SKRIPSI
KOMPRESI DATA TEKS MENGGUNAKAN ALGORITMA
PPM MPREDICTION BY PARTIAL MATCHING)
Disusun oleh :
Gilang Himawan Widya Putra
0735010026
PROGRAM STUDI SISTEM INFORMASI
FAKULTAS TEKNOLOGI INDUSTRI FTI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
JAWA TIMUR
TALAMAN JUDUL
TALAMAN PENGESATAN
ABSTRAK ………. i
KATA PENGANTAR ……….………..……... ii
DAFTAR ISI ………..……….……..…. iv
DAFTAR TABLE …….………..……….. ix
DAFTAR GAMBAR ………..………... x
BAB I.PENDATULUAN 1.1 Latar Belakang ………...……….. 1
1.2 Rumusan tasalah ………... 3
1.3 Batasan tasalah ………... 3
1.4 Tujuan ………...……... 3
1.5 tanfaat ……… 3
1.6 tetodologi Penelitian ………...…... 4
1.7 Sistematika Penulisan ……….. 5
2.2.2 Jenis Kompresi Data ………...…. 12
2.2.3 tetode Kompresi data ………...……..…. 12
2.2.4 Teknik Kompresi Data .………...…. 13
2.2.5 Klasifikasi Teknik Kompresi ...………. 14
2.2.6 Encoding Dan Decoding ….………..……...…. 15
2.3 Pengkodean Data ………..…………..………... 16
2.3.1 BCD (Binary Coded Decimal) ……….………. 17
2.3.2 SBCDIC(Standart Binary Coded Decimal Interchange Code) . 17 2.3.3 EBCDIC(Extended Binary Coded Decimal Interchange Code) 18 2.3.4 ASCII(American Standard Code For Information Interchange) 18 2.4 Algoritma Kompresi PPt ………...………...……… 18
2.4.1 Pembentukan Pohon String ……….……….. 20
2.4.2 Proses Encoding ………….……….……….. 22
2.4.1 Proses Decoding ………….……….……….. 24
2.5 Unified todelling Language ….……….………. 25
2.6 Semantik Dalam UtL ………...…...………. 30
2.7 Notasi Dalam UtL ...………...……….. 32
2.7.1 Aktor ………..………... 32
2.7.4 Interface ………..………..………… 34
2.7.5 Interaction …….………...……… 34
2.7.6 Note …..………...……… 35
2.7.7 Dependency ..……….…...……… 35
2.7.8 Associantion .………...……… 36
2.7.9 Generalization ………...………...……… 36
2.7.10 Realization ……….. 37
2.8 Embarcadero Delphi 2010 ………...…... 37
BAB III ANALISA PERMASALATAN 3.1 Analisa tasalah …..………..………. 42
3.2 Analisis Dan Kebutuhan Fungsional ……….………...……….. 43
3.3 Use Case Diagram ………..……… 43
3.4 Sequence Diagram ….………... 44
3.4.1 Sequence Diagram Compress .………...……….. 45
3.4.2 Sequence Diagram Decompress ……….……….. 45
Abstr ak
Seiring dengan berkembangnya teknologi saat ini, data memiliki peranan yang sangat penting, data tersebut tidak hanya berupa teks, gambar, audio atau bahkan video data yang digunakan tidak memiliki ukuran yang sangat besar, tapi kini dapat memiliki ukuran yang sangat besar. Untuk itu diperlukan sebuah teknik untuk mengubah ukuran data tersebut agar menjadi lebih kecil. Teknik ini disebut dengan pemampatan atau yang lebih dikenal dengan kompresi data
Kompresi Data adalah suatu proses pengubahan sekumpulan data menjadi suatu bentuk kode untuk menghemat kebutuhan tempat penyimpanan data. Algoritma Prediction By Partial Matching (PPM) menggunakan teknik lossless yaitu tidak menghilangkan informasi sedikitpun, hanya mewakili beberapa informasi yang sama dan dikelompokan dalam metode kompresi statis, metode ini bersifat two-pass.
Hasil yang akan dibandingkan meliputi, kapasitas hasil kompresi, rasio kompresi serta waktu kompresi dan dekompresi. Sesuai dengan hasil uji coba yang dilakukan terlihat bahwa data yang semula mempunyai ukuran lebih besar dapat terkompresi dengan sangat baik diimplementasikan pada file bertipe teks dan gambar bitmap karena mempunyai rasio yang tinggi.
.
segala limpahan Kekuatan-Nya sehingga dengan segala keterbatasan waktu,
tenaga, pikiran dan keberuntungan yang dimiliki penyusun, akhirnya penyusun
dapat menyelesaikan Skripsi yang berjudul “Kompresi Data Menggunakan
Algoritma PPM ( Pr ediction By Partial Matching) Untuk Keamanan Sistem
Infor masi” tepat pada waktunya. Skripsi dengan beban 4 SKS ini disusun guna
diajukan sebagai salah satu syarat untuk menyelesaikan program Strata Satu (S1)
pada program studi Sistem Informasi, Fakultas Teknologi Industri, UPN
”VETERAN” Jawa Timur.
Melalui Skripsi ini penyusun merasa mendapatkan kesempatan emas untuk
memperdalam ilmu pengetahuan yang diperoleh selama di bangku perkuliahan,
terutama berkenaan tentang penerapan teknologi perangkat bergerak. Namun,
penyusun menyadari bahwa Skripsi ini masih jauh dari sempurna. Oleh karena itu
penyusun sangat mengharapkan saran dan kritik dari para pembaca untuk
pengembangan aplikasi lebih lanjut.
Surabaya, November 2011
BAB I
PENDAHULUAN
1.1. Latar Belakang
Di era sekarang ini kebutuhan akan informasi semakin diperlukan. Maka
dari itu sekarang banyak layanan-layanan jasa dari internet yang berusaha sebaik
mungkin untuk menyediakan informasi yang disediakan setidaknya membutuhkan
jumlah data yang tidak lagi berukuran kecil. Semakin membesarnya jumlah data
tidak dapat diimbangi dengan semakin besarnya kapasitas media penyimpanan.
Disamping itu ukuran data yang besar akan mengakibatkan pemborosan pada
penggunaan resource jaringan ketika data tersebut diakses oleh user lain yang
berada di tempat yang jauh. Data-data yang dibutuhkan tersebut tidak hanya
berupa teks tetapi dapat juga berupa data audio (multimedia) dan juga dapat
berupa gambar. Oleh karena itu dibutuhkan cara untuk bagaimana mengkompres
data-data tersebut sehingga dapat disimpan dalam media penyimpanan yang
terbatas, sekaligus terjamin keamanannya karena hanya pihak tertentu saja yang
dapat mengakses data tersebut.
Teknologi kompresi data berkembang seiring dengan kemajuan teknologi
informasi. Melalui teknologi kompresi ini, penyebaran data menjadi lebih cepat
karena ukuran data yang lebih kecil dari ukuran aslinya sehingga mempermudah
proses pengiriman data atau dapat mengurangi kebutuhan terhadap kapasitas
Kompresi adalah proses pengubahan sekumpulan data menjadi bentuk
kode dengan tujuan untuk menghemat kebutuhan tempat penyimpanan dan waktu
untuk transmisi data. Kompresi data dilakukan dengan mengkodekan setiap
karakter di dalam pesan atau data dengan mengkodekan setiap karakter di dalam
pesan atau data dengan kode yang lebih pendek. Pada saat ini banyak sekali
algoritma yang digunakan untuk mengkompresi data. Antara lain algoritma
Huffman, LZ Family, RLE, LZMA, CTW, Deflate, Arithmetic coding, Half Byte
dan lain-lain. Pada pembuatan tugas akhir ini algoritma yang digunakan untuk
mengompresi data adalah algoritma Prediction by Partial Matching (PPM).
Algoritma Prediction by Partial Matching (PPM) adalah teknik kompresi
data statis berdasarkan konteks pemodelan dan prediksi.. Algoritma ini termasuk
dalam kelas losless compression yaitu tidak menghilangkan informasi sedikitpun
hanya mewakilkan beberapa informasi yang sama. Metode ini bersifat two-pass
yaitu menggunakan peta kode yang selalu sama, fase pertama untuk menghitung
kemungkinan tiap simbol dan menentukan peta kodenya dan fase kedua untuk
mengubah pesan menjadi kumpulan kode yang akan di transmisikan.
Berdasarkan uraian tersebut diatas, maka dalam tugas akhir topik yang
diambil adalah Kompr esi Data Teks Menggunakan Algoritma PPM
(Pr ediction By Partial Matching).
1.2. Perumusan Masalah
Bagaimana membuat aplikasi untuk memperkecil ukuran suatu data
melalui kompresi dengan menggunakan algoritma PPM ?
