PENERAPAN METODE KLASIFIKASI DATA MINING UNTUK PREDIKSI KELULUSAN TEPAT WAKTU
Asep Saefulloh1, Moedjiono2
1
STMIK Raharja, Jl. Jenderal Sudirman No.40 Cikokol Tangerang 2
Universitas Budi Luhur, Jl. Ciledug Raya, Petukangan Utara, jakarta Selatan Email : [email protected] , [email protected]
ABSTRACT
Raharja University amazingly had alot of data which is it contained in the two database are Online Absent information (AO) database and Student Information system (SIS) database. AO database use to manage total grade value index (IMK) with SIS database is the data source to manage total grade point average (GPA/IPK). The outcome of IMK and IPK data not yet given a useful information, for estimating on time graduation from student only gather forcast from IMK and IPK. From that statement we want to do a research to forcast on time graduation using datamining classification using C4.5
algorithm, Naïve bayes and Neural Network algorithm. While in this research we are using CRISP-DM research models. From our research the best algoritm result is the highest algoritm accuracy on classification datamining are C4.5 and Neural Network within 100% accuracy rate result, while Naïve Bayes reached 99.8878%. All the three of algoritm are includes on the best classification became they had AUC (Area Under Curve) grade between 0.90-1.00 so they can be use on graduation on time prediction application. The data mining algorithm result this research is using C4.5, we designed interface using engine java which can show on time graduation prediction application and it can be determine on each study program.
Keywords: Data Mining, IMK, GPA/IPK,CRISP-DM, Prediction
ABSTRAK
Kata kunci : Data Mining, IMK, IPK, CRISP-DM, Prediksi
PENDAHULUAN
Terkait dengan salah satu fungsi dari Perguruan Tinggi dalam pendidikan, pengajaran dan perihal ini menjadi salah satu butir akreditasi yaitu kelulusan tepat waktu bagi mahasiswa. Adanya informasi kelulusan tepat waktu tentu akan menjadikan suatu pengambilan keputusan yang tepat bagi manajemen Perguruan Tinggi dalam mengambil langkah strategis. Selama ini Perguruan Tinggi belum memiliki pola–pola prediksi kelulusan tepat waktu sebagai acuan untuk memprediksi jumlah lulus tepat waktu. Prediksi kelulusan tepat waktu yang dilakukan saat ini hanya berdasarkan
forecaster dari data IPK (Indeks Prestasi Kumulatif) dan IMK (Indeks Mutu Kumulatif) semester sebelumnya. Prediksi hampir sama dengan klasifikasi dan estimasi, hanya saja prediksi digunakan untuk menduga nilai-nilai tertentu yang akan terjadi di masa mendatang [8].
Sementara itu Perguruan Tinggi Raharja mempunyai dataset AO (Absensi Online) dan SIS
(Student Information Services) yang selama ini belum dimanfaatkan secara maksimal. Adalah hal yang sangat disayangkan jika dataset yang begitu besar tidak dimanfaatkan untuk digali informasi apa yang terdapat didalamnya. Selain itu, selama ini ada anggapan dari para forecaster Perguruan Tinggi bahwa untuk memprediksi tingkat kelulusan tepat waktu cukup dengan melihat data IPK dan IMK sebelumnya. Berangkat dari permasalahan tersebut maka dilakukanlah penelitian ini, yaitu untuk melakukan klasifikasi data mining terhadap dataset AO, SIS yang sudah tersimpan dalam database DMQ sehingga didapatkan prediksi kelulusan tepat waktu.
Dalam penelitian untuk memprediksi kelulusan tepat waktu, akan dilakukan komparasi terhadap tiga algoritma klasifikasi data mining yaitu C4.5, Naïve Bayes dan Neural Network. Data dari DMQ yang sudah dicleansing akan diproses dengan menggunakan tools Weka, untuk menguji model pada penelitian ini, digunakan metode Cross Validation, Confusion Matrix, dan kurva ROC
(Receiver Operating Characteristic).
PERMASALAHAN
Dalam melakukan prediksi kelulusan tepat waktu mahasiswa terdapat berbagai macam permasalahan, diantaranya yaitu bahwa metode prediksi masih menggunakan prinsip kekeluargaan sehingga dirasakan kurangnya tingkat profesionalisme dalam melakukan prediksi kelulusan tepat waktu.
