i
APLIKASI PENDETEKSI PLAGIARISME
DALAM KARYA TULIS ILMIAH
DENGAN ALGORITMA RABIN KARP
SKRIPSI
Diajukan untuk memenuhi salah satu syarat
memperoleh gelar Sarjana Teknik Informatika (S.Kom.)
Program Studi Teknik Informatika
Disusun Oleh:
AGUSTINUS PILIPUS TRIYUNIANTA ARUM SURYA
125314083
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
PLAGIARISM DETECTION APPLICATION
IN SCIENTIFIC WORKS
USING RABIN KARP ALGORITHM
THESIS
Presented as partial fulfillment of the requirements
to obtain the Bachelor Degree of Computer (S.Kom.)
in Informatics Engineering
Written by:
AGUSTINUS PILIPUS TRIYUNIANTA ARUM SURYA
125314083
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
HALAMAN PERSETUJUAN
iv
v
HALAMAN MOTTO
“ Tuhan tahu apa yang kita butuhkan,
tidak perlu meminta,
b
ersyukurlah ”
“
Some people dream of success while others wake up and work hard
at it
”
vi
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI
viii ABSTRAK
Berkembangnya teknologi informasi dan komunikasi yang semakin pesat
menyebabkan pencarian data dan informasi semakin mudah dan cepat. Namun
perkembangan teknologi informasi ini justru menimbulkan berbagai macam
dampak negatif, salah satunya adalah penjiplakan karya atau sering disebut plagiat.
Penelitian ini bertujuan untuk membuat suatu sistem untuk mengantisipasi
tindak plagiarisme yang semakin banyak. Salah satu algoritma yang diusulkan
untuk mendeteksi plagiarisme adalah dengan algoritma Rabin Karp. Algoritma
Rabin karp akan mencari kesamaan dua dokumen yang diuji dengan menampilkan
presentase kesamaan dua dokumen tersebut.
Pengujian sistem ini dilakukan dengan melakukan alpha test dan beta test.
Berdasarkan pengujian dengan alpha test yaitu dengan membandingkan keluaran
sistem dengan perhitungan manual menghasilkan rata-rata selisih 1,63 %.
Sedangkan pengujian dengan beta test yaitu kuisioner dengan 15 responden
menghasilkan nilai rata-rata 3.86 skala 1-5 untuk kaitannya dengan kegunaan
(perceived of usefulness) dan nilai rata-rata 4.14 skala 1-5 untuk kaitannya dengan
kemudahan (perceived ease of use).
ix ABSTRACT
The development of information and communication technology that
increasingly rapidly led to the search for information more easily and quickly. But
the development of information technology is actually causing a variety of
negative impacts, one of which is plagiarism works.
This research aims to create a system to anticipate the acts of plagiarism
that more and more. One of the proposed algorithms for detecting plagiarism is
with Rabin Karp's algorithm. The Rabin karp algorithm will look for the similarity
of two documents tested by presenting the equivalent percentage of the two
documents.
Testing this system is done by doing alpha test and beta test. Based on
the test with alpha test that is by comparing the output of the system with manual
calculations yield average of 1.63% difference. While the test with the beta test is
a questionnaire with 15 respondents produce an average value of 3.86 scale 1-5
for its relation with the usefulness (perceived of usefulness) and the average value
of 4.14 scale 1-5 for perceived ease of use.
x
KATA PENGANTAR
Puji Syukur kehadirat Tuhan Yang Maha Esa yang telah melimpahkan
rahmat-Nya, sehingga penelitian ini dapat berhasil dan selesai.
Penelitian ini dapat berjalan dari awal sampai akhir berkat adanya bimbingan, doa,
dan dukungan yang diberikan oleh banyak pihak. Dalam penyelesaian penelitian
ini, penulis ingin mengucapkan terima kasih kepada pihak-pihak tersebut, antara
lain:
1. Sudi Mungkasi,S.Si.,M.Math.Sc.,Ph.D selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
2. Dr. Anastasia Rita selaku Ketua Program Studi Teknik Informatika
Universitas Sanata Dharma Yogyakarta.
3. Ibu Agnes Maria Polina, S.Kom., M.Sc selaku dosen pembimbing
penelitian yang dengan sabar memberikan kritik dan saran kepada penulis.
4. Keluarga yang tercinta, Bapak Antonius Suwondo, Ibu Sutini, Mas Sigit,
Mbak Fitri, Gabriel “Biel” yang selalu memberikan dukungan terbaik.
5. Florentina Anggraeni yang selalu mendampingi, membimbing, dan
menemani penulis selama menyelesaikan penelitian ini.
6. Koh Eric yang telah membimbing dan memberikan bantuan selama
menyelesaikan penelitian ini
7. Teman-teman Teknik Informatika 2012 yang selalu mendukung dan
memberi motivasi.
Penulis menyadari bahwa penelitian ini masih jauh dari kata sempurna. Oleh sebab
itu penulis mengharapkan adanya kritik dan saran untuk penelitian di masa
mendatang.
Yogyakarta, ………
xi DAFTAR ISI
HALAMAN COVER ...i
HALAMAN COVER ... ii
HALAMAN PERSETUJUAN ... iii
SKRIPSI ... iii
HALAMAN PENGESAHAN SKRIPSI ...iv
HALAMAN MOTTO ... v
PERNYATAAN KEASLIAN KARYA ...vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... vii
KARYA ILMIAH ... vii
ABSTRAK ... vii
ABSTRACT...ix
KATA PENGANTAR ... x
DAFTAR ISI...xi
DAFTAR GAMBAR ... xiv
DAFTAR TABEL ... xvi
BAB I ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 1
1.3 Batasan Masalah ... 2
1.4 Tujuan Penelitian... 2
1.5 Metodologi Penelitian ... 2
1.6 Sistematika Penulisan ... 4
BAB II ... 5
STUDI PUSTAKA ... 5
2.1 Plagiarisme ... 5
2.2 Text Preprocessing ... 6
2.2.3 Stemming ... 6
2.2.4 Tokenizing ... 10
2.3 Algoritma String Matching... 10
xii
2.4 Rabin Karp ... 13
2.4.1 Hashing ... 14
2.4.2 Similarity ... 17
2.5 Metode Waterfall... 18
2.5.1 Definisi Waterfall ... 18
2.5.2 Tahapan Pengembangan Metode Waterfall ... 18
BAB III ... 20
PERANCANGAN SISTEM ... 20
3.1 Tahap Requirement Analysis... 20
3.1.1 Gambaran Umum Sistem... 20
3.1.2 Analisis Kebutuhan ... 20
3.1.3 Use Case ... 21
3.1.4 Flowchart... 21
3.1.5 Pemodelan Proses ... 22
3.2 Perancangan Sistem ... 25
3.2.1 Perancangan Basis Data... 25
3.2.2 Perancangan Antarmuka ... 27
4.1 Deskripsi Alat... 31
4.2 Algoritma Rabin Karp ... 31
4.3 Implementasi Basis Data ... 40
4.3.1 Table Login ... 40
4.3.2 Tabel Dokumen ... 40
4.3.3 Tabel Rootword_ina ... 41
4.3.4 Tabel Stopword_ina ... 41
4.4 Implementasi Sistem ... 41
4.4.1 Halaman Login ... 41
4.4.2 Halaman Utama ... 42
4.4.3 Halaman Deteksi dua Dokumen ... 43
4.4.4 Halaman Deteksi Dokumen di Database ... 46
4.4.5 Halaman Karya Tulis Tersimpan ... 49
4.4.6 Halaman Tambah Pengguna ... 50
BAB V ... 52
xiii
5.1 Analisa Hasil Uji Coba Sistem (Pengujian Alpha) ... 52
5.1.1 Ujicoba dokumen dengan sistem ... 52
5.1.2 Ujicoba dokumen secara manual ... 56
5.2 Analisa Hasil Uji Coba Pengguna (Pengujian Beta) ... 59
5.2.1 Hasil dan Pembahasan ... 59
BAB VI ... 73
KESIMPULAN ... 73
6.1 Kesimpulan ... 73
6.2 Saran ... 74
DAFTAR PUSTAKA ... 75
xiv
DAFTAR GAMBAR
Gambar 2.1 Waterfall menurut Pressman... 18
Gambar 3.1 Use Case aplikasi pendeteksi plagiarisme ... 21
Gambar 3.2 Flowchart aplikasi pendeteksi plagiarisme ... 22
Gambar 3.3 Data Flow Diagram level 0 ... 22
Gambar 3.4 Data Flow Diagram level 1 ... 23
Gambar 3.5 Data Flow Diagram level 2 proses 1 ... 23
Gambar 3.6 Data Flow Diagram level 2 proses 2 ... 24
Gambar 3.7 Data Flow Diagram level 2 proses 3 ... 24
Gambar 3.8 Data Flow Diagram level 2 proses 4 ... 25
Gambar 3.9 Perancangan ER Diagram ... 26
Gambar 3.10 Perancangan logikal basis data ... 26
Gambar 3.11 Perancangan halaman login ... 28
Gambar 3.12 Perancangan halaman utama aplikasi ... 29
