19 BAB III
PERANCANGAN DAN IMPLEMENTASI SISTEM
3.1.Diagram Alir Penelitian
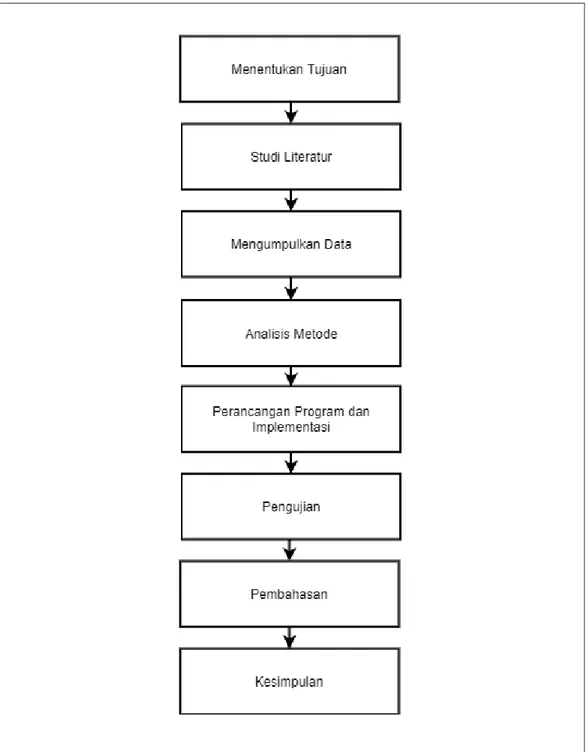
Penelitian ini memiliki alur kerja seperti pada gambar 3.1.
Gambar 3.1 Diagram Alir Penelitian
20 Pada Gambar 3.1, alur penelitian yang merupakan tahap-tahap yang dilalui oleh peneliti mulai dari awal penelitian sampai selesainya penelitian, yang dibentuk menjadi sebuah alur yang sistematis. Diagram alir penelitian ini digunakan sebagai pedoman peneliti dalam melakukan pelaksanaan penelitian ini agar mendapatkan hasil yang tidak menyimpang dari tujuan awal yang telah ditentukan sebelumnya.
Berikut merupakan penjelasannya.
3.1.1. Menentukan Tujuan
Tahap penentuan tujuan merupakan penjelasan tentang sasaran dari penelitian ini seperti melakukan analisis perbandingan algoritma K-Means clustering menggunakan Euclidean Distance, Manhattan Distance dan Canberra Distance yang merupakan suatu penelitian yang dapat mendukung penarikan kesimpulan metode penghitungan jarak paling baik dalam melakukan pengolahan data pasien diabetes menggunakan algoritma K-Means Clustering dengan metode elbow untuk menentukan jumlah k cluster yang akan dibentuk dan Silhouette Coefficient sebagai metode pengujian..
3.1.2. Studi Literatur
Studi literatur dibuat dengan tujuan untuk mendapatkan dasar-dasar referensi yang kuat untuk mengetahui metode apa yang sebaiknya digunakan dalam menyelesaikan permasalahan yang akan diteliti. Dasar-dasar referensi tersebut diambil melalui buku, jurnal, penelitian sebelumnya, e-book, dan lain-lain.
3.1.3. Mengumpulkan Data
Setelah mempelajari bahan referensi yang diperlukan, selanjutnya adalah proses pengumpulan data. Pada tahap ini dilakukan pengambilan data pasien diabetes.
Data pasien diabetes tersebut nantinya akan diolah ke dalam sistem menggunakan algoritma K-Means Clustering menggunakan Euclidean Distance, Manhattan Distance dan Canberra Distance dan Silhouette Coefficient sebagai metode
21 pengujian sehingga dapat diperoleh penarikan kesimpulan metode penghitungan jarak terbaik dalam melakukan pengolahan data pasien diabetes.
