PEMODELAN JARINGAN SYARAF TIRUAN
RECURRENT YANG TEROPTIMASI SECARA
HEURISTIK UNTUK PENDUGAAN CURAH HUJAN
BERDASARKAN PEUBAH ENSO
AFAN GALIH SALMAN
Tesis
Sebagai salah satu syarat untuk memperoleh gelar
Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2006
ABSTRAK
Pendugaan Curah Hujan yang akurat di sektor pertanian kini telah menjadi kebutuhan utama, disamping faktor lain seperti pemilihan bibit, pupuk, dan pemberantas hama. Informasi tentang banyak curah hujan sangat berguna bagi petani dalam mengantisip asi peristiwa-peristiwa ekstrim seperti kekeringan dan kebanjiran. Model pendugaan curah hujan yang telah dilakukan selama ini belum banyak yang menggunakan data peubah El-Nino Southern Oscilation (ENSO) sebagai masukan model padahal peubah ENSO cukup berpengaruh terhadap tinggi rendahnya curah hujan di sebagian besar wilayah Indonesia (Yusmen 1998). Penelitian yang pernah dilakukan sebelumnya hanya menggunakan data suhu dan curah hujan sebagai masukan model diantaranya adalah penerapan metode Principal Component Regression (Fitriadi 2004) menghasilkan R2 sebesar 63,16%, JST propagasi balik standar (Normakristagaluh 2004) menghasilkan R2 sebesar 74,02%, JST propagasi balik standar (Apriyanti 2005) menghasilkan R2 sebesar 48,179% dan JST dengan optimasi algoritma genetika menghasilkan R2 sebesar 87,7% (Apriyanti 2005) Berdasarkan tersebut penelitian di bidang ini masih layak dan perlu dilakukan untuk mendapatkan model pendugaan curah hujan yang lebih akurat.
Penelitian ini menggunakan JST recurrent Elman yang teroptimasi secara heuristik dengan penerapan 3 algoritma pembelajaran yaitu gradient descent adaptive learning rate, dengan variasi nilai parameter penambahan laju pembelajran (lr_inc) dan penurunan laju pembelajaran (lr_dec), gradient descent adaptive learning rate & momentum dengan variasi nilai parameter momentum (mc) serta resilient backpropagation dengan variasi nilai parameter penambahan bobot (delt_inc) & penurunan bobot (delt_dec). Teknik optimasi heuristik terbaik pada penelitian ini adalah algoritma resilient backpropagation. Hasil pendugaan curah hujan terbaik pada leap 0 menghasilkan nilai R2 maksimum 77%, leap 1 menghasilkan nilai R2 maksimum 84,8%, leap 2 menghasilkan nilai R2 maksimum 75,5%, dan leap 3 menghasilkan nilai R2 maksimum 54,1%. Hal ini membuktikan JST recurrent dapat diterapkan dalam pendugaan curah hujan berdasarkan peubah ENSO dengan tingkat keakuratan yang cukup baik.
Judul Tesis : Pemodelan Jaringan Syaraf Tir uan Recurrent yang Teroptimasi Secara Heuristik untuk Pendugaan Curah Hujan Berdasarkan Peubah ENSO
Nama : Afan Galih Salman
N R P : G651030204
Disetujui
Komisi Pembimbing
Ir. Agus Buono, M.Si., M. Kom. Ketua
Irman Hermadi, S. Kom.,MS. Anggota
Diketahui
Ketua Program Studi Ilmu Komputer
Dr. Sugi Guritman
Dekan Sekolah Pascasarjana
Prof. Dr. Ir. Syafrida Manuwoto, M.Sc.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia Nya sehingga karya ilmiah ini berhasil diselesaikan. Penelitian dilaksanakan sejak bulan Desember 2005 dengan judul Pemodelan Jaringan Syaraf Tiruan Recurrent Yang Teroptimasi Secara Heuristik Untuk Pendugaan Curah Hujan Berdasarkan Peubah ENSO.
Terima kasih penulis ucapkan kepada Bapak Ir. Agus Buono M.Si, M.Kom dan Bapak Irman Hermadi S.Kom, M.S selaku dosen pembimbing yang telah memberikan arahan serta saran dalam pembuatan karya ilmiah ini serta Bapak Aziz Kustiyo S.Si, M.Kom selaku dosen penguji.
Ucapan terima kasih juga saya sampaikan kepada Bapak Adang, peneliti pada Kantor BALIKLIMAT Bogor yang telah memberikan data curah hujan yang lengkap seluruh wilayah Indonesia.
Penulis juga mengucapkan terima kasih kepada Bapak serta Ibu ya ng telah memberi doa dan dorongannya demi selesainya penelitian ini, juga kepada rekan-rekan mahasisiwa Magister Ilmu Komputer IPB atas bantuan serta dorongan morilnya terutama Bapak M.Syafii, M.Si dan keluarga yang telah memberikan pinjaman peralatan komp uter serta buku-buku mengenai jaringan syaraf tiruan. Ungkapan terima kasih juga disampaikan kepada seluruh staf administrasi dan karyawan Pascasarjana Ilmu Komputer IPB Bogor serta isteri dan anak saya atas segala doa dan dukungannya.
Semoga karya ilmiah ini bermanfaat
Bogor, Mei 2006 Afan Galih Salman
RIWAYAT HIDUP
Penulis dilahirkan di Bandung pada tanggal 9 September 1969 dari ayah Kodir Ali dan ibu Mien Suliah. Penulis merupakan putra keempat dari enam bersaudara. Penulis beristerikan Ir. R. Tantie Kustiantie dan mempunyai 1 orang putri.
Tahun 1988, penulis lulus dari SMA Negeri 2 Bogor. Tahun 1994 lulus dari Fakultas Teknik Gas Petrokimia Universitas Indonesia. Tahun 2003 lulus seleksi masuk Program Pascasarjana Ilmu Komputer IPB Bogor.
Penulis mengawali karir pekerjaan dimulai pada tahun 1988 sampai saat ini menjadi supervisor di Perusahaan kontraktor CV. Menteng, Bogor. Mulai tahun 2005 sampai saat ini menjadi dosen luar biasa di Fakultas Teknik Informatika Universitas Ibnu Khaldun, Bogor.
Penulis tinggal di Jl Hateup no 30 Bantarjati Bogor 16153. Telpon (0251) 316963.
DAFTAR ISI
Halaman
DAFTAR TABEL ………...………. viii
DAFTAR GAMBAR……….. ix
DAFTAR LAMPIRAN ……….. x
PENDAHULUAN
Latar Belakang ……… Tujuan Penelitian ...………. Ruang Lingkup Penelitian...………. Manfaat Penelitian ……….. Blok Diagram Sistem ………..
1 2 2 3 3 TINJAUAN PUSTAKA
Pendugaan Curah Hujan.... ………...………... Jaringan Syaraf Tiruan...……….. Jaringan Saraf Tiruan Propagasi Balik...………. Optimasi Pembelajaran Heuristik...………. Jaringan Syarat Tiruan Recurrent Elman………. Inisialisasi Nguyen-Widrow………....………. Ketepatan Pendugaan...………. 4 5 6 7 12 13 13 DATA & METODE
Data... Metode. .………...
15 15 PERANCANGAN & IMPLEMENTASI SISTEM
Desain Arsitektur... ... Tahapan Penelitian..………... Desain Struktur Data... Desain Keluaran (Output) ………....……….. Perangkat Keras dan Lunak..………....………..
17 17 21 21 21 HASIL DAN PEMBAHASAN
Komposisi Data Pelatihan & Pengujian... Kelompok Data Pertama………... Kelompok Data Kedua...………... Komposisi Parameter Terbaik………...
22 22 27 32
SIMPULAN DAN SARAN Simpulan ... Saran ..………... 37 37 DAFTAR PUSTAKA ……… LAMPIRAN... 39 40
DAFTAR TABEL
Halaman 1 Struktur JST recurrent standar gradient descent adaptive learning
rate... 18 2 Struktur JST recurrent standar gradi ent descent adaptive learning rate &
momentum... 19 3 Struktur JST recurrent standar resilient backpropagation... 20 4 Data peubah ENSO & curah hujan... 21 5 Hasil percobaan kelompok data pertama gradient descent adaptive
learning rate... 22 6 Hasil percobaan kelompok data pertama gradient descent adaptive learning
rate & momentum...
22 7 Hasil percobaan kelompok data pertama resilient backpropagation... 23 8 Hasil percobaan kelompok data kedua gradient descent adaptive learning
rate... 27 9 Hasil percobaan kelompok data kedua gradient descent adaptive learning
rate & momentum... 27 10 Hasil percobaan kelompok data kedua resilient backpropagation... 28 11 Komposisi parameter terbaik gradient descent adaptive learning rate…. 33 12 Komposisi parameter terbaik gradient descent adaptive learning rate &
momentum...
34 13 Komposisi parameter terbaik resilient backpropagation...….. 36
DAFTAR GAMBAR
Halaman
1 Blok diagram pemodelan………..……… 3
2 Arsitektur JST recurrent………. 12
3 Kerangka berpikir penelitian... 16 4 Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok
data pertama untuk leap 0...
24 5 Korelasi terbaik JST recurrent resilient backpropagation kelompok data
pertama untuk leap 0...
24 6 Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent
resilient backpropagation kelompok pertama untuk leap 0...
25 7 Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok
data pertama untuk leap 1...
26 8 Korelasi terbaik JST recurrent resilient backpropagation kelompok data
pertama untuk leap 1...
26 9 Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent
resilient backpropagation kelompok pertama untuk leap 1...
27 10 Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok
data kedua untuk leap 0...
28 11 Korelasi terbaik JST recurrent resilient backpropagation kelompok data
kedua untuk leap 0...
29 12 Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent
resilient backpropagation kelompok data kedua untuk leap 0...
29 13 Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok
data kedua untuk leap 1...
30 14 Korelasi terbaik JST recurrent resilient backpropagation kelompok data
kedua untuk leap 1...
31 15 Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent
resilient backpropagation kelompok data kedua untuk leap1...
