i
SUSUNAN DEWAN REDAKSI JELIKU
Ketua
Agus Muliantara, S.Kom, M.Kom
Penyunting
Dra. Luh Gede Astuti, M.Kom
Ngurah Agus Sanjaya E.R., S.Kom, M.Kom
Ida Bagus Mahendra, S.Kom, M.Kom
Ida Bagus Gede Dwidasmara, S.Kom, M.Cs
Pelaksana
I Ketut Gede Suhartana, S.Kom., M.Kom
I Gede Santi Astawa, S.T., M.Cs
I Made Widiartha, S.Si., M.Kom
Alamat Redaksi
Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Udayana
Kampus Bukit Jimbaran – Badung
Telepon : 0361 – 701805
Email : [email protected]
iii
DAFTAR ISI
SUSUNAN DEWAN REDAKSI JELIKU ... i
DAFTAR ISI ... iii
PERANCANGAN SISTEM PENDETEKSI LAHAN PARKIR KOSONG MENGGUNAKAN METODE CANNY EDGE DETECTION
Jecky Rusman ... 1
PERANCANGAN DAN IMPLEMENTASI SISTEM PERHITUNGAN JARAK DEALER DAN KECAMATAN MENGGUNAKAN GOOGLE DISTANCE MATRIX API PADA SISTEM BAYONET ASTRA HONDA
AA N Oka Abhina Amitabha ... 8
PERANCANGAN SISTEM INFORMASI MUTASI BARANG DI CV TRISTARS BERBASIS WEB
I Ketut Catur Putra Gama ... 21
IMPLEMENTASI MIKROTIK UNTUK PEMBATASAN BANDWIDTH DOWNLOAD DI DINAS KOMUNIKASI DAN INFORMATIKA KOTA DENPASAR
I Made Agus Suryawan ... 27
NETWORK MONITORING SYSTEM DENGAN MENGGUNAKA TOOLS WHATSUP GOLD PADA JARINGAN INDONET DENPASAR
Wayan Pasek Satrya Utama ... 32
PENCARIAN RUTE TERPENDEK RUMAH SAKIT DI KOTAMADYA DENPASAR DENGAN MENGGUNAKAN ALGORITMA DIJKSTRA
Alfian Dwi Chandra Kusuma ... 39
PERANCANGAN SISTEM INFORMASI INVOICE CV. AVATAR SOLUTION MENGGUNAKAN CODE IGNITER
iv
SISTEM PENCARIAN DOKUMEN BERITA BERBAHASA INDONESIA MENGGUNAKAN PARTITIONING AROUND MEDOIDS (PAM)
Aurora Dwifhani, Ngurah Agus Sanjaya ER., I Made Widiartha... 52
SISTEM INFORMASI INVENTORY TRANSAKSI BERBASIS WEB (STUDI KASUS CV TRISTARS)
I Gede Mika Winata1, I Made Widhi Wirawan2 ... 60
MENGANALISA PEFORMA PROTOKOL UDP DAN PROTOKOL SCTP
Ida Bagus Indra Dahana ... 76
RANCANG BANGUN SISTEM PAKAR UNTUK PREDIKSI DINI DIAGNOSIS PENYAKIT KANKER PAYUDARA BERBASIS WEB MENGGUNAKAN METODE FORWARD
CHAINING
Kadek Dewi Inland Ari ... 85
IMPLEMENTASI SAMBA SEBAGAI TEMPAT PENYIMPANAN DATA PEGAWAI ( FILE SERVER )
Made Sakha Yudha ... 96
PENERAPAN SALES COMPARISON PADA SISTEM INFORMASI PORTAL
I Made Junaedi Purbaya ... 103
IMPLEMENTASI PEMROGRAMAN WEB PADA SISTEM INFORMASI MANAJEMEN DATA SALES PT. TELKOM UNER 7 AREA 1
52
SISTEM PENCARIAN DOKUMEN BERITA BERBAHASA INDONESIA MENGGUNAKAN PARTITIONING AROUND MEDOIDS (PAM)
Aurora Dwifhani1, Ngurah Agus Sanjaya ER.2, I Made Widiartha3
Program Studi Teknik Informatika, Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam,
Universitas Udayana
[email protected], [email protected], [email protected]
ABSTRAK
Masalah yang seringkali muncul pada Information Retrieval adalah pengukuran kemiripan yang dilakukan hanya pada keyword dan dokumen sehingga penyajian hasil pencarian didasarkan pada kemiripan tersebut tanpa melihat similaritas antar dokumen. Kasus yang sering terjadi dokumen yang sebenarnya relevan terhadap query karena frekuensi kata querynya kecil akan berada pada ranking bawah dan sebaliknya.
