246
Implementasi Metode SVM Untuk Pengenalan
Citra Pada Bangunan Bersejarah Di Kota
Bandung
Andhika Revky Fauzi
1, Cecep Nurul Alam
2, Rian Andrian
31,2,3
Jurusan Teknik Informatika, Fakultas Sains dan Teknologi, UIN Sunan Gunung Djati Bandung
Jalan A.H. Nasution No. 105, Cipadung, Cibiru, Kota Bandung, Jawa Barat 40614
1[email protected],
2[email protected],
3[email protected]
The machine can classify images into the appropriate class. This capability will be very useful when applied to an application. History is the human and scientific past which is composed scientifically and completely including the sequence of facts of the period with interpretations and explanations that give understanding and understanding of what is applicable [1]. When it comes to historic buildings, we can not be separated from the state of the building in the past. The existence of a historic building in the city of Bandung just be the object take pictures ria, so that people need to know about the building is a historical relic or not and provide detailed information about the building. SURF feature extraction to find the keypoint on each image. Therefore, the extraction of surf feature can be used for the classification of the image that is to identify and recognize an image by matching the data learning based on the results of classification. The purpose of this research is to implement Support Vector Machine (SVM) and Speed Up Robust Feature (SURF) in order to classify the building image based on the building's name. The dataset is 10 images for each class so that the sum of all classes is 90 images. The image in the form of RGB 120x100 pixels is converted into a matrix. This test is to extract the characteristics of each image. Then classified by the name of the building. In the research obtained the results of accuracy of historic building detection system with the result reached 67.44%.
Keywords : Building, Historic, Bandung, SURF, Support, Vector, Machine.
Mesin dapat mengklasifikasikan gambar ke dalam kelas yang sesuai. Kemampuan ini akan sangat berguna bila diterapkan pada sebuah aplikasi. Sejarah adalah adalah masa lalu manusia dan seputarnya yang disusun secara ilmiah dan lengkap meliputi urutan fakta masa tersebut dengan tafsiran dan penjelasan yang memberi pengertian dan pemahaman tentang apa yang berlaku [1]. Jika berbicara mengenai gedung bersejarah, kita tidak terlepas dari keadaan gedung itu di masa lampau. Keberadaan gedung bersejarah di kota bandung hanya menjadi objek berfoto ria, sehingga masyarakat pun perlu tahu mengenai gedung tersebut merupakan peninggalan sejarah atau bukan dan memberikan informasi detil mengenai gedung tersebut. Ekstraksi ciri SURF itu untuk mencari keypoint pada setiap gambar. Oleh karena itu, dari hasil ekstraksi ciri surf dapat digunakan untuk klasifikasi terhadap citra yaitu untuk mengidentifikasi dan mengenali suatu citra dengan mencocokkan dengan data learning berdasarkan hasil klasifikasi. Tujuan dari penelitian ini adalah untuk mengimplementasikan Support Vector Machine (SVM) dan Speed Up Robust Feature (SURF) agar bisa mengklasifikasikan gambar gedung berdasarkan nama gedung. Dataset berjumlah 10 citra untuk tiap kelas sehingga jumlah dari seluruh kelas adalah 90 citra. Citra yang berupa RGB 120x100 piksel diubah menjadi matriks. Uji coba ini untuk mengekstraksi ciri dari setiap citra. Kemudian diklasifikasikan menurut nama gedungnya. Pada penelitian didapatkan hasil dari akurasi sistem pendeteksi gedung bersejarah dengan hasil mencapai 67,44%.
Kata kunci : Gedung, Bersejarah, Bandung, SURF, Support, Vector, Machine
I. PENDAHULUAN
Sejarah adalah adalah masa lalu manusia dan seputarnya yang disusun secara ilmiah dan lengkap meliputi urutan fakta masa tersebut dengan tafsiran dan penjelasan yang memberi pengertian dan pemahaman tentang apa yang berlaku [1].
Jika berbicara mengenai gedung bersejarah, kita tidak terlepas dari keadaan gedung itu di masa lampau. Jika anda ingin melihat wajah sebuah kota pada masa lampau, lihatlah gedung-gedung bersejarahnya. Kota Bandung memiliki banyak sekali bangunan bersejarah mulai dari Gedung Merdeka, Museum Asia Afrika, Gedung Sate dll. Bangunan/kawasan cagar budaya kota Bandung dibagi dalam 3 golongan, yaitu golongan A (Utama), golongan B (Madya), dan golongan C (Pratama).
