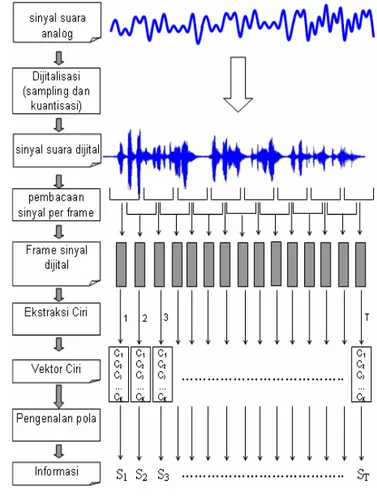
i
IDENTIFIKASI JENIS TANGIS BAYI
MENGGUNAKAN CODEBOOK UNTUK PENGENAL POLA
DAN MFCC UNTUK EKSTRAKSI CIRI
MEDHANITA DEWI RENANTI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
iii
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Identifikasi Jenis Tangis Bayi menggunakan Codebook untuk Pengenal Pola dan MFCC untuk Ekstraksi Ciri adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2013
Medhanita Dewi Renanti
RINGKASAN
MEDHANITA DEWI RENANTI. Identifikasi Jenis Tangis Bayi menggunakan
Codebook untuk Pengenal Pola dan MFCC untuk Ekstraksi Ciri. Dibimbing oleh
AGUS BUONO dan WISNU ANANTA KUSUMA.
Software yang dibuat ini merupakan otomatisasi dari Dunstan Baby Language. Software ini menggunakan MFCC untuk ekstraksi ciri dan codebook
untuk pengenalan suara bayi. Pembentukan codebook berasal dari hasil clustering semua data tangis bayi dengan menggunakan k-means clustering. Ruang lingkup penelitian ini adalah: 1) klasifikasi arti tangis bayi yang digunakan adalah versi Dunstan Baby Language, 2) software ini digunakan untuk identifikasi arti tangis
bayi usia 0-3 bulan.
Metode penelitian ini terdiri atas beberapa tahapan proses yaitu pengambilan data, preprocessing, pemodelan codebook tangis bayi, pengujian dan analisis, serta pembuatan antarmuka. Data tangis bayi ini diambil dari video
Dunstan Baby Language yang sudah diolah. Data dibagi menjadi dua yaitu data
latih dan data uji. Terdapat 140 data latih yang masing-masing mewakili 28 tangis bayi lapar, 28 tangis bayi mengantuk, 28 tangis bayi ingin bersendawa, 28 tangis bayi mengalami nyeri (ada angin) di perut, dan 28 tangis bayi tidak nyaman (bisa karena popoknya basah/udara yang terlalu panas/dingin atau hal lainnya). Data uji sebanyak 35, masing-masing 7 tangis bayi untuk setiap jenis tangis bayi. Pada tahap preprocessing dilakukan pemotongan silence dan ekstraksi ciri menggunakan MFCC. Pembuatan antarmuka identifikasi arti tangis bayi dibuat berdasarkan data latih yang menghasilkan akurasi tertinggi.
Penelitian ini dibuat menggunakan software Matlab R2010b version 7.11.0.584. Penelitian ini memvariasikan panjang frame: 25 ms/panjang frame = 275, 40 ms/panjang frame = 440, 60 ms/ panjang frame = 660; overlap frame: 0%, 40%, 60%; dan jumlah codeword: 1 sampai 18, untuk panjang frame = 275 dan overlap frame = 0% menggunakan jumlah codeword 1 sampai 29. Identifikasi jenis tangis bayi menggunakan jarak terkecil dari jarak euclid dan mahalanobis. Akurasi menggunakan jarak euclid berkisar antara 37% sampai 94%. Sedangkan nilai akurasi menggunakan jarak mahalanobis berkisar antara 9% sampai 83%. Model codebook dan MFCC yang menghasilkan akurasi tertinggi adalah: panjang frame = 440, overlap frame = 0.4, k=18. Sedangkan penggunaan jarak yang menghasilkan akurasi tertinggi adalah penggunaan jarak euclid. Model tersebut mampu menghasilkan akurasi pengenalan jenis tangis bayi tertinggi sebesar 94%. Suara ‘eh’ merupakan suara yang sering benar dikenali sedangkan suara ‘owh’ merupakan suara yang sering salah dikenali dan biasanya kesalahannya dikenali sebagai suara ‘neh’ dan ‘eairh’. Kelemahan penelitian ini adalah pemotongan
silence hanya dilakukan di awal dan di akhir. Penelitian selanjutnya diharapkan melakukan pemotongan silence di setiap segmen suara supaya data yang dihasilkan lebih mencirikan suara tersebut. Hal ini diharapkan mempunyai dampak terhadap akurasi yang lebih tinggi.
Kata kunci: Codebook, Dunstan baby language, Infant cries, K-means clustering, MFCC
iii
SUMMARY
MEDHANITA DEWI RENANTI. The Identification of Infant Cries by Using Codebook as Feature Matching, and MFCC as Feature Extraction. Supervised by AGUS BUONO and WISNU ANANTA KUSUMA.
In this paper, we focused on automation of Dunstan Baby Language. This software uses MFCC as feature extraction and codebook as feature matching. The codebook of clusters is made from the proceeds of all the baby’s cries data, by using the k-means clustering. The scope of this research are: 1) the infant cries classification used is the version of the Dunstan Baby Language, 2) this software is used to identify the meaning of 0-3 month old infant cries.
The methodology of this research consists of several stages of process: data collection, preprocessing, codebook modeling of infant cries, testing and analysis, and interface manufacturing. The data is taken from Dunstan Baby Language videos that has been processed. The data is divided into two, training data and testing data. There are 140 training data, each of which represents the 28 hungry infant cries, 28 sleepy infant cries, 28 wanted to burp infant cries, 28 in pain infant cries, and 28 uncomfortable infant cries (could be because his diaper is wet/too hot/cold air or anything else). The testing data is 35, respectively 7 infant cries for each type of infant cry. Silence cutting is in the preprocessing stage and the feature extraction uses MFCC method. The interface making of the infant cries identification is made based on the training data that produces the highest accuracy.
The making of this research is using Matlab R2010b version 7.11.0.584 software. The research varying frame length: 25 ms/frame length = 275, 40 ms/frame length = 440, 60 ms/ frame length = 660; overlap frame: 0%, 25%, 40%; the number of codewords: 1 to 18, except for frame length 275 and overlap frame = 0% using 1 to 29 clusters. The identification of this type of infant cries uses the minimum distance of euclidean and mahalanobis distance. Accuracy value using euclidean distance is between 37% and 94%. Whereas, accuracy value using mahalanobis distance is between 9% and 83%. Codebook model and MFCC with the higher accuracy is: frame length = 440, overlap frame = 0.4, k = 18. Eventhough the distance using that produce the higher accuracy is euclidean distance. That model can produce accuracy recognition of infant cries with the higher about 94%. Sound ‘eh’ is the most familiar, whereas sound ‘owh’ is always missunderstood and generally it is known as ‘neh’ and ‘eairh’. The weakness point of this research is the silence is only be cut at the beginning and at the end of speech signal. Hopefully, in the next research, the silence can be cut in each sound segment so that it can produce more specific sound. It has impact on the bigger accuracy as well.
Keywords: Codebook, Dunstan baby language, Infant cries, K-means clustering, MFCC
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apa pun tanpa izin IPB
i Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
IDENTIFIKASI JENIS TANGIS BAYI
MENGGUNAKAN CODEBOOK UNTUK PENGENAL POLA
DAN MFCC UNTUK EKSTRAKSI CIRI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
iii Judul Tesis : Identifikasi Jenis Tangis Bayi menggunakan Codebook untuk
Pengenal Pola dan MFCC untuk Ekstraksi Ciri Nama : Medhanita Dewi Renanti
NIM : G651110571
Disetujui oleh Komisi Pembimbing
Dr Ir Agus Buono, MSi, MKom Ketua
Dr Eng Wisnu Ananta Kusuma, ST, MT Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Yani Nurhadryani, SSi, MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
v
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan November 2012 ini ialah
speech recognition, dengan judul Identifikasi Jenis Tangis Bayi menggunakan Codebook untuk Pengenal Pola dan MFCC untuk Ekstraksi Ciri.
