Jurnal
Informatika dan
Komputer
PENS
www.jurnalpa.eepis-its.edu
Teknik Komputer
Vol.2, No.2, 2015
Politeknik Elektronika Negeri Surabaya
Aplikasi Pendeteksi Kemiripan Laporan Menggunakan
Text Mining
dan
Clustering
Fitria Dwi Indah Kusuma,
1)Tri Harsono,
1)Sigit Wasista,
2)Aliridho Barakbah
1) Program Studi D4 Teknik Komputer, 2) Program Studi D4 Teknik Informatika
Departemen Informatika dan Komputer Politeknik Elektronika Negeri Surabaya Kampus PENS, Jalan Raya ITS Sukolilo, Surabaya 60111
Tel: (031) 594 7280; Fax: (031) 594 6114
Email:[email protected], [email protected], [email protected], [email protected]
Abstrak
Dalam dunia pendidikan, khususnya di lingkungan perkuliahan yang identik dengan banyaknya jumlah mata kuliah teori maupun praktikum di setiap semesternya, selalu disertai pula dengan banyaknya tugas berupa laporan yang harus dikerjakan oleh setiap mahasiswa. Sebagian besar tugas maupun laporan tersebut berupa soft file. Tidak jarang seorang mahasiswa melakukan proses copy-paste-modify terhadap tugas maupun laporan milik mahasiswa lain, bahkan tidak jarang pula mahasiswa yang melakukan copy-paste
hanya mengganti jenis font yang digunakan tanpa melakukan perubahan apapun terhadap isi tugas dan laporan tersebut. Pada penelitian ini dideteksi kemiripan antar laporan resmi dengan cara membandingkan isi analisa dan kesimpulan dari laporan tersebut yang telah disimpan dalam bentuk teks berupa file .txt untuk mengetahui tingkat kemiripan antar laporan dimana hasil pembandingan tersebut dinyatakan dalam bentuk persentase atau nilai tingkat kemiripan isi antar laporan. Proses pembandingannya dilakukan dengan memanfaatkan adanya text mining dan clustering. Text mining itu sendiri terdiri dari beberapa tahap, yaitu tokenizing, filtering, stemming, tagging dan analyzing. Proses deteksi kemiripan laporan akan bekerja lebih optimal ketika diproses melalui tahap stemming
dan tagging meskipun membutuhkan waktu yang lebih lama dibandingkan tanpa melalui tahap stemming dan tagging. Deteksi kemiripan laporan menggunakan tahap stemming dan tagging menghasilkan persentase keberhasilan sebesar 65,19% dan ketika diproses tanpa menggunakan tahap stemming dan tagging menghasilkan persentase keberhasilan sebesar 64,23%.
Kata Kunci : kemiripan laporan, text mining, clustering.
1. Pendahuluan
Perkembangan teknologi saat ini semakin canggih, termasuk perkembangan teknologi digital di era modern saat ini. Teknologi digital telah menjadi kebutuhan bagi seluruh pengguna teknologi saat ini, salah satunya adalah dokumen teks. Dokumen teks dalam bentuk digital akan lebih memudahkan pengguna dalam melakukan penyimpanan karena lebih efisien, akan tetapi juga lebih memudahkan pengguna untuk melakukan penjiplakan. Penjiplakan atau plagiarisme merupakan tindakan mencontoh atau meniru hasil karya milik orang lain tanpa seizin pemilik asli karya tersebut yang selanjutnya diakui sebagai hasil karya milik sendiri [4].
Banyaknya mata kuliah praktikum yang diberikan dalam satu semester perkuliahan, serta jumlah praktikum dari setiap mata kuliah praktikum yang berjumlah 16 kali pertemuan menyebabkan banyaknya jumlah laporan praktikum yang harus dikumpulkan oleh setiap mahasiswa dalam satu semesternya. Oleh karena itu, mahasiswa diwajibkan untuk mengumpulkan laporan praktikum dalam bentuk soft file yang semakin memudahkan mahasiswa untuk melakukan tindakan plagiarisme. Tidak jarang seorang mahasiswa melakukan proses copy-paste-modify terhadap tugas maupun laporan milik mahasiswa lain, bahkan tidak jarang pula mahasiswa yang melakukan copy-paste hanya mengganti jenis font yang digunakan tanpa melakukan perubahan apapun terhadap isi laporan tersebut tersebut.
Tindakan plagiarismeyang dilakukan mahasiswa terhadap tugas-tugas berupa laporan soft file yang diberikan oleh dosen tersebut, menimbulkan banyak kerugian, baik bagi mahasiswa yang melakukan proses copy-paste maupun bagi mahasiswa yang dijiplak laporannya. Salah satu bentuk kerugian yang ditimbulkan akibat dari tindakan plagiarisme tersebut adalah menyebabkan mahasiswa menjadi kurang kreatif karena tidak terbiasa untuk menyelesaikan tugasnya sendiri akibat dari kebiasaan mahasiswa yang hanya sekedar melakukan proses editing terhadap tugas milik mahasiswa lain.
Berdasarkan kondisi banyaknya jumlah laporan praktikum yang dikumpulkan, menjadi menyulitkan untuk mendeteksi kemiripan laporan praktikum milik antar mahasiswa secara manual karena jumlahnya yang terlalu banyak sehingga sulit pula untuk mengetahui ada atau tidaknya tindakan plagiarisme yang dilakukan oleh mahasiswa.
