Fakultas Ilmu Komputer
Universitas Brawijaya
6556
Pengenalan Citra Makanan Tradisional menggunakan Fitur Hue
Saturation Value dan Fuzzy k-Nearest Neighbor
Refi Fadholi1, Yuita Arum Sari2, Fitra Abdurrachman Bachtiar3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Makanan dan jajanan tradisional merupakan pangan khas yang biasanya digunakan untuk acara atau tradisi. Sebagian masyarakat menganggap makanan dan jajanan tradisional adalah pangan yang sudah ketinggalan zaman, sehingga makanan dan jajanan tradisional tersebut banyak yang ditinggalkan oleh masyarakat dan mulai beralih pada kehidupan modern, padahal makanan dan jajanan tradisional sendiri adalah salah satu bentuk wujud warisan nenek moyang yang seharusnya tetap dilestarikan dari generasi penerus. Pembuatan sistem yang dapat mengenali jenis makanan tradisional dapat dilakukan menggunakan pengolahan citra digital. Dalam penelitian ini, citra yang digunakan adalah citra hasil segmentasi dengan pengujian tiga jenis data, yaitu 300 data citra hasil segmentasi paling bagus, 300 data citra dengan jumlah data tiap kelas hampir sama dan 400 data citra dengan hasil segmentasi paling bagus. Fitur citra yang digunakan adalah Hue Saturation Value (HSV) yang meliputi mean, deviasi standar, skewness dan kurtosis tiap dimensi warnanya. Klasifikasi dilakukan memakai metode Fuzzy k-NN dan k-Fold Cross Validation. Hasil pengujian nilai k (k-Fold) dan k (k-NN) didapatkan hasil akurasi rata-rata tertinggi sebesar 53,33%. Hasil pengujian juga menunjukkan bahwa kemiripan citra antar kelas, kualitas data citra yang kurang bagus dan tidak meratanya data membuat nilai akurasi pengujian menurun.
Kata kunci: makanan tradisional, hue saturation value, fuzzy-knn, k-fold cross validation. Abstract
Traditional food and snacks are typical of ancestors usually used for events or traditions. Some people consider that traditional food and snacks are obsolete, so that more traditional food and snacks are left behind by the people, and begin to shift to modern life, whereas traditional snacks themselves are one form of ancestral heritage that must preserved by next generation. Making system that can identify traditional types of food can be done using digital image processing. In this study, the image data used the result of image after segmentation with three types of data on testing, that is 300 images of the best segmentation result, 300 data of images with the amount of data each class is almost same and 400 data of images with the best segmentation results. Image feature used Hue Saturation Value (HSV) that contains mean, standard deviation, skewness and curtosis each color dimensions. Classification using the Fuzzy k-NN method and k-Fold Cross Validation. The test results based on values of k (k-Fold) and k (k-NN) obtained highest average accuracy at 53.33%. The test results also show that high color similarity between classes, poor image quality data and uneveness amount of data makes the test result decreased.
Keywords: traditional food, hue saturation value, fuzzy-knn, k-fold cross validation
1. PENDAHULUAN
Indonesia terdiri dari beberapa pulau besar dan mempunyai banyak provinsi berpotensi besar dalam wisata makanan (food tourism) karena memiliki kekayaan etnis dan budaya, yang masing-masing memiliki kuliner khas tersendiri. Hampir semua daerah di Indonesia
memiliki makanan khas yang bisa ditampilkan sebagai daya tarik bagi wisatawan misalnya dari daerah Tapanuli dan Samosir yang mempunyai Ikan Mas Arsik, Dengke Tombur dan lain-lain. Indonesia masih menyimpan ribuan jenis makanan dan minuman khas yang berpotensi untuk dikembangkan secara global sebagai daya
Fakultas Ilmu Komputer, Universitas Brawijaya
tarik wisata (Gultom, 2015). Makanan dan jajanan tradisional merupakan pangan khas dari nenek moyang dan biasanya digunakan untuk acara atau tradisi. Makanan tradisional disebut juga sebagai makanan pasar karena makanan tradisional pada waktu dulu banyak dijumpai di pasar-pasar tradisional. Pada zaman modern, pasar tidak hanya menjual makanan tradisional, melainkan banyak makanan dan jajanan modern antara lain: rainbow cake, quick chiken, hot dog dan pizza (Kusumaningtyas, Wibisono & Kusnadi, 2013).
Makanan dan jajanan tradisional sekarang jarang sekali ditemukan, karena adanya perubahan zaman. Sebagian masyarakat menganggap makanan dan jajanan tradisional adalah pangan yang sudah ketinggalan zaman, sehingga makanan dan jajanan tradisional tersebut banyak yang ditinggalkan oleh masyarakat dan mulai beralih pada kehidupan modern. Padahal makanan dan jajanan tradisional sendiri adalah salah satu bentuk wujud warisan nenek moyang yang seharusnya tetap dijaga dan dilestarikan dari generasi penerus (Kusumaningtyas, Wibisono & Kusnadi, 2013).
Salah satu fitur yang bisa digunakan pada citra adalah fitur warna. Pada penelitian tentang pencarian resep makanan menggunakan fitur SMSD, CIELAB Color Moment dan Local
Binary Pattern didapatkan bahwa fitur warna
memiliki hasil pengujian lebih optimal dengan nilai MAP yang lebih tinggi dibandingkan ekstraksi fitur warna, ekstraksi tekstur ataupun gabungan dari semua ekstraksi. Hue Saturation
Value (HSV) memiliki hasil terbaik dari
CIELAB dan CIELUV karena Hue Saturation
Value (HSV) memiliki kesamaan perseptual.
