LANDASAN TEORI
2.1 Kamus
Menurut Lauder (2005:223), “Kamus adalah sebuah karya yang berfungsi sebagai referensi. Kamus pada umumnya berupa senarai kata yang disusun secara alfabetis. Selain itu,
disertakan pula informasi mengenai ejaan, pelafalan, kelas kata, makna kata, kadang kala
sejarah kata, dan contoh pemakaian kata dalam kalimat (Widayati, 2011).
2.2 Android
Android adalah sistem operasi yang sangat populer, sistem operasi ponsel berbasis Linux yang dikembangkan oleh Google. Android adalah sebuah proyek open source. Google secara aktif mengembangkan platform Android dengan memberikan porsi secara gratis untuk produsen hardware dan operator telepon yang ingin menggunakan Android (Karch, 2016).
2.3 Sejarah Android
Perjalanan Android dimulai sejak Oktober 2003 ketika 4 orang pakar IT, Andi Rubin, Rich
Minner, Nick Sears dan Chris White mendirikan Android.Inc, di California US. Visi Android
untuk mewujudkan mobile device yang lebih peka dan mengerti pemiliknya, kemudian menarik raksasa dunia maya Google. Google kemudian mengakui sisi Android pada Agustus 2005. OS Android dibangun berbasis platform Linux yang bersifat open source, senada dengan Linux, Android juga bersifat Open Source. Dengan nama besar Google dan konsep open source pada OS Android, tidak membutuhkan waktu lama bagi android untuk bersaing dan menyisihkan
Mobile OS lainnya seperti Windos Mobile, Blackberry dan iOS. Kini siapa yang tak kenal Android yang telah menjelma menjadi penguasa Operating System bagi Smartphone (Lengkong, 2015).
2.5 Visual Basic
Visual Basic adalah salah satu bahasa pemrograman komputer. Bahasa pemrograman adalah
Bahasa pemrograman Visual Basic, yang dikembangkan oleh Microsoft sejak tahun 1991, merupakan pengembangan dari pendahulunya yaitu bahasa pemrograman BASIC (Beginner’s All-purpose Symbolic Instruction Code) yang dikembangkan pada era 1950-an. Visual Basic
merupakan salah satu Development Tool yaitu alat bantu untuk membuat berbagai macam
program komputer, khususnya yang menggunakan sistem operasi Windows. Visual Basic
merupakan salah satu bahasa pemrograman komputer yang mendukung object (Object
Oriented Programming = OOP) (Octovhiana, 2003).
2.6 Basic4Android
Basic4android adalah development tool sederhana yang powerful untuk membangun aplikasi
Android. Bahasa Basic4android mirip dengan Visual Basic dengan tambahan dukungan
untuk objek. Aplikasi Android (APK) yang dicompile oleh Basic4Android adalah aplikasi
Android native/asli dan tidak ada extra runtime seperti di Visual Basic yang ketergantungan
file msvbvm60.dll, yang pasti aplikasi yang dicompile oleh Basic4Android adalah NO
DEPENDENCIES (tidak ketergantungan file lain) (Seagrave, 2013).
2.7 Definisi Algoritma
Algoritma adalah pola pikir yang terstruktur yang berisi tahapan penyelesaian suatu
permasalahan, yang nantinya akan diimplementasikan ke dalam suatu bahasa pemograman
(Kristanto, 2003).
2.7.1 Algoritma String Matching
2.7.1.1 Pentingnya Algoritma String Matching
Pencocokan string adalah masalah klasik dalam ilmu Komputer. Pencocokan string dapat dijadikan sebagai solusi untuk banyak masalah. Misalnya dalam mendeteksi plagiat, keamanan informasi, pengenalan pola, dan pencocokan dokumen (Saikrishna, et al. 2012).
2.7.1.2 Pengertian String Matching (Pencocokan Karakter)
penting dari sebuah proses pencarian string (string searching) dalam sebuah dokumen. Hasil dari sebuah sebuah pencarian string dalam dokumen tergantung dari teknik dan cara pencocokan string yang digunakan (Buulolo, 2013).
