SISTEM KLASIFIKASI DOKUMEN BAHASA JAWA
DENGAN METODE K-NEAREST NEIGHBOR (K-NN)
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh
Veverly Widyastuti Palinoan
085314108
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
JAVANESE DOCUMENT CLASSIFICATION SYSTEM
USING K-NEAREST NEIGHBOR (K-NN)
ALGORITHMS
A Thesis
Presented as Partial Fulfillment of The Requirements
To Obtain Sarjana Komputer Degree
in Informatics Engineering Study Program
By
Veverly Widyastuti Palinoan
085314108
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
vi
HALAMAN MOTO
“Tuhan pasti memberikan yang terbaik
.
”
“Pikullah kuk yang kupasang dan belajarlah padaKu, sebab Aku ini
lemah lembut dan rendah hati, maka hatimu akan mendapatkan ketenangan
vii
HALAMAN PERSEMBAHAN
Tugas akhir ini saya persembahkan untuk :
Allah Tritunggal, Bunda Maria,
Orangtuaku, saudara- saudaraku,
sahabat – sahabatku
viii ABSTRAK
Bahasa Jawa merupakan salah satu bahasa daerah di Indonesia yang sangat sering digunakan. Banyak artikel Bahasa Jawa yang dapat kita jumpai setiap hari dalam bentuk dokumen digital. Untuk mempermudah seseorang dalam penemuan informasi dalam artikel Bahasa Jawa yang dicari dapat dilakukan dengan menggunakan klasifikasi dokumen. Penelitian ini bertujuan untuk membuat suatu aplikasi yang mampu mengklasifikasikan artikel bahasa Jawa menggunakan sistem pemerolehan informasi dan dikombinasikan dengan algoritma K-Nearest Neighbor.
Penelitian ini membagi dokumen ke dalam empat kategori yaitu politik, ekonomi, kesehatan, dan pendidikan. Proses klasifikasi dokumen diawali dengan membaca dokumen, tokenisasi, stopword, stemming, text frequency. Sistem ini menggunakan vektor ciri TF-IDF (term frequency/ Inverse document frequency).
Term frequency adalah jumlah kemunculan suatu kata dalam sebuah dokumen,
sedangkan inverse document frequency adalah inverse dari banyaknya dokumen dimana suatu term tersebut muncul. Setelah menghitung TF-IDF dilakukan perhitungan Cosine Similarity. Cosine Similarity merupakan algoritma yang digunakan untuk menghitung kemiripan antara dokumen baru dan dokumen pelatihan. Untuk melakukan klasifikasi dokumen digunakan algoritma K-Nearest
Neighbor. Metode K-Nearest Neighbor mengklasifikasikan dokumen dengan
menggunakan hasil dari perhitungan TF-IDF yang digunakan untuk menghitung kedekatan antar dokumen (cosine similarity)
Pada penelitian ini dilakukan pengujian yaitu dengan cross validation kemudian dilakukan uji presisi. Data yang digunakan sebanyak 40 dokumen. Tingkat akurasi untuk 3 fold k = 4 mencapai 95% dan k = 8 mencapai 92%, untuk 5 fold k = 4 mencapai 92% dan k = 8 mencapai 94%.
.
Kata kunci : klasifikasi dokumen bahasa Jawa, K-Nearest Neighbor, K-NN,
ix ABSTRACT
Javanese language is one of local / traditional languages in Indonesia which is always used. There are many Javanese language articles that always can be found in digital document form. Clasification document can be used to find information in Javanese . The purpose of this research is to create an aplication which is able to clasify Javanese language article by using the combination of the information retrieval system and K-Nearest neighbor algorithm.
This research divided the documents into 4 categories which consist of : politic, economy, health and education. The process of clasification begins with reading the document, tokenizing, stopword, stemming, text frequency . The system uses a feature vector is TF-IDF (term frequency/inverse document frequency). Term frequency is the sum of a word's frequency in one term, meanwhile, inverse document is the frequency of documents in one term. Cosine similarity will calculate after calculating TF-IDF . Cosine similarity is the algorithm which is used to calculate similarity between the new document and the exercise document. K-Nearest Neighbour algorithm is using to clasify the document. K-Nearest Neighbor methode clasified the document by using the equal of calculating TF-IDF is used to compute the proximity between documents (cosine similarity).
This research also tested by cross validation then presision test. Using 40 data of documents. Accurancy for 3 fold k = 4 reaches 95 % and k = 8 reaches 92%, for 5 fold k =4 reaches 94 % and k = 8 reaches 94% .
xi
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Tuhan Yang Maha Esa atas kasih
dan penyertaannyalah sehingga penulis dapat menyelesaikan penyususnan skripsi
dengan judul “Sistem Klasifikasi Dokumen Bahasa Jawa Dengan Metode
K-Nearest Neighbor (K-NN)”. Penulisan skripsi ini ditujukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer Universitas Sanata Dharma
Yogyakarta.
Penyusunan skripsi ini tidak terlepas dari bantuan, bimbingan, dan peran
berbagai pihak. Oleh karena itu pada kesempatan ini penulis mengucapkan
terimakasih kepada pihak-pihak berikut:
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu membimbing dan
menuntun untuk menyelesaikan tugas skripsi ini.
2. Ibu Paulina Heruningsih Prima Rosa,S.Si.,M.Sc selaku Dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma.
3. Ibu Ridowati Gunawan,S.Kom.,M.T. selaku Ketua Program Studi Teknik
Informatika sekaligus selaku dosen penguji.
4. Ibu Sri Hartati Wijono,S.Si.,M.Kom. selaku dosen pembimbing sekaligus
dosen pembimbing akademik yang telah meluangkan banyak waktu untuk
membimbing dan memotivasi penulis untuk terus membaca dan belajar.
5. Bapak Puspaningtyas Sanjoyo Adi,S.T., M.T. selaku dosen penguji.
6. Seluruh staff pengajar dan karyawan Program Studi Teknik Informatika
Fakultas Sains dan Teknologi Universitas Sanata Dharma.
7. Kedua orang tua saya bapak Putung Palinoan dan ibu Catarina Tandiayuk
yang selalu mendoakan, menasehati, dan memberi semangat dalam
mengerjakan tugas akhir ini.
8. Semua saudara tersayang, kakak Melianty Vemy Palinoan, Frans Fandy
Palinoan, Steven Richard Palinoan, dan adik Annabelle Keysa Florence
Palinoan yang terus memberikan dukungan sehingga dapat menyelesaikan
xii
9. Stevanus Pradibta yang selalu memberikan kasih sayang dan dorongan
dalam mengerjakan skripsi ini.
10.Teman-teman K2KAMSY yang selalu memberi dukungan dan menjadi
keluarga selama di Yogyakarta
11.Sahabat-sahabatku, Vio, Euz, Andre, Lia, Carla, Eka atas semua dukungan
dan semangat serta canda tawa dalam penyelesaian skripsi ini.
12.Semua pihak yang telah membantu penyelesaian skripsi ini yang tidak
dapat penulis sebutkan satu persatu.
Penulis menyadari masih banyak kekurangan dalam menyusun skripsi ini,
namun penulis tetap berharap skripsi ini bermanfaat bagi pengembangan ilmu
pengetahuan.