Agar lebih terarah dalam melakukan penelitian, maka dirumuskan masalah yang ada sebagai berikut :
a. Apakah algoritma C4.5, Naïve Bayes, dan Neural Network merupakan algoritma-algoritma yang dapat digunakan dalam menentukan prediksi kelulusan tepat waktu ?
b. Diantara tiga algoritma yang dibahas dalam penelitian ini yaitu algoritma C4.5, Naïve Bayes, dan Neural Network, algoritma manakah yang terbaik dalam menentukan prediksi kelulusan tepat waktu ?
c. Dari algoritma terpilih apakah dapat menampilkan data prediksi hasil klasifikasi datamining dengan menampilkan kelulusan tepat waktu ?
METODE PENELITIAN
Gambar 1. Kerangka Pemikiran Penelitian
Agar akurasi prediksi yang mendekati kebenaran, maka dilakukan aproach dengan melakukan data mining terhadap database DMQ. Sedangkan approach (model) yang digunakan yaitu algoritma C4.5, Naive Bayes, dan Neural Network untuk memecahkan permasalahan kemudian dilakukan pengujian terhadap kinerja dari ketiga metode tersebut.
Pengujian menggunakan metode Cross Validation, Confusion Matrix dan kurva ROC. Untuk mengembangkan aplikasi (development) berdasarkan model yang dibuat, digunakan tools data mining Weka, sedangkan untuk desain ekperimennya menggunakan CRISP-DM (Cross Industry Standard Process for Data Mining).
Langkah-Langkah Penelitian
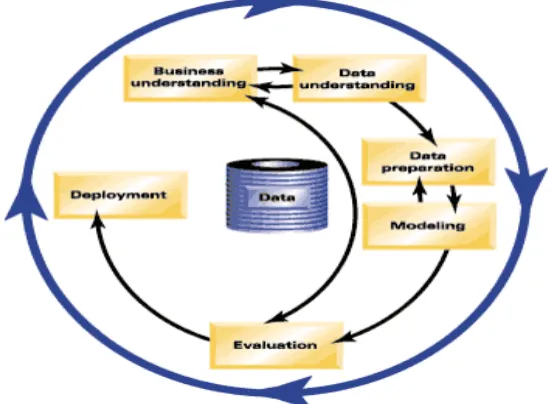
Penelitian ini didesain dengan menggunakan model CRISP-DM (Cross Industy Standard Process for Data Mining), dalam metode ini terdapat 6 tahapan [7]:
Gambar 2. Tahap CRISP-DM
Business/Research Understanding Phase
Data diperoleh dari data sekunder berupa database DMQ Perguruan Tinggi Raharja, dalam penelitian ini akan mengkaji dan membuat model hasil komparasi algoritma C4.5, Naïve Bayes dan Neural Network untuk menentukan algoritma yang paling akurat dan menghasilkan rule prediksi kelulusan tepat waktu.
PROBLEMS
Pemilihan algoritma yang akurat untuk prediksi
kelulusan tepat waktu
MEASUREMENT
Cross Validation, Confusion Matrix, Kurva ROC IMPLEMENTATION
Data mahasiswa untuk IPK dan IMK
RESULT
Algoritma klasifikasi paling akurat prediksi kelulusan tepat waktu
DEVELOPMENT
Framework Weka APPROACH
Data Understanding Phase (Fase Pemahaman Data)
Data pada database DMQ pada tahun 2013 sebanyak 5842. Data yang digunakan sebanyak 7 atribut yang digunakan dalam prediksi kelulusan tepat waktu adalah: Nim, Nama Mahasiswa, Jenjang Pendidikan, Jurusan, IPK, IMK dan Prediksi. Dari 7 atribut 2, predictor yaitu IPK dan IMKdan 1 attribut tujuan yaitu kelulusan tepat waktu.
Data Preparation Phase (Fase Pengolahan Data)
Dari 5842 data mahasiswa diambil data mahasiswa angkatan 2009 dan 2010 dengan pertimbangan sudah melewati semester II (tingkat stabilitas dalam menghadiri perkuliahan sudah tinggi) dan masih ada semester yang mereka akan tempuh (untuk memprediksi kelulusan tepat waktu). Setelah melakukan query terhadap database DMQ maka diperoleh 891 record yang akan diolah oleh Weka. Untuk selanjutnya dilakukan teknik preprocessing agar kualitas data yang diperoleh lebih baik [10].
