IMPLEMENTASI ALGORITMA APRIORI PADA SISTEM
PERSEDIAAN OBAT (STUDI KASUS : APOTIK
RUMAH SAKIT ESTOMIHI MEDAN)
Efori Buulolo
Dosen Tetap STMIK Budi Darma Medan Jl. Sisingamangaraja No. 338 Simpang Limun Medan
http: // www.stmik-budidarma.ac.id // Email: [email protected]
ABSTRAK
Data semakin lama akan semakin bertambah banyak. Jika dibiarkan saja, maka data-data transaksi tersebut hanya menjadi sampah yang tidak berarti. Dengan adanya dukungan perkembangan teknologi, semakin berkembang pula kemampuan dalam mengumpulkan dan mengolah data.
Data mining, sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining bisa dipakai untuk memperbaikin pengambilan keputusan dimasa depan.
Algoritma apriori adalah adalah algoritma yang paling terkenal untuk menemukan pola frekuensi tinggi. algoritma apriori dibagi menjadi beberapa tahap yang disebut narasi atau pass Pembentukan kandidat itemset, kandidat k-itemset dibentuk dari kombinasi (k-1)-itemset yang didapat dari iterasi sebelumnya. Satu cara dari algoritma apriori adalah adanya pemangkasan kandidat k-itemset yang subset-nya yang berisi k-1 item tidak termasuk dalam pola frekuensi tinggi dengan panjang k-1
Kata Kunci: Apriori, Persediaan, Data mining
1.1 Pendahuluan
Algoritma apriori pada saat ini telah diimplementasikan keberbagai bidang, salah satunya adalah dibidang bisnis atau perdangangan dan bidang pendidikan, dibidang bisnis misalnya implementasi data mining algoritma apriori untuk sistem penjualan tujuanya untuk membantu para pembisnis meningkatkan penjualan produk, Sedangkan dibidang pendidikan misalnya implementasi data mining untuk menemukan pola hubungan tingkat kelulusan mahasiswa dengan data induk mahasiswa.
Adanya kegiatan operasional sehari-hari data semakin lama akan semakin bertambah banyak. Jika dibiarkan saja, maka data-data transaksi tersebut hanya menjadi sampah yang tidak berarti. Dengan adanya dukungan perkembangan teknologi, semakin berkembang pula kemampuan dalam mengumpulkan dan mengolah data.
Persaingan di dunia bisnis, khususnya dalam industri apotik, menuntut para pengembang untuk menemukan suatu strategi yang dapat meningkatkan penjualan khusus penjualan obat dengan memaksimalkan pelayanan kepada konsumen. Salah satu caranya adalah dengan tetap tersediaannya berbagai jenis obat digudang apotik. Untuk mengetahui obat apa saja yang dibeli oleh para konsumen, dapat dilakukan dengan menggunakan teknik analisis keranjang pasar yaitu analisis dari kebiasaan membeli konsumen. Pendeteksian mengenai obat yang sering terbeli secara bersamaan disebut association rule (aturan asosiasi). Proses
pencarian asosiasi atau hubungan antar item data ini diambil dari suatu basis data relasional. Proses tersebut menggunakan algoritma apriori.
1.2 Perumusan Masalah
Berdasarkan uraian latar belakang, maka penulis merumuskan suatu permasalahan yaitu sebagai berikut:
1. Bagaimana membentuk pola kombinasi itemsets dengan menggunakan algoritma apriori pada sistem persediaan?
2. Bagaimana menghasilkan rules dari pola kombinasi itemsets yang interesting dengan association rules ?
1.3 Batasan Masalah
Agar tidak lepas dari latar belakang dan perumusan masalah, maka penulis membuat batasan masalahnya yaitu sebagai berikut :
1. Menggunakan data mining algoritma apriori untuk menemukan pola kombinasi itemset dan association rules untuk menghasilkan rules. 2. Data yang digunakan adalah data transaksi
penjualan (data obat keluar) dan menggunakan aplikasi atau tools data mining Tanagra 1.4 sebagai pengujian data.
1.4 Tujuan Penelitian
1. Membentuk pola kombinasi itemsets dari data penjualan (data obat keluar) dengan menggunakan algoritma apriori.
2. Menghasilkan rules dengan association rules dari pola kombinasi itemsets yang interesting.
2. Landasan Teori 2.1. Defenisi Data Mining
Data mining, sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining bisa dipakai untuk memperbaikin pengambilan keputusan dimasa depan (Budi Santosa, 2007).
Dari defenisi-defenisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah:
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada.
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang akan mungkin memberikan indikasi yang bermanfaat.
Gambar 1 Bidang Ilmu Data Mining
Data mining bukanlah suatu bidang yang sama sekali baru. Salah satu kesulitan untuk mendefenisikan data mining adalah kenyataan bahwa data mining mewariskan banyak aspek dan teknik bidang-bidang ilmu yang sudah mapan terlebih duhulu. Gambar 1 menunjukkan bahwa data mining memiliki akar yang panjang dari ilmu seperti ilmu kecerdasan buatan (artificial intelligent), machining learning, statistic, database, dan juga informasi retrievel.
