ABSTRAK
Ujian Nasional (UN) sebagai tolok ukur atau parameter akhir dari suatu proses pendidikan. Hasil Ujian Nasional digunakan sebagai dasar untuk pemetaan mutu program dan/atau satuan pendidikan di Indonesia. Setiap tahun UN diselenggarakan untuk mendapatkan sebuah informasi yang dapat bermanfat untuk peningkatan mutu pendidikan. Data mining merupakan salah satu bidang ilmu yang dapat digunakan untuk mendapatkan informasi dari kumpulan data. Pada tugas akhir ini digunakan algoritma K-means Clustering yang akan menghasilkan sebuah sistem perangkat lunak yang dapat digunakan untuk mengelompokkan Sekolah Menengah Atas di DIY berdasarkan nilai Ujian Nasional. Sistem ini diuji dengan perbandingan pengujian manual dengan hasil sistem, pengujian black box, pengujian hasil pengelompokan menggunakan Silhouette Coeficient.
Dalam melakukan proses mengubah data mentah menjadi sebuah informasi yang bermanfaat, penulis menggunakan proses Knowledge Discovery in Database (KDD) yang terdiri dari pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi data, dan presentasi pengetahuan. Pada tahap pembersihan data dilakukan secara manual, untuk itegrasi data dan transformasi data tidak dilakukan, sedangkan untuk seleksi data dan penambangan data penulis merancang perangkat lunak sebagai alat untuk melakukan tahap-tahap tersebut. Sedangkan untuk evaluasi pola dan presentasi pengetahuan, penulis melakukan evaluasi dari hasil penambangan data yang diperoleh dari hasil perangkat lunak dan menjelaskannya agar informasi tersebut dapat diterima oleh pihak-pihak yang membutuhkan. Perangkat lunak diujikan terhadap 8 dataset yang merupakan data Ujian Nasional SMA jurusan IPA dan IPS tahun 2014/2015.
Berdasarkan penelitian yang telah dilakukan, dapat diketahui bahwa algoritma K-means dapat digunakan untuk mengelompokkan data tersebut dengan nilai k yang diberikan. Pengujian hasil pengelompokan dengan menggunakan Silhouette Coeficient(SC) terhadap kedua set data yang digunakan yaitu IPA dan IPS tahun ajaran 2014/2015 dihasilkan nilai SC untuk data IPA sebesar 0.49 pada k = 2 yang dikategorikan sebagai weak Classification dan untuk data IPS sebesar 0.57 pada k = 2 dan 0.51 pada k=3 yang dikategorikan sebagai good Classification. Dengan demikian jumlah cluster yang disarankan untuk data nilai ujian jurusan IPA adalah 2 dan untuk IPS adalah 2 atau 3.
▸ Baca selengkapnya: pernyataan di atas, pengelompokan daerah pada fenomena di atas menggunakan konsep....
(2)ABSTRACT
As The National Exam is used as the final parameter of am educational proccess, the score resulted from National Exam is used as the basis to set the mapping of program quality and/or education unit in Indonesia. National Exam is conducted every year to get sufficient information in the purpose of upgrading the education quality. Data mining is one of disciplines aiming in gaining information among the data collection. In this undergraduate thesis, K-means Clustering alogarithm is used to develop a software that can be used to clasify Senior High School in Jogjakarta based on the the Final Score of National Exam. This system can be tested by compare the manual testing with result of system, black box testing, and result of clustering tested using Silhouette Coeficient.
In conducting the proccess of converting raw data into a useful information, the writer used the proccess of Knowledge Discovery in Database (KDD) consisting the data cleaning, data integration, data selection, data mining, data evaluation, and knowledge presentation. Data cleaning was done manually, data integration and data transformation were not conducted, while at the stage of data selection and data mining, the writer designed a software as the tool to succeed the whole stages. Meanwhile, for the pattern evaluation and knowledge presentation, the writer conducted an evaluation from the result of data mining that was obtained from the software result and the writer explained in order tohave the information accepted by the people who required it. The software will be observed toward 8 datasets that were National Exam of Senior High School, both from Social and Exact Discipline –Year 2014/2015.
According to the research conducted, it is known that the K-means Alogarithm can be used to clasify the data by the given value of k. Result of clustering, tested using Silhouette Coeficient, toward both data set, that is Social and Exact Discipline year 2014/2015, resulting the value of SC for Exact Discipline 0.49 at k = 2, categorized as weak Classification and for Social Discipline 0.57 at k = 2 and 0.51 at k=3 which was categorized as good Classification. Therefore, the number of clusters recommended for the scoring of Exact Discipline is 2, and 2 or 3 for Social Discipline.
i
PENGELOMPOKAN SEKOLAH MENENGAH ATAS DI PROVINSI DAERAH ISTIMEWA YOGYAKARTA BERDASARKAN NILAI UJIAN
NASIONAL MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Kresentia Nita Kurniadewi
125314031
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
THE CLUSTERING OF SENIOR HIGH SCHOOLS IN DAERAH
ISTIMEWA YOGYAKARTA PROVINCE BASED ON THE SCORE OF
NATIONAL EXAM USING K-MEANS CLUSTERING ALGORITHM FINAL PROJECT
Present as Partiaal Fullfillment of the Requirements to Obtain the Sarjana Komputer Degree in Informatics Engineering Study Program
By:
Kresentia Nita Kurniadewi
125314031
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATIC ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
MOTO
Mintalah, maka akan diberikan kepadamu; carilah, maka kamu akan
mendapat; ketoklah, maka pintu akan dibukakan bagimu.
vi
HALAMAN PERSEMBAHAN
Karya ini kupersembahkan kepada:
Tuhan Yesus Kristus
Bunda Maria
Keluarga
ix
ABSTRAK
Ujian Nasional (UN) sebagai tolok ukur atau parameter akhir dari suatu proses pendidikan. Hasil Ujian Nasional digunakan sebagai dasar untuk pemetaan mutu program dan/atau satuan pendidikan di Indonesia. Setiap tahun UN diselenggarakan untuk mendapatkan sebuah informasi yang dapat bermanfat untuk peningkatan mutu pendidikan. Data mining merupakan salah satu bidang ilmu yang dapat digunakan untuk mendapatkan informasi dari kumpulan data. Pada tugas akhir ini digunakan algoritma K-means Clustering yang akan menghasilkan sebuah sistem perangkat lunak yang dapat digunakan untuk mengelompokkan Sekolah Menengah Atas di DIY berdasarkan nilai Ujian Nasional. Sistem ini diuji dengan perbandingan pengujian manual dengan hasil sistem, pengujian black box, pengujian hasil pengelompokan menggunakan Silhouette Coeficient.
Dalam melakukan proses mengubah data mentah menjadi sebuah informasi yang bermanfaat, penulis menggunakan proses Knowledge Discovery in Database (KDD) yang terdiri dari pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi data, dan presentasi pengetahuan. Pada tahap pembersihan data dilakukan secara manual, untuk itegrasi data dan transformasi data tidak dilakukan, sedangkan untuk seleksi data dan penambangan data penulis merancang perangkat lunak sebagai alat untuk melakukan tahap-tahap tersebut. Sedangkan untuk evaluasi pola dan presentasi pengetahuan, penulis melakukan evaluasi dari hasil penambangan data yang diperoleh dari hasil perangkat lunak dan menjelaskannya agar informasi tersebut dapat diterima oleh pihak-pihak yang membutuhkan. Perangkat lunak diujikan terhadap 8 dataset yang merupakan data Ujian Nasional SMA jurusan IPA dan IPS tahun 2014/2015.
Berdasarkan penelitian yang telah dilakukan, dapat diketahui bahwa algoritma K-means dapat digunakan untuk mengelompokkan data tersebut dengan nilai k yang diberikan. Pengujian hasil pengelompokan dengan menggunakan Silhouette Coeficient(SC) terhadap kedua set data yang digunakan yaitu IPA dan IPS tahun ajaran 2014/2015 dihasilkan nilai SC untuk data IPA sebesar 0.49 pada k = 2 yang dikategorikan sebagai weak Classification dan untuk data IPS sebesar 0.57 pada k = 2 dan 0.51 pada k=3 yang dikategorikan sebagai good Classification. Dengan demikian jumlah cluster yang disarankan untuk data nilai ujian jurusan IPA adalah 2 dan untuk IPS adalah 2 atau 3.
x
ABSTRACT
As The National Exam is used as the final parameter of am educational proccess, the score resulted from National Exam is used as the basis to set the mapping of program quality and/or education unit in Indonesia. National Exam is conducted every year to get sufficient information in the purpose of upgrading the education quality. Data mining is one of disciplines aiming in gaining information among the data collection. In this undergraduate thesis, K-means Clustering alogarithm is used to develop a software that can be used to clasify Senior High School in Jogjakarta based on the the Final Score of National Exam. This system can be tested by compare the manual testing with result of system, black box testing, and result of clustering tested using Silhouette Coeficient.
