i
CLUSTERING POLA BATIK YOGYAKARTA
DENGAN ALGORITMA K-MEANS CLUSTERING
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Agnes Retnaningsih
NIM: 065314039
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
CLUSTERING THE YOGYAKARTA BATIK PATTERN
USING K-MEANS CLUSTERING ALGORITHM
A Thesis
Presented as Partial Fulfillment of The Requirements
To Obtain the Sarjana Komputer Degree In Department of Informatics Engineering
By:
Agnes Retnaningsih
Student ID: 065314039
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“ Apabila kamu punya mimpi, t aruh dia 5 cm di depan keningmu, jadi t ak akan pernah lepas dari mat amu. Dan sehabis it u yang kit a perlu :
Hanya kaki yang berjalan lebih jauh dari biasanya, t angan yang akan berbuat lebih banyak dari biasanya, dan mat a yang akan menat ap lebih lama.
Juga lapisan t ekad yang seribu kali lebih keras dari baja dan hat i yang akan bekerja lebih keras,
sert a mulut yang akan selalu berdoa.”
(quoted from 5cm: Donny Dhirgantoro)
Skripsi ini aku persembahkan untuk:
Y esus K ristus
K eluarga
para sahabat baik
viii
Abstrak
Terdapat keragaman pola batik di Indonesia, baik dalam ragam bentuk
maupun warnanya, seperti pada pola batik Yogyakarta, namun informasi melalui
pola yang ada tersebut tidak banyak diketahui. Pengelompokan pola batik
membantu untuk mengetahui batik yang mempunyai kemiripan informasi baik
bentuk ataupun warna.
Pengelompokan pola batik dapat dilakukan dengan algoritma K-means
clustering. Algoritma ini merupakan salah satu metode pengelompokan yang
sering digunakan karena prosesnya yang cepat dan sederhana. Algoritma K-means
dimulai dengan inisialisasi cluster awal kemudian cluster tersebut diperbaiki
hingga tidak terjadi perubahan anggota atau konvergen. Untuk mengetahui
kualitas clustering yang terbentuk dapat menggunakan nilai dissimilarity. Nilai
dissimilarity diperoleh dengan membandingkan 2 obyek hasil clustering, dimana
ketika nilai kedua obyek itu sama berarti nilai dissimilarity-nya0 dan jika berbeda
maka nilai dissimilarity-nya 1. Nilai dissimilarity yang rendah berarti
obyek-obyek dalam cluster memiliki nilai kesamaan yang tinggi. Pada dasarnya data
ditentukan similar atau dissimilar, berdasarkan atas kondisi jarak pada data
tersebut.
Terdapat 4 pola batik yang akan dikelompokan dimana masing-masing
batik memiliki 25 citra batik, sehingga terdapat 100 data citra batik. Percobaan
dilakukan dengan k=2,3,4,5,6 dan 7. Dari hasil pengujian diperoleh bahwa ciri
warna merupakan ciri yang paling baik digunakan dalam pengelompokan pola
ix
ABSTRACT
There are various Indonesian batik patterns, not only in shape but also its
color, such as Yogyakarta’s batik pattern, but the information of the patterns is not
too much known. Clustering batik pattern helps to know batik which having
similarity information both the shape and color.
Clustering batik pattern can be used K-means clustering algorithm. This
algorithm is one of clustering method that used because its process is quick and
simple process. K-means algorithm started by initializing first cluster then the
cluster is corrected until there’s no alteration of the group or convergence. To
know the quality of clustering made can be used dissimilarity value. The
dissimilarity value is reached from comparing 2 result of clustering which will be
have 0 value if its same object and will be have 1 if its different. The low value of
dissimilarity means the objects in the cluster has high similarity. Basically, data is
similar or dissimilar based on the condition of data distance.
There are 4 batik patterns which are clustered, where each batik pattern
has 25 images so that there are 100 batik images data. The experiment is
conducted with k= 2, 3, 4, 5, 6 and 7. From the experiments resulted that feature
color is the best feature used in Yogyakarta batik pattern clustering with 60%
xii
DAFTAR ISI
HALAMAN JUDUL BAHASA INDONESIA ... i
HALAMAN JUDUL BAHASA INGGRIS ... ii
HALAMAN PERSETUJUAN ...iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
HALAMAN PERNYATAAN KEASLIAN KARYA ... vi
HALAMAN PERSETUJUAN PUBLIKASI ... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xiv
DAFTAR TABEL ... xv
BAB I: PENDAHULUAN………...1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Tujuan ... 2
1.4 Batasan Masalah ... 2
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 4
BAB II : LANDASAN TEORI ... 5
2.1 Batik Yogyakarta ... 5
2.2 Clustering………..……….6
2.2.1 Karakteristik Clustering……….……….7
2.2.2 Algoritma Clustering………...……..………….…………8
2.3 Ciri...………...………..…………17
2.4 Perhitungan validasi cluster………...…….………....18
BAB III : ANALISA DAN PERANCANGAN SISTEM ... 20
xiii
3.1.1 Perancangan proses ekstraksi ciri...….…….……….…….21
3.1.2 Perancangan proses clustering………..27
3.1.3 Perancangan proses evaluasi………....……….27
3.2.Perancangan antar muka...…………... ……….……..30
3.2.1 Halaman home………...………..30
3.2.2 Halaman clustering……...……...………....31
3.2.3 Halaman help………...…...32
3.2.4 Halaman about…...…...…..……...……….32
3.3 Kebutuhan Perangkat Keras………...……….33
BAB IV : IMPLEMENTASI DAN ANALISA SISTEM………..34
4.1 Data………..34
4.2. Implementasi Proses…..……….……….34
4.3. Hasil Penelitian...………... ……….42
4.3.1 Set percobaan 1...………... ………….42
4.3.2 Set percobaan 2……….44
4.3.3 Set percobaan 3………...……….46
4.3.4 Set percobaan 4………...………….48
4.3.5 Set percobaan 5……….50
BAB V : KESIMPULAN DAN SARAN……….…….55
5.1 Kesimpulan………....……….….55
5.2 Saran………55
DAFTAR PUSTAKA………....56
LAMPIRAN 1: Coding Program………..……….59
LAMPIRAN 2 : Hasil………..…..………78
xiv
DAFTAR GAMBAR
Gambar 2.1 Contoh pola batik Yogyakarta ... 6
Gambar 2.2 Ilustrasi Algoritma Hierarchical Clustering. ... 9
Gambar 2.3 Ilustrasi Single Linkage ... 10
Gambar 2.4 Ilustrasi Centroid Linkage ... 10
Gambar 2.5Ilustrasi Complete Linkage ... 11
Gambar 2.6Ilustrasi Average Linkage ... 12
Gambar 2.7Proses K-means clustering ... 13
Gambar 3.1 Gambaran sistem secara umum ... 20
Gambar 3.2 Blok digram sistem ... 21
Gambar 3.3 Hasil ciriinformasi tepipada citra batik ... 23
Gambar 3.4 Citra batik dalam 8 vektor vertikal dan 8 vektor horisontal... 24
Gambar 3.5 Halaman home ... 30
Gambar 3.6. Tampilan halaman clustering ... 31
Gambar 3.7. Tampilan help ... 32
xv
DAFTAR TABEL
Tabel 2.1 Contoh data obat ...14
Tabel 2.2 Hasil pengelompokan ...17
Tabel 3.1. Matriks Mean 8 Vektor ...24
Tabel 3.2. Hasil clustering k=2 ...28
Tabel 3.3. Perhitungan dissimilaritas ...29
Tabel 4.1. Contoh hasil dissimilaritas pada percobaan 1 ...40
Tabel 4.2. Contoh hasil ekstraksi ciri warna ...41
Tabel 4.3. Contoh hasil ekstraksi ciri informasi tepi ...41
Tabel 4.4. Contoh hasil ekstraksi ciri warna dan informasi tepi ...41
Tabel 4.5. Contoh hasil pengelompokan ...41
Tabel 4.6. Hasil perhitungan dissimilaritas dengan ciri warna ...42
Tabel 4.7. Hasil perhitungan dissimilaritas dengan ciri informasi tepi. ...43
Tabel 4.8. Hasil dissimilaritas dengan ciri warna dan informasi tepi. ...43
Tabel 4.9. Hasil perhitungan dissimilaritas dengan ciri warna. ...44
Tabel 4.10. Hasil perhitungan dissimilaritas dengan ciri informasi tepi. ...45
Tabel 4.11. Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi...45
Tabel 4.12. Hasil perhitungan dissimilaritas dengan ciri warna. ...46
Tabel 4.13. Hasil perhitungan dissimilaritas dengan ciri informasi tepi. ...47
Tabel 4.14. Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi. ...47
Tabel 4.15. Hasil perhitungan dissimilaritas dengan ciri warna. ...48
Tabel 4.16. Hasil perhitungan dissimilaritas dengan ciri informasi tepi. ...49
Tabel 4.17. Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi. ...49
Tabel 4.18. Hasil perhitungan dissimilaritas dengan ciri warna. ...50
Tabel 4.19. Hasil perhitungan dissimilaritas dengan ciri informasi tepi. ...51
Tabel 4.20. Hasil perhitungan dissimilaritas dengan ciriwarna dan informasi tepi. ...51
Tabel 4.21. Hasil perhitungan percobaan 1 sampai 5...52
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Batik adalah suatu hasil karya asli dari masyarakat Indonesia. Setiap daerah
pembatik mempunyai keunikan dan kekhasan tersendiri, baik dalam ragam hias
maupun tata warnanya. Hal ini mengakibatkan keragaman pola batik di Indonesia,
seperti pada pola batik Yogyakarta, namun informasi melalui pola yang ada
tersebut tidak banyak diketahui. Pengelompokan pola batik atau image clustering
membantu untuk mengetahui batik yang mempunyai kemiripan informasi baik
bentuk, tekstur ataupun warna. Image Clustering merupakan suatu proses
pengelompokan yang bertujuan untuk mengelompokkan gambar menjadi
kelompok-kelompok dimana gambar dalam satu kelompok akan memiliki
karakteristik yang sama, sedangkan gambar dalam kelompok yang berbeda
memiliki karakteristik yang berbeda (Agusta Y,2011).
