ANALISIS PREDIKSI DROP OUT BERDASARKAN P
Teks penuh
Gambar
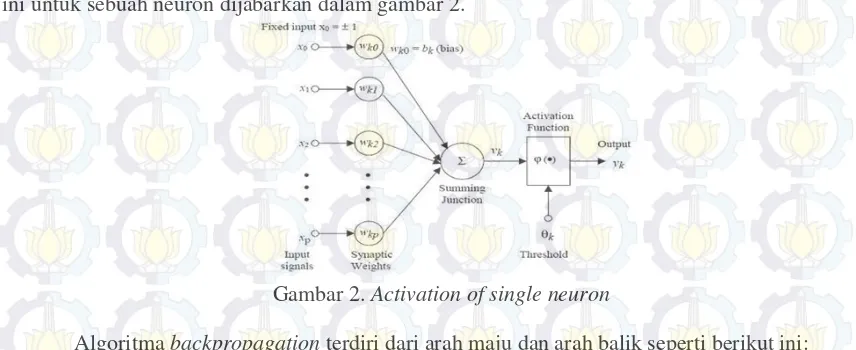
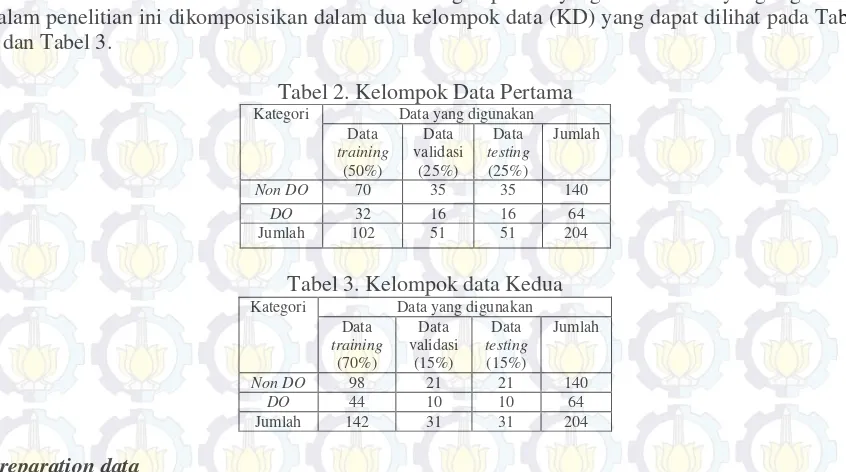
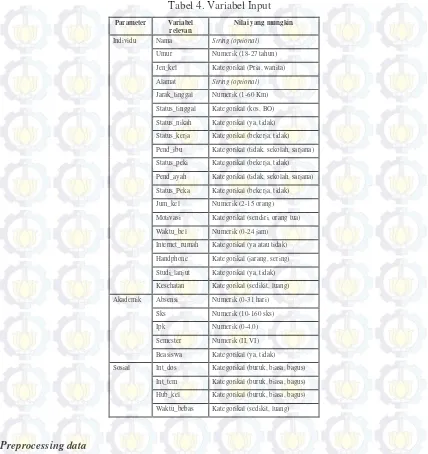
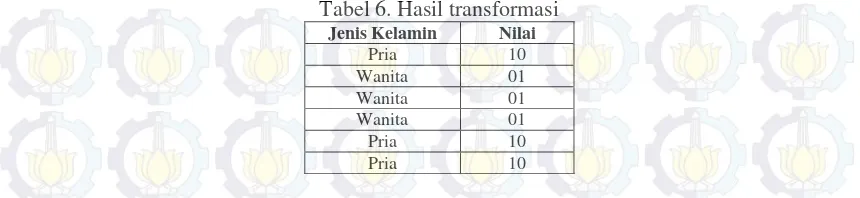
Garis besar
Dokumen terkait
Pondok Pesantren Modern ini menggunakan metode transformasi bentuk dan ciri arsitektur tropis menurut Lippsmeier, (1980), adapun prinsip-prinsip arsitektur tropis
Hasil dari uji lanjut Tukey menunjukkan bahwa perlakuan penambahan lumatan daging ikan yang berbeda memberikan pengaruh berbeda nyata terhadap nilai tensile strength mie
Untuk mencapai performa kompetensi komunikasi yang handal, seorang kepala daerah memulainya dengan kesadaran diri atau self-monitoring dalam membantu atau mendeteksi
Berdasarkan hasil enkripsi diatas terjadi pengulangan kunci untuk memenuhi panjang dari plainteks pada Vigenere Cipher dan One Time Pad misalnya pada algoritma vigenere
i. Sehat jasmani dan rohani. Teknik yang digunakan peneliti dalam mendapatkan data di lapangan adalah teknik langsung dan dokumentasi. Peneliti bertemu langsung dengan informan
PENGARUH LIKUIDITAS, LEVERAGE, DIVIDEN DAN PENGEMBALIAN INVESTASI TERHADAP NILAI PERUSAHAAN (PERUSAHAAN MANUFAKTUR YANG TERDAFTAR DI BEI PADA TAHUN 2004-2009).. Mowen,
Jika hasil penyamakan dibandingkan dengan standar kulit tersamak maka berbagai formulasi yang digunakan pada penyamakan kombinasi sudah memenuhi standar SNI
(di Kupang, 2005 – 2007 ...kerjasama dengan CDU Australia, UNDANA Kupang, Pemda Prop. NTT dan Pemda Kab. TTS) Seminar Pembangunan di kawasan Timur Indonesia. (di