Pembuatan aplikasi ini mengacu pada penelitian sebelumnya yang berjudul Aplikasi Pendeteksi Duplikasi Dokumen Teks Bahasa Indonesia Menggunakan Algoritma Winnowing dengan Metode K-Gram dan Synonym Recognition oleh Mudafiq Riyan Pratama, Eko Budi Cahyono, dan Gita Indah Marthasari [4]. Implementasi Deteksi Penjiplakan Dengan Algoritma Winnowing pada Dokumen Terkelompok oleh I Wayan Surya Priantara, Diana Purwitasari, dan Umi Laili Yuhana [3]. Penerapan Algoritma Boyer-Moore dan Algoritma Rabin Karp dalam Mendeteksi Aksi Plagiarisme oleh Arif Prasetiya [10]. Berdasarkan penelitian sebelumnya yang diacu, maka dibuatlah penelitian ini dengan mengajukan suatu pendekatan baru untuk mendeteksi kemiripan antar laporan resmi.
2. Desain Sistem
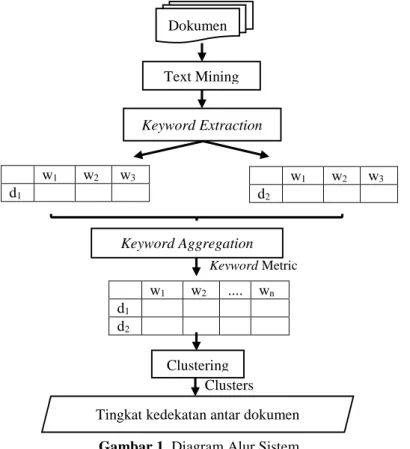
Secara garis besar, perancangan “Aplikasi Pendeteksi Kemiripan Laporan Menggunakan Text Mining dan Clustering” ditunjukkan pada Gambar 1
Gambar 1. Diagram Alur Sistem
Perancangan sistem yang akan dibuat adalah melakukan pembandingan antar dokumen berisi teks yang berupa txt berbahasa indonesia, dimana dalam 1 kali proses pembandingan terdapat 10 dokumen yang dibandingkan dengan tema yang sama, milik mahasiswa yang berbeda. 10 dokumen tersebut kemudian di proses menggunakan text mining yang menghasilkan output berupa matriks dari masing-masing dokumen, yang mana setiap dokumen memiliki kata kunci masing-masing sejumlah n. Setiap kata kunci tersebut memiliki bobotnya masing-masing yang diperoleh dari frekuensi kemunculan kata tersebut dalam dokumen yang bersangkutan. Seluruh matriks tersebut kemudian digabungkan menjadi 1 buah matriks besar melalui proses aggregation. Dalam 1 matriks besar tersebut, seluruh kata kunci pada 10 matriks sebelumnya digabungkan untuk kemudian dicari nilai bobot dari setiap kata kunci tersebut terhadap 10 dokumen. Setelah diketahui nilai bobot dari seluruh kata kunci pada 10 dokumen, maka akan dilakukan proses clustering atau pengelompokkan berdasarkan similaritas tertentu untuk mendapatkan hasil cluster berupa tingkat kedekatan antar kedua dokumen tersebut sehingga dapat diketahui tingkat kemiripan keduanya.
w1 w2 w3 d2 w1 w2 w3 d1 w1 w2 .... wn d1 d2 Keyword Metric Clusters Dokumen Text Mining KeywordAggregation Clustering KeywordExtraction
2.1. Dokumen
Berdasarkan gambar 3.1 terlihat bahwa input dari sistem yang dibuat ini adalah berupa dokumen laporan tugas milik mahasiswa. Dokumen yang digunakan sebagai input ini terdiri dari 10 buah laporan milik 10 orang mahasiswa yang berbeda yang memiliki tema tugas yang sama. Dokumen yang digunakan sebagai input ini hanya berisi teks, dan tidak berupa gambar yang disimpan dalam bentuk txt berbahasa indonesia.
2.2. Text Mining
Text mining secara umum mengacu pada proses ekstraksi informasi dari dokumen-dokumen teks tak terstruktur (unstructured). Text mining memiliki definisi menambang data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen [1].
Pada prinsipnya, text mining adalah bidang ilmu multidisipliner, melibatkan information retrieval (IR), text analysis, information extraction (IE), clustering, categorization, visualization, database technology, natural language processing (NLP), machine learning, dan data mining. Dapat pula dikatakan bahwa text mining merupakan salah satu bentuk aplikasi kecerdasan buatan (artificial intelligence / AI) [1].
Text mining mencoba memecahkan masalah information overload dengan menggunakan teknik-teknik dari bidang ilmu yang terkait. Text mining dapat dipandang sebagai suatu perluasan dari data mining atau knowledge-discovery in database (KDD), yang mencoba untuk menemukan pola-pola menarik dari basis data berskala besar. Namun text mining memiliki potensi komersil yang lebih tinggi dibandingkan dengan data mining, karena kebanyakan format alami dari penyimpanan informasi adalah berupa teks. Text mining menggunakan informasi teks tak terstruktur dan mengujinya dalam upaya mengungkap struktur dan arti yang “tersembunyi” di dalam teks [1].
2.2.1. Tahap Tokenizing
Tahap tokenizing atau parsing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya. Gambar 2 adalah contoh dari tahap tokenizing.