Yogyakarta, Desember 2014
Penulis
xiii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... v
HALAMAN MOTTO ... vi
HALAMAN PERSEMBAHAN ... vii
ABSTRAK ... viii
ABSTRACT ... ix
LEMBAR PERNYATAAN PERSETUJUAN ... x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR GAMBAR ... xvi
DAFTAR TABEL... xvii
DAFTAR LIST CODE ... xviii
BAB I PENDAHULUAN 1.1. Latar Belakang Masalah ... 1
1.2. Rumusan Masalah ... 2
1.3. Batasan Masalah ... 2
1.4. Tujuan Penelitian ... 3
1.5. Metodologi Penelitian ... 3
1.6. Sistematika Penulisan ... 4
BAB II LANDASAN TEORI 2.1. Pemerolehan Informasi ... 6
2.2. Proses Preprosesing Teks Dokumen ... 7
2.2.1.Tokenisasi ... 7
2.2.2.Stopword ... 8
2.2.3.Stemming ... 9
2.2.4.Text Frequency ... 13
2.3. Klasifikasi Teks ... 15
2.4. Metode k-Nearest Neighbor ... 15
xiv
BAB III ANALISA DAN PERANCANGAN SISTEM
3.1. Gambaran Umum Sistem ... 19
3.1.1.Proses Input Data ... 20
3.1.2.Preprocessing Dokumen ... 20
3.1.3.Proses Klasifikasi ... 21
3.2.3.1. Skenario Use Case Preprocessing Dokumen ... 23
3.2.3.2. Skenario Use Case Klasifikasi Dokumen ... 24
3.2.4.Definisi Use Case ... 25
3.3. Perancangan Model Penyimpanan Data ... 25
3.4. Diagram Konteks ... 26
3.5. Diagram Aktifitas ... 27
3.5.1.Diagram Aktifitas Preprocessing Dokumen ... 27
3.5.2.Diagram Aktifitas Klasifikasi Dokumen ... 28
3.6. Diagram Sekuensial ... 29
3.6.1.Diagram Sekuensial Preprocessing Dokumen ... 29
3.6.2.Diagram Sekuensial Klasifikasi Dokumen ... 30
3.7. Langkah Pengerjaan Klasifikasi Dokumen ... 30
3.7.1.Preprocessing ... 32
3.7.2.2. Perhitungan Bobot (tf-idf) ... 41
3.7.2.3. Perhitungan Inner Product ... 44
3.7.2.4. Perhitungan Panjang Dokumen ... 47
3.7.3.Skenario Pengujian... 50
3.8. Perancangan Antar Muka ... 51
xv
3.8.2.Halaman Klasifikasi Dokumen ... 52
BAB IV IMPLEMENTASI 4.1. Spesifikasi Software Dan Hardware yang Dibutuhkan ... 53
4.1.1.Spesifikasi Software ... 53
4.1.2.Spesifikasi Hardware ... 53
4.2. Implementasi Preprocessing Dokumen ... 54
4.2.1.Implementasi Pembacaan Isi Dokumen ... 54
4.2.2.Implementasi Tokenisasi, Menghapus Tanda Baca, Case Folding ... 54
4.2.3.Implementasi Stopword ... 55
4.2.4.Implementasi Stemming ... 56
4.2.5.Implementasi Save Dokumen Hasil Preprocessing ... 64
4.3. Implementasi Klasifikasi Dokumen ... 65
4.4. Implementasi Antar Muka ... 73
4.4.1.Halaman Preprocessing Dokumen ... 73
4.4.2.Halaman Klasifikasi Dokumen ... 74
BAB V HASIL DAN PEMBAHASAN 5.1. Hasil Percobaan ... 75
5.1.1.Cross Validation ... 75
5.1.1.1. 3 Fold ... 76
5.1.1.2. 5 Fold ... 80
5.2. Analisa ... 87
BAB VI KESIMPULAN DAN SARAN ... 90
Daftar Pustaka ... 91
xvi
DAFTAR GAMBAR
Gambar 3.1 Gambaran Umum Sistem ... 19
Gambar 3.2 Diagram Use Case ... 23
Gambar 3.3 Diagram Konteks ... 26
Gambar 3.4 Diagram Aktifitas Preprocessing Dokumen ... 27
Gambar 3.5 Diagram Aktifitas Klasifikasi Dokumen ... 28
Gambar 3.6 Diagram Sekuensial Preprocessing Dokumen... 29
Gambar 3.7 Diagram Sekuensial Klasifikasi Dokumen ... 30
Gambar 3.8 Contoh Proses Tokenisasi ... 33
Gambar 3.9 Contoh Proses Stopword ... 33
Gambar 3.10 Rancangan Halaman Preprocessing Dokumen ... 51
Gambar 3.11 Rancangan Halaman Klasifikasi Dokumen ... 52
Gambar 4.1 Halaman Preprosesing Dokumen ... 73
xvii
DAFTAR TABEL
Tabel 3.1 Deskripsi Use Case ... 25
Tabel 3.2 Contoh Data Training dan Testing ... 30
Tabel 3.3 Tabel Hasil Tokenisasi ... 33
Tabel 3.4 Tabel Hasil Stopword ... 35
Tabel 3.5 Tabel Hasil Stemming ... 36
Tabel 3.6 Perhitungan idf ... 38
Tabel 3.7 Perhitungan Bobot (w) ... 41
Tabel 3.8 Perhitungan Inner Product ... 44
Tabel 3.9 Perhitungan Panjang Dokumen ... 47
Tabel 5.1 Nama Dokumen ... 75
Tabel 5.2 Pembagian Dokumen 3 Fold ... 76
xviii
DAFTAR LIST CODE
List Code 4.2.1 Open File ... 54
List Code 4.2.2 Tokenisasi, Menghapus Tanda Baca, Case Folding ... 55
List Code 4.2.3 Stopword ... 56
List Code 4.2.4a Stemming ... 57
List Code 4.2.4b Stemming ... 64
List Code 4.2.5 Preprocessing ... 64
1
BAB I
PENDAHULUAN
1.1. Latar Belakang Masalah
Bahasa Jawa merupakan salah satu bahasa daerah di Indonesia yang
sangat sering digunakan. Banyak artikel Bahasa Jawa yang dapat kita
jumpai setiap hari dalam bentuk dokumen digital. Untuk mempermudah
seseorang dalam penemuan informasi dalam artikel Bahasa Jawa yang
dicari dapat dilakukan dengan menggunakan klasifikasi dokumen. Namun,
sebelum diklasifikasikan kita harus melakukan proses pemerolehan
informasi.
Pemerolehan informasi adalah pencarian material (biasanya berupa
dokumen) dari dokumen yang sifatnya tidak terstruktur (biasanya berupa
teks) yang bertujuan untuk memenuhi kebutuhan informasi dari suatu
kumpulan dokumen yang besar (biasanya disimpan di komputer) (Manning,
2008). Proses pemerolehan informasi melalui tahap prepocessing yang
meliputi tokenizing yaitu memecah kumpulan kata menjadi token serta
penghapusan karakter-karakter yang tidak penting, stopword yaitu
penghapusan kata-kata yang tidak mempengaruhi proses pemerolehan
informasi, lalu stemming yaitu proses mengembalikan semua bentuk kata ke
bentuk kata dasarnya, kemudian dilakukan perhitungan text frequency.
Setelah dilakukan proses pemerolehan informasi akan dilanjutkan dengan
Klasifikasi dokumen merupakan proses memisahkan sekumpulan
dokumen ke dalam beberapa kelompok atau kelas dengan menilai kemiripan
antar dokumen. Pengelompokan artikel-artikel yang saling berkait ini, akan
membantu pengguna untuk menemukan informasi yang dibutuhkan. Pada
proses ini digunakan metode k-Nearest Neighbor (k-NN). Metode
k-Nearest Neighbor (k-NN) mengklasifikasikan dokumen dengan
menggunakan hasil dari perhitungan text frequency dengan melihat
kemiripan cosine similarity tiap dokumen berdasarkan k (jumlah tetangga
terdekat).
1.2. Rumusan Masalah
Berdasarkan latar belakang di atas maka rumusan masalahnya yaitu :
1. Seberapa besar tingkat akurasi metode k-Nearest Neighbor (k-NN) dalam
mengklasifikasikan dokumen Bahasa Jawa ?
1.3. Batasan Masalah
Adapun batasan aplikasi klasifikasi dokumen skripsi Teknik
Informatika adalah sebagai berikut :
1. Dokumen yang dapat diproses adalah dokumen teks (*.txt).
2. Data dokumen diambil dari artikel yang berbahasa Jawa.
3. Jenis pengklasifikasian dokumen untuk pengujian dibagi menjadi 4
kategori yaitu ekonomi, politik, kesehatan, dan pendidikan.
1.4. Tujuan Penelitian
Adapun tujuan penulisan skripsi adalah sebagai berikut:
1. Menemukan tingkat akurasi metode k-Nearest Neighbor (k-NN) dalam
mengklasifikasikan dokumen Bahasa Jawa.
2. Mengklasifikasikan dokumen Bahasa Jawa dengan menggunakan metode
k-Nearest Neighbor (k-NN)
1.5. Metodologi Penelitian
Metodologi penelitian yanng digunakan yaitu :
1. Analisis
Melakukan analisis terhadap masalah dan kebutuhan sistem yang akan
dibangun.
2. Perancangan sistem
Melakukan perancangan umum sistem sesuai dengan kebutuhan sistem.
3. Pembuatan Sistem
Berdasarkan hasil analisis dan perancangan sistem, maka tahap selanjutnya
adalah pembuatan sistem.
4. Implementasi dan pengujian
Sistem yang telah dibuat dijalankan, kemudian dilakukan pengujian
terhadap ketepatan sistem klasifikasi dengan menggunakan metode
pemerolehan Informasi dan klasifikasi menggunakan metode k-Nearest
3. Evaluasi dan pengambilan kesimpulan
Menganalisis hasil implementasi sistem dan membuat kesimpulan
terhadap penelitian tugas akhir yang telah dikerjakan.
1.6.Sistematika Penulisan
BAB I PENDAHULUAN
Memberikan gambaran secara umum tentang isi skripsi yang
meliputi: latar belakang, rumusan masalah, batasan masalah, tujuan
dan manfaat, metode penelitian dan sistematika penulisan.
