Fakultas Ilmu Komputer
Universitas Brawijaya
53
Identifikasi Kesalahan Penulisan Kata (
Typographical Error
) pada
Dokumen Berbahasa Indonesia Menggunakan Metode N-gram dan
Levenshtein Distance
Arina Indana Fahma1, Imam Cholissodin2, Rizal Setya Perdana3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1arinafahmaa@gmail.com, 2imamcs@ub.ac.id, 3rizalespe@ub.ac.id
Abstrak
Teks merupakan salah satu media komunikasi dan sumber informasi dalam kehidupan manusia. Hal yang menjadi krusial dalam pembuatan teks adalah kesalahan dalam penulisan kata yang disebut typographical error. Kesalahan tersebut terjadi saat menggunakan keyboard pada komputer atau pada smartphone. Typographical error pada teks dapat mengakibatkan sesuatu yang tidak diinginkan oleh pihak tertentu. Berdasarkan hal tersebut, diperlukan suatu sistem untuk melakukan identifikasi typographical error pada teks dan melakukan proses koreksi terhadap typographical error. Metode N-gram dan Levenshtein Distance dapat digunakan untuk melakukan koreksi typographical error di dalam dokumen. Penelitian ini berfokus pada data dokumen skripsi mahasiswa Fakultas Ilmu Komputer Universitas Brawijaya. Metode Levenshtein Distance digunakan untuk mendeteksi banyaknya kandidat kata sesuai dengan typographical error yang sudah teridentifikasi. Dikarenakan kandidat kata hasil dari Levenshtein Distance masih belum terurut, metode N-gram digunakan untuk mengurutkan kandidat kata berdasarkan nilai cosine similarity. Di dalam penelitian ini, nilai N pada N-gram yang digunakan adalah 2 sehingga pada prosesnya, N-gram melakukan pemisahan setiap dua karakter pada kata yang teridentifikasi sebagai typographicalerror beserta kandidat katanya. Setelah karakter dipisah, perhitungan tf-idf digunakan untuk mendapatkan nilai cosine similarity. Dari hasil pengujian sistem, didapatkan nilai presisi terbaik sebesar 0.97 pada uji coba typographical error jenis insertion dan untuk nilai recall terbaik sebesar 1 yang didapatkan dari hasil uji coba typographical error jenis substitution.
Kata kunci: typographical error, levenshtein distance, n-gram, cosine similarity
Abstract
Text is one of communication and information media in human life. The crucial thing in text writing is a mistake in word writing called typographical error. The error occurs while using the keyboard on computer or on smartphone. Typographical error on a text can lead to something unpredictable for some people. Based on that reason, a system is needed to identify typographical error in a text and also make the correction of the error word. N-gram and Levenshtein Distance method can be used for correcting typographical error in the text. For detecting how many word candidates of typographical error, Levenshtein Distance can be implemented. Because the word candidates are unsorted, N-gram method is using to sort those word candidates based on the value of cosine similarity. In this research, the reason N-gram method using N=2 is to separated each two characters of identified typographical error and its word candidates.The value of cosine similarity calculated by tf-idf when the process of N-gram was done. The result of test scenario, the best value of precision is 0.97 from insertion type and the best value of recall is 1 from substitution type.
Keywords: typographical error, levenshtein distance, n-gram, cosine similarity
1. PENDAHULUAN
Teks merupakan salah satu komponen dalam kehidupan manusia yang terdiri dari wacana (berarti lisan) yang dijadikan dalam
untuk berkomunikasi di sekolah, kantor, kehidupan sehari-hari dan sebagainya. Pentingnya penggunaan bahasa Indonesia tidak selaras dengan ketersediaan language tool untuk penelitian yang berkaitan dengan bahasa Indonesia, karena jumlah tool yang sudah ada masih terbatas (Wicaksono dan Purwarianti, 2010).
Salah satu hal krusial dalam pembuatan dokumen maupun teks adalah kesalahan penulisan atau yang disebut dengan typographical error. Pada pembuatan dokumen dalam penelitian terutama skripsi atau tugas akhir, typographical error terjadi karena belum pahamnya mahasiswa dalam pembuatan dokumen dengan bahasa Indonesia yang baku dan sesuai dengan kaidah EYD. Faktor lain dalam terjadinya typographical error adalah pada saat proses pemilihan kata karena kata yang digunakan harus tepat dan menggunakan bahasa yang baku sehingga dapat dimengerti oleh pembaca. Selain itu, mengutip bacaan sekaligus menyatukan dengan ide dari mahasiswa itu sendiri bukan hal yang mudah.
Terdapat beberapa jenis typographical error yaitu insertion, deletion serta substitution. Dalam mendeteksi typographical error pada teks dibutuhkan suatu aplikasi disebut spelling checker. Spelling checker melakukan proses pengecekan terhadap pengejaan kata-kata untuk mendeteksi adanya kata yang mengalami kesalahan ejaan dan juga memberikan suggestion berupa kata-kata kandidat (Soleh dan Purwarianti, 2011).
