BAB III
METODOLOGI PENELITIAN
3.1
Kerangka
PikirSalah satu sifat penting dari kualitas teh adalah aroma.Identifikasi aroma teh dapat dilakukan dengan alat Electronic Nose(e-nose). Sistem pengenalan aroma menggunakan sensor e-noseakan menterjemahkan informasi yang diterima lalu diterjemahkan. Berbagai aroma teh, termasuk teh hitam dapat bisa dikenali menggunakan rangkaian sensor dari e-nose.
Sistem pengenalan pola aroma teh hitam menerima data masukan dari keluaran rangkaian sensor.Pengenalan pola aroma teh dapat dilakukan dengan Support Vector Machine (SVM).SVMmerupakansalahsatumetode
klasifikasiyangmenempatiurutan pertamasebagaimetode klasifikasidengantingkatakurasi tertinggi(Kotsiantis,2007).Ditambahlagi,
SVMmerupakansuatumetodeyang didasarkan pada statistikdan outputnya dapat dibuktikan secara matematis. SVMtetapmampumelakukanklasifikasi denganbaik.Halinidisebabkankarenamemberikan nilaioptimasi global.
Pada dasarnya,SVMdirancanghanyauntukmasalahklasifikasibiner, dimana data yang terdapat di dalam suatu model SVM hanya mungkin terklasifikasi ke dalam dua kelas saja. SVMmampumelakukanklasifikasiterhadaplebih dari dua kelasdimanacaranyaadalahdenganmenggunakanlebihdari satu persamaanhyperplane salah satunya adalah one-against-all.
Tesis ini mengajukan Discrete Wavelet Transform (DWT) untuk
m s
3
y
t t b s
3
memperoleh sebagai peng
3.2 Met
Meto yaitu proses
Meto teknikekstra teknik klasi bahwa SVM sudah terleb
3.2.1 Tra
h penciri at genalan pola
todologi
odologi yan ekstraksi da
Ga
odologi y aksifiturdanS
fikasi yang M harus terleb
ih dahulu di
nsformas
tau fitur dar a dari data te
ng diusulka an klasifikas
ambar 3.1 M
yang diu SVMsebagai
tergolong k bih dahulu d ketahui kela
si Wavele
ri data hasi eh hitam.
an pada pe i seperti pad
Metodologi ya
usulkan teknikklasifi ke dalam su dilatih denga asnya.
et
il pengukur
nelitian ini da gambar 3.
ang diusulka
menggunak fikasi.SVM upervised lea an diberikan
ran e-nose,
ada 2 tahap 1.
an
kan DWT merupaka arning. Hal sampel data
dan SVM
pan proses,
T sebagai an suatu
ini berarti a-data yang
Sinyal ditransformasikan menggunakan Discret Wavelet Transformation1dimensi (DWT 1-D).Wavelet yang digunakan dalam penelitian ini adalah keluarga Daubechies, karena Daubechies memberikan analisis orthogonal yang merupakan kondisi yang diperlukan untuk ekstraksi ciri (Distante dkk, 2011).Ekstraksi ciri sinyal menggunakan DWT ortogonal genap menunjukan hasil yang lebih baik dalam ekstraksi ciri, apabila dibandingkan dengan DWT orthogonal ganjil (Khot and Panigrahi, 2006). Tinjauan Khot and Panigrahi (2006) menunjukan db4, db8 dan db20 pada level 3 dan 6 sebagai wavelet yang umum untuk denoising dan kompresi dari sinyal.
Besar tingkatan level dekomposisi harus dipilih manual. Pemilihan level dengan skala kecil akan menimbulkan permasalahan over fitting dengan kehilangan kemampuan generalisasi. Pemilihan level dengan skala tinggi akan meningkatkan kesalahan dalam rekonstruksi sinyal. Dalam setiap aplikasi, level dekomposisi digunakan oleh peneliti berbeda-beda.Keriteria pemilihan level dokomposisi yang optimal adalah perbedaan antara siyal denoised dan asli (Phaisangittisagul & Nagle, 2010). Pemilihan level dekomposisi didasari atas pertimbangan bahwa pada level tersebut kualitas sinyal masih dapat dipertahankan dan noise yang melatarbelakangi sinyal mulai menunjukkan tanda- tanda pengurangan pengaruhterhadap sinyal.
