13 BAB III
METODOLOGI PENELITIAN
Pada penelitian ini dilakukan analisis evaluasi perhitungan jarak terhadap nilai Silhouette Coefficient pada algoritma K-Means. Masalah yang akan diselesaikan adalah menemukan metode yang paling optimal dalam perhitungan jarak data terhadap centroid pada algoritma K-Means dengan melakukan perbandingan tiga metode perhitungan jarak yaitu Euclidean Distance, Minkowski Distance, dan Chebyshev Distance dan mengevaluasinya menggunakan Silhouette Coefficient. Pada proses clustering dilakukan pengelompokkan data yang mirip, akan tetapi masih tetap diperlukan beberapa pengukuran untuk menentukan dua data atau objek mirip, kurang mirip ataupun tidak mirip sama sekali dan untuk menentukan kemiripan tersebut digunakan pengukuran yang disebut dengan distance measure. Langkah-langkah penelitian analisis pengaruh perhitungan jarak terhadap nilai Silhouette Coefficient pada algoritma K-Means adalah sebagai berikut:
1. Melakukan normalisasi dataset.
2. Mencari jumlah cluster teroptimal dengan Silhouette Coefficient
3. Melakukan clustering dataset dengan algoritma K-Means Clustering dengan metode distance measure yaitu Euclidean Distance, Minkowski Distance, dan Chebyshev Distance.
4. Evaluasi hasil clustering berdasarkan nilai Silhouette Coefficient. 5. Pengujian Kompleksitas Waktu
3.1 Analisis Permasalahan
Salah satu ciri clustering yang baik atau optimal adalah jika menghasilkan cluster yang berisi data dengan tingkat kemiripan (similarity) yang tinggi pada cluster yang sama dan tingkat kemiripan rendah pada cluster yang berbeda. Distance measure digunakan untuk mengukur kemiripan data dalam suatu cluster. Hasil dari proses clustering akan menghasilkan hasil yang berbeda apabila distance measure yang digunakan berbeda [1]. Penggunaan distance measure yang paling umum digunakan dalam K-Means Clustering adalah Euclidean Distance seperti yang dilakukan oleh penelitian terdahulu [2] dan [3]. Namun terdapat pula beberapa distance measure lainnya di antaranya Manhattan Distance /City Block, Minkowski Distance, dan Chebyshev Distance. Oleh karena itu, diperlukan penelitian untuk menganalisis perbandingan dari berbagai distance measure pada K-Means Clustering agar dapat menentukan jenis distance measure yang paling optimal dalam proses clustering.
Penelitian mengenai perbandingan dari berbagai distance measure pada K-Means Clustering sudah pernah dilakukan oleh penelitian terdahulu [4] yaitu perbandingan akurasi Euclidean Distance, Minkowski Distance, dan Manhattan Distance pada Algoritma K-Means Clustering berbasis Chi-Square, dengan tingkat akurasi yang baik pada kasus ini yaitu 84.47% (untuk Euclidean Distance). Dan penelitian lainnya [1] melakukan pemilihan distance measure pada K-Means Clustering dengan hasil penelitian ini mendapatkan distance measure paling optimal untuk kasus ini adalah Chebyshev Distance dengan nilai Silhouette Coefficient paling mendekati 1 adalah 0.242821. Dan pada penelitian [6] dilakukan perbandingan empat perhitungan jarak yang sering digunakan dalam KNN (K-Nearest Neighbour), yaitu Euclidean Distance, Chebyshev Distance, Manhattan Distance, dan Minkowski Distance, hasil penelitian ini menunjukkan bahwa jarak Euclidean Distance dan Minkowski Distance pada algoritma KNN menghasilkan akurasi terbaik dibandingkan Chebyshev Distance, maupun Manhattan Distance pada kasus ini.
Menurut Kaufman dan Rousseeuw, salah satu metode evaluasi yang dapat digunakan untuk melihat kualitas dan kekuatan cluster adalah metode Silhouette Coefficient. Metode ini merupakan metode validasi cluster yang menggabungkan metode cohesion dan separation. Penelitian mengenai perbandingan dengan metode evaluasi Silhouette Coefficient sudah pernah dilakukan oleh penelitian terdahulu [1] dan [5].
