ISSN: 2686-0260
Copyright ⓒ SENARIS 2020
Penerapan Algoritma K-Means untuk Mengetahui Tingkat Potensi
Penyakit di Daerah Simalungun
Dina Patresia Samuana Manurung
1, Remonaldi Purba
2, Reynaldo Saragih
3,
P.P.P.A.N.W Fikrul Ilmi R.H Zer
4, Dedy Hartama
51,2,3,4,5
STIKOM Tunas Bangsa Pematangsiantar
1[email protected],
2[email protected],
3[email protected]
4[email protected],
5[email protected]
Abstract
Health is the most important source in human life. Many people who do not pay
attention to their health are not even aware of the disease that occurs in the
surrounding environment, so that people are vulnerable to disease, especially in the
Simalungun area. The data source of this research is based on the results of the
Central Statistics Agency of Simalungun Regency in 2019. There are 32 subdistricts
with frequent disease outbreaks, including pneumonia, diarrhea and dengue fever. It
is necessary to apply the K-Means algorithm by grouping 3 types of diseases based on
the District in the Simalungun area. By using the K-Means algorithm in this study, it
can be seen the level of potential disease in Simalungun Regency.
Keywords : Disease, Algorithms, K-Means, Grouping, Potential
1. Pendahuluan
Kesejahteraan masyarakat dimulai dari kehidupan yang sehat. Kesehatan merupakan sumber yang terpenting di dalam kehidupan manusia. Upaya pemeliharaan kesehatan sangat dibutuhkan dalam mencegah penyebaran suatu penyakit. Perkembangan teknologi saat ini sebagai sumber informasi di dunia kesehatan dapat memudahkan masyarakat untuk menerapkan pola hidup sehat dan cara alternatif dalam mengetahui potensi penyakit yang rentan terjadi di suatu daerah[1]. Rendahnya tingkat kesadaran masyarakat di Indonesia akan kebersihan menjadi dampak buruk bagi kesehatan. Pembangunan kesehatan harus dimulai dengan meningkatkan kesadaran masyarakat lewat faktor-faktor yang menjadi pengaruh besar pada kesehatan, terutama faktor lingkungan. Tanpa pengetahuan masyarakat terhadap suatu penyakit di lingkungan sekitar, maka masyarakat dapat diserang oleh berbagai jenis penyakit. Berdasarkan data yang diperoleh Badan Pusat Statistik Kabupaten Simalungun pada tahun 2019 terdapat 3 jenis penyakit yang sering menyerang masyarakat di daerah Kabupaten Simalungun yaitu Pneumonia, Diare, dan DBD. Luasnya wilayah Kabupaten Simalungun yang terdiri dari 32 Kecamatan membuat masyarakat sulit untuk mengetahui tingkat potensi penyakit yang terjadi di setiap daerah. Dengan menggunakan Algotritma K-Means, data yang diperoleh akan dikelompokan untuk mendapatkan informasi tentang tingkat potensi penyakit di suatu daerah.
K-Means merupakan pengelompokan suatu data nonhierarki yang melakukan partisi
suatu data ke dalam bentuk dua maupun lebih kelompok. Partisi data yang dilakukan pada metode ini dengan data yang memiliki karakteristik sama akan dimasukkan ke dalam kelompok yang sama dan data yang memiliki karakteristik berbeda akan dikelompokan kedalam kelompok yang lain. Dengan tujuan bahwa pengelompokan data dilakukan untuk meminimalkan suatu fungsi objektif yang diatur dalam proses pengelompokan dan berusaha
316
meminimalkan variasi di dalam suatu kelompok dan memaksimalkan variasi antar kelompok[2].