1.3. Batasan Masalah
Agar pembahasan dan penyusunan tugas akhir ini dapat dilakukan secara
terarah dan tidak menyimpang serta sesuai dengan apa yang diharapkan, maka
perlu ditetapkan batasan-batasan dari masalah yang dihadapi, yaitu :
a. Aplikasi yang dibuat dapat dijalankan pada Sistem Operasi Windows 7
b. Perangkat lunak yang digunakan untuk membangun aplikasi ini adalah Delphi
c. Algoritma kompresi yang digunakan pada kompresi data ini adalah algoritma
Prediction by Partial Matching (PPM)
d. Data yang dijadikan bahan kompresi adalah berupa file dokumen yang
berekstensi .doc, .docx, .rtf, .txt, .xls, .xlsx, .ppt, .pptx, .dan pdf.
1.4. Tujuan
Adapun tujuan yang ingin dicapai dalam pengerjaan tugas akhir ini adalah
Untuk membangun suatu perangkat lunak aplikasi kompresi data
menggunakan algoritma PPM (Prediction by Partial Matching) pada dokumen
teks, sehingga dapat memperkecil ukuran data agar data tersebut dapat
1.5. Manfaat
Adapun manfaat dan tujuan yang ingin diperoleh dari pengerjaan tugas
akhir ini adalah :
a. Dapat menerapkan ilmu selama mengikuti perkuliahan untuk menyelesaikan
permasalahan dalam tugas akhir ini.
b. Dapat mengimplementasikan algorithma prediction by partial matching untuk
membuat aplikasi kompresi data dokumen teks.
c. Membantu pengamanan informasi data dokumen teks agar hanya pihak
tertentu saja yang dapat melihat informasi yang terdapat dalam dokumen teks.
1.6. Metodologi Penelitian
Adapun metode penelitian yang dipergunakan dalam pengerjaan tugas
akhir ini adalah :
a. Studi Literatur
Mencari referensi dan bahan pustaka tentang teori-teori yang berhubungan
dengan permasalahan yang akan dikerjakan dalam tugas akhir ini.
b. Studi Kasus
Mencari contoh-contoh kasus serupa yang berhubungan dengan permasalahan
dalam tugas akhir ini.
c. Analisis dan Perancangan
Membuat analisa berdasarkan data-data yang sudah dimiliki, membuat model
Perancangan aplikasi dimulai dengan perancangan basis data dan antar muka
aplikasi, kemudian merancang detail algoritma PPM.
d. Implementasi Program
Mengimplementasikan teknik algoritma yang akan digunakan. Detail
mengenai implementasi program dilakukan sesuai hasil analisis dan
perancangan aplikasi pada tahapan sebelumnya.
e. Pengujian Aplikasi
Pengujian dilakukan pada aplikasi yang telah dibuat. Menguji validitas dan
efektifitas algoritma yang diterapkan pada aplikasi.
f. Evaluasi dan Penarikan kesimpulan
Evaluasi dilakukan untuk mengetahui kinerja aplikasi kompresi data teks
sesuai ukuran dan format data teksnua, selanjutnya dilakukan penarikan
kesimpulan.
1.7. Sistematika Penulisan
Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi latar belakang masalah, identifikasi masalah, maksud
dan tujuan yang ingin dicapai, batasan masalah, metodologi
penelitian yang diterapkan dalam memperoleh dan mengumpulkan
data, waktu dan tempat penelitian, serta sistematika penulisan.
Membahas berbagai konsep dasar dan teori-teori yang berkaitan
dengan topik masalah yang diambil dan hal-hal yang berguna
dalam proses analisis permasalahan.
BAB III ANALISIS PERMASALAHAN
Menganalisis masalah dari model penelitian untuk memperlihatkan
keterkaitan antar variabel yang diteliti serta model matematis untuk
analisisnya.
.
BAB IV PERANCANGAN DAN IMPLEMENTASI
Membahas perancangan sistem menggunakan notasi UML dan
pengimplementasian hasil perancangan sistem yang telah dibuat ke
bentuk aplikasi yang akan dibangun.
BAB V UJ I COBA DAN EVALUASI
Membahas uji coba aplikasi yang dibuat, untuk mengetahui tingkat
keberhasilan kompresi dan prosentasi hasil kompresinya, kemudian
melakukan evaluasi keberhasilan sistem.
BAB VI PENUTUP
Berisi kesimpulan dan saran yang sudah diperoleh dari hasil
BAB II
TINJ AUAN PUSTAKA
2.1. Konsep Dasar Infor masi
Konsep dasar informasi adalah data yang kemudian diolah dengan
kriteria tertentu untuk menghasilkan informasi yang dibutuhkan. Data dapat
diartikan segala sesuatu yang perlu diolah terlebih dahulu untuk
mendapatkan suatu informasi. Definisi Sistem Informasi Informasi merupakan
hal yang sangat penting bagi manajemen dalam mengambil suatu keputusan.
Suatu informasi dapat diperoleh dari sistem informasi atau juga disebut
dengan Processing system atau information Processing system atau
information-generating system. Sistem informasi didefinisikan oleh Robert A.
Leitchdan K. Roscoe Davis adalah “suatu sistem didalam sebuah organisasi
yang mempertemukan kebutuhan pengolahan transaksi harian, mendukung
orperasi, bersifat menejerial dan kegiatan strategi dari suatu organisasi dan
menyediakan pihak luar tertentu dengan laporan-laporan yang diperlukan”.
Penggunaan teknologi komputer sangat diperlukan untuk membantu pengolahan
data yang bersifat rutin dan membutuhkan ketelitian yang tinggi diantaranya :
siklus informasi, kualitas informasi, nilai informasi.
a. Siklus Informasi
Siklus informasi data merupakan bentuk yang masih mentah sehingga perlu diolah
untuk proses lebih lanjut. Data diolah melalui suatu model untuk dihasilkan
informasi.Data yang diolah untuk menghasilkan informasi menggunakan suatu
diolah melalui suatu model menjadi informasi, penerima kemudian menerima
informasi tersebut, membuat suatu keputusan dan melakukan tindakan dan
menghasilkan suatu tindakan yang akan membuat sejumlah data kembali. Data
tersebut akan ditangkap sebagai input, diproses kembali melalui suatu model
sampai membentuk suatu siklus informasi.
Gambar 2.1 Siklus Informasi
b. Kualitas Informasi
Kualitas informasi merupakan bagian dari karakteristik informasi,diukur
berdasarkan Relevansi, Tepat waktu, dan Akurasi hal ini dapat digambarkan pada
c. Nilai Informasi
Nilai dari informasi ditentukan dari dua hal, yaitu manfaat dan biaya untuk
mendapatkannya. Suatu informasi dikatakan bernilai bila manfaatnya lebih efektif
dibandingkan dengan biaya untuk mendapatkannya. Akan tetapi perlu
diperhatikan bahwa informasi yang digunakan didalam suatu sistem informasi
umumnya digunakan untuk beberapa kegunaan. Sehingga tidak memungkinkan
dan sulit untuk menghubungkan suatu bagian informasi pada suatu masalah
tertentu dengan biaya untuk memperolehnya. Pengukuran nilai informasi biasanya
dihubungkan dengan analisis Cost Effectiveness atau Cost Benefit.
2.2. Kompr esi Data
Sistem komunikasi dirancang untuk mentransmisi informasi yang
dibangkitkan oleh sumber ke beberapa tujuan. Sumber informasi mempunyai
beberapa bentuk yang berbeda. Sebagai contoh, dalam radio broadcasting, sumber
biasanya sumber audio (suara atau music). dalam TV broadcasting, sumber
informasi biasanya sebuah sumber video yang keluarannya berupa image
bergerak. Output dari sumber-sumber ini adalah sinyal analog dan sumbernya
disebut sumber analog.
Kontras dengan komputer dan tempat penyimpanan data (storage) seperti
disk magnetic atau optical, menghasilkaan ouput berupa sinyal diskrit (biasanya
karakter binary atau ASCII). Sinyal yang menjadi sumbernya biasa disebut
dengan sumber diskrit. baik sumber analog maupun diskrit, sebuah komunikasi
digital dirancang untuk mentransmisi informasi dalam bentuk digital. Sehingga
sumber digital yang biasanya dilakukan pada source encoder. Keluaran dari
sumber tersebut dapat diasumsikan menjadi sebuah digit biner sekuensial.
Pada akhir tahun 40-an dimana dimulainya tahun teori informasi, ide
pengembangan metode coding yang efesien baru dimulai dan dikembangkan.
Dimulainya penjelajahan ide dari entropy, information content dan redudansi.
Salah satu ide yang popular adalah apabila probabilitas dari simbol dalam suatu
pesan diketahui, maka terdapat cara untuk mengkodekan simbol, sehingga pesan
memakan tempat yang lebih kecil. Ide inilah yang menjadi cikal bakal dalam
terciptanya kompresi data.
Model pertama yang muncul untuk kompresi sinyal digital adalah
Shannon-Fano coding. Shannon dan fano (1948) terus menerus mengembangkan
algoritma ini yang menghasilkan codeord biner untuk setiap symbol (unik) yang
terdapat pada data file.
