ANALISIS SENTIMEN KOMENTAR WARGANET
TERHADAP LAYANAN IT PADA BANK MANDIRI
MENGGUNAKAN ALGORITMA K-NEAREST
NEIGHBOR (K-NN) BERDASARKAN KRITERIA
ITSM
Skripsi
Oleh :
Febrian Wahyu Ramadhan
1113091000031
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UINVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA 2019 M/1440 H
ANALISIS SENTIMEN KOMENTAR WARGANET
TERHADAP LAYANAN IT PADA BANK MANDIRI
MENGGUNAKAN ALGORITMA K-NEAREST
NEIGHBOR (K-NN) BERDASARKAN KRITERIA
ITSM
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Strata -1
Oleh
Febrian Wahyu Ramadhan
1113091000031
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA 2019 M / 1440 H.
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI
Sebagai civitas akademik UIN Syarif Hidayatullah Jakarta, saya yang bertandatangan dibawah ini:
Nama : Febrian Wahyu Ramadhan
NIM : 1113091000031
Program Studi : Teknik Informatika
Fakultas : Fakultas Sains dan Teknologi Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti Non Eksklusif (Non-exclusive Royalti Free Right) atas karya ilmiah saya yang berjudul:
ANALISIS SENTIMEN KOMENTAR WARGANET TERHADAP LAYANAN IT PADA BANK MANDIRI MENGGUNAKAN ALGORITMA
K-NN BERDASARKAN KRITERIA ITSM
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non Eksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/formatkan, mengelola dalam bentuk pangkalan data (database), merawat, dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta. Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Tangerang Selatan Pada tanggal : 09 Januari 2019
Yang menyatakan
KATA PENGANTAR
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wa ta’ala yang telah memberikan rahmat dan karunianya kepada kita, sehingga penulis dapat menyelesaikan skripsi ini dengan judul “Pembuatan aplikasi analisis sentimen terhadap Bank Mandiri menggunakan algoritma K-NN berdasarkan kriteria ITSM”. Tujuan dari penyusunan skripsi ini guna memenuhi syarat kelulusan di Jurusan Teknik Informatika Fakultas Sains dan Teknologi, Universitas Islam Negeri Syarif Hidayatullah Jakarta.
Pada proses pengerjaan skripsi ini telah banyak melibatkan banyak pihak yang sangat membantu. Oleh sebab itu, disini penulis sampaikan rasa terima kasih sedalam – dalamnya kepada :
1. Orang tua penulis, Bpk Sujatmiko dan Ibu Siti Sabariah Wahyu Ningsih yang terus mendukung penulis untuk menyelesaikan skripsi ini.
2. Bapak Husni Teja Sukmana, Ph.D selaku Dosen Pembimbing I yang senantiasa memberi pengarahan dan bimbingan kepada penulis dalam menyusun skripsi ini.
3. Ibu Luh Kesuma Wardhani, M.T selaku Dosen Pembimbing II yang telah membantu dan memberi masukan terhadap penulisan pada skripsi ini. 4. Seluruh dosen yang telah mendidik penulis selama menuntut ilmu pada
program studi Teknik Informatika Fakultas Sains dan teknologi UIN Syarif Hidayatullah Jakarta.
5. Teman – teman seperjuangan TI 2013, yang selalu menghibur dan mendukung penulis untuk terus semangat mengerjakan skripsi
6. Jeanne Isbeanny L.F.H, yang senantiasa membantu dan mensupport penulis dalam hal teknis ataupun nonteknis.
7. Dzikri Chairullisan, yang telah membantu penulis.
Jakarta, Januari 2019
Nama : Febrian Wahyu Ramadhan Program Studi : Teknik Informatika
Judul : Analisis Sentimen Komentar Warganet Terhadap Layanan IT Pada Bank Mandiri Menggunakan Algoritma K-Nearest Neighbor (K-NN) Berdasarkan Kriteria ITSM
ABSTRAK
Analisis sentimen merupakan metode untuk mengulas produk atau layanan untuk menentukan opini atau perasaan terhadap suatu produk. Hasil dari analisis dapat digunakan oleh perusahaan sebagai bahan evaluasi dan pertimbangan untuk meningkatkan produk atau layanan yang disediakan. Penelitian ini bertujuan untuk menguji tingkat sentimen masyarakat terhadap kualitas layanan Bank Mandiri yang sudah mendapatkan ISO 20000-1 dengan aplikasi analisis sentimen menggunakan algoritma K-NN berdasarkan kriteria ITSM. Klasifikasi awal pada penelitian ini menggunakan metode lexicon dengan mendeteksi kata-kata yang termasuk ke dalam kata sentimen, yang hasilnya dicantumkan sebagai label pada data latih dan data uji. Pembentukan klasifikasi dengan algoritma K-NN dengan memperhatikan hasil dari indexing data latih dan pembobotan data uji, dengan nilai k sebagai batas pengambil keputusan. Hasil uji coba dari 10 skenario menunjukan bahwa klasifikasi dengan menggunakan algoritma K-NN sebagai klasifikasi sentimen adalah 98 % nilai akurasi 50 data uji terhadap 600 data latih, dengan 24 % mendapat sentimen positif, 22 % sentimen negatif dan 55 % sentimen netral, dengan f-measure 95,83 %. sedangkan pada pengujian 100 data uji didapatkan 79 % nilai akurasi dengan 21 % mendapat sentimen positif, 42 % sentimen negatif dan 38 % netral dengan nilai f-measure 68,42 %.
Kata kunci : Analisis Sentimen, opinion mining, Twitter, klasifikasi, K-NN, Lexicon, Confusion Matrix.
Name : Febrian Wahyu Ramadhan
Major : Informatics Engineering
Title : Netizen Comment Sentimen Analysis of IT Services at Bank Mandiri Using K-Nearest Neighbor (K-NN) Algorithm Based on ITSM Criteria
ABSTRACT
Sentiment analysis is a method for reviewing products or services to determine opinions or feelings about a product. The results of the analysis can be used by the company as an evaluation material and consideration to improve the product or service provided. This study aims to test the level of public sentimen towards Bank Mandiri service quality that has obtained ISO 20000-1 with the sentimen analysis application using the K-NN algorithm based on ITSM criteria. The initial classification in this study used the lexicon method by detecting words included in the sentiment word, the results of which are listed as labels on training data and test data. Formation of classification with the K-NN algorithm by paying attention to the results of indexing training data and weighting of test data, with k values as decision-making limits. The trial results from 10 scenarios show that the classification using the K-NN algorithm as sentiment classification is 98% accuracy value of 50 test data against 600 training data, with 24% getting positive sentiment, 22% negatif sentiment and 55% sentiment neutral, with f -measure 95.83%. while testing 100 test data obtained 79% accuracy value with 21% received positive sentiment, 42% negatif sentiment and 38% neutral with f-measure value of 68.42%.
Kata kunci : Sentiment analysis, opinion mining, Twitter, Classification, K-NN, Lexicon, Confusion Matrix.
Daftar Pustaka : 23 (Tahun 2011 – 2017)
DAFTAR ISI
PERNYATAAN ORISINALITAS ... ii
LEMBAR PERSETUJUAN... iii
LEMBAR PENGESAHAN ... iv
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI ... v
KATA PENGANTAR ... vi
DAFTAR ISI ... x
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiv
DAFTAR LAMPIRAN ... xvii
BAB I ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Batasan Masalah ... 3
1.4 Tujuan dan Manfaat ... 3
1.5 Metodologi Penelitian. ... 4 1.6 Sistematika Penulisan ... 5 BAB II ... 7 LANDASAN TEORI ... 7 2.1 Text Mining ... 7 2.2 Analisis Sentimen ... 9
2.3 IT Service Management (ITSM) ... 10
2.4 Klasifikasi Lexicon ... 11
2.4 Algoritma Stemming Nazief & Adriani ... 14
4.5 Pembobotan Kata TF IDF... 19
4.6 Algoritma K-Nearest Neighbor ... 21
4.7 Metode Pengujian Confusion Matrix ... 21
4.8 Bahasa Pemrograman PHP dan database MySQL ... 22
BAB III ... 25
3.1.1 Studi Pustaka ... 25 3.1.2 Data ... 27 3.2 Metode Simulasi ... 27 3.3 Pengujian ... 29 3.4 Alur Penelitian ... 29 BAB IV ... 31 IMPLEMENTASI ... 31 4.1 Problem Formulation ... 31 4.2 Conceptual Model ... 32
4.3 Collection input/output data ... 38
4.4 Modelling Phase ... 41
4.5 Simulation Phase ... 53
4.6 Verification, Validation and Experiment ... 75
