i
Analisis Data Cube Menggunakan Multiway Array Aggregation For F ull Cube Computation
(Studi Kasus Data Penyakit tahun 2010 hingga 2012 di Puskesmas Jebed Kabupaten Pemalang)
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat Mendapatkan Gelar Sarjana Komputer
Oleh
Ratna Yani Astuty 095314035
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
Cube Data Analysis Using Multiway Array Aggregation For F ull Cube Computation
(Case Study Disease Data from 2010 to 2012 at the health center Jebed Pemalang)
A Thesis
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree In Study Program of Informatics Engineering
By
Ratna Yani Astuty 095314035
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF SCIENCE AND TECHNOLOGY
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
PERNYATAAN KEASLIAN KARYA
Saya menyatakan bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 23 Agustus 2013 Penulis
vi
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Ratna Yani Astuty
NIM : 095314035
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
“Analisis Data Cube Menggunakan Multiway Array Aggregation For Full
Cube Computation (Studi Kasus Data Penyakit tahun 2010 hingga 2012 di Puskesmas Jebed Kabupaten Pemalang)”
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royaliti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta
Pada tanggal 23 Agustus 2013 Yang menyatakan,
vii
KATA PENGANTAR
Puji dan syukur kepada Allah Bapa Yang Maha Kuasa atas semua berkat dan Roh Kudus-Nya yang melimpah, sehingga penulis dapat menyelesaikan skripsi yang berjudul “Analisis Data Cube Menggunakan Multiway Array Aggregation For Full Cube Computation (Studi Kasus Data Penyakit tahun 2010 hingga 2012 di Puskesmas Jebed Kabupaten Pemalang)”.
Pada kesempatan ini saya ingin mengucapkan terima kasih kepada pihak – pihak yang telah membantu saya dalam menyelesaikan skripsi ini, baik dalam hal bimbingan, perhatian, kasih sayang, semangat, kritik, dan saran yang telah diberikan. Ucapan terima kasih ini saya sampaikan antara lain kepada :
1. Ibu PH.Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
2. Bapak Iwan Binanto, M.Cs., selaku Dosen Pembimbing Akademik Teknik Informatika Tahun 2009.
3. Ibu Ridowati Gunawan, S.Kom., M.T. selaku Ketua Prodi Teknik Informatika sekaligus Dosen Pembimbing TA, yang dengan sabar membimbing penulis dalam menyusun skripsi.
4. Ibu PH.Prima Rosa, S.Si., M.Sc., dan Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku dosen penguji yang telah meluangkan waktu untuk memberikan bimbingan, kritik dan saran untuk kesempurnaan skripsi ini.
viii
6. Kepala Puskesmas Jebed, Pemalang, dr. Setiawan Raharjana, dan seluruh keluarga besar Puskesamas Jebed, Pemalang.
7. Kedua Orang Tua, Bapak dan Ibu yang selalu memberikan dukungan, doa, perhatian dan sabar membimbing penulis. Adik tercinta, Retno, yang mendukung penulis dengan doa dan semangat.
8. Y.Deni Rahman Pranyoto, yang selalu menjadi sahabat, penyemangat, dan selalu ada di saat suka dan duka, terima kasih untuk segalanya. Maaf karena selalu merepotkanmu.
9. Bapak Andi, Ibu Tarmi, Elsa, yang dengan penuh kasih selalu memberikan dukungan, kasih sayang dan semangat yang tiada henti.
10.Astriana, Rafaela Rosi, Andhini, Retty, Kak Merry, Anas, Karl, Audris serta teman-teman seperjuangan TI’09 untuk kebersamaannya serta motivasi yang diberikan selama penulis menjalani masa studi.
11.Seluruh pihak yang membantu penulis baik secara langsung maupun tidak langsung, yang tidak dapat penulis sebutkan satu persatu.
Saya menyadari masih banyak kekurangan yang terdapat pada skripsi ini. Saran dan kritik selalu saya harapkan dari pembaca untuk perbaikan – perbaikan di masa yang akan datang. Akhir kata, saya berharap tulisan ini dapat bermanfaat bagi kemajuan dan perkembangan ilmu pengetahuan dan berbagai pihak pengguna pada umumnya.
Yogyakarta, 23 Agustus 2013
ix ABSTRAK
Analisis Data Cube Menggunakan Multiway Array Aggregation For F ull Cube Computation
Studi Kasus : Data Penyakit tahun 2010 hingga 2012 di Puskesmas Jebed Kabupaten Pemalang
Ratna Yani Astuty Universitas Sanata Dharma
Yogyakarta 2013
Data cube adalah model presentasi data multidimensi, contohnya pada studi kasus ini terdapat dimensi seperti nama penyakit, waktu, kelompok umur. Dimensi-dimensi pada data cube dapat dibuat bertingkat, contohnya dimensi waktu dapat dibagi menjadi bulan, tahun, dan lainnya.
Pembangunan data cube harus dilakukan sebaik mungkin agar data dapat ditampilkan dengan proses yang cepat. Sehingga, penerapan metode komputasi untuk pembangunan cube sangat diperlukan agar data dapat ditampilkan dengan lebih cepat. Dalam pembangunan cube digunakan Metode Multiway Array Aggregation yang memakai aturan group-by dimensi rendah diagregasikan dari group-by dengan dimensi tinggi (disebut juga pendekatan top-down). Metode komputasi ini digunakan dalam pembangunan cube untuk data penyakit tersebut agar dapat menentukan cube yang tepat untuk dipakai dalam OLAP sehingga data penyakit dapat ditampilkan lebih cepat.
x ABSTRACT
Cube Data Analysis Using Multiway Array Aggregation For F ull Cube Computation
Case Study : Disease Data from 2010 to 2012 at the health center Jebed Pemalang Ratna Yani Astuty
Universitas Sanata Dharma Yogyakarta
2013
The data cube is a presentation of multidimensional data models. In this case study, there are dimensions such as the name of the disease, time, age group. Dimensions in the data cube can be nested, for example, the time dimension can be divided into months and years.
The construction of the data cube should be well done so that the data can be displayed with a fast process. Thus, the application of computational methods for the construction of the cube is needed, so data can be displayed more quickly. The method used in the construction cube is Multiway Array Aggregation rules that use low-dimensional group-by aggregated from group-by with high dimensional (also called top-down approach). This computational method is used in the construction of a data cube for the disease data in order to determine the appropriate cube for the data used in OLAP disease so it can be displayed more quickly.
xi DAFTAR ISI
HALAMAN JUDUL……… i
HALAMAN JUDUL INGGRIS………. ii
HALAMAN PERSETUJUAN……… iii
HALAMAN PENGESAHAN……… iv
LEMBAR PERNYATAAN KEASLIAN KARYA……… v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI vi
KATA PENGANTAR ………... vii
ABSTRAK ………. ix
ABSTRACT……… x
DAFTAR ISI……… xi
DAFTAR TABEL……… xiv
DAFTAR GAMBAR……… xv
BAB I PENDAHULUAN 1.1 Latar Belakang ………..……… 1
1.2 Rumusan Masalah ……… 3
1.3 Tujuan Penelitian ………..………..…… 4
1.4 Batasan Masalah …..……….. 4
1.5 Metodologi ………….………. 4
1.6 Sistematika Penulisan ………. 5
BAB II LANDASAN TEORI 2.1 Gudang Data……….………. 7
xii
2.3 OLAP (Online Analytical Processing) …..………...……. 10
2.4 Pre-Processing ………..………. 11
2.5 Multidimensional Modelling………... 14
2.6 Skema Bintang (Star Schema)…….………... 15
2.7 Multiway Array Aggregation For Full Computation ……… 19
BAB III ANALISIS DAN DESAIN 3.1 Identifikasi dan Analisis Kebutuhuan.……….………….. 23
3.2 Mengumpulkan dan Menganalisis Sumber Data ……….. 25
3.3 Mengubah Data Penyakit ke dalam Gudang Data ……… 26
3.2.1 Membaca Data Legacy ………..…..….. 26
3.2.2 Menggabungkan Data dari berbagai Sumber Terpisah ……. 30
3.3.3 Memindahkan Data dari Sumber ke Server Gudang Data …… 33
3.3.4 Memecah Gudang Data ke dalam tabel fakta dan tabel dimensi 38 3.4 Membuat Skema Bintang…………..…….………... . 45
3.5 Membangun Cube……….……..………. 46
3.6 Menganalisis Cube………. . 51
BAB IV IMPLEMENTASI 4.1 Arsitektur Sistem………. ………. 52
4.2 Implementasi Usecase……….……… 53
BAB V ANALISIS HASIL 5.1 Penyelesaian Rumusan Masalah ……… 61
xiii BAB VI KESIMPULAN
6.1 Kesimpulan……….………… 76
6.2 Saran………..……….……… 77
xiv
DAFTAR TABEL
Tabel 2.1 Karakteristik Gudang Data ……….. 8
Tabel 3.1 Tabel Daftar Cube dan Cuboid ……….. 48