Gambar 2 Proses Data Mining (Beta Noranita dan Nurdin Bahtiar , 2010)
1. Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaikin kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses encrihment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformation pada data yang telah dipilih, sehingga data tersebut sesuia dengan untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat bergantung pada jenis dan pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah proses mancari pola atau informasi menarik dalam data yang terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan. 5. Interpretation/Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang
Pencaria
n
mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dangan fakta atau hipotesis yang ada sebelumnya.
2.2 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Kusrini dan Emha Taufiq Luthfi, 2009): 1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari data untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menentukan keterangan atau fakta bahwa siapa yang tidak cukup professional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelesan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik dari pada kearah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel predikasi. Sebagai contoh akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi.
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam predikasi nilai dari hasik akan ada dimasa mendatang.
Contoh prediksi bisnis dan penelitian adalah: a. Prediksi harga beras dalam tiga bulan yang
akan datang.
b. Prediksi persentasi kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori , yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
Contoh lain klasifikasi dalam bisnis dan penelitian adalah:
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau tidak.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk.
c. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa.
5. Pengklusteran
Pengkluteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogeny), yang mana kemiripan dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Contoh pengklusteran dalam bisnis dan penelitian adalah:
a. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari satu
suatu produk bagi perusahaan yang tidak memiliki dana pemesaran yang besar.
b. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku financial dalam baik dan mencurigakan. c. Melakukan pengklusteran terhadap ekspresi
dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar.
6. Asosiasi.
Tugas asosiasi dalam data mining adalah menemukan attribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah:
a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan. b. Menentukan barang dalam supermarket yang
dibeli secara bersamaan dan yang tidak pernah dibeli secara bersamaan.
Data mining menganalisis data menggunakan tool untuk menemukan pola dan aturan dalam himpunan data. Perangkat lunak bertugas untuk menmukan pola dengan mengidentifikasi aturan dan fitur pada data. Tool data mining diharapkan mampu mengenal pola ini dalam data dengan input minimal dari user (Dana Sulistiyo Kusumo et al, 2003).
2.4. Komponen Data Mining
Secara alami, material data mining sebenarnya sudah terbentuk karena faktor rutinitas dan waktu seraya perusahaan melakukan aktivitasnya. Tanpa disadari perusahaan berinvestasi dengan menggunakan bugdetnya untuk penggunaan teknologi informasi atau komputer (Feri Sulianto dan Dominikus Juju, 2010).
Tetapi, tanpa penanganan yang seksama, perusahaan tidak dapat memanfaatkan investasinya di level yang lebih tinggi, maka dari itu sebelum benar-benar melakukan mining, perusahaan harus mengeluarkan sedikit effort lagi untuk realokasi dan pengadaan tools seperti layaknya seseorang yang melakukan penambangan.
Gambar 3. Aliran Data Pada Pembentukan Data Warehouse
Sebuah perusahaan membangun data warehouse dan data mart menggunakan sumberdaya informasi internal dan (mungkin juga) eksternal, kelola data warehouse dengan mining tools akan meng-generate laporan-laporan orientasi strategi dan taktis, dengan view yang dimengerti para pemegang keputusan yang melibatkan pula statistik, pekerja ahli dan menager-menager yang ada setiap lini perusahaan.
2.5. Langkah-langkah Mining
Secara rinci, ada empat tahap yang dilalui dalam data mining, antara lain :
1. Tahap pertama : Pricise statement of the problem (pernyataan tepat terhadap permasalahan)
Sebelum mengakses perangkat lunak data mining, seorang analis harus memiliki kejelasan perihal ‘pertanyaan apa yang akan ingin dijawabnya’. Jika tidak ada formula yang tepat untuk problematika yang ada maka anda hanya akan
membuang-buang dan uang dalam membuat solusinya.
2. Tahap kedua : Initial exploration
Tahap ini dimulai dengan mempersiapkan data yang juga juga termasuk kedalam data mining “cleaning” (misalnya : mengedentifikasi dan menyikirkan data yang dikodekkan salah), transformasi data, memilih subset record, data set, langkah awal seleksi. Mendeskripsikan dan memvisualisasikan data adalah kunci dari tahap ini.
3. Tahap tiga : Model building and validation
Tahap ini melibatkan pertimbangan terhadap ragam permodelan dan memilih yang terbaik bagi performasi prediktif.
4. Tahap ke-empat : Deployment
Memilih aplikasi yang tepat berikut permodelan untuk membuat (generate) prediksi. Selanjutnya kita kan melihat rincian perihal tahapan-tahapan data mining.
