masspro (produksi massal) dengan produksi dalam jumlah banyak maka kemungkinan mesin akan mengalami penurunan efektivitas dan efisiensi kapasitas produksi pada mesin. Mesin juga tidak selalu memproduksi 100% produk bagus, produk-produk yang gagal juga dapat menghambat target produksi dan perusahaan mengalami kerugian.
Sebuah produksi dapat memenuhi target sesuai dengan yang sudah direncanakan dan dijadwalkan apabila mesin yang digunakan tidak mengalami kendala. Kendala yang umumnya disebabkan oleh mesin atau peralatan yang digunakan yang berasal dari lamanya waktu setup dan asjustment, mesin menghasilkan produk yang cacat dengan mesin yang beroperasi tetapi tidak menghasilkan produk. Oleh sebab itu perusahaan mendapatkan kerugian dan turunnya tingkat efisiensi dan efektivitas pada mesin (Kristono & Hudori, 2018).
Mesin-mesin yang digunakan mempunyai data masing-masing dalam memproses produk yang akan di produksi. Data merupakan hal yang penting dalam sebuah perusahaan. Semakin berkembangnya teknologi, data yang dimiliki oleh sebuah perusahaan dapat diolah agar menghasilkan informasi yang dapat digunakan untuk kebutuhan lain. Data dapat diolah menggunakan teknik data mining dan akan menghasilkan informasi yang biasa disebut dengan Knowledge Discovery In Database (KDD) (Asroni, Hidayatul Fitri and Eko Prasetyo, 2018).
Data mining dikelompokan menjadi beberapa cara, salah satunya adalah data mining dapat digunakan sebagai prediksi (Fajrin & Maulana, 2018). Prediksi juga mempunyai banyak keuntungan bagi perusahaan.
Yulia Rizki Amalia (Amalia, 2018) pada penelitiannya yang dilakukan di PT. Bintang Multi Sarana Palembang mengatakan masalah perusahaan tersebut adalah banyaknya permintaan dari konsumen pada produk yang dijual oleh perusahaan maka dari itu diperlukan prediksi penjualan produk tebanyak atau terlaris untuk memberitahukan pihak perusahaan tentang
produk-produk yang paling banyak di beli. Dalam penelitiannya Yulia Rizki Amalia memprediksi menggunakan data penjualan produk elektronik dengan proses data mining menggunakan tools RapidMiner, algoritma yang digunakan adalah K-Nearest Neighbor yang memiliki kelebihan dalam memprediksi tangguh terhadap training data yang noise dan efektif apabila training datanya besar. Pada PT. Tridaya Artaguna Santara informasi yang didapatkan dari data dan telah melakukan proses data mining dengan Knowledge Discovery In Database (KDD) dapat digunakan untuk prediksi efektivitas pada mesin injection berdasarkan data produksi mesin injaction itu sendiri. Dengan banyaknya fasilitas dan produk yang dimiliki oleh PT. Tridaya Artaguna Santara, penulis menggambil salah satu mesin yang digunakan oleh perusahaan berdasarkan rekomendasi dari wawancara dengan manajer mold maker tersebut yaitu mesin injection karena pengerjaan mesin tersebut bersifat masspro yang artinya dikerjakan secara massal atau secara terus menerus.
Salah satu algoritma pada data mining yang digunakan untuk prediksi adalah algortima C4.5. Sebelumnya terdapat beberapa penelitian yang menggunakan algoritma C4.5. Pada penelitian yang dilakukan oleh Abdul Rohman dan Anief Rufiyanto memiliki masalah banyaknya data mahasiswa yang tersimpan pada database dan dapat dijadikan sebuah informasi yang berguna dengan cara mengimplementasikan algoritma Decision Tree C4.5 untuk prediksi kelulusan mahasiswa di Universitas Pandanaran dengan hasil pengujian menggunakan confusion matrix dan kurva ROC dengan AUC (Area Under Curve) sebesar 0,874 dengan nilai akurasi baik. Decision Tree C4.5 mempunyai kelebihan lebih mudah dimengerti, fleksibel, dan dapat divisualisasikan dalam bentuk gambar (Rohman & Rufiyanto, 2019). Sedangkan penelitian oleh Nur Khotimah dan Deden Istiawan (Khotimah & Istiawan, 2018) dengan masalah tidak tersedianya data dan informasi obyektif kondisi hutan lindung dan lahan sasaran RHL (Rehabilitasi Hutan dan Lahan) dilakukan penelitian membandingkan algoritma C4.5, Naïve Bayes, dan K-Nearest Neighbor
Untuk Prediksi Lahan Kritis di Kabupaten Pemalang menunjukan hasil bahwa algoritma C4.5 paling tinggi nilai akurasinya. Masing-masing algoritma untuk prediksi mempunyai kekurangan dan kelebihan.
Algoritma K-Nearest Neighbor mempunyai kelebihan mampu memecahkan masalah multiclass dan kekurangannya adalah sulitnya menemukan tetangga terdekat pada titik query dari dataset yang digunakan. Lalu pada algoritma Naïve Bayes mudah digunakan dengan akurasi yg tinggi pada database yang besar namun memiliki asumsi atribut. Sedangkan algoritma C4.5 mempunyai kelebihan mudah digunakan dan diimplementasikan, dapat digambarkan, dapat mengolah dataset yang besar dan rumit, kekurangan algoritma ini adalah bias terhadap distribusi kecil (Khotimah & Istiawan, 2018). Dalam penelitian oleh (Pradeep & Naveen, 2018) terbukti bahwa algoritma C4.5 memiliki kinerja yang lebih baik dalam memprediksi kanker paru dengan peningkatan set data pelatihan berdasarkan nilai akurasi, presisi, dan AUC. Penelitian ini menggunakan alat bantu ORANGE untuk implementasi dan evaluasi. Selanjutnya penelitian oleh (Nasution, 2015) yang memprediksi indikasi-indikasi yang mempengaruhi kerusakan motor dinamo mengatakan data mining dengan Metode Decision Tree mampu menyelesaikan permasalahannya.
Berdasarkan latar belakang yang telah dijelaskan, ketiga penelitian sejenis mengatakan bahwa algoritma C4.5 adalah algoritma yang mudah digunakan untuk melakukan suatu prediksi dan merupakan algoritma yang paling tinggi akurasinya saat dibandingkan dengan algoritma k-nearest neighbor dan naïve bayes. Maka penulis melakukan penelitian dengan judul “Implementasi Data Mining untuk Prediksi Efektivitas pada Mesin Injection menggunakan Algoritma C4.5 (Studi Kasus : PT. Tridaya Artaguna Santara)”
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan diatas, maka di dapatkan rumusan masalah sebagai berikut: Bagaimana hasil prediksi efektivitas pada mesin injection menggunakan algoritma C4.5 (Studi Kasus : PT. Tridaya Artaguna Santara) ?