Dimensi warna HSV sering digunakan pada bidang penglihatan warna dimana setiap
channelnya berhubungan erat dengan kategori
persepsi warna manusia (Nabella, Sari & Wihandika, 2019). Adapun penelitian yang dilakukan oleh Sugiyanto & Wibowo (2015) untuk mengklasifikasikan kematangan buah pepaya menggunakan ruang warna HSV. Penelitian ini menghasilkan tingkat akurasi tertinggi 83,34% menggunakan k-NN dengan 5 buah jumlah k (ketetanggaan).
Terdapat beberapa metode yang bisa digunakan untuk mengklasifikasikan citra, salah satunya yaitu Fuzzy k-NN. Penelitian yang dilakukan oleh Billyan, Bhawiyuga dan Primananda (2017) yang membahas tentang Pengimplementasian metode klasifikasi Fuzzy
k-Nearest Neighbor (Fuzzy k-NN) untuk Fingerprint Access Point pada Indoor Positioning. Pada penelitian ini dilakukan
pengimplementasian Indoor Positioning dengan metode Fingerprint (metode pengenalan pola kekuatan sinyal) menggunakan pengukuran kekuatan sinyal (Received Signal Strength/RSS), yaitu dengan melihat pola
kekuatan sinyal access point yang datang ke penerima dari setiap ruangan. Hasil pengujian posisi client menghasilkan tingkat akurasi pada metode k-NN dengan nilai untuk k=1 nilainya mencapai 96%, k=2 hingga k=7 nilainya mencapai 76%, dan k=8 hingga k=10 nilainya mencapai 73%. Hasil pengujian menggunakan metode Fuzzy k-NN dengan nilai k=1 dan k=2 nilainya mencapai 96%, k=3 hingga k=8 nilainya mencapai 76%, k=9 nilainya mencapai 73%, dan k=10 nilainya mencapai 76%. Berdasarkan hasil akurasi tersebut maka implementasi metode klasifikasi Fuzzy
k-Nearest Neighbor (Fuzzy k-NN) untuk
Fingerprint Access point pada Indoor Positioning ini memiliki tingkat akurasi yang
lebih baik daripada metode k-NN.
Berdasarkan permasalahan diatas, dilakukan suatu usulan penelitian untuk mengklasifikasikan citra makanan tradisional untuk mengetahui jenis dari citra makanan tradisional tersebut. Adapun fitur yang digunakan adalah fitur warna menggunakan metode ruang warna HSV, sedangkan metode klasifikasi menggunakan metode Fuzzy K-NN. Hasil dari penelitian ini diharapkan dapat meningkatkan pengetahuan masyarakat terhadap makanan tradisional dan mendapatkan hasil akurasi baik.
2. LANDASAN KEPUSTAKAAN 2.1. Hue Saturation Value (HSV)
Untuk membuat proses deteksi yang lebih efisien, gambar RGB dikonversi menjadi gambar HSV. HSV merupakan representasi warna silinder, sedangkan RGB adalah representasi warna kartesius. HSV merupakan kependekan dari Hue, Saturation dan Value.
Hue menunjukkan seberapa murni warna
tersebut terhadap warna aslinya. Saturation menggambarkan seberapa putih warna dari citra. Nilai warna (value) menunjukkan kegelapan warna tertentu (Mazumder, Nahar & Atique, 2018).
ruang warna HSV menggunakan Persamaan 1 hingga Persamaan 5, diasumsikan nilai R, G, B berada pada rentang nilai 0 hingga 255.
𝑀 = max(𝑅, 𝐺, 𝐵) (1) 𝑚 = min(𝑅, 𝐺, 𝐵) (2) 𝑉 = 𝑀 (3) 𝑆 = { 0 𝑖𝑓 𝑉 = 0 (𝑉 − 𝑚) 𝑉⁄ 𝑖𝑓 𝑉 > 0 (4) 𝐻 = { 0 𝑖𝑓 𝑆 = 0 60 ∗ (𝐺 − 𝐵) (𝑀 − 𝑚)⁄ 𝑖𝑓 (𝑀 = 𝑅 𝑎𝑛𝑑 𝐺 ≥ 𝐵) 60 ∗ (𝐺 − 𝐵) (𝑀 − 𝑚)⁄ + 360 𝑖𝑓 (𝑀 = 𝑅 𝑎𝑛𝑑 𝐺 < 𝐵) 60 ∗ (𝐺 − 𝐵) (𝑀 − 𝑚)⁄ + 120 𝑖𝑓 𝑀 = 𝐺 60 ∗ (𝐺 − 𝐵) (𝑀 − 𝑚)⁄ + 240 𝑖𝑓 𝑀 = 𝐵 (5)
Dimana M dan m merupakan nilai maksimum dan minimum dari ketiga warna RGB (Li, Drew& Liu, 2014).
Setelah nilai HSV ditemukan, citra dikonversikan kedalam citra 8-bit dengan menggunakan Persamaan 6 hingga Persamaan 8 (Nabella, Sari & Wihandika, 2019).
