Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
STATISTIK KESEHATAN dr. Nur Aisyah Jamil, M.Sc Konsep dasar
Statistik adalah ilmu yang mempelajari tentang cara mengumpulkan, mengolah, menganalisis data dan menyimpulkanya serta melakukan inferensi (ke populasi) bila hanya sebagian data yang diperoleh (sampel). Biostatistik adalah cabang statistik dalam bidang ilmu biologi dan medis.
Bahan baku statistik adalah data, sebagian menyederhanakan sebagai angka. Angka adalah hasil dari pengukuran dan perhitungan. Data terdiri atas kumpulan angka. Setiap angka tersebut dinamakan datum.
Data yang dibutuhkan untuk analisis statistik adalah data yang dapat digunakan untuk menjawab pertanyaan (penelitian). Data tersebut dapat diperoleh dari berbagai sumber seperti :
1. Catatan rutin, seperti catatan follow-up dokter, rekam medis, laporan keuangan, dan sebagainya
2. Survey, data yang tidak dapat diperoleh dari catatan rutin, harus dicari dengan survey. Contoh untuk mengetahui tingkat kepuasan pasien terhadap pelayanan Puskesmas, kita dapat mengetahuinya dengan cara mengadakan survey terhadap pasien puskesmas.
3. Eksperimen yaitu data yang diperoleh setelah melakukan uji coba.
4. Sumber eksternal, yaitu data yang diperoleh dari hasil penelitian orang lain, jurnal yang dipublikasikan, textbook dan sebagainya.
Variabel adalah karakteristik yang diobservasi, yang berbeda pada tiap orang, tempat atau sesuatu. Variabel diskrit tidak memiliki desimal. Contoh variabel diskrit adalah jumlah jari tangan. Variabel kontinu mempunyai desimal, contohnya adalah tinggi badan anak sekolah. Variabel kuantitatif adalah yang dapat dihitung, variabel kualitatif adalah yang tidak dapat dihitung (seperti gender : laki-laki, perempuan). Variabel kualitatif biasanya merupakan skala nominal.
Pengukuran dan Skala Pengukuran
Pengukuran bertujuan untuk memberikan ukuran angka pada sebuah objek. Terdapat beberapa skala pengukuran, yaitu :
a) Skala nominal merupakan skala terendah, pengelompokan individu/objek/respon/benda berdasarkan kesamaan karakteristik tertentu dan dikategorikan secara mutually eksklusive (tidak dapat beririsan). Contohnya pria-wanita, anak-dewasa, menikah-belum menikah, islam-kristen-hindu, setuju-tidak setuju dan lain sebagainya.
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
b) Skala ordinal memiliki ciri khas nominal dan kelompok tersebut disusun ranking (order) dengan aturan tertentu. Contoh dibawah rata-rata, rata-rata, diatas rata-rata.
c) Skala interval tidak hanya dapat merangking, namun jarak diantara dua pengukuran diketahui. Skala interval memiliki starting point dan terminating point . Contoh 1-5,6-10,11-15, dan seterusnya.
d) Skala ratio merupakan skala pengukuran tertinggi (memiliki karakteristik nominal, ordinal dan interval) ditambah tujuannya sendiri dan memiliki
starting point yang tetap seperti nol. Dapat digunakan dalam perhitungan matematis. Contoh, usia 40 tahun adalah 2 kali lebih tua dari usia 20 tahun. Statistik Deskriptif
Statistik deskriptif merupakan hasil perhitungan sampel data yang dapat menggambarkan kondisi data tersebut. Cara paling umum untuk statistik deskriptif adalah tabel distribusi frekuensi, histogram, polygon frekuensi dan steam-leaf displays. Terdapat ukuran central tendensi (mean, median, modus) dan ukuran
dispersi/penyebaran (range, varian, standar deviasi)
Mean adalah rata-rata dari hasil pengukuran, median adalah hasil pengukuran yang berada di tengah (bila diurutkan dari kecil ke besar), dan modus adalah hasil pengukuran yang paling sering muncul. Range adalah selisih hasil pengukuran terbesar dan terkecil. Varian adalah jumlah kuadrat dari selisih hasil pengukuran dengan mean dibagi jumlah sampel dikurangi 1, menunjukkan besarnya penyebaran relatif dengan nilai mean-nya. Standar deviasi adalah akar dari varian, yang berguna untuk mengukur variasi dalam sebuah set data.