4.7 Output Analysis Phase ... 75
BAB V ... 76
HASIL DAN PEMBAHASAN ... 76
5.1 Verification, Validation and Experimentation ... 76
5.2 Output analysis phase ... 77
BAB VI ... 98
SARAN DAN KESIMPULAN ... 98
6.1 Kesimpulan ... 98
6.2 Saran ... 99
DAFTAR PUSTAKA ... 101
LAMPIRAN 1 ... 104
DAFTAR GAMBAR
Gambar 3.1 Tahapan pengambilan data twitter ... 27
Gambar 3.2 Alur Penelitian... 30
Gambar 4.1 Tahapan pengasmbilan data twitter 32
Gambar 4.2 Tahapan Preprocessing data twitter... 33
Gambar 4.3 Tahapan proses normalisasi kata ... 34
Gambar 4.4 Flowchart proses stopword filtering ... 35
Gambar 4.5 Flowchart proses stemming ... 35
Gambar 4.6 Flowchart klasifikasi pendekatan lexicon ... 37
Gambar 4.7 Flowchart algoritma K-NN ... 38
Gambar 4.8 Text preprocessing data uji ... 48
Gambar 4.9 Hasil simulasi crawling data twitter ... 54
Gambar 4.10 Simulasi hasil klasifikasi lexicon ... 55
Gambar 4. 11 Hasil pengujian dengan data 50 data nilai k = 1 ... 57
Gambar 4. 12 Hasil pengujian dengan data 100 data nilai k = 1 ... 57
Gambar 4. 13 Hasil pengujian dengan data 50 data nilai k = 2 ... 59
Gambar 4. 14 Hasil pengujian dengan data 100 dan nilai k = 2 ... 59
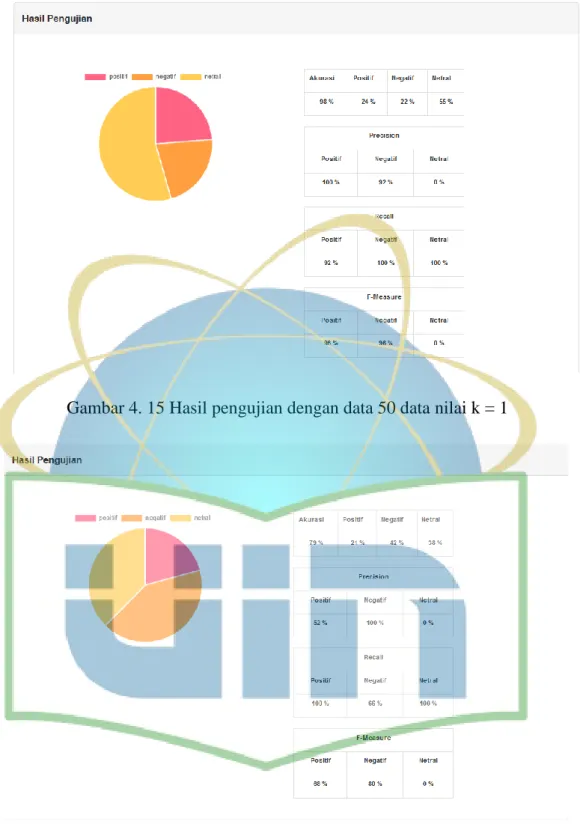
Gambar 4. 15 Hasil pengujian dengan data 50 dan nilai k = 3 ... 61
Gambar 4. 16 Hasil pengujian dengan data 100 dan nilai k = 3 ... 61
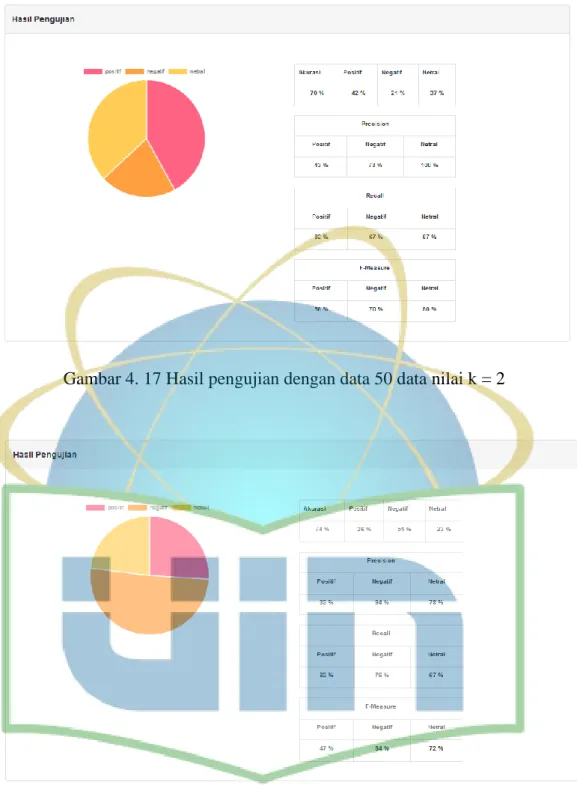
Gambar 4. 17 Hasil pengujian dengan data 50 dan nilai k = 4 ... 63
Gambar 4. 18 Hasil pengujian dengan data 100 dan nilai k = 4 ... 63
Gambar 4. 19 Hasil pengujian dengan data 50 dan nilai k = 5 ... 65
Gambar 4. 20 Hasil pengujian dengan data 100 dan nilai k = 5 ... 65
Gambar 4. 21 Hasil pengujian dengan data 50 dan nilai k = 6 ... 67
Gambar 4. 22 Hasil pengujian dengan data 100 dan nilai k = 6 ... 67
Gambar 4. 23 Hasil pengujian dengan data 50 dan nilai k = 7 ... 69
Gambar 4. 24 Hasil pengujian dengan data 100 dan nilai k = 7 ... 69
Gambar 4. 25 Hasil pengujian dengan data 50 dan nilai k = 8 ... 71
Gambar 4. 26 Hasil pengujian dengan data 100 dan nilai k = 8 ... 71
Gambar 4. 29 Hasil pengujian dengan data 50 dan nilai k = 10 ... 75 Gambar 4. 30 Hasil pengujian dengan data 100 dan nilai k = 10 ... 75 Gambar 5.1 perbandingan akurasi setiap skenario algoritma K-NN 92 Gambar 5.2 Grafik perbandingan presisi, recall dan f-measure setiap skenario
DAFTAR TABEL
Tabel 2. 1 Kombinasi awalan yang tidak diijinkan ... 17
Tabel 2. 2 Cara menentukan tipe awalan untuk kata yang diawali dengan te- ... 17
Tabel 2. 3 Jenis awalan berdasarkan tipe awalannya ... 17
Tabel 3.1 Perbandingan studi literatur sejenis 26
Tabel 4.1 Tabel daftar query 39
Tabel 4.2 Model data table data latih ... 39
Tabel 4.3 Model data tabel data uji ... 39
Tabel 4.4 Model data tabel kata dasar ... 39
Tabel 4.5 Model data kamus KBBI ... 39
Tabel 4.6 Model data kamus stopword ... 40
Tabel 4.7 Model data kamus lexicon positif ... 40
Tabel 4.8 Model data kamus lexicon negatif ... 40
Tabel 4.9 Model data kamus lexicon negasi ... 40
Tabel 4.10 Model data kamus slangword dan singkatan ... 40
Tabel 4.11 Contoh proses casefolding ... 41
Tabel 4.12 Contoh proses cleansing ... 41
Tabel 4.13 Contoh proses normalisasi ... 42
Tabel 4.14 Contoh proses stemming ... 42
Tabel 4.15 Contoh proses stopword removal ... 42
Tabel 4.16 Contoh proses tokenizing ... 43
Tabel 4.17 Perhitungan kata mengandung sentimen... 44
Tabel 4.18 Perhitungan kata bersifat negasi ... 44
Tabel 4.19 Perhitungan kata dengan klausa "tapi" ... 44
Tabel 4.20 Contoh data latih setelah klasifikasi lexicon ... 45
Tabel 4.21 Tokenisasi data latih... 46
Tabel 4.22 Proses indexing data latih ... 46
Tabel 4.23 Hasil nilai idf ... 48
Tabel 4.26 Seleksi stopword data uji ... 50
Tabel 4.27 Proses stemming data uji... 50
Tabel 4.28 Hasil pembobotan token data uji ... 51
Tabel 4. 29 Proses pengurutan hasil pembobotan ... 52
Tabel 4.30 Pemberian label hasil klasifikasi ... 53
Tabel 4. 31 Proses pembatasan nilai k ... 53
Tabel 4. 32 Hasil pengujian 50 data confision matrix dengan k = 1 ... 55
Tabel 4. 33 Hasil pengujian 100 data confision matrix dengan k = 1 ... 56
Tabel 4. 34 Hasil pengujian 50 data confusion matrix dengan k = 2 ... 58
Tabel 4. 35 Hasil pengujian 100 data confusion matrix dengan k = 2 ... 58
Tabel 4. 36 Hasil pengujian 50 data confusion matrix dengan k = 3 ... 60
Tabel 4. 37 Hasil pengujian 100 data confusion matrix dengan k = 3 ... 60
Tabel 4. 38 Hasil pengujian 50 data confusion matrix dengan k = 4 ... 62
Tabel 4. 39 Hasil pengujian 100 data confusion matrix dengan k = 4 ... 62
Tabel 4. 40 Hasil pengujian 50 data confusion matrix dengan k = 5 ... 64
Tabel 4. 41 Hasil pengujian 100 data confusion matrix dengan k = 5 ... 64
Tabel 4. 42 Hasil pengujian 50 data confusion matrix dengan k = 6 ... 66
Tabel 4. 43 Hasil pengujian 100 data confusion matrix dengan k = 6 ... 66
Tabel 4. 44 Hasil pengujian 50 data confusion matrix dengan k = 7 ... 68
Tabel 4. 45 Hasil pengujian 100 data confusion matrix dengan k = 7 ... 68
Tabel 4. 46 Hasil pengujian 50 data confusion matrix dengan k = 8 ... 70
Tabel 4. 47 Hasil pengujian 100 data confusion matrix dengan k = 8 ... 70
Tabel 4. 48 Hasil pengujian 50 data confusion matrix dengan k = 9 ... 72
Tabel 4. 49 Hasil pengujian 100 data confusion matrix dengan k = 9 ... 72s Tabel 4. 50 Hasil pengujian 50 data confusion matrix dengan k = 10 ... 74
Tabel 4. 51 Hasil pengujian 100 data confusion matrix dengan k = 10 ... 74
Tabel 5.1 Hasil algoritma K-NN dengan 50 data uji nilai k 1 s.d 5 77
Tabel 5. 2 Hasil algoritma K-NN dengan 100 data uji dengan nilai k 1 s.d 5 ... 80
Tabel 5. 3 Hasil algoritma K-NN dengan 100 data uji dengan nilai k 6 s.d 10 .... 83
Tabel 5. 4 Aturan Confusion Matrix ... 87
Tabel 5.5 Output analisis dengan k = 1 pada 50 data... 87
Tabel 5. 7 Output analisis dengan k = 2 pada 50 data ... 88
Tabel 5. 8 Output analisis dengan k = 2 pada 100 data ... 88
Tabel 5. 9 Output analisis dengan k = 3 pada 50 data ... 88
Tabel 5. 10 Output analisis dengan k = 3 pada 100 data ... 88
Tabel 5. 11 Output analisis dengan k = 4 pada 50 data ... 88
Tabel 5. 12 Output analisis dengan k = 4 pada 100 data ... 89
Tabel 5. 13 Output analisis dengan k = 5 pada 50 data ... 89
Tabel 5. 14 Output analisis dengan k = 5 pada 100 data ... 89
Tabel 5. 15 Output analisis dengan k = 6 pada 50 data ... 89
Tabel 5. 16 Output analisis dengan k = 6 dengan 100 data ... 89
Tabel 5. 17 Output analisis dengan k = 7 pada 50 data ... 90
Tabel 5. 18 Output analisis dengan k = 7 pada 100 data ... 90
Tabel 5. 19 Output analisis dengan k = 8 pada 50 data ... 90
Tabel 5. 20 Output analisis dengan k = 8 pada 100 data ... 90
Tabel 5. 21 Output analisis dengan k = 9 pada 50 data ... 90
Tabel 5. 22 Output analisis dengan k = 9 pada 100 data ... 91
Tabel 5. 23 Output analisis dengan k = 10 pada 50 data. ... 91
Tabel 5. 24 Output analisis dengan k = 10 pada 100 data ... 91
Tabel 5.25 Hasil Pengujian dengan 50 data dengan nilai k 1 s.d 5 ... 93
Tabel 5. 26 Hasil Pengujian dengan 50 data dengan nilai k 6 s.d 10 ... 93
Tabel 5. 27 Hasil Pengujian dengan 100 data dengan nilai k 1 s.d 5 ... 94
DAFTAR LAMPIRAN
BAB I
PENDAHULUAN 1.1 Latar BelakangPenggunaan internet saat ini sudah menjadi bagian dari kebutuhan manusia. Hampir semua alat gawai sudah dilengkapi dengan teknologi yang memungkinkan pengguna untuk berselancar secara online. Berdasarkan laporan hasil riset yang dikeluarkan oleh e-marketer yang merupakan lembaga riset pasar, menunjukan bahwa hampir 47% dari populasi dunia sudah terhubung dengan internet pada tahun 2017. Jumlah ini diprediksi akan mengalami peningkatan 5.3% atau sekitar 3.82 milyar penduduk dunia di tahun 2018, dan akan terus mengalami peningkatan di tahun–tahun selanjutnya.