Berbagai macam metode yang ada sesuai untuk membangun suatu sistem identifikasi typographical error pada teks seperti N-gram, Hidden Markov Model (HMM), Forward-Reversed Dictionary, Morphologically Analyzer, Bayes, Maximum Likelihood Estimation, Minimum Edit Distance, Similarity Key, Rule Based, Probabilistic dan Neural Network. Penelitian untuk pembuatan spelling correction tool menggunakan metode N-gram dengan beberapa macam pendekatan menghasilkan akurasi yang bagus. Hasil yang lebih unggul didapatkan dari nilai N sebesar 2, yang disebut dengan bigram, daripada dengan penggunaan N sebesar 3 (trigram). Penggunaan data uji berupa dataset bahasa Inggris menghasilkan akurasi sebesar 84% untuk bigram dan 73% untuk trigram (Ahmed, Luca dan Nürnberger, 2009). Selain itu terdapat penelitian menggunakan metode Levenshtein Distance dengan pendekatan yang lebih baik
yaitu penambahan metode Dictionary Lookup (Haldar dan Mukhopadhyay, 2011). Penggunaan dua metode pada data numerik tulisan tangan dengan sistem OCR ini menghasilkan fakta bahwa OCR yang tersedia tidak mampu mengenali 93 dari 500 data uji setelah proses pengolahan data melalui SVM. Selain itu, metode Levenshtein Distance akan mengurangi jumlah kata yang tidak dikenali oleh sistem OCR.
Dengan beberapa alasan di atas, maka dibuat sebuah sistem untuk identifikasi typographical error untuk teks berbahasa Indonesia menggunakan metode Levenshtein Distance. Metode Levenshtein Distance digunakan untuk menentukan kandidat kata untuk setiap typographical error yang teridentifikasi oleh sistem. Pada penelitian ini dikembangkan dengan penggunaan metode N-gram yang digunakan untuk menghitung nilai cosine similarity dalam menentukan ranking kandidat kata sebagai hasil keluaran dari sistem. Diharapkan sistem ini dapat membantu memberikan gambaran yang cukup baik terhadap koreksi error pada dokumen teks berbahasa Indonesia berdasarkan hasil pada sistem tersebut.
2. DASAR TEORI
2.1Teks
Dalam teori bahasa, apa yang dinamakan teks tidak lebih dari himpunan huruf yang membentuk kata dan kalimat, dirangkai dengan sistem tanda yang disepakati oleh masyarakat sehingga sebuah teks ketika dibaca bisa mengungkapkan makna yang dikandungnya (Riadi, 2015).
Menurut Loreta Auvil dan Duane Searsmith (Susanto, 2009), beberapa karakteristik dokumen teks adalah sebagai berikut:
1. Database teks berukuran besar
2. Memiliki dimensi yang tinggi yaitu satu kata merepresentasikan satu dimensi 3. Banyak mengandung kata atau arti yang
bias (mengandung ambiguitas)
4. Mengandung kumpulan kata yang saling terkait (frase) dan antara kumpulan kata satu dengan yang lain dapat memiliki arti yang berbeda
istilah slang seperti “r u there?”, “helllooo bosss, whatzzzzzzz up?”, dan sebagainya. Hal diatas terkait dengan objek penelitian ini yang membutuhkan dokumen dengan struktur bahasa yang baku. Dokumen skripsi merupakan salah satu dokumen teks yang memiliki struktur bahasa yang baku dan dapat digunakan dalam penelitian ini. Penggunaan dokumen skripsi sebagai data penelitian berpengaruh terhadap hasil output pada sistem. 2.2Typographical Error
Typographical error merupakan kesalahan yang terjadi pada saat proses mengetik teks dan dapat mengubah arti dari suatu kata bahkan arti dari suatu kalimat. Istilah ini mencakup kesalahan karena kegagalan mekanis atau slip tangan atau jari, dan juga timbul akibat ketidaktahuan penulis seperti kesalahan ejaan. Typographical error dapat disebabkan oleh,
misalnya, jari menekan dua
tombol keyboard yang berdekatan secara bersamaan.
