Perancangan dan Implementasi Intrusion Detection
System dengan Algoritma Data Mining Instance Based
Learning
Artikel Ilmiah
Peneliti :
Ari Santoso(672009307) Irwan Sembiring, ST., M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
Perancangan dan Implementasi Intrusion Detection
System dengan Algoritma Data Mining Instance Based
Learning
Artikel Ilmiah
Diajukan kepada
Fakultas Teknologi Informasi
untuk memperoleh gelar Sarjana Komputer
Peneliti :
Ari Santoso(672009307) Irwan Sembiring, ST., M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
Perancangan dan Implementasi Intrusion Detection System
dengan Algoritma Data Mining Instance Based Learning
1) Ari Santoso,2)Irwan Sembiring
Fakultas Teknologi Informasi Universitas Kristen Satya Wacana Jl. Diponegoro 52-60, Salatiga 50711, Indonesia Email: 1)[email protected], 2)[email protected]
Abstract
Secure communications is challenging due to the increasing threat of widespread and carried out attacks on the security of the network. Knowledge of the various threats and attacks were obtained from very large data from the network, by using data mining tools. Based on the knowledge gained from the mining process, it can be used to identify network security threats based on behavior patterns that exist in the network. an Intrusion Detection System can be built by using data mining algorithms Instance Based Learning. In this study produced an application that uses Intrusion Detection System IBL algorithm to learning and detecting attacks. The resulting conclusion is IBL algorithms can be implemented in the IDS, with the speed of detection process 0.050381 seconds / record.
Keywords: Intrusion Detection System, Instance Based Learning, Data Mining
Abstrak
Mengamankan komunikasi adalah tantangan luas karena meningkatnya ancaman dan serangan yang dilakukan pada keamanan jaringan. Pengetahuan tentang berbagai ancaman dan serangan tersebut diperoleh dari data yang sangat besar dari jaringan, dengan menggunakan data mining tools. Berdasarkan pengetahuan yang diperoleh dari proses mining, maka dapat digunakan untuk mengidentifikasi gangguan keamanan jaringan berdasarkan pola tingkah laku yang ada di jaringan. sebuah Intrusion Detection System dapat dibangun dengan menggunakan algoritma data mining Instance Based Learning. Pada penelitian ini dihasilkan sebuah aplikasi Intrusion Detection System yang menggunakan algoritma IBL untuk mempelajari dan mendeteksi serangan. Kesimpulan yang dihasilkan adalah algoritma IBL dapat diimplementasikan dalam IDS, dengan kecepatan proses deteksi 0.050381 detik/record.
Kata Kunci: Intrusion Detection System, Instance Based Learning, Data Mining
1)Mahasiswa Program Studi Teknik Informatika, Fakultas Teknologi Informasi, Universitas Kristen Satya Wacana
1
1. Pendahuluan
Pada era digital saat ini, tidak bisa dibayangkan dunia tanpa komunikasi. Manusia memiliki kepentingan untuk bertukar informasi untuk berbagai tujuan. Mengamankan komunikasi adalah tantangan luas karena meningkatnya ancaman dan serangan yang dilakukan pada keamanan jaringan.
Ancaman keamanan jaringan dikategorikan ke beberapa jenis. Kebocoran (leakage), merupakan jenis ancaman yang merupakan akses ilegal terhadap informasi yang ada di jaringan. Pengubahan (tampering), merupakan jenis ancaman yang berarti mengubah informasi tanpa ijin dari menyedia informasi. Pengerusakan (vandalism), adalah jenis ancaman yang merusak kondisi normal suatu jaringan, sehingga mengakibatkan malfunction.
Selain ancaman, terdapat juga serangan terhadap keamanan jaringan.
Eavesdropping, merupakan tindakan mengumpulkan salinan informasi tanpa ijin.
Masquerading, merupakan tindakan membuat percakapan menggunakan identitas pihak lain, tanpa seijin pemilik identitas. Message Tampering, merupakan tindakan mengubah isi informasi ketika informasi dilewatkan pada media komunikasi. Man-in-the-middle attack, adalah tindakan ikut campur terhadap pesan, dimana seorang penyerang mengubah pesan awal dalam pertukaran kunci terenkripsi untuk membangun saluran komunikasi yang aman. Pengetahuan tentang berbagai serangan tersebut diperoleh dari data yang sangat besar dari jaringan, dengan menggunakan data mining tools. Berdasarkan pengetahuan yang diperoleh dari proses mining, maka dapat digunakan untuk mengidentifikasi gangguan keamanan jaringan berdasarkan pola tingkah laku yang ada di jaringan.
