TATA TERTIB PRAKTIKUM
STATISTIKA INDUSTRI DAN PENELITIAN OPERASIONAL 2014
KELENGKAPAN PRAKTIKUM SIPO 2014
Modul Praktikum
Modul praktikum dapat diunggah di website laboratorium SIPO setelah pelaksanaan registrasi.
Kartu Praktikum
1. Kartu praktikum yang telah dicetak segera dilengkapi dengan foto semua anggota kelompok dan cap laboratorium.
2. Setiap kegiatan praktikum, seluruh praktikan harus membawa kartu praktikum.
3. Apabila kartu praktikum hilang, praktikan dapat mengganti kartu praktikum maksimal satu kali penggantian dan segera meminta cap laboratorium kepada asisten untuk legalisir sebelum praktikum selanjutnya.
Pre Test (PRE)
1. PRE dilaksanakan pada saat awal praktikum modul 1, 2, 3, 4, 5, 7, 8 dan 9.
2. PRE dilakukan dalam bentuk tes praktik, tulis, atau lisan.
3. Praktikan yang masuk dalam kategori keterlambatan level 1, diberi kesempatan mengikuti PRE tanpa perpanjangan waktu.
Final Test (FIN)
1. FIN dilaksanakan pada akhir praktikum modul 1, 2, 3, 4, 5, 7, 8 dan 9.
2. FIN dilakukan dalam bentuk tes praktik.
1. Memenuhi seluruh kelengkapan praktikum yang tercantum pada poin-poin kelengkapan praktikum SIPO 2014.
Modul Praktikum
KELENGKAPAN PRAKTIKUM SIPO 2014
Kartu Praktikum
Pre Test (PRE)
Final Test (FIN)
PERSYARATAN MENGIKUTI PRAKTIKUM
2. Memenuhi persyaratan administrasi dan akademis yang telah diumumkan oleh laboratorium SIPO.
3. Memenuhi kelengkapan persyaratan tiap modul (persyaratan tambahan akan diumumkan di mading atau website lab SIPO sebelum praktikum modul bersangkutan dimulai).
4. Apabila salah satu atau lebih dari syarat tersebut tidak terpenuhi maka praktikan tersebut tidak diperkenankan mengikuti praktikum.
1. Praktikan wajib memenuhi seluruh kelengkapan dan persyaratan praktikum. Apabila tidak, maka berlaku poin ke-4 dari persyaratan mengikuti praktikum.
2. Asisten dapat memperingatkan bahkan mengeluarkan praktikan yang tidak dapat menjaga ketenangan, ketertiban, kebersihan, dan kerapian lab saat kegiatan praktikum.
3. Setiap praktikan wajib menjaga sopan santun dalam bertutur kata baik sesama praktikan maupun kepada asisten.
4. Setiap barang yang digunakan dan dipinjam pada saat praktikum wajib dikembalikan pada tempatnya.
5. Tidak mengikuti praktikum salah satu modul atau lebih tanpa alasan yang dapat dipertanggungjawabkan dan diterima oleh seluruh asisten SIPO 2014 maka praktikan tersebut diwajibkan mengulang praktikum pada modul yang bersangkutan di tahun berikutnya.
6. Tukar jadwal
Praktikan dapat melakukan tukar jadwal praktikum dengan alasan yang dapat
dipertanggungjawabkan dan dapat diterima seluruh asisten SIPO 2014 paling lambat satu hari (24 jam) sebelum praktikum dilaksanakan dengan mengisi form tukar jadwal.
7. Jika praktikan berhalangan hadir karena sakit, maka diwajibkan menyerahkan surat keterangan dokter maksimal tiga hari setelah pelaksanaan praktikum. Jika tidak maka berlaku poin ke-5 di atas.
8. Praktikum susulan
• Praktikum susulan hanya diberikan kepada praktikan yang tidak dapat mengikuti praktikum dengan menyertakan alasan yang benar, resmi, jelas, dan dapat diterima oleh seluruh asisten SIPO 2014.
• Praktikum susulan maksimal dua modul (lebih dari dua modul dinyatakan tidak lulus) dengan jadwal yang akan ditetapkan kemudian.
TATA TERTIB PELAKSANAAN PRAKTIKUM
• Tidak mengikuti praktikum susulan dengan alasan yang tidak dapat dipertanggungjawabkan, maka wajib mengulang keseluruhan modul di tahun berikutnya.
• Aturan lainnya sama dengan aturan pada pelaksanaan praktikum.
9. Aturan mengenai pemakaian busana dan kelengkapan, praktikan diwajibkan untuk:
• Memakai pakaian seragam, yaitu kemeja/blouse warna putih, celana panjang/rok warna biru (bukan jeans), bersepatu bukan sandal dan berkaos kaki.
• Rambut mahasiswa pria harus rapi, tidak melebihi kerah kemeja yang dikenakan, dan tidak boleh diikat.
10. Praktikum
• Praktikum SIPO 2014 terdiri dari 9 modul meliputi 5 modul Statistika Industri, 3 modul Penelitian Operasional, dan 1 modul integrasi Statistika Industri.
• Praktikum dilaksanakan di lab SIPO yang jadwalnya akan ditentukan kemudian.
• Praktikan wajib hadir tepat waktu saat pelaksanaan praktikum. Setap keterlambatan mendapat konsekuensi:
a. Level 1 – Terlambat < 15 menit: praktikan masih boleh mengikuti praktikum dan tidak ada tambahan waktu dalam pengerjaan tes awal.
b. Level 2 – Terlambat 15-30 menit: praktikan masih boleh mengikuti praktikum tetapi nilai tes awal 0.
c. Level 3 – Terlambat > 30 menit: praktikan tidak diizinkan mengikuti praktikum dan modul yang bersangkutan dinyatakan gugur.
• Selama praktikum, praktikan tidak diperkenankan meninggalkan ruangan praktikum tanpa seizin asisten jaga.
• Alat komunikasi dinyalakan dalam mode silent atau dimatikan.
11. Lab SIPO tidak akan mentolerir segala bentuk kecurangan. Apabila praktikan terbukti berbuat curang, maka nilai praktikum SIPO 2014 dipastikan untuk mendapat nilai E.