Dalam pengelompokan dikenal beberapa teknik seperti pengelompokan
berdasarkan partisi, jarak, kepadatan dan hirarki. K-means merupakan salah satu
algoritma pengelompokan berdasarkan partisi dimana setiap data harus masuk ke
cluster tertentu (Zaiane, 1999). K-means memiliki kelebihan dalam kecepatan
memproses pengelompokan data (Wibisono Y dan Khodra, 2006), sehingga
algoritma K-means ini dipilih dalam pengelompokan pola batik daerah
1.2 Rumusan Masalah
Dari latar belakang masalah di atas, maka dapat diperoleh rumusan
masalah pada tugas akhir ini adalah :
a. Bagaimana pengelompokan pola batik Yogyakarta menggunakan
algoritma K-means?
b. Bagaimana unjuk kerja algoritma K-means dalam pengelompokan pola
batik Yogyakarta?
1.3 Tujuan
Mengetahui unjuk kerja pengelompokan pola batik daerah Yogyakarta
dengan algoritma K-means clustering.
1.4Batasan Masalah
a. Penelitian dilakukan pada 4 pola batik dari daerah Yogyakarta yaitu pola
kawunggalar, nitik cengkeh, parang barong dan parang pancing.
b. Data citra diambil dengan kamera digital dengan jarak rata- rata sekitar
30cm.
c. Setiap satu pola citra batik dibagi menjadi 25 file citra batik.
d. Citra yang diproses adalah citra bertipe JPG (*.jpg) dengan ukuran
200x200 piksel.
e. Algoritma yang digunakan dalam pengelompokan pola batik Yogyakarta
adalah algoritma K-means.
f. Program yang dibuat hanya sebuah prototype untuk membantu
menganalisa penerapan algoritma K-means dalam pengelompokan pola
1.5 Metodologi Penelitian
Metodologi yang digunakan dalam pengelompokan pola batik dengan
algoritma K-means adalah sebagai berikut:
a. Studi Pustaka
Pada tahap ini mengumpulkan informasi baik dengan mencari informasi ke
Museum Batik Yogyakarta, studi literatur dari buku, jurnal ataupun pencarian
informasi lain melalui internet.
b. Perancangan Sistem
Pada tahap ini dilakukan perancangan sistem yang akan dibuat.
c. Implementasi
Tahap untuk membuat aplikasi yang digunakan untuk mempermudah dalam
pengelompokan pola batik.
d. Pengujian dan Analisis Hasil
Tujuan dari tahap ini adalah mengetahui tingkat keakuratan algoritma
1.6 Sistematika Penulisan
Untuk mempermudah penyusunan skripsi, maka berikut ini akan
dijabarkan sistematika penulisan laporan sebagai berikut:
BAB I : PENDAHULUAN
Berisi latar belakang masalah, perumusan masalah, batasan masalah,
tujuan penulisan, metodologi penelitian dan sistematika penulisan.
BAB II : LANDASAN TEORI
Bab ini membahas tentang landasan teori yang digunakan dalam clustering
pola batik Yogyakarta.
BAB III :
ANALISA DAN PERANCANGAN SISTEM
Bab ini berisi tentang perancangan sistem yang akan di bangun untuk
mengelompokan pola batik Yogyakarta dan algoritma yang digunakan.
BAB IV : IMPLEMENTASI SISTEM DAN ANALISA HASIL
Bab ini membahas tentang implementasi program serta analisa hasil
pengujian sistem clustering pola batik dengan algoritma K-means.
BAB V : KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan dari keseluruhan proses pembuatan
5
BAB II
LANDASAN TEORI
2.1 Batik Yogyakarta
Batik Yogyakarta merupakan bagian dari perkembangan sejarah batik di
Jawa Tengah yang telah mengalami gabungan beberapa corak dari daerah lain.
Perjalanan batik Yogyakarta tidak bisa lepas dari perjanjian Giyanti 1755, begitu
Mataram terbelah dua, dan Kraton Yogyakarta berdiri, busana Mataram dibawa
dari Surakarta ke Yogyakarta, maka Sri Susuhunan Pakubuwono II merancang
busana baru dan pakaian adat Kraton Surakarta berbeda dengan busana
Yogyakarta (Anonim, 2009).
Ciri khas batik gaya Yogyakarta adalah ada dua macam latar atau warna
dasar kain yaitu putih dan hitam, sementara warna batik umumnya putih (warna
kain mori), biru tua kehitaman dan coklat soga. Ragam hias pertama geometris
yaitu garis miring lerek atau lereng, garis silang atau ceplok dan kawung, serta
anyaman dan limaran. Ragam hias yang kedua bersifat non-geometris yaitu
semen, lung-lungan dan boketan. Ragam hias yang bersifat simbolis erat
hubungannya dengan falsafah Hindu – Jawa antara lain Sawat melambangkan
mahkota atau penguasa tinggi, Meru melambangkan gunung atau tanah ( bumi ),
Naga melambangkan air, Burung melambangkan angin atau dunia atas dan Lidah
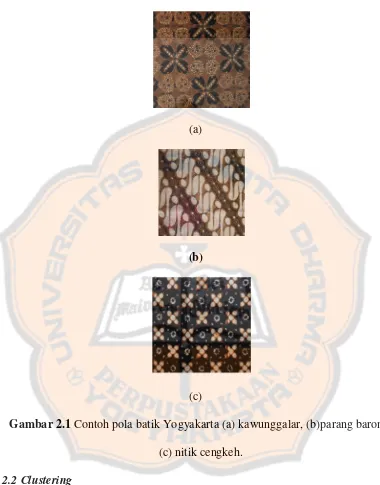
Contoh batik Yogyakarta :
(a)
(b)
(c)
Gambar 2.1 Contoh pola batik Yogyakarta (a) kawunggalar, (b)parang barong,
(c) nitik cengkeh.
2.2 Clustering
Clustering adalah proses mengelompokkan obyek berdasarkan informasi
yang diperoleh dari data yang menjelaskan hubungan antar obyek dengan prinsip
memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan
kesamaan antar kelas atau cluster (Agus I,2009). Tujuan dari clustering adalah
data mining berguna untuk menemukan pola distribusi di dalam sebuah data set
yang berguna untuk proses analisa data. Kesamaan obyek biasanya diperoleh dari
kedekatan nilai-nilai atribut yang menjelaskan obyek-obyek data, sedangkan
obyek-obyek data biasanya direpresentasikan sebagai sebuah titik dalam ruang
multidimensi.
Dengan menggunakan clustering, dapat diidentifikasi daerah yang padat,
pola-pola distribusi secara keseluruhan dan keterkaitan yang menarik antara
atribut-atribut data. Dalam data mining usaha difokuskan pada metode-metode
penemuan cluster pada basis data berukuran besar secara efektif dan efisien.
Image Clustering merupakan suatu proses pengelompokan yang bertujuan
untuk mengelompokkan gambar menjadi kelompok-kelompok, dimana gambar
dalam satu kelompok akan memiliki karakteristik yang sama, sedangkan gambar
dalam kelompok yang berbeda memiliki karakteristik yang berbeda (Agusta Y,
2011).