Tabel 4.1 Tabel daftar kelas ……… 54
Tabel 5.1 Tabel Pengujian Waktu ……….. 66
Tabel 5.2 Tabel Pengujian Waktu berdasarkan jumlah data ….. 68
Tabel 5.3 Tabel pengujian waktu berdasarkan penambahan jumlah data N = 1920,W = 36,K = 8………..………… 69
Tabel 5.4 Tabel pengujian waktu berdasarkan penambahan jumlah data N= 192, W = 365, K = 8……….. 70
Tabel 5.5 Tabel pengujian waktu berdasarkan penambahan jumlah data N=192, K=80, W=36……… 71
Tabel 5.6 Tabel perbandingan pengujian waktu dengan jumlah data N = 192,K = 8,W = 36 ……….. 72
Tabel 5.7 Tabel perbandingan pengujian waktu dengan jumlah data N = 1920, W = 36,K = 8 ……… 72
Tabel 5.8 Tabel perbandingan pengujian waktu dengan jumlah data N= 192, W = 365, K = 8 ……… 73
Tabel 5.9 Tabel perbandingan pengujian waktu dengan jumlah data N=192, K=80, W=36 ……….. 73
xv
DAFTAR GAMBAR
Gambar 2.1 Tahapan dalam data mining ……….. 14
Gambar 2.2 Skema bintang dari PHI Minimart……… 15
Gambar 2.3 3-D array dimensi A,B,C yang dipartisi 64 chunks.. …. 16
Gambar 3.1 Contoh data laporan data penyakit dan kunjungantotal bulan Januari tahun 2010………. 25
Gambar 3.2 Diagram usecase……….. 26
Gambar 3.3 Langkah Pre-prosessing mengubah header………. ……. 27
Gambar 3.4 Langkah Pre-prosessing menghapus data bukan penyakit 28 Gambar 3.5 Langkah Pre-prosessing menambah kolom bulan dan tahun .29 Gambar 3.6 Contoh Data I ……… 30
Gambar 3.7 Contoh Data II ……….. 32
Gambar 3.8 Contoh Data III ………. 33
Gambar 3.9 Database penyakit………. 34
Gambar 3.10 Nama_penyakit.ktr ……… 38
Gambar 3.11 Tabel dim_nama_penyakit ……… 39
Gambar 3.12 Waktu.ktr ……… 40
Gambar 3.13 Tabel dim_waktu ……… 40
Gambar 3.14 Kelompok_umur.ktr ………... 41
Gambar 3.15 Tabel dim_kelompok_umur ……….. 41
Gambar 3.16 Penyakit.ktr ………... 42
xvi
Gambar 3.18 Fact_penyakit.ktr ……….. 43
Gambar 3.19 Tabel fact_penyakit………. 44
Gambar 3.20 Skema Bintang……… 45
Gambar 3.21 Cube penyakit ………. 46
Gambar 4.1 Arsitektur Sistem………. 52
Gambar 4.2 Pemantauan Data Penyakit………. 54
Gambar 5.1 Hasil Implementasi Perhitungan Multiway Array Aggregation………. 63
Gambar 5.2 Hasil implementasi……….. 64
Gambar 5.3 Hasil implementasi OLAP……….. 65
Gambar 5.4 Contoh penggunaan calculating page loading time…… 66
BAB I PENDAHULUAN
Pada Bab I ini memaparkan latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian yang digunakan, dan sistematika penulisan.
1.1 Latar Belakang
Kesehatan adalah salah satu komponen utama selain pendidikan dan pendapatan. Kesehatan juga merupakan investasi untuk mendukung pembangunan ekonomi dan menanggulangi kemiskinan. Kesehatan dapat dipandang sebagai suatu investasi untuk meningkatkan kualitas sumber daya manusia (Depkes Jawa Tengah, 2006). Oleh sebab itu, memperoleh layanan kesehatan adalah salah satu hak dasar masyarakat.
Pemerintah memiliki peran penting dalam peningkatan kesehatan. Salah satu upayanya adalah menghitung jumlah penyakit dengan penderita terbanyak setiap bulan dalam setiap tahunnya untuk diprioritaskan dalam program pencegahan. Upaya ini dilakukan dengan memantau data penyakit mulai dari tingkat desa/kelurahan dengan melakukan survei kemudian membuat perhitungan jumlah penderita untuk setiap penyakit. Data – data penyakit dari survei ini disimpan oleh suatu teknologi penyimpanan untuk kemudian dipantau oleh dinas kesehatan untuk program pencegahan.
“gunungan” data. Namun, kemampuan teknologi informasi untuk menganalisis, meringkas, dan mengekstraksi “pengetahuan” dari sejumlah data
masih kurang. Seperti pada studi kasus dalam tugas akhir ini, data penyakit di Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah dikelola menggunakan MS Excel. Metodologi tradisional tersebut kurang cepat untuk menangani data dalam jumlah yang besar sehingga visualisasi data juga menjadi kurang, misalnya belum bisa merepresentasikan data dalam berbagai tampilan data serta belum mendukung untuk representasi data grafik yang dinamis.
Berdasarkan uraian tersebut, penelitian ini dilakukan untuk menganalisis data penyakit dari Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah agar dapat ditampilkan dengan cepat sehingga pemerintah dapat memprioritaskan dalam program pencegahan. Sehingga, untuk menjawab kebutuhan ini penelitian ini akan menggunakan Online Analytical Process yang merupakan teknologi untuk memproses dan menganalisis data dalam waktu yang singkat pada struktur yang multidimensi.
warehouse memungkinkan pemakai untuk menganalisis data operasi sehari-hari dengan berbagai sudut pandang. Oleh sebab itu, pembangunan cube harus dilakukan sebaik mungkin agar data dapat ditampilkan dengan proses yang cepat. Sehingga, penerapan metode komputasi untuk pembangunan cube sangat diperlukan agar data dapat ditampilkan dengan lebih cepat. Ada dua prinsip komputasi data cube yaitu sharing komputasi dan penggunaan iceberg constraint. Pada prinsip pertama ini berlaku aturan group-by dimensi rendah diagregasikan dari group-by dengan dimensi tinggi (disebut juga pendekatan top-down), contohnya metode Multiway Array Aggregation. Sedangkan prinsip kedua bertujuan untuk memangkas komputasi yang tidak penting dengan iceberg constraint. Dalam tugas akhir ini, penelitian ini akan membahas mengenai metode
komputasi dalam hal ini Multiway Array Aggregation dalam pembangunan cube untuk data penyakit tersebut agar dapat menentukan cube yang tepat untuk dipakai dalam OLAP sehingga data dapat ditampilkan lebih cepat.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah di atas, maka rumusan masalah yang dipaparkan sebagai berikut:
1.3 Tujuan Penelitian
Tujuan penelitian ini adalah untuk mendapatkan cube yang tepat untuk pembuatan database Online Analytical Process (OLAP) dari data penyakit dari Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah tahun 2010 hingga 2012 sehingga dapat divisualisasi dengan efektif dan cepat.
1.4 Batasan Masalah
Agar penulisan tugas akhir ini tidak keluar dari inti dan tujuannya serta tidak menjadi luas dan kompleks, maka ada beberapa batasan untuk tugas akhir ini, yaitu :
1. Data yang diambil adalah data penyakit dari Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah tahun 2010 hingga 2012.
2. Implementasi pembuatan tabel dimensi dan tabel fakta menggunakan Kettle (Pentaho Data Integration).
3. Sistem ini hanya digunakan untuk simulasi Multiway Array Aggregation untuk data penyakit dari Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah tahun 2010 hingga 2012.
4. Perangkat lunak yang digunakan untuk membangun simulasi Multiway Array Aggregation adalah bahasa pemrograman Java dan bahasa
pemrograman JSP.
1.5 Metodologi Penelitian
2. Mengumpulkan dan menganalisis sumber data
3. Mengubah data penyakit ke dalam gudang data (data warehouse) Membaca data legacy
Menggabungkan data dari berbagai sumber terpisah Memindahkan data dari sumber ke server gudang data
Memecah gudang data ke dalam tabel fakta dan tabel dimensi 4. Membuat skema bintang
5. Membangun cube 6. Menganalisis cube
1.6 Sistematika Penulisan Bab I. Pendahuluan
Bab ini berisi latar belakang pemilihan judul tugas akhir, rumusan masalah, batasan masalah, tujuan penelitian dilakukan, metodologi penelitian, dan sistematika penulisan tugas akhir.
Bab II. Landasan Teori
Bab III. Analisis dan Desain
Bab ini berisi analisis dan perancangan untuk metode Multiway Array Aggregation dalam analisis masalah dari data cube penyakit yang ada di Puskesmas Jebed,Pemalang, Jawa Tengah.
Bab IV. Implementasi
Pada bab ini berisi pembuatan sistem simulasi Multiway Array Aggregation.
Bab V. Analisis Hasil
Bab ini berisi laporan hasil simulasi Multiway Array Aggregation dan analisis perbandingan waktu akses dalam proses visualisasi data dengan cube.
Bab VI. Kesimpulan
BAB II
LANDASAN TEORI
Pada bab ini akan dipaparkan teori-teori yang digunakan untuk menyusun tugas akhir ini, yaitu data-warehouse, cube, Multiway Array Aggregation sebagai metode dalam perhitungan data cube.