Typographical error ini bervariasi mulai dari kesalahan ketik biasa sampai kesalahan dalam tatanan bahasa yang digunakan atau bahkan pengertian dari kata tersebut. Kesalahan-kesalahan tersebut dikategorikan ke dalam 2 jenis yaitu non-word error dan real-word error. Non-word error adalah error yang tidak terdapat makna didalamnya sedangkan pada real-word error, kata yang tertulis bernilai benar atau bisa disebut mempunyai arti dalam kamus namun tidak dimaksudkan dalam kalimat tersebut maupun mempunyai arti yang berbeda dan bahkan kalimat tersebut memiliki tata bahasa yang salah (Naradhipa et al., 2011). 2.3 Text Mining
Text Mining atau sering disebut Pemrosesan Teks merupakan salah satu bidang pengetahuan pada Artificial Intelligence yang menerapkan konsep dan teknik data mining untuk mencari pola dalam teks dengan proses ekstraksi pola yang berupa informasi dan pengetahuan berguna dari sejumlah besar sumber data yang tidak terstruktur. Dalam text mining dilakukan penambangan data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang memberikan penjelasan isi dari dokumen sehingga dapat dilakukan analisa keterkaitan antar dokumen (Baskoro, 2016).
Berdasarkan ketidakteraturan struktur data
teks, maka proses text mining memerlukan beberapa tahap awal yang pada intinya adalah mempersiapkan agar teks dapat diubah menjadi lebih terstruktur. Menurut ketidakaturan struktur data dalam teks, maka proses text mining membutuhkan tahapan-tahapan awal agar teks berubah menjadi data yang lebih terstruktur. Salah satu tahapan tersebut adalah preprocessing yang meliputi case folding, tokenizing, filtering dan stemming. Pada tahapan ini, sistem melakukan seleksi data yang diproses pada setiap dokumen yang ada.
Penggunaan huruf kapital pada dokumen tidak selalu konsisten, maka diperlukan proses case folding. Proses ini akan mengubah seluruh teks pada dokumen menjadi bentuk standar yaitu huruf kecil atau lowercase. Karakter
selain huruf ‘a’ hingga ‘z’ dianggap sebagai
delimiter sehingga karakter tersebut
dihilangkan. Setelah dilakukan proses case folding, dilakukan proses tokenizing/tokenisasi atau parsing. Pada proses ini, dilakukan pemotongan string input berdasarkan tiap kata penyusun dari dokumen. Hasil dari preprocessing teks adalah daftar kata yang terdapat dalam dokumen uji, dengan penghapusan tanda baca, karakter dan kata-kata dalam istilah asing.
2.4Information Retrieval
Information Retrieval (IR) merupakan pencarian material (berupa dokumen) yang bersifat tidak terstruktur (biasanya berupa teks) dimana memenuhi kebutuhan informasi user dalam koleksi data yang besar dan disimpan dalam beberapa komputer. IR adalah bidang pada persimpangan ilmu informasi dan ilmu komputer yang dikaitkan dengan aktivitas dimana beberapa pekerjaan yang berhubungan dengan teks seperti customer service, reference libraries, paralegal dan searcher profesional, namun seiring berjalannya waktu berjuta-juta manusia memanfaatkan IR setiap hari ketika mengakses website search engine atau mencari email. IR juga dapat mengatasi permasalahan data dan informasi serta berkutat dengan pengindeksan dan pengambilan informasi dari sumber informasi heterogen dan tekstual (Manning, Raghavan dan Schütze, 2009).
merumuskan suatu request atau query yang memiliki jawaban yaitu himpunan dokumen yang memuat informasi mengenai ekspresi yang diperlukan melalui pertanyaan user. User bisa mendapatkan dokumen yang diperlukan dengan membaca semua dokumen dalam tempat penyimpanan, menyimpan dokumen-dokumen yang berkaitan dan membuang dokumen yang tidak diperlukan.
2.5Spelling Checker
Deteksi error dalam kata dapat dilakukan dengan aplikasi berbasis komputer yang digunakan untuk mendeteksi dan menangani error dalam kata yang disebut spelling checker. Spelling checker mencari segala jenis error yang terdapat dalam dokumen yang kemudian memberi peringatan penulis dokumen tentang kesalahan yang dilakukan dan memberi beberapa suggestion untuk memperbaiki kesalahan tersebut. Terdapat dua metode utama yang digunakan untuk membangun aplikasi spelling checker yaitu identifikasi (error detection) dan koreksi (error correction). Selain itu, spelling checker dibagi menjadi dua tipe yaitu non-word error spell checker dan real-word spell checker. Non-word error spell checker menangani kata-kata salah ejaan yang terbentuk karena kesalahan ketik, sedangkan real-word error spell checker mengutamakan menangani kata-kata pengganti kata yang error pada kalimat (Soleh dan Purwarianti, 2011).
Dalam membuat spelling checker, terdapat beberapa tantangan yaitu dalam menemukan kata yang merupakan error dan memberikan suggestion berupa kata yang benar untuk menggantikan kata error tersebut. Pada error yang bersifat non-word, proses pengecekan huruf yang berlebih dan pengejaan kata akan berulang terus akan membuat infinite list untuk dicek satu persatu. Sedangkan pada error yang bersifat real-word, permasalahan terjadi pada proses pengenalan grammar atau tata bahasa pada setiap kalimat. Termasuk ambiguitas dan kata yang tidak terdapat pada dictionary atau yang biasa disebut Out of Vocabulary (OOV). Dan lagi, dalam dunia ini kamus bahasa akan terus berkembang dan bertambah seiring berjalannya waktu dan akan membuat OOV akan terus terjadi secara statis (Naradhipa et al., 2011).