Dalam sebuah berita yang dipublikasi oleh inet.detik.com yang juga mengutip dari laporan yang dikeluarkan (Tetra Pak Index 2017), terdapat sekitar 132 juta pengguna internet di Indonesia, dan 40% diantaranya merupakan pengguna sosial media. Dengan detail sekitar 106 juta orang indonesia menggunakan media sosial tiap bulannya, menunjukan bahwa Indonesia masih menjadi pasar yang luas untuk segala hal yang berkaitan dengan internet.
Twitter merupakan salah satu penyedia layanan microbloging atau sosial media yang populer dan seringkali dijadikan sebagai alat berkomunikasi. Berdasarkan artikel yang dikeluarkan JakartaGlobe (2017), jumlah akun twitter di dunia pada tahun 2017 mencapai 328 juta. Jumlah tersebut mengalami penambahan sekitar 14 % dibandingkan tahun 2016, di mana 24.34 juta akun dari Indonesia menempatkan Indonesia berada pada posisi tiga terbesar pengguna twitter.
Tingginya penggunaan sosial media di Indonesia akan memiliki dampak dalam pertumbuhan bisnis. Hal ini banyak dimanfaatkan oleh perusahaan atau instansi sebagai sarana untuk berkomunikasi dengan masyarakat secara interaktif. Sehingga perusahaan atau instansi dapat secara langsung mendapat feedback dari masyarakat (Setyanto, 2016). Feedback yang dihasilkan bisa berupa opini dari pengguna untuk mengekspresikan aspirasinya terhadap jasa atau layanan yang disediakan oleh perusahaan, yang nantinya dapat digunakan sebagai bahan evaluasi untuk meningkatkan kualitas dari produk atau jasa yang disediakan.
Bank Mandiri merupakan salah satu Badan Usaha Milik Negara (BUMN) yang bergerak di bidang perbankan, yang sudah menerapkan prinsip-prinsip kerja sesuai kriteria IT Service Management (ITSM), berdasarkan ISO 20000:2011 tentang IT Service Management. Hal tersebut tercantum di dalam laporan tahunan (Annual report) Bank Mandiri tahun 2014. Sebagaimana peran sebuah bank pada umumnya, yakni sebagai penghimpun data, penyalur dana dan pemberi jasa bank lainnya, Bank Mandiri harus selalu mengutamakan kepuasan nasabah dengan melakukan membangun tata kelola perusahaan yang baik (Good Corporate Governance) salah satunya adalah tata kelola layanan sistem informasi sesuai kriteria ITSM.
Analisis sentimen yang merupakan riset komputasional dari opini, sentimen dan emosi digunakan dalam menentukan sentimen dari opini yang diekspresikan (Ira & Edi, 2017). Analisis sentimen berfokus pada pencarian dan pengelompokan opini terhadap ketertarikan hal tertentu. Jenis sentimen dari opini tersebut dapat berupa opini positif, negatif maupun netral (Liu, 2012).
Proses klasifikasi dalam penelitian analisis sentimen ini menggunakan algoritma K-Nearest Neighbor. Kelebihan Algoritma K-NN yakni lebih tangguh terhadap data yang memiliki banyak noise dan lebih efektif terhadap jumlah data yang besar (Alfian et al, 2014) selain itu KNN bisa digunakan sebagai klasifikasi untuk berbagai domain (Imandoust dkk. 2013). Algoritma tersebut dipilih merujuk pada penelitian sebelumnya oleh (Rezwanul dkk. 2017) tentang Sentimen Analysis on Twitter Data Using KNN and SVM. Hasil penelitian tersebut menunjukkan nilai lebih baik baik berdasarkan akurasi, presisi, dan recall (Rezwanul dkk. 2017).
Oleh karena itu, penelitian ini penting untuk dilakukan, untuk mengetahui sentimen masyarakat terhadap kualitas layanan Bank Mandiri dengan aplikasi analisis sentimen menggunakan algoritma K-NN berdasarkan kriteria ITSM. Sehingga nantinya hasil dari analisis tersebut dapat digunakan oleh perusahaan sebagai bahan evaluasi dan pertimbangan untuk meningkatkan produk atau layanan yang disediakan.
1.2 Rumusan Masalah
Sesuai permasalahan yang diangkat pada latar belakang penulisan, maka masalah yang akan dibahas adalah dapat dirumuskan sebagai berikut.
1. Bagaimana melakukan analisis sentimen dan memberikan nilai akurasi dalam mengklasifikasikan opini positif, negatif dan netral ?
2. Bagaimana menentukan mengukur kualitas layanan IT dalam organisasi atau perusahaan menggunakan analisis sentimen ?
3. Bagaimana cara menentukan kriteria ITSM apa saja yang bisa dijadikan acuan dalam menentukan analisis sentimen di media sosial?
1.3 Batasan Masalah
Batasan pada penelitian ini adalah sebagai berikut.
1. Klasifikasi untuk data latih menggunakan pendekatan lexicon. 2. Klasifikasi untuk data uji menggunakan algoritma K-NN
3. Aplikasi analisis sentimen ini berbasis web dengan menggunakan bahasa pemrograman PHP dan MySQL sebagai databasenya.
4. Sumber yang dipakai berasal dari akun @mandiricare atau akun lain yang terkait dengan akun @mandiricare.
5. Data twitter diambil dari tanggal 1 – 17 Januari 2018 dengan jumlah 700 data. 6. Proses input, processing dan output menggunakan bahasa Indonesia
7. Algoritma Stemming yang digunakan adalah algoritma Nazief Adriani 8. Proses pembobotan menggunakan Algoritma TF - IDF
1.4 Tujuan dan Manfaat 1.4.1 Tujuan
Adapun tujuan dari penulisan skripsi ini adalah.
1. Menemukan hasil analisis sentimen penerapan ITSM di Bank Mandiri terhadap kepuasan pengguna.
1.4.2 Manfaat
1.4.2.1 Bagi Penulis
Penulis dapat menerapkan ilmu – ilmu yang diperlajari selama perkuliahan terutaman penerapan konsep NLP (Natural Language Processing) dengan menggunakan pendekatan Lexicon dan Algoritma K-NN pada proses klasifikasi sentimen.
1.4.2.2 Bagi Instansi
Membantu pihak perusahaan khususnya Bank Mandiri dalam mengevaluasi dan meningkatkan pelayanannya terhadap masyarakat.
1.4.2.3 Bagi Universitas
1. Mengetahui kemampuan mahasiswa dalam menguasai materi pelajaran
selama perkuliahan.
2. Sebagai karya tulis yang hak cipta dipegang oleh Universitas dan dapat
dijadikan rujukan untuk penelitian selanjutnya.
1.5 Metodologi Penelitian.
Dalam melakukan penelitian ini, penulis menggunakan dua acara dalam merancang aplikasi yaitu metode pengumpulan data dan metode simulasi sebagai perancangan aplikasi.
1.5.1 Pengumpulan Data
Pengumpulan data yang penulis lakukan adalah dengan ar studi literatur dan studi pustaka, yaitu dengan mencari referensi berupa jurnal, buku atau penelitian sejenis dan menggunakan data twitter sebagai objek yang akan diklasifikasi.
1.5.2 Metode Simulasi
Pada penelitian ini penulis menggunakan metode simulasi untuk proses perancangan dan eksekusi aplikasi yang dibuat. Adapun langkah – langkah yang dilakukan yaitu (M.L.Loper, 2015):
2. Formulate Conceptual Model 3. Acquire & Analyze Data
4. Develop Simulation Model & Program 5. Verify & Validate Model and Simulation 6. Design Experiments
7. Execute Simulation & Analyze Output 8. Configuration Control
9. Develop Documentation 1.6 Sistematika Penulisan
BAB I : PENDAHULUAN
Pendahuluan memberikan uraian mengenai alasan dalam memilih judul dan latar belakang masalah dan dijelaskan pula mengenai perumusan masalah pembatasan masalah dan metode penumpulan data.