31
DAFTAR LAMPIRAN
Halaman
1 Data penelitian………. 41
2 Pengkodean program JST recurrent adaptive learning rate……….…….. 43 3 Pengkodean program JST recurrent adaptive learning rate & momentum 45 4 Pengkodean program JST recurrent resilient backpropagation... 47
5 Hasil penelitian kelompok pertama JST recurrent gradient descent adaptive learning rate leap 0………..
49 6 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate leap 1……….. 51 7 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate leap 2………. 53 8 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate leap 3………. 55 9 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate & momentum leap 0………. 57 10 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate & momentum leap 1………. 58 11 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate & momentum leap 2………. 59 12 Hasil penelitian kelompok pertama JST recurrent gradient descent
adaptive learning rate & momentum leap 3………. 60 13 Hasil penelitian kelompok pertama JST recurrent resilient
backpropagation leap 0……….. 61 14 Hasil penelitian kelompok pertama JST recurrent resilient
backpropagation leap 1……….. 63 15 Hasil penelitian kelompok pertama JST recurrent resilient
backpropagation leap 2………..………... 65 16 Hasil penelitian kelompok pertama JST recurrent resilient
backpropagation leap 3……….……….. 67 17 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate leap 0……….. 69
DAFTAR LAMPIRAN (Lanjutan)
Halaman 18 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate leap 1……….. 71 19 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate leap 2………. 73 20 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate leap 3………. 75 21 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate & momentum leap 0………. 77 22 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate & momentum leap 1………. 78 23 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate & momentum leap 2………. 79 24 Hasil penelitian kelompok kedua JST recurrent gradient descent
adaptive learning rate & momentum leap 3………. 80 25 Hasil penelitian kelompok kedua JST recurrent resilient
backpropagation leap 0……….. 81 26 Hasil penelitian kelompok kedua JST recurrent resilient
backpropagation leap 1……….. 83 27 Hasil penelitian kelompok kedua JST recurrent resilient
backpropagation leap 2………..………... 85 28 Hasil penelitian kelompok kedua JST recurrent resilient
backpropagation leap 3……….……….. 87
PENDAHULUAN
1.1 Latar Belakang
Pendugaan curah hujan di sektor pertanian kini telah menjadi kebutuhan utama, seperti halnya pemilihan bibit, pupuk, dan pemberantas hama. Informasi tentang banyak curah hujan sangat berguna bagi petani dalam mengantisipasi peristiwa-peristiwa ekstrim seperti kekeringan dan banjir (Yusmen 1998). Oleh karena itu dibutuhkan pendugaan curah hujan yang cepat dan akurat.
Dengan menggunakan sistem komputasi di bidang Artificial Intellegence, yaitu Jaringan Syaraf Tiruan (JST), maka identifikasi pola data dari sistem pendugaan curah hujan dapat dilakukan dengan metoda pendekatan pembelajaran. Berdasarkan kemampuan belajar yang dimilikinya, maka JST dapat dilatih untuk mempelajari dan menganalisa pola data masa lalu dan berusaha mencari suatu formula atau fungsi yang akan menghubungkan pola data masa lalu dengan keluaran yang diinginkan pada saat ini. Keakuratan hasil prediksi JST diukur berdasarkan koefisien determinasi (R2) dan
Root Mean Square Error (RMSE) (Normakristagaluh 2004).
Model–model pendugaan curah hujan yang telah dilakukan selama ini belum banyak yang menggunakan data peubah El-Nino Southern Oscilation (ENSO) sebagai masukan model JST padahal peubah ENSO cukup berpengaruh terhadap tinggi rendahnya curah hujan di sebagian besar wilayah Indonesia (Yusmen 1998). Penelitian yang pernah dilakukan sebelumnya hanya menggunakan data suhu dan curah hujan sebagai masukan model JST, diantaranya adalah penerapan metode Principal
Component Regression (Fitriadi 2004) menghasilkan R2 sebesar 63,16%, JST propagasi balik standar (Normakristagaluh 2004) menghasilkan R2 sebesar 74,02% , JST propagasi balik standar (Apriyanti 2005) menghasilkan R2 sebesar 48,179% dan JST dengan optimasi algoritma genetika menghasilkan R2 sebesar 87,7% (Apriyanti 2005). Berdasarkan hal tersebut penelitian di bidang ini masih layak dan perlu dilakukan untuk mendapatkan model pendugaan curah hujan yang lebih akurat.
Dalam penelitian ini digunakan JST recurrent yang teroptimasi secara heuristik. Keunikan JST recurrent adalah adanya koneksi umpan balik yang membawa informasi gangguan (noise) pada saat masukan sebelumnya yang akan diakomodasikan bagi masukan berikutnya. Hal ini dapat meningkatkan kinerja JST recurrent khususnya dalam mengidentifikasi pola peubah ENSO terhadap pendugaan curah hujan. Data peubah ENSO yang digunakan yaitu : wind, Southern Oscillation Index (SOI), Sea
Surface Temperatur (SST) dan Outgoing Long Wave Radiation (OLR)
Optimasi heuristik adalah pengembangan dari suatu analisa kinerja pada algoritma gradient descent standard yang terdiri dari tiga algoritma pelatihan yaitu : gradient descent adaptive learning rate, gradient descent adaptive learning rate &
momentum serta resilient backpropagation.
1.2 Tujuan Penelitian
Penelitian ini bertujuan mengembangkan model JST recurrent yang teroptimasi secara heuristik untuk pendugaan curah hujan berdasarkan peubah ENSO.
1.3 Ruang Lingkup Penelitian
a. Model yang digunakan dalam pe nelitian ini dibatasi pada JST recurrent tipe Elman.
b. Optimasi pembelajaran yang dilakukan dengan menggunakan teknik heuristik yaitu : gradient descent adaptive learning rate, gradient descent
adaptive learning rate & momentum serta resilient backpropagation.
c. Data curah hujan berasal dari Balai Penelitian Agroklimat & Hidrologi (BALITKLIMAT) Bogor dan data ENSO berasal dari Lembaga Internasional seperti National Weather Service Center for Environmental Prediction Climate (NOAA).
d. Data masukan hanya terdiri dari peubah ENSO dan target data curah hujan sehingga faktor-faktor pengaruh curah hujan lainnya tidak diperhitungkan. e. Model penelitian terbatas untuk daerah Bongan Bali.
1.4 Manfaat Penelitian
Model JST recurrent yang diperoleh nantinya diharapkan dapat lebih meningkatkan keakuratan dan kecepatan dalam pendugaan curah hujan khususnya di wilayah Indonesia dengan menggunakan peubah-peubah ENSO dan membuka jalan bagi pengembangan penelitian di bidang yang sama dengan jumlah peubah yang berbeda.
1.5 Blok Diagram Sistem
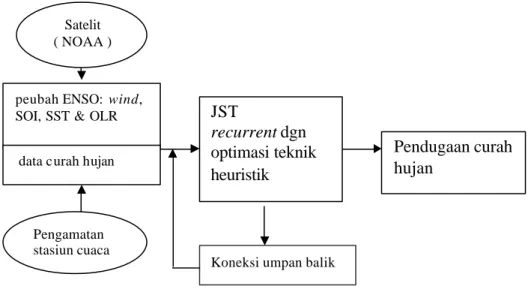
JST recurrent adalah jaringan yang mengakomodasi keluaran jaringan untuk menjadi input pada jaringan itu lagi dalam rangka menghasilkan keluaran jaringan berikutnya. Pada penelitian ini digunakan jaringan JST recurrent tipe Elman. Jaringan ini dapat terdiri dari satu atau lebih lapisan tersembunyi, lap isan pertama memiliki bobot-bobot yang diperoleh dari lapisan input, setiap lapisan akan menerima bobot dari lapisan sebelumnya. Jumlah neuron dan lapisan tersembunyi disesuaikan dengan kompleksitas permasalahan. Delay yang terjadi pada hubungan antara lapisan input dengan lapisan tersembunyi pertama pada waktu sebelumnya (t-1) dapat digunakan untuk saat ini (t) (Kusumadewi 2004). Blok diagram sistem proses pemodelan JST dalam pendugaan curah hujan berdasarkan peubah ENSO disajikan pada Gambar 1.
Gambar 1. Blok diagram pemodelan
peubah ENSO: wind,
SOI, SST & OLR JST
recurrent dgn
optimasi teknik heuristik
Koneksi umpan balik
Pendugaan curah hujan
data curah hujan
Pengamatan stasiun cuaca
Satelit ( NOAA )
BAB II.
TINJAUAN PUSTAKA
2. 1 Pendugaan Curah Hujan
Pendugaan curah hujan di sektor pertanian kini telah menjadi kebutuhan utama, seperti halnya pemilihan bibit, pupuk, dan pemberantas hama. Informasi curah hujan bahkan menjadi acuan dalam memilih jenis bibit, waktu tanam dan jumlah stok bahan pangan pokok yang harus disediakan untuk memenuhi kebutuhan masyarakat. Bila dugaan tentang datangnya awal musim, termasuk sifat hujan dan periode musim meleset jauh, dampaknya bisa berupa kerugian besar bagi petani karena gagal panen dan kelangkaan pangan ( Yusmen 1998).
Pendugaan curah hujan juga menjadi faktor penting di sektor pengairan atau pengelolaan daerah aliran sungai dalam kaitannya dengan sistem peringatan dini ketika terjadi banjir. Informasi curah hujan yang akurat, sangat penting bagi masyarakat khususnya yang berada di kawasan rawan banjir di bantaran sungai atau di daerah cekungan sehingga proses evakuasi dapat dilakukan lebih awal dan kerugian material serta korban jiwa dapat dihindari.
Curah hujan di Indonesia hampir seluruhnya dipengaruhi ENSO. ENSO adalah istilah yang terdiri dari dua fenomena yaitu El Nino merupakan fenomena lautan dan Southern Oscillation merupakan fenomena atmosfer. Istilah ENSO tidak begitu populer di kalangan media massa, istilah El Nino-lah yang sering dipakai. Peubah ENSO yang umumnya digunakan adalah SOI yaitu perbedaan antara nilai indeks tekanan udara di Tahiti dan Darwin, dan SST yaitu nilai anomali suhu permukaan laut, selain peubah lainnya wind dan OLR. Pemanasan suhu muka laut di sebelah barat Samudra Pasifik menimbulkan gangguan cuaca ENSO, yaitu berdampak kurangnya curah hujan di kawasan timur Pasifik termasuk Indonesia. Sebaliknya ketika pemanasan terjadi di timur Pasifik disebut anomali cuaca La Nina, hujan yang tinggi terjadi di wilayah tersebut (Lakshmi Sri et al. 2003).