BAB II LANDASAN TEORI
Berisi konsep dasar Pemerolehan Informasi, teknik-teknik dan
metode klasifikasi k-NN
BAB III ANALISA DAN PERANCANGAN
Berisi gambaran umum sistem, metode pengumpulan data, usecase
diagram, sekenario perancangan, analisa peracangan, perancangan
basis data, perancangan tampilan masukan dan keluaran untuk
pengguna.
BAB IV IMPLEMENTASI
Bab ini menjelaskan tentang implementasi ke dalam bentuk
program berdasarkan desain yang telah dibuat, berupa tampilan
BAB V HASIL DAN PEMBAHASAN
Pada bab ini akan dipaparkan mengenai hasil dan analisa dari hasil
percobaan yang telah dilakukan.
BAB VI KESIMPULAN DAN SARAN
Bab ini berisi semua kesimpulan yang didapatkan dari penelitian
yang telah dilakukan. Kesimpulan menjawab rumusan masalah
6 BAB II
LANDASAN TEORI
2.1Pemerolehan Informasi
Pemerolehan informasi adalah pencarian material (biasanya berupa
dokumen) dari dokumen yang sifatnya tidak terstruktur (biasanya berupa teks)
yang bertujuan untuk memenuhi kebutuhan informasi dari suatu kumpulan
dokumen yang besar (biasanya disimpan di komputer) (Manning, 2008).
Pemerolehan informasi berhubungan dengan representasi, media penyimpanan,
pengaksesan, dan pengorganisasian sesuatu yang memiliki informasi.
Pemerolehan informasi digunakan untuk mengurangi jumlah informasi
yang terlalu besar sehingga di dalam pencarian informasi akan menjadi lebih
efektif dan memberikan hasil pencarian dokumen yang relavan dengan query.
Query berupa kata kunci yang diberikan oleh pengguna kepada sistem sebagai
acuan untuk mendapatkan informasi yang relevan terhadap kebutuhan pada query.
Query yang dimasukkan ke dalam sistem akan diolah dengan menggunakan
metode yang diterapkan dalam sistem pemerolehan informasi untuk kemudian
ditampilkan berdasarkan urutan nilai relevansi yang paling tinggi. Untuk lebih
mempermudah lagi maka data yang didapatkan diklasifikasi.
Fungsi utama pemerolehan informasi sistem adalah
1. Mengidentifikasi sumber informasi yang relefan dengan minat masyarakat
2. Menganalisis isi sumber informasi (dokumen).
3. Merepresentasikan isi sumber informasi dengan cara tertentu yang
memungkinkan untuk dipertemukan dengan pertanyaan (query) pengguna.
4. Merepresentasikan pertanyaan (query) pengguna dengan cara tertentu
yang memungkinkan untuk dipertemukan sumber informasi yang terdapat
dalam basis data.
5. Mempertemukan pernyataan pencarian dengan data yang tersimpan dalam
basisdata.
6. Menemu-kembalikan informasi yang relevan.
7. Menyempurnakan unjuk kerja sistem berdasarkan umpan balik yang
diberikan oleh pengguna.
2.2 Proses Preprocessing Teks Dokumen
Fungsi preprocessing pada program ini adalah untuk mendapatkan kata
kunci yang nantinya akan digunakan sebagai pencocokan string atau
perbandingan dokumen. Proses-proses yang dilakukan pada proses ini adalah
membaca dokumen, tokenisasi, stopword, stemming, text frequency.
2.2.1. Tokenisasi
Menurut Manning, 2008, tokenisasi adalah proses memotong kalimat
menjadi potongan-potongan kata, yang disebut token, dan pada saat yang
Tokenisasi adalah tugas memisahkan deretan kata di dalam kalimat,
paragraf atau halaman menjadi token atau potongan kata tunggal. Tahapan ini
juga menghilangkan karakter-karakter tertentu seperti tanda baca dan
mengubah semua token ke bentuk huruf kecil (lower case).
2.2.2. Stopword
Stopword adalah kata yang sangat umum yang akan muncul menjadi
nilai yang kecil dalam membantu dokumen pilih yang cocok dengan
kebutuhan pengguna dikecualikan dari kosakata seluruhnya (Manning,
2008).
Pada proses stopword dilakukan penghapusan kata-kata yang tidak
mempengaruhi proses pemerolehan informasi. Stopword adalah kata umum
yang biasanya muncul dalam jumlah besar dan dianggap tidak memiliki
makna. Pada penerapan program ini daftar kata-kata yang digolongkan
sebagai stopword disimpan pada dokumen stoplist.txt. Kata-kata hasil
tokenizing kemudian dicocokkan dengan tabel stopword dalam dokuemn, jika
ternyata kata yang diperiksa sama dengan stopword maka kata hasil
tokenizing dihapus. Dan kata yang diperiksa tidak ada di dalam dokumen
maka kata tersebut dijadikan kata penting dan kemudian dilakukan proses
2.2.3. Stemming
Proses ini adalah proses mengembalikan semua bentukan kata
menjadi bentuk kata dasarnya dengan menghilangkan semua imbuhan baik
yang terdiri dari awalan(perfixes), sisipan(infixes), akhiran(surfixes) dan
confixes (kombinasi dari awalan dan akhiran) pada kata turunan.
Sebelum membuat aturan stemming untuk bahasa Jawa, diuraikan
terlebih dahulu penggunaan simbol-simbol dalam membuat stemmer rule.
(Joko, Sri Hartati, Mirna Adriani, JB. Budi Darmawan, Studi Pengaruh
Stemming dalam Bahasa Jawa. Penelitian Mibah Pekerti DIKTI, 2011).
1. Aturan substitusi/penghapusan menggunakan tanda =>.
ny =>”” (ny dihapus)
ny => s (ny diganti s)
2. Simbol <> digunakan untuk menyatakan tingkat affix yang mempengaruhi
urutan pengecekan di algoritma stemming.
Aturan yang digunakan adalah sebagai berikut :
SUFFIX
<1> e=>"",n=>"",a=>"",i=>"",ing=>"", ku=>"",mu=>""
<2> ke=>"", ki=>"",wa=>"",
ya=>"",na=>"",ne=>"",en=>"",an=>"",ni=>"",nira=>"", ipun=>"", on=>"u", ning=>""
<3> ake=>"", en=>"i", kna=>"n", kno=>"n", ana=>"", ono=>"", ane=>"", kne=>"", nan=>"", yan=>"", nipun=>"", oni=>"u", eni=>"i"
<5> kake=>"",kken=>"",aken=>"",kke=>"n",enana=>"i",enono=>"i",on en=>"u",enen=>"i",onana=>"u",onono=>"u",
ekna=>"i",ekno=>"i",okno=>"u",okna=>"u"
<6> ekken=>"i",kaken=>"n",okken=>"u",ekake=>"i",ekke=>"i",okake= >"u",okke=>"u", kaken=>"", kken=>"n"
<7> ekaken=>"i",okaken=>"u"
PREFIX
<1> dipun=>"",peng=>"",peny=>"",pem=>"",pam=>"",pany=>"",pra=>"
",kuma=>"",kapi=>"",
bok=>"",mbok=>"",dak=>"",tak=>"",kok=>"",tok=>"",ing=>"",ang
=>"",any=>"", am=>"", sak=>"",
se=>"",su=>"",mang=>"",meng=>"",nge=>"",nya=>"",pi=>"",ge=>"
",ke=>"",u=>"",
po=>"u",ke=>"u"
<2> mer=>"",mra=>"",mi=>"",sa=>"",ku=>"",an=>"",ka=>"",ny=>"s",n
g=>"k",di=>"",peng=>"k",pang=>"k",pany=>"c",
pam=>"p",ke=>"i",mang=>"k",meng=>"k"
<3> a=>"",k=>"",pam=>"w",pan=>"t",
pen=>"t",mang=>"w",meng=>"w", ny=>"c",ng=>""
<4> n=>"t", pan=>"s", pen=>"s",man=>"s",men=>"s"
<5> pan=>"",pen=>"",man=>"t",men=>"t",n=>""
<7> p=>"",ma=>"",me=>""
<8> m=>"w"
<9> m=>"p"
<10> m=>""
INFIX
<1> gum=>"b",gem=>"b",kum=>"p",kem=>"p"
<2> kum=>"w", kem=>”w”
Algoritma untuk melakukan proses stemming terhadap kata tunggal
atau duplikasi.
1. Kata berimbuhan adalah word. Kata sebagai hasil adalah stemW
2. Cek jumlah karakter word, jika < 2. Keluar.
3. Jika word mengandung “-“, maka pecah kata berdasar “-“ menjadi w1
dan w2. Dan lakukan langkah 4-13
4. w11 = w1 tanpa vokal dan w21 = w2 tanpa vokal.
5. Jika w11 = w21 dan panjang w1=w2 maka lakukan langkah 6-8
6. Jika w2 ada di kamus maka stemW=w2 dan keluar.
7. Jika w2 tidak ada di kamus, w22= hilangkan imbuhan(w2).
8. Jika w22 ada di kamus maka stemW=w22, jika tidak
9. Jika w11 != w21, lakukan langkah 10-13
10.ws11=hilangkan imbuhan(w1) dan ws21 = hilangkan
imbuhan(w2).
