BAB 2
TINJAUAN PUSTAKA
2.1. Algoritma
Algoritma ditemukan oleh seorang ahli matematika dari Uzbekistan, yang bernama
Abu Ja’far Muhammad Ibnu Al-Kwarizmi (770-840). Dalam bukunya yang berjudul
“Al-Jabr W’al Muqabala”, beliau telah menjelaskan langkah-langkah dalam penyelesaian berbagai persoalan aritmatika. Kata “Algoritma”, kemungkinan diambil
dari kata “Al-Kwarizmi” yang kemudian berubah menjadi “Algorizm”, selanjutnya
panggilan ini dipakai untuk menyebut konsep “Algorithm” yang ditemukan (Munir,
2007).
Algoritma adalah prosedur komputasi yang terdefinisi dengan baik yang menggunakan beberapa nilai sebagai masukan dan menghasilkan beberapa nilai yang disebut keluaran. Jadi, algoritma adalah deretan langkah komputasi yang mentransformasikan masukan menjadi keluaran (Munir, 2007). Tujuan algoritma memberikan petunjuk tentang langkah-langkah logika penyelesaian permasalahan dalam bentuk yang mudah dipahami nalar manusia sebagai acuan yang membantu dalam mengembangkan program komputer. Pemahaman tentang algoritma akan mencegah sejak dini kemungkinan terjadinya kesalahan logika pada program komputer yang dikembangkan. Untuk mencapai tujuan diatas terdapat lima syarat yang harus dipenuhi dalam algoritma menurut (Sutanta, 2004).
1. Logika prosedur pada algoritma harus cukup mudah dipahami nalar manusia. 2. Validitas prosedur pada algoritma dapat ditelusuri dengan mudah.
3. Tidak menimbulkan kerancuan interpretasi bagi orang lain.
1. Algoritma harus berhenti setelah mengerjakan sejumlah langkah terbatas. Sebagai contoh, tinjau kembali algoritma Euclidean. Pada langkah 1, jika n=0, algoritma berhenti. Jika n≠0, maka nilai n selalu berkurang sebagai akibat langkah 2 dan 3, dan pada akhirnya nilai n=0. Program yang tidak pernah berhenti mengindikasikan bahwa program tersebut berisi algoritma yang salah. 2. Setiap langkah harus didefinisikan dengan tepat dan tidak berarti dua (ambiguous). Pembaca harus mengerti apa yang dimaksud dengan “m dan n adalah bilangan bulat tak-negatif”. Contoh pernyataan, “bagilah p dengan
sejumlah beberapa buah bilangan bulat positif” dapat bermakna ganda.
Berapakah yang dimaksud dengan “berapa”?. Algoritma menjadi jelas jika langkah tersebut ditulis “bagilah p dengan 10 buah bilangan positif ”.
3. Algoritma memiliki nol atau lebih masukan (input). Masukan ialah besaran yang diberikan kepada algoritma untuk diproses. Algoritma Euclidean mempunyai dua buah masukan, m dan n.
4. Algoritma mempunyai nol atau lebih keluaran (output). Keluaran dapat berupa pesan atau besaran yang memiliki hubungan dengan masukan.
5. Algoritma harus sangkil (effective). Setiap langkah harus sederhana sehingga dapat dikerjakan dalam sejumlah waktu yang masuk akal.
Berdasarkan ciri algoritma yang dipaparkan oleh Donald Knuth dan defenisi algoritma maka dapat disimpulkan sifat utama suatu algoritma (Suarga, 2006) yaitu :
1. Input : Suatu algoritma memiliki input atau kondisi awal sebelum algoritma dilaksanakan dan bisa berupa nilai-nilai pengubah yang diambil dari himpunan khusus.
2. Output : Suatu algoritma menghasilkan output setelah dilaksanakan, atau algoritma akan mengubah kondisi awal menjadi kondisi akhir, dimana nilai output diperoleh dari nilai input yang telah diproses melalui algoritma.
3. Definiteness : Langkah-langkah yang dituliskan dalam algoritma terdefinisi dengan jelas sehingga mudah dilaksana oleh penggunaan algoritma.
5. Effectiveness : Setiap langkah dalam algoritma bisa dilaksanakan dalam suatu selang waktu tertentu sehingga pada akhirnya memberi solusi sesuai yang diharapkan.
