44 BAB III
METODE PENELITIAN
3.1. Desain Penelitian
Pada penelitian ini dilaksanakan secara eksperimen, yaitu peneliti menggunakan Data Mining metode Clustering algoritma K-means terhadap data kemampuan tahfidz siswa SMK Luqman Al Hakim Kudus tahun 2018 sampai dengan 2020. Selanjutnya data tersebut akan dianalisa dan diklasterisasi sesuai dengan kecepatan menghafal, makhorijul huruf, tajwid, dan kelancaran membaca Al Qur’an. Proses pengolahan data tersebut dilakukan dengan menggunakan aplikasi Micorsoft Excel dan RapidMiner.
Kemudian hasil dari pengolahan data akan dikelompokan sesuai dengan tingkat kemiripan data. Ada 4 kategori, yang pertama adalah sangat baik, kedua adalah baik, ketiga adalah cukup baik, dan yang ke empat adalah kurang baik. Dengan terkelompokannya tahfidz siswa sesuai dengan kemampuan yang dimiliki sebagai hasil akhir dari penelitian ini, maka diharapkan dapat membantu SMK Luqman Al Hakim Kudus dalam membentuk kelompok tahfidz serta menyusun strategi pembelajaran tahfidz.
3.2. Pengumpulan Data
Dalam melakukan perhitungan Data Mining dengan metode Clustering algoritma K-means, tentunya diperlukan sejumlah data yang sesuai dengan kebutuhan penelitian. Maka dari itu peneliti menggunakan data kemampuan tahfidz siswa SMK Luqman Al Hakim Kudus tahun 2018 sampai dengan 2020 dengan cara meminta ijin kepada Kepala Sekolah.
Kemudian setelah mendapat ijin, peneliti meminta data siswa SMK Luqman Al Hakim Kudus ke ruang Tata Usaha dengan cara mengkopi file excel data siswa angkatan tiga tahun terakhir.
File excel yang diterima peneliti adalah data siswa SMK Luqman Al Hakim Kudus tahun 2018 sampai dengan 2020. Di dalamnya terdapat data yang berjumlah 70 data siswa yang memiliki beberapa kolom, yaitu:
1. Nomor 2. Nama
3. NIPD (Nomor Induk Peserta Didik) 4. Jenis Kelamin
5. NISN (Nomor Induk Siswa Nasional) 6. Tempat Lahir
7. Tanggal Lahir 8. Alamat 9. Nama Ayah 10. Nama Ibu
Dari Data siswa yang diterima peneliti, tidak semua kolom akan digunakan. Peneliti hanya akan menggunakan kolom Nomor dan Nama saja.
Kemudian ditambahkan dengan kolom atribut yang akan digunakan dalam perhitungan Data Mining, diantaranya adalah kolom kecepatan menghafal, makhorijul huruf, tajwid, dan kelancaran membaca Al Qur’an.
Selanjutnya untuk melengkapi data dengan atribut yang sudah disesuaikan, peneliti meminta data kemampuan tahfidz siswa SMK Luqman Al Hakim Kudus kepada pengajar tahfidz.
3.3. Lokasi Penelitian
Lokasi dalam penelitian ini yaitu SMK Luqman Al Hakim Kudus.
Sekolah menengah kejuruan dengan basis pondok pesantren yang alamatnya berada di Jalan Raya Kudus-Jepara Km. 05, Desa Kedungdowo, Kecamatan Kaliwungu, Kabupaten Kudus, Provinsi Jawa Tengah 59463.
3.4. Pengolahan Data
Proses pengolahan data pada penelitian ini, diperlukan adanya perangkat keras (Hardware) dan juga perangkat lunak (Software).
Penjelasan dari perangkat-perangkat tersebut seperti berikut ini:
3.4.1. Perangkat Keras
Pada Penelitian ini, perangkat keras atau hardware yang digunakan adalah satu buah laptop. Laptop yang digunakan adalah ASUS yang memiliki spesifikasi X441N Series, Intel 2Core N3350 CPU 2.4 GHz, RAM 4 GB, Hardisk 1 TB, Operating System Windows 10 64-bit.
3.4.2. Perangkat Lunak
Peneliti menggunakan beberapa perangkat lunak atau software untuk mendukung penelitian ini. Perangkat lunak yang digunakan saat melaksanakan penelitian ini, yaitu:
1. Sistem Operasi
Peneliti menggunakan laptop dengan sistem operasi Windows 10 64-bit dalam penelitian ini.
2. Microsoft Word
Pada penelitian ini software Microsoft Word digunakan untuk membuat laporan penelitian. Versi dari Microsoft Word yang digunakan adalah versi 2010.
