Suhatati Tjandra
Dosen Teknik Informatika Sekolah Tinggi Teknik Surabaya
e-mail : [email protected]
ABSTRAK
Frequent itemset mining adalah algoritma yang digunakan untuk mencari frequent itemset. Frequent itemset mining dapat diklasikasifikan menjadi tiga kelompok yaitu : algoritma mining Frequent Itemset (FI), algoritma mining Frequent Closed Itemset (FCI), dan algoritma mining Maximal Frequent Itemset (MFI). Algoritma DF-Apriori adalah implementasi secara depth-first dari algoritma Apriori, salah satu algoritma frequent itemset mining (FIM) tercepat untuk menemukan semua frequent itemset pada sebuah database. Secara garis besar proses mining dengan menggunakan algoritma DF-Apriori terdiri dari tiga tahap yaitu tahap preprocessing dimana algoritma mencari frequent 1-itemset dari database input, tahap pembuatan trie dan tahap pembacaan hasil dari trie. Semua hasil frequent itemset dapat dibaca langsung dari trie ketika trie telah selesai dibentuk.
Kata kunci : Data Mining, DF-Apriori, Maximal Frequent Itemset, Itemset, trie.
ABSTRACT
Frequent itemset mining is algorithm which is used to find frequent itemset. Frequent itemset mining can be classify to Frequent Itemset (FI), Frequent Closed Itemset (FCI) and Maximal Frequent Itemset (MFI). DF-Apriori algorithm is one of frequent itemset mining algorithms which works in dept first and can work fast to find frequent itemset on database. Mining process use DF-Apriori algorithm concist of three phases. First, find frequent 1-itemset from input database. Second, build trie data structure and last, read the formed trie.
Keywords : Data Mining, DF-Apriori, Maximal Frequent Itemset, Itemset, trie.
PENDAHULUAN
Data mining adalah proses pencarian terhadap pengetahuan (yang sebelumnya tidak diketahui, valid, dan dapat digunakan) dari database yang besar dan kemudian menggunakan pengetahuan tersebut untuk membuat keputusan bisnis yang penting.
Istilah data mining yang sangat terkenal saat ini sebenarnya kurang tepat seharusnya istilah yang lebih tepat adalah knowledge mining from data. Akan tetapi istilah tersebut terlalu panjang dan oleh karena itu disingkat menjadi knowledge mining. Istilah knowledge mining tidak dapat memberikan tekanan pada sumbernya yaitu data dalam jumlah besar.
Banyak orang yang menganggap data mining sama dengan Knowledge Discovery in Database (KDD).
Sebenarnya kedua istilah itu berbeda karena data mining adalah salah satu bagian atau proses dari KDD.
Komponen-komponen utama dalam arsitektur sistem data mining adalah sebagai berikut :
• Database, data warehouse, atau media penyimpanan informasi yang lain.
Bagian ini merupakan satu atau kumpulan database, data warehouse, spreadsheet, atau jenis media penyimpanan informasi yang lain.
• Database atau data warehouse server.
Database dan data warehouse server bertang-gungjawab memberikan data yang relevan berdasarkan permintaan user yang melakukan mining.
• Knowledge base
Bagian ini merupakan pengetahuan utama yang digunakan sebagai penuntun untuk melakukan
proses pencarian atau mengevaluasi pola-pola yang dihasilkan. Pengetahuan yang dapat disertakan adalah konsep hierarki yang digunakan untuk mengatur atribut atau nilai atribut ke dalam tingkatan abstraksi yang berbeda. Pengetahuan seperti kepercayaan user dapat digunakan untuk mengakses ketertarikan pattern yang tidak terduga dapat juga dimasukkan ke dalam knowledge base. Contoh pengetahuan lain yang dapat dimasukkan adalah interestingness constraint atau threshold tambahan, dan metadata.
• Data mining engine
Bagian ini adalah bagian penting pada sistem data mining dan idealnya terdiri dari sekumpulan modul fungsional untuk suatu tugas seperti characterization (pengkarakteran), association, classification (pengklasifikasian), cluster analysis (analisa cluster), dan evolution and deviation analysis (analisa evolusi dan deviasi).
• Pattern evaluation module
Komponen ini menggunakan pengukuran ketertarikan dan berinteraksi dengan modul data mining untuk memfokuskan pencarian interesting pattern (pola-pola yang menarik). Selain itu, untuk mendapatkan pattern mungkin dapat menggunakan interestingness threshold. Modul untuk mengeva-luasi pattern dapat diintegrasikan dengan modul untuk mining, tergantung dari metode implementasi data mining yang digunakan. Agar proses data mining lebih efisien, maka direkomendasikan untuk menekan proses evaluasi pola-pola yang menarik sedalam mungkin pada proses mining.