Kekurangan tersebut dapat diatasi dengan menggunakan teknik clustering pada penyajian hasil pencarian. Teknik clustering digunakan untuk meningkatkan efektifitas dari hasil pencarian. Tujuan dari penelitian ini adalah membangun suatu sistem pencarian dokumen berita berbahasa Indonesia dengan mengimplementasi fungsi text mining dan algoritma PAM (Partitioning Around Medoids) yang dapat menampilkan hasil pencarian dokumen yang relevan dengan kata kunci yang dicari oleh user. Untuk mengukur performansi sistem pencarian, digunakan parameter Precission dan Recall. Sementara untuk mengetahui peningkatan pada efektifitas penggunaan PAM pada pencarian yang menggabungkan nilai Precission dan Recall, digunakan parameter F-measure.
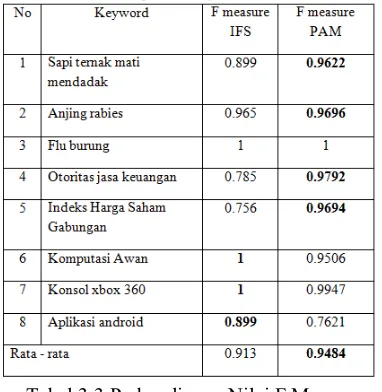
Dalam penelitian ini, didapatkan nilai rata-rata F-Measure untuk hasil pencarian menggunakan model IFS sebesar 0.913 dan untuk hasil pencarian menggunakan PAM sebesar 0.9484. Hal ini membuktikan adanya peningkatan nilai F-Measure sebesar 3.88%. Dengan adanya sistem pencarian dokumen berita berbahasa Indonesia menggunakan PAM ini maka efektivitas hasil pencarian dapat ditingkatkan sebesar 3.88% .
Kata Kunci : text mining , text preprocessing, clustering, PAM.
ABSTRACT
The problem that often arises in Information Retrieval similarity is measurements which are performed only on keywords and documents so that the presentation of search results is only based on the similarity without checking the similarity between documents. Most of the cases are the documents which exactly relevant to the query because the word frequency happens to be small will be ranked at the bottom.
These drawbacks can be overcome by using clustering techniques in the presentation of search result. Clustering techniques are used to increase effectiveness and search result. The aim of this study is to build a system of news document searching in Indonesian by implementing the functions of text mining and Partitioning Around Medoids (PAM) which can present search result for relevant documents with keyword looked for by the users. To measure the performance of the retrieval system, I use precission and recall parameters. Meanwhile to determine the increase in effectiveness of using PAM in the search that combines the value of precission and recall, I use F-measure parameters.
In this study, the average F-Measure value obtained for search results using IFS models is 0913 and by using PAM is 0.9484. It shows an increase in the value of the F-Measure of 3.88%. By using PAM in Indonesian language news document retrieval system, the effectiveness of search results can be improved by 3.88%.
Key Word : text mining , text preprocessing, clustering, PAM.
53 Penyimpanan dokumen secara digital meningkat dengan pesat seiring meningkatnya penggunaan komputer. Masalah yang timbul dari hal itu adalah sulitnya mengakses informasi yang dibutuhkan secara cepat dan akurat.
Dari masalah tersebut muncul kebutuhan untuk ekstraksi informasi secara otomatis dari kumpulan data tekstual yang besar agar mendapatkan sekumpulan informasi yang sesuai dengan kebutuhan. Solusi dari permasalahan tersebut dapat diatasi dengan pencarian informasi menggunakan metode text mining.