Terima kasih penulis ucapkan kepada Bapak Dr Ir Agus Buono, MSi, MKom dan Bapak Dr Eng Wisnu Ananta Kusuma, ST, MT selaku pembimbing yang telah banyak memberi saran, kepada Bapak Dr Ir Bib Paruhum Silalahi, MKom selaku penguji, kepada DIKTI atas beasiswa selama menempuh pendidikan dan Program Diploma IPB atas bantuan biaya penelitian. Selain itu, penghargaan penulis sampaikan kepada semua dosen dan staf Departemen Ilmu Komputer IPB, dosen dan staf Program Diploma IPB yang telah membantu selama proses penelitian. Ungkapan terima kasih juga disampaikan kepada suami Soni Trison, ananda Shofia Dzakka Hanifa, ayah Totok Darussalam dan Didin Kasrudin, ibu Lilik Hertantini dan Mimin Rohaeti, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2013
DAFTAR ISI
DAFTAR TABEL x DAFTAR GAMBAR x DAFTAR LAMPIRAN xi 1 PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 2Ruang Lingkup Penelitian 2
2 TINJAUAN PUSTAKA 3
Dunstan Baby Language 3
Ruang Lingkup Pemrosesan Suara 4
Speech Recognition 4
Sinyal 5
Transformasi Sinyal menjadi Informasi 5
Dijitalisasi Gelombang Suara 6
Ekstraksi Ciri Mel Frequency Cepstrum Coefficients 6
Codebook 8
K-means Clustering 10
3 METODE 11
4 HASIL DAN PEMBAHASAN 15
5 SIMPULAN DAN SARAN 26
Simpulan 26
Saran 26
DAFTAR PUSTAKA 27
LAMPIRAN 29
vi
i
DAFTAR TABEL
1 Faktor dan level penelitian 11
2 Hasil pengujian data uji saat k = 18, panjang frame = 440, dan overlap
frame = 0.4 menggunakan jarak euclid 16
3 Hasil pengujian data uji saat k = 18, panjang frame = 660, dan overlap
frame = 0.25 menggunakan jarak euclid 16
4 Hasil pengujian data uji saat k = 18, panjang frame = 275, dan overlap
frame = 0.25 menggunakan jarak euclid 16
5 Kisaran nilai akurasi menggunakan jarak euclid dan mahalanobis 20 6 Hasil pengujian data latih saat k = 17, panjang frame = 275, dan overlap
frame = 0.25 menggunakan jarak mahalanobis 20
7 Confusion matrix saat k = 18, panjang frame = 440, dan overlap frame
= 0.4 menggunakan jarak euclid 25
8 Confusion matrix saat k = 17, panjang frame = 275, dan overlap frame
= 0.25 menggunakan jarak mahalanobis 25
DAFTAR GAMBAR
1 Perbedaan kategori recognition (Reynolds 2002) 4
2 Contoh sinyal suara 5
3 Tahapan transformasi sinyal suara menjadi informasi (Jurafsky &
Martin 2007, dimodifikasi oleh Buono 2009) 6
4 Diagram Alur MFCC (Buono 2009) 9
5 Ilustrasi diagram konseptual dari formasi codebook VQ 9 6 Metodologi penelitian identifikasi jenis tangis bayi 11
7 Sinyal suara ‘owh’ 12
8 Sinyal ‘owh’ yang dipotong 12
9 Ilustrasi identifikasi jenis tangis bayi 14
10 Grafik perbandingan akurasi menggunakan jarak euclid pengujian
data uji 15
11 Ilustrasi codebook ‘eh’ dan ‘owh’ 17
12 Ilustrasi codebook ‘eairh’, ‘eh’, dan ‘owh’ 17
13 Grafik perbandingan akurasi menggunakan jarak euclid pengujian
data latih 18
14 Grafik perbandingan akurasi menggunakan jarak mahalanobis
pengujian data uji 19
15 Grafik perbandingan akurasi menggunakan jarak mahalanobis
pengujian data latih 19
16 Ilustrasi codebook ‘heh’ dan ‘owh’ 21
17 Akurasi pengujian data latih dan data uji menggunakan jarak euclid dengan panjang frame = 275 dan overlap frame = 0 22 18 Akurasi pengujian data latih dan data uji menggunakan jarak dengan
panjang frame = 275 dan overlap frame = 0 22
19 Ilustrasi codebook ‘owh’ dan ‘neh’, serta data uji ‘owh’ 23 20 Ilustrasi codebook ‘owh’ dan ‘neh’, serta data latih ‘owh’ 24
21 Hierarchical clustering 24
22 Antarmuka identifikasi jenis tangis bayi 26
DAFTAR LAMPIRAN
1 Hasil akurasi identifikasi jenis tangis bayi menggunakan jarak euclid
pengujian data uji 29
2 Hasil akurasi identifikasi jenis tangis bayi menggunakan jarak euclid
pengujian data uji 32
3 Hasil akurasi identifikasi jenis tangis bayi menggunakan jarak
mahalanobis pengujian data uji 35
4 Hasil akurasi identifikasi jenis tangis bayi menggunakan jarak
1 PENDAHULUAN
Komunikasi verbal pertama yang dikuasai bayi adalah menangis. Tangisan ini sebagai komunikasi dengan manusia dewasa untuk memenuhi kebutuhan dan keinginannya serta untuk menanggapi situasi tertentu. Hampir sebagian besar ibu akan menyusui anaknya atau menggendong bayinya ketika bayi tersebut menangis, tetapi adakalanya tindakan ibu tersebut tidak membuat tangis bayi berhenti bahkan ada bayi yang justru menangis lebih kencang. Hal ini berarti ibu tersebut salah menerjemahkan maksud dari tangis bayi dan membuat orang tua, khususnya ibu menjadi panik.
Saat ini terdapat sistem yang mempelajari arti tangis bayi untuk usia 0-3 bulan yang disebut Dunstan Baby Language (DBL). Dunstan (2006) menyatakan bahwa setiap bayi lahir mempunyai kemampuan untuk mengekspresikan kebutuhan dasar mereka melalui suara. Delapan tahun penelitian yang dilakukan oleh Priscilla Dunstan dari tahun 1998 sampai 2006 telah berhasil menemukan bahasa yang dimiliki oleh semua bayi di seluruh dunia. Bahasa tersebut dikenal dengan sebutan Dunstan Baby Language-DBL.
DBL diperkenalkan oleh Priscilla Dunstan, musisi asal Australia yang mempunyai bakat mengingat semua jenis suara atau yang dikenal dengan sound
photograph. Terdapat lima bahasa bayi versi DBL yaitu: “neh” berarti lapar,
“owh” berarti lelah yang mengindikasikan bayi sudah mulai mengantuk, “eh” berarti ingin bersendawa, “eairh” berarti nyeri (ada angin) di perut, dan “heh” berarti tidak nyaman (bisa karena popoknya basah, udara terlalu panas atau dingin, atau hal lainnya). Perintis DBL di Indonesia adalah dokter Adhiatma Gunawan yang menyebutkan bahwa seorang bayi mempunyai refleks primitif yang dimiliki sejak dilahirkan. Refleks ini bersifat universal dan lambat laun akan menghilang seiring dengan berkembangnya kemampuan untuk beradaptasi. DBL berlaku pada bayi hingga usia tiga bulan karena setelah usia tersebut bayi akan mengembangkan kemampuan berkomunikasinya sendiri dengan bantuan orang tua dan lingkungan. Penelitian membuktikan bahwa 90% dari ibu-ibu di seluruh dunia yang mengikuti DBL merasa puas dan terbantu dengan sistem tersebut dan merekomendasikan pada yang lain. Sementara lebih dari 70% orang tua merasa lebih percaya diri dalam mengasuh bayinya dan by the end of the day, tingkat stres mereka berkurang signifikan (Gunawan 2011).
Latar Belakang
Kepakaran untuk menentukan arti tangis bayi versi DBL masih agak jarang sehingga informasi arti tangis bayi ini belum mudah didapatkan oleh para orang tua. Saat ini sistem untuk mentrasfer pengetahuan mengenai DBL dengan cara mengikuti pelatihan atau seminar yang diadakan oleh pengelola atau dengan cara mempelajari sendiri materi jenis tangis bayi versi DBL dalam bentuk optical discs atau dapat juga mengunduh materi DBL di internet. Pengguna sistem DBL khususnya di Indonesia akan lebih yakin dengan kesimpulan yang mereka buat jika ada suatu software yang secara otomatis dapat menghasilkan arti tangisan bayinya. Hal ini dapat menguatkan kesimpulan mereka, karena jika hanya
2
mengikuti pelatihan kilat atau seminar, masih ada beberapa peserta yang belum paham bagaimana mengenali maksud tangisan bayi tersebut atau belum tepat memaknai tangisan bayi. Selain itu nantinya software ini juga bisa bermanfaat bagi orang tua yang belum mengikuti pelatihan atau seminar DBL sehingga para orang tua dapat memahami bahasa/tangis bayi.
Penelitian mengenai tangis bayi telah dilakukan oleh para peneliti, antara lain: klasifikasi tangis bayi bayi normal dan abnormal (menderita gangguan hipoksia-tubuh kekurangan oksigen) menggunakan neural network menghasilkan akurasi 85% (Poel & Ekkel 2006). Klasifikasi bayi sehat dan bayi yang mengalami sakit seperti kerusakan otak, bibir sumbing, hidrosefalus, dan sindrom kematian bayi mendadak menggunakan metode klasifikasi Hidden Markov
Model-HMM menghasilkan akurasi 91% (Lederman et al. 2008). Penelitian
lainnya adalah klasifikasi tiga jenis tangis yaitu bayi normal, bayi tuli, dan bayi yang menderita asfiksia (tidak dapat bernafas secara spontan dan teratur) pada usia satu hari sampai sembilan bulan menggunakan neural network menghasilkan akurasi 86% (Reyes-Galaviz dan Reyes-Garcia 2004).
Dari beberapa hasil penelitian tersebut dapat disimpulkan bahwa tangisan bayi berarti sinyal suara tangis bayi dapat digunakan untuk mendeteksi status kesehatan bayi. Hal ini sejalan dengan penelitian yang dilakukan oleh Priscilla Dunstan yang menyatakan bahwa tangis bayi sebagai alat komunikasi untuk memenuhi kebutuhan atau keinginannya dan tangis bayi mempunyai tujuan untuk mengungkapkan sesuatu.
Penelitian klasifikasi tangis bayi sebelumnya telah menggunakan neural
network atau HMM sebagai pengenal polanya. Penelitian untuk identifikasi jenis
bayi versi DBL ini menggunakan codebook untuk pengenal polanya dan
Mel-Frequency Cepstrum Coefficients (MFCC) untuk ekstraksi ciri. Pemilihan metode ini didasari beberapa penelitian diantaranya: penelitian Lee et al. (2006) melakukan pengenalan suara burung menggunakan MFCC dan Vector
Quantization (VQ) codebook dan berhasil mencapai akurasi 87%. Selain itu speaker recognition system juga berhasil dibuat menggunakan MFCC dan VQ
(Kumar 2011). Penelitian serupa dilakukan oleh Singh dan Rajan (2011) yang berhasil mencapai akurasi 98,57% dengan melakukan penelitian speaker
recognition menggunakan VQ dan MFCC. Penelitian mengenai speech recognition and verification menggunakan MFCC dan VQ yang dilakukan oleh
Patel dan Prasad (2013) berhasil melakukan pengenalan dengan training error
rate sebesar 13%. Codebook ini dibuat menggunakan k-means clustering.
Tujuan Penelitian
Penelitian ini bertujuan melakukan pemodelan codebook menggunakan
k-means clustering untuk identifikasi jenis tangis bayi dengan MFCC sebagai
ekstraksi ciri.
Ruang Lingkup Penelitian
Adapun ruang lingkup penelitian ini adalah:
1. Klasifikasi jenis tangis bayi yang digunakan adalah versi Dunstan Baby Language yang dibagi ke dalam kelompok bayi lapar, bayi lelah/mengantuk,
3
3
bayi ingin bersendawa, bayi mengalami nyeri (ada angin) di perut, dan bayi tidak nyaman.
2. Software ini digunakan untuk identifikasi jenis tangis bayi usia 0-3 bulan.
2 TINJAUAN PUSTAKA
Dunstan Baby Language
Gunawan (2011) mengungkapkan bahwa Dunstan Baby Language (DBL) diperkenalkan oleh Priscilla Dunstan, musisi asal Australia yang mempunyai bakat mengingat semua jenis suara atau yang dikenal dengan sound photograph. Ketika Priscilla menjadi seorang ibu, dia menyadari bahwa bayinya berusaha untuk berkomunikasi melalui suatu bahasa. Setelah delapan tahun meneliti dari tahun 1998 dan mengumpulkan bayi-bayi dari berbagai negara, suku bangsa, dan bahasa, akhirnya Priscilla menemukan suatu bahasa yang sama yang digunakan bayi-bayi tersebut untuk berkomunikasi, yaitu DBL. Terdapat lima bahasa bayi versi DBL yaitu:
1. “Neh” berarti lapar
Ketika lapar, bayi akan mengeluarkan suara “neh”. “Neh” dinyatakan sebagai bunyi yang dihasilkan ketika bayi mengecap untuk menghisap puting ibu. Pengenalan suara “neh” dengan mendengar sisipan huruf N pada tangisannya. Selain mengeluarkan bunyi “neh”, menurut teori DBL, bayi yang lapar biasanya:
- Menggerakan lidah ke langit-langit mulut (mengecap) - Menghisap jari atau kepala tangannya
- Menjilati bibirnya
- Menggelengkan kepalanya ke kiri dan kanan.