11.Cek ws21 di kamus, jika ada maka stemW=ws21 dan
keluar.
12.Cek ws11 di kamus, jika ada maka stemW=ws11 dan
keluar.
13.Jika tidak maka stemW=ws11-ws21 dan keluar.
14.stemW = hilangkan imbuhan(stemW). Cek stemW di dictionary. Jika
ada stemW dikembalikan dan keluar.
Algoritma untuk menghilangkan afiks pada kata berimbuhan.
1. Kata yang akan dihilangkan imbuhan adalah word.
2. ws1=hapus suffix (word). Cek di dictionary. Jika ada kembalikan kata.
3. ws1s2=hapus suffix (ws1). Cek di dictionary. Jika ada kembalikan
kata.
4. ws1i1=hapus infix (ws1). Cek di dictionary. Jika ada kembalikan kata.
5. dws1= pengulangan parsial (ws1). Cek di dictionary. Jika ada
kembalikan kata.
6. dws1s2= pengulangan parsial (ws1s2). Cek di dictionary. Jika ada
kembalikan kata.
8. dwp1= pengulangan parsial (wp1). Cek di dictionary. Jika ada
kembalikan kata.
9. wp1s1=hapus suffix(wp1). Cek di dictionary. Jika ada kembalikan
kata.
10.dwp1s1= pengulangan parsial (wp1s1). Cek di dictionary. Jika ada
kembalikan kata.
11.wp1s1s2=hapus suffix (wp1s1). Cek di dictionary. Jika ada kembalikan
kata.
12.wp1p2=hapus prefix (wp1). Cek di dictionary. Jika ada kembalikan
kata.
13.wp1p2s1=hapus suffix (wp1p2). Cek di dictionary. Jika ada
kembalikan kata.
14.wp1p2s1s2=hapus suffix (wp1p2s1). Cek di dictionary. Jika ada
kembalikan kata.
15.wi1=hapus infix (word). Cek di dictionary. Jika ada kembalikan kata.
16.wi1s1=hapus suffix (wi1). Cek di dictionary. Jika ada kembalikan kata.
2.2.4. Text Frequency
Semakin banyak kata yang mirip atau sama antara dua dokumen
maka semakin dekat kedua dokumen tersebut dan akan memiliki bobot atau
nilai yang lebih tinggi. (Manning, 2008). Sehingga diperlukan pemberian
bobot untuk setiap token dalam dokumen tergantung pada jumlah
adalah dengan memberikan bobot yang nilainya sama dengan jumlah
kemunculan token t dalam dokumen d. Pembobotan ini disebut term
ferquency dan disimbolkan dengan tft,d.
Namun, dalam sistem yang akan dibangun oleh penulis,
menggunakan teknik TF/IDF (term frequency/ Inverse document frequency).
Term frequency adalah jumlah kemunculan suatu kata dalam sebuah
dokumen, sedangkan inverse document frequency adalah inverse dari
banyaknya dokumen dimana suatu term tersebut muncul.
Rumus pembobotan Salton (1983) adalah sebagai berikut:
w(t,d) = tft,d * idft = tf(t,d )* log(N/nt) (1)
Keterangan :
1. w(t,d) = bobot dari term(kata) t dalam dokumen d.
2. tf(t,d) = frekuensi kemunculan term(kata) t dalam dokumen d.
3. Idfd = Inverse document frequency dari kata t
4. N = jumlah seluruh dokumen
5. nt = jumlah dari dokumen yang ditraining yang mengandung nilai t.
digunakan dalam referensi yang dijadikan acuan dalam pembuatan
Sistem klasifikasi yaitu nilai perbandingan antara jumlah
kemunculan suatu kata dalam dokumen dibagi dengan jumlah keseluruhan
kata yang ada dalam dokumen tersebut, sehingga jumlah dari semua tf dari
Dokumen Frequency (idf) atau kombinasi dari tf-idf juga dapat digunakan.
Namun dalam klasifikasi teks, tf-idf tidak selalu efektif.
2.3. Klasifikasi Teks
Han dan Kamber (2006) mengatakan bahwa klasifikasi merupakan
proses menemukan model atau fungsi yanng menjelaskan dan membedakan
kelas-kelas data fungsi tersebut digunakan untuk memperkirakan kelas dari
suatu objek yang labelnya tidak diketahui Proses klasifikasi ini terbagi
menjadi dua tahapan, yaitu tahap pelatihan (learning) dan tahap uji. Pada
tahap pelatihan, sebagian data yang telah diketahui kelas datanya
diumpankan untuk membentuk model prediksi.
2.4. Metode k-Nearest Neighbor
Mertode k-Nearest Neighbor atau k-NN merupakan salah satu
metode yang digunakan dalam sistem klasifikasi yang menggunakan
pendekatan Machine Leraning. Machine Learning merupakan proses yang
membangun sistem klasifikasi melalui pembelajaran dari sejumlah contoh
yang sudah diklasifikasikan sebelumnya (Feldman & Sanger, 2007).
Menurut Han dan Kamber (2006), metode k-NN bersifat lazy
learners di mana proses pembelajarannya menunggu hingga menit terakhir
sebelum model dibangun dibutuhkan untuk mengklasifikasi data uji.
Berbeda dengan eager leaners yang akan melakukan generalisasi pada kata
pelatihan sebelum menerima data uji. Lazy learners akan menyimpan data
bekerja lebih sedikit ketika diberikan data pelatihan dan bekerja lebih
banyak ketika diberikan data uji, dibandingkan dengan eager learners. Lazy
learners disebut juga instance-based learners karena menyimpan data
pelatihan atau instances.
Agoritma metode k-NN
1. Tentukan parameter k= jumlah dokumen tetangga.
2. Hitung kemiripan antara dokumen baru dan dokumen pelatihan dengan
menggunakan rumus cosine similarity
(2)
Keterangan :
Q : dokumen uji
Di : dokumen pelatihan
WQj : bobot token j dalam dokumen uji Q
Wij : bobot token j dalam dokumen pelatihan ke-i
Sim(Q,Di) : nilai kesamaan antara dokumen uji Q dan dokumen
pelatihan ke-i
3. Urutkan nilai kesamaan dan tentukan tetangga terdekat berdasarkan
jarak terbesar, banyak tetangga terdekat diambil dari parameter k.
5. Gunakan mayoritas sederhana dari kategori dokumen tetangga sebagai
nilai prediksi dokumen tes.
2.5. Perhitungan Akurasi
Perhitungan akurasi dilakukan dengan menggunakan metode
cross-validation. Pada metode cross-validation, data dibagi menjadi k subset atau
fold yang saling bebas secara acak, yaitu S1, S2, …., Sk, dengan ukuran
setiap subset sama. Pelatihan dan pengujian dilakukan sebanyak k kali. Pada
iterasi ke-i, subset S1 diperlakukan sebagai data pengujian, dan subset
lainnya sebagai data pelatihan. Tingkat akurasi dihitung dengan membagi
jumlah keseluruhan klasifikasi yang benar dengan jumlah semua instance
pada data awal (Han & Kamber 2006).
Tahap I
i. fold 1 sebagai data uji
ii. fold 2 sebagai data pelatihan
iii. fold 3 sebagai data pelatihan
Tahap II
i. fold 2 sebagai data uji
ii. fold 1 sebagai data pelatihan
Tahap III
i. fold 3 sebagai data uji
ii. fold 1 sebagai data pelatihan
iii. fold 2 sebagai data pelatihan
Setelah dilakukan cross validation maka digunakan precision untuk menentukan
akurasi. Yaitu dengan cara :
19 BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1Gambaran Umum Sistem
Sistem ini dibuat untuk mempermudah pencarian dokumen bahasa
Jawa dengan mengklasifikasikan dokumen berita bahasa Jawa menggunakan
proses information retrieval. Sistem terdiri atas 3 proses utama yaitu proses
input, preprocessing yang terdiri dari proses tokenizing, stopword, stemming,
dan text frequency, dan proses klasifikasi dokumen. Berikut ini adalah
gambaran klasifikasi dokumen secara umum :
Input Teks
Menghitung TF
IDF KNN
stemming stopword
Tokenisa si
Hasil klasifikasi
preprocessing
Gambar 3.1 Gambaran Umum Sistem
Proses utama dalam sistem ini yaitu proses preprocessing dan
klasifikasi. Hasil akhir dari proses preprocessing yang berupa bobot kata
disimpan dalam database kemudian digunakan untuk melakukan klasifikasi
menggunakan metode k-Nearest Neighbor.