Pencocokan string secara garis besar dapat dibedakan menjadi dua yaitu pencocokan string secara eksak/sama persis (exact string matching) dan pencocokan string berdasarkan kemiripan (inexact string matching/fuzzy string matching). Pencocokan string berdasarkan kemiripan masih dapat dibedakan menjadi dua yaitu berdasarkan kemiripan penulisan
(approximate string matching) dan berdasarkan kemiripan ucapan (phonetic string matching). Contoh phonetic string matching adalah kata step akan menunjukkan kecocokan dengan kata step, sttep, stepp, sstep, stepe, steb. Sedangkan bila kita menggunakan exact string matching kata step hanya akan menunjukkan kecocokan dengan kata step saja (Sagita & Prasetiyowati 2013).
Pada proses algoritma pencocoka string (string matching) selalu terdapat pattern, teks, dan jendela yang mana pattern adalah sejumlah string yang akan dicari dalam teks, sedangkan teks adalah urutan dari simbol yang ingin dicari untuk mendapatkan pola, dan jendela adalah teks yang selaras dengan pola (Crochemore & Hancart 1998).
Proses pencocokan antara teks dan pola tergantung pada perbandingan karakter dari
jendela teks dan pola. Panjang jendela harus sama dengan panjang dari pola ketika
melakukan perbandingan. Sebuah operasi perbandingan digunakan untuk menemukan
kecocokan antara karakter jendela, teks dan pola. Proses pergeseran adalah gerakan karakter
setelah operasi pencocokan dan akan berlanjut sampai karakter terakhir dari string teks.
Algoritma pencocokan string yang tepat dibagi menjadi lima kelompok, yang telah ditandai
2.7.2 Algoritma Colussi
Algoritma Colussi merupakan suatu pengembangan dari algoritma Knuth-Morris-Pratt. Algoritma Knuth-Morris-Pratt sendiri adalah algoritma pencocokan string dengan cara memelihara informasi karakter-karakter sebelumnya untuk melakukan jumlah pergesaran
yang lebih jauh.
Algoritma Knuth-Morris-Pratt diusulkan pada tahun 1977, perbandingan karakter dilakukan dari kiri ke kanan (Hussain, et al. 2013). Sedangkan Algoritma Colussi dipublikasikan oleh Livio Colussi pada tahun 1994 (Abdulrazzaq, et al. 2013).
Pada algoritma colussi himpunan dari posisi pola dibagi menjadi dua sub himpunan terpisah. Lalu percobaan pencocokan berlangsung selama dua fase:
• Fase pertama: Perbandingan dilakukan dari kiri ke kanan pada teks yang terletak pada posisi yang sama
• Fase kedua: Membandingkan posisi-posisi yang tersisa (dari arah kanan ke kiri) (Alapati & Mannava 2011).
Strategi ini memberikan dua kelebihan, yaitu: Ketika terjadi ketidak cocokan pada
fase pertama, maka setelah terjadi pergeseran tidak perlu untuk membandingkan teks pada
percobaan sebelumnya (Charras & Lecroq).
2.7.3 Proses pencarian Pattern menggunakan algoritma Colussi
Secara sistematis, proses yang dilakukan algoritma Colussi pada saat mencocokkan string adalah sebagai berikut :
1. Pencocokan pattern dan teks dimulai dari karakter yang pertama.
2. Proses pencocokan akan dimulai sesuai dengan nilai pada nilai h[i], jika pada nilai h[i] dimulai dari angka 1 maka proses pencocokan dimulai dari kolom indeks yang ke 1 dan selanjutnya sampai nilai h[i] yang terakhir.
3. Jika karakter pada teks dan pattern sama, maka proses pencocokan akan berlanjut pada karakter selanjutnya, namun jika karakter pada teks dan pattern tidak sama maka proses pencocokan string akan berpindah pada langkah pencarian selanjutnya.
4. Jika karakter pada teks dan pattern sama dari kiri ke kanan, dan selalu sama sampai nilai indeks yang ke m-1, maka algoritma colussi akan melakukan penccokan kembali dari kanan ke kiri, sesuai dengan nilai h[i].
Cara melakukan pergeseran dengan menggunakan algoritma Colussi adalah sebagai berikut :
Teks : DIAN SARTINI
Pattern (yang ingin dicari) : SARTINI.
