C-135
KLASIFIKASI TUGAS AKHIR UNTUK MENENTUKAN DOSEN
PEMBIMBING MENGGUNAKAN NAÏVE BAYES CLASSIFIER (NBC)
Putri Elfa Mas`udia1
Politeknik Negeri Malang
E-mail : [email protected]
Abstrak
Pemilihan dosen pembimbing tugas akhir yang sesuai dengan kompetensi sering menjadi
polemik yang harus dilakukan oleh sang pengambil keputusan (Decision Maker) dalam hal ini adalah
ketua program studi. Dosen pembimbing yang sesuai dan berkompeten akan mampu mengarahkan dan
menentukan keberhasilan tugas akhir mahasiswa yang dibimbing.
Data mining dapat diterapkan untuk mengklasifikasikan judul tugas akhir berdasarkan
keahlian dan pengalaman dosen pembimbing, dengan memasukkan judul tugas akhir beserta nama
dosen pembimbing tahun sebelumnya sebagai data training. Salah satu metode klasifikasi adalah
menggunakan Naïve Bayes Classifier (NBC).
Pada penelitian ini akan disimulasikan proses klasifikasi tugas akhir. input dari sistem ini
adalah data training dan data testing. Data training berupa 10 judul tugas akhir mahasiswa dan 4
nama dosen pembimbing . Sedangkan Data testing berupa judul tugas akhir yang akan diklasifikasikan
ke 4 nama dosen pembimbing. output dari sistem ini adalah rekomendasi nama dosen yang didapatkan
melalui perhitungan probabilistik pada proses klasifikasi menggunakan Naïve Bayes Classifier (NBC).
Learning dilakukan terhadap 10 judul tugas akhir dan 4 dosen pembimbing sebagai data training, hasil probabilitas klasifikasi data testing adalah P(Sarosa) = 0.00797, P(Azam) = 0.000332, P(Anshori) = 0.0099667 dan P(Koesmarijanto) = 0.00049. Dari hasil perhitungan, terlihat bahwa nilai probabilitas P(MA Anshori) lebih besar, maka MA.Anshori direkomendasikan untuk membimbing judul tugas akhir yang digunakan sebagai data
testing
Kata kunci : Naïve Bayes Classifier, data mining, data training, data testing, dosen pembimbing
1. Pendahuluan
Pada bagian pendahuluan disajikan latar belakang dan tujuan penelitian.
1.1. Latar Belakang
Tugas akhir merupakan syarat utama yang harus ditempuh mahasiswa untuk bisa lulus dan mendapatkan gelar. Dalam proses pengerjaan tugas akhir, mahasiswa membutuhkan dosen pembimbing sebagai tempat untuk berkonsultasi. Agar proses pengerjaan tugas akhir berjalan lancar dibutuhkan dosen pembimbing yang kompeten dibidang tersebut. Dosen pembimbing yang sesuai dan berkompeten akan mampu mengarahkan dan menentukan keberhasilan tugas akhir mahasiswa yang dibimbing. Penentuan dosen pembimbing tugas akhir biasanya dilakukan oleh KPS (Ketua Program Studi) dengan mencocokkan antara judul tugas akhir dengan keahlian masing-masing dosen.
Banyak pemodelan yang dapat digunakan untuk pengambilan keputusan salah satunya adalah menggunakan data mining. Menurut McLeod (2007),
Data mining adalah proses menemukan hubungan
dalam data yang tidak diketahui oleh pengguna dan menyajikannya dengan cara yang dapat dipahami sehingga hubungan tersebut dapat menjadi dasar pengambilan keputusan.
Berdasarkan latar belakang tersebut maka pada penelitian ini akan disimulasikan proses klasifikasi judul tugas akhir untuk merekomendasikan dosen pembimbing yang sesuai dengan kompetensi judul tugas akhir.