2.2.1 Karakteristik clustering
Karakteristik clustering dibagi menjadi 4 (Hasniawati,2007), yaitu :
a. Partitioning clustering
Partitioning clustering disebut juga exclusive clustering, dimana setiap
data harus masuk ke cluster tertentu. Karakteristik tipe ini juga memungkinkan
bagi setiap data yang termasuk cluster tertentu pada suatu tahapan proses, pada
tahapan berikutnya berpindah ke cluster yang lain.
b. Hierarchical clustering
Pada hierarchical clustering, setiap data harus masuk pada cluster
tertentu dan suatu data yang termasuk pada cluster tertentu pada suatu tahapan
proses, tidak dapat berpindah ke cluster lain pada tahapan berikutnya.
Contoh: Single Linkage, Centroid Linkage,Complete Linkage, Average
Linkage.
c. Overlapping clustering
Dalam overlappingclustering, setiap data memungkinkan termasuk ke
beberapa cluster. Data mempunyai nilai keanggotaan (membership) pada
beberapa cluster.
Contoh: Fuzzy C-means, Gaussian Mixture.
d. Hybrid
Karakteristik hybrid merupakan karakter yang menggabungkan
karakteristik dari partitioning, overlapping dan hierarchical.
2.2.2 Algoritma clustering
Terdapat beberapa algoritma yang sering digunakan dalam clustering
(Zaiane,1999), yaitu :
a. Hierarchical Clustering
Dengan metode ini, data tidak langsung dikelompokkan ke dalam
beberapa cluster dalam 1 tahap, tetapi dimulai dari 1 cluster yang mempunyai
kesamaan, dan berjalan seterusnya selama beberapa iterasi, hingga terbentuk
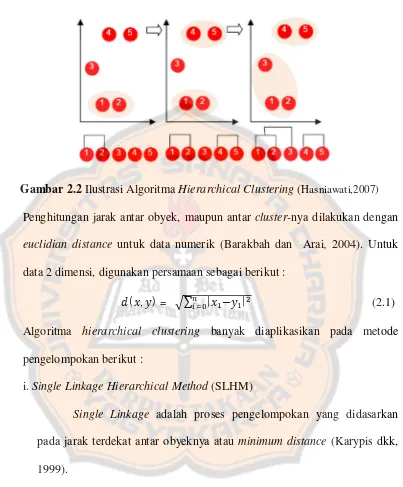
Gambar 2.2 Ilustrasi Algoritma HierarchicalClustering (Hasniawati,2007)
Penghitungan jarak antar obyek, maupun antar cluster-nya dilakukan dengan
euclidian distance untuk data numerik (Barakbah dan Arai, 2004). Untuk
data 2 dimensi, digunakan persamaan sebagai berikut :
( , ) = ∑ | − | (2.1)
Algoritma hierarchical clustering banyak diaplikasikan pada metode
pengelompokan berikut :
i. Single Linkage Hierarchical Method (SLHM)
Single Linkage adalah proses pengelompokan yang didasarkan
pada jarak terdekat antar obyeknya atau minimum distance (Karypis dkk,
1999).
Metode SLHM sangat bagus untuk melakukan analisa pada tiap tahap
pembentukan cluster. Metode ini juga sangat cocok untuk dipakai pada
kasus shape independent clustering, karena kemampuannya untuk
membentuk pattern atau pola tertentu dari cluster, sedangkan untuk kasus
Gambar 2.3 Ilustrasi Single Linkage (Hasniawati,2007).
ii. Centroid Linkage Hierarchical Method
Centroid Linkage adalah proses pengelompokan yang didasarkan
pada jarak antar centroidnya (Barakbah A.R., 2006). Metode ini cocok
untuk memperkecil variance within cluster karena melibatkan centroid
pada saat penggabungan antar cluster. Metode ini juga baik untuk data
yang mengandung outlier.
iii. Complete Linkage Hierarchical Method
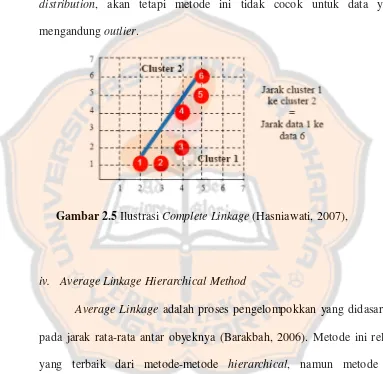
Complete Linkage adalah proses pengelompokan yang didasarkan
pada jarak terjauh antar obyeknya atau maximum distance (Barakbah,
2006). Metode ini baik untuk kasus clustering dengan normal data set
distribution, akan tetapi metode ini tidak cocok untuk data yang
mengandung outlier.
Gambar 2.5 Ilustrasi Complete Linkage (Hasniawati, 2007),
iv. Average Linkage Hierarchical Method
Average Linkage adalah proses pengelompokkan yang didasarkan
pada jarak rata-rata antar obyeknya (Barakbah, 2006). Metode ini relatif
yang terbaik dari metode-metode hierarchical, namun metode ini
memerlukan waktu komputasi yang paling tinggi dibandingkan dengan
Gambar 2.6 Ilustrasi Average Linkage (Hasniawati, 2007).
b. Algoritma K-means
Algoritma K-means adalah algoritma untuk mengelompokkan data
kedalam kelompok - kelompok atau cluster sejumlah k. K-means adalah teknik
yang cukup sederhana dan cepat dalam pekerjaan pengelompokkan data
(Wibisono dan Khodra, 2006). Prinsip utama dari teknik ini adalah menyusun k
centroid atau rata-rata (mean) dari sekumpulan data berdimensi tertentu.
Algoritma K-means dimulai dengan pembentukan inisialisasi cluster awal
kemudian secara iteratif cluster tersebut diperbaiki hingga tidak terjadi perubahan
anggota atau konvergen. Untuk perhitungan jarak dapat menggunakan
perhitungan jarak euclidean distance. Euclidean sering digunakan karena
penghitungan jarak dalam distancespace ini merupakan jarak terpendek yang bisa
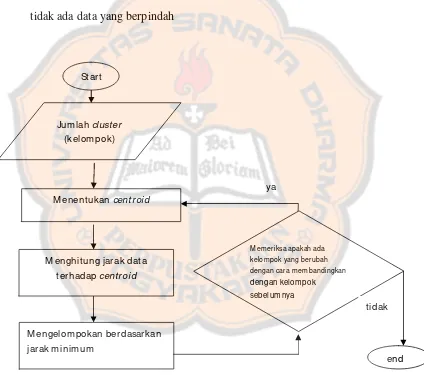
Algoritma K-means:
i.Tentukan jumlah cluster
ii. Menentukan centroid
iii. Hitung jarak data terhadap centroid
iv. Mengelompokan berdasarkan jarak minimum
v. Menentukan centroid yang baru kemudian kembali ke langkah 3, sampai
tidak ada data yang berpindah
Gambar 2.7 Proses K-meansclustering (Santoso, 2005)
St art
Jum lah clust er
(kelom pok)
ya M enent ukan cent roid
M emeriksa apakah ada kelompok yang berubah dengan caram em bandingkan dengan kelompok sebelumnya M enghit ung jarak dat a
t erhadap cent roid
t idak
end M engelom pokan berdasarkan
Contoh penerapan K-means (Teknomo,2006):
Terdapat 4 tipe obat dimana obat tersebut memiliki 2 atribut, x dan y.
Kelompokan data tersebut dalam k=2.
Tabel 2.1 Contoh data obat
Data atribut 1 (X):
weight index(x)
atribut 2 (Y): pH(y)
Obat A 1 1
Obat B 2 1
Obat C 4 3
Obat D 5 4
1. Inisialisasi centroid awal : misalkan Obat A and Obat B sebagai centroid
awal, sehingga c1(1,1) dan c2(2,1).
2. Menghitung jarak data terhadap centroid : hitung jarak antara centroid
dengan masing-masing data. Perhitungan jarak dapat menggunakan
euclidean distance, sehingga diperoleh matrik jarak pada iterasi 0 yaitu :
Tiap kolom matrik jarak tersebut melambangkan obyek data. Baris
pertama matrik jarak merupakan hasil perhitungan jarak dengan c1
Jarak obat C = (4, 3) terhadap c1(1,1) adalah ,
dan terhadap c2 (2,1)adalah , dsb.
3. Pengelompokan : menentukan kelompok data berdasarkan jarak terkecil
sehingga obat A dalam kelompok 1, obat B dalam kelompok 2, obat C ke
kelompok 2 dan obat D pada kelompok 2. Matrik dengan elemen 1
menandakan anggota kelompok tersebut.