Gambar 3.13 Perancangan halaman proses dua dokumen ... 29
Gambar 3.14 Perancangan halaman proses dokumen di database ... 30
Gambar 3.15 Perancangan halaman karya tulis tersimpan ... 30
Gambar 3.16 Perancangan halaman pengguna ... 31
Gambar 4.1 Halaman login ... 42
Gambar 4.2 Halaman utama ... 43
Gambar 4.3 Halaman deteksi dua dokumen ... 44
Gambar 4.4 Halaman deteksi dokumen di database ... 47
Gambar 4.5 Halaman karya tulis tersimpan ... 50
Gambar 4.6 Halaman pengguna ... 52
Gambar 5.1 Hasil keluaran sistem untuk pengujian 1 ... 54
Gambar 5.2 Hasil keluaran sistem untuk pengujian 2 ... 54
Gambar 5.3 Hasil keluaran sistem untuk pengujian 3 ... 55
Gambar 5.4 Hasil keluaran sistem untuk pengujian 4 ... 56
Gambar 5.5 Hasil keluaran sistem untuk pengujian 5 ... 56
Gambar 5.6 Grafik kegunaan pernyataan 1 ... 61
Gambar 5.7 Grafik kegunaan pernyataan 2 ... 62
Gambar 5.8 Grafik kegunaan pernyataan 3 ... 63
xv
Gambar 5.10 Grafik kegunaan pernyataan 5 ... 65
Gambar 5.11 Grafik kegunaan pernyataan 6 ... 67
Gambar 5.12 Grafik kemudahan pernyataan 1 ... 69
Gambar 5.13 Grafik kemudahan pernyataan 2 ... 69
Gambar 5.14 Grafik kemudahan pernyataan 3 ... 70
Gambar 5.15 Grafik kemudahan pernyataan 4 ... 71
Gambar 5.16 Grafik kemudahan pernyataan 5 ... 72
xvi
DAFTAR TABEL
Tabel 2.1 Tabel kombinasi awalan dan akhiran yang tidak diijinkan ... 7
Tabel 2.2 Tabel aturan penghapusan awalan, untuk awalan “me-“ ... 9
Tabel 2.3 Tabel aturan penghapusan awalan, untuk awalan “pe-“ ... 9
Tabel 2.4 Tabel aturan penghapusan awalan, untuk awalan “ber-“ ... 9
Tabel 2.5 Tabel aturan penghapusan awalan, untuk awalan “ter-“ ... 10
Tabel 2.6 Tabel ASCII ... 13
Tabel 3.1 Tabel login ... 27
Tabel 3.2 Tabel dokumen ... 27
Tabel 3.3 Tabel rootword_ina ... 28
Tabel 3.4 Tabel stopword ... 28
Tabel 4.1 Dua buah dokumen yang terindikasi terjadi plagiarisme ... 33
Tabel 4.2 Dua buah dokumen setelah melalui langkah case folding ... 33
Tabel 4.3 Dua buah dokumen setelah melalui langkah filtering ... 34
Tabel 4.4 Dua buah dokumen setelah melalui langkah stemming ... 35
Tabel 4.5 Dua buah dokumen setelah melalui langkah parsing kgram ... 36
Tabel 4.6 Dua buah dokumen setelah melalui langkah hashing ... 34
Tabel 4.7 Hash yang sama dalam dua buah dokumen ... 34
Tabel 4.6 Dua buah dokumen setelah melalui langkah hashing ... 34
Tabel 5.1 Pengujian dokumen dengan sistem... 57
Tabel 5.2 Pengujian dokumen secara manual... 60
Tabel 5.3 Tabel hasil kuisioner kegunaan pernyataan 1 ... 61
Tabel 5.4 Tabel hasil kuisioner kegunaan pernyataan 2 ... 62
Tabel 5.5 Tabel hasil kuisioner kegunaan pernyataan 3 ... 63
Tabel 5.6 Tabel hasil kuisioner kegunaan pernyataan 4 ... 64
Tabel 5.7 Tabel hasil kuisioner kegunaan pernyataan 5 ... 65
Tabel 5.8 Tabel hasil kuisioner kegunaan pernyataan 6 ... 66
Tabel 5.9 Tabel hasil kuisioner kemudahan pernyataan 1 ... 67
Tabel 5.10 Tabel hasil kuisioner kemudahan pernyataan 2 ... 68
Tabel 5.11 Tabel hasil kuisioner kemudahan pernyataan 3 ... 69
Tabel 5.12 Tabel hasil kuisioner kemudahan pernyataan 4 ... 70
Tabel 5.13 Tabel hasil kuisioner kemudahan pernyataan 5 ... 71
1 BAB I
PENDAHULUAN
1.1 Latar Belakang
Berkembangnya teknologi informasi dan komunikasi yang semakin
pesat menyebabkan pencarian data dan informasi melalui internet menjadi
semakin mudah dan cepat. Namun perkembangan teknologi informasi ini
justru menimbulkan berbagai macam dampak negatif, salah satunya adalah
penjiplakan karya atau sering disebut plagiat.
Plagiarisme sering dijumpai dalam sektor akademis maupun non
akademis. Dalam sektor akademis, plagiarisme dianggap sebagai tindak
pidana serius karena dianggap pengambilan karangan, pendapat, ide, dan
gagasan orang lain. Plagiarisme secara tidak sengaja juga dapat terjadi jika
dalam pembuatan karya tulis lalai dalam mencantumkan sumber pustaka
dengan lengkap dan cermat. Plagiarisme belum cukup dikenali dan
dipahami khususnya di kalangan mahasiswa sehingga tingkat kejadiannya
cukup tinggi dan sulit dipantau.
. Kemiripan dokumen karya tulis ilmiah tidak dikataan plagiat jika
menggunakan informasi yang berupa fakta umum, menuliskan kembali
(dengan mengubah kalimat atau parafrase) opini orang lain dengan
memberikan sumber jelas, mengutip secukupnya tulisan orang lain dengan
memberikan tanda batas jelas bagian kutipan dan menuliskan sumbernya.
Tindakan plagiarisme dalam instansi, sektor akademis, maupun non
akademis secara perlahan harus dicegah dan dihilangkan dengan melakukan
pendeteksian plagiat secara manual maupun dengan memanfaatkan metode
pencocokan string. Namun pendeteksian secara manual memiliki masalah
yang cukup besar yaitu sangat tidak memungkinkan melalukan
pendeteksian dokumen dengan membandingkannya dengan dokumen lain
yang berjumlah ratusan bahkan sampai ribuan. Dengan demikian
1
Metode kedua adalah dengan melakukan pembandingan dengan sumber
dokumen asli atau yang disebut dengan metode pencocokan string. Dengan
metode pencocokan string dapat dikembangkan untuk merancang sebuah
aplikasi pendeteksi plagiarisme. Metode pencocokan string
bermacam-macam antara lain Brute Force, Boyer-Morre, Knuth-Morris-Pratt,
Rabin-Karp, dan lain-lain.
Penelitian untuk pendeteksian plagiarisme sudah banyak dilakukan
dengan berbagai macam algoritma, tetapi beberapa penelitian tidak
mengikut sertakan proses preprocessing atau pengolahan kata terlebih
dahulu dan hanya dapat melalukan proses pendeteksian untuk dua dokumen
saja, hal tersebut membuat proses pendeteksian plagiarisme menjadi kurang
akurat dan kurang efisien.
Dari latar belakang tersebut, penulis tertarik untuk membangun sebuah
aplikasi pendeteksian plagiarisme karya tulis ilmiah dalam instansi dinas
pendidikan dengan menggunakan algoritma Rabin-Karp yang dapat
melakukan proses pendeteksian plagiarism lebih dari dua dokumen dan
dengan melakukan proses preprocessing terlebih dahulu. Algoritma
tersebut dipilih karena Rabin-Karp adalah algoritma multiple patterns
search yang sangat efesien untuk pencarian string dengan pola yang banyak
sehingga waktu dan keakuratan pencarian string menjadi lebih baik.
1.2 Rumusan Masalah
Berdasarkan latar belakang diatas dapat diuraikan rumusan masalah
sebagai berikut:
1. Bagaimana mendesain dan membangun aplikasi pendeteksi plagiarisme
dalam karya tulis ilmiah dengan metode Rabin Karp agar dapat
mendeteksi tingkat kesamaan yang terdapat pada dua dokumen karya
tulis ilmiah?
2. Seberapa akurat aplikasi pendeteksi plagiarisme dalam karya tulis
2
3. Apakah aplikasi pendeteksian plagiarism dalam karya tulis ilmiah
dengan motode Rabin Karp ini bermanfaat (perceived of usefulness) dan
mudah digunakan (perceived ease of use) dalam melakukan
pendeteskian file?
1.3 Batasan Masalah
Terdapat beberapa batasan masalah pada penelitian ini, yaitu:
1. Membandingkan dua buah dokumen teks dengan tipe .doc dan .docx
2. Data yang diuji menggunakan Bahasa Indonesia.
3. Tidak memperhatikan sinonim atau persamaan kata pada dokumen teks.
4. Tidak meperhatikan parafrase atau kutipan dengan atau tidak
menggunakan sumber terkait
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Mendesain dan membangun Apakah aplikasi pendeteksi plagiarisme
dalam karya tulis ilmiah dengan metode Rabin Karp.