In conducting the proccess of converting raw data into a useful information, the writer used the proccess of Knowledge Discovery in Database (KDD) consisting the data cleaning, data integration, data selection, data mining, data evaluation, and knowledge presentation. Data cleaning was done manually, data integration and data transformation were not conducted, while at the stage of data selection and data mining, the writer designed a software as the tool to succeed the whole stages. Meanwhile, for the pattern evaluation and knowledge presentation, the writer conducted an evaluation from the result of data mining that was obtained from the software result and the writer explained in order tohave the information accepted by the people who required it. The software will be observed toward 8 datasets that were National Exam of Senior High School, both from Social and Exact Discipline –Year 2014/2015.
According to the research conducted, it is known that the K-means Alogarithm can be used to clasify the data by the given value of k. Result of clustering, tested using Silhouette Coeficient, toward both data set, that is Social and Exact Discipline year 2014/2015, resulting the value of SC for Exact Discipline 0.49 at k = 2, categorized as weak Classification and for Social Discipline 0.57 at k = 2 and 0.51 at k=3 which was categorized as good Classification. Therefore, the number of clusters recommended for the scoring of Exact Discipline is 2, and 2 or 3 for Social Discipline.
xi
KATA PENGANTAR
Puji dan Syukur kepada Tuhan Yang Maha Esa, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang ber judul
“PENGELOMPOKAN SEKOLAH MENENGAH ATAS DI DIY
BERDASARKAN NILAI UJIAN NASIONAL MENGGUNAKAN
ALGORITMA K-MEANS CLUSTERING”
Dalam menyelesaikan seluruh penyusun tugas akhir ini, penulis tak lepas dari dosa, bantuan, dukungan, dan motivasi dari banyak pihak. Oleh karena itu, penulis ingin mengucapkan banyak terima kasih kepada:
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu memberikan anugrah, rahmat, kekuatan, dan keberuntungan sehingga penulis dapat menyelesaikan tugas akhir ini.
2. Kedua orang tua penulis, Johanes Bosco Heru Nuryono dan Maria Imaculata Respita Murti atas doa, kasih sayang, perhatian, kepercayaan, dukungan baik moral maupun financial yang diberikan kepada penulis. 3. Kakak penulis, Ambrosius Hans Gigih Kurniadi dan Ignasius Hans Veda
Kurnia yang selalu memberikan semangat, dukungan, dan doa kepada penulis. Skripsi yang telah memberikan waktu, bimbingan, nasihat, dan motivasi kepada penulis.
7. Bapak Iwan Binanto M.Cs. selaku Dosen Pembimbing Akademik penulis. 8. Seluruh Dosen yang telah mendidik dan memberikan pengetahuan dan
xiii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI...viii
ABSTRAK...ix
1.6. SISTEMATIKA PENULISAN ... 3
BAB II LANDASAN TEORI ... 6
2.1. PENAMBANGAN DATA ... 6
2.1.1. Pengertian Penambangan Data ... 6
2.1.2. Fungsi Penambangan Data ... 6
2.1.3. Knowledge Discovery in Database (KDD) ... 8
2.2. Ujian Nasional ... 10
2.2.1. Definisi Ujian Nasional ... 10
2.2.2. Tujuan dan Fungsi Ujian Nasional ... 10
2.2.3. Peserta Ujian Nasional ... 11
2.2.4. Penyelenggaran Ujian Nasional ... 12
2.2.5. Strandar Kelulusan ... 12
2.3. Konsep Data Mining ... 13
2.3.1. Clustering ... 13
2.3.2. K-Means... 13
xiv
2.4. Validitas Cluster ... 16
2.4.1. Analisis Cluster ... 16
2.4.2. Validitas Internal ... 17
2.4.3. Silhouette ... 17
BAB III METODOLOGI PENELITIAN... 23
3.1. Sumber Data ... 23
3.1.1. Data yang digunakan ... 23
3.2. Spesifikasi Alat ... 23
3.2.1. Spesifikasi Hardware ... 23
3.2.2. Spesifikasi Software ... 23
3.3. Tahap-Tahap Penelitian ... 23
3.3.1. Studi Kasus ... 23
3.3.2. Penelitian Pustaka ... 24
3.3.3. Knowledge Discovery in Database (KDD) ... 24
3.3.4. Pengembangan Perangkat Lunak ... 24
3.3.5. Analisis dan Pembuatan Laporan ... 26
BAB IV PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA ... 26
4.1. PEMROSESAN AWAL ... 26
4.1.1. Pembersihan Data (Data Cleaning) ... 26
4.1.2. Itegrasi Data (Data Integration) ... 26
4.1.3. Seleksi Data (Data Selection) ... 26
4.1.4. Tranformasi Data (Data Transformation) ... 29
4.2. PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA ... 29
4.2.2.3. Output Sistem... 33
4.2.3. Diagram Aktivitas (Activity diagram). ... 33
4.2.4. Diagram Kelas Desain ... 33
4.2.5. Diagram Sekuen (Sequence Diagram). ... 34
xv
4.2.7. Perancangan Struktur Data ... 34
4.2.7.1. Array ... 35
4.2.7.2. ArrayList ... 35
4.2.7.3 HashMap ... 36
4.2.8. Perancangan Antarmuka ... 37
4.2.8.1. Halaman Halaman Awal ... 37
4.2.8.2. Halaman Bantuan ... 38
4.2.8.3. Halaman Tentang ... 39
4.2.8.4. Halaman Clustering K-Means ... 40
BAB V IMPLEMENTASI PENAMBANGAN DATA DAN EVALUASI HASIL ... 41
5.1 IMPLEMENTASI RANCANGAN PERANGKAT LUNAK ... 41
5.1.1. Implementasi Kelas ... 41
5.2. EVALUASI HASIL ... 51
5.2.1. Pengujian Perangkat Lunak (Black Box) ... 51
5.2.1.1. Rencana Pengujian Black Box ... 51
5.2.1.2. Prosedur Pengujian Black Box dan Kasus Uji ... 52
5.2.1.3. Evaluasi Pengujian Black Box ... 52
5.2.2. Pengujian Perbandingan Hasil Hitung Manual dengan Hasil Perangkat Lunak ... 52
5.2.2.1. Penghitungan Manual ... 52
5.2.2.2. Penghitungan Perangkat Lunak ... 53
5.2.2.3. Evaluasi Pengujian Perbandingan Hitung Manual dengan Hasil Perangkat Lunak ... 54
5.2.2.4. Hasil Pengujian Dataset dengan Silhouette Coeficient Nilai Ujian Nasional Jurusan IPA Tahun Ajaran 2014/2015 ... 55
5.2.2.5. Hasil Pengujian Dataset dengan Silhouette Coeficient Nilai Ujian Nasional Jurusan IPS Tahun Ajaran 2014/2015... 58
5.3. KELEBIHAN DAN KEKURANGAN PERANGKAT LUNAK ... 62
5.3.1. Kelebihan Perangkat Lunak ... 62
5.3.2. Kekurangan Perangkat Lunak ... 62
xvi
DAFTAR TABEL
Tabel 2. 1 Kriteria Subjektif Kualitas Pengelompokkan Berdasarkan Silhouette
Coeficient (SC) ... 21
Tabel 3. 1Table Atribut Data Mentah Nilai Hasil Ujian Nasional Program IPA 2014/2015 ... 23
Tabel 3. 2 Table Atribut Data Mentah Nilai Hasil Ujian Nasional Program IPS 2014/2015 ... 23
Tabel 4. 1 Atribut yang tidak digunakan pada data Ujian Nasional 2015 ... 28
Tabel 4. 2 Tabel Atribut Terseleksi Data Nilai Ujian Nasional Program Strudi IPA di Daerah Istimewa Yogyakarta Tahun ajaran 2014/2015 ... 28
Tabel 4. 3 Tabel Atribut Terseleksi Data Nilai Ujian Nasional Program Strudi IPS di Daerah Istimewa Yogyakarta Tahun ajaran 2014/2015 ... 29
Tabel 5. 1 Implementasi Kelas Home ... 41
Tabel 5. 2 Implementasi Kelas Clustering_KMeans ... 43
Tabel 5. 3 Implementasi Kelas Tentang ... 47
Tabel 5. 4 Implementasi Kelas Bantuan ... 49
Tabel 5. 5 Implementasi Kelas KMeans ... 51
Tabel 5. 6 Implementasi Kelas KMeans ... 51
Tabel 5. 7 Rencana pengujian dengan menggunakan metode black box. ... 52
Tabel 5. 8 Hasil uji perbandingan member percluster secara manual dan sistem . 54 Tabel 5. 9 Hasil Pengujian Dataset dengan rata-rata Silhouette data set Nilai Ujian Nasional Jurusan IPA 2014/2015 ... 55
xvii
DAFTAR GAMBAR
Gambar 2. 1 Tahap-tahap proses Knowledge Discovery in Databese
(Han&Kamber, 2006). ... 8
Gambar 4. 1 Use Case Diagram ... 30
Gambar 4. 2 Diagram flowchart ... 32
Gambar 4. 3 Diagram Kelas Desain ... 34
Gambar 4. 4 Ilustrasi Konsep Array ... 35
Gambar 4. 5 Ilustrasi Konsep ArrayList ... 35
Gambar 4. 6 Perancangan ArrayList ... 36
Gambar 4. 7 Antarmuka Halaman Beranda ... 37
Gambar 4. 8 Antarmuka Halaman Bantuan ... 38
Gambar 4. 9 Antarmuka Halaman Tentang ... 39
Gambar 4. 10 Antarmuka Halaman Proses ... 40
Gambar 5. 1 Implementasi Antarmuka kelas Home ... 43
Gambar 5. 2 Implementasi Antaramuka Kelas Clustering_Kmeans ... 46
Gambar 5. 3 Implementasi Antaramuka Kelas Tentang ... 48
Gambar 5. 4 Implementasi Antaramuka Kelas Bantuan ... 50
Gambar 5. 5 Hasil Penambangan Data Menggunakan Perangkat Lunak ... 53
Gambar 5. 6 Rata-rata Silhouette data set Jurusan IPA ... 587
1
BAB I
PENDAHULUAN
1.1. LATAR BELAKANG
Data mining adalah proses yang menggunakan teknik statistik, matematika,
kecerdasan buatan, dan machine learning untuk mengekstrasi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dengan database besar (Kusrini, 2009). Data mining bisa digunakan oleh perusahan atau
instansi besar untuk menggali data untuk mendapatkan informasi yang dapat menunjang dan meningkatkan kualitas perusahaan/instansi tersebut. Terdapat banyak metode yang digunakan dalam data mining salah satunya adalah metode clustering. Clustering untuk menemukan kumpulan objek hingga objek-objek
dalam kelompok sama (atau punya hubungan) dengan yang lain dan berbeda (atau tidak berhubungan) dengan objek-objek dalam kelompok lain. Tujuan dari analisis cluster adalah meminimalkan jarak di dalam cluster dan memaksimalkan jarak antara cluster (Hermawati, 2013). Salah satu algoritma clustering adalah K-Means. Algoritma K-Means merupakan algoritma pengelompokan interaktif yang
melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal (Prasetyo, 2014). Salah satu data yang dapat digunakan dalam penambangan data adalah data Ujian Akhir Nasional.