Lebih jelasnya proses dibagi menjadi beberapa bagian sebagai berikut
3.1.1 Proses Input Data
Data yang diinputkan untuk klasifikasi ini adalah dokumen
Bahasa Jawa dengan file berekstensi *.txt yang membahas beberapa
topik yang berbeda yang kemudian topik tersebut dijadikan sebagai
acuan dalam pengklasifikasian. Dokumen yang digunakan pada
klasifikasi ini dibagi menjadi dua bagian, yaitu dokumen yang berfungsi
sebagai data pelatihan dan dokumen yang berfungsi sebagai data uji yang
akan digunakan sebagai uji coba terhadap data pelatihan. Dokumen yang
digunakan sebagai data tes ini belum diketahui kelasnya.
3.1.2 Preprocessing Dokumen
Pada tahap preprocessing ini akan dilakukan tahapan seperti
berikut :
a) Tokenisasi
Pada tahap ini, memecah kumpulan kata menjadi token dan
penghapusan karakter-karakter yang tidak penting.
b) Stopword
Penghapusan kata yang tidak mempengaruhi sistem
pemerolehan informasi
c) Stemming
Proses mengembalikan semua bentuk kata ke bentuk kata
dasarnya.
Pada proses ini dilakukan perhitungan bobot setiap kata yang
telah melalui proses preproses.
3.1.3 Proses Klasifikasi
Pada proses klasifikasi ini dokumen yang telah diproses hingga
tahap perhitungan text frequency akan diklasifikasikan berdasarkan kelas
yang telah ditentukan. Proses klasifikasi ini menggunakan metode
k-Nearest Neighbor (k-NN) sebagai berikut :
a. Menetukan K
Pada proses ini, user memasukkan nilai k, yaitu jumlah dokumen
tetangga terdekat. Sebagai contoh k=3, berarti akan diambil 3 dokumen
yang memiliki jarak terdekat dengan dokumen testing.
b. Perhitungan Cosine Similarity
Hitung kemiripan vektor [dokumen] query Q dengan setiap dokumen
yang ada. Kemiripan antar dokumen dapat menggunakan cosine
c. Pengurutan kemiripan Vektor
Urutkan hasil perhitungan kemiripan vektor dari hasil perhitungan
cosine similarity.
d. Mencari label mayoritas dengan menggunakan acuan k yang telah
ditentukan untuk menentukan hasil kasifikasi dengan melihat jumlah
kelas yang terbanyak diperoleh diantara k dokumen yang terdekat,
dilakukan prediksi untuk mengetahui kelas dari dokumen tes tersebut,
dengan melihat jumlah kelas yang terbanyak diperoleh diantara k
dokumen yang terdekat.
3.1.4 Keluaran
Sistem ini akan menghasilkan keluaran berupa klasifikasi
dokumen dengan K-Nearest Neighbor.
3.2Analisa Kebutuhan Sistem
3.2.1 Definisi Aktor
Aktor yang terlibat dalam sistem adalah user. User merupakan aktor
yang dapat mengakses dan mengelolah semua kebutuhan sistem. Hak
akses User dapat dilihat di bawah ini :
Aktor Hak Akses
User - Preprocessing
3.2.2 Diagram Use Case
Gambaran use case diagram sistem dapat dilihat pada gambar berikut ini
Klasifikasi Dokumen Preprocessing
pengguna
Gambar 3.2 Diagram Use Case
3.2.3 Skenario Use case
3.2.3.1 Skenario Use Case Preprocessing Dokumen
Nama use case Preprocessing dokumen
Id Use Case 1
Prioritas High
Pelaku Pengguna
Deskripsi Pengguna melakukan preprocessing dokumen
Pra kondisi Dokumen yang diklasifikasikan telah melalui proses preprocessing
Aksi Aktor Reaksi Sistem 1. User berada pada halaman
utama
2. User memilih Menu Preprosesing
3. Sistem menampilkan halaman
“Preprosesing” 4. User menekan tombol ambil
data dokumen
5. Sistem menampikan halaman
di- Preprocessing
7. Sistem menampilkan alamat direktori .
8. User menekan tombol Mulai 9. Sistem akan menyimpan data hasil Preprocessing pada folder testing
3.2.3.2Skenario Use Case Klasifikasi Dokumen
Nama use case Klasifikasi dokumen
Id Use Case 2
Prioritas High
Pelaku Pengguna
Deskripsi Pengguna melakukan klasifikasi dokumen
Pra kondisi Dokumen yang diklasifikasikan telah melalui proses preprocessing
Aksi Aktor Reaksi Sistem 1. User berada pada halaman
MainFrame
2. User memilih Menu Klasifikasi Dokumen
3. User menekan tombol ambil dokumen
4. Sistem menampilkan halaman
“browse”
5. User memilih dokumen yang akan diklasifikasi dan memasukkan nilai k kemudian menekan tombol klasifikasi
3.2.4 Definisi Use Case
Tabel di bawah ini menjelaskan secara umum use case yang terdapat pada
sistem klasifikasi dokumen/artikel Bahasa Jawa.
Tabel 3.1 Deskripsi Use Case
3.3Perancangan Model Penyimpanan Data
Media penyimpanan data yang dikelola oleh sistem adalah berupa file
plain text yang disimpan dengan ekstensi .txt. Setiap satu file mewakili satu
surat. File – file tersebut kemudian disimpan dalam folder yang mewakili
masing – masing kategori. Penjabaran folder dan file yang digunakan oleh
sistem:
1. Preprocessing
Menyimpan file hasil preprocessing yang dilakukan oleh pengguna
melalui sistem.
2. stopwords.txt
File yang berisi stopwords.
Contoh : aku, ada, ahh, aja, ana, apa.
No. Use Case Deskripsi Use Case
1. Klasifikasi dokumen
Use case ini menggambarkan proses
klasifikasi dokumen baru. Dokumen inputan akan ditentukan kategorinya secara otomatis.
2. Preprocessing
Use case ini menggambarkan proses
preprocessing mulai dari tokenisasi sampai
3. kamus.txt
File yang berisi kumpulan kata dasar yang ada dalam kamus bahasa Jawa.
Contoh : abab, abad, abang, abdi, abnormal, abot, absen, ada, adang, adat.
4. stemWord2.pl
File yang berisi metode stemming.
Contoh :
Lapangan _an lapang
pakaryane “_ne” pakarya“pa_ “ karya karya
5. Tanda baca.txt
File berisi tanda baca yang dihapus.
Contoh :
3.4Diagram Konteks
USER Sistem Klasifikasi
Dokumen Bahasa Jawa Klasifikasi dokumen
info hasil klasifikasi
3.5Diagram Aktifitas
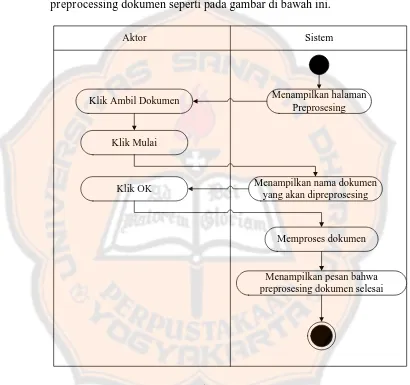
3.5.1 Diagram Aktifitas Preprocessing Dokumen
Pengguna akan melakukan preprocessing dokumen. Diagram aktivitas
preprocessing dokumen seperti pada gambar di bawah ini.
Menampilkan halaman Preprosesing Klik Ambil Dokumen
Klik Mulai
Memproses dokumen
Menampilkan pesan bahwa preprosesing dokumen selesai
Aktor Sistem
Menampilkan nama dokumen yang akan dipreprosesing Klik OK
3.5.2 Diagram Aktifitas Klasifikasi Dokumen
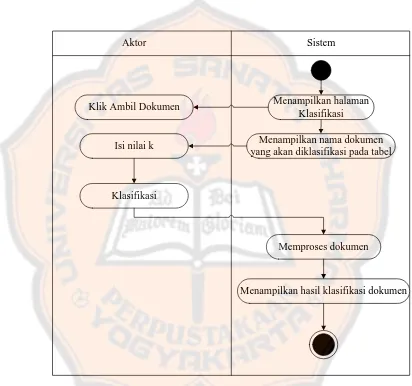
Pengguna akan melakukan klasifikasi dokumen. Diagram aktivitas
preprocessing dokumen seperti pada gambar di bawah ini.