Gambar 2. Tahap Tokenizing
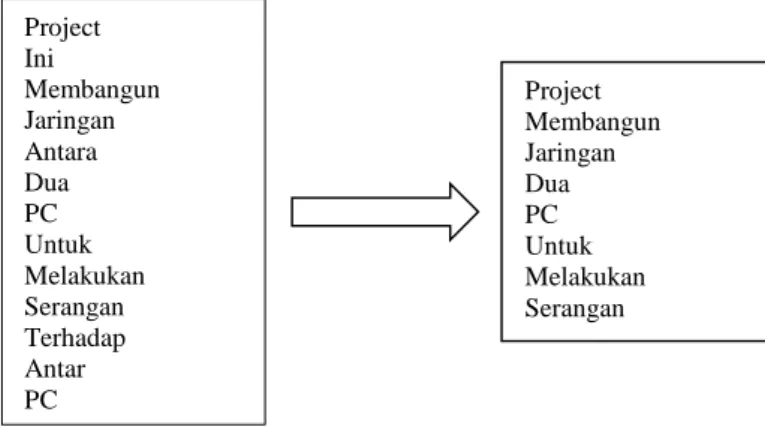
2.2.2. Tahap Filtering
Tahap filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa mengunakan algoritma stop list (membuang kata-kata yang kurang penting) atau word list (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekata-katan bag-of-words. Gambar 3 adalah contoh dari tahap filtering.
Gambar 3. Tahap Filtering Project Ini Membangun Jaringan Antara Dua PC Untuk Melakukan Serangan Terhadap Antar PC Project ini membangun jaringan
antara dua PC untuk melakukan serangan terhadap antar PC
Project Ini Membangun Jaringan Antara Dua PC Untuk Melakukan Serangan Terhadap Antar PC Project Membangun Jaringan Dua PC Untuk Melakukan Serangan
2.2.3. Tahap Stemming dan Tagging
Tahap stemming adalah tahap mencari root kata dari tiap kata hasil filtering. Pada tahap ini dilakukan proses pengembalian berbagai bentukan kata ke dalam suatu representasi yang sama. Tahap ini kebanyakan dipakai untuk teks berbahasa inggris dan lebih sulit diterapkan pada teks berbahasa Indonesia. Hal ini dikarenakan bahasa Indonesia tidak memiliki rumus bentuk baku yang permanen.
Tahap tagging adalah tahap mencari bentuk awal atau root dari tiap kata lampau atau kata hasil stemming. Tahap ini berlaku untuk dokumen teks berbahasa Inggris, sedangkan untuk dokumen teks berbahasa Indonesia, prosesnya digabungkan dengan tahap stemming. Gambar 4 adalah contoh dari tahap stemming dan tagging :
Gambar 4. Tahap Stemming dan Tagging
2.2.4. Tahap Analyzing
Tahap analyzing merupakan tahap penentuan seberapa jauh keterhubungan antar kata-kata antar dokumen yang ada. Term Frequency merupakan algoritma yang paling sederhana yang biasanya dipakai untuk scoring. Gambar 5 adalah contoh dari tahap analyzing.
Gambar 5. Tahap Analyzing
2.3. Keyword Extraction
Keyword extraction berasal dari 2 kata yaitu extract dan keyword. Extract sendiri sangat berhubungan dengan kata atau frasa dalam sebuah dokumen. Sedangkan keyword di definisikan sebagai rangkaian atau urutan dari satu atau lebih kata, yang merepresentasikan isi dari sebuah dokumen. Secara ideal, keyword merpresentasikan isi dari sebuah dokumen yang bersifat sangat penting dalam bentuk sederhana.
Berdasaran pengertian keyword extraction, pada sistem ini, isi dari kedua dokumen input akan di ekstraksi berdasarkan kata kunci dari masing-masing dokumen dan setiap kata kunci tersebut memiliki nilai bobot masing-masing yang menunjukkan frekuensi tingkat kemunculan kata dalam satu dokumen. Contoh keyword extraction ditunjukkan pada Tabel 1 dan Tabel 2
Tabel 1. Contoh Keyword Extraction untuk Dokumen 1
Praktikum Sensor Gerakan ADC Objek
d1 2 22 3 3 8
Tabel 1 menunjukkan contoh hasil dari proses keyword extraction dari dokumen 1. Contoh pada Tabel 3.1 tersebut terdapat 5 kata kunci yang dihasilkan dari proses text mining, yaitu praktikum, sensor, gerakan, ADC, dan objek. Masing-masing kata kunci tersebut memiliki frekuensi kemunculan yang bervariasi. Untuk kata praktikum, frekuensi kemunculannya pada dokumen 1 adalah sebanyak 2 kali. Untuk kata sensor adalah sebanyak 22 kali. Untuk kata gerakan adalah sebanyak 3 kali. Untuk kata ADC adalah sebanyak 3 kali dan untuk kata objek adalah sebanyak 8 kali.
Tabel 1. Contoh Keyword Extraction untuk Dokumen 2
Praktikum PIR Gerakan Output Data
d2 1 5 1 3 5
Tabel 2 menunjukkan contoh hasil dari proses keyword extraction dari dokumen 2. Contoh pada Tabel 3.2 tersebut terdapat 5 kata kunci yang dihasilkan dari proses text mining, yaitu praktikum, PIR, gerakan, output, dan data. Masing-masing kata kunci tersebut memiliki frekuensi kemunculan yang bervariasi. Untuk kata praktikum, frekuensi
Project Membangun Jaringan Dua PC Untuk Melakukan Serangan Project Bangun Jaring Dua PC Untuk Laku Serang Project Membangun Jaringan Dua PC Untuk Melakukan Serangan Project : 1 Bangun : 1 Jaring : 1 Dua : 1 PC : 1 Untuk : 1 Laku : 1 Serang : 1
kemunculannya pada dokumen 2 adalah sebanyak 1 kali. Untuk kata PIR adalah sebanyak 5 kali. Untuk kata gerakan adalah sebanyak 1 kali. Untuk kata output adalah sebanyak 3 kali dan untuk kata data adalah sebanyak 5 kali.