Daerah di Indonesia yang bakal terpengaruh El Nino atau La Nina adalah Papua, Maluku, Sulawesi, sebagian besar Sumatera, Sumatera Selatan, seluruh Pulau Jawa, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur,
Sulawesi, Maluku, Bali, Nusa Tenggara, dan Irian Jaya. Sementara daerah yang tidak terpengaruh oleh ENSO adalah Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi dan Bengkulu. Pengaruh ENSO yang paling kuat terjadi pada tahun 1987-1988. Prakiraan cuaca mengenai terjadinya kekeringan karena El Nino sebenarnya tidak dapat dipukul rata akan terjadi di seluruh wilayah Indonesia . Di wilayah Pare-Pare dan Sulawesi Selatan dapat terjadi empat gangguan cuaca dengan pola yang berbeda (Effendy 2001).
Berdasarkan hal tersebut di atas maka prakiraan cuaca di Indonesia tidak bisa diberlakukan secara umum, apalagi di negeri yang luas ini terbagi tiga tipe cuaca, yaitu ekuatorial, monsun dan lokal. Di wilayah dengan pola cuaca tersebut, datangnya musim kemarau dan hujan sepanjang tahun akan berbeda-beda, bahkan berkebalikan. Melihat fenomena tersebut maka di masa mendatang Indonesia perlu mengembangkan model pendugaan curah hujan sendiri karena wilayah Indonesia yang berada di antara dua benua dan dua samudera merupakan daerah yang memiliki karakteristik iklim dan c uaca yang tiada duanya di dunia (Yusmen 1998).
2.2 Jaringan Syaraf Tiruan
Peniruan cara berpikir otak manusia dengan menggunakan sistem komputer telah memberi inspirasi kepada para ilmuwan pada abad ini. Dimulai sejak lima puluh tahun yang lalu, ilmuwan telah menciptakan model perangkat elektronik pertama dari sel-sel syaraf. Semenjak itu banyak komunitas ilmuwan bekerja dalam model matematika baru ini beserta algoritma-algoritma pembelajaran. Sekarang, model itu lebih dikenal dengan nama jaringan syaraf tiruan. Jaringan syaraf tiruan menggunakan sejumlah unit komputasi sederhana yang disebut neuron, yang berusaha meniru perilaku sel tunggal otak manusia. Otak manusia sendiri mengandung 10 milyar sel – sel syaraf dengan sekitar 10000 synapses. Neuron-neuron biologis memancarkan sinyal elektrokimia pada jalur -jalur syaraf, yang terdiri atas bagian body, axon dan dendrit. Sinyal datang melalui dendrit, diolah oleh body dan dihantarkan melalui axon. Sel itu sendiri mengandung kernel dan bagian luarnya membrane elektrik. Setiap neuron mempunyai level aktivasi, dengan range diantara maksimum dan minimum. Setiap
neuron menerima sinyal-sinyal dari neuron lain melalui sambungan khusus synapses
lainnya. Synapses ini membawa level aktivasi dari neuron pengirim ke neuron penerima (Kristanto Andri 2004).
JST merupakan system pemrosesan informasi yang memiliki karakteristik serupa dengan jaringan syaraf biologis dengan ciri-ciri:
1. Pola hubungan antara elemen-elemen sederhana yakni neuron. 2. Metode penentuan bobot koneksi.
3. Fungsi aktivasinya.
JST mempunyai sifat dan kemampuan:
a. Akuisisi pengetahuan di bawah derau (noise) dan ketidakpastian (uncertainty). b. Representasi pengetahuan yang fleksibel.
c. Pemrosesan pengetahuan yang effisien.
d. Toleransi kesalahan, dengan representasi pengetahuan terdistribusi dan pengkodean informasi yang redundan, kinerja system tidak menururn drastic berkaitan dengan responnya terhadap kesalahan (Workshop JNB 2002).
2.3 Jaringan Syaraf Tiruan Propagasi Balik.
Model neuron yang pertama diperkenalkan pada tahun 1943 oleh McCulloch dan Pitts. Heb pada tahun 1949 mengusulkan sebuah aturan pembelajaran yang menjelaskan bagaimana sebuah jaringan sel-sel syaraf belajar. Kemudian Rosenblatt pada tahun 1958 menemukan algoritma pembelajaran perceptron, serta Widrow dan Hoff mengusulkan varian dari pembelajaran perceptron yang disebut aturan Widrow-Hoff. Kemudian pada tahun 1969, Minsky dan Papert menunjukkan keterbatasan teoritis dari jaringan neural lapis tunggal (single layer neural networks) sehingga menyebabkan penurunan riset di bidang ini. Tetapi pada tahun 1980-an pendekatan JST hidup kembali dimulai oleh Hopfield yang memperkenalkan ide minimasi energi dalam fisika ke dalam JST. Pada pertengahan dekade tersebut algoritma propagasi balik (backpropagation) yang dikembangkan Rumelhart, Hinton dan Williams memberikan pengaruh besar tidak hanya bagi riset-riset JST tetapi juga bagi ilmu komputer, kognitif dan biologi yang lebih luas. Algoritma ini menawarkan solusi untuk pembelajaran JST lapis banyak (multi-layer neural networks) sehingga dapat mengatasi keterbatasan jaringan syaraf lapis tunggal (Lakshmi Sri et.al 2003).
Prinsip dasar algoritma backpropagation memiliki tiga tahap : § Tahap feedforward pola input pembelajaran
§ Tahap kalkulasi dan backpropagation error yang diperoleh. § Tahap penyesuaian bobot.
Arsitektur yang digunakan adalah jaringan perceptron lapis banyak (multi-layer
perceptrons.). Hal ini merupakan generalisasi dari arsitektur perceptron lapis tunggal
(single layer perceptron). Secara umum, algoritma jaringan ini membutuhkan waktu pembelajaran yang memang lambat, tetapi setelah pembelajaran dan pelatihan selesai, aplikasinya akan memberikan output yang sangat cepat (Workshop JNB 2002).
2.4 Optimasi Pembelajaran Heuristik
Pada JST backpropagation dikenal optimasi teknik heuristik yaitu algoritma pelatihan yang berfungsi untuk lebih mempercepat proses pelatihan dan merupakan pengembangan dari suatu analisa kinerja pada algoritma steepest (gradient) descent
standard. Tiga algoritma optimasi teknik heuristik (Kusumadewi 2004) yang sering
dipakai :
2.4.1 Gradient Descent Adaptive Learning Rate.
Teknik heuristik ini memperbaiki bobot berdasarkan gradient descent dengan laju pembelajaran yang bersifat adaptive. Pada gradient descent standard, selama proses pembelajaran, laju pembelajaran (a) akan terus bernilai konstan. Apabila laju pembelajaran terlalu tinggi, maka algoritma menjadi tidak stabil. Sebaliknya, jika laju pembelajaran terlalu kecil maka algoritma akan sangat lama dalam mencapai kekonvergenan. Pada kenyataannya, nilai laju pemb elajaran yang optimal akan terus berubah selama proses pelatihan seiring dengan berubahnya nilai fungsi kinerja. Pada
gradient descent adaptive learning rate, nilai laju pembelajaran akan diubah selama
proses pelatihan untuk menjaga agar algoritma ini sena ntiasa stabil selama proses pelatihan. Kinerja jaringan syaraf dihitung berdasarkan nilai output jaringan dan error pelatihan. Pada setiap epoh, bobot-bobot baru dihitung dengan menggunakan laju pembelajaran yang ada. Kemudian dihitung kinerja jaringan syaraf baru. Jika perbandingan kinerja syaraf baru dan kinerja syaraf lama melebihi maksimum kenaikan kerja (max_perf_inc), maka bobot baru tersebut akan diabaikan, dan nilai laju
pembelajaran akan dikurangi dengan cara mengalikannya dengan parameter penurunan laju pembelajaran (lr_dec). Seba liknya, apabila perbandingan kinerja syaraf baru dan kinerja syaraf lama kurang dari maksimum kenaikan kerja, maka nilai bobot-bobot akan dipertahankan, dan nilai laju pembelajaran akan dinaikkan dengan cara mengalikannya dengan parameter penambahan laju pembelajaran (lr_inc).
Langkah- langkah teknik heuristik ini adalah :
1. Hitung bobot dan bias baru lapisan output dengan menggunakan persamaan: wjk(baru) = wjk(lama) + ? wjk
b2k(baru) = b2k(lama) + ?b2k
2. Hitung bobot dan bias baru lapisan tersembunyi dengan menggunakan persamaan :
vij(baru) = vij(lama) + ? vij b1j(baru) = b1j(lama) + ?b1j
3. Hitung kinerja jaringan syaraf baru (perf2) dengan menggunakan bobot-bobot baru tersebut.
4. Bandingkan kinerja jaringan syaraf baru (perf2) kinerja jaringan syaraf sebelumnya (perf ).
5. Jika perf2/perf >max_perf _inc maka laju pembelajaran (a) = a *lr_dec.
6. Jika perf2/perf < max_perf_inc maka laju pembelajaran (a) = a *lr_inc.
7. Jika perf2/perf = max_perf_inc maka bobot baru diterima sebagai bobot sekarang (Kusumadewi 2004).
2.4.2 Gradient Descent Adaptive Learning Rate dan Momentum.
Teknik heuristik ini memperbaiki bobot berdasarkan gradient descent dengan laju pembelajaran yang bersifat adaptive dan menggunakan momentum (mc).