No. 13 Tahun 2015 Pasal 68 menyebutkan bahwa Hasil Ujian Nasional digunakan sebagai dasar untuk pemetaan mutu program dan/atau satuan pendidikan, pertimbangan seleksi masuk jenjang pendidikan berikutnya, dan pembinaan dan pemberian bantuan kepada satuan pendidikan dalam upaya meningkatkan mutu pendidikan. Sesuai dengan konsep clustering yang membagi data menjadi kelompok-kelompok maka dapat dilakukan pengelompokan Sekolah Menengah Atas yang ada di DIY menggunakan data Nilai Ujian Nasional untuk melihat peta mutu pendidikan.
Berdasarkan hal di atas, maka penulis mengangkat judul skripsi yaitu
“Pengelompokan Sekolah Menengah Atas Di DIY Berdasarkan Nilai Ujian Nasional Menggunakan Algoritma K-Means Clustering”.
1.2. RUMUSAN MASALAH
Dari latar belakang diatas, maka rumusan masalah dalam penelitian ini adalah:
1. Apakah algoritma K-Means dapat dipergunakan untuk mengelompokkan Sekolah Menengah Atas di DIY berdasarkan nilai Ujian Nasional ?
2. Bagaimana evaluasi hasil clustering menggunakan Silhouette Coeficient?
1.3. TUJUAN PENELITIAN
Tujuan penelitian ini adalah mengimplementasi algoritma K-Means untuk mempermudah pengelompokkan Sekolah Menengah Atas berdasarkan nilai Ujian Nasional.
1.4. BATASAN MASALAH
Masalah dibatasi sebagai berikut:
1. Metode yang digunakan dalam penelitian ini adalah metode clustering algoritma K-Means
2. Data yang digunakan adalah data nilai Ujian Nasional SMA di DIY pada 2014/2015 jurusan IPA dan IPS.
1.5. MANFAAT PENELITIAN
Manfaat penulisan tugas akhir ini adalah sebagai berikut:
1. Penelitian ini diharapkan dapat memberikan manfaat untuk pihak-pihak dalam dunia pendidikan, terutama dinas pendidikan. Dinas pendidikan dapat menggunakan penelitian ini sebagai salah satu bahan masukan pengambilan kebijakan pembinaan dan pemberian bantuan kepada satuan pendidikan dalam upaya meningkatkan mutu pendidikan.
2. Sebagai referensi bagi peneliti yang berkaitan dengan clustering pemetaan atau pengelompokan sekolah.
1.6. SISTEMATIKA PENULISAN
Sistematika penulisan Tugas Akhir ini adalah sebgai berikut:
1. BAB I. PENDAHULUAN
Pada Bab ini memberikan gambaran singkat dan menyeluruh mengenai sistem pengelompokan nilai ujian nasional SMA pada tiap kompetensi. Bab I ini meliput latar belakang masalah, batasan masalah, tujuan dan manfaat penelitian, rumusan masalah, metodologi penelitian, dan sistematika penulisan.
2. BAB II. LANDASAN TEORI
Pada Bab ini mengemukakan teori-teori yang digunakan sebagai acuan dalam perancangan dan pengimplementasikan sistem pengelompokan nilai ujian nasional SMA pada tiap kompetensi.
3. BAB III. METODOLOGI PENELITIAN
Bab ketiga ini akan menjelaskan gambaran umum penelitian, data, spesifikasi alat, dan tahap-tahap penelitian.
4. BAB IV : PEMROSESAN AWAL DAN PERANCANGAN
Pada bab keempat ini berisi pemrosesan awal dalam proses Knowledge Discovery in Database (KDD) yaitu pembersihan data, integrasi data, seleksi
data, dan transformasi data. Selain itu bab ini juga akan berisi perancangan perangkat lunak yang akan digunakan dalam tahap penambangan data. Perancangan perangkat lunak tersebut terdiri dari perancangan umum, diagram use case, diagram aktivitas, diagram sekuen, algoritma per method, struktur data, dan perancangan antarmuka.
5. BAB V. IMPLEMENTASI PENAMBANGAN DATA DAN EVALUASI HASIL
Pada bab kelima ini berisi implementasi rancangan perangkat lunak penambangan data dan evaluasi hasil yang terdiri dari pengujian perangkat lunak (black box), pengujian perbandingan hitung manual dengan hasil sistem, Evaluasi hasil clustering menggunakan Silhouette Index, kelebihan sistem, dan kekurangan sistem.
6. BAB VI. PENUTUP
Pada Bab ini berisi tentang kesimpulan dan saran dari skripsi yang telah dibuat serta pengembangan penelitian ke depan.
5
BAB II
LANDASAN TEORI
2.1. PENAMBANGAN DATA
2.1.1. Pengertian Penambangan Data
Penambangan data (Data Mining) menghadirkan suatu proses yang dikembangkan untuk menguji sejumlah data besar. Data-data yang dapat digunakan dalam penambangan data adalah data pemasaraan, kesehatan, pendidikan, dan lain-lain.
Data mining adalah proses yang menggunakan teknik statistik,
matematika, kecerdasan buatan, dan machine learning untuk mengekstrasi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban,2005). Data mining mempunyai tujuan untuk mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
2.1.2. Fungsi Penambangan Data
Menurut Han dkk. (2006) fungsionalitas data mining yang digunakan untuk menentukan pola dapat ditemukan pada tugas data mining. Secara umum tugas data mining dapat di klasifikasikan ke dalam dua kategori: deskriptif dan prediktif. Tugas penambangan deskriptif adalah melakukan karakterisasi sifat umum dari data dalam basis data. Sedangkan Tugas penambangan prediksi adalah untuk melakukan inferensi pada data saat ini untuk membuat prediksi.
Fungsi data mining dan jenis pola yang dapat ditemukan, yaitu: a. Konsep/Deskripsi Kelas
set kelas komparatif (sering disebut kelas kontras), atau baik krakterisasi data dan diskriminasi.
b. Penambangan Kemunculan Pola, Asosiasi, Korelasi
Pola yang sering adalah pola yang sering terjadi di data. Jenis pola yang dimaksud adalah itemset, subsequences, dan substructure. Sebuah itemset biasanya mengacu pada satu set item yang sering muncul bersama-sama. Sebuah subsequences sering terjadi misalnya pada pola pelanggan cenderung membeli PC pertama, diikuti oleh kamera digital, dan kemudian kartu memori. Sebuah substructure dapat merujuk untuk bentuk struktural yang berbeda, seperti grafik, tree atau kisi yang dapat dikombinasikan dengan itemset atau subsequences. Substructure yang sering terjadi, itu disebut (Frequent) pola terstruktur. Penambangan pola yang sering mengarah pada penemuan asosiasi yang menarik dan korelasi dalam data. c. Klasifikasi dan Prediksi
Klasifikasi adalah proses menemukan model (fungsi) yang menggambarkan dan yang membedakan kelas data atau konsep dengan tujuan mampu menggunakan model untuk memprediksi kelas objek yang label kelas tidak diketahui. Ada banyak metode untuk membangun classificationmodels, seperti naive bayesian classification, support vector
machines, dan k-nearest neighbor classification.