2.6Metode N-gram
Ide penggunaan N-gram telah diterapkan untuk berbagai masalah seperti prediksi kata,
koreksi ejaan, pengenalan suara, koreksi kata terjemahan dan pencarian string. Salah satu keuntungan dari metode N-gram ini adalah bahwa bahasa bersifat independen. Dalam koreksi ejaan, N-gram merupakan urutan sebanyak N huruf dalam sebuah kata atau string. N-gram dapat digunakan untuk menghitung kesamaan antara dua string dengan cara menghitung jumlah N-gram yang sama. Semakin banyak jumlah N-gram yang sama antara 2 kalimat yang ada maka semakin mirip (Ahmed, Luca dan Nürnberger, 2009).
2.7Term Frequency-Inverse Document Frequency (tf-idf)
Metode pembobotan atau pemberian ranking yang digunakan dalam penelitian ini adalah Term Frequency-Inverse Document Frequency (tf-idf). Perhitungan tf-idf merupakan suatu cara yang digunakan untuk memberikan bobot terhadap relevansi antara suatu kata terhadap dokumen dengan menggabungkan dua konsep dalam perhitungan bobot yaitu frekuensi munculnya kata dalam dokumen serta inverse frekuensi dokumen yang mengandung kata tersebut (Lahitani, Permanasari dan Setiawan, 2016). Adapun rumus tf-idf seperti pada Persamaan 1, Persamaan 2 dan Persamaan 3 sebagai berikut:
idf
Wij = bobot kata/term terhadap dokumen
tfij = jumlah kemunculan kata
idf = jumlah dokumen dimana term muncul N = jumlah semua dokumen yang
dibandingkan
n = jumlah dokumen yang mengandung term
2.8Cosine Similarity
sebagai pengukur kesamaan antara query dengan setiap dokumen yang ada pada database. Dari perhitungan ini, dihasilkan tingkat kesamaan pada dokumen yang sesuai dengan query yang diinputkan.
Cosine similarity merupakan rumus yang digunakan untuk menghitung kesamaan atau similarity dengan menentukan sudut antara vektor dokumen dengan vektor query dalam dimensi V pada bidang Euclidean. Hasil dari cosine similarity memiliki nilai antara 0 sampai dengan 1. Nilai 0 merupakan nilai yang didapat apabila dokumen tidak berhubungan dengan query, sedangan nilai 1 berarti dokumen memiliki keterhubungan tinggi dengan query (Lahitani, Permanasari dan Setiawan, 2016). Berikut rumus cosine similarity seperti pada Persamaan 4 berikut:
2.9Metode Levenshtein Distance
Pada teori informasi dan ilmu komputer, Levenshtein Distance merupakan matriks untuk mengukur nilai jumlah perbedaan antara 2 string yaitu string sumber (s) dan string target (t). Nilai Levenshtein Distance antara dua kata merupakan nilai minimum dari pengeditan single-character (yaitu insertion, deletion maupun substitution) membutuhkan perubahan pada salah satu kata.
Levenshtein Distance antara dua string ditentukan berdasarkan jumlah minimum pengeditan yang diperlukan untuk melakukan transformasi dari satu bentuk string ke bentuk string yang lain. Notasi yang digunakan untuk Levenshtein Distance adalah 𝐿𝐷(𝑠, 𝑡) dengan s yaitu sumber dan t adalah target. Misalnya, jika source string (s) adalah “tihun” dan target string (t) dalah “tahun” maka nilai Levenshtein Distance adalah 1, dalam hal ini berarti dibutuhkan sebuah operasi yaitu substitution untuk mengubah source string (s) menjadi sama dengan target string (t).
Operasi dilakukan dengan cara menukar posisi karakter yang berdekatan dan menemukan kata yang sama dalam dictionary (Naradhipa et al., 2011). Secara matematis, Levenshtein Distance antara dua string, misal
string sumber
a
dan string targetb
(panjanga dan b ) dengan leva,b
a,b
pada indeks i dan j dimana telah dijelaskan pada Persamaan 5 berikut:2.10Presisi dan Recall
Kinerja sistem information retrieval dievaluasi dari metode standar yaitu presisi, recall dan F-measure (kombinasi presisi dan recall). Recall menghitung jumlah informasi relevan yang diekstraksi pada sistem. Sedangkan presisi, menghitung jumlah informasi bernilai benar/akurat yang dikembalikan oleh sistem (Mishra dan Vishwakarma, 2016).
