1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3 Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
PENERAPAN ALGORITMA AGGLOMERATIVE CLUSTERING UNTUK MENGKLASTER DATA AKADEMIK MAHASISWA FAKULTAS
TEKNIK UNIVERSITAS NEGERI GORONTALO
Arfin Usman Kilo[1], Moh. Hidayat Koniyo[2], Lillyan Hadjaratie[3] Prodi S1-Sistem Informasi / Informatika
ABSTRACT
A lot of data that involved in an organization can cause difficulties, or even error at the worse case, in the analyzing process. One of the solutions is using Data Mining, by having agglomerative clustering as the clustering technique. Agglomerative clustering will be used to cluster the students’ academic data of Engineering Faculty of Universitas Negeri Gorontalo. The researcher defines the class to the result of the clustering of students’ academic data become 16 clusters which is only at gap 1.41. From 1224 students, there are 623 or 51% students who form the cluster. The characteristic of each cluster is showed from the amount of excellent characteristic percentage of each cluster. The minimum percentage of characteristic was 60%. 60% was not considered as the characteristic of the cluster. The information gained from 16 cluster that were formed after being analyzed was almost all students come from Gorontalo city, who were schooled in SMK, from local selection, prefer to choose informatics engineering strata 1. The other information is that only at 11th cluster, which consist of civil engineering department as much as 82% of students, have high GPA (3.00-4.00), while their parents’ income only <Rp. 1 million. Based on the percentage, it showed that the amount of parents’ income does not influence the students’ GPA.
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3 Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
Data berukuran besar merupakan sesuatu yang biasa terjadi pada suatu organisasi. Dengan jumlah data yang banyak manusia seringkali tidak memiliki waktu dan ilmu yang cukup untuk mengelola data yang ada.
Banyaknya data yang dimiliki sebuah organisasi bisa menyebabkan kesulitan dalam menganalisis data tersebut. Selain itu bisa juga terjadi kesalahan dalam analisis data yang dilakukan. Salah satu cara mengatasi masalah ini adalah dengan menggunakan Data Mining (DM) dengan teknik clustering. Penggunaan teknik DM clustering berbeda dengan teknik-teknik Data Mining (DM) yang lainnya, seperti association rule mining dan classification yang memerlukan tahapan training dan evaluasi. Teknik ini menggunakan metode unsupervised
learning yang berarti DM tidak perlu melakukan training terlebih dahulu tapi bisa
langsung menggunakannya untuk pengelompokan.
Untuk penelitian ini sendiri menggunakan algoritama agglomerative
clustering dengan teknik single linkage. Algoritma agglomerative clustering
merupakan metode pengelompokan hierarki dengan pendekatan bawah-atas (bottom-up) yang dimulai dari masing-masing data sebagai satu buah kelompok, kemudian secara rekursif mencari kelompok terdekat sebagai pasangan untuk bergabung sebagai satu kelompok yang lebih besar.
Sedangkan single linkage merupakan metode tautan tunggal (MIN), yaitu kedekatan antara dua kelompok ditentukan dari jarak terdekat (terkecil) di antara pasangan dua data dari dua kelompok yang berbeda (satu dari kelompok pertama dan satu lagi dari kelompok yang lain) atau disebut juga nilai kemiripan termaksimal. Maka, dengan cara ini kita memulainya dari masing-masing data sebagai kelompok, kemudian mencari tetangga terdekat dan menggunakan tautan tunggal untuk menggabungkan dua kelompok berikutnya hingga semuanya bergabung menjadi satu kelompok.
Pengelompokan hierarki aglomeratif merupakan metode pengelompokan hierarki dengan pendekatan bawah-atas (bottom-up). Proses pengelompokan dimulai dari masing-masing data sebagai satu buah kelompok,
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
kemudian secara rekursif mencari kelompok terdekat sebagai pasangan untuk bergabung sebagai satu kelompok yang lebih besar. Proses tersebut diulang terus sehingga tampak bergerak ke atas membentuk jenjang (hierarki). Cara ini membutuhkan parameter kedekatan kelompok (cluster proximity).
Pengelompokan hierarki sering ditampilkan dalam bentuk grafis menggunakan diagram yang mirip pohon (tree) yang disebut dengan dendogram. Dendogram murupakan diagram yang menampilkan hubungan kelompok dan subkelompok dalam urutan, di mana kelompoknya digabung (agglomerative
view).