Momentum adalah suatu konstanta yang mempengaruhi perubahan bobot dan bernilai diantara 0 dan 1. Bila mc = 0 maka perubahan bobot akan dipengaruhi oleh
gradient saja dan bila mc = 1 maka perubahan bobot akan sama dengan perubahan
bobot sebelumnya. Langkah- langkah teknik heuristik ini adalah :
1. Hitung bobot dan bias baru unit output dengan menggunakan persamaan: ? wjk = a f 2jk untuk epoh = 1
? wjk = mc*? wjk (epoh sebelumnya) + (1-mc)*a f 2jk untuk epoh >1 ? b2k= a ß2k, untuk epoh = 1
? b2k = mc*?b2k (epoh sebelumnya) + (1-mc)*a ß2k; untuk epoh >1 2. Hitung bobot dan bias baru unit tersembunyi dengan menggunakan persamaan: ? vjk = ? vjk + a f 1ij ; untuk epoh = 1
? vjk = mc*? vjk (epoh sebelumnya) + (1-mc)*a f 1ij; untuk epoh >1 ? b1j= a ß1j, untuk epoh = 1
? b2j = mc*?b1j (epoh sebelumnya) + (1-mc)*a ß1j; untuk epoh >1 3. Hitung kinerja jaringan syaraf baru (perf2) dengan menggunakan bobot-bobot
baru tersebut
4. Bandingkan kinerja jaringan syaraf baru (perf2) kinerja jaringan syaraf sebelumnya (perf ).
5. Jika perf2/perf >max_perf _inc maka laju pembelajaran (a) = a *lr_dec, ? wjk = a f 2jk
? b2k = a ß2k ? vij = a f 1ij ? b1j = a ß1j
6. Jika perf2/perf <max_perf _inc maka laju pembelajaran (a) = a *lr_inc, ? wjk = a f 2jk
? b2k = a ß2k ? vij = a f 1ij ? b1j = a ß1j
7. Jika perf2/perf = max_perf_inc maka bobot baru diterima sebagai bobot sekarang (Kusumadewi 2004).
2.4.3 Resilient Backpropagation
Jaringan syaraf yang dibangun dengan struktur multilayer biasanya menggunakan fungsi aktivasi sigmoid. Fungsi aktivasi ini akan membawa input dengan
range yang tak terbatas ke nilai output dengan range yang terbatas, yaitu antara 0
sampai 1. Salah satu karakteristik dari fungsi sigmoid adalah gradiennya akan mendekati nol, apabila input yang diberikan sangat banyak. Gradient yang mendekati 0
ini berimplikasi pada rendahnya perubahan bobot. Apabila bobot-bobot tidak cukup mengalami perubahan, maka algoritma akan sangat lambat untuk mendekati nilai optimumnya (Kusumadewi 2004).
Algoritma resilient backpropagation berusaha untuk mengeliminasi besarnya efek dari turunan parsial dengan cara hanya menggunakan tanda turunannya saja dan mengabaikan besarnya nilai turunan. Tanda turunan ini akan menentukan arah perbaikan bobot bobot. Besarnya perubahan setiap bobot akan ditentukan oleh suatu faktor yang diatur pada parameter penambahan bobot (delt_inc) atau parameter penurunan bobot (delt_dec). Bila gradien fungsi kinerja berubah tanda dari suatu iterasi ke iterasi berikutnya, maka bobot akan berkurang sebesar delt_dec dan bila gradient fungsi kinerja tidak berubah tanda maka bobot akan bertambah sebesar delt_inc. Apabila gradien fungsi kinerja = 0, maka perubahan bobot sama dengan perubahan bobot sebelumnya. Langkah- langkah teknik heuristik ini adalah :
1. Inisialisasi perubahan bobot (?v, ? w, ?b1dan ?b2) dengan parameter delta. Besarnya perubahan tidak boleh melebihi batas maksimum yang terdapat pada parameter maksimum perubahan bobot (deltamax).
2. Simpan f1, f2, ß1 dan ß2 sebagai f1(lama), f2 (lama), ß1(lama) dan ß2(lama).
3. Hitung f 1, f2, ß1 dan ß2 baru dengan menggunakan persamaan: f 2jk = dk zj
ß2k = dk f 1ij = d1jx j ß1j = d1j
4. Hitung gradien fungsi kinerja dengan menggunakan persamaan: f f 2jk = f 2jk * f 2jk (lama)
ßß2k = ß2k * ß2k (lama) f f 1ij = f 1ij * f 1ij (lama) ßß2j = ß1j * ß1j (lama)
5. Hitung perubahan bobot: delt_inc; f f 2jk > 0 ? wjk = delt_dec; f f 2jk < 0 ? wjk(lama); f f 2jk = 0 ? wjk = min(?wjk,deltamax) -? wjk; f 2jk < 0 ? wjk = ? wjk; f 2jk > 0 0; f 2jk = 0 delt_inc; ßß2k > 0 ? b2k = delt_dec; ßß2k < 0 ? b2k(lama); ßß2k = 0 ? b2k = min( ?b2k,deltamax) -?b2k ; ß2k < 0 ? b2k = ?b2k; ß2k > 0 0; ß2k = 0 delt_inc; f f 1ij > 0 ? vij = delt_dec; f f 1ij < 0 ? vij(lama); f f 1ij = 0 ? vij = min(? vij,deltamax ) -? vij ; f 1ij < 0 ? vij = ? vij; f 1ij > 0 0; f 1ij = 0 delt_inc; ßß1j > 0 ? b1j = delt_dec; ßß1j < 0 ? b1j(lama); ßß1j = 0 ? b1j = min(?b1j,deltamax) -?b1j ; ß1j < 0 ? b1j = ?b1j ; ß1j > 0 0; ß1j = 0 (Kusumadewi 2004)
2.5 Jaringan Syaraf Tiruan Recurrent Elman
JST recurrent adalah jaringan yang mengakomodasi keluaran jaringan untuk menjadi masukan pada jaringan itu lagi dalam rangka menghasilkan keluaran jaringan berikutnya. Jaringan recurrent Elman terdiri atas satu atau lebih lapisan tersembunyi. Lapisan pertama memiliki bobot-bobot yang diperoleh dari lapisan input, setiap lapisan akan menerima bobot dari lapisan sebelumnya. Jaringan ini biasanya menggunakan fungsi aktivasi sigmoid bipolar untuk lapisan tersembunyi dan fungsi linear (purelin) untuk lapisan keluaran. Tidak seperti pada backpropagation, pada jaringan Elman ini, mempunyai fungsi aktivasi yang dapat berupa sembarang fungsi, baik yang kontinyu maupun diskontinyu. Delay yang terjadi pada hubungan antara lapisan input dengan lapisan tersembunyi pertama pada waktu sebelumnya (t-1) dapat digunakan untuk saat ini (t) (Kusumadewi 2004). Keunikan JST recurrent adalah adanya koneksi umpan balik yang membawa informasi gangguan (noise) pada saat masukan sebelumnya yang akan diakomodasikan bagi masukan berikutnya (Coulibaly et.al 2000) seperti disajikan pada Gambar 2.
Gambar 2. Arsitektur JST recurrent
• • …. • D D . . . D
Keluaran
Koneksi Umpan Balik
Lapisan Tersembunyi Node-node Recurrent Variabel Masukan Lapisan Keluaran Unit Delay
2.6 Inisialisasi Nguyen-Widrow.
Inisialisasi ini umumnya mempercepat proses pembelajaran dibandingkan dengan inisialisasi acak (Fauset 1994).
Inisialisasi Nguyen-Widrow didefinisikan sebagai persamaan berikut: a. Hitung harga faktor pengali ß
ß = 0.7 p1/n Dimana :
ß = Faktor pengali.
n = Jumlah neuron lapisan input. p = Jumlah neuron lapisan tersembunyi b. Untuk setiap unit tersembunyi ( j=1, 2, ...,p):
hitung vij (lama) yaitu bilangan acak antara -0.5 dan 0.5 (atau di antara -? dan sampai ?).
c. Hitung : ¦ vj ¦
Pembaharuan bobot vij (lama) menjadi vij (baru) yaitu : ß vij (lama)
vij (lama) = --- ¦ vj (lama) ¦
a. Set bias :
B1j = Bilangan random antara – ß sampai ß.
2.7 Ketepatan Pendugaan
Ketepatan pendugaan sebuah model regresi dapat dilihat dari koefisien determinasinya (R2) dan Root Mean Square Error (RMSE). Nilai R2 menunjukan proporsi jumlah kuadrat total yang dapat dijelaskan oleh sumber keragaman peubah bebas, sedangkan RMSE menunjukan besar simpangan nilai dugaan terhadap nilai aktualnya. R2 adalah kuadrat dari korelasi antara nilai vektor observasi y dengan nilai vektor penduga y (Walpole 1982).
Rumus R2 adalah :
Dimana :
yi = Nilai - nilai aktual yi = Nilai - nilai prediksi
dimana :
Xt = Nilai aktual pada waktu ke-t Ft = Nilai dugaan pada waktu ke-t
Nilai-nilai R2 berada pada selang 0 sampai 1. Kecocokan model semakin baik jika R2 mendekati 1 dan RMSE mendekati 0.
R2 =
n [ ? ( yi – y)(yi – y) ]2 i =1
n n ? ( yi – y)2 ?(yi – y)2 i=1 i=1 RMSE = n ? ( Xt - Ft )2 t =1 --- n n ? ( Xt - Ft )2 t =1 --- n
BAB III
DATA & METODE
3.1 Data
Data yang digunakan dalam penelitian ini adalah : a. Data ENSO
Data ini diperoleh dari lembaga internasional National Weather Service Center for Environmental Prediction Climate (NOAA) selama 83 bulan dengan domain cakupan data peubah ENSO ini adalah wilayah Nino-3,4 yaitu : 5o LU - 5o LS dan 90o BB - 150o BB.
b. Data Curah Hujan
Data curah hujan yang digunakan dalam penelitian ini adalah curah hujan rata-rata di daerah Bongan Bali selama 83 bulan dengan domain cakupan data 08o 33’ 05” S - 115o 05’ 48”E dengan ketinggian 124 meter yang diperoleh dari BALITKLIMAT Bogor.
3.2 Metode
Penelitian diawali dengan studi pustaka yaitu mengidentifikasi peubah ENSO dan pengaruhnya terhadap curah hujan di wilayah Indonesia. Langkah berikutnya mempelajari penelitian-penelitian yang pernah dilakukan uintuk mengetahui metoda yang digunakan dan ketepatan pendugaan yang telah dicapai.
Dari hasil studi pustaka diidentifikasi masalah yang ada, yaitu perlunya suatu pemodelan pendugaan curah hujan yang lebih akurat khususnya berdasarkan peubah ENSO. Selanjutnya dikembangkan model JST recurrent yang teroptimasi secara heuristik. Metodologi selengkapnya disajikan pada Gambar 3.