Ancaman dan serangan terhadap keamanan jaringan tersebut dapat dideteksi dengan suatu Intrusion Detection System (IDS). Untuk mengenali pola serangan, maka digunakan data instance. Pembelajaran data instance tersebut dapat dicapai dengan menggunakan algoritma data mining Instance Based Learning (IBL). Pada penelitian ini, dikembangkan sebuah, berbasis supervised learning dan teknik prediksi, menggunakan algoritma data mining Instance Based Learning (IBL). Sistem yang dikembangkan merupakan suatu aplikasi desktop untuk sistem operasi Windows.
2. Tinjauan Pustaka
Penelitian tentang keamanan jaringan salah satunya adalah "Rancang Bangun dan Implementasi Keamanan Jaringan Komputer Menggunakan Metode Intrusion Detection System (IDS) pada SMP Islam Terpadu PAPB"[1]. Penelitian tersebut membahas tentang IDS, untuk mendeteksi serangan dari penyusup baik dari luar atau dalam jaringan komputer sehingga mempermudah seorang admin dalam melakukan penanganan, dengan demikian akan tercipta keamanan jaringan yang lebih optimal.
2
Naive-Bayes, C4.5, dan Instance Based Learning. Hasil penelitian menunjukkan bahwa algoritma Instance Based Learning memiliki tingkat akurasi paling tinggi, dan waktu pembelajaran yang paling cepat.
Penelitian berjudul "A Novel Intrusion Detection System by using Intelligent Data Mining in Weka Environment" [3], membahas tentang pendekatan IDS dengan pengembangan lebih lanjut menggunakan intelligent data mining.
IDS yang dikembangkan merupakan kombinasi antara data mining dengan sistem pakar, dan disajikan dan diimplementasikan dengan software WEKA. Berdasarkan evaluasi dari desain yang dikembangkan, memberikan hasil yang lebih baik dalam hal efisiensi deteksi dan false alarm dari masalah yang ada sebelumnya.
Penelitian berjudul "A K-Means and Naive Bayes learning approach for better intrusion detection"[4], diimplementasikan sebuah IDS dengan dua pendekatan pembelajaran, yaitu K-Means dan Naive Bayes (KMNB).K-Means digunakan untuk mengidentifikasi kelompok sample data yang memiliki perilaku yang mirip dan tidak mirip.Naive Bayes digunakan pada tahap kedua untuk mengklasifikasikan semua data ke dalam kategori yang tepat.Hasil penelitian menunjukkan bahwa KMNB secara signifikan meningkatkan akurasi deteksi.
Penelitian yang membahas tentang Instance-Based Learning, salah satunya adalah "Cyber Situation Awareness: Modeling Detection Of Cyber Attacks with Instance-Based Learning Theory"[5]. Penelitian tersebut digunakan IBL untuk mempelajari pola serangan (cyber attacks) yang beragam.
Berdasarkan penelitian-penelitian yang telah dilakukan tentang IDS dan
data mining, maka dilakukan penelitian untuk pengembangan sebuah Intrusion Detection System (IDS), berbasis supervised learning dan teknik prediksi, menggunakan algorima data mining IBL. Rumusan masalah dalam penelitian ini adalah bagaimana merancang dan mengimplementasikan Intrusion Detection System dengan menggunakan Instance Based Learning. Tujuan dari penelitian yang dilakukan adalah untuk bagaimana merancang suatu IDS berbasis supervised learning dan teknik prediksi, menggunakan algorima data mining Instance Based Learning. Manfaat dari penelitian ini adalah untuk menghasilkan sebuah aplikasi desktop untuk mengamankan komunikasi jaringan komputer, lebih spesifiknya untuk mendeteksi ancaman dan serangan pada jaringan computer. Untuk mencapai tujuan yang telah dirumuskan, maka dalam perancangan dan pengembangan sistem, diberikan batasan masalah sebagai berikut: (1) Teknik pembelajaran sistem yang digunakan adalah supervised-learning; (2) Algoritma yang digunakan Instance Based Learning; (3) Aplikasi yang dikembangkan berfungsi untuk mendeteksi, bukan untuk mencegah; (4) Aplikasi diimplementasikan pada sistem operasi Windows, untuk pengguna komputer pribadi (PC).
Model komputer tunggal yang melayani seluruh tugas-tugas komputasi telah diganti dengan sekumpulan komputer berjumlah banyak yang terpisah-pisah tetapi tetapi saling berhubungan dalam melaksankan tugasnya, sistem tersebut yang disebut dengan jaringan komputer (computernetwork) [6].