Penelitian mengenai perbandingan dari ketiga distance measure berbeda yaitu Euclidean Distance, Minkowski Distance, dan Chebyshev Distance dengan metode evaluasi Silhouette Coefficient belum pernah dilakukan. Oleh karena itu, penulis akan melakukan penelitian untuk menemukan metode distance measure yang optimal untuk clustering algoritma K-Means pada kasus kepadatan penduduk Kota Bandar Lampung tahun 2019 dengan melakukan perbandingan dari ketiga distance measure berbeda yaitu Euclidean Distance, Minkowski Distance, dan Chebyshev Distance pada K-Means Clustering dengan metode evaluasi yang digunakan adalah Silhouette Coefficient pada kasus ini. Sehingga dapat memperoleh clustering tingkat kepadatan penduduk Kota Bandar Lampung dan menemukan metode distance measure yang optimal untuk clustering algoritma K-Means pada kasus ini.
3.2 Data Yang Digunakan
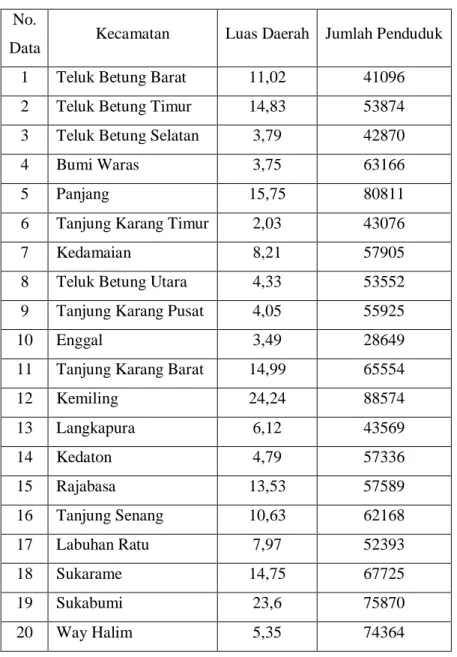
Data yang digunakan dalam penelitian ini adalah dua dataset yang berisi luas wilayah dan jumlah penduduk per kecamatan Kota Bandar Lampung Tahun 2020 dengan jumlah data sebanyak 20 record serta dataset per kelurahan Kota Bandar Lampung Tahun 2019 dengan jumlah data 126 record yang diambil dari publikasi oleh Badan Pusat Statistik (BPS) Kota Bandar Lampung yaitu Kota Bandar Lampung Dalam Angka 2021 [8], dan Kecamatan Dalam Angka 2020 [9-28]. Adapun dataset per kecamatan dapat dilihat pada Tabel 3.1 dan dataset per kelurahan dapat dilihat pada lampiran.
Tabel 3.1. Dataset Per Kecamatan
No.
Data Kecamatan Luas Daerah Jumlah Penduduk
1 Teluk Betung Barat 11,02 41096
2 Teluk Betung Timur 14,83 53874
3 Teluk Betung Selatan 3,79 42870
4 Bumi Waras 3,75 63166
5 Panjang 15,75 80811
6 Tanjung Karang Timur 2,03 43076
7 Kedamaian 8,21 57905
8 Teluk Betung Utara 4,33 53552
9 Tanjung Karang Pusat 4,05 55925
10 Enggal 3,49 28649
11 Tanjung Karang Barat 14,99 65554
12 Kemiling 24,24 88574 13 Langkapura 6,12 43569 14 Kedaton 4,79 57336 15 Rajabasa 13,53 57589 16 Tanjung Senang 10,63 62168 17 Labuhan Ratu 7,97 52393 18 Sukarame 14,75 67725 19 Sukabumi 23,6 75870 20 Way Halim 5,35 74364 3.3 Bagan Penelitian
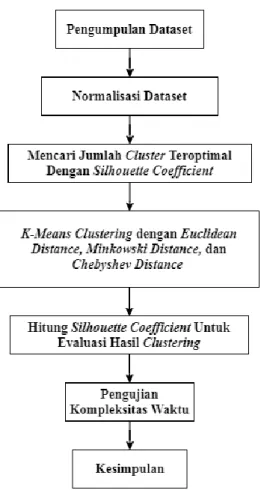
Pada penelitian ini dilakukan analisis pengaruh perhitungan jarak terhadap nilai Silhouette Coefficient pada K-Means Clustering. Adapun secara garis besarnya penelitian ini dapat digambarkan dalam bentuk bagan seperti pada Gambar 3.1.