BAB II : LANDASAN TEORI
Landasan teori memberikan uraian mengenai teori – teori yang berhubungan permasalahan yang diambil penulis, sumber referensi diambil dari berbagai jurnal, buku dan skripsi yang berkaitan terhadap penelitian ini.
BAB III : METODOLOGI PENELITIAN
Metodologi penelitian memberikan gambaran mengenai metode yang digunakan dalam skripsi ini, teknik pengumpulan data, teknik analisa data, teknik pengembangan aplikasi, dan teknik testing aplikasi.
BAB IV : IMPLEMENTASI
Analisa dan perancangan membahas tentang analisa proses, mulai dari pengumpulan data, seleksi data, proses preprocessing, pembobotan dan klasifikasi yang kemudian dilanjutkan dengan perancangan aplikasi analisis sentimen.
BAB V : HASIL DAN PEMBAHASAN
Hasil dan pembahasan berisikan hasil dari proses yang sudah dilakukan pada bab IV dan membahas tentang akurasi dari hasil yang sudah didapatkan
BAB VI : SARAN DAN KESIMPULAN
Pada bab ini akan diambil kesimpulan dari keseluruhan proses dan hasil didapatkan, dan juga penulis akan memberikan saran terhadap penelitian ini agar bisa dikembangankan lebih lanjut
BAB II
LANDASAN TEORI 2.1 Text MiningText mining adalah metode pangambilan informasi dari data tekstual untuk dicari pola yang berguna, mengekstrak informasi dari data tekstual untuk mencari knowledge dari teks yang tidak terstruktur (Vijayarani et al, 2016). adapun data teks yang sudah didapat melalui proses text mining akan dilakukan proses selanjutnya yang disebut dengan tahap preprocessing (Edi & Noviah, 2015). Preprocessing merupakan proses yang menjadikan data teks yang sudah didapat menjadi lebih teratur dan mudah untuk melalui tahap klasifikasi (Jaka, 2015). Hal ini bertujuan untuk menghilangkan noise, menyeragamkan bentuk kata dan mengurangi volume kata (Noviah & Edi, 2014).
Berikut merupakan gambaran proses text mining yang diambil pada penelitian (Vijayarani et al, 2016).
Gambar 2.1 Proses Text Mining
Langkah yang dilakukan untuk menyeleksi data yang masuk, yaitu proses text processing dan feature selection (Kurniawan Bambang et al, 2012).
1. Text Processing.
Merujuk pada penelitian (Falahah & Nur, 2015), tahap Text Processing merupakan tahap awal terhadap teks untuk menyiapkan teks menjadi data yang akan diolah lebih lanjut. Data yang diterima akan melewati proses sebagai berikut. a. Case Folding: mengubah semua huruf dalam dokumen menjadi huruf kecil b. Cleansing: proses membersihkan dokumen dari kata – kata yang tidak
cleansing yang diperlukan terhadap sebuah dokumen yang dijelaskan sebagai berikut:
1. Cleansing URL, Proses pembersihan url atau link yang mengarah pada situs lainnya
2. Cleansing mention, Mention merupakan cara untuk memanggil akun lain atau membalas pesan terhadap akun yang di-mention, menghapus mention diperlukan untuk mengurangi tweet yang berulang akibat penggunaan mention tersebut.
3. Cleansing hashtag, Hashtag adalah tanda (#) untuk mengumpulkan topik tertentu berdasarkan pada hashtag tersebut.
4. Cleansing Delimiter, proses menghilangkan karakter tanda baca yang tidak berguna seperti titik (.), koma (,), spasi dan lain lain.
5. Cleansing Emoticon, Penggunaan emoticon akan mengganggu proses analisis sentimen karena seseorang kadang salah atau kurang tepat dalam penggunakan emoticon (Buntoro et al, 2014).
c. Normalisasi Kalimat
Bertujuan untuk menormalkan kalimat sehingga kalimat yang tidak baku menjadi kalimat normal. sehingga bahasa tidak baku tersebut dapat dikenali sebagai bahasa yang sesuai dengan KBBI (Buntoro et al, 2014). Yang harus dilakukan untuk menormalisasi kalimat adalah
1. Meregangkan tanda baca (punctuation) dan symbol selain alphabet. 2. Mengubah menjadi huruf kecil semua
3. Normalisasi kata, Proses Normalisasi kata bertujuan menormalkan kalimat sehingga kalimat tidak baku menjadi normal, sehingga bahasa gaul tersebut dapat dikenali sebagai bahasa yang sesuai dengan KBBI (Buntoro et al, 2014). Menghilangkan huruf yang berulang
d. Tokenizing, Proses penghilangan tanda baca pada kalimat yang ada dalam dokumen sehingga menghasilkan kata – kata yang berdiri masing – masing (Karyono & Utomo, 2012).
2. Feature Selection
Feature pada text mining adalah berupa kumpulan kata, atau frase yang bermakna sebagai kata opini bisa berupa opini positif ataupun opini negatif (Haddi
at al, 2013). Untuk mempermudah dan meningkatkan akurasi sentimen pada sebuah kalimat perlu dilakukan 2 tahap selanjutnya, yaitu stopword removal dan stemming
1. Stopword Removal
Stopword merupakan kumpulan kata – kata yang sering muncul pada setiap bahasa yang memiliki pengaruh sangat kecil atau sama sekali tidak ada pada konteks semantik pada sebuah kalimat. Pada tahap ini, kata – kata ini harus dihapus untuk memudahkan tugas selanjutnya dan mempercepat proses text processing (Raulji & Saini, 2016).
2. Stemming
Stemming adalah proses pemetaan dan penguraian bentuk (variants) dari suatu kata menjadi bentuk kata dasarnya (stem) (Kurniawan et al, 2017). Tujuan dari proses stemming adalah menghilangkan imbuhan imbuhan baik berupa prefiks, sufiks maupun konfiks yang ada pada setiap kata.
2.2 Analisis Sentimen
Analisis Sentimen merupakan suatu metode untuk mengulas produk atau layanan untuk menentukan opini atau perasaan terhadap suatu produk (Haddi et al, 2013) selain itu menurut Medhat et al (2013), analisis sentimen adalah sebuah studi komputasional terhadap opini, sifat dan emosi seseorang terhadap suatu objek. Objek yang dimaksud bisa berupa produk, kegiatan ataupun topik.
Secara umum penggunaan analisis sentimen membantu dalam pengumpulan informasi untuk menentukan nilai positif dan negatif terhadap topik atau produk tertentu. Yang pada akhirnya produk yang mendapatkan sentimen tertinggi atau positif yang akan di rekomendasikan kepada pengguna. Pengguna mengekpresikan pendapatnya terhadap produk atau layanan yang digunakanya melalui blog, twitter atau lainnya yang memungkinkan penyedia layanan atau produk mengetahui atas respon layanannya.
Pradahan et all, 2016 menyebutkan, Ada beberapa tantangan atau kendala di dalam analisis sentimen, yang pertama terdapat kata yang bernilai positif pada satu situasi akan bisa menjadi bernilai negatif di situasi yang lain dan yang kedua pengguna tidak selalu mengekspresikan pendapat yang sama. Yang ketiga pada
platfom media sosial seperti twitter yang memiliki jumlah karakter yang terbatas sehingga akan menjadi sulit computer untuk mengekstrak opini.
2.3 IT Service Management (ITSM)
ITSM merupakan sub bidang dari Service Science (Ilmu Pelayanan) dengan mengutamakan penyampaian (delivery) dan dukungan (support) layanan TI terhadap pengguna. Dengan berbagai aspek yang terjadi dalam suatu bisnis, ITSM dapat dijelaskan sebagai implementasi dan kualitas pengaturan layanan IT yang mempertemukan kebutuhan bisnis, dengan kata lain memastikan pelayanan sesuai dengan kebutuhan dan ekspektasi pengguna (costumers) (Yazici, dkk, 2015)
Penelitian dari Gartner menemukan sekitar 70 % kegagalan pelayanan IT terjadi pada kegagalan proses, 10% pada rendahnya kompetensi dan keahlian pegawai dan 20 % terjadi pada kegagalan performa software atau hardware. Pada Microsoft 2004 IT Forum Conference, hasil studi menunjukan pengurangan IT service organization mencapai 48 % (Yazici, dkk, 2015).
ITIL V3 merupakan salah framework untuk IT service management yang memuat ITSM sebuah perusahaan. ITIL mendefinisikan layanan sebagai mengirimkan nilai ke pengguna dengan tanpa menambahkan biaya atau resiko“. Penerapan ITSM yang terdapat di dalam ITIL adalah Incident Management, Problem Management, Realease Management, Change Management, Configuration Management, Service-Level Management, Financial Management of IT Services, Capacity Management, IT Service Continuity Management dan Availlability Management (Ogc. 2007).
Selain ITIL ada beberapa Standar IT Service Management dan framework yang menyediakan masing masing matrik penilaian seperti Framework The Control Objectives for Information and related Technology (COBit), Microsoft Operation Frameworld (MOF) dan Process Reference Model for Information Technology (PRM-IT) (Yazici, dkk, 2015).
ISO/IEC 20000 merupakan ITIL-complaint pertama internasional sebagai standar audit untuk IT Service Management dan code-practice untuk service management (Yazici, dkk, 2015), ISO/IEC merupakan alat pengembangan bisnis yang membantu untuk membangun IT Service Management yang tidak hanya
beradaptasi dengan perubahan yang cepat terhadap teknologi tetapi juga membantu untuk mencapat objektif bisnis yang akan di capai.
ISO/IEC 20000 memastikan seluruh stakeholder memiliki pelayanan IT yang terbaik dimana setiap waktu dimonitor, diuji dan ditingkatkan. Dengan mengawasi proses secara teratur, akan mudah untuk mengindentifikasi peluang untuk melakukan pengembangan dan menyampaikan pelayanan yang terbaik untuk pengguna.