𝑉 = 𝑉 × 255 (6)
𝑆 = 𝑆 × 255 (7)
𝐻 =𝐻
2 (8)
Dimana:
- H: nilai piksel channel H
- S: nilai piksel channel S
- V: nilai piksel channel V
2.2. Fuzzy k-NN
Algoritme Fuzzy k-NN menetapkan kelas keanggotaan pada suatu vektor sampel daripada menempatkan kelas pada suatu kelas tertentu. Keuntungan dari algoritme ini adalah bahwa tidak ada kesembarangan penempatan dari keanggotaan dari algoritme ini. Selain itu pada vektor nilai keanggotaan harus terdapat suatu level kepastian yang dihasilkan pada hasil klasifikasi. Misalkan, jika sebuah vektor keanggotaan bernilai 0,9 dalam satu kelas dan 0,05 terhadap dua kelas lainnya, maka bisa dipastikan bahwa kelas yang memiliki nilai keanggotaan 0,9 merupakan kelas yang
termasuk kedalam vektor tersebut. Jika suatu vektor memiliki nilai keanggotaan 0,55 dalam kelas satu, 0,44 dalam kelas dua dan 0,01 dalam kelas tiga, kita tidak bisa menentukan bahwa kelas yang termasuk adalah kelas 3. Penandaan suatu keanggotaan harus dilakukan dengan menggunakan algoritme yang dapat digunakan dalam proses klasifikasi. Basis dari algoritme Fuzzy k-NN adalah untuk menandai keanggotaan sebagai suatu fungsi jarak pada suatu vektor dari ketetanggaan k terdekat dan keanggotaan ketetanggaannya dalam kelas yang memungkinkan (Keller, Gray & Given, 1985). Sebelum menghitung nilai keanggotaan pada Fuzzy k-NN, terlebih dahulu dilakukan proses perhitungan inisialisasi Fuzzy tiap data latih dengan data uji memakai Persamaan 9.
𝑈𝑖𝑗(𝑥) = { 0.51 +𝑛𝑗 𝑘 ∗ 0.49 (𝑗 = 𝑖) 𝑛𝑗 𝑘 ∗ 0.49 (𝑗 ≠ 𝑖) (9) Dimana:
Fungsi Uij(x) : Nilai keanggotaan kelas i
pada vektor j
nj : Banyak anggota kelas j pada
data latih n
k : Nilai ketetanggaan terdekat
j : Kelas data
Nilai 0,51 pada persamaan di atas menunjukkan bahwa instance yang digunakan memiliki jumlah nilai yang lebih dari total keanggotaan, sedangkan sisanya dibagi di antara kelas masalah yang lainnya. Nilai yang lebih rendah dari keanggotaan kelas bernilai 0, kecuali satu dari ketetanggaan terdekat pertama merujuk pada kelas tersebut. Nilai yang lebih tinggi dapat dianggap sebagai suatu pengukuran relatif dari kemunculan kelas tersebut diantara data training yang nilainya tidak lebih besar dari 0,49 (Derrac, et al., 2014).
Selanjutnya menghitung nilai keanggotaan masing-masing kelas dengan Persamaan 10 (Keller, Gray & Given, 1985).
𝑢𝑗(𝑥) =
∑𝑘𝑗=1𝑢𝑖𝑗(‖𝑥−𝑥𝑗‖−2 (𝑚−1)⁄ )
∑𝑘𝑗=1(‖𝑥−𝑥𝑗‖−2 (𝑚−1)⁄ ) (10)
Keterangan :
Uij : Nilai keanggotaan Fuzzy pada contoh
pengujian (x, xj)
k : Nilai tetangga terdekat
Fakultas Ilmu Komputer, Universitas Brawijaya
m : Bobot pangkat yang besarnya m> 1 3. METODOLOGI PENELITIAN 3.1. Pre-processing
Pre-processing adalah tahap awal dalam
pengolahan citra. Kegunaan dari pre-processing adalah untuk menghilangkan fitur-fitur atau bagian-bagian yang tidak diperlukan dalam tahapan pemrosesan selanjutnya. Merujuk pada penelitian yang dilakukan oleh Nabella, Sari dan Wihandika (2018) dengan penyesuaian, tahapan pre-processing pada penelitian ini adalah sebagai berikut.
1) Mengubah ukuran citra.
2) Mengkonversi citra RGB ke citra HSV. 3) Mengubah citra HSV ke citra greyscale. 4) Filtering menggunakan Gaussian Blur
dengan kernel 5x5.
5) Melakukan segmentasi citra Otsu dengan nilai threshold 120 kemudian mengubahnya menjadi citra biner.
6) Melakukan erosi dan dilasi pada citra. 7) Melakukan masking.
Gambar 2 menunjukkan proses
pre-processing data citra.
Gambar 2. Proses pre-processing citra 3.2. Ekstraksi Fitur Warna HSV
Fitur statistik warna dapat dihitung menggunakan Persamaan 11 sampai 14 (Kadir & Susanto, 2013) antara lain.
1) Mean
Mean merupakan nilai rata-rata, sehingga
memberitahu sesuatu tentang kecerahan umum gambar. Untuk menghitung nilai rata-rata bisa menggunakan rumus Persamaan 11.
𝜇 = 1 𝑀𝑁∑ ∑ 𝑃𝑖𝑗 𝑁 𝑗=1 𝑀 𝑖=1 (11)
M menunjukkan lebar citra, N merupakan
tinggi citra dan Pij yang merupakan piksel saat
ini.
2) Deviasi Standar
Deviasi standar menjelaskan sesuatu tentang kontras yaitu mengambarkan penyebaran dalam data, yang dihitung menggunakan Persamaan 12. 𝜎 = √ 1 𝑀𝑁∑ ∑ (𝑃𝑖𝑗 − µ) 𝑁 𝑗=1 2 𝑀 𝑖=1 (12) 3) Skewness
Skewness atau kecondongan citra merupakan ukuran ketidaksimetrisan citra, rumus yang digunakan ada pada Persamaan 13.
𝜃 =∑ ∑ (𝑃𝑖𝑗−µ) 𝑁 𝑗=1 3 𝑀 𝑖=1 𝑀𝑁𝜎3 (13) 4) Kurtosis
Kurtosis menunjukkan sebaran data bersifat meruncing atau mengumpul, yang didefinisikan pada rumus Persamaan 14.