2. “Owh” berarti lelah yang mengindikasikan bayi sudah mulai mengantuk “Owh” pada dasarnya merupakan bunyi yang dihasilkan ketika menguap.
Tetapi, “owh” ini tidak selalu dibarengi dengan kuapan, bisa juga dengan tanda-tanda seperti:
- Bayi mulai bergerak gelisah
- Mengusap-usap mata dan menggaruki/menarik telinganya - Mulai menggeliat dan melengkungkan tubuhnya.
Namun, tanda-tanda ini biasanya didahului dengan bunyi “owh”. 3. “Eh” berarti ingin bersendawa
Tangisan “eh” terjadi ketika dada bayi bekerja keras mengeluarkan angin yang masuk ke dalamnya. Biasanya, frekuensi tangisan 'eh' yang diucapkan lebih cepat dan pendek karena bayi berusaha untuk sendawa. Penting bagi ibu untuk menyendawakan bayi begitu bunyi 'eh' terdengar, karena dapat menghindari angin turun ke perut dan menyebabkan kolik serta menghindari bayi memuntahkan susunya kembali. Tanda-tanda lain saat bayi perlu sendawa adalah:
- Dada yang mengencang
- Gerakan menggeliat ketika diletakkan di tempat tidur - Berhenti minum susu dan mulai gelisah
4
4. “eairh” berarti nyeri (ada angin) di perut
Jika bayi sering menangis dengan keras dan nampak kesakitan, ibu mungkin akan mendengar bunyi 'eairh'. Tangis 'eairh' terjadi karena adanya gas dan angin di perut bayi yang menyebabkan rasa sakit (kolik). Tanda-tanda lain yang dibarengi dengan bunyi 'eairh' adalah:
- Kaki yang mengejang dan ditarik ke perut - Tubuh bayi menjadi kaku
- Jerit tangisan yang merintih kesakitan
Bila tangisan 'eairh' terdengar, segeralah telungkupkan bayi, kemudian usap punggungnya. Ibu juga bisa memijat lembut perutnya untuk mengeluarkan angin. Udara 'eairh' akan lebih sulit dikeluarkan, jadi akan lebih baik jika ibu segera menyendawakan bayi saat terdengar bunyi 'eh', untuk mencegah udara turun ke perut.
5. “heh” berarti tidak nyaman
Salah satu alasan mengapa bayi rewel adalah karena ia merasa tidak nyaman, bisa karena popoknya basah, udara yang terlalu panas atau dingin, atau hal lainnya. Tangisan 'heh' biasanya terengah-engah (seperti membuang udara) dan ada penekanan pada huruf H diawal katanya. Jika ibu mendengar tangisan 'heh' ini segera periksa kondisi bayi, apa yang membuatnya tidak nyaman, seperti kepanasan, kedinginan, atau popok yang kotor dan harus diganti.
Ruang Lingkup Pemrosesan Suara
Reynolds (2002) membagi recognition menjadi tiga yaitu: speech
recognition, language recognition, dan speaker recognition. Perbedaan kategori
ini ditampilkan pada Gambar 1.
Gambar 1 Perbedaan kategori recognition (Reynolds 2002) Speech Recognition
Sistem pengenalan suara (speech recognition) memuat dua modul utama yaitu feature extraction dan feature matching. Feature extraction merupakan proses mengekstraki sejumlah data dari sinyal suara yang nantinya dapat
5
5
digunakan untuk merepresentasikan setiap speaker. Feature matching adalah proses untuk mengidentifikasi suara dengan membandingkan ekstraksi ciri suara yang akan diidentifikasi dengan ciri suara yang telah diketahui sebelumnya (Gupta et al. 2012).
Sinyal
Sinyal didefinisikan sebagai kuantitas fisik yang bervariasi dengan waktu, ruang atau sembarang satu atau lebih variabel belas lainnya. Secara matematika, sinyal digambarkan sebagai fungsi dari satu atau lebih variabel bebas. Berikut merupakan contoh fungsi yang menggambarkan dua sinyal, pertama fungsi yang liner dengan variabel bebas t (time) dan kedua fungsi kuadratik dengan t (Proakis & Manolakis 1996).
s1(t) = 5t
s2(t) = 20t2 (1) Contoh lainnya sebagai berikut: s(x,y) = 3x + 2xy + 10y2 (2) Fungsi tersebut menggambarkan sinyal dari dua variabel bebas x dan y yang dapat direpresentasikan ke dalam dua koordinat spasial pada suatu bidang. Pada beberapa kasus, fungsi yang menghubungkan antara waktu dengan kuantitas sinyal tidak diketahui atau sangat kompleks sehingga penerapannya tidak praktis, seperti pada sinyal suara yang ditampilkan pada Gambar 2. Sinyal tersebut tidak dapat digambarkan seperti pada ekspresi (1). Umumnya, segmen dari suara direpresentasikan dengan akurasi tinggi yang merupakan penjumlahan beberapa fungsi sinus yang berbeda amplitudo dan frekuensinya, dan ditulis sebagai berikut:
∑𝑁𝑁𝑖𝑖=1𝐴𝐴𝑖𝑖 (𝑡𝑡) sin[2π Fi (t) t + θi(t)] (3)
Dengan {Ai (t)}, {Fi (t), dan {θi(t)} adalah himpunan dari kemungkinan amplitudo, frekuensi, dan fase dari gelombang sinus untuk setiap waktu t. Salah satu cara untuk merepresentasikan konten informasi atau pesan dari segmen sinyal suara adalah mengukur amplitudo, frekuensi, dan fase segmen tersebut. (Proakis & Manolakis 1996).
Gambar 2 Contoh sinyal suara
Transformasi Sinyal menjadi Informasi
Pemrosesan sinyal suara merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009).
6
Pada proses transformasi terdapat tahapan yang perlu dilakukan diantaranya dijitalisasi sinyal analog, ekstraksi ciri, dan pengenalan pola, seperti yang ditampilkan pada Gambar 3.
Gambar 3 Tahapan transformasi sinyal suara menjadi informasi (Jurafsky & Martin 2007, dimodifikasi oleh Buono 2009)
Dijitalisasi Gelombang Suara
Tahap pertama dari pemrosesan suara adalah mengonversi sinyal analog menjadi sinyal digital, proses ini disebut dijitalisasi. Proses dijitalisasi terdiri atas dua tahap yaitu sampling dan kuantisasi. Sampling adalah pengambilan sinyal dengan mengukur amplitudonya pada waktu tertentu. Sampling rate adalah jumlah sampel yang diambil per detik. Sampling rate yang umumnya digunakan untuk pengenalan suara adalah 8000 Hz sampai dengan 16000 Hz . Tahapan setelah sampling adalah proses kuantisasi. Proses ini menyimpan nilai amplitudo ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2007).
Ekstraksi Ciri Mel Frequency Cepstrum Coefficients
Ekstraksi ciri merupakan proses untuk menentukan satu nilai atau vektor yang dapat digunakan sebagai penciri objek atau individu. Ciri yang biasa digunakan
7
7
adalah koefisien cepstral dari sebuah frame. Mel Frequency Cepstrum
Coefficients (MFCC) merupakan ekstraksi ciri yang menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia (Buono 2009). MFCC
memiliki tahapan yang terdiri atas (Do 1994):
1. Frame Blocking. Pada tahap ini sinyal suara continous speech dibagi ke dalam beberapa frame serta dilakukan overlapping frame agar tidak kehilangan informasi.
2. Windowing. Windowing merupakan salah satu jenis filtering untuk meminimalisasikan distorsi antar frame. Proses ini dilakukan dengan mengalikan antar frame dengan jenis window yang digunakan. Jika didefinisikan window sebagai w(n), 0≤n≤N−1 , N adalah jumlah sampel setiap frame, maka hasil windowing dari sinyal tersebut adalah:
1 0 ), ( ) ( ) (n =x nw n ≤n≤N− yt t (4) Persamaan window Hamming adalah :
1 0 , 1 2 cos 46 . 0 54 . 0 ) ( ≤ ≤ − − − = n N N n n w π (5)
3. Fast Fourier Transform (FFT). Tahap selanjutnya adalah mengubah tiap frame
N sampel dari domain waktu ke dalam domain frekuensi. FFT adalah
algoritme yang mengimplementasikan Discrete Fouries Transform (DFT) yang didefinisikan pada set N samples {xn}, sebagai berikut:
𝑋𝑋𝑛𝑛 = ∑𝑁𝑁−1𝑘𝑘=0𝑋𝑋𝑘𝑘𝑒𝑒−2𝜋𝜋𝜋𝜋𝑘𝑘𝑛𝑛 /𝑁𝑁, 𝑛𝑛 = 0, 1, 2, … … , 𝑁𝑁 − 1 (6) Pada umumnya Xk adalah bilangan kompleks dan hanya mempertimbangkan
nilai absolut (frequency magnitudes). Hasil sequence {Xk} direpresentasikan sebagai berikut: frekuensi positif 0≤ f <Fs/2 untuk nilai 0≤n≤N/2−1 , sementara frekuensi negatif −Fs/2< f <0 untuk N/2+1≤n≤N−1 . Fs menunjukkan frekuensi sampling. Hasil akhir tahap ini sering disebut sebagai
spectrum atau periodogram.
4. Mel-Frequency Wrapping. Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara ternyata tidak mengikuti skala linear. Setiap nada dengan frekuensi aktual f, diukur dengan Hz, subjective pitch diukur pada skala yang disebut skala ‘mel’. Skala mel-frequency adalah jarak frekuensi di bawah 1000 Hz dan jarak logaritmik di atas 1000 Hz. Penerimaan sinyal suara untuk frekuensi rendah (<1000 Hz) bersifat linear, sedangkan untuk frekuensi tinggi (>1000 Hz) bersifat logaritmik. Skala inilah yang disebut dengan skala
mel-frequency yang berupa filter.
Ukuran persepsi dalam skala mel dan hubungan skala mel dengan frekuensi dirumuskan pada Persamaan 7. Dari persamaan 7, maka nilai frekuensi FHz sebagai fungsi dari skala mel ditampilkan pada persamaan 8 (Nilsson & Ejnarsson 2002).
𝐹𝐹𝑚𝑚𝑒𝑒𝑚𝑚 = �2595 ∙ 𝑚𝑚𝑙𝑙𝑙𝑙10�1 + 𝐹𝐹𝐻𝐻𝐻𝐻
700� 𝜋𝜋𝑖𝑖𝑘𝑘𝑗𝑗 𝐹𝐹𝐻𝐻𝐻𝐻 > 1000 𝐹𝐹𝐻𝐻𝐻𝐻 𝜋𝜋𝑖𝑖𝑘𝑘𝑗𝑗 𝐹𝐹𝐻𝐻𝐻𝐻 ≤ 1000
8
𝐹𝐹𝐻𝐻𝐻𝐻 = 700 ∙ � 10 𝐹𝐹𝑚𝑚𝑒𝑒𝑚𝑚
2595 − 1�
(8) Proses wrapping terhadap sinyal dalam domain frekuensi dilakukan menggunakan persamaan 9 (Ganchev 2005).