2.6. Association Rule
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan assosiatif antara kombinasi item. Contoh dari aturan assosiatif dari analisa pembelian di suatu pasar swalayan adalah dapat diketahui berapa besar kemungkinan seseorang membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang kampanye pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu (Amirudin et al, 2007)
2.6.1 Tahapan Association Rules
Analisis asosiasi dikenal juga sebagai salah satu teknik data mining yang menjadi dasar dari berbagai teknik data mining lainya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frekuensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efesien (Muhammad Ikhsan et al, 2007).
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap :
1. Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut:
Support (A) =
Sedangkan nilai dari support 2 item diperoleh dari rumus berikut :
9. Untuk setiap large itemset L, kita cari himpunan bagian L yang tidak kosong. Untuk setiap himpunan bagian tersebut, dihasilkan rule dengan bentuk aB(L-a) jika supportnya (L) dan supportnya
(a) lebih besar dari minimum support. Setelah semua pola frekuensi tinggi
ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat minimum untuk confidence dengan
menghitung confidence aturan assosiatif A
Nilai confidence dari aturan A diperoleh dari
rumus berikut : 2.7.Algoritma Apriori
Algoritma apriori adalah adalah algoritma yang paling terkenal untuk menemukan pola frekuensi tinggi. algoritma apriori dibagi menjadi beberapa tahap yang disebut narasi atau pass (Devi dinda setiawan, 2009).
Confidence = P(B|A) =
2.6.2. Langkah-Langkah Proses Penghitungan
Association Rules 1. Pembentukan kandidat itemset, kandidat k-itemset dibentuk dari kombinasi (k-1)-itemset yang didapat dari iterasi sebelumnya. Satu cara dari algoritma apriori adalah adanya pemangkasan kandidat itemset yang subset-nya yang berisi k-1 item tidak termasuk dalam pola frekuensi tinggi dengan panjang k-1.
Proses perhitungan association rule terdiri dari beberapa tahap adalah sebagai berikut (Eko Wahyu Tyas d, 2008).
1. Sistem men-scan database untuk mendapat kandidat 1-itemset (himpunan item yang terdiri dari 1 item) dan menghitung nilai supportnya. Kemudian nilai supportnya tersebut dibandingkan dengan minimum support yang telah ditentukan, jika nilainya lebih besar atau sama dengan minimum support maka itemset tersebut termasuk dalam large itemset.
2. Penghitungan support dari tiap kandidat k-itemset. Support dari tiap kandidat k-itemset didapat dengan menscan database untuk menghitung jumlah transaksi yang memuat semua item didalam kandidat k-itemset tersebut. Ini adalah juga ciri dari algoritma apriori dimana diperlukan penghitungan dengan cara seluruh database sebanyak k-itemset terpanjang.
2. Itemset yang tidak termasuk dalam large itemset tidak diikutkan dalam iterasi selanjutnya (di prune).
3. Tetapkan pola frekuensi tinggi. Pola frekuensi tinggi yang memuat k item atau k-itemset ditetapkan dari kandidat k-itemset yang supportnya lebih besar dari minimum support. 3. Pada iterasi kedua sistem akan menggunakan
hasil large itemset pada iterasi pertama (L1)
untuk membentuk kandidat itemset kedua (L2).
Pada iterasi selanjutnya sistem akan menggunakan hasil large itemset pada iterasi selanjutnya akan menggunakan hasil large itemset pada iterasi sebelumnya (Lk-1) untuk membentuk
kandidat itemset berikut (Lk). Sistem akan
menggabungkan (join) Lk-1 dengan Lk-1 untuk
mendapatkan Lk, seperti pada iterasi sebelumnya
sistem akan menghapus (prune) kombinasi itemset yang tidak termasuk dalam large itemset.
4. Bila tidak didapat pola frekuensi tinggi baru maka seluruh proses dihentikan. Bila tidak, maka k ditambah satu dan kembali bagian 1.
3. Pembahasan
Proses pembentukan pola kombinasi itemsets dan pembuatan rules dimulai dari analisis data. Data yang digunakan adalah data transaksi penjualan obat, kemudian dilanjutkan dengan pembentukan pola kombinasi itemsets dan dari pola kombinasi itemsets yang menarik terbentuk association rules.
4. Setelah dilakukan operasi join, maka pasangan itemset baru hasil proses join tersebut dihitung supportnya.
5. Proses pembentuk kandidat yang terdiri dari proses join dan prune akan terus dilakukan hingga himpunan kandidat itemsetnya null, atau sudah tidak ada lagi kandidat yang akan dibentuk.
3.2.1 Analisis Data
Dengan studi kasus pada apotik rumah sakit Estomihi Medan, dapat dilakukan analisa terhadap data khusus data penjualan (data obat keluar) dengan salah satu tujuan adalah untuk menemukan pola kombinasi penjualan obat dan hubungan antar item jenis obat didalam transaksi. Berikut ini adalah tabel 1 yaitu beberapa sampel data yang akan dijadikan sampel untuk analisis dan juga untuk pengujian. 6. Setelah itu, dari hasil frequent itemset tersebut
dibentuk association rule yang memenuhi nilai support dan confidence yang telah ditentukan. 7. Pada pembentukan association rule, nilai yang
sama dianggap sebagai satu nilai.