Pada penelitian ini, akan dilakukan pencarian pola terhadap data histori judul tugas akhir mahasiswa beserta dosen pembimbingnya sebagai
data training, dengan harapan peneliti bisa
mengklasifikasikan judul tugas akhir yang baru sebagai data testing melalui pola tersebut. Judul tugas akhir tersebut akan diklasifikasikan ke dalam 4 dosen. Metode klasifikasi yang dipakai adalah Naive
bayes classifier (NBC), Menurut Kamaruzaman
(2004), NBC telah sering digunakan sebagai metode pengklasifikasi dokumen teks dengan akurasi yang cukup baik. Dan menurut Santosa (2007) ide dasar dari Teorema Bayes adalah menangani masalah yang bersifat hipotesis yakni mendesain suatu klasifikasi untuk memisahkan objek.
1.2. Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah : 1. Mempermudah KPS (Ketua Program Studi)
dalam menentukan dosen pembimbing tugas akhir.
2. Merekomendasikan dosen pembimbing yang keahliannya sesuai dengan topik tugas akhir.
C-136
2. Kajian PustakaUntuk pustaka pendukung, disajikan secara ringkas mengenai hasil penelitian terkait dan tori klasifikasi menggunakan Naïve Bayes Classifier.
2.1. Hasil Penelitian Terkait
Ridwan, dkk (2013) telah melakukan penelitian tentang judul penerapan data mining untuk evaluasi kinerja akademik mahasiswa menggunakan algoritma Naïve Bayes Classifier (NBC). Penelitian ini difokuskan untuk mengevaluasi kinerja akademik mahasiswa pada tahun ke-2 dan diklasifikasikan dalam kategori mahasiswa yang dapat lulus tepat waktu atau tidak. Kemudian dari klasifikasi tersebut, sistem akan memberikan rekomendasi solusi untuk memandu mahasiswa lulus dalam waktu yang paling tepat dengan nilai optimal berdasarkan histori nilai yang telah ditempuh mahasiswa.
Azis (2011) pernah melakukan penelitian dengan judul Implementasi Naïve Bayes Classifier
(NBC) sebagai sistem pendukung keputusan pada Personal Resource Planning berbasis Mobile.
Penelitian ini terfokus pada salah satu modul PRP yaitu budget planning untuk pembelanjaan atau pengeluaran berdasarkan probabilitas. Hasil dari metode NBC akan dijadikan bahan dasar pada saat perhitungan untuk mendapatkan sistem rekomendasi pada modul budget planning. User akan mendapatkan rekomendasi pengeluaran apa yang paling diprioritaskan sesuai dengan hasil perhitungan probabilitas terbesar.
2.2. Text Mining
Menurut Fieldman (2007), Text Mining adalah proses ekstraksi pola (informasi dan pengetahuan yang berguna) dari sejumlah besar sumber data yang tak terstruktur. Penambangan teks memiliki tujuan dan menggunakan proses yang sama dengan penambangan data, namun memiliki masukan yang berbeda. Masukan untuk penambangan teks adalah data yang tidak (atau kurang) terstruktur, seperti dokumen Word, PDf, kutipan teks, dll. Sedangkan untuk masukan penambangan data adalah data yang terstruktur.
2.3. Text Preprocessing
Teks pada umumnya memiliki banyak noise dan struktur kata yang tidak baik. Untuk mengambil ekstraksi fitur pada teks, terlebih dahulu harus dilakukan text preprocessing. Struktur data ynag baik memudahkan proses komputerisasi secara otomatis. Menurut Fieldman (2007), pada Text
Mining, informasi yang akan digali berisi informasi
yang strukturnya sembarang. Oleh karena itu diperlukan proses pengubahan bentuk menjadi data yang terstruktur sesuai kebutuhannya untuk proses dalam data mining, yang biasanya akan menjadi
nilai-nilai numerik. Proses ini sering disebut Text
Preprocessing.