Nilai pada recall dan presisi saling bertolakbelakang satu sama lain, pada saat presisi bernilai tinggi, recall bernilai rendah (Butt, 2013). Nilai recall tertinggi dan optimal adalah 1, yang artinya seluruh teks dalam sistem berhasil ditemukan pada dokumen. Pada saat nilai 1 pada presisi, berarti seluruh teks yang ditemukan bersifat relevan. Formula untuk perhitungan presisi dan recall dijabarkan pada Persamaan 6 dan Persamaan 7:
𝑅𝑒𝑐𝑎𝑙𝑙 =𝑻𝒐𝒕𝒂𝒍 𝒋𝒂𝒘𝒂𝒃𝒂𝒏 𝒓𝒆𝒍𝒆𝒗𝒂𝒏 𝒅𝒂𝒍𝒂𝒎 𝒕𝒆𝒌𝒔𝑱𝒖𝒎𝒍𝒂𝒉 𝒋𝒂𝒘𝒂𝒃𝒂𝒏 𝒓𝒆𝒍𝒆𝒗𝒂𝒏 𝒔𝒊𝒔𝒕𝒆𝒎 (6)
𝑃𝑟𝑒𝑠𝑖𝑠𝑖 =𝑱𝒖𝒎𝒍𝒂𝒉 𝒋𝒂𝒘𝒂𝒃𝒂𝒏 𝒓𝒆𝒍𝒆𝒗𝒂𝒏 𝒔𝒊𝒔𝒕𝒆𝒎𝑻𝒐𝒕𝒂𝒍 𝒋𝒂𝒘𝒂𝒃𝒂𝒏 𝒑𝒂𝒅𝒂 𝒔𝒊𝒔𝒕𝒆𝒎 (7)
3. ALUR PENYELESAIAN MASALAH
Sistem memiliki alur untuk proses identifikasi dan koreksi typographical error. Alur proses identifikasi dan koreksi menjelaskan gambaran sekumpulan langkah dalam proses identifikasi typographical error serta memberikan daftar kandidat kata yang sesuai dengan kata typographical error berdasarkan ranking kandidat kata. Proses dilakukan menggunakan metode pendekatan Dictionary Lookup, metode Levenshtein
Distance dan metode N-gram berbasis
perhitungan cosine similarity.
Gambar 1. Alur Identifikasi dan Koreksi
Typographical Error
Berdasarkan Gambar 1, proses pertama dalam sistem adalah pemberian data input berupa dokumen skripsi dalam format .txt. Dalam memproses sebuah data yang tidak terstruktur, dibutuhkan tahapan preprocessing untuk mengubah data menjadi terstruktur. Preprocessing dalam sistem ini terdiri dari tokenisasi, case folding dan filtering. Setelah preprocessing selesai, typographical error diidentifikasi dengan menggunakan metode Dictionary Lookup. Kata yang teridentifikasi sebagai typographical error kemudian dilakukan proses koreksi menggunakan metode
Levenshtein Distance. Perhitungan nilai edit distance dilakukan dalam mencari nilai yang paling minimum untuk mendapatkan daftar kandidat kata pada kamus sesuai dengan kata typographical error. Penentuan ranking kandidat kata dilakukan menggunakan metode N-gram berbasis perhitungan cosine similarity. Hasil ranking kandidat kata menjadi hasil output pada sistem.
4. PENGUJIAN DAN ANALISIS
4.1Pengujian Seluruh Jenis Typographical
Error Berdasarkan Jumlah Dokumen
Jenis typographical error yang digunakan dalam pengujian adalah insertion (penambahan huruf), deletion (penghilangan huruf) dan substitution (penggantian huruf). Dokumen skripsi yang menjadi data uji pada sistem ini berjumlah 5 dokumen dengan jumlah kata
typographical error dan jenis kata
typographical error yang berbeda. Presisi dan recall digunakan di dalam pengujian ini. Hasil pengujian presisi dan recall untuk proses koreksi sesuai dengan seluruh jenis typographical error berdasarkan jumlah dokumen ditunjukkan pada Gambar 2.