Tabel yang digunakan untuk proses pergeseran:
Tabel 2.1 Tabel PreColussi
I 0 1 2 3 4 5 6 7
x[i] S A R T I N I *
hmax[i] 0 1 2 3 4 5 6 7
kmin[i] 0 1 2 3 4 5 6 0
rmin[i] 7 0 0 0 0 0 0
h[i] 1 2 3 4 5 6 0
shift[i] 1 2 3 4 5 6 7
Tanda (*) pada tabel diatas adalah untuk mewakili string selain dari string yang ada pada teks dan pattern. Cara mendapatkan angka pada tabel diatas adalah sebagai berikut :
Nilai hmax [i]
Fungsi hmax disebut juga sebagai fungsi special position, yang mana fungsi ini menjadi patokan utama untuk mencari nilai dari fungsi yang lain seperti kmin, rmin, h, dan shift. Jika nilai dari fungsi hmax berubah maka semua nilai dari kmin, rmin, h, dan shift akan berubah. Cara mendapatkan nilai hmax adalah sebagai berikut
Tabel 2.2 Proses Perhitungan hmax [i] i = k = 1
do
while (x[i] == x[i - k]) i++
hmax[k] = i q = k + 1
while (hmax[q - k] + k < i) hmax[q] = hmax[q - k] + k q++
k = q
if (k == i + 1) while (k<= m)
i = k = 1 do
while (x[1] == x[1 - 1]) i++
hmax[1] = 1 q = 1 + 1
while (hmax[2 - 1] + 1 < 1) hmax[q] = hmax[q - k] + k q++
2 = 2
i = k = 2
i = 6
Fungsi rmin adalah untuk menampung nilai special position (hmax) Cara mencari nilai rmin adalah sebagai berikut
Nilai h[i]
Fungis dari nilai h digunakan untuk melakukan pengecekan dan pencocokan data, karna proses pengecekan dan pencocokan pada algoritma Colussi bergantung dengan nilai h yang didapat. Cara mencari nilai h[i] adalah :
Nilai shift digunakan pada saat melakukan pergeseran nilai shift ditentukan menggunakan kmin [h[i]] dan rmin [h[i]]
Setelah mendapatkan hasil yang diperoleh dari tabel pergeseran maka pencocokan kata dapat
dilakukan dengan langkah-langkah berikut :
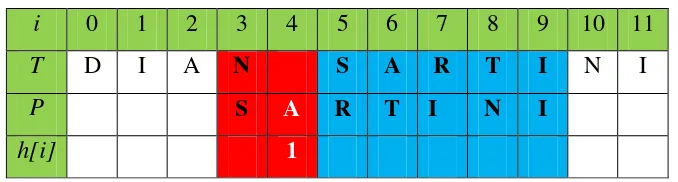
Tabel 2.7 Langkah pertama pergeseran dan pencocokan karakter i 0 1 2 3 4 5 6 7 8 9 10 11
T D I A N S A R T I N I
P S A R T I N I
h[i] 1
i = Indeks , T = Text, P = Pattern
Proses pencocokan dimulai sesuai dengan nilai h[i ] yang mana pada tabel 2.1 yang dibahas sebelumnya nilai h[i] adalah 1,2,3,4,5,6,0. Maka proses pencocokan dilakukan pada nilai h(i) ke 1 yang terdapat pada indeks ke 1
Dikarenakan pada urutan pencocokan indeks ke 1 string antara teks dan pattern berbeda, maka langkah pertama berhenti sampai indeks ke 1 yaitu antara I dan A. Pindah 1 karakter ke langkah selanjutnya, yang mana pada nilai shift, angka 1 berada
pada indeks yang ke 0, maka langkah selanjutnya : Pindah 1 karakter (shift[0]).