2.1 Gudang Data (Data Warehouse)
Menurut Inmon (dalam Jiawei, 2006:106), Data warehouse adalah koleksi data yang bersifat subject-oriented, terintegrasi, time-variant, dan non-volatile yang digunakan untuk mendukung proses pengambilan keputusan yang strategis, di mana setiap unit dari data adalah non-volatile dan relevan untuk waktu tertentu. Data warehouse memungkinkan pengguna untuk melakukan pemeriksaan
terhadap data untuk melakukan analisis terhadap data dalam beragam cara dan membuat keputusan yang didasarkan pada hasil analisis. Untuk pembuatan gudang data dilakukan langkah-langkah pokok, seperti di bawah ini (Wasito, 2010) :
1. Membaca data legacy.
Memperhatikan bagian-bagian data yang perlu dibersihkan. 2. Menggabungkan data dari berbagai sumber terpisah.
Setiap jenis informasi yang diinginkan mungkin berasal dari beberapa file yang harus digabungkan untuk digunakan pada gudang data.
4. Membuat standarisasi format dan copy-kan data dari sumber sekaligus data dibuat bersih (clean).
5. Memecah gudang data dalam tabel fakta dan tabel dimensi. Tabel fakta dan tabel dimensi disusun menurut kebutuhan subyek.
Gudang data memiliki karakteristik utama sebagai berikut : Tabel 2.1 : Karakteristik Gudang Data
Karakteristik Deskripsi
Subject Orientation Data diorganisir sesuai dengan kebutuhan user. Integrated Menghilangkan kerancuan dalam hal penamaan
dan kekacauan informasi. Data harus “clean”.
Non-volatile Data hanya dapat dibaca, tidak dapat diubah oleh user.
Time-series Data dalam rangkaian waktu, bukan hanya status saat ini.
Summarized Data operasional dikumpulkan (diringkas) untuk mendukung keputusan.
Larger Memelihara data dari waktu ke waktu selama diperlukan.
Not-Normalized Data dapat redundant.
Metadata Data mengenai data untuk user dan personil gudang data.
dibutuhkan.
2.2 Pentaho Data Integration (Kettle)
Pentaho Data Integration (PDI) atau Kettle adalah utilities ETL open source di bawah Pentaho Corp. Amerika. Kettle terdiri dari 4 aplikasi yang
dijalankan melalui shell atau batch script yang berkaitan, yaitu (http://pentaho.phi-integration.com/kettle) :
Spoon, yaitu aplikasi grafis berbasis swing yang digunakan untuk
merancang file skema job dan transformation
Pan, yaitu script yang digunakan untuk menjalankan file skema
transformation melalui terminal / command line
Kitchen, yaitu script yang digunakan untuk menjalankan file skema
job melalui terminal / command line
Carte, yaitu temporary web server yang digunakan untuk
mengeksekusi job/transformation secara cluster atau parallel
Saat ini Kettle merupakan utilitas ETL yang sangat popular dengan beberapa fitur sebagai berikut (http://pentaho.phi-integration.com/kettle) :
1. Memiliki utilitas grafik yang dapat digunakan merancang control flow umum maupun data flow (aliran data).
3. Bersifat concurrent, dalam arti row-row data diambil oleh suatu step dan diserahkan ke step lain secara parallel.
4. Scalable - dapat beradaptasi dengan penambahan kapasitas memori RAM atau pun storage (scale up) dan dapat node komputer / cluster (scale out).
5. Koleksi step transformation dan job yang cukup banyak
6. Extensible, kita dapat membuat step transformation dan job baru dengan sistem plugin.
7. Dukungan luas berbagai produk database yang terkenal di pasaran baik itu proprietary maupun free open source seperti Oracle, SQL Server, MySQL, PostgreSQL dan lain sebagainya.
2.3 OLAP (Online Analytical Processing)
(Han dan Kamber, 2006) :
Roll-up : melakukan konsolidasi data dengan cara meningkatkan
tingkat suatu hirarki cube data pada multidimensional data sehingga pada saat roll-up dilakukan, maka jumlah dimensi akan berkurang. Contohnya, operasi roll-up yang dilakukan pada cube data di tingkat kecamatan menjadi tingkat kabupaten.
Drill-down : merupakan kebalikan dari roll-up dengan menurunkan
tingkat suatu hirarki cube data sehingga dapat merepresentasikan cube untuk memberikan informasi lebih detil/terperinci.
Slicing dan dicing : digunakan untuk melihat data dari titik pandangan
yang berbeda. Dimana, slicing dilakukan dengan cara memilih satu dimensi dari suatu cube sedangkan dicing dilakukan dengan cara memilih dua atau lebih dimensi dari suatu cube sehingga menghasilkan subcube.
2.4 Pre-Processing
Pre-processing merupakan tahapan dalam membangun data mining yang digunakan untuk membersihkan data dari segala noise. Tahap ini akan dilakukan dalam pembentukan gudang data (data warehouse) karena di dalam gudnag data membutuhkan data yang sudah bersih. Berikut ini merupakan langkah-langkah pre-processing (Han&Kamber, 2006):
1. Pembersihan data ( data cleaning )
konsisten akan dihapus. Langkah pertama yang dilakukan dalam proses pembersihan data adalah mendeteksi ketidakcocokan. Ketidakcocokan tersebut dapat disebabkan oleh beberapa factor antara lain adanya kesalahan petugas ketika memasukkan data, kemungkinan adanya kesalahan yang disengaja dan adanya data yang tidak sesuai. 2. Integrasi data ( data integration )
Pada proses ini akan dilakukan penggabungan data. Data digabungkan dari beberapa tempat penyimpanan akan digabungkan ke dalam satu tempat penyimpanan data yang koheren.
3. Seleksi data ( data selection )
Pada proses ini data yang relevan akan diambil dari basis data untuk dianalisis. Pada langkah ini, akan dilakukan analisis korelasi untuk analisa fitur. Atribut – atribut data yang ada akan dilakukan pengecekkan apakah atribut tersebut relevan untuk di-mining. Atribut yang tidak relevan atau atribut yang mengalami redudansi tidak akan digunakan atau diabaikan. Atribut yang akan digunakan adalah atribut yang bersifat independen. Atribut yang independen adalah atribut yang antara satu atribut dengan atribut yang lainnya tidak saling mempengaruhi.
4. Transformasi data ( data transformation )
yang ada pada data, generalisasi ( generalization ) yaitu mengganti data primitive atau data level rendah menjadi data level tinggi, normalisasi ( normalization ) yaitu mengemas data atribut ke dalam skala yang kecil, dan konstruksi atribut atau fitur ( attribute construction atau feature construction ) yaitu mengkonstruksi dan menambahkan atribut baru untuk membantu dalam proses penambangan.
5. Penambangan data ( data mining )
Pada proses ini akan diaplikasikan metode yang tepat untuk mengekstrak pola data.
6. Evaluasi pola ( pattern evaluation )
Proses ini dilakukan untuk mengidentifikasi pola yang benar dan menarik. Pola tersebut akan direpresentasikan dalam bentuk pengetahuan berdasarkan beberapa pengukuran yang penting.
7. Presentasi pengetahuan ( knowledge presentation )
Pada langkah ini informasi yang sudah ditambang akan divisualisasikan dan direpresentasikan kepada pengguna.
Gambar 2.1 Tahapan dalam Data Mining Sumber : Han&Kamber(2006)
2.5 Multi Dimensional Modelling
Teknologi OLAP menganut multi dimensional modeling yang berarti user dapat melihat analisis pengukuran dengan berbagai dimensi sebagai pandangannya. Di dalam konsep ini, istilah - istilah yang berkaitan dengan OLAP adalah :
1. Cube : struktur multi dimensional konseptual, terdiri dari dimension dan measure dan biasanya mencakup pandangan bisnis tertentu. 2. Dimension : disebut juga dengan dimensi, merupakan view / sudut
pandang yang menyusun cube. Dimensi terdiri dari berbagai level.
4. Member : isi / anggota dari suatu dimensi / measure tertentu.
Di dalam model multi-dimensional, database terdiri dari beberapa tabel fakta dan tabel dimensi yang saling berkaitan. Tabel fakta merupakan tabel yang berisi fakta numerik. Suatu tabel fakta berisi berbagai nilai agregasi yang menjadi dasar pengukuran (measure) serta beberapa key yang terkait ke tabel dimensi yang akan menjadi sudut pandang dari measure tersebut. Tabel dimensi yaitu tabel yang berisi petunjuk ke tabel fakta, digunakan untuk menunjukan darimana data dapat ditemukan dan tabel terpisah dibutuhkan untuk setiap dimensi. Pada tabel dimensi terdapat surrogate key yang merupakan primary key untuk tabel tersebut. Nilai ini biasanya berupa nilai sekuensial dan tidak memiliki arti dari proses bisnis darimana sumber data berasal.
Dalam perkembangannya, susunan tabel fakta dan tabel dimensi ini memiliki standar perancangan atau yang disebut dengan schema karena terbukti meningkatkan performa dan kemudahan dalam penerjemahan ke sistem OLAP. Schema inilah yang nantinya menjadi dasar untuk melakukan data warehousing. Dua schema yang paling umum digunakan oleh berbagai OLAP engine adalah skema bintang (star schema) dan skema butir salju (snowflake schema).
