Informasi Dokumen
- Penulis:
- Adhi Kurniawan
- Sekolah: Universitas
- Mata Pelajaran: Metode Penarikan Sampel
- Topik: Metode Penarikan Sampel Systematic Random Sampling
- Tipe: Dokumen
Ringkasan Dokumen
I. Pengantar
Penarikan sampel acak sederhana (SRS) merupakan metode di mana setiap unit dalam populasi memiliki peluang yang sama untuk dipilih. Namun, metode ini dapat menjadi tidak efisien jika ukuran populasi besar. Oleh karena itu, systematic random sampling diperkenalkan sebagai alternatif yang lebih efisien. Dalam metode ini, satu unit pertama dipilih secara acak, dan unit-unit berikutnya dipilih berdasarkan interval yang telah ditentukan. Dengan cara ini, penarikan sampel menjadi lebih mudah dan cepat, serta mengurangi kesalahan dalam pemilihan unit sampel.
II. Prinsip
Dalam systematic random sampling, setiap unit dalam populasi diberi nomor urut dari 1 hingga N. Interval (k) ditentukan berdasarkan rumus k = N/n, di mana N adalah jumlah total unit dalam populasi dan n adalah jumlah unit sampel yang diinginkan. Unit sampel pertama dipilih secara acak dalam rentang 1 hingga k. Selanjutnya, unit-unit sampel berikutnya ditentukan dengan menambahkan interval k pada unit sebelumnya. Pemilihan unit pertama sangat penting karena akan mempengaruhi keseluruhan sampel yang diambil.
III. Linear Systematic Sampling
Dalam linear systematic sampling, langkah pertama adalah menghitung interval k. Kemudian, satu angka random (AR1) dipilih dari tabel angka random, yang akan menjadi unit sampel pertama. Unit-unit sampel berikutnya ditentukan dengan menambahkan k pada unit sebelumnya. Jika N tidak dapat dinyatakan dalam bentuk N=nk, maka k harus dibulatkan ke bilangan bulat terdekat. Metode ini memberikan cara yang sistematis dan terstruktur untuk memilih sampel dari populasi yang besar.
IV. Circular Systematic Sampling
Circular systematic sampling mirip dengan linear systematic sampling, tetapi dengan modifikasi yang memungkinkan pemilihan unit sampel yang lebih fleksibel. Dalam metode ini, jika unit yang dipilih melebihi N, maka unit tersebut akan kembali ke awal daftar. Langkah-langkahnya sama dengan linear systematic sampling, tetapi dengan tambahan penyesuaian untuk memastikan bahwa pemilihan unit tetap dalam batas populasi yang ada. Metode ini berguna untuk menghindari bias dalam pemilihan unit sampel.
V. Latihan
Latihan ini bertujuan untuk mengaplikasikan konsep systematic random sampling dalam konteks nyata. Contoh kasus diberikan untuk menghitung tingkat loyalitas pegawai dengan penarikan sampel sistematik. Peserta diminta untuk menentukan unit sampel menggunakan berbagai pendekatan, seperti linear dan circular systematic sampling. Latihan ini akan memperkuat pemahaman tentang metode pemilihan sampel dan aplikasi praktisnya dalam penelitian.
VI. Problem With Intervals
Masalah dapat timbul jika ukuran populasi N bukan merupakan kelipatan bulat dari k. Beberapa solusi yang bisa diterapkan termasuk membiarkan ukuran sampel menjadi n atau (n+1), menghilangkan unit-unit yang tidak diperlukan, atau mempertimbangkan daftar sebagai circular. Penggunaan interval pecahan juga dapat diterapkan untuk meningkatkan fleksibilitas dalam pemilihan sampel. Memahami masalah ini penting untuk memastikan bahwa pemilihan sampel tetap representatif.
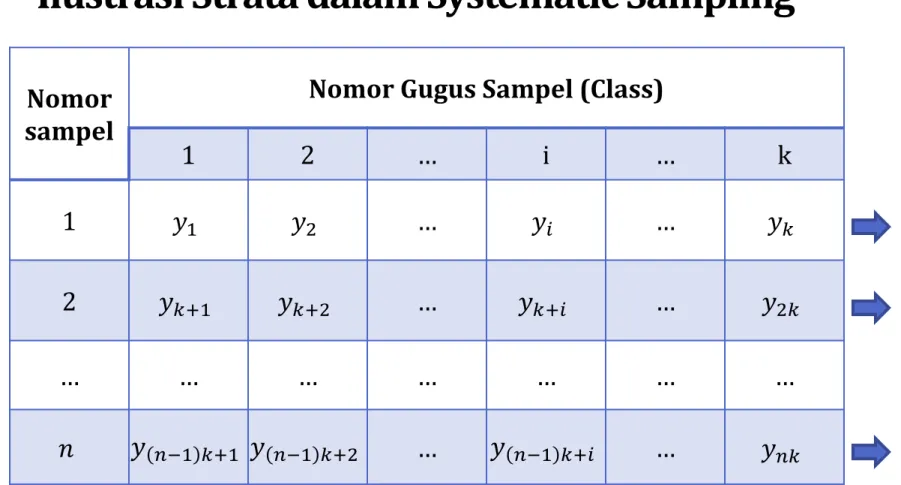
VII. Implicit Stratification
Implicit stratification adalah teknik yang digunakan untuk meningkatkan efisiensi desain sampling dengan mengatur unit-unit berdasarkan karakteristik tertentu sebelum melakukan penarikan sampel sistematik. Dengan cara ini, sampel yang diambil akan lebih representatif terhadap populasi yang lebih luas. Pengaturan ini dapat didasarkan pada kriteria geografis, demografis, atau sosial ekonomi. Keuntungan dari implicit stratification adalah kemudahan dalam pelaksanaan dan peningkatan presisi hasil estimasi.