Contoh dari 10 perhitungan didapatkan hasil : 1,2,2,3,4,4,4,5,7,9 Maka:
a. Mean= = =4,1
b. Median adalah posisi tengah, no 5=4, no 6= 4, maka median= =4
c. Modus adalah hasil pengukuran yang paling sering muncul yaitu 4(3 kali muncul) d. Range =9-1=8 e. Varians = = 5,8 f. Standar deviasi= =2,4
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
Distribusi Normal
Sampel yang diambil dengan teknik yang baik akan merepresentasikan keadaan populasi yang sesungguhnya. Hal ini mengurangi sampling error. Hasil perhitungan sampel tersebut selalu membentuk distribusi kurva normal (Gaussian distribution), yaitu suatu bentuk kurva distriusi frekuensi yang menyerupai bell (bell shape). Ciri-ciri distribusi normal adalah :
1. Bentuknya simetris (seperti bayangan di cermin), dengan mean ditengahnya
2. Mean, median dan modus sama
3. Area under curve(AUC) kanan dan kiri mean seimbang (50%) 4. Wilayah AUC + 1 SD= 68%, + 2 SD=95%, + 3 SD= 99,7%.
5. Standar deviasi yang lebar akan membuat kurva normal menjadi lebih flat. Dengan melihat hubungan nilai mean, median dan modus maka dapat menentukan bentuk distribusi data, yaitu :
- Bila mean, median, modus sama maka distribusi data adalah normal - Bila mean > median > modus maka distribusio data miring ke kanan - Bila mean < median < modus maka distribusio data miring ke kiri Berdasarkan soal di atas
Mean>median=modus, data dapat dikatakan normal
Cara lain untuk memeriksa normalitas data adalah menggunakan nilai kurtosis dan skewness (dari SPSS) dimana
dan maka data berdistribusi normal
Contoh : Hasil output statistic dskriptif adalah sebagai berikut
Mean 39.9667 Median 41.0000 Mode 45.00 Std. Deviation 13.98887 Skewness -.400 Std. Error of Skewness .427 Kurtosis -.385 Std. Error of Kurtosis .833 = =-1 dan = =-0,5
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
Maka data berdistribusi normal
Selain itu dapat dihitung menggunakan Kolmogorof-Smirnov. Berikut ini contoh pemakaian uji Kologorof-Smirnov terhadap variabel tekanan darah sistolik (TDS) pada program SPSS :
Klik Analyze → Descriptive statistic → Explore → Isikan pada kolom dependen list : TDS → Klik Plots → Pilih normality plots with test → Continue → OK
Hasil outputnya sebagai berikut :
Tests of Normality
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
Tekanan Darah Sistolik
.274 25 .000 .797 25 .000
a. Lilliefors Significance Correction
Interpretasi :
Pada uji normalitas Ho=data terdistribusi normal, Hi/Ha =data tidak normal
Nilai p TDS < 0.05 sehinggga Ho ditolak dan H1 diterima. Hal ini menunjukkan sebaran data tidak normal.
Menyajikan data 1. Tabel
Metode yang paling umum untuk mempresentasikan data adalah tabel. Tabel berguna untuk menyajikan data yang besar dalam bagian yang kecil. Jenis tabel berdasar pada jumlah variabelnya terdiri atas tabel univariat yang sering dikenal dengan tabel frekuensi, tabel bivariat biasanya dalam bentuk cross tabulation, dan tabel mutivariat. Komponen tabel adalah sebagai berikut :
a. Judul harus informatif,menggambarkan isinya. Penulisan variabel terikat terlebih dahulu baru varuabel bebasnya. Penomoran tabel pada tulisan desertasi dimulai dengan nomer bab-nya.
b. Stub/bagian vertical (Y-axis) memuat sub kategori dari variabel(terikat) yang informasinya dijelaskan pada kolom-kolom di sebelah kanan.
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
c. Caption/ judul kolom, pada tabel univariat, judul kolom biasanya jumlah/persentase responden. Jika bivariat, judul kolom memuat sub kategori variabel (X-axis).
d. Badan memuat data
e. Suplemen/footnotes, terletak di bawah tabel, merupakan keterangan tambahan seperti sumber (bila menggunakan tabel dari sumber tenrtentu), keterangan umum, keteragan bagian spesifik tabel, keterangan level of probability.