1.3 Tujuan Penelitian
Tujuan dari penelitian ini adalah membuat rule atau aturan model prediksi efektivitas pada mesin injection dengan mengimplementasikan algoritma C4.5 yang merupakan algoritma dari data mining, yang akan digunakan sebagai prediksi perkiraan efektivitas mesin injection pada produksi - produksi di masa mendatang dengan studi kasus PT. Tridaya Artaguna Santara.
1.4 Manfaat Penelitian
1.4.1. Manfaat Bagi Penulis
1. Penelitian ini sebagai salah satu syarat penulis untuk mendapatkan gelar Sarjana Komputer di Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta.
2. Sebagai tolak ukur kemampuan penulis selama mengemban Pendidikan di Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta.
3. Mempelajari bagian dan pengimplementasian dari Data Mining dan Knowledge Discovery In Database (KDD).
4. Mengetahui implementasi Algoritma C4.5 untuk prediksi efektivitas pada mesin injection.
5. Terjalin hubungan baik antara penulis dan perusahaan tempat penelitian dilakukan, yakni PT. Tridaya Artaguna Santara.
1.4.2. Manfaat Bagi Universitas
6. Mengetahui kemampuan dari penulis dalam menerapkan ilmu- ilmu yang telah dipelajarinya selama perkuliahan.
7. Menjadi referensi untuk penelitian penelitian selanjutnya.
1.4.3. Manfaat Bagi Perusahaan
8. Mendapatkan aturan dan model untuk memprediksikan efektivitas pada mesin injection.
9. Dapat merubah database atau catatan produksi sesuai dengan penelitian ini.
1.5 Batasan Masalah 1.5.1. Metode
1. Metode pengumpulan data yang digunakan adalah studi pustaka, wawancara, dan observasi.
2. Metode OEE (Overall Equipment Effectiveness) dengan tahapan perhitungan availability, performance, dan quality mesin untuk mengetahui efektifitas mesin yang digunakan yaitu mesin injeksi (machine injection).
3. Penulis menggunakan Knowledge Discovery in Database (KDD) yang mempunyai 5 tahapan yaitu selection, preprocessing, trasnformation, data mining, dan interpretation/evaluation untuk menemukan informasi yang ada pada data.
1.5.2. Tools
4. Penulis menggunakan Rapidminer Studio 9.8.001 untuk membuat model atau rule dan juga untuk menemukan keakuratan dari hasil algoritma yang digunakan yaitu algoritma C4.5.
5. Microsoft Excel 2019 untuk melakukan pengolahan data.
1.5.3. Proses
6. Penelitian ini hanya menggunakan dataset yang berasal dari mesin injection untuk produk under guard pada PT.
Tridaya Artaguna Santara sebanyak 314 data pada tahun 2018.
7. Penelitian ini menghitung OEE (Overall Equipment Effectiveness yang berisi avalilability, performance, dan quality untuk mengetahui efektivitas sebuah mesin.
8. Knowledge discovery in database digunakan hanya sebagai tahapan dan penggalian informasi dalam pembuatan penelitian ini, yang setiap tahapannya tidak ada metode atau teknik tertentu yang perlu digunakan. Perlakuan pada parameter dan variabel yang semuanya tergantung pada peneliti itu sendiri.
9. Untuk mengolah data pada tahap selection, preprocessing, dan transformation hanya menggunakan Microsoft Excel 2019.
10. Penelitian ini hanya menggunakan aplikasi rapidminer studio 9.8.001 dengan ekstensi WEKA J48 dan microsoft excel 2019 untuk tahapan data mining dan interpretation/evaluation dalam menemukan model pohon keputusan dan rule serta pengujian.
11. Penelitian ini hanya mengimplementasikan data mining menggunakan algoritma C4.5 untuk pembuatan rule dan model efektivitas pada mesin injection.
12. Penelitian ini hanya sampai pada tahap pembuatan pohon keputusan dan rule dan hanya sampai pada pengujian confusion matrix dan kurva ROC/AUC.
13. Pengujian dan validasi hanya menggunakan confusion matrix untuk mendapatkan nilai accuracy, recall, precision.
Serta kurva ROC/AUC untuk memvalidasi performance dari algoritma C4.5.
14. Hasil dari penelitian ini hanya ditujukan pada PT. Tridaya Artaguna Santara untuk mesin injection dengan produksi under guard.
1.6 Metodologi Penelitian
1.6.1. Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut :
1. Studi Pustaka
Studi pustaka merupakan suatu metode pengumpulan data dengan mencari informasi yang relevan dengan tujuan penelitian. Informasi ini tersedia dari berbagai referensi, termasuk buku, e-book, jurnal, skripsi atau tesis, situs web, dan sumber lainnya. Hal ini ditujukan untuk data pada latar belakang, landasan teori, literatur sejenis, serta pembelajaran dalam pembahasan penelitian.
2. Wawancara
Salah satu metode pengumpulan data dengan menanyakan langsung ke responden atau narasumber untuk mendapatkan sebuah informasi. Pada penelitian ini dilakukan wawancara dengan 2 responden dari PT. Tridaya Artaguna Santara yaitu dengan Bapak Sugeng, S.T selaku manajer mold maker dan Bapak Budi Ardyanto selaku staff operator mesin injection.
3. Observasi
Observasi merupakan suatu metode pengumpulan data dengan mengunjungi langsung ke lokasi penelitian guna mengumpulkan informasi yang didapat. Observasi yang dilakukan pada penelitian ini mendatangi langsung PT. Tridaya Artaguna Santara.
1.6.2. Metode Knowledge Discovery in Database
Penulis menggunakan Knowledge Discovery in Databse yang mempunyai proses atau tahapan sebagai berikut :
1. Selection 2. Preprocessing
3. Transformation 4. Data Mining
5. Interpretation/Evaluation 1.7 Sistematika Penulisan
Sistematika penulisan dalam skripsi ini dibagi menjadi enam bab yang akan diuraikan oleh penulis secara singkat sebagai berikut :
BAB I PENDAHULUAN
Pada bab pendahuluan ini berisi latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metode dan sistematika penulisan yang merupakan gambaran menyeluruh dari skripsi yang akan ditulis oleh penulis.
BAB II LANDASAN TEORI
Bab ini menjelaskan tentang teori – teori yang digunakan oleh penulis dalam penulisan skripsi dan sebagai panutan dalam penelitian.
BAB III METODOLOGI PENELITIAN
Pada bab ini menerangkan langkah-langkah metodologi penelitian dan metode yang digunakan selama penelitian.