2.6 Skema Bintang (Star Schema)
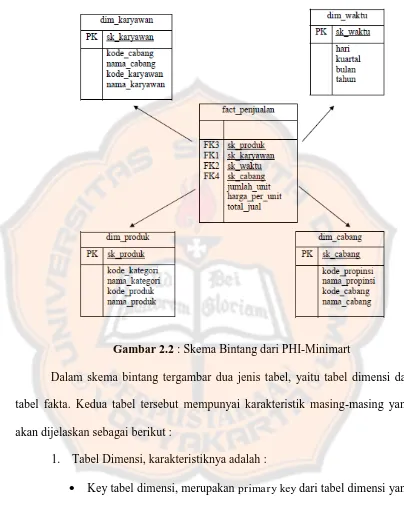
Gambar 2.2 : Skema Bintang dari PHI-Minimart
Dalam skema bintang tergambar dua jenis tabel, yaitu tabel dimensi dan tabel fakta. Kedua tabel tersebut mempunyai karakteristik masing-masing yang akan dijelaskan sebagai berikut :
1. Tabel Dimensi, karakteristiknya adalah :
Key tabel dimensi, merupakan primary key dari tabel dimensi yang mengidentifikasi setiap baris dalam tabel secara unik.
Atribut berupa teks. Dalam tabel dimensi, jarang ditemukan nilai numerik untuk perhitungan, atribut umumnya berupa teks yang merepresentasikan deskripsi tekstual dari komponen-komponen dalam dimensi bisnis.
Atribut-atribut tidak berhubungan secara langsung.
Tidak dinormalisasi. Untuk kinerja query yang efektif, paling baik jika query mengambil dari tabel dimensi dan langsung ke tabel fakta tanpa melalui tabel perantara yang akan terbentuk jika tabel dimensi dinormalisasi.
Kemampuan drill-down dan roll-up. Atribut-atribut dalam tabel dimensi menyediakan kemampuan untuk mendapatkan detail dari tingkat tinggi agregasi sampai tingkat detail yang rendah.
Terdapat beberapa hirarki. Berbagai bagian perusahaan dapat mengelompokkan dimensi dengan cara yang berbeda, sehingga terbentuk lebih dari 1 hirarki.
Jumlah record yang lebih sedikit. Tabel dimensi umumnya memiliki jumlah record atau baris yang lebih sedikit dari tabel fakta.
2. Tabel fakta, karakteristiknya adalah :
key dari tabel fakta merupakan gabungan primary key dari semua tabel dimensi.
Data grain, merupakan tingkat detail untuk pengukuran. Sebagai contoh, jumlah pemesanan berhubungan dengan jumlah produk tertentu pada suatu pesanan, tanggal tertentu, untuk pelanggan spesifik dan diperoleh oleh seorang perwakilan penjualan spesifik tertentu. Jika jumlah pesanan dilihat sebagai jumlah untuk suatu produk perbulan, maka data grain-nya berbeda dan pada tingkat yang lebih tinggi.
Fully additive measures. Agregasi dari fully additive measures dilaksanakan dengan penjumlahan sederhana nilai-nilai atribut tersebut.
Semiadditive measures. Semiadditive measures merupakan nilai yang tidak dapat langsung dijumlahkan, sebagai contoh persentase keuntungan. Tabel besar, tidak lebar. Tabel fakta umumnya memiliki lebih sedikit atribut daripada tabel dimensi, namun memiliki jumlah record yang lebih banyak.
Sparse data. Tabel fakta tidak perlu menyimpan record yang nilainya null. Maka tabel fakta dapat memiliki gap.
contoh, mencari rata-rata jumlah produk per pesanan, maka produk harus dihubungkan ke nomor pesanan untuk mendapatkan nilai rata-rata. Atribut-atribut tersebut disebut degenerate dimension dan disimpan sebagai atribut dari tabel fakta.
2.7 MultiwayArray Aggregation For Full Cube Computation
Multiway Array Aggregation merupakan metode untuk menghitung ukuran data cube dengan menggunakan array multidimensi sebagai struktur data yang dasar. Metode ini, digunakan dengan tujuan dapat mempersingkat waktu dalam menampilkan data. Metode ini menggunakan array untuk menangani perhitungan nilai-nilai dimensi. Nilai – nilai itu diakses melalui posisi atau indeks lokasi array yang terkait.
Metode ini menggunakan langkah – langkah untuk menghitung ukuran data cube, sebagai berikut :
1. Mempartisi array menjadi chunk.
Chunk merupakan sub-cube yang cukup kecil untuk dapat dimasukkan ke dalam memori yang tersedia yang digunakan untuk melakukan perhitungan cube. Chunking adalah metode untuk membagi array n-dimensi menjadi n-dimensi potongan, di mana potongan disimpan sebagai objek pada disk. Potongan dikompres sehingga dapat digunakan untuk menghapus ruang kosong yang dihasilkan dari sel array kosong (sel-sel yang tidak mengandung data yang valid atau yang jumlah selnya adalah nol).
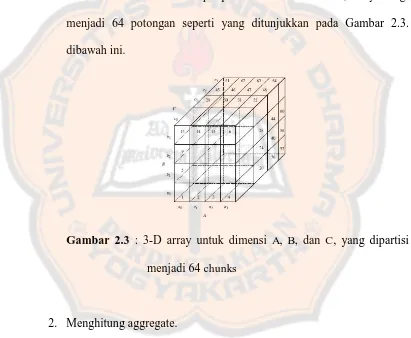
Misalkan, dimiliki cube dengan ukuran tiga dimensi (3D). Kemudian data dari dimensi ini diubah ke dalam data array untuk dapat dilakukan perhitungan. 3-D Data array yang berisi tiga dimensi A, B, dan C dipartisi menjadi chunk (sub-cube). Misalkan, dimensi A dibagi dalam empat sama besar partisi a0, a1, a2, a3 begitu pula Dimensi B dan C sama-sama diatur dalam empat partisi. Dalam contoh ini, array dibagi menjadi 64 potongan seperti yang ditunjukkan pada Gambar 2.3. dibawah ini.
Gambar 2.3 : 3-D array untuk dimensi A, B, dan C, yang dipartisi menjadi 64 chunks
2. Menghitung aggregate.
melibatkan chunking beberapa perhitungan agregasi sehingga disebut sebagai multiway array aggregation. Pada metode ini, penghitungan agregasi dilakukan secara bersamaan pada beberapa dimensi.
Untuk lebih jelasnya, dapat diperhatikan contoh berikut ini : Misalkan, dimiliki cube dengan ukuran tiga dimensi (3D) yaitu A, B, C dengan ukuran data untuk masing – masing dimensi adalah 40, 400, 4000. Kemudian untuk langkah pertama yang dilakukan adalah mempartisi ke dalam chunk. Masing – masing besar data dibagi sama besar yaitu dibagi dalam partisi 4 maka hasilnya adalah 10, 100, 1000. Kemudian urutan dari cubenya adalah sebagai berikut :
Base cuboid : ABC 2- cuboid : AB , AC, BC 1-cuboid : A, B, C 0-cuboid : all
Setelah itu dilakukan penghitungan agregasi, dengan mengakses nilai-nilai yang ada pada sel di dalam cube melewati dua alur yaitu kanan dan kiri, contohnya adalah :
ABC
AB AC BC
A B C
ABC
AB AC BC
A B C
Untuk perhitungannya adalah perkalian antara besar data setiap dimensi yang dilewati, namun ketika melewati dimensi yang pernah dilewati maka perkalian dilakukan dengan nilai partisi dari dimensi yang telah dilewati. Perhitungan untuk alur AB adalah sebagai berikut (A*B) + ((A`)*C) + ((B`)*(C`)) = (40*400)+(10*4000)+(100*1000) = 16000+40000+100000=156.000 memory unit, kemudian perhitungan
untuk alur BC adalah sebagai berikut
BAB III
ANALISIS DAN DESAIN
Bab ini menjelaskan mengenai analisis dan perancangan metode Multiway Array Aggregation untuk mendapatkan cube dari data penyakit yang ada di Puskesmas Jebed,Pemalang, Jawa Tengah dengan ukuran yang tepat untuk sebuah OLAP agar dapat merepresentasikan data penyakit secara cepat.
3.1. Identifikasi dan Analisis Kebutuhan
Puskesmas Jebed Kabupaten Pemalang membutuhkan sistem gudang data yang baik untuk memantau jumlah penyakit dengan penderita setiap bulan dalam setiap tahunnya. Hasil dari pemantauan jumlah penyakit tersebut dapat digunakan untuk menghitung jumlah penyakit dengan penderita terbanyak setiap bulan dalam setiap tahunnya untuk diprioritaskan dalam program pencegahan. Data yang digunakan bertipe spreadsheet. Data tersebut meliputi jenis penyakit, jumlah kasus baru, lama kunjungan kasus menurut golongan umur, jumlah.
SP2TP ICD-X JENIS PENYAKIT
0102 A01 Typus perut
0106 A06 Amoebiasis
0105 A09 Diare dan Gastroenteritis non spesifik
0201 A15 TB Paru BTA (+)
0701 B35 Penyakit kulit karena jamur
. . . . . . . . .