• Graphical user interface
Modul ini menghubungkan user dengan sistem data mining. Modul ini memungkinkan user berinteraksi dengan sistem dengan cara mendeskripsikan query atau tugas yang harus dikerjakan sistem, menyediakan informasi untuk membantu pencarian agar lebih fokus, dan melakukan penelitian data mining berdasarkan hasil yang didapat dari proses mining. Selain itu, modul ini memungkinkan user untuk melakukan browse terhadap database dan skema atau struktur data dari data warehouse, mengevaluasi pattern yang dimining, dan dapat melihat pattern secara visual dalam bentuk yang berbeda-beda.
Association Rule Mining
Motivasi awal pencarian association rule berasal dari keinginan untuk menganalisa sebuah data transaksi supermarket, yaitu ditinjau dari perilaku customer dalam membeli produk. Association rule
menjelaskan seberapa sering suatu produk dibeli secara bersamaan dengan produk lain. Sebagai contoh, association rule “shampo sabun (80%)” menunjukkan bahwa empat dari lima pelanggan yang membeli shampo juga membeli sabun. Dalam suatu association rule X Y; X disebut dengan antecedent dan Y disebut dengan consequent. Rule seperti ini berguna untuk mengambil keputusan yang berhubungan dengan promosi, penetapan harga suatu produk atau penataan produk dalam rak. Contoh manfaat association rule :
• Rule yang mengandung Y sebagai consequent dapat membantu merencanakan apa yang harus dilakukan oleh suatu toko untuk meningkatkan penjualan Y.
• Rule yang mengandung X sebagai antecedent dapat digunakan untuk membantu menentukan barang-barang apa saja yang terpengaruh apabila toko tersebut memutuskan untuk berhenti menjual X.
• Rule yang mengandung X sebagai antecedent dan Y sebagai consequent dapat digunakan untuk menentukan produk lainnya yang harus dijual bersama dengan X untuk meningkatkan penjualan Y.
• Rule yang berhubungan dengan barang yang terdapat pada rak A dan rak B pada suatu toko dapat membantu merencanakan pengaturan barang pada rak dengan menentukan bahwa penjualan barang di rak A berhubungan dengan penjualan barang di rak B.
Rule support dan rule confidence adalah dua ukuran ketertarikan pemakai association rule mining. Contoh : komputer aplikasi akuntansi [support = 2%, confidence = 60%]. Rule di atas berarti : 2% dari semua transaksi, komputer dan aplikasi akuntansi dibeli secara bersamaan. 60% dari pelanggan yang membeli komputer juga aplikasi akuntansi.
Jenis Association Rules
Ada banyak jenis association rule yang dapat diklasifikasikan dalam beberapa kelompok berdasarkan kriteria-kriteria sebagai berikut : • Berdasarkan tipe nilai yang dapat ditangani rule Jika suatu rule menangani asosiasi diantara ada atau tidaknya suatu item, maka rule tersebut disebut boolean association rule. Contoh dari boolean association rule adalah: komputer aplikasi akuntansi.
Jika suatu rule menunjukan asosiasi antara item-item kuantitatif atau atribut-atribut, maka rule tersebut disebut quantitative association rule. Pada
rule ini, nilai kuantitatif dari item-item atau atribut-atribut dibagi ke dalam interval-interval. Contoh dari quantitative association rule: umur( X, “30..39”) ^ pendapatan(X, “42K..48K”) beli(X, high resolution TV).
• Berdasarkan dimensi dari data yang ada pada rule Jika item atau atribut dalam association rule hanya melibatkan satu dimensi saja, maka rule tersebut adalah single-dimensional association rule. Contoh single-dimensional association rule: beli(X, “komputer”) beli (X, “aplikasi akuntansi”) Rule di atas merupakan bentuk lain dari contoh rule pada boolean association rule. Rule di atas disebut single-dimensional association rule karena rule tersebut hanya melibatkan satu dimensi yaitu beli. Jika rule melibatkan dua atau lebih dimensi seperti dimensi beli, waktu, dan kategori pelanggan, maka rule tersebut disebut multidimensional association rule. Contoh rule pada quantitative association rule juga termasuk rule jenis ini karena rule tersebut melibatkan tiga dimensi yaitu: umur, pendapatan dan beli.