Huffman coding (1952) memakai hampir semua karakteristik dari
Shannon-fano coding. Huffman coding dapat menghasilkan kompresi data yang
efektif dengan mengurangkan jumlah redudansi dalam mengkodingkan simbol.
Telah dapat dibuktikan, bahwa Huffman coding merupakan metode fixed-length
yang paling efesien.
Pada limabelas tahun terakhir, Huffman coding telah digantikan oleh
Arithmetic coding. Arithmetic coding melewatkan ide untuk menggantikan sebuah
simbol masukan dengan kode yang spesifik. Algoritma ini menggantikan sebuah
banyak bit dibutuhkan dalam angka keluaran, maka semakin rumit pesan yang
diterima.
Algoritma dictionary-based compression menggunakan metode yang
sangat berbeda dalam mengkompres data. Algoritma ini menggantikan string
variable-length dari simbol menjadi sebuah token. Token merupakan sebuah indek
dalam susunan kata di kamus. Apabila token kecil dari susunan kata, maka token
akan menggantikan prase tersebut dan kompresi pun terjadi.
Kompresi data (pemampatan data) merupakan suatu teknik untuk
memperkecil jumlah ukuran data (hasil kompresi) dari data aslinya. Pemampatan
data umumnya diterapkan pada mesin komputer, hal ini dilakukan karena setiap
simbol yang muncul pada komputer memiliki nilai bit-bit yang berbeda. Misal
pada ASCII setiap simbol yang dimunculkan memiliki panjang 8 bit, misal kode
A pada ASCII mempunyai nilai decimal 65, jika dirubah dalam bilangan biner
menjadi 010000001. Pemampatan data digunakan untuk mengurangkan jumlah
bir-bit yang dihasilkan dari setiap simbol yang muncul. Dengan pemampatan ini
diharapkan dapat mengurangi (memperkecil ukuran data) dalam ruang
penyimpanan.
2.2.1. Faktor Penting Kompr esi Data
Dalam kompresi data, terdapat 4 (empat) faktor penting yang perlu diperhatikan,
yaitu :
• Time process
Yaitu waktu yang dibutuhkan untuk menjalankan proses kompresi.
Yaitu kelengkapan data setelah data tersebut dikompresi.
• Ratio Compress
Yaitu ukuran data setelah data tersebut dikompresi
• Optimaly
Yaitu perbandingan ukuran data sebelum dikompresi dengan data yang
telah dikompresi.
2.2.2. J enis Kompr esi Data
Berdasarkan mode penerimaan data oleh manusia, kompresi data dapat
dibagi menjadi dua, yaitu :
a. Dialoque Mode
yaitu proses penerimaan data dimana pengirim dan penerima seakan berdialog
(real time), dimana kompresi data harus berada dalam batas penglihatan dan
pendengaran mausia. Contohnya pada video conference.
b. Retrieval Mode
yaitu proses penerimaan data tidak dilakukan secara real time. Jenis kompresi ini
dapat dilakukan random access terhadap data dan dapat bersifat interaktif.
2.2.3. Metode Kompr esi Data
Berdasarkan tipe peta kode yang digunakan untuk mengubah pesan awal (isi file
input) menjadi sekumpulan codeword, metode kompresi terbagi menjadi dua
kelompok, yaitu :
Menggunakan peta kode yang selalu sama. Metode ini membutuhkan dua fase
(two-pass) : fase pertama untuk menghitung probabilitas kemunculan tiap
simbol/karakter dan menentukan peta kodenya dan fase kedua untuk mengubah
pesan menjadi kumpulan kode yang akan ditransmisikan. Contohnya pada
Huffman static, arithmetic coding
b. Metode Dinamik (adaptif)
Menggunakan peta kode yang dapat diubah dari waktu ke waktu. Metode ini
disebut adaptif karena peta kode mampu beradaptasi terhadap karakteristik isi file
selama proses kompresi berlangsung. metode ini bersifat onepass, karena isi file
selama dikompres hanya diperlakukan satu kali pembacaan terhadap isi file.
Contohnya pada algoritma LZW dan DMC.
Berdasarkan teknik pengkodean atau pengubahan simbol yang digunakan, metode
kompresi dapat dibagi ke dalam tiga kategori, yaitu :
a. Metode simbolwise
Menghitung peluang kemunculan dari tiap simbol dalam file input, lalu
mengkodekan satu simbol dalam satu waktu, dimana simbol yang lebih sering
muncul diberi kode lebih pendek dibandinglan simbol yang lebih jarang muncul.
Contohnya pada Huffman coding, arithmetic coding.
b. Metode dictionary
Menggantikan karakter/fragmen dalam file input dengan indeks lokasi dari
karakter/fragmen tersebut dalam sebuah kamus (dictionary). Contohnya pada
c. Metode predictive
Menggunakan model finite-context atau finite-state untuk memprediksi distribusi
probabilitas dari simbol-simbol selanjutnya. Contohnya pada algoritma DMC
2.2.4. Teknik Kompr esi Data
Teknik kompresi data dapat digolongkan menjadi dua kelompok utama yaitu :
lossy dan lossless. Teknik kompresi secara lossy dimaksudkan dengan teknik
kompresi data dengan menghilangkan ketelitian data utama guna mendapatkan
data sekecil mungkin (kompresi data sebesar mungkin).
2.2.5. Klasifikasi Teknik Kompr esi
Teknik kompresi data dapat digolongkan menjadi dua kelompok utama yaitu :
lossy dan lossless. Teknik kompresi secara lossy dimaksudkan dengan teknik
kompresi data dengan menghilangkan ketelitian data utama guna mendapatkan
data sekecil mungkin (kompresi data sebesar mengkin). Teknik kompresi data
secara lossless yaitu teknik kompresi data dengan mengurangkan jumlah data
yang terjadi redudansi (memiliki symbol yang sama) sebelum terjadi kompresi.
a. Lossy Compression
Merupakan teknik kompresi yang menghilangkan beberapa informasi data yang
dianggap tidak penting. Sehingga hasil data yang telah terkompresi tidak sama
dengan data yang sebelum dikompresi. Namun data yang telah terkompresi
tersebut sudah cukup untuk digunakan, walaupun datanya telah berubah.
ukuran yang lebih kecil dari ukuran data aslinya. Biasanya teknik kompresi ini
banyak diaplikasikan pada data gambar dan data audio.
b. Lossless Compression
Merupakan teknik kompresi yang mempertahankan kebutuhan informasi yang
dikandung oleh data, sehingga informasi yang terkandung pada file yang telah
terkompresi tetap terjaga meskipun ukurannya telah berubah dari ukuran data
aslinya. Keunggulan dari teknik ini adalah data yang telah terkompresi, apabila
didekompresi kembali akan menghasilkan data yang sama persis dengan data
aslinya. Biasanya teknik kompresi ini banyak diaplikasikan pada data teks.
2.2.6. Encoding Dan Decoding
Teknik kompresi dapat diklasifikasikan menjadi tiga kelompok, antara lain :
a. Entropy Encoding
Merupakan klasifikasi teknik kompresi yang bersifat loseless compression.
Tekniknya tidak berdasarkan media dengan spesifikasi dan karakteristik tertentu,
namun berdasarkan urutan data. Dan statistical encoding pada klasifikasi teknik
ini tidak memperhatikan semantik data. Contoh kelompok teknik kompresi ini
adalah pada Run-Length coding, Huffman coding, Arithmetic coding.
b. Source Coding
Merupakan klasifikasi teknik kompresi yang bersifat lossy compression.
Tekniknya berkaitan dengan data semantik (arti data) dan media. Contoh
transformation (FFT, DCT), layered coding (bit position, subsampling, sub-band
coding), vector quantization
c. Hybrid Coding
Merupakan klasifikasi teknik kompresi yang bersifat gabungan antara lossy
compression dan loseless compression. Contoh kelompok teknik kompresi ini
adalah pada JPEG, MPEG, H.261, DVI.
Encoding merupakan teknik untuk mendapatkan kode-kode tertentu (encoder).
Dari kode-kode tersebut dapat diaplikasikan untuk pemampatan data dan
keamanan data. Dari data-data yang telah dikodekan tersebut, format-format isi
dari data tersebut berbentuk kode-kode yang tidak bisa dibaca oleh user. Agar
kode-kode tersebut bisa dibaca oleh user, maka kita perlu mengkodekan ulang
data tersebut. Hal ini biasa dikenal dengan nama decoding (decoder).
Secara umum pemampatan data merupakan merubah suatu simbol-simbol menjadi
suatu kode-kode. Pemampatan dikatakan efektif jika ukuran perolehan kode-kode
tersebut sangat kecil dibandingkan dengan ukuran kode simbol aslinya. Dari suatu
kode-kode atau simbol-simbol dasar suatu model akan dinyatakan dalam kode
khusus.