BAB IV ANALISIS DAN IMPLEMENTASI
Bab ini berisi tentang analisis data, analisis kebutuhan dan pengimplementasiannya.
BAB V HASIL DAN PEMBAHASAN
Bab ini menjelaskan tentang hasil dan pembahasan dari penelitian skripsi yang dibuat oleh penulis.
BAB VI PENUTUP
Pada bab yang terakhir adalah penutup yang merupakan kesimpulan dan saran dari penelitian yang telah dilakukan oleh penulis.
atau penerapan (Firdianti, 2018). Menurut Irawan dan Simargolang, implementasi adalah suatu proses untuk mendapatkan suatu hasil yang sesuai dengan tujuan atau sasaran kebijakan itu sendiri. Dimana pelaksana kebijakan melakukan suatu aktivitas atau kegiatan (Irawan &
Simargolang, 2018). Menurut Nurdin Usman, implementasi adalah bermuara pada aktivitas, aksi, tindakan atau adanya mekanisme suatu sistem, implementasi bukan sekedar aktivitas, tapi suatu kegiatan yang terencana dan untuk mencapai tujuan kegiatan (Usman, 2004).
Dari beberapa pengertian implementasi dapat disimpulkan bahwa implementasi adalah sebuah pelaksanaa atau penerapan untuk aktivitas atau kegiatan yang telah terencana agar dapat mencapai tujuan aktivitas atau kegiatan tersebut.
Implementasi pada bidang ilmu komputer yang ditulis oleh (Anugerah Ayu Sendari, 2021) pada artikel beritanya implementasi adalah realisasi dari spesifikasi teknis atau algoritma sebagai program, komponen perangkat lunak, atau sistem komputer lainnya melalui pemrograman dan penyebaran komputer. Banyak implementasi mungkin ada untuk spesifikasi atau standar tertentu.
2.2 Data Mining
Data mining dikenal juga sebagai Knowledge Discovery in Database (KDD). Sederhananya data mining mengekstraksi informasi atau pola penting dari data yang ada pada database besar. Data mining sebagai satu set teknik yang digunakan secara otomatis untuk meneksplorasi secara menyeluruh dan membawa ke permukaan relasi-relasi yang kompleks pada set data yang sangat besar. Teknik-teknik data mining
dapat diaplikasikan juga pada representasi data lain seperti domain dara soatial, berbasis teks, dan multimedia (citra) (Siregar & Puspabhuana, 2017).
Menurut Sigit Adinugroho dan Yuita Arum Sari, data mining membahas penggalian informasi yang berguna dari kumpulan data.
Informasi yang biasanya terkumpul adalah pola-pola tersembunyi yang ada pada data, hubungan antar elemen data, ataupun pembuatan model untuk keperluan peramalan data (Sigit Adinugroho & Yuita Arum Sari, 2018). Hal ini sejalan dengan apa yang tertulis dalam buku berjudul Data Mining : A Tutorial-Based Primer, Second Edition oleh Richard J. Roiger (Roiger, 2017) yaitu, data mining merupakan proses menemukan struktur yang menarik dalam data. Struktur yang dimaksud dapat menjadi berbagai bentuk seperti sebuah grafik, pohon, maupun persamaan. Data mining menggunakan satu atau banyak algoritma dengan tujuan mengidentifikasi trend atau pattern yang menarik dalam sebuah data.
Dari beberapa pengertian data mining diatas maka dapat ditarik kesimpulan bahwa data mining adalah memproses data menjadi sebuah informasi yang dapat digunakan lagi untuk keperluan lain.
2.2.1. Operasi Data Mining
Operasi dalam data mining dapat dikelompokan menjadi dua kategori, yaitu (Sigit Adinugroho & Yuita Arum Sari, 2018) : 1. Metode Deskriptif
Metode deskriptif memiliki tujuan untuk menemukan pola, relasi, atau anomali data yang dapat dengan mudah dipahami oleh manusia.
2. Metode Prediktif
Sedangkan metode prediktif memiliki tujuan untuk memperkirakan nilai suatu variabel berdasarkan variabel- variabel lainnya.
2.2.2. Pengelompokan Data Mining
Data mining memiliki banyak metode/algoritma/teknik penggalian atau pencarian suatu informasi. Setiap metode/algoritma/teknik tersebut memiliki fungsi dan tujuan yang berbeda-beda. Berikut pengelompokan data mining berdasarkan fungsi dan tujuan (Buulolo, 2020) :
1. Deskripsi
Deskripsi memiliki tujuan untuk menemukan atau mengidentifikasi pola yang sering muncul dan mengubah pola tersebut menjadi aturan yang dapat digunakan untuk mempromosikan aktivitas.
2. Klasifikasi
Klasifikasi adalah pengelompokan berdasarkan hubungan antara variabel standar dan variabel target.
3. Prediksi
Secara umum prediksi hampir sama dengan klasifikasi. Salah satu fungsi data mining adalah untuk memprediksi. nilai dari hasil prediksi akan digunakan untuk keperluan di masa mendatang menggunakan data-data yang sebelumnya sudah ada.
4. Estimasi
Estimasi pun bisa dikatakan hampir sama dengan prediksi atau klasifikasi, perbedaan terletak pada bentuk pengelompokan, estimasi pengelompokan ke arah numerik bukan ke arah kategori.
5. Pengklasteran
Clustering atau pengklasteran adalah pengelompokan data dengan nilai yang serupa. Bentuk data yang dapat dikelompokkan ke dalam cluster adalah observasi, rekaman data, atau hasil kelas dan objek yang serupa. Perbedaan antara
clustering dan klasifikasi adalah clustering tidak menggunakan variabel keputusan atau target.
6. Asosiasi
Asosiasi merupakan kumpulan, himpunan, persatuan, atau persekutuan. Dalam data mining proses asosiasi merupakan pencarian atribut yang muncul dalam waktu bersamaan.
2.2.3. Alat Bantu Data Mining
Berikut ini merupakan beberapa alat bantu atau aplikasi data mining.
1. Rapidminer, rapidminer dikhususkan untuk pengguna data mining, perangkat lunak ini merupakan perangkat lunak bersifat open source dan dibuat dengan menggunakan program Java di bawah lisensi GNU Public Licence.
Rapidminer juga dapat dijalankan di sistem operasi manapun (Haryati, Sudarsono, & Suryana, 2015).
2. WEKA, WEKA merupakan platform machine learning open source yang banyak digunakan. Lars Kotthoff, dkk. (Kotthoff, Leyton-brown, Thornton, Hoos, & Hutter, 2017) mendeskripsikan versi baru dari WEKA yaitu sistem yang dirancang akan memaksimalkan performa.