2.4. Keyword Aggregation
Keyword aggregation berasal dari 2 kata yaitu keyword dan aggregation. Aggregation sendiri memiliki pengertian dimana beberapa hal dikelompokkan secara bersama-sama menjadi satu. Proses keyword aggregation pada sistem ini adalah menggabungkan hasil dari keyword extraction dari kedua dokumen menjadi satu berupa keyword matric.
2.5. Keyword Metric
Keyword metric berasal dari 2 kata yaitu keyword dan metric. Metric merupakan bentuk representasi output dari proses keyword aggregation yang dinyatakan dalam bentuk matriks. Matriks sendiri dinyatakan dalam bentuk tabel. Contoh proses keyword metric ditunjukkan pada Tabel 3
Tabel 3. Contoh Keyword Matric
Praktikum Sensor PIR Gerakan Output Objek Data
d1 2 22 0 3 0 8 5
d2 1 0 5 1 3 0 0
Tabel 3 menunjukkan contoh keyword metric yang merupakan hasil dari proses keyword aggregation yaitu proses untuk menggabungkan hasil dari keyword extraction dokumen 1 yang ditunjukkan pada tabel 1 dan dokumen 2 yang ditunjukkan pada tabel 2. Terdapat 2 kata kunci yang sama antara dokumen 1 dan dokumen 2 yaitu kata praktikum dan gerakan. Selain kedua kata tersebut, kata kunci lainnya berbeda antara kedua dokumen. Untuk kata praktikum dan gerakan, masing-masing dokumen memiliki nilai frekuensi kemunculannya masing-masing sesuai dengan nilai yang terdapat pada tabel 1 dan 2, sedangkan untuk kata sensor, PIR, output, objek, dan data yang hanya dimiliki oleh salah satu dokumen, maka nilai frekuensi kemunculan pada dokumen yang tidak terdapat kata kunci tersebut adalah 0 sedangkan untuk dokumen yang didalamnya terdapat kata kunci tersebut, maka nilai frekuensi kemunculannya adalah sama dengan yang terdapat pada Tabel 1 dan 2.
2.6. Output
Output dari sistem ini adalah tingkat kedekatan antar dokumen yang diperoleh dari hasil clustering yang telah dilakukan proses pengelompokan berdasarkan similaritas tertentu. Berdasarkan tingkat kedekatan antar dokumen tersebut, maka dapat diketahui nilai persentase (%) tingkat kemiripan antar laporan tersebut sehingga kedua dokumen yang di proses tersebut dapat dikategorikan sebagai tindak plagiarismeatau tidak berdasarkan nilai persentase (%) yang dihasilkan.
Untuk menentukan jenis kesamaan antara dokumen yang diuji, terdapat 5 jenis penilaian persentase similarity (Mutiara-Agustina, 2008) yang ditunjukkan pada Tabel 4 [9].
Tabel 4. Jenis Penilaian Persentase Similarity
Persentase Similarity Jenis Kesamaan antar Dokumen
0% Kedua dokumen tersebut benar-benar berbeda baik dari segi
isi dan kalimat secara keseluruhan
<15% Kedua dokumen tersebut hanya mempunyai sedikit kesamaan
15% - 50% Kedua dokumen tersebut termasuk plagiat tingkat sedang
>50% Kedua dokumen tersebut mendekati plagiarisme
100% Kedua dokumen tersebut adalah plagiat karena dari awal
sampai akhir mempunyai isi yg sama persis.
3. Pengujian dan Pembahasan
Pada tahap ini, perancangan perangkat lunak direalisasikan sebagai serangkaian program atau unit program dengan melakukan beberapa pengujian terhadap fungsi-fungsi yang dimiliki oleh sistem, performa dari sistem maupun dari algoritma yang digunakan. Proses pengujian ini dilakukan terhadap 3 jenis dokumen yang berbeda, yaitu dokumen portsentry, dokumen scanning dan probing, dan dokumen password management dimana masing-masing jenis dokumen, terdapat 10 dokumen yang di proses.Output berupa nilai persentase similaritas antar laporan ini dihitung berdasarkan output dari tahap keyword aggregation sebelumnya, dimana setiap dokumen memiliki keyword masing-masing beserta frekuensi kemunculan dari keyword tersebut yang dihitung berdasarkan persamaan 1
S = 𝑁−𝐴
Keterangan :
S = Similaritas dalam bentuk persentase N = Jumlah keyword antar 2 dokumen