2.2. Konsep Algoritma
Penyelesain permasalahan dengan menggunakan alat bantu sistem komputer paling tidak akan melibatkan lima tahapan, yaitu:
1. Analisis masalah. 2. Merancang algoritma.
3. Membuat program komputer. 4. Menguji hasil program komputer. 5. Dokumentasi.
Tahapan-tahapan tersebut dapat dikelompokan menjadi dua, yaitu fase penyelesaian permasalahan (problem solving phase) dan fase implementasi (implementasi phase). Langkah pertama, yaitu analisis masalah merupakan langkah paling awal untuk mengetahui lebih jauh tentang permasalahan yang akan diselesaikan dengan menggunakan alat bantu komputer. Langkah kedua, yaitu merancang algoritma dilakukan dengan tujuan utama sebagai berikut (Sutanta, 2004).
a. Menentukan ide solusi. b. Menyatakan algoritma. c. Memvalidasi algoritma. d. Menganalisis algoritma.
2.3. String Matching
String matching adalah sebuah subjek yang banyak digunakan dalam lingkup
pencarian teks. Algoritma-algoritma string matching menjadi komponen dasar yang diaplikasi pada berbagai piranti lunak dan dapat ditemukan pada hampir semua jenis sistem operasi (Charras & Lecroq, 1997). Selain itu, algoritma-algoritma string matching mempengaruhi metode pemrograman yang menjadi pola/acuan dalam
bidang lainnya di computer science (baik sistem maupun perancangan piranti lunak). Algoritma-algoritma string matching juga mempunyai perubahan penting dalam lingkup teori computer science dengan menyediakan tantangan-tantangan dan permasalahan-permasalahan untuk dipecahkan.
Secara umum, String Matching merupakan proses pencarian kata (pattern) dalam sebuah kalimat teks (string), String matching bisa untuk menemukan satu pattern yang pertama kali ditemukan, atau yang lebih umum menampilkan semua pattern yang dapat ditemukan dalam teks (Charras & Lecroq, 1997). Jenis string matching bermacam-macam, dibedakan menurut hasil yang diinginkan. Yang akan dibahas pada tulisan ini adalah Exact String Matching, Artinya pencarian yang dilakukan untuk menemukan sebuah substring/pattern yang tepat sama dalam sebuah string/text. Pattern dilambangkan dengan P=P[O...m-1], yang mana m adalah panjang dari pattern tersebut atau bisa disebut P:Length. Teks dilambangkan dengan T=IIO ...n-1], yang mana n adalah panjang dari teks atau bisa disebut I:Length. String Matching dirumuskan sebagai berikut:
x = x[0…m-1]
Kedua string terdiri dari sekumpulan karakter yang disebut alfabet yang dilambangkan
Exact Matching digunakan untuk menemukan pattern yang berasal dari satu teks.
Contoh pencarian exact matching adalah pencarian kata “pelajar” dalam kalimat “saya
seorang pelajar” atau “saya seorang siswa”. Sistem akan memberikan hasil bahwa
kalimat pertama mengandung kata “pelajar” sedangkan kalimat kedua tidak, meskipun kenyataannya pelajar dan siswa adalah kata yang bersinonim (Sarno, et al, 2012). Cara kerja algoritma Exact String Matching adalah sebagai berikut: Posisi awal pencarian adalah pada ujung kiri (karakter pertama) dari P atau T, lalu karakter pada posisi tertentu di T dibandingkan dengan karakter pada P, bagian ini biasa disebut dengan pattern, dan setelah seluruh perbandingan telah dilakukan atau ditemukan ketidaksamaan maka P akan digeser ke kanan. Prosedur ini dilakukan berulang-ulang sampai ujung kanan P bertemu dengan ujung kanan T. Setiap pattern dengan posisi i pada T terjadi ketika P berada pada posisi m-1. Berdasarkan arah pemeriksaan karakter, metode yang digunakan dikelompokkan menjadi (Cahyo, 2007):
1. Metode pembacaan berawal dari posisi kiri mengarah ke kanan, salah satu contohnya adalah algoritma Knut-Morris-Pratt. Metode ini tergolong alamiah karena sesuai dengan arah pembacaan biasa dan memiliki karakteristik seperti proses pada automata.
2. Metode pembacaan berawal dari posisi kanan mengarah ke kiri, misalnya algoritma Boyer-Moore. Metode ini umumnya menghasilkan algoritma yang sederhana dan dianggap paling mangkus.
3. Metode pencarian dengan aturan tertentu, salah satunya adalah pencarian dua arah yang diawali dengan kemunculan algoritma dua jalur yang dicetuskan oleh Crochemore-Perrin. Metode ini melakukan dua jenis pencarian, yang pertama adalah mencari bagian kanan pola dari kiri ke kanan, dan jika tidak ada ketidakcocokan, pencarian dilanjutkan dengan bagian kiri.