Gambar 3. Kerangka Berpikir Penelitian
1 ) Peubah – Peubah
ENSO
2 ) Data curah hujan 3) Pemodelan JST recurrent dgn optimasi teknik heuristik Pembuatan model JST recurrent dgn optimasi teknik heuristik Data : -Training 75%
-Testing 25% Pengembangan aplikasi dgn
MATLAB
Pelatihan (Training)
Uji coba (Testing) Field
Record
Pembahasan, kesimpulan Dokumentasi & penulisan
laporan Mulai
Studi Pustaka
Identifikasi Masalah
Pengembangan Blok Diagram Sistem
& Data Riil
Teknik heuristik :
a) Adaptive learning rate b) Adaptive learning rate &
momentum c) Resilient backpropagation Data : -Training 50% -Testing 50% Selesai
BAB IV
PERANCANGAN & IMPLEMENTASI SISTEM
4.1 Desain Arsitektur.
Arsitektur yang digunakan adalah jaringan recurrent tipe Elman dengan 2 lapisan tersembunyi. Masukan terdiri dari data : wind, SOI, SST dan OLR dan target adalah data curah hujan. Pada saat proses penentuan arsitektur standar JST recurrent, dilakukan proses trial & error untuk mendapatkan unjuk kerja JST yg optimum dengan parameter :
§ Dimensi jaringan ( jumlah neuron dan hidden layer ). § Laju Pembelajaran ( learning rate )
Algoritma pembelajaran nantinya akan digunakan optimasi teknik heuristik yang terdiri dari 3 algoritma pembelajaran berikut:
(1) Gradient descent adaptive learning rate.
(2) Gradient descent adaptive learning rate & momentum (3) Resilient backpropagation
Setiap proses pelatihan dan pengujian diulang sebanyak 20 kali untuk dicari nilai rata-rata dan simpangan bakunya (Normakristagaluh 2004). Hasil dari pengujian adalah tingkat keakuratan antara nilai dugaan dengan nilai aktual berdasarkan dua parameter yaitu R2 dan RMSE. Nilai R2 yang diperoleh dikalikan 100% untuk memudahkan pembacaan tingkat keakurasian.
4.2 Tahapan Penelitian
Dalam penelitian ini akan dikaji permodelan JST recurrent yang teroptimasi secara heuristik untuk pendugaan curah hujan berdasarkan peubah ENSO.
Tahapan permulaan, masing-masing kelompok data akan mengalami proses inisialisasi dengan menggunakan metoda Nguyen-Widrow. Jumlah neuron dan hidden
layer ditetapkan dengan percobaan pendahuluan secara trial & error dan merujuk pada
a. Langkah pertama dilakukan pembelajaran terhadap ke empat peubah ENSO dan curah hujan sebagai target, dengan menggunakan kelompok data pertama yaitu 75% data pelatihan dan 25% data pengujian.
b. Langkah kedua dilakukan pembelajaran terhadap ke empat peubah ENSO dan curah hujan sebagai target, dengan menggunakan kelompok data kedua yaitu 50% data pelatihan dan 50% data pengujian.
Langkah di atas dilakukan terhadap ketiga algoritma pembelajaran heuristik yaitu : a. Gradient descent adaptive learning rate
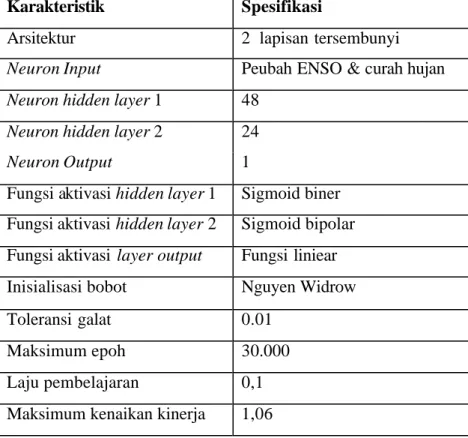
Struktur standar untuk penelitian dengan menggunakan algoritma pembelajaran
gradient descent adaptive learning rate seperti disajikan pada Tabel 1.
Tabe l 1. Struktur JST recurrent standar gradient descent adaptive
learning rate
Karakteristik Spesifikasi
Arsitektur 2 lapisan tersembunyi
Neuron Input Peubah ENSO & curah hujan
Neuron hidden layer 1 48
Neuron hidden layer 2 24
Neuron Output 1
Fungsi aktivasi hidden layer 1 Sigmoid biner Fungsi aktivasi hidden layer 2 Sigmoid bipolar Fungsi aktivasi layer output Fungsi liniear Inisialisasi bobot Nguyen Widrow Toleransi galat 0.01
Maksimum epoh 30.000 Laju pembelajaran 0,1 Maksimum kenaikan kinerja 1,06
Komposisi percobaan yang dilakukan adalah terhadap komposisi nilai: § lr_inc 1,20 & lr_dec 0,6
§ lr_inc 1,05 & lr_dec 0,6 § lr_inc 1,05 & lr_dec 0,7
b. Gradient descent adaptive learning rate & momentum.
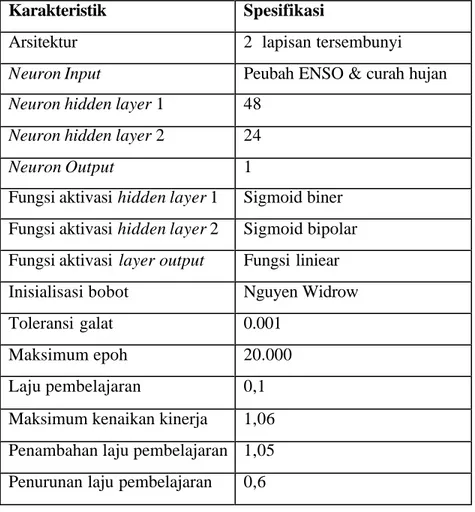
Struktur standar untuk penelitian dengan me nggunakan algoritma pembelajaran
Adaptive learning rate & momentum seperti disajikan pada Tabel 2.
Tabel 2. Struktur JST recurrent standar gradient descent adaptive
learning rate & momentum
Karakteristik Spesifikasi
Arsitektur 2 lapisan tersembunyi
Neuron Input Peubah ENSO & curah hujan
Neuron hidden layer 1 48
Neuron hidden layer 2 24
Neuron Output 1
Fungsi aktivasi hidden layer 1 Sigmoid biner Fungsi aktivasi hidden layer 2 Sigmoid bipolar Fungsi aktivasi layer output Fungsi liniear Inisialisasi bobot Nguyen Widrow Toleransi galat 0.001
Maksimum epoh 20.000 Laju pembelajaran 0,1 Maksimum kenaikan kinerja 1,06 Penambahan laju pembelajaran 1,05 Penurunan laju pembelajaran 0,6
Komposisi percobaan yang dilakukan adalah parameter momentum: § mc 0,7 & mc 0,9
c. Resilient backpropagation.
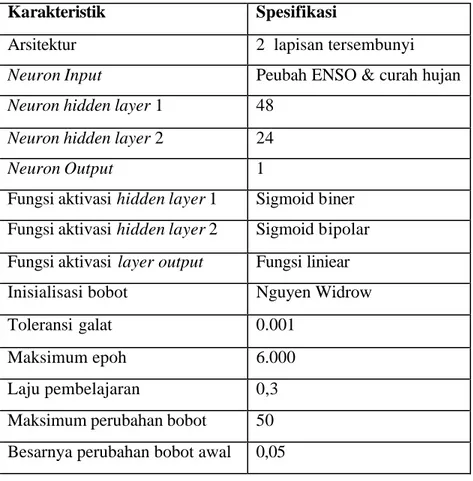
Struktur standar untuk penelitian dengan menggunakan algoritma pembelajaran
Tabel 3. Struktur JST recurrent standar resilient backpropagation
Karakteristik Spesifikasi
Arsitektur 2 lapisan tersembunyi
Neuron Input Peubah ENSO & curah hujan
Neuron hidden layer 1 48
Neuron hidden layer 2 24
Neuron Output 1
Fungsi aktivasi hidden layer 1 Sigmoid biner Fungsi aktivasi hidden layer 2 Sigmoid bipolar Fungsi aktivasi layer output Fungsi liniear Inisialisasi bobot Nguyen Widrow Toleransi galat 0.001
Maksimum epoh 6.000 Laju pembelajaran 0,3 Maksimum perubahan bobot 50 Besarnya perubahan bobot awal 0,05
Komposisi percobaan yang dilakukan adalah terhadap pasangan nilai: § delta_inc 1,5 & delta_dec 0,6
§ delta_inc 1,5 & delta_dec 0,5 § delta_inc 1,7 & delta_dec 0,4 § delta_inc 1,7 & delta_dec 0,5.
Pada setiap kelompok data dengan komposisi di atas dilakukan percobaan terhadap variasi leap yang berbeda-beda yaitu leap = 0, 1, 2, dan 3.
§ Leap 0 pendugaan curah hujan jatuh pada bulan yang sama. § Leap 1 pendugaan curah hujan jatuh pada satu bulan ke depan. § Leap 2 pendugaan curah hujan jatuh pada dua bulan ke depan. § Leap 3 pendugaan curah hujan jatuh pada tiga bulan ke depan.
Setiap percobaan dilakukan pengulangan/iterasi sebanyak 20 kali dengan tujuan memperoleh rata-rata R2 dan RMSE yang memiliki simpangan baku terkecil. Nilai R2
dan RMSE tiap kombinasi terletak pada selang nilai tertentu (minimum da n maksimum). Hasil percobaan pada penelitian ini difokuskan pada perbandingan ketepatan pendugaan JST menghasilkan R2 maksimum dan RMSE minimum.
4.3 Desain Struktur Data
Desain struktur data berupa tabel data bulanan peubah-peubah ENSO & curah hujan (selengkapnya pada Lampiran 1) seperti disajikan pada Tabel 4.
Tabel 4. Data peubah ENSO & curah hujan
4.4. Desain Keluaran (Output)
Data keluaran berupa tabel hasil penelitian berupa nilai-nilai epoch, R2 dan RMSE dari setiap kelompok data percobaan dengan 3 algoritma yang telah dilakukan juga dihitung nilai – nilai R2 minimum, R2 maksimum, rata-rata R2, standar deviasi R2, RMSE minimum, RMSE maksimum, rata-rata RMSE dan standar deviasi RMSE.