A = Total selisih absolut kemunculan keyword antar 2 dokumen
Contoh implementasi dari persamaan 1 terhadap hasil dari tahap keyword aggregation ditunjukkan pada Tabel 5
Tabel 5. Contoh Hasil Keyword Aggregation
Praktikum Sensor PIR Gerakan Output Objek Data Jumlah
d1 2 22 0 3 0 8 5 40
d2 1 0 5 1 3 0 0 10
Selisih 1 22 5 2 3 8 5 50
43
Berdasarkan data yang ditunjukkan pada Tabel 5 dapat dihitung persentase kedekatan antara dokumen 1 dan dokumen 2 menggunakan persamaan 1 yang ditunjukkan pada persamaan 2
S =50−43
50 𝑥 100%
S = 7
50𝑥 100%
S = 14% (2)
3.1. Pengujian Persentase Similarity Antar Dokumen
Proses perhitungan persentase similaritas ini dilakukan setiap antar 2 dokumen yang kemudian hasilnya ditampilkan ke dalam sebuah tabel yang di dalamnya berisi informasi persentase similaritas mulai dari dokumen 1 hingga dokumen 10, dimana untuk nilai persentase kemiripan lebih dari 50% diberikan indikator berupa warna merah pada baris dan kolom pada tabel yang merupakan indikasi dari kategori plagiarisme seperti yang ditunjukkan pada Tabel 6
Tabel 6.Output Persentase Kemiripan Antar Laporan
D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 D1 45% 50% 44% 45% 49% 53% 46% 44% 53% D2 45% 42% 92% 46% 40% 74% 84% 92% 74% D3 50% 42% 45% 52% 78% 47% 45% 45% 47% D4 44% 92% 45% 46% 43% 74% 87% 100% 74% D5 45% 46% 52% 46% 47% 53% 47% 46% 53% D6 49% 40% 78% 43% 47% 44% 42% 43% 44% D7 53% 74% 47% 74% 53% 44% 77% 74% 100% D8 46% 84% 45% 87% 47% 42% 77% 87% 77% D9 44% 92% 45% 100% 46% 43% 74% 87% 74% D10 53% 74% 47% 74% 53% 44% 100% 77% 74%
Hasil persentase similaritas yang ditunjukkan pada Gambar 7 kemudian dilakukan proses sorting atau pengurutan secara ascending yaitu mulai dari nilai persentase terkecil ke nilai persentase terbesar. Setelah proses sorting berhasil dilakukan, setiap nilai persentase similaritas tersebut dikategorikan ke dalam 5 jenis penilaian persentase similarity (Mutiara-Agustina, 2008) berdasarkan Tabel 4. yang disertai keterangan nama dokumen seperti yang ditunjukkan pada Gambar 6
Gambar 6. Kategori Penilaian Persentase Similarity
3.2. Pengujian Lama Waktu Pemrosesan Tahap Filtering
Waktu yang dibutuhkan untuk melakukan pemrosesan pada tahap filtering ini masih dalam hitungan detik untuk setiap dokumennya, sehingga estimasi total waktu yang dibutuhkan untuk menyelesaikan pemrosesan pada tahap filtering ini untuk 10 dokumen sekaligus berkisar antara 1 menit hingga 3 menit bergantung pada banyaknya jumlah kata yang digunakan pada setiap dokumen. Semakin sedikit jumlah kata yang digunakan dalam sebuah dokumen yang di proses, maka waktu yang dibutuhkan akan menjadi semakin singkat. Sebaliknya, semakin banyak jumlah kata yang digunakan dalam sebuah dokumen yang di proses, maka waktu yang dibutuhkan akan menjadi semakin lama. Hal tersebut disebabkan karena sistem harus melakukan pengecekan terhadap setiap kata hasil tokenizing yang disimpan dalam array untuk dibandingkan dengan daftar stopword / stoplist yang disimpan dalam database sejumlah 384 kata. Jika kata dalam array ditemukan dalam database, maka kata tersebut harus dibuang dengan mengosongkan isi dari indeks array yang bersangkutan. Hal tersebut terjadi secara terus menerus mulai dari indeks array pertama hingga indeks array terakhir yang menjadi indikator kata pertama hingga kata terakhir dalam setiap dokumen. Selain itu, jika kata hasil tokenizing yang disimpan dalam array berada pada urutan akhir dalam database stopword maka akan menyebabkan waktu pemrosesan menjadi lebih lama dibandingkan dengan kata yang terdapat pada urutan awal dalam database stopword, sehingga meskipun jumlah kata antar dokumen sama, waktu pemrosesannya bisa jadi berbeda meskipun berbeda tipis karena disebabkan oleh hal tersebut.