𝛾 =∑ ∑ (𝑃𝑖𝑗−µ) 𝑁 𝑗=1 4 𝑀 𝑖=1 𝑀𝑁𝜎4 − 3 (14) 3.3. Min-Max Normalization
Min-Max Normalization merupakan sebuah cara normalisasi sebuah data dengan
range minimal dan maksimal baru yang sudah
ditentukan, cara ini biasanya disebut
Interpolation Normalization. Untuk menggunakan cara ini cukup dengan rumus pada Persamaan 15 (Septianto, 2016).
𝑋𝑏 = (
𝑋𝑎−𝑀𝑖𝑛𝑎
𝑀𝑎𝑥𝑎−𝑀𝑖𝑛𝑎× (𝑀𝑎𝑥𝑏− 𝑀𝑖𝑛𝑏)) +
𝑀𝑖𝑛𝑏 (15)
Dimana:
Xb : Nilai X setelah dinormalisasi Xa : Nilai X sebelum dinormalisasi
Maxa : Nilai maksimum baris data sebelum
dinormalisasi
Mina : Nilai X minimum baris data sebelum
dinormalisasi
Maxb : Nilai maksimum baris data setelah
dinormalisasi
Minb : Nilai minimum baris data setelah
dinormalisasi
3.4. Metode Pengujian
Pengujian menggunakan 5 nilai k (k-NN) pada masing-masing nilai Fold, dimana nilai k
(k-fold) menggunakan 2 nilai. Pengujian
dilakukan menggunakan 3 variasi data pengujian antara lain, pengujian 300 dataset
citra dengan jumlah tiap kelas berbeda-beda dengan 24 kelas, pengujian 300 dataset citra dengan jumlah yang mendekati rata-rata dengan 20 kelas, serta pengujian menggunakan 400
dataset dengan jumlah kelas 24. Nilai akurasi
yang digunakan adalah nilai akurasi rata-rata dari k-fold pada tiap nilai k (k-NN)nya yang kemudian dianalisis pada tahapan analisis. Tiap pengujian nilai k (k-NN) yang digunakan adalah 1,3,5, 7 dan 9. Tujuan dari penggunaan nilai ganjil adalah untuk mengurangi resiko ambiguitas hasil klasifikasi. Pengujian menggunakan dataset yang berjumlah 300 dengan nilai k dari k-fold=5 dan 10.
4. HASIL DAN PEMBAHASAN
4.1.Pengujian 300 dataset (jumlah tiap kelas berbeda)
Tabel 1 merupakan tabel data makanan tradisional berdasarkan jenis disertai dengan jumlahnya yang digunakan pada pengujian. Jumlah data adalah 300 citra makanan tradisional.
Tabel 1. Dataset makanan tradisional pengujian pertama
Kelas Jenis Makanan Jumlah
A Kue Cucur 10
B Molen 12
C Bakso Bakar 23
D Lumpia 25
E Roti Goreng 9
F Dadar Gulung Kelapa 3
G Kue Sus 5 H Karipap 16 I Wingko 4 J Kue Apem 7 K Lemper Hijau 7 L Wingko Babat 19 M Gethuk 5 N Pisang Goreng 6 O Roti Bakar 18 P Kue Lumpur 12 Q Dadar Gulung 31 R Tahu Bakso 14 S Risol 20 T Kue Bugis 11 U Onde-onde 12 V Bika Ambon 13 W Tahu Isi 11 Y Klepon 7 Jumlah 300
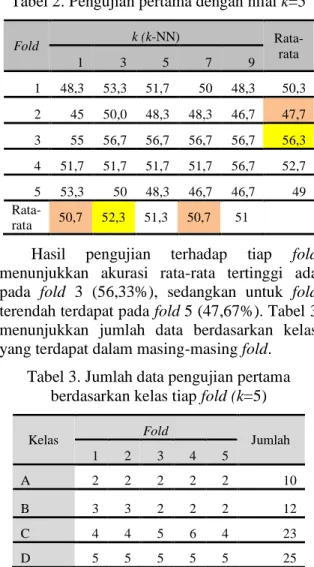
4.1.1. Pengujian k-fold dengan nilai k=5 Hasil pengujian dengan nilai k-fold=5 yang diujikan pada nilai k (k-NN)=1 hingga 9 ditunjukkan pada Tabel 2.
Hasil pengujian pada nilai k (k-NN) menunjukkan bahwa tingkat akurasi rata-rata tertinggi adalah 52,3% saat nilai k (k-NN)=3. Nilai akurasi rata-rata terendah dengan nilai 50,7% terdapat pada saat nilai k (k-NN)=1. Hal ini terjadi karena bobot data latih tidak diperhitungkan, sehingga tidak menjangkau bobot yang lebih kecil yang mungkin memiliki prioritas yang lebih tinggi. Klasifikasi k-NN cenderung tidak memprioritaskan nilai bobot data latih tertinggi, melainkan kelas dari data latih terhadap nilai bobot. Nilai akurasi terendah juga dicapai pada saat nilai k (k-NN)=7 dengan nilai yang sama. Derajat ketetanggaan yang terlalu banyak dapat mengakibatkan data dengan jarak ketetanggaan terdekat dengan anggota kelas yang salah mendapatkan prioritas dalam klasifikasi.