Modeling Phase (Fase Pemodelan)
Pada tahapan ini merupakan tahapan pemrosesan data training yang diklasifikasikan oleh model dan kemudian menghasilkan sejumlah aturan. Pada penelitian ini menggunakan tiga algoritma yaitu algoritma C4.5, Naïve Bayes dan Neural Network.
Evaluation Phase (Fase Evaluasi)
Pada fase ini dilakukan pengujian terhadap model-model yang bertujuan untuk mendapatkan model yang paling akurat. Evaluasi dan validasi dilakukan menggunakan metode Confusion Matrix
dan kurva ROC (Receiver Operating Characteristic).
Deployment Phase (Fase Penyebaran)
Setelah pembentukan model selanjutnya dilakukan analisa dan pengukuran pada tahap sebelumnya, pada tahap ini diterapkan model atau rule yang paling akurat dalam prediksi kelulusan tepat waktu dan selanjutnya dapat digunakan untuk mengevaluasi data baru.
PEMBAHASAN
Penelitian ini bertujuan untuk membandingkan tingkat akurasi yang dihasilkan oleh teknik atau model data mining yaitu algoritma C4.5, Naïve Bayes, dan Neural Network dalam melakukan prediksi terhadap kelulusan tepat waktu. Selain itu juga menjabarkan algoritma C4.5, Naïve Bayes, dan Neural Network kedalam rule serta menerapkan algoritma C4.5, Naïve Bayes, dan Neural Network dalam menentukan prediksi kelulusan tepat waktu.
Kajian Pustaka
Naïve Bayes, yang juga disebut idiots Bayes, simple Bayes, dan independence Ba yes, adalah metode yang baik karena mudah dibuat, tidak membutuhkan skema estimasi parameter perulangan yang rumit, ini berarti bisa diaplikasikan untuk data set berukuran besar [11]. Klasifikasi Bayes juga dikenal dengan Naïve Bayes, memiliki kemampuan sebanding dengan dengan pohon keputusan dan neural network [4]. Mudah diinterpretasikan sehingga pengguna yang tidak punya keahlian dalam bidang teknologi klasifikasi pun bisa mengerti. Efektifitas metode Naïve Bayes dan perbandingan empiris lebih jauh, dengan hasil yang sama terdapat pada Domingos dan Pazzani (1997) [11]. Klasifikasi Bayes adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu kelas [5]. Klasifikasi Bayes didasarkan pada teorema Bayes, diambil dari nama seorang ahli matematika yang juga menteri Prebysterian Inggris, Thomas Bayes (1702-1761)[1].
Neural network dikenal dengan nama lain yaitu Jaringan Syaraf Tiruan (JST), Artificial Neural Nerwork (ANN), disebut juga Simulated Neural Network (SNN), atau biasanya hanya disebut Neural Network (NN). Neural Network (NN) adalah jaringan dari sekelompok unit pemroses kecil yang dimodelkan berdasarkan susunan syaraf manusia. JST atau neural network
merupakan sistem adaptif yang dapat merubah strukturnya untuk memecahkan masalah berdasarkan informasi eksternal maupun internal yang mengalir melalui jaringan tersebut. Secara sederhana, neural network adalah alat pemodelan untuk memodelkan hubungan yang kompleks antara input dan output untuk menemukan pola-pola pada data. Pengertian lain Neural network
Network dimaksudkan untuk mensimulasikan perilaku sistem biologi susunan syaraf manusia, yang terdiri dari sejumlah besar unit pemroses yang disebut neuron, yang beroperasi secara paralel. Neuron mempunyai relasi dengan synapse yang mengelilingi neuron-neuron lainnya. Susunan syaraf tersebut dipresentasikan dalam neural network berupa graf yang terdiri dari simpul (neuron) yang dihubungkan dengan busur, yang berkorespondensi dengan synapse. Sejak tahun 1950-an, neural network telah digunakan untuk tujuan prediksi, bukan hanya klasifikasi tapi juga untuk regresi dengan atribut target kontinu [10].
C4.5 adalah algoritma decision tree yang dibuat oleh J.R. Quinlan. J48 adalah paket C4.5 yang terdapat di WEKA.