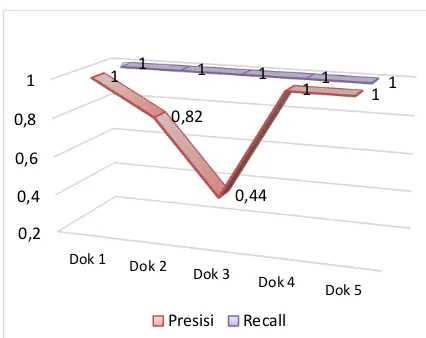
Gambar 2. Grafik Pengujian Seluruh Jenis
Typographical Error BerdasarkanJumlah Dokumen
Berdasarkan Gambar 2, dapat disimpulkan bahwa pengujian untuk recall terhadap 5 dokumen bernilai konsisten pada nilai 1. Nilai recall dapat mencapai nilai optimal 1 karena semua kata typographical error memiliki kandidat kata yang benar sehingga dapat diketahui bahwa semua kata typographical error memiliki nilai aktual. Sedangkan untuk nilai presisi menurun pada dokumen 2 dan pada dokumen 3 namun kembali meningkat pada
0,2 0,4 0,6 0,8 1
Dok 1
Dok 2 Dok 3 Dok 4
Dok 5
1
0,82
0,44
1 1
1 1
1 1 1
dokumen 4. Hal ini terjadi karena jumlah kata typographical error bervariasi pada setiap dokumen. Kata typographical error yang teridentifikasi pada dokumen 1, 4 dan 5 berjumlah lebih sedikit daripada jumlah kata typographical error pada dokumen 2 dan 3. Dokumen 1 memiliki kata yang teridentifikasi sebagai kata typographical error sejumlah 2 kata, dokumen 2 memiliki 5 kata typographical error, dokumen 3 berjumlah 4 kata typographical error, dokumen 4 berjumlah 2 kata typographical error dan dokumen 5 berjumlah 1 kata typographical error. Dari keberagaman jumlah kata typographical error, dapat diketahui alasan nilai presisi mengalami penurunan dan kenaikan.
4.2Pengujian Seluruh Jenis Typographical
Error Berdasarkan Jumlah Kata
Typographical Error dalam Satu
Dokumen
Pengujian ini dilakukan sebanyak 10 kali percobaan dengan jumlah kata typographical error yang dijumlahkan sebanyak 5 kata pada setiap percobaan. Dokumen mengandung jenis kata typographical error yang berbeda untuk setiap percobaan. Perhitungan nilai Hasil pengujian presisi dan recall untuk seluruh jenis typographical error berdasarkan jumlah kata typographical error dalam satu dokumen ditunjukkan pada Gambar 3.
Gambar 3. Grafik Pengujian Seluruh Jenis
Typographical Error Berdasarkan Jumlah Kata
Typographical Error dalam Satu Dokumen
Dari Gambar 3, dapat diambil kesimpulan pengujian dengan jenis typographical error berbeda pada satu dokumen menghasilkan nilai recall yang baik yaitu 1 serta nilai presisi yang
cenderung stabil. Nilai recall konsisten dan optimal pada setiap percobaan, sedangkan berbeda hal dengan nilai presisi yang mengalami penurunan dan kenaikan. Hasil kandidat kata memiliki pengaruh besar terhadap nilai presisi sistem, karena perhitungan nilai presisi membutuhkan jumlah kandidat kata pada hasil output sistem. Seperti halnya pengujian sebelumnya, hasil kandidat kata pada sistem tidak hanya didapatkan sesuai nilai aktual tapi didapatkan juga kandidat kata lain dari kamus dengan nilai edit distance yang paling minimum.
4.3Pengujian Jenis Typographical Error
Insertion Berdasarkan Jumlah Kata
Typographical Error dalam Satu
Dokumen
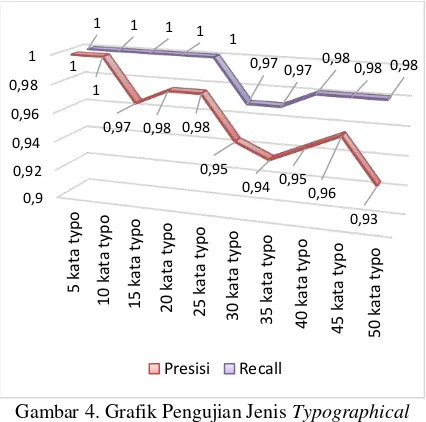
Pengujian berdasarkan perhitungan presisi dan recall dilakukan untuk mengetahui pengaruh typographical error dengan jenis insertion pada kata terhadap nilai presisi dan recall sistem. Jenis kata typographical error insertion merupakan jenis kata typographical error dimana kata mengalami penambahan huruf sehingga menjadi kata yang tidak dikenali dalam kamus yang digunakan. Pengujian jenis typographical error insertion berdasarkan jumlah kata typographical error dalam satu dokumen ditunjukkan pada Gambar 4.
Gambar 4. Grafik Pengujian Jenis Typographical
Error Insertion Berdasarkan Jumlah Kata
Typographical Error dalam Satu Dokumen
Dari grafik pengujian pada Gambar 4, dapat diketahui bahwa jenis kata typographical error insertion pada setiap percobaan menghasilkan nilai presisi dan recall yang cenderung stabil pada beberapa percobaan. Nilai presisi dan
0,7
0,97 0,97 0,980,98 0,98
recall mengalami penurunan dan kenaikan dipengaruhi oleh tidak adanya kandidat kata yang dihasilkan sistem terhadap kata yang teridentifikasi kata typographical error. Selain itu, nilai presisi juga dipengaruhi jumlah kandidat kata yang dihasilkan pada hasil output sistem pada masing-masing kata typographical error. Pengujian ini dapat diambil kesimpulan bahwa sistem dapat mengidentifikasi dengan baik dan memberikan hasil output sistem berupa kandidat kata terhadap kata typographical error jenis insertion.