Menampilkan halaman Klasifikasi Klik Ambil Dokumen
Isi nilai k
Memproses dokumen
Menampilkan hasil klasifikasi dokumen
Aktor Sistem
Menampilkan nama dokumen yang akan diklasifikasi pada tabel
Klasifikasi
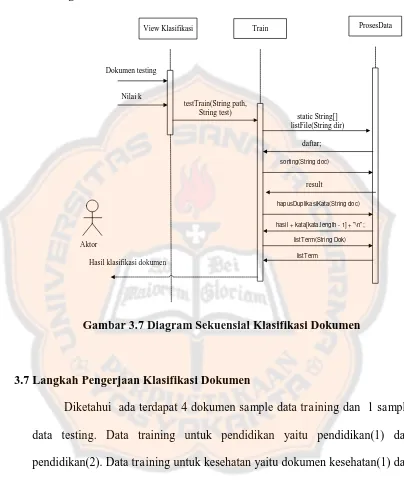
3.6Diagram Sekuensial
3.6.1 Diagram Sekuensial Prerocessing Dokumen
Aktor
save(String doc, String filePath, String fileName)
3.6.2 Diagram Sekuensial Klasifikasi Dokumen
Aktor
View Klasifikasi
Dokumen testing
Train
Nilai k
testTrain(String path, String test)
ProsesData
static String[] listFile(String dir)
daftar;
sorting(String doc)
result
hapusDuplikasiKata(String doc)
hasil + kata[kata.length - 1] + "\n";
listTerm(String Dok)
listTerm Hasil klasifikasi dokumen
Gambar 3.7 Diagram Sekuensial Klasifikasi Dokumen
3.7Langkah Pengerjaan Klasifikasi Dokumen
Diketahui ada terdapat 4 dokumen sample data training dan 1 sample
data testing. Data training untuk pendidikan yaitu pendidikan(1) dan
pendidikan(2). Data training untuk kesehatan yaitu dokumen kesehatan(1) dan
kesehatan (2). Data testing yaitu Test. Akan dicari kelas dari data testing,
apakah temasuk dalam kategori pendidikan atau kesehatan dengan
Tabel 3.2 Contoh Data Training dan Testing
Nama
Dokumen
Isi Dokumen
pendidikan
(1)
Guru Basa Jawa ing jaman saiki gunggunge ora akeh, sebab jurusan
basa Jawa iki dianggep angel lan ora nguntungake. Kejaba iku
dianggep ciut lapangan pakaryane, angel kanggo golek pangupa
jiwa. Lan isih akeh maneh panganggep remeh liyane, nanging apa
iya pancen asor banget ta basa Jawa kuwi? Dra. Warih Jatirahayu
nyoba njawab tantangan mau. Kabukten, ketekunane nggeluti basa
Jawa, ndadekake kariere muluk ndedel tansaya dhuwur.
pendidikan
(2)
Kanggo biyantu ningkatake kualitas pendhidhikan ing Kabupaten
Sleman, durung suwe iki kadhapuk pengurus Dewan Pendhidhikan
Kabupaten (DPK) Sleman. Kanthi anane DPK kasebut kaangkah
masarakat ing Kabupaten Sleman bisa menehi sumbangan awujud
saran, kritik lan liya-liyane kang tujuane kanggo ningkatake mutune
pendhidhikan ing Kabupaten Sleman.
kesehatan
(1)
Kanker mono mujudake momok mungguhing sok sapaa wae. Ora
sethithik pawongan kang koncatan nyawa karana lelara kanker kang
disandhang. Ora mokal menawa lelara mau kuwawa gawe giris,
luwih-luwih tumrap pawongan panandhang lelara mau kang nate
dioperasi nanging gagal
kesehatan
(2)
Ditambahake Gogok menawa Hikata Reiki tetela nduweni sipat
Reiki kejaba nduweni getaran energi sing dhuwur lan kuwat uga
bisa kanggo ngaWekani sawernaning jinis penyakit kanthi cepet.
Test
Jaman saiki "pendidikan" wus dudu bab sing aneh, nanging dadi
barang sing larang regane dhuwur pangajine. Mung wae mutune
durung mesthi. Kurikulum ing sekolah, mligine ing tingkat Sekolah
Dasar wulangan Basa Jawa babagan aksara jawa durung selaras
karo cak-cakane utawa prakteke. Awit ing "lapangan" wulangan
mligine bab aksara Jawa durung laras karo kurikulume.
Dalam pengerjaan dilakukan dalam dua tahap yaitu tahap preprocessing dan
klasifikasi.
3.7.1 Preprocessing
Langkah pertama yaitu Preprocessing terhadap semua (terdapat 5)
dokumen yang terlibat. D
3.7.1.1 Tokenisasi
Tokenisasi adalah tugas memisahkan deretan kata di dalam
kalimat, paragraf atau halaman menjadi token atau potongan kata tunggal.
Tahapan ini juga menghilangkan karakter-karakter tertentu seperti tanda
.
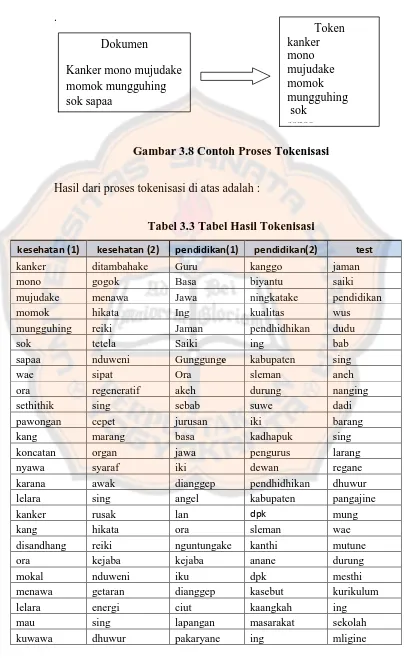
Gambar 3.8 Contoh Proses Tokenisasi
Hasil dari proses tokenisasi di atas adalah :
Tabel 3.3 Tabel Hasil Tokenisasi
kesehatan (1) kesehatan (2) pendidikan(1) pendidikan(2) test
kanker ditambahake Guru kanggo jaman
mono gogok Basa biyantu saiki
mujudake menawa Jawa ningkatake pendidikan
momok hikata Ing kualitas wus
mungguhing reiki Jaman pendhidhikan dudu
sok tetela Saiki ing bab
sapaa nduweni Gunggunge kabupaten sing
wae sipat Ora sleman aneh
ora regeneratif akeh durung nanging
sethithik sing sebab suwe dadi
pawongan cepet jurusan iki barang
kang marang basa kadhapuk sing
koncatan organ jawa pengurus larang
nyawa syaraf iki dewan regane
karana awak dianggep pendhidhikan dhuwur
lelara sing angel kabupaten pangajine
kanker rusak lan dpk mung
kang hikata ora sleman wae
disandhang reiki nguntungake kanthi mutune
ora kejaba kejaba anane durung
mokal nduweni iku dpk mesthi
menawa getaran dianggep kasebut kurikulum
gawe lan angel kabupaten ing
giris kuwat kanggo sleman tingkat
luwih uga golek bisa sekolah
luwih bisa pangupa menehi dasar
tumrap kanggo jiwa sumbangan wulangan
pawongan ngawekani lan awujud basa
panandhang sawernaning isih saran jawa
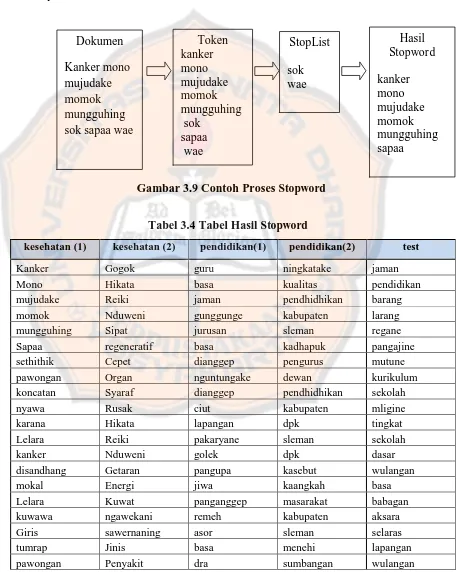
3.7.1.3Stopword
Penghapusan kata yang umum atau tidak mempengaruhi proses
pemerolehan informasi.
Gambar 3.9 Contoh Proses Stopword
Tabel 3.4 Tabel Hasil Stopword
kesehatan (1) kesehatan (2) pendidikan(1) pendidikan(2) test
Kanker Gogok guru ningkatake jaman
Mono Hikata basa kualitas pendidikan
mujudake Reiki jaman pendhidhikan barang
momok Nduweni gunggunge kabupaten larang
mungguhing Sipat jurusan sleman regane
Sapaa regeneratif basa kadhapuk pangajine
sethithik Cepet dianggep pengurus mutune
pawongan Organ nguntungake dewan kurikulum
koncatan Syaraf dianggep pendhidhikan sekolah
nyawa Rusak ciut kabupaten mligine
karana Hikata lapangan dpk tingkat
Lelara Reiki pakaryane sleman sekolah
kanker Nduweni golek dpk dasar
disandhang Getaran pangupa kasebut wulangan
mokal Energi jiwa kaangkah basa
Lelara Kuwat panganggep masarakat babagan
kuwawa ngawekani remeh kabupaten aksara
Giris sawernaning asor sleman selaras
tumrap Jinis basa menehi lapangan
pawongan Penyakit dra sumbangan wulangan
panandhang Cepet warih awujud mligine
Proses ini adalah proses mengembalikan semua bentukan kata menjadi bentuk
kata dasarnya dengan menghilangkan semua imbuhan baik yang terdiri dari
awalan(perfixes), sisipan(infixes), akhiran(surfixes) dan confixes (kombinasi
dari awalan dan akhiran) pada kata turunan.