JUMLAH KASUS BARU, LAMA DAN KUNJUNGAN KASUS MENURUT GOLONGAN UMUR
0-JUMLAH
B L K B+L+K
34 0 0 34
14 0 0 14
79 0 0 79
1 0 0 1
3 0 0 3
22 0 0 22
6 0 0 6
1 0 0 1
16 0 0 16
3 0 0 3
2 0 0 2
0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 1 0 0 5 0 0 9 0 0 2 0 0 4 0 0 1 0 0
0 0 0 0 0 0 1 0 0 2 0 0 3 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 2 0 0 6 0 0 8 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 2 0 0 0 0 0 0 0 0 0 0 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2 Mengumpulkan dan Menganalisa Sumber Data
Data penyakit dan kunjungan Total di Puskesmas Jebed, Kabupaten Pemalang periode tahun 2010 hingga 2012 berupa data Excel yang bertipe .xls. Dikarenakan pemantauan dari Puskesmas Jebed, Pemalang berdasarkan bulan dan tahun maka file terbagi dalam banyak sheet, di mana dalam satu sheet terdapat data yang meliputi jenis penyakit, jumlah kasus baru, lama kunjungan kasus menurut golongan umur, jumlah. Namun setelah melihat data yang ada, diharapkan penelitian ini dapat membantu memecahkan masalah tersebut dengan membuat gudang data untuk Puskesmas Jebed, Pemalang di mana gudang data tersebut menggunakan cube dengan ukuran yang baik. Berikut Diagram Usecase yang digunakan dalam sistem.
Gambar 3.2 Diagram Usecase
Ada dua aktor yang berperan menjalankan sistem ini, yaitu: 1. Admin
Aktor yang berperan dalam mengelola gudang data penyakit. Jika ada Pemantauan
Jumlah penyakit
Mengelola Gudang Data Penyakit Dinas Puskesmas
Jebed Pemalang
penambahan data yang digunakan di dalam sistem maka admin dapat menambahkannya.
2. Dinas Puskesmas Jebed Pemalang
Aktor yang berperan dalam memilih pemantauan jumlah penyakit. Dinas Puskesmas Jebed Pemalang dapat melihat hasil data penyakit yang telah diolah oleh sistem.
3.3 Mengubah data penyakit ke dalam gudang data (data warehouse) 3.3.1 Membaca Data Legacy
Data yang digunakan dalam tugas akhir ini berupa Laporan Bulanan Data Kesakitan Kunjungan Total di Puskesmas Jebed, Kabupaten Pemalang periode tahun 2010 hingga 2012. Bahan data tersebut berupa dokumen excel yang berisi :
1. Jenis Penyakit 2. Jumlah Kasus Baru 3. Jumlah Kasus Lama 4. Jumlah Kunjungan 5. Kelompok Umur 6. Jumlah Total 7. Bulan
Pada studi kasus ini, sumber data dari gudang data berbentuk dalam dokumen excel. Sebelum data dipindahkan dalam gudang data, harus dilakukan tahap preprocessing. Untuk tahap-tahap pre-processing yang dilakukan adalah :
Menghilangkan data yang bukan merupakan penyakit Menambahkan kolom bulan dan tahun
1. Mengubah spasi pada header dengan garis bawah ( _ ) karena pada database untuk penamaan kolom tidak bisa menggunakan spasi, sedangkan header pada excel digunakan untuk penamaan kolom.
Gambar 3.3 Langkah preprocessing mengubah header JENIS_PENYAKIT
Typus Perut
Infeksi Bakteri Lain
Amoebiasis
Diare dan Gastroenteritis non spesifik
TB paru BTA (+)
TB Klinis Termasuk Rongent (+)
BTA (-)
TB Klinis Termasuk Rongent (+)
BTA (-)
Kusta MB
Varicella
Herpes Zoster
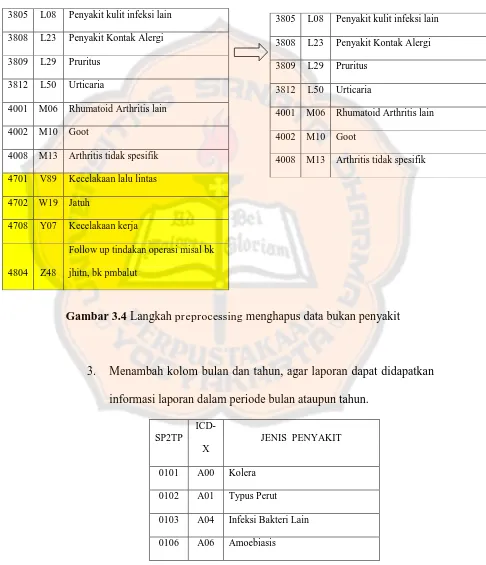
2. Menghilangkan data yang bukan merupakan penyakit, misalkan kecelakaan.
Gambar 3.4 Langkah preprocessing menghapus data bukan penyakit
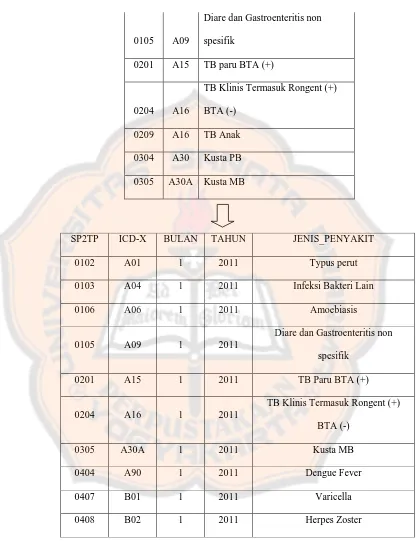
3. Menambah kolom bulan dan tahun, agar laporan dapat didapatkan informasi laporan dalam periode bulan ataupun tahun.
SP2TP 3805 L08 Penyakit kulit infeksi lain
3808 L23 Penyakit Kontak Alergi
3809 L29 Pruritus
3812 L50 Urticaria
4001 M06 Rhumatoid Arthritis lain
4002 M10 Goot
4008 M13 Arthritis tidak spesifik
4701 V89 Kecelakaan lalu lintas
4702 W19 Jatuh
4708 Y07 Kecelakaan kerja
4804 Z48
Follow up tindakan operasi misal bk
jhitn, bk pmbalut
3805 L08 Penyakit kulit infeksi lain
3808 L23 Penyakit Kontak Alergi
3809 L29 Pruritus
3812 L50 Urticaria
4001 M06 Rhumatoid Arthritis lain
4002 M10 Goot
0105 A09
Diare dan Gastroenteritis non
spesifik
0201 A15 TB paru BTA (+)
0204 A16
TB Klinis Termasuk Rongent (+)
BTA (-)
0209 A16 TB Anak
0304 A30 Kusta PB
0305 A30A Kusta MB
Gambar 3.5 Langkah preprocessing menambah kolom bulan dan tahun
Kemudian data laporan tersebut dipisah-pisah sesuai dengan kebutuhan pengguna untuk melihat laporan. Data yang terpisah ini nantinya juga akan
SP2TP ICD-X BULAN TAHUN JENIS_PENYAKIT
0102 A01 1 2011 Typus perut
TB Klinis Termasuk Rongent (+)
BTA (-)
0305 A30A 1 2011 Kusta MB
0404 A90 1 2011 Dengue Fever
0407 B01 1 2011 Varicella
digunakan dalam tugas akhir ini sebagai tabel dimensi dan tabel fakta. Data laporan tersebut dipisahkan sebagai berikut :
1. Nama penyakit, meliputi SP2TP, ICD-X, dan Jenis_Penyakit 2. Waktu, meliputi id_bulan, id_tahun, nama_bulan, tahun
3. Kelompok Umur, meliputi id_klpk_umur, nama_kelompok_umur 4. Penyakit, meliputi SP2TP, ICD-X, Bulan, Tahun, Jenis_Penyakit,
0-28hr_B, 0-28hr_L, 0-28hr_K, 1th_B, 1th_L, 28hr-1th_K, 1-4th_B, 1-4th_L, 1-4th_K, 5-14th_B, 5-14th_L, 5-14th_K, 15-44th_B, 15-44th_L, 15-44th_K, 54th_B, 54th_L, 45-54th_K, 55-60th_B, 55-60th_L, 55-60th_K, diatas_60th_B, diatas_60th_L, diatas_60th_K, B, L, K, B+L+K.
3.3.2 Menggabungkan data dari berbagai sumber terpisah
Data yang digunakan dalam tugas akhir ini dibuat dalam satu dokumen excel dari tahun 2010 hingga 2012. Data yang digunakan ini merupakan data yang
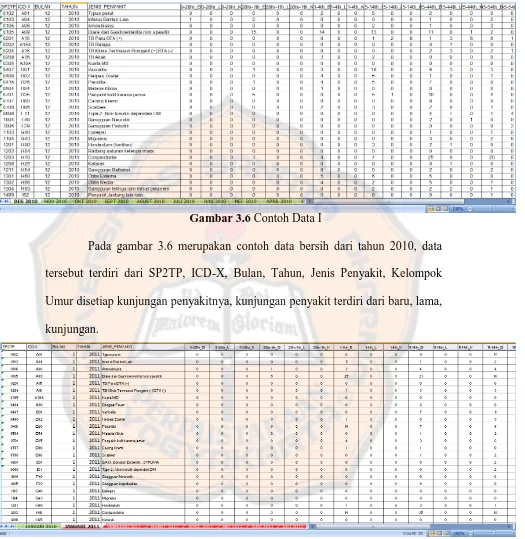
Gambar 3.6 Contoh Data I
Pada gambar 3.6 merupakan contoh data bersih dari tahun 2010, data tersebut terdiri dari SP2TP, ICD-X, Bulan, Tahun, Jenis Penyakit, Kelompok Umur disetiap kunjungan penyakitnya, kunjungan penyakit terdiri dari baru, lama, kunjungan.
