i
MENINGKATKAN UNJUK KERJA OLAP DENGAN TEKNIK
BITMAP INDEXING
DAN PEMROSESAN EFISIEN OLAP
QUERY
(Studi Kasus: Data Laporan Penyakit 2010 – 2012, Puskesmas Jebed, Pemalang) Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Yosefina Agustin Nugraheni Bere 095314078
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
IMPROVING OLAP PERFORMANCE BY THE BITMAP INDEXING TECHNIQUE AND EFFICIENT PROCESSING OF OLAP QUERIES (Case Study: Disease Report For 2010 – 2012, Puskesmas Jebed, Pemalang)
A Thesis
Presented As A Partial Fulfillment of The Requrements To Obtain The Bachelor Degree
Informatics Engineering Study Program
By:
Yosefina Agustin Nugraheni Bere 095314078
INFORMATIC ENGINEER STUDY PROGRAM
DEPARTMENT OF INFORMATIC ENGINEER
FACULTY OF SCIENCE AND TECHNOLOGY
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
v
HALAMAN MOTO
vi
HALAMAN PERSEMBAHAN
Kupersembahkan skripsi ini kepada:
Tuhan Yesus Kristus dan Bunda Maria atas lindungan dan kasih –
Nya. Skripsi ini dipersembahkan juga untuk keluarga terutama orang
tua dan nenek saya. Juga kepada semua teman seperjuangan yang
tidak mungkin disebutkan satu persatu, terima kasih atas dukungan
dan doanya. Serta terima kasih banyak untuk semua orang yang juga
terlibat dan mendukung dalam pembuatan skripsi ini sehingga dapat
vii
ABSTRAKSI
OLAP (Online Analytical Processing) merupakan teknologi yang memproses data di dalam gudang data menggunakan struktur multidimensi, menyediakan jawaban yang cepat untuk query analisis yang kompleks. OLAP merupakan alat atau tools yang digunakan untuk memproses gudang data. Untuk melakukan pemrosesan query pada OLAP menggunakan OLAP query atau biasa disebut dengan MDX (Multi Dimensional Expression). Gudang data menangani data dalam jumlah yang sangat besar. Dari dasar tersebut muncul sebuah permasalahan dalam penanganan query dan pengaruhnya terhadap unjuk kerja dari OLAP.
Masalah tersebut adalah menemukan OLAP query yang efisien untuk digunakan dalam pemrosesan query pada gudang data.
Dalam penelitian ini menggunakan dua teknik yang diharapkan dapat membantu mengefisiensikan OLAP query. Pertama, dengan mencari
query yang efisien dengan menggunakan cuboid. Query efisien adalah
query yang dapat dijalankan dalam waktu yang singkat serta tidak menggunakan sumber daya sistem secara berlebihan.Setelah mendapatkan
query efisien menggunakan cuboid, maka untuk semakin mempercepat waktu akses dari query efisien adalah dengan teknik yang kedua yaitu dengan melakukan indexing dengan menggunakan bitmap indexing.
viii
ABSTRACT
OLAP (Online Analytical Processing) is a technology which processes the data in the data warehouse using multidimensional structure, providing quick answers to complex analytical queries. OLAP is a tool or tools that are used to process the data warehouse. To perform on OLAP query processing using OLAP query or commonly referred to as MDX (Multi Dimensional Expression). The data in the data warehouse to handle a very large number. Of the base appears a problem in the handling of queries and their effects on the performance of OLAP. The problem is to find an efficient OLAP query processing to be used in a query to the datawarehouse
In this research with using two techniques, expected to make the processing OLAP queries efficiently. First, searching efficient query using Cuboid. Efficient query is a query that can be executed in a short time and not using system resources excessively. After getting an efficient query, to accelerate access time of efficient query is using the second technique. The second technique will indexing the table by using the bitmap indexing.
x
KATA PENGANTAR
Puji dan syukur kepada Tuhan karena atas segala berkat dan bimbingan-Nya, penulis dapat menyelesaikan tugas akhir ini dengan baik. Tugas akhir ini ditulis untuk memenuhi salah satu syarat untuk memperoleh gelar Sarjana Komputer dari Program Studi Teknik Informatika Universitas Sanata Dharma. Penulis menyadari bahwa selesainya tugas akhir ini tak lepas dari bantuan orang – orang di sekitar penulis. Oleh sebab itu, penulis mengucapkan terima kasih kepada:
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu membimbing dan menuntun penulis dalam menyelesaikan tugas akhir ini dan juga karena telah mengabulkan doa penulis sehingga tugas akhir ini dapat selesai dengan baik.
2. Ibu Ridowati Gunawan, S.Kom, M.T., selaku dosen pembimbing yang telah meluangkan waktu, ide, serta pikiran untuk membantu penulis dalam menyelesaikan tugas akhir ini.
3. Ibu P. H. Prima Rosa, S.Si., M.Sc., selaku ketua dosen penguji yang telah meluangkan waktu untuk menguji tugas akhir ini.
xi
5. Keluarga saya, Bapak Silverius, Ibu Kusnarti, adik-adik saya yang selalu mendoakan dan memberi dukungan kepada penulis sehingga tugas akhir ini dapat selesai dengan baik dan tepat pada waktunya. 6. Vincentius Ardha, yang selalu memberi dukungan semangat dan
menemani saya disaat mengalami kesulitan dalam mengerjakan tugas akhir ini. Serta semua orang yang tidak mungkin saya sebutkan satu persatu yang selalu memberikan doa dan dukungannya.
Yogyakarta, 14 Agustus 2013
xii
DAFTAR ISI
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... Error! Bookmark not defined. PERNYATAAN KEASLIAN KARYA ... Error! Bookmark not defined. HALAMAN MOTO ... iv
HALAMAN PERSEMBAHAN ... vi
ABSTRAKSI ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN ... Error! Bookmark not defined. KATA PENGANTAR ... x
1.2. Rumusan dan Batasan Masalah ... 3
1.3. Tujuan Penelitian ... 4
1.4. Manfaat Penelitian ... 5
1.5. Metodologi Penelitian ... 5
1.6. Luaran ... 6
1.7. Sistematika Penulisan ... 6
BAB II ... 8
LANDASAN TEORI ... 8
2.1. Teori Umum ... 8
2.1.2. Pengertian DataWarehouse ... 10
2.1.3. Data Mining ... 14
2.1.4. Langkah Dalam Membangun Gudang Data ... 20
2.1.5. Kettle / Pentaho Data Integration ... 21
2.1.6. OLAP (On-Line Analytical Processing) ... 23
2.1.7. Database ... 27
2.2. Teori Khusus ... 28
2.2.1. Efisiensi OLAP Query ... 28
2.2.2. Bitmap Indexing ... 33
2.2.3. MDX(Multi Dimensional Expression) ... 35
BAB III ... 39
ANALISIS DAN PERANCANGAN ... 39
3.1. Deskripsi Kasus ... 39
3.2. Data ... 40
3.3. Analisis Kebutuhan ... 42
3.4. Membangun Gudang Data ... 43
3.4.1. Membaca Data Legacy ... 44
3.4.2. Menggabungkan Data dari Berbagai Sumber ... 44
3.4.3. Memindahkan Data ke Server Gudang Data ... 45
3.4.4. Memecah Gudang Data dalam Tabel Fakta dan Tabel Dimensi... 48
3.5. Efisiensi Pemrosesan OLAP Query Menggunakan Cuboid ... 52
3.6. Menerapkan BitmapIndexing pada Qef ... 59
3.7. Langkah Pengujian ... 60
3.8. Perancangan Tampilan ... 62
IMPLEMENTASI ... 64
4.1. Spesifikasi Perangkat Keras dan Lunak ... 64
4.2. Langkah Membangun Gudang Data ... 64
4.2.1. Membaca Data Legacy ... 64
4.2.2. Menggabungkan Data dari Berbagai Sumber Terpisah ... 69
4.2.3. Memindahkan Data ke Server Gudang Data ... 69
4.2.4. Memecah Gudang Data dalam Tabel Fakta dan Tabel Dimensi... 72
4.3. OLAP ... 77
4.4. Tampilan Hasil Query I ... 80
4.5. Tampilan Hasil Query II ... 83
BAB V ... 85