3. Microsoft Excel
Dalam penelitian ini software Microsoft Excel digunakan untuk pengolahan data siswa SMK Luqman Al Hakim Kudus. Versi dari Microsoft Excel yang digunakan adalah versi 2010.
4. RapidMiner
Dalam penelitian ini juga digunakan software RapidMiner 5.3 untuk melakukan proses perhitungan Data Mining metode Clustering
menggunakan algoritma K-means terhadap data siswa SMK Luqman Al Hakim Kudus.
3.5. Tahapan Metode
Peneliti menggunakan salah satu metode pada Data Mining yaitu metode Clustering algoritma K-means. Di dalam metode ini, terdapat beberapa tahapan yang harus dilakukan, tahapan-tahapan tersebut adalah:
3.5.1. Pre-processing Data
Tahapan pre-processing data merupakan sebuah tahap dimana data yang sudah diperoleh, dipisahkan supaya didapatkan data sesuai dengan kebutuhan untuk proses selanjutnya. Tahapan pre-processing data ini memiliki beberapa proses dimana setiap prosesnya saling berkaitan satu sama lainnya. Berikut ini adalah proses-proses tersebut:
1. Data Cleaning
Proses cleaning mencakup beberapa tindakan seperti membuang duplikasi data, memeriksa data inkonsisten, serta memperbaiki kesalahan yang ada pada data, misalnya kesalahan cetak (tipografi). Selain itu dilakukan proses enrichment, yaitu proses untuk memperkaya data, dengan menggunakan data atau informasi lain yang relevan pada data yang sudah ada.
2. Data Integration
Penggabungan data yang berasal dari berbagai sumber basis data menjadi satu basis data yang baru. Terkadang data yang dibutuhkan untuk melakukan data mining bukan berasal dari satu basis data saja, akan tetapi berasal dari beberapa sumber basis data atau file teks. Integrasi data dilakukan terhadap atribut-atribut yang mengidentifikasikan entitas- entitas unik misalnya atribut nama, jenis produk, nomor pelanggan dan yang lainnya. Integrasi data harus dilakukan dengan cermat, dikarenakan kesalahan yang terjadi pada integrasi data dapat memberikan hasil yang
menyimpang, bahkan dapat menyesatkan untuk pengambilan aksi nantinya. Sebagai contoh melakukan integrasi data berdasarkan jenis produk yang menggabungkan produk dengan kategori berbeda, maka akan diperoleh suatu korelasi antar produk yang sebenarnya tidak ada.
3. Data Selection
Data yang terdapat dalam basis data terkadang tidak semuanya digunakan, maka dari itu data yang sesuai untuk dianalisis saja yang akan digunakan dari basis data. Contohnya, suatu kasus yang meneliti tentang faktor kecenderungan seseorang membeli dalam kasus market basket analisis, hanya perlu mengambil id pelanggan saja, tidak perlu nama pelanggan,
4. Data Transformation
Supaya data dapat diproses ke dalam data mining, maka data perlu diubah atau digabung menjadi format yang sesuai. Dalam data mining terdapat beberapa metode yang memerlukan format data khusus sebelum dapat diaplikasikan. Contohnya yaitu beberapa metode standar seperti analisis asosiasi dan clustering yang hanya dapat menerima masukan data kategorial. Oleh karena itu data dalam bentuk angka numerik yang berlanjut perlu untuk dibagi-bagi menjadi beberapa interval. Proses ini biasa dikenal dengan transformasi data.
3.5.2. K-means
Dari percobaan ini diambil beberapa sampel data siswa SMK Luqman Al Hakim Kudus. Sampel data siswa dari tahun 2018 sampai dengan 2020, seperti berikut ini:
Tabel 3.1 Data Siswa Tahun 2018 sampai dengan 2020
No Nama Kecepatan
Menghfal
Makhorijul
Huruf Tajwid Kelancaran Membaca
1 Abdul Hakim A A A A
2 Abdurrahman
Farros Arsalan B B B A
3 Ahmad Izhar
Maulana B B B A
4 Burhan Dwi
Fahmi C C C B
5 Dhuhaalhaq
Abdul Karim B C C B
6 Imam Samudra B B B B
7 Iqdam Haidar
Ahmad C C C C
8 Lukman Hakim C C C C
9 Mohammad
Hisyam Hidayat B B B B
10
Muhammad I Khadafi Djaelani
B B C B
11 Muhammad
Yanuar Rafly A A A A
12 Mush'ab Khalil C C C B
13
Rangga Muhammad Firman Saputra
C C C B
14 Reksi
Pamungkas A A B A
15 Afif Muizzuddin B B B B
16 Ahmad Ridwan
Khoironi B B B B
17 Cavan Rizal
Arrafi B B B B
18 Demas Panki B B B B
1. Transformasi Data
Sebelum masuk ke dalam proses pengolahan data, proses yang perlu dilakukan adalah mentrasformasi bentuk data yang belum memiliki entitas jelas menjadi bentuk data valid atau siap diolah dengan proses data mining.