2. Mendeteksi tingkat kesamaan dua buah dokumen dengan metode Rabin
Karp.
1.5 Metodologi Penelitian
Metodologi penelitian yang dilakukan penulis untuk menyelesaikan
masalah adalah sebagai berikut:
a. Survei awal
Dilakukan wawancara dengan pihak terkait yang dipergunakan untuk
mendesain sistem yang akan dibangun.
b. Studi pustaka
Studi pustaka dilakukan dengan mencari informasi tentang metode
Rabin Karp serta penggunaannya dalam kaitannya dengan pendeteksian
3
c. Pengembangan Aplikasi Pendeteksi Plagiarisme
Pengembangan aplikasi pendeteksi plagiarisme menggunakan metode
Waterfall. Tahap-tahap dalam metode ini adalah:
1. Requirement Analisis
Merupakan tahap awal dalam pengembangan sistem. Pada tahap ini
harus mendapatkan beberapa hal yang dianggap menunjang
penelitian yang dilakukan, seperti mencari permasalahan yang ada,
mengumpulkan data, wawancara dan lain-lain.
2. System Design
Tahap desain sistem membantu dalam menentukan perangkat keras,
tampilan, alur kerja sistem, pengoperasian sistem, dan lain-lain yang
disesuaikan dengan analisis kebutuhan tahap awal.
3. Implementation
Pada tahap ini, sistem pertama kali dikembangkan untuk
menghasilkan aplikasi yang telah di desain pada tahap sebelumnya.
4. Integration & Testing
Dalam tahap ini, dilakukan pengujian sistem, sehingga akan dapat
diketahui seperti apa hasil kinerja sistem yang baru ini dibandingkan
dengan sistem yang lama, kemudian dapat diketahui pula apakan
dalam sistem yang baru ini masih ada kelemahan yang kemudian
akan dikembangkan oleh peneliti berikutnya.
5. Operation & Maintenance
Tahap akhir dalam model waterfall adalah melakukan pemeliharaan
sistem. Pemeliharaan termasuk dalam memperbaiki kesalahan yang
4 1.6 Sistematika Penulisan
BAB 1 : PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, rumusan masalah, batasan
masalah, tujuan penelitian, manfaat penelitian, metode penelitian dan
sistematika penulisan.
BAB II : STUDI PUSTAKA
Bab ini berisi tentang sumber acuan, penjelasan dan uraian singkat
mengenai teori-teori yang berkaitan dengan topik dari tugas akhir ini.
BAB III : PERANCANGAN SISTEM
Bab ini berisi tentang proses-proses perancangan aplikasi dengan teori
yang berkaitan, perancangan alur kerja aplikasi, antar muka pemakai, dan
perancangan penelitian.
BAB IV : IMPLEMENTASI SISTEM
Bab ini berisi tentang implementasi basis data dan implementasi dari
sistem yang akan dibuat, pembahasan sistem dan implementasi antarmuka.
BAB V : ANALISA HASIL
Bab ini berisi tentang hasil implementasi aplikasi, serta analisa hasil
pengujian.
BAB V1 : PENUTUP
Bab ini berisi kesimpulan yang diambil dari analisa, desain, dan
implementasi serta uji coba yang telah dilakukan. Selain itu bab ini juga
berisi saran yang bermanfaat dalam pengembangan aplikasi di waktu yang
5 BAB II
STUDI PUSTAKA
Pada bab studi pustaka ini berisi tentang sumber acuan, penjelasan dan
uraian singkat mengenai teori-teori yang berkaitan dengan topik.
2.1 Plagiarisme
Plagiarisme atau sering disebut plagiat adalah penjiplakan atau
pengambilan karangan, pendapat, dan sebagainya dari orang lain dan
menjadikannya seolah karangan dan pendapat sendiri (KBBI, 1997).
“Plagiarisme adalah bentuk penyalahgunaan hak kekayaan intelektual milik
orang lain, yang mana karya tersebut dipresentasikan dan diakui secara tidak
sah sebagai hasil karya pribadi” (Sulianta, 2007).
Dalam buku Bahasa Indonesia: Sebuah Pengantar Penulisan
Ilmiah, (Utorodewo,2007) menggolongkan hal-hal berikut sebagai tindakan
plagiarisme:
1. Mengakui tulisan orang lain sebagai tulisan sendiri,
2. Mengakui gagasan orang lain sebagai pemikiran sendiri,
3. Mengakui temuan orang lain sebagai kepunyaan sendiri,
4. Mengakui karya kelompok sebagai kepunyaan atau hasil sendiri,
5. Menyajikan tulisan yang sama dalam kesempatan yang berbeda tanpa
menyebutkan asal usulnya,
6. Meringkas dan memparafrasekan (mengutip tak langsung) tanpa
menyebutkan sumbernya, dan
7. Meringkas dan memparafrasekan dengan menyebut sumbernya, tetapi
rangkaian kalimat dan pilihan katanya masih terlalu sama dengan
6 2.2 Text Preprocessing
Preprocessing merupakan tahapan awal dalam mengolah data input
sebelum memasuki proses selanjutnya. Preprocessing terdiri dari beberapa
tahapan, yaitu: case folding, tokenizing, filtering, dan stemming. Berikut
penjelasan empat tahapan dalam proses preprocessing.
2.2.1 Case Folding
Proses case folding adalah menghilangkan tanda baca maupun
karakter yang ada pada kata di dalam dokumen tersebut dan semua
huruf menjadi huruf kecil. (Manning, 2008).
2.2.2 Stopword Filtering
Stopword filtering merupakan salah satu dari empat tahapan dalam
preprocessing untuk menghilangkan kata yang tidak berguna dan
sering muncul dalam dokumen. Stopword perlu dieliminasi untuk
mengurangi waktu eksekusi query dengan cara menghindari proses
list yang panjang (Buttcher, 2010). Contoh stopword filtering dalam
Bahasa Indonesia adalah dengan menghilangkan konjungsi, kata
ganti orang, dan kata lainnya.
2.2.3 Stemming
Stemming merupakan bagian yang tidak terpisahkan dalam
Information Retrieval (IR). Stemming adalah salah satu cara yang
digunakan untuk meningkatkan performa IR dengan cara
mentransformasi kata-kata dalam sebuah dokumen teks ke bentuk
kata dasarnya.
2.2.3.1 Algoritma Nazief-Adriani
Algoritma Stemming Nazief – Adriani diperkenalkan oleh
Nazief dan Adriani (1996) dengan tahapan sebagai berikut:
1. Cari kata yang akan diistem dalam basis data kata dasar.
Jika ditemukan maka diasumsikan kata adalah root
word. Maka algoritma berhenti.
2. Selanjutnya adalah pembuangan Inflection Suffixes (“
7
particles (“-lah”, “-kah”, “-tah” atau “-pun”) dan
terdapat Possesive Pronouns (“-ku”, “-mu”, atau “
-nya”), maka langkah ini diulangi lagi untuk menghapus
Possesive Pronouns.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika
kata ditemukan di kamus, maka algoritma berhenti. Jika
tidak maka ke langkah 3a berikut ini :
a. Jika “-an” telah dihapus dan huruf terakhir dari kata
tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka
algoritma berhenti. Jika tidak ditemukan maka
lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”)
dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks
yang dihapus maka pergi ke langkah 4a, jika tidak pergi
ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak
diijinkan pada Tabel 2.1. Jika ditemukan maka
algoritma berhenti, jika tidak, pergi ke langkah 4b.
Tabel kombinasi awalan-akhiran yang tidak diijinkan
ditampilkan pada tabel berikut ini :
Awalan Akhiran yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tabel 2.1. Tabel kombinasi awalan dan akhiran yang tidak
8
b. Tentukan tipe awalan kemudian hapus awalan. Jika
awalan kedua sama dengan awalan pertama
algoritma berhenti.
c. Jika root word belum juga ditemukan lakukan
langkah 5, jika sudah maka algoritma berhenti.
5. Jika semua langkah telah selesai tetapi tidak juga
berhasil maka kata awal diasumsikan sebagai root
word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka
tipe awalannya secara berturut-turut adalah “di-”, “ke-”,
atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-”
maka dibutuhkan sebuah proses tambahan untuk
menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”,
“te-”, “be-”, “me-”, atau“pe-” maka berhenti.
Berikut adalah aturan untuk melakukan penghapusan
awalan. Dengan keterangan C adalah huruf konsonan, V
adalah huruf hidup, A adalah semua huruf, dan P adalah
karakter tertentu, misal ‘er’.
Aturan Kontruksi Prefix yang dihapus
1 me{l|r|w|y}V… me-
2 mem{b|f|v}… mem-
3 mempe… mem-pe
4 mem{rV|V}… me-m, me-p
9
6 mengV… meng-V… | meng-kV… |(mengV-…
ifV=’e’)
7 meng{g|h|q|k}… meng-
8 mengV… meng-
9 menyV… mensy-s
10 mempA… mem-pA… dimana A!=’e’
Tabel 2.2. Tabel aturan penghapusan awalan, untuk awalan
“me-“
Aturan Kontruksi Prefix yang dihapus
1 pe{w|y}V… pe-{w|y}V...