• Berdasarkan level abstraksi yang ada pada rule Misalkan rule-rule yang terdapat pada sebuah set dari association rule adalah sebagai berikut: umur(X, “30..39”) beli(X, “laptop”)
umur(X, “30..39”) beli(X, “komputer”)
Pada rule-rule diatas, item yang dibeli direferensikan pada level abstraksi yang berbeda (“komputer” adalah abstraksi pada level yang lebih tinggi daripada “laptop”). Rule yang demikian disebut multilevel association rule.
Tetapi apabila rule-rule pada sebuah set tidak mereferensikan item-item atau atribut-atribut pada level yang berbeda-beda, maka kumpulan rule tersebut dinamakan single-level association rule. • Berdasarkan berbagai perluasan ekstensi pada association mining
Dibedakan menjadi maximal frequent itemset mining dan closed association rule mining.
Sebuah maximal frequent itemset adalah sebuah frequent pattern p, dimana semua superpattern dari p adalah tidak frequent. Sebuah frequent pattern c disebut sebagai frequent closed itemset apabila tidak ada superset dari c, c’, sehingga semua transaksi yang mengandung c juga mengandung c’. Proses untuk menemukan seluruh association rule yang ada pada suatu database dapat dibagi menjadi dua fase utama yaitu sebagai berikut :
• Fase Pencarian Large Itemset
Fase ini adalah fase untuk menemukan seluruh item dari transaksi yang memenuhi minimum support threshold. Support untuk suatu itemset adalah jumlah transaksi dalam database yang mengandung itemset tersebut. Itemset yang
memenuhi persyaratan ini disebut frequent itemset (large itemset). Sedangkan itemset yang tidak memenuhi disebut infrequent itemset (small itemset).
• Fase Generate Strong Association Rule
Dengan menggunakan frequent itemset yang terbentuk maka dapat diperoleh association rule yang memenuhi minimum confidence threshold yang telah ditentukan.
Frequent Itemset Mining
Frequent itemset mining adalah algoritma yang digunakan untuk mencari frequent itemset.
Support sebuah itemset X adalah jumlah
transaksi dimana terdapat item X didefinisikan
sebagai (X). Sebuah itemset X disebut
frequent itemset apabila support X lebih besar
atau sama dengan nilai minimum support yang
dispesifikasikan ( (X) min_supp).
Minimum support adalah suatu nilai yang
menentukan sebuah itemset termasuk frequent
atau tidak. Misalkan nilai minimum support
adalah 40% dan jumlah transaksi dalam
database ada lima transaksi. Maka suatu
itemset dikatakan frequent bila itemset
tersebut minimal terdapat pada dua transaksi (
40% * 5 = 2 ).
Setelah mengetahui frequent itemset, maka
langkah selanjutnya adalah menghasilkan rule
yang confident. Sebuah rule disebut confident
rule apabila nilai confident dari rule tersebut
lebih besar atau sama dengan nilai minimum
confidence
yang
dispesifikasikan
(p
min_conf).
Nilai
confidence(p)
dihitung
dengan rumus p = (X) / (X’) atau dapat
dikatakan nilai confidence(p) adalah nilai
support X dibagi nilai support X’.
Input : Frequent itemset
Output : Strong association rule dari frequent
itemset
1. [Memanggil procedure genrule untuk semua frequent itemset yang jumlah itemnya lebih atau sama dengan 2] 1.1 forall large itemset lk, k 2
do
1.1.1 call genrules(lk,lk);
Algoritma 1 : Algoritma Association Rule
Input: Frequent itemset
Output: Strong association rule dari frequent itemset
1.[Memanggil procedure genrule untuk semua frequent itemset yang jumlah itemnya lebih atau sama dengan 2]
1.1 forall large itemset lk, k ≥ 2 do
1.1.1 call genrules(lk,lk);
Algoritma 1 merupakan algoritma untuk menghasilkan rule-rule. Masukan yang diminta untuk algoritma ini adalah frequent itemset yang diperoleh dari algoritma pencarian frequent itemset. Sedangkan hasilnya adalah strong association rule.
