ANALISIS PERBANDINGAN ALGORITMA APRIORI DAN
ALGORITMA FP-GROWTH UNTUK KORELASI
PEMBELIAN PRODUK ( STUDI KASUS:
SUMBER SWALAYAN MEDAN)
SKRIPSI
EVA CRISTY YULIANA MANURUNG
111421034
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
i
ANALISIS PERBANDINGAN ALGORITMA APRIORI DAN ALGORITMA FP-GROWTH UNTUK KORELASI PEMBELIAN PRODUK
( STUDI KASUS: SUMBER SWALAYAN MEDAN)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Ilmu Komputer
EVA CRISTY YULIANA MANURUNG 111421034
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
Judul : ANALISIS PERBANDINGAN ALGORITMA
APRIORI DAN ALGORITMA FP-GROWTH UNTUK
KORELASI PEMBELIAN PRODUK (STUDI KASUS:
SUMBER SWALAYAN MEDAN)
Kategori : SKRIPSI
Nama : EVA CRISTY YULIANA MANURUNG
Nomor Induk Mahasiswa : 111421034
Program Studi : EKSTENSI S1 ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Maya Silvi Lydia B.Sc, M.Sc Dr. Poltak Sihombing, M.Kom
NIP. 19740127 200212 2 001 NIP. 19620217 199103 1 001
Diketahui/disetujui oleh
Program Studi Ekstensi S1 Ilmu Komputer
Ketua,
Dr. Poltak Sihombing, M.Kom
iii
PERNYATAAN
ANALISIS PERBANDINGAN ALGORITMA APRIORI DAN ALGORITMA
FP-GROWTH UNTUK KORELASI PEMBELIAN PRODUK
( STUDI KASUS: SUMBER SWALAYAN MEDAN)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Januari 2014
Eva Cristy Yuliana Manurung
PENGHARGAAN
Puji syukur penulis panjatkan Tuhan Yang Maha Esa, karena atas berkat dan
kasih-Nya penulis mampu menyelesaikan Skripsi ini.
Skripsi ini dikerjakan sebagai salah satu syarat guna memperoleh gelar Sarjana
Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi Universitas
Sumatera Utara. Penulis mengungkapkan rasa terima kasih dan penghargaan kepada :
1. Bapak Prof. Dr. Muhammad Zarlis selaku Dekan Fakultas Ilmu Komputer dan
Teknologi Informasi Universitas Sumatera Utara.
2. Bapak Dr. Poltak M.Kom, selaku Ketua Program Studi Ilmu Komputer
sekaligus Dosen Pembimbing I yang telah memberikan banyak bimbingan,
saran, serta motivasi dalam pengerjaan skripsi ini.
3. Ibu Maya Silvi Lydia B.Sc, M.Sc selaku Sekretaris Program Studi S1 Ilmu
Komputer sekaligus pembimbing II yang telah memberikan masukan,
bimbingan, saran dan motivasi kepada penulis.
4. Bapak Dr. Nasruddin Noer M.Eng.Sc sebagai Dosen Pembanding I yang telah
memberikan kritik dan saran yang membangun bagi penulis.
5. Ibu Dian Rachmawati S.Si, M.Kom sebagai Dosen Pembanding II yang telah
memberikan kritik dan saran yang membangun bagi penulis.
6. Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi
Universitas Sumatera Utara berserta para pegawai yang bertugas di Program
Studi Ilmu Komputer FASILKOM-TI USU.
7. Orang tua tercinta, Ayahanda J. Manurung dan Ibunda tercinta M. Malau,
kakanda Jones Manurung, adinda Ayub Manurung atas semua doa, dukungan,
v
8. Seluruh sahabat buat Evi, Bella, Deni, Bora, Fenni, Jouhon, Bang Wahyu, buat
adik-adikku: Leni, Vivien, Ester, Yohana, Nugraha, Anwar, Lidia, Claudia,
Meli atas doa dan dukungannya.
9. Keluarga besar Ekstensi Ilmu Komputer, khususnya semua teman dan sahabat
angkatan 2011 yang tidak dapat disebutkan satu persatu, terima kasih atas
segala dukungan, doa dan kerja samanya selama ini.
Semoga Tuhan Yang Maha Esa membalas semua kebaikan kepada semua
pihak yang telah memberikan dukungan kepada penulis dalam menyelesaikan skripsi
ini.
Penulis,
Penelitian ini bertujuan untuk mendapatkan korelasi dari jenis produk-produk yang
sering dibeli secara bersamaan dalam suatu waktu dan menganalisis perbandingan waktu yang diperlukan di dalam menemukan frequent itemset dengan algoritma apriori dan FP Growth. Penelitian ini dengan menggunakan proses data mining dengan metode Association Rule dengan algoritma Apriori dan algoritma FP-Growth. Langkah-langkah yang diperlukan untuk memperoleh frequent itemsets menggunakan algoritma Apriori berbeda dengan langkah-langkah dengan menggunakan algoritma
FP-Growth. penelitian ini menyajikan rule dari aturan asosiasi dan perbandingan
waktu antara algoritma Apriori dan algoritma FP-Growth. Waktu yang diperoleh
dengan menggunakan Algotitma FP-Growth lebih cepat daripada Algoritma Apriori.
Kata kunci: data mining, Association Rule, algoritma Apriori, algoritma
vii
ANALYZE COMPARISON OF APRIORI ALGORITHM AND FP-GROWTH
ALGORITHM FOR CORRELATION BUYING PRODUCTS
(STUDY CASE: SUMBER SWALAYAN MEDAN)
ABSTRACT
This research aimed to get correlation of kinds product that often bought together in
the same time and analyze the comparation time to find frequent itemsets. The method
of this research is association rjule with aapriori algorithm and FP-Growth algorithm.
The steps of apriori algorithm are different with FP-Growth algorithm. This research
contains rule of association rule and comparison time of apriori algorithm and
FP-Growth algorithm. The time of apriori algorithm faster than FP-FP-Growth algorithm.
DAFTAR ISI
Hal.
PERSETUJUAN ii
PERNYATAAAN iii
PENGHARGAAN iv
ABSTRAK vi
ABSTRACT vii
DAFTAR ISI viii
DAFTAR TABEL xi
DAFTAR GAMBAR xiii
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 2
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 TINJAUAN PUSTAKA 7
2.1 DataBase 7
ix
2.3 Association Rule 10
2.4 Algoritma Apriori 12
2.5 Algoritma Fp-Growth 12
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 16
3.1 Analisis Kebutuhan 16
3.1.1 Analisis Data dengan Apriori 17
3.1.2 Pengelompokan Daftar Produk 19
3.1.3 Analisis Pencarian Pola Frekuensi Tinggi 21
3.1.4 Pembentukan Aturan Asosiasi 33
3.1.5 Analisis Data Dengan FP-Growth 35
3.2 Perancangan Sistem 49
3.2.1 Data Flow Diagram(DFD) 49
3.2.2 DFD Level 0 50
3.2.3 DFD Level 1 Apriori 51
3.2.4 DFD Level 1 FP-Growth 52
3.2.5 Flowchart Algoritma 53
3.3 Perancangan Sistem 57
3.4. Perancangan Tampilan Antarmuka 58
3.4.2 Form Login 59
3.4.3 Menu Utama 59
3.4.4 Transaksi 60
3.4.5 Olah Barang 61
3.4.6 Perancangan Proses Apriori 62
3.4.6 Perancangan Proses FP-Growth 63
3.4.7 Perancangan Output FP-Growth 64
3.4.8 Perancangan Output dengan Apriori 64
BAB 4 IMPLEMENTASI DAN PENGUJIAN
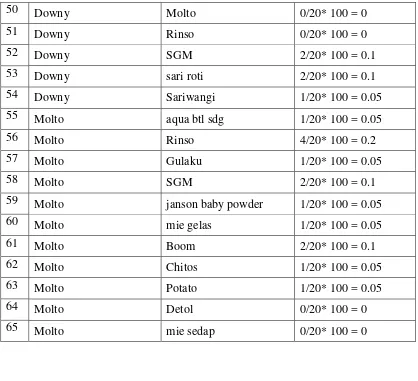
BAB 5 KESIMPULAN DAN SARAN 73
5.1 Kesimpulan 73
xi
DAFTAR TABEL
Hal.