12. Kepentingan mahasiswa secara resmi dilayani oleh laboratorium SIPO pada jam kerja sampai dengan pukul 21.00 WIB.
13. Hal-hal yang belum tercantum dalam peraturan ini akan ditentukan kemudian.
14. Peraturan dapat mengalami revisi jika ditemukan kelemahan atau ketidaksesuaian di kemudian hari.
1. Berikut proporsi penilaian tiap modul.
MODUL 1
MODUL 2
MODUL 3
MODUL 4
MODUL 5
PRE 25% 25% 20% 30% 25%
PRATIKUM 40% 40% 40% 40% 40%
FIN 35% 35% 40% 30% 35%
TUGAS
INTEGRASI - - - - -
PRESENTASI - - - - -
MODUL 6
MODUL 7
MODUL 8
MODUL 9
PRE - 20% 20% 20%
PRATIKUM 30% 35% 35% 30%
FIN - 20% 20% 25%
TUGAS
INTEGRASI - 25% 25% 25%
PRESENTASI 70% - - -
PENILAIAN PRAKTIKUM
Alat dan Bahan Praktikum Tujuan Praktikum
Referensi
MODUL 1
PENGENALAN MICROSOFT EXCEL, DATA, DAN TEKNIK SAMPLING
Tujuan Umum
1. Praktikan mampu mengoperasikan software Miscrosoft Excel 2013.
2. Praktikan memahami tipe data.
3. Praktikan memahami konsep teori sampling.
Tujuan Khusus
1. Praktikan memahami fungsi dan penggunaan fungsi statistik yang ada dalam Microsoft Excel 2013.
2. Praktikan dapat menyelesaikan studi kasus dengan menggunakan software Microsoft Excel 2013.
3. Praktikan dapat menerapkan teknik sampling dengan software Microsoft Excel 2013.
1. SIPO Laboratory. 2013. Modul Praktikum Statistika Industri dan Penelitian Operasional. Bandung:
Universitas Telkom
2. Boediono, DR., Koster, Wayan, DR.IR . 2008. Teori dan Aplikasi Statistika dan Probabilitias. Bandung:
Rosda
3. Anonim (2012) Microsoft Excel. [Online] Dikutip dari: http://id.wikipedia.org/wiki/Microsoft_Excel 4. Anonim (2012) Excel. [Online] Dikutip dari:
http://office.microsoft.com/id-id/excel-help/
5. Prof. Rozaini Nasution, SKM. [Online] Dikutip dari: http://library.usu.ac.id/download/fkm/fkm- rozaini.pdf
1. Komputer
2. Modul Praktikum SIPO 2014 3. Software Microsoft Excel 2013 4. Alat Tulis
5. Data
Pengenalan Microsoft Excel
Microsoft Excel adalah aplikasi spreadsheet yang dikembangkan oleh Microsoft Corporation untuk sistem operasi Microsoft Windows dan Mac OS (Sumber: Wikipedia). Microsoft Excel dirancang untuk merekam, mengolah, menganalisis, memproyeksikan, dan menampilkan informasi kuantitatif. Data yang ditampilkan bisa berbentuk tabel dengan berbagai jenis yang telah disediakan, mulai dari bentuk Batang, Grafik, Pai, Garis, dan lainnya. Microsoft Excel biasanya berkaitan dengan informasi-informasi kuantitatif diantaranya:
Tabel 1.1 Tabel Penggunaan Microsoft Excel untuk Data Kuantitatif
Manajemen Manufaktur
Laporan keuangan (Laba-Rugi, Neraca, Aliran Kas)
Database (penyimpanan informasi penting sebuah lembaga)
Pencatatan penjadwalan produksi
Pembuatan Master Requirement Planning
Forecasting demand dalam periode tertentu
Pencatatan persedian produk
Tampilan Workbook pada Microsoft Excel 2013
Gambar 1.1 Tampilan Workbook pada Microsoft Excel 2013
Keterangan :
Menu Bar/Tab : Berisi sederet menu yang dapat digunakan, di mana setiap menu memiliki sub-menu masing-masing sesuai dengan fungsi dari menu induknya.
Tool Bar : merupakan area yang sering digunakan yang berfungsi dalam hal memformat lembar kerja.
Seperti tulisan yang rata kiri, tengah, atau kanan, huruf cetak tebal, garis bawah, dan lain-lain.
Formula Bar : merupakan tempat untuk mengetikkan rumus-rumus (formula) yang akan digunakan untuk mengolah data. Dalam Microsoft Excel, pengetikkan rumus harus didahului dengan tanda “=”.
Sehubungan dengan fitur utama Microsoft Excel yakni untuk mengolah data kuantitatif, maka berikut ini adalah pilihan-pilihan untuk mengolah data tersebut.
1. Perhitungan dengan Formula
Formula dalam Microsoft Excel berfungsi untuk melakukan perhitungan sederhana pada data yang dimasukkan. Setiap formula selalu diawali dengan tanda “=”. Formula terdiri dari beberapa operasi dasar, sebagai berikut:
Tabel 1.2 Formula Operasi Dasar pada Microsoft Excel
Simbol Keterangan Contoh Formula
+
Untuk operasiPenjumlahan
Menjumlahkan bilangan 10 dengan
15
=10+15
-
Untuk operasipengurangan
Mengurangkan bilangan 30 dengan
20
=30-20
*
Untuk operasiperkalian
Mengalikan bilangan 15 dengan
4
=15*4
/
Untuk operasi pembagianMembagi bilangan 45 dengan 3
=45/3
^
Untuk operasiperpangkatan
Memangkatkan 10 dengan 2
=10^2
%
Untuk membuatnilai bilangan biasa menjadi persen
Menuliskan bilangan 8%, maka nilai aslinya adalah
0.08
=8%
2. Perhitungan dengan Menggunakan Fungsi
Fungsi adalah rumus-rumus yang telah disediakan oleh Microsoft Excel dan digunakan sebagai alat bantu untuk melakukan operasi perhitungan yang rumit. Penggunaan setiap fungsi selalu disertai dengan tiga elemen:
Tanda “=” di awal penulisan menunjukkan bahwa penulisan berikutnya adalah fungsi
Nama fungsi menunjukkan operasi apa yang akan dilakukan
Daftar argumen dituliskan di dalam tanda kurung (), menunjukkan range sel di mana nilai fungsi itu harus dilakukan
Berikut merupakan fungsi statistik yang umum digunakan:
Tabel 1.3 Fungsi Statistik pada Microsoft Excel 2013
No. Fungsi Statistik
Deskripsi Formula
1 AVERAGE Fungsi yang digunakan untuk
menghitung rata-rata (mean)
angka
2 COUNT Fungsi yang digunakan untuk menghitung jumlah sel yang berisi angka
3 COUNT BLANK
Fungsi yang digunakan untuk
menghitung semua sel yang
kosong dalam suatu range
4 COUNTA Fungsi yang digunakan untuk
menghitung semua sel yang berisi data baik angka maupun
kata
5 IF Fungsi yang
digunakan untuk menempatkan
dalam sel
6 LOOKUP Fungsi yang digunakan untuk
mencari data dari tabel
(Contoh:
pencarian angka 3,4 maka hasil
yang ditampilkan adalah data yg sesuai pencarian atau terdekat ke bawah dengan
3,4)
7 MAX Fungsi untuk
mencari nilai terbesar di dalam suatu
range
8 MIN Fungsi untuk mencari nilai terkecil di dalam
suatu range
9 SUM Fungsi ini
digunakan untuk menghitung jumlah angka dalam range sel
10 ROUNDUP Fungsi ini digunakan untuk
membulatkan
ke atas
11 COUNTIF Fungsi ini digunakan untuk
menghitung perhitungan
dengan persyaratan
12 MEDIAN Fungsi ini digunakan untuk menghitung nilai
tengah
13 SKEW Fungsi ini digunakan untuk
menampilkan nilai kemiringan
dalam suatu distribusi
14 FREQUENCY Fungsi ini digunakan untuk
mencari seberapa sering
data tertentu muncul dalam suatu distribusi
mencari dan mengestimasi standar deviasi
dalam suatu distribusi
16 VAR Fungsi untuk
menentukan nilai variance dari suatu range
17 MODE Fungsi untuk menampilkan nilai data yang
paling sering muncul. (jika data tidak mengandung
nilai modus maka hasil yang
akan ditampilkan adalah: #N/A)
18 LEFT Fungsi untuk
menampilkan beberapa karakter dari
bagian kiri
menampilkan beberapa karakter dari bagian kanan
20 MID Fungsi untuk
menampilkan beberapa
karakter terhitung dari
tengah
21 UPPER Fungsi untuk mengubah data
teks dari huruf kecil menjadi
huruf besar
22 LOWER Fungsi untuk mengubah data
teks dari huruf besar ke huruf
kecil
menghitung jumlah data yang memenuhi
dua atau lebih kriteria
24 RAND Fungsi untuk
membangkitkan bilangan random
(acak), antara 0 sampai 1
25 RANDBETWEEN Fungsi untuk membangkitkan bilangan random
diantara bilangan yang
ditentukan
26 SQRT Fungsi untuk menghasilkan suatu nilai akar
kuadrat dari sebuah bilangan
27 CORREL Fungsi untuk menentukan
derajat hubungan antara dua variabel
Catatan:
Tombol TAB
Di dalam penggunaan fungsi formula di Microsoft Excel bisa memudahkan user untuk mengetik formula dengan tepat (Autocorrecrt). Saat mulai mengetik formula biasanya aka muncul beberapa pilihan formula yang serupa dan dengan mengklik TAB maka formula akan muncul dengan benar.
Tombol F4
Digunakan untuk mengunci suatu data yang akan diolah dengan menggunakan fungsi formula.
Misalnya ada data pembagi yang digunakan terus-menerus dalam perhitungan, makan klik F4 pada sel yang berisikan data itu, untuk mengunci data.
Copy-Paste pada Fungsi RAND/RANDBETWEEN
Setelah membangkitkan bilangan random dengan fungsi RAND/RANDBETWEEN sebaiknya hasil yang muncul dicopy lalu dipaste-value di sel yang sama. Tujuannya agar bilangan yang dihasilkan pertama kali dari fungsi tersebut tidak berubah-ubah nilainya.
FREQUENCY
Dalam menggunakan fungsi Frequency, terdapat perbedaan dengan penggunaan fungsi pada umumnya.
Berikut adalah contoh cara menggunakan fungsi Frequency dalam Microsoft Excel 2013.
Terdapat data nilai Operational Research I yang telah dibuat dalam satu tabel seperti berikut ini:
Tabel 1.4 Tabel Nilai OR I
Selanjutnya, dibuat tabel interval untuk nilai-nilai tersebut. Dibuat ke dalam empat kelas. Nilai terkecil dimuai dari 60 hingga nilai terbesar yakni 100. Tabel interval dilengkapi dengan batas atas masing-masing kelas. Tabel interval terlihat sebagai berikut:
Tabel 1.5 Tabel Interval dengan Batas Atas
Berikutnya adalah menggunakan fungsi Frequency untuk memunculkan jumlah data nilai yang berada di dalam satu kelas interval.