Gambar 2. 2 Model Proses Kerja ITSM
ISO/IEC 20000 berdasarkan kepada model managemen sistem untuk
pengembangan yang berkelanjutan. Standar tersebut menyediakan framework dari requirement atau kebutuhan kebutuhan organisasi untuk:
a. Mengembangkan sebuah IT Service Managemen yang secara jelas mendefinisikan objectif dan target yang akan dicapai.
b. Mendefinsikan kebutuhan untuk service delivery (penyampaian pelayanan). c. Menjelaskan peran dan tanggungjawab.
d. Secara regular mereview seberapa efektif IT service yang sedang berjalan. e. Mengidentifikasi peluang untuk peningkatan pengembangan.
2.4 Klasifikasi Lexicon
Metode Lexicon adalah metode yang menggunakan kata – kata opini untuk melakukan klasifikasi, kata kata opini secara luas digunakan untuk menentukan
positif atau negatif objek yang di nilai, metode ini menghitung jumlah positif atau negatif kata kata dalam sebuah kalimat review atau sebuah produk, jadi jika dalam sebuah kalimat terdapat kata kata positif dibanding dengan kata kata negatifnya, maka opini akan cenderung terhadap kalimat positif daripada kalimat negatif. Klasifikasi Lexicon pada umumnya menggunakan kata – kata adjective atau kata sifat sebagai indikator untuk dicocokan terhadap kamus untuk ditentukan nilainya dan diklasifikasikan sebagai positif, negatif, ataupun netral (Asghar, ahmad & Khan, 2014). Klasifikasi lexicon bergantung pada kamus (dictionary) yang berisi kata – kata opini yang diproses melalui bootstrapping dengan menggunakan wordNet (http://wordnet.princeton.edu), contoh kata kata opini seperti, “great”, “poor”, “expensive”.
Menurut (Matulawa et al, 2017) data yang cocok dengan metode lexicon yaitu data kuisioner, data twitter, atau media sosial lainnnya yang berupa opini pelanggan tentang suatu produk atau pelayanan jasa.
Untuk memberikan orientasi tweet, Asghar dkk, 2015 pernah melakukan penelitian untuk melakukan scoring module dalam mengklasifikasikan tweet menjadi positif negatif atau netral. Scoring dilakukan terhadap kata-kata umum, kata slangs, sinonim dan antonim, negasi, bentuk singular dan plural. setiap kata positif diberi nilai (+1) dan (-1) pada setiap setiap kata negatif, Dan juga Tambahkan nilai (+1) dan (-1) untuk setiap emoticon positif dan negatif.
Dan bing dkk, menambahkan aturan pada proses penilaian untuk kata bersifat negasi, yang dikenal dengan negation rules. Contoh kata kata negasi yaitu tidak, bukan + kata kerja/katasifat. Apabila terdapat kata negasi pada sebuah kalimat berikut penentuan sentimennya. Negasi Negatif menjadi Positif //contoh “tidak masalah”, Negasi Positif menjadi Negatif //contoh “tidak baik”, Negasi Netral menjadi Negatif //contoh “tidak bekerja”
2.5 Kamus Lexicon
Karena lexicon merupakan klasifikasi analisis sentimen berdasarkan kata maka harus di sediakan kamus sebagai pembanding untuk dapat memberikan nilai
pada setiap kata yang ada, sebagai contoh kamus pada WordNet yang mengandung sinonim dan antonym untuk setiap kata.
Secara spesifik cara kerja kamus pada pendekatan lexicon seperti berikut, sekumpulan kata kata sentimen yang sudah diketahui orientasi positif atau negatif dikumpulkan secara manual, maka algoritma yang akan mencari di kamus sinonim dan antonimnya, jika ditemukan masukan kedalam list, perulangan selanjutnya dimulai hingga tidak temukan kata baru lagi maka proses selesai.
Kamus yang digunakan dalam metode lexicon dibedakan beberapa jenis kamus, yaitu kamus positif, kamus negatif, kamus lexicon, KBBI dan kamus stopwords
Kamus Positif adalah kamus positif berisi kumpulan kata yang berorientasi positif. Sumber kamus positif didapatkan dari https://github.com/masdevid/ID-OpinionWords/blob/master/positive.txt dengan jumlah kata sebanyak 1182 kata positif
Kamus Negatif adalah kamus yang berisi kumpulan kata yang berorientasi negatif. Sumber kamus negatif didapatkan dari https://github.com/masdevid/ID-OpinionWords/blob/master/negatif.txt dengan jumlah kata sebanyak 2.399 kata negatif
Kamus kata dasar adalah kamus yang berisi kumpulan kata dasar sebagai pembanding pada proses stemming. Sumber kamus kata dasar didapatkan dari https://github.com/nolimitid/nolimit-kamus/blob/master/kata-dasar/kata-dasar-all.txt dengan jumlah kata sebanyak 29.932 kata.
Kamus KBBI adalah kamus yang berisi kumpulan kata dasar sebagai pembanding pada proses stemming. Sumber kamus kata dasar didapatkan dari https://github.com/nolimitid/nolimit-kamus/blob/master/kata-dasar/kata-dasar-all.txt dengan jumlah kata sebanyak 61.434 kata.
Kamus Stopword adalah kamus yang berisi kata – kata yang dianggap tidak penting atau kata kata yang menyebabkan noise yang akan berpengaruh pada akurasi dan waktu eksekusi ketika aplikasi dijalankan. Sumber kamus stopword diambil dari https://github.com/masdevid/ID-Stopwords yang juga bereferensi
2.4 Algoritma Stemming Nazief & Adriani
Merujuk pada penelitian Hitosi (2012), Algoritma stemming Nazief dan Adriani ini dikembangkan berdasarkan aturan morfologi bahasa Indonesia yang mengelompokkan dan mengenkapsulasi imbuhan-imbuhan, termasuk di dalamnya adalah awalan (prefix), sisipan (infix), akhiran (suffix) dan gabungan awalan-akhiran (confixes). Pada umumnya kata dasar pada bahasa Indonesia terdiri dari kombinasi:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tersebut adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu” atau “-nya”) dibuang. Jika berupa pertikel (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini dulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu” atau “-nya”), jika ada. 3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di
kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a.
1. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan makan lakukan langkah 3b. 2. Akhiran yang dihapus (“-i”, “-an”, atau “-kan”) dikembalikan, lanjut ke
langkah 4.
4. Hapus Derivation Prefix (“di-”, “ke-”, “se-”, “te-”, “be-”, “me” atau “pe-”). Ada beberapa langkah pada tahap ini.
a. Tentukan tipe awalan, Jika terdapat tipe awalan (di-, ke-, se-) hapus dan cocokan dengan kamus, jika ada berhenti, jika tidak hapus derivation_suffixes dan lanjutkan.
1. Apabila ditemukan awalan (diper-) maka hapus awalan (diper-) dan hapus Derivation Suffixes kemudian cocokan dengan kamus, jika ditemukan berhenti, jika tidak kembalikan Derivation Suffixes dan dilanjutkan.
2. Apabila ditemukan awalan (keber- atau keter-), maka hapus awalan (keber- atau keter-), cek Derivation Suffixes jika ditemukan hapus, kemudian cocokan dengan kamus, jika ditemukan berhenti, jika tidak kembalikan Derivation Suffixes dan lanjut ke langkah berikutnya.
b. Jika ditemukan tipe awalan (te-, ter, be-, ber) maka hapus kemudian hapus Derivation Suffixes, cocokan dengan kamus, jika ditemukan algoritma berhenti, jika tidak kembalikan Derivation Suffixes lanjutkan ke langkah selanjutnya.
c. Jika ditemukan tipe awalan (me-, pe-) maka awalan dihapus, kemudian cocokan dengan kamus. Jika ditemukan maka algoritma dihentikan, jika tidak hapus Derivation Suffixes, kemudian cocokan lagi dengan kamus jika ditemukan berhenti, jika tidak lanjutkan kembalikan Derivation Suffixes dan ke langkah berikut.
1. Apabila ditemukan awalan (memper-) maka awalan dihapus, cocokan dengan kamus, apabila ditemukan algoritma berhenti, jika tidak, maka hapus Derivation Suffixes dan cocokan kembali dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak Derivation Suffixes dikembalikan dan dilanjutkan ke langkah berikutnya.
2. Jika ditemukan awalan (meng- atau peng-) maka awalan dihapus, cocokan dengan kamus apabila ditemukan algoritma berhenti, jika tidak maka hapus Derivation Suffixes kemudian cocokan kembali dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak maka Derivation Suffixes dikembalikan, dan awalan dikembalikan. Seleksi diulang kembali, jika awalan (meng- atau peng-) ditemukan ganti awalan tersebut dengan huruf “k” kemudian cek ke kamus, apabila ditemukan algoritma dihentikan jika tidak, hapus Derivation Suffixes kemudian cocokan kembali, jika ditemukan algoritma berhenti, jika tidak ditemukan, kembalikan awalan dan Derivation Suffixes.
3. Jika awalan (meny atau peny), maka hapus awalan tersebut kemudian cocokan dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak hapus Derivation Suffixes lalu cocokan kembali, jika ditemukan algoritma berhenti jika tidak awalan dan Derivation Suffixes dikembalikan.
4. Jika awalan (mel-, mer, pel atau per), maka hapus awalan tersebut kemudian cocokan dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak hapus Derivation Suffixes lalu cocokan kembali, jika
ditemukan algoritma berhenti jika tidak awalan dan Derivation Suffixes dikembalikan.
5. Jika awalan (men atau pen), maka hapus awalan dan ganti dengan huruf “t” tersebut kemudian cocokan dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak hapus Derivation Suffixes lalu cocokan kembali, jika ditemukan algoritma berhenti jika tidak awalan dan Derivation Suffixes dikembalikan dan ulang dari awal. Jika awalan (men- atau pen-) maka hapus awalan tersebut kemudian cocokan dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak hapus Derivation Suffixes lalu cocokan kembali, jika ditemukan algoritma berhenti jika tidak awalan dan Derivation Suffixes dikembalikan.