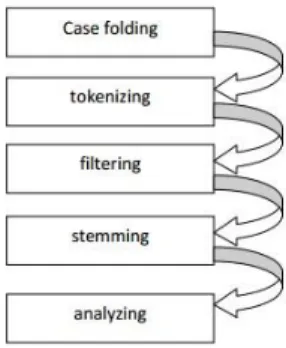
Setelah data menjadi data yang terstruktur, data tersebut dapat diolah lebih lanjut. Beberapa proses yang dilakukan pada text preprosesing adalah case
folding, tokenizing, stop word removal, dan stemming.
Gambar 1. Proses Text Preprocessing
a. Case folding
Menurut Fieldman (2007), case folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil. Hanya huruf ‘a’ sampai dengan ‘Z’ yang diterima. Karakter selain huruf dihilangkan dan dianggap delimiter.
b. Tokenizing
Menurut Salton (1989), tokenizing merupakan proses pemisahan suatu rangkaian karakter berdasarkan karakter spasi, dan mungkin pada waktu yang bersamaan dilakukan juga proses penghapusan karakter tertentu, seperti tanda baca. Token seringkali disebut sebagai term (kata), sebagai contoh sebuah token merupakan suatu urutan karakter dari dokumen tertentu yang dikelompokkan sebagai unit semantic yang berguna untuk diproses.
c. Filtering / stop word
Menurut Fieldman (2007), tahap filtering adalah tahap mengambil kata-kata penting dari hasil
tokenizing. Bisa menggunakan algoritma stoplist
(membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan
bag-of-words. d. Stemming
Menurut Tala (2003), proses stemming
digunakan untuk mengubah term yang masih melekat dalam term tersebut awalan, sisipan dan akhiran. Proses stemming dilakukan dengan cara menghilangkan semua imbuhan (affixes) baik yang terdiri dari awalan (prefixes), sisipan
(infixes), akhiran (suffixes) dan confixes (kombinasi dari awalan dan akhiran) pada kata turunan.
C-137
2.4. KlasifikasiSalah satu tugas utama dari data mining adalah klasifikasi. Klasifikasi digunakan untuk menempatkan bagian yang tidak diketahui pada data ke dalam kelompok yang sudah diketahui. Klasifikasi menggunakan variabel target dengan nilai nominal. Dalam satu set pelatihan, variabel target sudah diketahui. Dengan pembelajaran dapat ditemukan hubungan antara fitur dengan variabel target. Menurut Han (2006), ada dua langkah dalam proses klasifikasi:
a. Pembelajaran (learning) : pelatihan data dianalisis oleh algoritma klasifikasi.
b. Klasifikasi: data yang diujikan digunakan untuk mengkalkulasi akurasi dari aturan klasifikasi. Jika akurasi dianggap dapat diterima, aturan dapat diterapkan pada klasifikasi data tuple yang baru.
Dua tahapan klasifikasi adalah :
a. Learning / training : Pembelajaran menggunakan data training (untuk naïve bayes classifier, nilai probabilitas dihitung dalam proses pembelajaran)
b. Testing : menguji model menggunakan data
testing. (bing liu, web data mining)
Gambar 2. Tahapan Klasifikasi
2.5. Naïve Bayes Classifier
Naïve Bayes Classifier (NBC) merupakan
algoritma yang sederhana yang bisa digunakan untuk proses klasifikasi dengan menggunakan metode probablistik.
Jika X adalah vektor masukan yang berisi fitur dan Y adalah label kelas, Naive Bayes dituliskan dengan P(X|Y). Notasi tersebut berarti probabilitas label kelas Y didapatkan setelah fitur-fitur X diamati, notasi ini disebut juga Probabilitas akhir (posterior
probability) untuk Y, sedang P(Y) disebut
probabilitas awal (prior probability).
Selama proses pelatihan harus dilakukan pembelajaran probabilitas akhir P(X|Y) pada model untuk setiap kombinasi X dan Y berdasarkan informasi yang didapat dari data latih. Dengan membangun model tersebut, suatu data uji X dapat diklasifikasikan dengan mencari nilai Y dengan memaksimalkan nilai P(X | Y) yang didapat.