Gambar 3.2 menunjukkan diagram proses ekstraksi ciri sinyal sensor dari e-nose. Pada pengujian awal proses ekstraksi ciri dengan menggunakan wavelet Daubechies DB4 dengan tingkat dekomposisi 3. Dan dilanjutkan dengan dekomposisi tingkat 6.Kemudian digunakan kembali untuk Daubechies DB8 dan
Daubechies DB20 dengan masing-masing tingkat dekomposisi yang digunakan adalah 3 dan 6.
Gambar 3.2 Proses ekstraksi ciri sinyal
Transformasi wavelet dalam penelitian ini menggunakan wavelet toolbox dari MATLAB. Ada 4 tahapan dalam melakukan ekstraksi ciri menggunakan wavelet :
1. Dekomposisi wavelet 1-D 2. Rekonstruksi sinyal
3. Perhitungan nilai Reconstruction Squared Error (RSE)
4. Penentuan level dekomposisi yang akan digunakan untuk ekstraksi ciri
Proses ekstraksi ciri yang menjadi fokus pada penelitian ini dibagi ke dalam tiga proses ekstraksi ciri diantaranya dengan menggunakan Daubenchies DB4, DB8 dan DB 20.Masing-masing proses ekstraksi ciri di atas akan menghasilkan koefisien-koefisien(koefisien detail dan perkiraan) yang diperoleh dari hasil dekomposisi pada level 3 dan 6.
DB4 DB8 DB20
Level 3 Level 6 Sinyal
Sinyal yang akan diproses merupakan sinyal digital yang direpresentasikan ke dalam sebuah matriks. Sinyal tersebut kemudian ditransformasi menggunakan Wavelet Toolbox pada MATLAB untuk mendapatkan ekstraksi ciri.wavedec merupakan perintah dalam Wavelet Toolbox MATLAB untuk melakukan analisis multilevel wavelet 1-D dengan menggunakan wavelet tertentu atau level dekomposisi tertentu. Command line yang digunakan dalam sintaks MATLAB untuk proses multiple dekomposisi pada level X dengan S merupakan sinyal hasil proses sebelumnya adalah sebagai berikut :
[C,L] = wavedec(S,X,'wname') Dimana :
S = data sinyal X = level dekomposisi
wavename = keluarga wavelet yang akan digunakan
Pada penelitian ini koefisien yang diambil sebagai masukan ke proses selanjutnya adalah koefisien yang dihasilkan dari frekuensi rendah yaitu koefisien perkiraan (approximation) karena bagian penting dari suatu sinyal terletak pada frekuensi tersebut, yang mampu memberikan identitas dari suatu sinyal. Koefisien yang dihasilkan akan membentuk suatu vektor. Algoritma berikut adalah untuk mencari koefisien detail pada proses multiple dekomposisi :
• Sinyal yang masuk difilter ke dalam sinyal frekuensi rendah (low-pass filter) dan sinyal frekuensi tinggi (high-pass filter). Filter set tersebut berasal dari keluarga wavelet (wavename) yang digunakan. Sehingga
masing-masing wavelet Db4, Db8 dan Db20 memiliki jenis set filter yang berbeda.
• Melakukan downsampling, yaitu dengan menghilangkan nilai matriks dengan index ganjil dan mengambil matriks yang memiliki index genap pada kedua sinyal tersebut.
• low-pass frekuensi hasil downsampling selanjutnya melalui proses seperti tahap pertama.