Tabel 2. Pengujian pertama dengan nilai k=5
Fold k (k-NN) Rata-rata 1 3 5 7 9 1 48,3 53,3 51,7 50 48,3 50,3 2 45 50,0 48,3 48,3 46,7 47,7 3 55 56,7 56,7 56,7 56,7 56,3 4 51,7 51,7 51,7 51,7 56,7 52,7 5 53,3 50 48,3 46,7 46,7 49 Rata-rata 50,7 52,3 51,3 50,7 51
Hasil pengujian terhadap tiap fold
menunjukkan akurasi rata-rata tertinggi ada pada fold 3 (56,33%), sedangkan untuk fold terendah terdapat pada fold 5 (47,67%). Tabel 3 menunjukkan jumlah data berdasarkan kelas yang terdapat dalam masing-masing fold.
Tabel 3. Jumlah data pengujian pertama berdasarkan kelas tiap fold (k=5)
Kelas Fold Jumlah
1 2 3 4 5
A 2 2 2 2 2 10
B 3 3 2 2 2 12
C 4 4 5 6 4 23
Fakultas Ilmu Komputer, Universitas Brawijaya E 2 2 2 1 2 9 F 1 0 0 1 1 3 G 1 1 1 1 1 5 H 3 4 3 3 3 16 I 1 0 1 1 1 4 J 1 2 2 1 1 7 K 1 1 1 2 2 7 L 4 4 4 4 3 19 M 1 1 1 1 1 5 N 1 1 1 1 2 6 O 4 4 4 3 3 18 P 2 2 2 3 3 12 Q 7 6 6 6 6 31 R 2 3 3 3 3 14 S 4 4 4 4 4 20 T 2 3 2 2 2 11 U 2 2 3 3 2 12 V 3 3 2 2 3 13 W 2 2 3 2 2 11 Y 2 1 1 1 2 7 Jumlah 60 60 60 60 60
Fold 3 yang merupakan fold dengan nilai
akurasi rata-rata tertinggi memiliki penyebaran jumlah data pada tiap kelas yang hampir rata jumlahnya dengan fold yang lainnya, serta memiliki jumlah penyebaran data kelas yang sebagian besar lebih sedikit pada kelas yang memiliki jumlah data yang sedikit (kurang dari 10). Sebaliknya pada fold 5 yang merupakan
fold dengan rata-rata nilai akurasi terendah
memiliki penyebaran jumlah penyebaran data kelas yang sebagian besar lebih banyak pada kelas dengan jumlah data yang kurang dari 10. Data latih pada kelas lebih terkumpul pada data uji yang mengakibatkan kurangnya pelatihan data pada kelas tersebut.
4.1.2. Pengujian k-fold dengan nilai k=10 Hasil pengujian dengan nilai k-fold=10 yang diujikan dengan nilai k (k-NN)=1 hingga 9 ditunjukkan pada Tabel 4.
Tabel 4. Pengujian pertama dengan nilai k=10
Fold k (k-NN) Rata-rata 1 3 5 7 9 1 56,7 60,0 60,0 63,3 60,0 60,0 2 50,0 53,3 56,7 56,7 53,3 54,0 3 53,3 60,0 63,3 63,3 66,7 61,3 4 46,7 53,3 50,0 50,0 50,0 50,0 5 46,7 46,7 43,3 43,3 43,3 44,7 6 40,0 43,3 43,3 40,0 43,3 42,0 7 50,0 43,3 46,7 43,3 43,3 45,3 8 56,7 56,7 56,7 53,3 53,3 55,3 9 56,7 53,3 53,3 53,3 53,3 54,0 10 66,7 60,0 60,0 56,7 56,7 60,0 Rata-rata 52,3 53,0 53,3 52,3 52,3
Hasil pengujian pada nilai k (k-NN) menunjukkan bahwa tingkat akurasi rata-rata tertinggi saat nilai k (k-NN)=5 sebesar 53%. Nilai akurasi rata-rata terendah sebesar 52,33% terdapat pada saat nilai k (k-NN)=1, 7 dan 9. Hasil akurasi terendah menunjukkan bahwa nilai k (k-NN)=1 hanya menggunakan 1 ketetanggan terdekat sebagai hasil klasifikasi, sehingga mengabaikan hasil klasifikasi data dengan ketetanggaan yang lebih jauh yang memungkinkan hasil klasifikasi yang lebih akurat. Nilai ketetanggaan yang terlalu banyak juga dapat menghasilkan hasil akurasi yang terendah dikarenakan data dengan hasil kelas klasfikasi yang salah dapat masuk dalam prioritas klasifikasi, sehingga dapat menurunkan tingkat akurasi pengujian.
Fold 6 dengan nilai rata-rata akurasi
tertinggi (61,33%) memiliki data dengan citra yang cenderung lebih bagus pada warna dan hasil segmentasinya dibandingkan dengan citra lainnya. Sebaliknya fold 1 yang memiliki nilai rata-rata akurasi terendah (42%) memiliki lebih banyak citra dengan hasil segmentasi yang kurang bagus.
4.2. Pengujian 300 dataset (jumlah tiap kelas mendekati sama rata)
Pengujian 300 dataset dengan jumlah tiap kelas mendekati sama rata merupakan dataset citra yang memiliki hasil segmentasi bagus dan tidak bagus. Tujuan dari pengujian ini yaitu untuk menguji pengaruh pemerataan data dengan segmentasi citra kurang bagus terhadap hasil klasifikasi. Tabel 5 merupakan tabel data makanan tradisional berdasarkan jenis disertai dengan jumlahnya yang digunakan pada pengujian dimana kelas yang digunakan
berjumlah 20 kelas citra.