Proses decoding, yaitu proses pengembalian kode-kode yang telah dibuat menjadi
simbol-simbol yang dikenal oleh user. Proses decoder ini membaca header dari
kode-kode yang berisi informasi simbol dan jumlah simbol yang digunakan,
setelah pembacaan header proses encoder dengan model ditunjukan pada Gambar
2.3, sedangkan proses decoder dengan model ditunjukan pada Gambar 2.4
Gambar 2.3. Model Proses Enkoder
Gambar 2.4. Model Proses Dekode
2.3. Pengkodean Data
Data disimpan di dalam komputer pada main memory untuk diproses. Sebuah
karakter data disimpan dalam main memory menempati posisi 1 byte. Komputer
generasi pertama, 1 byte terdiri dari 4 bit, komputer generasi kedua, 1 byte terdiri
dari 6 bit dan komputer generasi sekarang, 1 byte terdiri dari 8 bit. Suatu karakter
data yang disimpan di main memory diwakili dengan kombinasi dari digit binary
(binary digit atau bit). Suatu kode biner dapat digunakan untuk mewakili suatu
karakter.
Suatu komputer yang berbeda menggunakan kode biner yang berbeda untuk
mewakili suatu karakter. Komputer yang 1 byte terdiri dari 4 bit, menggunakan
kode binary yang berbentuk kombinasi 4 bit, yaitu BCD (Binary coded decimal).
Komputer yang menggunakan 6 bit untuk 1 bytenya, menggunakan kode biner
Interchange Code). Komputer yang terdiri dari 8 bit, menggunakan kode biner
yang terdiri dari kombinasi 8 bit, yaitu EBCDIC (extended Binary coded decimal
interchange code) atau ASCII (American standard code of information
interchange).
2.3.1. BCD (Binary Coded Decimal)
BCD merupakan kode biner yang digunakan hanya untuk mewakili nilai desimal
saja, yaitu angka 0 sampai dengan 9. BCD menggunakan kombinasi dari 4 bit,
sehingga sebanyak 16 (24 = 16) kemungkinan kombinasi yang dapat diperoleh
dan hanya 10 kombinasi yang dipergunakan.
Kode BCD yang orisinil sudah jarang dipergunakan untuk komputer generasi
sekarang, karena tidak dapat mewakili huruf atau simbol-simbol karakter khusus.
2.3.2. SBCDIC (Standar d Binar y Coded Decimal Interchange Code)
SBCDIC merupakan kode biner perkembangan dari BCD. BCD dianggap
tanggung, karena masih ada 6 kombinasi yang tidak dipergunakan, tetapi tidak
dapat digunakan untuk mewakili karakter yang lainnya. SBCDIC menggunakan
kombinasi 6 bit , sehingga lebih banyak kombinasi yang bisa dihasilkan, sebanyak
64 kombinasi kode, yaitu 10 kode untuk digit angka, 26 kode untuk huruf
alphabet dan sisanya karakter-karakter khusus yang dipilih.
Posisi bit di SBCDIC dibagi menjadi 2 zone, yaitu 2 bit pertama disebut dengan
2.3.3. EBCDIC (Extended Binar y Coded Decimal Interchange Code)
EBCDIC terdiri dari kombinasi 8 bit yang memungkinkan untuk mewakili
karakter sebanyak 256 kombinasi karakter. Pada EBCDIC, high-order bits atau 4
bit pertama disebut dengan zone bits dan low order bits atau 4 bit kedua disebut
dengan numeric bit.
2.3.4. ASCII (American Standar d Code for Infor mation Interchange)
Kode ASCII yang standard menggunakan kombinasi 7 bit, dengan kombinasi
sebanyak 127 dari 128 kemungkinan kombinasi.
Kode ASCII 7 bit ini terdiri dari dua bagian, yaitu control characters dan
information characters merupakan karakter-karakter yang mewakili data [1].
Karakter-karakter graphic yang tidak dapat diwakili oleh ASCII 7 bit, dapat
diwakili dengan ASCII 8 bit karena lebiih banyak memberikan kombinasi
karakter.
2.4. Algoritma kompresi PPM
Algoritma Prediction by Partial Matching (PPM) adalah teknik kompresi data
statis berdasarkan konteks pemodelan dan prediksi.. Algoritma ini termasuk
dalam kelas losless compression yaitu tidak menghilangkan informasi sedikitpun,
hanya mewakilkan beberapa informasi yang sama. Metode ini bersifat two-pass
yaitu menggunakan peta kode yang selalu sama, fase pertama untuk menghitung
kemungkinan tiap simbol dan menentukan peta kodenya dan fase kedua untuk
Pada proses, PPM menjalankan rangkaian model deret konteks, dari 0 hingga nilai
maksimum k yang ditetapkan sebelumnya, untuk memprediksi karakter-karakter
berikutnya. Untuk tiap statistik model konteks order i yang memuat semua simbol
yang telah tersusun, setiap panjang i berikutnya dalam input dan berapa kali
kejadiannya. Peluang kemungkinan dihitung dari statistik-statistik dengan cara:
setiap model, deret 0 hingga deret k, diperoleh dari distribusi peluang
kemungkinan yang terpisah dan secara efektif disatukan ke dalam satu bagian.
Gambar 2.5. Flowchart Algorithma PPM
Model deret terbesar adalah salah satu model yang secara default, digunakan
untuk memprediksi simbol awal. Namun, jika suatu simbol yang tidak diketahui
untuk prediksi. Proses akan berlanjut hingga salah satu model deret tertentu
memprediksikan simbol berikutnya.
2.4.1. Pembentukan pohon str ing
Masalah utama dalam pembentukan string adalah membangun struktur data
dimana semua konteks saling berhubungan dari setiap simbol ke simbol lainnya.
Struktur yang digambarkan disini adalah suatu jenis pohon tertentu. Disebut juga
sebagai tree. Tree adalah pohon, dimana struktur bercabang dari setiap tingkat
ditentukan oleh sebagian item data, tidak oleh keseluruhan item. Dalam proses ini,
deretan konteks N adalah suatu string yang mencakup semua konteks dengan
deret-deret N – 1 hingga 0, sehingga setiap konteks secara efektif menambahkan
satu simbol pada pohon.
Berikut langkah-langkah dalam sebuah pembentukan pohon string zxzyzxxyzx
dalam algoritma PPM adalah sebagai berikut :
1. Masukkan sebuah karakter pada kalimat yang akan di input ke dalam pohon
PPM sebagai node baru pada level 1.
2. Masukkan karakter selanjutnya pada kalimat yang akan di input. Periksa
pohon PPM tersebut, apakah ada node jembatan atau tidak pada pohon PPM,
jika ya, tambahkan karakter sebagai anak node dari jembatan, dan jika tidak,
tambahkan karakter sebagai node baru pada level 1.
3. Periksa node baru yang ditambahkan pada pohon PPM, apakah node tersebut
terletak pada level 1, jika ya, maka proses telah selesai, dan jika tidak cari
node terakhir pada pohon PPM yang mengalami perubahan pada level 1,
4. Periksa node-node pada level 1, apakah ada karakter yang sama dengan
karakter node yang di input, jika ya, tambahkan node,jika tidak, buat node
baru pada level 1.
5. Ulangi langkah no 2, 3 dan 4 sampai karakter-karakter yang ada pada kalimat
yang akan di input telah digunakan pada pohon PPM.
Pada Gambar 2.6 diperlihatkan pembentukan pohon string zxzyzxxyzx di bawah ini :
Gambar 2.6. Proses Pembentukan Pohon String
2.4.2.Pr oses Encoding
Pada umumnya, algoritma kompresi data melakukan penggantian satu atau lebih
PPM menggantikan satu deretan simbol input dengan sebuah bilangan floating point.
Semakin panjang dan semakin kompleks pesan yang dikodekan, semakin banyak bit
yang diperlukan untuk keperluan tersebut.
Output dari algoritma kompresi PPM ini adalah satu angka yang lebih kecil dari 1 dan
lebih besar atau sama dengan 0. Angka ini secara unik dapat di- decode sehingga
menghasilkan deretan simbol yang dipakai untuk menghasilkan angka tersebut.
Untuk menghasilkan angka output tersebut, tiap simbol yang akan di- encode diberi
satu set nilai probabilitas. Contoh, andaikan kata SWISS_MISS akan di- encode.
Akan didapatkan tabel probabilitas berikut :
Tabel 2.1 Contoh Probabilitas Untuk Kata SWISS_MISS
Karakter Pr obabilitas
Setelah probabilitas tiap karakter diketahui, karakter akan diberikan range tertentu
yang nilainya berkisar di antara 0 dan 1, sesuai dengan probabilitas yang ada.
Dalam hal ini tidak ada ketentuan urut-urutan penentuan segmen, asalkan antara
encoder dan decoder melakukan hal yang sama. Dari Tabel 2.1 di atas dibentuk
Tabel 2.2 Range Simbol Untuk Kata SWISS_MISS
Dari tabel ini, satu hal yang perlu dicatat adalah tiap karakter melingkupi range
yang disebutkan kecuali bilangan yang tinggi.