4. Iterasi-1, menentukan centroid baru : setelah anggota kelompok diketahui
selanjutnya pada tiap kelompok,hitung centroid baru berdasarkan anggota
kelompok tersebut. Kelompok 1 hanya memiliki satu anggota sehingga
titik tersebut merupakan centroid baru pada c1 sedangkan pada kelompok
2 memiliki 3 anggota, sehingga centroid yang baru diperoleh dengan
mencari rata-rata dari ketiga data tersebut:
5. Iterasi-1, menghitung jarak terhadap centroid : langkah berikutnya adalah
menghitung jarak semua data terhadap centroid yang baru. Seperti pada
langkah ke-2, hasil perhitungan dapat kita lihat dalam matrik jarak sebagai
6. Iterasi-1, pengelompokan data: seperti pada langkah 3, kita tandai tiap
data berdasarkan jarak terkecil sehingga diperoleh hasil obat A dan obat
B berada pada kelompok 1 sedangkan obat C dan obat D berada pada
kelompok 2.
7. Iterasi-2, menentukan centroid baru:seperti pada langkah ke-4, maka
tentukan centroid baru berdasarkan perhitungan pengelompokan dari
iterasi sebelumnya.kelompok 1 dan kelompok 2 sama-sama memiliki 2
anggota, sehingga centroid baru diperoleh sebagai berikut:
= , = 1 , 1 dan = , = 4 , 3
8. Iterasi-2, menghitung jarak terhadap centroid : kembali ulangi langkah 2,
9. Iterasi-2,pengelompokan : menentukan anggota kelompok berdasarkan
jarak paling kecil.
Hasil di atas menunjukan sehingga tidak ada perubahan anggota
kelompok, berarti proses pengelompokan telah stabil dan tidak memerlukan
iterasi lagi. Hasil akhir pengelompokan sebagai berikut:
Tabel 2.2 Hasil pengelompokan
data atribut 1 (X):
weightindex
atribut 2 (Y): pH
hasil pengelompokan
obat A 1 1 1
obat B 2 1 1
obat C 4 3 2
obat D 5 4 2
Pada tabel di atas, obat A dan obat B termasuk dalam kelompok satu
sedang obat C dan obat D termasuk dalam kelompok 2.
2.3 Ciri
Ciri mewakili sesuatu yang khas pada citra yang akan di ekstraksi untuk
proses selanjutnya. Pada data citra terdapat beberapa ciri yang dapat digunakan
seperti warna dan bentuk (Herdiyeni, 2008). Pada pengelompokan pola batik
belum terdapat penelitian yang menyebutkan tentang ciri yang tepat, sehingga
penulis mencoba menggunakan ciri warna dan informasi tepi dengan harapan
a) Informasi tepi
Informasi tepi merupakan proses yang menghasilkan tepi-tepi dari
obyek-obyek citra, dimana tujuannya adalah menandai bagian yang menjadi
detail citra dan memperbaiki detail dari citra yang kabur, yang terjadi karena
error atau adanya efek dari proses akuisisi citra (Riyanto, 2006). Dalam
pengambilan informasi tepi ini digunakan metode canny karena merupakan
metode deteksi tepi yang paling baik (Fisher dkk, 2003) serta telah digunakan
dalam pengambilan ekstraksi dalam pengidentifikasian batik berdasarkan pola
batik dan ciri-ciri batik menggunakan ekstraksi ciri tekstur kain (Imanuddin,
2010).
b) Warna
Meneliti citra berdasarkan warna yang dikandungnya adalah salah satu
teknik yang paling banyak digunakan. Perhitungan kadar warna berdasarkan
atas percobaan yang telah dilakukan pada penelitian untuk klasifikasi tingkat
kematangan tomat merah menggunakan metode perbandingan kadar warna
(Noviyanto, 2009). Dalam sebuah citra terdapat 3 komponen warna utama,
yaitu red, green dan blue, atau yang sering disebut RGB. Komponen RGB
dalam setiap citra dapat digunakan sebagai ciri untuk proses pengolahan citra
selanjutnya.
2.4 Perhitungan validasi cluster
Konsistensi hasil clustering dapat di ukur dengan nilai dissimilarity (Adi
evaluasi dianggap semakin berbeda, namun jika semakin kecil nilai dissimilarity,
maka kedua obyek tersebut dianggap semakin mirip (Karhendana,2008).
Pada dasarnya data ditentukan similar atau dissimilar berdasarkan atas
kondisi jarak pada data tersebut, misalnya untuk kondisi similar interval yang
digunakan hanya 2 yaitu keadaan 0 (no similarity), 1(complete similarity).
Rumus Similarity :
= 1
0 (2.2)
Rumus Dissimilarity
= 0
1 (2.3)
p and q adalah nilai atribut untuk 2 data yang dibandingkan.
Rumus untuk menghitung rata –rata dissimilarity (Adi dkk, 2008) adalah:
, ∶= ∈ ∑ 1 ≠ (2.4 )
Dimana Pk adalah permutasi semua label, 1 ≠ = 1 ketika ≠ dan
bernilai 0 jika = . L adalah hasil clustering.
Permutasi digunakan untuk mengatasi adanya ketidakunikan label seperti
pada representasi label 1 pada pengelompokkan pertama dan label 2 pada
pengelompokan berikutnya yang terlihat berbeda, padahal kemungkinan kedua
label tersebut sama, sehingga semua data dibandingkan dengan hasil permutasi
untuk mengatasi adanya label yang berbeda yang sebenarnya mungkin sama pada
20
BAB III
ANALISA DAN PERANCANGAN SISTEM
Pada bab analisa dan perancangan sistem ini berisi tentang penjelasan
rancangan dan proses kerja sistem yang akan dibuat. Sistem yang akan dibuat
tersebut digunakan untuk mengelompokan data citra dan menguji keakuratan
metode clustering dengan algoritma K-means dalam pengelompokan pola batik
Yogyakarta.
3.1 Perancangan sistem secara umum
Sistem pengelompokan pola batik ini menggunakan algoritma K-means
untuk mengelompokan pola batik sehingga batik yang mempunyai kemiripan ciri
yang hampir sama akan dikelompokan menjadi satu kelompok. Proses berawal
dengan pembacaan data citra oleh sistem, kemudian data citra yang terbaca di
ekstraksi cirinya yaitu berupa informasi tepi dan warna. Dengan pengelompokan
menggunakan K-means, setiap citra yang telah di ekstraksi cirinya, kemudian
dikelompokkan. Setelah proses pengelompokkan selesai maka akan diperoleh
informasi tentang hasil pengelompokkan yang berupa label cluster untuk setiap
data dimana label yang sama menyatakan kelompok yang sama.
Gambar 3.1 Gambaran sistem secara umum
Pengelompokan
cit ra oleh sist em hasil User memasukan cit ra –cit ra yang
akan di kelom pokan
Keluaran berupa inf ormasi jumlah kelom pok yang ideal
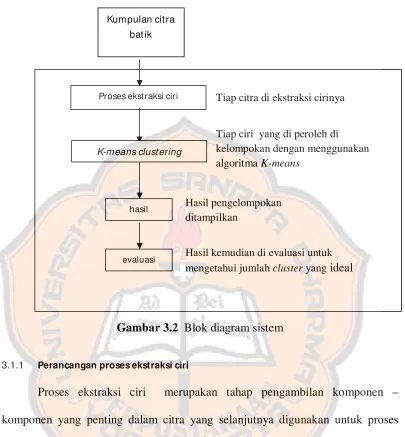
Gambar 3.2 Blok diagram sistem
3.1.1 Perancangan proses ekstraksi ciri
Proses ekstraksi ciri merupakan tahap pengambilan komponen –
komponen yang penting dalam citra yang selanjutnya digunakan untuk proses
pengelompokkan. Dalam proses pengelompokkan pola batik ini digunakan tiga
ciri yaitu warna,informasi tepi dan gabungan antara warna dan informasi tepi.
a. Ciri warna
Ciri warna diperoleh dengan mencari rata-rata Red ( ), rata-rata Green
( ̅), rata-rata Blue ( ), kadar Red, kadar Green dan kadar Blue seperti dalam
rumus berikut:
Tiap citra di ekstraksi cirinya
Tiap ciri yang di peroleh di kelompokan dengan menggunakan algoritma K-means
Hasil pengelompokan ditampilkan
Proses ekst raksi ciri
K-means clust ering
hasil
evaluasi Hasil kemudian di evaluasi untuk
mengetahui jumlah cluster yang ideal
i. Rata – rata R (meanRed)
R = ∑ ∑
(3.1)
ii. Rata – rata G (meanGreen)
G = ∑ ∑
(3.2)
iii. Rata – rata B (meanBlue)
B = ∑ ∑
(3.3)
iv. = ̅ (3.4)
v. = ̅̅ (3.5)
vi. = ̅ (3.6)
di mana
M = lebar citra (kolom matriks)
N = tinggi citra (baris matriks)
Rij = nilai piksel Red
Gij = nilai piksel Green
Bij = nilai piksel Blue
= rata-rata Red
̅ = rata-rata Green
= rata-rata Blue
Dari ciri warna diperoleh 6 atribut yang berupa matrik dengan ukuran 1x6.