Tabel 5. Dataset makanan tradisional pengujian kedua
Kelas Jenis Makanan Jumlah
A Kue Cucur 15
B Molen 15
C Bakso Bakar 16
D Lumpia 16
F Dadar Gulung Kelapa 15
G Kue Sus 15 H Karipap 15 J Kue Apem 15 L Wingko Babat 15 N Pisang Goreng 15 O Roti Bakar 15 P Kue Lumpur 13 Q Dadar Gulung 16 R Tahu Bakso 15 S Risol 16 T Kue Bugis 15 U Onde-onde 15 V Bika Ambon 13 W Tahu Isi 15 Y Klepon 15 Jumlah 300
Gambar 3 merupakan contoh citra hasil segmentasi kurang bagus yang digunakan pada pengujian ini.
Gambar 2. Contoh citra dengan hasil segmentasi kurang bagus
Hasil segmentasi yang bagus memiliki ciri berupa latar belakang yang terfilter sebanyak mungkin dan mempertahankan objek makanan sebanyak mungkin. Gambar 2 yang merupakan hasil segmentasi yang kurang bagus memiliki ciri banyak latar belakang yang ikut tersegmentasi serta terfilternya bagian dari makanan sebagian yang menyebabkan berkurangnya fitur dari citra.
4.2.1. Pengujian k-fold dengan nilai k=5 Hasil pengujian dengan nilai k-fold=5 yang diujikan dengan nilai k (k-NN)=1 hingga 9 ditunjukkan pada Tabel 6.
Hasil pengujian terhadap nilai k (k-NN) menunjukkan bahwa nilai akurasi rata-rata
tertinggi pada saat nilai k (k-NN)=3 sebesar 40%. Nilai akurasi rata-rata terendah terdapat pada saat nilai k (k-NN)=9 sebesar 38%. Hal ini terjadi karena perhitungan bobot data latih melibatkan banyak ketetangggaan, sehingga keterlibatan data tetangga dengan klasifikasi salah berpotensi menurunkan nilai akurasi pengujian. Hal tersebut diakibatkan oleh penambahan data dengan hasil segmentasi kurang bagus dalam dataset. Tabel 7 merupakan jumlah data dengan hasil segmentasi kurang bagus masing-masing fold.
Tabel 6. Pengujian kedua dengan nilai k
(k-fold)=5 Fold k (k-NN) Rata-rata 1 3 5 7 9 1 35 30 32 30 30 31,3 2 46,7 48,3 50 48 45 47,7 3 45,0 40,0 45 42 42 42,7 4 35,0 45,0 38 40 42 40,0 5 31,7 36,7 30 33 32 32,7 Rata-rata 38,7 40,0 39 39 38
Tabel 7. Data jumlah citra yang tersegmentasi kurang bagus (k=5)
Kelas Fold Jumlah
1 2 3 4 5
Jumlah 30 26 33 36 38 163
Jumlah data citra yang memiliki hasil segmentasi kurang bagus berjumlah banyak, yakni 163 dari 300 data citra yang digunakan menyebabkan banyak kesalahan pengambilan nilai fitur pada tahapan ekstraksi fitur citra-citra tersebut sehingga dapat menurunkan hasil klasifikasi pada tahapan pengujian dari hasil pengujian pertama.
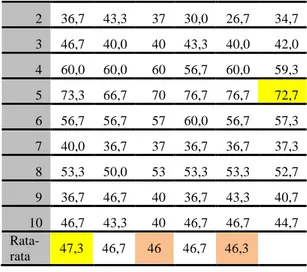
4.2.2. Pengujian k-fold dengan nilai k=10 Hasil pengujian dengan nilai k-fold=10 yang diujikan dengan nilai k (k-NN)=1 hingga 9 ditunjukkan pada Tabel 8.
Tabel 8. Pengujian kedua dengan nilai k
(k-fold)=10
Fold k (k-NN)
Rata-rata
1 3 5 7 9
Fakultas Ilmu Komputer, Universitas Brawijaya 2 36,7 43,3 37 30,0 26,7 34,7 3 46,7 40,0 40 43,3 40,0 42,0 4 60,0 60,0 60 56,7 60,0 59,3 5 73,3 66,7 70 76,7 76,7 72,7 6 56,7 56,7 57 60,0 56,7 57,3 7 40,0 36,7 37 36,7 36,7 37,3 8 53,3 50,0 53 53,3 53,3 52,7 9 36,7 46,7 40 36,7 43,3 40,7 10 46,7 43,3 40 46,7 46,7 44,7 Rata-rata 47,3 46,7 46 46,7 46,3
Hasil pengujian terhadap nilai k (k-NN) menunjukkan bahwa nilai akurasi rata-rata tertinggi pada saat nilai k (k-NN)=1 sebesar 47,33% sedangkan nilai akurasi rata-rata terendah terdapat pada saat nilai k (k-NN)=7 dan 9 dengan nilai 46,33%. Rata-rata akurasi dari hasil klasifikasi tiap nilai k memiliki perbedaan yang tidak terlalu signifikan, hal ini dikarenakan data dengan segmentasi yang kurang bagus sudah bercampur dengan data hasil segmentasi bagus seperti yang ada pada Gambar 4, dimana tidak terfilternya sebagian latar belakang pada citra dan terfilternya sebagian objek pada citra menyebabkan perubahan fitur dari data citra.
Tabel 9 merupakan data dengan hasil segmentasi kurang bagus masing-masing fold.
Tabel 9. Data jumlah citra yang tersegmentasi kurang bagus (k=10)
Dikarenakan hasil segmentasi telah dikombinasikan antara hasil segmentasi yang bagus dengan yang kurang bagus dengan jumlah yang cukup besar, yakni 163 data mengakibatkan berubahnya nilai fitur pada tahap ekstraksi fitur. Data citra yang memiliki segmentasi kurang bagus tiap foldnya juga membuat penurunan pada tahap klasifikasi dibandingkan dengan pengujian pertama.