4.5 Perangkat Keras dan Lunak
Penelitian ini menggunakan perangkat keras dan lunak sebagai berikut: a. Intel Pentium IV 2,66 GHz
b. Memori SDRAM 256 MB, hardisk 40 GB c. Matlab 7
d. Microsoft Excel Xp Professional
Bulan Indeks OLR Indeks WIND Indeks SOI Indeks SST Curah Hujan (mm) Januari 23,5 6,6 0,5 0,18 649,0 Februari 9,7 6,7 1,2 0,28 601, 0 Maret 21,7 7,4 0,9 0,52 321,0 April 5,4 5,3 1,0 0,9 151,0 Mei 19,7 5,9 0,5 1,06 14,0 Juni 22,4 6,1 0,6 0,79 176,0 Juli 25,9 8,2 -0,2 0,48 121, 0 Agustus 40,6 6,6 1,7 0,14 12,0 September 40,1 6,5 0,9 0,28 40,0 Oktober..dst 28,3 6,1 1,2 0,33 53,0
BAB V
HASIL DAN PEMBAHASAN
5.1 Komposisi Data Pelatihan & Pengujian
Komposisi data pelatihan & pengujian sangat berpengaruh terhadap keakuratan pendugaan dalam JST. Seperti yang dijelaskan dalam metodologi, data dibagi ke dalam 2 kelompok data percobaan yaitu kelompok data pertama, 75% data (62 bulan) pelatihan dan 25% data (21 bulan) pengujian serta kelompok data kedua 50% data (42 bulan) untuk pelatihan dan 50% data (41 bulan) untuk data pengujian. Masing- masing kelompok data akan dibahas dan diperlihatkan grafik hasil percobaan.
5.2 Kelompok Data Pertama.
Pada percobaan pertama, data peubah ENSO yaitu wind, SOI, SST dan OLR sebagai input dan curah hujan sebagai target. Hasil percobaan untuk kelompok data ini sebagai berikut seperti disajikan pada Tabel 5, Tabel 6 dan Tabel 7.
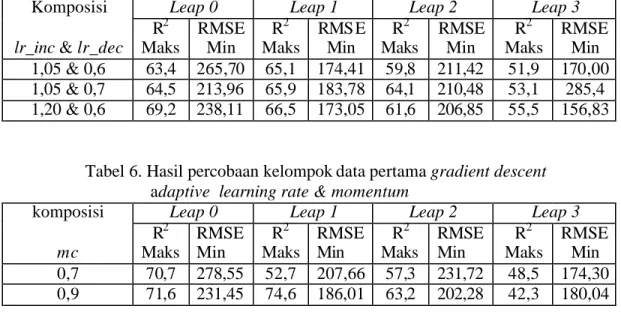
Tabel 5. Hasil percobaan kelompok data pertama gradient descent adaptive learning rate
Komposisi Leap 0 Leap 1 Leap 2 Leap 3 lr_inc & lr_dec
R2 Maks RMSE Min R2 Maks RMS E Min R2 Maks RMSE Min R2 Maks RMSE Min 1,05 & 0,6 63,4 265,70 65,1 174,41 59,8 211,42 51,9 170,00 1,05 & 0,7 64,5 213,96 65,9 183,78 64,1 210,48 53,1 285,4 1,20 & 0,6 69,2 238,11 66,5 173,05 61,6 206,85 55,5 156,83
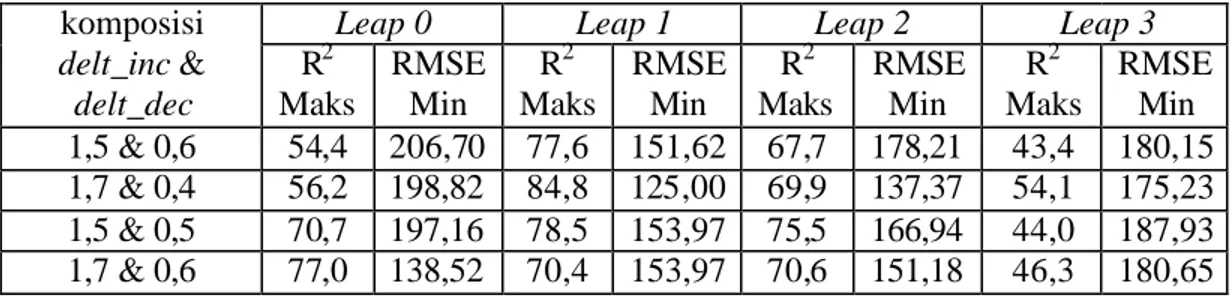
Tabel 6. Hasil percobaan kelompok data pertama gradient descent adaptive learning rate & momentum
komposisi Leap 0 Leap 1 Leap 2 Leap 3 mc R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min 0,7 70,7 278,55 52,7 207,66 57,3 231,72 48,5 174,30 0,9 71,6 231,45 74,6 186,01 63,2 202,28 42,3 180,04
Tabel 7. Hasil percobaan kelompok data pertama resilient
backpropagation
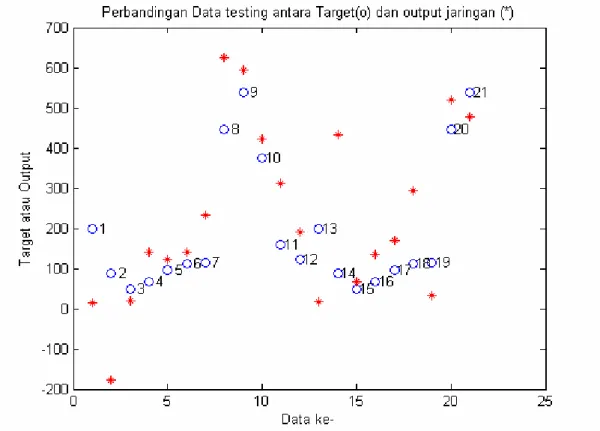
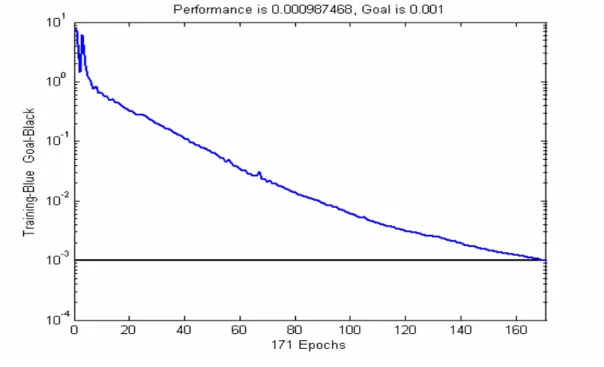
komposisi Leap 0 Leap 1 Leap 2 Leap 3 delt_inc & delt_dec R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min 1,5 & 0,6 54,4 206,70 77,6 151,62 67,7 178,21 43,4 180,15 1,7 & 0,4 56,2 198,82 84,8 125,00 69,9 137,37 54,1 175,23 1,5 & 0,5 70,7 197,16 78,5 153,97 75,5 166,94 44,0 187,93 1,7 & 0,6 77,0 138,52 70,4 153,97 70,6 151,18 46,3 180,65 Percobaan kelompok data pertama, hasil terbaik diperoleh pada saat menggunakan algoritma resilient backpropagation. Untuk leap 0, ketika nilai delt_inc dinaikkan dari 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi 0,4 hasilnya nilai R2 maksimum naik dari 54,4 menjadi 56,2 menunjukan adanya peningkatan sebesar 1,8 sedangkan nilai RMSE turun dari 206,7 menjadi 198,82. Ketika nilai delt_inc tetap 1,7 dan delt_dec dinaikkan dari 0,4 menjadi 0,6 hasilnya nilai R2 maksimum naik dari 56,2 menjadi 77 menunjukan adanya peningkatan sebesar 20,8 sedangkan nilai RMSE turun dari 198,82 menjadi 138,52. Hasil ini merupakan yang terbaik pada percobaan kelompok data pertama untuk leap 0 dengan komposisi nilai delt_inc 1,7 dan delt_dec 0,6. Jumlah epoh untuk hasil terbaik ini disajikan pada Gambar 4. Korelasi kecocokan
output jaringan dengan target bernilai 0,77 atau 77% seperti disajikan pada Gambar 5.
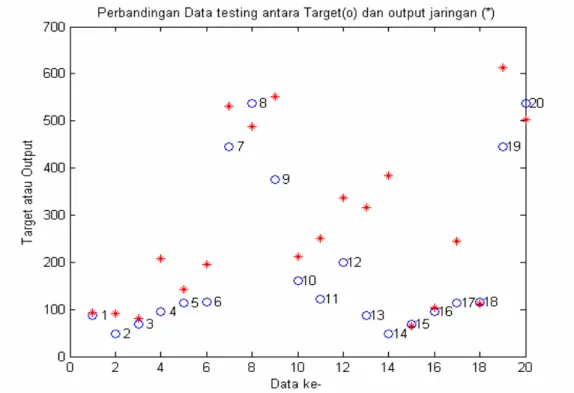
Perbandingan nilai prediksi (output) dan nilai aktual (target) disajikan pada Gambar 6, terlihat beberapa titik (output) sudah mulai berdekatan dengan beberapa bulatan (target). Hal tersebut dapat diartikan bahwa beberapa nilai dugaan/prediksi sudah mendekati nilai aktualnya. Hasil terbaik terjadi apabila titik dan bulatan berada pada posisi yang sama.
Gambar 4. Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok data pertama untuk leap 0
Gambar 5. Korelasi terbaik JST recurrent resilient backpropagation kelompok data pertama untuk leap 0
Gambar 6. Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent
resilient backpropagation kelompok data pertama untuk leap 0
Percobaan untuk leap 1, 2 dan 3, hasil pendugaan terbaik didapat pada saat leap 1. Nilai R2 maksimum yang dihasilkan sebesar 84,8% dalam selang nilai R2 diantara 28,5 sampai dengan 84,8 dengan nilai RMSE sebesar 125 dalam selang nilai RMSE 125 sampai dengan 321,52. Hasil percobaan terbaik untuk leap 1 ini diperoleh dengan komposisi nilai delt_inc 1,7 dan delt_dec 0,4 seperti disajikan pada Gambar 7, Gambar 8 dan Gambar 9. Dari hasil – hasil percobaan kelompok data pertama ini pendugaan curah hujan terbaik terjadi pada saat leap 1.