Algorit m a ekst raksi ciri w arna
Input : matrik dari citra batik berukuran 200x200 piksel
Output : matrik ciri warna berukuran 1x6 untuk setiap citra masukan
for x = 1: jumlah file citra Membaca citra
Mengambil keping warna hijau Mengambil keping warna biru Mencari rata-rata merah Mencari rata-rata hijau Mencari rata-rata biru
Kadar Merah = rata-rata merah/(rata-rata merah+rata-rata hijau+rata-rata biru)
Kadar Hijau = rata-rata hijau/(rata-rata merah+rata-rata hijau+rata-rata biru)
Kadar Biru = rata-rata biru/(rata-rata merah+rata-rata hijau+rata-rata biru)
Menyimpan matrik kepadatan end
b. Ciri informasi tepi
Citra yang digunakan adalah citra dengan ukuran 200 x 200 piksel.
Selanjutnya citra batik dirubah menjadi grayscale, kemudian dikenai proses
deteksi canny, metode ini dipilih karena deteksi canny memiliki hasil deteksi tepi
yang paling baik (Fisher dkk, 2003).
(a) (b) (c)
Gambar 3.3 Hasil ciri informasi tepipada citra batik. (a) citra asli, (b)
citra setelah proses grayscale, (c) citra setelah proses canny.
Citra selanjutnya dibuat menjadi 8 vektor secara vertikal dan 8 vektor secara
hitung rata- ratanya, maka diperoleh nilai rata – rata tiap vektor seperti dalam
tabel 3.1.
1 2 3 4 5 6 7 8
di hitung rata-rata tiap vektor
Gambar 3.4 Citra batik dalam 8 vektor vertikal dan 8 vektor horisontal
Tabel 3.1 Matriks mean 8 Vektor
mean11 mean12 mean13 …. …. …. …. mean18
mean21 …. …. …. …. …. …. ….
…. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. …. ….
mean81 …. …. …. …. …. …. mean88
Tabel di atas merupakan hasil perhitungan rata-rata tiap vektor dari citra
yang telah dibagi dalam 8 vektor vertikal dan 8 vektor horisontal. Mean11
merupakan rata – rata vektor pertama, mean12 merupakan rata – rata vektor
kedua, sampai seluruhnya di hitung rata – ratanya.
O Penjumlahan tiap kolom dihitung dengan rumus: Total1 = Mean11 + Mean21 + Mean31 + … + Mean81
Total2 = Mean12 + Mean22 + Mean32 + … + Mean82
Total3 = Mean13 + Mean23 + Mean33 + … + Mean83
…….
Total8 = Mean18 + Mean28 + Mean38 + … + Mean88
1
7 2 3
5 4
6
O Penjum lahan t iap baris dihit ung dengan rum us:
Total1 = Mean11 + Mean12 + Mean13 + … + Mean18
Total2 = Mean21 + Mean22 + Mean23 + … + Mean28
…..…
Total8 = Mean81 + Mean82 + Mean83 + … + Mean88
Matriks mean 8 vektor selanjutnya digunakan untuk penjumlahan tiap kolom dan
penjumlahan tiap baris sehingga 8 ciri diperoleh secara vertikal dan 8 ciri secara
horisontal, sehingga dihasilkan 16 atributatau matrik dengan ukuran 1x16.
Algoritma ekstraksi tepi
Input : matriks dari citraberukuran 200x200 piksel
Output : matriks ciri berukuran 1x16 untuk setiap citra masukan
for x=1 : jumlah file citra membaca file batik
membuat 64 atribut untuk menyimpan matrik rata-rata tiap vektor merubah citra menjadi biner
for a= 1 sampai panjang horizontal vektor pertama for b= 1 sampai panjang vertikal vector pertama
jika ditemukan obyek, maka di tambah satu end
ulangi sampai baris terakhir kolom pertama end
ulangi sampai kolom terakhir hitung rata-rata tiap vektor
jumlah tiap vektor secara horisontal dan vertikal simpan informasi kepadatan
end
c. Warna dan informasi tepi
Dari ciri warna diperoleh 6 ciri yaitu rata-rata Red ( ), rata-rata Green ( ̅),
diperoleh 16 ciri sehingga pada gabungan ciri warna dan informasi tepimemiliki
22 ciri yang digunakan untuk pengelompokan pola batik Yogyakarta, atau
diperoleh matrik dengan ukuran 1x22.
Algoritma ekstraksi warna dan informasi tepi
Input : matrik citra berukuran 200x200 piksel
Output : matrik ciri berukuran 1x22 untuk setiap citra masukan.
for x = 1: jumlah file citra Membaca file citra
membuat 64 atribut untuk menyimpan matrik rata-rata tiap vektor Mengambil keeping warna merah
Mengambil keeping warna hijau Mengambil keeping warna biru Mencari rata-rata merah Mencari rata-rata hijau Mencari rata-rata biru
Kadar Merah = rata-rata merah/(rata-rata merah+rata-rata hijau+rata- rata biru)
Kadar Hijau = rata-rata hijau/(rata-rata merah+rata-rata hijau+rata-rata biru)
Kadar Biru = rata-rata biru/(rata-rata merah+rata-rata hijau+rata-rata biru)
merubah citra menjadi biner
for a= 1 sampai panjang horizontal vektor pertama for b= 1 sampai panjang vertikal vector pertama
jika ditemukan obyek, maka di tambah satu end
ulangi sampai baris terakhir kolom pertama end
ulangi sampai kolom terakhir hitung rata-rata tiap vektor
jumlah tiap vektor secara horisontal dan vertikal simpan informasi kepadatan
3.1.2 Perancangan proses clustering
Setiap hasil ekstrasi ciri, baik warna ataupun informasi tepi pada masing -
masing citra selanjutnya dikelompokan dengan algoritma K-means. Data
dikelompokan menjadi k=2,3,4,5,6 dan 7 dengan nilai centroid awal ditentukan
secara acak atau random.
Algoritma clustering
Input : ciri-ciri dari citra masukan
Output : matrik hasil clustering
mengambil k centroid sacara acak
while
menghitung jarak data dengan centroid mengelompokan berdasarkan jarak minimum
jika kelompok sementara samadengan kelompok sebelumnya iterasi dihentikan
jika berbeda
maka disimpan dalam variable
menentukan centroid baru dengan mencari mean dari kelompok sementara
end
menyimpan hasil pengelompokan end
3.1.3 Perancangan proses evaluasi
Evaluasi merupakan tahap untuk mengetahui akurasi K-means clustering
dalam pengelompokan pola batik Yogyakarta. Dalam tahap ini digunakan nilai
dissimilarity untuk mengukur konsistensi hasil clustering. Implementasi
dissimilarity dilakukan pada pengelompokan yang dilakukan beberapa kali
Contoh perhitungan dissimilarity pada k=2, dengan proses clustering sebanyak 10
kali sehingga menghasilkan 10 hasil.
Tabel 3.2 Hasil clustering k=2
Percobaan ke-
1 2 3 4 5 6 7 8 9 10 1 1 1 1 2 1 1 2 1 2 1 2 2 1 2 2 1 2 2 2 1 1 2 2 1 1 2 1 1 1 2 1 2 1 2 1 1 2 1 2
Keterangan:
Hasil clustering k=2
Hasil pertama sebagai acuan
Pada kolom pertama digunakan sebagai acuan untuk dibandingkan dengan hasil
clustering yang lain, jika hasil yang dibandingkan sama maka akan bernilai 0
tetapi jika berbeda akan bernilai 1, kemudian data acuan dibandingkan dengan
data hasil permutasi dari label, jika k=2 maka permutasi dari 2 adalah 1,2 dan 2,1
sehingga nilai hasil clustering pembanding di ubah dengan 2 untuk label bernilai 1
dan menjadi 1 untuk label yang bernilai 2, lalu dibandingkan hasilnya. Hal yang
sama dilakukan pada 9 data hasil pengelompokan yang lain. Setelah itu dihitung
nilai dissimilaritas rata-ratanya dengan menjumlah nilai dissimilaritas dan
Tabel 3.3 Perhitungan dissimilaritas
Tabel di atas digunakan untuk mencari nilai dissimilaritas dengan
membandingkan dua data hasil pengelompokkan . Langkah tersebut dilakukan
pada semua hasil clustering pada k=2 sampai k=7 untuk memperoleh kelompok
dengan nilai rata – rata dissimilaritas terendah.
