TINJAUAN PUSTAKA
2.1. Data Mining
Definisi sederhana dari data mining adalah ekstraksi informasi atau pola yang penting
atau menarik dari data yang ada di database. Secara lengkap, Data mining merupakan
serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini
tidak diketahui secara manual dari suatu basis data dengan melakukan penggalian
pola-pola dari tumpukan data dengan tujuan untuk memanipulasi data menjadi
informasi yang lebih berharga.
Menurut Berry dan Linoff (2004): “Data mining adalah mengeksplorasi dan
menganalisis data dalam jumlah besar untuk menemukan pola dan rule yang berarti”.
Sedangkan menurut Han dan Kamber (2001): “Data mining adalah proses menambang
(mining) pengetahuan dari sekumpulan data yang sangat besar”. Data mining
merupakan suatu langkah dalam Knowledge Discovery in Database (KDD). Jadi,
dengan semakin berkembangnya kebutuhan akan informasi-informasi, semakin
banyak pula bidang-bidang yang rnenerapkan konsep data mining.
Data mining merupakan bidang dari beberapa bidang keilmuan yang
visualisai untuk penanganan permasalahan pengambilan informasi dari database yang
besar (Larose, 2005). Data mining adalah analisis otomatis dari data yang berjumlah
besar atau kompleks dengan tujuan untuk menentukan pola atau kecenderungan yang
penting yang biasanya tidak disadari keberadaannya (Moertini, 2002). Hal-hal penting
yang terkait dengan data mining adalah (Luthfi & Kusrini, 2009) :
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah
ada.
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang
mungkin memberikan indikasi yang bermanfaat.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua
atau lebih objek dalam satu dimensi yang sama. Misalnya dalam dimensi produk dapat
melihat keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu,
hubungan juga dapat dilihat antara dua atau lebih atribut dan dua atau lebih objek
(Ponniah, 2001). Masalah-masalah yang sesuai untuk diselesaikan dengan teknik data
mining dapat dicirikan dengan :
1. Memerlukan keputusan yang bersifat knowledge-based. 2. Mempunyai lingkungan yang berubah.
3. Metode yang ada sekarang bersifat sub-optimal. 4. Tersedia data yang bisa diakses, cukup dan relevan.
Data mining sering digunakan untuk membangun model prediksi/inferensi
yang bertujuan untuk memprediksi tren masa depan atau perilaku berdasarkan analisis
data terstruktur. Dalam konteks ini, prediksi adalah pembangunan dan penggunaan
model untuk menilai kelas dari contoh tanpa label, atau untuk menilai jangkauan nilai
atau contoh yang cenderung memiliki nilai atribut. Klasifikasi dan regresi adalah dua
bagian utama dari masalah prediksi, dimana klasifikasi digunakan untuk memprediksi
nilai diskrit atau nominal sedangkan regresi digunakan untuk memprediksi nilai
terus-menerus atau nilai yang ditentukan (Larose, 2005).
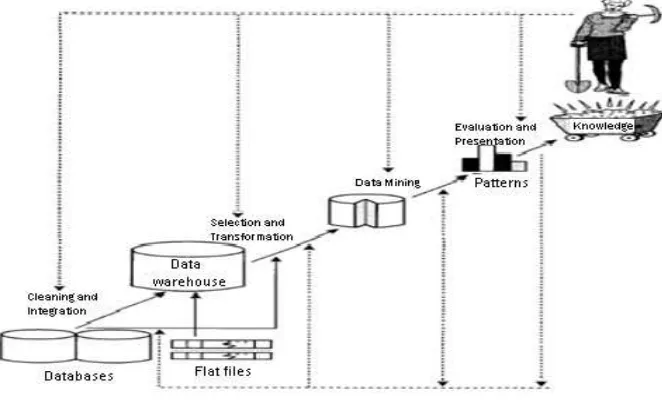
2.1.1. Tahapan Data Mining
Dalam aplikasinya, data mining sebenarnya merupakan bagian dari Knowledge
Discovery in Database (KDD), bukan sebagai teknologi yang utuh berdiri sendiri.