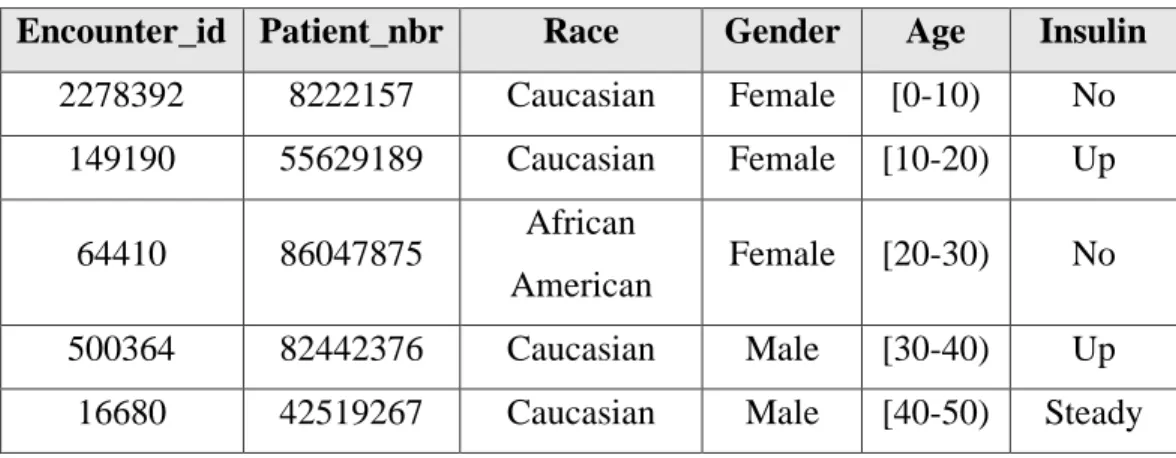
Untuk contoh beberapa data yang digunakan dalam penelitian ini dapat dilihat pada Tabel 3.1.
Tabel 3.1 Contoh Data Penelitian
Encounter_id Patient_nbr Race Gender Age Insulin 2278392 8222157 Caucasian Female [0-10) No
149190 55629189 Caucasian Female [10-20) Up
64410 86047875 African
American Female [20-30) No 500364 82442376 Caucasian Male [30-40) Up
16680 42519267 Caucasian Male [40-50) Steady
Setelah data didapatkan selanjutnya akan dilakukan tahap pengolahan data untuk mempermudah dalam proses data mining. Tahapan pengolahan data tersebut adalah sebagai betikut:
1. Pemilihan Data
Pemilihan data dari dataset yang dimiliki untuk dijadikan atribut data pada proses data mining nantinya.
2. Preprocessing Data
Pada tahap preprocessing data pada penelitian ini, dilakukan pensortiran atau pemilihan data pasien diabetes yang telah diperoleh sebelumnya. Adapun tujuan dari proses ini adalah untuk memisahkan data pasien diabetes yang tidak dapat diproses untuk perhitungan.
3. Transformation Data
Mengelompokkan data-data tersebut menjadi satu tabel seperti pada tabel 3.2 berikut:
22 Tabel 3.2 Atribut Terpilih
Gender Age Insulin
Female [0-10) No
Female [10-20) Up
Female [20-30) No
Male [30-40) Up
Male [40-50) Steady
Data yang berjenis nominal seperti gender dan insulin harus dilakukan proses inisialisasi data terlebih dahulu dalam bentuk angka (numeric) [19], dan untuk atribut age akan dilakukan perhitungan nilai tengah pasien diabetes agar dapat dilakukan proses perhitungan K-Means Clustering. Inisialisasi tersebut dapat dilakukan sebagai berikut:
1. Pada atribut gender dilakukan perhitungan frekuensi pada data pasien diabetes berdasarkan jenis kelamin yang selanjutnya diurutkan dari data terbesar ke terkecil seperti pada tabel 3.3.