Algoritma dissimilarity
Input : matrik hasil clustering
Output : matrik hasil perhitungan disimilaritas
pr = permutasi 1 sampai k
for col = 1 sampai jumlah kolom hasil cluster – 1
for brs =1 sampai jumlah baris hasil pengelompokan membandingkan acuan dengan hasil pengelompokan berikutnya, jika hasil berbeda maka bernilai 1 jika sama bernilai 0
end
for per = 1 sampai jumlah baris permutasi – 1 mengganti pembanding dengan hasil permutasi end
for pjg = 1 sampai jumlah baris hasil pengelompokan
membandingkan acuan dengan hasil permutasi, jika hasil berbeda bernilai 1 jika sama bernilai 0
jum= jumlah hasil
hasil penjumlahan paling kecil di simpan dalam indek nilai = menyimpan hasil berdasarkan indek terkecil
dissimilarity = jumlah((jumlah nilai)/jumlah baris nilai)/jumlah kolom nilai
end
3.2 Perancangan antar muka
Alat bantu pengelompokan ini terdiri dari halaman home, clustering,
about, help dan exit.
3.2.1 Halaman home
Gambar 3.5 Halaman home
Sistem pengelompokan pola batik Yogyakarta ini memiliki halaman utama, yang
berisi menu Clustering untuk proses pengelompokan pola batik Yogyakarta, about
yang berisi tentang identitas pembuat, help untuk bantuan dan exit untuk keluar
3.2.2 Halaman clustering
Gambar 3.6 Tampilan halaman clustering
Pada halaman clustering ini digunakan untuk proses pengelompokan pola
batik. Data berupa 100 citra batik yang terdiri dari 4 pola batik Yogyakarta .
Kemudian dilakukan ekstraksi ciri dari data tersebut. Terdapat tiga ciri yang
disediakan, yaitu warna, informasi tepi dan gabungan warna dan informasi tepi.
Selanjutnyaproses clustering dimulai dengan menekan tombol clustering. Untuk
evaluasi hasil cluster dapat diketahui dengan menekan tombol validasi.
Terdapat sebuah tabel yang digunakan untuk menampilkan hasil validasi,
sedangkan pada pojok kanan bawah menampilkan hasil proses yaitu informasi
tentang k ideal, jumlah k ideal yang memiliki nilai dissimilaritas minimum,
prosentase k ideal dalam 10 kali percobaan dan jumlah k=4 yang dissimilaritas
3.2.3 Halaman Help
Gambar 3.7 Tampilan help
Halaman help berisi tentang pengelompokan pola batik.
3.2.4 Halaman about
Gambar 3.8 Tampilan about
3.3 Kebutuhan Perangkat Keras
Kebutuhan perangkat keras dalam menyelesaikan tugas akhir ini adalah
sebuah notebook dengan spesifikasi:
Prosesor : Intel Core2 Duo Prosesor T6400
Sistem Operasi : Windows XP
Memori : 2 Giga Byte
34
BAB IV
IMPLEMENTASI DAN ANALISA SISTEM
Bab ini akan membahas hasil implementasi sistem berupa hasil penelitian
yang di lakukan dan analisa hasil yang diperoleh.
4.1 Data
Terdapat 4 pola batik yang akan diteliti yaitu pola batik kawung galar,
nitik cengkeh, parang barong dan parang pancing dimana untuk setiap pola
terdapat 25 citra batik, sehingga total data adalah 100 citra batik. Data yang
digunakan diperoleh dengan memotret kain batik yang terdapat di Museum Batik
Yogyakarta dengan jarak rata-rata 30cm. Untuk setiap hasil citra yang diperoleh
kemudian dilakukan pemotongan pada bagian pola batik yang diharapkan
merupakan ciri dari pola batik tersebut, dan kemudian membuat ukuran hasil
potongan tersebut menjadi 200x200 piksel. Ekstraksi ciri yang digunakan dalam
proses clustering yaitu menggunakan ciri warna, ciri informasi tepi dan ciri
gabungan warna dan informasi tepi.
4.2 Implementasi Proses
a. Implementasi algoritma ekstraksi ciri warna
Ciri warna diperoleh dari perhitungan rata-rata Red ( ), rata-rata Green
( ̅), rata-rata Blue ( ), kadar Red, kadar Green dan kadar Blue sehingga
Implementasi algoritma ekstraksi ciriwarna
feature(y,:) =[meanR,meanG,meanB,kadarR,kadarG,kadarB];
Setiap komponen warna di ambil kemudian di cari rata- ratanya menggunakan
fungsi yang telah tersedia dalam matlab yaitu mean. Untuk mendapatkan masing
-masing kadar warna dengan membagi hasil rata warna terhadap jumlah
rata-rata ketiga warna. Contoh ekstraksi ciri warna dapat di lihat pada tabel 4.2
b. Implementasi algoritma informasi tepi
Pada ciri informasi tepidiperoleh matrik berukuran 1x16 yang merupakan
penjumlahan matrik secara vertikal dan horisontal dari matrik mean 8 vektor.
Implementasi algoritma ekstraksi ciriinformasi tepi dapat dilihat sebagai berikut :
for f = 101 : 125
if(tepiGambar(a,f)==putih) sum5 = sum5+1; end
end
for g = 126 : 150
if(tepiGambar(a,g) == putih) sum6 = sum6+1; end
end
for h = 151 : 175
if(tepiGambar(a,h) == putih) sum7 = sum7+1; end
end
for i = 176 : 200
if(tepiGambar(a,i) == putih) sum8 = sum8+1; end
end
end
mean1 = sum1/625; mean2 = sum2/625; mean3 = sum3/625; mean4 = sum4/625; mean5 = sum5/625; mean6 = sum6/625; mean7 = sum7/625; mean8 = sum8/625;
Ciri berupa 8 vektor horisontal dan 8 vektor vertikal di buat dengan cara
menelusuri per piksel dalam satu kolom yang berhenti pada setiap kelipatan 25
(piksel ke-25, 50, 75, 100, 125, 150, 175, dan 200) untuk membaginya menjadi 8
vektor vertikal yang sama besar. Hal yang sama juga dilakukan untuk vektor
horisontal. Tiap menemukan sebuah titik piksel 1 maka menambahkan 1 pada
variabel penghitung. Hal ini dilakukan untuk semua citra batik. Contoh hasil
ekstraksi ciri informasi tepi dapat di lihat pada tabel 4.3
c. Implementasi gabungan ciri warna dan informasi tepi
Gabungan ciri warna dan informasi tepi menghasilkan matrik 1 x 22 yang
merupakan hasil penjumlahan matrik 1 x 6 pada ciri warna dan matrik 1 x 16 pada
ciriinformasi tepi. Implementasi algoritma ekstraksi ciriwarna dan informasi tepi
Proses ekstraksi pada cirigabungan warna dan informasi tepi hampir sama dengan
ekstraksi warna dan ekstraksi informasi tepi, hanya saja kedua proses tersebut di
gabungkan sehingga memperoleh matrik 1x22. Contoh hasil ekstraksi gabungan
ciriwarna dan informasidapat di lihat pada tabel 4.4
d. Implementasi algoritma K-means
Hasil ekstraksi ciri kemudian di kelompokan untuk k=2,3,4,5,6 dan 7.
Implementasi algoritma K-meansclustering
Pada proses clustering, centroid awal ditentukan secara random kemudian
menghitung jarak centroid terhadap data dan mengelompokan berdasarkan jarak
minimum. Dari kelompok tersebut dicari kembali rata-ratanya, kemudian dihitung
jaraknya terhadap data, dikelompokan lagi berdasarkan jarak minimum dan di
kelompok yang berubah anggotanya atau konvergen. Contoh hasil clustering pada
k=2 untuk 10 kali percobaan yang dapat di lihat dalam tabel 4.5.
e. Implementasi algoritma dissimilarity
Perhitungan nilai dissimilarity dilakukan setelah proses clustering
dissimilarity =(sum((sum(nilai))/rown))/coln;
end
Program di atas digunakan untuk menghitung nilai disimilaritas. Hasil
clustering pada kolom pertama dijadikan acuan sebagai pembanding dengan hasil
pengelompokan berikutnya. Nilai dissimilaritas diperoleh dengan rata-rata jumlah
perbandingan.
Dalam setiap ciri dilakukan 10 kali percobaan, untuk setiap percobaan
di cari nilai dissimilaritas terkecil yang di tandai dengan warna kuning pada tabel.
Nilai dissimilaritas terkecil menunjukan bahwa kelompok tersebut merupakan
kelompok ideal karena mempunyai nilai simmilaritas besar, yang berarti bahwa
sebagian besar data dalam kelompok tersebut adalah tetap atau tidak berpindah,
misalkan dalam percobaan dengan ciri warna pada percobaan 1, diperoleh hasil
seperti dalam tabel 4.1.