6. Jika awalan (mem- atau pem-), maka hapus awalan tersebut kemudian cocokan dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak hapus Derivation Suffixes lalu cocokan kembali, jika ditemukan algoritma berhenti jika tidak awalan dan Derivation Suffixes dikembalikan. Jika awalan (meny atau peny), maka hapus awalan tersebut dan ganti dengan huruf “p” kemudian cocokan dengan kamus, jika ditemukan maka algoritma berhenti, jika tidak hapus Derivation Suffixes lalu cocokan kembali, jika ditemukan algoritma berhenti jika tidak awalan dan Derivation Suffixes dikembalikan.
5. Melakukan Recoding.
6. Jika semua langkah telah selesasi tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah – langkah berikut :
1 Jika awalannya adalah : “di-”, “ke-” atau “se-” maka tipe awalanannya secara berturut – turut adalah “di-“, “ke-” atau “se-”.
2 Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-”, maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3 Jika dua katakter pertama “di-”, “ke-”, “se-”, “te-”, “me-” atau “pe” maka berhenti.
4 Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan “none” maka awalan dapat dilihat pada.
Tabel 2. 1 Kombinasi awalan yang tidak diijinkan
Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
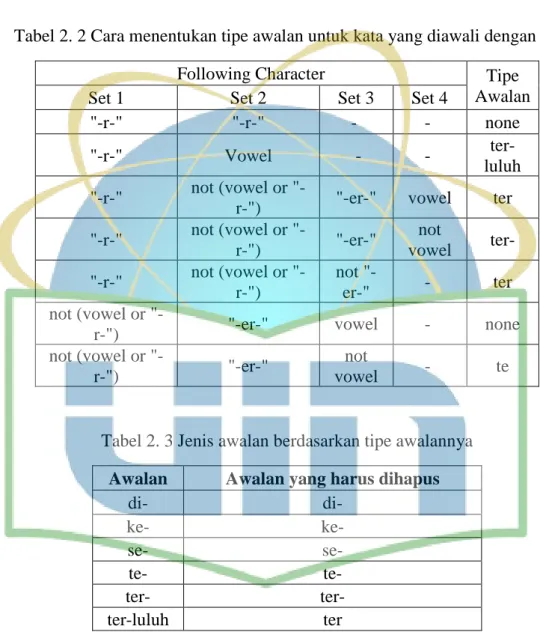
Tabel 2. 2 Cara menentukan tipe awalan untuk kata yang diawali dengan te-
Following Character Tipe
Awalan
Set 1 Set 2 Set 3 Set 4
"-r-" "-r-" - - none
"-r-" Vowel - -
ter-luluh "-r-" not (vowel or
"-r-") "-er-" vowel ter "-r-" not (vowel or "-r-") "-er-" not vowel ter- "-r-" not (vowel or "-r-") not "-er-" - ter not (vowel or
"-r-") "-er-" vowel - none not (vowel or
"-r-") "-er-"
not
vowel - te
Tabel 2. 3 Jenis awalan berdasarkan tipe awalannya
Awalan Awalan yang harus dihapus
di- di- ke- ke- se- se- te- te- ter- ter- ter-luluh ter
Untuk mengatasi keterbatasan pada algoritma diatas, maka ditambahkan aturan – aturan dibawah ini.
Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka root word adalah bentuk tunggalnya, contoh : “buku-buku” root wordnya adalah “buku”.
Kata lain, misalnya “bolak-balik”, “berbalas-balasan”, dan “seolah-olah”. Untuk mendapatkan root wordnya kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubaj menjadi bentuk tunggal, contoh kata “berbalas-balasan”, “berbalas” dan “balasan” memiliki root word yang sama yaitu “balas”, maka root word “berbalas-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “balik” memiliki root word yang berbeda, maka root wordnya adalah bolak-balik.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
Untuk tipe awalan “mem-”, kata yang diawali dengan awalan “memp-” memiliki tipe awalan “mem-”. Tipe awalan “meng”, kata yang diawali dengan awalan “mengk-” memiliki tipe awalan “meng-”.
Contoh kalimat untuk stemming nazief adriani adalah sebagai berikut. Kata = “Mengajar”.
1. Cek dikamus, pada kata tersebut tidak ditemukan kata dasar mengajar. 2. Cek apakah memiliki imbuhan Inflection Suffixes (lah”, kah”, ku”, “-mu” atau “-nya”), pada kata tersebut tidak ditemukan imbuhan Inflection Suffixes. 3. Cek apakah beimbuhan Derivation Suffixes (“-i”, “-an” atau “-kan”), pada kata tersebut tidak ditemukan imbuhan Derivation Suffixes.
4. Cek apakah berimbuhan Derivation Prefix (“di-”, “ke-”, “se-”, “te-”, “be-”, “me” atau “pe-”). Pada kata tersebut terdeteksi berawalan me-, hapus awalan me- menjadi “ngajar”, cek kamus tidak ditemukan kata dasar ngajar, awalan dikembalikan.
5. Cek apakah kata tersebut berawalan meng. Pada kata tersebut berawalan meng, maka awalan tersebut dihapus, menjadi “ajar”. Cek kamus, ternyata ditemukan maka algoritma dihentikan.
Kata = “Mengaduk – aduk”.
1. Cek kata pertama “mengaduk, cocokan ke kamus. Pada kata tersebut tidak ditemukan kata dasar mengaduk.
2. Cek apakah memiliki imbuhan Inflection Suffixes (lah”, kah”, ku”, “-mu” atau “-nya”), pada kata tersebut tidak ditemukan imbuhan Inflection Suffixes
3. Cek apakah beimbuhan Derivation Suffixes (“-i”, “-an” atau “-kan”), pada kata tersebut tidak ditemukan imbuhan Derivation Suffixes.
4. Cek apakah berimbuhan Derivation Prefix (“di-”, “ke-”, “se-”, “te-”, “be-”, “me” atau “pe-”). Pada kata tersebut terdeteksi berawalan me-, hapus awalan me- menjadi “ngaduk”, cek kamus tidak ditemukan kata dasar ngaduk, awalan dikembalikan menjadi mengaduk.
5. Cek apakah kata tersebut berawalan meng. Pada kata tersebut berawalan meng + aduk, maka awalan tersebut dihapus, menjadi “aduk”. Cek kamus, ternyata ditemukan maka algoritma dihentikan.
6. Simpan kata pertama pada temp variable, cek kata kedua apakah sama dengan temp variable, jika sama hapus.
4.5 Pembobotan Kata TF IDF
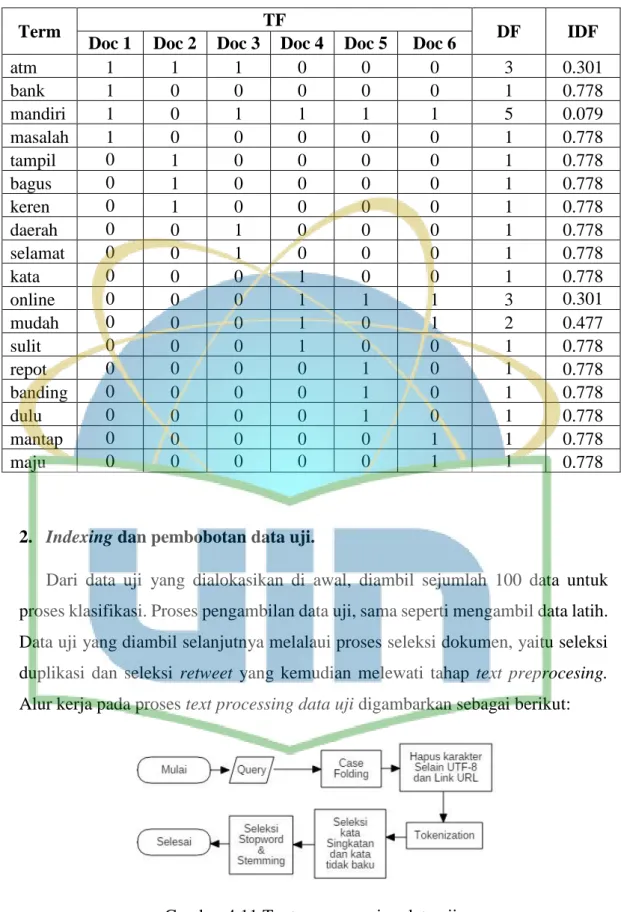
TF adalah bobot dari sebuah term yang diambil dari jumlah kemunculan term tersebut di sebuah dokumen. Semakin besar muncul di sebuah dokumen akan membuat bobot TF sebuah term akan menjadi semakin besar, sedangkan IDF menghitung seberapa sering sebuah term muncul di semua dokumen. Semakin sering muncul term di banyak dokumen akan membuat term tersebut dianggap kata umum dan tidak dapat digunakan untuk mewakili sebuah dokumen. Sebaliknya, term yang sedikit muncul dari semua dokumen dianggap unik dan bisa mewakili sebuah dokumen. (Wirawan et al, 2018). Sedangkan menurut Nurjanah et al, (2017) tahapan pada pembobotan kata yaitu sebagai berikut.
1. Term Frequency (TF), merupakan frekuensi kemunculan kata pada suatu dokumen teks. Term Frequency (TF) didefiniskan sebagai jumlah kemunculan term t pada dokumen d. Persamaan dari Term Frequency (tf) ditunjukan pada persamaan.
No. Rumus 1. 1. Persamaan menghitung term frequency Keterangan: tf adalah jumlah kemunculan term t pada dokumen d.
2. Document Frequency (DF), merupakan kata-kata yang banyak terdapat pada dokumen, kata tersebut tidak informatif, seperti kata dan, di, atau, bisa, dan merupakan.