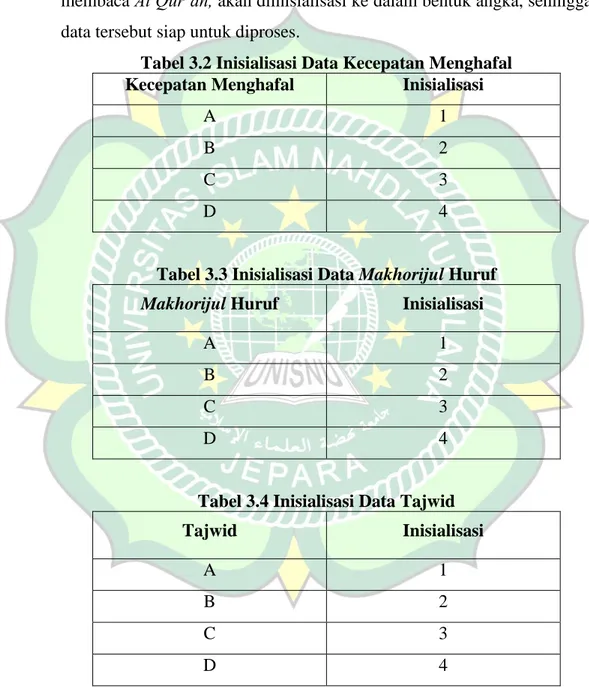
Data kecepatan menghafal, makhorijul huruf, tajwid, dan kelancaran membaca Al Qur’an, akan diinisialisasi ke dalam bentuk angka, sehingga data tersebut siap untuk diproses.
Tabel 3.2 Inisialisasi Data Kecepatan Menghafal Kecepatan Menghafal Inisialisasi
A 1
B 2
C 3
D 4
Tabel 3.3 Inisialisasi Data Makhorijul Huruf Makhorijul Huruf Inisialisasi
A 1
B 2
C 3
D 4
Tabel 3.4 Inisialisasi Data Tajwid
Tajwid Inisialisasi
A 1
B 2
C 3
D 4
Tabel 3.5 Inisialisasi Data Kelancaran Membaca Kelancaran Membaca Inisialisasi
A 1
B 2
C 3
D 4
2. Pengolahan Data
Apabila seluruh data siswa sudah ditransformasikan menjadi bentuk angka, maka data-data tersebut dapat diproses ke tahap selanjutnya, yaitu Data Mining menggunakan metode Clustering algoritma K-means.
Kemudian untuk proses pengelompokan data-data menjadi beberapa cluster perlu dilakukan langkah-langkah seperti berikut ini:
a. Tentukan jumlah cluster yang akan dibuat. Di dalam percobaan ini jumlah cluster adalah empat cluster.
b. Tentukan nilai secara random untuk pusat awal cluster sebanyak cluster yang telah ditentukan. Dengan jumlah cluster adalah empat, maka titik pusat cluster bisa diperhatikan pada tabel 3.6.
Tabel 3.6 Titik Pusat Awal Cluster Titik
Pusat Nama Kecepatan Menghafal
Makhorijul
Huruf Tajwid Kelancaran Membaca
Cluster 1
Abdurrahman Farros
Arsalan
2 2 2 1
Cluster 2 Burhan Dwi
Fahmi 3 3 3 2
Cluster 3 Dhuhaalhaq
Abdul Karim 2 3 3 2
Cluster 4
Muhammad I Khadafi Djaelani
2 2 3 2
c. Metode Hard K-means digunakan pada percobaan ini untuk menempatkan setiap data ke dalam satu cluster. Sehingga data akan dimasukkan ke dalam suatu cluster dengan jarak terdekat terhadap titik pusat dari setiap cluster. Selanjutnya jarak setiap data terhadap titik pusat setiap cluster dihitung untuk mengetahui cluster manakah yang terdekat dengan data. Dibawah ini adalah perhitungan jarak data siswa pertama terhadap pusat cluster pertama:
d(1, 1) = √( ) ( ) ( ) ( )
= √( ) ( ) ( ) ( )
= 1,732
Dari perhitungan di atas diperoleh hasil, jarak data siswa pertama terhadap pusat cluster pertama yaitu 1,732.