Tabel 3.1 Tabel Data Transaksi 18
Tabel 3.2 Tabel Data Produk 19
Tabel 3.3 Tabel C1 22
Tabel 3.4 Tabel L1 24
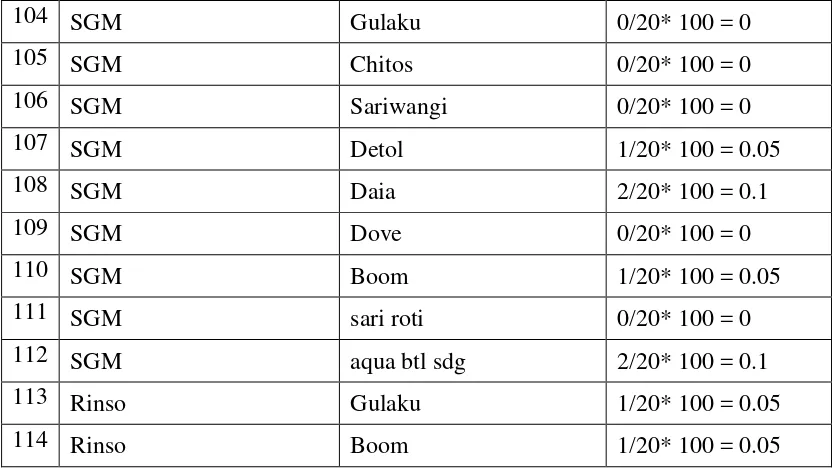
Tabel 3.5 Tabel C2 27
Tabel 3.5 Tabel L2 33
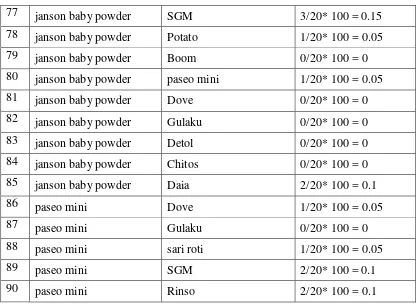
Tabel 3.7 Tabel Pembentukan Korelasi Produk 34
Tabel 3.8 Tabel Pembentukan Aruran Asosiasi 34
Tabel 3.9 Tabel Data Barang Fp-Growth 35
Tabel 3.10 Tabel Transaksi 37
Tabel 3.11 Tabel Data Barang 58
Tabel 3.12 Tabel Transaksi Barang 58
Hal.
Gambar 2.1 Arsitektur Data Mining 8
Gambar 2.2 Langkah-Langkah Algoritma FP-Growth 14
Gambar 3.1 Diagram Ishikawa 17
Gambar 3.2 TID 1 38
Gambar 3.3 TID 2 39
Gambar 3.4 TID 3 40
Gambar 3.5 TID 4 41
Gambar 3.6 TID 5 42
Gambar 3.7 TID 6 43
Gambar 3.8 TID 7 44
Gambar 3.9 TID 8 45
Gambar 3.10 TID 9 46
Gambar 3.11 TID 10 47
Gambar 3.12 Kondisi TID untuk Ya 48
Gambar 3.13 DFD Level 0 50
Gambar 3.14 DFD Level 1 Apriori 51
Gambar 3.15 DFD Level 1 FP-Growth 52
Gambar 3.16 Flowchart Algoritma Apriori 53
Gambar 3.17 Flowchart Algoritma Apriori(lanjutan) 54
Gambar 3.18 Flowchart Algoritma FP-Growth 55
Gambar 3.19 Flowchart Algoritma FP-Growth(lanjutan) 56
Gambar 3.20 Flowchart Sistem 57
xiii
Gambar 3.22 Perancangan Menu Utama 60
Gambar 3.23 Perancangan Transaksi 60
Gambar 3.24 Perancangan Olah Barang 61
Gambar 3.25 Perancangan Proses Mining dengan Apriori 62
Gambar 3.26 Perancangan Proses Mining dengan FP-Growth 63
Gambar 3.27 Tampilan Output FP-Growth 64
Gambar 3.28 Tampilan Output Apriori 64
Gambar 4.1 Tampilan login 67
Gambar 4.2 Proses Mining dengan Apriori 1 68
Gambar 4.3 Proses Mining dengan Apriori 2 69
Gambar 4.4 Proses Mining dengan FP-Growth 1 70
ABSTRAK
Penelitian ini bertujuan untuk mendapatkan korelasi dari jenis produk-produk yang
sering dibeli secara bersamaan dalam suatu waktu dan menganalisis perbandingan waktu yang diperlukan di dalam menemukan frequent itemset dengan algoritma apriori dan FP Growth. Penelitian ini dengan menggunakan proses data mining dengan metode Association Rule dengan algoritma Apriori dan algoritma FP-Growth. Langkah-langkah yang diperlukan untuk memperoleh frequent itemsets menggunakan algoritma Apriori berbeda dengan langkah-langkah dengan menggunakan algoritma
FP-Growth. penelitian ini menyajikan rule dari aturan asosiasi dan perbandingan
waktu antara algoritma Apriori dan algoritma FP-Growth. Waktu yang diperoleh
dengan menggunakan Algotitma FP-Growth lebih cepat daripada Algoritma Apriori.
Kata kunci: data mining, Association Rule, algoritma Apriori, algoritma
BAB 1
PENDAHULUAN
1.1Latar Belakang
Perusahaan ritel yang menyediakan berbagai kebutuhan berkembang pesat bukan
hanya di kota besar saja tetapi juga di kota-kota kecil. Untuk memperoleh keuntungan
yang maksimal banyak hal yang dilakukan perusahaan. Dimana, perusahaan berusaha
untuk menarik minat konsumen sehinnga dibutuhkan informasi yang
sebanyak-banyaknya. Informasi dapat dilihat dari transaksi penjualan yang tersimpan dalam
database.
Kumpulan data transaksi yang begitu besar sering kali hanya disimpan di
dalam suatu database dan kurang digali pemanfaatannya. Data penjualan tersebut bisa diolah lebih lanjut sehingga didapatkan informasi baru. Misalnya, dari informasi
dapat dilihat barang yang dibeli secara bersamaan. Pengetahuan tersebut dapat
digunakan sebagai pemasaran produk yang saling melengkapi dan membuat posisi
rak barang-barang yang dijual pada perusahaan ritel. Teknologi data mining sebagai solusi bagi para pengambil keputusan seperti manajer dalam menentukan strategi
pemasaran dan korelasi antara barang yang dibeli oleh konsumen sehingga dapat
meningkatkan pelayanan pada konsumen.
Proses data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan algoritma. Pemilihan fungsi atau algoritma yang
tepat sangat bergantung pada tujuan dan proses pencarian pengetahuan secara
berapa besar kemungkinan seorang pelanggan membeli roti bersamaan dengan
mentega. Dengan pengetahuan tersebut, pemilik swalayan dapat mengatur
penempatan barangnya dan merancang kampanye pemasaran dengan memakai kupon
diskon untuk kombinasi barang tertentu.
Banyak peneliti yang menjadikan data mining sebagai objek penelitiannya. Pathresia (2012) di dalam penelitiannya menggunakan teknik market basket analysis dengan menggunakan algoritma Apriori untuk memperoleh korelasi produk yang sering dibeli secara bersamaan pada swalayan. Selain itu juga Ahmad (2012) dalam
penelitiannya memanfaatkan data transaksi yang banyak tersimpan dengan
menggunakan Algoritma FP-Growth untuk membuat strategi dan kebijakan dalam
berbisnis. Demikian juga Erwin(2009) dalam penelitiannya menganalisis market
basket dengan algoritma Apriori dan Algoritma FP-Growth.
Banyak metode yang digunakan dalam data mining, yaitu estimation, prediction, classification, clustering, Association. Penelitian ini menggunakan association rule demgan menggunakan algoritma Apriori dan FP Growth. Kedua algoritma tersebut digunakan untuk mengetahui korelasi antara barang yang diminati
oleh konsumen yang tersimpan dalam database. Setelah diperoleh frequent itemsets, maka diambil suatu aturan dan kemudian menganalisis perbandingan waktu kedua
algoritma tersebut.
1.2Rumusan Masalah
Setelah melihat latar belakang masalah yang telah diuraikan maka rumusan masalah
dalam penelitian ini adalah bagaimana membuat perbandingan algoritma Apriori dan
algoritma FP Growth di dalam penambangan data dalam database untuk korelasi pembelian produk.
Adapun batasan masalah dalam penelitian ini adalah sebagai berikut:
1. Data yang diinput merupakan transaksi penjualan produk yang dibeli
selama 3 bulan di minimarket
2. Informasi berdasarkan produk yang dibeli konsumen secara bersamaan
3. Menggunakan korelasi dari 2 jenis produk yang dijual dengan parameter
support dan confidence. Dimana nilai maksimum support 0.3 dan maksimum confidence 1.
4. Jenis barang dalam penelitian ini yaitu: makanan dan minuman, produk
pembersih dan pewangi konsumen(hygiene care), pembersih dan pewangi pakaian.