8. Assosiotion rule yang terbentuk harus memenuhi nilai minimum yang telah ditentukan.
Tabel 1. Tabel Real Data Penjualan (Data Obat Keluar)
No No Slip Nama Obat
2 2012.1.502 Ringer Lactate Larutan,Pitogin Inj 10 IU/ ml /sintosin,Ceftriaxone Inj 1.0g,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml
3 2012.1.503 Ringer Lactate Larutan,Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,Ketorolac 3% Inj 30 mg/ml
4 2012.1.504 Ringer Lactate Larutan,Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,Ketorolac 3% Inj 30 mg/ml
5 2012.1.505 Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,Ketorolac 3% Inj 30 mg/ml,Ringer Lactate Larutan
6 2012.1.506
Ringer Lactate Larutan,Dexametason Inj 5mg/ml - 1ml
7 2012.1.507 Ringer Lactate Larutan,Pitogin Inj 10 IU/ ml /sintosin,Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,Ketorolac 3% Inj 30 mg/ml
8 2012.1.502 Ringer Lactate Larutan,Ceftriaxone Inj 1.0g,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml
9 2012.1.504 Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,Ketorolac 3% Inj 30 mg/ml,Ringer Lactate Larutan
10 2012.1.505 Ceftriaxone Inj 1.0g,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml,Ringer Lactate Larutan
11 2012.1.506 Ringer Lactate Larutan,Ceftriaxone Inj 1.0g,Pitogin Inj 10 IU/ ml /sintosin,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml
12 2012.1.511 Ringer Lactate Larutan,Ceftriaxone Inj 1.0g,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml
13 2012.1.2457 Ringer Lactate Larutan,Pitogin Inj 10 IU/ ml /sintosin,Infusion set dewasa/ makro,Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,spuit 10 cc,Ketorolac 3% Inj 30 mg/ml,Spuit 3 cc
14 2012.1.4143 spuit 5 cc,Infusion set dewasa/ makro,Abocath 18,Ringer Lactate Larutan,Pitogin Inj 10 IU/ ml /sintosin,Spuit 3 cc,Metronidazole Inj 5mg/ml - 100ml,Ceftriaxone Inj 1.0g,spuit 10 cc,Ketorolac 3% Inj 30 mg/ml,Spinocan 27 B Raun,Bupivacaine Spinal Inj 5 mg/ml - 4ml/Decain,Ranitidine Inj 25mg/ml - 2ml,Ethiferan / MetocLopramide Inj 5 mg/ml,Ephedrine Inj 50 mg/mL,Myo-Mergin Inj 200 mcg/mL,Tramadol Inj 100 mg/2 mL,Natrium klorida (NaCl) 500 ml,Glove size M / Handskun,masker
15 2012.1.4441 Infusion set dewasa/ makro,Abocath 18,Plester 5 yard x 2 inch,Ceftriaxone Inj 1.0g,spuit 10 cc,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml,Pitogin Inj 10 IU/ ml /sintosin,Spuit 3 cc, Ringer Lactate Larutan
16 2012.1.4442 Ringer Lactate Larutan,Ceftriaxone Inj 1.0g,spuit 10 cc,Metronidazole Inj 5mg/ml - 100ml,Ketorolac 3% Inj 30 mg/ml,Spuit 3 cc
17 2011.1.1237 Ringer Lactate Larutan,Abocath 18,Infusion set dewasa/ makro
18 2011.1.1949 Abocath 18,Ringer Lactate Larutan,Infusion set dewasa/ makro,Cefotaxime Inj 1.0g,Ketorolac 3% Inj 30 mg/ml,Transamin
19 2011.1.1956 Abocath 18,Ringer Lactate Larutan,Infusion set dewasa/ makro,Lidocain Kompositum Inj,Ketorolac 3% Inj 30 mg/ml,Cefotaxime Inj 1.0g
20 2012.1.395 Ceftriaxone Inj 1.0g, Ringer Lactate Larutan
21 2012.1.890 Ringer Lactate Larutan, Paracetamol 500 mg, Antasida Doen Syrup,Vitamin B Compleks
22 2012.1.2066 Antasida Doen Syrup,Diaform 20 mg,- Metronidazole
Data diatas adalah bentuk transaksi data penjualan (data obat keluar) real terdiri atas attribute nomor slip dan nama obat.