• Lakukan ulang sampai pada level yang diinginkan
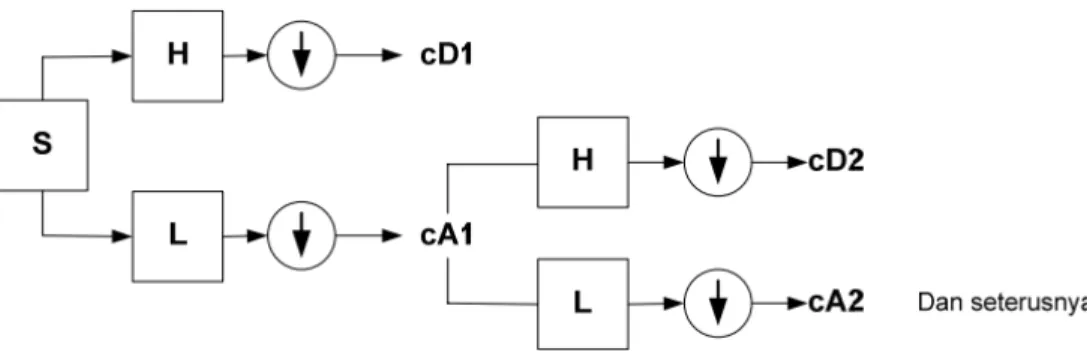
Jika diilustrasikan ke dalam gambar terlihat seperti gambar 3.3. Gambar 3.3 memperlihatkan sebuah sinyal S dengan panjang sinyal N yang melewati low- pass filter (L) dan high-pass filter (H) kemudian diikuti dengan downsampling.
Pada langkah pertama menghasilkan dua koefisien yaitu koefisien perkiraan (cA1) dan koefisien detail (cD1). Tahap selanjutnya adalah membagi koefisien perkiraan (cA1) dalam dua bagian menggunakan skema yang sama dengan skema pertama.
Pada langkah kedua menghasilkan cA2 dan cD2 dan seterusnya sampai level yang diinginkan.
Gambar 3.3 Proses Multiple dekomposisi
Untuk mendapatkan koefisien perkiraan (cAX) pada MATLAB digunakan sintaks :
cAX = appcoef(C,L, 'wname',X);
Sinyal yang dihasilkan dari koefisien perkiraan (approximation), yang dievakuasikan ke dalam diagram plot terlihat pada gambar 3.5.
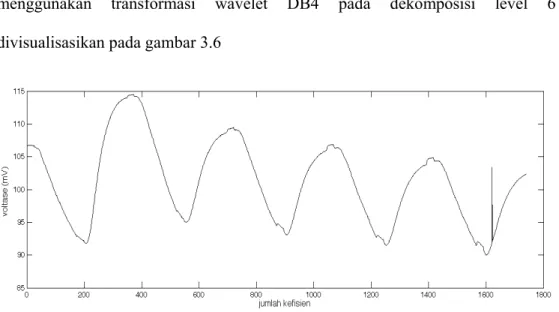
Pada Gambar 3.4 memperlihatkan plotting sinyal dari salah satu sensor pada jenis teh tertentu.Sinyal tersebut kemudian ditransformasi menggunakan wavelet DB4 pada dekomposisi level 3, dan dihasilkan koefisien perkiraan yang divisualisasikan ke dalam diagram plot pada gambar 3.5. Koefisien perkiraan menggunakan transformasi wavelet DB4 pada dekomposisi level 6 divisualisasikan pada gambar 3.6
Gambar 3.4 Grafik sinyal sensor dari jenis teh hitam
(a) (b)
Gambar 3.5 Sinyal koefisien perkiraan dari the hitam jenis BP2 dengan dekomposisi db4, (a) level 3, (b) level 6
Penentuan level dekomposisi optimal tidak hanya dipengaruhi oleh basis danteknik wavelet yang digunakan, akan tetapi juga tujuan dalam ekstraksi ciri itusendiri. Perbedaan dalam kualitas pada tiap level memberikan akhir yang berbeda dalam klasifikasi citra maupun ekstraksi ciri. Klasifikasi citra akan lebih akurat apabila citra hasil fusi memilikikualitas yang baik dancukup detail. Selain itu metode validasi yang digunakan untuk pemilihan level dekomposisi yang optimal adalah berdasarkan nilai terkecil dari Reconstruction Squared Error (RSE) yang dihitung dari perbedaan sinyal rekonstruksi (S’) dengan sinyal asli (S) dengan menggunakan sintaks:
RSE = norm(abs(S-S’))
Perubahan data sinyal dapat direpresentasikan dalam notasi matriks seperti yang disajikan dalam pada Gambar 3.6.