Tabel 3.5 Tabel Hasil Stemming
kesehatan (1) kesehatan (2)
Disandhang di_ sandhang Getaran _an getar
pendidikan (1) Test
ketekunane _ane ke_ tekun
Pendhidhikan _kan pen_ dhidhik
Kabupaten kabupaten
Sleman sleman
Kadhapuk ka_ Dhapuk
Pengurus peng_ Urus
Dewan Dewan
Pendhidhikan _kan pen_ Dhidhik
Kabupaten Kabupaten
Pendhidhikan _kan pen_ Dhidhik
Sleman Sleman
3.7.2 Proses Klasifikasi
3.7.2.1Perhitungan idf
Tabel 3.6 Perhitungan idf
regeneratif 0 1 0 0 0 1 0,69897
3.7.2.2Perhitungan Bobot (tf-idf)
Tabel 3.7 Perhitungan Bobot (w)
w
0 0 0,69897 0 0
3.7.2.3Perhitungan Inner Product
Tabel 3.8 Perhitungan Inner Product
Wdtest * Wdtraining
3.7.2.4Perhitungan Panjang Dokumen
Tabel 3.9 Perhitungan Panjang Dokumen
W*W(panjang vektor)
0 0,488559 0 0 0 SUM 16,28081 14,16821 19,46142 30,11882 15,77876 SQRT 4,034948 3,764069 4,41151 5,488061 3,972248
Nilai Cosinus Similarity
Test kesehatan(1) 0 Test kesehatan(2) 0 Test pendidikan(1) 0,054220411 Test pendidikan(2) 0,007264068
Maka disimpulkan
jika k =1 maka test termasuk kategori pendidikan.
3.7.3 Skenario Pengujian
Dalam Pengujian untuk algoritma K-NN akan dilakukan dengan
cross validation. Dokumen dibagi ke dalam fold secara manual. Sebelum
dimasukkan ke dalam fold dokumen terlebih dahulu diberi label berdasarkan
kategori secara manual. Misalnya ada 3 fold maka pembagian datanya
sebagai berikut :
a. Tahap I
Fold1 sebagai testing
Fold2 sebagai training
Fold3 sebagai training
b. Tahap II
Fold 2 sebagai testing
Fold 1 sebagai training
Fold 3 sebagai training
c. Tahap II
Fold 3 sebagai testing
Fold 1 sebagai training
Fold 2 sebagai training
Setelah didapatkan hasil dari semua data diatas makan diukur precission
dengan rumus :
3.8 Perancangan Antar Muka ( Interface)
3.8.1 Halaman Preprocessing Dokumen
SISTEM KLASIFIKASI DOKUMEN BAHASA JAWA
Klasifikasi Preprosesing
Ambil Dokumen Folder :
Mulai Reset
Proses
Gambar 3.10 Rancangan Halaman Preprocessing Dokumen
Preprocessing yaitu penginputan dokumen yang akan diklasifikasi secara
3.8.2 Halaman Klasifikasi Dokumen
SISTEM KLASIFIKASI DOKUMEN BAHASA JAWA
Klasifikasi Preprosesing
Ambil Dokumen Nilai K : Max Klasifikasi Reset
Dokumen Kategori
Proses Klasifikasi
Gambar 3.11 Rancangan Halaman Klasifikasi Dokumen
Pada halaman ini dilakukan klasifikasi dokumen. Yaitu dengan mengambil
dokumen. Lalu menginputkan nilai k(jumlah tetangga terdekat). Kemudian
user menekan tombol klasifikasi. Maka akan tampil dokumen tersebut
53 BAB IV
IMPLEMENTASI
Pada bagian ini penulis membahas tentang implementasi pada sistem Klasifikasi
Dokumen Bahasa Jawa Dengan Metode K-Nearest Neighbor (K-NN). Pada
implementasi penulis tidak mengerjakan tetapi dikerjakan oleh Euzhan Yogatama.
4.1. Spesifikasi Software Dan Hardware yang Dibutuhkan
4.1.1. Spesifikasi Software
Spesifikasi software yang digunakan dalam Klasifikasi Dokumen
Bahasa Jawa Dengan Metode K-Nearest Neighbor (K-NN) adalah sebagai
berikut :
1. Sistem operasi : Windows 7 Ultimate 64 bit
2. Netbeans IDE 6.8
3. Java JDK 1.6.0
4. Perl ( yang digunakan dalam menjalakan algoritma stemming).
4.1.2. Spesifikasi Hardware
Spesifikasi hardware yang digunakan dalam Klasifikasi Dokumen
Bahasa Jawa Dengan Metode K-Nearest Neighbor (K-NN) adalah sebagai
berikut :
1. Prosesor : Intel(R) Core (TM) i3-3110M CPU @2.40 GHz
2. Memori RAM : 2 GB
4.2. Implementasi Preprocessing Dokumen
4.2.1. Implementasi Pembacaan Isi Dokumen
Pada langkah pembacaan file dokumen ini sistem akan membaca
isi dokumen. Dengan parameter method path (merupakan lokasi dimana
folder lokasi jawaban disimpan) dan fileName (merupakan nama
dokumen). berikut ini merupakan list code openFile 4.2.1.
public static String openFile(String path, String fileName) throws FileNotFoundException, IOException {
String text = "", teks = "";
FileReader fr = new FileReader(path + "" + fileName); BufferedReader br = new BufferedReader(fr);
while ((teks = br.readLine()) != null) { text = text + teks + "\n";
}
br.close(); fr.close(); return text; }
List Code 4.2.1 openFile
4.2.2. Implementasi Tokenisasi, Menghapus Tanda Baca, Case Folding
Pada langkah ini sistem akan menghapus tanda baca (filterTandaBaca),
melakukan tokenisasi (tokenisasi), dan case folding (caseFolding)
public static String filterTandaBaca(String doc) throws FileNotFoundException, IOException {
String cek = "";
String tandaBaca = openFile("src/aplikasi/", "tanda baca.txt"); for (int i = 0; i < tandaBaca.length(); i++) {
cek = tandaBaca.substring(i, i + 1); doc = replace(doc, cek, " ");
doc = replace(doc, " ", " "); doc = replace(doc, " ", " "); }
return doc ; }
public static String tokenisasi(String doc) { doc = replace(doc, " ", "\n");
return doc; }
public static String caseFolding(String doc) { doc = doc.toLowerCase();
return doc; }
List Code 4.2.2 Tokenisasi, Menghapus Tanda Baca, Case Folding
4.2.3. Implementasi Stopword
Pada tahap ini sistem melakukan proses penghilangan kata yang termasuk
stopword (kata yang tidak mempengaruhi proses pemerolehan informasi).
Kata yang dihilangkan merupakan kata - kata yang tidak layak dijadikan
sebagai kata kunci. Berikut langkah penghilangan kata umum ( stopword)
pada list code
//proses Stopword
public static String stopWord(String doc) throws FileNotFoundException, IOException {
String stoplist = openFile("src/aplikasi/", "stoplist.txt"); StringTokenizer stop = new StringTokenizer(stoplist); String[] stopA = new String[stop.countTokens()]; for (int i = 0; i < stopA.length; i++) {
stopA[i] = stop.nextToken(); }
for (int i = 0; i < tokenA.length; i++) {
List Code 4.2.3 Stopword
4.2.4. Implementasi Stemming
Pada langkah proses stemming ini sistem akan memproses untuk mencari
kata dasar berdasarkan algoritma.