5. Analisis dilihat dengan perbandingan waktuuntuk menemukan frequent itemset
6. Menggunakan bahasa pemrograman PHP dan penyimpanan data di MySql.
1.4Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Mendapatkan korelasi dari jenis produk-produk yang sering dibeli secara
bersamaan dalam suatu waktu
2. Mengimplementasikan hasil dari korelasi jenis produk-produk ke dalam
sebuah aplikasi data mining pada pembelian produk menggunakan algoritma apriori dan FP Growth
3. Menganalisis perbandingan waktu yang diperlukan di dalam menemukan
frequent itemset dengan algoritma apriori dan FP Growth.
1.5Manfaat Penelitian
1. Dapat mempermudah mengetahui informasi pembelian produk yang sering
dibeli oleh konsumen secara bersamaan
2. Untuk mengetahui pencarian data yang sering muncul (frequent itemset) kemudian dapat diambil kesimpulan
3. Untuk mengatur tata letak produk yang sering dibeli secara bersamaan oleh
konsumen supaya diletakkan secara berdekatan
4. Untuk mengetahui perbandingan waktu yang dibutuhkan dalam menemukan
korelasi produk pembelian
1.6Metodologi Penelitian
Dalam menyusun tugas akhir ini penulis melakukan beberapa penerapan metode
penelitian untuk menyelesaikan permasalahan. Adapun metode penelitian yang
dilakukan adalah dengan cara:
1. Studi literature
Mempelajari konsep-konsep dasar mengenai data mining dan algoritma asosiasi yaitu algoritma apriori dan FP-Growth yang terdapat pada beberapa
sumber literatur. Sumber literatur berupa buku teks, paper, dan jurnal.
2. Metode Pengembangan Perangkat Lunak
2.1 Analisis Kebutuhan
Dalam tahap ini mengumpulkan semua kebutuhan yang diperlukan dalam
membangun perangkat lunak yang berupa data transaksi. Kemudian
melakukan analisa pengolahan data untuk menghasilkan suatu informasi
berupa pola (pattern) dengan teknik asosiasi (association rule).
2.2 Desain Sistem
Dalam proses desain sistem bertujuan untuk merealisasikan hasil analisis ke
dan dalam perancangan prosedur yang akan diterapkan dalam perangkat
lunak berdasarkan teknik asosiasi dengan algoritma apriori dan FP Growth.
3. Implementasi dan Pengujian
Pada tahapan ini menerapkan source code program untuk dijadikan hasil akhir yaitu perangkat lunak yang seutuhnya. Kemudian dilakukan proses
pengujian dengan memasukkan data transaksi, selanjutnya diketahui data
mana yang sering muncul (frequent itemset) secara bersamaan sesuai minimum support dan confidence yang diberikan. Kemudian, membandingkan waktu yang diperlukan oleh algoritma apriori dan algoritma
FP Growth.
4. Dokumentasi
Tahap dokumentasi ini berupa penulisan skripsi yang menjelaskan proses
analisis perbandingan algoritma Apriori dengan Algoritma FP Growth.
1.7Sistematika Penulisan
Peyusunan laporan tugas akhir ini menggunakan kerangka pembahasan yang
terbentuk dalam susunan bab, yang dapat dijelaskan sebagai berikut:
BAB 1 : PENDAHULUAN
Bab ini berisikan tentang latar belakang masalah, rumusan masalah,
batasan masalah, tujuan dan manfaat penelitian, metode penelitian, dan
sistematika penulisan.
Bab ini berisikan tentang landasan teori yang mendukung perancangan
aplikasi yang akan dibangun.
BAB 3 : ANALISIS DAN PERANCANGAN SISTEM
Bab ini membahas mengenai analisa data yang akan diproses
berdasarkan analisis asosiasi dengan algoritma apriori kemudian
membuat DFD, flowchart, struktur tabel dan merancang tampilan dari aplikasi datamining.
BAB 4 : IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini akan membahas tentang implementasi dari sistem yang dibuat
berdasarkan hasil analisis dan perancangan sistem yang telah dibuat.
Kemudian dilakukan pengujian sistem untuk mengetahui apakah sistem
dapat berjalan sesuai tujuan dan harapan perancangan.
BAB 5 : KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan dan saran yang diberikan untuk
perbaikan sistem sehingga menjadi lebih baik dan bermanfaat bagi
pengguna maupun pembaca skripsi.
BAB 2
LANDASAN TEORI
Basis data adalah kumpulan terintegrasi dari occurences file/table yang merupakan representasi data dari suatu model enterprise. Sistem basisdata sebenarnya tidak lain adalah sistem penyimpanan-record secara komputer (elektronis). Basis data sendiri dapat digambarkan sebagai suatu lemari file yang berisi berbagai kumpulan file data yang terkomputerisasi. Pemilik lemari file tentu saja dapat melakukan berbagai bentuk tindakan terhadap sistem yang dimilikinya, seperti berikut ini.
1. Penambahan file baru
2. Penambahan data pada file yang ada 3. Pengambilan data dari file yang ada 4. Pemutakhiran data dalam file yang ada 5. Penghapusan data dari file yang ada
6. Penghapusan file yang sudah tidak diperlukan
Perangkat lunak yang didesain untuk membantu dalam hal pemeliharaan dan
utilitas kumpulan data dalam jumlah besar atau untuk memudahkan pengelolaan
database disebut DBMS (Database Management System).
2.2 Data Mining
Data mining adalah sejumlah proses pencarian pola dari data-data dengan jumlah yang sangat banyak yang tersimpan dalam suatu tempat penyimpanan dengan
menggunakan teknologi pengenal data, teknik statistik, dan matematik. Data mining sebagai proses untuk menemukan korelasi atau pola dari ratusan atau ribuan field dari sebuah relasional database yang besar. Data mining dapat diartikan sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini
tidak diketahui secara manual dari suatu kumpulan data[6].
Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua atau lebih dalam satu dimensi. Penemuan pola merupakan keluaran dari data mining[4]. Misalnya suatu perusahaan ritel yang akan meningkatkan penjualan produk, maka perusahaan akan mencari pola dari pelanggan yang ada untuk
yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan,
pola atau hubungan dalam set berukuran besar[3].
2.2.1 Arsitektur Data mining
Arsitektur data mining dapat dilihat pada gambar berikut:
Knowledge base
Data cleaning & data integration fltering
Gambar 2.1 Arsitektur Data Mining
Keterangan :
1. Data cleaning (Pembersihan Data) : untuk membuang data yang tidak
konsisten dan noise
2. Data integration : penggabungan data dari beberapa sumber
3. Data Mining Engine : Mentranformasikan data menjadi bentuk yang sesuai
untuk di mining
4. Pattern evaluation : untuk menemukan pengetahuan yang bernilai melalui
knowledge base
5. Graphical User Interface (GUI) : untuk end user
Graphical User Interface (GUI)
Pattern Evaluation
Data Mining Engine
2.2.2 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu:
1. Deskripsi
Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan
penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Pada estimasi, model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya,
pada peninjauan berikutnya estimasi nilai dari variabel target dibuat
berdasarkan nilai variabel prediksi.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa
dalam prediksi nilai dari hasil akan ada di masa mendatang.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu
pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
5. Pengklusteran
Pengklusteran merupakan pengelompokkan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki
kemiripan.
6. Asosiasi
Tugas utama dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis
keranjang belanja.
2.3 Association Rule
Aturan asosiasi atau association rule adalah teknik data mining untuk menemukan aturan asosiatif antara suatu korelasi item. Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul bersamaan dalam suatu waktu. Contoh aturan
kemungkinan seorang pelanggan membeli kopi bersamaan dengan gula. Dengan
pengetahuan tersebut, pemilik pasar swalayan dapat mengatur penempatan
produknya atau merancang kampanye pemasaran dengan memakai kupon diskon
untuk korelasi barang tertentu.
Analisis asosiasi dikenal juga sebagai salah satu teknik data mining yang menjadi dasar dari berbagai teknik data mining lainnya. Secara khusus, salah satu tahap analisis asosiasi yang menarik banyak peneliti untuk menghasilkan algoritma
yang efisien adalah analisis pola frekuensi tinggi (frequent pattern mining). Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support adalah presentasi kombinasi item tersebut dalam database, sedangkan confidence adalah nilai probability suatu item akan dibeli bersama item lain.
2.4 Algoritma Apriori
Apriori adalah suatu algoritma yang sudah sangat dikenal dalam melakukan pencarian frequent itemset dengan menggunakan teknik association rule. Algoritma Apriorimenggunakan knowledge mengenai frequent itemset yang telah diketahui sebelumnya untuk memproses informasi selanjutnya pada
algoritma Apriori untuk menentukan kandidat-kandidat yang mungkin muncul dengan cara memperhatikan minimum support[1].
Adapun dua proses utama yang dilakukan dalam algoritma Apriori, yaitu: 1. Join (penggabungan).
Pada proses ini setiap item dikombinasikan dengan item yang lainnya sampai tidak terbentuk kombinasi lagi.