Algoritma 2 : Procedure Genrules(lk : large k-itemset,
am : large m-itemset)Algoritma Association Rule Input: Frequent itemset
Output: Strong association rule dari frequent itemset
1. [Cari subset]
1.1 A={(m-1)-itemset am-1 | am-1 am};
2. [Cek nilai confidence dari masing-masing subset]
2.1 for all am-1 A do begin
2.1.1 conf=support count(lk)/support
count(am-1);
2.1.2 if (conf minconf) then begin 2.1.2.1 output rule am-1 (lk-am-1),
2.1.2.2 if (m-1 > 1) then
2.1.2.2.1 call genrules(lk, am-1);
2.1.3 end 3. end
Pada algoritma diatas terdapat pemanggilan pada sebuah procedure genrules dengan parameter dua frequent itemset yang sama. Procedure ini digunakan untuk menghasilkan strong association rule yang meminta masukan berupa himpunan frequent k-itemset, Lk dan himpunan frequent m-itemset, am dimana frequent k-itemset sama dengan frequent m-k-itemset.
Trie
Pada computer science, trie atau prefix trie adalah sebuah struktur data tree yang tersusun yang digunakan untuk menyimpan sebuah associative array dimana key-nya adalah string. Sebuah node diberi label sebuah item, dan sebuah path dari root menuju sebuah node menunjukkan sebuah itemset. Semua descendant dari sebuah node manapun dari trie mempunyai common prefix yang sama dengan parent-nya. Root dari trie itu sendiri adalah sebuah empty itemset.
Algoritma DF-Apriori
Algoritma DF-Apriori adalah implementasi secara depth-first dari algoritma Apriori, salah satu algoritma frequent itemset mining (FIM) tercepat untuk menemukan semua frequent itemset pada
sebuah database. Frequent itemset adalah kumpulan dari satu atau beberapa item dengan kemunculan yang sama atau lebih banyak dari minimum support threshold pada sebuah database. Perbedaan utama algoritma DF-Apriori dengan algoritma Apriori biasa adalah apabila pada algoritma Apriori biasa trie dapat diasumsikan dibangun dengan metode layer by layer atau breadth first, maka pada algoritma DF-Apriori ini trie dibangun secara depth first. Pembangunan trie dimulai dari kanan dan berkembang ke kiri.1
Gambar 1
Blok Diagram Algoritma DF-Apriori
Secara garis besar proses mining dengan menggunakan algoritma DF-Apriori terdiri dari tiga tahap yaitu tahap preprocessing dimana algoritma mencari frequent 1-itemset dari database input, tahap pembuatan trie dan tahap pembacaan hasil dari trie. Semua hasil frequent itemset dapat dibaca langsung dari trie ketika trie telah selesai dibentuk.Struktur data yang digunakan pada algoritma DF-Apriori adalah trie. Untuk lebih jelasnya dapat dilihat pada contoh dibawah ini.
Tabel 1 Contoh Dataset Tid Items 1 B C D 2 A B E F 3 A B E F 4 A B C F 5 A B C E F 6 C D E F
1
Walter A. Kosters dan Wim Pijls, Apriori, A Depth
First Implementation, hal 2
Prepared Dataset Pembentukan trie Trie Pembacaan Trie Frequent Itemsets
Tabel 2
Frequent Itemset (Minimum Support = 3 Transaksi)
Support Frequent Itemset
5 B, F
4 A, AB, AF, ABF, BF, C, E, EF
3 AE, ABE, ABEF, AEF, BC, BE, BEF, CF
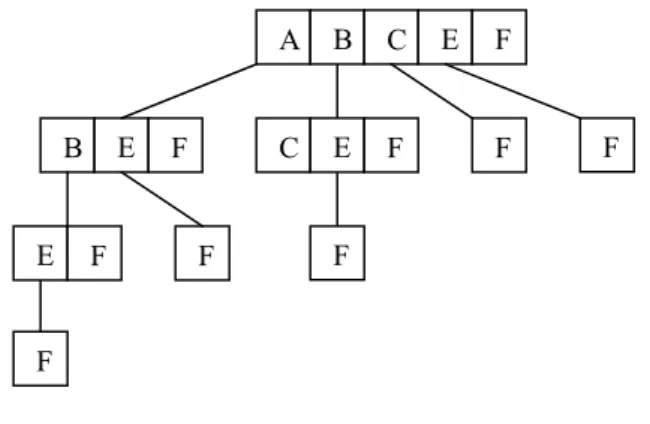
Tabel 1 menunjukkan sebuah contoh dataset dimana terdapat 6 transaksi yang telah tersorting secara ascending. Tid adalah nomor transaksi, sementara items adalah item-item yang terdapat pada transaksi itu sendiri. Tabel 2 menunjukkan semua frequent itemset apabila minimum support threshold = 3. Hasil trie lengkap untuk dataset ini berdasarkan algoritma DF-Apriori dapat dilihat pada Gambar 2.