4.3. Pengujian 400 dataset (jumlah tiap kelas berbeda)
Pengujian 400 dataset dengan jumlah tiap kelas berbeda merupakan dataset citra yang memiliki hasil segmentasi bagus dan tidak bagus dimana citra ditambahkan pada beberapa kelas. Tabel 10 merupakan tabel data makanan tradisional berdasarkan jenis disertai dengan jumlahnya yang digunakan pada pengujian dimana kelas yang digunakan berjumlah 24 kelas citra. Tujuan dari pengujian ini adalah untuk menguji pengaruh penambahan jumlah
dataset dengan data citra kurang bagus terhadap
hasil klasifikasi.
Tabel 10. Dataset makanan tradisional pengujian ketiga
Citra Jenis Makanan Jumlah
A Kue Cucur 11
B Molen 15
C Bakso Bakar 23
D Lumpia 28
E Roti Goreng 9
F Dadar Gulung Kelapa 13
G Kue Sus 14 H Karipap 16 I Wingko 7 J Kue Apem 20 K Lemper Hijau 8 L Wingko Babat 19 M Gethuk 8 N Pisang Goreng 15 O Roti Bakar 23 P Kue Lumpur 13 Q Dadar Gulung 32 R Tahu Bakso 18 S Risol 25 T Kue Bugis 23 U Onde-onde 16 V Bika Ambon 14 W Tahu Isi 16 Y Klepon 14 Jumlah 400
Penyebaran jumlah data dari masing-masing kelas menambahkan hasil citra kurang bagus yang paling bagus untuk ditambahkan
Kelas Fold Jumlah 1 2 3 4 5 163 Jumlah 15 11 15 13 17 Kelas Fold 6 7 8 9 10 Jumlah 15 15 18 23 21
kedalam citra yang berjumlah 300 pada pengujian pertama.
4.3.1. Pengujian k-fold dengan nilai k=5 Hasil pengujian dengan nilai k-fold=5 yang diujikan dengan nilai k (k-NN)=1 hingga 9 ditunjukkan pada Tabel 11.
Tabel 11. Pengujian ketiga dengan nilai k=5
Fold k (k-NN) Rata-rata 1 3 5 7 9 1 55 53,8 52,5 53 53 53,3 2 56,3 56,3 57,5 58 58 57,0 3 42,5 45 46,2 45 45 44,8 4 43,8 45 43,8 44 44 44,0 5 40 42,5 42,5 40 41 41,3 Rata-rata 47,5 48,5 48,5 48 48
Hasil pengujian terhadap nilai k (k-NN) menunjukkan bahwa nilai akurasi rata-rata tertinggi saat nilai k (k-NN)=3 dan k (k-NN)=5 dengan nilai 48,5%. Nilai akurasi rata-rata terendah terdapat pada saat nilai k (k-NN)=1 dengan nilai 46,75%. Hal ini terjadi karena bobot ketetanggaan data latih hanya bergantung pada 1 ketetanggaan sehingga menyebabkan proses klasifikasi tidak menjangkau bobot ketetanggaan yang lebih jauh dan memiliki kelas sesuai untuk dijadikan prioritas klasifikasi. Dominasi kemiripan warna pada citra pada kelas yang sama juga menghasilkan klasifikasi yang benar karena menghasilkan fitur citra yang mirip satu sama lain.
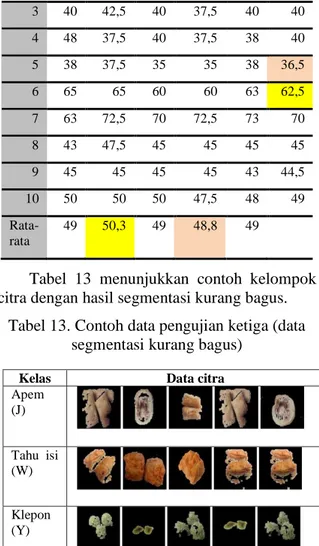
4.3.2.Pengujian k-fold dengan nilai k=10 Hasil pengujian saat k-fold bernilai 10 yang diujikan dengan nilai k (k-NN)=1 hingga 9 ditunjukkan pada Tabel 12..
Akurasi rata-rata terendah terdapat pada saat nilai k (k-NN)=7. Bercampurnya data segmentasi kurang bagus dengan yang kurang bagus mempengaruhi tahap ekstraksi fitur.
Tabel 12. Pengujian ketiga dengan nilai k=10
Fold k (k-NN) Rata-rata 1 3 5 7 9 1 55 60 58 57,5 58 57,5 2 45 45 48 50 50 47,5 3 40 42,5 40 37,5 40 40 4 48 37,5 40 37,5 38 40 5 38 37,5 35 35 38 36,5 6 65 65 60 60 63 62,5 7 63 72,5 70 72,5 73 70 8 43 47,5 45 45 45 45 9 45 45 45 45 43 44,5 10 50 50 50 47,5 48 49 Rata-rata 49 50,3 49 48,8 49
Tabel 13 menunjukkan contoh kelompok citra dengan hasil segmentasi kurang bagus.