2. Prune (pemangkasan).
Pada proses ini, hasil dari item yang telah dikombinasikan tadi lalu dipangkas dengan menggunakan minimum support yang telah ditentukan oleh user. Dua proses utama tersebut merupakan langkah yang akan dilakukan untuk mendapat
frequent itemset (Erwin).Contoh:
Aturan tersebut berarti “50% dari transaksi di database yang memuat item kopi dan gula dan juga memuat item roti. Sedangkan 40% dari seluruh transaksi yang ada di database memuat ketiga item tersebut. Langkah-langkah algoritma Apriori dibuat dengan diagram alir sebagai berikut. Secara terperinci, berikut adalah
langkah-langkah proses pembentukan Association Rule dengan algoritma apriori[6]:
1. Di iterasi pertama ini, support dari setiap item dihitung dengan men-scan database. Support artinya jumlah transaksi dalam database yang mengandung satu item dalam C1. Setelah support dari setiap item diperoleh, kemudian nilai support tersebut dibandingkan dengan minimum support yang telah ditentukan, jika nilainya lebih besar atau sama dengan minimum support maka itemset tersebut termasuk dalam large itemset. Item yang memiliki support di atas minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disebut Large 1-itemset atau disingkat L1.
2. Iterasi kedua menghasilkan 2-itemset yang tiap set-nya memiliki dua item. Sistem akan menggabungkan dengan cara, kandidat 2-itemset atau disingkat C2 dengan mengkombinasikan semua candidat 1-itemset (C1). Lalu untuk tiap item pada C2 ini dihitung kembali masing-masing support-nya. Setelah support dari semua C2 didapatkan, Kemudian dibandingkan dengan minimum support. C2 yang memenuhi syarat minimum support dapat ditetapkan sebagai frequent itemset dengan panjang 2 atau Large 2-itemset (L2).
3. Itemset yang tidak termasuk dalam large itemset atau yang tidak memenuhi nilai minimum support tidak diikutkan dalam iterasi selanjutnya (prune).
4. Setelah itu dari hasil frequent itemset atau termasuk dalam Large 2-itemset tersebut, dibentuk aturan asosiasi (association rule) yang memenuhi nilai minimum support dan confidence yang telah ditentukan.
Pseudocode Algoritma Apriori (Erwin, 2009):
Ck: Candidate itemset of size k Lk: frequent itemset of size k
Input :
D, a database of a transactions;
threshold
Output : L, frequent itemsets in D Mtehod :
Ct = subset (Ck,t); //get the subsets of t that are candidates
for each candidate c Ct
2.5 Algoritma FP Growth
Algoritma FP-Growth merupakan pengembangan dari algoritma Apriori. Sehingga
kekurangan dari algoritma Apriori diperbaiki oleh algoritma FP-Growth. Frequent Pattern Growth (FP-Growth) adalah salah satu alternatif algoritma yang dapat digunakan untuk menentukan himpunan data yang paling sering muncul (frequent itemset) dalam sebuah kumpulan data. Pada algoritma Apriori diperlukan generate candidate untuk mendapatkan frequent itemsets. Akan tetapi, di algoritma FP-Growth generate candidate tidak dilakukan karena FP-Growth menggunakan konsep pembangunan tree dalam pencarian frequent itemsets. Hal tersebutlah yang menyebabkan algoritma FP-Growth lebih cepat dari algoritma Apriori. Karakteristik algoritma FP-Growth adalah struktur data yang digunakan adalah tree yang disebut dengan FP-Tree. Dengan menggunakan FP-Tree, algoritma FP-growth dapat langsung mengekstrak frequent Itemset dari FP-Tree.
Metode FP-Growth dapat dibagi menjadi 3 tahapan utama yaitu sebagai [3]: 1. Tahap pembangkitan conditional pattern base,
Conditional Pattern Base merupakan subdatabase yang berisi prefix path (lintasan prefix) dan suffix pattern (pola akhiran). Pembangkitan conditional pattern base didapatkan melalui FP-Tree yang telah dibangun sebelumnya. 2. Tahap pembangkitan conditional FP-Tree
besar sama dengan minimum support count akan dibangkitkan dengan Conditional FP-Tree
3. Tahap pencarian frequent itemset
Apabila Conditional FP-Tree merupakan lintasan tunggal (single path), maka didapatkan frequent itemset dengan melakukan kombinasi item untuk setiap Conditional FP-Tree.
Gambar 2.2 Langkah-Langkah Algoritma FP-Growth
Jika bukan lintasan tunggal, maka dilakukan pembangkitan FP-Growth secara rekursif. Pseuducode FP-Growth sebagai berikut: Pseudocode algoritma FP-Growth (Erwin, 2009):
Pseuducode dapat dijelaskan sebagai berikut:
Input : FP-Tree Tree
Output : Rt sekumpulan lengkap pola frequent
Method : FP-growth (Tree, null) Procedure : FP-growth (Tree, _)
02: then untuk tiap kombinasi (dinotasikan _)
dari node-node dalam path do
03: bangkitkan pola _ _ dengan support dari node-node dalam _;
04: else untuk tiap a1 dalam header dari Tree do
2.6.1 Analisis frekuensi tinggi
Tahapan ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut:
Suport (A) =
x 100 %
Sedangkan nilai support dari 2 item diperoleh dari rumus 2 berikut: Suport (A,B) =
x 100 %
2.6.2. Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang
memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan assosiatif A B.
Nilai confidence dari aturan A B diperoleh dari rumus berikut:
Confidence (A,B) =
x 100 %
2.7 Penelitian Terdahulu
Penelitian yang menggunakan algoritma apriori dan algoritma FP-Growth antara lain
penelitian yang telah dilakukan Aritonang(2012) melakukan penelitian mengenai
pengambilan keputusan untuk menentukan korelasi pembelian produk yang
menggunakan algoritma apriori untuk mengetahui data yang sering muncul dan
mengetahui aturan tata letak produk dimana data yang diperoleh dari indomaret
medan.
Penelitian yang dilakukan Erwin(2009) dengan menggunakan Algoritma
Apriori dan Algoritma FP-Growth. Penggunaan FP-Tree yang digunakan bersamaan
generation, yaitu dengan melakukan scanning database secara berulang-ulang unuk menentukan frequent itemset. Penelitian ini juga menyajikan pembahasan mengenai perbandingan kompleksitas waktu antara algoritma FP-Growth dan diperoleh bahwa
waktu yang diperlukan algoritma FP-Growth untuk proses mining lebih cepat dibandingkan apriori.
Selain itu juga Ahmad(2012) dalam penelitiannya memanfaatkan data
transaksi yang banyak tersimpan dengan menggunakan algoritma FP-Growth untuk
membuat strategi dan kebijakan dalam berbisnis. Hasil dari penelitian itu yaitu
diperoleh aturan asosiasi denan menggunakan menggunakan algoritma FP-Growth.
BAB 3
ANALISIS DAN PERANCANGAN
Sebelum dilakukan perancangan sistem, terlebih dahulu dilakukan analisis sistem.
Analisis sistem yang akan dibangun meliputi analisis pengguna sistem, analisis
kebutuhan. Selanjutnya melakukan tahap perancangan sistem untuk membangun
aplikasi datamining. Pada tahap perancangan sistem, akan dibahas perancangan Data Flow Diagram (DFD), perancangan alur kerja sistem (flowchart), perancangan fungsi-fungsi program yang akan digunakan dan perancangan antarmuka pemakai (user interface).
3.1 Analisis Kebutuhan
Analisis kebutuhan adalah suatu proses yang sistematik dari pengembangan
kebutuhan. Dalam analisis kebutuhan perlu dilakukan suatu perencanaan,
pengumpulan data dan analisis data. Analisis kebutuhan dengan menggunakan
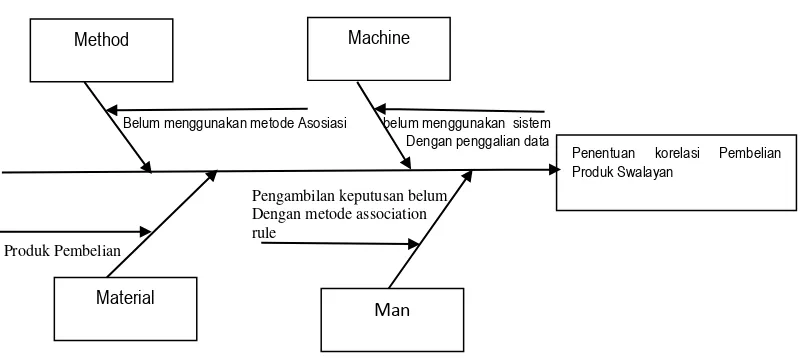
diagram fishbone/ishikawa. Diagram ishikawa digunakan untuk menolong menemukan akar penyebab masalah atau untuk mengidentifikasi kemungkinan
Belum menggunakan metode Asosiasi belum menggunakan sistem Dengan penggalian data
Pengambilan keputusan belum
Dengan metode association rule
Produk Pembelian
Gambar 3.1 Diagram Ishikawa
3.1.1 Analisis Data dengan Apriori
Analisa data dilakukan setelah data terkumpul dan sesuai dengan kebutuhan sistem.