2 perV… per-V... | pe-rV...
3 perCAP per-CAP... dimana C!= ‘r’ dan
P!= “er”
4 per CAerV… per-CAerV... dimana C!= ‘r’
5 pem{b|f|V}… pem-{b|f|V}...
6 pem{rV|V}… pe-m{rV|V}... | pe-p{rV|V}...
7 pen{c|d|j|z}… pen-{c|d|j|z}...
8 penV… pe-nV... | pe-tV...
9 pengC… peng-C...
Tabel 2.3. Tabel aturan penghapusan awalan, untuk awalan
“pe-“
Aturan Kontruksi Prefix yang dihapus
1 berV... ber-V... | be-rV...
2 berCAP... ber-CAP... dimana C!= ‘r’ danP!= “er”
3 berCAerV... ber-CaerV... dimana C!= ‘r’
4 belajar bel-ajar
5 beC1erC2… be-C1erC2... dimana C1!={ ‘r’|‘l’}
Tabel 2.4. Tabel aturan penghapusan awalan, untuk awalan
10
Aturan Kontruksi Prefix yang dihapus
1 terV... ter-V... | te-rV...
2 terCerV... ter-CerV... dimana C!= ‘r’
3 terCP... ter-CP... dimana C!= ‘r’ danP!= ‘er’
4 teC1erC2… te-C1erC2… dimana C1=’r’
Tabel 2.5. Tabel aturan penghapusan awalan, untuk awalan
“ter-“
2.2.4 Tokenizing
Tokenizing adalah proses pemisahan kata berdasarkan tiap kata yang
menyusunnya. Pada prinsipnya proses ini adalah memisahkan setiap
kata yang menyusun setiap dokumen sehingga menghasilkan suatu
kata yang berdiri sendiri, baik dalam bentuk perulangan maupun
tunggal (Manning, 2008). Metode tokenizing yang digunakan dalam
penelitian ini adalah metode k-gram, yaitu membentuk pola kata
dalam sebuah teks dengan memecah kata menjadi
potongan-potongan dimana setiap potongan-potongan mengandung karakter sebanyak k.
Penentuan nilai k adalah dengan melihat banyaknya banyaknya kata
yang akan diolah atau di hitung nilai hashnya, semakin banyak kata
yang diolah maka pemotongan kata (k) yang dipilih dapat semakin
besar (Mujahidin, 2013). Hasil yang paling bagus pada pengujian
adalah dengan menentukan nilai k-gram dan basis bilangan yang
tidak terlalu kecil dan tidak terlalu besar.
2.3 Algoritma String Matching
Algoritma string matching atau sering disebut juga dengan
algoritma pencocokan string adalah algoritma untuk melakukan pencarian
semua kemunculan string dengan pendek dan panjang, untuk string pendek
11
Persoalan pencarian string dirumuskan sebagai berikut (Munir,
2004) :
1. teks (text), yaitu (long) string yang panjangnya n karakter
2. pattern, yaitu string dengan panjang m karakter (m < n) yang akan dicari
di dalam teks.
Cara kerjanya adalah mencari lokasi pertama di dalam teks yang
bersesuaian dengan pattern. Diberikan contoh seperti dibawah:
Pattern : for
Teks : Teknik Informatika
Target
Algoritma pencarian string ini dapat juga diklasifikasikan menjadi
tiga bagian menurut arah pencariannya.
1. Dari kiri ke kanan, algoritma yang termasuk kategori ini adalah:
a. Algoritma Brute Force.
b. Algoritma dari Morris dan Pratt, yang kemudian dikembangkan
oleh Knuth, Morris, dan Pratt.
c. Algoritma Rabin Karp
2. Dari arah kanan ke kiri, algoritma yang termasuk kategori ini adalah:
a. Algoritma dari Boyer dan Moore, yang kemudian banyak
dikembangkan, menjadi Algoritma turbo Boyer-Moore,
Algoritma tuned Boyer-Moore, dan Algoritma Zhu-Takaoka.
3. Dari arah yang ditentukan secara spesifik oleh algoritma yang dipakai,
algoritma yang termasuk kategori ini adalah:
a. Algoritma Colussi
12
2.3.1 ASCII (American Standard Code for Information Interchange)
Kode Standar Amerika untuk Pertukaran Informasi atau
ASCII (American Standard Code for Information Interchange)
merupakan suatu standar internasional dalam kode huruf dan simbol
seperti Hex dan Unicode tetapi ASCII lebih bersifat universal,
contohnya 124 adalah untuk karakter "|". Ia selalu digunakan oleh
komputer dan alat komunikasi lain untuk menunjukkan teks. Kode
ASCII sebenarnya memiliki komposisi bilangan biner sebanyak 7
bit. Namun, ASCII disimpan sebagai sandi 8 bit dengan
menambakan satu angka 0 sebagai bit significant paling tinggi.
Jumlah kode ASCII adalah 255 kode. Kode ASCII 0..127
merupakan kode ASCII untuk manipulasi teks; sedangkan kode
ASCII 128..255 merupakan kode ASCII untuk manipulasi grafik.
Kode ASCII sendiri dapat dikelompokkan lagi kedalam beberapa
bagian:
1. Kode yang tidak terlihat simbolnya seperti Kode
10(Line Feed), 13(Carriage Return), 8(Tab), 32(Space).
2. Kode yang terlihat simbolnya seperti abjad (A..Z),
numerik (0..9), karakter khusus
(~!@#$%^&*()_+?:”{}).
3. Kode yang tidak ada di keyboard namun dapat
ditampilkan. Kode ini umumnya untuk kode-kode
13
Tabel 2.6 Tabel ASCII.
2.4 Rabin Karp
Algoritma Rabin Karp dibuat oleh Michael O. Rabin dan Richard
M. Karp pada tahun 1987 dengan memanfaatkan metode hashing dalam
pengoperasiannya untuk mekukan pencarian kata yang mecari pola berupa
substring. Algoritma Rabin Karp efektif dalam melakukan pencocokan kata
dengan pola yang banyak. Dengan menggunakan metode hashing,
kecepatan pencarian pola dapat dilakukan secara lebih cepat.
Menurut (Abdeen, 2011) pada prinsipnya algoritma Rabin-Karp
menghitung sebuah fungsi hash untuk mencari pola didalam sebuah teks
yang diberikan. Setiap karakter M subsequence dari pada teks akan
dikomparasi, jika nilai hash tidak sama algoritma akan menghitung nilai
hash untuk karakter M subsequence berikutnya. Dan jika nilai hash sama
14
pola dan karakter M subsequence, dengan cara ini hanya akan ada satu
perbandingan per teks subsequence dan brute-force hanya dibutuhkan jika
nilai hash cocok atau sama. (Jain, et., al, 2012).
Algoritma Rabin Karp adalah algoritma pencocokan string yang
menggunakan fungsi hash sebagai pembanding antara string yang dicari (m)
dengan substring pada teks (n). Apabila nilai hash keduanya sama maka
akan dilakukan perbandingan sekali lagi terhadap karakter-karakternya.
Apabila hasil keduanya tidak sama, maka substring akan bergeser ke kanan.
Pergeseran dilakukan sebanyak (n-m) kali. Perhitungan nilai hash yang
efisien pada saat pergeseran akan mempengaruhi performa dari algoritma
ini. (David Indra Lesmana, 2012).
Langkah-langkah dalam algortima Rabin Karp :
1. Menghilangkan tanda baca dan mengubah ke teks sumber dan kata yang
ingin dicari menjadi kata-kata tanpa huruf.
2. Membagi teks kedalam gram-gram yang ditentukan nilai k-gramnya
3. Mencari nilai hash dengan fungsi hash dari tiap kata yang terbentuk
4. Mencari nilai hash yang sama antara dua teks.
2.4.1 Hashing
Fungsi hash adalah sebuah fungsi untuk mengubah setiap
string menjadi bilangan yang disebut hash value. Sebuah string
diubah menjadi suatu nilai yang unik dengan panjang tertentu (
fixed-length)yang berfungsi sebagai penanda string tersebut. Pada sistem
ini proses hashing memanfaatkan tabel ascii dengan rumus Hash
(Mitra, 2003):
�� = � ∗ � �− + � ∗ � �− + ⋯ + �
15
Keterangan :
I = Nilai hash
p = Nilai ascii karakter (desimal)
m = Banyak karakter (indeks karakter)
d = Basis Bilangan (nilai dari basis bilangan harus
bilangan prima)
Fungsi hash dengan basis yang biasanya memanfaatkan
bilangan prima disebut dengan rolling hash. Untuk penentuan basis
bilangan adalah dengan memilih bilangan prima karena dapat
memperkecil terjadinya collision (Zeil, 2014)
.
Berikut ini adalah contoh penggunaan fungsi hash atau
rolling hash dengan basis. Menggunakan string “informasi” sebagai
sumber string dan “for” sebagai string polayang dicari.
1. Dengan menggunakan b = 2 lalu panjang string
“informasi” sebagai n = 8 dan string “for” untuk pola
yang dicari sebagai k = 3.