Sensor 1 Sensor 2 ... Sensor n
tk(0) x0,1 x0,2 x0,n
tk(1) x1,1 x1,2 x1,n
. . .
. . .
. . .
. . .
tk(k) xk,1 xk,2 xk,n
Sensor 1 Sensor 2 ... Sensor n
T(0) X0,1 X0,2 X0,n
T(1) X1,1 X1,2 X1,n
. . .
. . .
. . .
. . .
T(m) Xm,1 Xm,2 Xm,n
Gambar 3.7 Perubahan data sinyal
Dimana:
- m k
- x0,1 adalah respon sinyal dari sensor 1 pada waktu t= 0 - X0,1 adalah koefisien wavelete dari sensor 1 pada waktu T=0
3.2.2 Pengurangan Dimensi
Wf
Principal Component Analysis atau yang lebih populer dikenal dengan singkatnya ‘PCA’, adalah sebuah metode statistik yang banyak digunakan dalam sistem kompresi citra.Pengurangan dimensi menggunakan Principal Component Analysis (PCA) yang telah dikenal juga sebagai Karhunen-Loève. PCA pada dasarnya bekerja pada sekelompok data observasi yang pada awalnya memiliki kemungkinan saling berelasi, kemudian proses PCA mengkonversi data tersebut sedemikian rupa sehingga yang tersisa adalah data yang tidak saling berelasi satu sama lain yang disebut dengan Principal Component.
Jumlah Principal Component yang dihasilkan adalah kurang dari atau sama dengan jumlah data aslinya. Principal Component akan diurutkan dari data yang dianggap paling penting sampai data yang kurang penting. Sederhananya, data pada baris pertama hasil konversi adalah Principal Component pertama dan yang paling berpengaruh terhadap variasi data asli. Proses PCA dapat dilakukan dengan 2 cara:
1. Menggunakan eigen function dari covarian-nya.
2. Menggunakan SVD (Singular Value Decomposition).
Yang akan dibahas di sini adalah cara 1, yang diimplementasikan pada bahasa pemrograman MATLAB dengan menggunakan komponen standar dan komponen dari Statistics Toolbox.
PCA menghasilkan satu set baru variabel yang disebut komponen utama.
Setiap komponen utama adalah kombinasi linier dari variabel asli. Semua komponen utama ortogonal satu sama lain, sehingga tidak ada informasi yang
berlebihan. Principal komponen sebagai bentuk keseluruhan basis ortogonal untuk ruang data.
Komponen utama pertama (PCA 1) adalah sumbu tunggal dalam ruang.Ketika masing-masing data diproyeksikan ke sumbu tersebut, maka nilai- nilai data yang dihasilkan membentuk variabel baru.Varian dari variabel tersebut adalah nilai maksimal dari sumbu pertama. Komponen utama kedua (PCA 2) adalah sumbu lain dalam ruang, yang tegak lurus dengan PCA 1.
Memproyeksikan pengamatan pada sumbu ini menghasilkan variabel baru.Varian dari variabel tersebut adalah nilai maksimal dari sumbu kedua.
Pada penelitian, data yang digunakan untuk menghitung komponen adalah dengan menggunakan data hasil ekstraksi ciri dari wavelet.Perhitungan komponen menggunakan 4 indeks data (4 dimensi) yang berbeda yang merupakan data dari 4 sensor. Command line yang digunakan dalam sintaks MATLAB untuk menghitung komponen dengan S merupakan data hasil ekstraksi ciri dari wavelet adalah sebagai berikut :
[COEFF, SCORES,VARIANCES,t2] = princomp(S);
You can easily calculate the percent of the total variability explained by each principal component.