Secara umum pendekatan untuk membuat decision tree adalah : 1. Memilih atribut yang paling membedakan dalam menentukan output. 2. Buatlah cabang yang terpisah untuk setiap value atribut tersebut.
3. Membagi instances kedalam sub grup yang merefleksikan nilai atribut dari node yang dipilih. 4. Untuk setiap sub grup, hentikan proses pemilihan atribut jika :
a. Semua anggota dari sub grup mempunyai nilai output yang sama, hentikan proses pemilihan atribut untuk current path dan berilah label dengan nilai yang spesifik.
b. Sub grup yang berisi single node atau tidak ada atribut sebagai pembeda dapat dihentikan. Seperti di poin a, label pada cabang tersebut adalah sisa dari atribut yang mempunyai bagian lebih besar.
Lakukan proses diatas untuk setiap sub grup yang terpilih pada proses nomor 3 yang belum berhenti.
Algoritma C4.5/J48
Langkah-langkah untuk membuat algoritma C.45 dengan memakai data training yang berjumlah 891 data , yaitu [5]:
a. Siapkan data training. Data training yang digunakan dalam penelitian ini berjumlah 891 record.
b. Hitung nilai entropy.
Setelah dilakukan perhitungan entropy dengan menggunakan rumus sebagai berikut:
=
` = 0.289506617
c. Setelah itu, hitung nilai gain untuk setiap atribut, lalu pilih nilai gain yang tertinggi. Nilai gain
tertinggi itulah yang akan dijadikan akar dari pohon. Misalkan, untuk atribut IPK, akan didapat
gain :
=
Dari hasil perhitungan entropy dan gain, terlihat bahwa atribut status mempunyai nilai
gain tertinggi yaitu 0.540872042. Oleh karena itu, nilai status merupakan simpul akar pada pohon keputusan. Berikut hasil perhitungan entropy dan gain pada Tabel 1. Dalam algoritma ini diberlakukan pruning, pruning yang digunakan yaitu Pre-pruning untuk menghentikan pembangunan suatu subtree lebih awal. Saat seketika berhenti, maka node berubah menjadi leaf
Tabel 1. Hasil Nilai Entropy Dan Gain Untuk Menentukan Simpul Akar
Dari nilai entropy dan gain yang diperoleh tabel 1, selanjutnya tentukan simpul berikutnya yaitu simpul 1.1, dan dilakukan perhitungan entropy dan gain masing-masing atribut dari IPK. Jumlah kasus yang dihitung adalah nilai dari simpul IPK dan seterusnya sampai semua record
dalam simpul, mendapatkan kelas yang sama. Berikut ini adalah hasil uji dengan tools Weka terhadap IPK sehingga langsung ditentukan atribut prediktor merupakan penentu dari seluruh attribut lainnya.
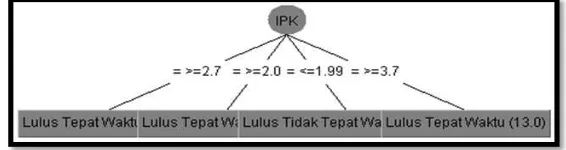
Gambar 3. Pohon Keputusan Classifier Trees J48
Dari gambar 3 pohon keputusan tersebut ditemukan aturan-aturan rule sebagai berikut: a. IPK adalah >= 3.7 THEN Lulus tepat waktu
b. IPK adalah >= 2.7 THEN Lulus tepat waktu c. IPK adalah >= 2.0 THEN Lulus tepat waktu d. IPK adalah <= 1.99 THEN Lulus tidak tepat waktu
Algoritma Naïve Bayes
Metode Naïve Bayes menggunakan data training sejumlah 891 record seperti pada metode C4.5. Perhitungan pemilihan prediksi kelulusan tepat waktu dengan nilai prediksi lulus tepat waktu dan lulus tidak tepat waktu terlihat pada Tabel 2 baris pertama. Baris-baris berikutnya adalah hasil perhitungan nilai probabilitas prior, yaitu probabilitas nilai lulus tepat waktu dan