String matching adalah pencarian sebuah pattern pada sebuah teks. Prinsip kerja
algoritma string matching adalah sebagai berikut (Effendi, et al, 2013):
1. Memindai teks dengan bantuan sebuah window yang ukurannya sama dengan panjang pattern.
2. Menempatkan window pada awal teks.
3. Membandingkan karakter pada window dengan karakter dari pattern. Setelah pencocokan (baik hasilnya cocok atau tidak cocok), dilakukan shift ke kanan pada window. Prosedur ini dilakukan berulang-ulang sampai window berada pada akhir teks. Mekanisme ini disebut mekanisme sliding-window.
Algoritma string matching mempunyai tiga komponen utama (Effendi, et al, 2013), yaitu:
1. Pattern, yaitu deretan karakter yang akan dicocokkan dengan teks, dinyatakan dengan x[0..m-1], panjang pattern dinyatakan dengan m.
2. Teks, yaitu tempat pencocokan pattern dilakukan, dinyatakan dengan y[0..n-1], panjang teks dinyatakan dengan n.
3. Alfabet, yang berisi semua simbol yang digunakan oleh bahasa pada teks dan pattern, dinyatakan dengan ∑ dengan ukuran dinyatakan dengan ASIZE.
2.4. Algoritma Maximal Shift
Algoritma Maximal Shift adalah algoritma yang mencari pola dalam teks dengan cara pola dicari dari karakter yang memiliki nilai minShift yang terbesar hingga minShift yang terkecil. Sunday merancang sebuah algoritma dimana karater pola yang satu akan menyebabkan pergeseran yang lebih besar dan yang satu lainnya menyebabkan pergeseran yang lebih pendek. Tahapan proses dari algoritma Maximal shift terdiri dari memilah karakter pola dalam urutan penurunan pergeseran, membangun bad-charaters shift dan fungsi good-suffix Shif. Fungsi tersebut disesuaikan dengan urutan
scanning karakter pola, (Charras & Lecroq, 2004). Langkah-langkah proses algoritma
Proses pertama adalah prosedur perhitungan nilai minShift karakter pola yang akan digunakan untuk proses pengurutan. Dapat dilihat pada Tabel 2.1.
.
Tabel 2.1 Menentukan Nilai MinShift pada Contoh.
Proses kedua adalah orderPattern yang digunakan untuk mengurutkan karakter pada pola dari nilai minShift tertinggi hingga terkecil pada pola. Jika menemukan karakter yang memiliki nilai minShift yang sama maka pengurutan didasarkan pada posisi pencarian dari kanan ke kiri, yaitu posisi karakter yang di temukan dahulu diurutkan lebih awal. Seperti pada Tabel 2.2.
Tabel 2.2 OrdernPattern Maximal Shift pada Contoh.
I 0 1 2 3 4 5 6 7
Pat[i].loc 3 2 7 6 5 4 1 0 Pat[i].c G A G A G A C G
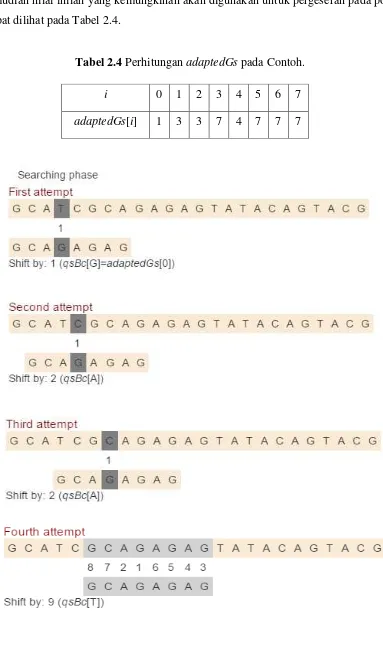
Proses keempat adalah preAdatedGs yang menghitung nilai pada tiap posisi dan kemudian nilai inilah yang kemungkinan akan digunakan untuk pergeseran pada pola. Dapat dilihat pada Tabel 2.4.
Tabel 2.4 Perhitungan adaptedGs pada Contoh.
i 0 1 2 3 4 5 6 7
Gambar 2.1 Tahap pencarian algoritma Maximal Shift.
2.5. Algoritma Quick Search
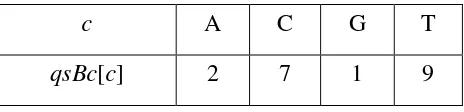
Menurut (Sunday, 1990) algoritma Quick Search adalah algoritma yang paling sederhana dimana perbandingan yang dilakukan secara ketat dari kiri ke kanan (Stephen, 1994). Algoritma Quick Search ini mencari data secara berurut pada tiap karater dalam teks sehingga pencarian disebut pencarian sekuensial atau sequential search. Algoritma Quick Search mencari pola karakter berdasarkan nilai Quick Search-bad character atau qsBc (Handik, 2006).
[ ] { { [ ] }}
Proses pertama yang dilakukan adalah mencari nilai Quick Search-bad character atau qsBc yang digunakan untuk proses pergeseran. Seperti pada Tabel 2.5.