Tahap dalam menganalisa data dengan algoritma apriori pada penjualan (data obat keluar) dimulai dengan menyeleksi dan membersihkan data-data yang akan dianalisis, kemudian dicari semua jenis item nama obat yang ada didalam list
pola maka langkah selanjutnya pembentuk rules association, rules yang akan dihasilkan dibentuk dari pola kombinasi itemsets yang memenuhi support minimal. Gambar 4 merupakan flowchart algorima apriori sebagai berikut:
Gambar 4. Flowchat Algoritma Apriori
3.2.2 Analisa Pola Frekuensi Tinggi
Sebelum dilakukan pencarian pola dari data transaksi terlebih dulu, dicari semua nama jenis item obat yang ada didalam transaksi seperti pada seperti pada tabel 4.2 sekaligus menentukan support peritem jenis obat, dimana tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database, nilai support sebuah item diperoleh dengan rumus berikut:
∑
=
Transaksi
A mengandung yang
transaksi Jumlaht
A
Support( ) _ _ _ _ S
edangkan nilai support dari dua item diperoleh dengan rumus berikut:
Support (A, B) =P(A ∩ B)
∑
∑
=
Transaksi
B dan A mengandung yang
Transaksi B
A
Support( , ) _ _ _ _ _
Tabel berikut merupakan tabel semua jenis item obat yang didalam transaksi penjualan (data obat keluar), seperti pada tabel berikut ini:
Tabel 2 Keterangan Jenis Items Obat
Items Support Suppo
rt(%)
Abocath 18 5 22,73
Antasida Doen Syrup 2 9,09 Bupivacaine Spinal Inj 5 mg/ml -
4ml/Decain 1 4,55
Cefotaxime Inj 1.0g 2 9,09
Ceftriaxone Inj 1.0g 16 72,73
Dexametason Inj 5mg/ml - 1ml 1 4,55
Diaform 20 mg 1 4,55
Ephedrine Inj 50 mg/mL 1 4,55 Ethiferan / MetocLopramide Inj 5
mg/ml 1 4,55
Glove size M / Handskun 1 4,55
Infusion set dewasa/ makro 6 27,27
Ketorolac 3% Inj 30 mg/ml 17 77,27
Lidocain Kompositum Inj 1 4,55
Masker 1 4,55
Metronidazole 1 4,55
Metronidazole Inj 5mg/ml – 100ml 15 68,18
Myo-Mergin Inj 200 mcg/mL 1 4,55
Natrium klorida (NaCl) 500 ml 1 4,55
Paracetamol 500 mg 1 4,55
Pitogin Inj 10 IU/ ml /sintosin 6 27,27
Plester 5 yard x 2 inch 1 4,55
Ranitidine Inj 25mg/ml - 2ml 2 9,09
Ringer Lactate Larutan 21 95,45
Spinocan 27 B Raun 1 4,55
spuit 10 cc 4 18,18
Spuit 3 cc 4 18,18
spuit 5 cc 1 4,55
Tramadol Inj 100 mg/2 mL 1 4,55
Transamin 1 4,55
Vitamin B Compleks 1 4,55
Data diatas menggambar bentuk data satu item, yang terdiri atas attribute item sebagai nama item jenis semua obat yang ada didalam transaksi, support yaitu jumlah setiap item yang ada disemua transaksi, sedangkan support (%) adalah presentasi jumlah item yang ada didalam transkasi, yang
Tabel 3 Keterangan Jenis Items Obat yang Memenuhi Support Minimal
Items Sup
port Sup port(%)
Abocath 18 5 22,73
Ceftriaxone Inj 1.0g 16 72,73
Infusion set dewasa/ makro 6 27,27
Ketorolac 3% Inj 30 mg/ml 17 77,27
Metronidazole Inj 5mg/ml – 100ml 15 68,18
Pitogin Inj 10 IU/ ml /sintosin 6 27,27
Ringer Lactate Larutan 21 95,45
3.2.3. Pembentukan Pola Kombinasi Dua Itemsets
Pembentukan pola frekuensi dua itemsets, dibentuk dari items-items jenis obat yang
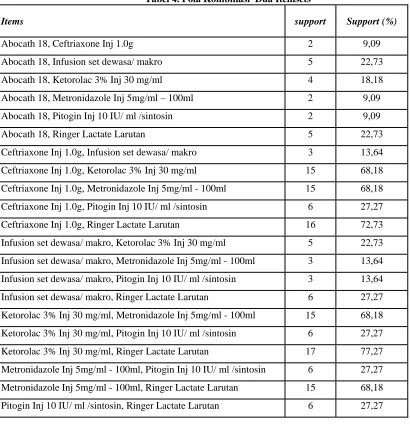
memenuhi support minimal yaitu dengan cara mengkombinasi semua items kedalam pola dua kombinasi, hasil pembentukan pola kombinasi dua itemsets yang dibentuk dari tabel 4 berikut ini:
Tabel 4. Pola Kombinasi Dua Itemsets
Items support Support (%)
Abocath 18, Ceftriaxone Inj 1.0g 2 9,09
Abocath 18, Infusion set dewasa/ makro 5 22,73
Abocath 18, Ketorolac 3% Inj 30 mg/ml 4 18,18
Abocath 18, Metronidazole Inj 5mg/ml – 100ml 2 9,09
Abocath 18, Pitogin Inj 10 IU/ ml /sintosin 2 9,09
Abocath 18, Ringer Lactate Larutan 5 22,73
Ceftriaxone Inj 1.0g, Infusion set dewasa/ makro 3 13,64