4.4Pengujian Jenis Typographical Error
Deletion Berdasarkan Jumlah Kata
Typographical Error dalam Satu
Dokumen
Pengujian presisi dan recall dilakukan untuk mengetahui pengaruh typographical error dengan jenis deletion pada kata terhadap nilai presisi dan recall sistem. Jenis kata typographical error deletion merupakan jenis kata typographical error dimana kata mengalami penghilangan huruf sehingga menjadi kata yang tidak dikenali dalam kamus. Pengujian jenis typographical error deletion berdasarkan jumlah kata typographical error dalam satu dokumen ditunjukkan pada Gambar 5.
Gambar 5. Grafik Pengujian Jenis Typographical
ErrorDeletion Berdasarkan Jumlah Kata
Typographical Error dalam Satu Dokumen
Dari Gambar 5, dapat diambil kesimpulan bahwa jenis kata typographical error deletion pada satu dokumen setiap percobaan menghasilkan nilai recall yang rendah pada awal percobaan namun meningkat dan cenderung stabil hingga percobaan 50 kata
typographical error. Begitu halnya dengan nilai presisi yang mengalami kenaikan konsisten setelah awal percobaan. Nilai presisi dan recall pada awal percobaan rendah dikarenakan terdapat kata typographical error tidak memiliki kandidat kata sehingga presisi dan recall bernilai 0. Selain itu, beberapa kata typographical error merupakan kata yang ada dalam kamus namun bukan kata yang dimaksud oleh user sehingga sistem tidak menampilkan kandidat kata. Untuk mengidentifikasi jenis typographical error deletion, sistem memiliki nilai presisi dan recall yang rendah pada sistem. 4.5Pengujian Jenis Typographical Error Substitution Berdasarkan Jumlah Kata
Typographical Error dalam Satu
Dokumen
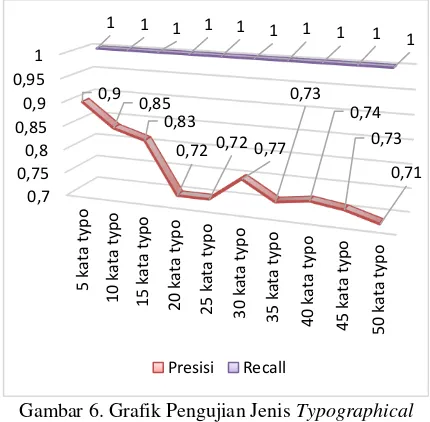
Jenis kata typographical error substitution merupakan jenis kata typographical error dimana kata mengalami pergantian huruf dari kata yang sebenarnya sehingga menjadi kata yang tidak dikenali dalam kamus. Pengujian presisi dan recall dilakukan untuk mengetahui pengaruh typographical error dengan jenis substitution pada kata terhadap nilai presisi dan recall sistem. Pengujian berdasarkan jumlah kata typographical error dalam satu dokumen ditunjukkan pada Gambar 6.
Gambar 6. Grafik Pengujian Jenis Typographical
ErrorSubstitution Berdasarkan Jumlah Kata
Typographical Error dalam Satu Dokumen
Dari Gambar 6, dapat diambil kesimpulan bahwa jenis kata typographical error substitution pada satu dokumen menghasilkan nilai recall yang optimal yaitu 1 namun untuk nilai presisi mengalami penurunan dan kenaikan. Hal tersebut dikarenakan hasil
kandidat kata pada sistem tidak hanya didapatkan sesuai nilai aktual, tapi didapatkan juga kandidat kata lain dari kamus dengan nilai edit distance yang paling minimum. Kandidat kata yang ditampilkan sistem berjumlah banyak sehingga mempengaruhi perhitungan nilai presisi. Untuk mengidentifikasi jenis typographical error substitution, sistem memiliki nilai recall yang optimal dan konsisten pada setiap percobaan serta nilai presisi yang cenderung stabil pada sistem.