Berikut ini adalah perhitungan jarak data siswa pertama terhadap pusat cluster kedua:
d(1, 2) = √( ) ( ) ( ) ( )
= √( ) ( ) ( ) ( )
= 3,606
Dari perhitungan di atas diperoleh hasil, jarak data siswa pertama terhadap pusat cluster kedua yaitu 3,606.
Berikut ini adalah perhitungan jarak data siswa pertama terhadap pusat cluster ketiga:
d(1, 3) = √( ) ( ) ( ) ( )
= √( ) ( ) ( ) ( )
= 3,162
Dari perhitungan di atas diperoleh hasil, jarak data siswa pertama terhadap pusat cluster ketiga yaitu 3,162.
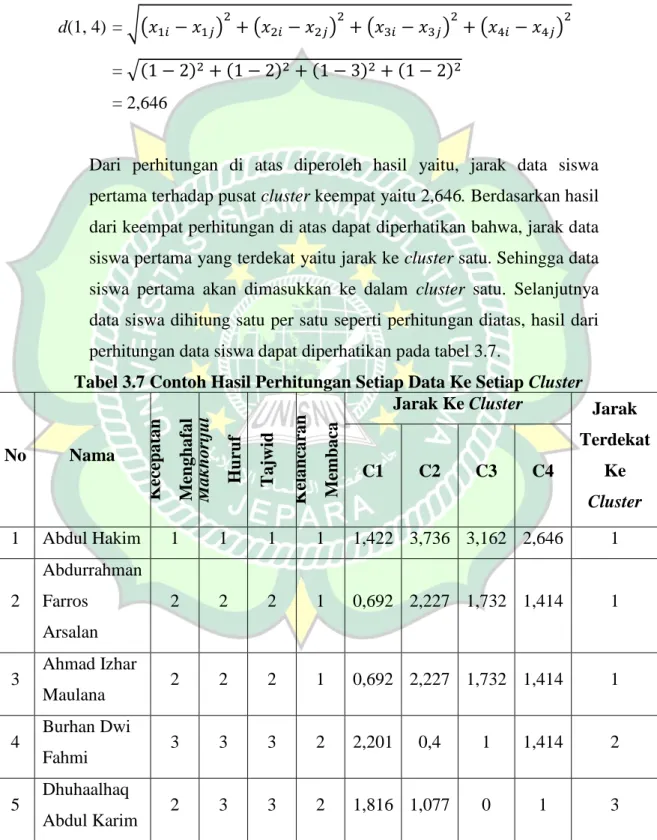
Berikut ini adalah perhitungan jarak data siswa pertama terhadap pusat cluster keempat:
d(1, 4) = √( ) ( ) ( ) ( )
= √( ) ( ) ( ) ( )
= 2,646
Dari perhitungan di atas diperoleh hasil yaitu, jarak data siswa pertama terhadap pusat cluster keempat yaitu 2,646. Berdasarkan hasil dari keempat perhitungan di atas dapat diperhatikan bahwa, jarak data siswa pertama yang terdekat yaitu jarak ke cluster satu. Sehingga data siswa pertama akan dimasukkan ke dalam cluster satu. Selanjutnya data siswa dihitung satu per satu seperti perhitungan diatas, hasil dari perhitungan data siswa dapat diperhatikan pada tabel 3.7.
Tabel 3.7 Contoh Hasil Perhitungan Setiap Data Ke Setiap Cluster
No Nama
Kecepatan Menghafal Makhorijul Huruf Tajwid Kelancaran Membaca
Jarak Ke Cluster Jarak Terdekat
Ke Cluster
C1 C2 C3 C4
1 Abdul Hakim 1 1 1 1 1,422 3,736 3,162 2,646 1
2
Abdurrahman Farros
Arsalan
2 2 2 1 0,692 2,227 1,732 1,414 1
3 Ahmad Izhar
Maulana 2 2 2 1 0,692 2,227 1,732 1,414 1 4 Burhan Dwi
Fahmi 3 3 3 2 2,201 0,4 1 1,414 2
5 Dhuhaalhaq
Abdul Karim 2 3 3 2 1,816 1,077 0 1 3
6 Imam
Samudra 2 2 2 2 0,624 1,778 1,414 1 1
7 Iqdam Haidar
Ahmad 3 3 3 3 2,599 0,6 1,414 1,732 2
8 Lukman
Hakim 3 3 3 3 2,599 0,6 1,414 1,732 2
9
Mohammad Hisyam Hidayat
2 2 2 2 0,624 1,778 1,414 1 1
10
Muhammad I Khadafi Djaelani
2 2 3 2 1,324 1,470 1 0 4
11 Muhammad
Yanuar Rafly 1 1 1 1 1,422 3,736 3,162 2,646 1 12 Mush'ab
Khalil 3 3 3 2 2,201 0,4 1 1,414 2
13
Rangga Muhammad Firman Saputra
3 3 3 2 2,201 0,4 1 1,414 2
14 Reksi
Pamungkas 1 1 2 1 1,178 3,311 2,646 2 1
15 Afif
Muizzuddin 2 2 2 2 0,624 1,778 1,414 1 1
16
Ahmad Ridwan Khoironi
2 2 2 2 0,624 1,778 1,414 1 1
17 Cavan Rizal
Arrafi 2 2 2 2 0,624 1,778 1,414 1 1
18 Demas Panki 2 2 2 2 0,624 1,778 1,414 1 1
d. Setelah semua data dialokasikan ke dalam cluster terdekat, gunakan rata-rata anggota yang terdapat pada cluster tersebut untuk menghitung kembali pusat cluster yang baru.