Tabel 3.3 Insialisasi Data Gender Gender Frekuensi Inisial
Female 26 1
Male 24 2
2. Pada atribut age dilakukan perhitungan nilai tengah usia pada data pasien diabetes seperti pada tabel 3.4.
Tabel 3.4 Perhitungan Nilai Tengah Usia
Age Nilai Tengah
[0-10) 5
[10-20) 15
[20-30) 25
23
Age Nilai Tengah
[30-40) 35
[40-50) 45
[50-60) 55
[60-70) 65
[70-80) 75
[80-90) 85
[90-100) 95
3. Untuk atribut insulin dilakukan perhitungan frekuensi pada data pasien diabetes berdasarkan tingkat insulin yang selanjutnya diurutkan dari data terbesar ke terkecil seperti pada tabel 3.5.
Tabel 3.5 Insialisasi Data Insulin Insulin Frekuensi Inisial
Steady 29 1
No 9 2
Down 8 3
Up 4 4
3.1.4. Analisis Metode 3.1.4.1.Analisis Clustering
Analisis cluster merupakan suatu analisis statistic perubah ganda (multivariant) yang memiliki tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya [20]. Analisis cluster bertujuan untuk mengklasifikasi objek sehingga setiap objek yang memiliki sifat yang mirip (paling dekat kesamaannya) akan dikelompokkan menjadi satu cluster yang sama.
24 3.1.4.2.Analisis K-Means
Algoritma K-Means yaitu algoritma yang menggunakan centroid untuk membuat cluster, centroid juga digunakan untuk menghitung jarak objek data terhadap centroid. Suatu objek data akan masuk ke dalam suatu cluster apabila memiliki jarak terpendek terhadap centroid cluster tersebut. Langkah-langkah proses analisis clustering menggunakan algoritma K-Means yang dilakukan secara manual dengan diambil sampel data secara acak berjumlah 50 sampel data.
3.1.4.3.Analisis Metode Elbow
Metode elbow merupakan suatu metode yang digunakan untuk menentukan jumlah k cluster dengan cara melihat hasil perbandingan antara jumlah cluster yang akan membentuk siku pada suatu titik. Hasil perbandingan tersebut ditunjukkan dengan sebuah gambar grafik sebagai sumber informasi yang dapat memudahkan dalam mendapatkan nilai k. Grafik yang menunjukkan penurunan paling besar merupakan nilai k cluster terbaik [5].
3.1.4.4.Analisis Euclidean Distance
Euclidean Distance merupakan rumus pengukur jarak yang menggunakan konsep Pythagoras. Rumus Euclidean umumnya digunakan untuk mengukur tingkat kemiripan data [7]. Berikut merupakan tahapan-tahapan dalam melakukan penghitungan jarak Euclidean Distance dengan menggunakan metode pengujian silhouette coefficient:
1. Perihitungan jarak dengan centroid menggunakan Euclidean Distance dengan menggunakan persamaan 3.1.
𝑑(𝑥, 𝑦) = ‖𝑥 − 𝑦‖ = √∑𝑛𝑖=1(𝑥𝑖− 𝑦𝑖)2 ; 𝑖 = 1,2,3 … 𝑛 ... (3.1) Dengan:
d = Jarak antara x dan y x = Data pusat cluster y = Data pada atribut
25 i = Setiap data
n = Banyaknya objek
𝑥𝑖 = Data pada pusat cluster ke i 𝑦𝑖 = Data pada setiap data ke i
2. Tahap pengujian dilakukan dengan tujuan untuk mengukur nilai metode penghitung jarak yang paling optimal. Pengujian dilakukan menggunakan algoritma Silhouette Coeffisien pada masing-masing hasil jarak. Adapun langkah-langkah pengujian tersebut adalah sebagai berikut:
- Hitung rata-rata jarak terhadap semua dokumen yang berada dalam satu cluster, yang kemudian disebut dengan a(i). Rumus a(i) dapat dilihat pada persamaan 3.2.
𝑎(𝑖) = ∑ 𝐷(𝑖,𝑗)
|𝐴|−1 ... (3.2) Dengan:
a(i) = Rata-rata jarak objek ke-i dengan semua objek pada satu cluster yang sama
A = Konstanta
- Hitung rata-rata jarak suatu data ke-i dengan semua objek-objek pada cluster lain pada persamaan 3.3 yang disebut bi.