Gambar 3.7 Contoh Data II
kunjungan
Gambar 3.8 Contoh Data III
Pada gambar 3.8 merupakan contoh data bersih dari tahun 2012, data tersebut terdiri dari SP2TP, ICD-X, Bulan, Tahun, Jenis Penyakit, Kelompok Umur disetiap kunjungan penyakitnya, kunjungan penyakit terdiri dari baru, lama, kunjungan
3.3.3 Memindahkan data dari sumber ke server gudang data
diberi nama penyakit.
Gambar 3.9 Database Penyakit
3.3.3.1 Nama penyakit, meliputi SP2TP, ICD-X, dan Jenis_Penyakit
File excel nama_penyakit
Merupakan pembentukan tabel nama_penyakit dari file excel nama_penyakit. Berisi atribut SP2TP, ICD-X, dan Jenis_Penyakit, serta ditambah dengan surrogate key yaitu sk_nama_penyakit.
Nama Penyakit PK sk_nama_penyakit SP2TP
ICD-X
Jenis_Penyakit
3.3.3.2 Waktu, meliputi id_bulan, id_tahun, nama_bulan, tahun, sk_waktu
File excel waktu
Merupakan pembentukan tabel waktu dari file excel waktu. Berisi atribut id_bulan, id_tahun, nama_bulan, tahun, serta ditambah dengan surrogate key yaitu sk_waktu.
Waktu PK sk_waktu id_bulan id_tahun nama_bulan tahun
3.3.3.3 Kelompok Umur, meliputi id_klpk_umur, nama_kelompok_umur
File excel kelompok_umur
Merupakan pembentukan tabel kelompok umur dari file excel kelompok umur. Berisi atribut id_klpk_umur, nama_kelompok_umur, serta ditambah dengan surrogate key yaitu sk_kelompok_umur.
3.3.3.4 Penyakit, meliputi SP2TP, ICD-X, Bulan, Tahun, Jenis_Penyakit, 0-28hr_B, 0-28hr_L, 0-28hr_K, 28hr-1th_B, 28hr-1th_L, 28hr-1th_K, 1-4th_B, 1-4th_L, 1-4th_K, 5-11-4th_B, 5-14th_L, 5-14th_K, 15-41-4th_B, 15-44th_L, 15-44th_K, 45-54th_B, 45-54th_L, 45-54th_K, 55-60th_B, 55-60th_L, 55-60th_K, diatas_60th_B, diatas_60th_L, diatas_60th_K, B, L, K, B+L+K
Kelompok Umur PK sk_kelompok_umur id_klpk_umur
nama_kelompok_umur
File excel penyakit
Merupakan pembentukan tabel penyakit dari file excel penyakit. Berisi atribut SP2TP, id_bulan, id_tahun, id_klpk_umur, B, L, K.
penyakit PK SP2TP id_bulan id_tahun id_klpk_umur B
L K
3.3.4 Memecah gudang data dalam tabel fakta dan tabel dimensi
Berikut ini akan dijelaskan pembuatan tabel-tabel yang akan disimpan dalam database penyakit yang kemudian akan dipakai untuk dimensi dalam OLAP:
1. Nama Penyakit
Gambar 3.10 nama penyakit.ktr
dim_nama_penyakit yang bertujuan untuk mengambil data excel nama penyakit untuk kemudian diletakkan dalam database dengan langkah sebagai berikut :
a. Ambil data dari excel
b. Menambahkan surrogate key dengan menggunakan step “add sequence”
c. Merubah metadata dengan menggunakan step “select values”
d. Memasukkan data yang telah diolah ke dalam tabel dim_nama_penyakit pada database penyakit
Gambar 3.11 Tabel dim_nama_penyakit
2. Waktu
Gambar 3.12 waktu.ktr
Gambar 3.12 merupakan rangkaian pembentukan tabel dim_waktu yang bertujuan untuk mengambil data excel waktu untuk kemudian diletakkan dalam database dengan langkah sebagai berikut :
a. Ambil data dari excel
b. Menambahkan surrogate key dengan menggunakan step “add sequence”
c. Merubah metadata dengan menggunakan step “select values”
d. Memasukkan data yang telah diolah ke dalam tabel dim_waktu pada database penyakit
Gambar 3.13 merupakan tabel dim_waktu. Terdapat kolom sk_waktu yang merupakan surrogate key, id_bulan, id_tahun, nama_bulan, tahun.
3. Kelompok Umur
Gambar 3.14 Kelompok Umur.ktr
Gambar 3.14 merupakan rangkaian pembentukan tabel dim_kelompok_umur yang bertujuan untuk mengambil data excel kelompok_umur untuk kemudian diletakkan dalam database dengan langkah sebagai berikut :
a. Ambil data dari excel
b. Menambahkan surrogate key dengan menggunakan step “add sequence”
c. Merubah metadata dengan menggunakan step “select values”
d. Memasukkan data yang telah diolah ke dalam tabel dim_kelompok_umur pada database penyakit
Gambar 3.15 merupakan tabel dim_kelompok_umur. Terdapat kolom sk_kelompok_umur yang merupakan surrogate key, id_klpk_umur, nama_kelompok_umur.
4. Penyakit
Gambar 3.16 Penyakit.ktr
Gambar 3.16 merupakan rangkaian pembentukan tabel penyakit dimana dalam tabel ini terdapat transaksi penyakit (dalam arti jumlah kunjungan penyakit), diawali dengan mengambil data excel penyakit untuk kemudian dilakukan perubaham metadata selanjutnya dinormalisasikan setelah itu dirubah kembali metadanya dan kemudian disimpan dalam tabel fact_penyakit untuk diletakkan dalam database penyakit.
Gambar 3.17 Tabel penyakit
id_bulan, B, L, K, id_klpk_umur, id_tahun. Jumlah recordnya adalah 5224. Setelah pembentukan tabel-tabel dimensi dilakukan, langkah berikutnya adalah membentuk tabel fakta.
Gambar 3.18 fact_penyakit.ktr
Gambar 3.18 merupakan rangkaian pembentukan tabel fact_penyakit dimana tabel ini digunakan dalam proses OLAP, diawali dengan memasukkan data dari tabel penyakit_tr kemudian menyamakan dengan dimensi-dimensi, merubah metadata atau memilih data, dan selanjutnya dinormalisasikan setelah itu dirubah kembali metadanya dan kemudian memasukkan data ke dalam tabel fact_peyakit untuk diletakkan dalam database penyakit.
Gambar 3.19 merupakan tabel fakta yang terdiri dari B (merupakan pasien baru), L (merupakan pasien lama), K (merupakan psien kunjungan atau pasien dari luar daerah). Didalam tabel ini juga berisi semua sk dari semua dimensi yang ada yakni sk_bulan, sk_tahun, sk_kelompok_umur, sk_nama_penyakit.
3.4 Membuat skema bintang
Dari tabel – tabel dimensi serta tabel fakta yang terbentuk, maka dibuatlah skema bintang seperti di bawah ini :
Skema bintang yang dibentuk ini berpusat pada tabel fakta yaitu fact_penyakit dan dikelilingi oleh 4 tabel dimensi, yaitu dimensi bulan, tahun, kelompok umur, dan nama penyakit.
3.5 Membangun cube
Pada tugas akhir ini, cube dibangun dengan dua cara yaitu dengan menggunakan Schema Workbench dan menggunakan Netbeans untuk simulasi dari Multiway Array Aggregation.
Gambar 3.21 Cube Penyakit Cube Penyakit
measure
Dimensi nama_penyakit
Dimensi waktu
Gambar 3.21 merupakan proses pembuatan cube yang memiliki tabel fakta fact_table2 dan 3 measure (nilai pengukuran) yaitu jumlah B, jumlah L, jumlah K. terdapat 3 dimensi yaitu NamaPenyakit, KelompokUmur, dan Waktu.
Dalam implementasi pembuatan cube menggunakan netbeans terdapat 6 kelas, diantaranya adalah :
1. InputDimensi.jsp
Pada kelas ini, dilakukan input data dimensi-dimensi untuk kemudian dipecah di dalam kelas berikutnya.
2. PecahDimensi.jsp
Pada kelas ini, dilakukan pemecahan dimensi untuk mendapatkan kombinasi dan jalur dari dimensi untuk dilakukan perhitungan menggunakan multiway array aggregation.
3. Coba.jsp
Pada kelas ini, memanggil kelas HitungHasil.java untuk menghitung inputan jalur serta menyimpannya ke dalam tabel pada sql untuk dapat ditampilkan hasilnya.
4. Generate.jsp
Kelas ini melakukan pembentukan file bertipe xml. 5. HitungHasil.java
Kelas ini terdapat method-method untuk dilakukannya perhitungan multiway array aggregation. Algoritma multiway array aggregation
- Mengakses nilai-nilai dimensi - Menghitung aggregate nilai-nilai
- Mengambil hasil minimum dari perhitungan
Dalam studi kasus ini, dimiliki 3 dimensi untuk membentuk suatu cube. Dimensi – dimensi tersebut adalah Nama Penyakit (N), Waktu (W), Kelompok Umur (K). Besar data untuk masing – masing dimensi tersebut adalah 109, 36, 8 kemudian masing – masing dimensi besar datanya dibagi sama besar yaitu dibagi dalam partisi 2 maka hasilnya adalah 55, 18, 4. Kemudian dari 3 dimensi itu didapatkan urutan cubenya adalah sebagai berikut :
Tabel 3.1 Tabel daftar cube dan cuboid
No. Base Cuboid 2-cuboid 1-cuboid 0-cuboid
1. NKW NK, NW, KW N,K,W all
2. NWK NW,NK,WK N,W,K all
3. KNW KN,KW,NW K,N,W all
4. KWN KW,KN,WN K,W,N all
5. WKN WK,WN,KN W,K,N all
6. WNK WN,WK,NK W,N,K all
Dari hasil perhitungan di atas, kemudian diambil nilai paling kecil yaitu 1714 yang dimiliki oleh KWN dan NWK, maka cube itulah yang baik karena dari perhitungan di atas cube tersebut memiliki jumlah memory unit yang kecil.