247 kawasan/bangunan cagar budaya dengan merevisi
Perda Kota Bandung No. 19 tahun 2009 atau menerbitkan peraturan walikota (Perwal).
Menurut berita yang diposting di pikiran-rakyat.com pada tanggal 28 Desember 2016, di kota Bandung, terdapat 60% bangunan asli sudah mengalami perubahan dari bentuk aslinya dan juga banyak bangunan cagar budaya yang dijual dan diberi pagar tinggi. Hal itu dikhawatirkan akan menghilangkan keberadaan bangunan cagar budaya. Dengan dibangunnya kawasan komersil di kawasan cagar budaya akan mengganggu kawasan cagar budaya tersebut. Kawasan cagar budaya seharusnya dimanfaatkan sebagai tempat kebudayaan, bukan dikomersialisasi. Masyarakat pun kurang kesadaran dan rasa tanggung jawab dalam penyelenggaraan kegiatan pengelolaan cagar budaya, dikarenakan kurangnya informasi yang berkaitan dengan pengelolaan serta pemugaran dan pemulihan kawasan dan/atau bangunan cagar budaya kepada masyarakat.
Dengan beroperasinya kembali bus bandros Bandung memberikan peluang untuk meningkatkan pemanfaatan potensi wisata khususnya kawasan/bangunan cagar budaya di kota Bandung. Dengan pemanfaatan kemajuan teknologi ini, diharapkan akan memberikan pengalaman baru bagi wisatawan dalam menikmati keindahan kota Bandung khususnya peninggalan cagar budayanya.
Pengertian Support Vector Machine (SVM) yaitu sistem pembelajaran yang menggunakan ruang hipotesis berupa fungsi–fungsi linier dalam sebuah fitur yang berdimensi tinggi dan dilatih dengan menggunakan algoritma pembelajaran yang didasarkan pada teori optimasi.
Kelebihan dari metode SVM adalah mempunyai kemampuan mengklasifikasikan pola dengan baik, pengimplementasian yang cukup mudah. Oleh karena itu metode SVM adalah salah satu metode dan algoritma yang tepat digunakan untuk mempermudah pengguna dalam mencari informasi mengenai peninggalan bangunan bersejarah di kota Bandung.
II. METODE PENELITIAN
Klasifikasi
Klasifikasi merupakan suatu proses yang bertujuan untuk menentukan suatu obyek kedalam suatu kelas atau kategori yang sudah ditentukan sebelumnya. Klasifikasi adalah proses dari pembangunan terhadap suatu model yang mengklasifikan suatu objek sesuai dengan atribut-atributnya. Klasifikasi data ataupun dokumen juga dapat dimulai dari membangun aturan klasifikasi tertentu yang menggunakan data training yang sering disebut sebagai tahapan pembelajaran dan pengujian digunakan sebagai data testing. Beberapa tugas dari klasifikasi yang melibatkan proses pembangunan terhadap model yang dibentuk untuk melakukan prediksi target atau variabel dari data set yang sudah jelas, ataupun variabel independen. Klasifikasi juga dapat dilakukan dengan
menggunakan beberapa metode atau berbagai jenis pengklasifikasian. Beberapa metode yang sering digunakan pada klasifikasi yakni decision-tree, rule based, ANN, nearest-neighbor, dan naive Bayesian[2].
Support Vector Machine
Pengertian Support Vector Machine (SVM) yaitu sistem pembelajaran yang menggunakan ruang hipotesis berupa fungsi–fungsi linier dalam sebuah fitur yang berdimensi tinggi dan dilatih dengan menggunakan algoritma pembelajaran yang didasarkan pada teori optimasi. SVM pertama kali diperkenalkan pada tahun 1992 oleh Vapnik sebagai rangkaian dari beberapa konsep–konsep unggulan dalam bidang pattern recognition.