2. Metode Peneletian
2.1. Data MiningIstilah Data Mining mulai dikenal sejak tahun 1990, ketika pekerjaan pemanfaatan data menjadi sesuatu yang penting dalam berbagai bidang, mulai dari bidang akademik, bisnis hingga medis[3]. Data mining adalah suatu metode pengolahan data untuk menemukan pola yang tersembunyi dari data tersebut. Hasil dari pengolahan data dengan metode data mining ini dapat digunakan untuk mengambil keputusan di masa depan. Data Mining ini juga dikenal dengan istilah pattern recognition. Data mining merupakan metode pengolahan data berskala besar oleh karena itu Data Mining ini memiliki peranan penting dalam bidang industri, keuangan, cuaca, ilmu dan teknologi. Secara umum kajian data mining membahas metode-metode seperti, clustering, klasifikasi, regresi, seleksi variabel, dan market basket analisis[4]. 2.2. Algoritma K-Means
Algoritma K-Means merupakan salah satu algoritma yang membutuhkan parameter input sebanyak k dan dapat membagikan sekumpulan n objek pada k cluster, sehingga tingkat kemiripan antar anggota dalam cluster yang tinggi sedangkan tingkat kemiripan dengan anggota dalam cluster lain sangat rendah. Kemiripan dari suatu anggota terhadap cluster dapat diukur dengan kedekatan objek terhadap suatu nilai mean pada cluster atau dapat disebut juga sebagai centroid cluster atau pusat massa [5].
Langkah-langkah yang terdapat pada Algoritma K-Means[6], yaitu : 1. Tentukan jumlah cluster (k) yang akan dibentuk dari data set.
2. Tentukan nilai pusat (centroid) yang dilakukan pada tahap awal dengan acak/random menggunakan rumus : Vij =
1
1
N
0 Ni kXkj
Keterangan :Vij= Centorid rata-rata cluster ke-i untuk variable ke-j Ni = Jumlah anggota cluster ke-i
i, k= Indeks dari cluster j = Indeks variabel
Xkj .... = Nilai data ke-k variablel ke-j untuk cluster tersebut
3. Hitung jarak terdekat menggunakan centroid. Dalam perhitungan jarak data ke pusat kelompok adalah Euclidean Distance dengan rumus :
2 2 ( ) ( ) De xisi yi ti Keterangan : De = Euclidean Distance i = Banyaknya objek (x,y)= Koordinat objek (s,t) = Koordinat Centroid
4. Pengelompokan objek terhadap jarak ke centroid terdekat.
5. Lakukan kembali langlah ke-3 hinggalangkah ke-4 dengan melakukan iterasi hingga
317
2.3. Tahap pengumpulan data
Dalam penerapan Algoritma K-Means untuk menentukan tingkat potensi penyakit di daerah Kabupaten Simalungun, diperlukan data yang berhubungan tentang hal tersebut. Sumber data yang digunakan pada penelitian ini diperoleh dari data sekunder yang dikelola oleh dinas kesehatan Kabupaten Simalungun pada tahun 2019.
3. Hasil Dan Pembahasan
Berdasarkan data yang telah diperoleh, akan dilakukan perhitungan terhadap jumlah data kasus penyakit pada tahun 2019 dengan 32 kecamatan di daerah Kabupaten Simalungun. Berikut ini adalah data jumlah kasus penyakit pada tahun 2019 :
Tabel 1. Data Kasus Penyakit
No Kecamatan Pneumonia Diare DBD
1 Silimakuta 20 167 77 2 Pematang Silimahuta 6 122 1 3 Purba 31 249 26 4 Haranggaol Horison 13 67 4 5 Dolok Pardamean 43 141 21 6 Sidamanik 50 282 15 7 Pematang Sidamanik 34 177 8
8 Girsang Sipangan Bolon 31 160 9
9 Tanah Jawa 109 474 50 10 Hatonduhan 36 221 15 11 Dolok Panribuan 50 193 17 12 Jorlang Hataran 43 167 13 13 Panei 42 237 34 14 Panombei Panei 44 213 24 15 Raya 50 269 28 16 Dolok Masagal 0 122 6 17 Dolok Silau 12 175 2 18 Silou Kahean 17 196 1 19 Raya Kahean 23 198 7 20 Tapian Dolok 109 415 31
21 Dolok Batu Nanggar 28 410 36
22 Siantar 151 668 141
23 Gunung Malela 34 360 36
24 Gunung Maligas 50 289 15
25 Hutabayu Raja 50 318 22
26 Jawa Maraja Bah Jambi 21 239 9
27 Pematang Bandar 55 8258 27 28 Bandar Huluan 31 278 12 29 Bandar 93 576 15 30 Bandar Masilam 21 254 9 31 Bosar Maligas 30 401 20 32 Ujung Padang 29 406 5
318
Jumlah Cluster yang digunakan : 3 Jumlah Data yang di peroleh : 32 Jumlah Atribut : 3
Berikut langkah-langkah pengolahan Algoritma K-Means pada studi kasus : 1. Menentukan centroid awal secara acak, data yang dipilih adalah:
Data {Pematang Silimahuta, Raya, Pematang Bandar} M1 = (6,122,1)
M2 = (50,269,28) M3 = (55,8258,27)