e. Kemudian apabila sudah diperoleh titik pusat baru pada setiap cluster.
Ulangi langkah ketiga sampai titik pusat dari setiap cluster tidak ada yang berubah dan tidak ada data yang berpindah antara satu cluster ke cluster yang lain.
Dalam percobaan ini, iterasi yang terjadi sebanyak dua kali. Pada iterasi kedua, titik pusat setiap cluster tidak berubah lagi dan tidak ada data yang berpindah antara satu cluster ke cluster yang lain lagi.
3.6. Evaluasi Metode BCV dan WCV
Pada percobaan sampel data siswa SMK Luqman Al Hakim Kudus tahun 2018 sampai dengan 2020, didapat hasil yang mempunyai nilai error.
Ketika hasil dari perhitungan mempunyai nilai error yang kecil, maka akan semakin baik hasil yang diperoleh. Ketika hasil perhitungan mempunyai nilai error tinggi maka hasil yang diperoleh kurang baik. Terdapat beberapa tahapan atau proses dalam melakukan pengujian ini. Berikut proses perhitungan nilai error yang digunakan pada penelitian ini:
1. Menentukan iterasi keberapa yang akan dihitung
Iterasi yang dipakai adalah iterasi terakhir, karena iterasi terakhir mempunyai centroid yang baik dibanding iterasi sebelumnya. Maka dari itu iterasi terakhirlah yang akan digunakan. Pada percobaan ini menggunakan sampel data siswa SMK Luqman Al Hakim Kudus tahun 2018 sampai dengan 2020. Data tersebut dapat diperhatikan pada tabel berikut:
Tabel 3.8 Nilai Centroid Pada Iterasi Terakhir Titik Pusat Kecepatan
Menghafal
Makhorijul
Huruf Tajwid Kelancaran Membaca
Cluster 1 1,7 1,7 1,8 1,5
Cluster 2 3 3 3 2,4
Cluster 3 2 3 3 2
Cluster 4 2 2 3 2
Selanjutnya hitung nilai centroid menggunakan persamaan BCV (Between-Class Variation)
BCV = √( ) ( ) ( ) ( ) √( ) ( ) ( ) ( ) √( ) ( ) ( ) ( ) √( ) ( ) ( ) ( ) √( ) ( ) ( ) ( ) √( ) ( ) ( ) ( )
= 3,839
2. Menentukan jarak minimum centroid
Jarak minimum pusat centroid yang digunakan berasal dari iterasi terakhir. Setelah jarak minimum dengan nilai pusat centroid diperoleh, selanjutnya menghitung seluruh jarak minimum menggunakan persamaan WCV (Within-Class Variation).
WCV =
= 9,927
Hasil yang diperoleh adalah WCV= 9,927.
3. Menghitung perbandingan BCV dan WCV
Hitung nilai perbandingan dari BCV (Between-Class Variation) dengan WCV (Within-Class Variation) sehingga diperoleh nilai error. Hitung menggunakan persamaan rasio, seperti berikut ini.
Rasio =
= 0,387
Setelah didapatkan hasil rasio, selanjutnya perhatikan kriteria pengukuran rasio untuk menentukan bagus atau tidaknya hasil pengujian yang diperoleh, kriteria pengukuran rasio dapat diperhatikan pada tabel 2.8. Nilai rasio yang diperoleh dari hasil pengujian menggunakan perbandingan BCV (Between-Class Variation) dan WCV (Within-Class Variation) adalah 0,387. Maka tingkat penggunaan nilai sample data centroid memiliki kualitas yang baik.