HASIL DAN PEMBAHASAN ... 85
5.1. Langkah Pengujian ... 85
5.2. Menentukan Query Efisien Menggunakan Cuboid ... 87
5.2.1. Query I ... 88
5.2.2. Query II ... 94
5.3. Pengujian Qef Menggunakan BitmapIndexing ... 99
5.3.1. Bitmap Indexing pada Query I ... 101
5.3.2. Bitmap Indexing pada Query II ... 103
BAB VI ... 107
KESIMPULAN DAN SARAN ... 107
6.1. Kesimpulan ... 107
6.2. Saran ... 108
xv
DAFTAR GAMBAR
Gambar 3. 1 Contoh data ... 41
Gambar 3. 2 Diagram use case ... 43
Gambar 3. 3 Ilustrasi menggabungkan data dari berbagai sumber ... 45
Gambar 3. 4 Skema Bintang ... 49
Gambar 3. 5 Hirarki yang terbentuk ... 53
Gambar 3. 6 Perancangan Tampilan ... 62
Gambar 4. 1 Tampilan Awal ... 80
Gambar 4. 2 Tampilan hasil dari Qb ... 81
Gambar 4. 3 Tampilan hasil Qef ... 81
Gambar 4. 4 Tampilan hasil dari Qp1 ... 82
Gambar 4. 5 Tampilan hasil dari Qp2 ... 82
Gambar 4. 6 Tampilan Awal dari query II ... 83
Gambar 4. 7 Tampilan hasil dari Qb ... 83
xvi
DAFTAR TABEL
Tabel 3. 1 Langkah membangun gudang data ... 43
Tabel 3. 2 Proses memindahkan data ke dalam tabel ms_penyakit ... 46
Tabel 3. 3 Keterangan atau penjelasan isi dari data penyakit ... 46
Tabel 3. 4 Proses memindahkan data ke dalam tabel ms_kelompok_umur ... 47
Tabel 3. 5 Keterangan atau penjelasan isi dari data kelompok umur... 48
Tabel 3. 6 Proses pembuatan dimensi nama penyakit ... 50
Tabel 3. 7 Proses pembuatan dimensi kelompok umur... 50
Tabel 3. 8 Proses pembuatan dimensi waktu ... 51
Tabel 3. 9 Qb pada query I ... 54
Tabel 3. 15 Bitmap indexing yang digunakan ... 60
Tabel 3. 16 Kombinasi bitmap indexing ... 61
Tabel 4. 1 Preprocessing dengan menghilangkan data yang bukan penyakit ... 66
Tabel 4. 2 Preprocessing dengan menambah kolom bulan ... 67
Tabel 4. 3 Preprocessing dengan menambah kolom tahun ... 68
Tabel 4. 4 ms_penyakit ... 70
Tabel 4. 5 ms_kelompok_umur... 71
Tabel 4. 6 tr penyakit ... 73
Tabel 4. 8 dim kelompok umur ... 75
Tabel 4. 9 dim waktu ... 76
Tabel 4. 10 tabel fakta ... 77
Tabel 4. 11 Listing skema penyakit ... 78
Tabel 5. 1 Query I ... 88
Tabel 5. 2 Hasil pencatatan waktu semua query pada query 1 ... 91
Tabel 5. 3 Query II ... 94
Tabel 5. 4 Hasil pencatatan waktu semua query pada query II ... 96
Tabel 5. 5 Kombinasi bitmap indexing ... 99
Tabel 5. 6 Hasil pencatatan waktu Qef menggunakan bitmap indexing pada query I ... 101
Tabel 5. 7 Hasil pencatatan waktu Qef menggunakan bitmap indexing pada query II ... 103
xviii
DAFTAR GRAFIK
Grafik 5. 1 Grafik rerata waktu akses Qef dan Qb ... 92
Grafik 5. 2 Grafik rerata pencatatan waktu semua query pada query I... 93
Grafik 5. 3 Grafik rerata waktu akses Qef dan Qb ... 97
Grafik 5. 4 Grafik rerata pencatatan waktu semua query pada query II ... 98
Grafik 5. 5 Grafik rerata waktu akses Qef pada query I dengan kombinasi bitmap indexing ... 102
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Kebutuhan akan media penyimpanan yang aman, fleksibel serta dapat diakses kapan saja dan dimana saja merupakan kebutuhan utama
user dan juga tuntutan perkembangan jaman. Hal tersebut dirasa belum cukup jika tidak diimbangi dengan kemampuan untuk mengolah data dengan jumlah banyak dengan cara yang efektif dan efisien. Untuk itu tidak cukup jika data diolah dengan pengelompokkan atau dibuat hanya dalam bentuk file fisik.
Saat ini telah banyak bermunculan alat atau tools untuk membantu
OLAP (Online Analytical Processing) merupakan teknologi yang memproses data di dalam gudang data menggunakan struktur multidimensi, menyediakan jawaban yang cepat untuk query analisis yang kompleks. OLAP merupakan alat atau tools yang digunakan untuk memproses gudang data.
Pengertian gudang data, menurut W.H. Inmon dan Richard D.H., (data warehouse) adalah koleksi data yang mempunyai sifat berorientasi subjek, terintegrasi, time-variant, dan bersifat tetap dari koleksi data dalam mendukung proses pengambilan keputusan manajemen. Di dalam gudang data, untuk melakukan pengolahan data dibutuhkan sebuah query. Query
adalah kemampuan untuk menampilkan suatu data dari database dimana mengambil dari tabel-tabel yang ada di database (Andri, 2012). Ada beberapa jenis query, sebagai contoh DMX, MDX, SQL, Xquery, Xpath. SQL query digunakan untuk mengolah data pada basis data, sedangkan pada OLAP menggunakan OLAP query. OLAP query merupakan query
yang digunakan untuk database OLAP. OLAP query juga sering disebut dengan MDX (en.wikipedia.org).
Gudang data menangani data dalam jumlah yang sangat besar. Dari dasar tersebut muncul sebuah permasalahan dalam penanganan query.
Indexing sangat membantu dalam mempercepat pencarian, sehingga unjuk kerja aplikasi dapat semakin tinggi. Metode bitmap indexing merupakan salah satu metode pada indexing.
Efisiensi query, mempengaruhi unjuk kerja sebuah aplikasi, sehingga perlu dilakukan pengujian terhadap query yang dapat dikatakan sebagai query efisien. Sebuah query dapat dikatakan efisien jika dapat dijalankan dalam waktu yang singkat serta tidak menggunakan sumber daya sistem secara berlebihan. Query efisien tersebut akan mempercepat waktu akses query ke database serta meningkatkan unjuk kerja sistem.
Petugas Puskesmas Jebed, memerlukan sebuah alat atau tools yang dapat membantu dalam mengefisienkan kinerja, khususnya untuk melakukan rekap penyakit. Pendekatan ilmu pada gudang data, dapat diterapkan pada kasus tersebut dengan membangun aplikasi gudang data untuk data penyakit. Efisiensi pemrosesan OLAP query dan penggunaan
bitmapindexing diharapkan dapat membantu mempercepat kinerja petugas dalam melakukan rekap penyakit.
1.2. Rumusan dan Batasan Masalah
Dari latar belakang masalah yang telah dijabarkan, muncul beberapa permasalahan yang dapat dirumuskan sebagai berikut:
2. Bagaimana cara menentukan query efisien beserta dengan bitmap indexing yang paling tepat?
Berdasarkan pada rumusan masalah yang ada, dapat diambil batasan sebagai berikut :
1. Penelitian hanya dilakukan di Puskesmas Jebed Pemalang, Kabupaten Pemalang, Jawa Tengah.
2. Data yang digunakan untuk membuat OLAP query adalah data laporan penyakit Puskesmas Jebed, dari tahun 2010 sampai 2012.
3. Query yang digunakan adalah OLAP query (MDX). 4. Penentuan query efisien menggunakan cuboid.
5. Indeks yang digunakan dalam penelitian adalah bitmap indexing. 6. Pengujian unjuk kerja dari OLAP berdasarkan waktu akses dari
masing-masing OLAP query yang menggunakan indeks maupun tanpa indeks.
7. Dalam penelitian ini, tampilan yang ada masih berupa prototype.
1.3. Tujuan Penelitian
1.4. Manfaat Penelitian
Manfaat yang diharapkan adalah dapat menentukan query efisien sebelum menggunakan query tersebut untuk melakukan pemrosesan data dengan menggunakan cuboid serta dapat menentukan bitmap indexing
yang cocok untuk query efisien tersebut. Dengan demikian unjuk kerja dari OLAP meningkat dan kinerja dari petugas dapat lebih optimal.
1.5. Metodologi Penelitian
Metodologi yang digunakan adalah sebagai berikut:
1. Melakukan pengumpulan serta penggabungan data, karena data yang ada dalam bentuk file dan dalam bentuk berkas laporan.