Berikut adalah langkah-langkah dalam algoritma pengelompokan hirarki aglomeratif (agglomerative hierarchical clustering algorithm) untuk mengelompokkan N objek (bagian atau variabel) (Khalil dkk, 2009):
1. Dimulai dengan N kelompok, masing-masing mengandung kesatuan yang tunggal dan matriks simetris N x N dari jarak (kesamaan), D dik
2. Dicari matriks jarak untuk pasangan kelompok terdekat (yang paling banyak kesamaan). Dimisalkan jarak antara kelompok U dan V yang paling sama dinotasikan dengan duv .
3. Gabungkan kelompok U dan V. Gabungan tersebut dinotasikan dengan (UV). Letakkan objek pada matriks jarak dengan:
a. menghapus baris dan kolom yang berkorespondensi dengan kelompok U dan V.
b. menambahkan baris dan kolom yang terdapat jarak antara kelompok (UV) dan kelompok yang tertinggal.
4. Ulangi langkah 2 dan 3 sebanyak N-1 kali. (Semua objek akan berada pada
single cluster saat algoritma terakhir). Catat identitas dari cluster yang
tergabung dan levelnya (jarak atau kesamaannya) dimana gabungannya ditempatkan.
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
METODOLOGI PENELTIAN
Metode yang digunakan dalam penelitian ini mengacu pada proses
Knowledge Discovery in Database (KDD). KDD dipilih karena menerapkan
algoritma agglomerative clustering yang merupakan salah satu algoritma dalam
data mining dibutuhkan beberapa tahapan yang berbeda di antaranya,
pengumpulan data, pemilihan data, pengolahan data awal, data mining, dan interpretation/evaluation.
HASIL DAN PEMBAHASAN HASIL
1. Pengolahan data awal (preprocessing data)
Praproses data bertujuan untuk meningkatkan kualitas data, sehingga diharapkan dapat membantu meningkatkan, akurasi, efektifitas, dan efisiensi dari suatu proses data mining. Praproses data merupakan langkah yang sangat penting dalam proses KDD karena kualitas hasil akhir suatu proses data mining sangat dipengaruhi oleh kualitas data.
a. Pengurangan dimensi data (dimensionalty reduction)
Data akademik terdapat banyak atribut, atribut-atribut tersebut tidak semua diperlukan dalam proses data mining, karena ukuran data besar akan memperlambat proses data mining maka dari itu perlu dilakukan pengurangan dimensi data yang bertujuan memilih atribut data yang menjadi fokus penelitian dan menghapus beberapa atribut yang tidak relevan. Atribut sebelumnya ada 44 atribut, yang kemudian direduksi tinggal 8 atribut, di antaranya Strata, Jenis kelamin, Jurusan, Seleksi, Penghasilan orang tua, Asal daerah, Asal sekolah, IPK. b. Pembersihan data
Pada data akademik masih terdapat nilai atribut yang tidak lengkap, nilai kosong, tidak konsisten, dan noisy. Untuk memperoleh kualitas data yang baik, maka dari itu perlu dilakukan pembersihan data. Jumlah data mahasiswa sebelum dilakukan
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
pembersihan data yaitu 1250 record, setelah dilakukan pembersihan data yaitu 1224 record. 1224 record ini yang kemudian digunakan dalam proses klastering menggunakan algoritma agglomerative clustering.
c. Transformasi data
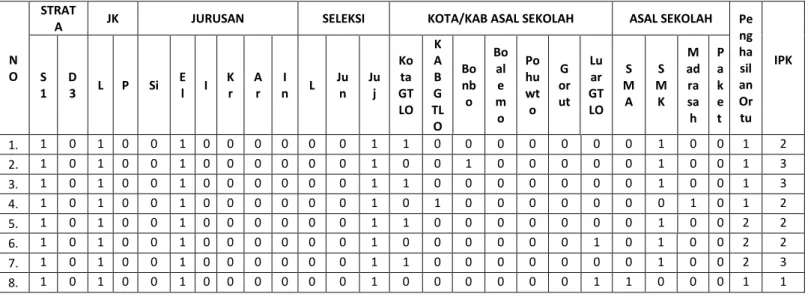
Pada tahap transfromasi beberapa nilai dari atribut-atribut/variabel-variabel diubah ke dalam bentuk variabel biner 1 – 0 yaitu atribut strata, jenis kelamin, jurusan, jalur seleksi, Asal daerah dan asal sekolah. Kemunculan atau ketakmunculan dari suatu karakteristik dapat digambarkan secara matematik dengan pengenalan suatu variabel biner (binary variable), yang mengasumsikan nilai 1 jika karakteristiknya muncul dan nilai 0 jika karakteristiknya tak muncul. selain mengubah ke dalam bentuk variabel biner, penulis juga melakukan transfromasi dengan cara mengubah beberapa nilai dari atribut ke dalam bentuk kode numerik yaitu pada atribut penghasilan orang tua dan ipk. Contoh <Rp. 1 Juta = 1, Rp. 1-3 juta = 2 dan Rp. 3-5 juta = 3. Untuk ipk tinggi (3.00-4.00) = 1, sedang (2.00 – 2.99) dan rendah (0.00 – 1.99). contoh hasil transformasi dapat dilihat pada tabel 1.