Gambar 2
Trie Hasil Algoritma DF-Apriori
Algoritma 3 Algoritma DF-Apriori
Input : D (Database Transaksi); σ (Minimum Support Threshold)
Output : Semua Frequent Itemset
1. [Baca dataset untuk preprocessing] 1.1 Scan D to find the set of
frequent 1-itemsets F1 2. [Bentuk trie dan cari frequent
itemset]
2.1 Insert F1 into trie and scan D to count their frequencies 3. [Tampilkan hasil frequent itemset]
3.1 Output FreqItems
Algoritma 3 merupakan algoritma utama pada algoritma DF-Apriori ini. Pertama-tama dataset yang telah dipersiapkan formatnya dibaca untuk mencari semua frequent 1-itemset (baris 1.1). Kemudian semua frequent 1-itemset tersebut dimasukkan kedalam trie dan dataset dibaca lagi untuk menghitung frekuensi sebenarnya dari masing-masing item pada trie (baris 2.1). Setelah
trie selesai dibentuk, hasil semua frequent itemset yang support-nya memenuhi minimum support threshold dapat langsung dibaca dari trie (baris 3.1).
Algoritma 4 Algoritma Preprocessing
Input: D (Database Transaksi); σ (Minimum Support Threshold)
Output: min_item, max_item, jumlah frequent items dan jumlah relevant transaction
1. [Cari min_item dan max_item] 1.1 first = true
1.2 for every transaction t in D 1.2.1 for every item i in t 1.2.1.1 if (first) 1.2.1.1.1 max_item = i 1.2.1.1.2 min_item = i 1.2.1.1.3 first = false 1.2.1.2 end if 1.2.1.3 if i < min_item 1.2.1.3.1 min_item = i 1.2.1.4 else 1.2.1.4.1 if i > max_item 1.2.1.4.1.1 max_item = i 1.2.1.4.2 end if 1.2.1.5 end if 1.2.2 end for 1.3 end for
2. [Cari frekuensi dari semua item dan jumlah frequent items] 2.1 item_range = max_item –
min_item
2.2 init_items_frequency = array[item_range]
2.3 for every transaction t in D 2.3.1 for every item i in t
2.3.1.1 insert i into init_items_frequency 2.3.2 end for
2.3.3 for every frequent item f in init_items_frequency 2.3.3.1 increment
number_freq_items 2.3.4 end for
2.4. end for
3. [Cari jumlah relevant transaction] 3.1 number_transactions = 0
3.2 for every transaction t in D 3.2.1 items_in_trans = 0
3.2.2 for every item i in t 3.2.2.1 if i is frequent 3.2.2.1.1 increment items_in_trans 3.2.2.2 end if 3.2.3 end for 3.2.4 if items_in_trans >= 2 3.2.4.1 increment number_transactions 3.2.5 end if 3.3 end for A B C E F B E F C E F E F F F F F F
4. [Sorting frequent 1-itemset] 4.1 sort items with respect to support and renumber
5. [Bentuk data_array] 5.1 arraywidth =
(number_freq_items -1)/8 + 1 5.2 rowcounter = 0
5.3 for every transaction t in D 5.3.1 next_transaction =
array[rowcounter][arraywidth] 5.3.2 for every item i in t 5.3.2.1 if i is frequent 5.3.2.1.1 insert i into next_transaction[r owcounter] with respect to its rank in the frequency order 5.3.2.2 end if 5.3.3 end for 5.3.4 increment rowcounter 5.4 end for
Algoritma 4 merupakan algoritma untuk melaku-kan proses preprocessing pada algoritma DF-Apriori. Pada proses ini, database dibaca empat kali :
Pembacaan pertama untuk menentukan item terkecil dan item terbesar. Hal ini diperlukan untuk menentukan range item.
Pembacaan kedua untuk mencari frekuensi dari semua item pada database dan mencari jumlah frequent item. Hal ini diperlukan karena urutan frekuensi juga menentukan urutan pada trie. Frequent item yang telah ter-sorting disimpan dalam sebuah array.
Pembacaan ketiga untuk menentukan jumlah relevant transaction. Relevant transaction adalah transaksi yang didalamnya terdapat dua atau lebih frequent item. Untuk transaksi yang hanya mempunyai satu atau nol frequent item telah diidentifikasi pada saat pembacaan kedua.