3. Invers Document Frequency (IDF), merupakan frekueansi kemunculan term pada keselurahan dokumen teks. Term yang jarang muncul pada keseluruhan dokumen teks memiliki nilai Invers Document Frequency lebih besar dibandinkan dengan term yang sering muncul (Nurjanah, 2017). Persamaan dari Invers Document Frequency (IDF) ditunjukan pada persamaan 2.
Gambar 2. 3 Persamaan menghitung IDF Dengan:
N adalah jumlah dokumen teks.
df adalah jumlah dokumen yang mengandung term t.
4. Term Frequency - Invers Document Frequency (TF-IDF), Nilai TF-IDF dari sebuah kata merupakan kombinasi dari nilai tf dan nilai idf dalam perhitungan bobot. Persamaan dari TF-IDF ditunjukan pada persamaan 3.
Gambar 2. 4 Persamaan menghitung bobot kata Keterangan :
wtf adalah Term Frequency.
4.6 Algoritma K-Nearest Neighbor
Klasifikasi merupakan salah satu permasalahan secara umum pada bidang data science dan pattern recognition secara spesifik. K-Nearest neighbor (KNN) merupakan salah satu algoritma yang tertua, sederhana dan akurat untuk proses klasifikasi dan model regresi (Prasath et al, 2017). Algoritma K-NN akan mencari nilai yang mirip dengan data latih untuk melakukan proses klasifikasi, sehingga algoritma ini disebut juga dengan lazy machine algorithm (Trstenjak et al, 2014).
Pada K-NN, sebuah jarak antara sampel uji dengan data latih di identifikasikan dengan berbagai jenis perhitungan. Penghitungan jarak memainkan peran penting dalam pengambilan keputusan terhadap hasil klasifikasi akhir keluaran. Ecludean distance merupakan salah satu metode perhitungan jarak yang paling sering digunakan dalam klasifikasi K-NN (Prasath et al, 2017). Tahap dasar dari proses klasifikasi KNN dijelaskan sebagai berikut (Prasath et al, 2017):
1. Tahap training: Data latih dan label kelas dari sampel tersebut disimpan, tidak boleh ada data yang hilang maupun data non numerik.
2. Tahap klasifikasi: setiap sampel uji diklasifikasikan menggunakan voting terbanyak oleh ketetanggaannya berdasarkan langkah-langkah berikut:
a. Jarak dari sampel terhadap semua data latih yang telah tersimpan di hitung menggunakan fungsi jarak spesifik atau similarity measures.
b. K-Nearest Neighbors dari sampel uji dipilih, yang mana K didefinisikan sebagai small integer.
K-Nearest Neighbors yang paling banyak diulang ditempatkan pada data sample. dengan kata lain, test sample ditempatkan pada kelas c, jika kelas tersebut muncul paling banyak di antara data K sampel training. Jika K= 1 maka kelas ketetanggaan yang terdekat ditempatkan pada sampel test.
4.7 Metode Pengujian Confusion Matrix
Hasil dari klasifikasi pada akan di uji menggunakan rule untuk memprediksi nilai akan dilakukan, dan rule tersebut harus dievaluasi dan divalidasi sehingga diketahui seberapa akurat hasil prediksi yang dilakukan. Confision matrix merupakan metode pengujian terhadap data uji yang benar diklasifikasi dan jumlah data uji yang salah diklasifikasi (Indriani, 2014). Confusion matrix akan
menghasilkan nilai akurasi, presisi dan recall (Mayadewi & Rosely, 2015). Contoh Confision matrix untuk klasifikasi biner ditunjukan pada tabel 2.
Gambar 2.5 Confusion Matrix untuk klasifikasi biner Keterangan untuk tabel 1 dinyatakan sebagai berikut :
1 True Positive (TP), yaitu jumlah dokumen dari kelas 1 yang benar dan diklasifikasi sebagai kelas 1.
2 True Negatif (TN), yaitu jumlah dokumen dari kelas 0 yang benar diklasifikasikan sebagai kelas 0.
3 False Positive (FP), yaitu jumlah dokumen dari kelas 0 yang salah diklasifikan sebagai kelas 1.
4 False Negatif (FN) yaitu jumlah dokumen dari kelas 1 yang salah diklasifikasi sebagai kelas 0.
Gambar 2. 6 Rumus perhitungan akurasi
4.8 Bahasa Pemrograman PHP dan database MySQL 4.8.1 Bahasa Pemrograman PHP
PHP adalah suatu bahasa pemrograman yang digunakan untuk menerjemahkan baris kode program menjadi kode mesin yang dapat dimengerti oleh komputer yang bersifat server-side yang dapat ditambahkan ke dalam HTML (Putratama, 2016).
Bahasa Pemrograman PHP merupakan bahasa pemrograman yang diketegorikan kepada serverside programming, yang artinya bahasa pemrograman ini memerlukan penerjemah dalam hal ini web server untuk menjalankannya. Berikut ini diberikan gambaran tentang cara kerja bahasa pemrograman PHP (Putratama, 2016):
Gambar 2.7 Prinsip kerja PHP (Putratama, 2016)
4.8.2 Kelebihan PHP.
Bahasa pemrograman PHP merupakan bahasa pemrograman yang paling banyak digunakan, tentu karena berbagai alasan, salah satunya adalah mempunyai beberapa kelebihan dibandingkan dengan bahasa pemrograman lainnya yang sejenis. Berikut ini kelebihan bahasa pemrograman PHP (Putratama, 2016). 1. PHP adalah bahasa multiplatform yang artinya dapat berjalan diberbagai mesin
dan sistem operasi (Linux, Unix, Macintosh, Windows) dan dapat dijalankan secara runtime melalui console serta juga dapat menjalankan perintah - perintah system lainnya.
2. PHP bersifat Open Source yang berarti dapat digunakan oleh siapa saja secara gratis.
3. Web Server yang mendukung PHP dapat ditemukan di mana-mana dari mulai apache, IIS, Ligttpd, nginx, hingga Xitami dengan konfigurasi yang relatif mudah dan tidak berbelit - belit, bahkan banyak yang membuat dalam bentuk paket atau package (PHP, MySQL dan Web Server).
4. Dalam sisi pengembangan lebih mudah, karena banyak nya milis-milis, komunitas dan developer yang siap membantu.
5. Dalam sisi pemahaman, PHP adalah bahasa scripting yang paling mudah karena memiliki referensi yang banyak.
6. banyak bertebaran aplikasi dan program PHP yang gratis dan siap pakai seperti wordpress, prestahop dan lain lain.
7. Dapat mendukung banyak database, seperti MySQL, Oracle, Ms-SQL dst.
4.8.3 Kekurangan PHP.
Dari sekian banyaknya kelebihan yang dimiliki oleh bahasa pemrograman PHP, tentu tidak berarti tidak ada kekurangannya. Berikut ini kekurangan bahasa pemrograman web PHP yang mungkin menjadi pertimbangan dalam memilih bahasa pemrograman ini (Putratama, 2016).
1. PHP tidak mengenal package.
2. Jika tidak di-encoding, maka kode PHP dapat dibaca semua orang dan untuk meng-encoding-nya dibutuhkan tool dari Zend yang mahal sekali biayanya. 3. PHP memiliki kelemahan keamanan. Jadi Programmer, harus jeli dan
berhati-hati dalam melakukan pemrograman dan konfigurasi PHP.
4.8.4 MySQL
MySQL adalah produk yang product opensource, multithread dan multi user SQL database management sistem dengan lebih dari 10 juta instalasi (Basil, 2011). Ada beberapa keutamaan menggunakan database MySQL dibandingkan dengan database lain (Sorin, 2011)
1. Tidak menggunakan biaya lisensi.
2. Produk bersifat open-source, peran komunitas membuat progress stabil. 3. Fungsi yang mirip dengan database sistem yang lain.
4. Banyak support dari perusahaan khususnya perusahaan hosting atau perusahaan yang menjual software) yang mendukung pada sistem database.
5. Tidak tergantung pada sebuah sistem operasi, MySQL dapat berjalan pada lebih dari 20 OS seperti Windows atau Linux.
BAB III
METODOLOGI PENELITIAN 3.1 Metode Pengumpulan Data
Pada penelitian ini, diperoleh data dan informasi yang berkaitan dengan objek penelitian yang dilakukan sekarang, adapun proses pengumpulan datanya sebagai berikut.
3.1.1 Studi Pustaka
Studi Pustaka adalah dengan melakukan pengumpulan data, berdasarkan teori teori yang didapatkan dari buku referensi, jurnal, skripsi sejenis dan artikel terkait. Selain itu penulis juga mengakses youtube, dan situs lainnya untuk mempelajari konsep analisis sentimen, natural language processing, klasifikasi lexicon dan algoritma K-NN
3.1.1.1 Studi Literatur
Studi pustaka adalah serangkaian kegiatan yang berkenaan dengan metode pengumpulan data pustaka, membaca dan mencatat serta mengolah bahan penelitian. Data dan informasi diperoleh dari 15 buku referensi, 2 ebook, 1 jurnal, 14 website dan 7 pustaka lainnya mengenai perancangan software aplikasi yang dijadikan acuan.