2. Menghitung centroid terdekat.
Setelah centroid ditentukan, selanjutnya akan dihitung jarak dari setiap data terhadap
centroid. Pemlihan centroid pada data akan ditentukan melalui jarak terdekat antara data
dengan centroid. Perhitungan centroid pertama dengan jarak data pertama adalah: DM1 = (20 6) 2(167 122) 2(77 1) 2 89.426
DM2 = (20 50) 2(167269)2(7728)2 117.068
DM3 = (20 55) 2(167 8258) 2(7727)2 8091.230
Perhitungan selanjutnya dilakukan sampai data ke-32, maka hasil yang akan diperoleh dapat dilihat pada tabel 2.
Tabel 2. Hasil Perhitungan Iterasi 1
Kecamatan C1 C2 C3 Silimakuta 89.426 117.068 8.091.230 Pematang Silimahuta 0 155.801 8.136.189 Purba 131.829 27.659 8.009.036 Haranggaol Horison 55.525 206.758 8.191.140 Dolok Pardamean 46.152 128.382 8.117.011 Sidamanik 166.529 18.385 7.976.011 Pematang Sidamanik 62.113 95.499 8.081.050
Girsang Sipangan Bolon 46.184 112.263 8.098.056
Tanah Jawa 370.019 214.453 7.784.221 Hatonduhan 104.389 51.662 8.037.031 Dolok Panribuan 85.047 76.792 8.065.008 Jorlang Hataran 59.481 103.334 8.091.021 Panei 124.940 33.526 8021.01 Panombei Panei 101.262 56.462 8.045.008 Raya 155.801 0 7.989.002 Dolok Masagal 7.810 156.822 8.136.213 Dolok Silau 53.348 104.671 8.083.153 Silou Kahean 74.813 84.540 8.062.131 Raya Kahean 78.109 78.810 8.060.088 Tapian Dolok 312.022 157.499 7.843.187
319
Kecamatan C1 C2 C3
Dolok Batu Nanggar 290.952 142.930 7.848.052
Siantar 582.015 426.815 7.591.463
Gunung Malela 242.184 92.742 7.898.033
Gunung Maligas 173.266 23.854 7.969.011
Hutabayu Raja 201.973 49.366 7.940.003
Jawa Maraja Bah Jambi 118.229 45.848 8.019.092
Pematang Bandar 8.136.189 7.989.002 0 Bandar Huluan 158.373 26.420 7.980.050 Bandar 462.473 310.269 7.682.103 Bandar Masilam 133.090 37.776 8.004.092 Bosar Maligas 280.674 133.746 7.857.043 Ujung Padang 284.958 140.496 7.852.074
3. Melakukan pengelompokan data berdasarkan cluster. Berikut merupakan hasil dari pengelompokan cluster pada Iterasi 1
Tabel 3. Pengelompokan Data Iterasi 1 Kecamatan Cluster Silimakuta C1 Pematang Silimahuta C1 Purba C2 Haranggaol Horison C1 Dolok Pardamean C1 Sidamanik C2 Pematang Sidamanik C1
Girsang Sipangan Bolon C1
Tanah Jawa C2 Hatonduhan C2 Dolok Panribuan C2 Jorlang Hataran C1 Panei C2 Panombei Panei C2 Raya C2 Dolok Masagal C1 Dolok Silau C1 Silou Kahean C1 Raya Kahean C1 Tapian Dolok C2
Dolok Batu Nanggar C2
Siantar C2
Gunung Malela C2
Gunung Maligas C2
Hutabayu Raja C2
Jawa Maraja Bah Jambi C2
Pematang Bandar C3
320
Bandar C2
Bandar Masilam C2
Bosar Maligas C2
Ujung Padang C2
4. Menentukan centroid baru pada iterasi selanjutnya. Dalam mendapatkan centroid baru dapat dilakukan dengan mencari nilai rata-rata dari setiap cluster, maka diperoleh centroid baru untuk iterasi 2.