Gambar 7. Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok data pertama untuk leap 1
Gambar 8. Korelasi terbaik JST recurrent resilient backpropagation kelompok data pertama untuk leap 1
Gambar 9. Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent
resilient backpropagation kelompok data pertama leap 1.
5.3 Kelompok Data Kedua
Hasil percobaan untuk kelompok da ta ini seperti disajikan pada Tabel 8, Tabel 9 dan Tabel 10.
Tabel 8. Hasil percobaan kelompok data kedua gradient descent adaptive
learning rate
Komposisi Leap 0 Leap 1 Leap 2 Leap 3 lr_inc & lr_dec
R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min 1,05 & 0,6 46,0 244,31 46,0 198,13 29,0 269,44 6,54 305,09 1,05 & 0,7 47,3 272,50 46,4 200,82 32,4 277,55 8,75 314,85 1,20 & 0,6 53,6 297,69 45,7 197,55 28,4 269,45 12,6 344,63
Tabel 9. Hasil percobaan kelompok data kedua gradient descent adaptive learning rate & momentum
komposisi Leap 0 Leap 1 Leap 2 Leap 3 mc R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min 0,7 45,7 279,28 45,6 223,23 29,2 314,04 8,72 300,87 0,9 46,3 313,93 49,8 209,37 36,3 283,95 12,9 312,54
Tabel 10. Hasil percobaan kelompok data kedua resilient
backpropagation
komposisi Leap 0 Leap 1 Leap 2 Leap 3 delt_inc & delt_dec R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min R2 Maks RMSE Min 1,5 & 0,6 45,0 198,63 59,5 156,46 59,5 156,46 21,0 248,22 1,7 & 0,4 58,1 201,63 56,3 169,77 56,2 188,12 29,1 225,73 1,5 & 0,5 42,8 228,19 56,0 172,67 56,0 172,67 27,5 234,18 1,7 & 0,6 46,6 229,47 59,9 155,29 54,0 171,03 24,1 250,92 Percobaan kelompok data kedua, hasil terbaik diperoleh pada saat menggunakan algoritma resilient backpropagation. Untuk leap 0, ketika nilai delt_inc dinaikkan dari 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi 0,4 hasilnya nilai R2 naik dari 45 menjadi 58,1 menunjukan adanya peningkatan sebesar 13,1. Nilai RMSE naik dari 198,63 menjadi 201,63. Hasil ini merupakan yang terbaik untuk leap 0 dengan komposisi nilai delt_inc 1,7 dan delt_dec 0,4 seperti terlihat pada Gambar 10 , Gambar 11 dan Gambar 12.
Gambar 10. Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok data kedua untuk leap 0
Gambar 11. Korelasi terbaik JST recurrent resilient backpropagation kelompok data kedua untuk leap 0
Gambar 12. Nilai prediksi (output) dan nilai aktual (target ) terbaik JST recurrent
Untuk leap 1, 2 dan 3, grafik pendugaan terbaik didapat pada saat leap 1. Ketika nilai
delt_inc dinaikkan dari 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi
0,4 hasilnya nilai R2 maksimum turun dari 59,5 menjadi 56,3 sedangkan nilai RMSE naik dari 156,46 menjadi 169,77. Ketika nilai delt_inc tetap 1,7 dan delt_dec dinaikkan dari 0,4 menjadi 0,6 hasilnya nilai R2 maksimum naik dari 56,3 menjadi 59,9 dalam selang nilai R2 diantara 19,5 sampai dengan 59,9 sedangkan nilai RMSE turun dari 169,77 menjadi 155,29 dalam selang nilai RMSE 155,29 sampai dengan 282,97. Hasil ini merupakan yang terbaik untuk percobaan kelompok data kedua untuk leap 1 dengan komposisi nilai delt_inc 1,7 dan delt_dec 0,6 seperti disajikan pada Gambar 11 , Gambar 12 dan Gambar 13.
Gambar 13. Jumlah epoh terbaik JST recurrent resilient backpropagation kelompok data kedua leap 1
Gambar 14. Korelasi terbaik JST recurrent resilient backpropagation kelompok data kedua leap 1
Gambar 15. Nilai prediksi (output) dan nilai aktual (target) terbaik JST recurrent kelompok data kedua leap 1.
Dari hasil – hasil percobaan kelompok data kedua ini pendugaan curah hujan terbaik terjadi pada saat leap 1.
5.4 Komposisi Parameter Terbaik
Topologi jaringan JST recurrent yang digunakan dalam penelitian ini berupa satu lapisan input, dua lapisan tersembunyi terdiri dari lapisan te rsembunyi pertama dengan jumlah 48 neuron dan lapisan tersembunyi kedua dengan 24 neuron serta satu lapisan output dengan 1 neuron. Topologi ini sudah ditetapkan terlebih dahulu berdasarkan percobaan pendahuluan secara trial & error, tujuannya agar penelitian utama lebih berfokus pada parameter dari algoritma pembelajaran yang akan diterapkan.
Hasil penelitian selengkapnya dapat dilihat pada lampiran 5 sampai dengan 28, pada lampiran itu dapat dilihat hasil pengukuran masing- masing parameter dalam proses pelatihan dan pengujian dengan nilai rata-rata, nilai maksimum, nilai minimum serta standar deviasi dari R2 dan RMSE.
5.4.1 Komposisi Parameter Terbaik Adaptive Learning Rate
Percobaan kelompok data pertama untuk leap 0, nilai parameter yang divariasikan adalah lr_inc dan lr_dec. Ketika nilai lr_inc tetap 1,05 dan nilai lr_dec dinaikkan dari 0,6 menjadi 0,7 hasilnya nilai R2 maksimum naik dari 63,4 menjadi 64,5. Nilai rata-rata R2 naik dari 31,4 menjadi 35,3 sedangkan nilai RMSE turun dari 265,7 menjadi 213,96. Kemudian, nilai lr_inc dinaikkan dari 1,05 menjadi 1,2 dan nilai lr_dec diturunkan dari 0,7 menjadi 0,6 hasilnya nilai R2 maksimum naik dari 64,5 menjadi 69,2. Nilai rata-rata R2 turun dari 35,3 menjadi 28,4 sedangkan nilai RMSE naik dari 213,96 menjadi 238,11. Komposisi parameter terbaik percobaan kelompok data pertama untuk
leap 0, adalah lr_inc 1,2 dan lr_dec 0,6.
Percobaan kelompok data kedua untuk leap 0. Ketika nilai lr_inc tetap 1,05 dan nilai lr_dec dinaikkan dari 0,6 menjadi 0,7 hasilnya nilai R2 maksimum naik dari 46 menjadi 47,3. Nilai rata-rata R2 turun dari 38,9 menjadi 38,4 sedangkan nilai RMSE naik dari 244,31 menjadi 272,5. Kemudian nilai lr_inc dinaikkan dari 1,05 menjadi 1,2 dan nilai lr_dec diturunkan dari 0,7 menjadi 0,6 hasilnya nilai R2 maksimum naik dari 47,3 menjadi 53,6. Nilai rata-rata R2 naik dari 38,4 menjadi 39,2 sedangkan nilai
RMSE naik dari 272,5 menjadi 297,69. Komposisi parameter terbaik percobaan kelompok data kedua untuk leap 0, adalah lr_inc 1,2 dan lr_dec 0,6.
Percobaan kelompok data pertama untuk leap 1. Ketika nilai lr_inc tetap 1,05 dan nilai lr_dec dinaikkan dari 0,6 menjadi 0,7 hasilnya nilai R2 maksimum naik dari 65,1 menjadi 65,9. N ilai rata-rata R2 naik dari 46 menjadi 42,1 sedangkan nilai RMSE naik dari 174 menjadi 183,78. Kemudian nilai lr_inc dinaikkan dari 1,05 menjadi 1,2 dan nilai lr_dec diturunkan dari 0,7 menjadi 0,6 hasilnya nilai R2 maksimum naik dari 65,9 menjadi 66,5. Nilai rata-rata R2 naik dari 42,1 menjadi 50,4 sedangkan nilai RMSE tur un dari 183,78 menjadi 173,05. Komposisi parameter terbaik percobaan kelompok data pertama untuk leap 1 adalah lr_inc 1,2 dan lr_dec 0,6.
Percobaan kelompok data kedua untuk leap 1. Ketika nilai lr_inc tetap 1,05 dan nilai lr_dec dinaikkan dari 0,6 menjadi 0,7 hasilnya nilai R2 naik dari 46 menjadi 46,4. Nilai rata-rata R2 naik dari 36,06 menjadi 37,8 sedangkan nilai RMSE naik dari nilai 198,13 menjadi 200,82. Kemudian nilai lr_inc dinaikkan dari 1,05 menjadi 1,2 dan nilai
lr_dec diturunkan dari 0,7 menjadi 0,6 hasilnya nilai R2 maksimum turun dari 46,4 menjadi 45,7. Nilai rata-rata R2 turun dari 37,8 menjadi 37,09 sedangkan nilai RMSE turun dari 200,82 menjadi 197,55. Komposisi parameter terbaik percobaan kelompok data kedua untuk leap 1 adalah lr_inc 1,05 dan lr_dec 0,7. Hasil sele ngkapnya disajikan pada Tabel 11.
Tabel 11.Komposisi parameter terbaik gradient descent adaptive learning rate
Leap 0 Leap 1 Leap 2 Leap 3
Kelompok
Data lr_in lr_dec lr_in lr_dec lr_in lr_dec lr_in lr_dec
Pertama 1,20 0,6 1,20 0,6 1,05 0,7 1,20 0,6 Kedua 1,20 0,6 1,05 0,7 1,05 0,7 1,20 0,6
5.4.2 Komposisi Parameter Terbaik Gradient Descent Adaptive Learning Rate & Momentum
Percobaan kelompok data pertama untuk leap 0, parameter yang divariasikan adalah nilai momentum (mc) sedangkan nilai lr_inc dan lr_dec d itetapkan 1,05 dan 0,6 berdasarkan percobaan pendahuluan. Ketika nilai mc dinaikkan dari nilai 0,7 menjadi
0,9 hasilnya nilai R2 maksimum naik dari 70,7 menjadi 71,6. Nilai rata-rata R2 naik dari 48,77 menjadi 51,48 sedangkan nilai RMSE turun dari nilai 278,55 menjadi 231,45. Komposisi parameter terbaik percobaan kelompok data pertama untuk leap 0 adalah mc 0,9.