3
memonitor kejadian pada jaringan komputer dan menganalisis masalah keamanan jaringan [7]. IDS bekerja pada lapisan jaringan OSI model dan sensor jaringan pasif yang secara khusus diposisikan pada choke point pada jaringan metode dari lapisan OSI. Jenis-jenis IDS adalah: (1) NetworkInstrusion Detection System
(NIDS) Memantau Anomali di jaringan dan mampu mendeteksi seluruh host yang berada satu jaringan dengan host implementasi IDS (Intrusion Detection System) tersebut. NIDS (Network Instrusion Detection System) pada umumnya bekerja dilayer 2 pada OSI layer, IDS (Intrusion Detection System) menggunakan “raw
traffic” dari proses sniffing kemudian mencocokkannya dengan signature yang telah ada dalam policy. Jika terdapat kecocokan antara signature dengan raw traffic hasil sniffing paket, IDS (Intrusion Detection System) memberikan allert atau peringgatan sebagai tanda adanya proses intrusi ke dalam sistem. NIDS (Network Instrusion Detection System) yang cukup banyak dipakai adalah snort karena signature yang customizable, sehingga setiap vulnerability baru ditemukan dapat dengan mudah ditambahkan agar jika terjadi usaha punyusupan atau intrusion dari intruder akan segera terdeteksi; (2) Host Instrusion Detection System (HIDS) Mamantau anomali di host dan hanya mampu mendeteksi pada
host tempat implementasi IDS (Intrusion Detection System) tersebut. HIDS (Host Instrusion Detection System) biasanya berupa tools yang mendeteksi anomali di sebuah host seperti perubahan file password dengan penambahan user ber UID 0, perubahan loadable kernel, perubahan ini script, dan gangguan bersifat anomali lainnya.
Instance Based Learning menggunakan prinsip Nearest Neighbour untuk membangun model prediksi.Dalam pendekatan ini, jarak antara contoh pelatihan dan uji contoh yang diberikan dihitung dengan ukuran jarak Euclidean. Jika lebih dari satu contoh memiliki jarak terkecil ke instance tes, digunakan contoh yang pertama ditemukan. Tetangga terdekat adalah salah satu algoritma pembelajaran yang paling signifikan, dapat disesuaikan untuk memecahkan masalah yang lebih luas [8]. Biarkan dataset D memiliki contoh X (X1, X2, X3 ... Xn) dan F fitur (F1, F2, F3, ... Fm) dengan label kelas Cj dimana j = 1,2 ... K. Algoritma ini meranking nilai jarak tetangga untuk memprediksi data yang berlabel X dengan label kelas. Ukuran jarak Euclidean digunakan untuk menghitung berat tetangga dari X. Dengan cara ini, data baru diprediksi oleh voting berat, untuk menghitung jarak tetangga terdekat dari kelas tertentu, untuk memprediksi data yang tidak diketahui. [9,10] .
Menurut Mitchell [11] keuntungan dari IBL adalah:
4
Salah satu metode IBL yang paling umum adalah K-Nearest Neighbour.Algoritma K-Nearest Neighbour (k-NN atau KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut.
K-Nearest Neighbour berdasarkan konsep 'learning by analogy'.Data learning dideskripsikan dengan atribut numerik n-dimensi.Tiap data learning merepresentasikan sebuah titik, yang ditandai dengan c, dalam ruang n-dimensi. Jika sebuah data query yang labelnya tidak diketahui diinputkan, maka K- Nearest Neighbor akan mencari K buah data learning yang jaraknya paling dekat dengan data query dalam ruang n-dimensi. Jarak antara data query dengan data learning dihitung dengan cara mengukur jarak antara titik yang merepresentasikan data query dengan semua titik yang merepresentasikan data learning dengan rumus Euclidean Distance.
Pada fase training, algoritma ini hanya melakukan penyimpanan vektor- vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur - fitur yang sama dihitung untuk testing data (klasifikasinya belum diketahui). Jarak dari vektor yang baru ini terhadap seluruh vektor training sample dihitung, dan sejumlah K buah yang paling dekat diambil.Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik - titik tersebut.
Nilai K yang terbaik untuk algoritma ini tergantung pada data; secara umumnya, nilai K yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi lebih kabur. Nilai K yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation.Kasus khusus di mana klasifikasi diprediksikan berdasarkan data pembelajaran yang paling dekat (dengan kata lain, K = 1) disebut algoritma nearest neighbor.
Ketepatan algoritma k-NN ini sangat dipengaruhi oleh ada atau tidaknya fitur-fitur yang tidak relevan, atau jika bobot fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi.Riset terhadap algoritma ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur, agar performa klasifikasi menjadi lebih baik.
K buah data learning terdekat akan melakukan voting untuk menentukan label mayoritas. Label data query akan ditentukan berdasarkan label mayoritas dan jika ada lebih dari satu label mayoritas maka label data query dapat dipilih secara acak di antara label-label mayoritas yang ada.
