PENENTUAN NOMINASI CALON PESERTA
Program Studi Teknik Elektro, Program Keahlian Telematika CIO Fakultas Teknologi Industri, ITS, Surabaya
Kampus ITS Keputih, Sukolilo, Surabaya 60111, Jawa Timur
Abstrak
Kepala Sekolah adalah salah satu unsur dalam komponen tenaga kependidikan yang mempunyai tumpuan dalam peningkatan mutu pendidikan secara nasional. Oleh karena itu pemerintah mencanangkan program penyiapan kepala sekolah yang meliputi nominasi rekrutmen, seleksi administratif, seleksi akademis serta pendidikan dan pelatihan calon kepala sekolah. Sistem yang selama ini dipakai dalam penentuan nominasi peserta adalah administrasi manual melalui pemilahan dengan program excell. Tetapi karena keterbatasan keterbacaan pengurutan dan melibatkan obyek data yang banyak maka permasalahan yang sering terjadi adalah banyaknya data yang tumpang tindih serta azas keadilan terabaikan.
Pada penelitian ini bertujuan untuk membuat sistem otomatisasi daftar nominasi dengan menggunakan clustering (pengklasteran) dengan metode K-Means Clustering dengan software WEKA 3.6.2 yang dianggap mampu mendukung penetapan daftar peserta nominasi rekrutmen dalam penerbitan pengambilan keputusan. Pembuatan aplikasi ini mengacu pada Permendiknas No. 28 Tahun 2010. Dataset yang dipakai adalah data pendidik pada Kota Mojokerto yang diperoleh dari database SIMNUPTK Padamu Negeri dengan menggunakan 11 (sebelas) atribut yaitu : usia, kualifikasi pendidikan, masa kerja, pangkat dan golongan, unit kerja, sertifikasi pendidik, DP3, PKG, pengembangan profesi, prestasi dan permasalahan hukum. Skema kerja penelitian ini meliputi : pengumpulan data, pemilihan data sesuai parameter, pembersihan data, konversi data ke skala numerik, proses k-means clustering sampai akhirnya terbentuk kluster pengelompokkan yang diinginkan. Dari hasil pengolahan data dihasilkan 3 (tiga) kluster yang mampu mewakili analisa data yaitu kluster tidak rekomendasi dengan jumlah anggota kluster sebanyak 44%, dan kluster direkomendasikan sebanyak 17% dan kluster paling direkomendasikan sebesar 39%.
Kata kunci: Program Penyiapan Calon Kepala Sekolah, Permendiknas No. 28 Tahun 2010, SIMNUPTK Padamu Negeri, K-Means Clustering, WEKA 3.6.2
1. PENDAHULUAN
guru yang mendapat tugas tambahan sebagai kepala sekolah adalah guru yang telah memenuhi persyaratan umum dan khusus serta telah mendapatkan sertifikat kelulusan program penyiapan kepala sekolah dari lembaga yang yang ditunjuk dan ditetapkan oleh menteri. Lembaga Penjaminan Mutu Pendidikan (LPMP) sebagai unit pelaksana teknis di tiap provinsi dari Kementrian Pendidikan dan Kebudayaan mempunyai kewajiban untuk mengawal kebijakan Pemerintah Pusat dalam penentuan calon Kepala Sekolah yang kompeten dan memenuhi standar yang telah ditentukan. Dengan terlaksananya implementasi dari Permendiknas No. 28 Tahun 2010 secara keseluruhan diharapkan akan berdampak pada meningkatnya mutu pembelajaran dan mutu pendidikan secara berkelanjutan. Program penyiapan kepala sekolah adalah salah satu implementasi riil dari pelaksanaan Permendiknas No. 28 Tahun 2010.