Formulasi Naïve Bayes untuk klasifikasi adalah :
𝑝(𝑤𝑖|𝐶𝑗) = 𝑁𝑁𝑐𝑤+ 1
𝑐+𝑉 (1)
Dimana :
𝑁𝑐𝑤 : jumlah kata 𝑤𝑖 yang ada dalam
dokumen training yang masuk ke dalam kategori 𝐶𝑗
𝑁𝑐 : jumlah semua kata yang ada dalam
dokumen training yang masuk kedalam kategori 𝐶𝑗(tanpa menghiraukan ada kata
ang sama atau tidak)
V adalah jumlah total jenis kata yang ada dalam dokumen training (kata yang sama hanya dihitung 1)
Menurut Han (2006), NBC menggunakan algoritma Bayessian untuk menghitung nilai total probabilitas. Prinsip dari NBC adalah probabilitas suatu kata akan masuk ke dalam suatu suatu kategori
(posterior probability), didasarkan pada nilai
probabilitas tertinggi yang telah dimiliki sebelumnya
(prior probability),yang dimiliki teks yang bersangkutan untuk suatu ketegori tertentu. Misalnya kata “processor” pada koleksi data memiliki probabilitas untuk kategori “komputer” sebesar 0.9, sedangkan untuk kategori “elektronik” sebesar 0.3. Sehingga kalau pada proses pengujian ditemukan kata “processor” maka akan masuk ke dalam kategori “komputer”.Dengan kata lain, NBC menggunakan asumsi bahwa kemunculan atau ketidakmunculan dari suatu kata atau fitur tidak terkait dengan kemunculan atau ketidakmunculan fitur yang lain.
3. Metode Penelitian
Pada bagian ini akan diuraikan metode yang digunakan untuk simulasi proses klasifikasi
3.1 Studi Pustaka
Melakukan studi literatur dengan cara mempelajari berbagai referensi dari buku, e-book, jurnal nasional/internasional,dll yang berhubungan dengan penelitian yang akan dilakukan.
3.2 Data
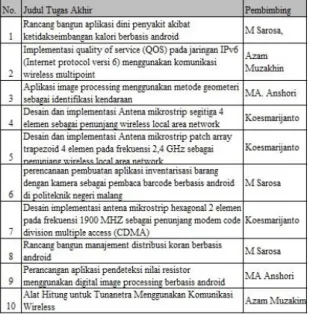
Data yang digunakan untuk simulasi dalam penelitian ini adalah judul tugas akhir mahasiswa sebagai data training dan data testing.
1. Data training : Data yang digunakan sebagai
data training adalah 10 data judul tugas akhir
mahasiswa beserta 4 nama dosen pembimbing. 2. Data testing : Untuk data testing
menggunakan 1 judul tugas akhir yang nantinya akan diklasifikasikan ke 4 nama dosen.
3.3 Metode Pengolahan Data
Secara umum proses klasifikasi menggunakan naïve bayes ditunjukkan pada Gambar 3.
C-138
Gambar 3. Proses Umum Klasifikasi NaïveBayes
Data training disini berupa 10 judul tugas
akhir yang telah diklasifikasikan pada 4 dosen pembimbing. Sebelum dilakukan proses klasifikasi, data ini harus melalui proses text preprocessing, tujuannya untuk menghilangkan noise, struktur kata yang tidak baik, dan untuk mempermudah proses klasifikasi menggunakan naive bayes.
Data testing berupa judul tugas akhir yang
nantinya akan diklasifikasikan ke 4 nama dosen sebagai rekomendasi dosen pembimbing. Data ini juga melalui text preprocessing sebelum akhirnya dihitung probabilitasnya menggunakan naive bayes
classifier. Adapun data training dalam penelitian ini
ditunjukkan dalam Tabel 1.
Tabel 1 Data training
Sedangkan data testing ditunjukkan dalam Tabel 2.