Prediksi digunakan untuk memprediksi hilang atau tidak tersedianya data nilai numerik pada label kelas. Analisis regresi adalah metodologi statistik yang paling sering digunakan untuk prediksi numerik. Prediksi juga meliputi identifikasi tren distribusi berdasarkan data yang tersedia.
d. Analisis Cluster
Analisis klaster objek data tanpa berkonsultasi dengan label kelas yang diketahui. Data dikelompokkan berdasarkan prinsip memaksimalkan kesamaan intraclass dan meminimalkan kesamaan antar kelas. Dengan kata lain, kelompok benda terbentuk sehingga objek dalam cluster memiliki kesamaan yang tinggi dibandingkan satu sama lain , tetapi sangat berbeda untuk objek dalam cluster lainnya . Setiap cluster yang terbentuk dapat dilihat sebagai kelas objek.
e. Analisi Outlier
Sebuah basis data dapat berisi objek data yang tidak sesuai dengan perilaku umum atau model data. Peristiwa langka bisa lebih menarik daripada yang terjadi lebih teratur . Sebagian besar metode data mining membuang outlier sebagai noise atau pengecualian. Namun, dalam beberapa aplikasi seperti deteksi penipuan, peristiwa langka bisa lebih menarik daripada peristiwa yang sering terjadi. Analisis data outlier disebut sebagai outlier mining.
Outlier dapat dideteksi menggunakan uji statistik yang
mengasumsikan distribusi atau model probabilitas data, atau menggunakan pendekatan jarak di mana objek yang berbeda dari setiap lainnya dianggap outlier .
f. Analisi Evolution
Analisis evolusi menggambarkan data dan model keteraturan atau tren untuk objek yang perilakunya berubah dari waktu ke waktu. Meskipun termasuk dalam karakterisasi, diskriminasi, asosiasi dan analisis korelasi, klasifikasi, prediksi, atau pengelompokan data, fitur yang berbeda dari analisis tersebut meliputi analisis data time-series, urutan atau periodisitas pencocokan pola, dan analisis data berbasis kesamaan.
2.1.3. Knowledge Discovery in Database (KDD)
Menurut Han dkk. (2006), penambangan data tidak dapat dipisahkan dari
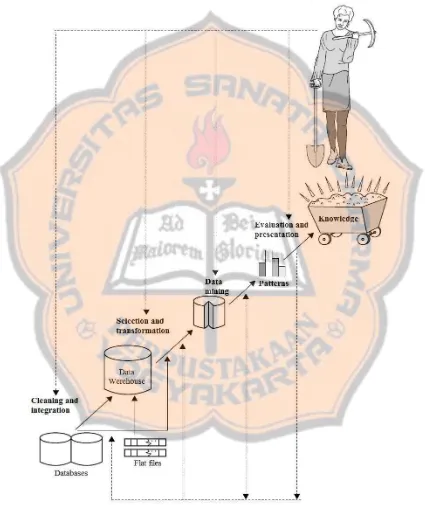
proses Knowledge Discovery in Databese (KDD). KDD merupakan sebuah proses mengubah data mentah menjadi suatu informasi yang berguna. Illustrasi proses KDD dapat dilihat pada gambar 2.1.
Knowledge Discovery merupakan suatu proses digambarkan dalam Gambar
2.1 dan terdiri dari langkah-langkah sebagai berikut: 1. Pembersihan Data ( Data Cleaning)
Pembersihan Data dilakukan untuk menghilangkan noise dan data yang tidak konsisten. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data
yang inkonsisten dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Lalu dilakukan juga proses enrichment, yaitu proses
“memperkaya” data yang sudah ada dengan data atau informasi lain yang
relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. 2. Integrasi Data (Data Integration)
Tahap ini berisikan penggabungann dari beberapa sumber data. 3. Seleksi Data (Data Selection)
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Seleksi data merupakan proses menganalisi data yang relevan dari dalam database. 4. Transformasi Data (Data Transformation)
Tahap ini mengubah atau mengkonsolidasi data ke dalam bentuk yang sesuai untuk dilakukan penambangan data.
5. Penambangan Data (Data Mining)
Data mining adalah proses proses penting di mana metode cerdas yang
diterapkan untuk mengekstrak pola data. 6. Evaluasi Pola (Pattern Evaluation)
Evaluasi pola digunakan untuk mengidentifikasi pola-pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan pada beberapa langkah penting.
7. Presentasi Pengetahuan (Knowledge Presentation)
2.2. Ujian Nasional
2.2.1. Definisi Ujian Nasional
Ujian adalah kegiatan yang dilakukan untuk mengukur pencapaian Kompetensi Peserta Didik debagai pengakuan prestasi belajar dan penyelesaian dari salah satu pendidikan. Ujian Nasional adalah evaluasi tahap Akhir yang merupakan salah satu proses pengukuran hasil belajar dan mutu pendidikan yang telah dilaksanakan secara nasional di Indonesia sejak tahun 1985. Ujian Nasional diadakan untuk peningkatan mutu pendidikan dan daya saing sumber daya manusia Indonesia. Pemerintah telah menetapkan standar kelulusan minimal yang harus dicapai peserta didik.
Hasil Ujian Nasional bertujuan untuk pemetakan mutu program dan satuan pendidikan yaitu; (1) pemetaan mutu pendidikan yaitu memperoleh gambaran perbandingan mutu pendidikan antar sekolah/madrasah, dan antar wilayah dari tahun ke tahun, (3) pertimbangan seleksi masuk jenjang pendidikan berikutnya, (5) pembinaan dan memberian bantuan kepada satuan pendidikan dalam upaya meningkatkkan mutu pendidikan di Indonesia.
Dalam pelaksanaan UN tahun 2015 mengenai standar nasional pendidikam pemerintah telah mengatur dalam Peratuaran Pemerinrah Republik Indonesia Nomor 13 Tahun 2015 tentang Perubahan Kedua Atas Peraturan Pemerintah Nomor 19 Tahun 2005 Tentang Standar Nasional Pendidikan. Disebut dalam pasal 1 ayat 29 Badan Standar Nasional Pendidikan (BSNP) adalah badan mandiri dan Independen yang bertugas mengembangkan, memantau, dan mengendalikan Standar Nasional Pendidikan.
Pembinaan sekolah misalnya oleh pengawas sekolah, pelaksanaan pembinaan oleh pengawas untuk SMP/MTs, SMA/MA, dan SMK/MAK paling sedikit 7 (tujuh) satuan pendidikan menurut Peraturan Menteri Pendidikan dan Kebudayaan No 143 Tahun 2014.
2.2.2. Tujuan dan Fungsi Ujian Nasional
lingkungan Pemerintah, Pemerintah provinsi, pemerintah kabupaten/kota dan satuan pendidikan sesuai dengan kurikulum yang berlaku.
Penilaian hasil belajar bertujuan untuk menilai pencapaian kompetensi lulusan secara nasional paada mata pelajaran tertentu dan di lakukan dalam bentuk ujian nasional. (ps. 66, peraturan pemerintah republik indonesia nomor 13 tahun 2015). Hasil ujian nasional digunakan sebagai dasar untuk :
a. pemetaan mutu program dan/atau satuan pendidikan. b. pertimbangan seleksi jenjang pendidikan berikutnya.
c. pembinaan dan pemberian bantuan kepada satuan pendidikan dalam upaya untuk meningkatkkan mutu pendidikan.
2.2.3. Peserta Ujian Nasional
2.2.4. Penyelenggaran Ujian Nasional
Dalam Peraturan Mentri Pendidikan dan Kebudayaan Republik Indonesia No 5 tahun 2015 pasal 14 menyebutkan bahwa BSNP (Badan Standar Nasional Pendidikan) menyelenggarakan UN bekerja sama dengan instansi terkait di lingkungan Pemerintah, pemerintah provinsi, pemerintah kabupaten/kota, dan satuan pendidikan. BSNP sebagai penyelengara UN bertugas untuk menelaah dan menetapkan kisi-kisi UN, menyusun dan menetapkan POS pelaksanaan UN, menelaah dan menetapkan naskah soal UN, memberikan rekomendasi kepada Menteri tentang pembentukan Panitia UN Tingkat Pusat, melakukan koordinasi persiapan dan pengawasan pelaksanaan UN secara nasional, dan melakukan evaluasi dan menyusun rekomendasi perbaikan pelaksanaan UN.