Tabel 4.1 Contoh hasil dissimilaritas pada percobaan 1
k Perc 1 2 0.0836 3 0.4249 4 0.1511 5 0.2498 6 0.2889 7 0.1698
Pada percobaan tersebut terdapat nilai dissimilaritas untuk
masing-masing k=2 sampai 7. Dari nilai tersebut di cari nilai dissimilaritas paling kecil
yaitu 0.0836 pada k=2 sehingga pada percobaan pertama, k =2 merupakan k ideal,
begitu juga untuk percobaan 2 sampai percobaan 10, kemudian di hitung jumlah k
yang memiliki nilai dissimilaritas paling kecil dengan jumlah terbanyak yang
Tabel 4.2 Contoh hasil ekstraksi ciri warna
Tabel 4.3 Contoh hasil ekstraksi ciri untuk informasi tepi
M at rik ekst raksi infor masi t epi
Tabel 4.4 Contoh hasil ekstraksi ciri untuk warna dan informasi tepi
M at rik ekst raksi w arna dan infor masi t epi
4.3Hasil penelitian
a. Implementasi hasil penelitian menggunakan 3 ciri yaitu warna,
informasi tepi,gabungan ciri warna dan informasi tepi.
b. Dari hasil ekstraksi ciri tersebut kemudian dilakukan pengelompokan
untuk k=2, 3, 4, 5, 6 dan 7.
c. Di buat 5 set percobaan dimana untuk setiap set percobaan, setiap ciri
dipakai untuk 10 kali percobaan.
4.3.1 Set percobaan 1
a. Pada percobaan 1 dengan ciri warna diperoleh hasil sebagai berikut :
Tabel 4.6 Hasil perhitungan dissimilaritas dengan ciri warna
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc 10 jum 2 0.2222 0.4444 0.4444 0.3333 0.1111 0.1111 0.2222 0.2222 0.1111 0.4444 3 0.3111 0.2044 0.2689 0.2511 0.2056 0.3122 0.2089 0.1533 0.2578 0.3578 4 0.1278 0.1611 0.0844 0.1511 0.0422 0.0378 0.2567 0.2589 0.2689 0.2456 7 5 0.1733 0.2456 0.2667 0.1944 0.1800 0.2467 0.2089 0.1744 0.1789 0.2556 6 0.3244 0.3589 0.2689 0.2222 0.2111 0.2989 0.2389 0.4378 0.3522 0.3222 7 0.2200 0.3767 0.2956 0.2722 0.2189 0.3011 0.4089 0.3367 0.2900 0.3244
Ket erangan w arna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dilakukan dengan 10 kali
percobaan. Pada k=4 memiliki nilai dissimilaritas paling kecil sebanyak 7 kali,
sehingga k=4 pada percobaan ini merupakan k ideal karena memiliki kemunculan
dissimilaritas yang paling banyak dan sesuai dengan jumlah pola batik sebenarnya
b. Pada percobaan 2 dengan ciri informasi tepi diperoleh hasil sebagai
berikut :
Tabel 4.7 Hasil perhitungan dissimilaritas dengan ciri informasi tepi.
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc 10 jum 2 0.2400 0.2833 0.2900 0.3067 0.3822 0.1811 0.3478 0.5089 0.2733 0.3200 7 3 0.2844 0.3167 0.3633 0.2967 0.2444 0.2989 0.3667 0.2889 0.3622 0.3511 4 0.3144 0.3656 0.3967 0.4156 0.3044 0.3944 0.4211 0.3822 0.3600 0.3567 0 5 0.3656 0.3844 0.3444 0.4044 0.4044 0.4033 0.4267 0.3811 0.4156 0.4489 6 0.4200 0.4467 0.4333 0.4744 0.4311 0.4711 0.4333 0.4011 0.4378 0.4478 7 0.4878 0.4944 0.4633 0.5078 0.4833 0.4578 0.4744 0.4822 0.4478 0.4411
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri informasi tepi dilakukan dengan
10 kali percobaan. Pada k=2 memiliki nilai dissimilaritas paling kecil sebanyak 7
kali sehingga pada percobaan ini k ideal adalah ketika k=2 karena memiliki
kemunculan dissimilaritas yang paling banyak namun k ideal ini tidak sesuai
dengan jumlah pola batik sebenarnya yaitu 4 pola batik.
c. Pada percobaan 3dengan ciri warna dan informasi tepi diperoleh hasil
sebagai berikut :
Tabel 4.8 Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dan informasi tepi
dilakukan dengan 10 kali percobaan. Pada k = 4 memiliki nilai dissimilaritas
paling kecil sebanyak 4 kali sehingga pada percobaan ini k=4 merupakan k ideal
karena memiliki kemunculan dissimilaritas yang paling banyak dan sesuai dengan
jumlah pola batik sebenarnya, yaitu 4 pola batik.
4.3.2 Set Percobaan 2
a. Pada percobaan 1 dengan ciri warna diperoleh hasil sebagai berikut :
Tabel 4.9 Hasil perhitungan dissimilaritas dengan ciri warna
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0.4500 0.2400 0.2989 0.2467 0.1789 0.3478 0.2411 0.3556 0.1022 0.3611 4 3 0.3056 0.2811 0.3178 0.3256 0.3500 0.2922 0.3344 0.3667 0.3678 0.3567 4 0.2989 0.2933 0.2911 0.2656 0.1767 0.3178 0.3133 0.4100 0.3111 0.3456 2 5 0.2922 0.4300 0.3500 0.3811 0.3578 0.2544 0.3067 0.2489 0.3100 0.3678 6 0.3078 0.3689 0.4067 0.4389 0.3689 0.3711 0.3744 0.3344 0.3911 0.3489 7 0.3078 0.3433 0.3156 0.3789 0.4344 0.3800 0.3833 0.3989 0.3478 0.3911
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dilakukan dengan 10 kali
percobaan. Pada k = 2 memiliki nilai dissimilaritas paling kecil sebanyak 4 kali
kemunculan dissimilaritas yang paling banyak namun tidak sesuai dengan jumlah
pola batik sebenarnya, yaitu 4 pola batik.
b. Pada percobaan 2 dengan ciri informasi tepi diperoleh hasil sebagai
berikut :
Tabel 4.10 Hasil perhitungan dissimilaritas dengan ciri informasi tepi
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0.3333 0.3333 0.4444 0.1111 0 0.4444 0 0.2222 0.5556 0.2222 3 0.2033 0.2022 0.2622 0.1033 0.2456 0.1511 0.1222 0.4422 0.2178 0.1567 4 0.1033 0.1767 0.2811 0.2367 0.1622 0.2100 0.2422 0.1922 0.2500 0.0889 4 5 0.1144 0.1800 0.1822 0.1189 0.1967 0.1956 0.2144 0.2089 0.1267 0.1522 6 0.1889 0.2189 0.1600 0.1989 0.2089 0.0756 0.2000 0.1978 0.2178 0.1633 7 0.2289 0.2822 0.2811 0.2289 0.2222 0.2444 0.1744 0.2044 0.2567 0.1867
Ket erangan w arna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri informasi tepi dilakukan dengan
10 kali percobaan. Pada k = 4 memiliki nilai dissimilaritas paling kecil sebanyak 4
kali sehingga pada percobaan k=4 adalah k ideal karena karena memiliki
kemunculan dissimilaritas yang paling banyak dan k ideal tersebut sesuai dengan
jumlah pola batik sebenarnya, yaitu 4 pola batik.
c. Pada percobaan 3 dengan ciri warna dan informasi tepi diperoleh hasil
sebagai berikut :
Tabel 4.11 Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi
Ket erangan w arna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dan informasi tepi
dilakukan dengan 10 kali percobaan. Pada k=4 memiliki nilai dissimilaritas paling
kecil sebanyak 4 kali sehingga k=4 pada percobaan ini merupakan k ideal karena
memiliki kemunculan dissimilaritas yang paling banyak dan sesuai dengan jumlah
pola data sebenarnya, yaitu 4 pola batik.
4.3.3 Set Percobaan 3
a. Pada percobaan 1 dengan ciri warna diperoleh hasil sebagai berikut :
Tabel 4.12 Hasil perhitungan dissimilaritas dengan ciri warna
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0 0.3333 0 0.2222 0.5556 0.3333 0.1111 0.1111 0 0.1111 3 0.2589 0.2056 0.1533 0.3044 0.1556 0.1533 0.3622 0.2556 0.1044 0.2122 4 0.1233 0.1533 0.1367 0.0944 0.1422 0.1700 0.0756 0.0522 0.1556 0.1689 5 5 0.2622 0.2022 0.2189 0.2567 0.2144 0.1911 0.2256 0.2422 0.2611 0.1578 6 0.2789 0.2378 0.3033 0.2733 0.3644 0.3100 0.3000 0.2689 0.3644 0.2367 7 0.3356 0.3311 0.2622 0.2911 0.2567 0.3644 0.3533 0.2767 0.2222 0.3667
Ket erangan w arna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dilakukan dengan 10 kali
percobaan. Pada k = 4 memiliki nilai dissimilaritas paling kecil sebanyak 5 kali
sehingga pada percobaan k=4 merupakan k ideal karena memiliki kemunculan
dissimilaritas yang paling banyak dan k ideal ini sesuai dengan jumlah pola batik
b. Pada percobaan 2 dengan ciri informasi tepi diperoleh hasil sebagai
berikut :
Tabel 4.13 Hasil perhitungan dissimilaritas dengan ciri informasi tepi.