Data mining merupakan suatu bagian langkah yang penting dalam KDD terutama
berkaitan dengan ekstraksi dan perhitungan pola-pola dari data yang ditelah. Seperti
Gambar 2.1. Tahapan Data Mining
Dari gambar dapat dijelaskan proses dari data mining dari setiap tahap yaitu berikut
ini:
1. Data cleaning
Tahapan ini dilakukan untuk menghilangkan data noise dan data yang tidak
konsisten atau relevan dengan tujuan akhir dari proses data mining.
2. Data integration
Tahapan ini dilakukan untuk menggabungkan atau mengkombinasikan dari
multiple data source.
Yang dilakukan pada tahapan ini adalah memilih atau menyeleksi data apa saja
yang relevan dan diperlukan dari database.
4. Data transformation
Untuk mentransformasikan data ke dalam bentuk yang lebih sesuai untuk di
mining.
5. Data mining
Proses terpenting dimana metode tertentu diterapkan dalam database untuk
menghasilkan data pattern.
6. Pattern evaluation
Untuk mengidentifikasi apakah interesting patterns yang didapatkan sudah cukup
mewakili knowledge berdasarkan perhitungan tertentu.
7. Knowledge presentation
Untuk mempresentasikan knowledge yang sudah didapatkan dari user.
2.1.2. Pengelompokkan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat
1. Deskripsi
Terkadang penelitian analisis secara sederhana ingin mencoba mencari cara untuk
menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai
contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan
atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam
pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan
kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke
arah numerik daripada ke arah kategori. Model dibangun menggunakan record
lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi.
Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat
berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi
tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis
kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan
darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan
menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan
untuk kasus baru lainnya.
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam
prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis
dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi presentase kenaikan kecelekaan lalu lintas tahun depan jika batas
bawah kecepatan dinaikkan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat
pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan
tinggi, pendapatan sedang, dan pendapatan rendah.
Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
1. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang
curang atau bukan.
2. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan
3. Mendiagnosis penyakit seorang pasien untuk mendapatkan kategori
penyakit apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang
lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster lain.
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target
dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi,
mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma
pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data
menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana
kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan
kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Contoh pengklusteran dalam bisnis dan penelitian adalah:
1. Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan
2. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari
suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang
besar.
3. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap
perilaku finansial dalam baik dan mencurigakan.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam
satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah :
1. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan
barang yang tidak pernah dibeli secara bersamaan.
2. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang
diharapkan untuk memberikan respons positif terhadap penawaran
2.2. Algoritma Apriori
Algoritma apriori adalah sebuah algoritma pencarian pola yang sangat populer dalam
teknik penambangan data (data mining). Algoritma ini ditujukan untuk mencari
kombinasi itemset yang mempunyai suatu nilai keseringan tertentu sesuai kriteria atau
filter yang diinginkan. Algoritma ini diajukan oleh R. Agrawal dan R. Srikant tahun
1994.
Hasil dari algoritma apriori dapat digunakan untuk membantu dalam
pengambilan keputusan pihak manajemen. Algoritma apriori melakukan pendekatan
iteratif yang dikenal dengan pencarian level-wise, dimana k-itemset digunakan untuk
mengeksplorasi atau menemukan (k+1)-itemset. Oleh karena itu, algoritma apriori
dibagi menjadi beberapa tahap yang disebut iterasi. Tiap iterasi menghasilkan pola
frekuensi tinggi (frequent itemset).
Dalam menentukan suatu association rule, terdapat suatu interestingness
measure (ukuran ketertarikan) yang didapatkan dari hasil pengolahan data dengan
perhitungan tertentu. Umumnya ada dua ukuran, yaitu:
1. Support (nilai penunjang/pendukung): suatu ukuran yang menunjukkan
seber-apa besar tingkat dominasi suatu item/itemset dari keseluruhan transaksi.