3. Orange, tools Orange merupakan tools data mining yang membantu menganalisis karakteristik data, dengan kata lain digunakan untuk pengenalan pola seperti clustering, classification, regression, neural network (Ambarsari, Khotijah, & Sunarmintyastuti, 2019).
Dalam penelitian oleh Heri Suroyo (Suroyo, 2019) mengatakan bahwa tools data mining orange dapat digunakan dan dimanfaatkan oleh orang awam sekalipun karena tools ini berbasis GUI, yang mana hasilnya akan menampilkan gambaran terkait penelitian.
4. Tanagara, tanagra merupakan salah satu tools yang ada di data mining. Seperti tools data mining lain tanagra dapat mengekplorasi analisis data, statistik, machine learning, dan database. Tanagra juga merupakan tools data mining berbasis open source (Widayu, Nasution, Silalahi, & Mesran, 2017) 2.3 Knowledge Discovery in Database (KDD)
Knowledge Discovery (KD) merupakan konsep yang melibatkan strategi dan prosedur untuk memahami data besar. Dalam beberapa tahun terakhir data yang tersedia ada dalam jumlah besar dengan memiliki banyak sumber, termasuk otomatisasi aktivitas bisnis (perdagangan, komunikasi seluler, reservasi maskapai penerbangan, atau penggunaan kartu kredit), (media sosial, jejaring sosial), aktivitas ilmiah (eksperimen, simulasi, dan sensor lingkungan), database biologis (DNA / RNA / struktur protein, profil ekspresi gen), dan lain -lain (Singh, Dey, Ashour, &
Santhi, 2017).
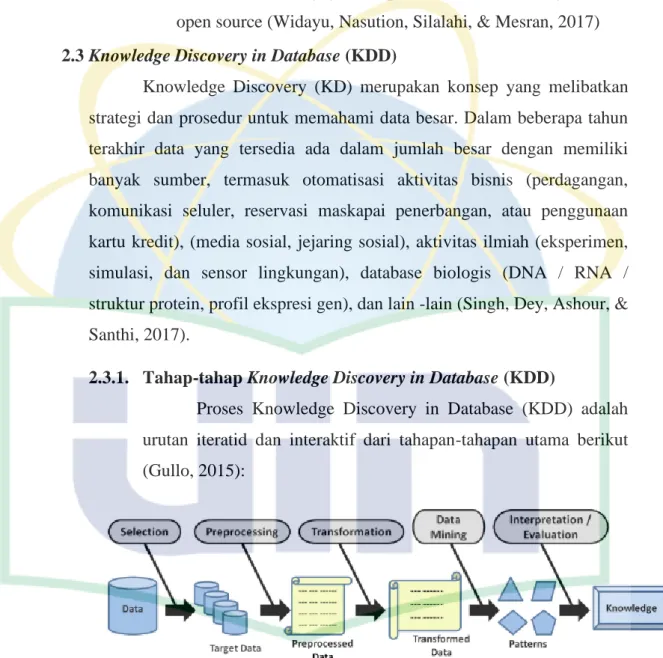
2.3.1. Tahap-tahap Knowledge Discovery in Database (KDD)
Proses Knowledge Discovery in Database (KDD) adalah urutan iteratid dan interaktif dari tahapan-tahapan utama berikut (Gullo, 2015):
Gambar 2. 1 Knowledge Discovery in Database (KDD) Process (Sumber : Gullo, 2015)
1. Selection atau Pemilihan, mempunyai tujuan utama membuat kumpulan data target dari data asli, yaitu memilih subset variabel atau sampel data.
2. Preprocessing, mempunyai tujuan untuk membersihkan data dengan melakukan berbagai operasi, seperti pemodelan dan penghapusan noise, menentukan strategi yang tepat untuk menangani bidang data yang hilang, menghitung informasi urutan waktu.
3. Transformation atau Transformasi, memiliki tugas untuk mengurangi dan memproyeksikan data untuk mendapatkan representasi yang sesuai untuk tugas tertentu yang akan dilakukan, biasanya dicapai dengan melibatkan teknik transformasi atau metode yang mempu menemukan representasi data yang tidak berubah.
4. Data Mining, tahap ini berhubungan dengan penggalian pola yang menarik dengan memilih metode atau data mining tertentu (misalnya, summarization, classification, clustering, regression, dan sebagainya), algortima yang tepat, dan representasi yang sesuai dari hasil keluaran.
5. Interpretation/Evaluation atau Interpretasi/Evaluasi, yang dimanfaatkan oleh pengguna untuk menafsirkan dan mengekstrak pengetahuan dari pola yang dihasilkan, dengan memvisualisasikan pola; interpretasi ini biasanya dilakukan dengan memvisualisasikan pola, model, atau data yang diberikan model tersebut dan, jika, secara berulang melihat kembali langkah-langkah proses sebelumnya.
2.4 Decision Tree
Pohon keputusan atau decision tree adalah model prediksi yang secara rekursif membagi ruang kovariat ke dalam ruang bagian sedemikian rupa sehingga setiap ruang bagian membentuk dasar untuk fungsi prediksi yang berbeda. Pohon keputusan dapat digunakan untuk berbagai tugas belajar termasuk klasifikasi, regresi dan analisis survival. Karena manfaatnya yang unik, pohon keputusan telah menjadi salah satu pendekatan paling kuat dan populer dalam ilmu data (Rokach, 2016).
2.4.1. Algoritma C4.5
C4.5 merupakan algoritma yang dibuat oleh J. Ross Quinlan untuk menyelesaikan masalah dalam machine learning dan juga data mining (Hanif Rahmawan & Azhari SN, 2020). C4.5 adalah salah satu algoritma pohon keputusan paling populer.
Mendukung atribut diskrit atau kontinu, berurusan dengan nilai atribut yang tidak diketahui, dan banyak pilihan fitur lainnya. C4.5 membangun pohon keputusan denga pendekatan divide-and- conquer. Untuk membangun simpul akar dari pohon keputusan, C4.5 mempertimbangkan semua kemungkinan pengujian (Yang &
Chen, 2016).
Dalam buku yang ditulis oleh Himansu Sekhar Behera (Behera, 2015) juga mengatakan bahwa C4.5 memiliki kemampuan untuk menangani atribut kontinu yang akan diolah terus menerus menggunakan proses binarisasi. Atribut kontinu tersebut akan diganti dengan yang diskrit menggunakan nilai ambang (threshold value) yang memisahkan data menjadi dua interval.
Secara umum untuk mendapatkan pohon keputusan menggunakan algoritma C4.5 adalah sebagai berikut (Mardi, 2017).