𝑋𝑋𝑖𝑖 = 𝑚𝑚𝑙𝑙𝑙𝑙10(∑𝑁𝑁−1𝑘𝑘=0|𝑋𝑋(𝑘𝑘)| ∙ 𝐻𝐻𝑖𝑖(𝑘𝑘)), 𝑖𝑖 = 1, 2, … . , 𝑀𝑀 (9)
Keterangan:
Xi = nilai frequency wrapping pada filter i=1,2 sampai n jumlah filter. X(k) = nilai magnitudo frekuensi pada k frekuensi.
Hi(k) = nilai tinggi pada filter i segitiga dan k frekuensi, dengan k=0, 1 sampai
N-1 jumlah magnitudo frekuensi.
5. Cepstrum. Tahap ini merupakan tahap terakhir pada MFCC. Pada tahap ini
mel-frequency akan diubah menjadi domain waktu menggunakan Discrete Cosine Transform (DCT) dengan persamaan 10.
𝐶𝐶𝜋𝜋 = ∑𝑀𝑀𝑖𝑖=1𝑋𝑋𝑖𝑖cos �𝜋𝜋(𝑖𝑖−1)2 𝑀𝑀𝜋𝜋� (10) Keterangan :
Cj = nilai koefisien C ke j.
j = 1, 2, sampai jumlah koefisien yang diharapkan
Xi = nilai X hasil mel-frequency wrapping pada frekuensi i= 1, 2 sampai n jumlah wrapping
M = jumlah filter
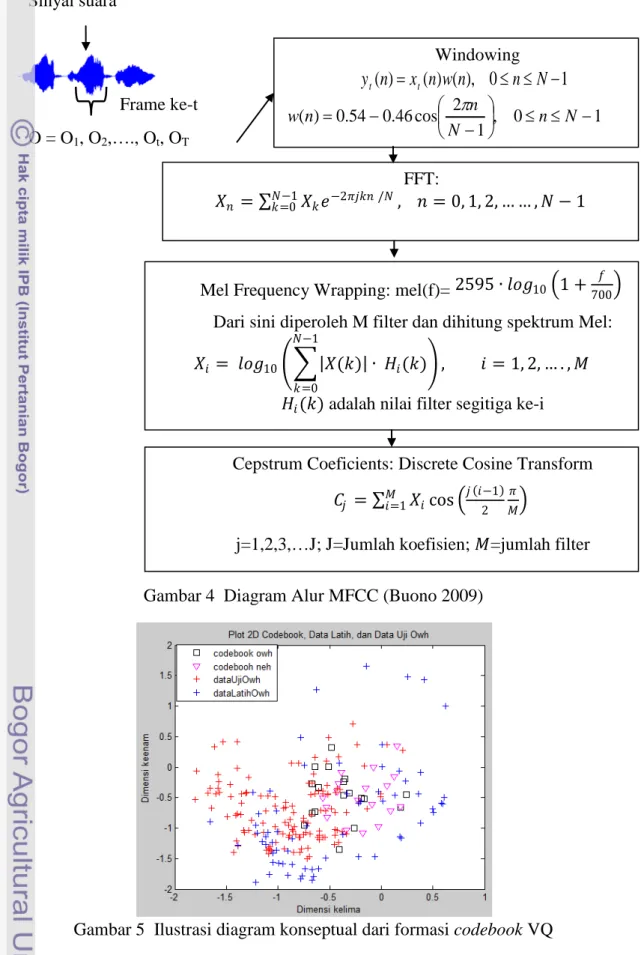
Diagram alur dari MFCC dapat dilihat pada Gambar 4. Codebook
Vector Quantization (VQ) merupakan proses memetakan vektor-vektor dari ruang
vektor yang besar menjadi ruang vektor dengan jumlah terbatas. Setiap daerah disebut cluster dan dapat direpresentasikan oleh pusatnya yang disebut codeword. Kumpulan codeword disebut codebook (Do 1994). Pemodelan speaker menggunakan pendekatan berbasis VQ dibentuk oleh clustering dari fitur speaker pada K yang tidak overlapping. Setiap cluster direpresentasikan oleh code vector ci yang disebut centroid. Hasil himpunan code vector ini disebut codebook.
Codebook ini berfungsi sebagai model pembicara (Linde et al. 1980). Codebook
adalah kumpulan titik (vektor) yang mewakili distribusi suara dari seorang pembicara tertentu dalam ruang suara. Setiap titik dari codebook dikenal sebagai
codeword. Oleh karena itu pada setiap pembicara dibuat sebuah codebook yang
merepresentasikan ciri suara dari pembicara tersebut dan setiap pembicara dibuat sebuah codebook yang terdiri atas beberapa codeword. Prinsipnya proses pengenalan yang dilakukan adalah setiap suara yang masuk dihitung jarak suara tersebut ke codebook setiap pembicara. Jarak sinyal suara masuk dengan
codebook seorang pembicara dihitung sebagai jumlah jarak setiap frame yang
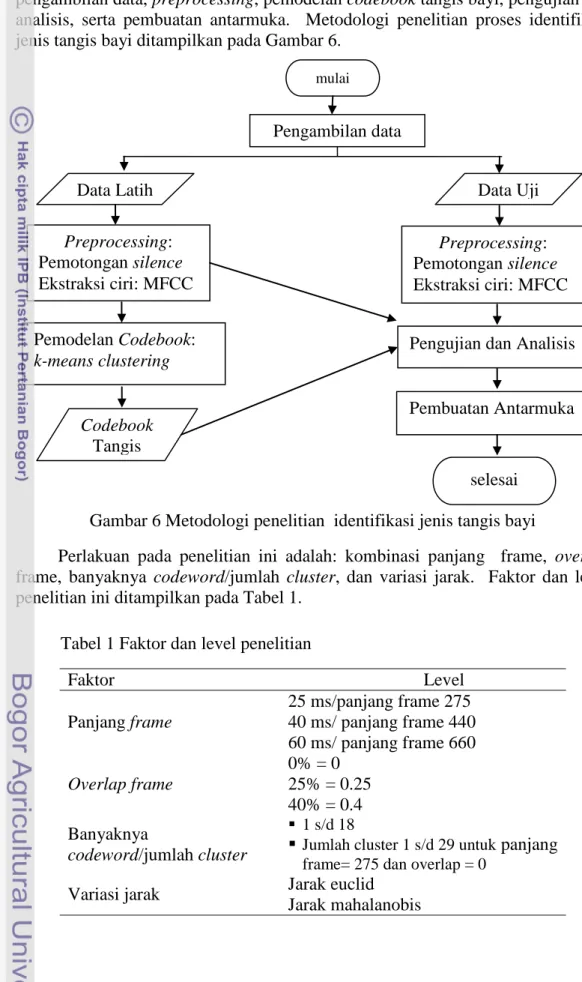
dibaca ke codeword terdekat pada codebook tersebut. Dari sini akhirnya sinyal masukan diberi label pembicara sesuai jarak codebook terkecil (Buono 2009). Gambar 5 menunjukkan diagram konseptual untuk mengilustrasikan proses pengenalan. Pada Gambar 5 terdapat dua codebook ‘owh’ dan ‘neh’. Simbol +
9
9
berwarna merah merupakan contoh data uji ‘owh’ dan symbol + berwarna biru merupakan contoh data latih ‘owh’.
Gambar 4 Diagram Alur MFCC (Buono 2009)
Gambar 5 Ilustrasi diagram konseptual dari formasi codebook VQ O = O1, O2,…., Ot, OT Windowing 1 0 ), ( ) ( ) (n =x n wn ≤n≤N− yt t 1 0 , 1 2 cos 46 . 0 54 . 0 ) ( ≤ ≤ − − − = n N N n n w π FFT: 𝑋𝑋𝑛𝑛 = ∑𝑁𝑁−1𝑘𝑘=0𝑋𝑋𝑘𝑘𝑒𝑒−2𝜋𝜋𝜋𝜋𝑘𝑘𝑛𝑛 /𝑁𝑁, 𝑛𝑛 = 0, 1, 2, … … , 𝑁𝑁 − 1
𝑋𝑋𝑖𝑖 = 𝑚𝑚𝑙𝑙𝑙𝑙10��|𝑋𝑋(𝑘𝑘)| ∙ 𝐻𝐻𝑖𝑖(𝑘𝑘) 𝑁𝑁−1 𝑘𝑘=0 � , 𝑖𝑖 = 1, 2, … . , 𝑀𝑀 Mel Frequency Wrapping: mel(f)= 2595 ∙ 𝑚𝑚𝑙𝑙𝑙𝑙10�1 +700𝑓𝑓 �
Dari sini diperoleh M filter dan dihitung spektrum Mel:
𝐻𝐻𝑖𝑖(𝑘𝑘) adalah nilai filter segitiga ke-i
Cepstrum Coeficients: Discrete Cosine Transform 𝐶𝐶𝜋𝜋 = ∑𝑀𝑀𝑖𝑖=1𝑋𝑋𝑖𝑖cos �𝜋𝜋 (𝑖𝑖−1)2 𝑀𝑀𝜋𝜋�
j=1,2,3,…J; J=Jumlah koefisien; 𝑀𝑀=jumlah filter
Sinyal suara
10
K-means Clustering
K-means clustering merupakan algoritma clustering eksklusif. Setiap objek
ditetapkan secara tepat ke dalam salah satu dari sekumpulan cluster. Metode
clustering ini dimulai dengan menentukan banyaknya cluster yang akan dibentuk
(disebut dengan nilai k). Nilai k umumnya nilai integer terkecil seperti 2, 3, 4, atau 5. Pengukuran kualitas satu cluster dapat menggunakan nilai dari fungsi objektif yang diambil dari jumlah kuadrat jarak setiap titik dari centroid yang telah ditentukan (euclidean distance). Pilih poin k yang umumnya sesuai dengan lokasi k dari suatu objek. Poin k ini nantinya dijadikan sebagai centroid dari k
cluster. Metode ini dapat bekerja maksimal jika pemilihan poin awal k yang
berjauhan. Selanjutnya dipilih setiap poin, satu per satu dari suatu cluster yang mempunyai centroid terdekat. Semua objek mempunyai k cluster berdasarkan k
initial centroid tetapi ‘centroid’ ini tidak akan menjadi centroid sejati suatu cluster. Langkah selanjutnya dihitung ulang centroid dari cluster dan dilakukan
langkah-langkah sebelumnya untuk menempatkan setiap objek ke cluster dengan
centroid terdekat. Algoritma k-means clustering sebagai berikut (Bramer 2007):
1. Pilih nilai k
2. Pilih objek k secara acak. Objek ini akan menjadi k initial centroid
3. Tetapkan setiap objek dari suatu cluster yang terdekat dengan centroid
4. Hitung ulang centroid dari k cluster
5. Ulangi langkah 3 dan 4 sampai perubahan nilai centroid pada iterasi satu dengan lainnya tetap (centroid tidak bergerak)
3 METODE
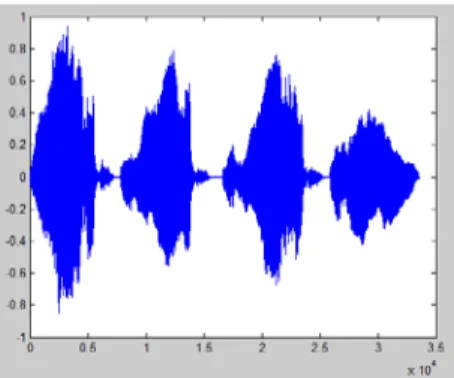
Metode penelitian ini terdiri atas beberapa tahapan proses yaitu pengambilan data, preprocessing, pemodelan codebook tangis bayi, pengujian dan analisis, serta pembuatan antarmuka. Metodologi penelitian proses identifikasi jenis tangis bayi ditampilkan pada Gambar 6.