2. Merancang dan membuat gudang data dari data laporan penyakit Tahapan yang dilakukan sebagai berikut :
a. Membaca data legacy
b. Menggabungkan data dari berbagai sumber yang terpisah c. Memindahkan data ke server gudang data
d. Memecah gudang data ke dalam tabel fakta dan dimensi 3. Membuat cube dengan struktur yang paling baik
a. Menentukan query yang dianggap efisien dan query lain yang mungkin untuk mencari informasi dengan menggunakan cuboid.
5. Membuktikan query yang dianggap efisien berdasarkan kecepatan waktu akses masing-masing query.
6. Membuat indeks dengan menggunakan bitmapindexing.
7. Menghitung kecepatan yang dihasilkan oleh masing-masing query baik yang menggunakan indeks maupun tanpa indeks.
1.6. Luaran
Luaran yang diharapkan dari penelitian ini adalah aplikasi gudang data dengan menerapkan bitmapindexing serta query yang efisien.
1.7. Sistematika Penulisan
Sistematika penulisan adalah sebagai berikut;
- BAB I berisi pendahuluan, yang membahas latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat penulisan, luaran yang diharapkan serta sistematika penulisan.
Teori yang digunakan diantaranya adalah gudang data, OLAP dan OLAP
query.
- BAB III pada bab ini berisi analisis dan perancangan sistem. Dalam bab ini dibahas mengenai analisis permasalahan serta perancangan sistem yang digunakan untuk menyelesaikan masalah yang ada.
- BAB IV berisi tentang implementasi sistem berdasar pada rancangan yang telah dibuat.
- BAB V berisi tentang hasil penelitian dan pembahasan dari penelitian yang telah dilakukan.
8
BAB II
LANDASAN TEORI
2.1. Teori Umum
2.1.1. Profil Puskesmas
Puskesmas Jebed adalah salah satu unit pelayanan kesehatan di Kabupaten Pemalang. Terletak di Kecamatan Taman, di desa Jebed Selatan. Wilayah kerjanya terdiri atas 11 desa dengan jumlah penduduk sekitar 78.000 jiwa. Desa yang ditangani adalah sebagai berikut:
Puskesmas Jebed juga berperan aktif dalam upaya pemerintah dalam meningkatkan peran teknologi dalam dunia kesehatan. Di Kabupaten Pemalang, hanya 2 puskesmas yang ikut berperan pada pemanfaatan kemajuan teknologi, yaitu Puskesmas Jebed dan Puskesmas Kebondalem.
Puskesmas Jebed memiliki visi dan misi. Visi dan misi puskesmas menjadi acuan untuk meningkatkan kesehatan masyarakat. Cakupan peningkatan kesehatan dikhususkan pada wilayah cakupan Puskesmas Jebed.
2.1.1.1. Visi
“Terdepan dalam Mewujudkan Kabupaten Pemalang yang Sehat
dengan didukung Pemberdayaan Masyarakat dan Kemitraan”
2.1.1.2. Misi
1. Meningkatkan pelayanan kesehatan yang berkualitas dan terjangkau.
2. Meningkatkan sumberdaya kesehatan secara merata baik kuantitas maupun kualitas.
3. Menggerakan dan meningkatkan pemberdayaan masyarakat, dunia swasta dan kerjasama lintas sektor.
2.1.2. Pengertian DataWarehouse
Gudang data menggeneralisasi dan mengkonsolidasikan data dalam ruang multidimensi. Pembuatan gudang data yang meliputi pembersihan data, integrasi data, dan transformasi data dan dapat dilihat sebagai langkah preprocessing penting untuk data mining. Selain itu, gudang data menyediakan Online Analytical Processing (OLAP).
Pengertian dari gudang data itu sendiri dapat dilihat dari berbagai macam pandangan. Menurut W.H. Inmon dan Richard D.H., data warehouse adalah koleksi data yang mempunyai sifat berorientasi subjek, terintegrasi, time-variant, dan bersifat tetap dari koleksi data dalam mendukung proses pengambilan keputusan manajemen. Menurut Vidette Poe, data warehouse merupakan database yang bersifat analisis dan read only yang digunakan sebagai fondasi dari sistem penunjang keputusan. Dari berbagai definisi dapat disimpulkan bahwa data warehouse adalah
database yang saling bereaksi yang dapat digunakan untuk query dan analisis, bersifat orientasi subjek, terintegrasi, time-variant, tidak berubah yang digunakan untuk membantu para pengambil keputusan.
Gudang data juga memiliki karakteristik memiliki empat karakteristik utama yakni subject-oriented (berorientasi subyek),
Integrated (terintegrasi), Time Variant (rentang waktu) dan Non-Volatile.
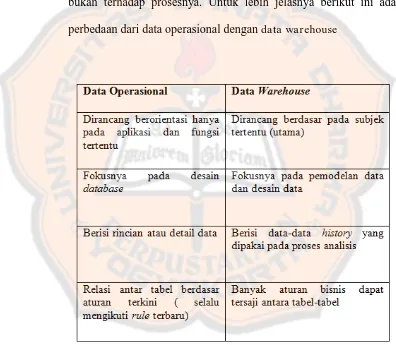
a. Berorientasi subjek artinya data warehouse didesain untuk menganalisis data berdasarkan subyek-subyek tertentu dalam organisasi, bukan pada proses atau fungsi aplikasi tertentu. Data warehouse menyimpan data yang bersifat sebagai penunjang suatu keputusan.
Data yang disimpan dalam data warehouse berorientasi subjek bukan terhadap prosesnya. Untuk lebih jelasnya berikut ini adalah perbedaan dari data operasional dengan data warehouse
b. Terintegrasi sebuah data warehouse biasanya dibuat dari berbagai macam sumber data, seperti relational database, file, dan on-line transactions records. Pembersihan dan integrasi data digunakan untuk menjaga konsistensi data dalam penamaan, encoding structures, attribute measures dan lain-lain
c. Time-Variant data disimpan untuk menyediakan informasi dari perspektif sejarah (Misalnya, data dari 5-10 tahun terakhir). Data yang di data warehouse dapat dikatakan akurat atau valid pada rentang waktu tertentu
d. NonVolatile setiap kali proses perubahan, data akan di tampung dalam tiap-tiap waktu. Jadi tidak di perbaharui terus menerus atau tidak di
update secara real time tetapi di refresh dari sistem operasional secara reguler. Data warehouse tidak memerlukan pemrosesan transaksi dan
recovery. Hanya ada dua operasi initial loading of data dan access of data. ( Jiawei et all, 2006)
Gudang data juga memiliki arsitektur tertentu. Data yang digunakan untuk membuat gudang data diperoleh dari berbagai sumber oleh sebab itu sebelum data tersebut digunakan untuk membuat gudang data perlu dilakukan proses dengan menggunakan ETL (Extract,Transform, Load).
Gambar 2. 2 Arsitektur Gudang Data
Didalam gudang data terdapat tiga proses besar yakni ETL
(Extract, Transform, Load). Berikut ini adalah penjelasan singkat mengenai ETL.(
a. Extract proses pengambilan data yang diperlukan dari sumber data warehouse dan selanjutnya dimasukkan pada staging area untuk diproses pada tahap berikutnya .Pada fungsi ini, akan banyak berhubungan dengan berbagai tipe sumber data. Format data, mesin yang berbeda, software dan arsitektur yang tidak sama. Sehingga sebelum proses ini dilakukan, sebaiknya perlu didefinisikan
requirement terhadap sumber data yang dibutuhkan untuk lebih memudahkan pada extra ction data ini.
aplikasi-aplikasi yang ada. Transformasi data ditujukan untuk mengatasi masalah ini. Dengan proses transformasi data melakukan standarisasi terhadap data pada satu format yang konsisten. Beberapa contoh ketidak konsistenan data tersebut dapat diakibatkan oleh tipe data yang berbeda, data length dan lain sebagainya.
c. Load, memindahkan data ke data warehouse. Ada dua load data yang dapat dilakukan pada data warehouse. Pertama adalah inisial load, proses ini dilakukan pada saat telah selesai mendesain dan membangun
data warehouse. Data yang dimasukkan tentunya akan sangat besar dan memakan waktu yang relatif lebih lama. Kedua Incremental load, dilakukan ketika data warehouse telah dioperasikan. Dengan melakukan data extraction, transformation dan loading terhadap data tersebut.
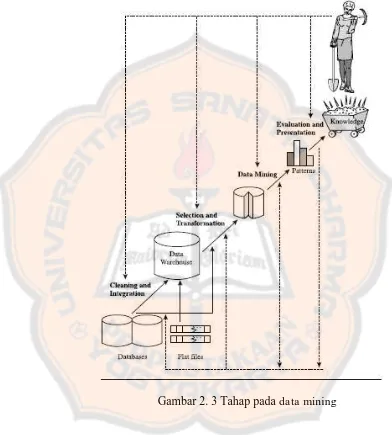
2.1.3. Data Mining
meliputi data cleaning, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola dan knowledge presentation.
