PENERAPAN TEKNIK KLASIFIKASI
DENGAN METODE DERAJAT KEANGGOTAAN
PADA DATA DIABETES
RATIH KUSUMAWARDANI
G64103008
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
RATIH KUSUMAWARDANI. Penerapan Teknik Klasifikasi dengan Derajat Keanggotaan pada Data Diabetes. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan ANNISA.
Hasil survey Organisasi Kesehatan Dunia (WHO) menyatakan jumlah penderita kencing manis (diabetes melitus) di Indonesia sekitar 17 juta orang (8,6% dari jumlah penduduk) atau menduduki urutan terbesar ke-4 setelah India, Cina dan Amerika Serikat. Berdasarkan hal tersebut, perlu kiranya dilakukan penelitian yang mengarah pada pembuatan aplikasi yang dapat mendeteksi timbulnya penyakit diabetes, sehingga terjadinya penyakit ini pada seseorang dapat diprediksi sedini mungkin agar dapat dilakukan tindakan antisipasi. Salah satu teknik yang dapat digunakan untuk melakukan penelusuran pada data historis untuk mengidentifikasi pola dan memprediksi trend adalah data mining. Data mining merupakan proses ekstraksi informasi atau pola dalam basis data yang berukuran besar. Salah satu teknik dalam data mining yaitu klasifikasi untuk menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas data, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksikan kelas atau objek yang memiliki label kelas yang tidak diketahui. Konsep fuzzy yang diterapkan dalam klasifikasi dapat lebih baik dalam menangani nilai numerik, karena himpunan fuzzy ”memperhalus” batasan yang tegas. Metode klasifikasi yang digunakan dalam penelitian ini adalah klasfikasi dengan derajat keanggotaan dalam fuzzy. Dari penelitian ini diharapkan dapat menemukan aturan yang dapat memprediksi apakah sesorang dinyatakan positif atau negatif berdasarkan data hasil pemeriksaan laboratorium.
Prinsip dasar dari metode derajat keanggotaan dalam fuzzy yaitu menghitung nilai kemenarikan antara dua atau lebih linguistic term. Perhitungan nilai kemenarikan dilakukan dengan menggunakan analisis residual. Penentuan data training dan testing dilakukan dengan menggunakan teknik 10-fold cross-validation.
Dari hasil percobaan diperoleh 15 aturan klasifikasi dengan akurasi sebesar 76,9% dan error rate 23,1%. Atribut yang sering muncul dalam aturan adalah GLUN dan GPOST, sehingga dapat dikatakan bahwa GLUN dan GPOST merupakan parameter yang sangat berpengaruh dalam penentuan hasil diagnosis. Aturan klasifikasi yang mengandung kelas target negatif diabetes sebanyak 2 aturan, sedangkan untuk kelas target positif diabetes sebanyak 13 aturan. Dengan menggunakan 15 aturan klasifikasi tersebut dapat digunakan untuk memprediksi apakah seseorang dinyatakan positif atau negatif diabetes.
PENERAPAN TEKNIK KLASIFIKASI DENGAN METODE DERAJAT
KEANGGOTAAN PADA DATA DIABETES
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
RATIH KUSUMAWARDANI
G64103008
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Penerapan Teknik Klasifikasi dengan Derajat Keanggotaan
pada Data Diabetes
Nama : Ratih
Kusumawardani
NIM :
G64103008
Menyetujui:
Pembimbing I,
Imas S. Sitanggang, S.Si., M.Kom.
NIP 132206235
Pembimbing II,
Annisa, S.Kom.
NIP 132311930
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131473999
iv
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala curahan rahmat dan karunia-Nya sehingga penelitian ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2007 ini ialah data mining, dengan judul Penerapan Teknik Klasifikasi dengan Derajat Keanggotaan pada Data Diabetes.
Penyelesaian penelitian ini tidak terlepas dari bantuan berbagai pihak, karena itu penulis mengucapkan terima kasih sebesar-besarnya kepada:
1. Bapak dan Ibu, kakak dan adikku, atas doa, kasih sayang, dan kehangatannya yang tidak pernah berhenti tercurah selama ini,
2. Ibu Imas S. Sitanggang, S.Si., M.Kom. selaku pembimbing I, Ibu Annisa, S.Kom. selaku pembimbing II dan Bapak Hari Agung Adrianto, S.Kom. selaku dosen penguji,
3. Vita, Sofi dan Ajeng, yang bersedia menjadi pembahas,
4. Eno, Sofi dan Firat, teman senasib dan seperjuangan di lab data mining,
5. Dina dan Meynar, atas kesediannya mengurus konsumsi untuk seminar dan sidang, 6. Sahabat-sahabat Ilkomerz 40, semoga Allah SWT mempererat tali silaturahim antara kita, 7. Seluruh staf dan karyawan Departemen Ilmu Komputer, serta pihak lain yang telah
membantu dalam penyelesaian penelitian ini,
8. Seluruh civitas akademika Departemen Ilmu Komputer IPB yang tidak dapat disebutkan satu persatu.
Segala kesempurnaan hanya milik Allah SWT, semoga hasil penelitian ini dapat bermanfaat, Amin.
Bogor, Mei 2007
v
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 20 Juli 1985 dari ayah Harisman dan ibu Indarningsih. Penulis merupakan putri ketiga dari empat bersaudara. Tahun 2003 penulis lulus dari SMU Negeri I Bogor. Pada tahun yang sama penulis diterima di Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Ujian Seleksi Masuk IPB (USMI).
Selama mengikuti perkuliahan, penulis pernah menjadi pengurus Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) tahun kepengurusan 2004/2005. Pada tahun 2006, penulis pernah melakukan kegiatan praktik lapangan selama dua bulan di Kantor Sub Direktorat Informasi dan Konservasi Alam di Bogor.
vi
DAFTAR ISI
Halaman
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... vii
DAFTAR LAMPIRAN... vii
PENDAHULUAN Latar Belakang...1
Tujuan Penelitian ...1
Ruang Lingkup Penelitian ...1
Manfaat Penelitian ...1
TINJAUAN PUSTAKA Knowledge Data Discovery (KDD) ...1
Data mining ...2
Klasifikasi ...2
Himpunan Fuzzy ...2
Peubah Linguistik ...2
Linguistic term ...3
Algoritma Derajat Keanggotaan dalam Fuzzy ...4
Aturan Kemenarikan dalam Data Fuzzy...4
Perhitungan Nilai Bobot Bukti ...5
Prediksi Nilai Yang Tidak Diketahui Menggunakan Aturan Fuzzy...5
K-Fold Cross Validation ...6
METODE PENELITIAN Proses Dasar Sistem...6
Lingkungan Pengembangan Sistem ...7
HASIL DAN PEMBAHASAN Pembersihan Data ...8
Transformasi Data...8
Data mining ...10
Training ...10
Penentuan Aturan Klasifikasi Akhir...11
Evaluasi Pola...13
Representasi Pengetahuan ...13
KESIMPULAN DAN SARAN Kesimpulan ...14
Saran...14
DAFTAR PUSTAKA ...14
vii
DAFTAR TABEL
Halaman
1 Nilai kategori untuk setiap atribut ...8
2 Hasil proses training ...11
3 Perhitungan bobot klasifikasi akhir ...12
4 Hasil testing aturan klasifikasi akhir...13
DAFTAR GAMBAR
Halaman 1 Tahapan Proses KDD (Han & Kamber 2001)...22 Algoritma data mining fuzzy (Au & Chan 2001) ...4
3 Himpunan fuzzy atribut GLUN ...8
4 Himpunan fuzzy atribut GPOST ...9
5 Himpunan fuzzy atribut TG...9
6 Himpunan fuzzy atribut HDL ...10
DAFTAR LAMPIRAN
Halaman 1Tahapan proses dasar sistem ...17
2 Contoh data diabetes ...18
3 Contoh data hasil transformasi...19
4 Contoh data training set pertama...20
1
PENDAHULUAN
Latar Belakang
Hasil survey Organisasi Kesehatan Dunia (WHO) menyatakan jumlah penderita kencing manis (diabetes melitus) di Indonesia sekitar 17 juta orang (8,6% dari jumlah penduduk) atau menduduki urutan terbesar ke-4 setelah India, Cina dan Amerika Serikat. Berdasarkan hal tersebut, perlu kiranya dilakukan penelitian yang mengarah pada pembuatan aplikasi yang dapat mendeteksi timbulnya penyakit diabetes, sehingga dapat menurunkan jumlah penderita diabetes. Salah satu teknik yang dapat digunakan untuk melakukan penelusuran pada data historis untuk mengidentifikasi pola dan memprediksi trend yaitu data mining. Data mining merupakan proses ekstraksi informasi atau pola dalam basis data yang berukuran besar. (Han & Kamber 2001). Teknik data mining yang digunakan, yaitu klasifikasi.
Klasifikasi merupakan salah satu metode dalam data mining untuk memprediksi label kelas yang tidak diketahui. Konsep fuzzy yang diterapkan dalam klasifikasi dapat lebih baik dalam menangani nilai numerik, karena himpunan fuzzy ”memperhalus” batasan yang tegas.