Program penyiapan kepala sekolah meliputi nominasi rekrutmen, seleksi administratif, seleksi akademis serta pendidikan dan pelatihan calon kepala sekolah. Persyaratan untuk menjadi peserta nominasi rekrutmen sesuai dengan Permendiknas No. 28 Tahun 2010 adalah sebagai berikut ;
1. Persyaratan umum meliputi :
a. Beriman dan bertaqwa kepadaTuhan Yang MahaEsa;
b. Memiliki kualifikasi akademik paling rendah sarjana (S1) atau diploma empat (D-IV) kependidikan atau non kependidikan perguruan tinggi yang terakreditasi; c. Berusia setinggi-tingginya 56 (lima puluh enam) tahun pada waktu
pengangkatan pertama sebagai kepala sekolah/madrasah;
d. Sehat jasmani dan rohani berdasarkan surat keterangan dari dokter Pemerintah; e. Tidak pernah dikenakan hukuman disiplin sedang dan/atau berat sesuai dengan
ketentuan yang berlaku; f. Memiliki sertifikat pendidik;
h. Pengalaman mengajar sekurang-kurangnya 5 (lima) tahun menurut jenis dan jenjang sekolah/madrasah masing-masing, kecuali di taman kanak-kanak/raudhatul athfal/taman kanak-kanak luar biasa (TK/RA/TKLB) memiliki pengalaman mengajar sekurang-kurangnya 3 (tiga) tahun di TK/RA/TKLB; i. Memiliki golongan ruang serendah-rendahnya III/c bagi guru pegawai negeri
sipil (PNS) dan bagi guru bukan PNS disetarakan dengan kepangkatan yang dikeluarkan oleh yayasan atau lembaga yang berwenang dibuktikan dengan SK inpasing;
j. Memperoleh nilai amat baik untuk unsur kesetiaan dan nilai baik untuk unsur penilaian lainnya sebagai guru dalam daftar penilaian prestasi pegawai (DP3) bagi PNS atau penilaian yang sejenis DP3 bagi bukan PNS dalam 2 (dua) tahun terakhir; dan
k. Memperoleh nilai baik untuk penilaian kinerja sebagai guru dalam 2 (dua) tahun terakhir.
2. Persyaratan khusus meliputi:
a. berstatus sebagai guru pada jenis atau jenjang sekolah/madrasah yang sesuai dengan sekolah/madrasah tempat yang bersangkutan akan diberi tugas tambahan sebagai kepala sekolah/madrasah;
2. TINJAUAN PUSTAKA
Pengklasteran adalah proses mengelompokkan objek berdasarkan informasi yang diperoleh dari data yang menjelaskan hubungan antar objek dengan prinsip untuk memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar kelas/klaster. Kesamaan objek diperoleh dari kedekatan nilai-nilai atribut yang menjelaskan objek-objek data, sedangkan objek-objek data direpresentasikan sebagai sebuah titik dalam ruang multidimensi. Dalam penambangan data, usaha pengklasteran difokuskan pada metode-metode penemuan untuk klaster pada basis data berukuran besar secara efektif dan efisien. Adapun kategori algoritma pengklasteran yaitu:
a. Metode Partisi, dimana pemakai harus menentukan jumlah k partisi yang diinginkan lalu setiap data dites untuk dimasukkan pada salah satu partisi sehingga tidak ada data yang overlap dan satu data hanya memiliki satu klaster. Contohnya: algoritma k-means.
b. Metode Hierarki, yang menghasilkan klaster yang bersarang artinya suatu data dapat memiliki klaster lebih dari satu. Metode ini terbagi menjadi dua yaitu buttom-up yang menggabungkan klaster kecil menjadi klaster lebih besar dan top-down yang memecah klaster besar menjadi klaster yang lebih kecil. Kelemahan metode ini adalah bila salah satu penggabungan atau pemecahan dilakukan pada tempat yang salah, tidak akan didapatkan klaster yang optimal. Contohnya: Agglomerative (Findit, Proclus), Divisive Hierarchical Pengklasteran (Clique, Mafia, Enclue).
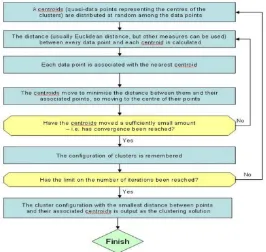
Gambar Algoritma Hierarchical clustering dengan K-means
Karakteristik algoritma k-means adalah sebagai berikut (Kantardzic 2003):
1. Kompleksitas algoritma k-means adalah O (nkl) dengan n adalah jumlah objek data, k adalah jumlah klaster dan l adalah banyaknya iterasi. Umumnya, k dan l adalah tetap sehingga algoritma ini memiliki kompleksitas linear terhadap ukuran data. 2. Algoritma k-means merupakan Algoritma yang tidak terpengaruh terhadap urutan
3. Algoritma k-means sangat sensitive terhadap noise dan outlier karena dapat sangat mempengaruhi nilai mean.
4. Karena kompleksitasnya linear, algoritma k-means relatif lebih terukur dan efisien untuk pemrosesan data dalam jumlah besar (higher-dimensionality).