Pembacaan keempat untuk menyimpan database kedalam sebuah array dua dimensi. Setiap frequent item akan diberikan nomor baru berdasarkan ranking yang dilihat dari besarnya frekuensi tiap-tiap item tersebut. Panjang setiap baris array ditentukan oleh banyaknya frequent item, sedangkan jumlah array ditentukan oleh jumlah relevant transaction dari pembacaan ketiga.
Algoritma 5 Algoritma Build_Up
Input: semua hasil dari proses pre-processing
Output: trie
1. [Bentuk trie]
1.1 T = the trie including only bucket in
1.2 for m = n-1 downto 1 1.2.1 T’ = T
1.2.2 T = T’ with im added to the
left and a copy of T’ is appended to im
1.2.3 S = T\T’ (= the subtrie rooted in im)
1.2.4 count(S, im)
1.2.5 delete the infrequent itemset from S
1.3 end for
2. [Procedure count]
2.1 for every transaction t including item im
2.1.1 for every itemset I in S 2.1.1.1 if t supports I 2.1.1.1.1 increment I.support 2.1.1.2 end if 2.1.2 end for 2.2 end for
Algoritma 5 merupakan algoritma untuk mem-bentuk trie pada algoritma DF-Apriori. Pada proses preprocessing, support dari setiap single item telah dihitung dan semua item yang tidak frequent telah dibuang. Misalkan n frequent item tersebut diberi nama i1, i2, …, in. Kemudian algoritma 5
dijalankan. Procedure count(S, im) berguna untuk
menentukan support dari setiap itemset pada subtrie S. Hal ini dilakukan dengan membaca database sebanyak satu kali dan hanya transaksi yang mengandung item im diproses. Proses ini
dilakukan sekaligus dengan meng-update count dari setiap bucket pada subtrie S. Pada akhir dari algoritma ini, T tepat hanya mengandung semua frequent itemset
Tracing Algoritma
Misalkan akan dilakukan proses mining semua frequent itemset dari sebuah database transaksi seperti yang ditunjukkan pada Tabel 3a dengan minimum support threshold dua transaksi. Database diasumsikan telah dalam format seperti pada Tabel 3a dan setiap item pada setiap transaksinya ter-sorting secara ascending.
Pertama-tama database akan dibaca sekali secara keseluruhan untuk mencari semua frequent 1-itemset. Karena minimum support threshold-nya adalah 2, maka semua item dengan kemunculan lebih kecil dari 2 tidak termasuk frequent item. Pada contoh database ini frequent item-nya adalah 1, 3, 4, 5 dan 7. Kemudian semua frequent item
tersebut akan dimasukkan secara ascending berdasarkan frekuensi kedalam tabel frequent item seperti ditunjukkan pada Tabel 3b.
Tabel 3
Contoh Database Transaksi Beserta Frequent Item-nya Untuk Minimum Support Threshold = 2
(a) (b) Contoh Database Transaksi Frequent Item
Tid Items Item Count
1 3 4 5 6 7 9 7 2 2 1 3 4 5 13 5 3 3 1 2 4 5 7 11 3 4 4 1 3 4 8 1 4 5 1 3 4 10 4 5
Setelah proses preprocessing selesai dilakukan, maka langkah selanjutnya adalah pembentukan trie. Setiap entry pada trie pada algoritma DF-Apriori dinamakan bucket, seperti yang juga dipakai pada hash-tree.2 Sebuah bucket dapat dikenali melalui path-nya menuju root yang merepresentasikan sebuah itemset yang unik. Jumlah iterasi pada pembentukan trie pada algoritma DF-Apriori adalah n-1 kali, dimana n adalah jumlah frequent 1-itemset. Hal ini berarti jumlah passing yang dilakukan terhadap database adalah sebanyak n-1 kali jumlah frequent 1-itemset. Pada contoh database diatas, jumlah frequent 1-itemset adalah 5, maka trie akan selesai dibentuk dalam 4 kali iterasi.
Pembentukan trie diawali dengan pembentukan bucket-bucket dari root. Bucket-bucket tersebut adalah semua frequent 1-itemset dari Tabel 3b. Item yang paling frekuensinya paling besar dibangun pertama kali dan diletakkan pada bucket root yang paling kanan. Hal ini dikarenakan waktu eksekusi algoritma ini akan lebih cepat apabila item-item dengan support tinggi diletakkan pada bagian root yang dangkal (kanan atas) dan item-item dengan support rendah pada bagian root yang dalam (kiri bawah). Pembentukan trie berjalan dari kanan ke kiri.