Data diabetes bersifat numerik sehingga dapat diterapkan teknik data mining dengan konsep fuzzy. Teknik klasifikasi yang digunakan, yaitu klasifikasi dengan metode derajat keanggotaan dalam fuzzy. Prinsip dasar dari metode derajat keanggotaan dalam fuzzy yaitu menghitung nilai kemenarikan antara dua atau lebih linguistic term. Perhitungan nilai kemenarikan dilakukan dengan menggunakan analisis residual. Dengan menerapkan data mining diharapkan dapat ditemukan aturan atau fungsi klasifikasi untuk memprediksi potensi seseorang terserang penyakit diabetes.
Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Menerapkan salah satu metode data mining, yaitu teknik klasifikasi menggunakan metode derajat keanggotaan dalam fuzzy.
2. Menemukan aturan-aturan klasifikasi pada data diabetes untuk memprediksi apakah seseorang dinyatakan positif atau negatif diabetes berdasarkan data hasil pemeriksaan laboratorium.
Ruang Lingkup Penelitian
Penelitian ini mencakup penerapan teknik klasifikasi dengan menggunakan derajat keanggotaan dalam fuzzy pada data hasil pemeriksaan laboratorium dan data catatan medis rawat inap dari tahun 2004 sampai 2005. Jumlah atribut dalam penelitian ini yaitu lima buah atribut yang terdiri dari empat atribut kuantitatif dan satu atribut kategorikal sebagai atribut kelas target.
Manfaat Penelitian
Dengan adanya suatu aplikasi yang dapat digunakan untuk memprediksi potensi penyakit diabetes, maka terjadinya penyakit ini pada seseorang dapat diprediksi sedini mungkin sehingga dapat dilakukan tindakan antisipasi.
TINJAUAN PUSTAKA
Knowledge Data Discovery (KDD)
Knowledge discovery in databases (KDD) adalah proses menemukan informasi yang berguna dan pola-pola yang ada dalam data (Goharian & Grossmann 2003). KDD merupakan sebuah proses yang terdiri dari serangkaian proses iteratif yang terurut dan data mining merupakan salah satu langkah dalam KDD (Han & Kamber 2001). Pada Gambar 1 dapat dilihat tahapan proses KDD secara berurut. Tahapan proses KDD menurut Han & Kamber (2001), yaitu :
1. Pembersihan data
Pembersihan terhadap data dilakukan untuk menghilangkan data yang tidak konsisten dan data yang mengandung noise.
2. Integrasi data
Proses integrasi data dilakukan untuk menggabungkan data dari berbagai sumber.
3. Seleksi data
Proses seleksi data mengambil data yang relevan digunakan untuk proses analisis. 4. Transformasi data
Proses menransformasikan atau menggabungkan data ke dalam bentuk yang tepat untuk di-mining.
5. Data mining
Data mining merupakan proses yang penting dimana metode-metode cerdas diaplikasikan untuk mengekstrak pola-pola dalam data.
2
6. Evaluasi pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola-pola yang menarik yang merepresentasikan pengetahuan.
7. Representasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukkan pengetahuan hasil penggalian gunung data kepada pengguna.
Gambar 1 Tahapan Proses KDD (Han & Kamber 2001)
Data mining
Data mining merupakan proses ekstraksi informasi data berukuran besar (Han & Kamber 2001). Menurut Kantardzic (2003), data mining merupakan keseluruhan proses mengaplikasikan komputer dan bermacam teknik untuk menemukan informasi dari sekumpulan data. Dari sudut pandang analisis data, data mining dapat diklasifikasi menjadi dua kategori, yaitu descriptive data mining dan predictive data mining. Descriptive data mining menjelaskan sekumpulan data dalam cara yang lebih ringkas. Ringkasan tersebut menjelaskan sifat-sifat yang menarik dari data. Predictive data mining menganalisis data dengan tujuan mengkonstruksi satu atau sekumpulan model dan melakukan prediksi perilaku dari kumpulan data yang baru.
Aplikasi data mining telah banyak diterapkan pada berbagai bidang, seperti analisa pasar dan manajemen, analisis perusahaan dan manajemen resiko, telekomunikasi, asuransi dan keuangan.
Klasifikasi
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat
digunakan untuk memprediksikan kelas atau objek yang memiliki label kelas yang tidak diketahui. Klasifikasi termasuk ke dalam kategori predictive data mining. Model yang diturunkan didasarkan pada analisis dari training data. Teknik klasifikasi adalah pendekatan sistematis untuk pembuatan model klasifikasi (classifier) dari sebuah data set input.
Proses klasifikasi dibagi menjadi dua fase, yaitu learning dan testing (Han & Kamber 2001). Pada fase learning, sebagian data yang telah diketahui kelas datanya (training set) digunakan untuk membentuk model. Selanjutnya pada fase testing, model yang sudah terbentuk diuji dengan sebagian data lainnya (test set) untuk mengetahui akurasi dari model tersebut. Jika akurasinya mencukupi maka model tersebut dapat dipakai untuk prediksi kelas data yang belum diketahui.
Himpunan Fuzzy
Konsep logika fuzzy pertama kali diperkenalkan oleh Prof. Lotfi A Zadeh dari Universitas California pada bulan Juni 1965. Logika fuzzy merupakan generalisasi dari logika klasik yang hanya memiliki dua nilai keanggotaan 0 dan 1. Dalam logika fuzzy nilai kebenaran suatu pernyataan berkisar dari sepenuhnya benar ke sepenuhnya salah. Inti dari himpunan fuzzy yaitu fungsi keanggotaan yang menggambarkan hubungan antara domain himpunan fuzzy dengan nilai derajat keanggotaan. Derajat keanggotaan menunjukkan nilai keanggotaan suatu objek pada suatu himpunan. Nilai keanggotaan ini berkisar antara 0 sampai 1. Dengan teori himpunan fuzzy suatu objek dapat menjadi anggota dari banyak himpunan dengan derajat keanggotaan yang berbeda dalam masing-masing himpunan (Cox 2005).
Peubah Linguistik
Peubah linguistik merupakan peubah yang mempunyai nilai linguistik berupa kumpulan kata (linguistic term) yang bersesuaian dengan derajat keanggotaan dalam suatu himpunan. Peubah linguistik dikarakterisasi oleh quintaple
(
x,T(x),X,G,M)
dengan x adalah nama peubah, T(x) adalah kumpulan dari linguistic term, X menunjukkan nilai interval x, G adalah aturan sintak yang membangkitkan term dalam T(x), M adalah aturan semantik yang bersesuaian dengan nilai linguistik M(A), dengan M(A) menunjukkanData Cleaning Data Integration Databases Data Warehouse Task-relevant Data
Selection and Transformation Data
mining Pattern Evaluation
3
fungsi keanggotaan untuk himpunan fuzzy dalam X. Sebagai contoh, jika umur diinterpretasikan sebagai peubah linguistik, maka himpunan dari linguistic term T(umur) menjadi :
T(umur) = {sangat muda, muda, tua} Setiap term dalam T(umur) dikarakterisasi oleh himpunan fuzzy dalam X. Aturan sintak membangkitkan term dalam T(x), sedangkan aturan semantik menunjukkan fungsi keanggotaan dari setiap nilai pada himpunan linguistic term (Kantardzic 2003).
Linguistic term
Linguistic term didefinisikan sebagai kumpulan himpunan fuzzy yang didasarkan pada fungsi keanggotaan yang bersesuaian dengan peubah linguistik (Au & Chan 2001).
D kumpulan dari record yang terdiri dari kumpulan atribut I={I1,...,In}, dengan
n v
Iv, =1,..., . Atribut I dapat berupa atribut numerik atau kategorikal. Untuk setiap record d elemen D, d
[ ]
Iv menotasikan nilai i dalam record d untuk atribut Iv.Kumpulan linguistic term dapat didefinisikan pada seluruh domain dari atribut kuantitatif. Himpunan fuzzy dapat didefinisikan untuk setiap Lvr dengan L , vr
v s
r=1,..., menotasikan linguistic term yang berasosiasi dengan atribut I . Himpunan v fuzzy, Lvr, r = 1,..., sv didefinisikan sebagai :
⎪ ⎪ ⎪ ⎪ ⎩ ⎪⎪ ⎪ ⎪ ⎨ ⎧ = ∫ ∑ kontinu jika diskret jika ) ( ) ( ) ( ) ( v I v I v i v i vr L v I dom v i v i vr L v I dom vr L µ µ
untuk semua iv∈dom(Iv), dengan
}
{
v vmvv i i I
dom( )= 1,..., .
Derajat keanggotaan dari nilai iv∈dom(Iv)
dengan beberapa linguistic term Lvr
dinotasikan oleh vr L
µ . Untuk atribut kategorikal, linguistic term Lvr, r=1,...,mv
direpresentasikan oleh himpunan fuzzy
vr
L
sebagai : vr i vr L = 1Secara umum untuk atribut numerik dan kategorikal, himpunan linguistic term dinotasikan oleh
{
vr|v=1,...,n,r=1,...,sv}
= L
L
dengan sv =mv, selama linguistic term
digambarkan sebagai himpunan fuzzy, maka himpunan linguistic term dapat dinyatakan sebagai himpunan fuzzy.