Tingkat akurasi pada model yang akan dihasilkan oleh proses peralihan dengan SVM sangat bergantung terhadap fungsi kernel dan parameter yang digunakan (Siagian, 2011) Berdasarkan dari karakteristiknya, metode SVM dibagi menjadi dua, yaitu SVM Linier dan SVM Non-Linier. SVM linier merupakan data yang dipisahkan secara linier, yaitu memisahkan kedua class pada hyperplane dengan soft margin. Sedangkan SVM Non-Linier yaitu menerapkan fungsi dari kernel trick terhadap ruang yang berdimensi tinggi.[2]
Kernel Trick
Pada umumnya untuk masalah yang ada dalam domain dunia nyata, kebanyakan bersifat non linier. Algoritma Support Vector Machine (SVM) dimodifikasi dengan cara memasukkan fungsi kernel kedalam non liniar SVM, dengan cara yang pertama yaitu data xi dipetakan ke dalam fungsi Φ (𝑥) ke ruang vector yang memiliki ukuran dimensi tinggi. Notasi matematika dari mapping akan ditunjukkan seperti pada rumus berikut
d
: R
Rq
d < q
→
(1)Dikarenakan transformasi Φ pada umumnya tidak diketahui, oleh karena itu fungsi dari Kernel Trick dapat digantikan sesuai rumus berikut):
( ,
i j)
( ). ( )
i jK x x
=
x
x
(
x,
y,
x,
y)
v
=
d
d
d
d
(2)
Fungsi dari nilai Φ (𝑥҃ i) pada dot product dengan menggunakan dua vector yang menunjukkan feature dari atribut sehingga dapat di hitung dengan baik pada feature space. Selanjutnya feature space akan dibuat sebuah fungsi linear yang mewakili fungsi dari non-linear pada input space. Di dalam input space tidak bisa dipisahkan secara linear, namun input space bisa dipisahkan di feature space dan dapat membantu proses klasifikasi menjadi lebih mudah. Untuk mendapatkan solusi pada fungsi klasifikasi dari data (x), didapatkan rumus berikut :
( , )
f(x)
n1, ,
a y K x xi i i bi
x eSV
+
=
Implementasi Metode SVM Untuk Pengenalan Citra Pada Bangunan Bersejarah Di Kota Bandung (Andhika Revky Fauzi, Cecep Nurul Alam, Rian Andrian)
248
SVM memiliki prinsip dasar linier classifier yaitu kasus klasifikasi yang secara linier dapat dipisahkan, namun SVM telah dikembangkan agar dapat bekerja pada problem non-linier dengan memasukkan konsep kernel pada ruang kerja berdimensi tinggi. Pada ruang berdimensi tinggi, akan dicari hyperplane yang dapat memaksimalkan jarak (margin) antara kelas data. Hyperplane klasifikasi linier SVM dinotasikan :
( )
Tf x
=
w x b
+
.sehingga menurut Vapnik dan Cortes (1995) diperoleh persamaan
dengan, xi = himpunan data training, i = 1,2,...n dan yi = label kelas dari xi
Untuk mendapatkan hyperplane terbaik adalah dengan mencari hyperplane yang terletak di tengah-tengah antara dua bidang pembatas kelas dan untuk mendapatkan hyperplane terbaik itu, sama dengan memaksimalkan margin atau jarak antara dua set objek dari kelas yang berbeda (Santosa, 2007). Margin dapat dihitung dengan
2 ||w||
Mencari hyperplane terbaik dapat digunakan metode Quadratic Progamming (QP) Problem yaitu meminimalkan
1
Solusi untuk mengoptimasi oleh Vapnik (1995) diselesaikan dengan menggunakan fungsi Lagrange sebagai berikut
dengan αi = pengganda fungsi Lagrange dan = 1,2,..., n
Nilai optimal dapat dihitung dengan memaksimalkan L terhadap αi, dan meminimalkan L terhadap w dan b. Hal ini seperti kasus dual problem
( )
(
,(
)
)
max
W
=
max
min
w bL w b a
, ,
Nilai minimum dari fungsi lagrange tersebut diberikan oleh
Untuk menyederhanakannya persamaan (1) harus ditransformasikan ke dalam fungsi Lagrange Multiplier itu sendiri, sehingga menurut Santosa (2007) persamaan (1) menjadi
Berdasarkan persamaan (2), maka persamaan (3) oleh Hastie et al (2001) menjadi sebagai berikut
1 1 1 dan diperoleh dual problem
1 1
Data training dengan terletak pada hyperplane disebut support vector. Data training yang tidak terletak pada hyperplane tersebut mempunyai αi = 0. Setelah solusi permasalahan quadratic progamming ditemukan (nilai αi), maka kelas dari data yang akan diprediksi atau data testing dapat ditentukan berdasarkan nilai fungsi berikut.