2. Grafik
Merupakan cara penyajian data yang lebih mudah difahami (informative dan komunikatif) dan lebih menarik (attractive). Untuk data kategorikal dapat menggunakan histogram, diagram batang dan
pie chart. Untuk data kontinu, selain dapat menggunakan histogram, diagram batang dan pie chart, juga dapat menggunakan diagram garis. Selain jenis data, jumlah variabel juga menentukan grafik apa yang paling baik digunakan. Berikut ini jenis-jenis grafik beserta kegunaannya:
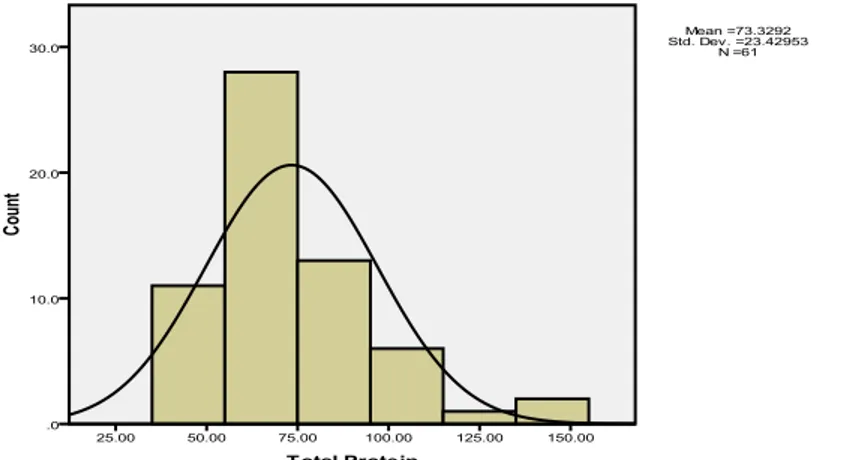
a. Histogram
Adalah penyajian data kontinu interval, tinggi masing-masing kotak histogram menunjukkan frekuensi/persentasenya. Sebelum membuat histogram, data terlebih dahulu dikelompokkan dengan interval tertentu.
Gambar 1 histogram kadar total protein pasien b. Diagram batang
Identik dengan histogram, namun antar batang terdapat spasi yang menunjukkan bukan data kontinu (bisa kategorikal, baik nominal atau ordinal).
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
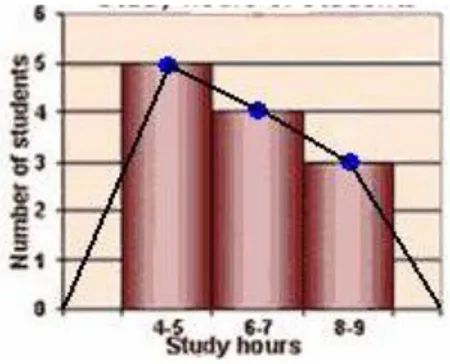
Gambar 2 diagram batang pendidikan reponden c. Frekuensi polygon
Frekuensi polygon didapatkan dengan cara menghubungkan nilai tengah masing-masing histogram. Contoh dibawah ini adalah frekuensi polygon jumlah jam belajar mahasiswa
sumber : http://www.icoachmath.com/math_dictionary/Frequency_Polygon.html
Gambar 3 frekuensi polygon jumlah jam belajar mahasiswa
d. Diagram Stem-leaf
Merupakan cara lain untuk menyajikan data distribusi frekuensi. Masih nyaman bila jumlah data tidak terlalu banyak (dapat mencapai digit 100 sampai 1000). Contoh diagram stem - leaf usia responden dari 30 reponden di bawah ini :
usia Stem-and-Leaf Plot Frequency Stem & Leaf 2 1 . 02 4 2 . 1223 9 3 . 245566789 7 4 . 3455556 0 2 4 6 8 10 12 14 16 SD SMP SMA PT
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
6 5 . 345567 2 6 . 04 Stem width: 10.00 Each leaf: 1 case(s)
Gambar 4 Diagram Stem-Leaf
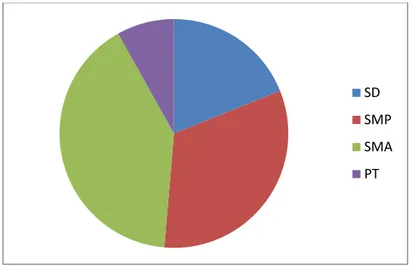
e. Pie Chart
Lingkaran pie yang mempunyai 360 derajat merupakan 100 persen data. Pembagian derajat bergantung pada frekuensi/persentase masing-masing sub kategorik. Idealnya pie chart digunakan untuk kategori yang tidak terlalu banyak. Pada data kontinu dapat digunakan, hanya sebelumnya perlu dikelompokkan terlebih dahulu.