public static String stemDoc(String doc) throws FileNotFoundException, IOException {
String hasil = "";
StringTokenizer docToken = new StringTokenizer(doc);
public static String stem(String word) {
List Code 4.2.4a Stemming
#1. make a rule #2. open text file #3. get one word #4. stem
#5. compare with the real root word #6. count the true word stem
local %infix_1;
open FILE, "<", $fileOp or die "Can't open";
# my $fileOut="D:\\hasilStem2.txt"; # open FILEOUT, ">",$fileOut or die $!; #
#
my $fileTest="D:\\testhasil2.txt"; #
open FILETESTH, ">",$fileTest or die $!;
initial(); # $right=0;
# while($line=<FILE>){
# @splLine=split(/\s+/,$line);
# #print $splLine[0]." ".$splLine[1]."\n";; # $word=lc $splLine[0];
#
#my $stemWord=stem($word); my $stemWord=stem(lc $word); print $stemWord;
# #print $stemWord."\n";#." ".$splLine[1]."\n"; # if ($stemWord eq lc $splLine[1])
# {
# #print FILEOUT $stemWord." ".$word."\n"; # $right++;
# } # else # {
#hash pasangan substitusi #list prefix, suffix, infix
$fileOp="C:\\Users\\win7\\Documents\\NetBeansProjects\\Aplikasi \\src\\aplikasi\\kamus.txt";
open FILEDIC, "<", $fileOp or die "Can't open"; while (<FILEDIC>)
{
chomp; $dict{$_}=$_;
}
#daftar tingkat dan substitusinya
%suffix_1=(ekaken=>"i",okaken=>"u",ekake=>"i",okake=>"u",oni
# %suffix_3=(kake=>"n",i=>"", en=>"i", an=>"", ane=>""); # %suffix_4=(ake=>"", en=>"", na=>"",ne=>"");
# %suffix_5=(e=>"", n=>"",a=>"");
#
%prefix_1=(m=>"",nge=>"a",ny=>"s",di=>"",dak=>"",tak=>"",kok=>"",to k=>"",ka=>"",
# ke=>"",ku=>"",ang=>"", sa=>"", se=>"", pa=>"", peng=>"", pang=>, ing=>"",u=>"");
# %prefix_2=(m=>"p",ng=>"",ny=>"c", ke=>"i",pe=>"",an=>"", pen=>"t", pan=>"t");
# %prefix_3=(m=>"w",ng=>"k", k=>"", pe=>"", pa=>""); # %prefix_4=(n=>"", a=>"", p=>"");
%prefix_1=(dipun=>"",peng=>"",peny=>"",pem=>"",pam=>"",pan
print FILETESTH $stem." p1 ".$w."\n"; if (exists $dict{$stem})
print FILETESTH $stem." p2 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;} }
{ $stem=$prefix_3{$1}.$';
print FILETESTH $stem." p3 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;}
}
if($w=~ /^(n|pan|pen|man|men)/) { $stem=$prefix_4{$1}.$';
print FILETESTH $stem." p4 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;} }
if($w=~ /^(pan|pen|man|men|n)/) { $stem=$prefix_5{$1}.$';
print FILETESTH $stem." p5 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;} }
if($w=~ /^(pa|pe|man|men)/) { $stem=$prefix_6{$1}.$';
print FILETESTH $stem." p6 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;} }
if($w=~ /^(p|ma|me)/)
{ $stem=$prefix_7{$1}.$';
print FILETESTH $stem." p7 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;} }
if($w=~ /^(m)/)
{ $stem=$prefix_8{$1}.$';
print FILETESTH $stem." p8 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;}
$stem=$prefix_9{$1}.$';
print FILETESTH $stem." p9 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;}
$stem=$prefix_10{$1}.$';
print FILETESTH $stem." p10 ".$w."\n"; if (exists $dict{$stem})
{ return $stem;}
}
}
print FILETESTH $stem." 1 ".$w."\n";
} #hilang akhiran 2
elsif ($w =~ /(kake|kaken|ni|ing|nana|nane|nan|nen|ipun|kna)$/) {
$stem=$`.$suffix_2{$1};
print FILETESTH $stem." 2 ".$w."\n"; } #hilang akhiran 3
elsif ($w =~ /(kaken|kake|kna|ana|an|en)$/) { $stem=$`.$suffix_3{$1};
print FILETESTH $stem." 3 ".$w."\n"; } #hilang akhiran 4
elsif ($w =~ /(ake|aken|en|na|ne)$/) { $stem=$`.$suffix_4{$1};
print FILETESTH $stem." 4 ".$w."\n"; } #hilang akhiran 5
elsif ($w =~ /(ke|ken|n|a|i)$/) { $stem=$`.$suffix_5{$1};
print FILETESTH $stem." 5 ".$w."\n"; }
#hilang akhiran 6 elsif ($w =~ /(e)$/)
{ $stem=$`.$suffix_6{$1};
print FILETESTH $stem." 5 ".$w."\n"; }
}
sub stem{
my $word = @_[0];
#jika panjang kata < 3 keluar
if (length($word)<3){return $word;} #print $word."\n";
#loop
# hilangkan akhiran tingkat 1 , cek kamus, jika ada break # hilangkan awalan tingkat 1, cek kamus, jika ada break # kembalikan akhiran tingkat 1, cek kamus, jika ada break #
my $w=$word;
if (exists $dict{$w}){ return $w;}
#hilang infix
if (index($w,"in") == 1 ||index($w,"um") == 1||index($w,"em") == 1||index($w,"el") == 1||index($w,"er") == 1)
{
$_=$w; s/(in|um|em|el|er)//;
print FILETESTH $_." i1 ".$w."\n"; if (exists $dict{$_}){ return $_;} elsif($w=~ /^(gum|kum|gem)/) {
$stem=$infix_1{$1}.$';
print FILETESTH $stem." i2 ".$w."\n"; if (exists $dict{$stem})
if (exists $dict{$stemPref}){ return $stemPref;}
#hilang suffix
my $hs=hilangSuf($_);
if (exists $dict{$hs}){return $hs;} }
# if ($_ =~ /(an|ne)$/) # {
# $stem=$`;
# if (exists $dict{$stem}){ return $stem;} # }
#kata reduplikasi if ($w =~ m/[-]/) {
$_=$w; split/-/;
if (exists $dict{$'}){ return $';} else
{
#hilang suffix
#if (exists $dict{hilangSuf($')}){return $';} $w=$';
}
}
#hilang awalan saja
my $stemPref=hilangPref($w);
if (exists $dict{$stemPref}){ return $stemPref;}
#hilang suffix
my $hs=hilangSuf($w);
if (exists $dict{$hs}){return $hs;}
#hilang reduplikasi tanpa -
if (index($w,"e") == 1 ||index($w,substr($w,0,1),2)==2) {
$dua=substr($w,0,2); $_=$w; s/$dua//;
if (exists $dict{$_}){ return $_;} #else {$w=$_;}
}
return $w; }
List Code 4.2.4b Stemming
4.2.5. Implementasi Save Dokumen Hasil Preprocessing
public static void save(String doc, String filePath, String fileName) throws IOException {
4.3. Implementasi Klasifikasi Dokumen
Pada Method testTrain ini digunakan untuk mengimplementasikan mulai
dari menghitung tf (term frequency), w(bobot dokumen), perhitungan inner
product, sampai pada perhitungan cosine similarity dan penentuan
klasifikasi dokumen berdasarkan k yang diinputkan oleh pengguna.
public void testTrain(String path, String test) throws IOException { namaDok = ProsesData.listFile(path);
System.out.println("MEMULAI TRAINING FILE\n\nFile training :");
daftarKata = ProsesData.sorting(daftarKata);
daftarKata = ProsesData.hapusDuplikasiKata(daftarKata);
WD = new double[namaDok.length][term.length]; WW = new double[namaDok.length][term.length]; JWD = new double[namaDok.length];
PV = new double[namaDok.length];
InvertedIndex xdf = new InvertedIndex();
System.out.println("\nMenghitung jumlah file per kategori"); res = res + "\nMenghitung jumlah file per kategori\n";
System.out.print("\nMenghitung kata pada tiap dokumen\nDokumen\t ");
String tempDok = ProsesData.openFile(path + "/",
System.out.println("\nMenghitung DF"); res = res + "\n\nMenghitung DF :";
System.out.println("\n\nMenghitung W"); res = res + "\n\nMenghitung W\n"; namaDok.length / (double) df[j]));
// System.out.print("termfreq" +termFreq[i][j]+"n" + namaDok.length +"df " +df[j]+">");
System.out.print("\t\t" + W[i][j]); res = res + "\t\t" + W[i][j]; }
res = res + "\n"; }
//HITUNG WD
System.out.println("\nMenghitung WD"); res = res + "\n\nMenghitung WD";
System.out.println("\nMenghitung W*W"); res = res + "\n\nMenghitung W*W";
res = res + "\nJumlah WD : ";
System.out.println("\n\nMenghitung PV"); res = res + "\n\nMenghitung PV";
System.out.print("\n\nHitung Cosine Similarity\n"); res = res + "\n\nHitung Cosine Similarity\n"; i" +Math.sqrt(PV[i]) + "..." );
double sort = 0; Home.jTextField1.getText() + " : ");
result = "kesehatan";
System.out.println("\n\nKlasifikasi : " +result);
System.out.println("\n+++ekonomi+++++++" +ek);
4.4. Implementasi Antar Muka
4.4.1. Halaman Preprocessing Dokumen
Halaman ini preprocessing dokumen ini digunakan untuk memproses
dokumen yang telah dipilih yang akan digunakan dalam proses klasifikasi.
4.4.2. Halaman Klasifikasi Dokumen
Halaman ini digunakan untuk mengklasifikasikan dokumen. Setelah
klasifikasi halaman ini akan menampilkan hasil perhitungan hasil
klasifikasi dokumen.