Ceftriaxone Inj 1.0g, Ketorolac 3% Inj 30 mg/ml 15 68,18
Ceftriaxone Inj 1.0g, Metronidazole Inj 5mg/ml - 100ml 15 68,18
Ceftriaxone Inj 1.0g, Pitogin Inj 10 IU/ ml /sintosin 6 27,27
Ceftriaxone Inj 1.0g, Ringer Lactate Larutan 16 72,73
Infusion set dewasa/ makro, Ketorolac 3% Inj 30 mg/ml 5 22,73
Infusion set dewasa/ makro, Metronidazole Inj 5mg/ml - 100ml 3 13,64
Infusion set dewasa/ makro, Pitogin Inj 10 IU/ ml /sintosin 3 13,64
Infusion set dewasa/ makro, Ringer Lactate Larutan 6 27,27
Ketorolac 3% Inj 30 mg/ml, Metronidazole Inj 5mg/ml - 100ml 15 68,18
Ketorolac 3% Inj 30 mg/ml, Pitogin Inj 10 IU/ ml /sintosin 6 27,27
Ketorolac 3% Inj 30 mg/ml, Ringer Lactate Larutan 17 77,27
Metronidazole Inj 5mg/ml - 100ml, Pitogin Inj 10 IU/ ml /sintosin 6 27,27
Metronidazole Inj 5mg/ml - 100ml, Ringer Lactate Larutan 15 68,18
Pitogin Inj 10 IU/ ml /sintosin, Ringer Lactate Larutan 6 27,27
Data diatas merupakan kombinasi dua itemsets yang merupakan hasil dari semua kombinasi semua jenis items. Dengan menetapkan support minimal sama dengan 22 persen (%), maka data yang memenuhi support minimal adalah seperti pada tabel 5 berikut ini:
Data diatas adalah pola kombinasi dua itemsets yang memenuhi support minimal, terlihat data kombinasi jenis obat Ketorolac 3% Inj 30 mg/ml dan Ringer Lactate Larutan, memiliki support yang terbanyak, itu menandakan bahwa pola kombinasi dua itemsets tersebut paling banyak didalam transaksi.
3.2.4 Pembentukan Association Rules
Setelah semua pola frekuensi tinggi ditemukan, baru dicari association rules yang memenuhi syarat minimum confidence, dengan menghitung confidence aturan asosiati A ke B. Nilai confidence dari aturan A ke B diperoleh dengan rumus:
Proses mencari jumlah kombinasi dan kuatnya
hubungan antara satu item dengan item yang lain dalam satu kombinasi disebut metode association rules. Pembentukan association rules adalah menganalisis pola frekuensi tinggi, tahap ini mencari kombinasi yang memenuhi syarat minimum dari support dalam database. Proses aturan association rules, dikenal dengan istilah mencari nilai confidence dan support, dimana support adalah jumlah item-item yang berkombinasi di dalam transaksi sedangankan confidence adalah nilai yang mendefinisikan kuat tidaknya hubungan antara item-item tersebut.
Sedangkan rumus untuk mendapat lift sebagai berikut:
Data tabel diatas merupakan tabel calon aturan asosiasi dari pola kombinasi dengan empat items, tabel diatas terdiri atas rules sebagai rules dari kombinasi empat itemsets, lift sebagai nilai tingkat kekuatan rules, support(itemsets) sebagai nilai support antara ke keempat itemsets yang berkombinasi, support sebagai nilai support item yang mengandung antecedent. Dengan menetapkan confidence minimal adalah 60 persen(%), maka rules yang interesting yang dihasilkan seperti pada tabel berikut ini:
Tabel 6. Assosiation Rules yang Memenuhi Confidence Minimal
Rules Lift Support Confi
dence (%) Jika dibeli Ceftriaxone Inj 1.0g : maka akan dibeli Ketorolac
3% Inj 30 mg/ml, Metronidazole Inj 5mg/ml - 100ml dan Ringer Lactate Larutan
1,37500 68.18 93,75
Association rules dari tabel diatas merupakan aturan yang terbentuk dari pola kombinasi empat item, tabel diatas terbagai atas beberapa bagian rules adalah aturan yang dihasilkan dari pola kombinasi empat itemsets, lift sebagai nilai tingkat kekuatan rules, support adalah nilai support antara ketiga items, sedangkan confidence adalah nilai
yang didapat dari support empat itemsets dibagi oleh nilai support antecedent di kalikan seratus persen.