Text mining merupakan proses menggali, mengolah, mengatur informasi dengan cara menganalisa pola, hubungan, juga aturan-aturan yang ada dalam data tekstual semi terstruktur atau tidak terstruktur. Selain klasifikasi, text mining juga digunakan untuk menangani masalah clustering, information extraction, dan information retrival [1]
Salah satu metode yang sering digunakan dalam bidang text mining adalah metode clustering. Dalam bidang Text Mining, metode clustering telah diterapkan pada berbagai sisi, misalnya dalam mempartisi corpus[2], mengekstrak konsep[3], atau meningkatkan kinerja clustering dengan membangun Sistem temu Kembali berbasis konsep[4]
Sementara pada penelitian ini, akan dikembangkan suatu system pencarian dokumen menggunakan Partitioning Around Medoids (PAM). Park dan Jun menawarkan algoritma K-Medoids (PAM) dimana menurut penelitiannya algoritma ini menghasilkan kinerja yang baik dibandingkan K-Means dan dengan waktu yang lebih cepat.
2. TINJAUAN PUSTAKA 2.1Text Mining
Secara umum text mining adalah proses ekstraksi informasi dari dokumen-dokumen teks tak terstruktur. Text mining dapat didefinisikan sebagai penemuan informasi baru dan tidak diketahui sebelumnya oleh komputer, dengan secara otomatis mengekstrak informasi dari sumber-sumber teks tak terstruktur yang berbeda. Kunci dari proses ini adalah menggabungkan informasi yang berhasil diekstraksi dari berbagai sumber
[1]
.
Tujuan yang paling utama dari proses ini adalah mendukung proses knowledge discovery pada koleksi dokumen yang besar. Selain itu, tujuan text mining juga untuk mendapatkan informasi yang berguna dari sekumpulan dokumen. Jadi, sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur [1]
Dalam memberikan solusi, text mining mengadopsi dan mengembangkan banyak teknik dari bidang lain, seperti Data mining, Information Retrieval, Statistik, Matematika, Machine Learning, Linguistic, Natural Languange Processing, dan Visualization. [1]
Seperti halnya data mining, text mining juga menghadapi masalah yang sama, termasuk jumlah data yang besar, dimensi yang tinggi, data dan struktur yang terus berubah, dan data “noise.” Berbeda dengan data mining yang utamanya memproses data terstruktur, data yang digunakan text mining pada umumnya dalam bentuk unstruktur, atau minimal semistruktur text. [6]
2.2.Text Preprocessing
Teks yang akan dilakukan proses text mining, pada umumnya memiliki beberapa karakteristik diantaranya adalah memiliki dimensi yang tinggi, terdapat noise pada data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan dalam mempelajari suatu data teks adalah dengan terlebih dahulu menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen. Sebelum menentukan fitur – fitur tersebut, diperlukan tahap preprocessing yang dilakukan dalam text mining pada dokumen [5]
2.3 Feature Selection
Pada clustering teks terdapat suatu permasalahan yaitu adanya fitur – fitur yang berdimensi tinggi. Kerja dari Clustering tidak akan optimal apabila di dalamnya terdapat fitur yang tidak relevan dan redundan. Oleh karena itu diperlukan metode untuk mengurangi dimensi fitur ini. Dalam hal ini ada 2 metode yang sering digunakan, yaitu feature extraction dan feature selection. [6]
54 subset fitur dari fitur asli. Kelebihan feature selection dibandingkan dengan Feature extraction adalah pada seleksi fitur memberikan pemahaman yang lebih baik mengenai data sedangkan Feature extraction tidak demikian. [6]
2.2.1 Document Frequency
Document Frequency adalah jumlah dokumen yang mengandung suatu term tertentu. Tiap term akan dihitung nilai Document Frequency-nya (DF). Lalu term tersebut diseleksi berdasarkan jumlah nilai DF. Jika nilai DF berada di bawah threshold yang telah ditentukan, maka term tersebut akan dibuang. [6]
Document Frequency merupakan metode future selection yang paling sederhana dengan waktu komputasi yang rendah [6] 2.2.2 Term Frequency
Term Frequency merupakan salah satu metode untuk menghitung bobot tiap term dalam dokumen. Dalam metode ini, tiap term diasumsikan memiliki nilai kepentingan yang sebanding dengan jumlah kemunculan term tersebut pada dokumen. [1]
2.2.3 Inverse Document Frequency
Jika Term Frequency fokus pada kemunculan term dalam sebuah dokumen, Inverse Document Frequency (IDF) fokus pada kemunculan term pada keseluruhan koleksi dokumen. Pada IDF, term yang jarang muncul pada keseluruhan koleksi term dinilai lebih berharga. Nilai kepentingan tiap term diasumsikan berbanding terbalik dengan jumlah dokumen yang mengandung term tersebut. [1]
2.3 Clustering
Clustering adalah suatu metode pengelompokan berdasarkan ukuran kedekatan (kemiripan). Clustering berbeda dengan group. Jika group diartikan kelompok yang sama kondisinya, sedangkan cluster tidak harus sama akan tetapi pengelompokan berdasarkan pada kedekatan dari suatu karakteristik sampel yang ada [2]
2.3.1 Partitioning Around Medoid
Seperti halnya dengan K-Means, algoritma PAM mengelompokkan data ke dalam sejumlah K cluster. Berbeda dengan K-means, representasi cluster pada PAM adalah salah satu titik yang dipilih menjadi perwakilan cluster yang disebut dengan
medoids. Cluster dibangun dengan menghitung kedekatan yang dimiliki antara medoid dengan objek non-medoid.