Di dalam kasus ini, hasil akan ditampilkan di dalam sel F2 hingga F5. Block terlebih dahulu range sel yang akan digunakan untuk menampilkan hasil (F2:F5).
Tabel 1.6 Tampilan Block
Setelah diblock, ketik fungsi Frequency. Penulisan seperti pada tampilan berikut:
Tabel 1.7 Tampilan Penulisan Fungsi Frequency
o Data array merupakan kumpulan data yang akan disesuaikan dengan bins array (data kunci).
o Bins array merupakan kumpulan data yang dijadikan data kunci untuk disesuaikan dengan data array.
Setelah mengetikkan fungsi, maka selanjutnya adalah menekan tombol Ctrl + Shift + Enter (secara bersamaan). Untuk mengeluarkan hasil secara langsung di dalam range sel yang telah diblock.
Tampilan hasil sebagai berikut:
Tabel 1.8 Tampilan Hasil Fungsi Frequency
AUTOSUM
Dalam melakukan penjumlahan data dalam suatu range selain dengan fungsi SUM, kita juga dapat menggunakan “Command Button AutoSum” ( ) yang ada pada Tab Formula. Command Button AutoSum akan membantu menjumlahkan data dalam baris maupun kolom secara otomatis. Command Button AutoSum tidak hanya digunakan untuk melakukan operasi penjumlahan tetapi juga dapat digunakan untuk menghitung rata-rata, banyak data, data tertinggi, data terendah, dan fungsi lainnya.
Gambar 1.2 Tampilan Penggunaan Autosum
Untuk pilihan lainnya terdapat pada “More Function” (dengan mengklik lambang segitiga kecil di sampingnya)
Gambar 1.3 Tampilan Dialog Box More Function pada Autosum
Tampilan AutoSum
Tabel 1.9 Tabel Output Autosum
FUNGSI LOOKUP
Ada dua jenis LOOKUP dalam Excel, yaitu:
HLOOKUP
Fungsi ini digunakan untuk membaca tabel yang tersusun secara horizontal. Ekspresi fungsi yang digunakan adalah “ =HLOOKUP “ (nilai kunci;array table;offset row).
Nilai kunci adalah sel yang dipakai dalam pembacaan tabel, yaitu yang berada pada baris pertama pada tabel dengan syarat isi baris pertama yang ada pada tabel sudah terurut.
Array tabel adalah tabel yang berisi data/informasi dimana data tersebut akan dibaca. Array tabel ini bisa berupa nama tabel (jika range tabel telah diberi nama) atau range dari tabel HLOOKUP.
Offset Row adalah baris kesekian yang berisi informasi yang akan ditampilkan.
VLOOKUP
Fungsi ini digunakan untuk membaca tabel yang tersusun secara vertikal. Ekspresi fungsi yang digunakan adalah “ =VLOOKUP “ (nilai kunci,array table;offset column)
Nilai kunci adalah kunci yang dipakai dalam pembacaan tabel yaitu yang berada pada kolom pertama pada tabel dengan syarat isi kolom pertama yang ada pada tabel sudah terurut.
Array tabel adalah tabel yang berisi data/informasi dimana data tersebut akan di baca. Array tabel ini bisa berupa nama tabel atau range dari tabel VLOOKUP.
Offset Column adalah kolom kesekian yang berisi informasi yang akan ditampilkan.
Contoh Penggunaan VLOOKUP
Dalam contoh ini, tujuan digunakannya VLOOKUP untuk mengetahui asal daerah pegawai berdasarkan kode daerahnya masing-masing pada database, dibantu oleh tabel referensi. Berikut tampilan tabel Database pegawai dan kode kota:
Tabel 1.10 Data Nama Pegawai dan Domisili
Tabel 1.11 Tabel Data Referensi Asal Daerah
=VLOOKUP(C2;$G$3:$H$7;2;FALSE)
Maka hasil yang ditampilkan adalah sebagai berikut:
Tabel 1.12 Tampilan Hasil VLOOKUP
FUNGSI LOGIKA
Fungsi ini digunakan untuk menyeleksi suatu kondisi dari data yang ada dan memberikan hasil atau nilai yang berbeda sesuai dengan ketentuan yang diberikan. Fungsi ini dibantu oleh operator relasi (pembanding) seperti berikut:
Tabel 1.13 Tabel Operator Relasi
Lambang Fungsi
= Sama Dengan
< Lebih Kecil dari
> Lebih besar dari
<= Lebih kecil atau sama dengan
>= Lebih besar atau sama dengan
<> Tidak sama dengan
Fungsi logika IF yang hanya memiliki satu kondisi/syarat sehingga dipastikan hanya memiliki dua hasil yang akan ditampilkan, yaitu hasil yang sesuai syarat atau hasil yang tidak sesuai syarat, akibat dari satu kondisi/syarat tersebut sehingga hanya membutuhkan satu IF (Tunggal).
Tabel 1.14 Tabel Contoh Penggunaan Fungsi IF (Tunggal)
2. Fungsi IF (Multi)
Fungsi logika IF yang memiliki lebih dari satu syarat sehingga dipastikan memiliki lebih dari dua hasil yang akan ditampilkan yaitu hasil yang sesuai syarat pertama, kedua, dan seterusnya dan yang terakhir hasil yang tidak sesuai syarat semuanya, akibat dari satu syarat tersebut sehingga membutuhkan lebih dari satu IF.
Tabel 1.15 Tabel Contoh Penggunaan Fungsi IF (Multi)
=IF(M2>=80;”LULUS”;”TIDAK LULUS”)
=IF(M2>89;"A";IF(M2>79;"B";IF(M2>69;"C";"D")))
3. Fungsi IF_OR
Penerapan logika dengan menggunakan kata sambung ATAU untuk memisahkan lebih dari satu syarat logika.
Tabel 1.16 Tabel Contoh Penggunaan Fungsi IF_OR
4. Fungsi IF_AND
Penerapan logika dengan menggunakan kata sambung DAN untuk memisahkan lebih dari satu syarat logika.
Tabel 1.17 Tabel Contoh Penggunaan Fungsi IF_AND
=IF(OR(B2="SMU/SMK";B2="D1");"Tes Tahap 1";"Gagal Tes")
=IF(AND(B2>=5;C2>=3);"Test Tahap 2";"Gagal Tes")
PIVOT TABLE
Pivot Table adalah tabel khusus yang merangkum informasi dari kolom-kolom tertentu dari sebuah sumber data (data source) sehingga informasi tersebut akan lebih mudah dilihat. Dengan fasilitas pivot table, kita dapat membuat tabel rekapitulasi yang meringkas data berdasarkan kriteria-kriteria tertentu.
Hal ini dimaksudkan agar kita lebih mudah dalam menganalisis suatu data yang berukuran besar tanpa mengganggu dan mempengaruhi data aslinya.
Contoh Penggunaan Pivot Tabel 1. Diketahui data sebagai berikut:
Tabel 1.18 Tabel Data Mahasiswa dan Domisili
2. Klik Insert > Pivot Tabel
Gambar 1.4 Tampilan Icon Pivot Tabel
3. Akan muncul kotak dialog seperti berikut
Gambar 1.5 Tampilan Dialog Box Create Pivot Table
4. Select a table or range, memilih seluruh sumber data utama
5. New Worksheet digunakan untuk menampilkan pivot table dengan sheet yang baru 6. Existing Worksheet digunakan untuk menampilkan pivot table dengan sheet awal 7. Klik OK.