Dan untuk menghitung menghitung persentase total variabilitas oleh masing- masing komponen, dengan perintah :
percent = 100*VARIANCES /sum(VARIANCES)
Fungsi ini akan menghitung eigen function dari covarians-nya dan menghasilkan tiga buah variabel yakni: COEFF, SCORE dan VARIANCES.
Output pertama dari fungsi princomp, COEFF, berisi koefisien dari kombinasi
linier dari variabel asli yang menghasilkan komponen utama.Output kedua, SCORES, berisi koordinat dari data asli dalam sistem koordinat baru yang ditentukan oleh komponen utama. Ukuran matriks dari SCORES sama dengan ukuran matriks input data.
Gambar 3.7 merupakan sebuah plot dua kolom pertama dari SCORES menunjukkan data diproyeksikan ke dalam dua principal komponen yang pertama.
princomp menghitung agar nilai rata-rata dari SCORES adalah nol.
Gambar 3.7 PC1 vs PC2
Penentuan jumlah komponen yang akan digunakan dengan melihat persentase keragaman total. Persentase keragaman total yang besar (lebih besar dari 60%) bisa dinilai cukup untuk menangkap struktur data.
3.2.3 Klasifikasi
Pengenalan pola-pola sampel teh hitam pada penelitian ini mengunakan Support Vector Machine (SVM). Dalam proses ini, data hasil pengukuran yang telah di extrak menggunakan PCA digunakan sebagai data masukan pada proses SVM. Data terebut dibagi menjadi dua bagian, yaitu data pelatihan dan data pengujian. Data pelatihan digunakan untuk melatih mesin pembelajaran mengenali pola-pola setiap sampel. Sedangkan data pengujian digunakan untuk menguji kemampuan jaringan dalam mengenali pola-pola sampel.
Banyak penelitian mengatakan bahwa teknik support vector machine merupakan teknik klasifikasi terbaik karena memiliki kelebihan sebagai berikut :
1. Generalisasi
Generalisasi didefinisikan sebagai kemampuan suatu metode untuk mengklasifikasikan suatu pattern, yang tidak termasuk data yang dipakai dalam fase pembelajaran metode itu.
2. Curse of dimensionality
Curse of dimensionality didefinisikan sebagai masalah yang dihadapi suatu metode pattern recognition dalam mengestimasikan parameter (misalnya jumlah hidden neuron pada neural network, stopping criteria dalam proses pembelajaran dsb.) dikarenakan jumlah sampel data yang relatif sedikit dibandingkan dimensional ruang vektor data tersebut. Semakin tinggi dimensi dari ruang vektor informasi yang diolah, membawa konsekuensi dibutuhkannya jumlah data dalam proses pembelajaran.Vapnik membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM tidak dipengaruhi oleh
dimensi dari input vector. Hal ini merupakan alasan mengapa SVM merupakan salah satu metode yang tepat dipakai untuk memecahkan masalah berdimensi tinggi, dalam keterbatasan sampel data yang ada.
3. Feasibility
SVM dapat diimplementasikan relative mudah, karena proses penentuan support vector dapat dirumuskan dalam Quadatric Programming problem. Dengan demikian jika kita memiliki library untuk menyelesaikan QP problem, dengan sendirinya SVM dapat diimplementasikan dengan mudah.Quadratic Programming merupakan metode untuk menyelesaikan permasalahan optimasi yang bersifat nonlinier
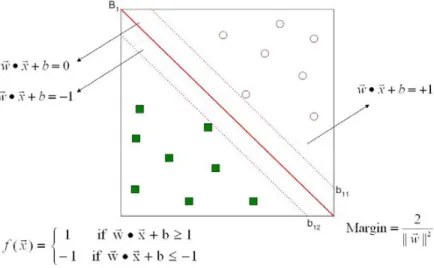
Gambar 3.8 Support Vector Machine
Gambar 3.8 memperlihatkan model support vector machine dimana dilakukan proses pemetaan nonlinier untuk mengubah training data menjadi dimensi yang lebih tinggi. Didalam dimensi baru akan dicari sebuah linear optimal yang memisahkan hyperplane (batas pemisah antar kelas). Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur
margin dari hyperplane tersebut dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane dengan pattern terdekat dari masing-masing kelas. Pattern yang paling dekat disebut sebagai support vector . Kelebihan SVM dibandingkan dengan metode lainnya terlihat pada kemampuannya menemukan hyperplane terbaik yang akan memisahkan dua kelas pada feature space agar mendapatkan hasil klasifikasi yang terbaik.