3. IMPLEMENTASI 3.1 Context Diagram
Berdasarkan spesifikasi kebutuhan sistem maka dibuat gambaran umum sistem yang akan dibangun dalam penelitian ini. Gambaran umum, sistem pada penelitian ini ditunjukkan pada context diagram berikut:
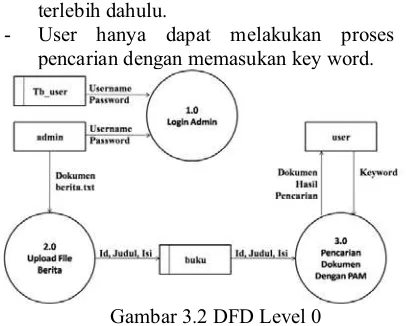
Gambar 3.1 Context Diagram Context diagram pada gambar 3.1 menjelaskan tentang gambaran sistem pencarian dokumen berita yang akan dibangun. Dari context diagram terlihat bahwa sistem yang akan dibangun. Berikut penjelasan mengenai workflow pada gambar 3.2 :
Interaksi pengguna sistem dibedakan menjadi dua diantaranya :
- Administrator dapat melakukan penambahan dokumen berita ke dalam database. Namun diperlukan proses login terlebih dahulu.
- User hanya dapat melakukan proses pencarian dengan memasukan key word.
Gambar 3.2 DFD Level 0
Gambar DFD Level 0 di atas menggambarkan 3 proses utama yang terjadi pada system pencarian dokumen berita ini, yaitu :
1. Proses Login
Proses untuk masuk ke sistem agar admin dapat menambahkan koleksi berita pada database berita.
55 Proses yang hanya dapat dilakukan admin yang sudah melakukan proses login. Pada proses ini admin melakukan upload dokumen berita ke database berita.
3. Proses Pencarian Dokumen
Merupakan proses utama dimana proses pencarian dokumen berita terjadi. Untuk proses yang lebih detail dapat dilihat pada gambar 3.3
Pada data flow diagram level 1 , proses pencarian dilakukan dengan memproses query yang dimasukan user.
1. Pada proses preprocessing, akan dilakukan preprocess pada query dan isi dari dokumen berita. Proses ini akan menghasilkan term list.
2. Kemudian pada proses feature selection akan dilakukan penghitungan DocId, Count, Bobot dan PanjangUnit. Dari proses ini dihasilkan vector dokumen yang telah dinormalisasi.
3. Kemudian dilakukan perhitungan kemiripan antar dokumen pada proses 3.3. 4. Setelah itu dokumen berita akan diklaster pada proses 3.5 menghasilkan cluster-cluster dokumen. Setiap cluster-cluster memiliki 1 dokumen sebagai perwakilan yang disebut medoid.