8. Kemudian akan muncul kotak dialog seperti berikut (di bagian kanan layar)
Gambar 1.6 Tampilan Pivot Tabel Fields
Column Labels berisi kategori yang akan diletakkan pada kolom
Row Labels berisi kategori yang akan diletakkan pada baris
Values berisi data yang nantinya akan muncul sesuai dengan kategori baris dan kolom
Report Filter digunakan untuk menyaring data yang akan dikeluarkan pada pivot table
Memasukkan data dengan men-drag Fields ke masing-masing area Contoh:
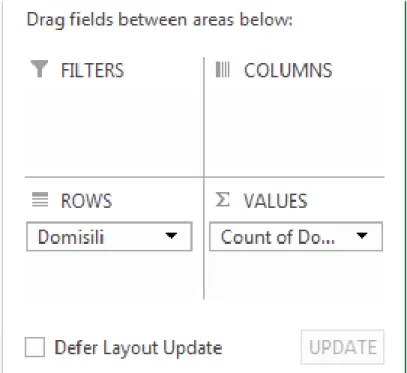
Akan dibuat pivot table yang menunjukkan banyak siswa per domisili
Gambar 1.7 Tampilan Pivot Tabel Fields Domisili
Gambar 1.8 Tampilan Pivot Tabel Rekap Domisili
REMOVE DUPLICATE
Dengan pivot table data dapat dikonfigurasikan, dengan klik tanda panah di samping Row Label, pilih kriteria yang diinginkan, klik OK
Gambar 1.9 Tampilan Konfigurasi dari Pivot Tabel
Fungsi remove duplicate dapat digunakan untuk menghilangkan data-data yang sama dalam satu kolom atau lebih, yang akan meninggalkan data/nilai yang unik pada kolom tersebut.
Contoh Penggunaan Remove Duplicate 1. Data pembangkit Variat Random
Tabel 1.19 Tabel Data Bilangan Random
2. Pilih kolom yang akan dihilangkan duplikatnya
Tabel 1.20 Tabel Tampilan Select Data
3. Pilih Data > Remove Duplicate
Gambar 1. 10 Tampilan icon Remove Duplicates
4. Untuk dialog box Remove Duplicate Warning yang muncul, selanjutnya pilih Continue with the current selection > Remove Duplicates.
Gambar 1.11 Tampilan Dialog Box Remove Duplicate Warning
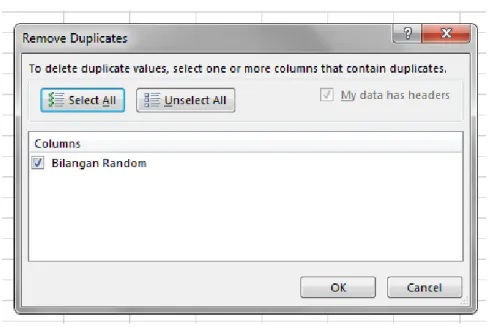
5. Checklist kolom yang ingin dihilangkan duplikatnya, kemudian klik OK
Gambar 1.12 Tampilan Dialog Box Remove Duplicate
DESKRIPTIF STATISTIK
6. Hasil kolom yang telah dihilangkan data yang memiliki duplikat
Gambar 1.13 Tampilan Informasi Remove Duplicates
Berdasarkan jenisnya, statistika dibedakan menjadi dua, yaitu (Teori dan Aplikasi Statistika dan Probabilitas, hal.8):
1. Statistika Deskriptif, adalah statistika yang berkenaan dengan metode atau cara mendeskripsikan, menggambarkan, menjabarkan, atau menguraikan data, tanpa berupaya untuk menyimpulkan kondisi keseluruhan
2. Statistika Inferensia, adalah statistika yang berkenaan dengan cara penarikan kesimpulan berdasarkan data yang diperoleh dari sampel untuk menggambarkan karakteristik atau ciri dari suatu populasi.
Tipe Data Statistik
Salah satu aspek yang penting untuk dipelajari dalam memahami data ataupun keperluan analisis statistika inferensia adalah skala pengukuran, yaitu yang menunjukkan kualitas data.
TEKNIK SAMPLING
Berdasarkan Santoso (2001, pp4-6), data dalam statistik berdasarkan tingkat pengukurannya (level of measurement) dapat dibedakan dalam empat jenis, yakni:
1. Data Kualitatif
Data yang bukan berupa angka dengan karakteristik tidak bisa dilakukan operasi matematika.
Data Nominal, merupakan skala yang paling rendah. Skala yang hanya memiliki ciri untuk membedakan skala ukur yang satu dengan skala ukur yang lain, data hanya bisa diklasifikasikan ke dalam kategori-kategori. Contoh: Jenis Kelamin (P/L), Ya/Tidak.
Data Ordinal, merupakan skala yang selain mempunyai ciri untuk membedakan juga mempunyai ciri untuk mengurutkan pada rentang tertentu. Misalnya rentang dari rendah, sedang, dan tinggi.
2. Data Kuantitatif
Data berupa angka, dalam arti yang sesungguhnya, dan bisa digunakan dalam operasi matematika.
Data Interval, merupakan skala pengukuran yang bisa bertingkat urutannya, dan urutan tersebut dikuantitatifkan. Data interval memiliki rentang tertentu. Contoh: Usia (Muda: 20 – 30 tahun; Dewasa: 31 – 40 tahun; Tua: 41 – 60 tahun).
Data Rasio, merupakan skala pengukuran tertinggi dengan data yang kuantifikasinya mempunyai nilai mutlak. Contoh: data tinggi badan, berat badan.
Sampling merupakan teknik pengambilan sampel dari populasi. Sampel yang diambil adalah sampel yang dapat mewakili populasi. Beberapa faktor yang menyarankan penggunaan teknik sampling, adalah sebagai berikut:
a. Dalam kasus populasi terbatas, pengamat tidak mungkin untuk melakukan sensus (pengumpulan setiap elemen dalam populasi)
b. Dalam kasus populasi homogen, sampling dianggap lebih efisien c. Pertimbangan dari segi waktu dan biaya
𝐾 =𝑵 (𝑗𝑢𝑚𝑙𝑎ℎ 𝑎𝑛𝑔𝑔𝑜𝑡𝑎 𝑝𝑜𝑝𝑢𝑙𝑎𝑠𝑖) 𝒏 (𝑗𝑢𝑚𝑙𝑎ℎ 𝑎𝑛𝑔𝑔𝑜𝑡𝑎 𝑠𝑎𝑚𝑝𝑒𝑙 Metode sampling dibagi menjadi dua, yaitu:
1. Probability Sampling, dan 2. Non-probability Sampling
A. Sample Acak/ Random Sampling/ Probability Sampling
Pada pengambilan sampel secara random, setiap unit populasi, mempunyai kesempatan yang sama untuk diambil sebagai sampel. Faktor pemilihan atau penunjukan sampel yang mana akan diambil, yang semata- mata atas pertimbangan peneliti, disini dihindarkan. Bila tidak, akan terjadi bias.
Dengan cara random, bias pemilihan dapat diperkecil, sekecil mungkin. Ini merupakan salah satu usaha untuk mendapatkan sampel yang representatif.
Keuntungan pengambilan sampel dengan probability sampling adalah sebagai berikut:
- Derajat kepercayaan terhadap sampel dapat ditentukan.
- Beda penaksiran parameter populasi dengan statistik sampel, dapat diperkirakan.
- Besar sampel yang akan diambil dapat dihitung secara statistik.
Cara pengambilan sample data Probability Sampling, sebagai berikut:
1. Sampel Random Sederhana (Simple Random Sampling)
Proses pengambilan sampel dilakukan dengan memberi kesempatan yang sama pada setiap anggota populasi untuk menjadi anggota sampel. Jadi disini proses memilih sejumlah sampel n dari populasi N yang dilakukan secara random. Ada 2 cara yang dikenal:
a. Bila jumlah populasi sedikit, bisa dilakukan dengan cara mengundi “Cointoss”
b. Bila populasi besar, perlu digunakan label “Random Numbers”
Keuntungan : Prosedur estimasi mudah dan sederhana
Kerugian : Membutuhkan daftar seluruh anggota populasi
Sampel mungkin tersebar pada daerah yang luas, sehingga biaya transportasi tinggi
2. Sampel Random Sistematik (Systematic Random Sampling)
Proses pengambilan sampel, setiap urutan ke “K” dari titik awal yang dipilih secara random, di mana:
Keuntungan : Perencanaan dan penggunaannya mudah;
Sampel tersebar di daerah populasi
Kerugian : Membutuhkan daftar populasi
3. Sampel Random Berstrata (Stratified Random Sampling)
Populasi dibagi strata-strata (sub-populasi), kemudian pengambilan sampel dilakukan di dalam setiap strata baik secara simple Random Sampling ataupun secara Systematic Random Sampling.
Keuntungan : Taksiran mengenai karakteristik pepulasi lebih tepat
Kerugian : Daftar populasi setiap strata diperlukan, Jika daerah geografisnya luas, maka biaya transportasi tinggi.
4. Sampel Berkelompok (Cluster Sampling)
Pengambilan sampel dilakukan terhadap sampling unit, di mana sampling unitnya terdiri dari satu kelompok (cluster). Tiap item (individu) di dalam kelompok yang terpilih akan diambil sebagai sampel.