Percobaan kelompok data kedua untuk leap 0, Ketika nilai mc dinaik kan dari nilai 0,7 menjadi 0,9 hasilnya nilai R2 maksimum naik dari 45,7 menjadi 46,3. N ilai rata-rata R2 turun dari 41,5 menjadi 41,1 sedangkan nilai RMSE naik dari 279,28 menjadi 331,93. Komposisi parameter terbaik percobaan kelompok data kedua untuk
leap 0 adalah mc 0,9.
Pada percobaan kelompok data pertama untuk leap 1, Ketika nilai mc dinaikkan dari nilai 0,7 menjadi 0,9 hasilnya nilai R2 maksimum naik dari 52,7 menjadi 74,6. N ilai rata-rata R2 naik dari 30,3 menjadi 30,4 sedangkan nilai RMSE turun dari nilai 207,66 menjadi 186. Komposisi parameter terbaik percobaan kelompok data pertama untuk
leap 1 adalah mc 0,9.
Pada percobaan kelompok data kedua untuk leap 1, Ketika nilai mc dinaikkan dari nilai 0,7 menjadi 0,9 hasilnya nilai R2 maksimum naik dari 45,6 menjadi 49,8. N ilai rata-rata R2 naik dari 36,4 menjadi 38,6 sedangkan nilai RMSE turun dari 223,23 menjadi 209,37. Komposisi parameter terbaik percobaan kelompok data pertama untuk
leap 1 adalah mc 1.
Hasil selengkapnya disajikan pada Tabel 12.
Tabel 12.Komposisi parameter terbaik gardient descent daptive learning rate
& momentum
Kelompok Leap 0 Leap 1 Leap 2 Leap 3
Data mc mc mc mc
Pertama 0,9 0,9 0,9 0,9
Kedua 0,9 0,9 0,9 0,9
5.4.3 Komposisi Parameter Terbaik Resilient Backpropagation.
Pada percobaan kelompok data pertama untuk leap 0, parameter yang divariasikan nilainya adalah delt_inc dan delt_dec. Ketika nilai delt_inc dinaikkan dari
nilai 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi 0,4 hasilnya nilai R2 maksimum naik dari 54,4 menjadi 56,2. N ilai rata-rata R2 turun dari 34,8 menjadi 33,7 sedangkan nilai RMSE turun dari nilai 206,7 menjadi 198,82. Kemudian nilai
delt_inc tetap 1,7 dan delt_dec dinaikkan dari 0,4 menjadi 0,6 hailnya nilai R2
maksimum naik dari 56,2 menjadi 77. Nilai rata-rata R2 naik dari 33,7 menjadi 41,4 sedangkan nilai RMSE turun dari 198,82 menjadi 138,52. Komposisi parameter terbaik percobaan kelompok data pertama untuk leap 0 adalah delt_inc 1,7 dan delt_dec 0,6.
Percobaan kelompok data kedua untuk leap 0. Ketika nilai delt_inc dinaikkan dari nilai 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi 0,4 hasilnya nilai R2 maksimum naik dari 45 menjadi 58,1. Nilai rata-rata R2 turun dari 35,4 menjadi 30,4 sedangkan nilai RMSE naik dari 198,63 menjadi 201,63. Kemudian nilai
delt_inc tetap 1,7 dan delt_dec dinaikkan dari 0,4 menjadi 0,6 hasilnya nilai R2
maksimum turun dari 58,1 menjadi 46,6 sedangkan nilai RMSE naik dari 201,63 menjadi 229,47. Komposisi parameter terbaik percobaan kelompok data kedua untuk
leap 0 adalah delt_inc 1,7 dan delt_dec 0,4.
Pada percobaan kelompok data pertama untuk leap 1. Ketika nilai delt_inc dinaikkan dari nilai 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi 0,4 hasilnya nilai R2 maksimum naik dari 77,6 menjadi 84,8 . Nilai rata - rata R2 naik dari 48,4 menjadi 53,3 sedangkan nilai RMSE turun dari nilai 151,62 menjadi 125. Kemudian nilai delt_inc tetap 1,7 dan delt_dec naikkan dari 0,4 menjadi 0,6 maka nilai R2 maksimum turun dari 84,8 menjadi 70,4. N ilai rata - rata R2 turun dari 53,3 menjadi 51,04 sedangkan nilai RMSE naik dari 125 menjadi 153,22. Komposisi parameter terbaik percobaan kelompok data pertama untuk leap 1 adalah delt_inc 1,7 dan
delt_dec 0,4.
Pada percobaan kelompok data kedua untuk leap 1. Ketika nilai delt_inc dinaikkan dari nilai 1,5 menjadi 1,7 dan nilai delt_dec diturunkan dari 0,6 menjadi 0,4 hasilnya nilai R2 maksimum turun dari 59,5 menjadi 56,3. N ilai rata-rata nilai R2 naik dari 42,1 menjadi 43,6 sedangkan nilai RMSE naik dari 156,46 menjadi 169,77. Kemudian nilai delt_inc tetap 1,7 dan delt_dec diturunkan dinaikkan dari 0,4 menjadi 0,6 hasilnya nilai R2 maksimum naik dari 56,3 menjadi 59,9 sedangkan nilai RMSE
turun dari 169,77 menjadi 155,29. Komposisi parameter terbaik percobaan kelompok data kedua untuk leap 1 adalah delt_inc 1,7 dan delt_dec 0,6.
Hasil selengkapnya disajikan pada Tabel 12.
Tabel 12.Komposisi parameter terbaik resilient backpropagation
Leap 0 Leap 1 Leap 2 Leap 3
Kelompok
Data delt_inc delt_dec delt_inc delt_dec Delt_inc delt_dec delt_inc delt_dec
Pertama 1,7 0,4 1,7 0,4 1,5 0,5 1,7 0,4 Kedua 1,7 0,4 1,7 0,6 1,5 0,6 1,7 0,4
BAB VI
SIMPULAN DAN SARAN
6.1 Simpulan
Simpulan penelitian ini adalah :
a. JST recurrent yang teroptimasi secara heuristik dapat diterapkan dalam pendugaan curah hujan berdasarkan peubah ENSO dengan tingkat keakuratan yang cukup baik.
b. Teknik optimasi heuristik terbaik pada penelitian ini adalah algoritma resilient
backpropagation.
c. Hasil pendugaan curah hujan terbaik pada leap 0 menghasilkan nilai R2 maksimum 77%, leap 1 menghasilkan nilai R2 maksimum 84,8%, leap 2 menghasilkan nilai R2 maksimum 75,5%, dan leap 3 menghasilkan nilai R2 maksimum 54,1%.
d. Komposisi 75% data pelatihan & 25% data pengujian menghasilkan R2 maksimum lebih tinggi dibandingkan komposisi 50% data pelatihan dan 50% data pengujian.
6.2 Saran
Penelitian ini masih diperlukan pengembangan model selanjutnya. Hal- hal yang mungkin perlu dikembangkan adalah :
a. Perlu dicoba penggunaan algoritma pembelajaran yang lain yang mungkin masih bisa menaikkan tingkat keakuratan pendugaan JST recurrent.
b. Perlu pengembangan jumlah peubah selain peubah ENSO, seperti arah angin dan parameter lainnya yang memungkin adanya korelasi dengan curah hujan.
c. Perlu dicoba komposisi data percobaan yang lain misalnya 90% data pelatihan dan 10% data pengujian.
d. Perlu penelitian lebih lanjut untuk menurunkan nilai RMSE.
DAFTAR PUSTAKA
Apriyanti, Novi. 2004. Optimasi Jaringan Syaraf Tiruan dengan Algoritma
Genetika untuk Peramalan Curah Hujan. Bogor : Jurusan Ilmu Komputer
FMIPA IPB.
Coulibaly, Rasmussen & Bobee. 2000. A Recurrent Neural Networks
ApproachUsing Indices of Low Frequency Climatic Variability to Forecast Regional Annual Runoff. Hydrol.Process. 14, 2755-2777.
Effendy, Sobri. 2001.Urgensi Prediksi Cuaca dan Iklim di Bursa Komoditas
Unggulan Pertanian. Bogor: Makalah Falsafah Sains Program Pasca Sarjana/S3.
Fausett, Laurene. 1994. Fundamentals of Neural Networks. Prentice-Hall.
Fitriadi. 2004. Kombinasi Model Regresi Komponen Utama dan Arima dalam
Statistical Downscaling. Skripsi.Bogor:Jurusan Ilmu Komputer FMIPA IPB.
Kusumadewi Sri. 2004. Membangun Jaringan Syaraf Tiruan menggunakan Matlab
& Excell Link. Penerbit Graha Ilmu.
Kristanto Andri. 2004. Jaringan Syaraf Tiruan (Konsep Dasar, Algoritma dan
Aplikasi). Penerbit Gaya Media.
Lakshmi Sri, R.K. Tiwari & Somvanshi. 2003. Prediction of Indian Rainfall Index
(IRF) using the ENSO variability and Sunspot Cycles-An Artificial Neural Network Approach. J.Ind.Geophys. Union vol.7, No.4.pp.173-181.
Normakristagaluh P. 2004. Penerapan Jaringan Syaraf Tiruan untuk Peramalan
Curah Hujan dalam Statistical Downscaling. Bogor:Jurusan Ilmu Komputer
FMIPA IPB.
Walpole,E.R. 1995. Pengantar Statistika. Jakarta : PT Gramedia Pustaka Utama. Workshop JNB. 2002. Aplikasi Jaringan Neural Buatan Pada Pattern Recognition.
Laboratorium Kecerdasan Komputasi Fakultas Ilmu Komputer Universitas Indonesia.
Yusmen, Dedi. 1998. Tugas Akhir: Pengaruh ENSO terhadap pola curah, hujan di
Wilayah DAS Brantas Selatan-Jawa Timur. Bandung: Jurusan Geofisika dan