1. Salah satu atribut dipilih sebagai akar atau node.
2. Buat cabang setiap nilai.
3. Membagi kasus dalam cabang.
4. Mengulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut sebagai akar atau node didasarkan pada gain tertinggi dari atribut yang telah ditemukan nilai gain tersebut.
Rumus untuk menghitung gain adalah sebagai berikut :
𝐺𝑎𝑖𝑛 𝑆, 𝐴 = 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 − ∑ |𝑆𝑖|
|𝑆|
𝑛 𝑖=1
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆𝑖 (1)
Keterangan :
S = Himpunan Kasus A = Atribut
n = jumlah partisi atribut A
|Si| = jumlah kasus pada partisi ke-i
|S| = jumlah kasus dalam S
Untuk perhitungan Entropy S, dapat dilihat pada persamaan 2 : 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 = ∑𝑛𝑖=1− 𝑝∗ log ₂ 𝑝𝑖 (2)
Keterangan :
S = Himpunan Kasus A = Fitur
n = jumlah partisi S
pi = proporsi dari Si terhadap S 2.5 Klasifikasi
Klasifikasi merupakan suatu proses pengkategorian yang dilakukan terhadap sekumpulan dokumen, yang mana klasifikasi ini sangat penting untuk kemudahan pengguna dalam melakukan pencarian dokumen (Indriani, 2014).
Menurut (Gorunescu, 2011) proses klasifikasi didasarkan pada empat komponen dasar, yaitu :
1. Kelas
Kelas/Class adalah variabel dependen model yang merupakan variabel kategorikal dengan ‘label’ yang diletakkan pada objek setelah klasifikasinya. Contoh kelas tersebut adalah : adanya infark miokard, loyalitas pelanggan, kelas bintang (galaksi), kelas gempa bumi (badai), dll.
2. Prediktor
Prediktor merupakan variabel independen dari model. Diwakili oleh karakteristik (atribut) dari data yang akan diklasifikasikan dan berdasarkan klasifikasi yang dibuat. Contoh prediktor tersebut adalah: merokok. konsumsi alkohol, tekanan darah, frekuensi pembelian, status perkawinan, karakteristik gambar (satelit). catatan geologi spesifik, arah angin dan kecepatan, musim, lokasi terjadinya fenomena. dll.
3. Pelatihan Dataset
Pelatihan Dataset yang merupakan kumpulan data yang berisi nilai untuk dua komponen sebelumnya, dan digunakan untuk 'melatih' model untuk mengenali kelas yang sesuai, berdasarkan prediktor yang tersedia. Contoh set tersebut adalah: kelompok pasien yang diuji pada serangan jantung, kelompok pelanggan supermarket (diselidiki oleh jajak pendapat internal), database yang berisi gambar untuk pemantauan teleskopik dan pelacakan objek astronomi (misalnya, Observatorium Palomar (Caltech), San Diego County. California. USA, http: // ww w.astro.caltech.etlu / palomar /), database tentang badai (mis. Pusat pengumpulan data dan perkiraan tipe National Hurricane Center. USA.
4. Pengujian Dataset
Pengujian Dataset berisi data baru yang akan diklasifikasikan oleh model (pengklasifikasi) yang dibangun di atas, dan akurasi klasifikasi (kinerja model) dapat dievaluasi.
2.6 Prediksi
Prediksi menurut (Mendrofa, 2019) adalah suatu ramalan atau perkiraan yang dicari berdasarkan metode ilmiah atau pun subjek belaka.
Sejalan dengan definisi prediksi pada penelitian (Zulfauzi, 2020) yaitu prediksi merupakan proses untuk memperkirakan secara sistematis tentang sesuatu yang mungkin terjadi di masa mendatang berdasarkan informasi yang dimiliki di masa sekarang dan masa lalu. Istilah prediksi juga sangat bergantung pada konteks atau permasalahannya. Prediksi masuk kedalam operasi data mining metode prediktif.
2.6.1. Teknik Prediksi
Prediksi mempunyai dua teknik, yaitu prediksi yang di dasarkan pada analisis kualitatif dan analisis kuantitatif (Karmita, Gaffar, Wiguna, & W.P, 2018).
1. Prediksi Kualitatif
Prediksi kualitatif didasarkan atas data kualitatif di masa lalu.
Prediksi ini mempunyai hasil yang bergantung pada penyusunnya, dikarenakan hasil prediksi kualitatif ditentukan berdasarkan opini, intuisi, pendapat atau pengetahuan dan juga pengalaman sang penyusun.
2. Prediksi Kuantitatif
Prediksi kuantitatif didasarkan atas data kuantitatif di masa lalu. Hasil prediksi kuantitatif tergantung pada metode apa yang digunakan saat prediksi. Jika metode yang dipakai berbeda maka akan mempunyai hasil yang berbeda juga.
Metode yang baik adalah metode yang memberikan nilai-nilai perbedaan atau penyimpangan yang mungkin.
2.7 Rapidminer
Rapidminer adalah platform perangkat lunak ilmu pengetahuan yang dikembangkan oleh perusahaan dengan nama yang sama.
Rapidminer menyediakan lingkungan terpadu untuk pembelajaran
machine learning, deep learning, text mining, dan predictive analytics.
Aplikasi ini digunakan untuk aplikasi bisnis dan komersial serta untuk penelitian, pendidikan, pelatihan, pembuatan prototype, dan pengembangan aplikasi dengan mendukung semua langkah proses pembelajaran mesin termasuk persiapan data, visualisasi hasil, validasi dan pengoptimalan (Muhammad, Rahmadhani, Rizqifaluthi, & Yaqin, 2018).
2.7.1. Operators dan Repositories View 1. Operator View
Semua operator yang dibutuhkan pada sebuah proses bisa dicari dan ditemukan sebagai gambar berikut (Rapidminer.com, 2001) :
Gambar 2. 2 Operators and Repositories View (Sumber :(Rapidminer.com, 2001)) Operator dasar terdiri dari :
• Proses Control
• Utility
• Repository Access
• Import
• Export
• Data Transformation
• Modeling
• Evaluation 2. Repositories View
Repositori untuk menyimpan data dan proses yang akan dipakai.
2.7.2. Confusion Matrix
Dalam penelitian yang dilakukan oleh Muti Astiningrum, dkk. menyebutkan Confusion Matrix adalah sebuah metode untuk mengukur performa dari klasifikasi machine learning dimana output kelas dapat berupa dua ataupun lebih. Bentuk confusion matrix adalah sebuah tabel dengan 4 kombinasi berbeda (Astiningrum, Syulistyo, & Caesaria, 2020). Selaras dengan pengertian yang disebutkan oleh John R. Vacca dalam bukunya, yang berbunyi Confsuion Matrix adalah matriks 2x2 yang menggambarkan apakah setiap instansi atau data telah diklasifikasikan dengan benar (Vacca, 2017).