Diberikan record d∈ D , linguistic term
vr L
∈
L dan himpunan fuzzy Lvr∈L, nilai derajatkeanggotaan dalam d dengan linguistic term vr
L , dinotasikan oleh µLvr(d
[ ]
Iv).d dikarakterisasi oleh term Lvrdengan derajat keanggotaan L (d
[ ]
Iv) vr µ . Jika[ ]
) 1 ( v = LvrdIµ , d secara utuh dikarakterisasi oleh term
L
vr. Jika µLvr(d[ ]
Iv )=0, d tidak dikarakterisasi oleh termL
vr. Jika[ ]
) 1 (0<µLvr d Iv < , secara parsial d
dikarakterisasi oleh term
L
vr.d dapat dikarakterisasi oleh lebih dari satu term
L
vr. Diberikan Iϕ, dengan{
| ϕ}
ϕ = Iv v∈I , berasosiasi oleh
linguistic term L , r = 1,..., sϕr φ dengan
∏ =
∈ϕ ϕ
v sv
s . Notasi ϕ menotasikan subset dari bilangan integer, ϕ=
{
v ,....,1 vm}
, dengan{
n}
m v v,..., 1,...., 1 ∈ ,v1≠ ....≠vmdan ϕ ≥ | |=h 1.Setiap Lϕr didefinisikan oleh kumpulan
linguistic term Lvr ,....,Lvmrm∈L 1
1 . Nilai derajat dengan d dikarakterisasi oleh term
r ϕ L
(
( )
d)
r ϕλ
L , didefinisikan oleh :[ ]
( )
(
[ ]
)
⎟⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ = m m ,..., 1 1 L min Lv r dIvm 1 v I d r v r µ µ ϕ λL D dapat direpresentasikan oleh kumpulan data fuzzy F yang dikarakterisasi oleh kumpulan atribut linguistik, L =(
L1,....,Ln)
.Untuk setiap atribut linguistik
L ∈
vL
nilai4
[ ]
v{
(
v1,
v1) (
,....,
,
vsv)
}
t
µ
µ
v vsL
L
L =
dengan Lvk sebagai linguistic term dan µvk
sebagai derajat keanggotaan, dengan
{
sϕ}
k∈ 1,..., . Untuk t
∈
F, oL Lpq ϕkmenotasikan nilai derajat dengan t dikarakterisasi oleh linguistic term Lpq dan
k
ϕ
L , p ∉ φ yang didefinisikan oleh :
k pq
oL Lψ = min
(
µ
Lpq,
µ
Lϕk)
(1)Jumlah dari derajat suatu record dalam F yang dikarakterisasi oleh linguistic term Lpq dan
k ϕ L didefinisikan oleh : = ∑ ∈F L L L Lpq k t
o
pq k deg ϕ ϕ (2) Dengan menggunakan linguistic term, dapat ditemukan suatu aturan fuzzy dari sejumlah data fuzzy dan merepresentasikannya dengan cara yang mudah dipahami oleh manusia (Au & Chan 2001).Algoritma Derajat Keanggotaan dalam Fuzzy
Prinsip dari algoritma data mining fuzzy yaitu menyajikan aturan fuzzy dengan beberapa orde. Orde pertama dari aturan fuzzy didefinisikan oleh aturan yang hanya melibatkan sebuah linguistic term dalam anteseden, orde kedua melibatkan dua buah linguistic term, orde ketiga melibatkan tiga buah linguistic term, dan selanjutnya. Algoritma data mining fuzzy dapat dilihat pada Gambar 2.
Untuk mencari nilai kemenarikan (interestingness) dari orde pertama digunakan ukuran kemenarikan objektif. Setelah ditemukan nilai kemenarikan maka disimpan pada peubah R1. Aturan di R1 digunakan untuk
membangkitkan orde kedua yang tersimpan dalam R2. R2 akan digunakan untuk
membangkitkan aturan orde ketiga yang tersimpan pada R3 dan begitu seterusnya.
Fungsi interesting (Lpq, Lϕk) menghitung
nilai hubungan kemenarikan antara Lpq
dengan Lϕk. Jika fungsi interesting (Lpq, Lϕk)
menghasilkan nilai benar maka aturan fuzzy tersebut dibangkitkan oleh fungsi rulegen, kemudian dihitung nilai bobot bukti. Semua aturan fuzzy yang dibangkitkan oleh rulegen disimpan dalam R dan akan digunakan untuk proses prediksi.
Gambar 2 Algoritma data mining fuzzy (Au & Chan 2001)
Aturan Kemenarikan dalam Data Fuzzy
Hubungan antara Lpq dengan Lϕk,
dikatakan menarik, jika nilai
(
)
k record k pq record k pq r P ϕ ϕ ϕ L L L L L oleh isasi dikarakter yang dari derajat jml dan oleh isasi dikarakter yang dari derajat jml | =berbeda dengan nilai
( )
M Pr pq record pq oleh isasi dikarakter yang dari derajat jml L L = dengan =∑ ∑ = = p s u s i pu i deg M 1 1 ϕ ϕ L L . Nilaiperbedaan tersebut, secara objektif dapat dievaluasi menggunakan nilai adjusted residual yang didefinisikan oleh :
pq pq k k pq k z d = ϕ ϕ ϕ γ L L L L L L (3) dengan pq k
zL Lϕ adalah nilai standardized residual, yang didefinisikan oleh :
ϕ ϕ ϕ ϕ pq k pq k pq k pq k deg e z e − = L L L L L L L L (4)
1) R1 ={first-order fuzzy rules}
2) for
(
m=2;Rm−1≠φ ;m++)
do3) begin
4)C = {each condition in the antecedent of r | r ∈ R m-1}
5) forall ϕ composed of m elements in C do 6) begin 7) forall t∈F do 8) forall
(
Lpq,µpq)
∈t[ ]
Lp ,(
Lϕk,µϕk)
∈t[ ]
Lϕ ,p∈ϕ do 9) min( pq, k) k L pq L ϕ += µ µϕ deg ; 10) forall(
Lpq,µpq)
∈t[ ]
Lp ,(
Lϕk,µϕk)
∈t[ ]
Lϕ ,p∈ϕ do 11) if interesting(
Lpq,Lϕk)
then 12) Rm=Rm∪rulegen(
Lpq,Lϕk)
; 13) end 14) end 15) U ; mRm R=5
dengan epq k
ϕ
L L adalah jumlah derajat dari record yang diduga dikarakterisasi oleh Lpq
dengan Lϕk yang didefinisikan oleh :
M deg deg e s i p s u pu k i pq k pq
∑
∑
= = = ϕ ϕ ϕ ϕ 1 L L 1 L L L L (5) dan pq k ϕγ
L L adalah nilai maximum likelihood estimate dari ragam pqk zL Lϕ , yang didefiniskan oleh : 1 1 1 1 ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡
∑
∑
= = − − = M M L L L L L L p s u s i k pq k pu i pq deg deg ϕ ϕ ϕ ϕ γ (6)Jika dL Lpq ϕk > 1.96 (nilai persentil dari
distribusi normal), dapat disimpulkan bahwa nilai antara Pr(Lpq |Lϕk) dan P (r Lpq) secara
signifikan berbeda sehingga hubungan antara Lpq dengan Lϕk menarik (interesting).
Perhitungan Nilai Bobot Bukti
Diberikan linguistic term Lϕk yang berasosiasi dengan linguistic term Lpq , dapat
dibentuk suatu aturan fuzzy
] [ k pq w pq k ϕ ϕ L L L L ⇒ dengan wL Lpq ϕk adalah nilai bobot bukti.
Selama hubungan antara Lpq dengan Lϕk
menarik, maka terdapat bukti berupa record yang dikarakterisasi oleh Lpq mempunyai
k
ϕ
L . Perhitungan nilai bobot bukti dikenal sebagai informasi mutual. Informasi mutual menghitung nilai ketidakpastian dari Lpq pada
suatu record yang mempunyai Lϕk, yang didefinisikan oleh :
( )
( : ) ( : ) log r pq k pq k r pq P I P = L L L L L ϕ ϕ (7)dengan berdasarkan nilai informasi mutual, perhitungan bobot bukti, didefinisikan sebagai:
(
)
(
)
(
)
⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ = ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − = ≠ ≠U
U
q i pi k r pq q i k pi k pq P I I w pq k L L L L L L L L L L | | P log | : k r ϕ ϕ ϕ ϕ ϕ (8) pq kwL Lϕ dapat diinterpretasikan secara intuitif sebagai perhitungan perbedaan dari record
k
ϕ
L yang dikarakterisasi oleh Lpq dan Lpi ,
i≠q. Diberikan Lϕk yang didefinisikan oleh kumpulan linguistic term,
L L
Lv ,....,1r1 vmrm∈ dapat dibentuk aturan fuzzy
pada tingkat yang lebih tinggi (high-order) sebagai : ] [ ,...., 1 1r vr w pq k v L m m Lpq L Lϕ L ⇒
dengan v ,....,1 vm∈ϕ (Au & Chan 2001).
Prediksi Nilai Yang Tidak Diketahui Menggunakan Aturan Fuzzy
Diberikan suatu record,
( )
I dom( )
Ip dom( )
In domd∈ 1 ×....× ×....× , d dikarakterisasi oleh n atribut,
n p α α
α1,..., ,...., dengan α adalah nilai p yang akan diprediksi.