𝑏(𝑖) = 𝑚𝑖𝑛 (𝐷(𝐼, 𝐶)) ... (3.3) Dengan:
b(i) = Rata-rata jarak objek ke-i dengan semua objek pada cluster yang berbeda
D = Jarak C = Cluster
- Menghitung nilai Silhouette Coeffisien untuk suatu titik pada persamaa 3.4.
𝑆𝑖= 𝑚𝑎𝑥 (𝑎(𝑏𝑖−𝑎𝑖)
𝑖,𝑏𝑖) ... (3.4) Dengan:
26 Si = Nilai Silhouette Coeffisien pada data ke-i
a(i) = Rata-rata jarak objek ke-i dengan semua objek pada satu cluster yang sama
b(i) = Rata-rata jarak objek ke-i dengan semua objek pada cluster yang berbeda
3.1.4.5.Analisis Manhattan Distance
Manhattan Distance merupakan metode pengukuran jarak yang digunakan untuk menghitung perbedaan mutlak antara koordinat dua buah objek [9]. Berikut merupakan tahapan-tahapan dalam melakukan penghitungan jarak Manhattan Distance dengan menggunakan metode pengujian silhouette coefficient:
1. Perihitungan jarak dengan centroid menggunakan Manhattan Distance dengan menggunakan persamaan 3.5.
𝑑(𝑥, 𝑦) = ∑𝑛𝑖=1|𝑥𝑖− 𝑦𝑖| ... (3.5) Dengan:
d = Jarak antara x dan y x = Data pusat cluster y = Data pada atribut i = Setiap data n = Jumlah data,
𝑥𝑖 = Data pada pusat cluster ke i 𝑦𝑖 = Data pada setiap data ke i
2. Tahap pengujian ini dilakukan dengan tujuan untuk mengukur nilai metode penghitung jarak yang paling optimal. Pengujian dilakukan menggunakan algoritma Silhouette Coeffisien pada masing-masing hasil jarak. Adapun langkah-langkah pengujian tersebut adalah sebagai berikut:
- Hitung rata-rata jarak terhadap semua dokumen yang berada dalam satu cluster, yang kemudian disebut dengan a(i). Rumus a(i) dapat dilihat pada persamaan 3.6.
27 𝑎(𝑖) = ∑ 𝐷(𝑖,𝑗)
|𝐴|−1 ... (3.6) Dengan:
a(i) = Rata-rata jarak objek ke-i dengan semua objek pada satu cluster yang sama
A = Konstanta
- Hitung rata-rata jarak suatu data ke-i dengan semua objek-objek pada cluster lain pada persamaan 3.7 yang disebut b(i).
𝑏(𝑖) = 𝑚𝑖𝑛 (𝐷(𝐼, 𝐶)) ... (3.7) Dengan:
b(i) = Rata-rata jarak objek ke-i dengan semua objek pada cluster yang berbeda
D = Jarak C = Cluster
- Menghitung nilai Silhouette Coeffisien untuk suatu titik pada persamaa 3.8.
𝑆𝑖= (𝑏𝑖−𝑎𝑖)
𝑚𝑎𝑥 (𝑎𝑖,𝑏𝑖) ... (3.8) Dengan:
Si = Nilai Silhouette Coeffisien pada data ke-i
a(i) = Rata-rata jarak objek ke-i dengan semua objek pada satu cluster yang sama
b(i) = Rata-rata jarak objek ke-i dengan semua objek pada cluster yang berbeda
3.1.4.6.Analisis Canberra Distance
Canberra Distance merupakan metode pengukuran jarak yang digunakan untuk mendapatkan jarak dari dua buah titik dimana data yang digunakan merupakan data asli dan berada dalam ruang vector [8]. Berikut merupakan tahapan-tahapan dalam melakukan penghitungan jarak Canberra Distance dengan menggunakan metode pengujian silhouette coefficient:
28 1. Perihitungan jarak dengan centroid menggunakan Canberra Distance dengan
menggunakan persamaan 3.9.