2.2.5. Strandar Kelulusan
Peserta didik dinyatakan lulus dari suatu pendidikan setelah menyelesaikan seluruh program belajar, memperoleh nilai sikap.perilaku minimal baik, dan lulus ujian S/M/PK. Kelulusan peserta didik dari ujian S/M ditetapkan oleh satuan pendidikan. Kelulusan peserta didik dari ujian PK ditetapkan oleh Dinas Pendidikan Provinsi. Dan Kelulusan peserta didik ditetapkan setelah satua pendidikan menerima hasil ujian nasional peserta didik yang bersangkutan. (ps.2 Peraturan menteri Pendidikan dan Kebudayaan Republik Indonesia No. 5 tahun 2015).
Kriteria kelulusan peserta didik mencakup minimal rata-rata nilai dan minimal nilai setiap mata pelajaran yang ditetapkan oleh satuan pendidikan. Nilai S/M/PK sebagaimana dimaksud pada ayat (1) dan ayat (2) diperoleh dari gabungan:
a. Rata-rata nilai rapor dengan bobot 50% (lima puluh persen) sampai dengan 70% (tujuh puluh persen):
1. Semester I sampai dengan semester V atau yang setara pada SMP/MTs, SMPLB, dan Paket B/Wustha;
2. Semester III sampai dengan semester V atau yang setara pada SMA/MA/SMAK/SMTK, SMALB, SMK/MAK, dan Paket C;
b. Nilai Ujian S/M/PK dengan bobot 30% sampai dengan 50% (lima puluh persen).
(ps. 4. Peraturan menteri Pendidikan dan Kebudayaan Republik Indonesia No. 5 tahun 2015).
Kelulusan peserta didik SMP/MTs, SMPLB, SMA/MA/SMAK/SMTK, SMALB, SMK/MAK ditetapkan oleh setiap satuan pendidikan yang bersangkutan dalam rapat dewan guru. (ps. 5. Peraturan menteri Pendidikan dan Kebudayaan Republik Indonesia No. 5 tahun 2015).
2.3. Konsep Data Mining 2.3.1. Clustering
Konsep cluster yaitu menemukan kumpulan objek hingga objek-objek dalam satu kelompok sama (punya hubungan) dengan yang lain dan berbeda (tidak berhunungan) dengan objek-objek dalam kelompok lain. Tujuan dari analisa cluster adalah meminimalkan jarak didalam cluster dan memaksimalkan jarak antar cluster. Tidak di perlukan label kelas untuk setiap data yang diproses karena label baru dapat diberikan ketika cluster sudah terbentuk.
Ada beberapa pendekatan yang digunakan dalam metode clustering. Dua pendekatan yang utama adalah clustering dengan pendekatan partisi yang biasa disebut partition-bassed clustering mengelomokan data dengan memilah-milah data yang dianalisa ke dalam cluster-cluster yang ada. Metode yang menggunakan partisi salah satunya adalah K-Means. Selain itu juga terdapat pendekatan hierarchical clustering yaitu mengelompokan data dengan membuat suatu hirarki
berupa dendogram dimana data yang mirip akan ditempatkan pada hirarki yang berdekatan dan yang tidak pada hirarki berjauhan (Prasetyo,2014).
2.3.2. K-Means
K-Means merupakan algoritma pengelompokan iteratif yang melakukan
K-Means dapat diterapkan pada data yang direpresentasikan dalam
r-dimensi ruang tempat. K-Means mengelompokan set data r-r-dimensi, X = {x1|i=1,
...,N}, dimana xiϵⱤd yang mengatakan bahwa data ke-i sebagai “titik data”. Perlu
diperhatikan titik harus berada dalam cluster yang mana, dilakukan dengan cara memberikan setiap titik sebuah ID cluster. Titik dengan ID yang sama berarti berada dalam satu cluster yang sama, sedangkan titik dengan ID cluster yang berbeda berada dalam cluster yang berbeda. Dapat dinyatakan dengan vektor keanggotaan cluster m dengan panjang N dimana mi bernilai ID cluster titik xi.
Parameter yang dimasukan ketika menggunakan algoritma K-Means adalah nilai K. Nilai K digunakan berdasarkan informasi yang diketahui sebelumnya tentang sebenarnya berapa banyak cluster data yang muncul dalam X.
Dalaam K-Means, setiap cluster dari K cluster diwakili oleh titik tunggal
dalam Ɽd
. Set representatif cluster dinyatakan C= {cj|j=1, ..., K}. Pada saat data
sudah dihutung ketidakmiripan terhadap centroid, maka dipilih ketidakmiripan yang paling kecil sebagai cluster yang akan diikuti sebagai relokasi data pada cluster di sebuah iterasi. Relokasi sebuah data dalam cluster yang diikuti dapat dinyatakan dengan nilai keanggotaan a yang bernilai 0 atau 1. Jika 0 maka tidak menjadi anggota cluster 1, begitupun sebaliknya. K-Means mengelompokan secara tegas data hanya pada satu cluster, maka dari nilai a sebuah data pada semua cluster, hanya satu yang bernilai 1, sedangkan lainnya 0 seperti dinyatakan oleh persamaan berkut:
= nilai keanggotaan i = index data
j = cluster ke j
= data yang masuk ke cluster
= ketidakmiripan (jarak) dari data ke-i ke cluster .
cluster. Rata-rata sebuah fitur dari semua data dalam sebuah cluster dinyatakan oleh persamaan berikut:
∑
Di mana: = cluster
= anggota cluster ke- k
= nilai pusat cluster baru
= banyaknya anggota cluster ke- k
Untuk meminimalkan fungsi objektif/fungsi biaya non-negatif dinyatakan oleh persamaan berikut:
∑ ∑
= jumlah cluster = jumlah data = data ke i
= data yang masuk ke cluster
= ketidakmiripan (jarak) dari data ke-i ke cluster .
Algoritma K-Means untuk mengelompokan suatu data X sebagai berikut: (Prasetyo, 2014)
1. Inisiasi: tentukaan nilai K sebagai jumlah cluster yang diinginkan dan metrik ketidakmiripan (jarak) yang diinginkan. Jika perlu, tetapkan ambang batas perubahan fungsi objektif dan ambang batas perubahan posisi centroid.
2. Pilih K data dari set data X sebagai centroid.
3. Alokasikan semua data ke centroid terdekat dengan metrik jarak yang sudah ditetapkan (memperbaharui cluster ID setiap data) 4. Hitung kembali centroid C berdasarkan data yang mengikuti cluster
5. Ulangi langkah 3 dan 4 hingga kondisi konvergen tercapai, yaitu (a) perubahan fungsi objektif sudah dibawah ambang batas yang diinginkan; atau (b) tidak ada data yang berpindah cluster; atau (c) perubahan posisi centroid sudah dibawah ambang batas yang ditetapkan.
2.3.3. Distance Space
Distance space adalah proses penghitungan jarak antara suatu dokumen
dengan dokumen lainnya. Euclidean distance adalah salah satu cara untuk menghitung Distance space. Rumus Euclidean distance dinyatakan pada persamaan berikut:
= jumlah atribut yang digunakan (Handoyo dkk, 2014).
2.4. Validitas Cluster 2.4.1. Analisis Cluster
Analisis cluster merupakan pemrosesan data secara alami dengan algoritma yang berjalan sendiri sehingga didapatkan kelompok-kelompok yang terbentuk secara alami pula. Selain parameter-parameter diawal algoritma yang berjalan, tidak ada lagi yang diberikan kepada sistem setelah alggoritma selesai dilakukan. Pada dasarnya analisis cluster adalah proses penggalian informasi yang sebelumnya tidak ada sehingga seolah-olah menjadi pertanyaan mengapa harus harus dilakukan evaluasi.
sejauh mana struktur cluster yang ditemukan olehh algoritma clustering cocok dengan struktur eksternal. Metode relatif melakukan perbandingan cluster menggunakan ukuran evaluasi unsupervised dan supervided. (Prasetyo, 2014).
2.4.2. Validitas Internal
Banyak matrik internal yang mengukur validitas cluster pada metode pengelompokan berbasis partisi didasarkan pada nilai kohesi dan separasi. Kohesi dalam pengelompokan berbasis partisi didefinisikan sebagai jumalh dari kedekatan data terhadap centroid dari cluster yang diikutinya. Sedangkan separasi di antara dua sluster dapat diukur dengan kedekatan dua prototipe (centroid) cluster. (Prasetyo, 2014)..
2.4.3. Silhouette
Ketepatan sebuah pengelompokan menunjukan seberapa baik proses pengelompokan dan kualitas kelompok yang terbentuk. Salah satu ukuran ketepatan yang dapat digunakan dalam menentukan ketepatan pengelompkan adalah Silhouette Coeficient (Muhammad).