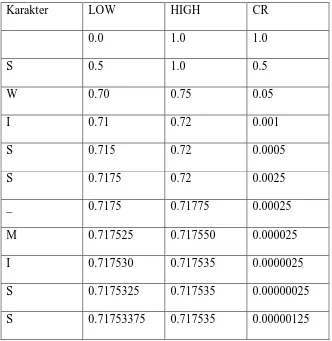
Hasil proses enkoding dapat dilihat dalam Tabel 2.3 berikut ini :
Tabel 2.3 Proses Encoding untuk Kata “SWISS_MISS”
Karakter LOW HIGH CR
0.0 1.0 1.0
S 0.5 1.0 0.5
W 0.70 0.75 0.05
I 0.71 0.72 0.001
S 0.715 0.72 0.0005
S 0.7175 0.72 0.0025
_ 0.7175 0.71775 0.00025
M 0.717525 0.717550 0.000025
I 0.717530 0.717535 0.0000025
S 0.7175325 0.717535 0.00000025
Dalam melakukan proses encoding dipakai algoritma berikut:
Set low = 0.0
Set high = 1.0
While (simbol input masih ada) do
Ambil simbol input
CR = high – low
High = low + CR*high_range (simbol)
Low = low + CR*low_range (simbol)
End While
Cetak Low
Di sini ‘’Low adalah output dari proses algoritma PPM.
Untuk kata ‘’SWISS_MISS di atas, pertama kita ambil karakter “S. Nilai CR
adalah 1-0 = 1. High_range (S) = 1.0, Low_range(S) = 0.5.
Kemudian didapatkan nilai high = 0.00 + CR*1.0 =1.0 low = 0.00 + CR*0.5 = 0.5
Kemudian diambil karakter „W. Nilai CR adalah 1.0 – 0.5 = 0.5.
High_range(W)= 0.5, Low_range (W) = 0.4. Kemudian didapatkan nilai
high = 0.5 + CR*0.5 = 0.75 low = 0.5 + CR*0.4 = 0.70
Dari proses ini didapatkan nilai
Low = 0.71753375 Nilai inilah yang ditransmisikan untuk membawa pesan
„SWISS_MISS.
2.4.3. Pr oses Decoding
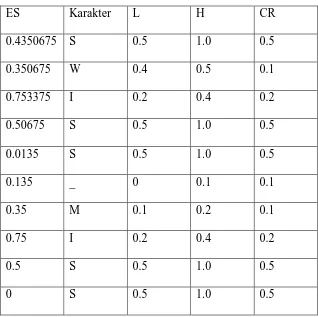
Tabel 2.4. Proses Decoding untuk Kata “SWISS_MISS”
Untuk melakukan decoding dipakai algoritma berikut:
Ambil encoded-symbol (ES)
Do
Cari range dari simbol yang melingkupi ES
Cetak simbol
CR = high_range – low_range
ES = ES – low_range
ES = ES / CR
Dalam hal ini simbol habis bisa ditandai dengan simbol khusus (End of File
misalnya) atau dengan menyertakan panjang teks waktu dilakukan proses
kompresi.
Untuk pesan yang tadi di- encode (ES = 0.71753375) dilakukan proses decoding
sebagai berikut. Didapatkan range simbol yang melingkupi ES adalah
simbol/karakter „T.
Unified Modelling Language (UML) adalah sebuah "bahasa" yang telah
menjadi standar dalam industri untuk menentukan, visualisasi, merancang dan
mendokumentasikan artifact dari sistem software, untuk memodelkan bisnis dan
sistem non software lainnya. UML merupakan suatu kumpulan teknik terbaik
yang telah terbukti sukses dalam memodelkan sistem yang besar dan kompleks.
Dengan menggunakan UML kita dapat membuat model untuk semua
jenis aplikasi piranti lunak, dimana aplikasi tersebut dapat berjalan pada piranti
pemrograman apapun. Tetapi karena UML juga menggunakan class dan operation
dalam konsep dasarnya, maka ia lebih cocok untuk penulisan piranti lunak dalam
bahasa-bahasa berorientasi objek seperti C++, Java, VB.NET. Walaupun
demikian, UML tetap dapat digunakan untuk modeling aplikasi prosedural dalam
VB atau C.
Seperti bahasa-bahasa lainnya, UML mendefinisikan notasi dan
syntax/semantik. Notasi UML merupakan sekumpulan bentuk khusus untuk
menggambarkan berbagai diagram piranti lunak. Setiap bentuk memiliki makna
tertentu, dan UML syntax mendefinisikan bagaimana bentuk-bentuk tersebut
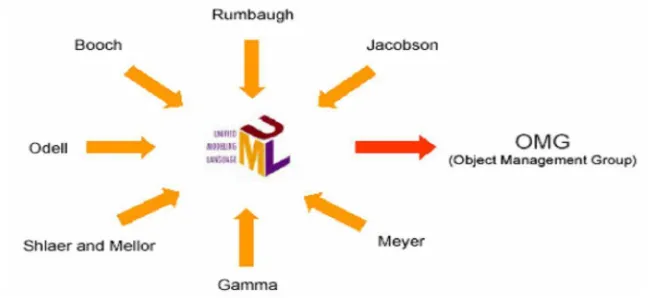
dapat dikombinasikan. Notasi UML terutama diturunkan dari 3 notasi yang telah
ada sebelumnya: Grady Booch OOD (Object-Oriented Design), Jim Rumbaugh
OMT (Object Modeling Technique), dan Ivar Jacobson OOSE (Object-Oriented
Software Engineering).
Sejarah UML sendiri cukup panjang. Sampai era tahun 1990 seperti kita
ketahui puluhan metodologi pemodelan berorientasi objek telah bermunculan di
dunia. Diantaranya adalah: metodologi Booch, metodologi Coad , metodologi
OOSE, metodologi OMT, metodologi Shlaer-Mellor, metodologi Wirfs-Brock,
dan sebagainya. Masa itu terkenal dengan masa perang metodologi (method war)
dalam pendesainan berorientasi objek. Masing-masing metodologi membawa
notasi sendiri-sendiri, yang mengakibatkan timbul masalah baru apabila kita
bekerja sama dengan group/perusahaan lain yang menggunakan metodologi yang
Dimulai pada bulan Oktober 1994 Booch, Rumbaugh dan Jacobson, yang
merupakan tiga tokoh yang boleh dikatakan metodologinya banyak digunakan
mempelopori usaha untuk penyatuan metodologi pendesainan berorientasi objek.
Pada tahun 1995 direlease draft pertama dari UML (versi 0.8). Sejak tahun 1996
pengembangan tersebut dikoordinasikan oleh Object Management Group (OMG –
http://www.omg.org). Tahun 1997 UML versi 1.1 muncul, dan saat ini versi
terbaru adalah versi 1.5 yang dirilis bulan Maret 2003. Booch, Rumbaugh dan
Jacobson menyusun tiga buku serial tentang UML pada tahun 1999. Sejak saat
itulah UML telah menjelma menjadi standar bahasa pemodelan untuk aplikasi
berorientasi objek.
Object Management Group, Inc. (OMG) adalah sebuah organisasi
international yang dibentuk pada 1989, didukung lebih dari 800 anggota, terdiri
dari perusahaan sistem informasi, software developer, dan pada user sistem
komputer. Organisasi ini salah satunya bertugas membuat spesifikasi “manajemen
objek” untuk menetapkan kerangka bersama dalam rekayasa software.
Gambar 2.7. Metodologi dalam UML
Sasaran OMG adalah membantu perkembangan object-oriented
Architecture (OMA). OMA menentukan infrastruktur konseptual yang didasarkan
pada seluruh spesifikasi yang dikeluarkan OMG.
OMG kemudian mengeluarkan UML, dimana dengan adanya UML ini
diharapkan dapat mengurangi kekacauan dalam bahasa pemodelan yang selama
ini terjadi dalam lingkungan industri. UML diharapkan juga dapat menjawab
masalah penotasian dan mekanisme tukar menukar model yang terjadi selama ini.
Saat ini piranti lunak semakin luas dan besar lingkupnya, sehingga tidak
bisa lagi dibuat asal-asalan. Piranti lunak saat ini seharusnya dirancang dengan
memperhatikan hal-hal seperti scalability, security, dan eksekusi yang robust
walaupun dalam kondisi yang sulit. Selain itu arsitekturnya harus didefinisikan
dengan jelas, agar bug mudah ditemukan dan diperbaiki, bahkan oleh orang lain
selain programmer aslinya. Keuntungan lain dari perencanaan arsitektur yang
matang adalah dimungkinkannya penggunaan kembali modul atau komponen
untuk aplikasi piranti lunak lain yang membutuhkan fungsionalitas yang sama.
Pemodelan (modeling) adalah proses merancang piranti lunak sebelum
melakukan pengkodean (coding). Model piranti lunak dapat dianalogikan seperti
pembuatan blueprint pada pembangunan gedung. Membuat model dari sebuah
sistem yang kompleks sangatlah penting karena kita tidak dapat memahami sistem
semacam itu secara menyeluruh. Semakin komplek sebuah sistem, semakin
penting pula penggunaan teknik pemodelan yang baik.