Untuk pengujian keakuratan hasil pencarian akan dievaluasi nilai recall, precision, accuracy, dan lain-lain (Melita, Amrizal, Suseno, & Dirjam, 2018). Berikut ini merupakan rumus dari confusion matrix (Pratiwi & Silvia, 2020) :
Gambar 2. 3 Confusion Matrix (Sumber : (Pratiwi & Silvia, 2020))
Keterangan :
TP : True Positif adalah jumlah data positif yang terklasifikasi dengan benar oleh sistem.
TN : True Negatif adalah jumlah data negatif yang terklasifikasi dengan benar oleh sistem.
FN : False Negatif adalah jumlah data negatif namun terklasifikasi salah oleh sistem.
FP : False Positif adalah jumlah data positif namun terklasifikasi salah oleh sistem.
1. Accuracy merupakan perbandingan kasus yang terklasifikasi benar dengan jumlah seluruh kasus.
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑁 + 𝐹𝑃× 100%
2. Recall menunjukan berapa persen data kategori positif yang terklasifikasi dengan benar oleh sistem.
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁× 100%
3. Precision mengevaluasi kemampuan sistem untuk menemukan peringkat yang paling relevan dan didefinisikan sebagai presentase dokumen yang di retrieve dan benar-benar relevan terhadap query.
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑃× 100%
4. Error rate merupakan kasus yang teridentifikasi salah dalam sejumlah data, sehingga dapat dilihat seberapa besar tingkat kesalahan pada sistem yang digunakan.
𝐸𝑟𝑟𝑜𝑟 = 𝐹𝑃
𝑇𝑃× 100%
2.8 Kurva ROC dan AUC
Receiver Operating Characteristic (ROC) adalah kurva untuk melihat kualitas dari klasifikasi dalam bentuk 2 dimensi, dimana garis horizontal menggambarkan nilai false positive sedangkan garis vertikal menggambarkan nilai true positive. Tetapi digunakan metode untuk menghitung luas daerah dibawah kurva ROC yang disebut AUC (Area Under the ROC Curve) yang diartikan sebagai probabilitas (Nengsih, Zein,
& Hayati, 2021).
Area Under the ROC Curve (AUC) mengukur kinerja diskriminatid dengan memperkirakan probabilitas output dari sampel yang dipili secara acak dan populasi positif atau negatif, semakin besar AUC, semakin kuat klasifikasi yang digunakan. Karena AUC adalah bagian dari darah unit persegi, nilainya akan selalu antara 0.0 dan 1.0 (Rahayuningsih
& Maulana, 2018). Keakurasian performance AUC dapat dikelompokan sebagai berikut (Rohman & Rufiyanto, 2019).
a. 0.50 – 0.60 = klasifikasi salah b. 0.60 – 0.79 = klasifikasi buruk c. 0.70 – 0.80 = klasifikasi cukup d. 0.80 – 0.90 = klasifikasi baik
e. 0.90 – 1.00 = klasifikasi sangat baik 2.9 Mesin Injection
Mesin Injection memproses Injection molding. Injection molding seperti operasi pada jarum suntik, dimana resin plastik yang dilelehkan di barrel disuntikan kedalam mold (cetakan) yang tertutup rapat sehingga lelehan tersebut memenuhi ruang pada mold sesuai dengan bentuk produk yang diinginkan (Yulianto, Prassetiyo, & Rispianda, 2014).
Gambar 2. 4 Mesin Injection (Sumber : Rizky Evita Putri, 2020)
Gambar 2. 5 Mesin Injection (Sumber: Rizky Evita Putri, 2020)
2.9.1. Bagian-bagian Mesin Injection
Bagian-bagian yang ada pada mesin injection dibagi menjadi tiga garis besar yaitu :
Gambar 2. 6 Gambar Bagian-bagian Mesin Injection (Sumber : Mulawarman, 2016)
1. Clamping Unit
Clamping unit berfungsi untuk memegang dan mengatur gerakan mold unit, serta gerakan ejector saat melepas benda dari molding unit. Pada clamping unit dapat mengatur berapa panjang gerakan molding saat dibuka dan seberapa panjang ejector harus bergerak.
2. Proses Injection Molding
Proses injection molding merupakan proses pembentukan benda kerja dari material thermoplastic berbentuk butiran yang ditempatkan kedalam suatu hopper dan masuk kedalam silinder barrel injeksi yang kemudian didorong oleh mekanisme screw melalui nozzle mesin dan sprue masuk kedalam rongga (cavity) cetakan yang sudah pada kondisi tertutup. Setelah beberapa saat didinginkan, mold akan dibuka dan produk akan dikeluarkan dengan mekanisme ejector. Material yang sangat sesuai adalah material thermoplastik, hal ini di sebabkan karena pemanasan material ini dapat melunak dan sebaliknya akan mengeras lagi bila di dinginkan. Perubahan-perubahan yang
terjadi hanya bersifat fisik, jadi bukan perubahan secara kimiawi sehingga memungkinkan daur ulang material sesuai dengan kebutuhan yang diinginkan (Wahyudi, 2015). Injection Unit terdiri dari beberapa bagian, yaitu :
a. Motor dan transmission gear unit b. Hopper
c. Barrel d. Screw
e. Nonreturn Valve f. Nozzle
3. Mold Unit
Mold Unit adalah elemen kunci pada proses injection molding.
Molding unit sebenarnya adalah bagian lain dari mesin plastic injection. Molding unit adalah bagian yang membentuk benda yang dibuat, secara garis besar molding unit memiliki dua bagian utama yaitu bagian cavity dan core, bagian cavity adalah bagian cetakan yang berhubungan dengan nozzle pada mesin, sedangkan bagian core adalah bagian yang berhubungan dengan ejector.
2.9.2. Rear Under Guard
Rear Under Guard adalah sebuah struktur logam atau plastik yang terdapat di sisi belakang mobil yang berfungsi untuk melindungi mobil dari benturan (Albahash & Ansari, 2016).
Buruknya kualitas rear under akan sangat berbahaya karena hal ini dapat menyebabkan kematian. Data di Amerika Serikat tahun 2009 sendiri terdapat 2843 orang meninggal disebabkan kecelakaan yang bersangkutan dengan rear under (Albahash &
Ansari, 2016). Sedangkan menurut The Washington Post (Hasley, 2015), di Amerika tiap tahunnya terjadi 1.7 juta kecelakaan yang menyebabkan 17.000 orang meninggal dan 500.000 orang terluka.