Gambar 6 Metodologi penelitian identifikasi jenis tangis bayi
Perlakuan pada penelitian ini adalah: kombinasi panjang frame, overlap frame, banyaknya codeword/jumlah cluster, dan variasi jarak. Faktor dan level penelitian ini ditampilkan pada Tabel 1.
Tabel 1 Faktor dan level penelitian
Faktor Level Panjang frame 25 ms/panjang frame 275 40 ms/ panjang frame 440 60 ms/ panjang frame 660 Overlap frame 0% = 0 25% = 0.25 40% = 0.4 Banyaknya codeword/jumlah cluster 1 s/d 18
Jumlah cluster 1 s/d 29 untuk panjang frame= 275 dan overlap = 0
Variasi jarak Jarak euclid Jarak mahalanobis mulai Pengambilan data Preprocessing: Pemotongan silence Ekstraksi ciri: MFCC Data Uji Data Latih Pemodelan Codebook: k-means clustering Codebook Tangis bayi
Pengujian dan Analisis
Pembuatan Antarmuka
selesai
Preprocessing:
Pemotongan silence Ekstraksi ciri: MFCC
12
1. Pengambilan data
Data yang digunakan untuk penelitian ini adalah diambil dari video Dunstan
Baby Language yang sudah dilakukan pengolahan data. Data terbagi menjadi dua
yaitu data latih dan data uji. Terdapat 140 data latih yang masing-masing mewakili 28 tangis bayi lapar, 28 tangis bayi mengantuk, 28 tangis bayi ingin bersendawa, 28 tangis bayi mengalami nyeri (ada angin) di perut, dan 28 tangis bayi tidak nyaman (bisa karena popoknya basah/udara yang terlalu panas/dingin atau hal lainnya). Data uji sebanyak 35, masing-masing 7 tangis bayi untuk setiap jenis tangis bayi. Sampling rate yang digunakan pada penelitian ini adalah 11000Hz.
2. Preprocessing
Pada tahap preprocessing ini dilakukan pemotongan silence dan ekstraksi ciri menggunakan metode Mel Frequency Cepstrum Coefficients (MFCC). Contoh sinyal suara tangis bayi lapar (‘owh’) ditampilkan pada Gambar 7 dan pemotongan silence pada suara tangis bayi tersebut ditampilkan pada Gambar 8. Pemotongan silence ini dilakukan di awal dan di akhir sinyal suara tangis bayi. Ekstraksi ciri merupakan proses untuk menentukan satu nilai atau vektor yang dapat digunakan sebagai penciri objek atau individu. Ciri yang biasa digunakan adalah koefisien cepstral dari sebuah frame. MFCC merupakan ekstraksi ciri yang menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia (Buono 2009). Diagram alur dari MFCC dapat dilihat pada Gambar 4.
Gambar 7 Sinyal suara ‘owh’ Gambar 8 Sinyal ‘owh’ yang dipotong
3. Pemodelan codebook tangis bayi
Pemodelan codebook ini berasal dari setiap data latih yang nantinya digunakan sebagai representasi sinyal tangis bayi yang akan dikenali. Codebook yang akan dibuat adalah codebook dari setiap data tangis bayi. Codebook dari
cluster yang dibuat berasal dari hasil clustering semua data tangis bayi dengan
menggunakan k-means clustering. Penjelasan codebook dan k-means clustering disajikan pada Bab 2.
Tahap pembuatan codebook untuk seorang pembicara sebagai berikut (Buono 2009):
1. Untuk setiap pengucapan (ada n pengucapan sebagai data training), dilakukan ekstraksi ciri menggunakan MFCC pada setiap frame dengan panjang dan
overlap tertentu.
13
13
2. Semua frame dari n pengucapan digabungkan menjadi satu set dan dilakukan
unsupervised clustering menggunakan teknik k-means clustering dengan
memilih banyaknya cluster sesuai dengan jumlah codeword yang diinginkan.
4. Pengujian dan Analisis
Tahapan pengujian berarti melakukan pengujian untuk identifikasi jenis tangis bayi. Alur proses untuk tahap identifikasi/pengenalan adalah (Buono 2009): 1. Untuk setiap ucapan baru yang masuk ke sistem dibaca frame demi frame, (misalkan jumlah frame yang diperoleh adalah T), dan dilakukan ekstraksi ciri menggunakan MFCC.
2. Hitung jarak sinyal input ucapan ini ke codebook setiap pembicara yang ada dalam sistem.
3. Keputusan: menetapkan label pada input suara sesuai dengan pembicara dengan jarak codebook terkecil.
Jarak input ucapan dengan codebook dirumuskan sebagai berikut (Buono 2009):
1. Untuk setiap frame dari input ucapan yang masuk, hitung jarak ke setiap
codeword dan dipilih codeword dengan jarak minimum.
2. Jarak antara input ucapan dengan codebook adalah jumah dari jarak minimum tersebut (persamaan 11):
𝜋𝜋𝑗𝑗𝑗𝑗𝑗𝑗𝑘𝑘(𝑖𝑖𝑛𝑛𝑖𝑖𝑖𝑖𝑡𝑡, 𝑐𝑐𝑙𝑙𝑐𝑐𝑒𝑒𝑐𝑐𝑙𝑙𝑙𝑙𝑘𝑘) = ∑𝑇𝑇𝑡𝑡=1∀𝑐𝑐𝑙𝑙𝑐𝑐𝑒𝑒𝑐𝑐𝑙𝑙𝑗𝑗𝑐𝑐𝑚𝑚𝑖𝑖𝑛𝑛𝑘𝑘[𝑐𝑐(𝑓𝑓𝑗𝑗𝑗𝑗𝑚𝑚𝑒𝑒𝑡𝑡, 𝑐𝑐𝑙𝑙𝑐𝑐𝑒𝑒𝑐𝑐𝑙𝑙𝑗𝑗𝑐𝑐𝑘𝑘)] (11) Variasi jarak yang digunakan pada penelitian ini adalah jarak euclid dan jarak mahalanobis. Jarak euclid antara objek i didefinisikan pada persamaan 12 (Brindha et al. 2013). Jarak mahalanobis didefinisikan pada persamaan 13 (Gomathy et al. 2012).
𝐷𝐷(𝑋𝑋, 𝑌𝑌) = �∑ (𝑥𝑥𝐷𝐷𝑖𝑖=1 𝑖𝑖− 𝑦𝑦𝑖𝑖)2 (12)
𝐷𝐷 = �(𝑥𝑥𝑠𝑠− 𝑦𝑦𝑠𝑠) ∗ 𝐶𝐶−1 ∗ (𝑥𝑥𝑠𝑠− 𝑦𝑦𝑠𝑠)𝑇𝑇 (13) C adalah covariance matrix, x = {x1,x2,….xs}T dan y = {y1, y2,….,ys}T
Pengujian dilakukan menggunakan data uji sebanyak 35 dan data latih yang berjumlah 140. Tahap analisis dilakukan berdasarkan hasil yang didapatkan pada tahap pengujian. Analisis dilakukan berdasarkan hasil dari kombinasi faktor dan level berikut:
• panjang frame : 25 ms/panjang frame 275, 40 ms/ panjang frame 440, 60 ms/ panjang frame 660.
• overlap frame : 0%, 25%, 40%.
• banyaknya codeword/jumlah cluster: 1 sampai dengan 18. Untuk panjang frame = 275 dan overlap frame = 0, jumlah k adalah 1-29 cluster.
14
Masing-masing kombinasi faktor dan level tersebut akan dihitung nilai akurasi menggunakan persamaan 14.
𝑗𝑗𝑘𝑘𝑖𝑖𝑗𝑗𝑗𝑗𝑠𝑠𝑖𝑖 = 𝜋𝜋𝑖𝑖𝑚𝑚𝑚𝑚𝑗𝑗 ℎ 𝑐𝑐𝑗𝑗𝑡𝑡𝑗𝑗 𝑖𝑖𝑒𝑒𝑛𝑛𝑙𝑙𝑖𝑖𝜋𝜋𝑖𝑖𝑗𝑗𝑛𝑛 𝑐𝑐𝑒𝑒𝑛𝑛𝑙𝑙𝑗𝑗𝑛𝑛 𝑖𝑖𝑐𝑐𝑒𝑒𝑛𝑛𝑡𝑡𝑖𝑖𝑓𝑓𝑖𝑖𝑘𝑘𝑗𝑗𝑠𝑠𝑖𝑖 𝑐𝑐𝑒𝑒𝑛𝑛𝑗𝑗𝑗𝑗𝜋𝜋𝑖𝑖𝑚𝑚𝑚𝑚𝑗𝑗 ℎ 𝑐𝑐𝑗𝑗𝑡𝑡𝑗𝑗 𝑖𝑖𝑒𝑒𝑛𝑛𝑙𝑙𝑖𝑖𝜋𝜋𝑖𝑖𝑗𝑗𝑛𝑛 ∗ 100% (14) Ilustrasi identifikasi jenis tangis bayi ditampilkan pada Gambar 9.
Gambar 9 Ilustrasi identifikasi jenis tangis bayi
Jarak sinyal O dengan codebook ‘neh’ :
5. Pembuatan Antarmuka
Pembuatan antarmuka identifikasi jenis tangis bayi dibuat berdasarkan data latih yang menghasilkan akurasi tertinggi.