Gambar 2. 3 Tahap pada data mining
Tahap-tahap data mining ada 6 yaitu :
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis,
tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining
membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi- bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5. Proses penambangan data
6. Evaluasi pola (pattern evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based
yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang diluar dugaan yang mungkin bermanfaat.
7. Presentasi pengetahuan (knowledge presentation) Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Adakalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining.
Secara sederhana data mining dapat diartikan sebagai proses
orang melihat data mining hanya sebagai langkah penting dalam proses penemuan pengetahuan. Penemuan pengetahuan sebagai suatu proses digambarkan pada gambar berikut ini : (Jiawei et all, 2006)
Gambar 2. 4 Architecture of a Typical Data mining System
Gambar 2. 5 Data mining merupakan irisan dari berbagai disiplin (Budi Santosa, 2007)
2.1.4. Langkah Dalam Membangun Gudang Data
Gudang data dapat diterapkan dengan mengikuti langkah-langkah pokok seperti berikut ini (Wasito, 2010).
1. Membaca data legacy
Memperhatikan bagian-bagian data yang perlu untuk dibersihkan. 1. Menggabungkan data dari berbagai sumber terpisah
Setiap jenis informasi yang diinginkan mungkin berasal dari beberapa
file yang harus digabungkan untuk digunakan pada gudang data. 2. Memindahkan data dari sumber ke server gudang data
Membuat standarisasi format copy-kan data dari sumber sekaligus data dibuat bersih (clean).
3. Memecah gudang data dalam tabel fakta dan tabel dimensi
2.1.5. Kettle / Pentaho Data Integration
Kettle adalah aplikasi ETL (Extract, Transformation, Load) open source yang sangat populer, dan merupakan salah satu yang terbaik di pasar BI dunia saat ini. Khusus di Indonesia, Kettle telah banyak digunakan sebagai tool standar untuk pengolahan data ketika ERP atau
sistem transaksional “kalah” kecepatan dengan proses bisnis yang dinamis.
Kettle merupakan bagian dari aplikasi Pentaho. Proyek ini berdiri sendiri dan merupakan inisiatif dari Mat Casters yang sampai saat ini tetap aktif sebagai project leader dari Kettle – sebelum diakuisisi oleh Pentaho pada tahun 2006. Sejak diakuisisi Kettle berubah nama menjadi Pentaho Data Integration (PDI).
Didalam Kettle terdapat kompenen-komponen yang terdiri dari 4 aplikasi yaitu Spoon, Pan, Kitchen dan Carte.
1. Spoon, yaitu aplikasi grafis berbasis swing yang digunakan untuk merancang file skema job dan transformation.
2. Pan, yaitu script yang digunakan untuk menjalankan file skema transformation melalui terminal / command line.
3. Kitchen, yaitu script yang digunakan untuk menjalankan file skema job melalui terminal / command line.
Dari semua aplikasi tersebut dijalankan melalui shell atau batch script yang berkaitan. Selain ke empat komponen diatas terdapat fitur-fitur dari Kettle.
1. Memiliki utilitas grafik yang dapat digunakan merancang control flow umum maupun data flow (aliran data).
2. Multi platform - karena dikembangkan di atas Java yang notabene berjalan di banyak platform sistem operasi.
3. Bersifat concurrent, dalam arti row-row data diambil oleh suatu step
dan diserahkan ke step lain secara parallel.
4. Scalable - dapat beradaptasi dengan penambahan kapasitas memori RAM atau pun storage (scale up) dan dapat node komputer / cluster (scale out).
5. Koleksi step transformation dan job yang cukup banyak.
6. Extensible, dapat membuat step transformation dan job baru dengan sistem plugin.
7. Dukungan luas berbagai produk database yang terkenal di pasaran baik itu proprietary maupun free open source seperti Oracle, SQL Server, MySQL, PostgreSQL dan lain sebagainya.(pentaho.phi-integration.com)
teknologi JSP(Java Server Pages). JPivot memiliki kemampuan berinteraksi dengan Mondrian secara native dan OLAP engine lain melalui meanisme layanan XMLA ( XML for Analysis). (www.phi-Integration.com)
2.1.6. OLAP (On-Line Analytical Processing)
Menurut Connoly dan Begg 2005, OLAP adalah perpaduan dinamis, analisis dan konsolidasi dari data multidimensional berukuran besar. Definisi lain menyebutkan OLAP adalah aplikasi analytical dengan kemampuan pivot menyerupai spreadsheet OLAP merupakan komponen penting dari aplikasi BI (Business Intelligence).
Perbedaan dengan spreadsheet adalah OLAP dirancang khusus untuk mampu menangani jumlah data besar dan memiliki ekspresi bahasa analisis yang lebih baik. Dan aplikasi OLAP ini biasanya memiliki arsitektur client / server. Database OLAP memiliki struktur skema tersendiri dan biasanya berupa suatu data warehouse.
Server basis data OLAP multidimensi mendukung operasi analitikal, seperti : rotation/ pivoting, drilldown & consolidation, slicing & dicing.
kata lain dapat memutar-mutar sumbu pada cube sehingga memperoleh data yang diinginkan sesuai dengan sudut pandang analisis yang diperlukan.
- drilldown & consolidation agregasi data bisa dilakukan dengan drill down dan consolidation. Penampilan data yang lebih detail dapat artinya data yang dipotong berdasarkan kategori tertentu. Sedangkan
dicing merupakan penyaringan subset data dari proses slicing. (Anonymous, 2010)
Didalam OLAP berkaitan erat dengan istilah-istilah seperti
measure, cube, multidimensi, surrogate key dan fact tabel (tabel fakta).
- Measure sebuah entitas yang dapat dinitor dan diukur dari dimensi. Contohnya seperti pendapatan dan rata-rata temperatur. (Nenny, 2012) - Cube merupakan contoh data multidimensi selain spreadsheet. Dengan cube data menjadi lebih mudah untuk dimanipulasi. Setiap sumbu cube mewakili dimensi-dimensi.
dilihat dari segi lokasi Buku, waktu, lokasi penjualan / toko dan sebagainya.(www.gudangmateri.com)
- Surrogate key merupakan salah satu elemen yang biasanya ditambahkan pada tabel dalam konsep pemodelan data warehouse, menurut Kimball dan Ross (2012,p4140) "Surrogate key adalah key berupa integer yang secara sequential ditambahkan sesuai keperluan dan staging area untuk membentuk sebuah tabel dimensi dan elemen
yang menggabungkannya dengan tabel fakta”.
- Fact tabel menurut Inmon (2002, p391) " Fact tabel is the center of a star join tabel that has many occurences will be located. Tabel yang tersentralisasi dalam sta r s ch ema disebut tabel fakta. (Anonymous, 2010)
2.1.6.1. Skema Bintang
Gambar 2. 6 Contoh Skema Bintang
Selain itu juga terdapat keuntungan menggunakan skema bintang yang tidak terdapat dalam struktur relational biasa. Keuntungan menggunakan skema bintang diantaranya :
1. Respon data yang lebih cepat dihasilkan dari perancangan database
2. Kemudahan dalam mengembangkan atau memodifikasi data yang terus berubah
3. End user dapat menyesuaikan cara berpikir dan menggunakan data, konsep ini dikenal juga dengan istilah paralel dalam perancangan
database.
4. Menyederhanakan pemahaman metadata bagi pemakai dan pengembang.
Skema bintang merupakan suatu struktur sederhana yang secara relatif terdiri dari beberapa tabel dan alur gabungan yang dirumuskan dengan baik. Perancangan database ini berlawanan dengan struktur organisasi yang digunakan untuk database proses transaksi. Database ini menyediakan response time, query, skema bintang dapat dibaca dan dipahami oleh analisis, end user bahkan bagi mereka yang belum terbiasa dengan stuktur database.
2.1.7. Database
Dalam penelitian ini menggunakan database yakni Oracle. Seperti yang sudah dibahas sebelumnya database C.J Date merupakan kumpulan data yang saling berelasi, diatur dan diorganisasikan dalam suatu cara yang sistematis untuk mengurangi atau menekan duplikasi data dan memberikan informasi pada sejumlah pemakai (user) pada beberapa aplikasi.