Metode validasi yang digunakan dalam penentuan data pelatihan dan pengujian adalah ini merujuk pada motode hold out. Dalam metode ini, data asli dipartisi menjadi dua himpunan yang saling terpisah yang dinamakan training set dan test set. Model klasifikasi kemudian dibangun berdasarkan training set dan hasilnya kemudian dievaluasi dengan menggunakan testing set. Akurasi dari masing-masing metode klasifikasi dapat diestimasi berdasarkan akurasi yang diperoleh dari test set. Proporsi antara training set dan test set tidak mengikat tetapi agar variansi dalam model tidak terlalu besar maka dapat ditentukan bahwa proporsi training set lebih besar daripada test setnya. Secara khusus, 2/3 dari data dijadikan training set dan l/3 lagi dijadikan testing set.
Perintah yang digunakan dalam sintaks MATLAB untuk penentuan training set dan test set adalah sebagai berikut :
[Train, Test] = crossvalind(Method, Group, P)
Group adalah vektor pengelompokan yang mendefinisikan kelas untuk setiap pengamatan dimana dalam penelitian ini adalah group dari teh hitam BP2, BT2 dan DT2.Pembagian kelompok tergantung pada jenis Method yang digunakan.Pada penetian in metode validasi menggunakan HoldOut.Nilai P harus
diantara 0 dan 1. Nilai P yang digunakan dalam penelitian ini adalah 1/3 atau 33,33% dari keseluruhan data input Group.
Untuk melakukan klasifikasi pola yaitu dengan menggunakan dua tahap yaitu pelatihan dan tes.SVM dalam MATLAB mengklasifikasikan data ke dalam dua kelas.Terdapat dua fungsi yang digunakan, yaitu svmtrain untuk pelatihan dan svmclassify untuk mengklasifikasikan data berdasarkan pelatihan sebelumnya.
3.2.3.1 Svmtrain
Perintah yang digunakan dalam sintaks MATLAB untuk training support vector machine classifier adalah sebagai berikut :
SVMStruct = svmtrain(Training, Group)
Pelatihan pada support vector machine (SVM) classifier menggunakan data Training. Data Training merupakan sebuah matriks data yang diambil dari kedua Group.svmtrain akan memperlakukan NaN atau data kosong pada Group sebagai data yang tidak terpakai dan mengabaikannya. Informasi pelatihan SVM classifier terdapat dalam SVMStruct, dimana terdapat informasi-informasi berikut:
• Bias
• KernelFunction
• ScaleData (sift dan scale)
Bias merupakan intercept dati hyperplane yang memisahkan kedua kelompok di ruang data yang ternormalisasi. shiftnilai negatif dari rata-rata seluruh observasi dalam pelatihan. Scaleadalahnilai 1 pada standar deviasi pelatihan.
Pada dasarnya, SVM dirancang hanya untuk masalah klasifikasi biner, dimana data yang terdapat di dalam suatu model SVM hanya mungkin terklasifikasi ke dalam dua kelas saja. Untuk memungkinkan SVM mampu melakukan klasifikasi terhadap lebih dari dua kelas dimana caranya adalah dengan menggunakan lebih dari satu persamaan hyperplane. Pada penelitian ini pendekatan yang dapat digunakan untuk memecahkan masalah SVM multikelas yaitu dengan menggunakan metode one-against-all.