Oleh sebab itu, untuk menghasilkan kesimpulan berdasarkan aturan (rule) pada analisis data, diperlukan data transaksi yang telah dibeli konsumen. Analisis data
tersebut dilakukan berdasarkan teknik aturan asosiasi menggunakan algoritma apriori dengan beberapa iterasi atau langkah-langkah.
Analisa data dengan menggunakan algoritma apriori dapat dilakukan dengan
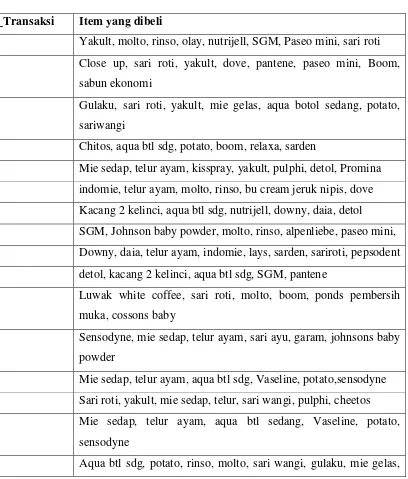
beberapa tahap, dimulai dengan pengelompokan data transaksi pada table 3.1. Data
yang diambil merupakan data transaksi pembelian produk pada bulan Mei-Juli tahun
Method Machine
Penentuan korelasi Pembelian Produk Swalayan
2013 pada Sumber Swalayan. Data tersebut adalah data yang mewakili keseluruhan
data transaksi sebanyak 20 transaksi dan dapat dilihat pada Tabel 3.1.
Tabel 3.1 Data Transaksi
ID_Transaksi Item yang dibeli
1 Yakult, molto, rinso, olay, nutrijell, SGM, Paseo mini, sari roti
2 Close up, sari roti, yakult, dove, pantene, paseo mini, Boom,
sabun ekonomi
3 Gulaku, sari roti, yakult, mie gelas, aqua botol sedang, potato,
sariwangi
4 Chitos, aqua btl sdg, potato, boom, relaxa, sarden
5 Mie sedap, telur ayam, kisspray, yakult, pulphi, detol, Promina
6 indomie, telur ayam, molto, rinso, bu cream jeruk nipis, dove
7 Kacang 2 kelinci, aqua btl sdg, nutrijell, downy, daia, detol
8 SGM, Johnson baby powder, molto, rinso, alpenliebe, paseo mini,
9 Downy, daia, telur ayam, indomie, lays, sarden, sariroti, pepsodent
10 detol, kacang 2 kelinci, aqua btl sdg, SGM, pantene
11 Luwak white coffee, sari roti, molto, boom, ponds pembersih
muka, cossons baby
12 Sensodyne, mie sedap, telur ayam, sari ayu, garam, johnsons baby
powder
13 Mie sedap, telur ayam, aqua btl sdg, Vaseline, potato,sensodyne
14 Sari roti, yakult, mie sedap, telur, sari wangi, pulphi, cheetos
15 Mie sedap, telur ayam, aqua btl sedang, Vaseline, potato,
sensodyne
chitos
17 Downy, daia, johnsons baby powder, SGM, garnier, mie gelas,
ponds pencuci muka
Tabel 3.2 Data Transaksi(lanjutan)
Id_Transaksi Item yang dibeli
18 Daia, aqua btl sedang, downy, mie gelas, olay, close up, Vaseline
19 Sariwangi, gulaku, kisspray, daia, sariroti, downy
20 SGM, Johnsons baby powder, downy, mie gelas, daia, mie gelas,
Maybelline, potato
3.1.2 Pengelompokkan Daftar Produk Berdasarkan Data Transaksi
Terdapat 20 transaksi yang masing- masing transaksi terdapat beberapa produk atau
item yang dibeli oleh konsumen. Untuk itu item yang dibeli diberikan kode produk untuk mempermudah dalam pencarian rule seperti tabel berikut:
Tabel 3.3 Data Produk
NO Item_Set Jumlah_item
1 Close up 2
2 Sensodyne 2
3 Ponds Pembersih muka 2
4 Olay 2
5 Garnier 1
6 Sari ayu 1
7 Telur ayam 7
8 Garam 1
9 Vaseline 2
Tabel 3.4 Data Produk(lanjutan)
No Itemset Jumlah_Item
Tabel 3.5 Data Produk(lanjutan)
No Itemset Jumlah_Item
35 Lays 1
36 Pulphi 2
37 Aqua botol sedang 8
38 Indomie 2
39 Mie sedap 5
40 Mie gelas 5
41 Potato 4
42 Chitos 3
43 Detol 3
44 Dove 3
45 Pepsodent 1
3.1.3 Analisis Pencarian Pola Frekuensi Tinggi
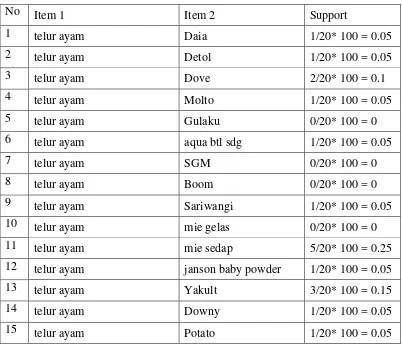
Misalkan diberikan nilai minimum support = 20% (Ф=4 dari 20 transaksi) dan kemudian dilakukan pencarian nilai support pada masing-masing item dengan rumus:
Support =
x
Boom 4/20* 100 = 0.2%
Berdasarkan Tabel yang berisi item-item dengan support yang dimilikinya, selanjutnya cari L1={large 1-itemset} dengan memilih item yang memenuhi nilai minimum support ≥15% seperti pada tabel 3.8.
Tabel 3.8 L1 (Large 1-itemset)
Item set Support
Yakult 0.3%
Downy 0.3%
Molto 0.25%
Johnsons Baby Powder 0.2%
SGM 0.15%
Rinso 0.25%
Daia 0.2%
Boom 0.3%
Gulaku 0.2%
Sariwangi 0.15%
Sari roti 0.2%
Aqua botol 0.35%
Mie Sedap 0.4%
Mie gelas 0.25%
Potato 0.25%
Chitos 0.2%
Detol 0.15%
Dove 0.15%
Langkah 3
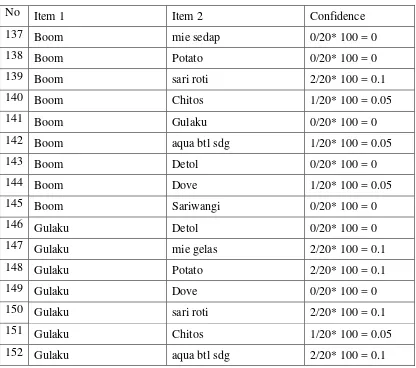
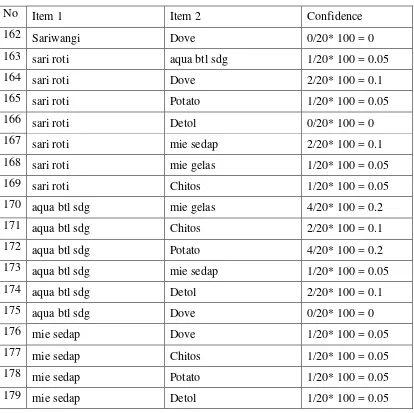
Tabel 3.9 C2 (Kandidat item set)
Tabel 3.10 C2 (lanjutan)
130 Daia Chitos 0/20* 100 = 0
131 Daia Sariwangi 1/20* 100 = 0.05
132 Daia aqua btl sdg 3/20* 100 = 0.15
133 Daia mie sedap 0/20* 100 = 0
134 Daia sari roti 2/20* 100 = 0.1
135 Daia mie gelas 3/20* 100 = 0.15
136 Boom mie gelas 0/20* 100 = 0
Tabel 3.15 (lanjutan)
No Item 1 Item 2 Confidence
137 Boom mie sedap 0/20* 100 = 0
138 Boom Potato 0/20* 100 = 0
139 Boom sari roti 2/20* 100 = 0.1
140 Boom Chitos 1/20* 100 = 0.05
141 Boom Gulaku 0/20* 100 = 0
142 Boom aqua btl sdg 1/20* 100 = 0.05
143 Boom Detol 0/20* 100 = 0
144 Boom Dove 1/20* 100 = 0.05
145 Boom Sariwangi 0/20* 100 = 0
146 Gulaku Detol 0/20* 100 = 0
147 Gulaku mie gelas 2/20* 100 = 0.1
148 Gulaku Potato 2/20* 100 = 0.1
149 Gulaku Dove 0/20* 100 = 0
150 Gulaku sari roti 2/20* 100 = 0.1
151 Gulaku Chitos 1/20* 100 = 0.05
180 mie sedap mie gelas 0/20* 100 = 0
Langkah 4
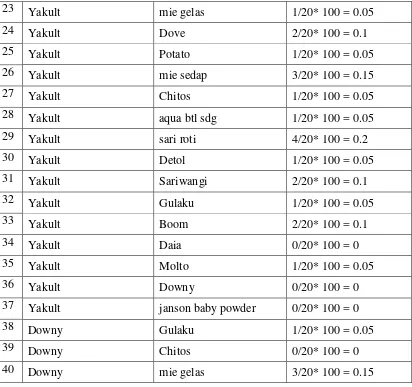
Setelah dihitung dan ditemukan support dari tiap kandidat 2-itemsets pada Tabel 3.8 sampai Tabel 3.1 maka dengan tahap pemangkasan (prune) yaitu menghilangkan item yang tidak memenuhi nilai minimum support ≥20% dapat dihasilkan pada table 3.17.