W1 W2 Wc = = ) ( : ) 1 ( .. .. .. ) ( ) 2 ( ) 1 ( ) ( ) 2 ( ) 1 ( 2 2 2 1 1 1 p W W p W W W p W W W Neh Codebook c c Frame 2 Frame T Frame 1 = ) ( : ) 1 ( .. .. .. ) ( ) 2 ( ) 1 ( ) ( ) 2 ( ) 1 ( 2 2 2 1 1 1 p f f p f f f p f f f O T T
∑
= ∀∈=
T t i cwi
ft
d
codebook
O
d
1 {1,2,...})}
,
(
{
min
)
,
(
min d(f1,wi) i=1,2,… c min d(f2,wi) i=1,2,… c4 HASIL DAN PEMBAHASAN
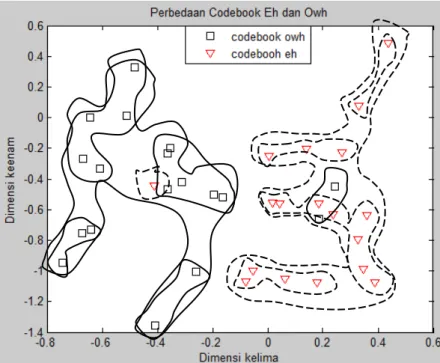
Penelitian ini dibuat menggunakan software Matlab R2010b version 7.11.0.584. Hasil perbandingan akurasi menggunakan jarak euclid pengujian data uji ditampilkan pada Gambar 10.
Gambar 10 Grafik perbandingan akurasi menggunakan jarak euclid pengujian data uji
Berdasarkan Gambar 10 dapat diketahui bahwa akurasi menggunakan jarak euclid pengujian data uji berkisar antara 37% sampai 94%. Akurasi tertinggi dicapai ketika panjang frame = 440, overlap frame = 0.4, dan k = 18 dengan akurasi 94%. Hasil akurasi 94% juga didapat ketika panjang frame = 660, overlap frame = 0.25, dan k = 14. Sedangkan akurasi terendah sebesar 37% diperoleh ketika panjang frame = 660, overlap frame = 0, dan k = 1. Hasil akurasi secara rinci ditampilkan pada Lampiran 1. Hasil akurasi tersebut menunjukkan bahwa semakin tinggi jumlah cluster, akurasi semakin tinggi yaitu >= 80%. Tetapi ketika k-nya kecil, misal k=1, maka akurasinya rendah yaitu antara 37%-51%.
Hasil pengujian data uji saat k = 18, panjang frame = 440, dan overlap frame = 0.4 menggunakan jarak euclid ditampilkan pada Tabel 2. Hasil pengujian data uji saat k = 18, panjang frame = 660, dan overlap frame = 0.25 ditampilkan pada Tabel 3. Hasil pengujian data uji saat k = 18, panjang frame = 275, dan
overlap frame = 0.25 ditampilkan pada Tabel 4.
30% 35% 40% 45% 50% 55% 60% 65% 70% 75% 80% 85% 90% 95% 100% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 akurasi jumlah cluster (k) 275 0 275 0.25 275 0.4 440 0 440 0.25 440 0.4 660 0 660 0.25 660 0.4
16
Tabel 2 Hasil pengujian data uji saat k = 18, panjang frame = 440, dan overlap frame = 0.4 menggunakan jarak euclid
Uji Data Ke- Jenis
Tangis
1 2 3 4 5 6 7
'a' 'a' 'a' 'a' 'a' 'a' 'a' a-eairh
'e' 'e' 'e' 'e' 'e' 'e' 'e' e-eh
'h' 'h' 'h' 'h' 'h' 'e' * 'h' h-heh
'n' 'n' 'n' 'n' 'n' 'n' 'n' n-neh
'o' 'o' 'o' 'o' 'a' * 'o' 'o' o-owh
Tabel 3 Hasil pengujian data uji saat k = 18, panjang frame = 660, dan overlap frame = 0.25 menggunakan jarak euclid
Uji Data Ke- Jenis
Tangis
1 2 3 4 5 6 7
'o' * 'a' 'a' 'a' 'a' 'a' 'a' a-eairh
'e' 'e' 'e' 'e' 'e' 'e' 'e' e-eh
'h' 'h' 'h' 'h' 'h' 'e' * 'h' h-heh
'n' 'n' 'n' 'n' 'n' 'n' 'n' n-neh
'n' * 'o' 'n' * 'o' 'a' * 'o' 'o' o-owh Tabel 4 Hasil pengujian data uji saat k = 18, panjang frame = 275, dan overlap frame = 0.25 menggunakan jarak euclid
Uji Data Ke- Jenis
Tangis
1 2 3 4 5 6 7
'a' 'a' 'a' 'a' 'a' 'a' 'a' a-eairh
'e' 'e' 'e' 'e' 'e' 'e' 'e' e-eh
'h' 'h' 'h' 'h' 'h' 'h' 'h' h-heh
'n' 'o' * 'n' 'n' 'n' 'o' * 'n' n-neh 'n' * 'o' 'o' 'a' * 'o' 'o' 'o' o-owh keterangan: * = salah identifikasi
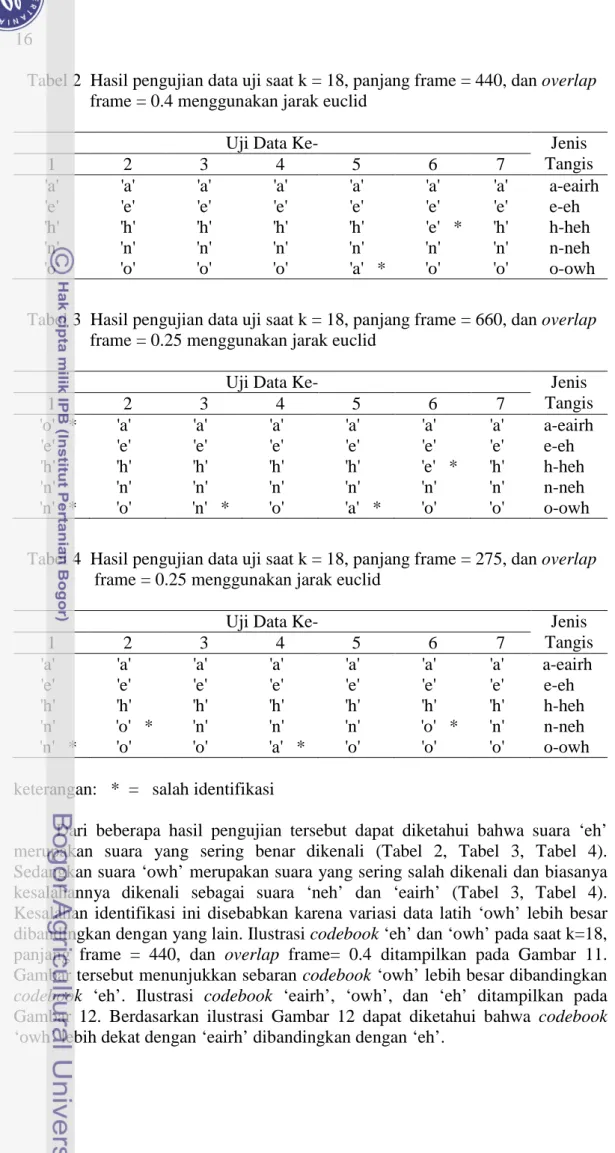
Dari beberapa hasil pengujian tersebut dapat diketahui bahwa suara ‘eh’ merupakan suara yang sering benar dikenali (Tabel 2, Tabel 3, Tabel 4). Sedangkan suara ‘owh’ merupakan suara yang sering salah dikenali dan biasanya kesalahannya dikenali sebagai suara ‘neh’ dan ‘eairh’ (Tabel 3, Tabel 4). Kesalahan identifikasi ini disebabkan karena variasi data latih ‘owh’ lebih besar dibandingkan dengan yang lain. Ilustrasi codebook ‘eh’ dan ‘owh’ pada saat k=18, panjang frame = 440, dan overlap frame= 0.4 ditampilkan pada Gambar 11. Gambar tersebut menunjukkan sebaran codebook ‘owh’ lebih besar dibandingkan
codebook ‘eh’. Ilustrasi codebook ‘eairh’, ‘owh’, dan ‘eh’ ditampilkan pada
Gambar 12. Berdasarkan ilustrasi Gambar 12 dapat diketahui bahwa codebook ‘owh’ lebih dekat dengan ‘eairh’ dibandingkan dengan ‘eh’.
17
17
Gambar 11 Ilustrasi codebook ‘eh’ dan ‘owh’
Gambar 12 Ilustrasi codebook ‘eairh’, ‘eh’, dan ‘owh’
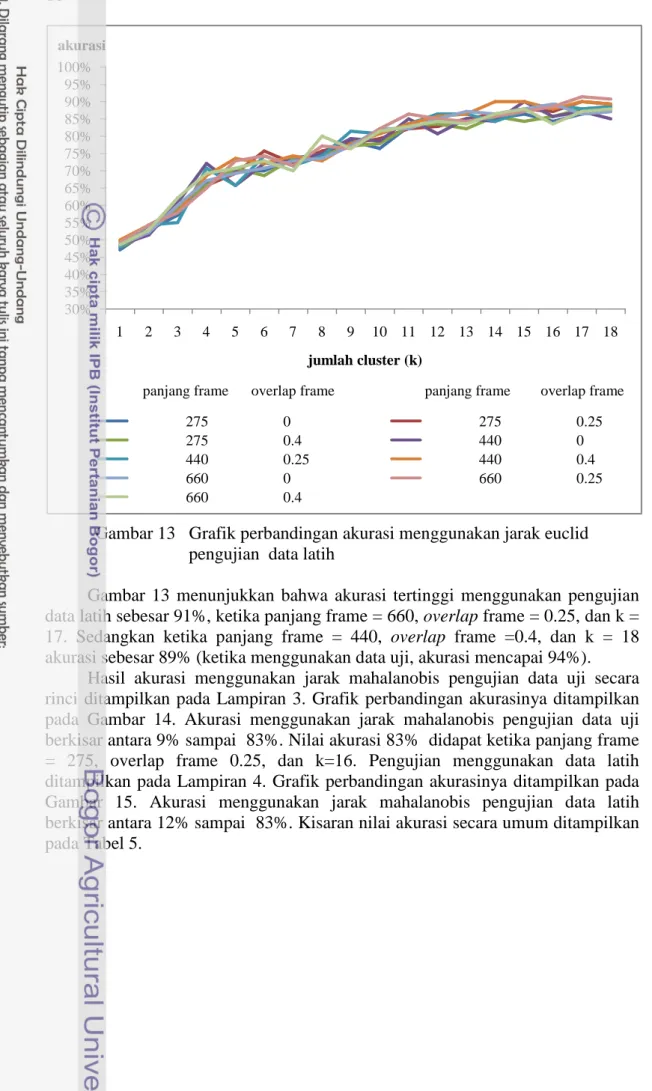
Perbandingan akurasi menggunakan jarak euclid pengujian data latih ditampilkan pada Gambar 13. Hasil akurasi secara rinci ditampilkan pada Lampiran 2. Akurasi menggunakan jarak euclid pengujian data latih berkisar antara 47% sampai 91%.