Tabel 4. Hasil Perhitungan Centroid Baru C1 Cluster 1
Kecamatan Pneumonia Diare DBD
Silimakuta 20 167 77
Pematang Silimahuta 6 122 1
Haranggaol Horison 13 67 4
Dolok Pardamean 43 141 21
Pematang Sidamanik 34 177 8
Girsang Sipangan Bolon 31 160 9
Jorlang Hataran 43 167 13 Dolok Masagal 0 122 6 Dolok Silou 12 175 2 Silou Kahean 17 196 1 Raya Kahean 23 198 7 Mean 22 153.818 13.545
Tabel 5. Hasil Perhitungan Centroid Baru C2 Cluster 2
Kecamatan Pneumonia Diare DBD
Purba 31 249 26 Sidamanik 50 282 15 Tanah Jawa 109 474 50 Hatonduhan 36 221 15 Dolok Panribuan 50 193 17 Panei 42 237 34 Panombeian Panei 44 213 24 Raya 50 269 28 Tapian Dolok 109 415 31
Dolok Batu nanggar 28 410 36
Siantar 151 668 141
Gunung Malela 34 360 36
Gunung Maligas 50 289 15
Hutabayu Raja 50 318 22
Jawa Maraja Bah Jambi 21 239 9
Bandar Huluan 31 278 12
Bandar 93 576 15
Bandar Masilam 21 254 9
321
Ujung Padang 29 406 5
Mean 52.95 337.6 28
Tabel 6. Hasil Perhitungan Centroid Baru C3 Cluster 3
Kecamatan Pneumonia Diare DBD
Pematang Bandar 55 8258 27
Mean 55 8258 27
Setelah mendapatkan centroid baru, maka dilakukan perhitungan pada iterasi selanjutnya. Dalam penelitian ini, perhitungan akan diberhentikan jika tahap iterasi telah mencapai hasil yang sama dan tidak ada lagi perpindahan dari cluster satu ke cluster lain. Oleh sebab itu, iterasi dilakukan sampai pada iterasi ke 6. Berikut ini adalah tabel dari hasil akhir dari cluster dan centroid ke 6 pada pengolahan data secara manual dengan 32 Kecamatan pada Tabel 7 :
Tabel 7. Pengelompokan Data Iterasi 6 Kecamatan Cluster Silimakuta C1 Pematang Silimahuta C1 Purba C1 Haranggaol Horison C1 Dolok Pardamean C1 Sidamanik C1 Pematang Sidamanik C1
Girsang Sipangan Bolon C1
Tanah Jawa C2 Hatonduhan C1 Dolok Panribuan C1 Jorlang Hataran C1 Panei C1 Panombei Panei C1 Raya C1 Dolok Masagal C1 Dolok Silau C1 Silou Kahean C1 Raya Kahean C1 Tapian Dolok C2
Dolok Batu Nanggar C2
Siantar C2
Gunung Malela C2
Gunung Maligas C1
Hutabayu Raja C1
Jawa Maraja Bah Jambi C1
Pematang Bandar C3
Bandar Huluan C1
Bandar C2
322
Bosar Maligas C2
Ujung Padang C2
Berikut adalah hasil pengolahan data menggunakan tools RapidMiner menggunakan
operator K-Means dengan 32 Kecamatan pada Gambar 1 :
Gambar 1. Hasil Cluster Pada RapidMiner