Tabel 3.17 L2 (Large 2-itemset)
Item 1 Item 2 Support
Gulaku Sariwangi 0.15
Aqua btl sdg Potato, 0.15
aqua btl sdg Potato 0.2
aqua btl sdg mie gelas 0.2
mie gelas Potato 0.15
3.1.4 Pembentukan Aturan Asosiasi
Untuk mencari aturan asosiasi dari iterasi terhadap langkah-langkah yang dilakukan
Confidence = P (A B) =
x 100 %
Tabel 3.18 Pembentukan Korelasi Produk
Item 1 Item 2 Confidence
Dimisalkan confidence 60 %, aturan yang terbentuk :
Tabel 3.19 Pembentukan Aturan Asosiasi
No Rule ( Korelasi Produk ) Support Confidence
1 Jika Konsumen Membeli telur ayam, maka membeli mie sedap
25 %
0.71
2 Jika Konsumen Membeli yakult, maka membeli sari roti
25 %
0.66
3 Jika Konsumen Membeli downy, maka membeli daia
25 %
1
4 Jika Konsumen Membeli molto, maka membeli rinso
25 %
0.8
5 Jika Konsumen Membeli janson baby powder, maka membeli SGM
15 %
0.75
Tabel 3.20 Pembentukan Aturan Asosiasi(Lanjutan)
No Rule(Korelasi Produk) Suport Confidence
6 Jika Konsumen Membeli gulaku, maka membeli sariwangi
15 %
1
7 Jika Konsumen Membeli
sariwangi, maka membeli sari roti
30 %
0.75
8 Jika Konsumen Membeli mie gelas, maka membeli potato
30 % 0.6
3.1.5 Analisis Data dengan FP-Growth
Pada tahap ini, untuk mempermudah dalam pembuatan tree, maka nama barang dibuat
dengan menggunakan abjad seperti pada tabel 3.9.
Tabel 3.21 Data Barang
Tabel 3.22 Data Barang(lanjutan)
No Item_Set Kode_Item
Tabel 3.23 Data Barang(lanjutan)
No Item_Set Kode_Item
39 Mie Sedap Ms
Tabel 3.24 Tabel Transaksi
TID Item
Pada tahap ini, diambil contoh data 10 transaksi. Diberikan batasan minimum support
0.2 dan confidence 0.75.
1. Pembacaan TID 1: Lintasan {} Ya, Bo,Ri,Sg, Pa, Mo, L
{ Root}
Ya:1
Bo:1
Ri:1
Sg:1
Pa:1
Mo:1
Gambar 3.2 TID 1
2. Pembacaan TID 2
{Root}
Y
B
R
S
P
M
Gambar 3.3 TID 2
3. Pembacaan TID 3
{Root}
S
A B
o Y
Gambar 3.4 TID 3
4. Pembacaan TID 4
{Root}
S
S
A B
o Y
Gambar 3.5 TID 4
5. Pembacaan TID 5
{Root}
T
P
D
S
S
A B
o P a Y
B
Gambar 3.6 TID 5
6. Pembacaan TID 6
{Root}
T
P
D
S
S
A B
o
S P a Y
B
R
Gambar 3.7 TID 6
7. Pembacaan TID
{Root}
N u
A
D
T
P
D
S
S
A B
o
S P a
Do Y
B
R
S
Gambar 3. 8 TID 7
8. Pembacaan TID 8
{Root}
S
P N
u
A
T
P
D
S
S
A B
o
S P a
Do Y
B
R
S
Gambar 3.10 TID 9
10.Pembacaan TID 10
Gambar 3.11 TID 10
Kemudian dicari frequent list nya dengan melihat kondisi FP-Growth dari item yang digambarkan dengan tree berikut.
1. Kondisi FP-Growth untuk Ya
Gambar 3.12 Kondisi FP-Growth Untuk Ya
Nilai Kemunculan yang bersamaan dengan Ya:
{Te,Ya},{Ya,Aq},{Do,Ya},{Ya,Bo},{Ya,Pa},{Ya,Pe},{Ya,Sr}. Dalam Association rule, minimal frequent itemset yang dihitung terdapat 2 item, jika membeli A maka membeli B.setelah diperoleh frequent itemset, maka membuat rule dengan
menghitung confidencenya ≥ 60 %. Karena perhitungan nya sangat banyak, maka penulis mengambil contoh dari frequent itemset {Ya,Sr}.
Ya Sr = 4/6 = 0.66
Sr Ya = 4/7 = 0.57
Dari perhitungan confidence terhadap pola diatas maka Association rule yang
memenuhi syarat confidence ≥ 60 % adalah:
1. Ya Sr ( jika konsumen membeli Yakult maka membeli Sari roti dengan
nilai confidence 0.66).
3.2 Perancangan Sistem
Perancangan sistem adalah suatu pengindentifikasian kebutuhan fungsional dalam
mempersiapkan rancangan implementasi yang bertujuan untuk mendesain sistem
dalam memenuhi kebutuhan user sistem. Perancangan sistem terdiri dari pembuatan flowchart sistem, perancangan database, dan perancangan antarmuka pemakai (user interface).
3.2.1 Data Flow Diagram (DFD)
T
D
Data Flow Diagram (DFD) adalah suatu model logika data atau proses yang dibuat untuk menggambarkan dari mana asal data dan kemana tujuan data yang keluar dari
sistem, dimana data disimpan, proses apa yang menghasilkan data tersebut dan
interaksi antara data yang tesimpan serta proses yang dikenakan pada data tersebut.
DFD menunjukan hubungan antar data pada sistem dan proses pada sistem.
Pada sistem ini digunakan DFD level-0, DFD Level-1, untuk penjelasan lebih
1.0 Info hasil pola pembelian produk
Gambar 3.13 DFD Level 0
Pada DFD Level 0, merupakan proses dalam sistem yang dirancang. User memasukan data transaksi ke dalam sistem, kemudian data transaksi diproses di dalam sistem
dengan melalui beberapa iterasi dengan menggunakan masing-masing algoritma yaitu
Algoritma Apriori dan algoritma FP-Growth. kemudian menghasilkan association rule yang merupakan korelasi pembelian produk yang merupakan informasi yang berguna. Setelah rule diperoleh, maka dilakukan perbandingan waktu antara kedua
algoritma dengan menggunakan sistem tersebut.
Gambar 3.14 DFD Level-1(Apriori)
Pada DFD level-1, proses yang terjadi lebih terperinci lagi bila dibandingkan pada
diagram Level-0. User menginput data transaksi dan diproses di sistem dengan
menggunakan masing-masing algoritma, yaitu algoritma Apriori dimulai dengan
proses login, kemudian dilakukan pengelolan data barang dan data transaksi barang
dan menginput nilai minimum suport dan confidence sehingga memperoleh hasil pola
Start 3.2.4 DFD Level 1 (FP-Growth)
user
Info hasil pola pembelian produk
Gambar 3.15 DFD Level 1(FP-Growth)
User menginput data transaksi dan diproses di sistem dengan menggunakan algoritma
FP-Growth dimulai dengan proses login, kemudian dilakukan pengelolan data barang
dan data transaksi barang dan menginput nilai minimum suport dan confidence
sehingga memperoleh hasil pola pembelian produk.