Jumlah Data
Lulus tepat waktu
Lulus tdk tepat
waktu Entropy Gain
IPK 891 729 162 0.289506617 0.289506617
>=3.7 13 13 0 0
>=2.7 502 502 0 0
>=2.0 214 214 0 0
<=1.99 162 0 162 0
IMK 891 729 162 0.289506617 0.452555394
>=3.7 88 88 0 0
>=2.7 723 629 94 0.20093563
>=2.0 79 12 67 2.718818247
<=1.99 1 0 1 0
Jenis
Kelamin 891 729 162 0.289506617 0.115503557
Laki-laki 609 481 128 0.340405334
Perempuan 282 248 34 0.185355042
Status 891 729 162 0.289506617 0.540872042
Aktif 671 634 37 0.081829926
Tidak Aktif 195 74 121 1.397876948
Cuti 25 21 4 0.251538767
Jenjang 891 729 162 0.289506617 0.128283251
Sarjana 739 612 127 0.272042711
lulus tidak tepat waktu masing-masing atribut terhadap total lulus tepat waktu dan lulus tidak tepat waktu dari seluruh data. Dalam data training terdapat 891 record dengan 729 kasus lulus tepat waktu dan 162 kasus lulus tidak tepat waktu, untuk menentukan prior probability dengan menggunakan rumus [1]:
Bayes : Naïve Bayes :
P (x|y) = P (y|x) P (x)
P(Lulus tepat waktu,n) = 729/891 = 0.818182 P(Lulus tidak tepat waktu,n) = 162/891 = 0.181818
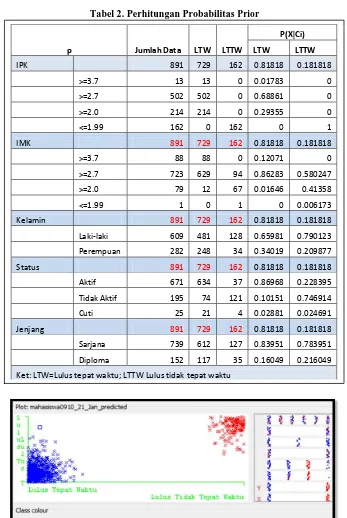
Tabel 2. Perhitungan Probabilitas Prior
Gambar 5. Plot Prediksi Kelulusan Tepat Waktu pada Algoritma Bayes
p Jumlah Data LTW LTTW
P(XCi)
LTW LTTW
IPK 891 729 162 0.81818 0.181818
>=3.7 13 13 0 0.01783 0
>=2.7 502 502 0 0.68861 0
>=2.0 214 214 0 0.29355 0
<=1.99 162 0 162 0 1
IMK 891 729 162 0.81818 0.181818
>=3.7 88 88 0 0.12071 0
>=2.7 723 629 94 0.86283 0.580247
>=2.0 79 12 67 0.01646 0.41358
<=1.99 1 0 1 0 0.006173
Kelamin 891 729 162 0.81818 0.181818
Laki-laki 609 481 128 0.65981 0.790123
Perempuan 282 248 34 0.34019 0.209877
Status 891 729 162 0.81818 0.181818
Aktif 671 634 37 0.86968 0.228395
Tidak Aktif 195 74 121 0.10151 0.746914
Cuti 25 21 4 0.02881 0.024691
Jenjang 891 729 162 0.81818 0.181818
Sarjana 739 612 127 0.83951 0.783951
Diploma 152 117 35 0.16049 0.216049
Algoritma Neural Network
Neural network yang menggunakan algoritma back propagation pada 6 (enam) langkah pembelajaran yaitu dengan menghitung atau menginisialisasi nilai bobot awal antara -0.1 sampai dengan 1.0 untuk input layer, hidden layer dan bias atau threshold. MLP terdiri dari input layer, satu atau lebih hidden layer, dan output layer [10].
Pada simpul bias terdiri dari dua, yaitu: simpul bias pada input layer yang terhubung dengan simpul-smpul hidden layer dan simpul bias pada hidden layer yang menghubungkan pada
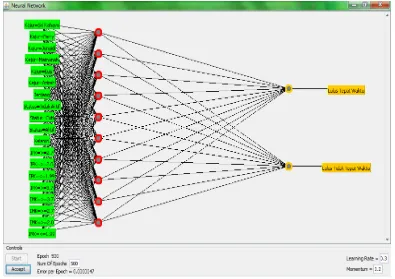
output layer. Setelah hitung input untuk simpul berdasarkan nilai input dan bobot jaringan saat itu, lalu bangkitkan output untuk simpul menggunakan fungsi aktifasi sigmoid. Kemudian tentukan nilai error baru yang pada akhirnya nilai error tersebut digunakan kembali untuk memperbaharui bobot relasi berikutnya. Berikut adalah neural net yang dihasilkan dari data training menggunakan multilayerperceptron pada tools Weka.