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Patut diingat bahwa kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu data mining
5
dan penemuan ilmiah. Telah digunakan selama bertahun-tahun oleh bisnis, ilmuwan dan pemerintah untuk menyaring volume data seperti catatan perjalanan penumpang penerbangan, data sensus dan supermarket scanner data untuk menghasilkan laporan riset pasar[2].
Alasan utama untuk menggunakan data mining adalah untuk membantu dalam analisis koleksi pengamatan perilaku.Data tersebut rentan terhadap collinearity karena diketahui keterkaitan. Fakta yang tak terelakkan data mining
adalah bahwa subset/set data yang dianalisis mungkin tidak mewakili seluruh domain, dan karenanya tidak boleh berisi contoh-contoh hubungan kritis tertentu dan perilaku yang ada di bagian lain dari domain .Untuk mengatasi masalah semacam ini, analisis dapat ditambah menggunakan berbasis percobaan dan pendekatan lain, seperti Choice Modelling untuk data yang dihasilkan manusia. Dalam situasi ini, yang melekat dapat berupa korelasi dikontrol untuk, atau dihapus sama sekali, selama konstruksi desain eksperimental.
Beberapa teknik yang sering disebut-sebut dalam literatur data mining
dalam penerapannya antara lain: clustering, classification, association rule mining, neural network, genetic algorithm dan lain-lain. Hal yang membedakan persepsi terhadap data mining adalah perkembangan teknik-teknik data mining
untuk aplikasi pada database skala besar. Sebelum populernya data mining, teknik-teknik tersebut hanya dapat dipakai untuk data skala kecil saja.
Data mining adalah kegiatan mengekstraksi atau menambang pengetahuan dari data yang berukuran/berjumlah besar, informasi inilah yang nantinya sangat berguna untuk pengembangan.Langkah-langkah untuk melakukan data mining
adalah sebagai berikut [12]:
6
1. Data cleaning (untuk menghilangkan noise data yang tidak konsisten)dan data integration (di mana sumber data yang terpecah dapat disatukan)
2. Data selection (di mana data yang relevan dengan tugas analisis dikembalikan ke dalam database)
3. Data transformation (di mana data berubah atau bersatu menjadi bentuk yang tepat untuk menambang dengan ringkasan performa atau operasi agresi)
4. Data mining (proses esensial di mana metode yang intelejen digunakan untuk mengekstrak pola data)
5. Pattern evolution (untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan atas beberapa tindakan yang menarik)
6. Knowledge presentation (di mana gambaran teknik visualisasi dan pengetahuan digunakan untuk memberikan pengetahuan yang telah ditambang kepada user).
Learning mempunyai arti menambah pengetahuan, memahami atau menguasai dengan belajar, mengikuti instruksi atau melalui pengalaman. Machine learning adalah sebuah studi yang mempelajari cara untuk memprogram sebuah komputer untuk belajar. Ada 4 kategori besar dimana sebuah aplikasi sulit untuk dibuat. Pertama, bila tidak ada manusia yang menguasai bidang tersebut. Kedua, bila ada manusia yang menguasai hal tersebut namun tidak mampu untuk menjelaskannya. Ketiga, adalah saat keadaan dapat berubah dengan cepat. Keempat, bila aplikasi harus dibuat berbeda untuk masing- masing pengguna. Seorang manusia selama hidupnya tidak pernah henti- hentinya melakukan learning. Hal ini terjadi tanpa disadari dan alamiah. Namun untuk membuat sebuah mesin dapat berpikir tentu bukanlah hal yang mudah. Manusia belajar melalui pengalaman yang dialami sehari-hari. Dari pengalaman tersebut, manusia akan mendapatkan knowledge. Untuk mendapatkan knowledge dapat melalui berbagai cara. Cara yang paling sederhana adalah rote learning atau menyimpan informasi yang sudah dikalkulasi. Cara lainnya adalah dengan mendapatkan pengetahuan dari orang lain yang sudah ahli. Manusia juga dapat belajar melalui pengalaman pemecahan masalah yang ia lakukan. Setelah berhasil mengatasi sebuah masalah, manusia akan mengingat struktur dan cara mengatasi masalah tersebut. Apabila manusia mengalami sebuah masalah yang hampir serupa, maka manusia dapat mengatasi masalah tersebut secara lebih efisien.
Dalam teknik supervised learning, maka sebuah program harus dapat membuat klasifikasi – klasifikasi dari contoh- contoh yang telah diberikan. Misalnya sebuah program diberikan benda berupa bangku dan meja, maka setelah beberapa contoh, program tersebut harus dapat memilah- milah objek ke dalam klasifikasi yang cocok.
7
training set juga digunakan test set. Dari situ akan diukur persentase keberhasilannya. Semakin tinggi berarti semakin baik program tersebut.