( )
1 .dengan
yang akan diprediksi kelasnya (data testing) support vector, s=1,2, ...ns
data support vector Pada kasus linier non-separable beberapa data mungkin tidak bisa dikelompokkan secara benar atau terjadi misclassification. Sehingga persamaan dimodifikasi dengan menambahkan variabel slack. Variabel slack ini merupakan sebuah ukuran kesalahan klasifikasi Berikut ini adalah pembatas yang sudah dimodifikasi oleh Gunn (1998) untuk kasus non-separable:
(
T.
)
1
,
1, 2,...,
i i i
y
w x
+
b
−
i
=
n
Sehingga persamaan (2.6) menjadi meminimalkan
1 yang dikembangkan dengan asumsi kelinieran, sehingga algoritma yang dihasilkan terbatas untuk kasus-kasus yang linier. SVM dapat bekerja pada data non-linier dengan menggunakan pendekatan kernel pada fitur data awal himpunan data. Fungsi kernel yang digunakan untuk memetakan dimensi awal (dimensi yang lebih rendah) himpunan data ke dimensi baru (dimensi yang relatif lebih tinggi). Macam-macam fungsi kernel diantaranya:
1. Kernel Gaussian Radial Basic Function (RBF)
249 xi dan xj adalah pasangan dua data training. Parameter
, c, d > 0 merupakan konstanta. Fungsi kernel mana yang harus digunakan untuk subtitusi dot product di feature space sangat tergantung pada data karena fungsi kernel ini akan menentukan fitur baru di mana hyperplane akan dicari (Santosa, 2007). Pada awalnya SVM dikembangkan untuk persoalan klasifikasi dua kelas, kemudian dikembangkan kembali untuk klasifikasi multikelas. Dalam klasifikasi kasus multikelas, hyperplane yang terbentuk adalah lebih dari satu[3].
SURF
Fitur SURF ini merupakan keypoint dari sebuah gambar. Keypoint adalah titik-titik dari sebuah gambar yang nilainya tetap ketika mengalami perubahan skala, rotasi, blurring, pencahayaan, dan juga perubahan bentuk. Perubahan bentuk ini bisa terjadi karena bentuk gambar query yang tidak utuh atau tidak sesempurna gambar yang ada didalam database gambar tersebut. Gambar query yang tidak utuh mungkin karena objek lain yang menutupi, atau pengambilan gambar yang tidak sempurna, atau keadaan objek itu sendiri yang mengalami perubahan. Agar invarian terhadap perubahan skala maka proses yang dilakukan pertama kali adalah membuat ruang skala (scale space)[4].
Ruang Skala (Scale Space)
Scale space terbagi kedalam bilangan yang disebut octave. Setiap octave merepresentasikan respon filter yang diperoleh dengan melakukan proses konvolusi gambar yang diinputkan dengan ukuran filter yang menaik[4].
Lokalisasi Keypoint
Lokalisasi keypoint dilakukan dengan beberapa proses. Proses pertama, menentukan treshold untuk
keypoint Ketika treshold dinaikkan jumlah keypoint yang terdeteksi lebih kecil begitu pun sebaliknya. Oleh karena itu, treshold bisa disesuaikan pada setiap aplikasi[4].
Proses berikutnya non-maxima suppresion, proses ini dilakukan untuk mencari sekumpulan calon keypoint
dengan membandingkan tiap-tiap pixel gambar pada scale space dengan 26 tetangga. 26 tetangga pixel itu terdiri atas 8 titik di scale asli dan 9 titik di tiap-tiap scale diatas dan dibawahnya. Proses inilah yang menghasilkan keypoint
dari suatu gambar. Gambar 2.2 menunjukkan non-maxima suppresion[4].