Uku-ran ini menentukan apakah suatu item/itemset layak untuk dicari confidence
domi-2. Confidence (nilai kepastian/keyakinan): suatu ukuran yang menunjukkan hubun-gan antar 2 item secara conditional (misal, seberapa sering item B dibeli jika
orang membeli item A).
Kedua ukuran ini nantinya berguna dalam menentukan interesting association
rules, yaitu untuk dibandingkan dengan batasan (threshold) yang ditentukan oleh user.
Batasan tersebut umumnya terdiri dari min_support dan min_confidence, dimana hal
tersebut ditempuh dengan cara sebagai berikut :
1. Mencari semua frequent itemset yaitu itemset dengan nilai support ≥ minimum support yang merupakan ambang batas yang diberikan oleh user. Dimana
itemset itu merupakan himpunan item yaitu kombinasi produk yang dibeli.
2. Mencari aturan asosiasi yang confidence dari frequent itemset yang didapat. 3. Sedangkan tahap selanjutnya adalah mencari rule-rule yang sesuai dengan
tar-get user yang didapat dari proses association rule mining sebelumnya.
Rule-rule yang didapat mendeskripsikan kombinasi itemset yang dijadikan
pertim-bangan di dalam membuat kesimpulan.
Secara terperinci, berikut adalah langkah-langkah proses pembentukan Association Rule
dengan algoritma apriori :
satu item dalam C1. Setelah support dari setiap item didapat, Kemudian nilai
sup-port tersebut dibandingkan dengan minimum support yang telah ditentukan, jika
nilainya lebih besar atau sama dengan minimum support maka itemset tersebut
termasuk dalam large itemset. Item yang memiliki support di atas minimum
sup-port dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disebut
Large 1-itemset atau disingkat L1.
2. Iterasi kedua menghasilkan 2-itemset yang tiap set-nya memiliki dua item. sistem akan menggabungkan dengan cara, kandidat 2-itemset atau disingkat C2 dengan
mengkombinasikan semua candidat 1-itemset (C1). Lalu untuk tiap item pada C2
ini dihitung kembali masing-masing support-nya. Setelah support dari semua C2
didapatkan, Kemudian dibandingkan dengan minimum support. C2 yang
memenuhi syarat minimum support dapat ditetapkan sebagai frequent itemset
den-gan panjang 2 atau Large 2-itemset (L2).
3. Itemset yang tidak termasuk dalam large itemset atau yang tidak memenuhi nilai minimum support tidak diikutkan dalam iterasi selanjutnya (di prune).
4. Setelah itu dari hasil frequent itemset atau termasuk dalam Large 2-itemset terse-but, dibentuk aturan asosiasi (association rule) yang memenuhi nilai minimum
support dan confidence yang telah ditentukan.
2.3. Algoritma FP-Growth
Algoritma FP-Growth merupakan pengembangan dari algoritma Apriori.
FP-algoritma yang dapat digunakan untuk menentukan himpunan data yang paling
sering muncul (frequent itemset) dalam sebuah kumpulan data. Pada algoritma
Apriori diperlukan generate candidate untuk mendapatkan frequent itemsets.
Akan tetapi, di algoritma FP-Growth generate candidate tidak dilakukan karena
FP-Growth menggunakan konsep pembangunan tree dalam pencarian frequent
itemsets. Hal tersebutlah yang menyebabkan algoritma FP-Growth lebih cepat
dari algoritma Apriori.
Karakteristik algoritma FP-Growth adalah struktur data yang digunakan
adalah tree yang disebut dengan FP-Tree. Dengan menggunakan FP-Tree,
algoritma FP-growth dapat langsung mengekstrak frequent Itemset dari FP-Tree.