Tabel 2.8 Langkah kedua pergeseran dan pencocokan karakter i 0 1 2 3 4 5 6 7 8 9 10 11
T D I A N S A R T I N I
P S A R T I N I
h[i] 1 2
Pergeseran dimulai dari karakter selanjutnya yaitu antara I dan S, dan pencocokan
dilakukan sesuai dengan nilai h[i] yaitu 1,2,3,4,5,6,0 yang mana pada tabel diatas ditunjukkan antara karakter A dan A, dikarenakan A dan A “SAMA” maka lanjut ke nilai h[i] selanjutnya yaitu pada karakter N dan R, dikarenakan N dan R adalah karakter yang berbeda, maka langkah kedua telah selesai.
Tabel 2.9 Langkah ketiga pergeseran dan pencocokan karakter i 0 1 2 3 4 5 6 7 8 9 10 11
T D I A N S A R T I N I
P S A R T I N I
h[i] 1
Dikarenakan pencocokan pada tabel diatas karakter antara teks dan pattern berbeda, maka langkah ketiga berhenti di spasi dan karakter A
Pindah 1 karakter ke langkah selanjutnya, yang mana pada nilai shift, angka 1 berada pada indeks yang ke 0, maka langkah selanjutnya : Pindah 1 karakter (shift[0]).
Tabel 2.10 Langkah keempat pergeseran dan pencocokan karakter i 0 1 2 3 4 5 6 7 8 9 10 11
T D I A N S A R T I N I
P S A R T I N I
h[i] 1
Dikarenakan pencocokan pada tabel diatas karakter antara teks dan pattern berbeda, maka langkah keempat berhenti di karakter S dan A
Pindah 1 karakter ke langkah selanjutnya, yang mana pada nilai shift, angka 1 berada pada indeks yang ke 0, maka langkah selanjutnya : Pindah 1 karakter (shift[0])
Tabel 2.11 Langkah kelima pergeseran dan pencocokan karakter i 0 1 2 3 4 5 6 7 8 9 10 11
T D I A N S A R T I N I
P S A R T I N I
h[i] 7 1 2 3 4 5 6
Jika dilihat pada tabel 2.18 atau langkah kelima pattern telah ditemukan.
Pencocokan dimulai dari nilai h[i] yang pertama yaitu 1 pada tabel diatas nilai h[i] ke 1 terdapat di karakter antara A dan A, jika sama maka lanjut ke karakter selanjutnya
belum ditemukan maka algoritma colussi melakukkan pencarian kembali yaitu dari kanan ke kiri yang dicontohkan pada tabel diatas yaitu karakter S dan S dengan posisi
h[i] yang terakhir yaitu 0
Oleh karna itu proses pencocokan karakter menggunakan algoritma Colussi telah
selesai dan berhenti pada langkah kelima. Dan berikut adalah pseudocode algoritma Colussi pada tahap pencarian.
Procedure ColussiSerach(
input m,n : integer,
input P : array[0..n-1] of char, input T : array[0..n-1] of char, output ketemu : array[0..n-1] of boolean )
Deklarasi :
i, j, nd, last : integer
h : array[0..n] of integer
shift : array[0..n] of integer
next : array[0..n] of integer
Algoritma :
i := j := 0 last := -1
while (j <= n - m) do
while (i < m and last < j + h[i] and x[h[i]] == y[j + h[i]])
i++
if (i >= m || last >= j + h[i]) { ketemu(j)
i = m }
if (i > nd)
last := j + m - 1 j := shift[i]
![Tabel 2.2 Proses Perhitungan hmax [i]](https://thumb-ap.123doks.com/thumbv2/123dok/2040624.1194476/5.595.74.529.543.707/tabel-proses-perhitungan-hmax-i.webp)
![Tabel 2.3 Proses Perhitungan kmin [i]](https://thumb-ap.123doks.com/thumbv2/123dok/2040624.1194476/6.595.71.530.70.563/tabel-proses-perhitungan-kmin-i.webp)
![Tabel 2.4 Proses Perhitungan rmin [i]](https://thumb-ap.123doks.com/thumbv2/123dok/2040624.1194476/7.595.72.532.71.262/tabel-proses-perhitungan-rmin-i.webp)
![Tabel 2.6 Proses perhitungan nilai shift[i]](https://thumb-ap.123doks.com/thumbv2/123dok/2040624.1194476/8.595.75.530.168.488/tabel-proses-perhitungan-nilai-shift-i.webp)