Gambar 1 Non Maxima Suprresion
Proses terakhir yaitu proses mencari lokasi keypoint
menggunakan interpolasi data yang dekat dengan keypoint
hasil proses sebelumnya. Ini dilakukan dengan mencocokan quadratic 3D yang diajukan oleh Brown [4]. H(x, y, σ) adalah determinan Hessian, didefinisikan sebagai berikut [3]:
2 2
1 (x) H
2
T
T
H H
H x x x
x x
= + +
(1)
Lokasi ekstrim yang xˆ=(x, y, ) diinterpolasi, ditemukan dengan mencari turunan dari fungsi diatas dan diberi nilai nol, sehingga:
2 2
ˆ H H
x
x x
= −
(2)
Deskriptor Keypoint dan Proses Matching
Deskriptor merupakan daerah piksel disekitar keypoint
yang dihasilkan. Deskriptor menggambarkan distribusi intesitas piksel tetangga di sekitar keypoint.
Proses pertama yang dilakukan adalah mencocokkan orientasi yang dihasilkan berdasarkan informasi dari daerah yang berbentuk lingkaran disekitar piksel yang menjadi keypoint.
Kemudian proses berikutnya membuat daerah berbentuk kotak pada orientasi yang terpilih dan mengekstrak deskriptor SURF dari daerah tersebut. kemudian proses matching fitur antara dua gambar dilakukan. Berikut ini dua proses perhitungan deskriptor
keypoint yang akan dijelaskan lebih detail[4].
Dalam metode SVM, tujuan utamanya adalah mencari
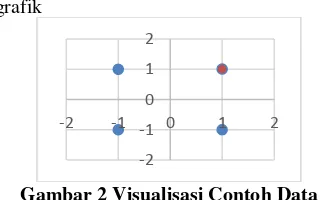
hyperplane terbaik yang berfungsi sebagai pemisah dua kelas data serta support vector untuk membentuk model yang akan digunakan dalam proses klasifikasi. Disini ada contoh data pada tabel berikut :
Tabel 1 Contoh data
x1 x2 Kelas(y)
1 1 1
1 -1 -1
-1 1 -1
-1 -1 -1
Dan pada Gambar berikut adalah visualisasi data dalam bentuk grafik
Gambar 2 Visualisasi Contoh Data
Karena ada dua fitur (x1 dan x2), maka w juga akan memiliki 2 fitur (w1 dan w2). Formulasi yang digunakan
adalah sebagai berikut:
-2 -1 0 1 2
Implementasi Metode SVM Untuk Pengenalan Citra Pada Bangunan Bersejarah Di Kota Bandung (Andhika Revky Fauzi, Cecep Nurul Alam, Rian Andrian)
250 Sehingga didapatkan beberapa persamaan berikut :
(
)
Setelah itu menjumlahkan persamaan (1) dengan (2) untuk mencari nilai w2 : menjumlahkan persamaan (2) dengan (3)(
)
Maka didapatlah persamaan hyperplane sebagai berikut :
1 1 2 2
Sehingga dari persamaan hyperplane diatas dapat divisualisasikan dalam bentuk grafik pada Gambar :
Gambar 3 Visualisasi Data III.HASIL DAN PEMBAHASAN
Implementasi Antarmuka
Implementasi antarmuka pengguna merupakan proses tahapan yang dilakukan pada analisis atau design yang
diimplementasikan menjadi bentuk aplikasi yang akan dipakai oleh user.
1. Tampilan form menu utama
Pada tampilan form menu utama, user dapat memilih beberapa menu, diantaranya menu kamera atau galeri. User
diberikan pilihan mengambil gambar dari kamera langsung atau dari galeri. Adapun tampilan form menu utama dapat dilihat pada Gambar 4.
Gambar 4 Tampilan form menu utama
2. Tampilan form kamera
Pada tampilan form kamera, disini hanya dihadapkan pada 1 tombol yaitu untuk mengambil gambar. Adapun tampilan form kamera dapat dilihat pada Gambar 5.
Gambar 5 Tampilan form kamera
Pada form kamera, user dapat menginputkan citra yang akan dideteksi oleh sistem dengan memotret bangunan tersebut lewat kamera smartphone.
