adalah sistem penyimpanan-record secara komputer (elektronis). Basis data sendiri dapat digambarkan sebagai suatu lemari file yang berisi berbagai kumpulan file data yang terkomputerisasi. Pemilik lemari file tentu saja dapat melakukan berbagai bentuk tindakan terhadap sistem yang dimilikinya, seperti berikut ini.
1. Penambahan file baru
2. Penambahan data pada file yang ada 3. Pengambilan data dari file yang ada 4. Pemutakhiran data dalam file yang ada 5. Penghapusan data dari file yang ada
6. Penghapusan file yang sudah tidak diperlukan
Perangkat lunak yang didesain untuk membantu dalam hal pemeliharaan dan utilitas kumpulan data dalam jumlah besar atau untuk memudahkan pengelolaan database disebut DBMS (Database Management System).
2.2 Data Mining
Data mining adalah sejumlah proses pencarian pola dari data-data dengan jumlah yang sangat banyak yang tersimpan dalam suatu tempat penyimpanan dengan menggunakan teknologi pengenal data, teknik statistik, dan matematik. Data mining sebagai proses untuk menemukan korelasi atau pola dari ratusan atau ribuan field dari sebuah relasional database yang besar. Data mining dapat diartikan sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data[6].
7
yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set berukuran besar[3].
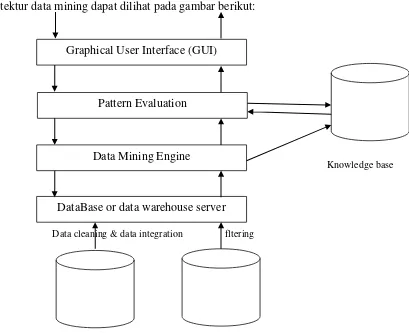
2.2.1 Arsitektur Data mining
Arsitektur data mining dapat dilihat pada gambar berikut:
Knowledge base
Data cleaning & data integration fltering
Gambar 2.1 Arsitektur Data Mining
Keterangan :
1. Data cleaning (Pembersihan Data) : untuk membuang data yang tidak konsisten dan noise
2. Data integration : penggabungan data dari beberapa sumber
3. Data Mining Engine : Mentranformasikan data menjadi bentuk yang sesuai untuk di mining
4. Pattern evaluation : untuk menemukan pengetahuan yang bernilai melalui knowledge base
5. Graphical User Interface (GUI) : untuk end user Graphical User Interface (GUI)
Pattern Evaluation
Data Mining Engine
dilakukan, yaitu: 1. Deskripsi
Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Pada estimasi, model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
5. Pengklusteran
Pengklusteran merupakan pengelompokkan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
6. Asosiasi
Tugas utama dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
2.3 Association Rule
9
kemungkinan seorang pelanggan membeli kopi bersamaan dengan gula. Dengan pengetahuan tersebut, pemilik pasar swalayan dapat mengatur penempatan produknya atau merancang kampanye pemasaran dengan memakai kupon diskon untuk korelasi barang tertentu.
Analisis asosiasi dikenal juga sebagai salah satu teknik data mining yang menjadi dasar dari berbagai teknik data mining lainnya. Secara khusus, salah satu tahap analisis asosiasi yang menarik banyak peneliti untuk menghasilkan algoritma yang efisien adalah analisis pola frekuensi tinggi (frequent pattern mining). Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support adalah presentasi kombinasi item tersebut dalam database, sedangkan confidence adalah nilai probability suatu item akan dibeli bersama item lain.
2.4 Algoritma Apriori
Apriori adalah suatu algoritma yang sudah sangat dikenal dalam melakukan pencarian frequent itemset dengan menggunakan teknik association rule. Algoritma Apriori menggunakan knowledge mengenai frequent itemset yang telah diketahui sebelumnya untuk memproses informasi selanjutnya pada algoritma Apriori untuk menentukan kandidat-kandidat yang mungkin muncul dengan cara memperhatikan minimum support[1].
Adapun dua proses utama yang dilakukan dalam algoritma Apriori, yaitu: 1. Join (penggabungan).
Pada proses ini setiap item dikombinasikan dengan item yang lainnya sampai tidak terbentuk kombinasi lagi.
2. Prune (pemangkasan).
Pada proses ini, hasil dari item yang telah dikombinasikan tadi lalu dipangkas dengan menggunakan minimum support yang telah ditentukan oleh user. Dua proses utama tersebut merupakan langkah yang akan dilakukan untuk mendapat frequent itemset (Erwin). Contoh:
ada di database memuat ketiga item tersebut. Langkah-langkah algoritma Apriori dibuat dengan diagram alir sebagai berikut. Secara terperinci, berikut adalah langkah-langkah proses pembentukan Association Rule dengan algoritma apriori [6]:
1. Di iterasi pertama ini, support dari setiap item dihitung dengan men-scan database. Support artinya jumlah transaksi dalam database yang mengandung satu item dalam C1. Setelah support dari setiap item diperoleh, kemudian nilai support tersebut dibandingkan dengan minimum support yang telah ditentukan, jika nilainya lebih besar atau sama dengan minimum support maka itemset tersebut termasuk dalam large itemset. Item yang memiliki support di atas minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disebut Large 1-itemset atau disingkat L1.