Basis data Oracle ini pertama kali dikembangkan oleh Larry Ellison, Bob Miner dan Ed Oates lewat perusahaan konsultasinya bernama
Software Development Laboratories (SDL) pada tahun 1977. Pada tahun 1983, perusahaan ini berubah nama menjadi Oracle Corporation sampai sekarang. (id.wikipedia.org)
2.2. Teori Khusus
2.2.1. Efisiensi OLAP Query
2.2.1.1. Konsep Hirarki dengan Jumlah Nilai Berbeda Setiap Atribut
Untuk memilih cuboid mana yang paling untuk melakukan query, hal yang harus diperhatikan diantaranya adalah hirarki. Menggunakan bantuan hirarki maka sangat dimudahkan ketika memilih cuboid mana yang paling tepat untuk melakukan query, karena dengan menggunakan hirarki maka dapat melihat level dari dimensi-dimensi yang digunakan pada gudang data. Sebagai contoh terdapat hirarki “day < month < quarter
data data. Granularity data merupakan tingkat kedetailan dari data dalam suatu data warehouse.
Dalam penelitian ini cara yang digunakan untuk menentukan hirarki dari dimensi yang ada yakni dengan cara, pertama lakukan sorting secara ascending pada setiap atribut yang ada. Kedua hasil dari sorting tersebut diurutkan dari atas ke bawah dengan susunan atribut pertama berada pada bagian paling atas. Dengan hasil hirarki yang didapat maka dapat menentukan apakah perlu ada perubahan susunan hirarki atau tidak.
Gambar 2. 7 Contoh hirarki yang terbentuk
2.2.1.2. Cuboid
Data warehouse pada umumnya berisi data dalam jumlah besar. Untuk itu OLAP dituntut untuk dapat melakukan pemrosesan query
dengan cepat. Didalam data cube terdapat cuboid yang menggambarkan dimensi yang ada didalam sebuah cube atau group by yang ada didalam
cube tersebut.
Cuboid berasal dari banyak dimensi, pengertian dari cuboid itu sendiri adalah “data cube is a lattice of cuboids”, atau data cube
merupakan pola-pola dari cuboids. Cuboid yang paling rendah disebut dengan base cuboid, sedangkan cuboid dengan tingkat paling tinggi disebut apex cuboid. (Jiawei et all, 2006). Untuk lebih jelasnya dapat dilihat pada gambar 2.8 pada base cuboid terdiri dari tiga dimensi yakni
city, item dan year, sedangkan pada apex cuboid atau 0-D cuboid
Gambar 2. 8 Lattice of cuboids, 3-D data cube untuk 3 dimensi. Setiap cuboid menunjukkan derajat yang berbeda.
( 1 )
Li adalah jumlah level yang berhubungan dengan suatu dimensi.
Perhitungan cuboid tanpa hirarki maupun dengan hirarki diatas bertujuan agar tidak terjadi curse of dimensionality. Curse of dimensionality
merupakan kondisi dimana kebutuhan penyimpanan berlebihan saat banyak dimensi memiliki hirarki dengan beberapa level.
Sebelum melakukan query pada gudang data, tahap yang harus dilakukan yaitu menentukan cuboid-cuboid yang mungkin yang akan digunakan dalam melakukan query. Dari cuboid yang mungkin tersebut kemudian dipilih cuboid yang paling tepat untuk melakukan query. (Jiawei
et all, 2006). Cuboid-cuboid yang mungkin dipilih menggunakan hirarki, dengan bantuan hirarki dapat memilih cuboid yang mungkin dengan level yang baik. Jika level cuboid yang dipilih semakin baik maka besar kemungkinan cuboid tersebut akan digunakan untuk melakukan pemrosesan query.
2.2.2. Bitmap Indexing
Indeks merupakan objek yang paling penting yang dibutuhkan pada saat membuat sebuat aplikasi. Begitu juga pada database Oracle, indeks menjadi salah satu faktor yang sangat menentukan unjuk kerja aplikasi. (Samsyiar, 2004)
Untuk memudahkan dalam mengakses data, sebagian besar data warehouse mendukung struktur indeks. Didalam OLAP terdapat dua metode indexing yang dapat digunakan yakni bitmap indexing dan join indexing. Namun didalam OLAP yang paling banyak digunakan adalah
indexing dengan menggunakan bitmap. Bitmap indexing memungkinkan pencarian data dengan cepat didalam data cube. (Jiawei et all, 2006).
Dalam bitmap indexing sebuah bitmap dibuat untuk setiap nilai kunci suatu daftar RowID seperti yang dilakukan dalam indeks B+ Tree.
Setiap bit dalam bitmap menunjuk pada sebuah RowID. Ketika bit diberi nilai 1, berarti RowID yang terkait berisi nilai kunci yang dimaksud. Fungsi pemetaan akan mengubah posisi bit ke RowID sesungguhnya sehingga record dapat ditemukan ketika dilakukan operasi query.
Bitmap indexing biasanya digunakan pada kolom yang mempunyai
low cardinality. Seperti kolom jenis kelamin yang mempunyai jumlah data
hanya „L‟ dan „P ‟ saja. Atau data yang lain dimana jika jumlah data dibagi
bitmap indexing pada kolom yang mempunyai data yang unik, karena membutuhkan jumlah space yang lebih besar.
Bitmap indexing sangat cepat apabila digunakan pada aplikasi yang sering menggunakan ad hoc query karena biasanya kriteria dari perintah
where yang dipakai melibatkan kombinasi diantara kolom- kolom yang ada pada setiap tabel. Bitmap indexing sendiri tidak telalu banyak melakukan scanning terhadap data yang akan dicari sebab struktur dari
bitmap indexing yang sangat kecil yaitu hanya terdiri atas beberapa key
indeks entries saja. Oracle hanya akan mencari data dari single bitmap indexing yang mempunyai nilai 1 dan 0 saja. (Samsyiar, 2004)
Keuntungan menggunakan bitmap indexing antara lain (Budi Susanto, 2007):
1. Bekerja dengan baik dengan tabel yang berisi jutaan record.
2. Bitmap indexing meningkatkan waktu respon secara drastis saat kondisi multiple join yang diberikan menunjuk pada kolom yang memiliki bitmap indexing. Indeks inijuga bekerja dengan baik untuk
query yang memiliki beberapa klausa kondisi join (AND, OR).
3. Bitmap indexing bekerja dengan baik jika kolom yang ditunjuk dalam indeks tidak sering di-update atau dihapus.
4. Bitmap indexing bekerja dengan baik ketika kolom yang berada dalam
adalah sebuah kolom yang hanya memiliki perbedaan nilai kurang dari 12 macam nilai yang berbeda. Sebagai contoh jenis kelamin ya atau tidak.
Selain keuntungan yang ditawarkan oleh bitmap indexing terdapat juga kekurangan dari bitmap indexing, antara lain :
1. Tidak dapat bekerja dengan baik dengan tabel yang memiliki bitmap indexing, dimana kolom kunci indeksnya sering di update atau dihapus
2. Bitmap indexing memerlukan pembangunan indeks kembali secara berkala
2.2.3. MDX(Multi Dimensional Expression)
MDX adalah suatu bahasa yang mengekspresikan seleksi, kalkulasi dan definisi metadata terhadap database OLAP, dan memiliki kapabilitas untuk menentukan bagaimana hasil query ditampilkan. Didalam MDX juga terdapat MDX query. Query didalam MDX merupakan konstruksi bahasa yang digunakan untuk mengakses dan mengambil data oleh klien MDX. Sintaks dasar query MDX adalah sebagai berikut:
Select
Sebagai penjelasan singkat dapat dilihat contoh berikut ini
Keterangan contoh query
- Didalam select memasukkan measure, pada contoh query diatas
measurenya adalah jumlah B, L dan K kemudian diikuti oleh on columns
- Untuk baris selanjutnya isikan dimensi-dimensi yang digunakan dalam
cube diikuti dengan on rows selanjutnya diikuti dengan from (cube) pada contoh diatas adalah cube PENYAKIT.
2.2.3.1 Tuple dan Set
Selain itu terdapat sebuah konsep yang sangat fundamental di MDX yakni tuple dan set. Tuple adalah intserseksi dari satu (dan hanya satu ) member yang diambil dari satu atau beberapa dimensi didalam tabel. Sedangkan Set adalah kumpulan dari nol atau lebih tuple yang memiliki
select NON EMPTY {[Measures] .[Jumlah B] , [Measures] .[Jumlah L] , [Measures] .[Jumlah K] } ON COLUMNS,
Hierarchize({([ Waktu] .[Semua Waktu] , [Nama Penyakit] .[Semua Penyakit] , [Kelompok Umur] .[Semua Kelompok Umur] )}) ON ROWS
karakteristik dimension yang sama. jika tidak memiliki tuple maka disebut kosong (empty set). Didalam ekspresi MDX, tuple biasanya diikuti oleh pasangan kurung biasa () sedangkan set oleh kurung kurawal {}.