Penggalian itemset yang frequent dengan menggunakan algoritma FP-Growth
akan dilakukan dengan cara membangkitkan struktur data tree atau disebut
dengan FP-Tree. Metode FP-Growth dapat dibagi menjadi 3 tahapan utama yaitu
sebagai berikut :
1. Tahap pembangkitan conditional pattern base,
2. Tahap pembangkitan conditional FP-Tree, dan
Dengan menggunakan algoritma FP-Growth, dapat dilakukan pencarian
frequent itemset tanpa harus melalui candidate generation. FP-Growth
menggunakan struktur data FP-Tree, sehingga cara kerja algoritma ini adalah
melaui scan database yang dilakukan hanya dua kali saja. Data kemudian
ditampilkan dalam bentuk FP-Tree, dan setelah FP-Tree terbentuk, digunakan
pendekatan devide dan conquer untuk mendapatkan frequent itemset.
2.4. Market Basket Analysis
Kehadiran teknologi informasi terutama basis data dalam suatu perusahaan sudah
menjadi hal yang umum bahkan mungkin menjadi kebutuhan pokok perusahaan. Basis
data tersebut mulanya hanya digunakan untuk menyimpan data transaksi penjualan
yang dilakukan oleh perusahaan. Tetapi dengan berkembangnya perusahaan, basis
data tersebut sebenarnya memiliki informasi yang dapat dimanfaatkan oleh pihak
manajemen untuk dapat meningkatkan kinerja penjualan pada perusahaan.
Contoh-contoh dari pemanfaatan basis data misalnya aplikasi manajemen
bisnis, pengawasan produksi dan analisa pemasaran dengan desain produksi. Untuk
memperoleh pengetahuan dari basis data tersebut dapat memanfaatkan yaitu algoritma
data mining. Pengertian data mining itu sendiri adalah analisis otomatis dari data yang
berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau
kecendrungan yang penting yang biasanya tidak disadari keberadaannya (Moertini,
diaplikasikan untuk bidang usaha retail yaitu analisis keranjang pasar atau Market
Basket Analysis.
Market Basket Analysis adalah suatu analisis atas perilaku konsumen secara
spesifik dari suatu golongan atau kelompok tertentu. Market basket juga merupakan
salah satu cara yang digunakan pada transaksi penjualan untuk merancang strategi
penjualan atau pemasaran yang efektif dengan memanfaatkan data transaksi penjualan
yang telah tersedia di perusahaan (Budhi et al. 2006). Market basket dapat
menemukan pola yang berupa produk-produk yang dibeli bersamaan atau cenderung
muncul bersama dalam sebuah transaksi. Perusahaan lalu dapat menggunakan pola ini
untuk menempatkan produk yang sering dibeli bersamaan ke dalam sebuah area yang
berdekatan. Sumber data dari market basket analysis dapat bersumber dari transaksi
kartu kredit, kupon diskon dan juga dapat dari struk belanjaan yang didapatkan oleh
konsumen. Market basket analysis umumnya dimanfaatkan sebagai titik awal
pencarian pengetahuan dari suatu transaksi data yang tidak diketahui pola spesifiknya.
Ide dasar dari market basket itu sendiri yaitu dari trolley ataupun keranjang
belanja yang dibawa oleh konsumen untuk meletakkan belanjaan mereka ke dalam
keranjang tersebut. Di dalam keranjang tersebut berisi berbagai macam produk yang
menginformasikan tentang apa saja yang dibeli oleh konsumen.
Dari keranjang belanja tersebut atau trolley dapat memberikan informasi
kepada pihak perusahaan (apotek) berupa daftar lengkap pembelian yang dilakukan
olek konsumen. Daftar lengkap pembelian ini memiliki sebuah bagian penting dari
bisnis ritel seperti barang apa saja yang dibeli oleh konsumen, konsumen membeli
waktu yang berbeda. Market basket analysis menggunakan informasi tentang apa saja
yang dibeli oleh konsumen untuk menghasilkan sebuah pengetahuan untuk melakukan
tindak lanjut terhadap strategi pemasaran yang telah dilakukan oleh perusahaan
selama ni, apakah harus diadakan promosi untuk meningkatkan minat konsumen
berbelanja di perusahaan tersebut ataupun untuk mengatur ulang tata letak produk
pada perusahaan berdasarkan struk-struk belanjaan konsumen.