Gambar 5 pie-chart pendidikan responden f. Diagram garis / kurva trend
Berguna untuk menyajikan data kontinu (skala interval atau ratio). Data long term, dapat dilihat kecenderungan/trend sesuatu kejadian. Contoh trend angka kematian bayi Indonesia.
SD SMP SMA PT
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
sumber 2007 Indonesia Demographic and Health Survey
Gambar 6 Kurva Trend Angka Kematian Bayi Indonesia Tahun 1971-2007
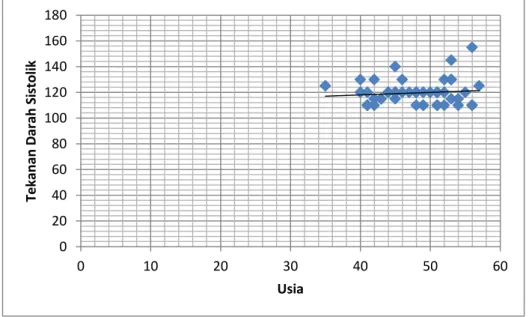
g. Diagram hambur(scattergram)
Tidak dapat digunakan pada variabel yang kategorik. Hanya pada data continue (interval/ratio) dan memiliki dasar hipotesis kedua variabel berhubungan. Semakin teratur letak hamburnya akan mendekati garis tertentu , maka kedua variabel memiliki hubungan yang linear.
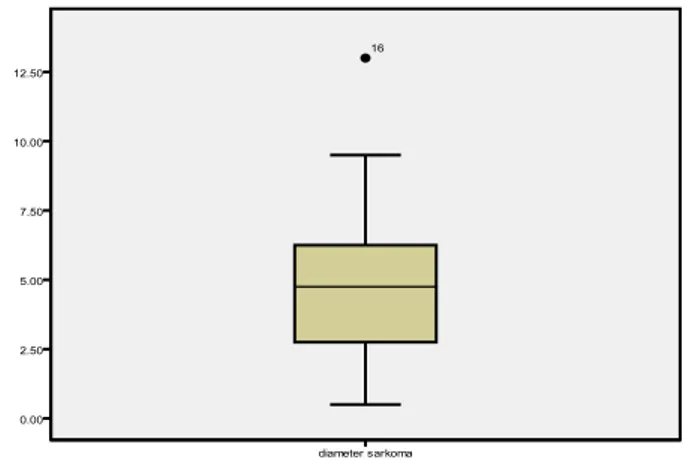
Gambar 7 diagram hambur usia dan tekanan darah sistolik h. Blox plot 0 20 40 60 80 100 120 140 160 180 0 10 20 30 40 50 60 Tekan an D ar ah Si stol ik Usia
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
Adalah salah satu penyajian data distribusi frekuensi berdasarkan ukuran kuartil. Batas bawah box adalah kuartil1 (Q1), batas atas box adlah kuartil 3 (Q3), garis tengah box adalah median (Q2). Garis paling bawah adalah hasil pengukuran terendah, garis paling tinggi adalah hasil pengukuran tertinggi.
Gambar 8 Diagram Box-Plot Statistik Inferensi
Statistik inferensi adalah prosedur pengambilan simpulan dari sebuah populasi berdasarkan sampel yang diambil dari populasi tersebut. Untuk dapat melakukan inferensi, diperlukan uji statistik yang akan menguji hipotesis penelitian. Berikut ini adalah tabel yang merangkum uji statistik yang digunakan berdasarkan jumlah dan sifat variabel bebas dan variabel terikatnya.