Dengan menggunakan model, diharapkan pengembangan piranti lunak
dapat memenuhi semua kebutuhan pengguna dengan lengkap dan tepat, termasuk
suatu pemodelan piranti lunak ditentukan oleh tiga unsur, yang kemudian terkenal
dengan sebutan segitiga sukses (the triangle for success). Ketiga unsur tersebut
adalah metode pemodelan (notation), proses (process) dan tool yang digunakan.
Memahami notasi pemodelan tanpa mengetahui cara pemakaian yang sebenarnya
(proses) akan membuat proyek gagal. Dan pemahaman terhadap metode
pemodelan dan proses disempurnakan dengan penggunaan tool yang tepat.
UML menyediakan beberapa notasi dan artifact standar yang bisa
digunakan sebagai alat komunikasi bagi para pelaku dalam proses analisis dan
desain. Artifact didalam UML didefinisikan sebagai informasi dalam bentuk yang
digunakan atau dihasilkan dalam proses pengembangan perangkat. Contohnya
adalah source code yang dihasilkan oleh proses pemrograman.
Yang harus diperhatikan untuk menjaga konsistensi antar artifact selama
proses analisis dan desain adalah bahwa setiap perubahan yang terjadi pada satu
artifact harus juga dilakukan pada atifact sebelumnya.
o collaboration diagram
implementation diagram
component diagram
deployment diagram
Diagram-diagram tersebut diberi nama berdasarkan sudut pandang yang
berbeda-beda terhadap sistem dalam proses analisis atau rekayasa.
Dibuatnya berbagai jenis diagram diatas karena :
1. Setiap sistem yang kompleks selalu paling baik jika didekati melalui
himpunan berbagai sudut pandang yang kecil yang satu sama lain hampir
saling bebas (independent). Sudut pandang tunggal senantiasa tidak
mencukupi untuk melihat sistem yang besar dan kompleks.
2. Diagram yang berbeda-beda tersebut dapat menyatakan tingkatan yang
berbeda-beda dalam proses rekayasa.
3. Diagram-diagram tersebut dibuat agar model yang dibuat semakin mendekati
realitas.
2.6. Semantik Dalam UML
OMG telah menetapkan semantik (makna istilah) semua notasi UML
dalam model struktural dan model behavior. Model struktural (model statis),
menekankan stuktur obyek dalam sebuah sistem, menyangkut kelas-kelas,
interface, atribut dan hubungan antar komponen. Model behavioral (model
dinamis), menekankan perilaku obyek dalam sebuah sistem, termasuk metode,
Tujuan utama UML diantaranya untuk :
1. Memberikan model yang siap pakai, bahasa pemodelan visual yang ekspresif
untuk mengembangkan dan saling menukar model dengan mudah dan
dimengerti secara umum.
2. Memberikan bahasa pemodelan yang bebas dari berbagai bahasa
pemrograman dan proses rekayasa.
3. Menyatukan praktek-praktek terbaik yang terdapat dalam bahasa pemodelan.
Pertama, UML menggabungkan konsep Booch, OMT dan OOSE, sehingga UML
merupakan suatu bahasa pemodelan tunggal yang umum dan digunakan secara
luas oleh para user ketiga metode tersebut dan bahkan para user metode lainnya.
Kedua, UML menekankan pada apa yang dapat dikerjakan dengan metode-meode
tersebut.
Ketiga, UML berfokus pada suatu bahasa pemodelan standar, bahkan pada proses
standar. Meskipun UML harus diaplikasikan dalam konteks sebuah proses, dari
pengalaman, bahwa organisasi dan masalah yang berbeda juga memerlukan
proses yang berbeda pula.
UML tidak mencakup :
a. Bahasa Pemrograman
UML adalah bahasa pemodelan visual, bukan dimaksudkan untuk menjadi suatu
bahasa pemrograman visual, tetapi UML memberikan arah untuk bergerak kearah
kode.
Membuat standar sebuah bahasa diperlukan oleh tool-tool dan proses. UML
mendefinisikan semantik dan notasi, bukan sebuah tool. Contoh tool yang
menggunakan UML sebagai bahasanya adalah Rational Rose dan Enterprise
Architect.
c. Proses rekayasa
UML digunakan sebagai bahasa dalam proyek dengan proses yang berbeda-beda.
UML bebas dari proses dan mendefinisikan sebuah proses standar bukan tujuan
UML atau RFP dari OMG. Dalam pembahasan ini kita akan menggunakan sebuah
proses yang dikeluarkan Rational Software, yaitu Rational Unified Process (RUP)
2.7. Notasi Dalam UML
2.7.1. Actor
Gambar 2.8. Notasi Actor
Actor menggambarkan segala pengguna software aplikasi (user). Actor
memberikan suatu gambaran jelas tentang apa yang harus dikerjakan software
aplikasi. Sebagai contoh sebuah actor dapat memberikan input kedalam dan
menerima informasi dari software aplikasi, perlu dicatat bahwa sebuah actor
berinteraksi dengan use case, tetapi tidak memiliki kontrol atas use case. Sebuah
actor mungkin seorang manusia, satu device, hardware atau sistem informasi
lainnya.
2.7.2. Use Case
Gambar 2.9. Notasi Use Case
Use case menjelaskan urutan kegiatan yang dilakukan actor dan sistem
untuk mencapai suatu tujuan tertentu. Walaupun menjelaskan kegiatan, namun
use case hanya menjelaskan apa yang dilakukan oleh actor dan sistem bukan
bagaimana actor dan sistem melakukan kegiatan tersebut.
Use-case Konkret adalah use case yang dibuat langsung karena keperluan actor.
Actor dapat melihat dan berinisiatif terhadapnya
Use-case Abstrak adalah use case yang tidak pernah berdiri sendiri. Use case
abstrak senantiasa termasuk didalam (include), diperluas dari (extend) atau
memperumum (generalize) use case lainnya. Untuk menggambarkannya dalam
use case model biasanya digunakan association relationship yang memiliki
stereotype include, extend atau generalization relationship. Hubungan include
menggambarkan bahwa suatu use case seluruhnya meliputi fungsionalitas dari use
case lainnya. Hubungan extend antar use case berarti bahwa satu use case
merupakan tambahan fungsionalitas dari use case yang lain jika kondisi atau
2.7.3. Class
Gambar 2.10. Notasi Class
Class merupakan pembentuk utama dari sistem berorientasi obyek,
karena class menunjukkan kumpulan obyek yang memiliki atribut dan operasi
yang sama. Class digunakan untuk mengimplementasikan interface.
Class digunakan untuk mengabstraksikan elemen-elemen dari sistem yang sedang
dibangun. Class bisa merepresentasikan baik perangkat lunak maupun perangkat
keras, baik konsep maupun benda nyata.
Notasi class berbentuk persegi panjang berisi 3 bagian: persegi panjang
paling atas untuk nama class, persegi panjang paling bawah untuk operasi, dan
persegi panjang ditengah untuk atribut.
Atribut digunakan untuk menyimpan informasi. Nama atribut
menggunakan kata benda yang bisa dengan jelas merepresentasikan informasi
yang tersimpan didalamnya. Operasi menunjukkan sesuatu yang bisa dilakukan
oleh obyek dan menggunakan kata kerja.
2.7.4. Inter face
Interface merupakan kumpulan operasi tanpa implementasi dari suatu class.
Implementasi operasi dalam interface dijabarkan oleh operasi didalam class. Oleh
karena itu keberadaan interface selalu disertai oleh class yang
mengimplementasikan operasinya. Interface ini merupakan salah satu cara
mewujudkan prinsip enkapsulasi dalam obyek.
2.7.5. Interaction
Gambar 2.12. Notasi Interaction
Interaction digunakan untuk menunjukkan baik aliran pesan atau informasi antar
obyek maupun hubungan antar obyek. Biasanya interaction ini dilengkapi juga
dengan teks bernama operation signature yang tersusun dari nama operasi,
parameter yang dikirim dan tipe parameter yang dikembalikan.
2.7.6. Note
Gambar 2.13. Notasi Note
Note digunakan untuk memberikan keterangan atau komentar tambahan dari suatu
elemen sehingga bisa langsung terlampir dalam model. Note ini bisa disertakan ke
2.7.7. Dependency
Gambar 2.14. Notasi Dependency
Dependency merupakan relasi yang menunjukan bahwa perubahan pada salah satu
elemen memberi pengaruh pada elemen lain. Elemen yang ada di bagian tanda
panah adalah elemen yang tergantung pada elemen yang ada dibagian tanpa tanda
panah.
Terdapat 2 stereotype dari dependency, yaitu include dan extend. Include
menunjukkan bahwa suatu bagian dari elemen (yang ada digaris tanpa panah)
memicu eksekusi bagian dari elemen lain (yang ada di garis dengan panah).
Extend menunjukkan bahwa suatu bagian dari elemen di garis tanpa panah bisa
disisipkan kedalam elemen yang ada di garis dengan panah.