Tabel 2.5 Perhitungan preQsBc pada Contoh QS
Langkah-langkah pencarian dengan algoritma Quick Search. 1. Pertama dihitung selisih panjang pola dan panjang teks.
C A C G T
3. Jika terjadi kecocokkan maka pencarian diteruskan dengan mencocokkan karakter pola selanjutnya dengan karakter pada teks.
4. Jika semua pola ditemukan maka dianggap telah menemukan ouput string yang dicari.
Gambar 2.2 Tahap pencarian algoritma Quick Search
2.6. Kompleksitas Algoritma
Kompleksitas dari suatu algoritma merupakan ukuran seberapa banyak komputasi yang dibutuhkan algoritma tersebut untuk menyelesaikan masalah. Algoritma yang dapat menyelesaikan suatu permasalahan dalam waktu yang singkat memiliki kompleksitas yang rendah, sementara algoritma membutuhkan waktu yang lama untuk menyelesaikan masalahnya mempunyai kompleksitas yang tinggi. Kompleksitas algoritma terdiri dari dua macam yaitu kompleksitas waktu dan kompleksitas ruang (Azizah, 2013).
Kompleksitas waktu dinyatakan oleh T(n), diukur dari jumlah tahapan komputasi yang dibutuhkan untuk menjalankan sebagai fungsi dari ukuran masukan n, dimana ukuran masukan (n) merupakan jumlah data yang diproses oleh algoritma. Waktu yang diperlukan untuk menjalankan suatu algoritma harus semakin cepat. Karena kompleksitas waktu menjadi hal yang sangat penting, maka analisis kompleksitas algoritma deteksi tepi akan dilakukan terhadap running time algoritma tersebut.
2.6.1. Notasi Asimptotik
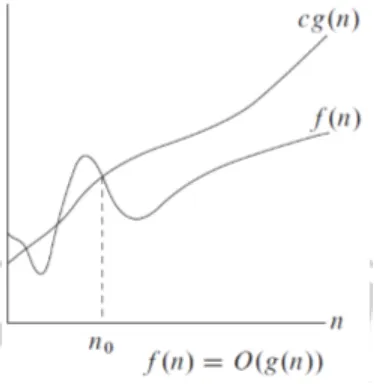
3. Keadaan terburuk (worsh case) dilambangkan dengan notasi ( ) Big-O.
Gambar 2.3 Contoh Grafik Notasi Asimptotik Ω.
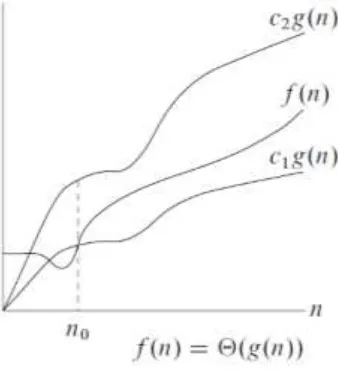
Gambar 8.3 menunjukan notasi Ω menjadi batas bawah dari suatu fungsi agar berada dalam suatu faktor konstan. Dinyatakan jika terdapat konstanta positif dan sedemikian sehingga pada dan dikanan , nilai selalu berada tepat pada atau diatas (Lavitin, 2011).
Gambar 2.4 Contoh Grafik Notasi Asimptotik .
, , dan sedemikian sehingga pada dan di kanan , nilai selalu berada tepat pada , tepat pada , atau diantara dan .
Gambar 2.5 Contoh Grafik Notasi Asimptotik .
2.7. Farmakologi
Farmakologi adalah ilmu yang mempelajari tentang obat, bertujuan agar dapat
menggunakan obat untuk pencegahan, diagnosis, dan pengobatan penyakit. Prinsip farmakologi adalah molekul obat harus dapat mempengaruhi secara kimia satu atau
lebih isi sel agar mengahasilkan respons farmakologi. Cabang-cabang farmakologi mencakup (Susanti & Kumala, 2011) :
1. Farmakoqnosi adalah ilmu yang mempelajari tentang sifat-sifat tumbuhan dan bahan lain yang merupakan sumber obat.
2. Farmasi adalah ilmu yang mempelajari tentang cara membuat, memformulasikan, menyimpan dan menyediakan obat.
3. Farmakologi klinik adalah ilmu yang mempelajari tentang efek obat pada manusia.
4. Farmakokinetika adalah ilmu yang mempelajari tentang nasib obat dalam tubuh yaitu absorpsi, distribusi, metabolisme, dan ekskresinya.
5. Farmakodinamika adalah ilmu yang mempelajari tentang efek obat terhadpa fisiologi dan biokimia berbagai organ tubuh mekanisme kerjanya.