2. Selanjutnya ubah pola yang dicari dengan fungsi hash
atau rolling hash dengan persamaan diatas.
3. Nilai hash dari “for” adalah 744 yang didapat dari:
(nilai ascii f = 102, o = 111, r = 114)
I = 102*22 + 111*21 + 114*20
= 408 + 222 + 114
= 744
4. Percobaan pencocokan pola dilakukan berawal dari
indeks ke 0 sampai ke 7 dari string “informasi” dengan
pola string “for”.
a. Percobaan pertama
0 1 2 3 4 5 6 7 8
16
Hash(for) = 744
Hash(y[0..2]) = 105*22 + 110*21 + 102*20
= 420 + 220 +102
= 724
Nilai hash dari indeks 0 sampai 2 tidak cocok, maka
dilakukan percobaan selanjutnya dengan bergeser ke
indeks 1 sampai 3.
b. Percobaan kedua
0 1 2 3 4 5 6 7 8
i n f o r m a s i f o r
Hash(for) = 744
Hash(y[1..3]) = 110*22 + 102*21 + 111*20
= 440 + 204 +111
= 755
Nilai hash dari indeks 1 sampai 3 tidak cocok, maka
dilakukan percobaan selanjutnya dengan bergeser ke
indeks 2 sampai 4.
c. Percobaan ketiga
0 1 2 3 4 5 6 7 8
i n f o r m a s i f o r
Hash(for) = 744
Hash(y[2..4]) = 102*22 + 111*21 + 114*20
= 408 + 222 + 114
= 744
Nilai hash dari indeks 2 sampai 4 terjadi kecocokan,
maka algoritma akan menandai lokasi penemuan
17
sampai percobaan keenam atau sampai karakter pada
sumber string habis.
2.4.2 Similarity
Fungsi kemiripan atau similarity adalah menghitung
kesamaan dan ketidaksamaan antara dua objek yang
diobservasi. Objek yang dimaksud disini adalah komunitas
yang saling berbeda. Ludwig & Reynolds (1988)
menyatakan bahwa kemiripan suatu komunitas dengan
komunitas lain dapat dinyatakan dengan similarity
coefficients. Similarity coefficients memiliki nilai yang
bervariasi antara 0 (jika kedua komunitas benar-benar
berbeda) hingga 1 (jika kedua komunitas identik).
Pada sistem pendeteksian plagiarisme ini digunakan
indeks Sørensen atau disebut juga dengan Dice's coefficient
dengan persamaan:
� = � + � ��
Keterangan:
S : Similaritas indeks Sørensen
� : Jumlah nilai hash komunitas x
� : Jumlah nilai hash komunitas y
�� : Jumlah hash yang sama dari komunitas x dan y
Kisaran nilai indeks Sørensen adalah antara 0 sampai
1, dimana semakin mendekati angka 0 maka indeks
disimilaritas tidak ada perbedaan dan indeks similaritas
kecil, sedangkan semakin mendekati nilai 1, menunjukkan
18
2.5 Metode Waterfall
2.5.1 Definisi Waterfall
Metode waterfall pertama kali diperkenalkan oleh Windows
W. Royce pada tahun 1970. Walaupun sering dianggap kuno,
metode ini paling banyak dipakai dalam Software Engineering (SE)
karena metode ini melakukan pendekatan yang sistematis dan
berurutan. Metode ini disebut waterfall karena tahap demi tahap
yang dilalui harus menunggu tahap sebelumnya selesai dan berjalan
berurutan Menurut (Pressman, 2010), model waterfall adalah model
klasik yang bersifat sistematis, berurutan dalam membangun
software.
Gambar 2.1 Waterfall menurut Pressman
2.5.2 Tahapan Pengembangan Metode Waterfall
Langkah-langkah yang dilakukan dalam pengembangan waterfall
adalah:
1. Requirement Analisis
Merupakan tahap awal dalam pengembangan sistem. Pada tahap
ini harus mendapatkan beberapa hal yang dianggap menunjang
penelitian yang dilakukan, seperti mencari permasalahan yang
ada, mengumpulkan data, wawancara dan lain-lain.
2. System Design
Tahap desain sistem membantu dalam menentukan perangkat
19
lain-lain yang disesuaikan dengan analisis kebutuhan tahap
awal.
3. Implementation
Pada tahap ini, sistem pertama kali dikembangkan untuk
menghasilkan aplikasi yang telah di desain pada tahap
sebelumnya.
4. Integration & Testing
Tahap ini merupakan tahap pengujian sistem yang artinya sistem
yang telah dibuat dari hasil analisis masalah yang telah melalui
tahap desain dan implementasi kemudian masuk kedalam
pengujian sistem, sehingga akan dapat diketahui seperti apa hasil
kinerja sistem yang baru ini dibandingkan dengan sistem yang
lama, kemudian dapat diketahui pula apakan dalam sistem yang
baru ini masih ada kelemahan yang kemudian akan
dikembangkan oleh peneliti berikutnya.
5. Operation & Maintenance
Tahap akhir dalam model waterfall adalah
melakukan pemeliharaan sistem. Pemeliharaan termasuk dalam
memperbaiki kesalahan yang tidak ditemukan pada langkah
sebelumnya
Ada 3 alasan perlunya pemeliharaan sistem, yaitu:
a. Untuk membenarkan kesalahan atau kelemahan sistem yang
tidak terdeteksi pada saat pengujian.
b. Untuk membuat sistem up to date.
20 BAB III
PERANCANGAN SISTEM
Pada bab perancangan sistem ini berisi tentang penjelasan rancangan, proses
kerja sistem, dan perancangan antarmuka pengguna yang akan dibangun oleh
penulis.
3.1 Tahap Requirement Analysis
3.1.1 Gambaran Umum Sistem
Sistem pendeteksi plagiat yang akan dibangun merupakan
sistem yang akan mendeteksi tingkat kesamaan dua dokumen teks.
Masukan sistem diperoleh dari dokumen teks yang akan diunggah
oleh pengguna. Selanjutnya dokumen akan melewati tahap
preprocessing menggunakan text mining. Padatahap
preprocessing, dilakukan case folding (mengubah isi dokumen
menjadi huruf kecil), filtering (membuang kata yang tidak
penting), stemming (mengubah kata kedalam bentuk aslinya atau
kata dasar), dan tokenizing (pembentukan rangkaian k-gram).
Setelah melakukan preprocessing, dokumen akan masuk ke dalam
proses pencocokan kata dengan menggunakan algoritma Rabin
Karp. Hasil pencocokan dokumen kemudian dihitung similarity
dengan indeks Sorensen dengan nilai 0 sampai 1. Jika similarity
yang dihasilkan mendekati angka 1, maka disimpulkan bahwa
tingkat plagiarisme dalam dokumen tersebut semakin besar.
3.1.2 Analisis Kebutuhan
Analisis kebutuhan digunakan untuk mengidentifikasi
terhadap kebutuhan sistem. Kebutuhan sistem meliputi analisis
kebutuhan pengguna atau admin sebagai berikut:
1. Mengolah data file dokumen untuk dideteksi tingkat
21 3.1.3 Use Case
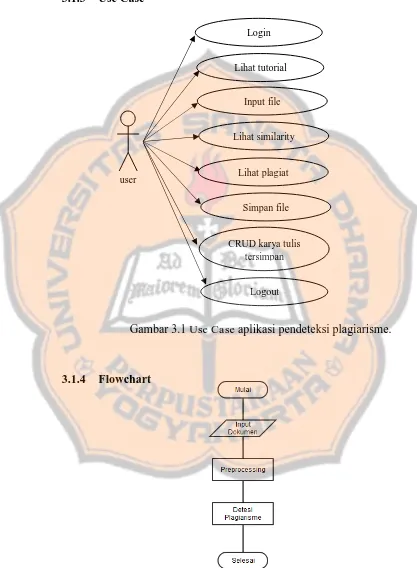
Gambar 3.1 Use Case aplikasi pendeteksi plagiarisme.
3.1.4 Flowchart
Gambar 3.2 Flowchart aplikasi pendeteksi plagiarisme. Lihat tutorial
Input file
Lihat similarity
Simpan file
CRUD karya tulis tersimpan
user Lihat plagiat
Login
22
3.1.5 Pemodelan Proses
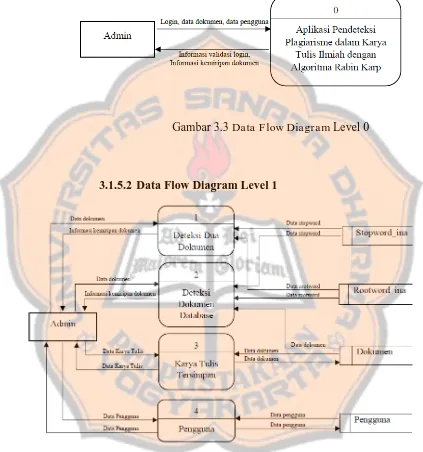
3.1.5.1 Data Flow Diagram Level 0
Gambar 3.3 Data Flow Diagram Level 0
3.1.5.2 Data Flow Diagram Level 1
23
3.1.5.3 Data Flow Diagram Level 2 Proses 1
Gambar 3.5 Data Flow Diagram Level 2 proses 1
3.1.5.4 Data Flow Diagram Level 2 Proses 2
24
3.1.5.5 Data Flow Diagram Level 2 Proses 3
Gambar 3.7 Data Flow Diagram Level 2 proses 3
3.1.5.6 Data Flow Diagram Level 2 Proses 4
25
3.2 Perancangan Sistem
3.2.1 Perancangan Basis Data
Perancangan basis data pada sistem meliputi pembuatan
tabel-tabel basis data.