ϕ s p p, =1,....,
L adalah linguistic term dari atribut kelas Ip. lplinguistic term dengan
domain dom
( )
Ip ={
Lp1,...,Lpsp}
. Nilai dari α didefinisikan oleh nilai lp p. Untukmemprediksi nilai lp digunakan pendekatan
aturan fuzzy dengan Lpq ∈dom
( )
Ip sebagai konsekuen.Kombinasi dari nilai atribut
α
ϕ,p∉ϕ
dari d dikarakterisasi oleh linguistic term Lϕkdengan derajat λLϕk( )d untuk setiap
{
sϕ}
k∈ 1,..., . Nilai bobot bukti dari
] [ ,...., 1 1r vr w pq k v L m m Lpq L Lϕ L ⇒ , untuk
semua k∈ζ ⊆
{
1,....,sϕ}
, didefinisikan oleh :( )
d w w k k pq pq k ϕ ϕ ϕλ
ζ α L L L L∑
. ∈ = (9)Misalkan, n-1 atribut (tanpa α ), p [ ] α[ ] α[ ]β
6
[ ]j =
{
αi|i∈(
1,...,n)
−{p}}
αditemukan untuk menyamakan satu atau lebih aturan, maka bobot bukti untuk nilai lp
diberikan oleh :
∑
= = β α 1 [] j q w pq j w L (10) Nilai α didefinisikan oleh p(
) (
)
(
)
{
Lp1,w1 ,...,Lpq,wq ,...,Lpsp,wsp}
. Jika Ip kategorikal, lp diberikan ke Lpc jikac g p s g g w c w > , =1,..., ' dan ≠ (11) dengan s'p(≤sp) adalah linguistic term yang tercantum dalam aturan, dan α p diberikan ke ipc∈dom
( )
Ip .Jika Ip kuantitatif, diberikan linguistic term
p s p L p L ,...., 1 , bobot bukti w ,....,1 wpsp,
( )
p Lpu i 'µ bobot derajat keanggotaan dari ip
( )
Ip dom∈ dengan himpunan fuzzy L , pu
{
1,....,sp}
u∈ . ⎜⎝⎛ip⎟⎠⎞ pu L ' µ didefinisikan oleh : µ'Lpu( )
ip =wu.µLpu( )
ip (12)dengan ip∈dom
( )
Ip dan u∈{
1,....,sp}
.Nilai defuzifikasi ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ = = −
U
p s u pu L F 1 1 untuk p α didefinisikan sebagai :( )
( )
( )
( )
∫
∫
∪ ∪ ∪ ∪ = ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ = = − p p ps L p p p ps L p p I dom p p L I dom p p p L s u pu di i di i i L F . ' . ' ... 1 ... 1 1 1 µ µU
(13) dengan µX∪Y( )
i =max(
µ'X( )
i,µ'Y( )
i)
untuk himpunan fuzzy X dan Y. Untuk mengevaluasi hasil perhitungan digunakan root-mean-squared error. Nilai root-mean squared error (rms) didefinsikan oleh :
∑
∈ − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − − = D r l r r l u o u t n rms 2 1 1 1(14)
dengan D sekumpulan test record, n sebagai jumlah test record dalam D, untuk record
D
r∈ dan
[ ]
l,u ⊂ℜ sebagai atribut kelas, t r sebagai nilai target dari atribut kelas dalam r dan or nilai yang diprediksi (Au & Chan2001).
K-Fold Cross Validation
K-Fold Cross Validation dilakukan untuk membagi training set dan test set. K-Fold Cross Validation mengulang k-kali untuk membagi seluruh himpunan contoh secara acak menjadi k subset yang saling bebas, setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan (Fu 1994). Pada metode tersebut, data awal dibagi menjadi k subset atau “fold“ yang saling bebas secara acak, yaitu S1,S2,…,Sk,
dengan ukuran setiap subset kira-kira sama. Pelatihan dan pengujian dilakukan k kali. Pada iterasi ke-i, subset Si diperlakukan
sebagai data pelatihan. Pada iterasi pertama S2,…,Sk menjadi data pelatihan dan S1 menjadi
data pengujian, pada iterasi kedua S1,S3,…,Sk,
menjadi data pelatihan dan S2 menjadi data
pengujian, dan seterusnya.
METODE PENELITIAN
Proses Dasar Sistem
Data yang digunakan dalam penelitian ini adalah data hasil pemeriksaan laboratorium dan data catatan medis rawat inap dari tahun 2004 sampai 2005. Tahapan proses dasar sistem dapat dilihat pada Lampiran 1.
Proses tersebut dapat diuraikan sebagai berikut :
a. Pembersihan data, dilakukan jika ditemukan data yang mengandung noise, nilai hilang dan data yang duplikat.
b. Transformasi data, proses transformasi data ke bentuk yang dapat di-mining. Sebelum di-mining, data diabetes diubah ke dalam bentuk data fuzzy.
c. Aplikasi teknik data mining, merupakan tahap yang penting karena pada tahap ini teknik data mining diaplikasikan terhadap data. Teknik data mining yang digunakan yaitu klasifikasi. Klasifikasi dilakukan melalui dua tahapan proses, yaitu :
1. Membangun model untuk menemukan aturan klasifikasi (training). Tahap pembangunan model memerlukan
7
training set yang berisi record dengan label kelas diketahui dan algoritma pembelajaran. Pada penelitian ini, metode yang digunakan dalam proses pembelajaran, yaitu metode derajat keanggotaan dalam fuzzy. Langkah-langkah pembentukan aturan dengan metode derajat keanggotaan dalam fuzzy, yaitu :
a. Menentukan nilai variabel Lpq dan k
ϕ
L . Lpq menotasikan linguistic term
konsekuen dan Lϕk linguistic term dari anteseden. Pada tahap awal hanya melibatkan sebuah linguistic term dalam anteseden.
b. Mencari hubungan kemenarikan antara Lpq dan Lϕk. Lpq dan Lϕk
dikatakan menarik jika nilai antara
( | )
r k
P Lpq Lϕ dan P (rLpq) secara
signifikan berbeda. Nilai perbedaan dihitung menggunakan adjusted residual k L pq L ϕ d . Perhitungan nilai k L pq L ϕ
d berdasarkan pada analisis residual (persamaan 3 sampai dengan 6). Jika nilai k L pq L ϕ d > 1.96 maka dapat dikatakan bahwa
( | )
r k
P Lpq Lϕ dan P (rLpq) secara
signifikan berbeda, sehingga hubungan antara Lpq dengan Lϕk
menarik (interesting).
c. Menghitung nilai bobot dari aturan yang menarik, menggunakan persamaan 8.
d. Menggunakan aturan yang telah terbentuk untuk mencari aturan dengan orde yang lebih tinggi dan mengulangi langkah b dan c.
e. Aturan-aturan menarik yang telah terbentuk akan dilakukan pemilihan terhadap aturan-aturan yang mengandung kelas target sebagai konsekuennya.
f. Aturan-aturan kelas target yang telah terpilih merupakan aturan klasifikasi untuk setiap proses training.
g. Aturan klasifikasi akhir diperoleh dari aturan klasifikasi yang selalu muncul pada 10 proses training.
2. Evaluasi terhadap model yang telah terbentuk (testing). Proses evaluasi dilakukan dengan menghitung banyaknya test record yang diprediksi secara benar atau tidak benar oleh model klasifikasi. Untuk memprediksi nilai digunakan persamaan (9 sampai dengan 11). Model dapat diterima jika mencapai nilai akurasi yang tinggi dan error rate yang rendah ketika diaplikasikan ke test set.
e. Representasi pengetahuan, merupakan tahap akhir dimana pada tahap ini pola yang telah ditemukan direpresentasikan ke pengguna dengan teknik visualisasi agar pengguna dapat memahaminya. Deskripsi aturan klasifikasi akan disajikan dalam bentuk aturan logika.
Lingkungan Pengembangan Sistem
Spesifikasi perangkat keras dan perangkat lunak pada komputer personal yang digunakan dalam pengembangan sistem adalah sebagai berikut :
Perangkat keras berupa komputer personal dengan spesifikasi :
• Processor: AMD AthlonTM XP
2400+
• Memori 512 MB • Harddisk 120 GB
• Alat input mouse dan keyboard • Monitor 15”
Perangkat lunak :
• Sistem Operasi : Windows XP Professional 2002
• Matlab 7.0.1 sebagai bahasa pemograman.
• Microsoft Excel 2003 sebagai media penyimpanan data.
HASIL DAN PEMBAHASAN
Data diabetes diperoleh dari data hasil pemeriksaan laboratorium dan data catatan medis pasien rawat inap dari tahun 2004 sampai 2005. Data catatan medis rawat inap terdiri dari sembilan atribut, yaitu KEY_id, TGL_Periksa, MRN (medical record number), tensi, nadi, suhu, tinggi, berat dan diagutama.
Namun, atribut tensi, nadi, suhu, tinggi dan berat bernilai null, sehingga atribut tersebut tidak dapat digunakan untuk membuat model atau aturan klasifikasi. Data hasil pemeriksaan laboratorium terdiri dari8
sepuluh atribut, antara lain key_transaksi, no.RM (nomor rekam medis/MRN), tgl.proses, ordertest_code, test_name, result, unit, flag, ref_range, status. Atribut result berisi data laboratorium dari pemeriksaan GLUS (Glukosa Darah Sewaktu dalam mg/dL), AST, GLUN, GPOST, Tg dan HDL.