2.7.8. Association
Gambar 2.15. Notasi Asociation
Association menggambarkan navigasi antar class (navigation), berapa banyak
obyek lain yang bisa berhubungan dengan satu obyek (multiplicity antar class)
dan apakah suatu class menjadi bagian dari class lainnya (aggregation).
Navigation dilambangkan dengan penambahan tanda panah di akhir garis.
Bidirectional navigation menunjukkan bahwa dengan mengetahui salah satu class
navigation hanya dengan mengetahui class diujung garis association tanpa panah
kita bisa mendapatkan informasi dari class di ujung dengan panah, tetapi tidak
sebaliknya. Aggregation mengacu pada hubungan “has-a”, yaitu bahwa suatu
class memiliki class lain, misalnya Rumah memiliki class Kamar.
2.7.9. Generalization
Gambar 2.16. Notasi Generalization
Generalization menunjukkan hubungan antara elemen yang lebih umum ke
elemen yang lebih spesifik. Dengan generalization, class yang lebih spesifik
(subclass) akan menurunkan atribut dan operasi dari class yang lebih umum
(superclass) atau “subclass is superclass”. Dengan menggunakan notasi
generalization ini, konsep inheritance dari prinsip hirarki dapat dimodelkan.
2.7.10.Realization
Gambar 2.17. Notasi Realization
Realization menunjukkan hubungan bahwa elemen yang ada di bagian tanpa
panah akan merealisasikan apa yang dinyatakan oleh elemen yang ada di bagian
dengan panah. Misalnya class merealisasikan package, component merealisasikan
2.8. Embarcadero Delphi 2010
Delphi merupakan alat bantu pengembangan aplikasi yang berbasis
visual. Perangkat ini merupakan hasil pengembangan dari bahasa pemrograman
pascal yang diciptakan oleh Niklaus Wirth. Pada masa itu, Wirth bermaksud
membuat bahasa pemrograman tingkat tinggi sebagai alat bantu mengajar logika
pemrograman komputer kepada para mahasiswanya.
Bahasa pemrograman pascal ini kemudian dikembangkan oleh Borland
yang merupakan salah satu perusahaan software menjadi sebuah tools dengan
dibuatkan kompiler dan dijual ke pasar dengan nama TURBO PASCAL.
Seiring dengan ditemukannya metode pemrograman berorientasi obyek,
bahasa pemrograman pascal berevolusi menjadi object pascal dan dikembangkan
oleh Borland dengan nama Borland Delphi.
Keberhasilan Borland dalam mengembangkan Delphi menjadikan salah
satu bahasa yang populer dan disukai oleh banyak programmer, disamping Visual
Basic yang dikeluar Microsoft di kemudian hari.
Lingkungan pengembangan Delphi yang mudah, intuitif dan
memudahkan pemakai, berhasil melampaui popularitas rivalnya, yaitu Visual
Basic, sehingga pernah menyandang predikat “VB-Killer”.
Karena tuntutan perkembangan teknologi, Borland berganti nama
menjadi Code Gear, tetapi tetap mempergunakan nama Delphi untuk tools yang
Embarcadero dan namanya pun berubah menjadi Embarcadero RAD Studio
dengan tetap mempertahankan Delphi sebagai salah satu tools-nya.
Beberapa kelebihan yang dimiliki oleh Embarcadero Delphi 2010 ini
antara lain :
1. Delphi dibangun dengan menggunakan arsitektur native compiler, sehingga
proses kompilasi instruksi menjadi bahasa mesin menjadi lebih cepat.
2. Semua file yang disertakan saat proses kompilasi, digabungkan menjadi satu
sesuai dengan arsitektur native compiler, sehingga mengurangi
ketergantungan terhadap library ataupun file-file pendukung lainya, sesuai
dengan prinsip build once, runs everywhere
3. Delphi mempunyai kemampuan selective object linking, sehingga apabila
terdapat pemanggilan sebuah library dan ternyata tidak terdapat instruksi
dalam library tersebut yang dipergunakan dalam system, maka secara
otomatis, kompiler tidak akan menyertakan library tersebut dalam proses
kompilasinya. Hal ini berbeda dengan tools lain yang tidak mempunyai
kemampuan seperi itu. Dengan adanya kemampuan tersebut, maka file
eksekusi yang dihasilkan delphi menjadi lebih optimal.
4. Lingkungan pengembangan Delphi sangat intuitif karena semua komponen
yang menjadi alat utama desain visual telah ditampilkan saat pertama kali
langsung dapat diamati oleh user dan dapat digunakan secara langsung.
Gambar 2.19. Tampilan Awal Delphi
Dalam delphi seperti halnya bahasa visual lainnya menyediakan
komponen. Komponen adalah “jantung” bagi pemograman visual. Componen
Palette telah terbagi menjadi berbagai jenis komponen, diantaranya adalah
Standard, Additional, Win32, System, dan beberapa lainnya. Berikut ini adalah
uraian yang komponen palet yang paling sering dipergunakan, termasuk dalam
tugas akhir ini.
Tampak pada palet standard diatas (dengan urutan dari kiri ke kanan),
adalah frame, main menu, pop up menu, label, edit text, memo, button, check box,
radio button, list box, combo box, scroll bar, group box, radio group, panel dan
action list.
Gambar 2.21. Daftar Komponen Palet Additional
Pada palet additional terdapat komponen bit button, speed button, mask
edit, string grid, draw grid, image, shape, bevel, scroll box, list box, splitter, static
text, tlink label, control bar, application events, value list edit, labeled edit,
buttoned edit, color box, color list box, category button, button group, dock tab
set, tab set, tray icon, flow panel, grid panel, balloon hint, category group dan
action manager.
Gambar 2.22. Daftar Komponen Palet Win 32
Pada palet win 32 terdapat komponen tab control, page control, image
month calendar, tree view, list view, header control, status bar, tool bar, cool bar,
page scroller, Combo Box Ex, XP Manifest, Shell Resource.
Gambar 2.23. Daftar Komponen Palet System
Komponen yang terdapat dalam palet system adalah timer, paint box,
media player, ole container, comadmin dialog, DDE Client Conv, DDE Client
Item, DDE Server Conv dan DDE Server Item.
Gambar 2.24. Komponen Palet Dialog
Komponen yang terdapat dalam palet dialog adalah open dialog, save
dialog, open picture dialog, save picture dialog, open text file dialog, save text file
dialog, font dialog, color dialog, print dialog, printer setup dialog, find dialog,
replace dialog, page setup dialog.
Sebuah proyek Delphi akan terdiri dari berberapa file. Ada file yang
menyimpan program dan ada file lain yang menyimpan binari, gambar. Karena
sebuah aplikasi pada sebuah folder. Berbagai jenis file yang dibuat saat
membangun aplikasi menggunakan Delphi adalah sebagai berikut :
Tabel 2.5. Jenis-jenis File Dalam Delphi
Jenis File Keterangan
.dproj File proyek, fungsinya untuk linking object
.dfm File form, fungsinya menyimpan nilai properti form
.pas File unit, berisi source code prosedur dan fungsi
.dpk File package, berisi instalasi komponen
.res File resource
.cfg File konfigurasi proyek
.dof File pilihan proyek
.dcu Hasil kompilasi file .pas
Analisa adalah tahap aktifitas kreatif dimana analis berusaha memahami
permasalahan secara mendalam. Ini adalah proses interative yang terus berjalan
hingga permasalahan dapat dipahami dengan benar. Analisis bertujuan untuk
mendapatkan pemahaman secara keseluruhan tentang sistem yang akan dibuat
berdasarkan masukan dari pihak-pihak yang berkepentingan dengan sistem
tersebut.
3.1. Analisa Masalah
Permasalahan yang dibuat dalam tugas akhir ini adalah membuat
simulasi algoritma PPM untuk mengompresi data, kemudian
mengimplementasikannya pada proses pengiriman data. Hasil simulasi algoritma
PPM yang telah dibuat ini kemudian dilakukan uji coba, sehingga kita bisa
melihat hasil kompresi dan simulasi yang telah dibuat. Data dari hasil penelitian
dengan metode PPM ini beserta pengimplementasiannya akan dibandingkan
dengan data aslinya. Perbandingan yang akan dilakukan adalah berupa ukuran dan
waktu kompresi pada data yang sebelum dikompresi dan data yang sesudah
dikompresi serta perbandingan proses transfer data antara data yang sebelum
Dari perbandingan ini akan diperoleh kelebihan dan kekurangan dari
algoritma ini, dan selanjutnya dari perbandingan tersebut akan diperoleh
kesimpulan.