Gambar 3.1 Bagan Penelitian
Pada awalnya dilakukan pengumpulan dataset dan dilakukakan normalisasi dataset, selanjutnya proses awal yang dilakukan adalah mencari jumlah cluster teroptimal dengan Silhouette Coefficient dan dilakukan clustering dengan K-Means pada dataset menggunakan perhitungan jarak dari data ke centroid cluster (pusat cluster) menggunakan metode Euclidean Distance, Minkowski Distance, dan Chebyshev Distance. Kemudian dilakukan evaluasi hasil clustering dengan metode Silhouette Coefficient serta pengujian kompleksitas waktu, dan penarikan kesimpulan yang bertujuan untuk memberikan informasi perbandingan perhitungan jarak terhadap nilai Silhouette Coefficient dan kompleksitas waktunya.
3.4 Normalisasi Dataset
Sebelum melakukan clustering, maka pada dataset dilakukan normalisasi data agar nilai dari masing-masing variabel ke dalam rentang yang sama yakni rentang [0,1] dengan menggunakan rumus sebagai berikut [4]:
Keterangan :
= bobot atribut ke i
= bobot minimum atribut i = bobot maksimum atribut i Untuk Data-1 dengan atribut:
Untuk Data-2 dengan atribut:
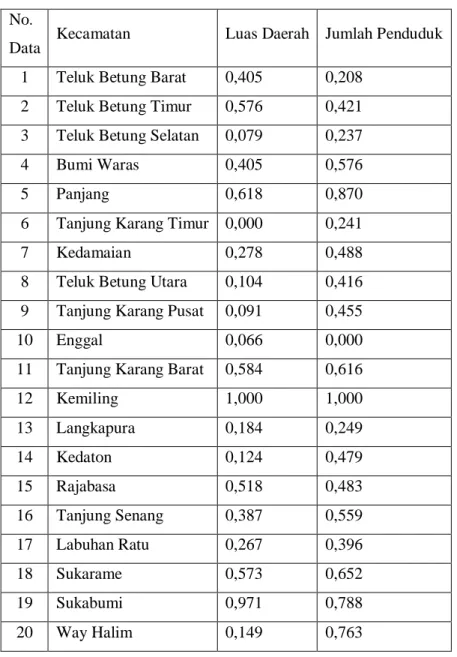
Dari perhitungan normalisasi untuk Data-1 dan Data-2 diatas dimasukkan ke dalam tabel dan untuk perhitungan normalisasi data selanjutnya dilakukan dengan cara yang sama. Hasil normalisasi semua data dari dataset dapat dilihat seperti pada Tabel 3.2.
Tabel 3.2. Dataset Per Kecamatan Hasil Normalisasi
No.
Data Kecamatan Luas Daerah Jumlah Penduduk 1 Teluk Betung Barat 0,405 0,208
2 Teluk Betung Timur 0,576 0,421 3 Teluk Betung Selatan 0,079 0,237
4 Bumi Waras 0,405 0,576
5 Panjang 0,618 0,870
6 Tanjung Karang Timur 0,000 0,241
7 Kedamaian 0,278 0,488
8 Teluk Betung Utara 0,104 0,416 9 Tanjung Karang Pusat 0,091 0,455
10 Enggal 0,066 0,000
11 Tanjung Karang Barat 0,584 0,616
12 Kemiling 1,000 1,000 13 Langkapura 0,184 0,249 14 Kedaton 0,124 0,479 15 Rajabasa 0,518 0,483 16 Tanjung Senang 0,387 0,559 17 Labuhan Ratu 0,267 0,396 18 Sukarame 0,573 0,652 19 Sukabumi 0,971 0,788 20 Way Halim 0,149 0,763
3.5 Mencari Jumlah Cluster Teroptimal
Tahapan-tahapan menentukan nilai k teroptimal pada K-Means Clustering dengan metode Silhouette Coefficient sebagai berikut [7] :
1. Lakukan clustering algoritma K-Means pada setiap nilai k, mulai dari k=2,3,4,5.
2. Hitung hasil Silhouette Coefficient dari tiap nilai k.
3. Melihat hasil Silhouette Coefficient dari nilai k yang memiliki nilai tertinggi
cluster teroptimal.
5. Gunakan k teroptimal untuk proses K-Means Clustering. 3.6 Algoritma K-Means Clustering
Pada penelitian ini dilakukan clustering dataset dengan algoritma K-Means dengan metode distance measure Euclidean Distance, Minkowski Distance, dan Chebyshev Distance.