Gambar 6. Neural Net Yang Dihasilkan MLP
Dari gambar 6 tersebut dijabarkan secara spesifik dari 7 attribute yang digunakan dalam menggenerate setiap simpul dari seluruh attribute, sehingga seluruh simpul berjumlah 20 simpul hiden layer dan dibagian akhir terdapat 2 dua simpul yang mewakili atribut kelas yaitu lulus tepat waktu dan lulus tidak tepat waktu.
EVALUASI dan VALIDASI
Dari ketiga algoritma C4.5, Naïve Bayes, dan Neural Network akan dievaluasi dan dilakukan uji validitas data dengan data training. Uji validitas dilakuan dengan Confusion Matrix
dan ROC (Receveir Operating Characteristic), pengukuran yang biasa digunakan adalah precision, recall dan accuracy [9].
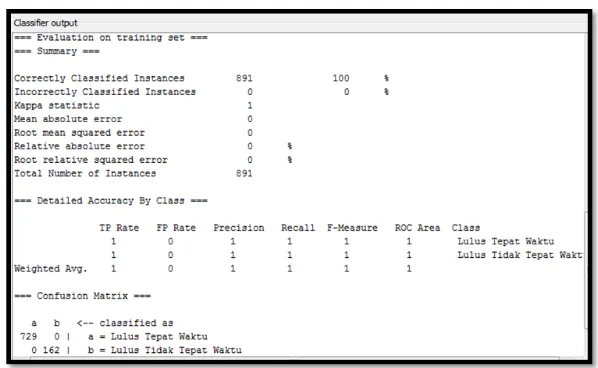
Confusion Matrix Algoritma C4.5
Dari perhitungan terhadap 7 attribut dengan 891 record maka ditemukan 4 leave dan 5 Size of tree, dengan hasil Confusion Matrix sebagai berikut:
Gambar 7. Confusion Matrix untuk Algoritma C4.5
Maka diketahui nilai akurasi data pada algoritma C4.5 sebesar 100% dengan nilai
Confusion Matrix yang diklasifikasikan Lulus Tepat Waktu untuk nilai a dan Lulus Tidak Tepat Waktu untuk nilai b. Untuk nilai Confusion Matrix klasifikasi a memiliki 729 record dengan kriteria Lulus Tepat Waktu dan 162 record dengan kriteria Lulus Tidak Tepat Waktu.
Confusion Matrix Naïve Bayes
Berikut ini adalah perhitungan nilai confusion matrix terhadap algoritma naïve bayes dengan 7 attribut dan 891 record yang menghasilkan tingkat akurasi 99.8878 %.
Gambar 8. Confusion Matrix pada Algoritma Naïve Bayes
Confusion Matrix Neural Network
Berikut ini adalah perhitungan nilai confusion matrix terhadap NeuralNetwork:
Gambar 9. Confusion Matrix pada Neural Network
Pengujian dengan Neural Network menghasilkan tingkat akurasi sebesar 100% menggunakan 891 record yang diuji dari data training. Hasil dari Confusion Matrix dengan klasifikasi a yang memiliki kriteria nilai Lulus Tepat Waktu terdapat 729 record dan klasifikasi b kriteria Lulus Tidak Tepat Waktu terdapat 162 record.
Maka jika diperhatikan dari perbandingan ke tiga algoritma yaitu Algoritma C4.5, Naïve Bayes
dan Neural Network pada tabel 3 ditemukan nilai akurasi tertinggi diperoleh melalui pengujian
Neural Network dan Algoritma C4.5 serta diikuti nilai terandah yakni Naïve Bayes.