2.10 Overall Equipment Effectiveness (OEE)
OEE atau kepanjangannya adalah Overall Equipment Effectiveness merupakan salah satu metode yang digunakan untuk mengukur efektivitas sebuah mesin, yang didasarkan dengan 3 rasio utama yaitu availability, performance, dan quality (Suliantoro, Susanto, Prastawa, Sihombing, &
Anita, 2017). Rumus OEE adalah sebagai berikut.
OEE = Availability × Performance × Quality
Japan Institute of Plant Maintenance (JIPM) telah menetapkan standar benchmark dari OEE yang digunakan oleh seluruh dunia. Standar benchmark tersebut adalah (Hidayat, Arnita, & Irdas, 2017) :
Gambar 2. 7 Standar Benchmark OEE (Sumber : (Hidayat et al., 2017))
Dikatakan bahwa OEE dengan predikat perfect (sempurna) adalah hasil efektivitas dengan persentase 100%. OEE dengan predikat world class (kelas dunia) adalah hasil efektivitas dengan persentase lebih dari sama dengan 85%. OEE dengan predikat normal adalah hasil efektivitas dengan persentase lebih dari sama dengan 60% dan kurang dari 85%.
Sedangkan OEE dengan predikat low (rendah) adalah hasil efektivitas dengan persentase lebih dari sama dengan 40% dan kurang dari 60%.
2.10.1. Availability
Availability adalah rasio waktu yang tersedia untuk aktivitas pengoperasian mesin dan peralatan. Availability merupakan rasio waktu pengoperasian (operation time) yang diperoleh dengan menghilangkan waktu henti peralatan (downtime)
dan waktu pemuatan. Rumus yang digunakan untuk mengukur availability adalah sebagai berikut :
Availability = 𝐿𝑜𝑎𝑑𝑖𝑛𝑔 𝑡𝑖𝑚𝑒−𝑑𝑜𝑤𝑛𝑡𝑖𝑚𝑒
𝐿𝑜𝑎𝑑𝑖𝑛𝑔 𝑡𝑖𝑚𝑒 X 100%
2.10.2. Performance
Performance merupakan rasio yang menunjukkan kemampuan dari peralatan dalam menghasilkan barang. Data yang dibutuhkan adalah total produksi, cycle time, dan operation time, dengan menggunakan rumus perhitungan adalah sebagai berikut:
Performance = 𝐼𝑑𝑒𝑎𝑙 𝑐𝑦𝑐𝑙𝑒 𝑡𝑖𝑚𝑒 × 𝑝𝑟𝑒𝑐𝑒𝑠𝑠𝑒𝑑 𝑎𝑚𝑜𝑢𝑛𝑡
𝑂𝑝𝑒𝑟𝑎𝑡𝑖𝑛𝑔 𝑡𝑖𝑚𝑒 X 100%
2.10.3. Quality
Quality adalah rasio yang menunjukkan kemampuan dari peralatan untuk menghasilkan barang sesuai dengan standar yang ditentukan. Data yang dibutuhkan adalah total produksi dan banyaknya defect, dengan menggunakan rumus perhitungan adalah sebagai berikut:
Quality = 𝑃𝑟𝑜𝑐𝑒𝑠𝑠𝑒𝑑 𝑎𝑚𝑜𝑢𝑛𝑡−𝐷𝑒𝑓𝑒𝑐𝑡 𝑎𝑚𝑜𝑢𝑛𝑡
𝑃𝑟𝑜𝑐𝑒𝑠𝑠𝑒𝑑 𝑎𝑚𝑜𝑢𝑛𝑡 X 100%
2.11 Microsoft Excel
Microsoft excel adalah aplikasi untuk mengolah data secara otomatis yang dapat berupa perhitungan dasar, rumus, pengolahan data dan tabel, pembuatan grafik dan menajemen data. Microsoft excel memiliki fungsi untuk membuat grafik persamaan matematika, membuat daftar nilai sekolah maupun universitas, melakukan perhitungan statistika, dan lain-lain (Sudarsana et al., 2019).
2.12 Metode Pengumpulan Data
Disebutkan ada dua metode utama dalam pengumpulan data.Terkadang informasi yang diperlukan telah tersedia dan hanya perlu diambil lalu dianalisis. Tetapi sering kali data yang menjadi
sebuah infomasi harus dikumpulkan sendiri oleh peneliti. Berdasarkan cara pengumpulan informasi tersebut, maka ada dua kategori metode pengumpulan data, yaitu (Widi, 2018) :
1. Data Primer
Data Primer adalah data yang dikumpulkan oleh peneliti secara langsung dari sumber datanya.
2. Data Sekunder
Data Sekunder adalah data yang diperoleh atau dikumpulkan peneliti dari berbagai sumber yang telah ada (peneliti sebagai tangan kedua).
2.12.1. Wawancara
Wawancara adalah salah satu dari beberapa teknik dalam mengumpulkan sebuah informasi maupun data (Edi, 2016).
Menurut Albi Anggito dan Johan Setiawan dalam bukunya, wawancara terbagi menjadi 3. Yaitu bagaimana cara wawancara bisa terjadi (Anggito & Setiawan, 2018) :
a. Wawancara Informal
Wawancara informal dilakukan dengan berbicara dengan narasumber seperti layaknya berbicara kepada teman atau orang yang lebih dekat dengan pewawancara.
b. Wawancara menggunakan petunjuk umum wawancara
Pewawancara diharuskan membuat kerangka pertanyaan secara garis besar dan berurutan. Wawancara hanyalah berisi petunjuk agar proses dan isi mencakup keseluruhan pokok-pokok yang direncanakan.
c. Wawancara Baku Terbuka
Wawancara baku terbuka merupakan jenis wawancara yang menggunakan seperangkat pertanyaan baku. Urutan pertanyaan dan cara penyajiannya sama untuk semua responden.
Wawancara dapat dilakukan secara terstruktur maupun tidak terstruktur. Wawancara terstruktur digunakan sebagai teknik pengumpulan data, bila peneliti atau pengumpul data telah mengetahui dengan pasti mengenai informasi apa yang akan diperoleh. Wawancara tidak terstruktur atau terbuka sering digunakan dalam penelitian pendahuluan atau untuk penelitian yang lebih mendalam tentang responden (Sugiyono, 2015).
2.12.2. Observasi
Peranan yang paling penting dalam menggunakan metode observasi adalah pengamat. Pengamat harus jeli dalam mengamati adalah menatap kejadian, gerak atau proses. Mengamati bukanlah pekerjaan yang mudah karena manusia banyak dipengaruhi oleh minat dan kecenderungan-kecenderungan yang ada padanya (Siyoto & Sodik, 2015).