Persentase tersebut dapat ditingkatkan dengan diketahuinya temporal dependence dari sebuah data. Misalnya diketahui bahwa 70% mahasiswa dari jurusan Teknik Informatika adalah laki- laki dan 80% mahasiswa dari jurusan Sastra adalah wanita. Maka program tersebut akan dapat mengklasifikasi dengan lebih baik.
Misalkan akan dibuat suatu program komputer yang ketika diberi gambar seseorang, dapat menentukan apakah orang dalam gambar tersebut pria atau wanita. Program yang dibuat tersebut adalah yang disebut sebagai classifier, karena program tersebut berusaha menetapkan kelas (yaitu pria atau wanita) ke sebuah objek (gambar). Tugas supervised learning adalah untuk membangun sebuah classifier dengan memberikan sekumpulan contoh training yang sudah diklasifikasi (pada kasus ini, contohnya adalah gambar yang telah dimasukkan ke kelas yang tepat). Tantangan utama pada supervised learning adalah generalisasi: Setelah menganalisa beberapa contoh gambar, supervised learning harus menghasilkan suatu classifier yang dapat digunakan dengan baik pada semua gambar. Pasangan objek, dan kelas yang menunjuk pada objek tersebut adalah suatu contoh yang telah diberi label. Himpunan contoh yang telah diberi label akan menghasilkan suatu algoritma pembelajaran yang disebut training set. Misalkan kita menyediakan suatu trainingset kepada algoritma pembelajaran, dan algoritma tersebut menghasilkan output yang berupa classifier. Solusi yang umumnya digunakan untuk mengukur classifier adalah dengan menggunakan himpunan contoh berlabel yang lain yang disebut sebagai test set. Persentase contoh dapat diukur apakah telah diklasifikasi dengan benar atau persentase contoh yang mengalami kesalahan klasifikasi. Pendekatan yang dilakukan untuk menghitung persentase mengasumsikan bahwa setiap klasifikasi adalah independen, dan setiap klasifikasi sama pentingnya. Asumsi ini sering sekali dilupakan.
8
positive. Supervised learning tidak hanya mempelajari classifier, tetapi juga mempelajari fungsi yang dapat memprediksi suatu nilai numerik. Contoh: ketika diberi foto seseorang, kita ingin memprediksi umur, tinggi, dan berat orang yang ada pada foto tersebut. Tugas ini sering disebut sebagai regresi. Pada kasus ini, setiap contoh training yang terlah diberi label berisi sebuah objek, dan nilai yang dimilikinya. Kualitas dari fungsi prediksi biasanya diukur sebagai kuadrat perbedaan nilai perkiraan.
3. Metode dan Perancangan Sistem
Penelitian yang dilakukan, diselesaikan melalui tahapan penelitian yang terbagi dalam empat tahapan, yaitu: (1) Analisis kebutuhan dan pengumpulan data, (2) Perancangan sistem, (3) Implementasi sistem yaitu Perancangan aplikasi/program, dan (4) Pengujian sistem serta analisis hasil pengujian.
Analisis Kebutuhan dan Pengumpulan Data
Perancangan Sistem meliputi Perancangan Proses, dan
Perancangan Antarmuka
Implementasi dan Pengujian Sistem, serta Analisis Hasil Pengujian
Penulisan Laporan Hasil Penelitian
Gambar 2 Tahapan Penelitian
Tahapan penelitian pada Gambar 2, dapat dijelaskan sebagai berikut. Tahap pertama: yaitu melakukan analisis kebutuhan-kebutuhan user dalam proses pengiriman gambar; Tahap kedua: yaitu melakukan perancangan sistem yang meliputi perancangan database, perancangan antarmuka yakni sebagai media penghubung interaksi antara user dan sistem; Tahap ketiga: yaitu mengimplementasikan rancangan yang telah dibuat di tahap dua ke dalam sebuah aplikasi/program sesuai kebutuhan sistem; Tahap keempat: yaitu melakukan pengujian terhadap sistem yang telah dibuat, serta menganalisis hasil pengujian tersebut, untuk melihat apakah aplikasi yang telah dibuat sudah sesuai dengan yang diharapkan atau tidak, jika belum sesuai maka akan dilakukan perbaikan.
9
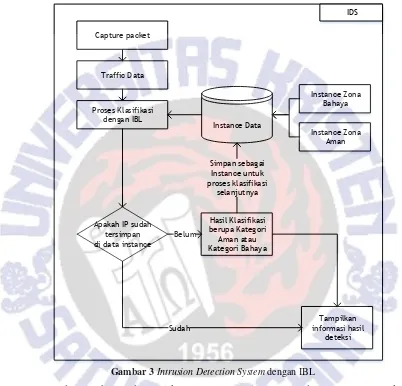
IBS yang dikembangkan memiliki rancangan ditunjukkan pada Gambar 3.Input sistem berupa data instance dan data traffic jaringan. Output sistem berupa kesimpulan hasil deteksi yaitu masuk Zona Aman atau Zona Bahaya.Output
sistem digunakan sebagai input untuk proses selanjutnya.