Pembentukan aturan asosiasi berikutnya dibentuk dari pola kombinasi lima itemsets tampak pada tabel berikut ini:
Tabel 7. Calon Association rules
Rules Lift Support
(itemsets)
Support Confi dence
(%) Jika Pitogin Inj 10 IU/ ml /sintosin : maka akan
dibeli Ceftriaxone Inj 1.0g, Ketorolac 3% Inj 30 mg/ml, Metronidazole Inj 5mg/ml – 100ml dan Ringer Lactate Larutan
1,46667 6 6 100
Jika dibeli Metronidazole Inj 5mg/ml - 100ml: maka akan dibeli Ceftriaxone Inj 1.0g , Ketorolac 3% Inj 30 mg/ml, Ringer Lactate
Larutan dan Pitogin Inj 10 IU/ ml /sintosin
Jika dibeli Ringer Lactate Larutan: maka akan dibeli Ceftriaxone Inj 1.0g, Ketorolac 3% Inj 30 mg/ml, Metronidazole Inj 5mg/ml - 100ml dan Pitogin Inj 10 IU/ ml /sintosin
1,04757 6 21 28,57
Data tabel diatas merupakan tabel calon association rules dari pola kombinasi dengan lima itemsets, tabel diatas terdiri atas rules sebagai rules dari pola kombinasi lima itemsets, lift sebagai nilai tingkat kekuatan rules, support(itemsets) sebagai nilai support antara kelima items yang berkombinasi,
support sebagai nilai support item yang mengandung antecedent. Dengan menetapkan nilai confidence minimal sama dengan 60 persen(%), maka rules yang interesting yang dihasilkan seperti pada tabel berikut ini:
Tabel 8. Association Rules yang Memenuhi Nilai Confidence Minimal
Rules Lift Support Confi
dence (%) Jika dibeli Pitogin Inj 10 IU/ ml /sintosin : maka akan dibeli
Ceftriaxone Inj 1.0g, Ketorolac 3% Inj 30 mg/ml, Metronidazole Inj 5mg/ml - 100ml dan Ringer Lactate Larutan
1,46667 27,27 100
Association rules dari tabel diatas merupakan aturan yang terbentuk dari pola kombinasi lima itemsets, tabel diatas terbagai atas beberapa bagian yaitu rules sebagai aturan yang dihasilkan dari pola kombinasi lima itemsets, lift sebagai nilai tingkat kekuatan rules, support adalah nilai support antara kelima itemsets, sedangkan confidence adalah nilai yang didapat dari support lima itemsets dibagi oleh nilai support antecedent di kalikan seratus persen.
3.3. Format Tabular Data Transaksi
Format tabular data adalah format data dalam bentuk 1 dan 0 atau format data dalam bentuk biner. Berhubungan dengan aplikasi yang digunakan dalam pengujian adalah aplikasi yang
menggunakan salah satu database Microsoft Exel dengan data dalam bentuk tabular data, maka data transaksi penjualan (data obat keluar), di konversi ke dalam bentuk biner. Proses konversinya adalah nomor slip dari data yang akan diuji dibuat dalam bentuk horizontal kebawah, sedangkan semua jenis items akan menjadi attribute berbentuk vertical, sehingga membentuk seperti sebuah tabel, berdasarkan data real penjualan (data obat keluar) titik ketemu antara nama jenis obat dengan nomor slip akan menjadi biner 1, sedangkan yang tidak menjadi titik temu akan menjadi biner 0. Hasil proses konversi data transaksi penjualan ke format data dalam bentuk tabular data adalah seperti pada tabel berikut ini:
3.4. Pengujian Untuk Menghasilkan Rules
Setelah melakukan pengujian untuk menghasilkan jenis items dan pola kombinasi, mulai dari kombinasi dua items sampai dengan pola kombinasi lima items, , dimana rules-rules tersebut terbentuk dari pola kombinasi items pada pengujian sebelumnya. Pengujian yang dilakukan pertama adalah pengujian untuk menghasilkan rules-rules yang terbentuk dari pola kombinasi dua items. . Jendela Association rules adalah seperti pada gambar 5 berikut:
Gambar 5. Jendela Association Rules Paremeters
Setelah dilakukan penentuan nilai parameters, maka rules-rules yang dihasilkan dari parameters diatas adalah seperti pada gambar 6 berikut ini:
Gambar 7. Pengujian Dengan Rules Dari Pola Kombinasi Dua, Tiga, Empat dan Lima
Itemsets.
Rules diatas merupakan rules yang dihasilkan dari pengujian dengan parematers sama dengan support sama dengan 22 persen(%), confidence sama dengan 60 (%), maksimal card itemsets sama dengan 5 (lima) dan lift sama dengan 0. Dengan maksimal card itemsets sama dengan 5 (lima) maka rule yang terbentuk adalah berasal dari pola kombinasi dua itemset sampai dengan pola kombinasi lima itemsets jadi rule yang dihasilkan bertambah menjadi sebanyak 128 rules. Rules yang dihasilkan diatas ada didalam bentuk tabel dengan attribute adalah antecedent sebagai kondisi dari pada rules, consequent sebagai pernyataan dari rules yang dihasilkan, lift sebagai tingkat kekuatan rules, support sebagai nilai support items-items yang ada didalam rules didalam bentuk kombinasi, sedangkan confidence adalah nilai kekuatan antar items yang ada didalam satu rules.