6. DatabaseConnection.java
Pada kelas ini terdapat pengaturan koneksi database yang digunakan untuk penyimpanan data.
3.6 Menganalisis cube
Setelah cube penyakit terbentuk maka selanjutnya dilakukan pembuatan gudang data dengan cube yang terbaik dari perhitungan multiway array aggregation. Untuk mendapatkan cube yang terbaik dilakukan perbandingan. Proses perbandingan dilihat dari kecepatan saat proses load gudang data dari database. Pada proses ini, dilakukan pengujian dengan metode yang disebut
BAB IV
IMPLEMENTASI
Pada bab IV ini akan menjelaskan implementasi sistem.
4.1 Arsitektur Sistem
Gambar 4.1 Arsitektur Sistem
sebagai gudang data kemudian dilakukan proses OLAP. Melalui proses OLAP, dinas puskesmas Jebed dapat memantau jumlahpenyakit yang ada di kabupaten Pemalang.
Untuk mendukung arsitektur di atas, maka diperlukan beberapa software dan hardware dalam pembuatannya, yaitu :
1. Dalam proses pembentukan gudang data ini akan memakai database MySQL.
2. Tools yang digunakan adalah Kettle-Spoon-4.1.0, Schema Workbench, Mondrian, dan aoache-tomcat-7.0.16
3. Spesifikasi hardware yang digunakan dalam penelitian ini adalah sebagai berikut :
Processor : IntelIntel(R) Core(TM) i3-2330M CPU @ 2.20GHz (4
CPUs), ~2.2GHz Memory: 2048MB RAM
Hardisk : 500GB
Web browser : Mozilla
Operating – System : Windows 7 Ultimate 32-bit (6.1, Build 7600)
4.2 Implementasi Usecase
waktu, kelompok umur, kemudian jumlahnya. Hasil dari implementasi tersebut dapat dilihat pada gambar 4.2 di bawah ini :
Gambar 4.2 Pemantauan Data Penyakit
Implementasi dalam pembuatan cube menggunakan 6 kelas, diantaranya adalah :
Tabel 4.1 Tabel daftar kelas
No. Nama Kelas Fungsi
1. InputDimensi.jsp input dimensi – dimensi
untuk kemudian dikirim ke kelas berikutnya untuk dipecah
2. PecahDimensi.jsp mendapatkan kombinasi
untuk dilakukan perhitungan
menggunakan multiway array aggregation
3. Coba.jsp memanggil kelas
HitungHasil.java untuk menghitung inputan jalur serta menyimpannya ke dalam tabel pada sql untuk dapat ditampilkan hasilnya
4. Generate.jsp generate hasil
perhitungan, kemudian dibentuk menjadi file xml
5. HitungHasil.java terdapat method untuk
perhitungan multiway array aggregation
6. DatabaseConnection.java pengaturan koneksi
1. HitungHasil.java
case 2: { int bil1; int bil2;
if (jalur.get(i).charAt(0) == 'N') { bil1 = Math.round((float) N / 2); } else if (jalur.get(i).charAt(0) == 'K') { bil1 = Math.round((float) K / 2); } else {
bil1 = Math.round((float) W / 2); }
if (jalur.get(i).charAt(1) == 'N') { bil2 = Math.round((float) N / 2); } else if (jalur.get(i).charAt(1) == 'K') { bil2 = Math.round((float) K / 2); } else {
bil2 = Math.round((float) W / 2); }
hasil1 += (bil1 * bil2); break;
} } }
public static void data(int[] jumlah) { N = jumlah[0];
W = jumlah[1]; K = jumlah[2]; }
try {
com.penyakit.DataBaseConnection conn = new com.penyakit.DataBaseConnection();
conn.getDataBaseConnection();
String query1 = "insert into simpanHasil values ('" +
pilihDimensi + "','" + pilihJalur + "','" + hasil1 + "','" + hasil2 + "')"; Statement statement = conn.getConnection().createStatement(); statement.executeUpdate(query1);
conn.getConnection().close(); } catch (SQLException ex) {
Logger.getLogger(HitungHasil.class.getName()).log(Level.SEVERE, null, ex);
2. DatabaseConnection.java
Pada kelas ini terdapat pengaturan koneksi database yang digunakan untuk penyimpanan data.
private String jdbcURL = "jdbc:mysql://localhost:3306/penyakit"; private String user = "root";
private String password = "admin"; private Connection connection; public boolean isConnected(){
BAB V ANALISIS HASIL
Bab V akan membahas mengenai analisa hasil dari implementasi sistem.
5.1. Penyelesaian Rumusan Masalah
Pada bab pendahuluan yang dibuat penulis, penulis merumuskan masalah yang akan diselesaikan dalam penelitian ini. Adapun rumusan masalah yang dibuat adalah Bagaimana Multiway Array Aggregation menentukan cube yang tepat untuk pembuatan OLAP bagi data penyakit dari Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah sehingga data dapat ditampilkan dengan cepat. Tujuan dari perumusan masalah ini adalah mendapatkan cube yang tepat untuk pembuatan database Online Analytical Process (OLAP) dari data penyakit dari Puskesmas Jebed, Kabupaten Pemalang, Jawa Tengah tahun 2010 hingga 2012 sehingga dapat ditampilkan dengan cepat untuk pemantauan data penyakit di puskesmas Jebed, Kabupaten Pemalang. Hasil dari perhitungan Multiway Array Aggregation dari masing-masing cube dengan jumlah data N = 192, W = 36, dan
Gambar 5.1 Hasil Implementasi Perhitungan Multiway Array Aggregation
Dari hasil yang didapatkan di atas dapat diketahui bahwa perhitungan program simulasi Multiway Array Aggregation dengan perhitungan manual menghasilkan hasil yang sama, maka program dapat dikatakan valid.
menggunakan metode calculating page loading time. Penulis memberikan rentang waktu yang baik dalam akses cepat cube adalah 0,1 s hingga 4 s. Apabila waktu akses berada di dalam rentang waktu yang telah ditentukan maka program dapat dikatakan valid. Untuk mendapatkan cube yang terbaik, diambil cube yang memiliki rentang waktu paling kecil.
Pada bab ini, hasil implementasi gudang data menggunakan database MySQL dengan mengambil cube yang terbaik dari Multiway Array Aggregation dan memiliki rentang waktu terkecil.
Gambar 5.2 Hasil Implementasi
Gambar 5.3 Hasil Implementasi olap
Gambar 5.3 merupakan hasil implementasi gudang data untuk memantau jumlah penyakit pada setiap waktu dan golongan umur menggunakan cube dari Schema Workbench.
Hasil pembentukan OLAP dengan menggunakan cube terbaik dari Multiway Array Aggregation yang telah dibuat mempunyai hasil sama dengan
OLAP menggunakan cube dari Schema Workbench.
5.2 Pengujian
Gambar 5.4 Contoh penggunaaan metode calculating page loading time Hasil pengujian perhitungan akses waktu menggunakan metode calculating page loading time untuk masing – masing cube dan OLAP biasa adalah sebagai berikut :
Tabel 5.1 Tabel Pengujian Waktu
NO. NWK KWN NKW WKN WNK KNW OLAP
11. 0.122 s 0.122 s 0.115 s 0.145 s 0.137 s 0.145 s 0.103 s 12. 0.121 s 0.194 s 0.176 s 0.21 s 0.136 s 0.109 s 0.22 s 13. 0.096 s 0.143 s 0.137 s 0.187 s 0.111 s 0.126 s 0.167 s 14. 0.095 s 0.093 s 0.135 s 0.166 s 0.124 s 0.151 s 0.143 s 15. 0.106 s 0.11 s 0.146 s 0.151 s 0.148 s 0.138 s 0.139 s Rerata 1.672/15 1.772/15 2.51/15 2.54/15 2.279/15 2.271/15 2.304/15
0.111 s 0.118 s 0.167 s 0.169 s 0.151 s 0.1514 s 0.1536 s
Tabel 5.1 merupakan tabel pengujian waktu akses masing – masing cube untuk membandingkan kembali cube mana yang terbaik. Pada tabel diatas dilakukan pengujian sebanyak 15 kali kemudian didapatkan rata – rata waktu untuk setiap cube yang diakses. Dari tabel diatas dapat terlihat cube yang terbaik adalah NWK karena memiliki rata-rata waktu akses 0,111 s dari rentang waktu yang telah ditentukan adalah 0,1 s hingga 4 s sehingga waktu akses cube NWK merupakan waktu akses yang minimum sehingga ketika representasi data di dalam gudang data dapat dikatakan cepat.