3. METODE PENELITIAN
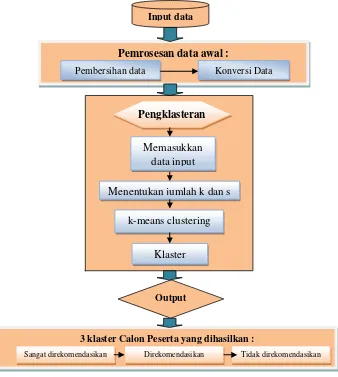
Berdasarkan tujuan penelitian, berikut ini akan diuraikan metode dan tahapan-tahapan penelitian yang akan dilakukan. Proses dasar pengembangan secara umum pada penelitian ini terdiri dari beberapa tahapan sesuai gambar berikut :
Gambar 3.1 Blok diagram sistem kerja penelitian
Pengambilan Data Masukan; Data masukan yang digunakan dalam penelitian ini adalah database SIM NUPTK Padamu Negeri Kota Mojokerto Provinsi Jawa Timur yang didalamnya terdapat informasi data individu pendidik yaitu antara lain nama, nomor unik, unit kerja, status pegawai, masa kerja, golongan/jabatan fungsional, kualifikasi pendidikan, jurusan, usia, status sertifikasi, mata pelajaran yang diampu, mata pelajaran yang disertifikasi, jumlah jam per minggu, dan pengembangan profesi serta data sekolah terkait dengan nama sekolah, alamat sekolah, jenjang sekolah, status sekolah, status akreditasi sekolah dan lain sebagainya.
Pembersihan Data; Data yang telah diperoleh dibersihkan dari indikator data yang tidak diperlukan seperti misalnya data jenis kelamin, status perkawinan, mata pelajaran
Pemrosesan data awal :
Pembersihan data Konversi Data
3 klaster Calon Peserta yang dihasilkan :
Sangat direkomendasikan
Memasukkan data input
Menentukan jumlah k dan s
k-means clustering
Klaster Pengklasteran
Output
yang diampu, mata pelajaran sertifikasi, jabatan dalam tugas, tahun lulus, jurusan dan LPTK penyelenggara. Data – data tersebut dihapus kemudian ditambahkan kembali data yang digunakan sebagai parameter proses pengolahan data melalui metode klustering. Data yang ditambahkan adalah data nilai DP3, nilai PKG, pengembangan profesi, prestasi dalam pelaksanaannya sebagai guru serta keterangan keterlibatan permasalahan hukum. Penambahan data dilakukan menggunakan program MS Access.
Konversi Data; Untuk parameter usia, masa kerja, nilai DP3, nilai PKG bertipe numerik sedangkan parameter lainnya yaitu golongan, pendidikan terakhir, prestasi, pengembangan profesi, sertifikasi pendidik dan keterlibatan permasalahan hukum bertipe kategorik. Supaya algoritma k-means bekerja dengan baik maka parameter yang bersifat kategorik dikonversikan menjadi nilai numerik yaitu untuk parameter golongan, kualifikasi pendidikan, pengembangan profesi, sertifikasi pendidik, permasalahan hukum dan prestasi. Kemudian data masukan yang sudah lengkap sesuai dengan parameter yang akan diujikan akan diubah formatnya dari excell menjadi bentuk arff.
Proses Pengklasteran; Semua data yang menjadi data masukan dilakukan proses
pengklasteran menjadi kelompok-kelompok data. Kelompok data ini mewakili setiap aspek parameter persyaratan calon peserta program.
Keluaran; output dari penelitian ini adalah nominasi peserta Program Penyiapan Calon Kepala Sekolah yang terbagi dalam 3 klaster, yaitu : (1) Paling direkomendasikan; nominasi yang teratas yang dapat dijadikan sebagai sistem pengambilan keputusan yang sangat tepat, (2) Direkomendasikan; nominasi yang direkomendasikan dengan mempertimbangkan kondisi dan situasi pelaksanaan program di lapangan dan (3) Tidak direkomendasikan; nominasi yang paling terendah dan tidak dapat digunakan sebagai bahan pengambilan keputusan karena tidak memenuhi parameter penilaian yang disyaratkan.
Pengujian Data Klaster; Pada bagian ini akan dilakukan analisis dan pengujian data untuk mengetahui seberapa baik hasil klasifikasi yang dilakukan dengan mengukur tingkat akurasi dari hasil klastering data nominasi calon peserta Program Penyiapan Calon Kepala Sekolah dengan metode k-means dan membandingkannya dengan metode dari sistem manual yang selama ini digunakan.