Cara ini dipakai bila populasi dapat dibagi dalam kelompok dan setiap karakteristik yang dipelajari ada dalam setiap kelompok.
Keuntungan : Tidak memerlukan daftar populasi
Kerugian : Prosedur estimasi sulit
5. Sampel Bertingkat (Multi Stage Sampling)
Proses pengambilan sampel dilakukan bertingkat, baik bertingkat dua, maupun lebih. Contohnya dari tingkat provinsi kabupaten kecamatan desa lingkungan Kepala Keluarga.
Cara ini digunakan bila:
a. Populasinya cukup homogen b. Jumlah populasi sangat besar
c. Populasi menempati daerah yang sangat luas d. Biaya penelitian kecil
Keuntungan : Biaya transportasi kecil
Kerugian : Prosedur estimasi sulit; Prosedur pengambilan sampel memerlukan perencanaan yang lebih cermat.
B. Sampel Tidak Acak/Non-Random Sampling/Non-Probability Sampling
Sampel tidak acak adalah setiap elemen populasi tidak mempunyai kemungkinan yang sama untuk dijadikan sampel. Jika peneliti tidak mempunyai kemauan melakukan generalisasi hasil penenlitian maka sampel bisa diambil secara tidak acak. Sampel tidak acak biasanya diambil jika peneliti tidak mempunyai data pasti tentang ukuran populasi dan informasi lengkap tentang setiap elemen populasi.
Convenience Sampling
Dalam memilih sampel, peneliti tidak mempunyai pertimbangan lain kecuali berdasarkan kemudahan saja. Seseorang diambil sebagai sampel karena kebetulan orang tadi ada di tempat tersebut atau kebetulan dia mengenal orang tersebut. Oleh karena itu, ada beberapa penulis menggunakan istilah accidental sampling – tidak disengaja – atau juga captive sample (man-on-the-street). Jenis sampel ini sangat baik jika dimanfaatkan untuk penelitian penjajagan yang kemudian diikuti oleh penelitian lanjutan yang sampelnya diambil secara acak (random). Beberapa kasus penelitian yang menggunakan jenis sampel ini hasilnya ternyata kurang obyektif.
Purposive Sampling
Sesuai dengan namanya, sampel diambil dengan maksud atau tujuan tertentu. Seseorang atau sesuatu diambil sebagai sampel karena peneliti menganggap bahwa seseorang atau sesuatu tersebut memiliki informasi yang diperlukan bagi penelitiannya. Dua jenis sampel ini dikenal dengan nama judgement dan quota sampling.
a. Judgment Sampling
Sampel dipilih berdasarkan penilaian peneliti bahwa dia adalah pihak yang paling baik untuk dijadikan sampel penelitiannya. Misalnya, untuk memperoleh data tentang bagaimana satu proses produksi direncanakan oleh suatu perusahaan, maka manajer produksi merupakan orang yang terbaik untuk memberikan informasi. Jadi, judgment sampling umumnya memilih sesuatu atau seseorang menjadi sampel karena mereka mempunyai “information rich”.
b. Quota Sampling
Teknik Sampel ini adalah bentuk dari sampel distratifikasikan secara proporsional, namun tidak dipilih secara acak melainkan secara kebetulan saja.
𝑛 = 𝑁 𝑁. 𝑑2+ 1
Snowball Sampling
Cara ini banyak dipakai ketika peneliti tidak banyak tahu tentang populasi penelitiannya. Dia hanya tahu satu atau dua orang yang berdasarkan penilaiannya bisa dijadikan sampel. Karena peneliti menginginkan lebih banyak lagi, lalu dia minta kepada sampel pertama untuk menunjukan orang lain yang kira-kira bisa dijadikan sampel.
C. Penentuan Jumlah Sampel a. Dengan Perhitungan
Winarno Surachmad (1990), Suharsimi Arikunto (1990), Kartini Kartono (1990), menyatakan bahwa ukuran sampel sangat ditentukan oleh besarnya ukuran populasi. Untuk populasi dengan ukuran kurang dari seratus, sampel dapat diambil seluruhnya (seluruh anggota populasi menjadi sampel atau disebut juga sebagai sampel total). Namun demikian, Burhan Bungin (2005), memiliki pendapat bahwa ukuran sampel dapat dihitung dengan menggunakan rumus:
Keterangan:
n = ukuran sampel N = ukuran populasi
d = Nilai presisi/ketepatan meramalkan
b. Tanpa Perhitungan
1. Menurut Gay dan Diehl, 1992
Untuk penelitian deskriptif, sampelnya 10% dari populasi. Untuk penelitian korelasional, paling sedikit 30 elemen populasi. Untuk penelitian perbandingan kausal, 30 elemen perkelompok, dan untuk penelitian eksperimen 15 elemen per kelompok.
2. Menurut Roscoe (1975) dalam Uma Sekaran (1992)
Pedoman dalam penentuan jumlah sampel adalah sebagai berikut:
Sebaiknya ukuran sampel di antara 30 s/d 500 elemen.
Jika sampel dipecah lagi ke dalam sub sampel (laki/perempuan, SD/SLTP/SMA, dsb), jumlah minimum sub sampel harus 30.
Pada penelitian multivariat (termasuk analisis regresi multivariat) ukuran sampel harus beberapa kali lebih besar (10 kali) dari jumlah variabel yang akan dianalisis.
Untuk penelitian eksperimen yang sederhana, dengan pengendalian yang ketat, ukuran sampel bisa antara 10 s/d 20 elemen.
3. Menurut Krejcie dan Morgan (1970)
Krejcie dan Morgan membuat daftar yang biasa diapakai untuk menentukan jumlah sampel sebagai berikut:
Tabel. 1.21 Tabel Penentuan Jumlah Sampel Menurut Kreijce dan Morgan
4. Menurut Champion (1981)
Champion mengatakan bahwa sebagian besar uji statistik selalu menyertakan rekomendasi ukuran sampel. Dengan kata lain, uji-uji statistik yang ada akan sangat efektif jika diterapkan pada sampel yang jumlahnya 30 s/d 60 atau dari 120 s/d 250. Bahkan jika sampelnya di atas 500, tidak direkomendasikan untuk menerapkan uji statistik. (Penjelasan tentang ini dapat dibaca di Bab 7 dan 8 buku Basic Statistics for Social Research, Second Edition).
MODUL 2
PENGOLAHAN DAN PENYAJIAN DATA STATISTIKA DESKRIPTIF
Tujuan Praktikum Tujuan Umum
1. Praktikan mampu memahami konsep statistika deskriptif.
2. Praktikan mampu mengolah data statistika deskriptif menggunakan software Microsoft Excel 2013 dan SPSS 20.
Tujuan Khusus
Praktikan dapat melakukan pengolahan data dan menyajikan data kedalam bentuk tabel, diagram, dan tools lainnya.
Referensi
1. Nugroho, Sigit. 2007. Dasar-dasar Metode Statistika. Jakarta: Grasindo 2. Rasyad, Rasdihan. 2008. Metode Statistik Deskriptif. Jakarta: Grasindo
3. SIPO Laboratory. 2013. Modul Praktikum Statistika Industri dan Penelitian Operasional. Bandung:
Institut Teknologi Telkom
4. Priyatno, Duwi. 2009. 5 Jam Belajar Olah Data dengan SPSS 17. Yogyakarta : CV ANDI OFFSET
Alat dan Bahan Praktikum 1. Komputer
2. Modul Praktikum SIPO 2014 3. Software Microsoft Excel 2013 4. Software SPSS 20
5. Data
Deskriptif Statistik
Dasar Teori
Statistik
Berasal dari kata Statistics, yaitu informasi yang ditampilkan dalam bentuk angka, tabel, grafis (Oxford Pocket, 2008)
Statistika
Merupakan metode pengumpulan data, analisis, interpretasi dan penyimpulan hasil analisis (Jonnson dan Bhattacharya, 1985)
Populasi
Wilayah generalisasi yang terdiri atas subjek atau objek yang mempunyai kualitas dan karakter tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya (Sugiono, 2006 : 90)
Sampel
Sebagian atau wakil populasi yang diteliti (Arikunto, 1993 :109)
Parameter
Karakteristik suatu populasi, seperti rata-rata, standar deviasi, median dan lain-lain. secara umum parameter-parameter populasi secara statistik diperkirakan dan tidak langsung dihitung dari data aritmatika dan populasi.