Iterasi pertama dimulai dari bucket yang ke n-1 dari root, yang dalam contoh diatas adalah bucket 1. Untuk child dari bucket 1 akan disalin dari semua bucket lain di sebelah kanannya pada root beserta semua child-nya. Karena setelah bucket 1
2
Walter A. Kosters dan Wim Pijls, Apriori, A Depth
First Implementation, hal 1
pada root hanya ada bucket 4, maka bucket tersebut menjadi child dari bucket 1. Keadaan trie setelah iterasi pertama ini dapat dilihat pada Gambar 3.
Gambar 3
Hasil Iterasi Pertama Pada Pembentukan Trie Kemudian database akan ditelusuri untuk menghitung frekuensi sebenarnya dari bucket 1 dan 4 beserta semua child-nya. Dimulai dari root yaitu itemset {4} yang menghasilkan count = 4. Kemudian proses bergeser ke kiri dan menghitung itemset {1} yang menghasilkan count = 4 dan itemset {1, 4} yang menghasilkan count = 4. Karena semua hasil perhitungan pada iterasi pertama ini memenuhi minimum support threshold maka semua itemset pada trie termasuk frequent itemset. Frequent itemset yang didapat dari iterasi pertama ini adalah :
{4} = 5. {1} = 4. {1, 4} = 4.
Iterasi kedua akan melakukan proses pada bucket selanjutnya yaitu bucket 3. Untuk child dari bucket ini akan disalin dari semua bucket lain di sebelah kanannya pada root beserta semua child-nya. Jadi bucket 1 dan bucket 4 beserta semua child-nya akan menjadi child dari bucket 3. Keadaan trie setelah iterasi kedua ini dapat dilihat pada Gambar 4.
Gambar 4
Hasil Iterasi Kedua Pada Pembentukan Trie Kemudian database akan ditelusuri untuk menghitung frekuensi sebenarnya dari bucket 3 beserta child-nya. Dimulai dari root yaitu itemset {3} yang menghasilkan count = 4. Setelah itu
1 4 4
I
3= 3
1 4 4 3 1 4 4I
4= 1
itemset {3, 1} menghasilkan count = 3, itemset {3, 1, 4} menghasilkan count = 3 dan itemset {3, 4} menghasilkan count = 4. Karena semua hasil perhitungan pada iterasi kedua ini memenuhi minimum support threshold maka semua itemset pada trie termasuk frequent itemset. Frequent itemset yang didapat dari iterasi kedua ini adalah : {3} = 4.
{3, 1} = 3. {3, 1, 4} = 3. {3, 4} = 4.
Iterasi ketiga akan melakukan proses pada bucket selanjutnya yaitu bucket 5. Untuk child dari bucket ini akan disalin dari semua bucket lain di sebelah kanannya pada root beserta semua child-nya. Jadi bucket 3, 1 dan 4 beserta semua child-nya akan menjadi child dari bucket 5. Keadaan trie setelah iterasi kedua ini dapat dilihat pada Gambar 5.
Gambar 5
Hasil Iterasi Ketiga Pada Pembentukan Trie Kemudian database akan ditelusuri untuk menghitung frekuensi sebenarnya dari bucket 5 beserta child-nya. Dimulai dari root yaitu itemset {5} yang menghasilkan count = 3. Setelah itu itemset {5, 3} menghasilkan count = 2. Kemudian proses berlanjut ke itemset {5, 3, 1} menghasilkan count = 1. Karena tidak memenuhi minimum support threshold maka itemset {5, 3, 1} dicoret dari trie dan tidak termasuk frequent itemset. Apabila sebuah bucket telah dicoret pada trie, maka otomatis semua child-nya juga akan dicoret. Dalam contoh diatas bucket 4 di pojok kiri bawah dicoret dan itemset {5, 3, 1, 4} tidak termasuk frequent itemset. Kemudian proses berlanjut ke itemset {5, 3, 4} menghasilkan count = 2, itemset {5, 1} menghasilkan count = 2, itemset {5, 1, 4} menghasilkan count = 2 dan itemset {5, 4} menghasilkan count = 2. Frequent itemset yang didapat dari iterasi ketiga ini adalah :
{5} = 3. {5, 3} = 2. {5, 3, 4} = 2. {5, 1} = 2. {5, 1, 4} = 2. {5, 4} = 2.