Tabel 1 Hasil transformasi
N O
STRAT
A JK JURUSAN SELEKSI KOTA/KAB ASAL SEKOLAH ASAL SEKOLAH Pe
ng ha sil an Or tu IPK S 1 D 3 L P Si E l I K r A r I n L Ju n Ju j Ko ta GT LO K A B G TL O Bo nb o Bo al e m o Po hu wt o G or ut Lu ar GT LO S M A S M K M ad ra sa h P a k e t 1. 1 0 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 1 2 2. 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 1 0 0 1 3 3. 1 0 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 1 3 4. 1 0 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 2 5. 1 0 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 2 2 6. 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 0 0 2 2 7. 1 0 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 2 3 8. 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0 1 1
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo) 2. Data Mining
a. Mengukur jarak (euclidean distance)
Pada tahap ini diukur jarak antara objek yang satu dengan objek lainnya. Semakin besar nilai menunjukan sedikit kesamaan, sebaliknya semakin kecil nilai menunjukan bahwa suatu objek semakin mirip dengan objek yang lainya. Untuk menghitung jarak digunakan persamaan Euclidean distance
√∑ .
b. Agglomerative Clustering (single linkage)
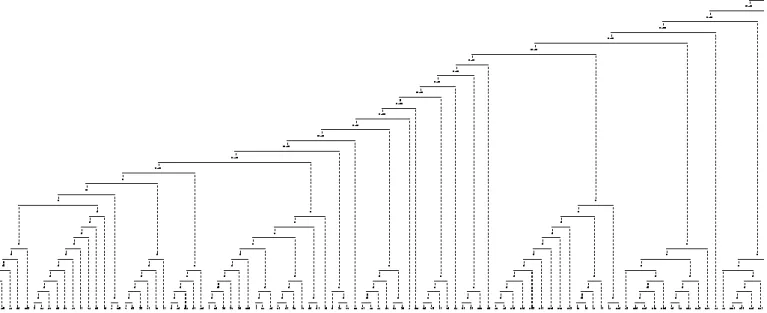
Setelah melalui proses iterasi perhitungan jarak di atas, maka terbentuklah matrik nxn (n = jumlah objek/mahasiswa). Hasil keseluruhan dari proses agglomerative clustering berupa dendogram menggunakan agglomerative
clustering terhadap data akademik mahasiswa FT UNG dapat dilihat pada gambar
1 berikut ini.
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
PEMBAHASAN
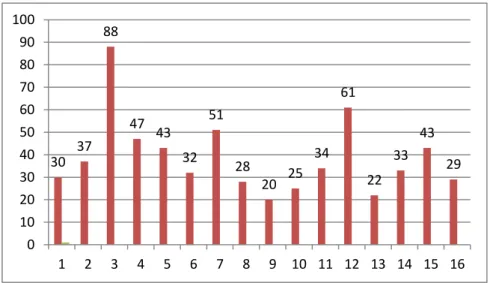
Berdasarkan proses data mining dengan teknik klustering menggunakan algoritma agglomerative clustering single linkage yang diterapkan pada data akademik mahasiswa FT UNG, penulis mendefinisikan class terhadap hasil klastering data akademik mahasiswa FT UNG menjadi 16 klaster yaitu hanya pada masing-masing jarak 1.41. Jumlah anggota tiap klaster dapat dilihat pada gambar 2 berikut ini.
Gambar 2 Jumlah anggota tiap klaster
Dari 1224 mahasiswa, yang membentuk klaster ada 623 mahasiswa, jika dipersentasikan sebesar 51%, minimal dalam satu klaster 15 anggota/mahasiswa, jika kurang dari 15 anggota dari klaster yang terbentuk, maka tidak didefinisi sebagai klaster dan 601 mahasiswa tidak masuk dalam definisi klass yang terbentuk, jika dipersentasikan sebesar 49%. Hal ini menandakan bahwa 51% mahasiswa FT UNG memiliki karakteristik yang homogen dan 49% heterogen, dengan kata lain mahasiswa pada FT UNG memiliki karakteristik-karakteristik yang mirip.