Kelebihan dari proses market basket analysis adalah sebagai berikut:
1. Hasilnya jelas dan mudah dimengerti sebab hanya merupakan suatu pola
“jika-maka”. Misalnya : jika produk A dan B dibeli secara bersamaan, maka
kemungkinan produk C turut dibeli.
2. Market basket analysis sangat berguna untuk undirected mining yaitu
pencarian awal pola.
3. Market basket analysis dapat memproses transaksi tanpa harus kehilangan
informasi sebab dapat memproses banyak variabel tanpa perlu dirangkum
(summarization) terlebih dahulu.
4. Proses komputasi yang lebih muda daripada teknik yang kompleks seperti
algoritma genetik & sistem syaraf, meskipun jumlah perhitungan akan
meningkat pesat bersamaan dengan peningkatan jumlah transaksi dan jumlah
1. Tingkat pertumbuhan proses secara eksponensial sebagai akibat pertumbuhan
ukuran data.
2. Memilki keterbatasan untuk atribut data, misalnya hanya berdasarkan tipe
produk.
3. Sulit untuk menemukan items yang akan diolah secara tepat, sebab frekuensi
dari item tersebut harus diusahakan seimbang
2.5. Visual Basic Net
Microsoft Visual Basic. NET adalah sebuah alat untuk mengembangkan dan
membangun aplikasi yang bergerak di atas sistem . NET Framework, dengan
menggunakan bahasa Basic. Dengan menggunakan alat ini, para programmer dapat
membangun aplikasi Windows Forms, Aplikasi web berbasis ASP. NET, dan juga
aplikasi command-line. Bahasa Visual Basic. NET sendiri menganut paradigma
bahasa pemrograman berorientasi objek yang dapat dilihat sebagai evolusi dari
Microsoft Visual Basic versi sebelumnya yang diimplementasikan di atas .NET
Framework.
Visual Basic yang sekarang digunakan oleh jutaan programmer adalah berawal
Thomas Kurtz pada tahun 1964 dengan nama BASIC yang kepanjangan dari Beginner
All Purpose Symbolic Intruction Code. Bahasa BASIC ini tergolong bahasa
pemrograman yang paling mudah dipelajari.
2.5.1 Kelebihan Visual Basic Net
Visual Basic mempunyai banyak kelebihan dibandingkan Software/bahasa
pemograman yang lain. Di antaranya adalah :
VB.NET mengatasi semua masalah yang sulit disekitar pengembangan aplikasi
berbasis windows.
Cocok digunakan untuk mengembangkan aplikasi/program yang bersifat “Ra-pid Application Development”.
Sangat cocok digunakan untuk membuat program/aplikasi Bisnis.
Digunakan oleh hampir semua keluarga Microsoft Office sebagai bahasa Macro-nya, segera akan diikuti oleh yang lain.
Mendekati Object Oriented Programming.
Dapat menjalankan server tersebut dari mesin yang sama atau bahkan dari mesin/komputer yang lain.
2.5.2 Kekurangan Visual Basic Net
Visual Basic juga mempunyai kekurangan/kelemahan, yaitu :
Visual Basic (VB) tidak memiliki database sendiri dan biasanya VB
menguna-kan database seperti : mysql, sql server, microsoft access.
VB tidak punya pendukung untuk membuat report dari bawaan VB sendiri
Program/aplikasi yg dibuat dgn VB.Net harus menggunakan .Net Framework untuk menjalaninya
Visual Basic. NET bukan merupakan bahasa pemprograman yang open source,
sehingga akan sulit bagi programmer untuk lebih mendalami VB. NET secara