Dari beberapa rules yang dihasilkan dari pengujian diatas yang paling tinggi nilai support dan confidencenya adalah salah satunya dari rules, if Ketorolac 3% Inj 30 mg/ml=true" - "Metronidazole Inj 5mg/ml - 100ml=true" : maka "Ringer Lactate Larutan=true", dimana supportnya sama dengan 68,182% dan confidencenya sama dengan 100%. Berhubungan karena jumlah pola kombinasi maksimal lima items, maka pengujian dengan paremeters maksimal card itemset sama dengan enam dan seterusnya tidak dapat dilakukan, jadi rulesnya
4. Kesimpulan Dan Saran 4.1 Kesimpulan
Berdasarkan hasil analisis dengan algoritma apriori dan pengujian dengan aplikasi Tanagra maka penulis menarik sebuah kesimpulan, dimana kesimpulan tersebut nanti dapat kiranya berguna bagi pembaca, sehingga penulisan tesis ini dapat lebih berguna dan bermanfaat. Adapun kesimpulan-kesimpulan tersebut antara lain sebagai berikut:
1. Dengan algoritma apriori dan pengujian dengan aplikasi Tanagra menghasilkan pola kombinasi itemsets dan rules sebagai ilmu pengetahuan dan informasi penting dari data penjualan (data obat keluar).
2. Teknik data mining denga algoritma apriori dapat diimplementasikan pada sistem persediaan dengan data yang digunakan adalah data penjualan (data obat keluar).
3. Hasil yang diperoleh dengan algoritma apriori dan pengujian dengan aplikasi adalah salah satunya, Pola kombinasi yang paling tinggi supportnya adalah pola kombinasi Ketorolac 3% Inj 30 mg/ml, Ringer Lactate Larutan, sedangkan pola kombinasi yang paling banyak itemnya adalah kombinasi itemsets Ceftriaxone Inj 1.0g, Ketorolac 3% Inj 30 mg/ml, Metronidazole Inj 5mg/ml - 100ml, Ringer Lactate Larutan dan Pitogin Inj 10 IU/ ml /sintosin
4. Data mining dengan algoritma apriori memiliki kelemahan karena harus melakukan scan database setiap kali iterasi, sehingga waktu bertambah setiap kali iterasi.
5. Banyaknya asosiasi antar data dan pola kombisi dan rules yang makin akurat, didapat berdasarkan volume data dan level confidence dan support yang bervariasi.
4.2 Saran
Untuk kepentingan lebih lanjut dari penulisan tesis ini maka penulis memberikan beberapa saran sebagai berikut :
1. Disarankan dapat dikembangkan dengan menambah volume data serta penggunaan level confidence dan support yang bervariasi sehingga diperoleh lebih banyak asosiasi antar data.
2. Berdasarkan kelememahan data mining dengan algoritma apriori yaitu membutuhkan waktu yang lama, maka perlu menggunakan algoritma FP ( frequent pattern) Growth. Dimana algoritma FP Growth merupakan pengembangan dari algoritma apriori.
3. Perlu dilakukan perbandingan dengan algoritma lain, untuk menguji serta mendapatkan kesimpulan bahwa algoritma apriori berkinerja baik untuk memproses dan menemukan pola hubungan (asosiasi) antar item dari suatu basis data data transaksi.
DAFTAR PUSTAKA
2. Feri Sulianto dan Dominikus Juju (2010). Data Mining, Meramalkan Bisnis Perusahaan. Jakarta. Penerbit Elex Media Komputindo.19-22.
3. Kusrini dan Emha Taufig Luthfi (2009). Algoritma Data Mining. Yogyakarta. Penerbit Andi.3-12,
4. Sani Susanto dan Dedy Suryadi (2010). Pengantar Data Mining. Yogyakarta. Penerbit Andi.97.
5. Devi Dinda Setiawati (2009). Penggunaan Metode Apriori Untuk Analisa Keranjang Pasar Pada Data Transaksi Penjualan Minimarket Menggunakan Java dan Mysql.
6. Eko Wahyu Tyas D (2008). Penerapan Metode Association Rules Menggunakan
Algoritma Apriori Untuk Analisa Pola Data Hasil Tangkapan Ikan.
7. M.Ikhsan, M. Dahria dan Sulindawaty (2011). Penerapan Association Rules Dengan Algoritma Apriori Pada Proses Pengelompokan Barang di Perusahaan Retail.
8. Dana Sulistiyo, Moch.Arief Bijaksana dan Dhinta Darmantoro (2003). Data Mining Dengan Algoritma Apriori pada RDBMS ORACLE.