Dari segi proses pelaksanaan pengumpulan data, observasi dapat dibedakan menjadi (Sugiyono, 2015) :
1. Observasi Nonpartisipan
Penelitian terlibat dalam kegiatan sehari-hari orang atau objek yang sedang diamati.
2. Observasi Berperan Serta
Peneliti tidak terlibat dalam kegiatan objek, melainkan hanya melakukan pengamatan independen.
Sedangkan berdasarkan segi instrumentasi yang digunakan, observasi dibedakan menjadi :
1. Observasi Tersetruktur
Observasi yang dirancang secara sistematis, tentang apa yang akan diamati, kapan, dan dimana tempatnya.
2. Observasi Tidak Terstruktur
Observasi yang tidak dipersiapkan secara sistematis tentang apa yang akan diobservasi.
2.13 Studi Literatur Sejenis
Pada penelitian ini, penulis menggunakan literatur sejenis dari penelitian terdahulu. Literatur sejenis dengan penelitian terdahulu guna membandingkan penelitian-penelitian tersebut. berikut adalah tabel literatur sejenis yang penulis gunakan :
Tabel 2. 1 Penelitian Sejenis No Judul – Penulis –
Tahun
Proses Hasil Kelebihan Kekurangan
1 Implementasi Data Mining dengan Algoritma Decision Tree C4.5 untuk Prediksi Kelulusan Mahasiswa di Universitas Pandanaran – Abdul Rohman, Anief Rufiyanto – 2019
1. Menggunakan data kelulusan mahasiwa jenjang D3 Universitas Pandanaran sebanyak 235 data mahasiswa yang diambil dari 53 mahasiswa Teknik Sipil, 95 mahasiswa Teknik Mesin, 45 mahasiswa Teknik Elektronika, 25 mahasiswa Teknik Lingkungan, 17 mahasiswa Teknik Kimia. 151 mahasiswa lulus tepat waktu dan 54 mahasiswa yang terlambat.
2. Atribut jurusan, umur, jenis kelamin, pekerjaan, ipk.
Menghasilkan model dan rule dengan algoritma decision tree C4.5. dari model tersebut
menghasilkan nilai akurasi 65,98% dengan nilai AUC 0,874 termasuk klasifikasi data
Algoritma decision tree dapat meghasilkan pohon keputusan yang mudah
diinterprestasikan, memiliki tingkat akurasi yang dapat diterima, efisien dalam menangani atribut bertipe diskret dan dapat menangani atribut bertipe diskret
Algoritma C4.5 bias terhadap distribusi kecil.
3. Metode Decision Tree sebagai model dengan C4.5 sebagai algoritmanya untuk mendukung pembangunan pohn keputusan.
4. Pengembangan dengan menggunakan framework Rapidminer Studio 9.3.
5. Pengujian, evaluasi dan validasi menggunakan k-fold cross validation, confusion matrix dan kurva ROC dengan AUC (Area Under Curve).
Baik. dan numerik.
Sedangkan Algoritma C4.5 untuk membangun sebuah pohon
keputusan mudah dimengerti, fleksibel, dan menarik karena dapat divisualisasikan dalam bentuk gambar.
2 Lung Cancer Survivability Prediction Based on Performance Using
Classification Techniques of Support Vector Machines (SVM), C4.5, and Naive
1. Atribut yang digunakan jenis kelamin, usia, perokok, lokasi tumor, stadium t, stadium n, stadium, waktu, diabetes, status, meal.cal, wt.loss, ph.ecog, ph.karno
2. Menggunakan teknik klasifikasi SVM, C4.5 dan NB.
3. Meggunakan tools ORANGE untuk implementasi dan evaluasi.
Menghasilkan model dengan menggunakan teknik Support Vector Machine, Naive Bayes dan C4.5. Setelah di bandingkan dengan nilai akurasi, presisi,
Algoritma C4.5 mempunyai tingkat akurasi yang tinggi dalam memprediksi kanker paru jika data set pelatihan semakin besar/meningkat.
Support Vector Machine memiliki 3 model
pendekatan atau yang biasa disebut kernel.
Dalam penelitian ini kernel yang
Bayes for Healthcare Analytics – Pradeep K R dan Naveen N C – 2018
dan AUC terbukti bahwa C4.5 memiliki kinerja yang lebih baik dalam
memprediksi kanker paru dengan
peningkatan set data pelatihan.
C4.5 semakin besar data set semakin tinggi presisnya, paling besar data set berukuran 2200 dengan presisi 82.6%. Naive Bayes presisinya berubah-ubah
digunakan hanya kernel linier.
tidak tentu, data set berukuran 2200 dengan presisi 66.1%.
dan terakhir SVM juga tidak menentu hasil presisinya, data set ukuran 2200 menghasilkan presisi 54.9%
3 Analyzing Political Opinions and Prediction of Voting Patterns in The US Election with Data Mining Approaches – Md.
Sohel Ahammed, Md. Nahid Newaz,
1. Data preprocessing digunakan untuk menghapus nilai yang hilang, menidentifikasi atribut terbaik, dan menghapus nilai duplikat.
2. Membagi dataset menjadi data training dan data testing.
3. Menerapkan 4 algortima yaitu Tree J48/C4.5, Naive Bayes Classifier, Trees Random Forest dan Rule Zero.
Dari 8 model yang diujikan menghasilkan 3 model terbaik yaitu model yang akurasinya paling tinggi sebesar 98.1609%
menggunakan
Bisa disimpulkan bahwa algoritma Trees Random Forest mempunyai akurasi paling tinggi untuk mengidentifikasi preferensi dan
kecenderungan politik penduduk AS. Pada
Tidak dijelaskan secara detail pemrosesan analisis model model tersebut menggunakan apa.
dan Arunavo Dey – 2019
4. Menggunakan tool WEKA untuk menghapus duplikat pada data.
5. Untuk experimen digunakan 8 model, setiap algoritma menggunakan 2 model.
6. Parameter penilaian menggunakan akurasi, recall, presisi, dan f-measure.
algoritma trees random forest, lalu pada posisi kedua ada model ke 1 dengan akurasi 96.3303%
menggunakan algoritma J48/C4.5, posisi ketiga ada model ke 2 dengan akurasi 96.7816%
menggunakan algoritma J48/C4.5.
posisi kedua ditempati oleh algoritma Trees J48 karena nilai akurasinya hampir mendekati algoritma Trees Random Forest.
4 Penerapan Data Mining untuk Prediksi Penjualan
1. Digunakan tahapan Knowledge Discovery in Database (KDD)
2. Untuk klasifikasi digunakan algoritma
Algoritma C4.5 menghasilkan sebuah rule untuk
Algoritma C4.5 dapat digunakan untuk memeberi keputusan
Tidak dilakukan pengujian algoritma.