30 37 88 47 43 32 51 28 20 25 34 61 22 33 43 29 0 10 20 30 40 50 60 70 80 90 100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
Karakteristik dari setiap klaster dilihat dari besarnya persentase karakteristik yang unggul pada setiap klaster tersebut, minimal karakteristik tersebut sebesar 60%. Di bawah dari 60% berarti tidak dianggap sebagai karakteristik dari klaster tersebut. Dari 16 klaster yang terbentuk, setelah dianalisis diperoleh informasi yaitu sebagian besar mahasiswa FT UNG berasal dari kota gorontalo, asal sekolah SMK, melalui jalur seleksi lokal dan lebih memilih jurusan Teknik Informatika dengan strata S1. Informasi lainnya, ternyata hanya pada klaster 11 yaitu jurusan Teknik Sipil sebesar 82% mahasiswa yang berada pada klaster tersebut memiliki IPK tinggi (3.00-4.00) yang penghasilan orang tua < Rp. 1 juta, dari persentase ini dapat dilihat bahwa penghasilan dari orang tua tidak terlalu berpengaruh terhadap IPK yang diperoleh oleh mahasiswa.
KESIMPULAN
Dari hasil penelitian dapat disimpulkan hal-hal sebagai berikut :
1. Proses algoritma agglomerative clustering dimulai dari sebuah objek dianggap sebagai satu klaster yang kemudian akan mencari klaster terdekat atau nilai paling kecil dan bergabung untuk membentuk klaster yang lebih besar. Sehingga pada akhir pengklasteran akan membentuk satu klaster yang lebih besar dan membentuk sebuah hierarki.
2. Dari proses agglomerative clustering terhadap data akademik mahasiswa FT UNG. Didapatkan beberapa informasi di antaranya, sebagian besar mahasiswa FT UNG berasal dari kota gorontalo, asal sekolah SMK, melalui jalur seleksi lokal dan lebih memilih jurusan Teknik Informatika dengan strata S1. Informasi lainnya yaitu hanya pada klaster 11 yaitu jurusan Teknik Sipil sebesar 82% mahasiswa yang berada pada klaster tersebut memiliki IPK tinggi (3.00-4.00) yang penghasilan orang tua < Rp. 1 juta, dari persentase ini dapat dilihat bahwa penghasilan dari orang tua tidak terlalu berpengaruh terhadap IPK yang diperoleh oleh mahasiswa.
1Arfin Usman Kilo “Penerapan Algoritma Agglomerative Clustering Untuk Mengklaster Data
Akademik Mahasiswa Fakultas Teknik Universitas Negeri Gorontalo”(Mahasiswa Teknik Universitas Negeri Gorontalo)
2 Moh. Hidayat Koniyo, ST.,M.Kom (Dosen Fakultas Teknik Universitas Negeri Gorontalo) 3
Lillyan Hadjaratie, S.Kom.,M.Si (Dosesn Fakultas Teknik Universitas Negeri Gorontalo)
3. Semakin jauh jarak antar klaster atau karakteristik dari suatu klaster terlalu hetorogen, maka akan semakin sulit mendefinisikan jumlah klaster dari hasil klaster yang terbentuk.
SARAN
Terdapat beberapa teknik dalam algoritma agglomerative clustering yang dapat digunakan untuk mengelompokkan objek-objek, namun penulis hanya menerapkan salah satu teknik saja yaitu single linkage. Untuk itu saran untuk peneliti selanjutnya bisa menerapkan teknik agglomerative clustering yang lain seperti complete linkage dan average linkage.
DAFTAR RUJUKAN
Hermawati, F.A. 2013. Data Mining. Yogyakarta: Andi.
Kusrini dan Luthfi, E.T. 2009. Algoritma Data Mining. Yogyakarta: Andi.
Khalil, A., Aji, C., Iriawan, E., Rahmawati, R., dan Rohimah. 2009. Clusterinng. Bandung.
Nerwati. 2012. Pengelompokan Mahasiswa Menggunakan Algoritma K-Means. Seminar Nasional Aplikasi Teknologi Informasi. Yogyakarta.
Prasetyo, E. 2012. Data Mining Konsep dan Aplikasi Menggunakan Matlab. Yogyakarta: Andi.
Rahayu, D.P. 2009. Analisis Karakteristik Mahasiswa Non Aktif Universitas
Terbuka Dengan Pendekatan Cluster Ensemble. Bogor : IPB.
Rindengan, A.J dan Salaki, D.T. 2011. Pengelompokan Data Wajah Menggunakan Metode Agglomerative Clustering dengan Analisis Komponen Utama. Jurnal Ilmiah Sains, Vol. 11, No.3.
Soraya, Y. 2011. Perbandingan kinerja metode single Linkage, metode complete
linkage dan Metode k-means dalam analisis cluster. [Skripsi] tidak