Tabel 2 Data testing
3.3.1 Text Preprocessing
Baik data training maupun data testing akan melalui text preprocessing sebelum diolah lebih lanjut menggunakan naive bayes classifier (NBC). Proses text preprocessing ditunjukkan dalam Gambar 4, 5, 6, dan 7.
Gambar 4. Proses Case Folding
Gambar 5 Proses Tokenisasi
C-139
Gambar 7. Proses Stemming4. Hasil dan Pembahasan
Sebelum data dihitung probabilitasnya dengan NBC, data harus melalui text preprocessing supaya lebih mudah dalam perhitungan. Hasil teks preprocessing ditunjukkan dalam Tabel 3 dan Tabel 4.
Tabel 3. Hasil Text Preprocessing untuk Data Training
Tabel 4. Hasil Text Preprocessing untuk Data Testing
4.1 Pengujian Data Testing
Dari dataset tersebut akan diklasifikasikan menjadi 4 buah kelas klasifikasi yaitu:
Kategori 1 (
𝐶
1) : M.Sarosa Kategori 2 (𝐶
2) : Azam Muzakim Kategori 3 (𝐶
3) : MA Anshori Kategori 4 (𝐶
4) : KoesmarijantoDengan mengacu dari Gambar 10 nilai (𝐶1) = 3/10 ,
𝑝(𝐶2) = 2/10 , 𝑝(𝐶3) = 2/10 , 𝑝(𝐶4) = 3/10 dan probabilitas masing-masing kata (image, process,
deteksi, kecepatan, kendaraan, basis, android)
adalah:
Perhitungan Probabilitas P(Sarosa)
𝑝(𝑖𝑚𝑎𝑔𝑒 | 𝐶1) = 0 + 1 23 + 63= 1 86 𝑝(𝑝𝑟𝑜𝑐𝑒𝑠𝑠 | 𝐶1) =23 + 630 + 1 =861 𝑝(𝑑𝑒𝑡𝑒𝑘𝑠𝑖 | 𝐶1) = 0 + 1 23 + 63= 1 86 𝑝(𝑘𝑒𝑐𝑒𝑝𝑎𝑡𝑎𝑛 | 𝐶1) = 0 + 1 23 + 63= 1 86 𝑝(𝑘𝑒𝑛𝑑𝑎𝑟𝑎𝑎𝑛 | 𝐶1) =23 + 860 + 1 =861 𝑝(𝑏𝑎𝑠𝑖𝑠 | 𝐶1) =23 + 863 + 1 =864 𝑝(𝑎𝑛𝑑𝑟𝑜𝑖𝑑 | 𝐶1) = 3 + 1 23 + 86= 4 86 𝑝( 𝐶 1 | 𝑑11) = 𝑝(𝐶1). 𝑝(𝑖𝑚𝑎𝑔𝑒 | 𝐶1). 𝑝(𝑝𝑟𝑜𝑐𝑒𝑠𝑠| 𝐶1). 𝑝(𝑑𝑒𝑡𝑒𝑘𝑠𝑖| 𝐶1). 𝑝(𝑘𝑒𝑐𝑒𝑝𝑎𝑡𝑎𝑎𝑛| 𝐶1). 𝑝(𝑘𝑒𝑛𝑑𝑎𝑟𝑎𝑎𝑛| 𝐶1). 𝑝(𝑏𝑎𝑠𝑖𝑠| 𝐶1). 𝑝(𝑎𝑛𝑑𝑟𝑜𝑖𝑑| 𝐶1) 𝑝( 𝐶 1 | 𝑑11 ) = 3 10. 1 86. 1 86. 1 86 1 86. 1 86. 4 86 4 86= 48 6020 = 𝟎. 𝟎𝟎𝟕𝟗𝟕
Probabilitas masing-masing dosen dihitung berdasarkan rumus 1. Hasil dari perhitungan probabilitas tiap kata pada tiap dosen ditunjukkan pada Tabel 5.