Statistika Deskriptif dan Inferensia
Statistika merupakan metode pengumpulan data, analisis, interpretasi dan penyimpulan hasil analisis (Johnson dan Bhattacharya, 1985). Statistika dibedakan menjadi dua, yaitu:
1. Statistika Deskriptif (Statistika Deduktif)
Statistika deskriptif adalah kegiatan pengumpulan data, pengolahan data, dan penyajian data yang digambarkan dalam bentuk tabel, grafik, diagram, dan pengukuran numerik tanpa berupaya untuk menyimpulkan kondisi keseluruhan.
2. Statistika Inferensia (Statistika Induktif)
Statistika inferensia adalah metode statistik yang digunakan sebagai alat untuk mencoba menarik kesimpulan yang bersifat umum dari sekumpulan data yang telah disusun dan diolah.
Mulai
Pengumpulan data
Pengolahan data
Penyajian hasil olahan data
Penggunaan hasil olahan data sampel untuk menaksirkan dan/
atau menguji karakteristik populasi yang dihipotesiskan
Penarikan kesimpulan tentang karakteristik populasi yang
ditelaah
Berhenti
Statistika Inferensia Mulai
Pengumpulan data
Pengolahan data
Penyajian hasil olahan data
Penggunaan data untuk menganalisis karekter populasi yang
ditelaah
Berhenti Statistika
Deskriptif
Gambar 2.1 Sistematika Penggunaan Statistika
Pengolaan Data Statistika Deskriptif
𝑥 =𝑥1+ 𝑥2+ ⋯ + 𝑥𝑛
𝑛 =1
𝑛 𝑥𝑖
𝑛
𝑖=1
Gambar 2.2 Bagan Statistika Deskriptik
1. Pengolahan Data Tunggal Pengukuran terpusat
Rata-rata hitung (Mean)
Keterangan :
n = Jumlah observasi xi = Data ke-i
Data Tunggal
Pengukuran terpusat
•Mean
•Median
•Modus
Pengukuran Penyebaran
•Range
•Quartile deviation
•Vaiance
•Standard deviation
•Skewness (Kemiringan)
•Kurtosis (Keruncingan)
Data Berkelompok
Pengukuran terpusat
•Mean
•Median
•Modus
Pengukuran penyebaran
•Range
•Quartile deviation
•Vaiance
•Standard deviation
•Skewness (Kemiringan)
•Kurtosis (Keruncingan)
𝑚𝑑 =1
2 (𝑥𝑘+ 𝑥𝑘+1)
Range = Q3 – Q1
𝑄𝑢𝑎𝑟𝑡𝑖𝑙𝑒 𝑑𝑒𝑣𝑖𝑎𝑡𝑖𝑜𝑛 =𝑄3− 𝑄1 2
𝑠2 = 1
𝑛 − 1 (𝑥𝑖− 𝑥 )2
𝑛
𝑖=1
𝑠 = 1
𝑛 − 1 (𝑥1− 𝑥 )2
𝑛
𝑛=1
Median Keterangan:
- Jika data ganjil n = 2k-1 - Jika data genap
n = 2k, jika xk ≠xk-1
dimana, n = jumlah observasi; k = posisi
Modus
Modus pada data tunggal adalah data yang paling sering muncul Pengukuran penyebaran
Range
Selisih antara nilai maksimum dan minimum. Jangkauan data dapat menunjukkan kualitas suatu data.
Semakin kecil jangkauan suatu data, maka kualitas data semakin baik, dan sebaliknya.
Jangkauan Quartil
Variansi
Rata – rata kuadrat selisih atau kuadrat simpangan dari semua nilai data terhadap rata – rata hitung.
Standar deviasi
Standar deviasi adalah akar pangkat dua dari variansi. Standar deviasi merupakan ukuran dispersi yang dianggap paling baik sehingga sering digunakan dalam analisis data.
𝐹𝑜𝑟 𝑢𝑛𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑑 𝑑𝑎𝑡𝑎 => 𝛼3 =1 𝑛
(𝑥𝑖− 𝑥 )3
𝑛𝑖=1
𝑠3
𝐹𝑜𝑟 𝑢𝑛𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑑 𝑑𝑎𝑡𝑎 => 𝛼4 =1 𝑛
(𝑥𝑖− 𝑥 )4
𝑛𝑖=1
𝑠4
Kemiringan (Skewness)
Kemiringan adalah derajat ketidaksimetrisan suatu distribusi. Kemiringan atau Skewness dapat juga disebut ukuran distribusi data di mana skewness biasanya digunakan untuk mengetahui apakah data terdistribusi normal atau tidak dengan menghitung rasio skewness dengan standard error of skewness dari output software SPSS. Kriteria yang digunakan, yaitu jika rasio skewness antara -2 sampai 2 maka data terditribusi normal.
Gambar 2.3 Grafik Sknewness
Keruncingan (Kurtosis)
Kurtosis adalah derajat keruncingan suatu distribusi (biasa diukur relatif terhadap distribusi normal).
Kurtosis sama halnya dengan skewness, di mana Kurtosis digunakan untuk mengukur distribusi data.
Dengan menggunakan software SPSS untuk mengetahui apakah data terdistribusi normal atau tidak, maka dihitung rasio Kurtosis dengan standard error Kurtosis. Kriteria yang digunakan, yaitu jika rasio Kurtosis diantara -2 sampai 2, maka data berdistribusi normal.
Kriteria dari nilai Kurtosis, yaitu : - a4 = 3, Mesokurtic Curve - a4 > 3, Leptokurtic Curve - a4 < 3, Platycurtic Curve
Gambar 2.4 Grafik Kurtosis
2. Pengolahan Data Berkelompok
Apabila data cukup banyak, maka data dikelompokkan dalam beberapa kelompok. Kelompok- kelompok data disebut dengan kelas dan banyaknya data pada setiap kelas disebut frekuensi kelas. Selang yang memisahkan kelas yang satu dengan yang lain disebut interval kelas. Besarnya interval kelas untuk semua kelas harus sama. Suatu tabel yang menyajikan data yang telah dikelompokkan pada kelas-kelas beserta frekuensi kelasnya disebut tabel distribusi frekuensi. Ada beberapa hal yang perlu diperhatikan agar suatu tabel distribusi frekuensi dapat memberikan informasi yang baik, antara lain sebagai berikut :
1. Jumlah kelas pada suatu tabel distribusi frekuensi jangan terlalu banyak atau jangan terlalu sedikit.
2. Hindari adanya suatu kelas yang tidak dapat menampung data (frekuensi kelas nol).
3. Semua data harus dapat ditampung ke dalam tabel distribusi frekuensi tersebut dan tiap kelas frekuensinya tidak boleh memuat data yang ada pada kelas frekuensi lain.
Langkah-langkah yang dilakukan untuk membuat tabel distribusi frekuensi adalah sebagai berikut:
1. Urutkan data dari data terkecil ke data yang terbesar.
2. Tentukan banyak kelas pada tabel distribusi frekuensi. Dapat digunakan metode Sturgess.
Keterangan : k = banyaknya kelas n = banyaknya data
𝑘 = 1 + 3,3 log 𝑛
𝑥 =𝑥1𝑓1+ 𝑥2𝑓2+ ⋯ + 𝑥𝑘 𝑓𝑘 𝑓1+ 𝑓2+ ⋯ + 𝑓𝑘 =1
𝑛 𝑥𝑖𝑓𝑖
𝑘
𝑖=1
𝑚𝑑 = 𝑏𝑏 + (𝑛
𝑄 − 𝑓𝑜)
𝑓 𝑐
𝑚𝑜 = 𝑏𝑏 + 𝑓1 𝑓1+ 𝑓2 𝑐 3. Tentukan Interval kelas dengan rumus :
4. Tentukan batas atas dan batas bawah kelas Pengukuran Terpusat
Rata-rata hitung (Mean)
Keterangan : x = interval median f = frekuensi kelas n = jumlah observasi k = banyaknya kelas
Median
Keterangan :
bb = batas bawah pada median kelas
fo = frekuensi kumulatif sebelum median kelas c = interval kelas
f = frekuensi pada median kelas Q = kuartil, Q =1, 2, 3
Modus
𝐼 =𝑅 𝑘
𝑐 =𝑋𝑚𝑎𝑘𝑠 − 𝑋𝑚𝑖𝑛 1 + 3,322 log 𝑛
𝑄𝑢𝑎𝑟𝑡𝑖𝑙𝑒 𝑑𝑒𝑣𝑖𝑎𝑡𝑖𝑜𝑛 =𝑄3− 𝑄1 2
𝜎 = 1
𝑛 (𝑥1− 𝜇)2
𝑛
𝑖=1
Keterangan :
bb = batas bawah kelas modus
f1 = Perbedaan selisih frekuensi kelas modus dengan kelas sebelumnya f2 = perbedaan selisih frekuensi kelas modus dengan kelas setelahnya c = interval kelas
Pengukuran Penyebaran
Range
Selisih antara nilai maksimum dan minimum. Jangkauan data dapat menunjukkan kualitas suatu data. Semakin kecil jangkauan suatu data, maka kualitas data semakin baik, dan sebaliknya.