4. HASIL DAN PEMBAHASAN
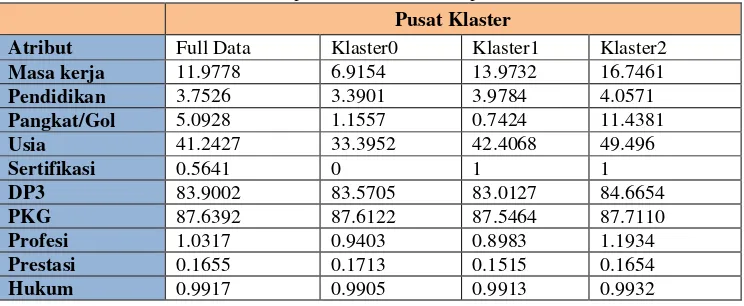
Pengklasteran; Tahapan ini dilakukan klustering menggunakan algoritma K-Means dengan aplikasi Weka 3.6.2. Algoritma K-Means akan menghasilkan pusat klaster (centroid) untuk masing-masing klaster sesuai dengan atribut. Pusat klaster (centroid) untuk klaster (k) 3 dan seed (s) 20 sebagai berikut:
Tabel Data pusat centroid terhadap atribut
Pusat Klaster
Atribut Full Data Klaster0 Klaster1 Klaster2
Masa kerja 11.9778 6.9154 13.9732 16.7461
Pendidikan 3.7526 3.3901 3.9784 4.0571
Pangkat/Gol 5.0928 1.1557 0.7424 11.4381
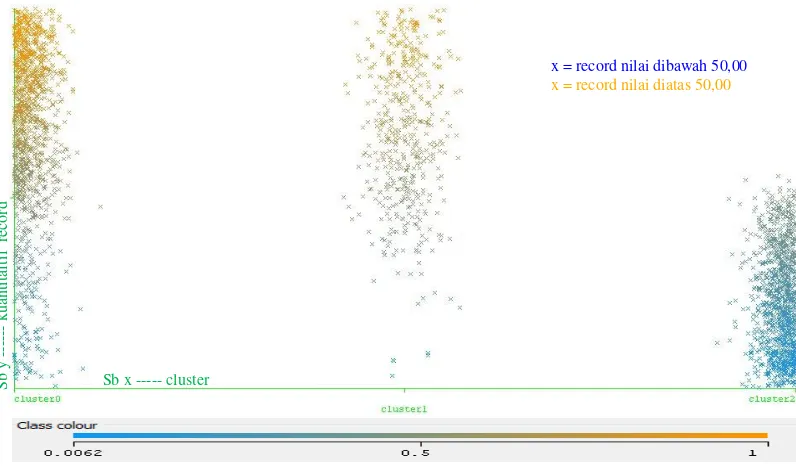
Uji Klasterisasi Semua Atribut yang dipergunakan
Gambar uji klasterisasi semua atribut
Setelah proses pengklasteran, maka akan didapat jumlah anggota pada masing-masing klaster yang dapat dilihat pada gambar berikut :
Gambar Grafik jumlah anggota kluster
Evaluasi Klaster; Hasil klastering dari setiap kombinasi klaster(k) dan seed(s) dievaluasi menggunakan SSE (Sum of Squared Error (SSE)). Nilai SSE tergantung pada jumlah cluster dan bagaimana data dikelompokkan ke dalam cluster-cluster tersebut. Semakin kecil nilai SSE, semakin bagus hasil clustering-nya.
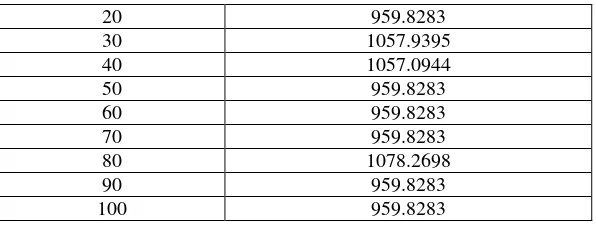
Tabel Hasil SSE pada k=3
x = record nilai dibawah 50,00 x = record nilai diatas 50,00
20 959.8283
Hal ini menyatakan bahwa tidak diketemukan SSE yang paling kecil, sehingga apabila menggunakan seed 20 juga termasuk klastering pada seed terbaik. Selain itu evaluasi kluster juga dilakukan dengan penghitungan varian between kluster (Vb) yang menunjukkan rata – rata jarak pengelompokkan antar kluster. Semakin besar nilai perbedaannya maka kluster yang terbntuk semakin baik.