Pada metodeone-against-all, setiap data yang terdapat di dalam salah satu kelas SVM akan diadu/dibandingkan dengan gabungan dari data- data yang bukan merupakan anggota kelas tersebut. Hal ini berarti bahwa model SVM dibuat terhadap masing-masing kelas. Ada 3 kelas dari data train yaitu kelas BP2, BT2, dan DT2 dimana kelas tersebut merepresentasikan jenis-jenis teh hitam yang akan diklasifikasi. Masing-masing kelas akan memiliki persamaan hyperplane- nya masing-masing, yaitu hyperplane BP2 (data BP2 dibandingkan data bukan BP2), hyperplane BT2 (data BT2 dibandingkan data bukan BT2), dan hyperplane DT2 (data DT2 dibandingkan data bukan BT2). Hal ini berarti bahwa pengujian terhadap data input harus dilakukan minimal 1 kali (terhadap salah satu kelas) dengan maksimum 3 kali (terhadap keseluruhan kelas).
Gambar 3.9 merupakan data train dari data yang sebelum nya telah ditransformasi dengan wavelet dan PCA. Data ‘1’ merupakan kelompok data train
dari teh hitam jenis BP2 dan ‘0’ merupakan data train dari teh hitam yang bukan jenis BP2 (BT2 dan DT2).
Gambar 3.9Datatrain
SVM non-linear dikembangkan untuk memecahkan masalah yang tidak dapat dipecahkan oleh SVM linear.Ide dasardarimodelSVMnon- lineariniadalahmemetakandatadarisuatu bidang dengan dimensi tertentu, ke dalam bidang dengan dimensi yang lebih tinggi. Kernel trick digunakan untuk memecahkan masalah SVM non-linear dengan mudah tanpa melakukan perhitungan yang rumit. Kernel Radial Basis Function (RBF) dapat menghasilkan performa klasifikasi mendekati tepat dengan penggunaan waktu dan memori yang sedikit (H. Cao dkk, 2008).
Perintah yang digunakan dalam sintaks MATLAB untuk training support vector machine classifier dengan menggunakan kernel RBF adalah sebagai berikut :
svmStruct = svmtrain(Train, Group, 'Kernel_Function','rbf')
Gambar 3.10memperlihatkan sebuah hyperplane dengan menggunakan kernel RBF.Data training dipisahkan oleh Garis Hyperplane yang tidak linear.
Gambar 3.10 Data train yang sudah di training
3.2.3.2 Svmclassify
Setelah training dilakukan, proses selanjutnya adalah melakukan testing terhadap hasil training. Perintah yang digunakan dalam sintaks MATLAB untuk training support vector machine classifier dengan menggunakan kernel RBF adalah sebagai berikut :
classes = svmclassify(svmStruct,Test);
Svmclassify mengklasifikasikan setiap baris data test dengan menggunakan informasi dalam struktur SVM (svmStruct). Gambar 3.12 menggambarkan proses klasifikasi dengan memasukkan data testke dalam ruang hasil pengujian, yang kemudian informasi hasil klasifikasi disimpan ke dalamclasses. Performa klasifikasi (cp)dapat dihitung dengan perintah :
classperf(cp,classes,test);
Gambar 3.11 Klasifikasi data menggunakan SVM
Proses pelatihan svmtrain dan tes svmclassify dilakukan untuk setiap jenis teh. Setelah klasifikasi BP2 dilakukan kemudian dilakukan kembali untuk BT2 dan DT2.Performa klasifikasi yang diambil berdasarkan hasil rata-rata performa setiap jenis teh yang dilakukan 10 kali pengujian.
3.3 Metode Pengumpulan Data
3.3.1 Bahan Penelitian
Bahan yang digunakan dalam penelitian ini berupa sampel teh hitam dengan berbagai jenis yang menunjukkan tingkat kualitas nya.Sampel yang digunakan dalam penelitian ini diperoleh dari Pusat Penelitian Teh dan Kina (PPTK), Badan Penelitian dan Pengembangan Departemen Pertanian Jawa Barat.