3.2.1.1 Perancangan Basis Data Konseptual (ERD)
Gambar 3.9 Perancangan ER Diagram
3.2.1.2 Perancangan Basis Data Logikal
Gambar 3.10 Perancangan logikal basis data
Login Dokumen Stopword_ina Rootword_ina
*Id Nama Username Password
*Id Path Judul Penulis
Tahun
*Id Stopword
26
3.2.1.3 Perancangan Basis Data Fisikal
3.2.1.3.1 Tabel Login
Tabel untuk menyimpan data admin seperti
id, nama, username, dan password yang
digunakan untuk keperluan login sebelum
masuk ke sistem.
Tabel 3.1 Tabel Login
Field Tipe Keterangan
Id Int (10) Primary key table login
Nama Varchar (50) Nama admin
Username Varchar (50) Username admin
Password Varchar (50) Password admin
3.2.1.3.2 Tabel Dokumen
Tabel untuk menyimpan data dokumen
seperti id, path, judul, penulis, dan tahun.
Tabel 3.2 Tabel Dokumen
Field Tipe Keterangan
Id Int (10) Primary key table ini
Path Varchar (100) Path dokumen terkait
Judul Varchar (100) Judul dokumen terkait
Penulis Varchar (100) Penulis dokumen terkait
Tahun Int (5) Tahun penulisan
27
3.2.1.3.3 Tabel Rootword_ina
Tabel untuk menyimpan kamus kata dasar
yang digunakan untuk stemming dokumen.
Tabel 3.3 Tabel Rootword_ina
Field Tipe Keterangan
Id Int (10) Primary key tabel ini
Rootword Varchar (50) Daftar kata rootword
(dasar)
3.2.1.3.4 Tabel Stopword_ina
Tabel untuk menyimpan kamus kata tidak
penting padadokumen.
Tabel 3.4 Tabel Stopword_ina
Field Tipe Keterangan
Id Int (10) Primary key tabel ini
Stopword Varchar (50) Daftar kata stopword
(tidak penting)
3.2.2 Perancangan Antarmuka
3.2.2.1 Halaman Login
Rancangan antarmuka untuk halaman login. Pada
halaman ini pengguna akan mengisi username dan
password untuk bisa masuk ke sistem. Dapat dilihat pada
28
Gambar 3.11 Perancangan halaman login
3.2.2.2 Halaman Utama
Rancangan antarmuka untuk halaman utama sistem.
Halaman utama sistem ini terdiri dari empat buah menu
yaitu menu untuk mendeteksi dua dokumen, menu untuk
mendeteksi dokumen dengan dokumen yang sudah
tersimpan di database, menu karya tulis tersimpan, dan
menu pengguna. Dapat dilihat pada gambar 3.12.
Gambar 3.12 Perancangan halaman utama aplikasi
3.2.2.3 Halaman Deteksi dua Dokumen
Rancangan antarmuka untuk halaman deteksi dua
dokumen. Pada halaman ini dua buah dokumen akan di
proses untuk dilihat presentase kemiripannya. Dapat
dilihat pada gambar 3.13.
Aplikasi Pendeteksi Plagiat
Username Password
Login
Aplikasi Pendeteksi Plagiat
Deteksi dua Dokumen
Karya Tulis Tersimpan
X ?
Deteksi Dokumen di
Database
29
Gambar 3.13 Perancangan halaman proses dua dokumen
3.2.2.4 Halaman Deteksi Dokumen di Database
Rancangan antarmuka untuk halaman deteksi
dokumen di database. Pada halaman ini dokumen yang
akan diuji akan dibandingkan dengan beberapa dokumen
yang sudah tersimpan di database. Dapat dilihat pada
gambar 3.14.
Gambar 3.14 Perancangan halaman proses dokumen di database
3.2.2.5 Halaman Karya Tulis Tersimpan
Rancangan antarmuka untuk halaman karya tulis
tersimpan. Pada halaman ini path dari karya tulis yang
tersimpan di komputer akan disimpan di database. Dapat
dilihat pada gambar 3.15.
Aplikasi Pendeteksi Plagiat
Dokumen 1
X
Dokumen 2
Aplikasi Pendeteksi Plagiat
XDokumen 1
upload
upload
Proses
Kembali
?
upload
Proses
Karya Tulis Ilmiah tersimpan
?
30
Gambar 3.14 Halaman karya tulis tersimpan
Gambar 3.15 Perancangan halaman karya tulis tersimpan
3.2.2.6 Halaman Pengguna
Rancangan antarmuka halaman pengguna. Halaman
ini merupakan proses pengelolaan pengguna. Dapat
dilihat pada gambar 3.16.
Gambar 3.16 Perancangan halaman pengguna
Aplikasi Pendeteksi Plagiat
? XTabel Pengguna
NIP Nama Password
Simpan
Aplikasi Pendeteksi Plagiat
Tabel Karya Tulis Tersimpan
31 BAB IV
IMPLEMENTASI SISTEM
Pada bab implementasi sistem berisi tentang implementasi dari sistem yang
akan dibuat, pembahasan sistem, implementasi antarmuka, dan hasil implementasi
aplikasi.
4.1 Deskripsi Alat
Pada implementasi sistem, penulis menggunakan komputer pribadi
dengan spesifikasi sebagai berikut:
1. Processor : AMD A8-5550M
2. RAM : 4 GB
3. Kapasitas Penyimpanan : 500 GB
Sedangkan perangkat lunak yang penulis gunakan adalah:
1. Sistem Operasi : Windows 10
2. Bahasa Pemrograman : Java
3. Tools Perancang : Netbeans IDE 8.0.2
4.2 Algoritma Rabin Karp
Dalam pembuatan aplikasi pendeteksi plagiat, penulis memilih
algoritma Rabin Karp karena memungkinkan melakukan pencarian pola
tulisan dari substring-substring pada sebuah teks dalam dokumen.
Algoritma Rabin Karp tidak melakukan pergeseran yang rumit untuk
menyelesaikan masalah, algoritma ini mempercepat pengecekan kata pada
suatu teks dengan menggunakan fungsi hash.
Contoh perbandingan dua buah dokumen yang terindikasi
32
Tabel 4.1 Dua buah dokumen yang terindikasi terjadi plagiarisme.
Dokumen 1
Dalam The 100 Greatest Disasters of All Time karya Stephen J Spignesi,
dua bencana di Indonesia berada di peringkat ke-22 dan ke-30. Pertama,
letusan Gunung Tambora di Sumbawa (1815) yang merenggut 150.000
jiwa dan menurunkan suhu bumi. Kedua, letusan Gunung Krakatau
(1883) yang menelan 36.000 nyawa.
Dokumen 2
Dalam buku The 100 Greatest Disasters of AllTime karya Stephen J
Spignesi, dua bencana di Indonesia masuk peringkat ke-22 dan 30.
Letusan Gunung Tambora di Sumbawa tahun 1815 merenggut 150.000
jiwa dan menurunkan suhu Bumi. Adapun letusan Gunung Krakatau
tahun 1883 menelan 36.000 nyawa.
Dari table 4.1 diatas, dapat dilihat kemiripan dokumen sangat
terlihat. Namun untuk mengetahui tingkat kemiripan atau similarity antara
dua buah dokumen digunakan algoritma Rabin Karp.
Langkah pertama adalah dengan melakukan preprocessing
dokumen, yaitu:
1. Case folding
Proses ini adalah dengan mengubah semua huruf menjadi huruf
kecil.
Tabel 4.2 Dua buah dokumen setelah melalui langkah case folding.
Dokumen 1
dalam the 100 greatest disasters of all time karya stephen j spignesi, dua
bencana di indonesia berada di peringkat ke-22 dan ke-30. pertama,
33
jiwa dan menurunkan suhu bumi. kedua, letusan gunung krakatau (1883)
yang menelan 36.000 nyawa.
Dokumen 2
dalam buku the 100 greatest disasters of alltime karya stephen j
spignesi, dua bencana di indonesia masuk peringkat ke-22 dan 30.
letusan gunung tambora di sumbawa tahun 1815 merenggut 150.000
jiwa dan menurunkan suhu bumi. adapun letusan gunung krakatau tahun
1883 menelan 36.000 nyawa.
2. Filtering
Langkah yang kedua adalah menghilangkan kata-kata yang
kurang penting. Pada proses filtering, kata-kata yang akan
dihapus meliputi kata-kata yang kurang penting atau kata
sambung seperti kata “dari”, “dan”, dan kata sambung lainnya.
Pada proses ini tanda baca juga dihilangkan.
Tabel 4.3 Dua buah dokumen setelah melalui langkah case filtering.