18
Gambar 13 Grafik perbandingan akurasi menggunakan jarak euclid pengujian data latih
Gambar 13 menunjukkan bahwa akurasi tertinggi menggunakan pengujian data latih sebesar 91%, ketika panjang frame = 660, overlap frame = 0.25, dan k = 17. Sedangkan ketika panjang frame = 440, overlap frame =0.4, dan k = 18 akurasi sebesar 89% (ketika menggunakan data uji, akurasi mencapai 94%).
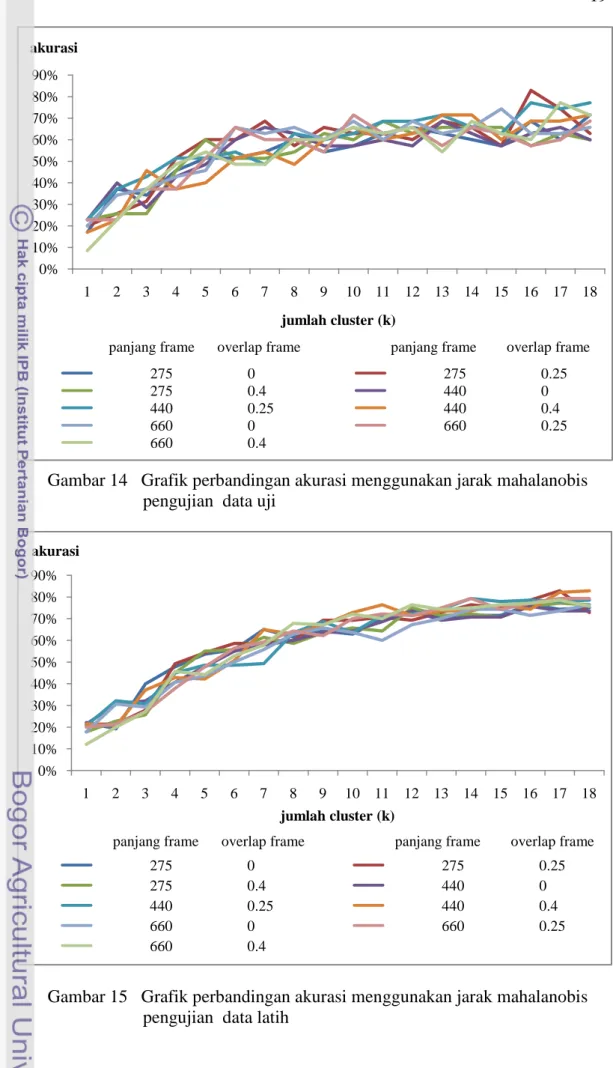
Hasil akurasi menggunakan jarak mahalanobis pengujian data uji secara rinci ditampilkan pada Lampiran 3. Grafik perbandingan akurasinya ditampilkan pada Gambar 14. Akurasi menggunakan jarak mahalanobis pengujian data uji berkisar antara 9% sampai 83%. Nilai akurasi 83% didapat ketika panjang frame = 275, overlap frame 0.25, dan k=16. Pengujian menggunakan data latih ditampilkan pada Lampiran 4. Grafik perbandingan akurasinya ditampilkan pada Gambar 15. Akurasi menggunakan jarak mahalanobis pengujian data latih berkisar antara 12% sampai 83%. Kisaran nilai akurasi secara umum ditampilkan pada Tabel 5. 30% 35% 40% 45% 50% 55% 60% 65% 70% 75% 80% 85% 90% 95% 100% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 akurasi jumlah cluster (k) 275 0 275 0.25 275 0.4 440 0 440 0.25 440 0.4 660 0 660 0.25 660 0.4
19
19
Gambar 14 Grafik perbandingan akurasi menggunakan jarak mahalanobis pengujian data uji
Gambar 15 Grafik perbandingan akurasi menggunakan jarak mahalanobis pengujian data latih
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 akurasi jumlah cluster (k) 275 0 275 0.25 275 0.4 440 0 440 0.25 440 0.4 660 0 660 0.25 660 0.4 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 akurasi jumlah cluster (k) 275 0 275 0.25 275 0.4 440 0 440 0.25 440 0.4 660 0 660 0.25 660 0.4
panjang frame overlap frame panjang frame overlap frame
20
Tabel 5 Kisaran nilai akurasi menggunakan jarak euclid dan mahalanobis Jarak dan Jenis Pengujian Nilai Minimum
Akurasi
Nilai Maksimum Akurasi
Jarak euclid pengujian data uji 37% 94%
Jarak euclid pengujian data latih 47% 91%
Jarak mahalanobis pengujian data uji 9% 83%
Jarak mahalanobis pengujian data latih 12% 83% Berdasarkan Gambar 14 dan 15 dapat diketahui bahwa hasil akurasi terbesar ketika menggunakan jarak mahalanobis pengujian data latih adalah 83%. Akurasi tertinggi ini dicapai ketika panjang frame = 275, overlap frame = 0.25, dan k = 17. Hasil pengujian ketika k = 17, panjang frame = 275, dan overlap frame = 0.25 ditampilkan pada Tabel 6.
Tabel 6 Hasil pengujian data latih saat k = 17, panjang frame = 275, dan overlap frame = 0.25 menggunakan jarak mahalanobis
Uji Data Ke- Jenis
Tangis
1 2 3 4 5 6 7
'a' 'a' 'a' 'a' 'a' 'a' 'a' a-eairh
'e' 'e' 'e' 'n' * 'e' 'e' 'e' e-eh
'h' 'h' 'h' 'h' 'h' 'h' 'h' h-heh
'n' 'n' 'n' 'n' 'n' 'n' 'n' n-neh
'a' * 'o' 'o' 'o' 'o' 'o' 'o' o-owh
Tabel 6 Hasil pengujian data latih saat k = 17, panjang frame = 275, dan overlap frame = 0.25 menggunakan jarak mahalanobis (lanjutan)
Uji Data Ke- Jenis
Tangis
8 9 10 11 12 13 14
'a' 'a' 'a' 'a' 'a' 'a' 'a' a-eairh
'e' 'e' 'e' 'h' * 'e' 'o' * 'e' e-eh
'h' 'h' 'e' * 'h' 'h' 'h' 'h' h-heh
'n' 'n' 'n' 'n' 'n' 'n' 'h' * n-neh
'n' * 'o' 'n' * 'o' 'a' * 'n' * 'o' o-owh Tabel 6 Hasil pengujian data latih saat k = 17, panjang frame = 275, dan overlap frame = 0.25 menggunakan jarak mahalanobis (lanjutan)
Uji Data Ke- Jenis
Tangis
15 16 17 18 19 20 21
'n' * 'a' 'a' 'n' * 'e' * 'a' 'a' a-eairh
'e' 'n' * 'e' 'e' 'e' 'e' 'e' e-eh
'h' 'h' 'h' 'h' 'h' 'h' 'h' h-heh
'e' * 'n' 'n' 'n' 'n' 'h' * 'n' n-neh 'a' * 'o' 'e' * 'o' 'o' 'a' * 'o' o-owh
21
21
Tabel 6 Hasil pengujian data latih saat k = 17, panjang frame = 275, dan overlap frame = 0.25 menggunakan jarak mahalanobis (lanjutan)
Uji Data Ke- Jenis
Tangis
22 23 24 25 26 27 28
'a' 'a' 'a' 'a' 'a' 'a' 'a' a-eairh
'e' 'e' 'h' * 'e' 'e' 'e' 'e' e-eh
'h' 'h' 'e' * 'h' 'h' 'h' 'h' h-heh
'n' 'a' * 'n' 'n' 'n' 'n' 'n' n-neh 'o' 'o' 'o' 'a' * 'h' * 'o' 'o' o-owh keterangan: * = salah identifikasi
Dari beberapa hasil pengujian tersebut dapat diketahui bahwa suara ‘heh’ merupakan suara yang sering benar dikenali. Hasil ini berbeda ketika menggunakan jarak euclid pengujian data uji. Hasil sebelumnya menunjukkan suara ‘eh’ yang mudah dikenali. Sedangkan suara ‘owh’ merupakan suara yang sering salah dikenali dan biasanya kesalahannya dikenali sebagai suara ‘neh’ dan ‘eairh’. Hasil ini sama dengan hasil sebelumnya yang menggunakan jarak euclid pengujian data uji. Kesalahan identifikasi ini disebabkan karena variasi data latih ‘owh’ lebih besar dibandingkan dengan yang lain. Ilustrasi codebook ‘heh’ dan ‘owh’ pada saat k=17, panjang frame = 275, dan overlap frame= 0.25 ditampilkan pada Gambar 16.
Gambar 16 Ilustrasi codebook ‘heh’ dan ‘owh’
Perbedaan hasil akurasi menggunakan data latih dan data uji ditampilkan pada Gambar 17 dan Gambar 18. Perbedaannya, pada Gambar 17 menggunakan jarak euclid, sedangkan Gambar 18 menggunakan jarak mahalanobis. Kedua gambar tersebut menampilkan perbedaan hasil akurasi ketika panjang frame = 275,
overlap frame = 0, jumlah cluster (k) = 1 s/d 29. Jumlah cluster di sini dibuat
22
Gambar 17 Akurasi pengujian data latih dan data uji menggunakan jarak euclid dengan panjang frame = 275 dan overlap frame = 0
Gambar 18 Akurasi pengujian data latih dan data uji menggunakan jarak mahalanobis dengan panjang frame = 275 dan overlap frame = 0
Berdasarkan Gambar 17 dapat diketahui bahwa ketika k < 12, akurasi pengujian menggunakan data uji lebih baik dibandingkan data latih. Sedangkan
40% 50% 60% 70% 80% 90% 100% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 akurasi jumlah cluster (k) data latih data uji 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 akurasi jumlah cluster (k) data latih data uji
23
23
ketika k > 25 akurasi data latih lebih bagus dibandingkan data uji. Hal ini berarti pada cluster rendah, akurasi data uji lebih tinggi, sedangkan pada cluster tinggi, akurasi data latih lebih bagus. Hal ini disebabkan karena data latih sangat bervariasi dibandingkan data uji, sehingga hasil akurasi untuk data uji lebih baik ketika cluster rendah. Cluster rendah tidak bisa mengakomodasi data latih. Namun ketika cluster tinggi, data latih dapat terakomodasi sehingga pengujian menggunakan data latih hasilnya lebih bagus. Hal ini sesuai dengan prinsip dasar bahwa akurasi data latih pasti lebih bagus dibandingkan data uji. Gambar 18 menunjukkan hasil yang berbeda yaitu ketika k > 9, akurasi menggunakan data latih lebih tinggi dibandingkan data uji. Hal ini dikarenakan pada jarak mahalanobis sudah ada pembagi variasi sehingga akurasi data latih lebih bagus. Ilustrasi yang menggambarkan penjelasan tersebut ditampilkan pada Gambar 19 dan Gambar 20. Ilustrasi codebook ‘owh’, ‘neh’, dan data uji ‘owh’ ditampilkan pada Gambar 19. Ilustrasi codebook ‘owh’, ‘neh’, dan data latih ‘owh’ ditampilkan pada Gambar 20.