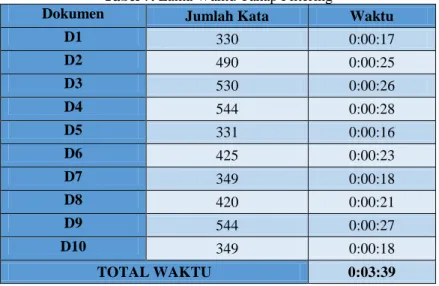
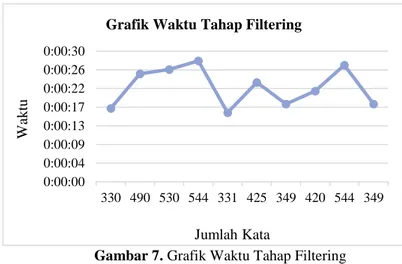
Dokumen yang di proses adalah dokumen berisi analisa dan kesimpulan dari materi praktikum tentang portsentry yang jumlah katanya berkisar antara 330 kata hingga 544 kata sehingga lama waktu pemrosesannya pun menjadi lebih lama berkisar antara 16 detik hingga 28 detik untuk setiap dokumennya dan 3 menit 39 detik untuk total waktu pemrosesan 10 dokumen. Data waktu pemrosesan filtering ini ditunjukkan pada Tabel 7 sedangkan untuk data waktu berupa grafik ditunjukkan pada Gambar 7
Tabel 7. Lama Waktu Tahap Filtering
Dokumen Jumlah Kata Waktu
D1 330 0:00:17 D2 490 0:00:25 D3 530 0:00:26 D4 544 0:00:28 D5 331 0:00:16 D6 425 0:00:23 D7 349 0:00:18 D8 420 0:00:21 D9 544 0:00:27 D10 349 0:00:18 TOTAL WAKTU 0:03:39
Gambar 7. Grafik Waktu Tahap Filtering
3.3. Pengujian Lama Waktu Pemrosesan Tahap Stemming dan Tagging
Tahap ini merupakan tahap yang paling memakan waktu lama untuk satu kali proses jenis dokumen. Dalam satu kali proses jenis dokumen, terdapat 10 dokumen yang di proses secara bergantian mulai dari dokumen pertama hingga dokumen terakhir, dan untuk masing-masing dokumen tersebut membutuhkan waktu dalam hitungan menit untuk menyelesaikan proses stemming dan tagging ini sehingga untuk 10 dokumen dapat membutuhkan waktu dalam hitungan jam. Hal tersebut dikarenakan untuk mengembalikan ke kata dasar, terdapat beberapa tahapan proses yang harus dilalui. Kata hasil proses filtering yang disimpan dalam array, dilakukan pengecekan satu per satu terhadap isi folder kamus yang di dalamnya terdapat file .txt mulai dari angka 0 hingga 9 serta alphabet A-Z yang berisi kata dasar berbahasa Indonesia. Jika kata dalam array tersebut ditemukan di dalam salah satu file .txt dalam folder kamus, maka proses untuk kata tersebut berhenti karena sudah termasuk kata dasar, sehingga proses akan dilanjutkan ke indeks array selanjutnya untuk memproses kata yang lain. Sebaliknya, jika tidak ditemukan dalam folder kamus, maka kata tersebut akan di proses untuk melakukan pengecekan imbuhan berupa akhiran, jika tidak mengandung akhiran, maka akan dilakukan pengecekan imbuhan berupa awalan. Sebaliknya, jika ditemukan imbuhan berupa akhiran, maka kata tersebut akan di proses untuk menghilangkan akhiran tersebut, jika telah selesai dihilangkan akan kembali dicocokan dengan kamus sama seperti proses pertama. Jika tidak ditemukan dalam kamus, maka proses berlanjut ke penghapusan awalan. Proses yang sama terjadi pada pengecekan imbuhan berupa awalan serta kata ganti kepemilikan. Oleh karena itu, membutuhkan waktu yang lama untuk pemrosesan setiap dokumennya. Secara keseluruhan, semakin sedikit jumlah kata yang di proses maka waktu yang dibutuhkan untuk melakukan prosesnya juga semakin cepat, sebaliknya semakin banyak jumlah kata yang di proses maka akan waktu yang dibutuhkan untuk melakukan prosesnya juga semakin lama. Jumlah kata yang dijadikan acuan untuk tahap stemming dan tagging ini adalah jumlah kata hasil filtering, sehingga hanya kata-kata penting saja yang digunakan, dan jumlahya lebih sedikit dibandingkan dengan jumlah kata yang digunakan pada tahap filtering.
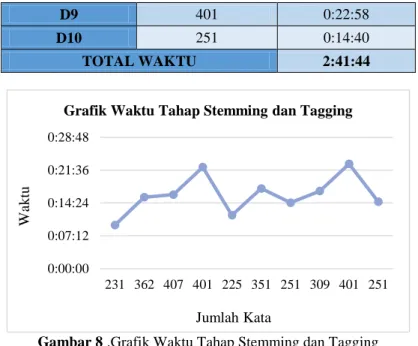
Dokumen yang di proses adalah dokumen berisi analisa dan kesimpulan tentang materi praktikum portsentry merupakan dokumen yang memiliki jumlah kata rata-rata paling banyak dibandingkan dengan dokumen jenis kedua dan ketiga yaitu sejumlah 225 kata hingga 407 kata, sehingga membutuhkan waktu proses yang sangat lama untuk setiap dokumennya yang berkisar antara 9 menit hingga 22 menit sehingga total waktu yang dibutuhkan untuk melakukan proses stemming dan tagging terhadap 10 dokumen jenis ini adalah selama 2 jam 41 menit 44 detik. Jumlah kata masing-masing dokumen serta lama waktu prosesnya ditunjukkan pada Tabel 8 sedangkan untuk data dalam bentuk grafik ditunjukkan pada Gambar 8
Tabel 8. Lama Waktu Tahap Stemming dan Tagging
Dokumen Jumlah Kata Waktu
D1 231 0:09:32 D2 362 0:15:40 D3 407 0:16:14 D4 401 0:22:15 D5 225 0:11:42 D6 351 0:17:35 D7 251 0:14:27 D8 309 0:17:00 0:00:00 0:00:04 0:00:09 0:00:13 0:00:17 0:00:22 0:00:26 0:00:30 330 490 530 544 331 425 349 420 544 349 W ak tu Jumlah Kata
D9 401 0:22:58
D10 251 0:14:40
TOTAL WAKTU 2:41:44
Gambar 8 .Grafik Waktu Tahap Stemming dan Tagging
Berdasarkan pengujian yang telah dilakukan mulai dari pengujian persentase similarity antar dokumen, pengujian persentase kemiripan laporan dengan stemming dan tanpa stemming, pengujian lama waktu pemrosesan tahap filtering dan pengujian lama waktu pemrosesan tahap stemming dan tagging, dapat disimpulkan bahwa persentase kemiripan antar laporan yang dihasilkan akan lebih tinggi jika di proses dengan melalui tahap stemming dan tagging akan tetapi waktu yang dibutuhkan akan menjadi lebih lama. Hasil persentase kemiripan antar laporan tersebut akan menunjukkan tingkat plagiarisme antar dokumen yang dibagi menjadi 5 jenis penilaian, sehingga user dapat mengetahui dokumen mana sajakah yang memiliki isi yang benar-benar berbeda, memiliki sedikit kesamaan, plagiat tingkat sedang, plagiarisme dan memiliki isi yang sama persis.