Tabel 3. Komparasi Nilai Accuracy, Precision, dan Recall
C4.5 Naïve Bayes Neural network
Accuracy 100% 99.8878% 100%
Precision 1% 0.999% 1%
Recall 1% 0.999% 1%
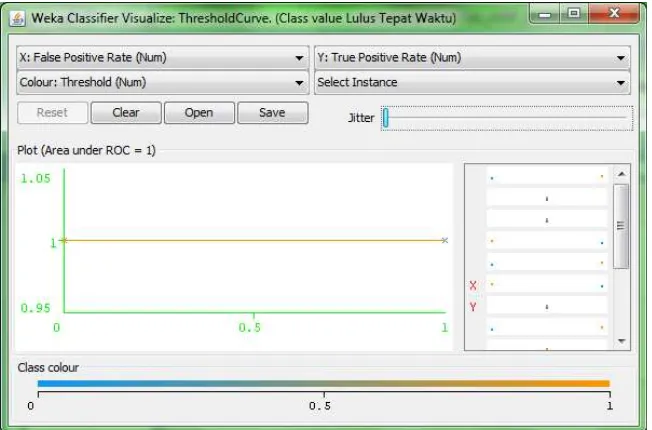
Kurva ROC
Pada setiap pengujian dalam Weka pada dasarnya langsung akan dimunculkan nilai ROC (Receveir Operating Characteristic). Hasil dari ROC akan divisualisasikan dalam bentuk plot.
Area Under Curve (AUC) dihitung menggunakan rumus [6]:
Di mana
Nilai Area Under ROC atau Area Under Curve (AUC) adalah 1 untuk perhitungan class dengan nilai Lulus Tepat Waktu pada algoritma C4.5. Sedangkan untuk Neural Network nilai kurva ROC atau Area Under Curve (AUC) adalah 1 untuk perhitungan class dengan nilai Lulus Tidak Tepat Waktu.
Tabel 4. Komparasi Nilai AUC
C4.5 Naïve Bayes Neural network
AUC 1 1 1
ANALISA HASIL KOMPARASI
Model dengan metode C4.5, Naïve Bayes dan Neural Network yang diuji tingkat akurasinya menghasilkan perbandingan nilai accuracy,precision, sensitivity, dan recall yang terlihat pada tabel 3 , dan pada tabel 4 terlihat komparasi nilai AUC (Area Under Curve) antara ketiga model tersebut. Dari ketiga model, dapat diketahui bahwa nilai accuracy, precision, sensitivity, recal, dan nilai AUC yang paling tinggi diperoleh pada pengujian model C4.5 dan Neral Network dengan hasil yang seimbang dan terakhir model Naïve Bayes
seperti pada tabel 5 berikut:.
Tabel 5. Komparasi Nilai Accuracy dan AUC
C4.5 Naïve Bayes Neural network
Accuracy 100% 99.8878% 100%
AUC 1 1 1
Pada tabel 5, terlihat perbandingan nilai accuracy dan AUC dari tiap metode. Terlihat bahwa nilai secara keseluruhan hampir sama tingkat akurasinya, accuracy algoritma C4.5 dan neural network paling tinggi begitu pula dengan nilai AUC-nya mempunyai nailai yang sama. Untuk metode Naïve Bayes berada paling bawah dalam tingkat accuracy namun memiliki AUC yang sama. Untuk klasifikasi data mining, nilai AUC dapat dibagi menjadi beberapa kelompok [3]. a. 0.90-1.00 = klasifikasi sangat baik
b . 0.80-0.90 = klasifikasi baik c. 0.70-0.80 = klasifikasi cukup d. 0.60-0.70 = klasifikasi buruk e. 0.50-0.60 = klasifikasi salah
Berdasarkan pengelompokkan di atas dan Tabel IV.7 maka dapat disimpukan bahwa metode C4.5, naïve bayes, dan neural network termasuk klasifikasi sangat baik karena memiliki nilai AUC antara 0.90-1.00.
Penerapan Algoritma Terpilih
tersebut yang dipergunakan dalam penerapan yaitu algoritma C4.5. Penerapan aplikasi menggunakan interface yang dibangun dengan java engine.
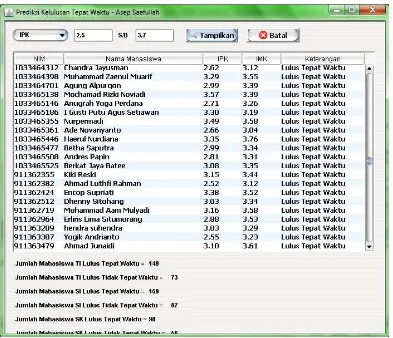
Gambar 11. Interface dari C4.5 Menggunakan Java Engine
Hasil olahan data mining akan dibaca oleh program yang dirancangbangun menggunakan Java Creator, GUI akan menampilkan IPK dan IMK pada radio button, range IPK atau IMK, NIM, nama mahasiswa, tampilkan hasil prediksi baik lulus tepat waktu maupun tidak lulus tepat waktu, tampilan seperti gambar 12.