Tabel 5. Hasil Probabilitas Tiap Kata Pada Tiap Dosen
Dari probabilitas tiap kata yang didapat pada Gambar 11, akan dilakukan perhitungan total tiap data testing dengan masing-masing dosen P (Cn | dn) dimana Cn adalah kategori dosen dan dn adalah data testing. Hasil perhitungan probabilitas P (Cn | dn) ditunjukkan dalam Tabel 6.
Tabel 6. Hasil Probabilitas Tiap Dosen pada Data Testing.
Dari hasil perhitungan, terlihat bahwa nilai probabilitas P(MA Anshori) atau 𝑝( 𝐶3| 𝑑511 ) lebih
besar, sehingga dokumen testing atau dokumen 𝑑11
masuk ke dalam klasifikasi 𝐶 3. Dengan kata lain
judul tugas akhir “Image Processing untuk
C-140
android” masuk dalam klasifikasi dosen pembiming MA. Anshori.4. Kesimpulan
Metode klasifikasi Naïve Bayes Classifier (NBC) dapat digunakan untuk mengklasifikasikan judul tugas akhir ke sejumlah nama dosen pembimbing.
Learning dilakukan terhadap 10 judul tugas akhir dan 4 dosen pembimbing sebagai data training, hasil probabilitas klasifikasi data testing adalah P(Sarosa) = 0.00797, P(Azam) = 0.000332, P(Anshori) = 0.0099667 dan P(Koesmarijanto) = 0.00049. Dari hasil perhitungan, terlihat bahwa nilai probabilitas P(MA Anshori) lebih besar, maka MA.Anshori direkomendasikan untuk membimbing judul tugas akhir yang digunakan sebagai data
testing.
5. Saran
Terdapat banyak metode untuk klasifikasi,
diharapkan untuk para pengembang dapat
menggunakan metode tersebut untuk objek
yang sama dan membandingkan metode
klasifikasi mana yang paling baik dalam kasus
klasifikasi tugas akhir untuk menentukan dosen
pembimbing.
6. Daftar Pustaka
Azis, Gilang Abdul. (2011). Implementasi Naïve
Bayes Classifier Sebagai System Pendukung Keputusan Pada Personal Resource Planning Berbasis Mobile. Jurnal Ilmu Komputer
Feldman, Ronen, and James Sanger. (2007). The
Text Mining Handbook Advanced Approaches in Analyzing Unstrustured Data. Cambridge;
New York : Cambridge University Press. Kamaruzzaman,S.M.Chowdhury Mofizur Rahman.
(2004). Text Categorization using Association
Rule and Naive Bayes Classifier. Asian Journal
of Information Technology, Vol. 3, No. 9, pp 657-665, Sep. 2004
McLeod, Jr.R. dan G.P. Schell. (2007). Management
Information System. 10th ed. Pearson Education, Inc. Ali Akbar Yulianto dan Afia R. Fitriati (penterjemah). 2008. Sistem Informasi Manajemen. Edisi 10. Nina Setyaningsih (editor). Salemba Empat. Jakarta.
Ridwan, Mujib. dkk (2013). Penerapan Data Mining
untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive bayes classifier (NBC). Jurnal EECCIS Vol.7 No.1, PP 59-64
Juni 2013.
Santosa, B. (2007). Data Mining: Teknik
Pemanfaatan Data untuk Keperluan Bisnis.
Graha Ilmu. Yogyakarta.
Salton, G, (1989). Automatic Text Processing :The
Transformation, Analysis, and Retrieval of Information by Computer, Addison-Wesley,
Boston, MA, USA
Tala, F. Z. (2003). A Study of Stemming Effect on
Information Retrieval in Bahasa Indonesia,
M.S. Thesis.
Han, Jiawei dan Kamber, Micheline. (2006). Data
Mining : Concept and Techniques Second Edition, Morgan Kaufmann Publisher.