Gambar 5.5 Hasil Implementasi Multiway Array Aggregation dengan penambahan data
metode calculating page loading time untuk masing – masing cube dengan jumlah data N = 1920, W=365, K=80.
Tabel 5.2 Tabel pengujian waktu berdasarkan penambahan jumlah data
NO. NWK KWN NKW WKN WNK KNW
1. 0.66 s 0.458 s 0.98 s 0.92 s 0.761 s 0.847 s
2. 0.589 s 0.548 s 0.739 s 0.9 s 0.857 s 0.733 s
3. 0.458 s 0.3 s 0.882 s 0.7 s 0.816 s 0.626 s
4. 0.389 s 0.45 s 0.655 s 0.889 s 0.695 s 0.52 s 5. 0.475 s 0.67 s 0.576 s 0.775 s 0.789 s 0.738 s
6. 0.599 s 0.378 s 0.8 s 0.68 s 0.698 s 0.89 s
7. 0.479 s 0.599 s 0.669 s 0.834 s 0.745 s 0.542 s
8. 0.52 s 0.475 s 0.462 s 0.97 s 0.787 s 0.875 s
9. 0.458 s 0.36 s 0.574 s 0.675 s 0.733 s 0.647 s 10. 0.43 s 0.57 s 0.789 s 0.545 s 0.538 s 0.925 s 11. 0.418 s 0.63 s 0.545 s 0.511 s 0.744 s 0.937 s 12. 0.35 s 0.458 s 0.624 s 0.68 s 0.719 s 0.743 s
13. 0.47s 0.46 s 0.787 s 0.522 s 0.826 s 0.811 s
14. 0.35 s 0.375 s 0.766 s 0.328 s 0.651 s 0.624 s
15. 0.38 s 0.3 s 0.551 s 0.489 s 0.893 s 0.848 s
Rerata 7.025/15 7.031/15 10.399/15 10.418/15 11.252/15 11.306/15 0.468333 s 0.468733 s 0.693267 s 0.694533 s 0.750133 s 0.753733 s
cube mana yang terbaik. Pada tabel diatas dilakukan pengujian sebanyak 15 kali kemudian didapatkan rata – rata waktu untuk setiap cube yang diakses. Dari tabel diatas dapat terlihat cube yang terbaik adalah NWK karena memiliki rata-rata waktu akses 0,4683 s dari rentang waktu yang telah ditentukan adalah 0,1 s hingga 4 s sehingga waktu akses cube NWK merupakan waktu akses yang minimum sehingga ketika representasi data di dalam gudang data dapat dikatakan cepat.
Dalam pengujian ini dilakukan penambahan data untuk melihat bagaimana struktur cube yang baik saat terjadi penambahan data. Berikut ini adalah tabel – tabel pengujian waktu berdasarkan penambahan jumlah data :
Tabel 5.3 Tabel pengujian waktu berdasarkan penambahan jumlah data N = 1920,W = 36,K = 8
NO. NWK KWN NKW WKN WNK KNW
11. 0.122 s 0.145 s 0.176 s 0.1875 s 0.145 s 0.237 s
12. 0.2 s 0.21 s 0.1 s 0.215 s 0.19 s 0.136 s
13. 0.16 s 0.187 s 0.137 s 0.187 s 0.186 s 0.211 s 14. 0.195 s 0.166 s 0.135 s 0.166 s 0.151 s 0.124 s 15. 0.106 s 0.151 s 0.156 s 0.161 s 0.138 s 0.148 s Rerata 2.527/15 2.54/15 2.876/15 2.8872/15 2.551/15 2.679/15
0.168467 s 0.16933 s 0.19173 s 0.19248 s 0.17007 s 0.1786 s
Tabel 5.4 Tabel pengujian waktu berdasarkan penambahan jumlah data N= 192, W = 365, K = 8
NO. NWK KWN NKW WKN WNK KNW
1. 0.17 s 0.1 s 0.2 s 0.2 s 0.1 s 0.176 s
2. 0.12 s 0.162 s 0.162 s 0.162 s 0.102 s 0.12 s 3. 0.198 s 0.171 s 0.171 s 0.181 s 0.11 s 0.191 s
4. 0.15 s 0.17 s 0.17 s 0.18 s 0.1 s 0.155 s
5. 0.17 s 0.167 s 0.167 s 0.167 s 0.143 s 0.167 s
6. 0.1 s 0.151 s 0.151 s 0.15 s 0.112 s 0.1 s
7. 0.169 s 0.17 s 0.17 s 0.17 s 0.135 s 0.169 s
8. 0.12 s 0.16 s 0.16 s 0.178 s 0.122 s 0.162 s
9. 0.14 s 0.172 s 0.172 s 0.174 s 0.184 s 0.14 s
10. 0.176 s 0.15 s 0.15 s 0.18 s 0.224 s 0.1 s
11. 0.15 s 0.16 s 0.16 s 0.16 s 0.122 s 0.145 s
13. 0.187 s 0.146 s 0.146 s 0.17 s 0.16 s 0.187 s
14. 0.168 s 0.15 s 0.15 s 0.16 s 0.195 s 0.166 s
15. 0.15 s 0.151 s 0.151 s 0.151 s 0.106 s 0.151 s Rerata 2.3/15 2.315/15 2.415/15 2.518/15 2.115/15 2.239/15
0.15333 s 0.15433 s 0.161 s 0.16787 s 0.141 s 0.14927 s
Tabel 5.5 Tabel pengujian waktu berdasarkan penambahan jumlah data N=192, K=80, W=36
NO. NWK KWN NKW WKN WNK KNW
1. 0.17 s 0.1 s 0.1 s 0.16 s 0.2 s 0.212 s
2. 0.1 s 0.162 s 0.12 s 0.12 s 0.152 s 0.162 s
3. 0.138 s 0.171 s 0.11 s 0.191 s 0.161 s 0.171 s
4. 0.15 s 0.17 s 0.1 s 0.155 s 0.171 s 0.163 s
5. 0.17 s 0.167 s 0.13 s 0.167 s 0.17 s 0.16 s
6. 0.1 s 0.151 s 0.112 s 0.1 s 0.165 s 0.15 s
7. 0.16 s 0.17 s 0.125 s 0.139 s 0.162 s 0.17 s
8. 0.12 s 0.13 s 0.122 s 0.12 s 0.15 s 0.17 s
9. 0.14 s 0.152 s 0.14 s 0.14 s 0.172 s 0.174 s
10. 0.16 s 0.15 s 0.124 s 0.1 s 0.143 s 0.156 s
11. 0.15 s 0.14 s 0.122 s 0.135 s 0.16 s 0.161 s
12. 0.132 s 0.135 s 0.2 s 0.11 s 0.155 s 0.15 s
15. 0.15 s 0.155 s 0.106 s 0.11 s 0.151 s 0.162 s Rerata 2.175/15 2.249/15 1.966/15 2.09/15 2.407/15 2.467/15
0.145 s 0.14993 s 0.131067 s 0.13933 s 0.16047 s 0.16447 s
Tabel 5.6 Tabel perbandingan pengujian waktu dengan jumlah data N = 192,K = 8,W = 36
Cube Jumlah Data Jumlah Memori Rerata Waktu NWK N = 192,K = 8,W = 36 Kanan = 1714,
Tabel 5.7 Tabel perbandingan pengujian waktu dengan jumlah data N = 1920, W = 36,K = 8
Tabel 5.8 Tabel perbandingan pengujian waktu dengan jumlah data N= 192, W = 365, K = 8
Cube Jumlah Data Jumlah Memori Rerata Waktu NWK N= 192, W = 365, K =
Tabel 5.9 Tabel perbandingan pengujian waktu dengan jumlah data N=192, K=80, W=36
Cube Jumlah Data Jumlah Memori Rerata Waktu NWK N=192, K=80, W=36 Kanan = 12288,
Tabel 5.10 Tabel perbandingan pengujian waktu dengan jumlah data N=1920, K=80, W=365
Cube Jumlah Data Jumlah Memori Rerata Waktu NWK N=1920, K=80,
W=365
Kanan = 186280, Kiri = 709212
KWN N=1920, K=80,
Maka dari hasil di atas, Multiway Array Aggregation mampu menghasilkan cube terbaik dengan melihat jumlah memori yang sedikit sehingga waktu akses untuk cube yang didapatkan itu menjadi lebih relevan karena dapat
BAB VI
KESIMPULAN DAN SARAN
Bab VI akan membahas mengenai penutup skripsi ini yang berisi tentang kesimpulan mengenai penelitian dan saran untuk pengembangan sistem lebih lanjut.
6.1 Kesimpulan
Setelah dilakukan perbandingan pengujian proses waktu akses cube dalam gudang data penyakit, maka didapatkan hasil bahwa cube terbaik diambil dari perhitungan multiway array aggregation yang menghasilkan jumlah memori yang kecil sehingga dapat memberikan waktu akses yang cepat. Dengan penambahan data, dapat disimpulkan bahwa jumlah memori juga bertambah, hal tersebut membuat waktu akses untuk cube tersebut juga bertambah. Dengan penambahan data, struktur cube yang terbaik juga dapat berubah, penyusunan sesuai dengan jumlah data dari masing – masing dimensi. Apabila lebih besar, maka dimensi diletakkan di awal sehingga cube tersebut yang menghasikan jumlah memori yang minimal dan waktu akses yang cepat.
6.2 Saran