Pada aplikasi klasifikasi data mining untuk prediksi kelulusan tepat waktu pada gambar 12 dihasilkan klasifikasi Lulus Tepat Waktu dan Lulus Tidak Tepat Waktu. Input data prediksi pada program tersebut sesuai dengan atribut yang dibutuhkan IPK atau IMK, kemudian klik tombol TAMPILKAN, maka secara otomatis tampil hasil klasifikasi prediksi kelulusan tepat waktu dan
kelulusan tidak tepat waktu. Untuk menginput kembali data baru pilih IPK atau IMK kemudian isi range dari IPK atau IMK, dan tombol BATAL digunakan untuk clear data input dan hasil prediksi dari aplikasi tersebut.
Implikasi Penelitian
Implikasi dari temuan penelitian ini mencakup pada dua aspek, yaitu manajerial dan sistem. Pada Aspek Manajerial dengan memperhatikan hasil pengukuran dan evaluasi maka Algoritma C4.5 dan Nerural Network menunjukan algoritma terbaik dalam pengklasifikasian data sehingga metode Algoritma C4.5 dan Neural Network dapat memberikan solusi dalam prediksi kelulusan tepat waktu.
Sedangkan pada aspek sistem, untuk mendukung pengambilan keputusan dan pengembangan sistem informasi manajemen strategik, model ini dapat diterapkan pada perusahaan menggunakan
software Weka ataupun aplikasi interface kelulusan tepat waktu yang telah dirancang menggunakan java engine.
KESIMPULAN
Berdasarkan hasil pengolahan data dan analisa, maka dapat diambil kesimpulan sebagai berikut :
a. Bahwa algoritma C4.5, Naïve Ba yes, dan Neural Network merupakan algoritma-algoritma yang dapat digunakan dalam menentukan prediksi kelulusan tepat waktu.
b. Algoritma terbaik adalah algoritma yang paling tinggi tingkat accuracy pada model klasifikasi yaitu C4.5 dan Neural Network dengan tingkat accuracy 100% sedangkan Naïve Bayes 99.8878% . Ketiga algoritma tersebut termasuk klasifikasi sangat baik karena memiliki nilai AUC (Area Under Curve) antara 0.90-1.00 sehingga dapat dipergunakan untuk aplikasi prediksi.
c. Dari algoritma terpilih dapat menampilkan NIM, Nama Mahasiswa, IPK, IMK, Prediksi kelulusan tepat waktu yang merupakan hasil klasifikasi datamining dengan menggunakan
engine java.
DAFTAR RUJUKAN
1. Bramer. 2007. Principles of Data Mining, Springer
2. Garner, R Stephen. WEKA: The Waikato Environment for Knowledge Analisys. Diambil November 2012 dari http://www.cs.waikato.ac.nz/~ml/publications/1995/Garner95-WEKA.pdf
3. Gorunescu Florin. 2011. Data Mining: Concept, Models and Techniques. Springer-Verleg Berlin Heidelberg
4. Han, Jiawei. Pei, Jian. 2007. Mining Frequent Pattern by Pattern-Growth: Metodology and
Implication. Diambil November 2012 dari
http://www.acm.org/sigs/sigkdd/explorations/issues/2-2-2000-12/han.pdf 5. Kusrini, luthfi taufiq Emha. 2009. Algoritma Data Mining, Penerbit Andi 6. Yogyakarta
7. Liu, Bing.2007. Integrating Classification and Association Rule Mining. Diambil November 2012 dari http://www.comp.nus.edu.sg/~dm2/publications/kdd98_1.ps
9. Prabowo. 2012. Aneka Teknik, Piranti dan Penerapan Data Mining: Studi Kasus Peramalan Harga Saham Industri Telekomunikasi Berbasis Jaringan Saraf Tiruan. Modul Perkuliahan Universitas Budi Luhur
10. She, Jyh-Jian. 2008. An Efficient Two-Phase Spam Filtering Method Based on E-Mails Categorization. International Journal of Network Security, Vol.8, No.3, PP.334-343, Taiwan 11. Vercellis, C., 2009. Business Intelligence; Data Mining and Optimization for Decision
Making. John Wiley & Sons, Ltd., UK