Tabel Hasil Vb pada kluster k=3
Pada tabel diatas menunjukkan bahwa nilai Vb terbesar yaitu 443675.322 ada pada seed 20, 60 dan 90. Sehingga bisa dikatakan bahwa pengklusteran dengan nilai seed 20 seperti dalam penelitian ini telah membentuk kluster yang terbaik.
Analisa Klaster; Sedangkan untuk menguji kualitas kluster yang dihasilkan dianalisa berdasarkan nilai varian within claster (Vw) yang menunjukkan nilai perbandingan antara jarak atribut data dengan centroid klaster. Semakin kecil nilai Vw maka klaster yang terbentuk semakin rapat dan semakin baik klaster yang dibentuk. Nilai Vw untuk 3 klaster yang terbentuk adalah sebagai berikut :
Tabel Hasil Vw pada tiap kluster
KLASTER VARIAN WITHIN CLUSTER
0 9754.087
1 7980.632
2 6256.534
Pengujian Akurasi Data; bagian ini akan dilakukan pengujian kluster untuk mengetahui seberapa baik hasil clustering yang dilakukan dengan mengukur tingkat akurasi dari hasil klaster data nominasi calon peserta Program Penyiapan Calon Kepala Sekolah dengan metode k-means clustering dan membandingkannya dengan sistem manual yang dipakai selama ini.
Tabel Hasil Perbandingan Tingkat Akurasi 2 Metode
Metode Data Uji Akurasi Grade Akurasi
Manual 1231 49,19 % Failure
K-means clustering 2650 97,69 % Excellent
Dari tabel diatas menunjukkan bahwa metode pengelompokkan data dengan k-means clustering mempunyai tingkat akurasi jauh lebih tinggi dari sistem manual yang dipakai selama ini.
5. KESIMPULAN
Kesimpulan dari hasil penelitian ini adalah sebagai berikut:
Metode clustering dengan algoritma K-Means Clustering untuk melakukan pengelompokan guna pemilihan nominasi daftar calon peserta Program Penyiapan Calon Kepala Sekolah lebih baik digunakan jika dibandingkan dengan pengelompokkan manual yang selama ini dipakai karena keakurasian datanya mempunyai kenaikan sebesar 48,5 % dari nilai akurasi sistem manual yang hanya 49,19 % menjadi 97,69 % dengan menggunakan metode k-means clustering.
Teknik k-means clustering pada penelitian kali ini yang menggunakan pilihan seed 20 menghasilkan klaster terbaik dibuktikan dengan nilai SSE (Sum of Squared Error) yang terkecil yaitu 959.8283 dibandingkan nilai SSE dengan pemilihan seed lainnya serta ditunjukkan pula nilai Vb (Varian between cluster) terbesar yaitu 443675.322 dan Vw (Varian within cluster) terkecil.
Hasil Klastering masing-masing atribut menunjukkan bahwa klaster 2 memiliki nilai atribut yang dominan lebih baik dibandingkan dengan klaster 0 dan klaster 1, hal ini dibuktikan dengan nilai Vw (Varian within cluster) pada klaster 2 yang paling kecil yaitu 6256.534 dibandingkan dengan nilai Vw pada klaster 0 dan 1 . Klaster 2 memiliki anggota yang mempunyai atribut memenuhi semua atau hampir semua parameter sedangkan anggota pada klaster 1 memiliki atribut yang sesuai dengan parameter tetapi selisih antara atribut dengan paramater terpaut jauh. Dan anggota klaster 0 memiliki nilai atribut acak yang jauh dari parameter yang ditentukan. Dari hasil analisa ini dapat disimpulkan bahwa klaster 2 dikategorikan dalam kriteria sangat rekomendasikan, klaster 1 adalah kelompok yang direkomendasikan serta klaster 0 adalah kriteria yang tidak direkomendasikan.
6. DAFTAR PUSTAKA
Fawcett, T. (2006), “An introduction to ROC analysis”, Pattern Recognition Letters, Vol. 27, hal. 861–874.
Hardle, W.danSimar, L. 2003. Applied Multivariate Statistical Analysis. Berlinand Louvain-la-Neuve
Kantardzic m. 2003. Data mining: Concepts, Models, Methods, and Algorithm. New Jersey: John Wiley & Sons Inc.
Oyelade, O. J ,Oladipupo, O. O dan Obagbuwa, I. C. 2010. Application of k-Means
Clustering algorithm for prediction of Students’ Academic Performance. International Journal of Computer Science and Information Security, Vol. 7, No. 1.
Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untukKeperluanBisnis, TeoridanAplikasi. Yogyakarta: GrahaIlmu.