3.2.5 Flowchart Algoritma
Tabel L2 Terbentuk P1
If confidence > = min confidence
Tabel L2 yang confidence > = min
confidence Y
Kesimpulan hasil asosiasi terbentuk
End
T P1
Gambar 3.17 Flowchart Algoritma Apriori ( lanjutan )
P2
Kombinasi barang 1 dan kombinasi barang 2
hasil perhitungan = jumlah_ kombinasi/ jumlah_ barang
Apakah hasil perhitungan > = confidence
Nilai confidence, hasil perhitungan, dan support
Input data barangI
Perancangan flowchart sistem, dimulai dengan menginput data barang. Kemudian dilakukan penambangan data dengan masing-masing algoritma, yang pertama dengan
algoritma Apriori. Setelah dilakukan proses mining maka diperoleh hasil dalam
bentuk kombinasi barang pembelian. Setelah itu dilakukan penambangan data dengan
algoritma FP-Growth. setelah dilakukan proses, maka diperoleh hasil dalam bentuk
kombinasi barang. Lalu setelah diperoleh hasil dari kedua algoritma maka dilakukan
perbandingan waktu antara kedua algoritma. Kemudian diperoleh waktu yang lebih
cepat antara kedua algoritma. Kemudian selesai(end).
3.3 Perancangan Basis Data
Pada perancanngan basis data terdapat perancangan struktur table barang dan
struktur table transaksi.
3.3.1 Struktur tabel
Dalam struktur table, table-tabel yang digunakan di database adalah sebagai
berikut:
1. Struktur Tabel Barang
Tabel barang berguna untuk menyimpan data barang penjualan. Struktur tabel
Login to Admin
Username Password
Tabel 3.25 Data Barang
Nama Field Type Length Keterangan
id_barang(*) Integer 10
Nama_barang Varchar 30
2. Struktur Tabel Transaksi
Tabel Transaksi berguna untuk menyimpan data transaksi penjualan. Struktur
Tabel transaksi dapat dilihat tabel 3.13.
Tabel 3.26 Data Transaksi
Nama Field Type Length Keterangan
id_transaksi(*) Integer 10 Id Transaksi
kode_transaksi Integer 10 Kode Transaksi
tgl_transaksi Date 5 Tgl Transaksi
id_barang(**) Integer 10 Id Barang
Keterangan : * = Primary Key
** = Foregn Key
3.4 Perancangan Tampilan Antarmuka
Perancangan tampilan program dari aplikasi datamining yang akan dibuat adalah sebagai berikut :
Menu Utama
Projek: Datamining Supermarket Algoritma Apriori dan FPGrowth Tanggal : xx-xx-xx
About Me Barang Transaksi
Untuk masuk ke dalam sistem, terlebih dahulu memasukan username(1) dan
password(2), dan jika keduanya sudah sesuai maka klik login. Dan sudah dapat masuk
ke sistem.
3.4.2 Perancangan Menu Utama
Gambar 3.22 Perancangan Menu Utama
Keterangan gambar:
3. Nama Projek Datamining Supermarket Algoritma Apriori dan FP-Growth
4. Tanggal
5. Menu home
6. About me, menu tentang penulis
7. Menu barang berisikan menginput dan penyimpanan nama barang
8. Menu transaksi berisikan pengolahan transaksi barang
9. Menu logout untuk keluar dari sistem
10. Algoritma Apriori, untuk proses mining dengan algoritma Apriori
11. Algoritma FP-Growth, untuk proses mining dengan algoritma FP-Growth
12. Halaman admin
Pada menu utama, terdapat beberapa sub menu, yaitu: home, about me, barang,
transaksi, dan logout. Terdapat juga tombol untuk proses mining dengan algoritma
apriori dan algoritma FP-Growth. Menu barang digunakan untuk mengolah barang.
3.4.3 Perancangan Transaksi
Gambar 3.23 Perancangan Data Transaksi
Pada Perancangan Transaksi terdapat tanggal transaksi. Di dalam pengelolaan
transaksi, dapat menambah transaksi dengan mengklik yang ditandai no 5, dan dapat
melihat data transaksi yang sudah di input, dengan memilih kode transaksi yang
ditandai no 2, dan dapat memilih kode transaksi sesuai yang diinginkan dengan cara
mengklik search ditandai no 3.No 4 adalah no nama barang yang diinput, sedangkan no 5 adalah kode transaksi, No 6 Tanggal transaksi, no 7 nama-nama barang, no 8
adalah options delete dan edit yaitu untuk menghapus atau mengedit nama barang.
3.4.4 Perancangan Olah Barang
Transaksi
Projek: Datamining Supermarket Algoritma Apriori dan FPGrowth Tanggal : xx-xx-xx
About Me Barang Transaksi
No Kode Transaksi Tanggal Transaksi Transaksi Barang Options
1
Projek: Datamining Supermarket Algoritma Apriori dan FPGrowth Tanggal : xx-xx-xx
About Me Barang Transaksi
Id Barang Nama Barang Options
1 3
4 5 6
Scanning Data Transaksi Dengan Algoritma Apriori
Algoritma Apriori Scanning Data Transaksi Dengan Algoritma Apriori
Minimum support
Minimum confidence
Jumlah transaksi
Gambar 3.24 Perancangan Olah Barang
Pada perancangan olah barang, dapat menambah, mengedit, dan menghapus data
barang. Dengan cara menginput nama barang yang ditandai no 5, untuk menampilkan
barang yang sudah diinput dapat mengklik publish yang ditandai no 3 , dan untuk
membatalkan dengan dengan mengklik cansel yang ditandai no 2. No 4 merupakan id barang, dan no. 5 merupakan nama barang yang sudah diinput, dan pada no 6
merupakan options dimana nama barang yang sudah diinput dapat dihapus dengan
mengklik delete dan dapat diedit dengan mengklik edit.
3.4.5 Perancangan Apriori
1
2
Gambar 3.25 Perancangan Proses Mining dengan Algoritma Apriori
Pada proses mining Apriori, dengan menginput minimum support yang ditandai no 5,
minimum confidence yang ditandai no 2, dan jumlah transaksi yang ditandai no 3,
kemudian kirm queri yang ditandai no 4. Maka tampil output, yaitu rule yang
dihasilkan dengan menggunakan apriori.
3.4.6 Perancangan FP-Growth
Scanning Data Transaksi Dengan Algoritma FP-Growth
Algoritma FP-Growth Scanning Data Transaksi Dengan Algoritma FP-Growth
Minimum support
Pada proses mining FP-Growth, dengan menginput minimum support yang ditandai
no 1, minimum confidence yang ditandai no 2, dan jumlah transaksi yang ditandai no
3, setelah semua diinput kemudian kirm queri yang ditandai no 4. Maka tampil output,
yaitu rule yang dihasilkan dengan menggunakan FP-Growth.
3.4.7 Perancangan Tampilan Out put FP-Growth
Setelah dikirm queri, maka tampil minimum confidence, minimum support, jumlah
transaksi, dan tampil table kesimpulan(rule) dengan menggunakan apriori yang berisi
kombinasi item yang sering dibeli konsumen. Waktu proses filtering juga tampil.
1
2
3
4
Algoritma FP-Growth
Scanning Data Transaksi Dengan Algoritma FP-Growth
Minimum support : xx Minimum confidence : xx
Jumlah transaksi : xx Tabel Kesimpulan
Waktu proses filtering : xx
1
Setelah dikirim queri data yang sudah diinput, maka tampil table kesimpulan berupa
kombinasi barang dengan menggunakan algoritma FP-Growth yang ditandai no. 1,
dan waktu proses filtering yang ditandai no. 2.
3.4.8 Perancangan Tampilan Out Put Apriori
Setelah dikirm queri, maka tampil minimum confidence, minimum support, jumlah
transaksi, dan tampil table kesimpulan(rule) dengan menggunakan FP-Growth yang
berisi kombinasi item yang sering dibeli konsumen. Waktu proses filtering juga
tampil.
Setelah dikirim queri maka tampil output dengan menggunakan algoritma FP-Growth.
yang berupa Tabel kesimpulan yang ditandai no. 1. Tabel kesimpulan berisi korelasi
barang pembelian yang merupakan informasi yang sangat berguna. Waktu proses
dfiltering juga muncul yang ditandai no.2.
BAB 4
IMPLEMENTASI
Algoritma Apriori Scanning Data Transaksi Dengan Algoritma Apriori
Minimum support : xx Minimum confidence : xx
Jumlah transaksi : xx
Tabel Kesimpulan
Waktu proses filtering : xx
Gambar 3.28 Out Put Algoritma Apriori
1
Setelah melalui tahap perancangan sistem kemudian dilanjutkan ke tahap
implementasi dan pengujian. Implementasi ini harus berdasarkan pada perancangan
ditahap sebelumnya. Dalam mengimplementasikan sistem ini, dibutuhkan 3 buah
komponen, yang meliputi kebutuhan hardware (perangkat keras), software (perangkat lunak), dan brainware (unsur manusia). Sedangkan dalam pengujian dilakukan terhadap hasil association rule yang dimasukkan dengan nilai minimum support dan minimum confidence yang berbeda.