Silhouette dapat digunakan untuk memvalidasi baik sebuah data, cluster
tunggal (satu cluster dari sejumlah cluster), atau keseluruhan cluster. Metode ini paling banyak digunakan untuk memvalidasi cluster yang menggabungkan nilai kohesi dan separasi. Untuk menghitung nilai SI dari sebuah data ke-i, ada 2 komponen yaitu dan . adalah rata-rata jarakdata ke- terhadap semua data
lainnya dalam satu cluster, sedangkan bi didapatkan dengan menghitung rata-rata
jarak data ke- terhadap semua data dari cluster yang lain tidak dalam satu cluster dengan data ke- , kemudian diambil yang terkecil. (Prasetyo, 2014).
Berikut formula untuk menghitung
∑
Di mana: = cluster
= rata-rata jarak data ke – terhadap semua data lainnya dalam satu cluster.
= jumlah data dalam cluster ke- .
adalah jarak data ke- dengan data ke- dalam suatu cluster .
Berikut adalah formula untuk menghitung
{ ∑
}
Di mana:
= cluster n = cluster
= index data
= jumlah data dalam cluster ke- .
= Nilai terkecil dari rata-rata jarak data ke- terhadap semua data dari cluster yang lain tidak dalam satu cluster dengan data ke- .
= jarak data ke- dalam cluster j dengan data ke- dalam suatu cluster .
(Prasetyo, 2014).
Untuk mendapatkan nilai jumlah Silhouette data ke- menggunakan persamaan berikut:
{ }
Di mana:
= Silhouette data ke i dalam 1 cluster
= Nilai terkecil dari rata-rata jarak data ke- terhadap semua data dari
= rata-rata jarak data ke – terhadap semua data lainnya dalam satu cluster.
(Kaufman dan Rousseeuw, 2005)
Nilai S( rata dari sebuah cluster didapatkan dengan menghitung rata-rata nilai S( semua data yang bergabung dalam cluster tersebut, seperti pada persamaan berikut:
∑
= Rata-rata Silhouette cluster j
= Silhouette data ke i dalam 1 cluster j
= index
= jumlah data dalam cluster ke- .
Nilai rata-rata dari data set didapatkan dengan menghitung rata-rata nilai dari semua cluster seperti pada persamaan berikut:
∑
= jumlah cluster.
= Rata-rata Silhouette dari data set
= Rata-rata Silhouette cluster j
(Prasetyo, 2014).
Hasil perhitungan nilai Silhouette Coeficient dapat bervariasi antara -1 hingga 1. Jika = 1 maka objek berada dalam cluster yang tepat. Jika = 0 maka objek berada di antara dua cluster sehingga objek tersebut tidak jelas harus dimasukan ke dalam cluster A atau B. Akan tetapi, jika = -1 artinya cluster yang dihasilkan overlapping, sehingga objek lebih tepat dimasukan ke dalam cluster lain.(Alfian dkk, 2012). Silhouette Coeficient adalah ukuran yang berguna dari jumlah struktur clustering yang telah ditemukan oleh algoritma klasifikasi. Silhouette Coeficient adalah berdimensi kuantitas yang paling sama dengan 1.
Perhitungan nilai Silhouette Coeficient dapat dirumuskan sebagai berikut:
Di mana:
SC = Silhouette Coeficient
= Nilai Silhouette
= cluster
= Nilai maksimum dari semua k.
Rata-rata dari untuk semua objects pada sebuah cluster, yang disebut rata-rata silhouette dalam sebuah cluster. Rata-rata dari untuk = 1,2,...n, yang disebut rata-rata silhouette pada data set. Nilai maksimum didapatkan dari semua percobaan k pada silhouette, dimana = 2,3,... n-1.
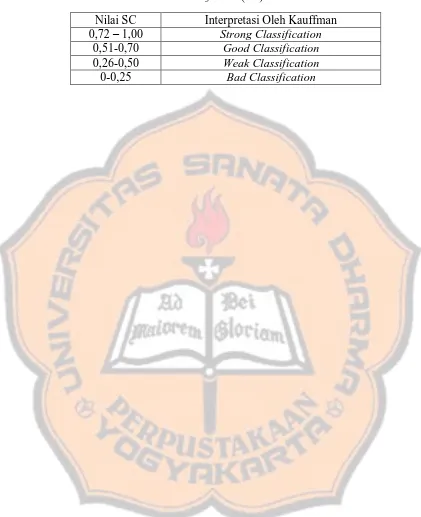
Tabel 2. 1 Kriteria Subjektif Kualitas Pengelompokkan Berdasarkan Silhouette Coeficient (SC)
Nilai SC Interpretasi Oleh Kauffman 0,72 – 1,00 Strong Classification
0,51-0,70 Good Classification
0,26-0,50 Weak Classification
22
BAB III
METODOLOGI PENELITIAN 3.1.Sumber Data
Data yang digunakan pada penelitian ini didapat dari situs http://litbang.kemdikbud.go.id/index.php/un untuk data tahun ajaran 2014/2015. Data yang didapatkan berekstensi .xls dan berisikan nilai SMA dari jurusan IPA dan IPS.
3.1.1. Data yang digunakan
Data yang digunakan merupakan data nilai siswa program IPA dan IPS. Untuk program studi IPA terdiri dari mata pelajaran Bahasa Indonesia, Bahasa Inggris, Matematika, Biologi, Fisika dan Kimia. Sedangkan untuk program studi IPS terdiri dari mata pelajaran Bahasa Indonesia, Bahasa Inggris, Matematika, Ekonomi, Sosiologi, dan Geografi. Salah satu contoh data yang digunakan berisi data seperti yang terdapat dalam tabel 3.1 sampai dengan tabel 3.4.
Tabel 3. 1Table Atribut Data Mentah Nilai Hasil Ujian Nasional Program IPA 2014/2015
Nama Atribut Keterangan
Kode Sek. Kode Sekolah
NAMA SEKOLAH Nama Sekolah
Sts Sek. Status Sekolah(Swasta/Negeri)
Jm. Pes Jumlah Peserta
BIN Ujian Nasional Bahasa Indonesia ING Ujian Nasional Bahasa Ingris
MAT Ujian Nasional Matematika
FIS Ujian Nasional Fisika
KIM Ujian Nasional Kimia
BIO Ujian Nasional Biologi
Tabel 3. 2 Table Atribut Data Mentah Nilai Hasil Ujian Nasional Program IPS 2014/2015
Nama Atribut Keterangan
Kode Sek. Kode Sekolah
NAMA SEKOLAH Nama Sekolah
Sts Sek. Status Sekolah(Swasta/Negeri)
Jm. Pes Jumlah Peserta
BIN Ujian Nasional Bahasa Indonesia ING Ujian Nasional Bahasa Ingris
MAT Ujian Nasional Matematika
EKO Ujian Nasional Ekonomi
SOS Ujian Nasional Sosiologi
GEO Ujian Nasional Geografi
TOT Total Nilai Ujian
3.2.Spesifikasi Alat
Sistem dibuat dengan menggunakan hardware dan software sebagai berikut:
3.2.1. Spesifikasi Hardware
a. Proses Intel Pentium Core i5 2.40GHz b. RAM 2.00 GB
3.2.2. Spesifikasi Software
a. Sistem Operasi Microsoft Windows 7 b. Compiler IDE NetBeans 7.2
Software ini akan digunakan untuk membuat interface dan sekaligus untuk membuat source code.
3.3. Tahap-Tahap Penelitian 3.3.1. Studi Kasus
mengevaluasi nilai ujian nasional agar dapat terlihat pemetaannya dapat menggunakan nilai dari mata pelajaran yang diujikan pada program IPA maupun IPS. Dengan penelitian ini diharapkan dapat menemukan suatu pengelompokan sekolah yang telah menjalankan Ujian Nasional untuk mengetahui keberhasilan dari Ujian Nasional.
3.3.2. Penelitian Pustaka
Pada tahap ini, dilakukan penelitian pustaka untuk memperoleh informasi dan menggali teori-teori tentang teknik data mining. Dalam penelitian ini penulis mempelajari literatur yang berkaitan dengan teknik data mining asosiasi khususnya algoritma K-Means dan literatur lainnya yang berguna bagi sistem yang akan dibangun.
3.3.3. Knowledge Discovery in Database (KDD)
Dalam melakukan proses mengubah data mentah menjadi suatu informasi yang bermanfaat, penulis menggunakan proses Knowledge Discovery in Database (KDD) yang terdiri dari pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola, dan presentasi pengetahuan.
Pada tahap pembersihan data dan integrasi data, penulis melakukan secara manual dengan menggunakan aplikasi microsoft excel. Tahap selanjutnya yaitu seleksi data, transformasi data, dan penambangan data, penulis mengembangkan perangkat lunak sebagai alat bantu untuk melakukan tahap-tahap tersebut. Sedangkan untuk tahap evaluasi pola dan presentasi pengetahuan, penulis melakukan evaluasi dari hasil penambangan data yang didapat dari perangkat lunak yang telah dibangun dan menjelaskan hasil evaluasi tersebut agar informasi yang didapat dapat diterima oleh pihak-pihak yang membutuhkan.