Pada penelitian sebelumnya (Herwanto 2006), jumlah atribut yang digunakan untuk membuat model atau aturan klasifikasi sebanyak 12 atribut, antara lain umur, jenis kelamin, GLUN, GPOST, Tg, HDL, Upost, Actn, Actpp, Ldl, Urn dan Chol. Nilai atribut-atribut tersebut dinyatakan dalam bentuk bilangan crisp. Penelitian tersebut (Herwanto 2006) menghasilkan model atau aturan klasifikasi yang hanya melibatkan empat buat atribut, yaitu GLUN, GPOST, Tg dan HDL. Pada penelitian ini, atribut yang digunakan untuk membuat model atau aturan klasifikasi, yaitu GLUN (Glukosa Darah Puasa dalam mg/dL), GPOST (Glukosa Darah Pasca Puasa dalam mg/dL), Tg (Trigliserida dalam mg/dL), HDL (Kolesterol HDL dalam mg/dL) mengacu pada model klasifikasi yang dihasilkan pada penelitian sebelumnya.
Nilai atribut GLUN, GPOST, Tg dan HDL diperoleh dari data hasil pemeriksaan laboratorium, sedangkan nilai atribut Diagnosis diperoleh dari data diagutama catatan medis rawat inap dengan nomor rekam medis yang sama. Atribut Diagnosis merupakan atribut kelas target. Jumlah record data sebanyak 300 buah record. Contoh sebagian data diabetes dapat dilihat pada Lampiran 2.
Pembersihan Data
Pembersihan data dilakukan karena ditemukannya data yang bernilai kosong dan duplikat. Pembersihan data dilakukan dengan menghapus record yang mengandung nilai kosong dan duplikat, sehingga diperoleh data bersih sebanyak 290 record.
Transformasi Data
Proses transformasi data dilakukan dengan mengubah data bersih ke dalam bentuk fuzzy. Kelima buah atribut tersebut satu-persatu akan ditransformasi ke dalam bentuk himpunan fuzzy. Penentuan himpunan fuzzy untuk atribut GLUN, GPOST, Tg dan HDL berdasarkan pada nilai kategori yang terdapat pada masing-masing atribut (Tabel 1). Penentuan pembentukan nilai kategori terhadap data hasil pemeriksaan laboratorium berdasarkan referensi yang ada di sebuah rumah sakit. Di bawah ini akan dijelaskan himpunan fuzzy dan
fungsi keanggotaan untuk masing-masing atribut.
Tabel 1 Nilai kategori untuk setiap atribut
Atribut Nilai Kontinyu
GLUN GLUN < 70 GLUN 70 <= GLUN < 110 GLUN 110 <= GLUN < 140 GLUN GLUN >= 140 GPOST GPOST < 100 GPOST 100<= GPOST <140 GPOST 140 <= GPOST < 200 GPOST GPOST >= 200 HDL HDL< 40 HDL 40<= HDL< 60 HDL HDL>= 60 TG TG < 50 TG 50<=TG < 150 TG TG >=150 • Atribut GLUN
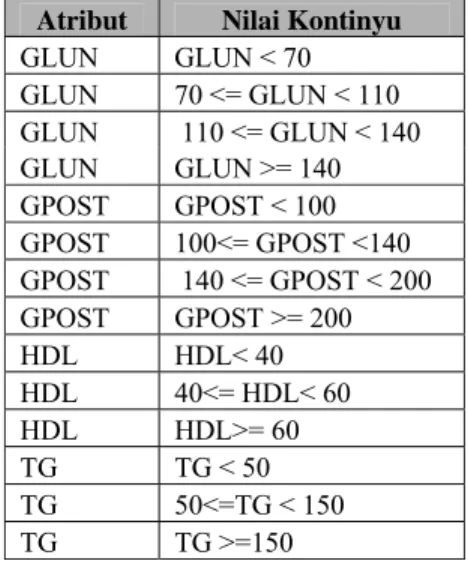
Atribut GLUN direpresentasikan oleh empat buah linguistic term yaitu rendah (GLUN < 70 mg/dL), sedang (70 mg/dL <= GLUN < 110 mg/dL), tinggi (110 mg/dL <= GLUN < 140 mg/dL), dan sangat tinggi (GLUN >= 140 mg/dL) (Herwanto 2006). Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 3.
Gambar 3 Himpunan fuzzy atribut GLUN Fungsi Keanggotaan : ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 75 ; 0 75 65 ; 10 75 65 ; 1 ) ( x x x x x rendah µ
9 ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= − <= < < <= − < = 115 ; 0 115 105 ; 10 115 105 75 ; 1 75 65 ; 10 65 65 ; 0 ) ( x x x x x x x x sedang µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= − <= < < <= − < = 145 ; 0 145 135 ; 10 145 135 115 ; 1 115 105 ; 10 105 105 ; 0 ) ( x x x x x x x x tinggi µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 145 ; 1 145 135 ; 10 135 135 ; 0 ) ( x x x x x gi sangatTing µ • Atribut GPOST
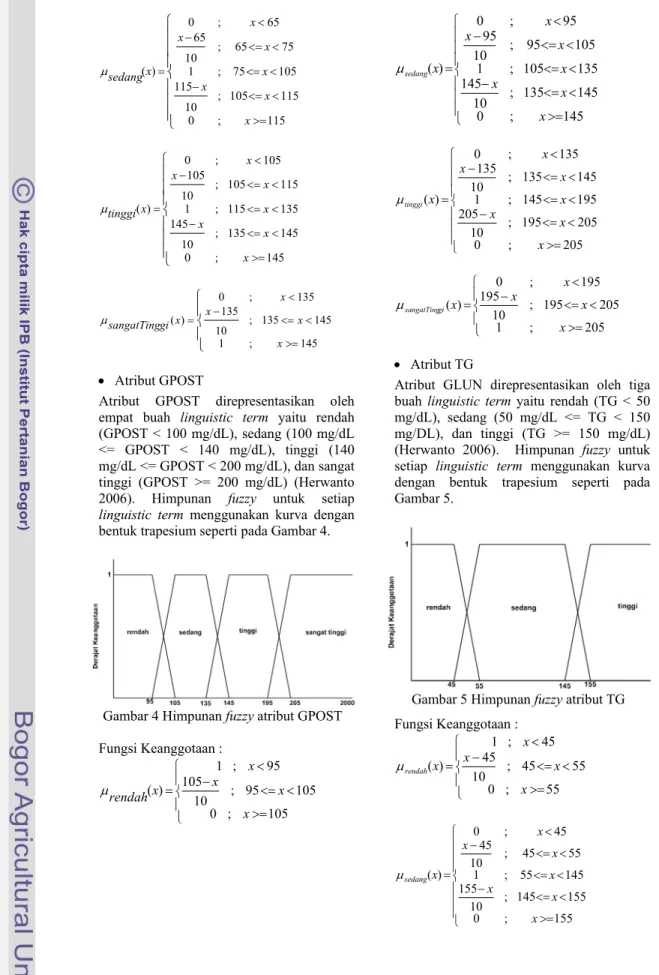
Atribut GPOST direpresentasikan oleh empat buah linguistic term yaitu rendah (GPOST < 100 mg/dL), sedang (100 mg/dL <= GPOST < 140 mg/dL), tinggi (140 mg/dL <= GPOST < 200 mg/dL), dan sangat tinggi (GPOST >= 200 mg/dL) (Herwanto 2006). Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 4.
Gambar 4 Himpunan fuzzy atribut GPOST Fungsi Keanggotaan : ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 105 ; 0 105 95 ; 10 105 1 ; 95 ) ( x x x x x rendah µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= − <= < < <= − < = 145 ; 0 145 135 ; 10 1451 ; 105 135 105 95 ; 10 95 ; 95 0 ) ( x x x x x x x x sedang µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= − <= < < <= − < = 205 ; 0 205 195 ; 10 2051 ; 145 195 145 135 ; 10 135 ; 135 0 ) ( x x x x x x x x tinggi µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 205 ; 1 205 195 ; 10 1950 ; 195 ) ( x x x x x gi sangatTing µ • Atribut TG
Atribut GLUN direpresentasikan oleh tiga buah linguistic term yaitu rendah (TG < 50 mg/dL), sedang (50 mg/dL <= TG < 150 mg/DL), dan tinggi (TG >= 150 mg/dL) (Herwanto 2006). Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 5.