Tabel 1 Jenis Uji Statistik Berdasarkan Jumlah dan Sifat Variabel Jumlah
Variabel Terikat
Sifat Variabel Bebas Sifat Variabel Terikat Jenis Uji Statistik
1 0 Variabel Bebas
(1 populasi)
interval & normal one-sample t-test
ordinal or interval one-sample median
Kategorikal (2
kategori) binomial test
Kategorikal Chi square
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
1 Variabel Bebas
dengan 2 kelompok
(independent groups)
interval & normal 2 independent
sample t-tes
ordinal or interval Wilcoxon-Mann
Whitney test
Kategorikal Chi- square test
Fisher's exact test
1 Variabel Bebas
dengan 2 kelompok atau
lebih (independent
groups)
interval & normal One way ANOVA
ordinal or interval Kruskal Wallis
Kategorikal Chi- square test
1 Variabel Bebas
dengan 2 kelompok
(berpasangan)
interval & normal paired t-test
ordinal or interval Wilcoxon signed
ranks test
Kategorikal Mc Nemar
1 Variabel Bebas
dengan 2 kelompok atau lebih (berpasangan)
interval & normal one-way repeated
measure ANOVA
ordinal or interval Friedman test
Kategorikal repeated measures
logistic regression
2 Variabel Bebas atau
lebih (independent
groups)
interval & normal factorial ANOVA
ordinal or interval ?
Kategorikal factorial Logistic
Regression
1 Variabel Bebas
(interval)
interval & normal
correlation
simple linear
regression
ordinal or interval non-parametric
correlation
Kategorikal simple logistic
regression
1 Variabel Bebas
(interval) atau lebih dan atau 1 Variabel Bebas (kategorik) atau lebih
interval & normal
multiple regression analysis of covariance Kategorikal multiple logistic regression discriminant analysis 2 atau lebih 1 Variabel Bebas
dengan dua kelompok atau lebih (independent groups)
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
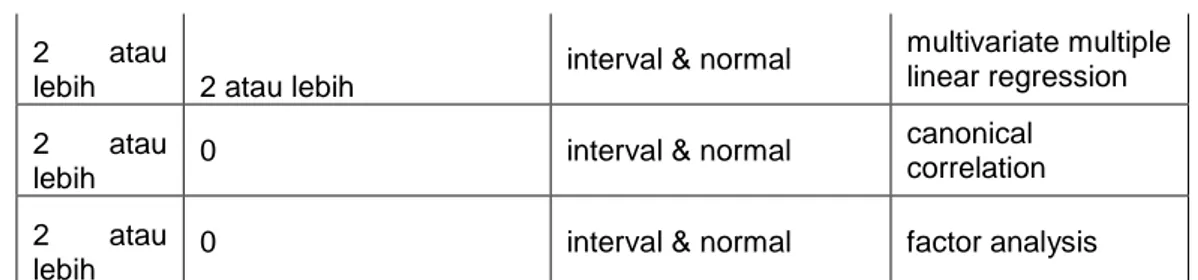
2 atau
lebih 2 atau lebih interval & normal
multivariate multiple linear regression
2 atau
lebih 0 interval & normal
canonical correlation
2 atau
lebih 0 interval & normal factor analysis
Sumber (http://www.ats.ucla.edu/stat/mult_pkg/whatstat/default.htm)
P value adalah peluang mendapatkan hasil yang paling ekstrim dari sampel yang diobservasi bila hipotesis nol benar.
Gambar 9 p value pada one-tail
Gambar 10 p value pada two tail.