Contoh tuple
Contoh set
2.2.1.2\\\\MDX Expression
MDX Expression adalah statement parsial atau potongan kode kecil yang dapat digunakan untuk mendefinisikan calculated member, set
atau member property. Ekspresi dari MDX ini mengambil suatu tuple atau
2.2.3.2 MDX Functions
Function tentunya merupakan bagian ekspresion dari MDX yang sangat penting digunakan untuk berbagai tujuan dan keperluan. Function
39 BAB III
ANALISIS DAN PERANCANGAN
Dalam bab ini akan dijelaskan mengenai data yang digunakan, serta dibahas juga mengenai perancangan mulai dari penggabungan data, membuat basis data hingga membuat gudang datanya. Tujuan dari penelitian ini sendiri yakni untuk mendapat query yang paling optimal dengan menggunakan OLAP query.
3.1. Deskripsi Kasus
Di Puskesmas Jebed data laporan penyakit diolah menggunakan Microsoft Excel, demikian juga untuk melihat data penyakit setiap tahunnya Puskesmas hanya mengandalkan Excel. Hal tersebut tentu akan menjadi sulit untuk mengambil informasi tertentu, misalnya untuk melihat penyakit yang paling sering muncul setiap tahunnya maupun informasi penting lainnya.
Berdasarkan fakta tersebut, peneliti berusaha untuk membantu memecahkan masalah tersebut menggunakan kemampuan yang dimiliki oleh gudang data. Mengingat gudang data sangat membantu dalam query
memikirkan cara bagaimana jika user melakukan query tidak memerlukan waktu yang lama. Dengan kata lain bagaimana cara meningkatkan unjuk kerjanya, mengingat data yang ada dalam jumlah besar. Hal tersebut coba dicari solusinya dengan melakukan indexing dengan menggunakan bitmap indexing, karena indeks ini sangat cocok digunakan untuk tabel-tabel yang jarang melakukan proses DML pada database.
3.2. Data
Data merupakan sumber yang sangat penting dalam sebuah penelitian. Sumber data terbagi menjadi dua yaitu data primer dan data sekunder. Data primer adalah data yang diperoleh peneliti secara langsung (dari tangan pertama), sementara data sekunder adalah data yang diperoleh peneliti dari sumber yang sudah ada.
Data yang digunakan untuk tugas akhir ini merupakan data dari sumber data sekunder. Data yang digunakan berupa Laporan Bulanan Data Kesakitan Kunjungan Total di Puskesmas Jebed, Kabupaten Pemalang. Data ini merupakan Laporan Bulanan Data Kesakitan Kunjungan Total selama tiga tahun, yakni tahun 2010 hingga 2012. Data tersebut berisi :
3. Jenis Penyakit
4. Jumlah Kasus Baru (B) 5. Jumlah Kasus Lama (L) 6. Jumlah Kunjungan (K) 7. Kelompok Umur 8. Jumlah Total(B+L+K)
Berikut ini adalah contoh data Laporan Bulanan Data Kesakitan Kunjungan Total di Puskesmas Jebed, Kabupaten Pemalang.
Gambar 3. 1 Contoh data
yang sama. Data ini menjadi penting untuk tugas akhir ini karena dengan data yang ada dapat digunakan atau dimanfaatkan dengan semestinya, dalam hal ini adalah untuk membantu dalam penelitian mengenai mengoptimalkan unjuk kerja OLAP.
3.3. Analisis Kebutuhan
Analisis kebutuhan digunakan untuk mengetahui apa yang sebenarnya dibutuhkan oleh user. Seperti yang telah dijelaskan sebelumnya, di puskesmas Jebed untuk melihat laporan-laporan penyakit masih menggunakan Microsoft Excel. Hal tersebut tentu akan menjadi sulit jika misal ada user ingin melihat penyakit tertentu pada kelompok umur tertentu di tahun 2012, dengan adanya gudang data ini, diharapkan
Gambar 3. 2 Diagram use case
3.4. Membangun Gudang Data
Pada tahap ini merupakan tahapan untuk membangun gudang data dimulai dari melakukan preprocessing hingga membuat tabel fakta. Tabel berikut ini berisi gambaran tahap yang dilakukan pada bagian ini.
Tabel 3. 1 Langkah membangun gudang data
No Langkah yang dilakukan Penjelasan Singkat
3.4.1 Membaca data legacy Merupakan tahap untuk menganalisis data
3.4.2 Menggabungkan data dari
berbagai sumber terpisah
Merupakan tahap menggabungkan semua
data, jika berbeda format maka disamakan
bagaimana cara menggabungkan data
3.4.3 Memindahkan data ke
server gudang data
Merupakan tahap memindahkan data ke
dalam server, tahap ini dimulai dengan
membuat tabel master terlebih dahulu.
3.4.4 Memecah gudang data ke
dalam tabel fakta dan
dimensi
Berdasarkan pada tahap 3.4.3, dengan
menggunakan sumber data dari tabel
master maka dapat digunakan untuk
membuat dimensi.
3.4.1. Membaca Data Legacy
Pada tahap ini melakukan analisis data kemudian melakukan pembersihan data yang tidak konsisten, menghapus atau menambah kolom yang dirasa perlu. Pada tahap ini juga dilakukan pemilihan data karena tidak semua data digunakan. Tujuan dari tahap ini adalah memudahkan ketika memindahkan data tersebut ke dalam basisdata.
3.4.2. Menggabungkan Data dari Berbagai Sumber
data yang ada masih terdiri dari banyak file dengan tujuan untuk mempermudah dalam mengkonversi data ke dalam basis data . File yang telah digabungkan tersebut berisi data laporan penyakit dari tahun 2010 sampai 2012.
Gambar 3. 3 Ilustrasi menggabungkan data dari berbagai sumber
3.4.3. Memindahkan Data ke Server Gudang Data
dimensi pada gudang data. Berikut ini adalah penjelasan mengenai rancangan tabel master, dimensi-dimensi, serta tabel fakta.
1. Membuat tabel master ms_penyakit
Tabel 3. 2 Proses memindahkan data ke dalam tabel ms_penyakit
Tabel 3.2 merupakan proses pembuatan tabel ms_penyakit. Sumber data dari tabel ms_penyakit berasal dari file excel data penyakit. Tabel ini berisi id_penyakit yang merupakan primary key, SP2TP, ICD_X dan jenis_penyakit.
Tabel 3. 3 Keterangan atau penjelasan isi dari data penyakit Data penyakit
ICD-X Merupakan kode diagnosis, ICD-X sendiri merupakan buku petunjuk dari WHO yang menjadi standar pengkodean atas penyakit dan tanda-tanda, gejala, temuan-temuan yang abnormal, keluhan, keadaan sosial dan eksternal menyebabkan cedera atau penyakit, seperti yang diklasifikasikan oleh World Health Organization (WHO)
Jenis Penyakit Merupakan data yang berisi berbagai macam jenis penyakit atau data yang berisi nama-nama penyakit
Id Penyakit Merupakan data yang berisi id dari masing-masing penyakit
2. Membuat tabel ms_kelompok_umur
Tabel 3. 4 Proses memindahkan data ke dalam tabel ms_kelompok_umur
Tabel 3.4 merupakan proses dari pembuatan tabel ms_kelompok_umur, yang terdiri dari id kelompok umur yang merupakan
dari tabel ini berupa file excel yang berisi id kelompok umur dan nama kelompok umur. Penjelasan mengenai isi data kelompok umur terdapat pada Tabel 3.5.
Tabel 3. 5 Keterangan atau penjelasan isi dari data kelompok umur Data kelompok umur
Id kelompok umur Merupakan data yang berisi id dari masing-masing kelompok umur
Nama kelompok umur Merupakan data yang berisi nama dari masing-masing kelompok umur. Terdiri dari 8 kelompok umur yakni 0-28 hari, 28 hari-1 tahun, 1-4 tahun, 5-14 tahun, 15-44 tahun, 45-54 tahun, 55-60 tahun, diatas 60 tahun
3.4.4. Memecah Gudang Data dalam Tabel Fakta dan Tabel Dimensi
Hal penting yang menjadi perhatian dalam perancangan gudang data adalah pengumpulan data dan tahap ini sebelumnya telah dilakukan. Kemudian tahap penting lain yang harus dilakukan adalah membuat perancangan di gudang data dalam penelitian ini perancangan gudang datanya dengan menggunakan skema bintang.