5. Medoid masing-masing cluster akan dihitung nilai kemiripannya dengan query pada proses 3.6. medoid yang memiliki nilai kemiripan lebih dari 0 akan ditampilkan sebagai hasil pencarian
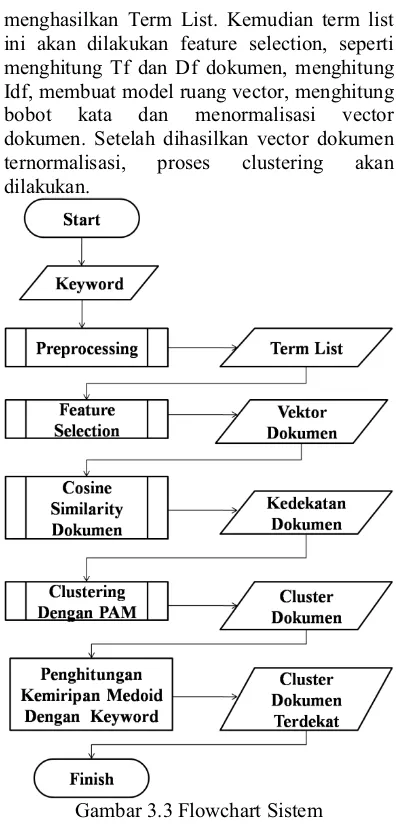
Gambar 3.3 DFD Level 1 3.2 Flowchart Sistem
Proses pencarian dokumen berita dapat dilihat pada gambar 3.3. Pada tahap awal dilakukan tahap preprocessing terhadap keyword dan dokumen. Proses ini akan
menghasilkan Term List. Kemudian term list ini akan dilakukan feature selection, seperti menghitung Tf dan Df dokumen, menghitung Idf, membuat model ruang vector, menghitung bobot kata dan menormalisasi vector dokumen. Setelah dihasilkan vector dokumen ternormalisasi, proses clustering akan dilakukan.
Gambar 3.3 Flowchart Sistem
56 kata query dengan frekuensi besar akan berada pada ranking atas.
Gambar 3.4 Flowchart Clustering PAM
3.3 Rancangan Database
Database yang digunakan dalam sistem ini adalah databse mysql dengan 8 tabel di antaranya :
1. Tabel “buku”
Tabel koleksi dokumen berita 2. Tabel “indeks”
Tabel hasil proses indexing. 3. Tabel “jarakdoc”
Tabel jarak antara dokumen berita 4. Tabel “kmedoid”
Tabel medoid dan jarak medoid dengan keyword
5. Tabel “query”
Tabel keyword yang dimasukan user 6. Tabel “queryindeks”
Tabel hasil indexing keyword 7. Tabel “tb_katadasar”
Tabel kumpulan kata dasar bahasa Indonesia
8. Tabel “vektor”
Tabel vektor dokumen berita 3.4 Hasil Pembahasan
3.4.1 Tampilan Antarmuka
Tampilan antarmuka penguna dalam sistem ini dibuat berbasis web dengan menggunakan bahasa pemrograman PHP. Tampilan indeks pada sistem ini adalah
halaman pencarian. Untuk dapat menambahkan dokumen berita, administrator harus melalui proses login administrator. Adapun tampilan antarmuka dari system pencarian ini adalah sebagai berikut.
1. Tampilan Halaman Pencarian Gambar 3.5 merupakan tampilan dari halaman pencarian.
Gambar 3.5 Tampilan Halaman Pencarian Pada halaman ini , user memasukan keyword pencarian, kemudian memilih menggunakan model IFS atau menggunakan PAM sebagai teknik penyajian. Jika user memilih PAM, maka hasil pencarian akan dikelompokan sesuai dengan hasil clustering seperti yang ditampilkan pada gambar 3.6
Gambar 3.6 Tampilan grup pada hasil pencarian menggunakan metode PAM 2. Halaman Utama Administrator
57 Gambar 3.7 Tampilan halaman login admin
Gambar 3.8 Tampilan halaman insert dokumen
3. Halaman pustaka
Pada halaman pustaka, terdapat koleksi dokumen berita.
Gambar 3.9 Tampilan halaman pustaka 3.4.2 Implementasi PAM Pada Penyajian Hasil Pencarian
Pada penelitian ini, PAM digunakan untuk meningkatkan efektifitas hasil pencarian. Setelah kotak isian keyword, terdapat menu pilihan jenis pencarian. Pilihan pertama adalah IFS. Pada IFS, hasil pencarian tidak disajikan dalam kelompok. Hasil pencarian diurutkan berdasarkan kedekatan keyword dengan dokumen.