Dokumen 1
100greatest disasters all time karya stephen j spignesi dua bencana
indonesia berada peringkat 22 30 pertama letusan gunung tambora
sumbawa 1815 merenggut 150000 jiwa menurunkan suhu bumi kedua
letusan gunung krakatau 1883 menelan 36000 nyawa
Dokumen 2
buku 100 greatest disasters alltime karya stephen j spignesi dua
bencana indonesia masuk peringkat 22 30 letusan gunung tambora
sumbawa tahun 1815 merenggut 150000 jiwa menurunkan suhu bumi
34
3. Stemming
Langkah ketiga adalah dengan melakukan stemming, yaitu
mengubah kata kedalam bentuk aslinya atau dengan kata lain
mengubah ke bentuk kata dasar. Dalam penelitian ini, kata
yang diubah ke bentuk kata dasar hanya kata dalam Bahasa
Indonesia saja.
Tabel 4.4 Dua buah dokumen setelah melalui langkah stemming.
Dokumen 1
100greatest disasters all time karya stephen j spignesi dua bencana
indonesia ada tingkat 22 30 pertama letus gunung tambora sumbawa
1815 renggut 150000 jiwa turun suhu bumi dua letus gunung krakatau
1883 telan 36000 nyawa
Dokumen 2
buku 100 greatest disasters all time karya stephen j spignesi dua
bencana indonesia masuk tingkat 22 30 letus gunung tambora sumbawa
tahun 1815 renggut 150000 jiwa turun suhu bumi letus gunung krakatau
tahun 1883 telan 36000 nyawa
4. Tokenizing
Langkah terakhir dalam proses preprocessing adalah proses
pemotongan string input berdasarkan tiap kata penyusunnya
dan pembentukan pola kata dalam rangkaian k-gram. Langkah
tokenizing dibagi menjadi dua proses, yaitu :
a. Proses parsing k-gram
Merupakan pemotongan kata sebanyak k = 5. Penentuan
nilai k adalah dengan melihat banyaknya banyaknya kata
35
Tabel 4.5 Dua buah dokumen setelah melalui langkah parsing k-gram
dalam tokenizing.
Dokumen 1
{100 g}{00 gr}{0 gre}{ grea}{great}{reate}{eates} {atest}{testd} {estdi}{stdis}
{tdisa}{disas}{isast}{saste}{aster}{sters}{ters }{ers a}{rs al}{s all}{ all }{all t}{ll
th}{l the}{ the }{the t}{he ti}{e tim}{ time}{time }{ime k}{me ka}{e kar}{ kary}
{karya}{arya }{rya s}{ya st}{a ste}{ step}{steph}{tephe}{ephen}{phen }{hen j}{en j
}{n j s}{ j sp}{j spi}{ spig}{spign}{pigne}{ignes}{gnesi} {nesi }{esi d}{si du}{i
dua}{ dua }{dua b}{ua be}{a ben}{ benc}{benca}{encan}{ncana}{cana }{ana i}{na
in}{a ind}{ indo} {indon}{ndone}{dones} {onesi} {nesia}{esia }{sia a}{ia ad}{a
ada}{ ada }{ada t}{da ti}{a tin} { ting} {tingk} {ingka}{ngkat}{gkat }{kat 2}{at
22}{t 22 }{ 22 3}{22 30}{2 30 }{ 30 p}{30 pe}{0 per}{ pert} {perta}
{ertam}{rtama}{tama }{ama l}{ma le}{a let}{ letu} {letus}{etus }{tus g}{us gu}{s
gun}{ gunu} {gunun}{unung}{nung }{ung t}{ng ta}{g tam}{ tamb}
{tambo}{ambor} {mbora}{bora }{ora s}{ra su}{a sum}{ sumb} {sumba} {umbaw}
{mbawa}{bawa }{awa 1}{wa 18}{a 181}{ 1815}{1815 }{815 r} {15 re}{5 ren}{
reng}{rengg} {enggu}{nggut}{ggut } {gut 1}{ut 15}{t 150}{ 1500} {15000}
{50000}{0000 } {000 j}{00 ji}{0 jiw}{ jiwa} {jiwa }{iwa t}{wa tu} {a tur} {
turu}{turun}{urun }{run s}{un su}{n suh}{ suhu}{suhu }{uhu b}{hu bu}{u bum}{
bumi}{bumi }{umi d}{mi du}{i dua}{ dua } {dua l}{ua le}{a let}{
letu}{letus}{etusa} {tusan{usan }{san g}{an gu}{n gun}{ gunu}{gunun}{unung}
{nung }{ung k}{ng kr}{g kra}{ krak}{kraka} {rakat}{akata}{katau}{atau }{tau
1}{au 18}{u 188}{ 1883}{1883 } {883 t}{83 te}{3 tel}{ tela}{telan}{elan }{lan
3}{an 36}{n 360}{ 3600} {36000} {6000 }{000 n}{00 ny}{0 nya}{ nyaw} {nyawa}
Dokumen 2
{buku }{uku 1}{ku 10}{u 100}{ 100 }{100 g}{00 gr} {0 gre}{ grea}{great}{reate}
{eates}{atest}{test }{est d}{st di}{t dis}{ disa}{disas}{isast}{saste}{aster}{sters}
{ters }{ers a}{rs al}{s all}{ all }{all t}{ll ti}{l tim}{ time}{time }{ime k}{me ka}{e
kar}{ kary}{karya}{arya }{rya s}{ya st}{a ste}{ step}{steph} {tephe}{ephen}{phen
}{hen j}{en j }{n j s} { j sp}{j spi}{ spig} {spign}{pigne}{ignes}{gnesi}{nesi }{esi
d}{si du}{i dua}{ dua }{dua b}{ua be}{a ben}{ benc}{benca}{encan}{ncana}{cana
}{ana i}{na in}{a ind}{ indo}{indon}{ndone}{dones} {onesi} {nesia}{esia }{sia
m}{ia ma}{a mas}{ masu}{masuk}{asuk }{suk t}{uk ti}{k tin}{ ting}{tingk}
{ingka}{ngkat}{gkat }{kat 2}{at 22}{t 22 }{ 22 3}{22 30}{2 30 }{ 30 l}{30 le}{0
36
t}{ng ta}{g tam}{ tamb}{tambo} {ambor}{mbora}{bora }{ora s}{ra su}{a sum}{
sumb}{sumba} {umbaw}{mbawa}{bawa }{awa t}{wa ta}{a tah}{ tahu}{tahun}
{ahun }{hun 1}{un 18}{n 181}{ 1815}{1815 }{815 r}{15 re} {5 ren}{
reng}{rengg}{enggu}{nggut}{ggut }{gut 1}{ut 15}{t 150}{
1500}{15000}{50000}{0000 }{000 j}{00 ji}{0 jiw}{ jiwa}{jiwa }{iwa t}{wa tu}
{a tur}{ turu} {turun}{urun }{run s}{un su}{n suh}{ suhu}{suhu }{uhu b}{hu bu}
{u bum}{ bumi} {bumi }{umi l}{mi le}{i let}{ letu}{letus}{etus }{tus g}{us gu}
{s gun}{ gunu}{gunun} {unung}{nung }{ung k}{ng kr}{g kra}{
krak}{kraka}{rakat}{akata}{katau}{atau }{tau t}{au ta}{u tah}{ tahu}{tahun}{ahun
}{hun 1}{un 18}{n 188}{ 1883}{1883 }{883 t}{83 te}{3 tel}{ tela}{telan}{elan }
{lan 3}{an 36} {n 360}{ 3600}{36000}{6000 }{000 n}{00 ny}{0 nya}{
nyaw}{nyawa}
b. Proses hashing
Proses yang kedua adalah mengubah setiap string
menjadi angka. Dengan menggunakan persamaan:
�� = � ∗ � �− + � ∗ � �− + ⋯ + �
�− ∗ � + ��− ∗ �
Maka kedua dokumen yang telah diproses sampai ke
tahap tokenizing dapat dihitung nilai hash nya dengan
basis bilangan (d) = 7. Untuk penentuan basis bilangan
adalah dengan memilih bilangan prima karena dapat
memperkecil terjadinya collision.
Tabel 4.6 Dua buah dokumen setelah melalui langkah hashing dalam
38
Dari proses hashing fedua dokumen diatas, dapat
39
Tabel 4.7 Hash yang sama dalam dua buah dokumen setelah melalui
langkah hashing dalam tokenizing.
Dokumen 1 dan Dokumen 2
1341
Setelah jumlah hash diketahui, yaitu hash pada dokumen
pertama sebanyak 242, hash dokumen uji sebanyak 240 dan hash
yang sama sebanyak 163, proses selanjutnya adalah menghitung
40
Langkah selanjutnya dalam algoritma Rabin Karp adalah melakukan
uji similarity. Uji similarity menggunakan indeks Sørensen dengan
persamaan:
� = � + � ��
� = ∗+ = .
Diketahui similary antar dua buah dokumen sebesar 0.67634 yang artinya
kedua dokumen memiliki similarity yang besar dan dapat dikatakan
plagiarisme.