K. Gambar berikut merupakan hasil perancangan dengan menggunakan data laporan dari tahun 2010 sampai 2012.
Gambar 3. 4 Skema Bintang
1. Dimensi nama penyakit
Tabel 3. 6 Proses pembuatan dimensi nama penyakit
Dimensi ini terbentuk dari tabel ms_penyakit, dimensi ini terdapat kolom SP2TP, ICD_X, jenis penyakit, id penyakit serta sk nama penyakit yang merupakan primary key. Sk nama penyakit merupakan surrogate key
yang bernilai integer yang ditambahkan pada dimensi nama penyakit.
2. Dimensi kelompok umur
Tabel 3. 7 Proses pembuatan dimensi kelompok umur
umur yang merupakan primary key dari dimensi kelompok umur. Sk kelompok umur merupakan surrogate key yang ditambahkan pada dimensi ini.
3. Dimensi waktu
Tabel 3. 8 Proses pembuatan dimensi waktu
Dimensi ini sedikit berbeda dengan dimensi nama penyakit maupun dimensi kelompok umur. Karena dimensi ini terbentuk bukan dari tabel master melainkan dari tr_penyakit. Pada dimensi waktu terdapat kolom bulan, nama bulan, id tahun, tahun serta sk waktu yang merupakan
primay key serta merupakan surrogate key dari dimensi ini.
Setelah semua tahap dalam membangun gudang data sudah dilakukan, maka langkah selanjutnya adalah menentukan informasi apa saja yang akan diambil atau dengan kata lain menentukan query-query
3.5. Pemrosesan Efisien OLAP Query Menggunakan Cuboid
Langkah yang dilakukan dalam melakukan efisiensi pemrosesan OLAP query dengan menggunakan cuboid adalah :
1. Membentuk hirarki untuk setiap dimensi yang digunakan. Hirarki yang digunakan dalam penelitian ini dibentuk berdasarkan jumlah atribut yang berbeda.
2. Menggunakan bantuan hirarki, menentukan cuboid-cuboid
yang mungkin untuk melakukan query.
Berikut ini penjelasan detail dari kedua tahap tersebut.
3.5.1. Hirarki
Gambar 3.5 ini merupakan hasil pembentukan hirarki menggunakan tiga dimensi yaitu dimensi nama penyakit, dimensi kelompok umur, dan dimensi waktu. Hirarki tersebut dibentuk berdasarkan pada jumlah atribut yang berbeda. Semakin luar level hirarki maka semakin mungkin cuboid tersebut dipilih. Hal tersebut dikarenakan jika melakukan query maka tidak perlu melakukan query terlalu dan jumlah level terluar memiliki jumlah row yang paling sedikit. Hirarki pada Gambar 3.5 digunakan untuk membantu dalam menentukan cuboid-cuboid
Gambar 3. 5 Hirarki yang terbentuk
3.5.2. Cuboid Pada Query I dan Query II
Pemilihan cuboid yang tepat jika cuboid tersebut memiliki kriteria: 1. Bukan merupakan data yang umum.
2. Memiliki level yang baik, ditentukan dengan menggunakan hirarki.
3. Sesuai dengan tujuan query.
Didalam penelitian ini menggunakan dua contoh query. Query I merupakan query yang digunakan untuk melihat data rekap tahunan, sedangkan untuk query II digunakan untuk melihat data rekap penyakit setiap bulannya. Selain menggunakan query yang dipilih berdasarkan
a. Query efisien (Qef) yang dipilih menggunakan cuboid yang paling baik.
b. Query biasa(Qb) atau query yang tidak dipilih menggunakan
cuboid.
c. Query Pembanding (Qp1, Qp2, ...., Qn) merupakan query yang terbentuk berdasarkan cuboid yang mungkin, namun bukan
cuboid yang paling tepat. Qb digunakan untuk membuktikan apakah Qef merupakan query yang tercepat.
3.5.2.1. Query I
Query ini yang digunakan untuk melihat data rekap tahunan. Pada
query I terdapat query biasa dan query yang dipilih menggunakan cuboid.
Berikut ini adalah query biasa untuk query I, query biasa merupakan query
yang bukan didapat dari cuboid yang mungkin Qb juga merupakan query
yang memenuhi tujuan dilakukannya query I yakni melihat data rekap tahunan.
Tabel 3. 9 Qb pada query I
select NON EMPTY {[Measures].[Jumlah B], [Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{([Waktu].[Semua Waktu], [Nama Penyakit].[Semua Penyakit],[Kelompok Umur].[Semua Kelompok Umur])} ON ROWS
Sebelum melakukan query digudang data, maka dengan tujuan
query yang sama yaitu melihat data penyakit dengan ICD_X= A15 yaitu penyakit TB Paru BTA (+) di tahun 2010 tentukan terlebih dahulu cuboid
yang mungkin. Tujuannya adalah agar mendapatkan query yang efisien dengan waktu akses cepat untuk melihat data data penyakit dengan ICD_X= A15 yaitu penyakit TB Paru BTA (+) di tahun 2010.
Tabel 3. 10 Cuboid yang mungkin pada query I
Tujuan query I Cuboid yang mungkin
Melihat data penyakit dengan ICD_X= A15 yaitu penyakit TB ICD-X=A15 and nama penyakit= TB Paru BTA (+) and tahun=2010
Cuboid 3 : { Kelompok umur, tahun } where ICD-X=A15 and nama penyakit= TB Paru BTA (+) and tahun=2010
Berdasarkan cuboid-cuboid yang mungkin pada query I maka didapat cuboid 1 merupakan cuboid yang paling tepat digunakan untuk melakukan query. Hal ini dikarenakan jika melakukan pemrosesan query
menggunakan cuboid 1 maka tidak perlu mengambil banyak row karena pada cuboid 1 hanya terdapat kelompok umur. Berikut ini ditampilkan
Tabel 3. 11 Query yang digunakan pada query I
select NON EMPTY {[Measures].[Jumlah B], [Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{[Kelompok Umur].[Semua Kelompok Umur]} ON ROWS
from [penyakit]
where {([Nama Penyakit].[Semua Penyakit].[A15].[TB Paru BTA (+)], [Waktu].[Semua Waktu].[2010])}
with member [Nama Penyakit].[Semua Penyakit] as 'Aggregate({[Nama Penyakit].[Semua Penyakit]})' select NON EMPTY {[Measures].[Jumlah B], [Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{[Kelompok Umur].[Semua Kelompok Umur]} ON ROWS
from [penyakit]
where {([Nama Penyakit].[Semua Penyakit].[A15].[TB Paru BTA (+)], [Waktu].[Semua Waktu].[2010])}
[Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{[Kelompok Umur].[Semua Kelompok Umur]} ON ROWS
from [penyakit]
where {([Nama Penyakit].[Semua Penyakit].[A15].[TB Paru BTA (+)], [Waktu].[Semua Waktu].[2010])}
Qb select NON EMPTY {[Measures].[Jumlah B],
[Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{([Waktu].[Semua Waktu], [Nama Penyakit].[Semua Penyakit],[Kelompok Umur].[Semua Kelompok Umur])} ON ROWS
3.5.2.2. Query II
Pada query II juga memiliki query biasa dan query yang dipilih menggunakan cuboid. Berikut ini adalah query biasa untuk query II.
Tabel 3. 12 Qb pada query II
select NON EMPTY {[Measures].[Jumlah B], [Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{([Waktu].[Semua Waktu], [Nama Penyakit].[Semua Penyakit],[Kelompok Umur].[Semua Kelompok Umur])} ON ROWS
from [penyakit]
Sebelum melakukan query digudang data, maka dengan tujuan
query yang sama yaitu melihat melihat data nama penyakit dan kelompok umur di bulan tertentu yakni bulan oktober pada tahun 2012 dan disemua kelompok umur tentukan terlebih dahulu cuboid yang mungkin. Tujuannya adalah agar mendapatkan query yang efisien dengan waktu akses cepat untuk melihat data nama penyakit dan kelompok umur di bulan tertentu yakni bulan oktober pada tahun 2012 dan disemua kelompok umur.
Tabel 3. 13 Cuboid yang mungkin pada query II
Tujuan query II Cuboid yang mungkin
Melihat data nama penyakit dan kelompok umur di bulan tertentu yakni bulan oktober pada tahun
2012 dan disemua kelompok
Berdasarkan cuboid-cuboid yang mungkin pada query II ini maka didapat cuboid 1 merupakan cuboid yang paling tepat digunakan untuk melakukan query. Berikut ini merupakan query yang terbentuk dari masing-masing cuboid.