3. Tampilan form galeri
Tampilan form galeri adalah mengambil gambar yang sudah tersimpan dalam memori hp untuk dideteksi gedung apakah yang dimaksud. Adapun tampilan form galeri dapat dilihat pada Gambar 6
Gambar 6 Tampilan form galeri
Pada form galeri, user dapat menginputkan citra yang akan dideteksi dengan mengambil gambar yang sudah ada
251 di memori smartphone. User tinggal memilih gambar
mana yang akan dideteksi olek aplikasi 4. Tampilan form hasil deteksi gedung
Berikut ini merupakan tampilan form data uji, dapat dilihat pada Gambar 7.
Gambar 7 Tampilan form data uji
Setelah user menginputkan gambar dari kamera ataupun galeri, aplikasi akan menampilkan hasil deteksi berupa nama gedung, serta hasil deteksi surf pada gedung. Bulatan-bulatan kecil yang berwarna warni itulah yang disebut descriptor. Serta ada tombol deskripsi untuk mendapatkan penjelasan lebih lanjut mengenai gedung tersebut.
5. Tampilan form deskripsi
Berikut ini merupakan tampilan form data uji, dapat dilihat pada Gambar 8.
Gambar 8 Tampilan form deskripsi
Jika user memilih tombol deskripsi pada form hasil deteksi, inilah tampilan form deskripsi. Disini ada foto gedung pada masa tempo dulu dan beberapa informasi singkat mengenai gedung tersebut. Serta terdapat sedikit cerita sejarah tentang gedung tersebut.
Pengujian pengaruh jumlah data training
Pada pengujian ini dilakukan pada IDE Eclipse Java, untuk memperoleh jumlah data training yang akan dimasukkan. Dalam hal ini akan diuji cobakan dengan jumlah data training yang berbeda, yaitu 3, 6, 9 buah. Hal
ini dilakukan untuk mencari jumlah data training yang ideal agar pendeteksian citra gedung akurat.
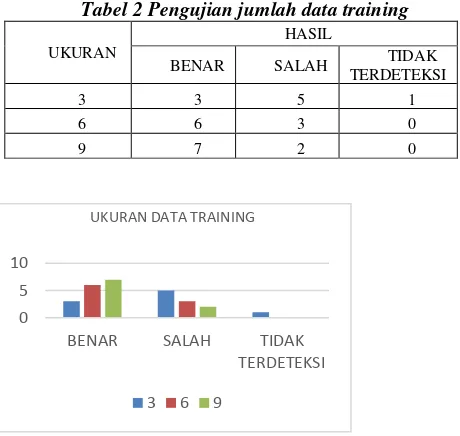
Untuk setiap proses learning disimpan dalam file xml, kemudian diuji dengan cara mendeteksi 9 gedung yang berbeda, hasil pengujian disajikan dalam tabel tersebut
Tabel 2 Pengujian jumlah data training
UKURAN
HASIL
BENAR SALAH TIDAK
TERDETEKSI
3 3 5 1
6 6 3 0
9 7 2 0
Gambar 9 Grafik Pengujian data training Dari data diatas dapat disimpulkan bahwa, semakin besar jumlah data training semakin besar pula kemungkinan akurat, karena jika jumlah data training semakin banyak, maka sistem pun semakin terbiasa mengenali setiap gedung yang akan diuji
Pengujian hubungan antara jumlah data training, ukuran file, dan ukuran row terkecil
Pada pengujian ini dilakukan untuk mengetahui hubungan antara jumlah data training, ukuran file, dan ukuran row terkecil. Hal ini dilakukan untuk membandingkan berapa jumlah data training yang ideal dan mencari ukuran file data learning terkecil. Karena pada nantinya jika data training yang diperoleh cukup besar akan membebani aplikasi yang dibuat atau device yang akan dipakai
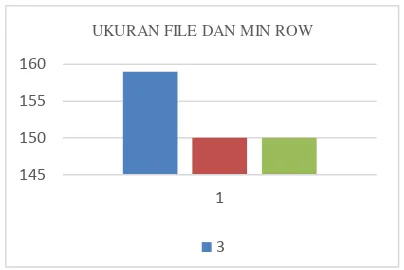
Untuk setiap proses learning disimpan dalam file xml, kemudian diuji dengan cara mendeteksi 9 gedung yang berbeda, hasil pengujian disajikan dalam tabel tersebut
Tabel 3 Pengujian ukuran file dan row terkecil
UKURAN DATA
UKURAN FILE
UKURAN ROW TERKECIL
3 6.173 KB 159
6 5.825 KB 150
9 5.825 KB 150
0 5 10
BENAR SALAH TIDAK
TERDETEKSI
UKURAN DATA TRAINING
Implementasi Metode SVM Untuk Pengenalan Citra Pada Bangunan Bersejarah Di Kota Bandung (Andhika Revky Fauzi, Cecep Nurul Alam, Rian Andrian)
252 Gambar 10 Grafik Pengujian ukuran file dan row
terkecil
Ukuran file tidak berbeda jauh, namun pada percobaan dengan data training 3 buah, diperoleh file yang lebih besar, hal ini diakibatkan karena min row pada pengumpulan informasi descriptor lebih besar yaitu 159, sedangkan yang lain 150. Ukuran file dipengaruhi oleh besarnya row terkecil yang dihasilkan, hal ini dapat dilihat pada ukuran data training yang berjumlah 6 dan 9 tidak ada perbedaan yang cukup signifikan karena ukuran row
terkecilnya pun persis sama.