VIII. Hubungan dengan Stratified Sampling
Systematic sampling dapat dianggap sebagai bentuk stratified sampling ketika populasi dibagi menjadi strata yang berbeda. Dalam hal ini, unit-unit terletak pada posisi yang relatif sama dalam strata. Meskipun systematic sampling dan stratified random sampling berbeda dalam metode pemilihannya, keduanya dapat memberikan hasil yang serupa dalam hal presisi estimasi. Memahami hubungan ini penting untuk merancang studi yang lebih efektif.
IX. Hubungan dengan Cluster Sampling
Dalam cluster sampling, populasi dibagi menjadi beberapa kelompok besar, dan satu unit cluster dipilih secara acak. Systematic sampling dapat diterapkan pada pemilihan satu unit dari setiap cluster. Hal ini memungkinkan peneliti untuk memperoleh sampel dari cluster yang lebih besar dengan efisiensi yang lebih tinggi. Memahami perbedaan dan kesamaan antara metode ini membantu peneliti dalam merancang studi yang lebih komprehensif.
X. Penduga Rata-rata Populasi
Dalam systematic sampling, penduga rata-rata dari sampel sistematik dapat menjadi unbiased jika N=nk. Namun, jika N tidak sama dengan nk, penduga rata-rata dapat menjadi biased. Penggunaan circular systematic sampling selalu menghasilkan penduga yang unbiased, terlepas dari hubungan antara N dan n. Memahami konsep ini penting untuk analisis statistik dan interpretasi hasil penelitian.
XI. Latihan
Latihan ini dirancang untuk menguji pemahaman peserta tentang konsep-konsep yang telah dipelajari. Peserta diminta untuk menghitung rata-rata dan varians dari sampel sistematik yang diambil dari populasi yang berbeda. Dengan melakukan latihan ini, peserta akan mampu menerapkan teori dalam praktik dan memahami dampak dari metode pemilihan sampel terhadap hasil penelitian.
XII. Varians Penduga Rata-rata
Varians dari penduga rata-rata dalam systematic sampling dapat dihitung menggunakan rumus yang melibatkan jumlah unit dalam sampel dan populasi. Memahami varians ini penting untuk mengevaluasi ketepatan estimasi yang dihasilkan dari sampel. Varians yang tinggi menunjukkan ketidakpastian yang lebih besar dalam estimasi, sedangkan varians yang rendah menunjukkan estimasi yang lebih akurat.
XIII. Intraclass Correlation Coefficient
Koefisien korelasi intraclass digunakan untuk mengukur tingkat kehomogenan dalam sampel sistematik. Ini memberikan informasi penting tentang hubungan antar unit dalam sampel. Jika koefisien ini tinggi, maka unit-unit dalam sampel cenderung homogen, sedangkan jika rendah, menunjukkan heterogenitas. Memahami intraclass correlation coefficient membantu peneliti dalam menilai kualitas sampel yang diambil.
XIV. Pembuktian
Pembuktian varians dan koefisien korelasi intraclass dilakukan untuk menunjukkan bahwa metode yang digunakan menghasilkan estimasi yang valid. Dengan melakukan pembuktian ini, peneliti dapat memastikan bahwa hasil penelitian dapat diandalkan dan representatif. Pembuktian ini juga membantu dalam memahami batasan dan kekuatan dari metode yang diterapkan.
XV. Efisiensi
Efisiensi dari systematic sampling dapat dibandingkan dengan metode lain seperti simple random sampling (SRS) dan stratified sampling. Dengan memahami efisiensi ini, peneliti dapat memilih metode yang paling sesuai untuk situasi tertentu. Efisiensi yang tinggi menunjukkan bahwa metode tersebut dapat menghasilkan estimasi yang akurat dengan biaya dan waktu yang lebih rendah.
XVI. Penduga Rata-rata Populasi dan Varians (Ringkasan)
Ringkasan mengenai rumus-rumus untuk penduga rata-rata dan varians dalam systematic sampling memberikan gambaran umum yang jelas. Memahami rumus-rumus ini penting untuk analisis statistik dan interpretasi hasil penelitian. Ringkasan ini membantu peserta untuk mengingat dan menerapkan rumus yang relevan dalam konteks penelitian mereka.
XVII. Contoh
Contoh praktis dari penerapan systematic sampling dalam populasi nyata memberikan wawasan tambahan bagi peserta. Dengan melihat contoh, peserta dapat memahami bagaimana teori diterapkan dalam praktik dan bagaimana hasilnya dapat dianalisis. Contoh ini juga dapat membantu peserta dalam merancang studi mereka sendiri.