3.6.1 Clustering dengan Distance Measure Euclidean Distance
Pertama-tama beri nilai awal pusat cluster sebanyak k=2, pada penelitian ini akan dilakukan pemilihan nilai awal pusat cluster sebagai berikut :
1. Urutkan data berdasarkan luas daerah dan jumlah penduduk mulai dari terkecil hingga terbesar, seperti berikut :
No. Data Luas Daerah Jumlah Penduduk 1 0,079 0,576 2 0,370 0,492 3 0,576 0,208 4 0,673 0,507
2. Kemudian bagi data sesuai banyak cluster yang akan dilakukan, misal jumlah cluster (k) = 2. No. Data Luas Daerah Jumlah Penduduk 1 0,079 0,576 2 0,370 0,492 3 0,576 0,208 4 0,673 0,507
3. Terakhir pilih random satu indeks data dari setiap data yang telah dibagi untuk dijadikan nilai awal pusat cluster
Cluster 1 0,079 0,576
Dengan menggunakan persamaan (2.2) berikut adalah contoh perhitungan jarak data dengan centroid dengan meminimalkan jarak melalui iterasi menggunakan Euclidean Distance.
Untuk Data-1 dengan Cluster-1
1 0,405 0,208 √∑ √∑ √∑ √∑
Untuk Data-1 dengan Cluster-2
√∑ √∑
√∑ √∑
Untuk Data-2 dengan Cluster-1
2 0,576 0,421 √∑ √∑ √∑ √∑
Untuk Data-2 dengan Cluster-2
√∑ √∑
√∑ √∑
Untuk Data-3 dengan Cluster-1 3 0,079 0,237 √∑ √∑ √∑ √∑
Untuk Data-3 dengan Cluster-2
√∑ √∑
√∑ √∑
Untuk Data-4 dengan Cluster-1
4 0,405 0,576 √∑ √∑ √∑ √∑
Untuk Data-4 dengan Cluster-2
√∑ √∑
√∑ √∑
Setelah dilakukan perhitungan pada seluruh data pada kedua cluster, dilakukan pemilihan cluster dengan jarak paling kecil sehingga diperoleh tabel 3.3 sebagai contoh hasil clustering dengan Euclidean Distance sebagai berikut.
Tabel 3.3 Contoh Hasil Clustering Dengan Euclidean Distance No. Data Luas Daerah Jumlah Penduduk
Iterasi 1 Iterasi 2 Iterasi 3
C1 C2 C1 C2 C1 C2
1 0,405 0,037 0,492 0,171 0,257 0,137 0,257 0,137 2 0,576 0,293 0,521 0,213 0,334 0,136 0,334 0,136 3 0,079 0,244 0,339 0,498 0,236 0,419 0,236 0,419
4 0,405 0,620 0,326 0,406 0,235 0,275 0,235 0,275
3.6.2 Clustering dengan Distance Measure Minkowski Distance
Dengan menggunakan persamaan (2.4) dan p =1,5 berikut adalah contoh perhitungan jarak data dengan centroid dengan meminimalkan jarak melalui iterasi menggunakan Minkowski Distance.
Untuk Data-1 dengan Cluster-1
1 0,405 0,208 ∑ ∑ ∑ ∑ Untuk Data-1 dengan Cluster-2
∑ ∑ ∑ ∑ Untuk Data-2 dengan Cluster-1
2 0,576 0,421
∑
∑ ∑ ∑ Untuk Data-2 dengan Cluster-2
∑ ∑ ∑ ∑ Untuk Data-3 dengan Cluster-1
3 0,079 0,237 ∑ ∑ ∑ ∑ Untuk Data-3 dengan Cluster-2
∑ ∑ ∑ ∑ Untuk Data-4 dengan Cluster-1
4 0,405 0,576
∑
∑
∑
Untuk Data-4 dengan Cluster-2
∑ ∑ ∑ ∑
Setelah dilakukan perhitungan pada seluruh data pada kedua cluster, dilakukan pemilihan cluster dengan jarak paling kecil sehingga diperoleh tabel 3.4 sebagai contoh hasil clustering dengan Minkowski Distance sebagai berikut.
Tabel 3.4 Contoh Hasil Clustering Dengan Minkowski Distance
No. Data Luas Daerah Jumlah Penduduk
Iterasi 1 Iterasi 2 Iterasi 3
C1 C2 C1 C2 C1 C2
1 0,405 0,037 0,511 0,171 0,288 0,154 0,288 0,154 2 0,576 0,293 0,553 0,213 0,336 0,152 0,336 0,152 3 0,079 0,244 0,339 0,502 0,264 0,434 0,264 0,434
4 0,405 0,620 0,326 0,442 0,264 0,293 0,264 0,293
3.6.3 Clustering dengan Distance Measure Chebyshev Distance
Dengan menggunakan persamaan (2.3) berikut contoh perhitungan jarak data dengan centroid dengan meminimalkan jarak melalui iterasi menggunakan Chebyshev Distance.