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0.5300 0.2511 0.3878 0.3500 0.4633 0.2311 0.4311 0.2489 0.3433 0.2333 3 0.3744 0.3078 0.2744 0.3467 0.3100 0.3278 0.2689 0.2344 0.3556 0.3156 5 4 0.3844 0.3944 0.4089 0.3211 0.3333 0.3811 0.4067 0.3067 0.4044 0.3722 1 5 0.4122 0.3933 0.4189 0.4278 0.3778 0.4478 0.4233 0.4511 0.4689 0.4244 6 0.4656 0.4756 0.4567 0.4411 0.4389 0.3978 0.4211 0.4622 0.4500 0.4211 7 0.5100 0.4567 0.4733 0.4811 0.4756 0.4800 0.5033 0.4989 0.4878 0.4067
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri informasi tepi dilakukan dengan
10 kali percobaan. Pada k=3 memiliki nilai dissimilaritas paling kecil sebanyak 5
kali sehingga k=3 merupakan k ideal karena memiliki kemunculan dissimilaritas
yang paling banyak namun tidak sesuai dengan jumlah pola batik sebenarnya,
yaitu 4 pola batik.
c. Pada percobaan 3 dengan ciri warna dan informasi tepi diperoleh hasil
sebagai berikut :
Tabel 4.14 Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi.
k Perc 1
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dan informasi tepi
dilakukan dengan 10 kali percobaan. Pada k=3 memiliki nilai dissimilaritas
paling kecil sebanyak 3 kali sehingga k=3 merupakan k ideal karena memiliki
kemunculan dissimilaritas yang paling banyak namun k ideal tersebut tidak sesuai
dengan jumlah pola batik sebenarnya, yaitu 4 pola batik.
4.3.4 Set percobaan 4
a. Pada percobaan 1 dengan ciri warna diperoleh hasil sebagai berikut :
Tabel 4.15 Hasil perhitungan dissimilaritas dengan ciri warna
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0.2222 0.2222 0.3333 0.2222 0.2222 0 0.1111 0.2222 0.5556 0.3333 3 0.3278 0.2078 0.2556 0.2089 0.3600 0.2144 0.2056 0.1578 0.2578 0.1556 4 0.1222 0.1767 0.1033 0.1333 0.1200 0.2067 0.1978 0.0422 0.1178 0.1267 8 5 0.2278 0.2611 0.3356 0.2633 0.1967 0.1744 0.1711 0.3489 0.1389 0.2067 6 0.2289 0.3356 0.3300 0.2689 0.3144 0.2611 0.3556 0.2833 0.2944 0.2011 7 0.4100 0.2889 0.2933 0.2400 0.3033 0.3111 0.3122 0.2622 0.2333 0.3100
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dilakukan dengan 10 kali
percobaan. Pada k=4 memiliki nilai dissimilaritas paling kecil sebanyak 3 kali
dissimilaritas yang paling banyak dan k ideal tersebut sesuai dengan jumlah pola
batik sebenarnya, yaitu 4 pola batik.
b. Pada percobaan 2 dengan ciri informasi tepi diperoleh hasil sebagai
berikut :
Tabel 4.16 Hasil perhitungan dissimilaritas dengan ciri informasi tepi
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 2 0 0.3333 0.2222 0.1111 0.2222 0.2222 0.3333 0.3333 0.3333 0.3333 3 0.1133 0.1200 0.0067 0.1400 0.1267 0.0267 0.0767 0.1400 0.0633 0.0267 6 4 0.1900 0.1044 0.1900 0.1489 0.2667 0.0767 0.1856 0.1067 0.1067 0.0978 2 5 0.1578 0.2244 0.2033 0.1611 0.3000 0.2033 0.2389 0.2067 0.1900 0.1933 6 0.2911 0.2978 0.3122 0.2522 0.2633 0.2189 0.2900 0.2844 0.2378 0.3011 7 0.3011 0.3933 0.3000 0.2589 0.2889 0.2422 0.3544 0.2389 0.3144 0.2578
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri informasi tepi dilakukan dengan
10 kali percobaan. Pada k=3 memiliki nilai dissimilaritas paling kecil sebanyak 6
kali sehingga k=3 pada percobaan merupakan k ideal karena memiliki
kemunculan dissimilaritas yang paling banyak namun k ideal tersebut tidak sesuai
dengan jumlah pola batik sebenarnya, yaitu 4 pola batik.
c. Pada percobaan 3 dengan ciri warna dan informasi tepi diperoleh hasil
sebagai berikut :
Tabel 4.17 Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi.
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dan informasi tepi
dilakukan dengan 10 kali percobaan. Pada k=3 memiliki nilai dissimilaritas paling
kecil sebanyak 8 kali sehingga k=3 merupakan k ideal karena memiliki
kemunculan dissimilaritas yang paling banyak namun k ideal tersebut tidak sesuai
dengan jumlah pola batik sebenarnya, yaitu 4 pola batik.
4.3.5 Percobaan 5
a. Pada percobaan 3 dengan ciri warna diperoleh hasil sebagai berikut :
Tabel 4.18 Hasil dissimilaritas dengan ciri warna
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0.3333 0.4489 0.3300 0.3233 0.2722 0.2878 0.2600 0.2344 0.1722 0.3756 3 0.2533 0.2622 0.2556 0.2100 0.3267 0.2756 0.2922 0.3067 0.3022 0.3000 5 4 0.3800 0.3289 0.3022 0.2800 0.2500 0.3211 0.3356 0.2344 0.3878 0.3500 2 5 0.3567 0.3033 0.3456 0.3378 0.3567 0.3778 0.4222 0.3511 0.3833 0.2833 6 0.3911 0.3656 0.3878 0.4011 0.4289 0.3178 0.3156 0.3256 0.3544 0.3411 7 0.3500 0.3600 0.3300 0.4178 0.3844 0.3189 0.4267 0.3867 0.3922 0.4100
Keterangan warna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri warna dilakukan dengan 10 kali
percobaan. Pada k = 3 memiliki nilai dissimilaritas paling kecil sebanyak 5 kali
paling banyak namun k ideal tersebut tidak sesuai dengan jumlah pola batik
sebenarnya, yaitu 4 pola batik.
b. Pada percobaan 2 dengan ciri informasi tepi diperoleh hasil sebagai
berikut :
Tabel 4.19 Hasil dissimilaritas dengan ciri informasi tepi.
k Perc 1 Perc 2 Perc 3 Perc 4 Perc 5 Perc 6 Perc 7 Perc 8 Perc 9 Perc10 jum 2 0.2822 0.2556 0.3233 0.3544 0.2811 0.1944 0.3944 0.1833 0.2711 0.3967 6 3 0.4011 0.3389 0.2533 0.3533 0.3144 0.2689 0.2889 0.2989 0.3189 0.3167 4 0.4078 0.3189 0.3578 0.3844 0.3522 0.3767 0.3456 0.2922 0.3333 0.4211 0 5 0.2933 0.3233 0.3744 0.3344 0.3944 0.3478 0.3300 0.3833 0.4567 0.3856 6 0.3911 0.4000 0.3511 0.3378 0.3467 0.4544 0.2811 0.3767 0.3133 0.3556 7 0.4367 0.4478 0.3956 0.3544 0.3644 0.3444 0.3478 0.3100 0.4589 0.4489
Ket erangan w arna
Nilai dissimilaritas terkecil pada tiap percobaan Jumlah k ideal terbanyak berdasarkan dissimilar terkecil pada ki
jumlah k=4 dalam 10 kali percobaan
Pada tabel di atas, percobaan dengan ciri informasi tepi dilakukan dengan
10 kali percobaan. Pada k=2 memiliki nilai dissimilaritas paling kecil sebanyak 6
kali sehingga k=2 merupakan k ideal karena memiliki kemunculan dissimilaritas
yang paling banyak namun k ideal tersebut tidak sesuai dengan jumlah pola batik
sebenarnya, yaitu 4 pola batik.
c. Pada percobaan 3 dengan ciri warna dan informasi tepi diperoleh hasil
sebagai berikut :
Tabel 4.20 Hasil perhitungan dissimilaritas dengan ciri warna dan informasi tepi.