Jangkauan Quartil
Variansi
Rata – rata kuadrat selisih atau kuadrat simpangan dari semua nilai data terhadap rata – rata hitung.
µ = rata-rata populasi
Standar deviasi
Standar deviasi adalah akar pangkat dua dari variansi. Standar deviasi merupakan ukuran dispersi yang dianggap paling baik sehingga sering digunakan dalam analisis data.
µ = rata-rata populasi
Range = Q3 – Q1
𝜎2=1
𝑛 (𝑥𝑖− 𝜇)2
𝑛
𝑖=1
𝐹𝑜𝑟 𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑑 𝑑𝑎𝑡𝑎 => 𝛼3= 1 𝑛
(𝑥𝑖− 𝑥 )3𝑓𝑖
𝑛𝑖=1
𝑠3
𝐹𝑜𝑟 𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑑 𝑑𝑎𝑡𝑎 => 𝛼3= 1 𝑛
(𝑥𝑖− 𝑥 )4𝑓𝑖
𝑛𝑖=1
𝑠4
Kemiringan (Skewness)
Kemiringan yang terdapat pada data berkelompok sama dengan data tunggal di mana kemiringan adalah derajat ketidaksimetrisan suatu distribusi.
Gambar 2.5 Grafik Skewness
Keruncingan (Kurtosis)
Keruncingan yang terdapat pada data berkelompok sama dengan data tunggal. Dimana; Kurtosis adalah derajat keruncingan suatu distribusi (biasa diukur relatif terhadap distribusi normal)
Kriteria dari nilai Kurtosis, yaitu : - a3 = 3, Mesokurtic Curve - a3 > 3, Leptokurtic Curve - a3 < 3, Platycurtic Curve
Gambar 2.6 Grafik Kurtosis
Penyajian Data Statistika Deskriptif
Penyajian Data Tunggal
Gambar 2.7 Penyajian Data Tunggal Tabel
Alat untuk menampilkan informasi dalam bentuk matriks.
Diagram Batang (Bar Chart)
Penyajian data dengan menggunakan batang- batang berbentuk persegi panjang dan dilengkapi dengan skala tertentu.
Diagram Batang Daun (Stem and Leaf Plot) Metode penyajian data statistik dalam kelompok batang (Puluhan) dan kelompok daun (satuan) dari suatu data.
Diagram Garis (Line Chart)
Penyajian data pada bidang cartesius dengan menghubungkan titik-titik data pada bidang cartesius (sumbu-x dan sumbu-y).
Diagram Lingkaran (Pie Chart)
Penyajian berupa daerah lingkaran yang telah dibagi menjadi juring juring sesuai dengan data yang bersangkutan.
Box Plot
Grafik yang menyediakan informasi mengenai range, mean, median, Q1, Q3, Outlier, kemiringan dan keruncingan dari suatu data.
Deskripsi SPSS
Gambar 2.8 Penyajian Data Berkelompok
SPSS (Statistical Product and Service Solutions) adalah sebuah program komputer yang digunakan untuk membuat analisis statistika. SPSS memberi tampilan data yang lebih informatif, yaitu menampilkan data sesuai nilainya (menampilkan label data dalam kata-kata) meskipun sebetulnya kita sedang bekerja menggunakan angka-angka (kode data).
Menubar Dalam SPSS
Gambar 2.9 Menu-Bar Dalam SPSS 1. File
Menu file digunakan untuk keperluan yang berhubungan dengan file data, seperti membuka data baru, output baru, membuka database, menutup file, menyimpan, print, dan sebagainya.
Tabel distibusi frekuensi kumulatif
Frekuensi kumulatif adalah frekuensi yang dijumlahkan, yaitu frekuensi suatu kelas dijumlahkan dengan frekuensi kelas sebelumnya. Tabel distribusi kumulatif dibuat dengan cara menjumlahkan frekuensi data secara berurutan.
Histogram
Histogram merupakan diagram kotak yang lebarnya menunjukan interval kelas, sedangkan batas-batas tepi kotak merupakan tepi bawah dan tepi atas kelas, dan tingginya menunjukan frekuensi kelas tersebut.
Ogive
Grafik yang digambarkan berdasarkan data yang sudah disusun dalam bentuk tabel ditibusi frekuensi kumulatif.
Gambar 2. 10 Menu File 2. Edit
Menu edit digunakan untuk keperluan yang berhubungan dengan perbaikan dan pengubahan data seperti undo, redo, cut, copy, clear, insert veriable, insert case, dan sebagainya.
Gambar 2. 11 Menu Edit
3. View
Menu View digunakan untuk mengatur toolbar pada halaman SPSS, seperti status bar, font, value label, dan sebagainya.
Gambar 2. 12 Menu View 4. Data
Menu Data digunakan untuk membuat perubahan data SPSS secara keseluruhan, seperti mengurutkan data, validasi data, menggabungkan data, membagi data, pembobotan, dan sebagainya.
Gambar 2. 13 Menu Data
5. Transform
Menu Transform digunakan untuk membuat perubahan pada variabel yang telah dipilih dengan kriteria tertentu, seperti, compute variable, rank case, create time series, dan sebagainya.
Gambar 2. 14 Menu Transform
6. Analyze
Menu Analyze digunakan untuk olah data atau menganalisis data yang telah kita masukkan ke dalam komputer. Menu ini merupakan menu yang sangat penting karena semua pemrosesan dan analisis data dilakukan di menu ini. Submenu yang terdapat dalam menu ini antara lain report, descriptive statistics, table, compare Means, general linier model, mixed model, dan sebagainya.
Gambar 2. 15 Menu Analyze
7. Graphs
Menu Graphs digunakan untuk membuat grafik, seperti Bar, Dot, Line, Pie, Histogram, Bloxplot, dan sebagainya.
Gambar 2. 16 Menu Graphs
8. Utilities
Menu Utilities digunakan untuk mengatur tampilan menu, Data File Comment, Run Script, dan sebagainya.
Gambar 2. 17 Menu Utilities 9. Add-ons
Menu Add-ons adalah menu yang berisi tentang aplikasi tambahan, servis, dan sebagainya yang dapat dilihat di website SPSS.
Gambar 2. 18 Menu Add-ons
10. Windows
Menu Windows digunakan untuk split file, minimize, minimize all windows, dan sebagainya.
Gambar 2. 19 Menu Window 11. Help
Menu help digunakan untuk bantuan informasi mengenai program SPSS yang dapat diakses secara mudah dan jelas.
12. Direct Marketing
Menu direct marketing menyediakan alat analisis untuk memperbaiki teknik marketing yang dipilih user seperti identifikasi demografi, pembelian, karakteristik lain. Beberapa pilihan teknik yang ditawarkan adalah RFM, cluster, prospect profiles, postal code responde rate, prospensity to purchase dan control package test.
Halaman Kerja Pada SPSS 1. Variable View
Halaman Variable View digunakan untuk memasukkan dan mendefinisikan variabel.
Gambar 2. 20 Variable View
Berikut ini merupakan Variable View dan fungsinya.
Tabel 2.1 Variable View
Name Untuk memasukkan nama variabel, misalnya “pendapatan”.
Type Untuk mendefinisikan tipe variabel apakah itu bersifat numeric atau string.
Width Untuk menuliskan panjang pendek variabel.
Decimal Untuk menuliskan jumlah decimal di belakang koma.
Label Untuk menuliskan label variabel.
Values Untuk menuliskan nilai kuantitatif dari variabel yang skala pengukurannya ordinal dan nominal bukan scale.
Missing Untuk menuliskan ada dan tidaknya jawaban kosong.
Columns Untuk menuliskan lebar kolom.
Align Untuk menuliskan rata kanan, kiri, atau tengah penempatan teks atau angka di Data View.
Measure Untuk menentukan skala pengukuran variabel, misalnya nominal, ordinal, atau scale.
Role Untuk menentukan tipe variabel seperti input, target, partition, both, none, dan split.
2. Data View
Halaman Data View digunakan untuk memasukkan data pada kolom yang telah dibuat.