3.4. Persentase Kemiripan Laporan dengan Menghilangkan Kata yang Harus Ada
Persentase similarity yang dihasilkan dari aplikasi ini merupakan hasil dari proses perhitungan yang mengacu pada jumlah kemunculan kata dasar dari masing-masing dokumen tanpa memperhatikan kata tertentu yang selalu muncul di setiap dokumen. Hal tersebut berpengaruh terhadap output persentase similarity yang dihasilkan.
Dokumen jenis pertama yaitu portsentry memiliki beberapa kata yang selalu muncul di setiap dokumen yang tercantum pada Tabel 9
Tabel 9. Kata yang selalu Muncul pada Setiap Dokumen Portsentry
No Keyword D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 33 Aktif 5 4 4 4 3 3 2 3 4 2 63 Blokir 4 6 6 6 2 3 5 6 6 5 66 Cara 8 4 9 4 4 4 4 2 4 4 83 Deny 1 5 5 5 2 3 3 5 5 3 97 Etc 1 2 10 3 5 7 2 3 3 2 101 File 3 3 13 3 5 12 3 3 3 3 107 Guna 8 9 9 11 1 10 10 7 11 10 119 Ignore 2 2 4 2 3 5 2 2 2 2 134 Ip 4 13 8 12 3 7 8 12 12 8 162 Konfigurasi 2 7 4 7 4 3 6 7 7 6 166 Laku 9 16 10 19 12 7 10 15 19 10 194 Mode 2 4 5 6 2 2 5 6 6 5 203 Nmap 3 2 3 3 1 3 4 2 3 4 0:00:00 0:07:12 0:14:24 0:21:36 0:28:48 231 362 407 401 225 351 251 309 401 251 W ak tu Jumlah Kata
224 Port 6 13 10 14 11 10 8 7 14 8 226 Portsentry 15 22 35 27 17 28 17 24 27 17 246 Rver 2 2 1 2 1 1 2 2 2 2 261 Serang 4 18 3 19 8 2 11 12 19 11 281 Syslog 1 1 1 2 1 1 1 2 2 1 282 System 2 2 1 2 1 1 1 1 2 1 294 Tcp 2 3 9 5 4 8 2 5 5 2 297 Tdeteks 2 2 4 3 3 4 3 2 3 3 317 Untuk 12 14 10 17 7 12 11 11 17 11
Berdasarkan kata yang selalu muncul pada dokumen portsentry yang tercantum pada Tabel 9 maka proses perhitungan persentase similarity antar dokumen dikurangi dengan jumlah kemunculan masing-masing kata pada setiap dokumen. Output persentase similarity yang dihasilkan setelah dikurangi dengan kata yang selalu muncul pada setiap dokumen menjadi lebih kecil dibandingkan dengan output persentase similarity ketika semua kata dihitung. Selisih output yang dihasilkan antara keduanya berkisar antara 0% hingga 23,70%. Selisih yang dihasilkan bervariasi disebabkan oleh jumlah kemunculan kata yang dikurangi untuk menghitung persentase juga bervariasi jumlahnya. Semakin besar jumlah kemunculan kata yang dikurangi akan menyebabkan selisih yang besar. Sebaliknya, semakin kecil jumlah kemunculan kata yang dikurangi akan menyebabkan selisih yang kecil. Data persentase kemiripan laporan ini ditunjukkan pada Tabel 10
Tabel 10. Persentase Kemiripan Laporan dengan Menghilangkan Kata yang Harus Ada
Nama Dokumen Semua Kata Dihitung Kata Tertentu Dihilangkan Selisih
D1 – D2 44,6% 23,5% 21,10% D1 – D3 50,2% 36,2% 14,00% D1 – D4 44,1% 25,8% 18,30% D1 – D5 44,7% 22,5% 22,20% D1 – D6 49,5% 33,9% 15,60% D1 – D7 53,1% 29,5% 23,60% D1 – D8 46,0% 25,2% 20,80% D1 – D9 44,1% 25,8% 18,30% D1 – D10 53,1% 29,5% 23,60% D2 – D3 42,4% 20,9% 21,50% D2 – D4 91,7% 91,0% 0,70% D2 – D5 45,7% 25,3% 20,40% D2 – D6 40,2% 18,5% 21,70% D2 – D7 73,5% 65,1% 8,40% D2 – D8 83,7% 79,3% 4,40% D2 – D9 91,7% 91,0% 0,70% D2 – D10 73,5% 65,1% 8,40% D3 – D4 44,6% 22,7% 21,90% D3 – D5 51,6% 38,6% 13,00% D3 – D6 78,4% 72,1% 6,30% D3 – D7 46,8% 25,7% 21,10% D3 – D8 44,8% 22,3% 22,50% D3 – D9 44,6% 22,7% 21,90% D3 – D10 46,8% 25,7% 21,10% D4 – D5 46,1% 28,1% 18,00% D4 – D6 42,6% 20,5% 22,10% D4 – D7 74,0% 68,7% 5,30% D4 – D8 86,7% 85,5% 1,20% D4 – D9 100,0% 100,0% 0,00% D4 – D10 74,0% 68,7% 5,30% D5 – D6 46,5% 27,6% 18,90% D5 – D7 52,5% 30,5% 22,00%
D5 – D8 46,9% 25,2% 21,70% D5 – D9 46,1% 28,1% 18,00% D5 – D10 52,5% 30,5% 22,00% D6 – D7 43,9% 20,2% 23,70% D6 – D8 41,9% 19,3% 22,60% D6 – D9 42,6% 20,5% 22,10% D6 – D10 43,9% 20,2% 23,70% D7 – D8 76,6% 68,7% 7,90% D7 – D9 74,0% 68,7% 5,30% D7 – D10 100,0% 100,0% 0,00% D8 – D9 86,7% 85,5% 1,20% D8 – D10 76,6% 76,1% 0,50% D9 – D10 74,0% 68,7% 5,30%