3.3.4. Pengembangan Perangkat Lunak
Metode yang digunakan oleh penulis dan pengembang sistem adalah metode waterfall. Metode ini merupakan metode yang paling sering digunakan oleh para pengembang perangkat lunak. Metode ini menggunakan sistem linier yaitu apa yang dilakukan pada tahap sebelumnya akan mempengaruhi tahap selanjutnya.
Metode waterfall mempunyai langkah-langkah sebagai berikut: 1. Analisa
Pada langkah ini analisa terhadap kebutuhan sistem. Pengumpulan data dalam tahap ini bisa dilakukan melalui sebuah penelitian, wawancara atau studi literatur. Seorang sistem analis bertugas dalam mencari informasi sebanyak mungkin dari user sehingga sistem yang dibuat dapat sesuai dengan kebutuhan user. Pada tahapan ini menghasilkan dokumen user requirement yang dapat digunakan sistem analis untuk menerjemahkan ke dalam bahasa pemrograman.
2. Desain
Pada proses desain akan menerjemahkan syarat kebutuhan ke sebuah perancangan perangkat lunak yang dapat dapat diperkirakan sebelum diubah ke dalam bahasa pemrograman. Fokus dari proses ini pada struktur data, arsitektur perangkat lunak, representasi interface, dan detail algoritma. Tahapan ini akan menghasilkan dokumen yang disebut software requirement. Dokumen ini yang digunakan seorang programmer untuk membangun sistemnya.
3. Pemrograman
Pemrograman merupakan penerjemahan design ke dalam bahasa pemrograman. Pada tahap ini programmer akan mengubah proses transaksi yang diinginkan user ke dalam sistem yang dibangun.
4. Pengujian Perangkat Lunak
kesalahan – kesalahan yang terdapat pada perangkat lunak tersebut agar kemudian dapat diperbaiki.
3.3.5. Analisis dan Pembuatan Laporan
Analisis yang akan dilakukan adalah analisis kinerja dari alat uji yang dibuat menggunakan algoritma K-Means, dan hasil analisis tersebut nantinya akan
27
BAB IV
PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA
4.1. PEMROSESAN AWAL
4.1.1. Pembersihan Data (Data Cleaning)
Sebelum proses data mining dapat dilakukan, perlu proses cleaning pada data yang menjadi fokus. Pemrosesan pendahuluan dan pembersihan data merupakan operasi dasar seperti penghapusan noise dilakukan. Pada penelitian ini ada beberapa sekolah yang tidak ada nilainya maka peneliti menghapus sekolah yang tidak ada nilai hasil ujian.
4.1.2. Itegrasi Data (Data Integration)
Tahap ini berisikan penggabungan data dari bermacam-macam sumber. Peneliti menggunakan 2 data terdiri dari data nilai ujian nasional 2014/2015 jurusan IPA dan IPS. Peneliti tidak menggunakan tahap ini dikarenakan data berasal dari sumber yang sama sehingga tidak perlu melakukan proses integrasi data karena range nilai yang digunakan juga sudah sama.
4.1.3. Seleksi Data (Data Selection)
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Seleksi data merupakan proses menganalisis data yang relevan dari dalam database.
Tabel 4. 1Atribut yang tidak digunakan pada data Ujian Nasional 2015
Tahun Atribut 2015 No.
Kode Sek. Sts Sek.
Jumlah Peserta TOT
RANK
Atribut pada tabel tabel 4.5 tidak digunakan sebab atribut dalam tabel-tabel tersebut hanya atribut pendukung yang tidak digunakan dalam proses clustering. Proses clustering membutuhkan atribut nama sekolah dan mata pelajaran.
Hasil dari seleksi atribut pada data nilai ujian nasional IPA dan IPS di Daerah Istimewa Yogyakarta tahun ajaran 2014/2015 dijelaskan pada tabel 4.2 dan 4.3.
Tabel 4. 2 Tabel Atribut Terseleksi Data Nilai Ujian Nasional Program Strudi IPA di Daerah Istimewa Yogyakarta Tahun ajaran 2014/2015
Nama Atribut Keterangan
NAMA SEKOLAH Nama Sekolah
BIN Ujian Nasional Bahasa Indonesia ING Ujian Nasional Bahasa Ingris
MTK Ujian Nasional Matematika
FSK Ujian Nasional Fisika
KMA Ujian Nasional Kimia
Tabel 4. 3 Tabel Atribut Terseleksi Data Nilai Ujian Nasional Program Strudi IPS di Daerah Istimewa Yogyakarta Tahun ajaran 2014/2015
4.1.4. Tranformasi Data (Data Transformation)
Pada penelitian ini tidak dilakukan normalisasi karena data yang digunakan memiliki interval yang sama, yaitu 0-100, sehingga tahap ini tidak dilakukan.
Tahap kedua dalam transformasi data yaitu mengubah data numerik menjadi sebuah keputusan misal Tuntas atau Tidak Tuntas. Dalam penelitian ini pada tahap ini tidak dilakukan.
4.2. PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA
4.2.1. Diagram Use Case
Suatu sistem selalu memiliki interaksi antara pengguna dengan sistem itu sendiri, hal ini digambarkan dalam bentuk diagram use case. Diagram use case dapat dilihat pada gambar 4.1.
Nama Atribut Keterangan
NAMA SEKOLAH Nama Sekolah
BIN Ujian Nasional Bahasa Indonesia ING Ujian Nasional Bahasa Ingris MTK Ujian Nasional Matematika
EKO Ujian Nasional Ekonomi
SOS Ujian Nasional Sosiologi
Gambar 4. 1 Use Case Diagram
Pengguna dalam sistem yang akan dibangun ini hanya satu, diinisialkan dengan nama pengguna. Interaksi yang dilakukan pengguna adalah: memilih berkas atau memasukkan data yang akan di kelompokkan, seleksi atribut yang digunakan, sistem melakukan proses clustering, dan simpan hasil clustering menggunakan algoritma K-Means dan menyimpan hasil clustering.
4.2.1. 1. Gambaran Umum Use Case
Diagram use case pada lampiran 2 memiliki gambaran umum dari masing-masing use case. Gambaran umum use case terlampir pada lampiran 3.
4.2.1. 2. Narasi Use Case
Diagram use case pada gambar 4.1 juga memiliki narasi yang merupakan penjelasan lebih lengkap dari masing-masing use case. Narasi tersebut terdapat pada lampiran 4.
4.2.2. Perancangan Umum 4.2.2.1. Input Sistem
User juga berperan untuk memasukan nilai k pada textfield yang diinginkan oleh
user. Data yang digunakan adalah data nilai hasil ujian nasional IPA dan IPS
untuk tahun ajaran 2011/2012 sampai 2014/2015.
4.2.2.2. Proses Sistem
Proses sitem yang akan dibangun terdiri dari beberaapa tahap untuk dapat melakukan pengelompokan (clustering). Proses sistem yang terdiri dari beberapa langkah berikut:
1. Pengambilan data yang sudah melalui preprosesing untuk digunakan pada proses data mining.
2. Menentukan k sesuai dengan keinginan user 3. Proses pengelompokan menggunakan K-Means.
Proses sistem digambarkan pada gambar 4.2 dibawah ini:
4.2.2.3. Output Sistem
Sistem yang dibangun akan memberikan keluaran (output) berupa data hasil pengelompokan menggunakan K-Means sesuai dengan k yang telah di berikan oleh user.
4.2.3. Diagram Aktivitas (Activity diagram).
Diagram aktivitas digunakan untuk menunjukan aktivitas yang dikerjakan oleh pengguna dan sistem dalam setiap use case yang disebutkan dalam gambar 4.1. Berikut adalah diagram aktivitas dari setiap use case.
1. Diagram Aktivitas Input Berkas File .xls 2. Diagram Aktivitas Seleksi Atribut
3. Diagram Aktivitas Proses Clustering input k 4. Diagram Aktivitas Simpan Hasil Clustering.
Detail diagram aktivitas dari setiap use case dapat dilihat pada bagian lampiran 5.
4.2.4. Diagram Kelas Desain
Detail kelas dapat dilihat pada gambar dibawah ini: + Bantuan () : Constractor - JMenuBerandaMouseClicked :void + Tentang () : Constractor - JMenuBerandaMouseClicked :void
+ Centroid (ArrayList<String> ) : ArrayList<Integer> + findCentroid(ArrayList<ArrayList<String>> arr, int[] indexCluster, int indexCentroid, int ClusterKei) :float + KMeans getKmeans() : Constractor + min() : static
+sequentialsearch (Double[] number2, double value2) :int
Sillhouette
+ Sillhoutte getsillhoutte() : Constractor + hitungjarakSilhoute(ArrayList<ArrayList<String>>
Gambar 4. 3 Diagram Kelas Desain
4.2.5. Diagram Sekuen (Sequence Diagram).
Diagram Sekuen adalah diagram yang memperlihatkan atau menampilkan interaksi-interaksi antar objek di dalam sistem. Diagram sekuen pada sistem ini terdiri dari 3 diagram sesuai dengan usecase. Diagram dapat dilihat pada lampiran 7.