4.1 Implementasi
Implementasi adalah suatu prosedur yang dilakukan untuk menyelesaikan sistem yang
ada dalam dokumen rancangan sistem yang telah disetujui dan telah diuji, menginstal
dan memulai menggunakan sistem baru yang diperbaiki.
4.2 Persiapan Teknis
Dalam implementasi dari program data mining ini membutuhkan perangkat keras (hardware) dan perangkat lunak (software). Adapun hardware dan software yang akan dibutuhkan adalah sebagai berikut :
1. Perangkat Keras ( Hardware )
1. Micro processor minimal Pentium 4
2. Harddisk minimal 40 GB
3. RAM berkapasitas 512MB
4. Monitor Super VGA 14 inchi
5. Keyboard
2. Perangkat Lunak yang digunakan dalam membangun sistem ini yaitu:
1. PHP
2. XAMPP ( MySQL )
Brainware merupakan faktor manusia yang menangani fasilitas komputer yang ada. Faktor ini mutlak diperlukan karena aplikasi ini memerlukan perawatan atau
maintenance, baik perawatan hardware maupun software. Aplikasi ini tidak dapat beroperasi sendiri tanpa adanya instruksi dari user. User diperlukan untuk proses update data dan proses menjalankan proses lainnya.
4.3 Menjalankan Aplikasi
Setelah semua persiapan teknis dilakukan, selanjutnya menjalankan aplikasi data
mining dengan teknik association rule menggunakan algoritma apriori ini dapat dilakukan. Untuk dapat menjalankannya, terlebih dahulu install aplikasi data mining pada personal computer (PC) atau laptop kemudian buka aplikasi pada menu start program.
Gambar 4.1 Tampilan login
Admin dapat masuk ke system dengan memasukan username dan password, lalu
menekan tombol login.
4.3.5 Proses Mining dengan Algoritma Apriori
Untuk melihat perbandingan waktu antara Algoritma Apriori dan Algoritma
FP-Growth, maka dilakukan 3 kali pengujian tergadap sistem yang sudah dibuat.
Proses mining dengan menggunakan apriori, dengan minimum support 0.15 dan
minimumconfidence 0.60 dan jumlah transaksi 20 dalam waktu 7.2 detik.
Gambar 4.3 Proses Mining dengan Apriori
Proses mining dengan menggunakan apriori, dengan minimum support 0.25 dan
minimum confidence 0.75 dan jumlah transaksi 300 menghasilkan 1 rule dalam
4.3.4 Proses Mining dengan FP-Growth
Gambar 4.4 Proses Mining dengan Algoritma FP Growth
Bentuk rule yang dihasilkan dengan FP-Growth dalam waktu 1.09 detik. Dengan
Gambar 4.5 Proses Mining dengan Algoritma FP-Growth.
Bentuk rule yang dihasilkan dengan FP-Growth dalam waktu 28 detik. Dengan
minimum support 0.15 dan minimum confidence 0.8 dan jumlah transaksi 300.
Perbandingan waktu Algoritma Apriori dan Algoritma FP-Growth dapat dilihat pada
tabel 4.1.
Tabel 4.1 Perbandingan Waktu Algoritma Apriori dan Algoritma FP-Growth
Algoritma Min Support Min Confidence Waktu
(detik)
Jlh Transaksi
Apriori 0.15 0.6 7 20
Apriori 0.15 0.8 63 300
Apriori 0.25 0.75 5.6 300
FP-Growth 0.15 0.6 3.6 20
FP-Growth 0.15 0.8 28 300
Dengan melihat table 4.1, waktu yang diperlukan untuk mendapatkan korelasi barang
pembelian dengan menggunakan algoritma apriori dan FP-Growth, maka waktu yang
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan pembahasan, implementasi dan pengujian dari sistem, diperoleh beberapa
kesimpulan:
1. Metode Association Rule dengan menggunakan Algoritma Apriori dan Algoritma FP-Growth dengan parameter support dan confidence dapat memperoleh korelasi barang pembelian untuk lebih meningkatkan penjualan
maupun dalam hal promosi barang yang dapat meningkatkan pendapatan yang
lebih besar lagi bagi pemilik minimarket.
2. Dari hasil pengujian dapat dilihat, bahwa waktu yang diperlukan Algoritma
FP-Growth lebih cepat bila dibandingkan Algoritma Apriori untuk
memperoleh hasil korelasi barang pembelian.
5.2Saran
Untuk memperoleh hasil yang lebih maksimal dan lebih baik lagi, diperlukan
saran dari berbagai pihak. Adapun saran dari penulis yaitu:
1. Bagi pengembang berikutnya agar dapat langsung mengolah data langsung
mengakses database perusahaan secara langsung.
2. Bagi pengembang berikutnya agar menggunakan lebih dari 2 kombinasi
DAFTAR PUSTAKA
[1]. Aritonang Pathresia. 2012. Implementasi Data Mining dengan Association Rule dalam pengambilan keputusan Untuk korelasi pengambilan Produk Menggunakan Algoritma Apriori. Skripsi: Ekstensi S1 Ilmu Komputer Universitas Sumatera Utara.
[2]. Berry J.A. Michael, Linoff Gordon. 1997. Data Mining Techniques. New York: Wiley Computer Publishing.
[3]. Erwin. 2009. Analisis Market Basket dengan Algoritma Apriori dan Algoritma FP-Growth. Jurnal Generik, hal. 26-30.
[4]. Goldie Gunadi, Dana Indra Sensue. (2012), penerapan metode data mining market basket analysis terhadap data penjualan produk bukudengan menggunakan algoritma apriori danfrequent pattern growth (fp-growth) : studi kasus percetakan pt. gramedia. Jurnal Telematika MKOM Vol. 1 hal. 118-132.
[5]. Kadir, Abdul. 2008. Dasar Perancangan dan Implementasi Database
Relasional. Yogyakarta: Andi
[6]. Kusrini, Emma Taufiq Luthfi. 2009. Algoritma Data Mining. Yogyakarta: Andi
[7]. Olson David, Yong Shi. 2007. Introduction to Business Data Mining. The McGraw-Hill: New York.
[9]. Thomas Connoly, Carolyn Begg. 2005. Database Systems A Practical Approach to Design, Implementation, and MAnagement. Addison-Wesley: New York.
[10]. Suprasetyo Fendi Achmad.Market Basket Analysis Menggunakan Algoritma Frequent-Pattern-Growth Pada Data Transaksi Penjualan Barang Hariandi Swalayan XYZ. Skripsi: Sistem Informasi Fakultas Teknik Universitas Negeri Gorontalo
LAMPIRAN
Listing program aplikasi data mining menggunakan algoritma apriori dan FP-Growth adalah sebagai berikut:
1. Proses pembuatan tabel C1
$ld_barang=$data['id_barang'];
$count_barang = mysql_query("SELECT count(*) AS jum_barang FROM transaksi_barang where id_barang='$ld_barang' and kode_transaksi <=
'$jum_transaksi'") or die(mysql_error());
$array_count_barang = mysql_fetch_array($count_barang);
$distinc_transaksi = mysql_query("select count(distinct(kode_transaksi)) as jum_transaksi
from transaksi_barang where kode_transaksi <= '$jum_transaksi'");
$array_count_transaksi = mysql_fetch_array($distinc_transaksi);
$support =
$array_count_barang['jum_barang']/$array_count_transaksi['jum_transaksi'];
$sql_rows_support = mysql_query("SELECT * FROM support_apriori WHERE id_barang='$ld_barang' and nilai_support='$support'");
if(mysql_num_rows($sql_rows_support)){
echo '';
} else {
$insert_support = mysql_query("INSERT INTO support_apriori VALUES ('', '$ld_barang', '$support')");
}
$l++;
2. Proses pembuatan tabel C2
$TRecord = mysql_query("SELECT a.*,b.* FROM barang a, support_apriori b where a.id_barang=b.id_barang and b.nilai_support >= '$min_support'
order By a.id_barang ASC") or die(mysql_error());
$j=1;
while($data=mysql_fetch_array($TRecord))
$i=$data['id_barang'];
$TRecord2 = mysql_query("SELECT a.*,b.* FROM barang a, support_apriori b where a.id_barang=b.id_barang
and b.nilai_support >= '$min_support' order By a.id_barang ASC") or die(mysql_error());
while($data2=mysql_fetch_array($TRecord2)){
$id_barang2=$data2['id_barang'];
$nilai_support = $min_support;
if($i!=$id_barang2){
$sql_cek_kombinasi = mysql_query("SELECT * FROM kombinasi_apriori WHERE id_barang='$i' and id_kombinasi='$id_barang2'
and support_count='$nilai_support'");
if(mysql_num_rows($sql_cek_kombinasi)){
echo '';