4.3 Implementasi Basis Data
Pada tahap ini dilakukan pembangunan database untuk menunjang
sistem yang dibangun. Berikut query untuk membuat database dan
tabel-tabel yangada di dalamnya.
4.3.1 Table Login
create table login(
nip int(10) primary key,
nama varchar(50),
username varchar(50),
password varchar(50));
4.3.2 Tabel Dokumen
create table dokumen(
id int 10 primary key,
path varchar(100),
judul varchar(100),
penulis varchar(100),
41
4.3.3 Tabel Rootword_ina
create table rootword_ina(
id int(10) primary key,
rootword varchar(50));
4.3.4 Tabel Stopword_ina
create table stopword_ina(
id int(10) primary key,
stopword varchar(50));
4.4 Implementasi Sistem
Pada tahap ini dilakukan pembangunan sistem sesuai dengan
rancangan yang dibuat pada bab sebelumnya.
4.4.1 Halaman Login
Pada halaman login ini, pengguna harus memasukkan
username dan passwordlalu menekan tombol “Login” untuk masuk ke
halaman utama sistem. Dapat dilihat pada gambar 4.1.
42
Berikut adalah potongan listing program bagian tombol “Login”.
4.4.2 Halaman Utama
Halaman utama adalah halaman yang muncul saat pengguna
sudah login ke sistem. Pada halaman ini terdapat tiga menu utama
yaitu deteksi dua dokumen, deteksi dokumen di database, dan karya
tulis tersimpan serta terdapat menu tambahan yaitu menu edit
pengguna. Dapat dilihat pada gambar 4.2.
Gambar 4.2 Halaman utama
try {
Connection conn = new Database().connect();
String sql = "select * from LOGIN where USERNAME='"+ jTextFieldUsername.getText() +"' and PASSWORD='" + jPasswordField.getText()+ "'";
PreparedStatement ps = conn.prepareStatement(sql); ResultSet rs = ps.executeQuery();
if(rs.next()){ this.dispose();
HalamanUtama i = new HalamanUtama(); i.setVisible(true);
} else{
43
4.4.3 Halaman Deteksi dua Dokumen
Halaman Deteksi dua dokumen merupakan halaman yang
digunakan dalam proses pendeteksian dua dokumen yang terindikasi
plagiat. Pada halaman ini pengguna akan memilih dokumen asli dan
dokumen uji kemudian penguna bisa memilih batas toleransi
plagiarisme dengan memilih pada combobox presentase, dan untuk
memulai proses pengujian adalah dengan menekan tombol “proses”.
Setelah proses selesai, hasil akan ditampilkan pada panel sebelah
kanan halaman ini. Dapat dilihat pada gambar 4.3.
Gambar 4.3 Halaman deteksi dua dokumen
Berikut adalah beberapa potongan listing program untuk proses
pendeteksian dua dokumen.
1. Listing program case folding
private String deleteDelimiter(String isiDoc){ String [] delimiter =
{"0","1","2","3","4","5","6","7","8","9","`","~","!","@","#","$","%","%","^","&","*","(",") ","-","_","=","+","{","}","[","]",":",";","'",",","<",".",">","?","/"};
for (String delimiter1 : delimiter) {
44
2. Listing program filtering
3. Listing program stemming
4. Listing program parsing k-gram
5. Listing program hashing public String removeStopWord(String words) { String[] wordArray = words.split("\\s+"); String newSentence = "";
for (String word : wordArray) { boolean inList = false;
try {
inList = isInList(word); } catch (SQLException ex) {
Logger.getLogger(StopWordRemover.class.getName()).log(Level.SEVERE, null, ex);} if(!inList && !containNumeric(word))
newSentence = newSentence + word + " ";}} return newSentence;}
private String Stem(String isiDoc){ StringBuilder result = new StringBuilder(); if (isiDoc!=null && isiDoc.trim().length()>0){ StringReader tReader = new StringReader(isiDoc);
IndonesianAnalyzer analyzer = new IndonesianAnalyzer(Version.LUCENE_34); org.apache.lucene.analysis.TokenStream tStream = analyzer.tokenStream("contents", tReader);
TermAttribute term = tStream.addAttribute(TermAttribute.class); try {
while (tStream.incrementToken()){ result.append(term.term()); result.append(" ");} } catch (IOException ioe){
System.out.println("Error: "+ioe.getMessage());}} if (result.length()==0)
result.append(isiDoc);
return result.toString().trim();}}
private void parsingKgram(String pattern, String teks, int jumKgram) for (int i = 0; i < jumKgram; i++) {
int nextKgram = Kgram + i;
matching(pattern.substring(i, nextKgram), teks);}}
private int hash(String pattern) {//fungsi hash int h = 0;
for (int i = 0; i < pattern.length(); i++) {
45
6. Listing program Rabin-Karp
7. Listing program similarity
8. Listing program tombol “Start” private void matching(String pattern, String teks) {//rabin karp int panjangPattern = pattern.length();
int panjangTeks = teks.length(); int i, j;
int hashPattern = hash(pattern);
int hashTeks = hash(teks.substring(0, panjangPattern)); for (i = 0; i < panjangTeks - panjangPattern; i++) { if (hashPattern == hashTeks) {
for (j = 0; j < panjangPattern; j++) {
if (teks.charAt(i + j) != pattern.charAt(j)) {break;}} if (j == panjangPattern) {
jumPatternSama++; patternSama[i] = pattern; break;}} else {
hashTeks = hash(teks.substring(i + 1, panjangPattern + i + 1));}}}
public double getSimilarity() {
DecimalFormat twoDForm = new DecimalFormat("#.##"); double A = 2*jumPatternSama;
double B = jumPatternDocAsli + jumPatternDocUji; double C = (A / B) * 100;
int decimalPlace = 2;
BigDecimal bigDecimal = new BigDecimal(C);
bigDecimal = bigDecimal.setScale(decimalPlace, BigDecimal.ROUND_UP); if (similarity == null) {
similarity = bigDecimal.doubleValue();} return similarity;}
SwingUtilities.invokeLater(() -> {
boolean p = TestPlagiat.isPlagiarism(sumberDocAsli, sumberDocUji, kgram, presentase, (rk) -> {
similarity = rk.similarity;viewDocAsli = rk.DocAsli;viewDocUji = rk.DocUji; waktuProses = rk.waktuProses;patternSama = rk.patternSama;
46
4.4.4 Halaman Deteksi Dokumen di Database
Halaman Deteksi dokumen di database merupakan halaman
proses pengujian dokumen uji terhadap dokumen yang tesimpan di
database. Pada halaman ini terdapat dua tiga panel yaitu panel input
dokumen, panel karya tulis tersimpan, dan panel hasil pengujian.
Untuk memulai proses pengujian, pengguna memilih dokumen yang
akan diuji dan memilih batas toleransi plagiarisme dengan memilih
pada combobox presentase. Untuk memulai poengujian pengguna
dapat menekan tompol “proses”. Hasil pengujian akan ditampilkan
pada panel hasil di sebelah bawah. Pengguna dapat menyimpan
dokumen yang sudah diuji dengan menekan tombol “simpan dokumen” Dapat dilihat pada gambar 4.4.
Gambar 4.4 Halaman deteksi dokumen di database
Berikut adalah beberapa potongan listing program untuk proses
pendeteksian dokumen di database.
1. Listing program case folding
private String deleteDelimiter(String isiDoc){
String [] delimiter = {"0","1","2","3","4","5","6","7","8","9", "`","~","!","@","#","$","%","%","^","&","*","(",")","-","_", "=","+","{","}","[","]",":",";","'",",","<",".",">","?","/"}; for (String delimiter1 : delimiter) {
47
2. Listing program filtering
3. Listing program stemming
4. Listing program parsing k-gram
5. Listing program hashing
public String removeStopWord(String words) { String[] wordArray = words.split("\\s+"); String newSentence = "";
for (String word : wordArray) { boolean inList = false;
try {
inList = isInList(word); } catch (SQLException ex) {
Logger.getLogger(StopWordRemover.class.getName()).log(Level.SEVERE, null, ex);} if(!inList && !containNumeric(word))
newSentence = newSentence + word + " ";}} return newSentence;}
private String Stem(String isiDoc){ StringBuilder result = new StringBuilder(); if (isiDoc!=null && isiDoc.trim().length()>0){ StringReader tReader = new StringReader(isiDoc);
IndonesianAnalyzer analyzer = new IndonesianAnalyzer(Version.LUCENE_34); org.apache.lucene.analysis.TokenStream tStream = analyzer.tokenStream("contents", tReader);
TermAttribute term = tStream.addAttribute(TermAttribute.class); try {
while (tStream.incrementToken()){ result.append(term.term()); result.append(" ");} } catch (IOException ioe){
System.out.println("Error: "+ioe.getMessage());}} if (result.length()==0)
result.append(isiDoc);
return result.toString().trim();}}
private void parsingKgram(String pattern, String teks, int jumKgram) for (int i = 0; i < jumKgram; i++) {
int nextKgram = Kgram + i;
matching(pattern.substring(i, nextKgram), teks);}}
private int hash(String pattern) {//fungsi hash int h = 0;
for (int i = 0; i < pattern.length(); i++) {