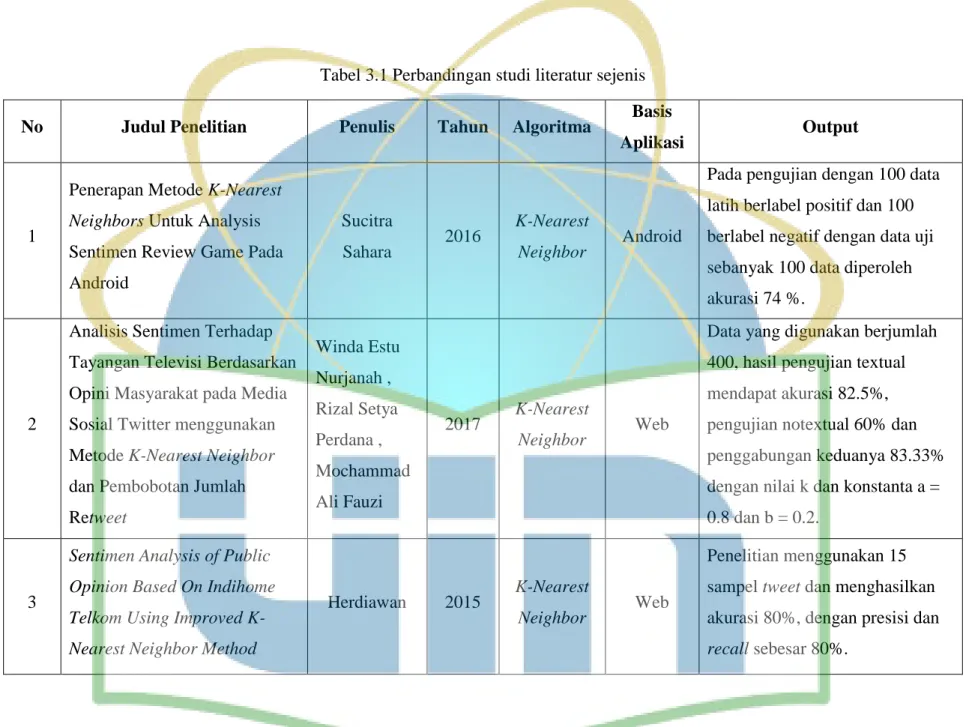
Tabel 3.1 Perbandingan studi literatur sejenis
No Judul Penelitian Penulis Tahun Algoritma Basis
Aplikasi Output
1
Penerapan Metode K-Nearest Neighbors Untuk Analysis Sentimen Review Game Pada Android
Sucitra
Sahara 2016
K-Nearest
Neighbor Android
Pada pengujian dengan 100 data latih berlabel positif dan 100 berlabel negatif dengan data uji sebanyak 100 data diperoleh akurasi 74 %.
2
Analisis Sentimen Terhadap Tayangan Televisi Berdasarkan Opini Masyarakat pada Media Sosial Twitter menggunakan Metode K-Nearest Neighbor dan Pembobotan Jumlah Retweet Winda Estu Nurjanah , Rizal Setya Perdana , Mochammad Ali Fauzi 2017 K-Nearest Neighbor Web
Data yang digunakan berjumlah 400, hasil pengujian textual mendapat akurasi 82.5%, pengujian notextual 60% dan penggabungan keduanya 83.33% dengan nilai k dan konstanta a = 0.8 dan b = 0.2.
3
Sentimen Analysis of Public Opinion Based On Indihome Telkom Using Improved K-Nearest Neighbor Method
Herdiawan 2015 K-Nearest
Neighbor Web
Penelitian menggunakan 15 sampel tweet dan menghasilkan akurasi 80%, dengan presisi dan recall sebesar 80%.
3.1.2 Data
Observasi data diambil dari akun twitter @mandiricare sebagai sumber data yang berkaitan dengan layanan IT Bank Mandiri melalui akun @mandiricare untuk dijadikan data latih dan data uji pada aplikasi analisis sistem. Pengambilan tweet yang dilakukan Mulai dari bulan September hingga bulan Oktober 2018. Proses pengambilan data twitter penulis menggunakan library yang sudah dibuat pada situs https://github.com/abraham/twitteroauthdemo/blob/master/templates/index.html/ menggunakan Bahasa pemrograman PHP. Data twitter yang berhasil di dapat kemudian di simpan ke dalam database MySQL, Adapun data yang berhasil di dapatkan dan dijadikan sumber informasi pada penelitian ini sebanyak 700 tweet, dengan pembagian 100 tweet dijadikan data uji dan 600 tweet dijadikan data latih yang sudah melewati proses klasifikasi lexicon dengan hasil 200 data latih positif, 200 data negatif dan 200 data netral.
Gambar 3.1 Tahapan pengambilan data twitter
3.2 Metode Simulasi
Pengembangan aplikasi pada penelitian ini menggunakan metode simulasi dengan langkah – langkah berikut.
3.2.1 Problem Formulation
Pada tahap ini, dilakukan indentifikasi masalah, dengan mempelajari penelitian yang sudah dilakukan sebelumnya (lihat tabel 3.1) yang berkaitan dengan analisis sentimen menggunakan lexicon dan algoritma K-NN. Pada penelitian (Sucitra sahara, 2015) dengan 1000 dokumen dengan 900 sebagai data latih dan 100 dokumen sebagai data uji, dengan menggabungkan dihasilkan peningkatan akurasi sebesar 78 % dibanding pengujian terpisah. Sementara pada penelitian (Estu dkk) melakukan penelitian dengan 400 data sebagai data latih dan menghasilkan akurasi sebesar 82.5% dan meningkat menjadi 83.3% ketika dikombinasikan dengan lexicon. Dengan mengambil kesimpulan dari beberapa penelitian tersebut yang menghasilkan keluaran akurasi dan cukup baik, maka peneliti akan menggunakan algoritma K-NN dan lexicon untuk proses klasifikasi sentimen analisis.
3.2.2 Conceptual Model
Pada tahap ini conceptual model atau konsep pemodelan akan membahas keseluruhan proses input, proses dan output. Yang menjadi input pada penelitian ini adalah komentar warganet terhadap Bank Mandiri yang berkaitan dengan layanan IT, yang kemudian data tweet tersebut diproses dan ditentukan labelnya dengan pendekatan lexicon yang kemudian disimpan sebagai data latih atau data latih dan algoritma K-NN sebagai klasifikasi data uji atau data uji. Hasilnya akan dihitung besar akurasi, presisi dan recall.
3.2.3 Collection of input/output data
Data tweet yang berhasil di crawling akan dijadikan sebagai masukan (input), masukan dibagi menjadi tiga kategori, dari data tweet yang di crawling didapatkan 700 data tweet, 600 tweet dijadikan data latih, dan 100 tweet akan dijadikan data uji. Data latih akan dibagi menjadi 3 kategori, 200 menjadi tweet sentimen positif, 200 menjadi tweet dengan sentimen negatif dan 200 menjadi tweet dengan sentimen netral. Pembagian 3 katagori data latih diperoleh setelah dilakukan proses klasifikasi dengan menggunakan pendekatan lexicon, dan 100 data uji akan diklasifikan menggunakan algoritma KNN untuk diperoleh orientasi sentimennya.
3.2.4 Modelling Phase
Pada tahap ini, perancangan sistem yang akan dibuat. Aplikasi akan dirancang menggunakan pendekatan lexicon untuk memberikan label data latih dan algoritma K-NN untuk klasifikasi data uji
3.2.5 Simulation Phase
Tahap ini merupakan tahap dimana aplikasi sudah selesai, dan siap untuk di simulasikan Mulai dari proses input, proses dan output yang dihasilkan. Input berupa data latih dan data uji, yang kemudian akan dilakukukan proses klasifikasi, data latih dilakukan pelabelan menggunakan pendekatan lexicon, dan data uji akan klasifikasikan menggunakan algoritma K-NN. Output yang dihasilkan berupa orientasi terhadap data uji, yang akan diuji akurasi, presisi dan recall pada tahap selanjutnya.
3.2.6 Verification, Validation and Experimentation
Tahap ini penulis akan melakukan verifikasi, validasi dan experimen dengan tujuan hasil yang diperoleh sesuai dengan yang sudah di rancang pada tahap sebelumnya dan menmstikan aplikasi yang sudah dibuat berjalan dengan baik.
3.2.7 Output Analysis Phase
Hasil yang didapat akan di analisis terkait akurasi, presisi dan recall dari algoritma yang dijadikan penelitian.
3.3 Pengujian
Pengujian yang dilakukan setelah aplikasi selesai maka dilakukan pengujian terhadap aplikasi tersebut. Pengujian yang akan dilakukan pengujian terhadap algoritma K-NN dalam mengklasifikasikan sentimen data uji. Pengujian dilakukan berdasarkan nilai k yaitu k=1 sampai k=10. Hal yang diuji adalah pengujian akurasi, presisi, recall dan f-measure dengan menggunakan model confusion matrix.
3.4 Alur Penelitian
Alur penelitian adalah alur proses penulis untuk melakukan penelitian, penulis melakukan penelitian berdasarkan alur penelitian sebagai berikut.
BAB IV
IMPLEMENTASI 4.1 Problem FormulationIdentifikasi masalah yang dilakukan penulis adalah berdasarkan studi literatur tentang sertifikasi ISO 20000:1 mengenai information technology service management. Dalam situs https://www.iso.org/standard/51986.html disebutkan bahwa ada beberapa parameter yang dijadikan penilaiannya seperti perencanaan (plan), pendirian (establish), pemasangan(implement), pengoperasian (operate), memonitor (monitor), mengkaji (review), memelihara (maintain) dan mengembangkan (improve).
Perusahaan atau Lembaga yang sudah tersertifikasi ISO 20000 dianggap sudah memenuhi syarat – syarat sesuai standar ISO / IEC 20000 yang didalamnya termasuk design, transition, delivery dan improvement service baik untuk costumer ataupun penyedia layanan.
Dari hasil observasi penulis, pada situs https://apmg-international.com/iso-20000 penulis menjadikan bank Mandiri sebagai objek penelitian karena bank mandiri sudah terdaftar sebagai organisasi yang telah memegang ISO: 20000, dan dianggap sudah memenuhi standar yang sesuai.
ISO/IEC 20000 memastikan pekerjaan yang melibatkan seluruh stakeholder untuk memberikan pelayanan IT yang terbaik, secara berkala di monitor, di uji dan ditingkatkan setiap waktu. Dengan pengawasan terhadap proses tersebut setiap waktu, akan meningkatkan pengembangan dan memberikan pelayanan terbaik untuk pengguna, yang diharapkan akan meningkatkan respon positif pengguna terhadap pelayanan yang disediakan.
Sumber data yang akan penulis gunakan bersumber dari data twitter dengan menggunakan API Twitter, dengan menggunakan query layanan IT yang disediakan oleh Bank Mandiri.
Pada penelitian ini penulis akan mengukur opini pengguna Bank Mandiri terhadap layanan IT dengan menggunakan Algoritma K-NN dan pendekatan