Terdapat 2 codebook pada Gambar 19 dan Gambar 20 yaitu codebook ‘owh’ dan ‘neh’. Ketika dilakukan pengujian menggunakan data uji owh, suara ‘owh’ dikenali sebagai owh (ilustrasi Gambar 19). Tetapi ketika data latih ‘owh’ diuji, dikenali sebagai ‘neh’ (ilustrasi Gambar 20). Hal ini karena data latih ‘owh’ (simbol * berwarna merah pada Gambar 20) tersebut memang dekat ke codebook neh (simbol ο berwarna hijau) (Gambar 20). Hal ini membuktikan walaupun data latih ‘owh’ tersebut sudah dimodelkan sebagai codebook ‘owh’ tetapi hasil pengujiannya teridentifikasi ‘neh’. Perbedaan lainnya antara Gambar 17 dan Gambar 18 adalah pengujian menggunakan jarak mahalanobis lebih stabil. Hal ini dapat dilihat ketika k > 9, akurasi menggunakan data latih selalu lebih tinggi dibandingkan akurasi data uji. Sedangkan pada Gambar 18, perbandingan akurasi data uji dan data latih berubah-ubah (fluktuatif) sampai k = 25.
24
Gambar 20 Ilustrasi codebook ‘owh’ dan ‘neh’, serta data latih ‘owh’
Hierarchical clustering codebook ‘eairh’, ‘eh’, ‘heh’, ‘neh’, dan ‘owh’
ditampilkan pada Gambar 21. Berdasarkan Gambar 21 dapat diketahui bahwa
codebook ‘eairh’ dekat dengan ‘owh’. Hal ini sebagai penyebab tangis ‘owh’
sering dikenali sebagai tangis bayi ‘eairh’ (Tabel 2, Tabel 3, Tabel 4, Tabel 6). Selain dekat dengan ‘eairh’, selanjutnya codebook ‘owh’ juga mempunyai kedekatan dengan codebook ‘neh’, ‘heh’, dan ‘eh’. Hal ini dapat dibuktikan dengan hasil identifikasi pada Tabel 3, Tabel 4, dan Tabel 6 yang menampilkan hasil kesalahan identifikasi tangis ‘owh’. Jenis tangis ‘owh’ dikenali sebagai jenis tangis ‘neh’, ‘heh’ atau ‘eh’.
25
25
Confusion matrix saat k = 18, panjang frame = 440, dan overlap frame = 0.4
menggunakan jarak euclid ditampilkan pada Tabel 7. Sedangkan confusion matrix saat k = 17, panjang frame = 275, dan overlap frame = 0.25 menggunakan jarak mahalanobis ditampilkan pada Tabel 8.
Tabel 7 Confusion matrix saat k = 18, panjang frame = 440, dan
overlap frame = 0.4 menggunakan jarak euclid
Jenis Tangis Bayi Eairh Eh Heh Neh Owh Akurasi
Eairh 7 0 0 0 0 100% Eh 0 7 0 0 0 100% Heh 0 1 6 0 0 86% Neh 0 0 0 7 0 100% Owh 1 0 0 0 6 86% Rata-rata 94.40% Tabel 8 Confusion matrix saat k = 17, panjang frame = 275, dan
overlap frame = 0.25 menggunakan jarak mahalanobis
Jenis Tangis Bayi Eairh Eh Heh Neh Owh Akurasi
Eairh 25 1 0 2 0 89% Eh 0 23 2 2 1 82% Heh 0 2 26 0 0 93% Neh 1 1 2 24 0 86% Owh 5 1 1 3 18 64% Rata-rata 82.80%
Berdasarkan Tabel 8, dapat diketahui bahwa jenis tangis ‘owh’ merupakan jenis suara yang sering salah dikenali, dan seringnya dikenali sebagai ‘eairh’. Hal ini sesuai dengan hierarchical clustering pada Gambar 21 yang menunjukkan bahwa codebook ‘owh’ dekat dengan ‘eairh’.
Antarmuka identifikasi jenis tangis bayi ditampilkan pada Gambar 22. Model codebook yang diambil adalah panjang frame = 440, overlap frame = 0.4, k=18, dan jarak yang digunakan adalah jarak euclid. Model ini dipilih karena dapat menghasilkan akurasi paling besar yaitu 94%. Terdapat 2 command button yaitu browse dan rekam. Command button browse digunakan untuk memilih suara bayi yang masuk ke kategori data latih atau data uji. Sedangkan command
26
Gambar 22 Antarmuka identifikasi jenis tangis bayi
5 SIMPULAN DAN SARAN
SimpulanSoftware ini digunakan untuk identifikasi jenis tangis bayi versi Dunstan Baby Language. Identifikasi ini menggunakan codebook untuk pengenal pola dan
MFCC untuk ekstraksi ciri. Penelitian ini memvariasikan panjang frame, overlap frame, dan banyaknya codeword. Model codebook dan MFCC yang menghasilkan akurasi tertinggi adalah: panjang frame = 440, overlap frame = 0.4, k=18. Penggunaan jarak yang menghasilkan akurasi tertinggi adalah jarak euclid. Model tersebut mampu menghasilkan akurasi pengenalan jenis tangis bayi tertinggi sebesar 94%.
Saran
Penelitian yang dilakukan hanya memotong silence di awal dan di akhir sinyal suara. Penelitian selanjutnya diharapkan melakukan pemotongan silence di setiap segmen suara supaya data yang dihasilkan lebih mencirikan suara tersebut. Selain itu disarankan melakukan optimasi pembentukan codebook menggunakan
genetic algorithm. Hal ini diharapkan mempunyai dampak terhadap akurasi yang
27
27
DAFTAR PUSTAKA
Bramer M. 2007. Principles of Data Mining. London: Springer.
Brindha M, Tamilselvan GM, Valarmathy S, Kumar MA, Suryalakshmipraba M. 2013. A Comparative Study of Face Authentication Using Euclidean and Mahalanobis Distance Classification Method. International Journal of
Emerging Technology and Advanced Engineering 3(1): 263-268.
Buono A. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Indentifikasi Pembicara di Lingkungan Ber-noise Menggunakan HMM. [disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Speaker Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of Technology, Lausanne, Switzerland.
Dunstan P. 2006. Open Up and Discover Your Baby’s Language. [Internet]. [diunduh 2012 Maret 19]. Tersedia pada: http://www.babytaal.nl/media/PDF/ Comprehensive Booklet(2).pdf.
Ganchev TD. 2005. Speaker Recognition. [disertasi]. Greece: Department of Computer and Electrical Engineering, University of Patras.
Gomathy M, Meena K, Subramaniam KR. 2012. Gender Clustering and Classification Algorithms in Speech Processing: A Comprehensive Performance Analysis. International Journal of Computer Applications 51(20): 9-17.
Gunawan A. 2011. Dunstan Baby Language Indonesia. [Internet]. [diunduh 2012 September 8]. Tersedia pada: http://www.mommeworld.com/ post/view/49/ dunstan-baby-language-indonesia/.
Gupta D, C Mounima R, Manjunath N, PB Manoj. 2012. Isolated Word Speech Recognition Using Vector Quantization (VQ). International Journal of
Advanced Research in Computer Science and Software Engineering 2(5).
Jurafsky D, Martin JH. 2007. Speech and Language Processing: An Introduction
to Natural Language Processing, Computational Linguistic, and SpeechRecognition. New Jersey: Prentice Hall.
Kumar C. Rao PM. 2011. Design of an Automatic Speaker Recognition System using MFCC, Vector Quantization, and LBG Algorithm. International Journal
on Computer Science and Engineering (IJCSE) 3(8): 2942-2954.
Lederman D, Zmora E, Hauschildt S, Stellzig-Eisenhauer A, Wermke K. 2008. Classification of cries of infants with cleft-palate using parallel hidden Markov models. International Federation for Medical and Biological Engineeering 46: 965-975.
Lee C, Lien C, Huang R. 2006. Automatic Recognition of Birdsongs Using Mel-frequency Cepstral Coefficients and Vector Quantization. International
MultiConference of Engineers and Computer Scientists; 2006 June 20-22;
Hong Kong.
Linde Y, Buzo A, Gray RM. 1980. An Algorithm for Vector Quantizer Design.
28
Nilsson M, Ejnarsson M. 2002. Speech Recognition using Hidden Markov Model: Performance Evaluation in Noisy Environment. [tesis]. Sweden: Department of Telecommunications and Signal Processing, Blekinge Institute of Technology. Patel K, Prasad RK. 2013. Speech Recognition and Verification Using MFCC &
VQ. International Journal of Emerging Science and Engineering (IJESE) 1(7): 33-37.
Poel M, Ekkel T. 2006. Analyzing Infant Cries Using a Committee of Neural Networks in order to Detect Hypoxia Related Disorder. International Journal
on Artificial Intelligence Tools (IJAIT) 15(3): 397-410.
Proakis JG, Manolakis DG. 1996. Digital Signal Processing: Principles,
Algorithms, and Applications. Edisi ke-3. New Jersey: Prentice Hall, Inc.
Reyes-Galaviz OF, Reyes-Garcia CA. 2004. A System for the Processing of Infant Cry to Recognize Pathologies in Recently Born Babies with Neural Networks. International Speech Communication Association; 2004 September 20-22; Rusia.
Reynolds D. 2002. Automatic Speaker Recognition Acoustics and Beyond. Tutorial note, MIT Lincoln Laboratory.
Singh S, Rajan EG. 2011. Vector Quantization Approach for Speaker Recognition using MFCC and Inverted MFCC. International Journal of
29
29
Lampiran 1 Hasil akurasi identifikasi jenis tangis bayi menggunakan jarak euclid pengujian data uji
Panjang dan Overlap Frame Jumlah Cluster (k) akurasi Panjang dan Overlap Frame Jumlah Cluster (k) akurasi 275 dan 0 1 49% 275 dan 0.25 1 49% 2 63% 2 54% 3 66% 3 74% 4 77% 4 77% 5 77% 5 80% 6 77% 6 83% 7 77% 7 74% 8 77% 8 80% 9 86% 9 80% 10 86% 10 89% 11 86% 11 83% 12 86% 12 91% 13 89% 13 86% 14 80% 14 91% 15 83% 15 80% 16 89% 16 80% 17 89% 17 91% 18 91% 18 89% 275 dan 0.4 1 51% 440 dan 0 1 43% 2 57% 2 46% 3 69% 3 66% 4 77% 4 80% 5 86% 5 86% 6 86% 6 83% 7 86% 7 80% 8 80% 8 77% 9 80% 9 77% 10 86% 10 83% 11 83% 11 83% 12 80% 12 83% 13 83% 13 80% 14 80% 14 83% 15 89% 15 91% 16 83% 16 91% 17 89% 17 83% 18 91% 18 91%