4.2.6. Algoritma per Method
Rincian algoritma per method terdapat pada lampiran 8.
4.2.7. Perancangan Struktur Data
4.2.7.1. Array
Array adalah sebuah struktur data yang mampu menyimpan banyak nilai
dalam sebuah variabel dengan tipe data yang sama. Array bagaikan basis data mini yang berada di memori.
Untuk dapat menggunakan Array dalam kode program, dapat dengan cara mendeklarasikan sebuah variabel untuk direferensikan ke Array dan menspesifikasikan tipe data dari Array. Deklarasi variable Array tidak mengalokasi ruang di memori hanya mengalokasikan tempat untuk referensi ke Array yang dibuat. Ukuran Array tidak dapat diubah setelah Array dibuat.
Perhatikan ilustrasi Array pada gambar 4.4 berikut ini:
Gambar 4. 4 Ilustrasi Konsep Array
4.2.7.2. ArrayList
ArrayList merupakan sebuah struktur data yang mampu menyimpan
banyak nilai dalam sebuah variabel dengan tipe data yang sama dan ukurannya bisa berubah secara dinamis.
Perhatikan ilustrasi ArrayList pada gambar 4.5 berikut ini:
java.util.ArrayList size:5
0 1 2 3 4 ... ...
elementData
Value1 Value2 Value3 Value4 Value5
Pada Penelitian ini, penulis menggunakan arraylist dalam arraylist ArrayList<ArrayList<String>> untuk membuat matriks. Daftar nilai ujian nasional sebagai elementData. Daftar nilai ujian nasional memiliki nama sekolah yang saling terhubung dengan nilai mata pelajaran akan berada dalam index yang sama pada ArrayList. Objek arraylist baru akan selaku dibuat untuk setiap kode sekolah yang berbeda. Setelah membuat objek arraylist untuk setiap sekolah maka akan dibuat objek arraylist untuk
menjadikan satu semua objek arraylist sebelumnya. Sebagai contoh akan dijelaskan pada gambar 4.6 berikut ini:
java.util.ArrayList size:5
Gambar 4. 6 Perancangan ArrayList
4.2.7.3 HashMap
4.2.8. Perancangan Antarmuka
Sistem clustering yang akan dibangun, memiliki 4 antarmuka yang terdiri dari antar muka halaman awal, antarmuka bantuan, antarmuka tentang, dan antarmuka proses clustering.
4.2.8.1. Halaman Halaman Awal
Perancangan antarmuka halaman awal dapat dilihat pada gambar 4.7 berikut ini:
Table Nilai Ujian Nasional
Application Title Tentang Bantuan
Beranda
Logo
Masuk Sistem
KRESENTIA NITA KURNIADEWI – 125314031
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA YOGYAKARTA
2016
Pengelompokan Nilai Ujian Nasional Sekolah Menengah Atas Menggunakan Metode Clustering K-Means
Gambar 4. 7 Antarmuka Halaman Beranda
4.2.8.2. Halaman Bantuan
Perancangan antarmuka halaman awal dapat dilihat pada gambar 4.8 berikut ini:
Table Nilai Ujian Nasional
Application Title Tentang Bantuan
Beranda
KRESENTIA NITA KURNIADEWI – 125314031
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA YOGYAKARTA
2016
Pengelompokan Nilai Ujian Nasional Sekolah Menengah Atas Menggunakan Metode Clustering K-Means
Panduan Penggunaan
Gambar 4. 8 Antarmuka Halaman Bantuan
4.2.8.3. Halaman Tentang
Perancangan antarmuka halaman awal dapat dilihat pada gambar 4.9 berikut ini:
Table Nilai Ujian Nasional
Application Title
Tentang Bantuan
Beranda
KRESENTIA NITA KURNIADEWI – 125314031
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA YOGYAKARTA
2016
Pengelompokan Nilai Ujian Nasional Sekolah Menengah Atas Menggunakan Metode Clustering K-Means
Informasi Sistem
Gambar 4. 9 Antarmuka Halaman Tentang
4.2.8.4. Halaman Clustering K-Means
Perancangan antarmuka halaman awal dapat dilihat pada gambar 4.10 berikut ini:
Table Nilai Ujian Nasional
Application Title
Tentang Bantuan
Beranda
Seleksi Atribut Atribut Output
KRESENTIA NITA KURNIADEWI – 125314031
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA YOGYAKARTA 2016
Data Browse
Pilih
Proses
Pengelompokan Nilai Ujian Nasional Sekolah Menengah Atas Menggunakan Metode Clustering K-Means
Jumlah Cluster
Reset Simpan
Runing Time
Gambar 4. 10 Antarmuka Halaman Proses
Halaman ini merupakan halaman yang akan ditampilkan ketika pengguna menekan tombol Masuk Sistem pada halaman Beranda. Halaman ini berfungsi sebagai sarana untuk memasukan data, memilih atribut yang akan digunakan serta memberikan k yang diinginkan.
41
BAB V
IMPLEMENTASI PENAMBANGAN DATA DAN EVALUASI HASIL 5.1 IMPLEMENTASI RANCANGAN PERANGKAT LUNAK
Perangkat lunak pengelompokan menggunakan meetode K-Means ini memiliki 5 buah kelas.
5.1.1. Implementasi Kelas
Selanjutnya dijelaskan spesifikasi detail dari setiap antarmukka yang ada pada perangkat lunak ini. Spesifikasi detail dari kelas home dapat dilhat pada tabel 5.1 berikut:
Tabel 5. 1 Implementasi Kelas Home
ID_Objek Jenis Teks Keterangan
jMenuBeranda JMenu Beranda Jika di klik, akanmenuju ke halaman home.java jMenuBantuan JMenu Bantuan Jika di klik,
akanmenuju ke halaman Bantuan.java jMenuTentang JMenu Tentang Jika di klik,
akanmenuju ke halaman Tentang.java jtitle1 JLabel Pengelompokan
Nilai Ujian Nasional Sekolah Menengah Atas
Judul perangkat lunak yang dibangun
jtitle2 JLabel Menggunakan
Metode Clustering
K-Means
Judul perangkat lunak yang dibangun
Clustering_Kmeans.ja va
jLabel1 JLabel KRESENTIA
NITA
KURNIADEWI-125314031
Identitas pembuat perangkat lunak
jLabel2 JLabel FAKULTAS
SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA
Identitas fakultas dan universitas pembuat perangkat lunak
jLabel5 JLabel YOGYAKARTA Identitas fakultas dan universitas pembuat perangkat lunak
jLabel6 JLabel 2016 Identitas tahun
Implementasi antarmuka dari kelas home dapat dilihat pada gambar 5.1 berikut ini.
Gambar 5. 1 Implementasi Antarmuka kelas Home
Spesifikasi detail dari kelas Clustering_Kmeans dapat dilhat pada tabel 5.2 berikut:
Tabel 5. 2 Implementasi Kelas Clustering_KMeans
ID_Objek Jenis Teks Keterangan
jMenuBeranda JMenu Beranda Jika di klik, akan menuju ke halaman home.java
jMenuBantuan JMenu Bantuan Jika di klik, akan menuju ke halaman Bantuan.java
Tentang.java
jtitle1 JLabel Pengelompokan
Nilai Ujian
jtitle2 JLabel Menggunakan
Metode Clustering
K-Means
Judul perangkat lunak yang dibangun
jData JLabel Data Keterangan label
Jpath JTextField Isi path directory dari
file yang dimasukkan
ke dalam tabel. Jpilihfile JButton Browse Jika diklik, akan
membuka directory file yang akan dipilih
Table JTable Menampilkan data file
yang dipilih TableSeleksiAt
ribut
JTable Menampilkan nama
kolom (atribut) pada tabel, yang akan di seleksi.
jButtonPilihAt ribut
JButton Pilih Jika diklik, akan menampilkan nama kolom (atribut) ke jtableatribut2.
jtableatribut2 JTable Menampilkan nama
kolom (atribut) pada tabel, yang telah di seleksi.
Jmlclustertext JTextField Untuk memasukan jumlah klaser Jproses JButton Proses Jika di klik, sistem
akan melakukan proses clustering.
jTextArea1 jTextArea Menampilkan hasil
clustering
jLabel9 JLabel Runing Time : Keterangan label
runTime JTextField Menampilkan running
time
Jreset JButton Reset Jika di klik akan
mereset sistem. Jsimpan JButton Simpan Jika di klik akan
menyimpan hasil clustering kedalam
Implementasi antarmuka dari kelas home dapat dilihat pada gambar 5.2 berikut ini.