Pengujian metode SVM antara linear dengan sigmoid Pada dasarnya metode dalam klasifikasi SVM ada dua, yaitu secara linear dan non linear. Sigmoid adalah salah satu metode klasifikasi SVM secara non linear.
a. Hasil Perbandingan Metode Linear dengan Sigmoid Pada pengujian ini dilakukan learning menggunakan bahasa java pada IDE Eclipse untuk memperoleh data training SVM dengan 2 metode yang berbeda yaitu sigmoid dan linear. Kedua metode tersebut diuji untuk menentukan metode terbaik dalam klasifikasi citra gedung menggunakan metode SVM
Untuk setiap proses learning disimpan dalam file xml, kemudian diuji dengan cara mendeteksi 9 gedung yang berbeda, hasil pengujian disajikan dalam tabel tersebut
Tabel 4 Perbandingan Metode Linear dengan Sigmoid
Berdasarkan Tabel 4, disimpulkan bahwa : 1. Dihasilkan kualitas dengan metode linear
lebih baik daripada sigmoid,
2. Hal ini karena dengan metode sigmoid, data tidak bisa tersebar dengan cukup luas, karena fungsinya dipengaruhi oleh fungsi eksponensial.
3. Ukuran File: Sigmoid lebih kecil daripada linear, karena metode ini diperkirakan menghasilkan
hyperplane (support vector) dengan dimensi yang lebih sedikit
4.
Pembahasan Hasil Pengujian Deteksi Gedung a. Pengujian Deteksi Dari Galeri
Pada pengujian ini dilakukan langsung pada aplikasi android yang telah dibuat. Tujuan dari pengujian ini adalah mengetahui keakuratan deteksi citra.
Untuk setiap prosesnya gambar diambil dari galeri langsung dilakukan 4 kali pada setiap gedung yang berbeda, untuk gambar yang diujikan berasal dari data
learning yang diambil secara acak, hasil pengujian dapat dilihat pada Tabel 4.6
Tabel 5 Hasil Pengujian Deteksi Gedung Dari Galeri
Gedung ke- Percobaan ke- Hasil
1 2 3 4 5 6
Gedung isola 100
St bandung 100
Hotel savoy
homann 100
Smpn 5
bandung 100
Kantor pos
bandung 100
Gereja bethel X 83
Gedung
merdeka 100
Gedung sate X X X 50
Bank bjb
syariah 100
Rata-rata 92,55
Dari semua percobaan yang dilakukan, hanya gedung sate yang mengalami kesalahan hingga 2 kali. Jika diperhatikan titik keypoint antar gambar cukup berbeda jauh, artinya pada gambar tersebut kurang cocok menggunakan metode SURF. Hal ini dipengaruhi oleh struktur gedung yang cukup kompleks, dan data learning
yang kurang cukup sehingga masih ada kesalahan dalam mendeteksi gedung.
b. Pengujian Deteksi Dari Kamera
Pada pengujian kali ini hampir sama dengan pengujian dari galeri, hanya saja gambar yang diinputkan diambil dari kamera langsung dan datanya berasal dari data learning. Gambar yang diujikan berasal dari data learning yang diambil secara acak, hasil pengujian dapat dilihat pada Tabel 6.