Interval Kepercayaan 95% (95% Confidence Interval) dengan level terendah=a dan level tertinggi=b , semisal dalam 100 kali pengambilan sampel, peneliti memiliki kepercayaan 95 kali hasilnya akan jatuh pada nilai diantara a dan b. Jadi tingkat kesalahan hanya 5 persen. Interval a dan b semakin kecil hasilnya semakin precise. Formula untuk interval kepercayaan adalah :
95% IK untuk µ=ẋ±1,96(δ/ ) dan 99 % IK untuk µ=ẋ±2,58(δ/ )
µ=rata-rata populasi
ẋ=rata-rata sampel yang diobservasi
1,96 dan 2,58 dari standar deviasi rata-rata populasi = Z score dari α 0,05 dan 0,01
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM) δ = standar deviasi
n= jumlah sampel
Contoh Seseorang mengklaim bahwa rata-rata usia populasi 7683 orang di Honolulu adalah 53 tahun (µ0), Apakah klaim ini benar?. Maka seorang peneliti melakukan Penelitian Honolulu Heart Study dengan mengambil 100 orang sampel didapatkan nilai rata-rata usia (ẋ ) = 54,85 tahun dan standar deviasi (δ ) = 5,5, maka 95% interval kepercayaan dari penelitian (53,78-55,93) dan 99% interval kepercayaan dari penelitian (53,43-56,27)
Gambar 95% IK dan 99% IK
Dari hasil perhitungan, µ0 (53) tidak berada di dalam rentang IK, maka H0 tertolak, H1 diterima, bahwa populasi sampel (54,85) berbeda signifikan dengan rata-rata populasi.
Sumber Kuzma JW and Bohnenblust S (2005)
Untuk mempersempit IK maka dapat melakukan beberapa hal berikut ini: a) Memperbesar jumlah sampel
b) Menurunkan level konfiden, seperti dari 99% IK ke 95% IK
c) Meningkatkan presisi dengan menurunkan kesalahan pengukuran (measurement error termasuk non random teknik) sehingga varian lebih kecil.
Uji Hipotesis
Pada uji perbandingan dua mean (independent t-test, paired t-test), maka rumusan uji hipotesis:
a) Ho= u1=u2= tidak terdapat perbedaan mean antara kelompok 1 dan kelompok 2
b) H1/Ha= u1=u2=mean kelompok 1 berbeda dengan mean kelompok 2 c) Dimana bila p<0,05 , Ho ditolak, H1 diterima
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM) Pada uji ANOVA, maka rumusan uji hipotesis: a) Ho=u1=u2=u3=u4
b) H1/Ha= satu atau lebih mean berbeda dari yang lain c) Dimana bila p<0,05 , Ho ditolak, H1 diterima
Berikut ini adalah tabel makna p<0,05 (Ho ditolak dan H1 diterima pada masing-masing uji statistik.
Tabel Makna p <0,05 pada Berbagai Uji Statistik
No Nama Uji Makna bila p<0,05 (Ho ditolak, H1 diterima)
1
Uji Normalitas
Kolmogorov-Smirnov dan
Shapro-wilk
Distribusi data tidak normal
2 Uji Varians levene's test
Distribusi beberapa set data yang dibandingkan mempunyai varians yang berbeda
3 Uji t berpasangan
Terdapat perbedaan rerata yang bermakna antara dua kelompok data
4 Uji t tidak
berpasangan 5 Uji Wilcoxon 6 Uji Mann-Whitney
7 Uji ANOVA Paling tidak terdapat dua kelompok data yang
mempunyai perbedaan rerata yang
bermakna(post hoc analisis digunakan untuk mengetahui kelompok mana yang berbeda secara bermakna)
8 Uji Friedman 9 Uji Kruskal-Wallis
10 Uji McNemar Terdapat perbedaan proporsi yang bermakna antara dua kelompok data
11 Uji Homogenity
12 Uji Cochran
Paling tidak terdapat dua kelompok data yang mempunyai perbedaan proporsi yang bermakna(post hoc analisis digunakan untuk mengetahui kelompok mana yang berbeda secara bermakna)
13 Uji Chi-Square
Terdapat hubungan yang bermakna antara variabel A dan B
14 Uji Kolmogorov-Smirnov
15 Uji Fisher 16 Uji Pearson
Terdapat korelasi yang bermakna antara variabel A dan B
17 Uji Spearman 18 Uji Koefisien
Kontingensi 19 Uji Lambda
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
20 Uji
Gamma&Somers'd
Elearning Pendidikan Klinik Stase Ilmu Kesehatan Masyarakat (IKM)
Daftar Pustaka
1. Dahlan S, Statistik untuk Kedokteran dan Kesehatan,2011, Jakarta: Salemba Medika
2. Daniel WW, Biostatistik,7th ed, 1999, New York: John and Willey Son. 3. Kumar R, Research Methodology, 1999, Malaysia : Sage Publication
4. Kuzma JW, Bohnenblust S, Basic Statistic for the Health Sciences, 4th ed, 2005, USA : McGraw Hill