Gambar 5 Himpunan fuzzy atribut TG Fungsi Keanggotaan : ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 55 ; 0 55 45 ; 10 45 45 ; 1 ) ( x x x x x rendah µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= − <= < < <= − < = 155 ; 0 155 145 ; 10 1551 ; 55 145 55 45 ; 10 45 ; 45 0 ) ( x x x x x x x x sedang µ
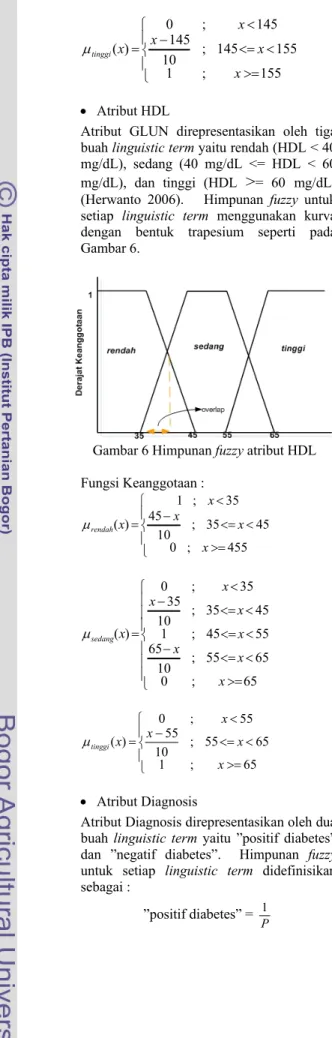
10 ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 155 ; 1 155 145 ; 10 145 ; 145 0 ) ( x x x x x tinggi µ • Atribut HDL
Atribut GLUN direpresentasikan oleh tiga buah linguistic term yaitu rendah (HDL < 40 mg/dL), sedang (40 mg/dL <= HDL < 60 mg/dL), dan tinggi (HDL
>
= 60 mg/dL) (Herwanto 2006). Himpunan fuzzy untuk setiap linguistic term menggunakan kurva dengan bentuk trapesium seperti pada Gambar 6.Gambar 6 Himpunan fuzzy atribut HDL Fungsi Keanggotaan : ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 455 ; 0 45 35 ; 10 45 35 ; 1 ) ( x x x x x rendah µ ⎪ ⎪ ⎪ ⎩ ⎪ ⎪ ⎪ ⎨ ⎧ >= < <= − <= < < <= − < = 65 ; 0 65 55 ; 10 651 ; 45 55 45 35 ; 10 35 ; 35 0 ) ( x x x x x x x x sedang µ ⎪ ⎩ ⎪ ⎨ ⎧ >= < <= − < = 65 ; 1 65 55 ; 10 55 ; 55 0 ) ( x x x x x tinggi µ • Atribut Diagnosis
Atribut Diagnosis direpresentasikan oleh dua buah linguistic term yaitu ”positif diabetes” dan ”negatif diabetes”. Himpunan fuzzy untuk setiap linguistic term didefinisikan sebagai : ”positif diabetes” = P 1 ”negatif diabetes” = N 1
Setelah dilakukan percobaan terhadap himpunan fuzzy dengan nilai overlap 2,5 dan 5 hasil akurasi yang diperoleh mempunyai perbedaan selisih yang sedikit. Nilai overlap 2,5 memliki akurasi lebih tinggi, namun karena pertimbangan range data yang terlalu besar, maka pada penelitian ini nilai overlap yang digunakan untuk atribut linguistik GLUN, GPOST, TG dan HDL adalah 5.
Hasil transformasi dari data awal yang semula terdiri dari 5 atribut adalah data dengan 21 atribut yang tiap record-nya berisi derajat keanggotaan. Contoh hasil transformasi tersebut sebagian dapat dilihat pada Lampiran 3.
Data mining
Pada tahap ini dilakukan teknik data mining menggunakan metode klasifikasi dengan derajat keanggotaan dalam fuzzy. Data yang telah ditransformasi akan dibagi menjadi training set dan test set. Pembagian data ini menggunakan metode 10-fold cross-validation. Data akan dibagi menjadi 10 subset (S1,....,S10) yang berbeda dengan
jumlah yang sama besar, kemudian proses training dan testing dilakukan sebanyak 10 kali. Setiap kali sebuah subset digunakan sebagai test set dan 9 buah partisi lainnya sebagai training set.
Training
Pembentukan aturan klasifikasi untuk setiap proses training menggunakan metode derajat keanggotaan. Sebagai contoh akan dijelaskan pembentukan aturan klasifikasi untuk proses training pertama. Contoh sebagian data yang digunakan untuk proses training pertama dapat dilihat pada Lampiran 4.
Langkah-langkah pembentukan aturan klasifikasi dengan metode derajat keanggotaan dalam fuzzy, yaitu:
1. Mendefinisikan atribut linguistik dan linguistic term untuk setiap atribut.
L1 = GLUN; L4 = HDL;
L2 = GPOST; L5 = Diagnosis;
L3 = TG;
L1= {rendah, sedang, tinggi, sangat
tinggi};
L2= {rendah, sedang, tinggi, sangat
tinggi};
11
L4= {rendah, sedang, tinggi};
L5= {positif, negatif};
2. Menentukan nilai variabel Lpq dan Lϕk.
Pada tahap awal hanya melibatkan sebuah linguistic term pada anteseden (orde 1). Sebagai contoh, didefinisikan Lpq = L52
dan Lϕk = L12 untuk mengetahui
kemenarikan antara linguistic term GLUN sedang dan linguistic term diagnosis negatif. 3. Menghitung nilai 12 d L 52 L dengan
menggunakan persamaan (3 sampai dengan 6). Setelah dilakukan perhitungan, diperoleh nilai 12 d L 52 L = 3,11. Nilai 12 dL L 52 > 1,96 sehingga hubungan linguistic term GLUN sedang dan diagnosis negatif menarik.
4. Menghitung nilai bobot dari aturan yang menarik dengan menggunakan persamaan (8). Misalnya, nilai bobot untuk L52 dan
21
L adalah wLpqLϕk = 0,52.
5. Pada contoh training dengan menggunakan training set pertama, diperoleh 34 aturan menarik pada orde satu. Aturan-aturan tersebut akan digunakan untuk membangkitkan aturan untuk orde kedua. Misalnya, aturan menarik orde pertama L ⇒21 L52 akan digunakan untuk membangkitkan aturan yang menarik pada orde dua. Sebagai contoh, didefinisikan Lpq = L52 dan
ϕk = 12L41
L L untuk mengetahui
kemenarikan antara linguistic term GLUN sedang dan HDL rendah dengan linguistic term diagnosis negatif.
6. Tahapan perhitungan untuk membangkitkan orde kedua sama seperti pada orde pertama. Pada contoh di atas, setelah dilakukan perhitungan diperoleh nilai 41 L 12 d L 52 L = 2,22. Nilai 41 L 12 d L 52 L > 1,96 sehingga hubungan
linguistic term GLUN sedang dan HDL rendah dengan linguistic term diagnosis negatif menarik., dengan bobot
k pq wL Lϕ = 0,75.
7. Setelah dilakukan proses seperti pada tahap 2 sampai 4, diperoleh 128 aturan
menarik pada orde kedua. Aturan-aturan pada orde kedua akan digunakan untuk membangkitkan orde ketiga dan begitu seterusnya.
8. Jumlah seluruh aturan menarik yang ditemukan untuk contoh training pertama, yaitu 960 buah aturan. Aturan klasifikasi diperoleh dari aturan-aturan menarik yang mengandung kelas target sebagai konsekuennya. Untuk proses training pertama diperoleh 68 aturan klasifikasi. Contoh sebagian aturan klasifikasi yang dihasilkan pada proses training pertama dapat dilihat pada Lampiran 4.
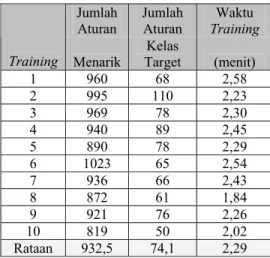
Pembentukan aturan klasifikasi untuk 9 proses training lainnya dilakukan sama seperti pada proses training pertama. Jumlah aturan menarik dan jumlah aturan kelas target yang dihasilkan dari 10 proses training dapat dilihat pada Tabel 2.
Tabel 2 Hasil proses training Jumlah
Aturan Jumlah Aturan Training Waktu Training Menarik Target Kelas (menit)
1 960 68 2,58 2 995 110 2,23 3 969 78 2,30 4 940 89 2,45 5 890 78 2,29 6 1023 65 2,54 7 936 66 2,43 8 872 61 1,84 9 921 76 2,26 10 819 50 2,02 Rataan 932,5 74,1 2,29
Penentuan Aturan Klasifikasi Akhir
Pada Tabel 2 dapat dilihat bahwa jumlah aturan kelas target berbeda untuk setiap proses training, sehingga untuk menentukan aturan klasifikasi akhir dilakukan dengan memilih aturan kelas target yang selalu muncul pada 10 proses training. Setelah dilakukan pemilihan, diperoleh 15 buah aturan klasifikasi akhir. Aturan-aturan tersebut antara lain :
1. Jika GLUN sangat tinggi maka Postif Diabetes.
2. Jika GPOST sangat tinggi maka Postif Diabetes.
3. Jika GLUN sedang maka Negatif Diabetes.
12
4. Jika GPOST sedang maka Negatif Diabetes.
5. Jika GLUN sangat tinggi dan GPOST sangat tinggi maka Positif Diabetes. 6. Jika TG tinggi dan GLUN sangat
tinggi maka Positif Diabetes.