Traffic Data
Gambar 3 Intrusion Detection System dengan IBL
Pada Gambar 3 ditampilkan rancangan sistem IDS dengan menggunakan algoritma data mining IBL. Traffic data diperoleh dengan cara melakukan capture TCP Packet. Traffic data kemudian menjadi input untuk proses IBL. IBL juga membaca instance data yang tersimpan sebagai input. Hasil dari proses IBL masuk ke dalam rule, untuk dikenali apakah suatu traffic data masuk ke dalam kategori Zona Aman atau Zona Bahaya. KA berarti jumlah data pada Zona Aman, KB berarti jumlah data pada Zona Bahaya
Proses deteksi diawali dengan proses pembelajaran rule deteksi zona aman dan zona bahaya, yaitu dengan menggunakan instancedata sebagai traning data. Berdasarkan instance tersebut, dibentuk (construct) aturan untuk deteksi.
10
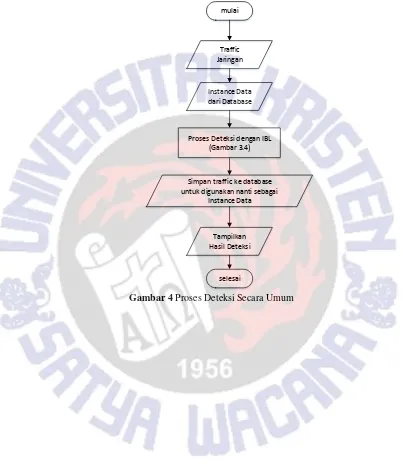
komputer atau sebaliknya. Berdasarkan data instance yang tersimpan di database, dilakukan proses deteksi dengan aturan yang terbentuk oleh IBL. Hasil deteksi akan disimpan ke database untuk digunakan kembali sebagai data instance.
Proses Deteksi dengan IBL (Gambar 3.4)
mulai
selesai Traffic Jaringan
Instance Data dari Database
Tampilkan Hasil Deteksi Simpan traffic ke database untuk digunakan nanti sebagai
Instance Data
11
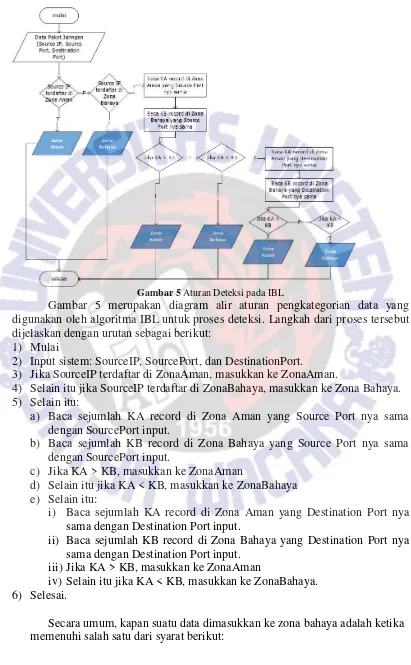
Gambar 5 Aturan Deteksi pada IBL
Gambar 5 merupakan diagram alir aturan pengkategorian data yang digunakan oleh algoritma IBL untuk proses deteksi. Langkah dari proses tersebut dijelaskan dengan urutan sebagai berikut:
1) Mulai
2) Input sistem: SourceIP, SourcePort, dan DestinationPort.
3) Jika SourceIP terdaftar di ZonaAman, masukkan ke ZonaAman.
4) Selain itu jika SourceIP terdaftar di ZonaBahaya, masukkan ke Zona Bahaya. 5) Selain itu:
a) Baca sejumlah KA record di Zona Aman yang Source Port nya sama dengan SourcePort input.
b) Baca sejumlah KB record di Zona Bahaya yang Source Port nya sama dengan SourcePort input.
c) Jika KA > KB, masukkan ke ZonaAman
d) Selain itu jika KA < KB, masukkan ke ZonaBahaya e) Selain itu:
i) Baca sejumlah KA record di Zona Aman yang Destination Port nya sama dengan Destination Port input.
ii) Baca sejumlah KB record di Zona Bahaya yang Destination Port nya sama dengan Destination Port input.
iii) Jika KA > KB, masukkan ke ZonaAman
iv) Selain itu jika KA < KB, masukkan ke ZonaBahaya. 6) Selesai.
12
1) Source IP termasuk dalam daftar zona bahaya. 2) Destination IP termasuk dalam daftar zona bahaya.
3) Source Port yang digunakan, juga digunakan minimal 5 data di zona bahaya. 4) Destination Port yang digunakan, juga digunakan minimal 5 data di zona
bahaya.