Gambar 1 menjelaskan hasil cluster pada RapidMiner dengan hasil Cluster 0 sebagai
cluster tertinggi dengan jumlah 1 item, cluster 1 sebagai cluster sedang dengan jumlah 23 item, dan cluster 2 sebagai cluster rendah dengan jumlah 8 item. Adapun hasil grafik dari RapidMiner dapat dilihat pada Gambar 2 berikut :
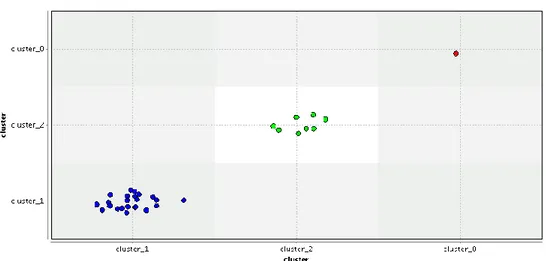
Gambar 2. Hasil Grafik Pengelompokkan pada RapidMiner
Gambar 2 menjelaskan grafik pengelompokkan dalam menentukan tingkat potensi penyakit di Daerah Simalungun dengan RapidMiner. Item yang berwarna merah merupakan
cluter 0 yaitu cluster tertinggi dengan jumlah 1, item yang berwarna biru merupakan cluster 1
yaitu cluster sedang dengan jumlah 23 dan item yang berwarna hijau merupakan cluster 2 yaitu cluster sedang jumlah 8 item.
4. KESIMPULAN
Pada penelitian ini dengan hasil dari perhitungan menggunakan Algoritma K-Means dalam mengelompokan tingkat potensi penyakit berdasarkan jumlah kasus penyakit di 32 kecamatan kabupaten simalungun dapat disimpulkan bahwa :
1. Terdapat 3 pusat Cluster, yaitu pada Cluster pertama terdapat pada Pematang Silimahuta,
Cluster kedua terdapat pada Raya, dan Cluster ketiga terdapat pada Pematang Bandar
323 3. Pada Cluster kedua dan ketiga merupakan daerah-daerah yang memiliki tingkat potensi
penyakit yang cukup tinggi sehingga perlu perhatian oleh pemertintah dan paramedis
DAFTAR PUSTAKA
[1] A. Bastian, H. Sujadi and G. Febrianto, “ Penerapan Algoritma K-Means Clustering Analysis Pada Penyakit Menular Manusia (Studi Kasus Kabupaten Majalengka)”, Jurnal Sistem Informasi (Journal of Information System)., vol. 14, Issue 1, (2018).
[2] Prasetyo, Eko, “Data Mining: Konsep dan Aplikasi menggunakan MATLAB”, Yogyakarta: CV Andi Offset,
(2012).
[3] M. Kantardzic, J. Wiley and Sons, “Data Mining: Concepts, Models, methods, and Algorithms”, (2003). [4] Santosa, Budi, “Data Mining: Teknik Pemanfaatan Data untuk Keperluan Bisnis”, Yogyakarta: Graha Ilmu,
(2007).
[5] Nango, D Noviati, "Penerapan algoritma K-Means untuk clustering data anggaran pendapatan belanja daerah di Kabupaten XYZ.", Universitas Gorontalo (2012).
[6] Agusta, Yudi, "K-Means–Penerapan, Permasalahan dan Metode Terkait.", Jurnal Sistem dan Informatika 3.1