7. Jika HDL sedang dan GLUN sangat tinggi maka Positif Diabetes.
8. Jika TG tinggi dan GPOST sangat tinggi maka Positif Diabetes.
9. Jika HDL rendah dan GPOST sangat tinggi maka Positif Diabetes.
10. Jika HDL sedang dan GPOST sangat tinggi maka Positif Diabetes.
11. Jika TG tinggi dan GPOST sangat tinggi dan GLUN sangat tinggi maka Positif Diabetes.
12. Jika HDL sedang dan GPOST sangat tinggi dan GLUN sangat tinggi maka Positif Diabetes.
13. Jika HDL sedang dan TG tinggi dan GLUN sangat tinggi maka Positif Diabetes.
14. Jika HDL sedang dan TG tinggi dan GPOST sangat tinggi maka Positif Diabetes.
15. Jika HDL sedang dan TG tinggi dan GPOST sangat tinggi dan GLUN sangat tinggi maka positif diabetes. Dari 15 aturan tersebut hanya 2 aturan yang mengandung kelas target negatif
diabetes dengan melibatkan sebuah linguistic term pada anteseden, sedangkan 13 aturan lainnya mengandung kelas target positif diabetes yang melibatkan satu sampai empat buah linguistic term pada anteseden.
Pada aturan ke 5 memperlihatkan jika glukosa darah puasa (GLUN) sangat tinggi dan glukosa 2 jam pasca puasa (GPOST) sangat tinggi maka positif diabetes.
Nilai bobot untuk setiap aturan klasifikasi diperoleh dari rata-rata bobot aturan yang bersesuian dengan aturan klasifikasi dari 10 proses training. Nilai bobot setiap aturan pada 10 proses training dan nilai rata-rata bobot yang diperoleh untuk setiap aturan klasifikasi dapat dilihat pada Tabel 3. Dari Tabel 3 dapat dilihat pada aturan ke lima, yaitu jika GLUN sangat tinggi dan GPOST sangat tinggi maka positif diabetes, mempunyai nilai bobot sebesar 0,64.
Nilai bobot menunjukkan seberapa besar data yang mendukung suatu aturan. Semakin besar nilai bobot dari suatu aturan maka semakin banyak data yang mendukung aturan tersebut.
Dari 15 aturan klasifikasi yang terbentuk bobot tertinggi sebesar 0,96 terdapat pada aturan ke 13, yaitu jika HDL sedang dan TG tinggi dan GLUN sangat tinggi maka Positif Diabetes.
Tabel 3 Perhitungan bobot klasifikasi akhir
No. Aturan T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 Rataan Bobot 1 0,58 0,69 0,63 0,55 0,59 0,53 0,58 0,55 0,55 0,57 0,58 2 0,53 0,59 0,59 0,55 0,59 0,52 0,54 0,57 0,53 0,48 0,55 3 0,53 0,63 0,53 0,50 0,52 0,54 0,50 0,54 0,65 0,59 0,55 4 0,85 0,00 0,82 0,80 0,85 0,82 0,81 0,87 0,78 0,79 0,74 5 0,61 0,72 0,69 0,62 0,70 0,59 0,63 0,61 0,59 0,61 0,64 6 0,65 0,84 0,76 0,62 0,69 0,67 0,80 0,70 0,63 0,80 0,72 7 0,72 0,68 0,72 0,56 0,65 0,58 0,59 0,59 0,59 0,66 0,63 8 0,57 0,62 0,66 0,61 0,66 0,65 0,69 0,69 0,54 0,64 0,63 9 0,41 0,56 0,52 0,52 0,50 0,45 0,48 0,52 0,49 0,45 0,49 10 0,62 0,57 0,64 0,51 0,68 0,53 0,52 0,58 0,51 0,56 0,57 11 0,61 0,78 0,70 0,64 0,76 0,65 0,78 0,69 0,53 0,79 0,69 12 0,70 0,66 0,73 0,60 0,81 0,61 0,60 0,62 0,59 0,68 0,66 13 0,96 0,98 1,05 0,83 0,99 0,91 0,98 0,93 0,87 1,05 0,96 14 0,78 0,71 0,77 0,63 0,85 0,71 0,77 0,81 0,61 0,80 0,75 15 0,97 0,91 0,93 0,81 1,17 0,90 0,98 0,93 0,79 1,07 0,95
13
Evaluasi Pola
Tahap evaluasi dilakukan dengan melakukan pengujian terhadap aturan klasifikasi akhir yang telah terbentuk pada tahap data mining dengan nilai masukan dari test set.
Untuk mendapatkan akurasi prediktif dilakukan dengan melakukan testing terhadap aturan klasifikasi yang telah terbentuk sebanyak 10 kali. Setiap testing menggunakan test set yang berbeda, namun dengan jumlah data yang sama besar.
Nilai akurasi diperoleh dengan menghitung jumlah record yang diprediksi secara benar dibagi jumlah test set. Error rate diperoleh dengan menghitung jumlah record yang diprediksi secara salah dibagi jumlah test set.
Pada Tabel 4 dapat dilihat bahwa rata-rata akurasi prediktif dari aturan klasifikasi sebesar 76,9% dengan error rate 23,1%. Dari hasil percobaan, nilai rata-rata akurasi yang diperoleh tidak terlalu besar, hal ini disebabkan oleh penggunaan data yang kurang representatif.
Tabel 4 Hasil testing aturan klasifikasi akhir Waktu Testing Testing Akurasi error rate (menit) 1 72,41% 27,59% 0,50 2 65,52% 34,48% 0,55 3 68,97% 31,03% 0,47 4 75,86% 24,14% 0,48 5 72,41% 27,59% 0,55 6 93,10% 6,90% 0,49 7 75,86% 24,14% 0,56 8 72,41% 27,59% 0,48 9 86,21% 13,79% 0,56 10 86,21% 13,79% 0,43 Rataan 76,90% 23,10% 0,51 Representasi Pengetahuan
Deskripsi dari aturan klasifikasi yang ditemukan, disajikan dalam bentuk aturan “jika maka” beserta nilai bobot (w) untuk setiap aturan. Aturan klasifikasi yang diperoleh melibatkan satu sampai empat linguistic term pada anteseden.
Jumlah aturan dengan sebuah linguistic term pada anteseden sebanyak 4 buah aturan, yaitu :
1. Jika GLUN sangat tinggi maka positif diabetes, w = 0,58.
2. Jika GPOST sangat tinggi maka positif diabetes, w = 0,55.
3. Jika GLUN sedang maka negatif diabetes, w = 0,55.
4. Jika GPOST sedang maka negatif diabetes, w = 0,74.
Aturan dengan 2 buah linguistic term pada anteseden, yaitu
1. Jika GLUN sangat tinggi dan GPOST sangat tinggi maka positif diabetes, w = 0,64.
2. Jika TG tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,72. 3. Jika HDL sedang dan GLUN sangat
tinggi maka positif diabetes, w = 0,63. 4. Jika TG tinggi dan GPOST sangat
tinggi maka positif diabetes, w = 0,63. 5. Jika HDL rendah dan GPOST sangat
tinggi maka positif diabetes, w = 0,49. 6. Jika HDL sedang dan GPOST sangat
tinggi maka positif diabetes, w = 0,57. Aturan dengan 3 buah linguistic term pada anteseden, yaitu
1. Jika TG tinggi dan GPOST sangat tinggi Dan GLUN sangat tinggi maka positif diabetes, w = 0,69.
2. Jika HDL sedang dan GPOST sangat tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,66.
3. Jika HDL sedang dan TG tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,96.
4. Jika HDL sedang dan TG tinggi dan GPOST sangat tinggi maka positif diabetes, w = 0,75.
Untuk aturan dengan 4 linguistic term pada anteseden hanya diperoleh satu buah aturan, yaitu :
Jika HDL sedang dan TG tinggi dan GPOST sangat tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,95.
Dari aturan-aturan tersebut dapat diketahui suatu model yang dapat membedakan kelas target positif diabetes dengan negatif diabetes. Aturan klasifikasi untuk kelas target negatif diabetes sebanyak 2 aturan, sedangkan kelas target positif diabetes sebanyak 13 aturan. Aturan-aturan tersebut dapat digunakan untuk memprediksi data baru.
Pada aplikasi, untuk memprediksi data baru pengguna dapat memasukkan parameter pengukuran seperti GLUN, GPOST, TG dan HDL. Berdasarkan aturan klasifikasi yang diperoleh dari hasil percobaan, untuk
14
memprediksi kelas negatif diabetes hanya diperlukan satu parameter input yaitu GLUN atau GPOST, sedangkan untuk kelas positif diabetes dapat digunakan satu sampai empat parameter input.
Sebagai contoh untuk kelas negatif diabetes, pengguna dapat memasukkan parameter input GLUN. Misalnya, pengguna memasukan nilai parameter GLUN sebesar 78, setelah melalui proses fuzzifikasi nilai tersebut termasuk ke dalam kategori sedang maka kelas yang dihasilkan adalah negatif diabetes.
KESIMPULAN DAN SARAN
Kesimpulan
Dari berbagai percobaan yang dilakukan terhadap data diabetes didapat kesimpulan sebagai berikut :
1. Metode derajat keanggotaan telah dapat diterapkan pada data diabetes. 2. Terdapat 15 buah aturan yang
menjelaskan atau membedakan kelas target positif diabetes dan negatif diabetes, dengan akurasi sebesar 76,9% dan error rate 23,1%.