Tabel 3. 14 Query yang digunakan pada query II Jenis
select NON EMPTY {[Measures].[Jumlah B], [Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{([Nama Penyakit].[Semua Penyakit], [Kelompok Umur].[Semua Kelompok Umur])} ON ROWS from [penyakit]
with member [Waktu].[Semua Waktu] as 'Aggregate({[Waktu].[Semua Waktu]})' select NON EMPTY {[Measures].[Jumlah B], [Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
{([Nama Penyakit].[Semua Penyakit], [Kelompok Umur].[Semua Kelompok Umur])} ON ROWS from [penyakit]
where [Waktu].[Semua Waktu].[2012].[Oktober]
Qb select NON EMPTY {[Measures].[Jumlah B],
[Measures].[Jumlah L], [Measures].[Jumlah K]} ON COLUMNS,
3.6. Menerapkan BitmapIndexing pada Qef
Setelah mempertimbangkan query mana yang dirasa cocok maka tahap selanjutnya adalah melakukan indexing pada gudang data dengan menggunakan bitmap indexing. Bitmap indexing dipilih karena sangat cocok dengan ad hoc query dan juga sangat membantu dalam melakukan pencarian data dengan cepat didalam cube.
Untuk melakukan bitmap indexing ada beberapa kriteria yang harus diperhatikan diantaranya indeks ini sangat tepat digunakan pada kolom yang low cardinality. Melihat keunggulan dari bitmap indexing
maka untuk membuktikan hal tersebut, dibuat bitmap indexing setiap kolom untuk setiap dimensi yang ada. Bitmap indexing yang dibuat juga bervariasi tujuannya untuk mendapatkan indeks yang terbaik yang paling cocok digunakan untuk query tertentu.
Tabel 3. 15 Bitmap indexing yang digunakan Dimensi dan Kolom Kolom yang menggunakan
Bitmap indexing masing-masing dimensi kecuali dimensi kelompok umur
3.7. Langkah Pengujian
Langkah-langkah yang dilakukan dalam pengujian sebagai berikut 1. Mencatat waktu akses dari Qb
2. Mencatat waktu akses dari Qef 3. Mencatat waktu akses Qp.
4. Mencatat waktu akses Qef yang dikombinasikan dengan
Langkah pertama yang dilakukan adalah mencatat waktu akses dari Qb, hal ini dimaksudkan Qb akan menjadi pembanding untuk Qef yang dipilih menggunakan cuboid. Pencatatan waktu akses dari Qb dan Qf nantinya dapat digunakan untuk melakukan perbandingan waktu akses kedua query tersebut. Langkah kedua dalam pengujian adalah mencatat waktu akses dari Qef , waktu akses dari Qef akan digunakan juga untuk perbandingan waktu akses dari Qp yang merupakan query yang terbentuk dari cuboid yang mungkin. Waktu akses Qp dicatat dengan tujuan agar dapat dibuktikan apakah Qef merupakan query yang tercepat yang terbentuk dari cuboid yang paling tepat, pengujian ini dilakukan pada pengujian langkah ketiga.
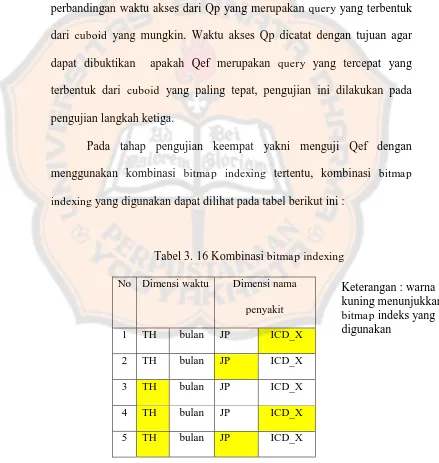
Pada tahap pengujian keempat yakni menguji Qef dengan menggunakan kombinasi bitmap indexing tertentu, kombinasi bitmap indexing yang digunakan dapat dilihat pada tabel berikut ini :
Tabel 3. 16 Kombinasi bitmap indexing
No Dimensi waktu Dimensi nama
Waktu akses dari Qef dengan menggunakan bitmap indexing
tertentu akan dicatat, hal tersebut bertujuan untuk membandingkan waktu akses dari Qef menggunakan semua kombinasi bitmap indexing. Dari perbandingan waktu tersebut maka akan didapat Qef dengan waktu tercepat menggunakan bitmap indexing pada kolom tertentu, dari hasil yang didapat maka diharapkan dapat membantu dalam menarik kesimpulan untuk penelitian ini.
3.8. Perancangan Tampilan
64 BAB IV IMPLEMENTASI
4.1. Spesifikasi Perangkat Keras dan Lunak
Dalam penelitian ini DBMS yang digunakan adalah Oracle 11g. Perangkat keras yang digunakan untuk melakukan pengujian query dengan spesifikasi sebagai berikut :
- Processor : Intel(R) Core(TM) i3 CPU
- Memory : 6144 MB RAM
- Sistem Operasi : Windows 7 Ultimate 32-bit - Browser : Mozilla Firefox
4.2. Langkah Membangun Gudang Data
4.2.1. Membaca Data Legacy
pembersihan data dan seleksi data sedangkan untuk tahap lainnya menggunakan tahap dalam membangun gudang data. Berikut ini adalah penjelasan tersebut.
1. Pembersihan data
Tabel 4. 1 Preprocessing dengan menghilangkan data yang bukan penyakit
1. Melakukan
preprocessing
dengan
menghapus data yang bukan merupakan penyakit
Tabel 4. 2 Preprocessing dengan menambah kolom bulan 2. Melakukan
preprocessing dengan menambah kolom bulan. Agar dapat mengetahui penyakit tersebut muncul di bulan apa.
Tabel 4. 3 Preprocessing dengan menambah kolom tahun
3. Melakukan
preprocessing dengan menambah kolom tahun. Agar dapat mengetahui penyakit terjadi pada tahun berapa.
69 2. Seleksi data
Dari data yang ada dilakukan seleksi data karena tidak semua data digunakan. Pada kasus ini SP2TP tidak digunakan dan diganti dengan kolom nama penyakit. Karena SP2TP juga bukan merupakan data yang dirasa penting karena hanya berisi nomor urut dari nama penyakit yang digunakan untuk pelaporan. Untuk tahap selanjutnya setelah melakukan tahap preprocessing kemudian melakukan tahap menggabungkan data dari berbagai sumber terpisah.
4.2.2. Menggabungkan Data dari Berbagai Sumber Terpisah
Seperti yang telah diilustrasikan pada bab 3, penggabungan data perlu dilakukan karena data yang ada tidak seluruhnya berbentuk file Excel.
4.2.3. Memindahkan Data ke Server Gudang Data
1. Master penyakit
Gambar 4. 1 Proses pembuatan tabel ms_penyakit di Oracle .ktr
Gambar 4.1 merupakan proses pembuatan tabel ms_penyakit di Oracle, dengan inputan berupa file excel. Sort rows berfungsi untuk mengurutkan data, karena untuk menghilangkan redundancy data dengan menggunakan unique rows data harus diurutkan terlebih dahulu. Pada id_penyakit menggunakan bantuan add sequence untuk membuat id penyakitnya mengingat data penyakit yang ada dalam jumlah besar. Select values untuk mengkonversi data dari file ke dalam format database yang diinginkan atau mengubah nama kolom atau menghapus kolom yang tidak digunakan. Table output digunakan untuk membuat tabel pada database.
Tabel 4. 4 ms_penyakit
2. Master kelompok umur
Gambar 4. 2 Proses pembuatan tabel ms_kelompok_umur di Oracle .ktr
Gambar 4.2 merupakan proses pembuatan tabel ms_kelompok_umur, untuk membuat tabel master ini menggunakan inputan berupa file excel. Select values untuk mengkonversi data dari file
ke dalam format database yang diinginkan atau mengubah nama kolom atau menghapus kolom yang tidak digunakan. Table output digunakan untuk membuat tabel pada database.
Tabel 4. 5 ms_kelompok_umur
Tabel 4.5 adalah hasil dari tabel ms_kelompok_umur pada
4.2.4. Memecah Gudang Data dalam Tabel Fakta dan Tabel Dimensi
1. Tr penyakit
Gambar 4. 3 Proses pembuatan tr_penyakit di Oracle .ktr
Sumber data dari tr_penyakit berupa data penyakit tahun 2010 sampai 2012 .xls, sumber lainnya berasal dari tabel ms_penyakit dan ms_kelompok_umur. Terdapat stream lookup pada ms kelompok umur yang digunakan untuk membaca id kelompok umur dari ms kelompok umur dan tr penyakit, demikian juga stream lookup pada ms penyakit berfungsi untuk membaca id penyakit dari tr penyakit dan ms penyakit. Add sequence