𝑑(𝑥, 𝑦) = ∑ |𝑥|𝑥𝑖−𝑦𝑖|
𝑖|+|𝑦𝑖|
𝑛𝑖−1 ... (3.9)
Dengan:
d = Jarak antara x dan y x = Data pusat klaster y = Data pada atribut i = Setiap data n = Jumlah data,
𝑥𝑖 = Data pada pusat klaster ke i 𝑦𝑖 = Data pada setiap data ke i
2. Tahap pengujian ini dilakukan dengan tujuan untuk mengukur nilai metode penghitung jarak yang paling optimal. Pengujian dilakukan menggunakan algoritma Silhouette Coeffisien pada masing-masing hasil jarak. Adapun langkah-langkah pengujian tersebut adalah sebagai berikut:
- Hitung rata-rata jarak terhadap semua dokumen yang berada dalam satu cluster, yang kemudian disebut dengan a(i). Rumus a(i) dapat dilihat pada persamaan 3.10.
𝑎(𝑖) = ∑ 𝐷(𝑖,𝑗)
|𝐴|−1 ... (3.10) Dengan:
a(i) = Rata-rata jarak objek ke-i dengan semua objek pada satu cluster yang sama
A = Konstanta
- Hitung rata-rata jarak suatu data ke-i dengan semua objek-objek pada cluster lain pada persamaan 3.11 yang disebut b(i).
𝑏(𝑖) = 𝑚𝑖𝑛 (𝐷(𝐼, 𝐶)) ... (3.11) Dengan:
b(i) = Rata-rata jarak objek ke-i dengan semua objek pada cluster yang berbeda
29 D = Jarak
C = Cluster
- Menghitung nilai Silhouette Coeffisien untuk suatu titik pada persamaa 3.12.
𝑆𝑖= (𝑏𝑖−𝑎𝑖)
𝑚𝑎𝑥 (𝑎𝑖,𝑏𝑖) ... (3.12) Dengan:
Si = Nilai Silhouette Coeffisien pada data ke-i
a(i) = Rata-rata jarak objek ke-i dengan semua objek pada satu cluster yang sama
b(i) = Rata-rata jarak objek ke-i dengan semua objek pada cluster yang berbeda
3.1.5. Perancangan Program dan Implementasi
Pada tahap ini dilakukan perancangan program dan implementasi dari penelitian yang dilakukan. Dalam melakukan perhitungan secara manual dilakukan menggunakan excel dan dalam melakukan perhitungan lainnya menggunakan bahasa pemrograman python yang merupakan bahasa pemrograman untuk melakukan pengolahan data. Dengan menggunakan python dapat mempermudah melakukan perhitungan dengan data yang sangat banyak.
3.1.6. Pengujian
Tahapan kelima dalam metode penelitian ini adalah tahapan pengujian yang dilakukan terhadap keseluruhan perhitungan yang telah dilakukan menggunakan metode penghitung jarak Euclidean Distance, Manhattan Distance dan Canberra Distance. Untuk mengetahui perbandingan ketiga metode penghitung jarak tersebut dilakukan evaluasi menggunakan metode pengujian Silhouette Coeffisien.
Penggunaan metode pengujian Silhouette Coeffisien dengan tujuan untuk mengukur nilai metode penghitung jarak yang paling optimal.
30 3.1.7. Pembahasan
Pada tahap ini dilakukan pembahasan terhadap beberapa pengujian yang telah dilakukan sebelumnya. Tujuan dari tahapan ini adalah untuk mengetahui sejauh mana sistem yang telah dibuat mampu menyelesaikan permasalahan yang telah ditentukan sebelumnya. Pada tahap ini juga dapat digunakan sebagai tahapan untuk menghasilkan kesimpulan metode yang paling baik dalam melakukan pengolahan data pasien diabetes.
3.1.8. Penarikan Kesimpulan
Tahapan terakhir adalah pengambilan kesimpulan, tahapan kesimpulan digunakan untuk menyimpulkan suatu hasil yang didapatkan dari tahapan pembahasan.