Tabel 6 Hasil Pengujian Deteksi Gedung Dari
Kamera
Gedung ke- Percobaan ke- Hasil
1 2 3 4 5 6
Gedung isola X X X X 33
St bandung X X X X X 16
Hotel savoy
homann X X X 50
Smpn 5
bandung X X 66
Kantor pos
bandung X X X X 33
Gereja bethel X X X X X X 0
JUMLA H DATA
HASIL UKURAN
DATA TRAINING BENA
R
SALA H
9 7 2 5.8 MB
9 1 8 4.5 MB
145 150 155 160
1
UKURAN FILE DAN MIN ROW
253 Gedung
merdeka X X X 50
Gedung sate X X X X 33
Bank bjb
syariah 100
Rata-rata 42,33
Hasil rata rata pengujian yang diambil dengan kamera adalah 42,33%. Hal ini dipengaruhi oleh beberapa faktor, yaitu pada saat pengambilan gambar tidak mendapatkan posisi yang tepat, resolusi gambar yang terlalu kecil, dan kualitas kamera yang kurang baik. Memang wajar hasil dari pengujian galeri akan berbeda secara signifikan dari pengujian kamera, tetapi disini dapat membuktikan bahwa metode SVM dan ekstraksi ciri surf dapat bekerja mendeteksi objek gedung dengan cukup baik.
Sehingga hasil akhir dari rata-rata keakurasian aplikasi ini adalah :
Pengujian Galeri + Pengujian Kamera
rata-rata akurasi 2
92,55 42,33 134,88
67, 44
2 2
=
+ = =
IV.PENUTUP Kesimpulan
Kesimpulan yang dapat diambil dari skripsi yang berjudul “Pengenalan Citra Gedung Bersejarah di Kota Bandung Dengan Metode SVM” ini adalah:
1. Telah dibuat sebuah aplikasi yang membantu masyarakat/pemkot/dinas/pihak terkait dalam mengawasi serta menumbuhkan rasa tanggung jawab terhadap pengelolaan bangunan cagar budaya di kota bandung.
2. Selain itu dapat memberikan informasi yang singkat, ringkas, dan informatif kepada pengguna mengenai gedung cagar budaya yang dimaksud. Diharapkan dengan adanya ini bisa menumbuhkan rasa cinta dan bangga memiliki kekayaan intelektual sejarah.
3. Dapat diterapkannya metode SVM untuk mengenali citra bangunan bersejarah di kota Bandung, dalam hal ini mencapai keakuratan sebesar 67,44%.
Saran
Pada aplikasi ini masih terdapat banyak sekali kekurangan, maka dari itu diperlukan beberapa pembaharuan sebagai penyempurnaan dari aplikasi ini diantaranya :
1. Kurangnya data data bangunan sejarah yang dimiliki, terutama foto tempo dulunya dikarenakan dokumentasi pada saat itu masih sulit dan terbatas.
2. Dapat ditambahkannya fitur lain agar pengguna merasa tertarik untuk menggunakan aplikasi ini
3. Diharapkannya dengan adanya aplikasi ini dapat menambah pengalaman dalam menjelajahi wisata di kota Bandung, terutama dalam hal cagar budaya
4. Masih adanya salah deteksi/error yang berakibat pada salahnya pemberian informasi kepada masyarakat awam.
5. Ditambah lagi data learning yang dimiliki agar hasil pendeteksian dapat meningkat
6. Dapat mendeteksi dalam berbagai kondisi alam, lingkungan, dan perangkat yang dipakai pengguna
V. REFERENSI
[1] “Pengertian Sejarah.” [Online]. Available: http://www.artikelsiana.com/2015/08/pengertian-sejarah-para-ahli-menurut.html.
[2] D. E. Ratnawati and A. W. Widodo, “Klasifikasi Penyakit Gigi Dan Mulut Menggunakan Metode Support Vector Klasifikasi Penyakit Gigi Dan Mulut Menggunakan Metode Support Vector Machine,” Res. Gate, vol. 2, no. March, pp. 802–
810, 2018.
[3] P. A. Octaviani, Yuciana Wilandari, and D. Ispriyanti, “Penerapan Metode Klasifikasi Support Vector Machine (SVM) pada Data Akreditasi Sekolah Dasar (SD) di Kabupaten Magelang,” J. Gaussian, vol. 3, no. 8, pp. 811–
820, 2014.