Pilihan kedua adalah PAM. Pada metode ini, hasil pencarian akan dikelompokan berdasarkan kedekatan antara
dokumen. Perbedaannya terhadapa IFS adalah pada proses penyajiannya, dokumen dikelompokan berdasarkan kedekatan. Masing-masing kelompok memiliki 1 representasi yang disebut medoid. Pada penyajian, akan dihitung kedekatan keyword dan medoid-medoid tersebut. Medoid yang nilai kedekatannya tidak sama dengan 0 akan diretrieve sebagai hasil pencarian bersama dengan anggota kelompoknya.
Gambar 3.10 Pilihan jenis pencarian 3.4.3 Pengujian Sistem
Pengujian sistem menggunakan 86 dokumen berita yang didapatkan dari situs portal berita kompas.com. Pengujian dilakukan untuk menentukan akurasi dan efektifitas penggunaan PAM dalam penyajian hasil pencarian. Berikut merupakan rata-rata precision dan recall hasil pencarian menggunakan PAM dalam penyajian dalam 10 kali percobaan:
Tabel 3.1 Hasil Pengujian Pencarian Menggunakan PAM
58 Tabel 3.2 Hasil Pengujian Pencarian
Menggunakan IFS Keterangan :
N : Jumlah dokumen yang relevan dengan query dan terambil
M : jumlah seluruh dokumen yang terambil X : Jumlah dokumen yang relevan dengan query dan terambil sistem
Y : jumlah seluruh dokumen relevan dalam koleksi dokumen
Dari nilai precision dan recall percobaan di atas, kita dapat menghitung nilai F measure masing-masing metode.
Tabel 3.3 Perbandingan Nilai F Measure Berdasarkan tabel 3.3, didapatkan rata-rata nilai F measure masing-masing metode. Setelah dilakukan kedua pengujian, diketahui terdapat peningkatan Fmeasure pada F measure PAM sebesar 3.88%. Peningkatan pada nilai F measure merupakan tanda
efektifitas hasil pencarian meningkat karena disajikan dengan teknik clustering.
4. KESIMPULAN
Kesimpulan yang dapat diambil dari perancangan dan implementasi sistem pencarian dokumen berita berbahasa Indonesia menggunakan PAM ini adalah sebagai berikut :
1. Dengan adanya sistem sistem pencarian dokumen berita berbahasa Indonesia ini akan dapat mempermudah dalam pencarian dokumen berita. Dengan digunakannya clustering sebagai penyajian akan mempermudah user menemukan dokumen yang memiliki keterkaitan dengan dokumen hasil pencarian.
2. Dengan menyajikan hasil pencarian menggunakan teknik clustering dapat meningkatkan efektifitas mesin pencarian.
5. SARAN
Untuk pengembangan sistem ini lebih lanjut penulis ingin menyampaikan beberapa saran, antara lain :
1. Pada penelitian selanjutnya penulis diharapkan ketepatan hasil stemming dapat ditingkatkan dengan menggunakan algoritma stemming kata lain.
2. Pada penelitian selanjutnya penulis diharapkan dapat menggunakan objek penelitian lain dengan jumlah yang lebih besar sehingga hasil penelitian akan lebih akurat.
DAFTAR PUSTAKA
[1] Arifin, Agus Zainal dan Ari Setiono, Novan. Klasifikasi Dokumen Berita Kejadian Berbahasa Indonesia dengan Algoritma Single Pass Clustering. Institut Teknologi Sepuluh November (ITS). Surabaya.
[2] Chisholm, E., & Kolda, T. G. (1999). New Term Weighting Formulas For The Vector Space. 20.
[3] Feldman, R., Sanger, J. (2007). The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. New York: Cambridge University Press.
59 For Software Engineering With System Development Life Cycle. IOSR Journal of Engineering.
[5] Tala, Fadillah Z., 2003, A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia. Institute for Logic, Language and Computation Universeit Van Amsterdam.
[6] Triawati, Chandra. (2009). Metode