Untuk Data-1 dengan Cluster-1
1 0,405 0,208
Untuk Data-1 dengan Cluster-2
Untuk Data-2 dengan Cluster-1
2 0,576 0,421
Untuk Data-2 dengan Cluster-2
Untuk Data-3 dengan Cluster-1
3 0,079 0,237
Untuk Data-3 dengan Cluster-2
Untuk Data-4 dengan Cluster-1
4 0,405 0,576
Untuk Data-2 dengan Cluster-2
Setelah dilakukan perhitungan pada seluruh data pada kedua cluster, dilakukan pemilihan cluster dengan jarak paling kecil sehingga diperoleh tabel 3.5 sebagai contoh hasil clustering dengan Chebyshev Distance sebagai berikut.
Tabel 3.5 Contoh Hasil Clustering Dengan Chebyshev Distance No. Data Luas Daerah Jumlah Penduduk
Iterasi 1 Iterasi 2 Iterasi 3
C1 C2 C1 C2 C1 C2
1 0,405 0,037 0,368 0,171 0,199 0,107 0,199 0,107 2 0,576 0,293 0,497 0,213 0,334 0,106 0,334 0,106 3 0,079 0,244 0,339 0,497 0,170 0,412 0,170 0,412
4 0,405 0,620 0,326 0,368 0,169 0,261 0,169 0,261
3.7 Perhitungan Silhouette Coefficient
Adapun langkah-langkah beserta contoh untuk menghitung Silhouette Coefficient adalah sebagai berikut berdasarkan data pada Tabel 3.5 :
1. Hitung rata-rata jarak dari suatu objek, misalkan i dengan semua objek lain yang berada dalam satu klaster dengan menggunakan rumus persamaan (2.5). √ √ √ √ √ √ √ √ √ √ √ √
√ √ √ √
2. Hitung rata-rata jarak dari dokumen i tersebut dengan semua dokumen di klaster lain menggunakan rumus persamaan (2.6).
√ √ √ √ √( - ) ( - ) ( - ) ( - ) √ √ √ √ √ √
√ √ √ √ √
Dan diambil nilai terkecilnya dengan menggunakan rumus persamaan (2.7) sebagai berikut [4] :
3. Hitung nilai Silhouette Coefficient-nya dengan rumus persamaan (2.8) sebagai berikut [4] : ( ) ( ) ( ) ( ) Berikut adalah tabel 3.6 yang berisi contoh hasil perhitungan nilai Silhouette Coefficient berdasarkan perhitungan yang telah dilakukan.
Tabel 3.6 Contoh Hasil Perhitungan Nilai Silhouette Coefficient No. Data Luas Daerah Jumlah
Penduduk a(i) d(i,C) b(i) s(i) 1 0,405 0,208 0,273 0,246 0,246 -0,099 2 0,576 0,421 0,273 0,289 0,289 0,055 3 0,079 0,237 0,470 0,311 0,311 -0,338 4 0,405 0,576 0,470 0,217 0,217 -0,538
Maka nilai Silhouette Coefficient rata-ratanya sebagai berikut :
Berdasarkan Kaufman dan Rousseeuw, hasil nilai Silhouette Coefficient-nya menghasilkan no structure atau tidak ada struktur. Hal ini dapat dikarenakan pada contoh ini menggunakan contoh dataset yang sangat sedikit, sehingga cluster-cluster yang didapatkan tidak sepenuhnya mewakili dan menjadi ciri tertentu.
3.8 Pengujian Kompleksitas Waktu
Tahapan-tahapan pengujian kompleksitas waktu pada setiap Clustering berdasarkan waktu yang dibutuhkan untuk memperoleh hasil Clustering sebagai berikut :
1. Lakukan clustering algoritma K-Means pada setiap metode distance measure sebanyak 30 kali percobaan dan catat waktu setiap percobaannya. 2. Hasil dari 30 kali percobaan tersebut maka dihitunglah rata-ratanya.
3. Waktu rata-rata tersebut merupakan waktu yang menjadi hasil pengujian kompleksitas waktu untuk setiap hasil Clustering.