3.2. Analisis dan Kebutuhan fungsional
a. Actor Identification
Tahap pertama yang dilakukan dalam melakukan analisis berorientasi
objek menggunakan UML adalah menentukan actor atau pengguna sistem. Kata
aktor dalam konteks UML, menampilkan peran (roles) yang pengguna (atau
sesuatu di luar sistem yang dikembangkan yang dapat berupa perangkat keras, end
user, sistem yang lain, dan sebagainya).
b. Analisis dan Kebutuhan non-fungsional
Analisis dan kebutuhan non-fungsional meliputi analisis dan kebutuhan
pengguna, analisis dan kebutuhan perangkat keras, serta analisis dan kebutuhan
perangkat lunak.
c. Analisis dan Kebutuhan Pengguna (user)
Pengguna diartikan sebagai orang yang mengakses dan menggunakan
perangkat lunak aplikasi kompresi algoritma PPM, dalam hal ini pengguna harus
memiliki kemampuan dasar untuk mengoperasikan komputer dan memiliki
3.3. Use Case Diagram
Use case diagram digunakan untuk menggambarkan fungsionalitas yang
diharapkan dari sebuah sistem. Sebuah use case merepresentasikan sebuah
interaksi antara aktor dengan sistem. Use case diagram pada Gambar 3.1
menggambarkan bagaimana proses yang terjadi pada aplikasi kompresi data dan
transfer data serta bagaimana pengguna melakukan interaksi terhadap user.
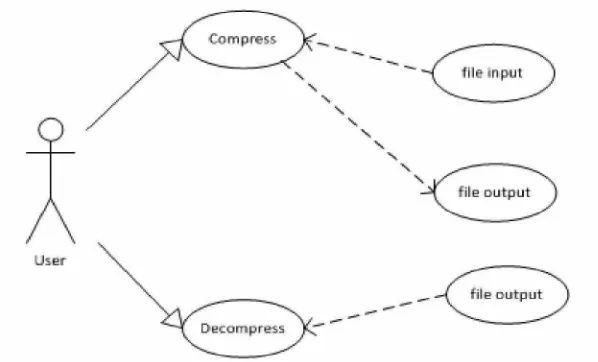
Pada use case dalam gambar 3.1 tersebut terjadi beberapa proses yaitu :
1. User dapat melakukan proses kompresi file
2. User dapat melakukan proses dekompresi file
Gambar 3.1. Use Case Diagram Aplikasi Kompresi Data
3.4 Sequence Diagram
Data Sequence diagram menggambarkan interaksi antar objek di dalam
dan di sekitar sistem (termasuk pengguna, display, dan sebagainya) berupa
message yang digambarkan terhadap waktu. Sequence diagram terdiri atar
Sequence diagram biasa digunakan untuk menggambarkan skenario atau
rangkaian langkah-langkah yang dilakukan sebagai respons dari sebuah event
untuk menghasilkan output tertentu. Diawali sesuatu yang men-trigger aktivitas
tersebut, proses dan perubahan apa saja yang terjadi secara internal dan output apa
yang dihasilkan.
Sequence Diagram yang digambarkan dalam perancangan sistem adalah
sebagai berikut :
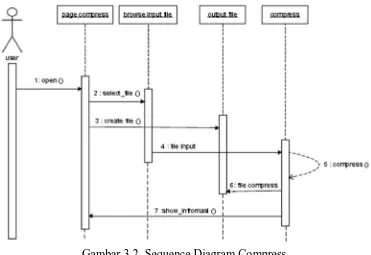
3..4.1 Sequence Diagr am Compress
Sequence diagram menu compress dapat dilihat pada gambar :
Gambar 3.2. Sequence Diagram Compress
Pada sequence diagram di atas terjadi beberapa proses yaitu :
1. User masuk ke page compress
3. Membuat file hasil kompresi
4. Melakukan proses kompresi dan sistem menampilkan informasi file yang telah
dikompres
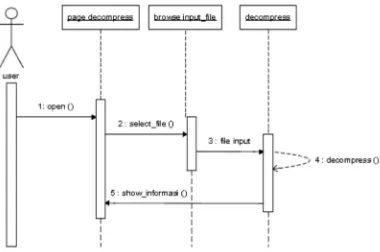
3.4.2 Sequence Diagram Decompress
Pada sequence diagram decompress di bawah ini terjadi beberapa proses yaitu :
1. User masuk ke page decompress
2. Menyimpan file hasil dekompresi
3. Melakukan proses dekompresi dan sistem menampilkan informasi file yang telah
didekompres.
Sequence diagram menu decompress dapat dilihat pada gambar 3.3 dibawah ini :
Gambar 3.3. Sequence Diagram Decompress
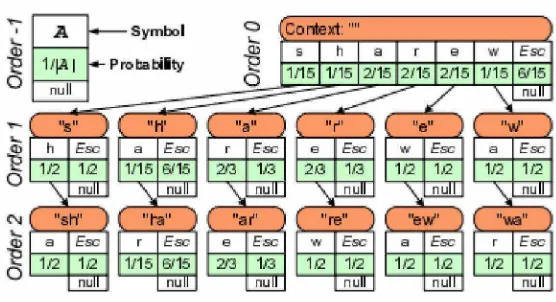
Untuk dapat memahami algorithma PPM berikut ini adalah cara kerja
algorithma PPM :
Gambar 3.4. Model Sekuensial Urutan Prediksi Kode Dalam Algorithma PPM
Input stream data sebagai xn = (X1, x2,..., Xn), xi ∈ A, di mana x n adalah
urutan simbol n dari alfabet A. Kemudian Untuk setiap simbol xi, I ∈ {1, 2,. . . ,
N}, dari aliran data masukan berdasarkan probabilitas kondisional p (xi| xi-1).
Encoder dan decoder beroperasi secara independen dari satu sama lain.
Dalam rangka untuk berhasil encode dan decode semua simbol, baik encoder dan
probabilitas kondisional p sama (xi| s) untuk masing-masing diberikan simbol xi
urutan s.
Kemudian gunakan konteks yang terbatas-model simbol untuk
memperkirakan distribusi probabilitas untuk simbol mendatang. Sebuah konteks k
order urutan simbol k berturut-turut dari aliran input data. Konteks ketertiban k
dari xi simbol arus adalah urutan simbol c ki = (xi-k, xi-(k-1),. . . , Xi-1).
Demikian pula, konteks dari setiap simbol k dilambangkan sebagai ck.
Himpunan semua konteks kemungkinan dari panjang k dapat
direpresentasikan sebagai pohon M-ary dengan kedalaman k, di mana M = | A |.
Mengingat K konteks panjang maksimum, model PPM adalah sebuah M-ary
konteks kedalaman pohon K dimana setiap konteks ck, K ≤ K, berisi satu set entri
simbol α ∈ A yang yang sebelumnya terlihat di ck. Setiap entri berisi hit ungan
jumlah penampilan simbol yang sesuai di ck.
P kondisional probabilitas (α | ck) menunjukkan perkiraan probabilitas
simbol α yang ditemukan di c konteks k, Dan itu adalah ditentukan berdasarkan
jumlah frekuensi dari semua simbol dilihat dalam konteks ck. untuk kasus ketika
simbol α sebelumnya tidak terlihat di ck (yaitu p (α | ck) = 0, model PPM
menerapkan mekanisme melarikan diri untuk beralih antara lama untuk konteks
yang berisi semua symbol dari alfabet A. Dengan cara ini, masalah
memperkirakan prediksi probabilitas peristiwa novel diterjemahkan ke konteks
switching dari konteks lebih lama untuk yang lebih pendek sampai simbol
masukan ditemukan.
Perhatikan bahwa simbol masukan xi dikodekan dengan perkiraan
probabilitas dari p (xi| c) = Li karena jumlah kumulatif dari semua simbol yang
sebelumnya dihadapi, xi, Adalah de facto dikodekan dengan p (xi| xi). Setelah
pemrosesan setiap simbol, frekuensi jumlah untuk entri yang sudah ada dan
Perancangan sistem adalah suatu proses yang menggambarkan
bagaimana suatu sistem dibangun untuk memenuhi kebutuhan pada fase analisis.
Adapun tahapan yang dilakukan dalam perancangan sistem ini membahas
mengenai tujuan perancangan sistem, dan perancangan antar muka.
4.1. Tujuan Perancangan Sistem
Perancangan sistem merupakan tindak lanjut dari tahap analisa.
Perancangan sistem bertujuan untuk memberikan gambaran sistem yang akan
dibuat. Dengan kata lain perancangan sistem didefinisikan sebagai penggambaran
atau pembuatan sketsa dari beberapa elemen yang terpisah kedalam satu kesatuan
yang utuh dan berfungsi. Selain itu juga perancangan bertujuan untuk lebih
mengarahkan sistem yang terinci, yaitu pembuatan perancangan yang jelas dan
lengkap yang nantinya akan digunakan untuk pembuatan simulasi. Aplikasi
kompresi ini dibuat dengan sederhana, sehingga diharapkan user dapat dengan
mudah menggunakan aplikasi kompresi ini.
Manfaat lain yang didapat dari perancangan sistem adalah apabila dalam
proses implementasi terjadi hambatan, dapat dilakukan perancangan ulang sistem
secara lebih mudah dengan demikian pengembang dapat menghemat waktu dan