2. Iterasi kedua menghasilkan 2-itemset yang tiap set-nya memiliki dua item. Sistem akan menggabungkan dengan cara, kandidat 2-itemset atau disingkat C2 dengan mengkombinasikan semua candidat 1-itemset (C1). Lalu untuk tiap item pada C2 ini dihitung kembali masing-masing support-nya. Setelah support dari semua C2 didapatkan, Kemudian dibandingkan dengan minimum support. C2 yang memenuhi syarat minimum support dapat ditetapkan sebagai frequent itemset dengan panjang 2 atau Large 2-itemset (L2).
3. Itemset yang tidak termasuk dalam large itemset atau yang tidak memenuhi nilai minimum support tidak diikutkan dalam iterasi selanjutnya (prune).
4. Setelah itu dari hasil frequent itemset atau termasuk dalam Large 2-itemset tersebut, dibentuk aturan asosiasi (association rule) yang memenuhi nilai minimum support dan confidence yang telah ditentukan.
Pseudocode Algoritma Apriori (Erwin, 2009):
Ck: Candidate itemset of size k Lk: frequent itemset of size k
Input :
D, a database of a transactions;
11
threshold
Output : L, frequent itemsets in D Mtehod :
Ct = subset (Ck,t); //get the subsets of t that are candidates
Algoritma FP-Growth merupakan pengembangan dari algoritma Apriori. Sehingga kekurangan dari algoritma Apriori diperbaiki oleh algoritma FP-Growth. Frequent Pattern Growth (FP-Growth) adalah salah satu alternatif algoritma yang dapat digunakan untuk menentukan himpunan data yang paling sering muncul (frequent itemset) dalam sebuah kumpulan data. Pada algoritma Apriori diperlukan generate candidate untuk mendapatkan frequent itemsets. Akan tetapi, di algoritma FP-Growth generate candidate tidak dilakukan karena FP-Growth menggunakan konsep pembangunan tree dalam pencarian frequent itemsets. Hal tersebutlah yang menyebabkan algoritma FP-Growth lebih cepat dari algoritma Apriori. Karakteristik algoritma FP-Growth adalah struktur data yang digunakan adalah tree yang disebut dengan FP-Tree. Dengan menggunakan FP-Tree, algoritma FP-growth dapat langsung mengekstrak frequent Itemset dari FP-Tree.
Metode FP-Growth dapat dibagi menjadi 3 tahapan utama yaitu sebagai [3]: 1. Tahap pembangkitan conditional pattern base,
Conditional Pattern Base merupakan subdatabase yang berisi prefix path (lintasan prefix) dan suffix pattern (pola akhiran). Pembangkitan conditional pattern base didapatkan melalui FP-Tree yang telah dibangun sebelumnya. 2. Tahap pembangkitan conditional FP-Tree
3. Tahap pencarian frequent itemset
Apabila Conditional FP-Tree merupakan lintasan tunggal (single path), maka didapatkan frequent itemset dengan melakukan kombinasi item untuk setiap Conditional FP-Tree.
Gambar 2.2 Langkah-Langkah Algoritma FP-Growth
Jika bukan lintasan tunggal, maka dilakukan pembangkitan FP-Growth secara rekursif. Pseuducode FP-Growth sebagai berikut: Pseudocode algoritma FP-Growth (Erwin, 2009):
Pseuducode dapat dijelaskan sebagai berikut: Input : FP-Tree Tree
Output : Rt sekumpulan lengkap pola frequent
Method : FP-growth (Tree, null) Procedure : FP-growth (Tree, _)
02: then untuk tiap kombinasi (dinotasikan _)
dari node-node dalam path do
03: bangkitkan pola _ _ dengan support dari node-node dalam _;
04: else untuk tiap a1 dalam header dari Tree
do {
05: bangkitkan pola
06: bangun _ = a1 _ dengan support = a1. support
07: if Tree _ = _
08: then panggil FP-growth (Tree, _)
} }
13
2.6.1 Analisis frekuensi tinggi
Tahapan ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut:
Suport (A) =
x 100 %
Sedangkan nilai support dari 2 item diperoleh dari rumus 2 berikut: Suport (A,B) =
x 100 %
2.6.2. Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan assosiatif A B.
Nilai confidence dari aturan A B diperoleh dari rumus berikut:
Confidence (A,B) =
x 100 %
2.7 Penelitian Terdahulu
Penelitian yang menggunakan algoritma apriori dan algoritma FP-Growth antara lain penelitian yang telah dilakukan Aritonang(2012) melakukan penelitian mengenai pengambilan keputusan untuk menentukan korelasi pembelian produk yang menggunakan algoritma apriori untuk mengetahui data yang sering muncul dan mengetahui aturan tata letak produk dimana data yang diperoleh dari indomaret medan.