4. Kesimpulan dan Saran
Berdasarkan hasil pengujian dan analisa yang dilakukan maka dapat diambil kesimpulan :
1. Rata-rata total waktu yang dibutuhkan untuk menyelesaikan proses pada tahap filtering untuk 10 dokumen adalah 2 menit 13 detik
2. Waktu yang dibutuhkan untuk proses pada tahap filtering bergantung pada banyaknya kata hasil tokenizing yang harus di proses karena perlu dilakukan pencocokan antara kata hasil tokenizing dengan daftar stopword dalam database
3. Rata-rata total waktu yang dibutuhkan untuk menyelesaikan proses pada tahap stemming dan tagging untuk 10 dokumen adalah 1 jam 30 menit
4. Proses stemming dan tagging membutuhkan waktu yang lama karena setiap kata hasil filtering dicocokkan dengan kamus bahasa Indonesia terlebih dahulu, jika tidak ditemukan dalam kamus, kemudian di proses untuk melakukan pengecekan terhadap possesive pronoun, suffix, dan prefix
5. Semakin banyak jumlah kata yang di proses, maka semakin lama waktu yang dibutuhkan untuk menyelesaikan proses filtering maupun proses stemming dan tagging
6. Untuk dokumen berbahasa Indonesia, proses tagging dijadikan dalam satu proses dengan stemming karena dalam bahasa Indonesia tidak terdapat kata lampau
7. Tahap analyzing dan keyword extraction memiliki output yang sama karena keduanya bertujuan untuk menghitung frekuensi kemunculan kata kunci dalam 1 dokumen
Adapun saran yang diberikan oleh penulis untuk pengembangan aplikasi pendeteksi duplikasi ini, yaitu:
1. Proses stemming dan tagging membutuhkan waktu yang lama, sehingga dibutuhkan metode maupun teknik pemrograman yang lebih baik agar proses menjadi lebih cepat
2. Input sistem tidak hanya terbatas pada file .txt
Referensi
[1] Eko Nugroho. “Perancangan Sistem Deteksi Plagiarisme Dokumen Teks dengan Menggunakan Algoritma Rabin Karp” . Program Studi Ilmu Komputer, Jurusan Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Brawijaya, Malang. 2011
[2] Sandy Dewanto, Indriati, ST, M.Kom & Imam Cholissodin, S.Si, M.Kom. “Deteksi Plagiarisme Dokumen Teks Menggunakan Algoritma Rabin-Karp dengan Synonym Recognition”. Program Studi Ilmu Komputer, Program Teknologi Informaika dan Ilmu Komputer, Universitas Brawijaya Malang
[3] I Wayan Surya Priantara, Diana Purwitasari & Umi Laili Yuhana. “Implementasi Deteksi Penjiplakan dengan Algoritma Winnowing pada Dokumen Terkelompok”. Teknik Informatika, Fakultas Teknologi Informasi, ITS
[4] Mudafiq Riyan Pratama, Eko Budi Cahyono & Gita Indah Marthasari. “Aplikasi Pendeteksi Duplikasi Dokumen Teks Bahasa Indonesia Menggunakan Algoritma Winnowing Dengan Metode K-Gram dan Synonym Recognition”. Jurusan Teknik Informatika, Universitas Muhammadiyah Malang
[5] Farid Thalib & Ratih Kusumawati. “Pembuatan Program Aplikasi untuk Pendeteksian Kemiripan Dokumen Teks dengan Algoritma Smith-Waterman”. Universitas Gunadarma.
[6] Ali Ridho Barakbah. ”Introduction to Text Mining” . Department of Information and Computer Engineering, Electronic Engineering Polytechnic Institute of Surabaya
[7] Ali Ridho Barakbah. ”Clustering” . Department of Information and Computer Engineering, Electronic Engineering Polytechnic Institute of Surabaya
[8] Raymond J. Mooney. “Text Mining” . University of Texas, Austin. 2006
[9] Mukani Nawi. “Sistem Pengukuran Tingkat Similaritas Dokumen Menggunakan Algoritma Rabin-Karp dan Enhanced Confix Stripping Stemmer”. Program Studi Teknik Informatika, Fakultas Teknik, Universitas Nusantara PGRI, Kediri
[10] Arif Prasetiya. “Penerapan Algoritma Boyer-Moore dan Algoritma Rabin-Karp dalam Mendeteksi Aksi Plagiarisme”. Program Studi Teknik Informatika, Sekolah Teknik Elektro dan Informatika, Bandung