3. Aturan yang mengandung kelas target negatif diabetes sebanyak 2 aturan dan aturan yang mengandung kelas target positif diabetes sebanyak 13 aturan. 4. Parameter yang sering muncul pada
setiap aturan klasifikasi yaitu GLUN dan GPOST, sehingga dapat dikatakan bahwa GLUN dan GPOST merupakan parameter yang sangat berpengaruh dalam penentuan hasil diagnosis. 5. Terdapat empat buah aturan yang
memiliki bobot tinggi, yaitu :
• Jika GPOST sedang maka negatif diabetes, w = 0,74.
• Jika TG tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,72.
• Jika HDL sedang dan TG tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,96 .
• Jika HDL sedang dan TG tinggi dan GPOST sangat tinggi dan GLUN sangat tinggi maka positif diabetes, w = 0,75.
• Jika HDL sedang dan TG tinggi dan GPOST sangat tinggi dan GLUN
sangat tinggi maka positif diabetes, w = 0,95.
6. Kelebihan metode derajat keanggotaan dalam fuzzy, yaitu tidak diperlukannya input nilai threshold pada saat proses pencarian aturan.
Saran
Hasil penelitian ini, dapat lebih dikembangkan lebih lanjut pada :
1. Pada penelitian ini, data yang digunakan kurang representatif karena jumlah data untuk positif diabetes hanya 17 record, sedangkan untuk negatif diabetes sebanyak 273 record. Pada penelitian selanjutnya diharapkan menggunakan data yang lebih representatif dengan perbandingan jumlah data positif dan negatif diabetes yang sama besar, sehingga aturan klasifikasi yang dihasilkan memiliki akurasi yang lebih baik lagi.
2. Penggunaan kelas target berupa atribut kuantitatif sehingga hasil diagnosis untuk positif dan negatif diabetes didukung oleh nilai derajat keanggotaan yang berkisar dari 0 sampai 1.
DAFTAR PUSTAKA
Au Wai-Ho, Keith C.C Chan. 2001. Classification with Degree of Membership : A Fuzzy Approach. IEEE International Conference on Data mining Proceedings. Cox E. 2005. Fuzzy Modelling and Genetic
Algorithms for Data mining and Exploration. USA: Academic Press. Fu L. 1994. Neural Network In Computer
Intelligence. Singapura : McGraw Hill. Goharian, Grossman. 2003. Intoduction to
Data mining. http://ir.iit.edu/~nazli/cs422/CS422- Slides/DM-Itroduction.pdf[2November 2006].
Han J, Kamber M. 2001. Data mining Concepts and Technique. USA: Academic Press.
Herwanto. 2006. Pengembangan Sistem Data mining untuk Diagnosis Penyakit Diabetes Menggunakan Algoritme
15
Classification Based Association [Tesis]. Bogor. Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Kantardzic M. 2003. Data mining Concepts, Models, Methods and Algorithm. Wiley-Interscience. New Jersey. USA.
17
18
Lampiran 2 Contoh data diabetes
GLUN GPOST TG HDL Diagnosis
115 159 117 32 N 151 212 235 40 N 63 147 94 26 N 84 93 120 33 N 149 153 63 44 N 83 90 179 29 N 144 210 139 47 N 124 202 139 30 N 100 98 201 38 N 184 196 103 48 N 119 112 152 25 N 85 95 361 36 N 105 102 134 37 N 167 391 100 41 N 131 209 153 42 N 0 0 104 104 N 78 149 52 41 N 115 138 186 46 N 197 330 186 32 P 88 108 329 52 N 97 101 108 89 N 92 94 60 39 N 92 107 112 36 N 93 95 232 42 N 148 175 63 42 N 75 76 127 55 N 96 97 154 41 N 0 0 72 72 N 75 97 319 48 N 77 86 110 53 N 0 0 186 186 N 230 365 189 56 P 117 152 277 23 P 90 138 133 69 P 83 140 218 34 N 82 86 52 83 N 147 148 127 40 N 107 143 186 45 N 89 97 298 45 N Keterangan: N = negatif diabetes M = positif diabetes
Lampiran 3 Contoh data ha sil tr ansformas i 19
GLUN MF_ MF_ MF_ MF_ GPOST MF_ MF_ MF_ MF_ TG MF_ MF_ MF_ HDL MF_ MF_ MF_ Diag MF_ MF_
rendah sedang tinggi SgtTinggi rendah sedang tinggi SgtTinggi rendah sedang tinggi rendah sedang tinggi nosa Positif Negatif
115 0 0 1 0 159 0 0 1 0 117 0 1 0 32 1 0 0 N 0 1 151 0 0 0 1 212 0 0 0 1 235 0 0 1 40 0,5 0,5 0 N 0 1 63 1 0 0 0 147 0 0 1 0 94 0 1 0 26 1 0 0 N 0 1 84 0 1 0 0 93 1 0 0 0 120 0 1 0 33 1 0 0 N 0 1 149 0 0 0 1 153 0 0 1 0 63 0 1 0 44 0,1 0,9 0 N 0 1 83 0 1 0 0 90 1 0 0 0 179 0 0 1 29 1 0 0 N 0 1 144 0 0 0,1 0,9 210 0 0 0 1 139 0 1 0 47 0 1 0 N 0 1 124 0 0 1 0 202 0 0 0,3 0,7 139 0 1 0 30 1 0 0 N 0 1 100 0 1 0 0 98 0,7 0,3 0 0 201 0 0 1 38 0,7 0,3 0 N 0 1 184 0 0 0 1 196 0 0 0,9 0,1 103 0 1 0 48 0 1 0 N 0 1 119 0 0 1 0 112 0 1 0 0 152 0 0,3 0,7 25 1 0 0 N 0 1 85 0 1 0 0 95 1 0 0 0 361 0 0 1 36 0,9 0,1 0 N 0 1 105 0 1 0 0 102 0,3 0,7 0 0 134 0 1 0 37 0,8 0,2 0 N 0 1 167 0 0 0 1 391 0 0 0 1 100 0 1 0 41 0,4 0,6 0 N 0 1 131 0 0 1 0 209 0 0 0 1 153 0 0,2 0,8 42 0,3 0,7 0 N 0 1 0 1 0 0 0 0 1 0 0 0 104 0 1 0 104 0 0 1 N 0 1 78 0 1 0 0 149 0 0 1 0 52 0,3 0,7 0 41 0,4 0,6 0 N 0 1 115 0 0 1 0 138 0 0,7 0,3 0 186 0 0 1 46 0 1 0 N 0 1 197 0 0 0 1 330 0 0 0 1 186 0 0 1 32 1 0 0 P 1 0
Lamp iran 4 C ont oh da ta traini ng s et pertam a 20
GLUN MF_ MF_ MF_ MF_ GPOST MF_ MF_ MF_ MF_ TG MF_ MF_ MF_ HDL MF_ MF_ MF_ Diag MF_ MF_
rendah sedang tinggi SgtTinggi rendah sedang tinggi SgtTinggi rendah sedang tinggi rendah sedang tinggi nosa Positif Negatif
115 0 0 1 0 159 0 0 1 0 117 0 1 0 32 1 0 0 N 0 1 151 0 0 0 1 212 0 0 0 1 235 0 0 1 40 0,5 0,5 0 N 0 1 63 1 0 0 0 147 0 0 1 0 94 0 1 0 26 1 0 0 N 0 1 84 0 1 0 0 93 1 0 0 0 120 0 1 0 33 1 0 0 N 0 1 149 0 0 0 1 153 0 0 1 0 63 0 1 0 44 0,1 0,9 0 N 0 1 83 0 1 0 0 90 1 0 0 0 179 0 0 1 29 1 0 0 N 0 1 144 0 0 0,1 0,9 210 0 0 0 1 139 0 1 0 47 0 1 0 N 0 1 124 0 0 1 0 202 0 0 0,3 0,7 139 0 1 0 30 1 0 0 N 0 1 100 0 1 0 0 98 0,7 0,3 0 0 201 0 0 1 38 0,7 0,3 0 N 0 1 184 0 0 0 1 196 0 0 0,9 0,1 103 0 1 0 48 0 1 0 N 0 1 119 0 0 1 0 112 0 1 0 0 152 0 0,3 0,7 25 1 0 0 N 0 1 85 0 1 0 0 95 1 0 0 0 361 0 0 1 36 0,9 0,1 0 N 0 1 105 0 1 0 0 102 0,3 0,7 0 0 134 0 1 0 37 0,8 0,2 0 N 0 1 167 0 0 0 1 391 0 0 0 1 100 0 1 0 41 0,4 0,6 0 N 0 1 131 0 0 1 0 209 0 0 0 1 153 0 0,2 0,8 42 0,3 0,7 0 N 0 1 0 1 0 0 0 0 1 0 0 0 104 0 1 0 104 0 0 1 N 0 1 78 0 1 0 0 149 0 0 1 0 52 0,3 0,7 0 41 0,4 0,6 0 N 0 1 115 0 0 1 0 138 0 0,7 0,3 0 186 0 0 1 46 0 1 0 N 0 1 197 0 0 0 1 330 0 0 0 1 186 0 0 1 32 1 0 0 P 1 0