5. KESIMPULAN
Berdasarkan hasil pengujian dan analisis pada identifikasi typographical error pada dokumen bahasa Indonesia menggunakan metode N-gram dan Levenshtein Distance dapat diambil kesimpulan bahwa metode pendekatan Dictionary Lookup pada proses identifikasi typographical error pada dokumen bahasa Indonesia dapat diterapkan dengan baik untuk mencari kata typographical error dalam dokumen data input. Untuk menentukan kandidat kata, metode Levenshtein Distance dapat menghasilkan kandidat kata yang sesuai dengan nilai aktual yang diharapkan user. Namun untuk kata typographical error tertentu, jumlah kandidat kata yang ditampilkan dalam sistem terlalu banyak. Hasil presisi dan recall pada penelitian ini memiliki nilai yang beragam pada setiap skenario pengujian. Nilai presisi terbaik yang dihasilkan sistem sebesar 0.97 pada skenario pengujian typographical error jenis insertion. Sementara itu, nilai recall terbaik yang dihasilkan sistem sebesar 1 pada skenario pengujian typographical error jenis substitution.
Untuk penelitian serupa selanjutnya, sistem dapat dikembangkan pada proses identifikasi typographical error menggunakan kamus Bahasa Indonesia yang lebih lengkap dan terdapat istilah-istilah dalam dunia pendidikan, terutama metode-metode yang digunakan dalam penelitian. Nilai N pada metode N-gram dapat dikembangkan dengan nilai N bersifat dinamis sesuai dengan kebutuhan user untuk mendapatkan penentuan ranking yang lebih baik. Sistem dapat dikembangkan dengan metode yang digunakan untuk dapat mendeteksi istilah lain selain katakata dalam kamus seperti nama orang, nama tempat, nama metode serta istilah-istilah lain.
Keterkaitan kata dalam satu kalimat dapat juga diperhatikan dalam penelitian selanjutnya,
karena dalam penelitian ini hanya berupa identifikasi kata berdasarkan kata-kata dalam kamus atau dapat disebut dengan non-word error. Selain itu, sebaiknya dilakukan pengujian terhadap urutan/ranking pada kandidat kata yang diperoleh dari proses perhitungan cosine similarity pada metode N-gram. Pengujian dilakukan dengan pengukuran nilai evaluasi menggunakan Korelasi Ranking Spearman yang dimodifikasi sehingga bisa menghitung nilai korelasi yang salah satu anggota himpunannya hanya berisi satu anggota.
6. DAFTAR PUSTAKA
Ahmed, F., Luca, E.W. De dan Nürnberger, A., 2009. Revised N-Gram based Automatic Spelling Correction Tool to Improve Retrieval Effectiveness. Research J. on Computer, [online] (40), hal.39–48.
Tersedia di:
<http://www.gelbukh.com/polibits/2009_ 40/40_06.pdf\nhttp://polibits.gelbukh.co m/2009_40/40_06.pdf>.
Baskoro, S.Y., 2016. Pencarian Pasal pada Kitab Undang-Undang Hukum Pidana
(KUHP) Berdasarkan Kasus
Menggunakan Metode Cosine Similarity dan Latent Semantic Indexing (LSI). Malang, Indonesia.
Butt, M., 2013. Precision and Recall. [online] Tersedia di: <http://ling.uni-konstanz.de/pages/home/butt/main/materi al/precision-recall.pdf>.
Haldar, R. dan Mukhopadhyay, D., 2011. Levenshtein Distance Technique in
Dictionary Lookup Methods : An
Improved Approach. Web Intelligence & Distributed Computing Research Lab, (Ld), hal.1–5.
Lahitani, A.R., Permanasari, A.E. dan Setiawan, N.A., 2016. Cosine similarity to determine similarity measure: Study case in online essay assessment. Proceedings of 2016 4th International Conference on Cyber and IT Service Management, CITSM 2016.
Manning, C.D., Raghavan, P. dan Schütze, H., 2009. An Introduction to Information Retrieval. Online ed. [online] Tersedia di:
<http://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf>. Mishra, A. dan Vishwakarma, S., 2016.
Proceedings - 2015 International
Conference on Computational
Intelligence and Communication
Networks, CICN 2015, hal.772–776. Naradhipa, A.R., Kamayani, M., Reinanda, R.,
Simbolon, S., Soleh, M.Y. dan Purwarianti, A., 2011. Application of Document Spelling Checker for Bahasa Indonesia. ICACSIS, hal.249–252. Riadi, M., 2015. Pengertian dan Kriteria Teks.
[online] Tersedia di:
<http://www.kajianpustaka.com/2015/09/ pengertian-dan-kriteria-teks.html> [Diakses 5 Nov. 2016].
Soleh, M.Y. dan Purwarianti, A., 2011. A Non Word Error Spell Checker for Indonesian using Morphologically Analyzer and HMM. Dalam: International Conference
on Electrical Engineering and
Informatics. Bandung, Indonesia.
Susanto, B., 2009. Text Mining. Dalam: Text dan Web Mining. [online] Yogyakarta.
Tersedia di:
<http://lecturer.ukdw.ac.id/budsus/pdf/te xtwebmining/TextMining_Kuliah.pdf>. Wicaksono, A.F. dan Purwarianti, A., 2010.