Sedangkan suatu data dimasukkan ke zona aman adalah ketika memenuhi salah satu dari syarat berikut:
1) Source IP termasuk dalam daftar zona aman. 2) Destination IP termasuk dalam daftar zona aman.
3) Source Port yang digunakan, juga digunakan minimal 5 data di zona aman. 4) Destination Port yang digunakan, juga digunakan minimal 5 data di zona aman.
Jika suatu data tidak memenuhi salah satu dari 8 syarat-syarat deteksi tersebut, maka akan masuk ke dalam zona warning (zona intruder). Jika data tersebut terdeteksi sebanyak 5 kalinya, maka akan otomatis dimasukkan ke daftar zona bahaya.
IDS yang dikembangkan, memiliki beberapa aturan-aturan deteksi.Desain ini ditunjukkan pada Gambar 6.
Gambar 6 Desain Sistem
13
4. Hasil dan Pembahasan
Pada bagian ini dijelaskan tentang hasil penelitian yang telah dilakukan. Pembahasan terbagi pada pembahasan hasil implementasi sistem dan pembahasan pengujian sistem.
Sistem diimplementasikan dalam bentuk aplikasi desktop. Teknologi yang digunakan adalah .Net Framework 4.5 dengan bahasa pemrograman C#. Database yang digunakan untuk menyimpan log traffic jaringan adalah SQLite. SQLite dipilih karena kelebihan dalam hal mudah dipindahkan ke komputer lain, tanpa perlu melakukan instalasi database server. Spesifikasi software dan hardware yang digunakan untuk proses pembuatan dan pengujian sistem ditunjukkan pada Tabel 1.
Tabel 1 Spesifikasi Software dan Hardware untuk Pembuatan dan Pengujian Sistem
No. Perangkat Spesifikasi
Hardware
1. Prosesor Intel Pentium Core i3 1.8 GHz Cache 3MB
2. RAM 4 GB DDR3
3. Kecepatan Harddisk 5400 RPM
Software
1. Integrated Development Tool - perangkat untuk membuat/menulis program
Visual Studio 2012 Express for Desktop. .NetFramework 4.5
2. Database SQLite 3
Gambar 7 Tampilan Utama Aplikasi IDS
14
ke dalam kategori bahaya. Zona Aman menampilkan daftar end point yang masuk ke dalam kategori aman. Jika suatu data tidak termasuk ke dalam Zona Aman atau Bahaya maka akan masuk ke dalam zona warning (zona intruder). Jika data tersebut terdeteksi untuk 5 kalinya, maka akan otomatis dimasukkan ke daftar zona bahaya.
Aturan deteksi dijelaskan dengan urutan sebagai berikut: 1) Input: SourceIP, SourcePort, dan DestinationPort.
2) IFSourceIP terdaftar di ZonaAman, masukkan ke ZonaAman.
3) ELSE IF SourceIP terdaftar di ZonaBahaya, masukkan ke Zona Bahaya. 4) ELSE:
d) ELSE IF KA < KB, masukkan ke ZonaBahaya e) ELSE:
iv) ELSE IF KA < KB, masukkan ke ZonaBahaya. .
Kode Program 1 Perintah Deteksi menggunakan IBL
1. class IBLearning
7. .Where(x => x.SourcePort == log.SourcePort);
8. var destPortZona = neighbour
9. .Where(x => x.DestinationPort
10. == log.DestinationPort);
11. var s = Analyze(log, sourcePortZona);
12. var d = Analyze(log, destPortZona);
13.
14. if (s.Jumlah > d.Jumlah)
15. {
16. return s.Zona;
17. }
18. else if (d.Jumlah > s.Jumlah)
15
29. TrafficLog log, IEnumerable<TrafficLog> neighbour)
30. {
31. NeighbourCount[] n = new NeighbourCount[3];
32.
52. .Where(x => x.Size > 1).Count();
53. n[2] = new NeighbourCount()
Kode Program 1 merupakan class implementasi algoritma IBL berdasarkan rancangan flowchart pada Gambar 4.
Pengujian dilakukan dengan tujuan untuk memastikan bahwa sistem yang dikembangkan telah melakukan proses deteksi dengan tepat sesuai rancangan. Pengujian dilakukan dengan memasukkan data uji traffic ke dalam aplikasi, dan mencatat hasil deteksi dan waktu respon. Hasil pengujian ditunjukkan pada Tabel 2. Hasil pencatatan waktu proses ditunjukkan pada Tabel 3.