Gambar 2. 21 Data View
Menu yang Digunakan untuk Statistika Deskriptif
Menu dari SPSS yang berhubungan dengan statistika deskriptif adalah Descriptive Statistic yang ada pada menu Analyze pada SPSS. Dalam menu ini terdapat beberapa submenu untuk menentukan statistika deskriptif, yaitu :
Frequencies atau analisis frekuensi dipakai untuk menghitung frekuensi data pada variabel untuk analisis statistik seperti mean, median, kuartil, persentil, standar deviasi, serta menampilkan grafik.
Contoh Kasus
Seorang peneliti ingin menganalisis statistika (frekuensi) tentang berat badan sampel sebanyak 20 orang.
Berikut ini adalah data berat badan 20 orang yang dijadikan sampel peneliti.
Tabel 2.2 Data Berat Badan 1. Frequencies
A. Tabel Frekuensi untuk Berat Badan Langkah-langkah Penyelesaian
1. Buka software SPSS 20 lalu klik Variable View dan definisikan kedua variabel. Baris pertama definisikan variabel Berat Badan dan baris kedua untuk mendefinisikan Gender. Untuk tipe data pastikan Numeric.
Pada kolom Measure, pilih Scale untuk variabel Berat Badan dan pilih Nominal untuk variabel Gender.
Gambar 2. 22 Pengisian Variabel View pada SPSS
2. Selanjutnya klik Data View, copy data Berat Badan dari Gender dari microsoftexcel kemudian paste di masing-masing kolom variabel. Ingat , SPSS tidak bisa mengolah data yang bersifat string seperti ”P”
atau “L”. Oleh karena itu, kita harus mengkodekan data tersebut ke dalam bentuk 1 = Laki-laki dan 2 = perempuan.
Gambar 2. 23 Pengisian Data View pada SPSS
3. Selanjutnya, klik Analyze >> Descriptive Statistics >> Frequencies
Gambar 2. 24 Langkah memilih alat analisis
4. Setelah itu, kotak dialog Frequencies akan tampil sebagai berikut:
Gambar 2. 25 Kotak dialog Frequencies
5. Karena ingin membuat frekuensi dari variabel Berat Badan, maka klik variabel Berat_Badan, kemudian
klik tanda , maka variabel Berat Badan akan berpindah ke kolom Variable(s). Kemudian klik pilihan Statistics, maka akan muncul tampilan berikut.
Gambar 2. 26 Dialog Box untuk Menginputkan Data pada Menu Frequencies
Gambar 2. 27 Dialog Box pada Frequencies Statistics
Kemudian cheklist semua bagian Central Tendency, Dispersion, dan Distribution. Lalu, klik Quartiles dan Percentile(s), masukkan angka 10 Add. Klik lagi Percentile masukkan 90 Add setelah itu klik Continue.
6. Setelah itu klik tab Chart dan pilih Histograms untuk keseragaman data. Saat Histograms di klik, maka akan muncul With Normal Curve. Kemudian klik With Normal Curve lalu klik Continue.
Gambar 2. 28 Dialog Box pada Frequencies Charts
7. Klik OK dan akan muncul Output seperti berikut:
Tabel 2.2 Output Statistics Berat Badan Statistics
Berat_Badan
N Valid 20
Missing 0
Mean 54,9500
Std. Error of Mean 1,67564
Median 52,0000
Mode 49,00 Std. Deviation 7,49368
Variance 56,155
Skewness ,883
Std. Error of Skewness ,512
Kurtosis ,414
Std. Error of Kurtosis ,992
Range 29,00
Minimum 45,00
Maximum 74,00
Sum 1099,00
Percentiles
10 47,1000
25 49,0000
50 52,0000
75 60,0000
90 64,8000
Gambar 2. 29 Output Histogram Berat Badan
Analisis
Output Statistics
N adalah jumlah data; dalam hal ini jumlah data yang valid ada 20 buah dan tidak ada data yang hilang(missing).
Mean adalah rata-rata; rata-rata berat badan adalah 54,95 kg.
Standard error of mean, yaitu standar kesalahan untuk populasi yang diperkirakan dari sampel dengan menggunakan ukuran rata-rata. Nilai sebesar 1,676 kg
Median adalah titik tengah, yaitu semua data diurutkan dan dibagi dua sama besar. Nilai median adalah 52,00
Mode adalah modus data, yaitu sebesar 49.
Std Deviation, yaitu ukuran penyebaran data dari rata-ratanya. Nilainya sebesar 7,494 kg.
Minimum adalah nilai terendah dalam hal ini adalah 45.
Maximum adalah nilai tertinggi dalam hal ini adalah 74.
Range adalah jarak data, yaitu data maksimum dikurangi data minimum. Nilai range adalah 29.
Interquartile Range, yaitu selisih antara nilai persentil yang ke-25 dan 75. Nilai sebesar 11 kg.
Skewness, yaitu ukuran distribusi data. Untuk mengetahui apakah data terdistribusi normal atau tidak, maka dihitung rasio skewness dengan standard error of skewness atau 0,883/0,512 = 1,725.
Kriteria yang digunakan, yaitu jika rasio skewness antara -2 sampai 2, maka distribusi data normal.
Karena nilai rasionya 1,725 , maka data berdistribusi normal.
Kurtosis; sama halnya dengan skewness, kurtosis juga digunakan untuk mengukur distribusi data.
Untuk mengetahui apakah data terdistribusi dengan normal atau tidak, maka dihitung rasio kurtosis dengan standard error of kurtosis atau 0,414/0,992 = 0,417. Kriteria yang digunakan , yaitu jika rasio kurtosis diantara -2 sampai 2, maka distribusi normal. Dalam hal ini data berdistribusi normal.
B. Tabel Frekuensi untuk Gender
Karena variabel gender bukan data kuantitatif namun kategori, maka tidak perlu dilakukan deskripsi statistik seperti mean, median, standar deviasi, dan sebagainya. Untuk data kualitatif, chart yang sesuai adalah pie chart.
Langkah-langkah Penyelesaian
1. Pilih menu Analyze, lalu pilih submenu Descriptive Statistics, lalu pilih lagi submenu Frequencies.
Klik variabel gender, kemudian klik tanda , maka variabel gender akan berpindah ke kolom Variable(s). Kemudian akan muncul tampilan seperti berikut.
Gambar 2. 30 Dialog Box pada Frequencies
2. Klik Charts, kemudian klik Pie Chart lalu klik Continue. Kemudian akan muncul tampilan seperti berikut.
Gambar 2. 31 Dialog Box pada Frequencies Chart
3. Klik menu Format kemudian pilih Ascending Values. Selanjutnya klik Continue.
Gambar 2. 32 Dialog Box pada Frequencies Format
4. Klik OK dan akan muncul tampilan seperti berikut.
Tabel 2.3 Output Frequencies Gender
Gambar 2. 33 Output Pie Chart
Menu ini berfungsi untuk mengetahui skor-z dari suatu distribusi data dan menguji apakah data berdistribusi normal atau tidak. Untuk contoh kasus diambil dari data Berat Badan yang telah didapatkan dari contoh kasus sebelumnya.
Langkah-langkah Penyelesaian
1. Klik Analyze Descriptive Statistics Descriptives. Kemudian klik variabel Berat_Badan,
kemudian klik tanda , maka variabel Berat Badan akan berpindah ke kolom Variable(s).
Kemudian akan muncul tampilan berikut ini.
Gambar 2. 34Dialog Box pada Descriptives
2. Klik Oprtions, kemudian klik Mean, Std. Deviation, Maximum, Minimum dan klik Continue. Maka akan muncul tampilan berikut ini.
2. Descriptive
Gambar 2. 35Dialog Box pada Descriptive options
3. Cheklist kotak Save standardized value as variable kemudian klik OK seperti tampilan berikut ini.
Gambar 2. 3 Dialog Box pada Descriptives
4. Setelah klik OK, maka akan muncul Output sebagai berikut.
Tabel 2.4 Descriptive Statistics
5. Lihat kembali Data View SPSS. Selain Berat_Badan dan gender, sekarang muncul variabel baru, yaitu Zberat_Badan seperti tampilan berikut.
Tabel 2.5 Tampilan Variabel Baru pada Data View
Karena SPSS pada umumnya menggunakan selang kepercayaan 95%, maka batas nilai z-nya, yaitu - 1,96 hingga 1,96. Jika terdapat nilai z di luar batas tersebut, maka data tersebut merupakan data outlier. Berdasarkan data Zberat_Badan terdapat 1 buah data outlier, yaitu data ke-19 karena Zberat_Badannya adalah 2,54214.