Tabel 13. Contoh data pengujian ketiga (data segmentasi kurang bagus)
Peningkatan hasil akurasi saat hasil segmentasi kurang bagus disebabkan oleh citra dengan hasil segmentasi kurang bagus cenderung mendominasi kelas tertentu. Dominasi kemiripan warna citra pada kelas sama juga menghasilkan klasifikasi benar karena fitur citra mirip satu sama lain
5. PENUTUP
Berdasarkan pengujian dan analisis yang telah dilakukan dapat diambil kesimpulan bahwa penerapan klasifikasi citra makanan tradisional menggunakan fitur HSV dan Fuzzy
k-NN dilakukan dengan cara mengekstraksi
fitur HSV dari sejumlah dataset yang diklasifikasikan menggunakan metode Fuzzy k-NN. Hasil akurasi yang didapatkan tergolong rendah sebesar 53,33% disebabkan oleh tidak meratanya jumlah antar kelas serta kualitas hasil segmentasi citra yang digunakan banyak yang kurang bagus. Kualitas segmentasi citra dan kemiripan warna memiliki pengaruh yang lebih besar daripada jumlah data citra pada masing-masing kelas, semakin bagus hasil
Kelas Data citra
Apem (J) Tahu isi (W) Klepon (Y)
Fakultas Ilmu Komputer, Universitas Brawijaya
segmentasi citra serta kemiripan warna pada satu kelas semakin baik hasil klasifikasinya.
Adapun hal yang perlu dilakukan untuk meningkatkan hasil penelitian selanjutnya adalah menggunakan data citra dengan hasil segmentasi yang lebih bagus. Pengujian menggunakan kelas-kelas dengan jumlah yang lebih rata tiap kelasnya serta penambahan fitur lain dapat dilakukan untuk meningkatkan performa pelatihan data dan meningkatkan akurasi penelitian.
6. DAFTAR PUSTAKA
Adha, S. N., Sari, Y. A. & Wihandika, R. C. (2018). Klasifikasi Jenis Citra Makanan Tungggal berdasarkan Fitur Local Binary Patterns dan Hue Saturation Value menggunakan Improved KNearest Neighbor. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer,
3(3), 2416-2424.
Bakry, M. E., Safwat, S. & Hegazy, O. (2015). Big Data Classification using Fuzzy K-Nearest Neighbor. International Journal of
Computer Applications, 132(10), 8-13.
Brownlee, J. (2016). K-Nearest Neighbors for Machine Learning [online] Tersedia di: <https://machinelearningmastery.com/k-nearest-neighbor-for-machine-learning/> [Diakses 12 Juni 2019]
Billyan, B. F., Bhawiyuga, A. & Primananda, R. (2018). Implementasi Metode Klasifikasi Fuzzy K-Nearest Neighbor (FK-NN) untuk Fingerprint Access Point pada Indoor Positioning. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 1(11), 1195-1205.
Derrac, J., Chiclana, F., Garcia, S. & Herrera, F. (in press) Evolutionary Fuzzy K-Nearest Neighbors Algorithm using Interval-Valued Fuzzy Sets. Information Sciences. (Diterima untuk publikasi November 2014).
Dzikrullah, N. N., Indriati, & Setiawan, B. D. (2016). Penerapan Metode K-Nearest Neighbor (KNN) dan Metode Weighted Product (WP) dalam Penerimaan Calon Guru dan Karyawan Tata Usaha Baru Berwawasan Teknologi (Studi Kasus: Sekolah Menengah Kejuruan Muhammadiyah 2 Kediri). Jurnal Pengembangan Teknologi Informasi dan
Ilmu Komputer, 5(1), 378-385.
Gerhana, Y. A., Zulfikar, W. B., Ramdani, A. H. & Ramdhani, M. A. (2018). Implementation of Nearest Neighbor using HSV to Identify Skin Disease. The 2nd
Annual Applied Science and Engineering Conference (AASEC 2017), 1-5.
Ichsan, R., Putra, P., Wibisono, W. & Studiawan, H. (2013). Sistem Pendeteksi Posisi dalam Ruangan Menggunakan Kekuatan Sinyal Wi-Fi dengan Penerapan Algoritma Cluster Filtered KNN. Jurnal
Teknik Promits, 2(1), 1-5.
Kadir, A. & Susanto, A. (2013). Teori dan
Aplikasi Pengolahan Citra. Yogyakarta:
Penerbit ANDI.
Keller, J. M., Gray, M. R. & Givens, J. A., Jr. (1985). A Fuzzy K-Nearest Neighbor Algorithm. IEEE Transactions on Items,
Man and Cybernetics, 15(4), 580-585.
Kusumaningtyas, A., Wibisono, B. & Kusnadi (2018). Penggunaan Istilah Makanan dan Jajanan Tradisional pada Masyarakat di Kabupaten Banyuwangi Sebuah Kajian Etnolinguistik. Jurnal Sastra Indonesia
Fakultas Sastra Universitas Jember, 1(1),
2416-2424.
Majumdar, A., & Ward, R. K. (2000). Fingerprint Recognition with Curvelet Features and Fuzzy KNN Classifier.
Department of Electrical and Computer Engineering University of British Colombia, 1-6.
Mazumder, J., Nahar, L. N. & Atique, M. U. (2018). Finger Gesture Detection and Application using Hue Saturation Value.
I.J. Image, Graphics and Signal Processing, 8, 31-38.
Nabella, F. Y., Sari, Y. A. & Wihandika, R. C. (2019). Seleksi Information Gain pada Citra Klasifikasi Makanan menggunakan Hue Saturation Value dan Gray Level Co-Occurence Matrix. Jurnal Pengembangan
Teknologi Informasi dan Ilmu Komputer,
3(2), 1892-1900.
Septiyanto, T. 2016. Min Max Normalitation
[online] tersedia di:
<https://asliapik.com/2016/min-max-normalization/> [Diakses 9 Mei 2019] Sugiyanto, S. & Wibowo, F. (2015). Klasifikasi
Kematangan Buah Pepaya (Carica Papaya L) California (Callina-Ipb 9) dalam Ruang Warna HSV dan Algoritma K-Nearest Neighbors. Prosiding Senatek Fakultas