Iterasi keempat akan melakukan proses pada bucket selanjutnya yaitu bucket 7. Untuk child dari bucket ini akan disalin dari semua bucket lain di sebelah kanannya pada root beserta semua nya. Jadi bucket 5, 3, 1 dan 4 beserta semua child-nya akan menjadi child dari bucket 7. Keadaan trie setelah iterasi kedua ini dapat dilihat pada Gambar 6.
Gambar 6
Hasil Iterasi Keempat Pada Pembentukan Trie Kemudian database akan ditelusuri untuk menghitung frekuensi sebenarnya dari bucket 7 beserta child-nya. Dimulai dari root yaitu itemset {7} yang menghasilkan count = 2. Kemudian itemset {7, 5} menghasilkan count = 2, itemset {7, 5, 3} menghasilkan count = 1 (dicoret), itemset {7, 5, 1} menghasilkan count = 1 (dicoret), itemset {7, 5, 4} menghasilkan count = 2, itemset {7, 3} menghasilkan count = 1 (dicoret), itemset {7, 1} menghasilkan count = 1 (dicoret) dan itemset {7, 4} menghasilkan count = 2.
Tabel 4
Frequent Itemset Yang Dihasilkan
Itemset Count Itemset Count Itemset Count {7} 2 {5, 3, 4} 2 {3, 1, 4} 3 {7, 5} 2 {5, 1} 2 {3, 4} 4 {7, 5, 4} 2 {5, 1, 4} 2 {1} 4 {7, 4} 2 {5, 4} 2 {1, 4} 4 {5} 3 {3} 4 {4} 5 {5, 3} 2 {3, 1} 3
Frequent itemset yang didapat dari iterasi keempat ini adalah : {7} = 2. {7, 5} = 2. 1 4 4 1 3
I
3= 5
5 3 1 1 4 4 4 4 4 4 1 4 4 1 3 I1 = 7 5 4 4 7 1 3 5 1 4 4 4 4 3 1 4 4 3 1 4 4 4 4{7, 5, 4} = 2. {7, 4} = 2.
Dengan berakhirnya iterasi keempat diatas, maka trie telah dibentuk secara lengkap. Total didapat 17 frequent itemset seperti yang ditunjukkan pada Tabel 4.
Untuk proses generate rule dapat dilakukan dengan algoritma strong association rule. Misal untuk itemset {7, 5, 4} dengan confidence = 0, rule yang dihasilkan dapat dilihat pada Tabel 5.
Tabel 5
Association Rule Untuk Itemset {7, 5, 4} (Confidence = 0)
Rule Support Confidence
{7} {5, 4} 2/5 2/2 {5} {7, 4} 2/5 2/3 {4} {7, 5} 2/5 2/5 {7, 5} {4} 2/5 2/2 {7, 4} {5} 2/5 2/2 {5, 4} {7} 2/5 2/3
PENUTUP
Semakin tinggi nilai minimum support, semakin sedikit waktu yang diperlukan untuk melakukan mining dan semakin sedikit pula frequent itemset yang dihasilkan. Hal ini dikarenakan apabila nilai support tinggi, maka jumlah frequent item pada database yang memenuhi nilai tersebut akan semakin sedikit, sehingga trie yang terbentuk juga kecil. Sebaliknya, semakin rendah nilai minimum support, semakin banyak waktu yang diperlukan untuk melakukan mining dan semakin banyak pula frequent itemset yang dihasilkan.
Untuk dataset dense, nilai minimum support yang diberikan harus tinggi dan sebaliknya untuk dataset sparse, nilai minimum support yang diberikan harus rendah. Hal ini dikarenakan pada dataset dense transaksi satu dengan lainnya banyak yang mirip. Oleh karena itu besar kemungkinan sebuah item untuk menjadi frequent. Sebaliknya untuk dataset sparse, transaksi satu dengan lainnya jarang yang mirip. Oleh karena itu kecil kemungkinan sebuah item untuk menjadi frequent.
DAFTAR PUSTAKA
1. Jiawei Han dan Micheline Kamber, Data Mining, Concepts and Techniques, Morgan
Kaufmann Publishers. 340 Pine Street, Sixth Floor, San Fransisco, USA, 2001.
2. R. Agrawal dan R. Srikant, Fast Algorithms for Mining Association Rules, Proceedings of the 20th International Conference on Very Large Databases, Santiago, Chile, 1994.
3. Walter A. Kosters dan Wim Pijls, APRIORI : A Depth First Implementation, Leiden Institute of Advanced Computer Science, Universiteit Leiden, Netherlands.