Tabel 3.1 Jenis teh hitam untuk sampel penelitian
No. Jenis Keterangan
1 BP2 Broken Pekoe
2 DT2 Dust
3 BT2 Broken Tea
3.3.2 Alat Penelitian
Alat yang dipakai dalam penelitian yaitu seperangkat E-nose merk EnaBlue, neraca digital, tabung sampel, dan airflow meter. E-nose yang digunakan dalam penelitian ini dilengkapi dengan 4 buah sensor gas, yaitu :
• TGS880 yang peka terhadap bau/aroma secara umum
• TGS826 yang peka terhadap amonia
• TGS822 yang peka terhadap gugus alkohol
• TGS825 yang peka terhadap hidrogen sulfida
Menurut Rahayu (2007) E-nose memiliki serangkaian gas sensor yang masing-masing akan memberikan reaksi terhadap perubahan aroma teh. Aroma
teh akan memberikan reaksi berupa perubahan tahanan pada setiap gas sensor.
Dengan adanya perubahan tahanan dari setiap gas sensor ini akan mengakibatkan timbul nya perubahan voltase. Daya yang diperoleh dari perubahan voltase ini berupa data digital komputer. Untuk selanjutnya data tersebut akan diolah dalam penelitian ini
3.3.3 Preparasi Sampel
Proses preparasi sample dilakukan di Lab Fisika Material Jurusan Fisika FMIPA UGM. Sampel teh hitam ditimbang sebanyak 5 gram dengan menggunakan neraca digital, dibungkus dengan kertas khusus pembungkus teh dan disimpan dalam tabung plastik 500 mL. Setiap jenis sampel diambil 250 gram (50 bungkus) yang digunakan untuk lima kali pengukuran denga menggunakan e- nose, sekali pengukuran membutuhkan 50 gram sampel.
3.3.4 Pengukuran Aroma
Pengukuran aroma sampel menggunakan e-nose yang dilakukan di Laboratorium Penelitian dan Pengujian Terpadu (LPPT) UGM.
Sampel sebanyak 50 ram (10 bungkus) diletakkan dalam tabung sampel berupa tabung Pyrex 500 mL.Semua prosedur pengukuran dikontrol menggunakan program yang dinamakan program akuisisi data. Tombol start pada program akuisisi data diaktifkan dan aroma sampel yang berada dalam tabung sampel akan dihisap oleh pompa sampel dan didorong ke tabung sensor. Dalam tabung sensor aroma sampel akan dideteksi oleh larik sensor gas lalu dihisap oleh pompa exhaust untuk dibuang.Selanjutnya pompa udara bersih akan menghisap
aroma udara bersih dari tabung udara bersih dan didorong ke tabung sensor, kemudian deteksi oleh larik sensor gas dan setelah dideteksi dibuang oleh pompa exhaust.
Setiap pengukuran mengandung lima siklus, artinya larik sensor gas melakukan proses pendeteksian aroma sampel dan aroma udara bersih sebanyak lima kali. Hasil pendeteksian aroma sampel dan aroma udara bersih tersebut disimpan dalam komputer dengan melihat konsistensi grafik perubahan tegangan, bila larik sensor gas mendeteksi aroma sampel maka grafik nya naik sedangkan bila mendeteksi aroma udara bersih maka grafik nya turun.Nilai parameter perlakuan yang paling konsisten digunakan untuk melakukan pengukuran sampel- sampel yang dipakai dalam penelitian ini.
Hasil pendeteksian aroma sampel dan aroma udara bersih tersebut disimpan dalam komputer berupa data perubahan tegangan. Untuk satu jenis sampel dilakukan lima kali pengukuran dengan menggunakan sampel yang baru (fresh) setiap pengukuran. Setelah selesai pengukuran untuk sampel kemudian dilakukan pengukuran untuk sampel jenis tehlain seperti pengukuran sebelumnya sampai semua sampel selesai diukur.
Pengambilan jumlah data teh hitam yang diambil dengan menggunakan e-nose dapat dilihat pada tabel 3.2.
Table 3.2Pengambilan Data Teh Hitam
No. Jenis Keterangan Banyaknya
pengambilan data
1 BP2 Broken Pekoe 5
2 DT2 Dust 5
3 BT2 Broken Tea 5