Tabel 2 Hasil Pengujian Deteksi
No Source IP Source
3. 134.170.104.32 443 77 Source Port termasuk sebagian besar
data di Zona Aman
4. 124.160.124.32 443 67 Source Port termasuk sebagian besar
16
9. 118.98.36.102 443 77 Source Port termasuk sebagian besar
data di Zona Bahaya
10. 118.98.36.95 443 67 Source Port termasuk sebagian besar
data di Zona Bahaya
11. 107.22.245.143 5228 63382 Destination Port termasuk sebagian besar data di Zona Bahaya
12. 74.125.68.188 5228 63382 Destination Port termasuk sebagian besar data di Zona Bahaya
Tabel 3 Hasil Pencatatan Lama Waktu Proses Deteksi
No Ukuran Instance dikembangkan telah berhasil melakukan proses deteksi sesuai dengan aturan IBL. Kecepatan proses akan semakin besar ketika ukuran data instance yaitu Zona Aman dan Zona Bahaya. Lama waktu proses baca tulis instance dipengarui oleh perfoma komputer dan database server.
5. Simpulan
Berdasarkan penelitian, pengujian dan analisis terhadap sistem, maka dapat diambil kesimpulan sebagai berikut: (1) Suatu IDS berbasis supervised learning dan teknik prediksi, dapat diimplementasikan dengan menggunakan algorima data mining IBL; (2) Berdasarkan hasil pengujian aplikasi IDS yang dikembangkan telah berhasil melakukan proses deteksi sesuai dengan aturan IBL; (3) Kecepatan proses akan semakin besar ketika ukuran data instance yaitu Zona Aman dan Zona Bahaya. Lama waktu proses baca tulis instance dipengarui oleh perfoma komputer dan database server. Rata-rata waktu proses deteksi berdasarkan hasil pengujian adalah 0.050381 detik/record.
Saran yang dapat diberikan untuk penelitian lebih lanjut adalah sebagai berikut: Selain dapat mendeteksi, sistem dapat diarahkan untuk dapat mencegah
traffic data yang dikategorikan bahaya.
6. Daftar Pustaka
17
SMP Islam Terpadu PAPB. Fakultas Teknologi Informasi dan Komunikasi Universitas Semarang
[2]. Singh, G., Antony, D. A. & Leavline, E. J. 2013. Data Mining In Network Security - Techniques & Tools: A Research Perspective. Journal of
Theoretical & Applied Information Technology 57.
[3]. Mohammad, M. N., Sulaiman, N. & Muhsin, O. A. 2011. A novel Intrusion Detection System by using intelligent data mining in WEKA environment. In Procedia Computer Science, pp. 1237–
1242.(doi:10.1016/j.procs.2010.12.198)
[4]. Muda, Z., Yassin, W., Sulaiman, M. N., Udzir, N. I. & others 2011. A K-Means and Naive Bayes learning approach for better intrusion detection. Information technology journal 10, 648–655.
[5]. Dutt, V., Ahn, Y.-S. & Gonzalez, C. 2013. Cyber situation awareness: modeling detection of cyber attacks with instance-based learning theory.
Human factors 55, 605–18. (doi:10.1177/0018720812464045)
[6]. Sugeng, W. 2010. Jaringan Komputer dengan TCP/IP. Modula, Bandung [7]. Ariyus, D. 2007. Intrusion Detection System Sistem Pendeteksi Penyusup
Pada Jaringan Komputer. Andi, Yogyakarta
[8]. Kuramochi, M. & Karypis, G. 2005. Gene classification using expression profiles: a feasibility study. International Journal on Artificial Intelligence Tools 14, 641–660.
[9]. Singh, D. A. A. G., Balamurugan, S. A. A. & Leavline, E. J. 2012. Towards higher accuracy in supervised learning and dimensionality reduction by attribute subset selection-A pragmatic analysis. In Advanced
Communication Control and Computing Technologies (ICACCCT), 2012 IEEE International Conference on, pp. 125–130.
[10]. Singh, A. G., Asir, D., Leavline, E. J. & others 2012. An empirical study on dimensionality reduction and improvement of classification accuracy using feature subset selection and ranking. In Emerging Trends in Science, Engineering and Technology (INCOSET), 2012 International Conference on, pp. 102–108.
[11]. Mitchell, T. M. 1997. Machine Learning. (doi:10.1145/242224.242229) [12]. Van Der Aalst, W. 2012. Process mining: Overview and opportunities.
ACM Transactions on Management Information Systems (TMIS) 3, 7. [13]. Bleeping Computer 2014. Public Block Lists of Malicious IPs and URLs.
http://www.selectrealsecurity.com/public-block-lists. Diakses pada 3 September 2014
[14]. Internet Storm Center 2014. Suspicious Domains.
![Gambar 1 Langkah-langkah data mining[12]](https://thumb-ap.123doks.com/thumbv2/123dok/4017136.1960556/15.595.100.503.400.720/gambar-langkah-langkah-data-mining.webp)